
Abstract
Diabetic Retinopathy (DR) is defined as the Diabetes Mellitus difficulty that harms the blood vessels in the retina. It is also known as a silent disease and cause mild vision issues or no symptoms. In order to enhance the chances of effective treatment, yearly eye tests are vital for premature discovery. Hence, it uses fundus cameras for capturing retinal images, but due to its size and cost, it is a troublesome for extensive screening. Therefore, the smartphones are utilized for scheming low-power, small-sized, and reasonable retinal imaging schemes to activate automated DR detection and DR screening. In this article, the new DIY (do it yourself) smartphone enabled camera is used for smartphone based DR detection. Initially, the preprocessing like green channel transformation and CLAHE (Contrast Limited Adaptive Histogram Equalization) are performed. Further, the segmentation process starts with optic disc segmentation by WT (watershed transform) and abnormality segmentation (Exudates, microaneurysms, haemorrhages, and IRMA) by Triplet half band filter bank (THFB). Then the different features are extracted by Haralick and ADTCWT (Anisotropic Dual Tree Complex Wavelet Transform) methods. Using life choice-based optimizer (LCBO) algorithm, the optimal features are chosen from the mined features. Then the selected features are applied to the optimized hybrid ML (machine learning) classifier with the combination of NN and DCNN (Deep Convolutional Neural Network) in which the SSD (Social Ski-Driver) is utilized for the best weight values of hybrid classifier to categorize the severity level as mild DR, severe DR, normal, moderate DR, and Proliferative DR. The proposed work is simulated in python environment and to test the efficiency of the proposed scheme the datasets like APTOS-2019-Blindness-Detection, and EyePacs are used. The model has been evaluated using different performance metrics. The simulation results verified that the suggested scheme is provides well accuracy for each dataset than other current approaches.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Nowadays, nearly 10% of adult peoples are suffering from diabetics and it is one of the major threat in our country. After cancer and heart disorder, diabetics is the third most deadly disease. However, most of the parts of human body affected by the diabetics “DIABETIC RETINOPATHY” is one among them [32]. Loss of vision is occurred by the DR. Once the patient is affected by DR, the retinal blood vessels are damaged. Hence, the DR patient’s blind, because it blocks the light that passes through the optical nerves [25]. Moderate Non-Proliferative Retinopathy (NPDR), Pre-Proliferative Retinopathy, Severe Proliferative Retinopathy, Mild Non-Proliferative Retinopathy, and Proliferative Retinopathy (PDR) are the 5 types of DR. By extracting various features like micro aneurysms, hard and soft exudates, hemorrhage etc. from the fundus image [17], the DR can be easily detected and classified. Hence, automated system for detecting the DR will help the ophthalmologist to diagnose the patient easily in time rather than manual screening which takes enormous amount of time for screening and detection of DR [6].
Apremature DR finding technique is acute for the deterrence of visualization impairment and also for its active treatment. The segmentation quality may varies based on the ability as well as the user experience and the quality of image. While performing the manual operation, about an hour could be taken for two eyes. In order to reduce the clinicians’ workload and to save the time, a fully automated system is introduced that segments the diseases in the retinal images [4]. In a retinal color fundus image, different structures are included such as fovea, optic disc, vascular tree, and red lesions, namely hemorrhages and MAs. Various cases of blindness exist in the world that owing to the DR problem and the primary symptom of DR is the exudates [35]. There are two types of exudates namely soft and hard exudates. At the NPDR, the exudates are found that is said to be soft exudates and the proliferative phase of exudates are termed as the hard exudates. Moreover, the retinal lesions and the landmark features are the two groups of the retinal features. The former is also known as the exudates, the micro aneurysm or the hemorrhage. The latter is also termed as the fovea, the blood vessels or the optic disc. The appearance of both these features are same [11]. In some fields such as recognition of patterns and bioinformatics, the feature selection is a difficult process and for their ability to increase the accuracy and to decrease the time required for computation [20].
Classification is one of supervised learning approach in which the input data contains the number of features. These features are categorized by the different classifier schemes. Using the input data, the classifier will be trained for constructing the classification which are suitable to the unidentified class data [12]. However, the input contains the number of irrelevant feature that can enhance the time taken for estimating and also disturb harmfully the classification exactness. The choice of optimal features will be a very active scheme in which efficacy and accuracy are enhanced [30]. Singular ophthalmicmaneuvers such as an ophthalmoscope, 20D lens, and fundus camera are used by doctors in the retina inspection. To identify eye infections, fundus cameras are extensively applied along with their digital imaging features owing to the informal storage, enhanced quality of image, and quicker electronic transfer. Still, the retinal imaging using fundus camera consume more time and procedure is manual [18]. To capture a retinal image, the expertise is needed and also it may take few days by the expertise to submit an expert evaluation report. However, a widespread screening is done by the fundus cameras. These fundus cameras are inconvenient tools and difficult to be bought by each fitness clinic, because too costly, it is heavy to be transported and the size is too large [33]. Moreover, it is very difficult to discover the apparatus and knowledge in rural zones that have a high diabetes degree [33].
The lack of apparatus is the key obstacle to premature analysis of DR as emergent states suffer from high DR fractions. In addition, the rural area’s patients may not have access to the existing diagnosis devices, named fundus cameras. An ophthalmologist take 1–2 days for image analysis, even if they have enough equipment [14]. Therefore, there is a growing demand for computerization of sensing such eye illnesses and inexpensive and portable smartphone-based devices. A smartphones are mostly applied for the current technologies to make the low-power, small-sized and reasonable biomedical structure. Also, these structures applicable for onboard processing and wireless communication [7]. Therefore, they create current approaches movable and small in various applications ranging from fitness care to performing the smartphone-based structures are most common. As fundus cameras are heavy-weight, high-price and large-size devices, they are a better applicants to be converted into a movable device for executing the fast DR screening [13]. In the developing research field, the new movable retinal imaging structures have been introduced in various industries based on the smartphones.
Diabetes is caused by an increment of blood sugar level and is one of the most chronic and deadly diseases. Many difficulties were raised due to unidentified and untreated diabetes. Consulting the doctor and visiting the clinic resulted by identifying the process considered as tedious work. With the rise in the approaches utilized by the ML solved this tedious work. Lots of people suffering from diabetes because of rising tedious work day by day. Before disease analysis, most of the patient not knowing their health condition and the difficulties. The foremost difficulty is to refine or resolve the correctness of the prediction model. The automated system of fundus images can reduce the burden of health structure for a DR screening due to a lot of people rise with diabetes, the lack of trained retinal authorities and graders of retinal photos. Nowadays, ML based approaches have been developed for the investigation of retinal images with diabetes.
The main contributions of the article as follows:
-
To develop new effective schemes for DR severity classification using smartphone based retinal imaging system.
-
To design the new DIY smartphone enabled camera using available materials for smartphone based DR detection.
-
To detect Optic disk, Exudates, Microaneurysms, Haemorrhages, and IRMA using watershed transform and THFB methods for the segmentation process.
-
To project a new meta-heuristic optimization algorithm named as LCBO for an optimal feature selection
-
To design new optimized hybrid machine learning architecture with the combination of NN and DCNN for smartphone based DR classification in which the SSD algorithm is introduced to find the optimal weight values of hybrid ML classifier.
-
This new optimized hybrid classifier enhanced the overall classification accuracy for the smartphone based DR detection.
The organization of the article is defined as trails: Section 2 describes the related works. Section 3 provides the proposed work of smartphone based retinal imaging structure. The simulation outcomes and discussions are mentioned in the fourth section. Lastly, the conclusion and scope of future works are presented in the fifth section.
2 Related work
A smartphone-based retinal imaging structures using deep learning (DL) architectures was presented by Mahmut et al. [19] in DR detection. To enhance the DR recognition performance, the different structures like GoogleNet, CNN-based AlexNet, and ResNet50 were used. The DL structures were compared and also analyze the influence of FoVs in smartphone-based retinal imaging structures to enhance the accuracy of DR discovery. In the result of DR detection, the ResNet50 structure provides the best performances in terms of exactness, sensitivity and specificity.
In India, a smartphone based fundus imaging was introduced by Maximilian et al. [15] for a DR screening. Here, the four several methods were analyzed with respect to the quality of image and diagnostic accuracy for the screening of DR. As related to the fundus camerawork and medical inspection, diagnostic accuracy, quality of image, examination time and field of-view were examined in the DR screening. In the outreach structure, the DR screening necessities were satisfied by the Smartphone-based fundus imaging. Even though not all devices were appropriate for the diagnostic accuracy and quality of image. In small and centralrevenuestates, the problem of DR screening could be reduced by the smartphone-based fundus imaging system. For DR screening, this outcomes were permitted for the superior choice of SBFI devices.
Convolutional neural network (CNN) was discussed by Sarah and Uvais [23] for the smartphone based DR severity classification. To detect the portions of retina, the different 4 classifiers like VGG16, Resnet50, InceptionV3 and DenseNet121 approaches were analyzed using retinal fundus Kaggle dataset. Moreover, the various image processing approaches were analyzed and utilized different hyper component tuning to make a better design. To forecast the severity of retinal fundus images, this model was employed in the android application and further it could tested in medical surroundings.
Using a handheld smartphone-based camera, a DR screening was discussed by Jacira et al. [28] in metropolitan primary care setting. The training of non-specialized healthcare workers, telemedicine and a handheld maneuverwere included in the possibility of a small cost DR screening approach. Such procedure was well-matched with the family health approach and the capable to enhance the DR screening coverage in underserved regions. For the DR screening in the situation of the COVID-19 epidemic, the likelihood of mobile units were applicable as the alternate to clinical inspection. The main target was to offer well-timed action for identified cases of sight-threatening DR and cataract.
For the identification of sight-threatening DR (STDR), an exactness of the smartphone-based non mydriatic (NM) retinal camera was introduced by Prathiba et al. [31]. For the DR recognition and STDR in a tertiary eye care facility, the sensitivity and specificity of smartphone-based NM camera were analyzed. The better quality could offered by the smartphone-based NM camera and provides high performances in terms of sensitivity and specificity for the STDR recognition. It does not require high technical skills for the handheld cameras and it was substantially lighter in contrast to desktop cameras. For DR detection, the low-cost smartphone-based nonmydriatic camera could probably utilized as a screening tool in rural areas in the low-and middle-income countries.
3 Proposed methodology
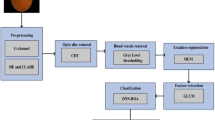
DR damages the blood vessels in the retina and deliberated as the difficulty of Diabetes Mellitus. In most of the diabetic subjects, this DR categorized as a thoughtful vision-threatening issue. In the medical field, the efficient automatic classification of DR is an interesting task. In this article, the new effective DIY smartphone enabled camera is introduced for the smartphone based DR detection. The new portable ophthalmoscope is designed in which a smartphone, retinal lens and frame among them are included to assist patients take fundus images anywhere and anytime. The proposed method involves various processes namely preprocessing, segmentation, feature extraction, feature selection and classification as shown in Fig. 1.

Proposed Methodology of DR Detection
To resolve the shortages in images like poor contrast, low quality and distortion, a pre-processing is used to provide the improved images which are more applicable for informal and perfect mining of valuable data. These shortages are generated due to the unsuitable lighting and focusing. CLAHE Algorithm and Green Channel Extraction are used in the pre-processing stage. To enhance the image brightness, the most popular scheme of CLAHE is utilized. Due to the high contrast, the abnormalities are clearly visible in the green channel conversion. Also it provides the extreme local contrast among the foreground and background than the gray scale image which provides only the luminance data from the color image after removing the hue and saturation. For the segmentation process, the WT and THFB are utilized to detect the optic disc, Exudates, microaneurysms, haemorrhages, and IRMA. In the field of topography, the watershed transform is the most popular scheme and it is widely applied for the morphological segmentation. The segmentation can be accomplished properly once the marker is mined accurately. It is a fast, simple and intuitive scheme. This method delivers closed contour and it needs small computation time and also it is capable to achieve whole divider of the image. Another segmentation scheme is Triplet based method. This approach provides the low computational complexity and it is possible for several applications. This kind of segmentation fulfills perfect reconstruction and it delivers regularity, linear phase, near-orthogonality, better time- frequency localization and frequency-selectivity. Further, Haralick and ADTCWT features are mined. Based on the second-order statistics, the Haralick features are utilized, and the directional features are extracted via the ADTCWT in images. Then LCBO algorithm is used to select the optimal features for the feature selection process. This optimizer utilized the two features such as exploration and exploitation. The general competence of this algorithm is extremely reliant on these two features.
This two features are significant because the enhanced exploration leads to local optima avoidance and the enhanced exploitation leads to fast convergence to optimum solution. Hence, for a better optimization algorithm, there must occur a balance among exploration and exploitation. These selected features are given to the hybrid machine learning algorithm with the combination of NN and DCNN. A deep learning scheme of DCNNs can be applied to provide the target result prediction. Using the fundus images, the possibility of DCNN to perfectly identify and categorize the DR. Traditional ML and DL structures are only weakly inspired from the human brain. Therefore, hybrid machine learning model is introduced. In the hybrid classifier scheme, the SSD is used to choose the ideal weights. The main aim of SSD is to decrease the intricacy and enhances the speed of convergence, therefore, in the hybrid machine learning model SSD algorithm is utilized to enhance the classification performance. Finally, this optimized hybrid classifier to classify the severity levels.
3.1 DIY smartphone enabled camera based retinal imaging systems
The eye specialist uses a fundus camera for the analysis and detection of diabetic retinopathy. But, it is very big, expensive, limited in number and only skilled operators can manage it. Therefore, a low-cost handheld indirect ophthalmoscope is needed, which is personally activated with little practice. Now, in our life, mobile phones/smartphones have become an important item. Because, anybody can bring it to any location at any duration, perform multiple operations, handy, simple, and it is very profitable. For medical examination and application like in ophthalmology as imaging devices, this affected a great interest on a mobile phone. For the smartphone-based retinal imaging systems, the new cost-effective DIY (do it yourself) smartphone-enabled camera is used in this article.
The available materials for DIY smartphone enabled camera [8] is shown in Fig. 2. Here, 1 denotes the smartphone and its hard back cover. 2 denotes the condensing lens (20D) and 3 defines the PVC pipes. Here, 17 cm long and 50 mm diameter pipe is used for optical tube, and 10 cm long and 40 mm pipe is used for slit lamp mount. Then 4 denotes the reducer base in which large is 50–65 mm and small (2 numbers) is 35/45 mm. 5 denotes the superglue and 6 defines the 3 mm cardboard. Here 2 pieces cardboard is required to measure 12 × 6 cm each. 7 denotes the 8 mm/6 mm bolt with matching hexagon and washer. Then 8 denotes the black sandpaper and 9 denotes the electrical insulation tape. At last, number 10 denotes the scissors, a ruler and mica cutter.

Materials of DIY Smartphone Enabled Camera [8]
3.1.1 Assembling the DIY smartphone enabled camera
The huge reducer base is aligned and centered on the camera hole of the smartphone cover. The region of interaction of the reducer and shield are pasted. The optical tube is the 50 mm pipe. A 17 cm × 14.8 cm smooth piece is inserted and rolled into the pipewhich is glued, and also to prevent the dazzle, the sanded surface facing inward. Toward the wider end, additional 15.5 cm × 2 cm rub is pasted within the reducer base leaving 1.0 cm plain region. To camouflage the reducer base and the optical tube, insulation tape is used. For the condensing lens at one end, the 8–12 rounds of tape is applied for warm fit of the lens. The handheld device is ready when the phone is located in the cover. The optical tube is implanted into the reducer with 20D lens. A longer optical tube is mostly used for phones. Here camera centers and flash are separated away from 1 cm.
3.1.2 Assembling the slit lamp mount
By the way of a scissor and pointed knife/Mica cutter, the hole is created on every cardboard to fitting the bolt which placed at 2.5 cm from one of its boundaries. On bolt, the nut is stiffenedand then in the cardboard pieces the bolt is distributed by holes and tightened. Then pasted the washer, and placing the interior loop on the bolt at the underneathoutward of the boards. For the slit lamp mount, the platform is created by the two cardboards are pasted together. Around the nut the glue is used as illustrated in Fig. 3a. With its broader area facing up at the reverse edge, the small size of reducer is pasted on the platform as displayed in Fig. 3b. As illustrated in Fig. 3c, the 10 cm long and 40 mm pipe is set to the reducer. At around two-third of its diameter, cut the 50 mm pipe is diagonally with the length of 10 cm. Theminor part is eliminated for the optical tube holder. The higher piece is pasted to the additional minor reducer on to its thinner end with its concave surface facing up as displayed in Fig. 3d. As illustrated in Fig. 3e, the mount is arranged. The patients’ eye is faced by the smaller portion of the optical tube holder. With the insulation tape, the mount is masked.

CutLamp Base. (A) The Nut, Bolt, and Washer in Place. (B) Reducer Is Static. (C) Set 40 Mm Pipe. (D) Optical Tube Container. (E) AmassedMount. (F) Bolt Located In the Slot. (G) The DIY Smartphone Enabled Camera on the Slit Lamp [8]
3.1.3 Using the DIY smartphone enabled camera
The columns of observation illumination are moved to the one side for utilizing the DIY smartphone-enabled camera and the mount is set by positioning the bolt in the slot to concentrate rod as illustrated in Fig. 3f. For the slot, the various diameters are included in the numerous slit lamps. The stability is enhanced by some sequences of padding tape on the bolt for the slit lamps with higher diameter slots. The optical tube is positioned on the holder. By the way of the joystick, the DIY smartphone-enabled camera is employed as like a fundus camera as illustrated in Fig. 3g in the nonstop flash on mode with the camera. The images are perpendicularly reversed and horizontally inverted in indirect ophthalmoscopy. Hence, the actions to support the arena of view in the opposite way to the images. The camera is employed in the video or photo mode and one can hold the camera or the optical tube or the 20D lens in the handheld scheme as illustrated in Figs. 4a and b. Along with concurrent scleral depression, imaging of the outer retinal till pars plana is conceivable in video mode as illustrated in Fig. 4c.

(A) DIY Smartphone Enabled Camera Employed As a Hand Held Device. (B) DIY Smartphone Enabled Camera Can Be Held At The Contracting Lens And Maintained With The Other Pointer On The Camera. (C) After Stabilizing the DIY Smartphone Enabled Camera, Scleral Depression Is Done Like In Indirect Ophthalmoscopy [8]
For elementary fundus photography, in the smartphone, the camera app is preloaded which is morally sufficient. For android and camera plus for iPhone, Cinema FV-5 and Camera FV-5 are employed. Along with different choices like exposure lock and focus lock, the extra control is offered by these apps on the capture of images. The cost-effective quality fundus images are offered by the DIY smartphone-enabled camera. With scleral depression, it is proficient in imaging up to the pars plana. Along with the DIY smartphone-enabled camera, the stereo fundus photography of the peripheral and the central retina are conceivable.
In retinopathy of prematurity and in disabled patients one of the cost-effective alternative for documenting the fundus variation is the DIY smartphone enabled camera. Even though, it is helpful for the documentation, the fundus camera replacement is not intended by this system particularly in macular imaging. The macular information with high resolution is provided by the fundus camera through the better-quality as well as reflex free imaging. At the time of learning curve, the device is stabilized by holding the 20 D lens and the phone with two hands respectively. If this method is well-known, then hold the device with 20 D lens in one hand along with optical tube resting inside index finger and thumb’s web. Hence, in the proposed method, the DIY smartphone enabled camera is used for the DR detection. However, there is no accessible real data captured by the DIY smartphone enabled camera device in the literature. Therefore, we generate retina images by simulating the field of view for a device using the retina images from APTOS-2019-Blindness-Detection, and EyePacs datasets.
3.2 Preprocessing
In medical analysis, the medicinal fundus images are mostly applied in the recent decades to detect the retinal disorders. Due to the low contrast problems, the fundus images are commonly affected. In fundus images these problems create it challenging for ophthalmologist to identify and understand diseases. Hence, for the quality improvement the necessity of preprocessing step is important. At first, the retinal fundus images are considered as the input in the preprocessing and it executes the green channel conversion and CLAHE [3] process to enhance the image contrast.
3.2.1 Green Channel conversion
Generally, RGB image contains three channels like red, green and blue. The RGB image is taken as the input fundus image that are transformed into the green channel image. Usually, RGB images are low contrast. Green channel images are high contrast in which the abnormalities are clearly detected.
3.2.2 CLAHE
To enhance the image brightness, this approach is more suitable. The procedure for enhancing the image contrast by CLAHE method is described below.
-
1)
All image is separated into the number of non-overlapping backgroundareas with an identical dimension of 8× 8 blocks. The region of 64 pixels are denoted by every block.
-
2)
For each contextual region, the histogram of intensity is computed.
-
3)
To alter the image brightness the threshold constraint is used in effective manner. Here the clip limits are fixed to clip the histograms. Using the higher clip limits, the local image brightness is improved therefore it should be fixed to a minimum optimum value.
-
4)
All histogram is changed by choosing transformation purposes.
-
5)
All histogram is altered by not beyond the selected clip limit. Using CLAHE method, the changed gray levels with uniform distribution is given by:
Here, the maximum pixel is signified asgrmax, the lowest pixel value is defined asgrmin, the computed pixel value is defined asgrand the value of CPD is denoted asPD(f). Using eq. (2) the gray level is computed to enhance the exponential distribution. Here the clip constraint is denoted asα.
-
6)
The neighboring tiles are combined with the help of bilinear interpolation. Based on the altered histograms, the image grayscale values are modified.
Finally, the preprocessed image is further applied to watershed transform to detect the optic disc.
3.3 Segmentation
Different elements like blood vessels, optic disc, fovea and macula are included in the retinal image. The procedure of dividing and investigating these elements for efficient feature extraction is termed segmentation. Hence, the segmentation process is more challenging if the retinal is affected with diseases and creates to display pathological signs. Therefore, in this work the watershed transform (WT) and THFB methods are applied to detect the optic disc, Haemorrhage, Microaneurysm, Exudates and IRMA.
3.3.1 Optic disc segmentation using watershed transform
Various hemorrhages are parallel in color and size of optic disc. For this reason, optic disc segmentation plays a major role for the red lesions detection. Hence, WT controlled with markers is employed to detect the optic disc from the fundus images. Generally, the watershed algorithm [24] is utilized along with gray scale image. Therefore, this process is directly applied on the preprocessed gray scale fundus image. Various stages like morphological gradient (MG), marker-controlled watershed segmentation (MWS), erosion and dilation based gray scale image reconstruction are included in the WT method for the segmentation of optic disc.
Mg
At first, the gray scale image is altered into the gradient image and it denotes the pixel boundary quality. To adapt each pixel to the non-edge or edge point, the limit is fixed with an exact target. To accomplish higher robustness to noise, a multiscale gradient procedure is employed. The review of the images with various size arranging components are denoted by the term multiscale. The incorporation of MG has strong acceptance to noise in various scales and it mines a types of distinction of the boundaries.
Here, the disc arranging component is denoted as b with 3 pixel radius and the gray scale image is represented asI.
MWS
For sectionalisation of object with protected frameworks, the WT controlled with marker is most significant approach. This scheme is more efficient for the reduction on segmentation of gray scale image when one identifies in what manner to place marker within the image. The binary image contains large regions or isolated points which are included in the marker image applied watershed segmentation. All attached marker is placed within the object. Each marker contain synchronized relationship to watershed region. Therefore, the amount of marker is corresponding to the final bit of watershed region. Then the internal and external marker is created after creating MG of gray scale image.
Erosion-based gray-scale image reconstruction
Along with short flat arranging componentDthe morphological restoration of I8from the marker fis given by:
Here, the conditional erosion is denoted as\( \left(f{\varTheta}_{I_8}D\right)=\left( f\varTheta D\right)\vee {I}_8 \). The nconditional erosion is given by:
Dilation-based gray scale reconstruction
Along with short flat arranging componentDthe morphological reconstruction of I8from the marker fis given by:
Here, the conditional dilation is denoted as\( \left(f{\oplus}_{I_8}D\right)=\left(f\oplus D\right)\wedge {I}_8 \). The nconditional dilation is computed by:
Here, using the connectivity specified by the arranging componentD, the endless restoration of I8 from the markerfis denoted asI8ΔDf. The pixel wise least among two images is defined asI8 ∧ f. The pixel wise maximum among two images is represented asI8 ∨ f. After that, the regional maxima is employed in the resulting image. To generate the internal marker, the restoration by opening can considered. In the unique image, the interior marker is superimposed. Around the optic disc of predefined radius centre, the external marker is generated. To detect the optic disc, the WT method is employed in the superimposed image. Due to the external marker, the optic disc is only separated from gay scale image.
3.3.2 Abnormality segmentation using THFB
Using the THFB approach, the different abnormalities like Haemorrhage, Microaneurysm, Exudates and Intra Retinal Microvascular Abnormalities (IRMA) are identified. The class of equivalent three half-band filters based on the investigation and synthesis LPF (low pass filter) are computed as [22]:
Here, three half band filters are denoted asQ0(a), Q1(a)andQ2(a). These filters are approximate as 0 in the stopband and 1 in passband. The constraint qprovide the flexibility to choose the magnitude atω = 0.5π. Similarly, by the subsequent equation the analysis and synthesis HPF (high pass filter) are accomplished.
At last, the segmented abnormalities are given to the feature extraction process.
3.4 Feature extraction
For an efficient classification of disease, this process plays a major role that improve the effectiveness of the entire structure. From the segmented abnormalities the various features are mined using the Haralick and ADTCWT methods [10] in this process.
3.4.1 Haralick features
Using the Haralick method, 13 textural features are mined from the symmetric GLCM (grey level co-occurrence matrix). At a specific distance in the allotted direction, the intensity correlation among two pixels are denoted by these features in an image. GLCM provide the periodicity, inter-pixel affiliation and the spatial grey level addictions. For every GLCM, 13 Haralick features are mined in the developed approach. In four directions like 00, 450, 900, and 1350, GLCM approach is described that provides 4 × 13 features for all images.
3.4.2 ADTCWT features
For a classification of DR, the image texture features are not adequate in the time domain because it consists of hidden frequency data. The frequency and spatial information are utilized by the wavelet transform. Using the ADTCWT method, the wavelet features are mined from the segmented images in the developed scheme. The sub bands are disintegrated into horizontally or vertically only in anisotropic decomposition (AD). Also, the DTCWT sub bands are maneuvering. The combination of AD and DTCWT named as ADTCWT provide the maneuvering and anisotropic base purposes. In the developed approach, for the feature extraction 10 sub bands of ADTCWT are employed. For the classification process, from these 10 sub bands the homogeneity (H) and energy (E) based texture feature are mined. Since, for texture analysis, the method of GLCM is most efficient tool and also the advantage of shift invariance and multi-directionality are offered by the ADTCWT approach. These two feature extraction approaches provide all essential features from the segmented images.
3.5 Feature selection using life choice-based optimizer (LCBO)
In the developed approach the new optimization algorithm is introduced to pick the optimal features from the different features that provide high classification accuracy and also avoids the redundant and unwanted features that reduce the accuracy performance. The algorithm to create fast computation and provide better classification. The LCBO algorithm is used to choose the optimal features. The human being life cycle and his work ethics for the duration of active life are described in the LCBO algorithm [1]. Here a persons has various goals and objectives to accomplish and also a person is encouraged. It is significant that human is really the utmost knowledgeable species, smarter and strategic. Human continuously procured creativeness from nature and thus erudite novel things. The subsequent three stages are described in the LCBO procedure.
Learning from the common best group
By few personality or colleague mates, whether it is his/her senior and one thing or the other, human is continuously encouraged. To accomplish goals, he/she considers and studies about in what way the top people to generate the approach in the field work if a person has few goal in sight. To accomplish goal, from the finest in the fields He/she continuously attempts to yield a little resourceful and also through detecting the effectiveness of the higher person’s a constraint or pattern is derived. Therefore, to resolve the issue or to obtain the goal a few skills are developed by Him/her. The learning from the finest feature for a specified populationXwith minimum fitness values is given by:
Where, the value of kis varied from 1 ton. Here, the constraint is denoted as n which is identical to ceil of the square root of the inhabitants. The current search agent (SA) is denoted asXjand the updated current SA is denoted as\( {X}_j^{\prime } \)if \( {X}_j^{\prime } \) has improved fitness thanXj.
Knowing very next best
Every person needs to accomplish his/her goal, like buying a dream car or obtaining the dream job, but to achieve big goal or dream, it consumes lot of time and persistence. One must be capable to understand the present location and the actual nearby goal in sight rather than totally concentrating on enormous goals. From the present location one also desires to comprehend how to move to a superior location. Hence, the present goal should be ordered. So, to accomplish upcoming targets there is a necessity to concentrate on last endpoint and on the very next endpoint. By the subsequent expressions, this procedure is executed.
Here, the constant is denoted asr1 and its value is 2.35. The value of f1and f2 are linearly varied from 0 to 1 and 1 to 0 individually. The SA location is denoted as Xj − 1 and their fitness is superior as related to present SA till the earlier iteration. The finest location of SA is defined as X1and it has been accomplished till the earlier iteration. If \( {X}_j^{\prime } \) has well fitness thanXjthe location of Xjis updated to\( {X}_j^{\prime } \).
Reviewing mistakes
Human take the natural intellect to analysis things and ensure suitable analysis of the method when persons are jammed anywhere or the method they have been employing to resolve the issue below consideration is not functioning. They are also able to perform things to assess and approach the issue in an entirely dissimilar way. Moreover, it enhances the exploration stage by trying to look at things from a totally dissimilar standpoint.
The Avi escape method is described in Eq. (17) and also it employed as the generalized approach for the enhancement of exploration stage. The maximum and minimum boundary values are defined as Xmax and Xminindividually. The present agent is denoted asXj.
Objective function
In this process, two objective functions are employed for the classification of DR. The main one concentrates on the minimization of the correlation among the features and another one concentrates on the minimization of the error variance among the forecast and goal result of classification. At first the features are chosen using LCBO that reduce the correlation among the features. This process provide the more accuracy if the correlation among the features is minimum. For the two features a and bthe correlation is computed as:
Here the amount of feature pairs is represented asNP. The forecast output is defined as Beand the actual output is denoted asAe. The error function can be computed as:
Therefore, the fitness function of the LCBO based feature selection is to reduce the correlation among features and the classification error. The fitness is computed by:
Using the LCBO, the fitness function is computed in the feature selection procedure, therefore the better accuracy is accomplished.
3.6 Hybrid NN-DCNN with SSD based DR classification
In this section, the new optimized hybrid ML classifier named as SSD based NN-DCNN is used for the classification of DR. This is the combination of proposed SSD algorithm with NN and DCNN classifier. The aim of SSD algorithm is to determine the optimal weight values of NN-DCNN classifier. Finally, this optimized hybrid classifier to classify the severity levels for the accuracy enhancement of DR classification.
DCNN
The chosen features are considered as the input to the DCNN for the classification of DR. Three layers are included in DCNN such as convolutional (conv) layer, pooling (POOL) layer and FC (fully connected layer). From the common NN, the DCNN is varied because the single neuron is associated to other in NN. But in the DCNN the patch of neurons are associated in the consecutive layers with the neurons. In DCNN, the distinct layers execute their own task of obtaining the narrow features, sub-sampling and classification.
Conv layers
The confine features hidden in the input feature vector are obtained using this layer and also the in this layer the conv filters are used to the input. By the accessible fields the input features are given to the subsequent layer and the connection to the consecutive layers which are empowered with a set of the trainable weights. Along with the convolutional operator, the conv layer function is connected. Here, with the kernel filter the input data is convoluted and the optimal weights are computed by SSD. The set of confine features are obtained at the outcome of every set of the layers. These are considered as the input to the consecutive layers of conv units. In DCNN, the h amount of conv layers are considered. These layers are linked with the classification accuracy. In DCNN, the accuracy is directly relative to the entire amount of the conv layers. Therefore, the athconv layer output is computed as:
Here the convolutional operator is denoted as*. From the input of the earlier conv layer, the local patterns are mined by the conv layera. The fixed feature map is defined as\( {\left({c}_f^a\right)}_{P,Q} \)and also from athconv layer it marks the output which is placed at(P, Q). The output from the preceding (a − 1)thconv layer is taken as the input to athconv layer. The weight and bias of athconv layer is signified as\( {\chi}_{f,{d}_1}^a \), \( {B}_f^a \) individually. Assume the hamount of conv layers and its representations such asd1, d2, and d3that signify the feature maps. By employing the conv filter to the input feature vector, the output of the feature maps are achieved from the distinct conv layers. To mine the features in all the dimensions, the neurons obtainable in the conv layers are prearranged in 3-dimensions with its depth, width and height. Then the conv layer output is applied to the ReLU layer. The output of ReLU layer is computed by:
For the classification, the confine features are mined by the speed of deep CNN. The capability is enlarged by the ReLU to handle with large amount of the layers in the classifier.
Pool layers
POOL layer is the non-parametric layer without considering any weight or bias to hold the stable procedure.
Fully connected layers
In this layer, the classification is executed. Here the confined features are obtained from the features by conv layers. To define the DR severity the classification of the features are empowered by the classification at FC layer. The output of this layer is computed as:
NN
This network is most famous structure in numerous applications for the classification because it is flexible. The hidden layer output is computed as:
Here, the amount of input neurons is signified asn, \( {w}_{(Hl)}^{(A)} \)is the bias weight to the hidden neuron, \( {w}_{(kl)}^{(A)} \)is the weight from input to hidden neuron, the chosen features are denoted as χand ACFis the activation function. The entire network output is computed as:
Here, mis the amount of hidden neurons, \( {w}_{(Hm)}^{(B)} \)is the bias weight to the output neuron, and\( {w}_{(lm)}^{(B)} \)is the weight from hidden to output neuron. In the hybrid NN-DCNN classifier, the perfect classification of the DR is only depends on the biases and weights. Therefore, the SSD algorithm is introduced to obtain the weights and biases of hybrid NN-DCNN classifier.
SSD
This new SSD [2] algorithm does not need memories and it takes low speed complexity. Moreover, the algorithm provides best outcomes than other algorithms. The procedures of SSD is given below.
-
The agents’ locations are denoted asXi ∈ Rn. Here, the dimension number is signified asn. The objective functions are calculated by the agents’ location at these points. These locations are arbitrarily set.
-
The prior finest location is denoted asPi. For each agent, the fitness is estimated using the fitness function. The estimated fitness is related for every agent with its present location and the finest locations is kept.
-
The mean of finest three solutions is signified asMiand it is computed by:
Here, the finest three solutions are denoted asXa, Xy andXz.
-
The agents’ velocity is represented asVi. The locations of the agents’ is updated by adding Vi as given in Eq. (27). The velocity of agents’ is arbitrarily set and it is updated as Eq. (28).
Here,
Here, the velocity of Xiis signified asVi. The arbitrary numbers are denoted asr1and r2that lies among 0 and 1. The finest solution of ith agent is signified asPi, for an entire inhabitants the mean global solution is represented asMi, and the constraint cis employed to create a stability among exploitation and exploration, and it is estimated as: ct + 1 = αct. Here, the present iteration is defined astand the value of cis decreased by0 < α < 1.
4 Results & discussions
The proposed DR detection methodology is implemented by python environment and the performance of suggested scheme is evaluated. To test the effectiveness of the proposed scheme, the datasets such as APTOS-2019-Blindness-Detection, and EyePacs are employed for the performance evaluation. The different performance metrics such as sensitivity, specificity, accuracy, NPV, FNR, FPR, MCC, F1-score, FDR and precision are computed for the proposed method and it compared to the individual NN, DCNN, and DCNN with NN. The k-fold cross validation is employed in this work. The data samples are separated into a k-folds and every fold is employed as the testing at the particular point. The k value is fixed to 10 and this process is repeated 10 times.
4.1 Dataset description
In this work, the two different dataset like EyePacs and APTOS-2019-Blindness-Detection are applied for the performance evaluation. For each dataset, 70% images are employed for training process and 30% images for testing process. For both left and right eyes, there are 35,126 retina images are presented in the EyePacs dataset. Five stages of DR or the severity level 0 to 4 presented in the dataset, where, no DR indicated by 0, mild DR represented by 1, moderate DR is represented as label 2, severe DR is denoted by label 3 and proliferate DR is represented as label 4. APTOS-2019-Blindness-Detection is another dataset, produced by the Asia Pacific Tele-Ophthalmology Society (APTOS) as portion of the 2019 blindness finding competition. 3648 high resolution fundus images were selected from the Kaggle dataset of 3661 images by different designs and cameras type in manifold health center on the lengthy time period. Images were scored on 0 to 4 scale (No DR-0, Mild-1, Moderate-2, Severe-3, and Proliferate-4). The 10 fold cross validation is applied for each dataset. The entire samples are separated into 10 several subsets. In every time, the nine sub sets are considered for the training process and the remaining one is considered for the testing process.
4.2 Performance metrics
In this work, the various performance metrics are employed to compute the performance of the suggested approach. The description of each metrics are described below. Here, true positive (TP) and true negative (TN) are denoted asAPandANindividually. Similarly the false positive (FP) and false negative (FN) are denoted asBPandBNindividually.
Accuracy
It defined as the fraction of observation of accurately forecast to the entire observations.
Sensitivity
It computes the amount of TPs that are properly predicted.
Specificity
It estimates the amount of TNs that are correctly recognized.
Precision
It defined as the fraction of progressive comments that are recognized properly to the entire amount of comments that are absolutely recognized.
F1-score
It estimates the harmonic mean among sensitivity and precision.
False positive rate (FPR)
It defined as the fraction of amount of FP forecasts to the whole amount of negative forecasts.
False negative rate (FNR)
It is the fraction of positives that provide negative test outputs with the test.
Negative predictive value (NPV)
It is the likelihood that focuses with a negative screening test truly doesn’t have the disease.
False discovery rate (FDR)
It defined as the amount of FPs in all of the excluded assumptions.
Matthews’s correlation coefficient (MCC)
It defined as the correlation coefficient estimated by four values.
4.3 Performance analysis
In this article, DIY smartphone enabled camera is used for the smartphone based DR detection. At first, the low cost DIY smartphone enabled camera is described. Further, the preprocessing, segmentation, feature extraction, feature selection and classification are performed by the efficient approaches for the smartphone based DR detection. In this work, the new optimized hybrid ML classifier named as NN-DCNN-SSD is proposed for the DR detection. This optimized hybrid approach enhances the overall accuracy of DR detection. The different performances are evaluated and it compared to the individual NN, DCNN and NN-DCNN methods and also the proposed work is compared with the different existing approaches. The performances are evaluated using the datasets like EyePacs and APTOS-2019-Blindness-Detection. The simulation results proved that the proposed work is provide the better outcomes for all the performance metrics as related to other existing methods.
For each dataset, the performances are evaluated and it compared with other schemes. The proposed method obtained 98.9% accuracy for EyePacs dataset and 99% for APTOS-2019-Blindness-Detection dataset which are maximum than other approaches. The confusion matrix of the proposed method using two datasets is shown in Fig. 5. For each dataset, the confusion matrix is computed for the suggested scheme. It can effectively categorize the different phases of DR like normal, mild, severe, moderate and proliferative. For each category, the confusion matrix is computed using the two different datasets. In each category, some images are properlyforecast and other remaining images are wrongly forecast. For example, in EyePacs dataset, 97 proliferative DR images are properly predicted as proliferative DR and remaining proliferative DR images are wrongly predicted as severe (3), moderate (2), mild (1) and normal (1). Similarly for APTOS-2019-Blindness-Detection dataset, 196 proliferative DR images are properly predicted as proliferative DR and remaining proliferative DR images are wrongly predicted as severe (2), moderate (1), mild (1) and normal (0). Therefore, from the analysis, the proposed method achieved highest accuracy for each dataset as related to other approaches.

Confusion Matrix of the Proposed Method Using (A) Eyepacs and (B) APTOS-2019-Blindness-DetectionDatasets
The comparison performances of accuracy and sensitivity are illustrated in the Fig. 6. Using the two datasets like APOTS 2019 and EyePacs, the accuracy and sensitivity performances are evaluated for the proposed and existing methods. The proposed (NN-DCNN-SSD) method given the highest performances as related to other individual methods like NN, DCCN, and DCNN-NN. Because the proposed work using the optimized hybrid approach with the combination of NN and DCNN with SSD algorithm. The SSD algorithm enhance the training speed of the hybrid classifiers and also provide the optimal weight values. Therefore, this optimized hybrid classifier enhances the accuracy and sensitivity performances for each dataset in the proposed scheme than other individual approaches. The proposed method achieved 99% accuracy for the EyePacs dataset and 98.9% for the APOTS 2019 dataset which are highest than other schemes.

Performance Evaluation for (A) Accuracy and (B) Sensitivity
The performances of specificity and precision are shown in the Fig. 7 for the proposed and existing methods. The performances are computed using two datasets. The proposed method obtained the maximum performances in terms of specificity and precision as related to other individual method like NN, DCNN, and DCNN-NN. For each dataset, the suggested method obtained the highest performances because in this work the optimized hybrid ML classifier is used for the DR detection. This optimized hybrid classifier enhances the overall classification performances than other approaches.

Performance Evaluation for (A) Specificity and (B) Precision
The performances of F1-score and NPV are illustrated in the Fig. 8. The suggested approach achieved the high performances than other individual approaches such as NN, NN-DCNN and DCNN. Using EyePacs and APTOS 2019 datasets the F1-score and NPV values are obtained for the proposed and existing methods. The existing schemes of NN, DCNN, and NN-DCNN are achieved the lowest performance than the proposed method. The high values are obtained in the proposed scheme for the performances of F1-score and NPV.

Performance Evaluation for (A) F1-Score and (B) NPV
Figures 9 and 10 shows the FPR, FNR, FDR and MCC performances of proposed method and existing approaches of NN, DCNN and NN-DCNN. For every dataset, the suggested method accomplished the highest values for the FPR, FNR, FDR and MCC performances as relate to other existing methods. Moreover, in this work, the optimization algorithm named as SSD is introduced in the hybrid classifier for the DR detection. This optimization enhanced the training speed of the network and provide the optimal weight values in the hybrid classifier. Therefore, the proposed methodology given the best performances in all the performance metrics than other current approaches. The suggested method accurately classify the different phases of DR. Hence, the developed system is well-suitable for the smartphone based DR detection.

Performance Evaluation for (A) FPR and (B) FNR

Performance Evaluation for (A) FDR and (B) MCC
Figures 11 and 12 represents the simulation results on each dataset. The results from EyePacs dataset and Aptos 2019 dataset from different techniques such as Green Channel conversion, CLAHE are described in these Figures. The original images are treated with Green channel conversion and CLAHE, and segmented images. From these analysis, we can identify the type of DR.

Simulation Outcomes of Green Channel Conversion, CLAHE, Segmented Images Using EyePacs Dataset

Simulation Outcomes of Green Channel Conversion, CLAHE, Segmented Images Using Aptos 2019 Dataset
Tables 1 and 2 provide the different performance comparison of the suggested method and the existing methods of NN, DCNN, and NN-DCNN using EyePacs and APTOS 2019 datasets. For each dataset, the various performances are evaluated. Using EyePacs dataset, the suggested method obtained 98.9% accuracy performance which is highest than other approaches. Similarly in the APTOS 2019 dataset the suggested scheme achieved the 99% accuracy which is maximum as related to other schemes of NN, DCNN and NN-DCNN. For each performance metrics, the suggested scheme obtained better performances than other current approaches.
Table 3 provide the different state-of-the-art comparison with the suggested approach using two different datasets like EyePacs and APTOS 2019. As compared to other articles, the suggested approach given the better accuracy performances for each dataset. The proposed scheme developed a new low cost DIY smartphone enabled camera is designed for the DR detection. In the suggested approach, the new optimized hybrid classifier is introduced for the smartphone based DR detection. The suggested work perfectly classify the different DR stages like normal, mild, severe, moderate and proliferative. The suggested method provide superior performances to other approaches. Therefore, the suggested method is more suitable for the smartphone based DR detection.
5 Conclusion
In this article, the optimized hybrid ML approach has been proposed for smartphone based DR detection. The new effective DIY smartphone enabled camera was designed for the smartphone based retinal imaging systems. At first, the green channel conversion and CLAHE methods were performed in the preprocessing step. Further, the optic disc segmentation was performed by watershed transform and abnormality segmentation was executed by THFB method. Using the Haralick and ADTCWT methods, the different features were mined from the segmented images. Then the optimal feature selection was performed by the LCBO algorithm. At last, the selected features were given to the optimized hybrid ML classifier named as NN-DCNN with SSD algorithm. Here, the SSD algorithm was applied for the optimal weight values of hybrid ML classifier. The overall approach was done by python environment. Two datasets such as APTOS-2019-Blindness-Detection, and EyePacs were utilized to check the efficacy of suggested method. The different evaluation metrics were evaluated for each dataset. The simulation outcomes proved that the proposed system offers better performances for each dataset as related to other existing approaches. In future, the classification stage may be enlarged using enhanced ML and DL methods with new different optimization algorithms for accomplishing the maximum detection rate.
References
Abhishek K, Gaba A, Rana KPS, and Kumar V (2020) A novel life choice-based optimizer. Soft computing 24(12):9121–9141.
Alaa T, and Gabel T (2020) Parameters optimization of support vector machines for imbalanced data using social ski driver algorithm. Neural computing and Applicationsn 32(11):6925–6938.
Ambaji JS, Patil PB, and Biradar S (2020) Optimal feature selection-based diabetic retinopathy detection using improved rider optimization algorithm enabled with deep learning. Evolutionary intelligence 14(4):1431–1448.
Aujih AB, Izhar LI, Mériaudeau F and Shapiai MI (2018) Analysis of retinal vessel segmentation with deep learning and its effect on diabetic retinopathy classification. In 2018 international conference on intelligent and advanced system (ICIAS), IEEE pp, 1–6.
Bajwa MN, Taniguchi Y, Malik MI, Neumeier W, Dengel A, Ahmed S (2019) Combining fine-and coarse-grained classifiers for diabetic retinopathy detection. In: Annual conference on medical image understanding and analysis. Springer, Cham, pp 242–253
Bhagirath TN, and Reddy DU (2020) Improving the accuracy of diabetic retinopathy severity classification with transfer learning. In 2020 IEEE 63rd international Midwest symposium on circuits and systems (MWSCAS), IEEE, pp. 1003–1006.
Bhavana S, Sosale AR, Murthy H, Narayana S, Sharma U, Gowda SGV, and Naveenam M (2019) Medios—a smartphone-based artificial intelligence algorithm in screening for diabetic retinopathy.
Biju R, Raju NSD, Akkara JD, Pathengay A (2016) Do it yourself smartphone fundus camera–DIYretCAM. Indian J Ophthalmol 64(9):663
Devi BJ, Veeranjaneyulu N, Shareef SN, Hakak S, Bilal M, Maddikunta PKR, Jo O (2020) Blended multi-modal deep ConvNet features for diabetic retinopathy severity prediction. Electronics 9(6):914
Gayathri S, Adithya KK, Gopi VP, Palanisamy P (2020) Automated binary and multiclass classification of diabetic retinopathy using Haralick and multiresolution features. IEEE Access 8:57497–57504
Hosseinzadeh KS, Kassani PH, Khazaeinezhad R, Wesolowski MJ, Schneider KA, and Deters R (2019) Diabetic retinopathy classification using a modified Xception architecture. In 2019 IEEE international symposium on signal processing and information technology (ISSPIT), IEEE, pp. 1–6.
Javeria A, Sharif M, Rehman A, Raza M, Mufti MR (2018) Diabetic retinopathy detection and classification using hybrid feature set. Microsc Res Tech 81(9):990–996
Kim TN, Aaberg MT, Li P, Davila JR, Bhaskaranand M, Bhat S, Ramachandra C (2021) Comparison of automated and expert human grading of diabetic retinopathy using smartphone-based retinal photography. Eye 35(1):334–342.
Mahmut K, Hacisoftaoglu RE (2020) Comparison of smartphone-based retinal imaging systems for diabetic retinopathy detection using deep learning. BMC bioinform 21(4):1–18
Maximilian WWM, Mishra DK, Hartmann L, Shah P, Konana VK, Sagar P, Berger M et al. (2020) Diabetic retinopathy screening using smartphone-based fundus imaging in India. Ophthalmology 127(11):1529–1538.
Omar D, Naglah A, Shaban M, Ghazal M, Taher F, and Elbaz A (2019) Deep learning based method for computer aided diagnosis of diabetic retinopathy. In 2019 IEEE international conference on imaging systems and techniques (IST), IEEE, pp. 1–4.
Peng WF, Saraf SS, Zhang Q, Wang RK, Rezaei KA (2020) Ultra-widefield protocol enhances automated classification of diabetic retinopathy severity with OCT angiography. Ophthalmol Ret 4(4):415–424
Ramachandran R, Subashini RK, Anjana RM, Mohan V (2018) Automated diabetic retinopathy detection in smartphone-based fundus photography using artificial intelligence. Eye 32(6):1138–1144
Recep HE, Karakaya M, Sallam AB (2020) Deep learning frameworks for diabetic retinopathy detection with smartphone-based retinal imaging systems. Pattern Recogn Lett
Rishi SP, Elman MJ, Singh SK, Fung AE, Stoilov I (2019) Advances in the treatment of diabetic retinopathy. J Diabetes Complicat 33(12):107417
Robiul IM, Hasan MAM, and Sayeed A (2020) Transfer learning based diabetic retinopathy detection with a novel preprocessed layer. In 2020 IEEE region 10 symposium (TENSYMP) IEEE, pp. 888–891.
Santosh Nagnath RS, Rahulkar AD, Senapati RK (2018) LVP extraction and triplet-based segmentation for diabetic retinopathy recognition. Evol Intel 11(1–2):117–129
Sarah S, and Qidwai U (2020) Smartphone-based diabetic retinopathy severity classification using convolution neural networks." In proceedings of SAI intelligent systems conference, springer, Cham. pp. 469–481.
Shailesh K, Adarsh A, Kumar B, Singh AK (2020) An automated early diabetic retinopathy detection through improved blood vessel and optic disc segmentation. Opt Laser Technol 121:105815
Shanthi T, SabeenianRS (2019) Modified Alexnet architecture for classification of diabetic retinopathy images. Comput Electr Eng 76:56–64
Sharmin M, Elloumi Y, Akil M, Kachouri R, and Kehtarnavaz N (2020) A deep learning-based smartphone app for real-time detection of five stages of diabetic retinopathy. In real-time image processing and deep learning 2020. International Society for Optics and Photonics 11401:1140106
Shidqie T, Handayani A, Hermanto BR, and Mengko TLER (2020) Diabetic Retinopathy Classification Using A Hybrid and Efficient MobileNetV2-SVM Model. In 2020 IEEE REGION 10 CONFERENCE (TENCON), IEEE, pp. 235–240.
Silva QM, de Carvalho JX, Bortoto SF, de Matos MR, Dias Cavalcante CDG, Silva Andrade EA, Giannella MLC and Malerbi FK (2020) Diabetic retinopathy screening in urban primary care setting with a handheld smartphone-based retinal camera. Acta Diabetologica 57(12):1493–1499.
Usman N, Khushi M, Khan SK, Waheed N, Mir A, Alshammari AQB, Poon SK (2020) Diabetic retinopathy detection using multi-layer neural networks and Split attention with focal loss. In international conference on neural information processing. Springer, Cham, pp 26–37
Valentina B, Lim G, Rim TH, Tan GSW, Cheung CY, Sadda SV, He MG (2019) Artificial intelligence screening for diabetic retinopathy: the real-world emerging application. Current Diabet Rep 19(9):72
Vijayaraghavan P, Rajalakshmi R, Arulmalar S, Usha M, Subhashini R, Gilbert CE, Anjana RM, Mohan V (2020) Accuracy of the smartphone-based nonmydriatic retinal camera in the detection of sight-threatening diabetic retinopathy. Indian J Ophthalmol 68:42
Xiaoliang W, Lu Y, Wang Y, and Chen WB (2018) Diabetic retinopathy stage classification using convolutional neural networks. In 2018 IEEE international conference on information reuse and integration (IRI) IEEE pp. 465–471.
Yannick B, Katte JC, Koki G, Kagmeni G, Obama ODN, Fofe HRN, Mvilongo C (2019) Validation of smartphone-based retinal photography for diabetic retinopathy screening. Ophthalmic Surgery, Lasers Imagin Ret 50(5):18–22
Yi Z, He X, Cui S, Zhu F, Liu L, Shao L (2019) High-resolution diabetic retinopathy image synthesis manipulated by grading and lesions. In: International conference on medical image computing and computer-assisted intervention. Springer, Cham, pp 505–513
Zhan W, Shi G, Chen Y, Shi F, Chen X, Coatrieux G, Yang J, Luo L, Li S (2020) Coarse-to-fine classification for diabetic retinopathy grading using convolutional neural network. Artif Intell Med 108:101936
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Gupta, S., Thakur, S. & Gupta, A. Optimized hybrid machine learning approach for smartphone based diabetic retinopathy detection. Multimed Tools Appl 81, 14475–14501 (2022). https://doi.org/10.1007/s11042-022-12103-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-022-12103-y