
Abstract
Ragweed Pollen Alarm System (R-PAS) has been running since 2014 to provide pollen information for countries in the Pannonian biogeographical region (PBR). The aim of this study was to develop forecast models of the representative aerobiological monitoring stations, identified by analysis based on a neural network computation. Monitoring stations with 7-day Hirst-type pollen trap having 10-year long validated data set of ragweed pollen were selected for the study from the PBR. Variables including forecasted meteorological data, pollen data of the previous days and nearby monitoring stations were used as input of the model. We used the multilayer perceptron model to forecast the pollen concentration. The multilayer perceptron (MLP) is a feedforward artificial neural network. MLP is a data-driven method to forecast the behaviour of complex systems. In our case, it has three layers, one of which is hidden. MLP utilizes a supervised learning technique called backpropagation for training to get better performance. By testing the neural network, we selected different sets of variables to predict pollen levels for the next 3 days in each of the monitoring stations. The predicted pollen level categories (low–medium–high–very high) are shown on isarithmic map. We used the mean square error, mean absolute error and correlation coefficient metrics to show the forecasting system’s performance. The average of the Pearson correlations is around 0.6 but shows big variability (0.13–0.88) among different locations. Model uncertainty is mainly caused by the limitation of the available input data and the variability in ragweed season patterns. Visualization of the results of the neural network forecast on isarithmic maps is a good tool to communicate pollen information to general public in the PBR.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Pollen emitted in high amounts by wind-pollinated plants can provoke numerous respiratory problems such as allergic rhinoconjunctivitis and asthma. Almost 40% of the European population suffer from pollen allergies (D’Amato et al. 2007). Common ragweed (Ambrosia artemisiifolia L.) produces highly allergenic pollen. This plant was introduced to Europe at the beginning of the twentieth century (Csontos et al. 2010) and greatly spread during the last two decades. The largest populations of ragweed in Europe can be found in the Pannonian biogeographical region (PBR), but the Po and Rhône valleys (Italy and France, respectively) are also considered to be highly infested regions (Mandrioli et al. 1998; Járai-Komlódi 2000; Chauvel and Cadet 2011; Thibaudon et al. 2014). The PBR lies in the south-eastern part of Central Europe and forms a topographically discrete unit set in the European landscape. It is dominated by a large flat alluvial basin transected by two major rivers—the Danube and the Tisza (Sundseth 2009). The basin (once an ancient inland sea) is almost completely enclosed on all sides by imposing geographical boundaries—the Carpathian Mountains, the Alps and the Dinarics. PBR includes the entire area of Hungary, large regions of Croatia, Serbia, Slovakia and Slovenia, and peripheral areas of Austria, Czech Republic, Romania and Ukraine. Ragweed found an optimal habitat in this region (Török et al. 2003; Peternel et al. 2005; Chrenová et al. 2010; Csontos et al. 2010; Rodinkova et al. 2012), causing extreme levels of pollen concentrations (Smith et al. 2013; Šikoparija et al. 2017). In Hungary, almost 50% of allergic patients (2.5 million people) suffer from ragweed allergy. Approximately 5 million hectares (around 85%) of the Hungarian agricultural area are endangered by ragweed, and approximately 0.7 million hectares are strongly invaded by this plant (Tóth et al. 2004; Basky and Magyar 2009). However, ragweed infestation of PBR is more than a local problem, because it acts as a source of long-distance transport of pollen grains, detected in ragweed-free regions in Northern and Western Europe (Smith et al. 2008; Zink et al. 2012; de Weger et al. 2016; Cecchi et al. 2006; Grewling et al. 2016). Due to its enormous populations and geomorphology-driven transport mechanism of airborne pollen (Šikoparija et al. 2013), PBR is often called the ‘epicentre’ of ragweed pollution in Europe. Recognizing the cross-boundary nature of this problem, PBR countries started Ragweed Pollen Alarm System (R-PAS), a joint project initiated by the Hungarian Aerobiological Network in 2014, with the aim of creating a forecast of daily pollen concentrations and visualizing the predicted levels according to symptom thresholds on high resolution maps. Symptom levels of pollen allergy could be different by regions on ethnic (genetic) basis (Sofiev and Bergmann 2014). Because of this, data of PBR patients of Pollen Hayfever Diary (Bastl et al. 2014) were used to set region-specific threshold levels.
Advanced techniques such as neural networks, multilayer perceptron and the support vector regression learning methods have been used for forecasting air quality parameters (Juhos et al. 2009; Paschalidou et al. 2011; Voukantsis et al. 2011; Kassomenos et al. 2013). However, methods of machine learning have only been scarcely applied in airborne pollen-related studies. They were used for forecasting (a) daily pollen concentrations of ragweed pollen (Csépe et al. 2014), olive pollen (Aznarte et al. 2007), Oleaceae, Poaceae and Urticaceae pollen (Voukantsis et al. 2010) and Betula pollen (Puc 2012) (b) pollen-induced symptoms (Voukantsis et al. 2013), (c) risk level of pollen in the air (Csépe et al. 2014; Castellano-Méndez et al. 2005) and (d) the severity of the Poaceae pollen season (Sánchez Mesa et al. 2005). Furthermore, Aznarte et al. (2007) used neuro-fuzzy models for forecasting olive pollen concentrations. The above-mentioned applications of neural networks and neuro-fuzzy models produced better results than traditional statistical methods (Sánchez Mesa et al. 2005). These methods of machine learning (1) can deal with the complexity of the mechanisms concerning the release and dispersion of the airborne pollen, (2) can be applied for different tasks (e.g. optimization and forecasting), (3) are computationally efficient and can be easily integrated into operational use of the models (Voukantsis et al. 2010).
The aim of this study is to develop a forecast model of the aerobiological monitoring stations based on a neural network computation for the PBR.
2 Materials and methods
We used the multilayer perceptron (MLP) model to forecast the pollen concentration. The multilayer perceptron is a feedforward artificial neural network, a data-driven method to forecast complex systems. MLP utilizes a supervised learning technique called backpropagation for training to get better performance and uses sigmoid activation function for the decision making. Pollen data from 3 days before (3-day lagged pollen) were used as input of the model. 1-day and 2-day lagged data were not considered because these are often unavailable in operational practice. Monitoring stations with 7-day Hirst-type pollen traps (Hirst 1952) having 10-year long validated data set of ragweed pollen were selected for the study from 28 monitoring stations of the PBR or nearby areas.
Meteorological data (daily mean, minimum and maximum temperature, precipitation, daily mean wind speed and relative humidity) of the actual and the previous day were obtained from the + 3 h and + 6 h forecast files of the GDAS FNL (Global Data Assimilation System—Final) data set through the NCAR Research Data Archive (NOAA 2015). Linear interpolation was performed on the 0.25-degree model grid to obtain data at a specific location.
Model validation has been performed on data collected in 2018 which were not included in the training of models. Three monitoring stations were chosen for validating the models in order to represent area in the centre (Budapest), the edge (Novi Sad) and outside the PBR (Zadar).
The following statistical indices were used to compare the performance of the models: (1) correlation coefficient as a measure of the strength; (2) root mean square error (RMSE); and (3) mean absolute error (MAE) as measures of the error in the forecast. Results were compared to the performance of 3-day persistence forecasts as a baseline method.
Categories of pollen levels used in the forecast (0–9, 10–29, 30–99, 100–499, > 500 pollen/m3) are calculated from symptom levels collected with the Hungarian version of the Pollen Hayfever Diary (Bastl et al. 2014). Category accuracy is defined as the number of data pairs where the observed and predicted concentrations fall in the same category, divided with the number of all observed and predicted data pairs. As only the categories, and not the concentration values, are communicated to the public, category accuracy is an important measure of model accuracy from the operational perspective.
The predicted pollen levels are shown on isarithmic map using nearest-neighbour interpolation and a Gaussian smoothing with 0.1° kernel. Points are masked with grey (no data) in a distance larger than 100 km from the nearest data point or in an elevation higher than 700 m above mean sea level. For the latter, 1-km terrain data from the GLOBE digital elevation model were used (Hastings and Dunbar 1999). Visualization was performed with Cartopy and the Scientific Python libraries (Oliphant 2007; Met Office 2010).
3 Results
3.1 The structure of the model
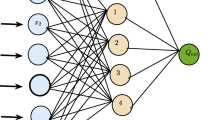
Testing of the multilayer perceptron model of the neural network selected different sets of variables to predict pollen levels for the next 3 days in each of the monitoring stations. The trained model consists of three layers with one hidden layer (Fig. 1). Independent variables selected by the model were the day of the year (DOY), 3-day lagged pollen concentration and meteorological variables. The predicted 24-h mean ragweed pollen levels (pollen/m3) are shown on isarithmic map using categories according to region-specific threshold levels. In another forecast model, we use the same explanatory variables except the lagged pollen measurements. The labelling of the variable sets is ‘with lagged pollen’ and ‘without lagged pollen’ based on the use of lagged pollen concentration as input variable.

The trained neural network model for the Ragweed Pollen Alarm System of the Pannonian biogeographical region
3.2 Performance of the forecasting models
We investigated the connection between the measured and the forecasted pollen levels. The statistical evaluation showed that the performance had wide variability (Fig. 2). The best correlation was around 0.9 in both correlation types. The average Pearson correlations were 0.63 and 0.65, the Spearman average correlations were 0.73 and 0.62, and the Kendall average correlations were 0.73 and 0.62, obtained by ‘with lagged pollen’ and ‘without lagged pollen’ methods, respectively (Fig. 2). The 3-day persistence forecast had average correlations of 0.61, 0.77 and 0.69 (Pearson, Spearman and Kendall, respectively). Pearson correlations improved in the ‘with lagged pollen model’ compared to 3-day persistence at 22 of 28 stations; however, Spearman correlations and RMSE only improved at 12 stations. Model outputs that have max, median and min. MAE are shown in Figs. 3, 4 and 5. If we consider the forecast of the categories, then the category accuracy is 53%. A general observation is that better correlations were obtained for stations with higher mean concentrations. However, this pattern is not entirely consistent, as spatial variability of concentrations is high and each station is affected by local effects. Peaks in the RMSE plot help to identify stations with significant local impacts (Fig. 2). Lagged pollen data improved correlation only at 11 (Pearson) and 16 (Spearman) of the 28 stations. This warns us that lagged values might gain too large weights compared to the meteorological variables, which can decrease the model’s sensitivity on the weather-related variability.

The statistical evaluation of the neural network (multilayer perceptron) forecasting model in the Pannonian biogeographical region. Stations are ordered in a descending order based on their 10-year mean concentration. Baseline method is the 3-day persistence forecast

Model output for Zadar

Model output for Budapest

Model output for Novi Sad
The performance of the prediction of pollen concentrations and categories is demonstrated in three monitoring stations (Zadar, Budapest and Novi Sad), representing high, average and low MAE values, respectively (Figs. 6, 7, 8).

Predicted ragweed pollen concentration data (left) and on alarm thresholds (right) with and without pollen data in Zadar

Predicted ragweed pollen concentration data (left) and on alarm thresholds (right) with and without pollen data in Budapest

Predicted ragweed pollen concentration data (left) and on alarm thresholds (right) with and without pollen data in Novi Sad
4 Discussion
Pollen forecasts are important tools enabling allergy sufferers to anticipate high levels and reduce or prevent symptoms. R-PAS forecast maps (Fig. 9) were published daily from mid-July to mid-October, during ragweed pollen season in the PBR (Mányoki et al. 2014). According to Kiotseridis et al. (2013), a pollen alarm system should be evidence based and easy to understand. The presentation of the pollen forecast in colour-coded maps fulfils these criteria, as this map is informative for the public in the PBR. Most of the people who followed pollen information found the information and services useful (Szigeti and Magyar 2018). The colour-coding of the map was adapted to express extreme pollen levels occurring in the peak period in this region (> 500, but sometimes even > 1000 pollen grains/m3/day). Such high levels do not occur in Western Europe; consequently, their former maps had no details of pollen concentrations with values higher than 50 pollen grains/m3/day (European Aeroallergen Network 2016).

Maps of observed and predicted ragweed pollen concentrations on 22 August 2018
The average Pearson correlations were 0.63 and 0.65, and the Spearman average correlations were 0.73 and 0.62. This showed weaker connection than that demonstrated by Csépe et al. (2014). This is probably due to the smaller training set. When we considered the forecast by each of the categories, then the category hit rate was 53%. More training variables gave better forecasts for high concentrations, but there was a larger noise in the early and late season. Periods and stations with low concentrations had lower correlation values as the ragweed pollen concentration categories are more sensitive to low concentrations. Better correlations generally correspond to stations with higher concentrations and lower variability among years. Therefore, Pearson correlation coefficients ranged from 0.13 (Wien, with relatively low concentrations) to 0.88 (Subotica, one of the most infested locations). As Pearson correlation is sensitive to extreme values, the correct forecasting of a short period with high concentration can produce a good Pearson correlation. For low to medium pollen levels, both the reference measurement and the output of the network are likely to be uncertain, and hence the correlations are low.
Traditional pollen monitoring (i.e. Hirst-type sampling) and manual pollen counting are time-consuming (Crouzy et al. 2016). Another disadvantage of the traditional systems is that data are produced on working days, but not during vacation times and holidays. Csépe et al. (2014) showed that 3-day lagged pollen data provided acceptable forecast results in Szeged. The same result was found in the current study using the data of 28 monitoring stations. In a large international pollen alarm system, such as R-PAS, the coordination of data update is the most critical point during the routine operation. Obtaining 1- or 2-day lagged pollen data from all monitoring stations on every day of the pollen season would have unnecessarily high costs compared to the added value. However, 3-day lagged pollen data are available on holidays as well, and therefore pollen forecast could be published continuously.
To improve the performance of the forecast model, further developments are needed. It is planned to investigate new explanation variable set in the neural network model (e.g. cumulated meteorological variables). Predicted values of pollen data may be used in transport (source-based) models (Zink et al. 2012; Prank et al. 2013; Burki et al. 2019). It is expected that source-based models would be improved when pollen forecasts based on 3-day lagged pollen monitoring data are added. High-resolution pollen inventories (Skjøth et al. 2010, 2019) and real-time data (Crouzy et al. 2016) may also improve the system’s performance. Meanwhile, some error sources can not be ruled out. These are the incidental large-scale transport events, the variability of the pollen season pattern, the changes in near-site ragweed population and the error of input meteorological data. Variability in the pollen season characteristic (Fehér and Járai-Komlódi 1997) is caused by climatic-phenological reasons and is the subject of active research (Stjepanović et al. 2015).
The strength of the model is its rapid operational run-time and low computational resource utilization (a generic virtual private server is sufficient to run). It can be easily adapted to other monitoring stations by adding a new neural network to the existing models. The daily produced data can be integrated into neural networks, thus increasing its performance. The disadvantage, however, is that the system is very sensitive to the input data of training set of neural network. The size of the training database is important, because longer data sets show better performance (lower RMSE and higher correlations). The forecast efficiency of the algorithm decreases in the case of an unusual season timeline, if pollens are present in early or late periods which are not represented by the training data set.
References
Aznarte, J. L., Sánchez, J. M. B., Lugilde, D. N., Fernández, C. D. L., de la Guardia, C. D., & Sánchez, F. A. (2007). Forecasting airborne pollen concentration time series with neural and neuro-fuzzy models. Expert Systems with Applications,32, 1218–1225.
Basky, Z., & Magyar, D. (2009). Impact of indigenous aphids on development of the invasive common ragweed (Ambrosia artemisiifolia L.) in Hungary. Journal of Pest Science,82(1), 19–25.
Bastl, K., Kmenta, M., Jäger, S., Bergmann, K. C., & Berger, U. (2014). Development of a symptom load index: Enabling temporal and regional pollen season comparisons and pointing out the need for personalized pollen information. Aerobiologia,30(3), 269–280.
Burki, C., Šikoparija, B., Thibaudon, M., Oliver, G., Magyar, D., Udvardy, O., et al. (2019). Artificial neural networks can be used for Ambrosia pollen emission parameterization in COSMO-ART. Atmospheric Environment, 218. https://doi.org/10.1016/j.atmosenv.2019.116969.
Castellano-Méndez, M., Aira, M. J., Iglesias, I., Jato, V., & González-Manteiga, W. (2005). Artificial neural networks as a useful tool to predict the risk level of Betula pollen in the air. International Journal of Biometeorology,49, 310–316.
Cecchi, L., Morabito, M., Domeneghetti, P., Crisci, M. A., Onorari, M., & Orlandini, S. (2006). Long distance transport of ragweed pollen as a potential cause of allergy in central Italy. Annals of Allergy, Asthma & Immunology,96(1), 86–91.
Chauvel, B., & Cadet, É. (2011). Introduction et dispersion d’une espèce envahissante: Le cas de l’ambroisie à feuilles d’armoise (Ambrosia artemisiifolia L.) en France. Acta Botanica Gallica,158, 309–327. https://doi.org/10.1080/12538078.2011.10516276.
Chrenová, J., Mičieta, K., & Ščevková, J. (2010). Monitoring of Ambrosia pollen concentration in the atmosphere of Bratislava (Slovakia) during years 2002–2007. Aerobiologia,26, 83–88. https://doi.org/10.1007/s10453-009-9145-3.
Crouzy, B., Stella, M., Konzelmann, T., Calpini, B., & Clot, B. (2016). All-optical automatic pollen identification: Towards an operational system. Atmospheric Environment,140, 202–212.
Csépe, Z., Makra, L., Voukantsis, D., Matyasovszky, I., Tusnády, G., Karatzas, K., et al. (2014). Predicting daily ragweed pollen concentrations using computational intelligence techniques over two heavily polluted areas in Europe. Science of the Total Environment,476, 542–552.
Csontos, P., Vitalos, M., Barina, Z., & Kiss, L. (2010). Early distribution and spread of Ambrosia artemisiifolia in Central and Eastern Europe. Botanica Helvetica,120, 75–78. https://doi.org/10.1007/s00035-010-0072-2.
D’Amato, G., Cecchi, L., Bonini, S., Nunes, C., Annesi-Maesano, I., Behrendt, H., et al. (2007). Allergenic pollen and pollen allergy in Europe. Allergy,62(9), 976–990.
deWeger, L. A., Pashley, C. H., Šikoparija, B., Skjøth, C. A., Kasprzyk, I., Grewling, Ł., et al. (2016). The long distance transport of airborne Ambrosia pollen to the UK and the Netherlands from Central and south Europe. International Journal of Biometeorology,60(12), 1829–1839. https://doi.org/10.1007/s00484-016-1170-7.
European Aeroallergen Network [webpage on the Internet]. Polleninfo.org. Retrieved May 1, 2016, from https://www.polleninfo.org/GB/en/current-data.html?poll=6&month=9&tabber=6&time=1.
Fehér, Z., & Járai-Komlódi, M. (1997). An examination of the main characteristics of the pollen seasons in Budapest, Hungary (1991–1996). Grana,36(3), 169–174.
Grewling, Ł., Bogawski, P., & Smith, M. (2016). Pollen nightmare: Elevated airborne pollen levels at night. Aerobiologia,32(4), 725–728.
Hastings, D., & Dunbar, P. (1999). Global land one-kilometer base elevation (GLOBE) digital elevation model, documentation. Key to Geophysical Records Documentation (KGRD), 34.
Hirst, J. M. (1952). An automatic volumetric spore trap. Annals of Applied Biology, 39, 257–265.
Járai-Komlódi, M. (2000). Some details about ragweed airborne pollen in Hungary. Aerobiologia,16, 291–294. https://doi.org/10.1023/A:1007660804839.
Juhos, I., Makra, L., & Tóth, B. (2009). The behaviour of the multi-layer perceptron and the support vector regression learning methods in the prediction of NO and NO2 concentrations in Szeged, Hungary. Neural Computing and Applications,18, 193–205.
Kassomenos, P. A., Paschalidou, A. K., & Vlachogianni, A. (2013). One-day-ahead prediction of maximum carbon monoxide concentration in urban environments. Stochastic Environmental Research and Risk Assessment,27, 561–572.
Kiotseridis, H., Cilio, C. M., Bjermer, L., Tunsäter, A., Jacobsson, H., & Dahl, Å. (2013). Grass pollen allergy in children and adolescents—Symptoms, health related quality of life and the value of pollen prognosis. Clinical and Translational Allergy,3(1), 19.
Mandrioli, P., Di Cecco, M., & Andina, G. (1998). Ragweed pollen: The aeroallergen is spreading in Italy. Aerobiologia,14(1), 13–20. https://doi.org/10.1007/BF02694590.
Mányoki, G., Magyar, D., Apatini, D., Udvardy, O., & Páldy, A. (2014) Human health issues and risks. In: G. Kazinczi, & R. Novák (Eds.), Integrated methods for suppression of ragweed. National Food Chain Safety Office, Directorate of Plant Protection, Soil Conservation and Agri-environment, Budapest (pp. 52–58). Budapest: Easy Solution Kft..
Met Office. (2010). Cartopy: A cartographic python library with matplotlib interface. Exeter, UK. http://scitools.org.uk/cartopy.
NOAA. (2015). NCEP GDAS/FNL 0.25 degree global tropospheric analyses and forecast grids. Research Data Archive at the National Center for Atmospheric Research, Computational and Information Systems Laboratory, Boulder, CO.
Oliphant, T.-E. (2007). Python for scientific computing. Computing in Science Engineering,9, 10–20.
Paschalidou, A. K., Karakitsios, S., Kleanthous, S., & Kassomenos, P. A. (2011). Forecasting hourly PM10 concentration in Cyprus through artificial neural networks and multiple regression models: Implications to local environmental management. Environmental Science and Pollution Research,18, 316–327.
Peternel, R., Čulig, J., Srnec, L., Mitić, B., Vukušić, I., & Hrga, I. (2005). Variation in ragweed (Ambrosia artemisiifolia L.) pollen concentration in central Croatia, 2002–2003. Annals of Agricultural and Environmental Medicine,12, 11–16.
Prank, M., Chapman, D. S., Bullock, J. M., Belmonte Soler, J., Berger, U., Dahl, A., et al. (2013). An operational model for forecasting ragweed pollen release and dispersion in Europe. Agricultural and Forest Meteorology,182–183(15), 43–53.
Puc, M. (2012). Artificial neural network model of the relationship between Betula pollen and meteorological factors in Szczecin (Poland). International Journal of Biometeorology,56, 395–401.
Rodinkova, V., Palamarchuk, O., & Kremenska, L. (2012). The most abundant Ambrosia pollen count is associated with the southern, eastern and the northern-eastern Ukraine. Alergologia et Immunologia,9(2–3), 181.
Sánchez Mesa, J. A., Galán, C., & Hervás, C. (2005). The use of discriminant analysis and neural networks to forecast the severity of the Poaceae pollen season in a region with a typical Mediterranean climate. International Journal of Biometeorology,49, 355–362.
Šikoparija, B., Skjøth, C. A., Celenk, S., Testoni, C., Abramidze, T., Alm Kübler, K. A., et al. (2017). Spatial and temporal variations in airborne Ambrosia pollen in Europe. Aerobiologia,33(2), 181–189.
Šikoparija, B., Skjøth, C., Kübler, K. A., Dahl, Å., Sommer, J., Radišić, P., et al. (2013). A mechanism for long distance transport of Ambrosia pollen from the Pannonian Plain. Agricultural and Forest Meteorology,180, 112–117.
Skjøth, C. A., Smith, M., Šikoparija, B., Stach, A., Myszkowska, D., Kasprzyk, I., et al. (2010). A method for producing airborne pollen source inventories: An example of Ambrosia (ragweed) on the Pannonian Plain. Agricultural and Forest Meteorology,150(9), 1203–1210.
Skjøth, C. A., Sun, Y., Karrer, G., Sikoparija, B., Smith, M., Schaffner, U., et al. (2019). Predicting abundances of invasive ragweed across Europe using a “top-down” approach. Science of The Total Environment, 686, 212–222.
Smith, M., Cecchi, L., Skjøth, C. A., Karrer, G., & Šikoparija, B. (2013). Common ragweed: A threat to environmental health in Europe. Environment International,61, 115–126.
Smith, M., Skjøth, C. A., Myszkowska, D., Uruska, A., Puc, M., Stach, A., et al. (2008). Long-range transport of Ambrosia pollen to Poland. Agricultural and Forest Meteorology,148(10), 1402–1411.
Sofiev, M., & Bergmann, K.-C. (2014). Allergenic pollen. Dordrecht: Springer.
Stjepanović, B., Svečnjak, Z., Hrga, I., Večenaj, A., Šćepanović, M., & Barić, K. (2015). Seasonal variation of airborne ragweed (Ambrosia artemisiifolia L.) pollen in Zagreb, Croatia. Aerobiologia,31(4), 525–535.
Sundseth, K. (2009). Natura 2000 in the Pannonian Region. European Commission, Environment Directorate General, Belgium. https://doi.org/10.2779/79432.
Szigeti, T., & Magyar, D. (2018). Do people know enough about pollen information in Hungary? Central European Journal of Occupational and Environmental Medicine, 24(3–4), 221–228.
Thibaudon, M., Šikoparija, B., Oliver, G., Smith, M., & Skjøth, C. A. (2014). Ragweed pollen source inventory for France—The second largest centre of Ambrosia in Europe. Atmospheric Environment,83, 62–71. https://doi.org/10.1016/j.atmosenv.2013.10.057.
Török, K., Botta-Dukát, Z., Dancza, I., Németh, I., Kiss, J., Mihály, B., et al. (2003). Invasion gateways and corridors in the Carpathian Basin: Biological invasions in Hungary. Biological Invasions,5(4), 349–356.
Tóth, Á., Bencés, P. Z., & Szentey, L. (2004). The role of allelopathy in swelling of Ambrosia artemisiifolia and Cirsium arvense in Hungary (In Hungarian). Gyomnövények Gyomirtás, 2, 21–29.
Voukantsis, D., Karatzas, K., Jaeger, S., Berger, U., & Smith, M. (2013). Analysis and forecasting of airborne pollen-induced symptoms with the aid of computational intelligence methods. Aerobiologia,29, 175–185.
Voukantsis, D., Karatzas, K., Kukkonen, J., Rasanen, T., Karppinen, A., & Kolehmainen, M. (2011). Intercomparison of air quality data using principal component analysis, and forecasting of PM10 and PM2.5 concentrations using artificial neural networks, in Thessaloniki and Helsinki. Science of the Total Environment,409, 1266–1276.
Voukantsis, D., Niska, H., Karatzas, K., Riga, M., Damialis, A., & Vokou, D. (2010). Forecasting daily pollen concentrations using data-driven modeling methods in Thessaloniki, Greece. Atmospheric Environment,44, 5101–5111.
Zink, K., Vogel, H., Vogel, B., Magyar, D., & Kottmeier, C. (2012). Modeling the dispersion of Ambrosia artemisiifolia L. pollen with the model system COSMO-ART. International Journal of Biometeorology,56(4), 669–680. https://doi.org/10.1007/s00484-011-0468-8.
Acknowledgements
Open access funding provided by National Public Health Center. The Hungarian part of this work was financially supported by the Széchenyi 2020 program through EFOP-1.8.0-VEKOP-17-2017-00001 project; City Administration for Environmental Protection, City of Novi Sad for the pollen monitoring in Novi Sad; Provincial Secretariat for Urban Planning and Environmental Protection AP Vojvodina for the pollen monitoring in Sombor, Vrbas, Kikinda, Zrenjanin and Sremska Mitrovica; Grant Agency VEGA (Bratislava), Grant No. 1/0056/20 for the pollen monitoring in Bratislava; National Laboratory of Health, Environment and Food, Slovenia for the monitoring in Izola, Ljubljana and Maribor.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Csépe, Z., Leelőssy, Á., Mányoki, G. et al. The application of a neural network-based ragweed pollen forecast by the Ragweed Pollen Alarm System in the Pannonian biogeographical region. Aerobiologia 36, 131–140 (2020). https://doi.org/10.1007/s10453-019-09615-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10453-019-09615-w