
Abstract
Precise assessment of bark stripping damage is of high economic importance, since bark stripping makes wood unusable for saw timber and it is important for compensation payments for game damage. Bark stripping is clustered and decreases with increasing tree diameter, so that common forest inventories, optimized for assessing timber production variables such as standing timber volume, do not provide adequately precise estimates of bark stripping damage. In this study we analysed different sampling designs (random sampling, systematic sampling), tree selection methods (fixed radius plot, angle count sampling) and number of plots and plot sizes (plot radius: 2–20 m; basal area factor: 1–6m2/ha) for bark stripping assessment. The analysis is based on simulation studies in 9 fully censused stands (9026 trees). Simulations were done for actually assessed damage and randomly distributed damage and each scenario was repeated 100 times with different random points or different random grid locations. Systematic sampling was considerably more precise than random sampling in both scenarios. Sampling intensities to attain a standard error of 10% ranged between 12 and 18% dependent on the plot size. For a given sampling intensity, precision increased with decreasing plot size or increasing basal area factor. This implies, however, a large number of plots to be measured, which is expensive, when travel costs are high. Differences between tree selection by fixed radius plots or angle count sampling were minor. For bark stripping damage, we recommend sampling with fixed radius plots with a radius of 4–6 m and the measurement of approximately 230 or 150 plots, respectively.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Reliable statistical inference is central for forest management. The Global Climate Observing System mandates the inferential uncertainty for essential variables must not exceed 20% (Sessa and Dolman 2008) a challenging but necessary requirement, because biased or imprecise estimates would mislead analysis and hence may cause wrong conclusions and policy-making (Conn et al. 2017). Many forest inventories were designed with the primary idea that wood (volume and volume increment) was the characteristic of interest (Roesch 1993). Nowadays forest inventories often encompass many other variables, such as tree damages, dead wood or measures of biodiversity, which need to be simultaneously evaluated (Roesch 1993). Less emphasis has been dedicated to the precise assessment of these variables.
In Central Europe, populations of ungulates are overabundant (Apollonio et al. 2010), which has detrimental effects on forest economy, biodiversity and ecosystem functioning. Stem damages, amounting to 9.1% of individual trees in Austria (BFW 2018), lead to subsequent infection with wood decaying fungi, which make the wood unusable for the sawtimber industry causing high economic losses. Recently, the costs for bark stripping damage were estimated to be 53€/ha/year and the reduction of the timber yield was estimated to be 19% (Ligot et al. 2023). Also, stand stability is negatively affected by infection of the single trees with fungi because of the loss of mechanical stability (Čermák et al. 2004).
The distribution of bark stripping damage is largely dependent on habitat selection by red deer, related to the availability of forage quality and water, disturbances due to human activities (Gill 1992) and shelter (Coppes et al. 2017). Since red deer typically seek shelter in pole stands, damages are concentrated in younger stands, on trees with small breast height diameters and on species of which the bark can be easily removed (Norway spruce (Picea abies), European ash (Fraxinus excelsior), sweet chestnut (Castanea sativa) and Sorbus spp.) (Vospernik 2006). Bark stripping damage is spatially aggregated within stands (Gill 1992; Hahn and Vospernik 2022; Hahn et al. 2023), because suitable habitat is often restricted to patches and individual animals tend to aggregate (McGarvey et al. 2016). The habitat factors that are spatially aggregated may however vary from stand to stand and in addition to the above-mentioned factors may include areas visible from the counter slope, wind prone areas and areas in the vicinity of flight routes (Hahn and Vospernik 2022; Hahn et al. 2023).
The high economic losses due to bark stripping on the one hand and income from hunting on the other hand causes conflicts between forest managers and hunters: While hunters are often interested in large red deer populations, forest managers favour smaller populations causing less damage. Also, hunters need to pay for the damage caused by wildlife (e.g. Austria, Germany); often such payments lack an objective basis (Ehrhart et al. 2022) and also an objective foundation for planning the number of hunted animals is lacking (Land Oberösterreich 2023; Simon and Petrak 1998).
An efficient procedure to assess bark stripping damages in large scale inventories and also at the stand level is therefore crucial.
Inventory design
When designing a forest inventory, selecting an appropriate sampling design, using an appropriate selection method for trees and defining the sample size for a given accuracy and using an appropriate estimation design are important (Kershaw et al. 2016; Simon and Petrak 1998).
There are numerous basic forest inventory designs (e. g. simple random sampling, systematic sampling, stratified sampling, selective sampling, …) (Kershaw et al. 2016). While simple random sampling (SRS) is the fundamental selection method, systematic sampling (SS) has been more widely applied by national forest inventories and monitoring networks around the world. Systematic sampling (SS) is design-based and the corresponding estimators are design-unbiased when target variables are randomly distributed; it has a long history of serving as official reporting instruments at local, regional, ecosystem and national scales (Kangas and Maltamo 2006). Also, SS is convenient for logistics; specifically, it is often less costly to measure a collection of SS plots than to measure an equal number of plots selected at random (Heikkinen 2006).
A common selection method for trees in forest inventories are fixed radius plots (FRP) or angle count samples (ACS) (Bitterlich 1952, 1984). While in fixed radius plots there is an equal selection probability for each tree, the selection probability in angle count sampling depends on the individual tree basal area. Thus, in angle count sampling, the larger trees are preferentially selected, leading to more precise estimates of basal area and volume with the same measurement effort, but angle count sampling is known to estimate stem numbers very imprecisely (e.g. Henttonen and Kangas 2015). Fixed radius plots are therefore thought to be more precise for trees with smaller diameters and angle count samples for larger diameters (Schreuder et al. 1987).
Sampling intensity expresses the ratio of area included in the sample to the total area. The same sampling intensity can be achieved with different combinations of plot size and number of plots. If the sampling intensity of a given area is held constant, there is no appreciable effect of plot size on the standard error for randomly distributed variables of interest (Kershaw et al. 2016). Considering only measurement time on the plot, smaller plots are however thought to be more efficient in the field because the decision which trees to include is easier and because it is easier to control trees near the borderline. Also, it is physically easier to move from tree to tree on a small plot (Kershaw et al. 2016). The probability not to detect trees increases with increasing plot size (Ritter et al. 2013), and non-detection bias may be excessive on very large plots. The chief draw-back of small plots is an increasing sampling variance as plot size declines and an increasing time required to travel between plots. While this may be a minor issue in stand-level inventories, travel times and costs are substantial on large scale inventories (Henttonen & Kangas 2015).
When the variable of interest is not randomly distributed, smaller plots are recommended; for clustered variables, large but few inventory points are less precise with the same SI than many but small points (Kershaw et al. 2016). When near things are more related than distant things, sampling few but large plots in a single location becomes inefficient.
In Austria, angle count sampling with a basal area factor of 4m2ha−1 is common practice in both stand level and national forest inventories (BFW 2018). Given the distribution of bark stripping damage, this inventory method might not be optimal for assessing bark stripping damage. The aim of this paper is to analyse different sampling designs, tree selection methods and sampling intensities for the assessment of bark stripping damage. In detail, we want to examine the following hypothesis:
-
1.
The clustered occurrence of bark stripping damage results in higher SE than would be expected for a randomly distributed variable
-
2.
Small plots are more efficient than larger plots with the same SI in inventories of bark stripping damage because of the clustered occurrence
-
3.
ACS is less efficient for the assessment of bark stripping damage because of the higher inclusion probability for larger trees, which is inefficient for assessing bark stripping damage mainly occurring on smaller trees
Material and methods
Study area
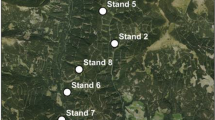
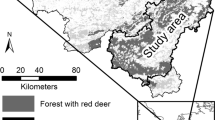
The study area is located in Austria (Lat = 47.2°, Long = 15.1°) at an elevation of 1009–1622 m (Fig. 1). The mean annual temperature is 6.6 °C and mean annual precipitation is 817 mm. The predominant soil types are Cambisols on quartz, granite and feldspar. A full census was done in 9 stands with a stand size of 0.29–1.75 ha from 2019–2020. Stands were mainly composed of Norway spruce (Picea abies (L.) Karst.) with minor admixtures of European larch (Larix decidua Mill.). For each tree, tree coordinates, tree species, diameter at breast height (DBH), height and bark stripping damage were assessed using a combination of terrestrial laser scanning and subsequent field assessment. In total, 9026 trees were measured; the number of trees differed between 502 and 1524 stems per ha between the stands with a quadratic mean diameter range of 21.5–33.7 cm and a damage rate of 12.4–60.9% of the stem number (total damage rate: 29.9% of the stem number). Details on the assessment can be found in Hahn and Vospernik (2022).

Location of the nine stands in the forest company Wasserberg/Austria
Simulation scenarios
To quantify the effect of the clustered occurrence of bark stripping damages on the sampling intensity required to obtain a predefined precision all simulations were done for two sets of data: (i) a data set where damages were randomly assigned (uniform random numbers) to the 9026 measured trees based on the observed damage percentage in the stand (ii) and a data set with the actual distribution of damages. For both data sets a comprehensive set of simulation scenarios was calculated.
Sampling designs simulated were (1) systematic sampling with grid spaces varying from 10 to 70 m and (2) random sampling with an equal number of sampling plots per stand (varying from 2 to 20). At each sample point, trees were selected using fixed radius plot (FRP) and angle count sampling (ACS) with different sampling intensities. For FRP, plot radii varied from 2 to 10 m and for the ACS (Bitterlich 1952, 1984) basal area factors varied from 1 to 6 m2/ha. To compare the sampling intensity of the two methods, the plot size of the angle count sample was calculated according to Matérn (1969) (Eq. 1). From the plot area, the corresponding plot radius was also calculated (Eq. 2).
With: F Plot area [m2].
π Circular constant (3.1415 …).
BAF Basal area factor [m2/ha].
DBH Diameter at breast height [m].
z Number of sample trees in the ACS.
rMatérn Plot radius [m].
As given in Eqs. 1 and 2, the plot area estimated for the ACS and the corresponding plot radius depend on the basal area factor (BAF), the number of sample trees in the ACS (z) and their DBH. For sample points with no trees, the plot radius of the ACS, rMatérn, is undefined because of the division by z = 0. For these cases rMatérn was set to the average rMatérn from all other plots of the respective simulation scenario. The average rMatérn varied from 5 to 15 m (Fig. S1 supplementary material) for the basal area factors of 1–6 m2/ha and the ACS scenarios simulated therefore corresponded well to the range of radii simulated for the fixed radius plot, which was 2–20 m. The variation of rMatérn within a scenario was however substantial (Fig. S1 supplementary material), and individual values of rMatérn ranged from 5 to 20 m.
For both methods (FRP, ACS) the boundary slopover bias was taken into account (Beers 1969; Schmid-Haas 1969). This bias occurs, when sample trees are located in proximity to the stand boundary so that part of their inclusion zone falls outside the area where the point is located. As corrective action, the “mirage method” was used: Thereby, the part of the sample plot falling outside the stand is reflected towards the interior of the plot. This is done by establishing a “mirage point” that is located by reflecting the original sample point through the stand boundary. The trees selected from the mirage point, which are inside the stand the original sample point is located in, are tallied twice (Beers 1969; Schmid-Haas 1969). Fig. S2 in the supplementary material illustrates the “mirage method”.
Each scenario, was simulated 100 times with different random sample points or different random starting locations for the systematic grid. For each sample point and scenario, stand volume of all trees and stand volume of the damaged trees was calculated by the formulas given in the annex using the Austrian form factor equation (Pollanschütz 1985) and for the ACS the formulas given by Bitterlich (1952, 1984). Figures 2 and 3 gives a graphical overview of the simulation scenarios.

Sample design simulted: Top: Different grid spaces. Centre: Fixed number of randomly located sample points. Bottom: Different fixed radius plots and angle count samples were simulated at each sample point. Location of random start points resp. each random sample points differ between each simulation run

Schematic diagram of the simulation scenarios
Finally, the standard error (SE) of the damaged volume in percent of the total volume was selected as target variable. For each scenario the sampling intensity (SI) was calculated. For fixed radius plots the sampling intensity was obtained by dividing the plot area by the total area; likewise the sampling intensity for angle count sampling was obtained by dividing the plot area according to Matérn (1969) by the total area.
Only scenarios with a SI of less than 20% were analysed in detail and displayed in the graphics. Also, the mean number of sample trees per plot that would need to be assessed was evaluated for each scenario, as a proxy for the measurement effort at the plot. All calculations were done using R statistical software.
Results
In general, systematic sampling is more precise than random sampling (Figs. 4, 5). Assuming inferential uncertainty should not exceed 20% as proposed by Sessa and Dolman (2008) then standard errors should not exceed 10%. Target standard errors of 10% can be achieved with systematic sampling and smaller plot sizes, but can’t be achieved with random sampling (Figs. 4, 5).

Standard error [%] of the different inventory designs for systematic sample points depending on the sampling intensity [%] (top left: fixed radius plot for true damage values; top right: fixed radius plot for random distributed damages; bottom left: angle count sample for true damage values; bottom right: angle count sample for randomly distributed damages)

Standard error [%] of the different inventory methods for random sampling depending on the sampling intensity [%] (top left: fixed radius plot for true damage values; top right: fixed radius plot for random damages; bottom left: angle count sample for true damage values; bottom right: angle count sample for random damages)
To quantify the effect of the clustered occurrence on the precision of bark stripping damage assessment, the simulations were also done for randomly distributed damages. For scenarios with randomly distributed bark stripping damages, the SE of the damaged tree volume is always lower than for the real clustered damage distribution (Figs. 4, 5). Also, the difference between different methods resulting in the same SI is less for randomly distributed damages than for the real clustered damage distribution in all cases.
Generally, the SE decreases with sampling intensity (SI) (Figs. 4, 5). When selecting sampling units systematically (Fig. 4), the low SI’s (< 3%) have high SE’s of more than 30% for the FRP and of more than 25% for the ACS. For high SI’s (> 10%), the gain in precision with increasing SI becomes very small. As stated above, the target precision of less than 10% SE can only be reached by simulation scenarios with small plot sizes (FRP with 2 and 4 m radius; ACS with BAF 5 and 6 m2/ha), which implies that a large number of plots, is necessary to achieve the predefined sampling intensity.
For random sampling (Fig. 5), the difference between the methods (FRP, ACS) for the same SI is less pronounced than for the systematic sampling. The target precision of less than 10% SE can’t be reached for any scenario. In random sampling, there is a more pronounced difference between the real (clumped) damage distribution and the random distribution.
The mean number of sample trees to be included at each plot obviously depends on the plot size (Fig. 6); smaller plot sizes have a smaller number of sample trees than large plot sizes. A fixed radius plot with a radius of 2 m includes less than 5 trees/plot, a plot with a radius of 10 m includes approximately 30 trees/plot in the stands investigated. For ACS, the average number of trees included, varies from approximately 45 trees/plot (BAF = 1 m2/ha) to 10 trees per plot (BAF = 6 m2/ha). The mean values of trees included are independent of the sampling design, but the standard error (SE) is higher for random sampling: The standard error ranges from approximately 1 tree/plot (radius = 2 m) to 3 trees/plot (radius = 10 m) for FRP and from approximately 3 trees/plot (BAF = 1 m2/ha) to 1 tree/plot (BAF = 6 m2/ha) for ACS with systematic sampling; in random sampling, the range varies from approximately 1–5 trees/plot for the given radii (FRP) and from 1 and 7 trees/plot for the given BAF (ACS) and is thus twice as high as for systematic sampling.

Mean number and mean standard error of sample trees per fixed radius plot resp. angle count sample from 100 simulations. Top-left: Mean number of sample trees (FRP–systematic sampling vs. random sampling); top-centre: Standard error (FRP–systematic sampling); top-right: Standard error (FRP–random sampling); bottom-left: Mean number of sample trees (ACS–systematic sampling vs. random sampling); bottom-centre: Standard error (ACS–systematic sampling); bottom-right: Standard error (ACS–random sampling)
Discussion
Systematic sampling vs. random sampling and clustered occurrence
Simulation of samples, such as carried out here, is an excellent way to explore sample design. Our results show that inventories with randomly distributed sample points have a higher standard error of bark stripping damage than inventories with a systematic sampling design. This effect can be explained by the location of the points: If they are randomly located, some plots may lie close together and plots may have a clumped distribution, which represents only a part of the stand. In systematic sampling, plots are spread out over the entire population, leading to higher precision of bark stripping damage estimates (McGarvey et al. 2016; Kershaw et al. 2016). The advantage of the systematic design increases with increasing clustering (autocorrelation) (McGarvey et al. 2016). In our study, especially for low sampling intensities with very small plot sizes, there is a clear advantage of systematic sampling in terms of precision.
Another advantage of systematic sampling is the ease of planning travel time between the plots since the travel distance between successive samples is constant, and travel time is usually less than for random sampling (Kershaw et al. 2016). Also, since fixed directional bearings are followed, locating plots is easier (Kershaw et al. 2016). With modern GPS technology this issue might, however, nowadays be a lesser disadvantage than in the past.
If the total population of sampling units in a forest were randomly distributed, exhibiting no pattern of variation, random sampling and systematic sampling would be equivalent (Kershaw et al. 2016). For basal area and volume, the sampling error of systematic and random sampling is often similar, and the errors obtained from systematic sampling are only slightly smaller (Kershaw et al. 2016). The clear differences between random and systematic sampling observed in our study, however, confirm that bark stripping damage is a highly clustered variable (Hahn and Vospernik 2022; Hahn et al. 2023). Taking the real spatial damage distribution into account is therefore key, when designing an inventory for bark stripping damage; the assumption of a random distribution of this target variable would lead to too optimistic and erroneous results.
In a forest, components are rarely, if ever, completely arranged independent of each other. The larger the forest area inventoried, the greater the variation that can be expected and the more clustered a variable is, the more likely a systematic sample will give a better estimate of the mean than a random sample. Another important issue when designing an inventory for a clustered variable may be avoiding that sampling units coincide with the periodic pattern (Kershaw et al. 2016).
Many other studies of systematic sampling in comparison to random sampling confirm substantial differences between random and systematic sampling. For instance, Tokola and Shrestha (1999) assessed different inventory designs—line-sampling with 1, 2 and 3 plots/cluster, triangle-sampling (3 plots/cluster), L-shaped (5 plots/cluster) and square-sampling (4 and 8 points/cluster)—by simulating the spatial variation of volume. In all cases, the systematic arrangement of the clusters was more precise than random sampling. Precision obtained was for instance: point-sampling: 7.8 versus 8.8 m3/ha, line-cluster sampling (4 points/cluster) 8.3 versus 11.7 m3/ha and square-cluster sampling (8 points/cluster) 10.5 versus 16.0 m3/ha. McGarvey et al. (2016) analysed the precision of systematic vs. random sampling for six different spatial arrangements of trees (complete spatial randomness, complete spatial randomness in two patches of equal density, complete spatial randomness in two patches of differing densities, Mátern clustered, Mátern clustered in two patches of equal density, Mátern clustered in two patches of differing density). Their results showed that (1) only random sampling is design unbiased while systematic sampling always had a bias and (2) that the systematic survey is much more precise than the random sampling (18–36%). Similarly, Perret et al. (2022) found that for spatially aggregated plant species systematic sampling (SYS) (up to 80%) and spatially balanced sampling (SBS) (up to 60%) were always more precise than simple random sampling. In their study, the highest precision for the estimation of population size was given for an average distance between the sampling units that was equal to the cluster diameters. Further inventory efficiency improvements for bark stripping might be attained by incorporating tree and stand information and by using stratified sampling. While gains in precision by stratification at the stand level are likely to be minor, at the inventory scale precision could be increased by increasing sample density in high-risk stands and decrease it in low-risk areas. Bark stripping is correlated with many variables commonly assessed by forest inventories including mean tree diameter (or age and height as proxies), stand density or elevation (see for example Vospernik (2006)). Some of these variables such as mean heights or elevation can also be easily obtained from auxiliary digital elevation models and digital surface models allowing an efficient stratification without previous inventories. The goodness of fit of bark stripping models is often very good (e.g. Vospernik 2006) so that model based inference could be a promising alternative. While these prospective gains in precision for bark stripping inventories still need to be explored, this study allows to quantify the gain in precision through selecting systematic sampling with an appropriate plot size and tree selection method.
Sampling intensity and plot size
Inventories for bark stripping damage are more precise, if the plot size is quite small and the number of plots in the stand is correspondingly higher. There are, however, restrictions which have to be considered: If the plot size is small, there are numerous plots with no trees included and the variation of individual plots becomes high. In general, larger plots have a lower standard error, but if viewed as a function of the sampling intensity, the relationship is reversed, and the larger plots have the higher standard error for a given sampling intensity. E.g. Becker and Nichols (2011) simulated different inventory frameworks (ACS with different BAF and FRP with different radii) to assess stem number, basal area, volume and biomass. In their results, the confidence interval decreased with increasing radius resp. decreasing BAF, but they did not compare results for the same SI.
In theory, for the same sampling intensity there should be no difference, at least for a randomly distributed variable (Kershaw et al. 2016). The clustered pattern, however, makes small and many plots more precise in our study. When designing a forest inventory, the most efficient design is a design with the desired precision at the lowest cost (Henttonen and Kangas 2015; Kershaw et al. 2016). Inventory costs are composed of costs for travelling between plots and costs for the measurements to be taken at the plots. In general, travel costs increase with the distance between plots and costs for plot measurement increase with plot size on a per unit basis. Also, the more units need to be measured the higher the costs. So, in general there will be a trade-off and the optimal design will depend on the type of inventory. If a constant measurement time per tree is assumed, costs on a per unit basis and number of trees per plot will result in the same total measurement time for a given sampling intensity. Using a grid space of 20 m and a plot radius of 4 m results in a sampling intensity of 12.6% and 232 plots to be measured in our stands. Assuming a measurement time of 5 min per tree, the measurement time per plot with an average of 5.14 trees per plot is 25.7 min per plot, resulting in 5970 h for measuring all plots without travel time. Using a grid space of 30 and 6 m radius plots results in the same sampling intensity of 12.6% and 103 plots to be measured. 58 h per plot would be required, in total also 5970 h for measuring all plots. Thus, the optimal design will highly depend on the travel time and distances between plots. At the stand scale, measuring many small plots is likely to be efficient, since travel time between plots is minor, whereas in large-scale inventories larger plots might be more efficient, because of travel costs. Assuming a travel time of 5 min between plots for stand- level inventories would result in a travel time of 1160 h for the 232 plots of the 20 m grid, and a travel time of 515 h for the 6 m grid in the above example. Assuming a travel time of 20 min between plots for stand level inventories would result in a travel time of 4640 and 2060 h respectively. An excellent analysis of this trade off can be found in Henttonen and Kangas (2015): Taking all costs into account they recommend plot sizes of 6–7 m radius for volume assessment and a maximum plot radius of 7 m (for all BAFs) also for ACS. 20–25 plots per sampling unit and a maximum sampling intensity of 5% are recommended by Kramer and Akḉa (2008) for stand volume assessment. Becker and Nichols (2011) suggest plot sizes varying from 405 to 808 m2 for fixed radius plots; or BAF 1.15–6.89 m2/ha. Note that the decimal numbers result from a conversion from imperial units.
Kershaw et al. (2016) also suggest medium-size plots for forest inventories. They argue, that small plots are costly, because of travel time, while large plots might be inefficient because of high measurement costs due to intensive field work at the plot; Large plots are also prone to bias, because of unobserved trees (Piqué, et al. 2010; Ritter, et al. 2013; Kershaw et al. 2016). Plots including more than 20 trees should therefore be avoided (Kershaw et al. 2016).
The non-detection bias is most pronounced in ACS, where the border line distance depends on the chosen BAF and the DBH for each tree (Bitterlich 1948, 1984), so that the plot size is potentially infinite. As a remedy truncated angle count sampling was suggested. The basic idea of trunked ACS is to limit the plot size of the angle count samples by introducing a maximum plot radius (Berger et al. 2020; Hauk et al. 2020). The benefit of this is the reduced field work and the reduction of the non-detection bias (Tomppo and Toumainen 2010). In NFI’s, they were often incorporated to improve the precision of large area forest attribute estimators (Næsset et al. 2013). The combination of trunked ACS with ALS was also carried out in several studies (e.g. Hollaus et al. 2007, 2009; Maltamo et al. 2007; Scrinzi et al. 2015). In our study, the influence of non-detection-bias was not simulated, but might be substantial for the larger plots.
Fountain et al. (1983) advocate large plots (BAF 1, 2, 2.5 and 3 m2/ha at 40 points/16.14 ha and 1 m2/ha at 20 points/16.14 ha). This is opposite to our results, but can be explained with the structure of the analysed forest: Their assessments were done in a 16.14 ha area in Arkansas consisting of a natural hardwood-pine forest. The structure of the forest was a typical “reverse J-shaped curve” with a comparatively low basal area density (377.86 m2/16.14 ha = 23.4 m2/ha; assessed by full-census). In these stands, the within stand variability is very high, with little between stand variability. In such circumstances, larger plots are advantageous. The pole stands examined in this study exhibit little local variation, but high variation between plots resulting in a better precision of small plots, so that small plots were found to be more efficient for a given sampling intensity.
Selection of sample trees (FRP vs. ACS)
Sampling trees with a variable selection probability (ACS) and an equal selection probability (FRP) only had a minor effect on the precision of our target variable for a given sampling intensity. In general, a variable selection probability selecting trees proportional to their basal area (ACS) would be more efficient, if the variable of interest is preferentially found on larger trees, and less efficient if the target variable is rather found on smaller trees (Schreuder et al. 1987). Henttonen and Kangas (2015) confirmed that FRP are more precise for the assessment of stem numbers and that relascope measurements are more precise for stand volume and basal area assessment; they conclude that installing concentric plots is a good compromise. FRP plots are expected to be advantageous for the assessment of bark stripping damage, since bark stripping damage is concentrated on small trees (Gheysen, et al. 2011). The simulated differences in our study between the two selection methods were, however, minor. Differences between the two methods (FRP, ACS) might be larger if a larger range of stands were considered. A small or no effect of the sampling method to select trees is also confirmed in other studies for different target variables (Piqué et al. 2010; Becker and Nichols 2011).
Inventory frameworks assessing bark stripping damage
For detailed planning of forest and hunting management, inventories at the stand-level are often prescribed by law (Milner et al. 2006). Different methods such as line-transect-sampling, 3-segment-sampling, cluster-sampling to assess bark stripping damage were analysed with respect to workload and set-up times (Simon and Petrak 1998). The precision of the assessment was however not reported in this study, nor did the authors consider the clustered occurrences of bark stripping damages in their recommendations.
Damage assessment is usually also part or large-scale forest inventories. These inventories focus on stand volume, basal area and stem number and information about damages is only additional (Roesch 1993). The precision of the information of bark stripping damage might however not be sufficient, because of the clustered occurrence of bark peeling damages (Hahn and Vospernik 2022; Hahn et al. 2023). In particular, in some cases the target variable might be new bark stripping damage, which is even more difficult to assess because of its rare occurrence. In general, it is not possible to downscale forest inventory results to the level of forest stands, which is often the spatial unit for compensation payments.
Conclusions–practical considerations
Assessing variables with a clumped occurrence with sufficient accuracy is a difficult task. If the target variable is clustered, there is a very clear advantage of systematic sampling and small plot sizes are more precise for a given sampling intensity. The result obtained for bark stripping damage are valid for any variable showing a clustered distribution and inventory design for bark stripping damages are also transferable to other types of damages or other variables which are spatially clustered. An example could be rockfall damage or harvesting damage, where the occurrence depends on the terrain or skid-trails.
When designing an efficient assessment method, recommendations will differ between the stand level and large-scale forest inventories. At the stand level, a systematic inventory with FRP plots could be used. Fixed radius plots are more precise than ACS, and the systematic inventory has the advantage that less preparation is necessary, since only stand boundaries, a random starting point for the grid and a grid space are needed. Also, simple measurement devices can be used and no expensive equipment is necessary. If a 10% standard error of bark stripping volume is desired, approximately 230 sample points (in our stands this corresponds to a sampling intensity of 12%) and FRP with a radius of 4 m could be used. For our assessment area, this would result in a grid space of 20 m and 25 sample points per ha. Alternatively, if a plot radius of 6 m were used, the SI should be 18% to obtain the desired precision. This is feasible with a grid space of 25 m and 16 sample points per ha in total 150 sample points. If for the same plot size, a larger grid space and less sample points (30 m; 11.1 sample plots per ha; approximately 100 plots in total; SI of 12.57%) were used, the resulting standard error would be 15%, which in our opinion is still acceptable. The more important point is to assess bark stripping objectively and in an unbiased manner.
Bark stripping assessments are often done in the course of forest inventories at the large-scale level. In Austria, almost all forest inventories use ACS with a BAF 4 m2/ha. While measuring bark stripping damages with ACS is in principle possible, a high SI (approximately 17 to 18%) and large BAF of 5 or 6 m2/ha would be necessary to obtain the desired precision. This is problematic because the standard measurement device, the relascope, only has the BAFs 1, 2 and 4 m2/ha. Also, large BAFs result in a high number of sample points to be measured, which is too costly for the total inventory. A possible way to improve the bark stripping assessment during forest inventories is to preselect stands with a high damage vulnerability (e. g. age classes, tree species, elevation, supplementary feedings in the proximity, …) and to carry out an additional bark stripping inventory in these stands. Here, the same considerations as for the stand level inventory apply.
Based on the above considerations, we recommend the following procedure:
-
Systematic sampling with a grid space between 20 and 25 m.
-
Fixed radius plots with a radius of 4 or 6 m.
-
For implementing in large-scale inventories: Preselection of vulnerable stands and inserting of additional sample points (measure using FRP)
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Apollonio M, Andersen R, Putman R (2010) European ungulates and their management in the 21st Century. Cambridge University Press, Cambridge
Becker P, Nichols T (2011) Effects of basal area factor and plot size on precision and accuracy of forest inventory estimates. Northern J Appl for. https://doi.org/10.1093/njaf/28.3.152
Beers TW (1969) Slope correction in horizontal point sampling. J Forest 67:188–192
Berger A, Gschwandtner T, Schadauer K (2020) The effects of trunking the angle count sampling method on the Austrian National Forest Inventory. Ann for Sci 77:16. https://doi.org/10.1007/s13595-019-0907-y
BFW (2018) Österreichische Waldinventur - Auswahl: Bund_Stammschäden_Stammzahl Wuchklassen_Erhebung 2007–2009. http://bfw.ac.at/rz/wi.auswahl (14.07 2018)
Bitterlich, W. (1948). Die Winkelzählprobe. Allg. Forst-u. Holzw. Ztg. 59 (1/2): 4–5.
Bitterlich W (1952) Die Winkelzählprobe - Ein optisches Meßverfahren zur raschen Aufnahme besonders gearteter Probeflächen für die Bestimmung der Kreisflächen pro Hektar an stehenden Waldbeständen. Forstwissenschaftliches Centralblatt 71:215–225
Bitterlich W (1984) The relascope idea: relative measurements in forestry. Slough Commonwealth Agricultural Bureaux (U.K.)
Čermák P, Jankovský L, Glogar J (2004) Progress of spreading Stereum sanguinolentum (Alb. et Schw.: Fr.) Fr. wound rot and its impact on the stability of spruce stands. J for Sci 50(8):360–365
Conn PB, Thorson JT, Johnson DS (2017) Confronting preferential sampling and analysing population distributions: diagnosis and model-based triage. Methods Ecol Evol 8:1535–1546. https://doi.org/10.1111/2041-210X.12803
Coppes J, Burghardt F, Hagen R, Suchant R, Braunisch V (2017) Human recreation affects spatio-temporal habitat use patterns in red deer (Cervus elaphus). PLoS ONE. https://doi.org/10.1371/journal.pone.0175134
Ehrhart S, Stühlinger M, Schraml U (2022) The relationship of stakeholders´ social identities and wildlife value orientations with attitudes toward red deer management. Hum Dimens Wildlife 27(1):69–83. https://doi.org/10.1080/10871209.2021.1885767
Fountain MS, Hunt EV Jr, Hassler CC (1983) Comparison of five metric basal area factors. J for. https://doi.org/10.1093/jof/81.1.26
Gheysen T, Bostaux Y, Hébert J, Ligot G, Rondeux J, Lejeune P (2011) A regional inventory and monitoring setup to evaluate bark peeling damage by red deer (Cervus elaphus) in coniferous plantations in Southern Belgium. Environ Monit Assess 181:335–345. https://doi.org/10.1007/s10661-010-1832-6
Gill RM (1992) A review of damage by mammals: 1. Deer. Forestry 65(2):145–169
Hahn C, Vospernik S (2022) Position, size, and spatial patterns of bark stripping wounds inflicted by red deer (Cervus elaphus L.) on Norway spruce using generalized additive models in Austria. Ann for Sci 79:13. https://doi.org/10.1186/s13595-022-01134-y
Hahn C, Vospernik S, Gollob C, Ritter T (2023) Bark stripping damage by red deer (Cervus elaphus L.): assessing the spatial distribution on the stand level using generalised additive models. Eur J for Res. https://doi.org/10.1007/s10342-023-01545-0
Hauk E, Niese G, Schadauer K (2020) Instruktion für die Feldarbeit der Österreichischen Waldinventur 2016 +. Dienstanweisung des Bundesforschungs- und Ausbildungszentrums für Wald, Naturgefahren und Landschaft (BFW), Wien
Heikkinen J (2006) Assessment of uncertainty in spatially systematic sampling. Dordrecht (The Netherlands): Springer, pp 155–176. https://doi.org/10.1007/1-4020-4381-3_10
Henttonen HM, Kangas A (2015) Optimal plot design in a multipurpose forest inventory. For Ecosyst 2:31. https://doi.org/10.1186/s40663-015-0055-2
Hollaus M, Wagner W, Maier B, Schadauer C (2007) Airborne laser scanning of forest stem volume in a mountainous environment. Sensors 7:1559–1577. https://doi.org/10.3390/s7081559
Hollaus M, Wagner W, Schadauer K, Maier B, Gabler K (2009) Growing stock estimation for alpine forests in Austria: a robust lidar-based approach. Can J for Res 39:1387–1400. https://doi.org/10.1139/X09-042
Kangas A, Maltamo M (2006) Forest inventory: methodology and applications. Springer, Dordrecht (NL)
Kershaw JA Jr, Ducey MJ, Beers TW, Husch B (2016) Forest mensuration, 5th edn. Wiley-Blackwell, Hoboken (New Jersey)
Kramer H, Akḉa A (2008) Waldmeßlehre, 5th edn. J. D. Sauerländer’s Verlag, Frankfurt am Main
Land Oberösterreich (2023) Oberösterreichische Abschussplanverordnung (StF LGBl. Nr. 74/2004); Version from April 17th 2023. Linz: Amt der Oö. Landesregierung
Ligot G, Gheysen T, Perin J, Candaele R, de Coligny F, Licoppe A, Lejeune P (2023) From the simulation of forest plantation dynamics to the quantification of bark-stripping damage by ungulates. Eur J for Res. https://doi.org/10.1007/s10342-023-01565-w
Maltamo M, Korhonen KT, Packalén P, Mehtätalo L, Suvanto S (2007) Testing the usability of truncated angle count sample plots as ground truth in airborne laser scanning-based forest inventories. Forestry 80(1):73–81. https://doi.org/10.1093/forestry/cpl045
Matérn B (1969) Wie groß ist die “Relaskop-Fläche”? Allgemeine Forstzeitung 79:21–22
McGarvey R, Burch P, Matthews JM (2016) Precision of systematic and random sampling in clustered populations: habitat patches and aggregating organisms. Ecol Appl 26(1):233–248. https://doi.org/10.1890/14-1973
Milner JM, Bonenfant C, Mysterud A, Gaillard J-M, Csányi S, Stenseth NC (2006) Temporal and spatial development of red deer harvesting in Europe: biological and cultural factors. J Appl Ecol 43:721–734. https://doi.org/10.1111/j.1365-2664.2006.01183.x
Næsset, E., Gobakken, T., Bollandsås, O.M., Gergoire, T.G., Nelson, R., Ståhl, G. (2013). Comparison of precision of biomass estimates in regional field sample surveys and airborne LiDAR-assisted surveys in Hedmark County, Norway. Remote Sens 130: p. 108–120. https://doi.org/10.1016/j.rse.2012.11.01
Perret J, Charpentier A, Pradel R, Papuga G, Busnard A (2022) Spatially balanced sampling methods are always more precise than random ones for estimating the size of aggregated populations. Methods Ecol Evolut 13:2743–2756. https://doi.org/10.1111/2041-210X.14015
Piqué M, Obon B, Cordés S, Saura S (2010) Comparison of relascope and fixed-radius plots for the estimation of forest stand variables in northeast Spain: an inventory simulation approach. Eur J for Res 130:851–859. https://doi.org/10.1007/s10342-010-0477-x
Pollanschütz J (1985) Formzahlfunktionen der Hauptbaumarten Österreichs. Allgemeine Forst- Jagdzeitschrift 85:341–343
Ritter T, Nothdurft A, Saborowski J (2013) Correcting the nondetection bias of angle count sampling. Can J for Res 43:344–354. https://doi.org/10.1139/cjfr-2012-0408
Roesch FA (1993) Adaptive cluster sampling for forest inventories. For Sci. https://doi.org/10.1093/forestscience/39.4.655
Schmid-Haas P (1969) Stichproben am Waldrand (Sampling at the edge of the forest). Mitteilungen Der Eidgenössischen Anstalt Für Forstliches Versuchswesen 43:234–303
Schreuder HT, Banyard SG, Brink GE (1987) Comparison of three sampling methods in estimating stand parameters for a tropical forest. For Ecol Manag. https://doi.org/10.1016/0378-1127(87)90076-4
Scrinzi G, Clementel F, Floris A (2015) Angle count sampling reliability as ground truth for area-based LiDAR applications in forest inventories. Can J for Res 45:506–514. https://doi.org/10.1139/cjfr-2014-0408
Sessa R, Dolman H (eds) (2008) Terrestrial essential climate variables: for climate change assessment, mitigation and adaption. Food and Agriculture Organisation of the United Nations (FAO), Rome
Simon O, Petrak M (1998) Zur Methodik der Linientaxation bei der Erhebung von Schälereignissen. Zeitschrift Für Jagdwissenschaften 44:133–122
Tokola T, Shrestha SM (1999) Comparison of cluster-sampling techniques for forest inventory in southern Nepal. For Ecol Manage 116:219–231. https://doi.org/10.1016/S0378-1127(98)00457-5
Tomppo E, Toumainen T (2010) Individual country reports: Finland. In: Tomppo E et al (eds). National forest inventories - pathways for common reporting. Berlin: Springer
Vospernik S (2006) Probability of bark stripping damage by red deer (Cervus elaphus) in Austria. Silva Fennica 40(4):589–601
Acknowledgements
We are thankful to the forest company Wasserberg / Stift Heiligenkreuz, and in particular to P. Cœlestin Klemens Nebel OCist. for the opportunity to make the measurements for our study on their sites and for their support. We thank Ralf Kraßnitzer, Franz Gollob and Philipp Waltl for the careful fieldwork.
Funding
Open access funding provided by University of Natural Resources and Life Sciences Vienna (BOKU).
Author information
Authors and Affiliations
Contributions
Conceptualization: CH, SV; Methodology: CH, SV; Formal Analysis: CH, SV; Data curation: CH, SV; Writing–original draft: CH, SV; Writing–review & editing: CH, SV.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Consent for publication
All authors gave their informed consent to this publication and its content.
Ethical approval
The authors declare that they follow the rules of good scientific practice.
Additional information
Communicated by Thomas Knoke.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Appendix: Formulas
Appendix: Formulas
FRP: \(BF=\frac{10 000}{\pi *{r}^{2}}\)
ACS:\({V}_{ total}=\sum_{i=1}^{z}\left[BAF*{H}_{i}*{f}_{i}\right]\)
With:Vtotal Total volume of all trees per ha.
Vdamaged Volume of all damaged trees per ha
BF Blow-up-factor; is equivalent to representative stem number per ha
BAF Basal area factor [m2/ha] (differs between the simulation scenarios)
z Number of sample trees included in FRP or ACS, respectively
π Circular constant
r Radius of the FRP [m] (differs between the simulation scenarios)
DBHi Diameter at breast height (1.3 m) of the ith sample tree [m]
Hi Height of the ith sample tree [m]
fi Form factor according to Pollanschütz (1985); fi = f(species; DBHi; Hi)
Di Damage indicator. Di = 1 for damaged trees and Di = 0 for undamaged trees
With: SDStandard deviation [Vfm/ha]
SE Standard error [Vfm/ha]
n Number of sample units (FRP or ACS) in the simulation scenario
vi Volume of damaged trees in the ith sample unit [Vfm/ha]
\(\overline{v}\)Mean volume of the damaged trees in a scenario [Vfm/ha].
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hahn, C., Vospernik, S. Stand-level sampling designs for bark stripping caused by red deer (Cervus elaphus L.): simulation studies based on nine fully censused stands. Eur J Forest Res (2024). https://doi.org/10.1007/s10342-024-01670-4
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10342-024-01670-4