
Abstract
Situational risk has been postulated to be one of the most important contextual factors affecting operator’s trust in automation. However, experimentally, it has received only little attention and was directly manipulated even less. To close this gap, this study used a virtual reality multi-task environment where the main task entailed making a diagnosis by assessing different parameters. Risk was manipulated via the altitude, the task was set in including the possibility of virtually falling in case of a mistake. Participants were aided either by information or decision automation. Results revealed that trust attitude toward the automation was not affected by risk. While trust attitude was initially lower for the decision automation, it was equally high in both groups at the end of the experiment after experiencing reliable support. Trust behavior was significantly higher and increased during the experiment for the decision automation supported group in the form of less automation verification behavior. However, this detrimental effect was distinctly attenuated under high risk. This implies that negative consequences of decision automation in the real world might have been overestimated by studies not incorporating risk.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
1.1 Human–automation interaction and trust
A key goal when implementing new automation is that operators appropriately trust it. Appropriateness is given when operators’ trust behavior aligns with the automation’s real capabilities (Parasuraman and Riley 1997). In a work context associated with high risks (e.g., aviation, nuclear energy, medicine), especially an overreliance in terms of an automation-induced complacency has been identified as severely problematic possibly leading to catastrophic consequences (Parasuraman and Riley 1997; Bailey and Scerbo 2007; Parasuraman and Manzey 2010).
Most work on trust in automation conceptualizes trust as a construct with two different components, trust attitude and trust behavior. The first is the cognitive and affective component, which has been defined as the operator’s attitude that the automation will help achieve the individual’s goals in a situation characterized by uncertainty and vulnerability (Lee and See 2004). It is the most important factor determining an operator’s willingness to rely on an automation (Lee and See 2004; Hoff and Bashir 2015). Reliance is the behavioral component of trust, called the operator’s trust behavior.
Both components have been under extensive investigation in the past decades, even though not in all studies, the distinction between the attitudinal and behavioral manifestations of trust is explicitly made. There is a lot of evidence (Parasuraman and Manzey 2010; Mosier and Manzey 2019) showing that operators’ trust behavior increases when they interact with automation supporting the decision-making process (stage 3 and 4; Parasuraman et al. 2000; summarized as decision automation (DA); Rovira et al. 2007) in comparison to automation only aiding the information acquisition and analysis (stage 1 and 2; Parasuraman et al. 2000; summarized as information automation (IA); Rovira et al. 2007). This increased trust behavior is manifested, for example, in insufficient monitoring and automation verification of automated diagnoses (Lee and See 2004). Consequently, the operator might be less likely to detect an unexpected automation’s mistake and would have more difficulty in taking over the control if automation breaks down altogether (Parasuraman and Manzey 2010). In contrast, there is evidence that an increase of the degree of automation can have attenuating effects on operators’ trust attitude (Sheridan and Verplank 1978). However, evidence is limited for the latter, and it has been argued that this might mainly be due to the decrease in system understandability often associated with higher degrees of automation (Lewis et al. 2018). Nevertheless, these studies exemplify that it is crucial to incorporate both trust components to understand differential effects of automation and to reveal reasons for congruence (e.g., Bailey and Scerbo 2007) or incongruence (e.g., Bustamante 2009; Wiczorek and Manzey 2010) of trust attitude and behavior in interaction with automation. One such reason might be related to the task context as most research did not incorporate one of the key factors of Lee and See’s definition of trust: a situation characterized by vulnerability (2004). Most studies in the context of human–automation interaction are conducted in laboratories using computer simulations of complex systems (e.g., Manzey et al. 2012; Onnasch 2015). These experimental paradigms are great at reproducing the cognitive demands and common strains on the operator of the real-life work context. However, their capability of inducing a vulnerable situation, i.e., a risk for the participants, is arguably limited. This lack of vulnerability might explain differing findings with regard to trust attitude and trust behavior. For instance, assuming the trust attitude of a participant toward automation is low in an experiment without the manipulation of risk: said participant might blindly follow the automation’s recommendation without further verification because they would not face any negative consequences. In this example, the participants’ trust attitude is low, while their measurable trust behavior is high. In contrast, under high risk, a participant’s low trust attitude toward the automated aid should cause them to show appropriate verification behavior (i.e., less trust behavior) in fear of the negative consequence (Chancey 2016).
1.2 Situational risk
Risk can be defined as the product of the probability multiplied by the severity of a negative event (German Institute for Standardization 2010). Both, an increase of either probability or severity increases the risk. It has repeatedly been postulated in the literature that the magnitude of a present situational risk is one of the most important environmental factors that influence the operator’s behavior (e.g., Mayer et al. 1995; Parasuraman and Riley 1997; Hoff and Bashir 2015; Lewis et al. 2018; Mosier and Manzey 2019).
Despite the theoretical derivation regarding the importance of risk in human–automation research, it has only rarely been directly manipulated. Evidence concerning its effects on trust is therefore rather scarce. Concerning trust attitude, Sato et al. (2020) investigated the effects of risk on task performance, attention allocation and trust attitude when working with an IA. They operationalized risk between groups by either claiming that poor performance will result in a repetition of the experiment (high risk) or giving no such information (low risk). Results revealed no main effect of their operationalization of risk on any of the dependent variables. Only under high workload, the group in the high-risk condition reported a slightly higher trust attitude toward their IA which was revealed by an interaction effect. Unfortunately, different degrees of automation were not compared, and effect sizes were small despite a substantial group difference in perceived risk.
Perkins et al. (2010) investigated participants’ trust behavior in a route-planning task with DA support. Risk was manipulated by a cover story concerning driving hazards on the route. When risk was high, participants reduced their reliance on the automation. Lyons and Stokes (2012) also compared participants’ trust behavior toward an automation (stage 1, information acquisition; Parasuraman et al. 2000) and a human aid under different levels of risk (cover story in a military navigation task with varying probability of an attack). Results revealed that under high risk, participants showed more reliance toward the automated tool, which has been suggested to be evidence for a general inclination toward automation under risk (Hoff and Bashir 2015). However, the decreased trust behavior toward the human might have merely been due to the low level of intelligibility in contrast to the automation. The human aid proposed a route without any reasoning, which in the high-risk condition always opposed the historic information about previous attacks. Intelligibility and transparency are important factors enhancing trust (Hoff and Bashir 2015; Lewis et al. 2018). It therefore does not seem surprising that operators tended to decrease their trust behavior toward an incomprehensible human aid contradicting the only information available.
Whereas these studies support the theoretically postulated importance of risk, they do not inform about the influence of risk on the relation of trust attitude and trust behavior as they each refer to only one component. The relational aspect was addressed by Chancey et al. (2017) who investigated effects of automation with different reliability and error bias on trust. Risk was manipulated between subjects by either claiming that poor performance in the task will extend the experiment without further compensation (high risk) or giving no such information (low risk). Results of a mediation analysis revealed that participants’ compliance was only mediated by their trust attitude toward automation in the high-risk condition but not in the low-risk condition (Chancey et al. 2017). This corresponds to results of a study conducted by Bustamante (2009). Risk was not manipulated and therefore comparable to the low-risk condition in the experiment by Chancey et al. (2017). They revealed that the error-proneness of automation did have effects on the participants’ trust behavior, but this was not mediated by the subjective trust attitude (Bustamante 2009). Similarly, in another study without the manipulation of risk, the mediation of trust attitude between the reliability of automation and compliance behavior could not be found in a path analysis (Wiczorek and Manzey 2010). All of this is evidence for the assumption that trust attitude is only effective and predictive for behavior if vulnerability is a key characteristic of the situation, i.e., if there is risk. Once again, this clearly stresses the importance to incorporate risk in human-automation research.
The gap between empirical necessity and actual data availability regarding risk might be due to the justified ethical considerations concerning the operationalization of an experienceable risk. Self-evidently, participants cannot be exposed to a risk with an actual pronounced extent of damage. One way to try to circumvent this problem, is by framing the experiment’s cover story in a way that a participant’s mistake has a hypothetical negative consequence (e.g., Perkins et al. 2010; Lyons and Stokes 2012; Hanson et al. 2014). However, the challenge to create a cover story generating a high enough level of immersion for participants to feel an actual risk is difficult to nearly impossible. Certainly, in the previously mentioned studies, different degrees of hypothetical negative consequences proved to have varying impacts on participants’ behavior. Then again, compared to the mere prospect of a hypothetical threat, a directly experienceable risk involving oneself should arguably influence behavior to a much larger extent.
In a more self-referential approach, risk has been operationalized by claiming that participants must stay longer for the experiment if they perform poorly (e.g., Chancey et al. 2017; Sato et al. 2020). Thus, the negative consequence of a mistake entails a possible waste of time. In a further approach, risk has been induced using payoff-matrices where participants receive money dependent on their performance (e.g., Wiczorek and Manzey 2010). Compared to mere cover stories, these kinds of risk operationalization entail actual consequences. Nevertheless, it remains unclear if these mere inconveniences are comparable to the situation of some real-life operators, in which a mistake entails a threat to their own physical integrity (e.g., pilots).
To tackle this difficult challenge of ethically operationalizing risk, new approaches apply virtual reality (VR) to create an immersive experience while not exposing participants to real harm (e.g., Pallavicini et al. 2016; Wuehr et al. 2019; Ahir et al. 2019). Following this idea, we have developed and validated an experimental multi-task paradigm applicable to automation research called Virtual Reality Testbed for Risk and Automation Studies (ViRTRAS; Hoesterey and Onnasch 2021). In ViRTRAS, situational risk is operationalized through the altitude participants must perform their task in, including the possibility of virtually falling in case of a mistake. Therefore, concerning the stochastic definition of risk, the severity of a negative event is manipulated–in this case falling. The consequence of falling from only half a meter is (usually) much less severe than falling from much higher altitudes. As a result, ViRTRAS thus simulates a situation where a mistake could have severe potential consequences for one’s physical integrity. It therefore overcomes the problem of having to merely pretend that there could be negative consequences (cover stories) or resort to rather inconveniences (increased time investment or a slightly reduced monetary reward). The new paradigm can therefore be used for investigating effects of human–automation function allocation (i.e., differing degrees of automation) while also incorporating the context factor of risk that is more comparable to the situation in which one’s physical integrity is at stake in a way that is safe and ethical (Hoesterey and Onnasch 2021).
1.3 Research question and hypotheses
Aim of this study is to investigate the impact of situational risk on trust attitude and trust behavior in interaction with IA and DA. Generally, we expect former experimental findings concerning effects of human-automation function allocation on overall joint performance and trust attitude to be replicated in the low- as well as high-risk condition. However, results concerning trust behavior should only be replicated in the low-risk condition as most experimental evidence is based on studies without the manipulation of risk. We expect in the low-risk condition that participants with DA support show more trust behavior in the form of affording less resources verifying the automation compared to the reference group (IA). However, when risk is high, we expect the effect of function allocation to be minimized. To prevent more severe negative consequences, participants of the DA group will presumably show the same level of information sampling behavior as participants of the reference group (IA), who ought to do so for goal achievement.
1.3.1 Overall effects
If automation functions properly, there is an automation benefit under routine task performance. This effect increases with the degree of automation (Onnasch et al. 2014). The assistance systems used in this study are programmed to be 100% reliable. Therefore, we expect an automation benefit in joint task performance for the higher automated support.
-
H1:
Participants working with DA support will be better and faster in the primary and secondary task compared to a reference group (IA support).
It has repeatedly been demonstrated that trust attitude as well as trust behavior toward automation can fluctuate depending on participants’ experience with automation (Hoff and Bashir 2015). Since the automated aids used in this experiment are perfectly reliable, we expect participants’ trust to increase.
-
H2:
Trust attitude and trust behavior will increase during the experiment.
The main system property affecting participants’ trust attitude is the system’s reliability (Lewis et al. 2018). Both automated aids are programmed to be equally reliable (100%). We therefore expect no general difference in participants’ trust attitude.
Moreover, Sato et al. (2020) did not find a main effect of their risk manipulation on trust attitude toward their IA. Similarly, we do not expect differences in trust attitude.
-
H3:
Trust attitude does not differ in either automation or risk condition.
1.3.2 Low risk
Most of the presented studies investigating effects of human–automation function allocation on trust behavior were conducted in a low-risk condition, because participants did not face evident negative consequences following a mistake. Presumably, this is similar to the operationalization of the low-risk condition in this paradigm. Thus, in this study, we expect that former results of trust behavior will be replicated in this condition.
-
H4:
In the low-risk condition participants being supported by DA will show more trust behavior compared to participants in the reference group (IA).
1.3.3 High risk
In contrast, in the high-risk condition in the event of a mistake, participants must face simulated negative consequences. Therefore, we hypothesize that participants supported by DA will reduce their trust behavior and show similar information sampling behavior as the reference group (IA).
-
H5:
In the high-risk condition, the effect of function allocation will be minimized so that trust behavior of both groups will not differ.
2 Methods
2.1 Participants
An a priori power analysis revealed that a total of 62 participants are sufficient for medium effect sizes in a repeated measures ANOVA with a between factor for the dependent variables of our focus (trust and performance measures; f = 0.25, α = 0.05, 1–β = 0.8; GPower 3.1; Faul et al. 2009).
We invited participants to the study via the university’s e-mail distribution list for experimental studies. For compensation, participants could decide between course credit or € 15. A total of 82 subjects came to participate in the study of which 17 had to be excluded prior to either data collection or analysis. Due to technical errors of the head-mounted display (HMD), data collection could not be completed for the whole experiment for five participants. We further excluded seven participants because they were not able to proficiently conduct the task. This became clear to the experimenter when clarifying questions during and after the tutorial and practice trials. These individuals did not participate in the experiment and were compensated for the time they invested until then. A further participant was excluded prior to the VR exposure because they met the criterion for acrophobia (a priori defined exclusion criterion) while another subject decided to stop the experiment after being exposed to the high altitude for the first time. Also, we excluded three participants after an outlier analysis of their information sampling behavior. Despite the instruction to verify the automation’s recommendation, they did not do so in any trial of the experiment. This nonexistent verification behavior is 2.4 SD below the sample’s mean (68%) and 2.6 SD below the median (72%). This leaves a sample of 65 subjects (IA = 31, DS = 34) for data analysis (age range: 18 to 61). Table 1 depicts their demographic information.
2.2 Apparatus and tasks
ViRTRAS was rendered using Unreal Engine software (Version 4.24; Epic Games Inc., Cary, NC). An HMD (HTC Vive Pro, HTC, Taiwan, ROC) was used to expose participants to the virtual environment while their head-in-space movements were tracked by two base stations. Participants therefore had to physically walk within the laboratory to move within the virtual environment. Note that in case the simulation provoked an emotional reaction which was too unpleasant, taking off the HMD enabled participants to quickly return to reality. This was possible because VR only affected visual and auditory perception which ended abruptly once the HMD was removed.
2.2.1 Cover story
The cover story was set in the not-so-distant future where mankind has started to build information networks on other planets. Participants took on the role of an operator on a prototype of one of these transmitter facilities. The functioning of these facilities is mainly dependent on the oval so-called information clouds that travel through long vertical transparent masts (Fig. 1). Due to the early stage of development, these frequently crash and freeze. This can occur close to the ground (low risk) or in higher altitudes (high risk). Whenever this happens, the operator must travel to the place the information cloud froze at and reset it by hand. Participants were transported to the respected location in a small capsule approximately the size of a small elevator. Once participants arrived, they could extend a ramp from the capsule on which they could walk toward and manually reset the information cloud (Fig. 1). This was the main overall goal of the operator.

Screenshots of the VR environment: A Mast with information clouds (right) and capsule from behind (left); B Participants’ point of view from inside the capsule toward the open door, extended ramp, and the frozen information cloud in the high-risk condition
Particular about this planet are a total of seven distinct atmospheric conditions that can quickly change. Six out of these conditions are harmful to the ramp participants had to walk over. Therefore, before crossing the ramp, diagnosis of the current atmospheric condition was necessary to potentially apply one of six different alloys which protected the material of the ramp from their corresponding atmospheric condition. If participants did not apply the correct alloy before walking on the ramp despite its necessity, the ramp was damaged and started to crack accompanied by visual and auditory warning cues. If participants did not return to the capsule quickly enough, the ramp broke and they virtually fell for 1.5 s. The virtual environment then faded out and turned white, making it impossible for the participants to experience hitting the ground from higher altitudes.
2.2.2 Primary task
The primary task could be divided into three different phases: (1) diagnosis of the current atmospheric condition, (2) deciding on the correct protective alloy for the ramp, if necessary, and (3) stepping out of the capsule and manually resetting the information cloud.
First, the atmospheric condition depended on the state of four different fictious parameters: atmospheric electricity, temperature, cosmic radiation, and pH value. If one or two parameters were out of normal range, this indicated an anomaly and a harmful atmospheric condition the ramp needed to be protected from. There was a maximum of seven different atmospheric conditions possible composed of the four different parameters’ states (Fig. 2A).

A Control panel without automation support; Top: Screen used for parameter access with opened readings of the atmospheric electricity; Bottom: Key for all possible atmospheric conditions (top row) and the parameters’ (left column) corresponding states (cells: exclamation point stands for deviation from normal range); Right: Screen for the automation support, which in the manual condition only provides the current altitude; B Panel used for mixing and application of the protective alloy
There was a specific test procedure for each of these parameters, which participants were trained for in a prior tutorial. The parameters’ state could be accessed and viewed via a control panel inside the capsule (Fig. 2A).
Secondly, once, the participant diagnosed the current atmospheric condition, they had to decide if a protective alloy was necessary for the ramp and if so, which one. If all parameters were within normal range, no alloy was necessary. In all other cases, the correct alloy had to be mixed and applied to the ramp. This was possible using the alloy panel and four different liquids within the capsule (Fig. 2B).
Finally, if the correct alloy was applied participants could safely achieve the main goal: resetting the information cloud within the transmitter mast. For this task, they could extent the ramp toward the frozen information cloud via a button press. Next, they had to cross the ramp to reach the information cloud. Once they arrived, they had to place their right-hand controller into the information cloud and pull the trigger of their controller. Afterward, the cloud changed its color and started moving again. When participants returned to the capsule the automatic door closed, which constituted the completion of one trial. Between two trials, there was a pause of three to seven seconds accompanied by noises indicating the capsules’ traveling. When the automatic door reopened, the next trial started.
2.2.3 Secondary task
There was a continuous auditory reaction time task—the connection check. Before the start of the experiment, participants were assigned an operator number. During the experiment, every 10–20 s they heard a voice announcing a number, asking for feedback. In 25 percent of these announcements, participants’ assigned number was called. In these cases, they had to press the trigger of their left-hand controller as fast as possible to indicate a proper connection. If a different number was announced, they were not supposed to react to the probe. A correct response to their number (hit), a miss and false reaction to a different operator number was indicated to the participant with different sounds.
2.2.4 Automation
Two different automated aids supporting the primary task were implemented for this experiment. They were introduced to the participants as the “atmospheric testing system” (ATS). Participants were not informed that the assistance system was 100% reliable. They were told that the ATS was very reliable but for their own safety they should always verify its diagnosis.
Information automation (IA). The IA was a basic automation supporting participants in the atmospheric analysis and therefore represented the reference condition. The system indicated whether an anomaly was detected or not. Second, in case an anomaly was detected, the IA indicated whether the origin of the anomaly was either “chemical” or “energetic” (Fig. 3A). This narrowed down the possible remaining atmospheric condition options from six to only three. Participants were still required to at least assess two parameters to conclusively arrive at a diagnosis and fulfill the task. Also, the IA did not help with mixing and applying the protective alloy. The IA therefore corresponded to a stage 2 automation according to Parasuraman et al. (automation of information acquisition and analysis; 2000).

Depiction of both automations in the beginning of a trial with “alpha” as the current atmospheric condition when no parameter reading has been selected yet; A Information automation, B Decision automation
Decision automation (DA). In case of an anomaly, the DA not only narrowed down the atmospheric conditions but also presented the participant with an exact diagnosis and highlighted this on the control panel (Fig. 3B). Therefore, information sampling was not absolutely required for task completion, although participants were asked to verify the automations’ diagnosis. Note that for a conclusive verification of the DA’s diagnosis, participants needed to verify the same number of parameters (two) as participants being aided by IA support. Additionally, the DA aided with the second phase of the primary task by indicating which liquids needed to be mixed for the correct protective alloy. As this automation suggested a final decision and proposed further action the DA corresponded to a stage 3 automation (additional automation of decision selection; Parasuraman et al. 2000).
2.3 Design
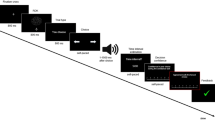
A 2 (automation, between) × 2 (risk, within) × 4 (block, within) mixed design was used. Each block contained four trials either belonging to the low-risk (0.5 m) or high-risk condition (70 m). The order of the risk condition was alternating. Whether participants started their first block in the low- or high-risk condition was balanced within both groups (Fig. 4).

Depiction of the study design: Participants either started in the high- (top) or low-risk condition (bottom), and completed a total of eight blocks with four trials each. After the first and last block in each condition, participants answered queries within the VR; SI single item, Q questionnaire
2.4 Metrics
2.4.1 Exclusion criterion and manipulation check
Height intolerance. Prior to the experiment, the visual Height Intolerance Severity Scale (vHISS; Huppert et al. 2017) was used for the identification of a diagnosis of acrophobia which was an exclusion criterion.
Risk perception. While the successful induction of risk via altitude has been validated with subjective as well as objective measures (Hoesterey and Onnasch 2021), we included two metrics serving as a manipulation check. First, a single item with a 6-point Likert scale assessed the temporal change of risk perception after the first and last block in each risk condition (“Walking over the ramp felt risky”). Moreover, the risk perception scale used by Chancey (2016); originally based on Simon et al. 2000) was adapted to this particular paradigm and translated into German. Participants answered each item on a 12-point Likert scale. One item was dropped because it was not applicable to the paradigm. The possible sum score therefore ranged from 4 to 48. Participants responded to this scale after the last block of each risk condition.
2.4.2 Performance
Two qualitatively different performance measures for the primary and secondary task were calculated for each block.
Primary task. For the primary task, the percentage of correct diagnoses represented the effectiveness of task performance. Moreover, as a metric of efficiency of task performance, the total time of trial was assessed. The duration of a trial was recorded from start of the trial until the participant returned to the capsule and the door closed again.
Secondary task. As an effectiveness measure for the secondary task, the percentage of correct responses to the auditory reaction time task was calculated. A correct response consists of the situation when either the participant correctly pulled the trigger after being addressed or if they refrained from a response after a different operator number was called. The efficiency of the secondary task performance was the response time participants took to pull the trigger when their operator number was announced.
2.4.3 Trust attitude
For a more precise assessment of participants’ initial trust attitude, the German translation of the Scale of Trust in Automated Systems by Jian et al. (2000) was used (Pöhler et al. 2016). It contained 11 Items on a 7-point Likert-Scale with a possible sum score ranging from 11 to 77 and was only measured after the first block in each risk condition. Additionally, a single item was used to assess the formation of trust attitude over time. After their first and last block per risk condition, participants were asked to state how much they trust the automation on a scale from zero to 100%.
2.4.4 Trust behavior
Two qualitatively different measures assessed trust behavior. First, information sampling behavior represented the percentage of parameters participants checked, which were necessary for conclusively diagnosing the atmospheric condition. For example, in every trial with an anomaly, two specific parameters had to be checked for a conclusive diagnosis of the atmospheric condition. If a participant checked only one of them and omitted the other one, the value of information sampling in this trial was 50%. Whereas in case of an anomaly, two parameters had to be checked for a conclusive diagnosis, a total of four parameters had to be checked in case of no anomaly to be sure that no further action was necessary (applying alloy to the ramp). A high level of trust behavior was represented by a low level of information sampling behavior.
Second, the duration participants needed to come to a decision (IA group) or to verify the automation (DA group) was assessed. This decision time was recorded from the beginning of the trial until the participant either started the procedure of mixing the alloy or extracted the ramp (in case no alloy is necessary). Shorter times represented a higher level of trust behavior.
2.5 Procedure
We informed participants about the exposure to extreme altitudes and the possibility of virtually falling in the invitation to the study and reminded them upon arrival at the lab. After their written consent, participants completed the vHISS with a pen and paper (Huppert et al. 2017). If they did not meet the criterion for a diagnosis of acrophobia, they answered further queries (demographic information) on a tablet computer. To minimize the chance of an unpleasant experience, participants were told that they could end the experiment at any time without negative consequences. They were also encouraged to take off the head-mounted display whenever they felt uncomfortable. Afterward, participants were familiarized with the cover story, the tasks and their automation system using a computer presentation they worked through themselves. They were told to feel free to ask questions and take the time they needed to understand the information. Subsequently, participants conducted a detailed tutorial within the VR environment, in which they practiced the primary task without an automation. Later, the secondary task was introduced as well. After completing the tutorial, participants conducted three training trials without automated support and additional three trials with support from their respective automation. If the experimenter realized that participants could not proficiently perform the tasks, they did not partake in the experiment and received compensation for the duration of their attendance until then. In contrast to the actual experiment, in the tutorial as well as all training trials, the capsule was set in a white environment with very limited altitude cues.
After completion of the training, participants started with the first experimental block. After the first and last block in each risk condition, within the VR environment, participants were instructed to answer questionnaire items using their hand-held controllers. In the first block of each risk condition, they were presented with both metrics assessing trust attitude as well as the single item of risk perception. After the last block of each risk condition, subjects once again answered the single item of trust attitude and risk perception as well as the risk perception scale (Fig. 4). In between blocks, participants could take breaks if desired.
The study was registered at Open Science Framework (https://doi.org/10.17605/OSF.IO/7BQHM) and was approved by the ethics committee of the department of psychology, Humboldt-Universität zu Berlin.
2.6 Data analysis
All measures concerning task performance and trust behavior were analyzed by a 2 (automation, between) × 2 (risk, within) × 4 (block, within) ANOVA with repeated measures and a between-subject factor. Additionally, we used independent sample t tests to analyze group differences in trust behavior within each risk condition. For these, a Bonferroni-adjusted alpha level of 0.025 (0.05/2) was used to control for erroneous inferences. For the Scale of Trust in Automated Systems and the risk perception questionnaire, a 2 (automation, between) × 2 (risk, within) mixed ANOVA was calculated. To additionally analyze the temporal change of trust attitude and risk perception, a 2 (automation, between) × 2 (risk, within) × 2 (time, within) mixed ANOVA was used for the respective single items. If results in Mauchly’s sphericity test for the ANOVAs revealed violation of sphericity, the Greenhouse–Geisser adjustment was applied to correct the degrees of freedom.
3 Results
3.1 Manipulation check: risk perception
Results from the single item showed a significant difference for risk perception in both risk conditions, F(1, 63) = 64.62, p < 0.001, \({\eta }_{p}^{2}\) = 0.51 (Fig. 5). Independent of automation support (F < 1), the high-risk condition was always perceived as riskier. The main effect of time, F(1, 63) = 14.64, p < 0.001, \({\eta }_{p}^{2}\) = 0.19, indicated that risk perception significantly decreased from the first to the last block. This was especially the case in the high-risk condition, which was supported by a risk x time interaction effect, F(1, 63) = 9.45, p < 0.01, \({\eta }_{p}^{2}\) = 0.13.

Risk perception ratings: Mean of the risk perception ratings for the single item after the first and last block in each condition for both groups (left) and mean of the risk perception questionnaire assessed after the last block in each condition for both groups (right); error bars depict the 95% confidence intervals
The sum score of the risk perception questionnaire significantly differed between both risk conditions as well, F(1, 63) = 24.61, p < 0.001, \({\eta }_{p}^{2}\) = 0.28. Participants perceived the high-risk condition as riskier (Fig. 5). There was no significant interaction between automation and risk condition, F < 1.
In summary, the manipulation of risk via altitude was successful.
3.2 Performance
3.2.1 Primary task
Participants in the DA group had a significantly higher percentage of correct diagnoses compared to subjects in the IA group which was signified by a main effect of automation, F(1, 63) = 10.63, p < 0.01, \({\eta }_{p}^{2}\) = 0.14 (Fig. 6A). There were no other significant main or interaction effects for this variable.

Performance in the primary task: A Overall mean percentage of diagnoses separate for each group; B Overall mean time of trial in seconds separate for each group; error bars depict the 95% confidence interval
Participants in the DA group were also significantly faster in performing the task (time of trial) compared to the reference group (IA), F(1, 63) = 26.70, p < 001, \({\eta }_{p}^{2}\) = 0.30 (Fig. 6B). Moreover, there was a significant main effect of risk, F(1, 63) = 7.13, p < 0.05, \({\eta }_{p}^{2}\) = 0.10. Participants took longer for task completion in the high-risk condition (DA low: M = 38.72, SD = 11.20; DA high: M = 42.58, SD = 10.96; IA low: M = 54.21, SD = 13.26; IA high: M = 55.92, SD = 12.57). Moreover, during the experiment, participants became faster in task completion. This was supported by a main effect of block, F(2.39, 189) = 70.11, p < 0.001, \({\eta }_{p}^{2}\) = 0.53. There was no interaction effect.
3.2.2 Secondary task
In the DA group, participants had a significantly higher percentage of correct responses to the auditory probe (DA: M = 97.5%, SD = 1.29; IA: M = 95.9%, SD = 0.86) compared to the reference group (IA), F(1, 63) = 8.20, p < 0.01, \({\eta }_{p}^{2}\) = 0.12. There were no further significant main or interaction effects for this dependent variable.
Unfortunately, there were several missing values for the variable time to respond. Due to the configurations of the secondary task, multiple participants were not addressed in the probe in at least one block. This resulted in them not having to respond, which made it impossible to calculate a mean of time to respond for these particular blocks. This applied especially to the DA group because their time of trial was shorter, leaving them a smaller probability of being addressed. This resulted in only 14 participants remaining for evaluation in the DA group and 19 in the IA group for this metric. Participants supported by DA (M = 0.26 s, SD = 0.17) were faster in responding to the probe in comparison to the reference group (IA; M = 0.34 s, SD = 0.21), F(1, 31) = 4.47, p < 0.05, \({\eta }_{p}^{2}\) = 0.13. There were no other significant main or interaction effects.
In summary, results for the primary and secondary task were evidence for a clear automation benefit for participants in the DA group compared to the reference group (IA), which supported hypothesis 1.
3.3 Trust attitude
In the assessment of trust attitude with the Scale of Trust in Automated Systems after the first block in each risk condition, there was a significant group difference, F(1, 63) = 9.18, p < 0.01, \({\eta }_{p}^{2}\) = 0.13. Participants in the IA group reported a more pronounced trust attitude toward their automation compared to the DA group (Fig. 7). There was no interaction effect or main effect of risk, F < 1.

Mean trust attitude ratings for both groups: The scale of trust in automated systems was only assessed after the first block in each condition (left) and the single item of trust attitude was only assessed after the first and last block in each condition (right); error bars depict the 95% confidence intervals
trust attitude with the single item increased over time in both groups. This was supported by a main effect of time, F(1, 63) = 47.39, p < 0.001, \({\eta }_{p}^{2}\) = 0.43 (Fig. 7). While the main effects of automation and risk were not significant, F < 1, there was an interaction effect of automation x time, F(1, 63) = 6.15, p < 0.05, \({\eta }_{p}^{2}\) = 0.09. While participants in the DA group trusted the automation less compared to the IA group at the beginning of the experiment, both groups showed comparably high trust ratings at the end of the experiment (second assessment).
The results concerning trust attitude were in support of hypothesis 2 and partially supported hypothesis 3.
3.4 Trust behavior
The three-way ANOVA for information sampling revealed a main effect of risk, F(1, 63) = 7.32, p < 0.01, \({\eta }_{p}^{2}\) = 0.10. Participants generally showed less information sampling in the low-risk compared to the high-risk condition. Figure 8 illustrates that this main effect of risk was largely due to the DA group as the IA group’s information sampling remained the same in both conditions and throughout all blocks. This was further underlined by the significant risk x automation interaction effect, F(1, 63) = 4.17, p < 0.05, \({\eta }_{p}^{2}\) = 0.06, and a main effect of automation, F(1, 63) = 11.73, p < 0.01, \({\eta }_{p}^{2}\) = 0.16. Only the DA group demonstrated reduced information sampling in the low-risk compared to the high-risk condition. Additionally, only the DA group decreased their information sampling during the experiment (significant automation x block interaction, F(3, 189) = 7.22, p < 0.001, \({\eta }_{p}^{2}\) = 0.10), which was even more pronounced in the low-risk condition. The latter was underlined by a significant risk x automation x block interaction effect, F(3, 189) = 5.35, p < 0.01, \({\eta }_{p}^{2}\) = 0.08. The independent sample t test revealed significant group differences not only in the low-risk, t(63) = 3.78, p < 0.001, d = 0.94, but also in the high-risk condition, t(63) = 2.77, p < 0.01, d = 0.69. The DA group showed generally less information sampling than the IA group.

Information sampling under low and high risk for both groups; error bars depict the 95% confidence interval
Moreover, results of the decision time painted a similar picture. There was a significant main effect of risk, illustrating that participants afforded less decision time in the low-risk condition, F(1, 63) = 4.24, p < 0.05, \({\eta }_{p}^{2}\) = 0.06. Figure 9 reveals that this was primarily because of the DA group demonstrating shorter decision times indicating more trust behavior in the low-risk condition. The corresponding risk x automation interaction effect barely missed the conventional level of significance (F(1, 63) = 3.98, p = 0.051, \({\eta }_{p}^{2}\) = 0.06). Moreover, while both groups became faster during the experiment (significant main effect of block, F(2.38, 150.13) = 87.98, p < 0.001, \({\eta }_{p}^{2}\) = 0.58), this was even more pronounced in the DA group (significant automation x block interaction effect, F(3, 189) = 4.59, p < 0.01, \({\eta }_{p}^{2}\) = 0.07). Moreover, there was a main effect of automation, F(1, 63) = 14.17, p < 0.001, \({\eta }_{p}^{2}\) = 0.18. The independent sample t test revealed significant group differences not only in the low-risk, t(63) = 4.07, p < 0.001, d = 0.1.01, but also in the high-risk condition, t(63) = 3.14, p < 0.01, d = 0.78. The DA group was generally faster than the IA group.

Decision time under low and high risk for both groups; error bars depict the 95% confidence interval
The results of the three-way ANOVAs were in support of hypothesis 2. Hypothesis 5 was supported by the ANOVAs as the effect of automation was significantly less pronounced under high risk. However, the results of the t tests opposed hypothesis 5 as there was a significant effect of automation in the high-risk condition.
4 Discussion
Aim of this study was to investigate the influence of risk on trust attitude and trust behavior in interaction with DA. Results were compared to data from a reference group which was supported by an IA. Unlike previous attempts, risk was operationalized in VR as a directly experienceable simulated threat to one’s own physical integrity. The risk associated with a mistake was therefore more comparable to the work context of many real-life operators.
The manipulation check of the risk operationalization was successful. Participants reported a more pronounced risk perception in the high-risk condition in two separate measures. Additionally, results revealed a habituation effect as risk perception decreased from the first to last block in both conditions. This is also consistent with the results of the paradigm’s validation study (Hoesterey and Onnasch 2021). Thus, the results further illustrate that the duration of a risk exposure is an important factor attenuating a person’s evaluation of risk (Rohrmann and Renn 2000). Moreover, an interaction effect revealed that this habituation was stronger in the high-risk condition. The reason for that mainly one-sided decrease could be a floor effect in the low-risk condition as participants’ rating was already very low in the first assessment. This left little room for further reduction. Still, the sum scores of the risk perception questionnaire assessed at the very end of the experiment revealed significant differences between conditions with a large effect size according to Cohen (1988).
One might argue that the way risk was operationalized here still does not go far enough to be comparable to real-life situations of operators. Obviously, participants were aware that the threat of possibly falling was merely simulated. However, previous studies utilizing altitude in VR have demonstrated that immersion is high enough to provoke similar physical and psychological reactions as the real-altitude exposure (Diemer et al. 2016; Wuehr et al. 2019). In the high-risk condition, the reported risk perception was distinctively higher but not in extreme ranges. An even more pronounced risk perception was not intended as this could come close to crossing the line of ethical conduct. This way the paradigm’s operationalization seems to be an appropriate solution to achieve an experienceable simulated risk to one’s own body but at the same time using an ethical approach.
Results of the performance measures of the primary and secondary task revealed a clear automation benefit for participants in the DA group compared to the reference group (IA). They were more effective and more efficient in conducting both tasks, which supports hypothesis 1 and is in line with the literature: Under reliable support joint task performance increases with the degree of automation (Onnasch et al. 2014). The results for the efficiency measure of the secondary task (response time) must be treated with caution, though. Due to the configuration of the task, there were missing values for multiple participants because they were not addressed during at least one block. These particular subjects could therefore not be included in the ANOVA limiting the generalizability of the results of the secondary task to the whole sample. Even though the expected automation benefit was nevertheless significant, in future studies, the settings of the secondary task need to be adjusted by increasing the number of times subjects are probed and addressed. This will also help to raise the secondary task’s difficulty and variance. In summary, results revealed the expected automation benefit with medium to large effect sizes for the higher automated aid in all measures regardless.
Furthermore, results of participants’ trust attitude were partially surprising. Consistent with hypothesis 2, trust attitude increased during the experiment in both groups. Also, in line with hypothesis 3, the reported trust attitude did not differ between both risk conditions. This is consistent with reported results by Sato et al. (2020) who also did not find a main effect of risk. However, in contrast to hypothesis 3, in the early assessment, participants in the DA group reported a lower trust attitude toward their automation compared to the IA group. After the second assessment, trust attitude was comparably high in both conditions. Possibly these findings can be explained with reference to the bases for trust in automation proposed by Lee and See (2004). According to the authors, trust is based on the operator’s perception of the automation’s performance, process, and purpose. Performance includes the operator’s appraisal on the automation’s observable capabilities. Process corresponds to the mechanics and functionality of the automation and purpose describes the perceived intention why the automation was implemented. In the present experiment, when trust attitude was assessed for the first time, participants had little experience in interaction with the automation at that point. Presumably, they therefore based their initial judgment mainly on the perceived purpose of their automation (Meyer and Lee 2013). The respective automation’s purpose might have been perceived different in both groups: The DA prompted a final diagnosis which left participants with the question to either blindly follow or verify the automation. The participants might have therefore evaluated the DA’s purpose to take the task off their hands they previously learned to conduct themselves (in the tutorial). Consequently, they might have interpreted their role as a supervisor who must inherently question or challenge their automation for conscientious task performance as blindly following its diagnosis would be inappropriate. In contrast, the IA pointed in the broad direction of the correct diagnosis, but the concrete diagnosis still had to be identified by the participants. The purpose of the IA might have therefore been evaluated as a helpful tool that enhances the efficiency of task completion. Thus, participants in the IA group were possibly less skeptical toward their automation initially. At the end of the experiment, participants had more experience in interaction with their automation, which increased the significance of the performance component of trust (Lee and See 2004). The functionality of the automation was not revealed to participants. Thus, this likely did not play a distinct role in trust formation). As all participants experienced a perfectly reliable system, it is not surprising that trust attitude was comparably high in both groups at the end of the experiment.
Besides participants’ trust attitude, focus of the present study was their trust behavior in interaction with the automation. Participants working with the IA had to assess the necessary parameters for task completion. In contrast, the DA gave participants leeway to show trust behavior as the automation proposed a final diagnosis. Results revealed that the DA group took advantage of this leeway especially in the low-risk condition. They afforded significantly less resources to verify their automation compared to the information sampling behavior of the reference group (IA). This was observable in the time they invested as well as the number of parameters they assessed which were necessary to conclusively verify the automation. This is in support of hypothesis 4 and in line with experimental results showing an increase in trust behavior simultaneous to an increase of the degree of automation (Parasuraman and Manzey 2010; Mosier and Manzey 2019). In these studies, risk was not manipulated and thus comparable to the low-risk condition of this paradigm.
In contrast, a high present risk had clear attenuating effects on participants’ trust behavior. Participants in the DA group afforded significantly more resources for automation verification when risk was high. They took more time to verify and assessed more parameters. This is in line with other results where trust behavior toward an aid was decreased when risk was involved (Perkins 2010; Lyons and Stokes 2012; Chancey 2016). These effects of risk on trust behavior are especially noteworthy considering that trust attitude did not differ between risk conditions. This further supports for the reasoning that to find behavioral effects of trust in the laboratory, consequences associated with task performance are important (Chancey 2016).
In addition to risk, interaction experience with a perfectly reliable automation strongly shaped trust behavior. Participants of the DA group considerably reduced their trust behavior during the experiment. Not experiencing an automation error is the most important factor increasing reliance (Lewis et al. 2018). When comparing both risk conditions, results demonstrate that the strong decrease in information sampling during the experiment was much less pronounced in the high-risk compared to low-risk condition. While information sampling was generally lower in the DA compared to the reference group, the clear drop during the later blocks observable under low risk could not be observed under high risk. This is clear evidence that the common negative effects of higher degrees of automation on trust behavior (Mosier and Manzey 2019) can be buffered when incorporating negative consequences associated with poor task performance. These findings indicate that previous human–automation research might have overestimated the detrimental effects of higher degrees of automation in the real world. Again, this emphasizes the importance to take the contextual factor of risk into account when conducting human-automation research (Mosier and Manzey 2019). This is in line with hypothesis 5. Nevertheless, contrary to the hypothesis, information sampling behavior was different in both groups under high-risk. The DA group showed significantly less information sampling and afforded less decision time than the reference group (IA), even though effect sizes were smaller under high-risk compared to low-risk. These mixed results are an indication that the basic rationale of hypothesis 5 seems to apply, but to an attenuated extend.
This might imply that in a work context where redundancy is necessary because errors can have catastrophic consequences the automated aid should not offer the leeway for an inappropriate reduction of automation verification in the first place. Moreover, even though results indicate that a present risk buffers negative effects of a higher degree of automation, former results demonstrated that the perception and acceptance of risk decreases with one’s time of exposure to it (Rohmann and Renn 2000). Presumably, the magnitude of the risk’s buffering effect will therefore decrease simultaneous to the operators’ exposure, hence the habituation to that risk. Due to ethical considerations, participants should not be exposed to the VR for an excessive time because this can be too exhaustive, which could be considered a general limitation of the paradigm. However, effects of habituation to a risk over time on trust behavior might still be possible to conduct in multiple sessions with the same participants. Future studies should address this. As a further limitation, the present experiment only used fully reliable automations. Experimentally provoking a conflict between the operator and the automation by including automation errors, for which operators would have to be vigilant to detect them (i.e., potential conflicts of availability; Vanderhaegen, 2021), will most likely affect their attitudinal and behavioral trust toward the automation as well as their risk perception over time. Presumably, the experience of an automation failure after a long time of reliable automation support might cause a sudden breakdown in operator’s trust attitude simultaneous to a leap in their risk perception. Future studies using this paradigm should therefore additionally vary the experience of one or multiple automation failures when investigating function allocation effects while varying risk.
5 Conclusion
In sum, the current study endorsed calls to incorporate important factors of the real-world work context into the laboratories of human–automation research such as the associated risk (Chancey 2016; Jamieson and Skraaning 2020). Established negative effects on operator’s trust and verification behavior with a higher automated automation were replicated under low risk but were attenuated under high risk. While this confirms that risk can in fact buffer negative behavioral effects, risk did not cancel them out entirely. Participants took advantage of the leeway offered by the automation and showed inappropriate trust behavior even under high risk, although to a much lesser extent. This implies that results from laboratory experiments without the manipulation of risk can still be considered for transferability to the real world but might overestimate negative consequences of increasing degree of automation. This study’s paradigm could be a useful approach to further increase that transferability.
Data availability
The dataset analyzed during the current study is available in the Open Science Framework repository, https://osf.io/yxuvg/.
References
Ahir K, Govani K, Gajera R, Shah M (2019) Application on virtual reality for enhanced education learning, military training and sports. Augment Hum Res 5:1–9. https://doi.org/10.1007/s41133-019-0025-2
Bailey NR, Scerbo MW (2007) Automation-induced complacency for monitoring highly reliable systems: the role of task complexity, system experience, and operator trust. Theor Issues Ergon Sci 8:321–348. https://doi.org/10.1080/14639220500535301
Bustamante EA (2009) A reexamination of the mediating effect of trust among alarm systems’ characteristics and human compliance and reliance. Proc Hum Factors Ergon Soc Ann Meet 53:249–253. https://doi.org/10.1177/154193120905300419
Chancey ET (2016) The effects of alarm system errors on dependence: moderated mediation of trust with and without risk Dissertation. Old Dominion University. https://doi.org/10.25777/34GR-X929
Chancey ET, Bliss JP, Yamani Y, Handley HAH (2017) Trust and the compliance–reliance paradigm: the effects of risk, error bias, and reliability on trust and dependence. Hum Factors 59:333–345. https://doi.org/10.1177/0018720816682648
Cohen J (1988) Statistical power analysis for the behavioral sciences. Academic Press, New York, p 54
Diemer J, Lohkamp N, Mühlberger A, Zwanzger P (2016) Fear and physiological arousal during a virtual height challenge—effects in patients with acrophobia and healthy controls. J Anxiety Disord 37:30–39. https://doi.org/10.1016/j.janxdis.2015.10.007
Faul F, Erdfelder E, Buchner A, Lang A-G (2009) Statistical power analyses using G*Power 3.1: tests for correlation and regression analyses. Behavior Res Methods 41:1149–1160. https://doi.org/10.3758/BRM.41.4.1149
German Institute for Standardization (2010) Safety of machinery – general principles for design – Risk assessment and risk reduction. EN ISO Standard No 12100:2010
Hanson JA, Bliss JP, Harden JW, Papelis Y (2014) The effects of reliability and criticality on an IED interrogation task. Proc Hum Factors Ergon Soc Ann Meet 58:2340–2344. https://doi.org/10.1177/1541931214581487
Hoff KA, Bashir M (2015) Trust in automation: integrating empirical evidence on factors that influence trust. Hum Factors 57:407–434. https://doi.org/10.1177/0018720814547570
Hoesterey S, Onnasch L (2021) Manipulating situational risk in human-automation research – validation of a new experimental paradigm in virtual reality. Proc Hum Factors Ergon Soc Ann Meet 65:1109–1113. https://doi.org/10.1177/1071181321651161
Huppert D, Grill E, Brandt T (2017) A new questionnaire for estimating the severity of visual height intolerance and acrophobia by a metric interval scale. Front Neurol 8:211. https://doi.org/10.3389/fneur.2017.00211
Jamieson GA, Skraaning G (2020) The absence of degree of automation trade-offs in complex work settings. Hum Factors 62:516–529. https://doi.org/10.1177/0018720819842709
Jian J-Y, Bisantz AM, Drury CG (2000) Foundations for an empirically determined scale of trust in automated systems. Int J of Cogn Ergon 4:53–71. https://doi.org/10.1207/S15327566IJCE0401_04
Lee JD, See KA (2004) Trust in automation: designing for appropriate reliance. Hum Factors 46:50–80. https://doi.org/10.1518/hfes.46.1.50_30392
Lewis M, Sycara K, Walker P (2018) The role of trust in human-robot interaction. In: Abbass H, Scholz J, Reid DJ (eds) Foundations of trusted autonomy. Springer International Publishing, Cham, pp 135–159
Lyons JB, Stokes CK (2012) Human–human reliance in the context of automation. Hum Factors 54:112–121. https://doi.org/10.1177/0018720811427034
Manzey D, Reichenbach J, Onnasch L (2012) Human performance consequences of automated decision aids: the impact of degree of automation and system experience. J Cogn Eng Decis Mak 6:57–87. https://doi.org/10.1177/1555343411433844
Mayer RC, Davis JH, Schoorman FD (1995) An integrative model of organizational trust. Acad Manage Rev 20:709–734. https://doi.org/10.5465/amr.1995.9508080335
Meyer J, Lee JD (2013) Trust, reliance, and compliance. In: Lee JD, Kirlik A (eds) The Oxford handbook of cognitive engineering. Oxford University Press, Oxford, pp 109–124
Mosier KL, Manzey D (2019) Humans and automated decision aids: A match made in heaven? In: Mouloua M, Hancock PA, Ferraro J (eds) Human performance in automated and autonomous systems. CRC Press, Boca Raton, pp 19–42
Onnasch L (2015) Crossing the boundaries of automation—function allocation and reliability. Int J Hum Comput Stud 76:12–21. https://doi.org/10.1016/j.ijhcs.2014.12.004
Onnasch L, Wickens CD, Li H, Manzey D (2014) Human performance consequences of stages and levels of automation: An integrated meta-analysis. Hum Factors 56:476–488. https://doi.org/10.1177/0018720813501549
Pallavicini F, Argenton L, Toniazzi N, Aceti L, Mantovani F (2016) Virtual reality applications for stress management training in the military. Aerosp Med Hum Perform 87:1021–1030. https://doi.org/10.3357/AMHP.4596.2016
Parasuraman R, Manzey DH (2010) Complacency and bias in human use of automation: an attentional integration. Hum Factors 52:381–410. https://doi.org/10.1177/0018720810376055
Parasuraman R, Riley V (1997) Humans and automation: use, misuse, disuse, abuse. Hum Factors 39:230–253. https://doi.org/10.1518/001872097778543886
Parasuraman R, Sheridan TB, Wickens CD (2000) A model for types and levels of human interaction with automation. IEEE Trans Syst Man Cybe: Syst Hum 30:286–297. https://doi.org/10.1109/3468.844354
Perkins L, Miller JE, Hashemi A, Burns G (2010) Designing for human-centered systems: situational risk as a factor of trust in automation. Proc Hum Factors Ergon Soc Ann Meet 54:2130–2134. https://doi.org/10.1177/154193121005402502
Pöhler G, Heine T, Deml B (2016) Itemanalyse und Faktorstruktur eines Fragebogens zur Messung von Vertrauen im Umgang mit automatischen Systemen. Z Arb Wiss 70:151–160. https://doi.org/10.1007/s41449-016-0024-9
Rohrmann B, Renn O (2000) Risk perception research: An introduction. In: Renn O, Rohrmann B (eds) Cross-Cultural Risk Perception. Springer, US, Boston, pp 11–53
Rovira E, McGarry K, Parasuraman R (2007) Effects of imperfect automation on decision making in a simulated command and control task. Hum Factors 49:76–87. https://doi.org/10.1518/001872007779598082
Sato T, Yamani Y, Liechty M, Chancey ET (2020) Automation trust increases under high-workload multitasking scenarios involving risk. Cogn Tech Work 22:399–440. https://doi.org/10.1007/s10111-019-00580-5
Sheridan TB, Verplank WL (1978) Human and computer control of undersea teleoperators. MIT Man-Machine Systems Laboratory Report.
Simon M, Houghton SM, Aquino K (2000) Cognitive biases, risk perception, and venture formation: How individuals decide to start companies. J Bus Ventur Insights 15:113–134. https://doi.org/10.1016/S0883-9026(98)00003-2
Vanderhaegen F (2021) Heuristic-based method for conflict discovery of shared control between humans and autonomous systems – A driving automation case study. Rob Auton Syst 146:103867. https://doi.org/10.1016/j.robot.2021.103867
Wiczorek R, Manzey D (2010) Is operators’ compliance with alarm systems a product of rational consideration? Proc Hum Factors Ergon Soc Ann Meet 54:1722–1726. https://doi.org/10.1177/154193121005401976
Wuehr M, Breitkopf K, Decker J, Ibarra G, Huppert D, Brandt T (2019) Fear of heights in virtual reality saturates 20 to 40 m above ground. J Neurol 266:80–87. https://doi.org/10.1007/s00415-019-09370-5
Acknowledgements
Many thanks to Markus Ahrendt for the fantastic work programming the VR environment and implementing all of our wishes. Also, many thanks to Isabelle Wenck for data collection.
Funding
Open Access funding enabled and organized by Projekt DEAL. The authors did not receive support from any organization for the submitted work.
Author information
Authors and Affiliations
Contributions
Conceptualization: S.H., L.O.; Methodology: S.H., L.O.; Formal analysis: S.H.; Data curation: S.H.; Writing - original draft preparation: S.H.; Writing - review and editing: L.O.; Visualization: S.H.; Project administration: S.H.; Supervision: L.O.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Conflict of interest
The authors have no competing interests to declare that are relevant to the content of this article References.
Informed consent
All subjects gave informed consent before participation. The study was approved by the ethics committee of the department of psychology, Humboldt-Universität zu Berlin.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hoesterey, S., Onnasch, L. The effect of risk on trust attitude and trust behavior in interaction with information and decision automation. Cogn Tech Work 25, 15–29 (2023). https://doi.org/10.1007/s10111-022-00718-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10111-022-00718-y