
Abstract
We propose a random-subspace algorithmic framework for global optimization of Lipschitz-continuous objectives, and analyse its convergence using novel tools from conic integral geometry. X-REGO randomly projects, in a sequential or simultaneous manner, the high-dimensional original problem into low-dimensional subproblems that can then be solved with any global, or even local, optimization solver. We estimate the probability that the randomly-embedded subproblem shares (approximately) the same global optimum as the original problem. This success probability is then used to show almost sure convergence of X-REGO to an approximate global solution of the original problem, under weak assumptions on the problem (having a strictly feasible global solution) and on the solver (guaranteed to find an approximate global solution of the reduced problem with sufficiently high probability). In the particular case of unconstrained objectives with low effective dimension, we propose an X-REGO variant that explores random subspaces of increasing dimension until finding the effective dimension of the problem, leading to X-REGO globally converging after a finite number of embeddings, proportional to the effective dimension. We show numerically that this variant efficiently finds both the effective dimension and an approximate global minimizer of the original problem.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
We address the global optimization problem
where \(f: \mathcal {X} \rightarrow \mathbb {R}\) is Lipschitz continuousFootnote 1 and possibly non-convex, and where \(\mathcal {X} \subseteq \mathbb {R}^D\) is a set with non-empty interior, and possibly unbounded, which thus includes the unconstrained case \(\mathcal {X} = \mathbb {R}^D\). We propose a generic algorithmic framework, named X-REGO (\(\mathcal {X}\)-Random Embeddings for Global Optimization) that (approximately) solves a sequence of realizations of the following randomized reduced problem,

where \(\varvec{A}\) is a \(D\times d\) Gaussian random matrix (see Definition A.1) with \(d \ll D\), and where \(\varvec{p} \in \mathcal {X}\) may vary between realizations, may be arbitrary/user-defined, and provides additional flexibility that can be exploited algorithmically. For example, choosing \(\varvec{p}^k\) adaptively, as the best point found so far, allows us to maintain and exploit the progress of the algorithm over iterations. The reduced problem (\(\hbox {RP}\mathcal {X}\)) can be solved by any global, or even local or stochastic, optimization solver.
When a (possibly stochastic) global solver is used in the subproblems, we prove that X-REGO converges, with probability one, to a global \(\epsilon \)-minimizer of (P) (namely, a feasible point \(\varvec{x}\) satisfying \(f(\varvec{x}) \le f^* + \epsilon \) for some accuracy \(\epsilon >0\)); we also provide estimates of the corresponding convergence rate. For this, we need to evaluate the \(\epsilon \)-success of the reduced problem (\(\hbox {RP}\mathcal {X}\)).
Definition 1.1
(\(\hbox {RP}\mathcal {X}\)) is \(\epsilon \)-successful if there exists \(\varvec{y} \in \mathbb {R}^d\) such that \(\varvec{A} \varvec{y} + \varvec{p} \in \mathcal {X}\) and \(f(\varvec{A} \varvec{y} + \varvec{p}) \le f^* + \epsilon \), where \(\epsilon >0\) is the desired/user-chosen accuracy tolerance.
Our analysis heavily relies on the probability of (\(\hbox {RP}\mathcal {X}\)) to be \(\epsilon \)-successful. Equivalently, this success probability can be rephrased as follows.
What are the chances that a random low-dimensional subspace spanned by the columns of a (rectangular) Gaussian matrix contains a global \(\epsilon \)-minimizer of (P)?
We use crucial tools from conic integral geometry to estimate the probability above. Applications of these bounds to functions with low effective dimensionality (see Definition 7.1) are also provided.
1.1 Related work
Dimensionality reduction is essential for solving efficiently high-dimensional optimization problems. Sketching techniques reduce the ambient dimension of a given subspace by projecting it randomly onto a lower dimensional one while preserving lengths [69]; such techniques have been used successfully for improving the efficiency of linear and nonlinear least squares (local) solvers and of those for more general functions; see for example, [8, 18, 48, 54, 57, 66] and the references therein. Here, we sketch the problem variables/search space in order to reduce its dimension with the specific aim of global optimization; furthermore, our results are not derived using sketching techniques but conic integral geometry ones.
In a huge-scale setting, where full-dimensional vector operations are computationally expensive, Nesterov [50] advocates the use of coordinate descent, a local optimization method that updates successively one of the coordinates of a candidate solution using a coordinate-wise variant of a first-order method, while keeping other coordinates fixed. Coordinate descent methods and their block counterparts have become methods of choice for many large-scale applications, see, e.g., [4, 56, 70] and have been extended to random subspace descent [44, 46] that operates over a succession of random low-dimensional subspaces, not necessarily aligned with coordinate axes. See also [38] for a random proximal subspace descent algorithm, and [35, 40] for higher-order random subspace methods for local nonlinear optimization.
In local derivative-free optimization, several algorithms explore successively one-dimensional [9, 51, 60] and low-dimensional [16] random subspaces. Gratton et al. [36, 37] propose and explore a randomized version of direct search where at each iteration the function is explored along a collection of directions, i.e., one-dimensional half-spaces. Golovin et al. [34] develop convergence rates to a ball of \(\epsilon \)-minimizers for a variant of randomized direct search for a special class of quasi-convex objectives. Their convergence analysis heavily relies on high-dimensional geometric arguments: they show that sublevel sets contain a sufficiently large ball tangent to the level set, so that at each iteration, with a given probability, sampling the next iterate from a suitable distribution centred at the current iterate decreases the cost.
Unlike the above-mentioned works, our focus here is on the global optimization of generic Lipschitz-continuous objectives. Stochastic global optimization methods abound, such as simulated annealing [32], random search [59], multistart methods [32], and genetic algorithms [41]. Our proposal here is connected to random search methods, namely, it can be viewed as a multi-dimensional random search, where a deterministic or stochastic method is applied to the subspace minimization. Recently, random subspace methods have been developed/applied for the global optimization of objectives with special structure, assuming typically, low-effective dimensionality of the objective [10, 11, 15, 20, 43, 55, 68]. These functions only vary over a low-dimensional subspace, and are also called multi-ridge functions [29, 63], functions with active subspaces [22], or functions with functional sparsity when the subspace of variation is aligned with coordinate axes [67]. Assuming the random subspace dimension d (in (\(\hbox {RP}\mathcal {X}\))) to be an overestimate of the objective’s effective dimension \(d_e\) (the dimension of the subspace of variation), these works have proven that one random embedding is sufficient with probability one to solve the original problem (P) in the unconstrained case (\(\mathcal {X} = \mathbb {R}^d)\) [15, 68] while several random embeddings are required in the constrained case [20]. In particular, in [20], an X-REGO variant is proposed that is designed specifically for the bound-constrained optimization of functions with low effective dimensionality. As such it sets the random subspace dimension d in (\(\hbox {RP}\mathcal {X}\)) to be constant over the iterations and greater or equal than the effective dimension, that is assumed to be known. Here, X-REGO is designed and analysed for a generic objective and a possibly unbounded/unconstrained and nonconvex domain \(\mathcal {X}\), and the random subspace dimension d is arbitrary and allowed to vary during the optimization. Despite sharing the same name, the X-REGO framework considered in this paper is thus significantly more generic that the X-REGO variant explored in [20], and analysed under much more general assumptions than in [20].
Recently, random projections have been successfully applied to highly overparametrized settings, such as in deep neural network training [42, 47] and adversarial attacks in deep learning [14, 64]. Though there is no theoretical guarantee at present that a precise low-dimension subspace exists in these problems, it is a reasonable assumption to make given the high dimensionality of the search space and the supporting numerical evidence. Our approach here investigates the validity of random subspace methods when low effective dimensionality is absent or unknown to the user; we find - both theoretically and numerically - that for large scale problems, such techniques are still beneficial, and furthermore, at least in the unconstrained case, they can naturally adapt and capture such special structures efficiently. We hope that this provides a general theoretical justification to a broader application of such techniques.
The second part of the paper applies the generic X-REGO convergence results and the (\(\hbox {RP}\mathcal {X}\)) related probabilistic bounds to the case when the objective is unconstrained and has low effective dimension, but the effective dimension \(d_e\) is unknown. Related results have been proposed that aim to learn the effective subspace before [25, 27, 29, 63] or during the optimization process [21, 23, 30, 71]; additional costs/evaluations are needed in these approaches. Some apply a principal component analysis (PCA) to the gradient evaluated at a collection of random points [22, 23, 27]. Alternatively, [25, 29, 63] recast the problem into a low-rank matrix recovery problem, and [30] proposes a Bayesian optimization algorithm that sequentially updates a posterior distribution over effective subspaces, and over the objective, using new functions evaluations. Still in the context of Bayesian optimization, Zhang et al. [71] estimate the effective subspace using Sliced Inverse Regression, a supervised dimensionality reduction technique in contrast with the above-mentioned PCA, while Chen et al. [21] extend Sliced Inverse Regression to learn the effective subspace in a semi-supervised way. Instead, our proposed algorithm explores a sequence of random subspaces of increasing dimension until it discovers the effective dimension of the problem. Independently, a similar idea has been recently used in sketching methods for regularized least-squares optimization [45].
Our contributions. We explore the use of random embeddings for the generic global optimization problem (P). Our proposed algorithmic framework, X-REGO, replaces (P) by a sequence of reduced random subproblems (\(\hbox {RP}\mathcal {X}\)), that are solved (possibly approximately and probabilistically) using any global optimization solver. As such, X-REGO extends block coordinate descent and local random subspace methods to the global setting.
Our convergence analysis for X-REGO crucially relies on a lower bound on the probability of \(\epsilon \)-success of (\(\hbox {RP}\mathcal {X}\)), whose computation, exploiting connections between (\(\hbox {RP}\mathcal {X}\)) and the field of conic integral geometry, is a key contribution of this paperFootnote 2. Using asymptotic expansions of integrals, we derive interpretable lower bounds in the setting where the random subspace dimension d is fixed and the original dimension D grows to infinity. In the box-constrained case \(\mathcal {X} = [-1,1]^D\), we also compare these bounds with the probability of success of the simplest random search strategy, where a point is sampled in the domain uniformly at random at each iteration. We show that when the point \(\varvec{p}\) at which the random subspace is drawn is close enough to a global solution \(\varvec{x}^*\) of (P), the random subspace is more likely to intersect a neighbourhood of a global minimizer than random search would be in finding such a neighbourhood. Provided that the reduced problem can be solved at a reasonable cost, random subspace methods are thus provably better than random search in some cases; and even more so, numerically.
In the second part of the paper, we address global optimization of functions with low effective dimension, and propose an X-REGO variant that progressively increases the random subspace dimension. Instead of requiring a priori knowledge of the effective dimension of the objective, we show numerically that this variant is able to learn the effective dimension of the problem. We also provide convergence results for this variant after a finite number of embeddings, using again our conic integral geometry bounds. Noticeably, these convergence results have no dependency on D. We compare numerically several instances of X-REGO when the reduced problem is solved using the (global and local) KNITRO solver [13]. We also discuss several strategies to choose the parameter \(\varvec{p}\) in (\(\hbox {RP}\mathcal {X}\)).
Paper outline. Section 2 presents the geometry of the problem, and motivates the use of conic integral geometry to estimate the probability of (\(\hbox {RP}\mathcal {X}\)) being \(\epsilon \)-successful. Section 3 summarizes key results from conic integral geometry that are used later in the paper. In Sect. 4, we derive lower bounds on the probability of (\(\hbox {RP}\mathcal {X}\)) to be \(\epsilon \)-successful, obtain asymptotic expansions of this probability, and compare the search within random embeddings with random search. Section 5 presents the X-REGO algorithmic framework, and Sect. 6 the corresponding convergence analysis. Finally, Sect. 7 proposes a specific instance of X-REGO for global optimization of functions with low effective dimension, with associate convergence results, and Sect. 8 contains numerical illustrations.
Notation. We use bold capital letters for matrices (\(\varvec{A}\)) and bold lowercase letters (\(\varvec{a}\)) for vectors. In particular, \(\varvec{I}_D\) is the \(D \times D\) identity matrix and \(\varvec{0}_D\), \(\varvec{1}_D\) (or simply \(\varvec{0}\), \(\varvec{1}\)) are the D-dimensional vectors of zeros and ones, respectively. We write \(a_i\) to denote the ith entry of \(\varvec{a}\) and write \(\varvec{a}_{i:j}\), \(i<j\), for the vector \((a_i \; a_{i+1} \cdots a_{j})^T\). We let \({{\,\mathrm{range}\,}}(\varvec{A})\) denote the linear subspace spanned in \(\mathbb {R}^D\) by the columns of \(\varvec{A} \in \mathbb {R}^{D \times d}\). We write \(\langle \cdot , \cdot \rangle \), \(\Vert \cdot \Vert \) (or equivalently \(\Vert \cdot \Vert _2\)) for the usual Euclidean inner product and Euclidean norm, respectively.
Given two random variables (vectors) x and y (\(\varvec{x}\) and \(\varvec{y}\)), the expression \(x {\mathop {=}\limits ^{law}} y\) (\(\varvec{x} {\mathop {=}\limits ^{law}} \varvec{y}\)) means that x and y (\(\varvec{x}\) and \(\varvec{y}\)) have the same distribution. We reserve the letter \(\varvec{A}\) for a \(D\times d\) Gaussian random matrix (see Definition A.1).
Given a point \(\varvec{a} \in \mathbb {R}^D\) and a set S of points in \(\mathbb {R}^D\), we write \(\varvec{a}+S\) to denote the set \(\{ \varvec{a}+\varvec{s}: \varvec{s} \in S \}\). Given functions \(f(x):\mathbb {R}\rightarrow \mathbb {R}\) and \(g(x):\mathbb {R}\rightarrow \mathbb {R}^+\), we write \(f(x) = \Theta (g(x))\) as \(x \rightarrow \infty \) to denote the fact that there exist positive reals \(M_1,M_2\) and a real number \(x_0\) such that, for all \(x \ge x_0\), \(M_1g(x)\le |f(x)| \le M_2g(x)\).
2 Geometric description of the problem
Let \(\epsilon >0\) denote the accuracy to which problem (P) is to be solved, and so let \(G_\epsilon \) be the set of \(\epsilon \)-minimizers of (P),
Note that, by Definition 1.1, the reduced problem (\(\hbox {RP}\mathcal {X}\)) is \(\epsilon \)-successful if and only if the intersection of the (affine) subspace \(\varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A})\) and \(G_{\epsilon }\) is non-empty:
To further characterize this probability, let us now introduce the following assumptions.
Assumption LipC (Lipschitz continuityFootnote 3 of f) The objective function \(f : \mathcal {X} \rightarrow \mathbb {R}\) is Lipschitz continuous with constant L, i.e., there holds \(|f(\varvec{x})-f(\varvec{y})| \le L \Vert \varvec{x}-\varvec{y} \Vert _2\) for all \(\varvec{x}, \varvec{y} \in \mathcal {X}\).
Assumption FeasBall (Existence of a ball of \(\epsilon \)-minimizers) There exists a global minimizer \(\varvec{x^*}\) of (P) that satisfies \(B_{\epsilon /L}(\varvec{x}^*) \subset \mathcal {X}\), where \(B_{\epsilon /L}(\varvec{x}^*)\) is the D-dimensional closed Euclidean ball of radius \(\epsilon /L\) and centred at \(\varvec{x}^*\), where L is the Lipschitz constant of f and \(\epsilon >0\) is the desired accuracy tolerance.
In the remainder of this section, we relate the probability (2.2) to the probability of the random subspace \({{\,\mathrm{range}\,}}(\varvec{A})+\varvec{p}\) to intersect a ball of \(\epsilon \)-minimizers \(B_{\epsilon /L}(\varvec{x}^*)\), defined in Assumption FeasBall; this probability will then be quantified in the following sections using tools from conic integral geometry.
Remark 2.1
Note that, in general, the point \(\varvec{x}^*\) in Assumption FeasBall is not uniquely defined; in that case, we select arbitrarily one such point for our analysis. For simplicity, we refer to the selected point \(\varvec{x}^*\) as “the point in Assumption FeasBall”.
We then have the following result.
Proposition 2.2
Let Assumption LipC hold. Let \(\varvec{A}\) be a \(D \times d\) Gaussian matrix, \(\epsilon >0\) an accuracy tolerance, \(\varvec{x}^*\) the point in Assumption FeasBall and \(\varvec{p} \in \mathcal {X}\) a given vector. Then,
Proof
Let \(\varvec{x} \in B_{\epsilon /L}(\varvec{x}^*)\). Then, \(\varvec{x} \in G_{\epsilon }\) due to the Lipschitz continuity property of f, namely
The result follows then simply from (2.2). \(\square \)
Following on from Remark 2.1, if \(\varvec{x}^*\) is not uniquely defined by Assumption FeasBall, each such \(\varvec{x}^*\) provides a different lower bound in Proposition 2.2. If all the balls \(B_{\epsilon /L}(\varvec{x}^*)\) associated with different \(\varvec{x}^*\) are disjoint, the probability of \(\epsilon \)-success of \(\hbox {RP}\mathcal {X}\) is lower bounded by the sum over all such minimizers \(\varvec{x}^*\), of the probability \({\mathbb {P}}[ \varvec{p} + {{\,\mathrm{range}\,}}(\varvec{A}) \cap B_{\epsilon /L}(\varvec{x}^*) \ne \varnothing ]\). In this paper, we estimate the latter probability for an arbitrary \(\varvec{x}^*\); this is a worst-case bound in the sense that it clearly underestimates the chance of subproblem success (for a(ny) \(\varvec{x}^*\)) in the presence of multiple global minimizers of (P).
Given \(\varvec{x}^*\), the point in Assumption FeasBall, let us assume that \(\varvec{p} \notin B_{\epsilon /L}(\varvec{x}^*)\) (otherwise, the reduced problem (\(\hbox {RP}\mathcal {X}\)) is always \(\epsilon \)-successful, which can be seen by simply taking \(\varvec{y} = \varvec{0}\)). To estimate the right-hand side of (2.3), we first construct a set \(C_{\varvec{p}}(\varvec{x}^*)\) containing the rays connecting \(\varvec{p}\) with points in \(B_{\epsilon /L}(\varvec{x}^*)\),
Note that \(C_{\varvec{p}}(\varvec{x}^*)\) is a convex cone that has been translated by \(\varvec{p}\) (see Fig. 1). We can easily verify this fact by recalling the definition of a convex cone.

Abstract illustration of the embedding of an affine d-dimensional subspace \(\varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A})\) into \(\mathbb {R}^D\), in the case \(\mathcal {X} = [-1,1]^D\). The red line represents the set of solutions along \(\varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A})\) that are contained in \(\mathcal {X}\) and the blue dot represents a global minimizer \(\varvec{x}^*\) of (P). (\(\hbox {RP}\mathcal {X}\)) is \(\epsilon \)-successful when the red line intersects \(B_{\epsilon /L}(\varvec{x}^*)\). We construct a cone \(C_{\varvec{p}}(\varvec{x}^*)\) in such a way that the following condition holds: \(\varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A})\) intersects \(B_{\epsilon /L}(\varvec{x}^*)\) if and only if \(\varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A})\) and \(C_{\varvec{p}}(\varvec{x}^*)\) share a ray
Definition 2.3
A convex set C is called a convex cone if for every \(\varvec{c} \in C\) and any non-negative scalar \(\rho \), \(\rho \varvec{c} \in C\).
Remark 2.4
Note that, according to Definition 2.2, a d-dimensional linear subspace in \(\mathbb {R}^D\) is a cone. Hence, \({{\,\mathrm{range}\,}}(\varvec{A})\) is a cone.
The next result indicates that, based on (2.3) and the definition of \(C_{\varvec{p}}(\varvec{x}^*)\), we can rewrite the right-hand side of (2.3) as
— the probability of the event that translated cones \(\varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A})\) and \(C_{\varvec{p}}(\varvec{x}^*)\) share a ray. It turns out that this probability has a quantifiable expression based on conic integral geometry, where a broad concern is the quantification/estimation of probabilities of a random cone (e.g., \(\varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A})\)) and a fixed cone (e.g., \(C_{\varvec{p}}(\varvec{x}^*)\)) sharing a ray. We then present in Sect. 3 key tools from conic integral geometry to help us estimate the probability of \(\epsilon \)-success of (\(\hbox {RP}\mathcal {X}\)).
Theorem 2.5
Let Assumption LipC hold. Let \(\varvec{A}\) be a \(D \times d\) Gaussian matrix, \(\epsilon > 0\) an accuracy tolerance, \(\varvec{x}^*\) the point in Assumption FeasBall and \(\varvec{p} \in \mathcal {X}\setminus G_{\epsilon }\) a given vector. Let \(C_{\varvec{p}}(\varvec{x}^*)\) be defined in (2.5). Then,
Proof
Note that the result immediately follows from (2.3) and (2.6), where the latter was stated without a proof. Instead of proving (2.6), we prove a weaker result, which suffices to establish (2.7):
We prove this by showing that the event \(\{\varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A}) \cap C_{\varvec{p}}(\varvec{x}^*) \ne \{\varvec{p}\}\}\) is a subset of the event \(\{ \varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A}) \cap B_{\epsilon /L}(\varvec{x}^*) \ne \varnothing \}\). In other words, we must show that if there exists a point in \(\varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A}) \cap C_{\varvec{p}}(\varvec{x}^*)\) that is different from \(\varvec{p}\), then there exists a point in \(\varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A}) \cap B_{\epsilon /L}(\varvec{x}^*)\), i.e., this set is non-empty.
Suppose that there exists a point \(\varvec{x}' \ne \varvec{p}\) in \(\varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A}) \cap C_{\varvec{p}}(\varvec{x}^*) \). Define \(R = \{\varvec{p}+ \theta (\varvec{x}'-\varvec{p}) : \theta \ge 0\}\) and note that \( R \subset \varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A})\). Now, since \(\varvec{x}' \in C_{\varvec{p}}(\varvec{x}^*)\), by definition of \(C_{\varvec{p}}(\varvec{x}^*)\) there exists \(\tilde{\varvec{x}} \in B_{\epsilon /L}(\varvec{x}^*)\) and \(\tilde{\theta } > 0\) such that \(\varvec{x}' = \varvec{p}+ \tilde{\theta }(\tilde{\varvec{x}}-\varvec{p}) \). We express \(\tilde{\varvec{x}}\) in terms of \(\varvec{x}'\): \(\tilde{\varvec{x}} = \varvec{p}+\theta '(\varvec{x}'-\varvec{p}) \), where \(\theta ' = 1/\tilde{\theta } > 0\). By definition of R, \(\tilde{\varvec{x}} \in R\) and, thus, \(\tilde{\varvec{x}}\) also lies in \(\varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A})\). This proves that the set \( \varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A}) \cap B_{\epsilon /L}(\varvec{x}^*)\) is non-empty. \(\square \)
3 A snapshot of conic integral geometry
A central question posed in conic integral geometry is the following:
What is the probability that a randomly rotated convex cone shares a ray with a fixed convex cone?
The answer to this question is given by the conic kinematic formula [58].
Theorem 3.1
(Conic kinematic formula) Let C and F be closed convex cones in \(\mathbb {R}^D\) such that at most one of them is a linear subspace. Let \(\varvec{Q}\) be a \(D \times D\) random orthogonal matrix drawn uniformly from the set of all \(D \times D\) real orthogonal matrices. Then,
where \(v_k(C)\) denotes the kth intrinsic volume of cone C.
Proof
A proof can be found in [58, p. 261]. \(\square \)
We plan to use the conic kinematic formula to estimate (2.6). This formula expresses the probability of the intersection of the two cones in terms of quantities known as conic intrinsic volumes. It is thus important to understand the conic intrinsic volumes and ways to compute them.
3.1 Conic intrinsic volumes
Conic intrinsic volumes are commonly defined through the spherical Steiner formula (see [2]), which we do not define here as it is beyond the scope of this work/not needed here. Instead, we will familiarise ourselves with the conic intrinsic volumes through their properties and specific examples. This is a short introductory review of conic intrinsic volumes; for more details, an interested reader is directed to [1,2,3, 49, 58] and the references therein.
For a closed convex cone C in \(\mathbb {R}^D\), there are exactly \(D+1\) conic intrinsic volumes: \(v_0(C)\), \(v_1(C)\),\(\dots \), \(v_{D}(C)\). Conic intrinsic volumes have useful properties, some of which are summarized below. Given a closed convex cone \(C \subseteq \mathbb {R}^D\), we have (see [3, Fact 5.5]):
-
(1)
Probability distribution. The intrinsic volumes of the cone C are all nonnegative and sum up to 1, namely
$$\begin{aligned} \sum _{k=0}^{D} v_k(C) = 1\hbox { and }v_k(C) \ge 0\hbox { for }k=0,1, \dots , D. \end{aligned}$$(3.2)In other words, they form a discrete probability distribution on \( \{0,1, \dots , D \}\).
-
(2)
Invariance under rotations. Given any orthogonal matrix \(\varvec{Q} \in \mathbb {R}^{D \times D}\), the intrinsic volumes of the rotated cone \(\varvec{Q}C\) and the original cone C are equal:
$$\begin{aligned} v_k(\varvec{Q}C) = v_k(C). \end{aligned}$$(3.3) -
(3)
Gauss-Bonnet formula. If C is not a subspace, we have
$$\begin{aligned} \sum _{\begin{array}{c} k = 0 \\ k even \end{array}}^{D} v_k(C) = \sum _{\begin{array}{c} k = 1 \\ k odd \end{array}}^{D} v_k(C)= \frac{1}{2}. \end{aligned}$$(3.4)The Gauss-Bonnet formula implies that \(v_k(C)\le 1/2\) for any \(k \in \{0, \dots , D\}\).
Remark 3.2
Conic intrinsic volumes can be viewed as ‘cousins’ of the more familiar Euclidean intrinsic volumes. For a compact convex set K \(\subset \) \(\mathbb {R}^D\), Euclidean intrinsic volumes \(v_0^E(K)\), \(v_{D-1}^E(K)\) and \(v_D^E(K)\) have familiar geometric interpretations: \(v_0^E(K)\) — Euler characteristic, \(2v_{D-1}^E(K)\) — surface area and \(v_D^E(K)\) is the usual volume.
Remark 3.3
Conic intrinsic volumes can also be understood using polyhedral cones — cones that can be generated by intersecting a finite number of halfspaces. If C is a polyhedral cone in \(\mathbb {R}^D\), then the kth intrinsic volume of C is defined as follows (see [3, Definition 5.1])

Footnote 4 Here, \(\varvec{a}\) denotes the standard Gaussian vectorFootnote 5 in \(\mathbb {R}^D\) and \( \varvec{\Pi }_Y(\varvec{x}) := \arg \min _{\varvec{y}} \{ \Vert \varvec{x} - \varvec{y} \Vert : \varvec{y} \in Y \} \) denotes the Euclidean/orthogonal projection of \(\varvec{x}\) onto the set Y, namely the vector in Y that is the closest to \(\varvec{x}\).

A depiction of the two-dimensional polyhedral cone \(C_{\pi /3}\) in Example 3.4. The projection \(\varvec{\Pi }_{C_{\pi /3}}(\varvec{a})\) of \(\varvec{a}\) onto \(C_{\pi /3}\) falls onto the one-dimensional face of the cone
Example 3.4
Let us consider a simple two-dimensional polyhedral cone \(C_{\pi /3}\) illustrated in Fig. 2 and let us calculate \(v_0(C_{\pi /3})\), \(v_1(C_{\pi /3})\) and \(v_2(C_{\pi /3})\) using (3.5).
The cone \(C_{\pi /3}\) has a single two-dimensional face (filled with blue), which is the interior of \(C_{\pi /3}\). If a random vector \(\varvec{a}\) belongs to this face then \(\varvec{\Pi }_{C_{\pi /3}}(\varvec{a}) = \varvec{a}\) and, therefore,
Let us now calculate \(v_0(C_{\pi /3})\). Note that \(C_{\pi /3}\) has only one zero-dimensional face, which is the origin. Note also that \(\varvec{\Pi }_{C_{\pi /3}}(\varvec{a}) = \varvec{0}\) if and only if \(\varvec{a} \in C_{\pi /3}^{\circ }\). Hence,
To calculate \(v_1(C_{\pi /3})\), we simply use (3.2) to obtain
Example 3.5
(Linear subspace) The kth intrinsic volume of a d-dimensional linear subspace \(\mathcal {L}_d\) in \(\mathbb {R}^D\) is given by
We already mentioned in Remark 2.4 that a d-dimensional linear subspace \(\mathcal {L}_d\) is a cone. In fact, \(\mathcal {L}_d\) is a polyhedral cone which has only one (d-dimensional) face. Therefore, the projection of any vector in \(\mathbb {R}^D\) onto \(\mathcal {L}_d\) will always belong to its (only) d-dimensional face. Hence, (3.6) follows from (3.5).
Example 3.6
(Circular cone) A circular cone is another important example; they have a number of applications in convex optimization (see, e.g., [7, Section 3] and [12, Section 4]). The circular cone of angle \(\alpha \) in \(\mathbb {R}^D\) is denoted by \({{\,\mathrm{Circ}\,}}_D(\alpha )\) and is defined as
The circular cone can be viewed as a collection of rays connecting the origin and some D-dimensional ball which does not contain the origin in its interior. The intrinsic volumes of \({{\,\mathrm{Circ}\,}}_D(\alpha )\) are given by the formulae (see [3, Appendix D.1]):
for \(k = 1,2,\dots , D-1\), where \(\left( {\begin{array}{c}i\\ j\end{array}}\right) \) is the extension of the binomial coefficient to noninteger i and j through the gamma function,
The 0th and Dth intrinsic volumes of the circular cone are given by (see [1, Ex. 4.4.8]):
The following property of circular cones will be needed later.
Lemma 3.7
Let \({{\,\mathrm{Circ}\,}}_D(\alpha )\) and \({{\,\mathrm{Circ}\,}}_D(\beta )\) be two circular cones with \(0 \le \alpha \le \beta \le \pi /2\). Then, \({{\,\mathrm{Circ}\,}}_D(\alpha ) \subseteq {{\,\mathrm{Circ}\,}}_D(\beta )\).
Proof
Let \(\varvec{v}\) be any point in \({{\,\mathrm{Circ}\,}}_D(\alpha )\). By definition of \({{\,\mathrm{Circ}\,}}_D(\alpha )\), \( v_1 \ge \Vert \varvec{v} \Vert \cos (\alpha )\). Since \(0 \le \alpha \le \beta \le \pi /2\), it follows that \( v_1 \ge \Vert \varvec{v} \Vert \cos (\beta )\), which by definition of \({{\,\mathrm{Circ}\,}}_D(\beta )\), implies that \(\varvec{v}\) must also belong to \({{\,\mathrm{Circ}\,}}_D(\beta )\). \(\square \)
3.2 The Crofton formula
We now present a useful corollary of the conic kinematic formula. If one of the cones in Theorem 3.1 is given by a linear subspace then the conic kinematic formula reduces to the Crofton formula.
Corollary 3.8
(Crofton formula) Let C be a closed convex cone in \(\mathbb {R}^D\) and \(\mathcal {L}_d\) be a d-dimensional linear subspace. Let \(\varvec{Q}\) be a \(D \times D\) random orthogonal matrix drawn uniformly from the set of all \(D \times D\) real orthogonal matrices. We have
with
The Crofton formula is easily derived from (3.1) using the fact that the kth intrinsic volume of a linear subspace \(\mathcal {L}_d\) is 1 if \(d = k\) and 0 otherwise. The Crofton formula will be essential in estimating the probability of \(\epsilon \)-success of (\(\hbox {RP}\mathcal {X}\)).
4 Bounding the probability of \(\epsilon \)-success of the reduced problem (\(\hbox {RP}\mathcal {X}\))
Building on the tools developed in the last section, we can estimate the right-hand side of (2.7) in Theorem 2.5, and thereby obtain bounds on the probability of \(\epsilon \)-success of (\(\hbox {RP}\mathcal {X}\)). This probability is key for the convergence analysis of our proposed X-REGO algorithm.
Let us first provide a roadmap of this section. Corollary 4.2 relates the probability of \(\epsilon \)-success of (\(\hbox {RP}\mathcal {X}\)) to the probability of intersection of a (random) linear subspace with a (fixed) circular cone, whose angle depends on the distance between \(\varvec{p}\) and the point \(\varvec{x}^*\) in Assumption FeasBall. This probability is quantified in Theorem 4.3 using Crofton formula; this theorem provides a lower bound, which depends on \(\varvec{p}\), on the probability of success of (\(\hbox {RP}\mathcal {X}\)). As our convergence analysis requires a bound that is independent of \(\varvec{p}\), in Theorem 4.4, we derive a uniform lower bound on the probability of success of (\(\hbox {RP}\mathcal {X}\)) under the assumption that \(\Vert \varvec{p} - \varvec{x}^* \Vert < R_{\max }\) for some constant \(R_{\max }\). The latter boundedness assumption can be shown to hold under several natural selection rules for \(\varvec{p}\), e.g., if \(\varvec{p}\) is a random variable with compact support or if \(\varvec{p}\) is selected as the best point found over previous embeddings and the objective is coercive (see Corollary 6.8).
As a second step, we propose in Sect. 4.2 an asymptotic analysis to characterize explicitly the dependency of the lower bounds in Theorems 4.3 and 4.4 on D and d, as \(D \rightarrow \infty \). The main result of our analysis, summarized in Corollary 4.7, shows an exponential decrease of the probability of \(\epsilon \)-success as D increases. In Sect. 4.3, for the case \(\mathcal {X} = [-1,1]^D\), we compare the probability of \(\epsilon \)-success of (\(\hbox {RP}\mathcal {X}\)) with the probability to select an \(\epsilon \)-minimizer when sampling points uniformly in \(\mathcal {X}\). We show that there exists a threshold \(\Delta _0\) such that, if \(\Vert \varvec{p}-\varvec{x}^*\Vert _2 \le \Delta _0\), (\(\hbox {RP}\mathcal {X}\)) is more likely to find an \(\epsilon \)-minimizer than the uniform sampling strategy.
4.1 Rewriting the probability of success using Crofton formula
Note that if \(\varvec{p} \notin B_{\epsilon /L}(\varvec{x}^*)\), then \(C_{\varvec{p}}(\varvec{x}^*)\) defined in (2.5) is a circular cone \({{\,\mathrm{Circ}\,}}_D(\alpha ^*_{\varvec{p}})\) with \(\alpha ^*_{\varvec{p}} = \arcsin (\epsilon /(L\Vert \varvec{x}^* - \varvec{p} \Vert ))\) that has been rotated and then translated by \(\varvec{p}\), see (3.7). Therefore, the intersection \(\varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A}) \cap C_{\varvec{p}}(\varvec{x}^*)\) in (2.7) is that of a random d-dimensional linear subspace and the rotated circular cone both translated by \(\varvec{p}\). We can translate these ‘cones’ back to the origin and then, using the Crofton formula, evaluate the right-hand side of (2.7) exactly since the expressions for the conic intrinsic volumes of the circular cone \(C_{\varvec{p}}(\varvec{x}^*)\) are known (see (3.8), (3.10) and (3.11)). The Crofton formula and the right-hand side of (2.7) only differ in the formulation of a random linear subspace: in the former, a random linear subspace is given as \(\varvec{Q}\mathcal {L}_d\), whereas in (2.7) it is represented by \({{\,\mathrm{range}\,}}(\varvec{A})\). The following theorem states that these two representations are equivalent.
Theorem 4.1
Let \(\varvec{A} \in \mathbb {R}^{D \times d}\) be a Gaussian matrix. Let \(\varvec{Q}\) be a \(D \times D\) random orthogonal matrix drawn uniformly from the set of all \(D \times D\) real orthogonal matrices and let \(\mathcal {L}_d\) be a d-dimensional linear subspace in \(\mathbb {R}^D\). Then,
Proof
See proof of [33, Theorem 1.2]. \(\square \)
The transformation of (2.7) into a form suitable for the application of Crofton formula is given in the following corollary.
Corollary 4.2
Let Assumption LipC hold. Let \(\varvec{A}\) be a \(D \times d\) Gaussian matrix, \(\varvec{Q}\) be a \(D \times D\) random orthogonal matrix drawn uniformly from the set of all \(D \times D\) real orthogonal matrices and \(\mathcal {L}_d\) be a d-dimensional linear subspace in \(\mathbb {R}^D\). Let \(\epsilon > 0\) be an accuracy tolerance, \(\varvec{x}^*\) the point in Assumption FeasBall and \(\varvec{p} \in \mathcal {X}\setminus G_{\epsilon }\) a given vector. Let \({{\,\mathrm{Circ}\,}}_D(\alpha ^*_{\varvec{p}})\) be the circular cone with \(\alpha ^*_{\varvec{p}} = \arcsin (\epsilon /(L\Vert \varvec{x}^* - \varvec{p}\Vert ))\). Then,
Proof
As mentioned earlier, by definition, \(C_{\varvec{p}}(\varvec{x}^*)\) is the rotated and translated (by \(\varvec{p}\)) circular cone \({{\,\mathrm{Circ}\,}}_D(\alpha ^*_{\varvec{p}})\). That is, there exists a \(D \times D\) orthogonal matrix \(\varvec{S}\) such that \(C_{\varvec{p}}(\varvec{x}^*) = \varvec{p}+\varvec{S}{{\,\mathrm{Circ}\,}}_D(\alpha ^*_{\varvec{p}})\). Then, Theorem 2.5 implies
where the penultimate equality follows from the orthogonal invariance of Gaussian matrices and where the last equality follows from Theorem 4.1. \(\square \)
Corollary 4.2 now allows us to use the Crofton formula to quantify the lower bound in (4.2). In the next theorem, we derive our first lower bound, that is dependent on the location of \(\varvec{p}\) in \(\mathcal {X}\). In particular, note that \(\varvec{p}\) is assumed to be at a distance at least \(\epsilon /L\) from \(\varvec{x}^*\).
Theorem 4.3
(A lower bound on the success probability) Let Assumption LipC hold. Let \(\varvec{A}\) be a \(D \times d\) Gaussian matrix, \(\epsilon > 0\) an accuracy tolerance, \(\varvec{x}^*\) the point in Assumption FeasBall and \(\varvec{p} \in \mathcal {X}\setminus G_{\epsilon }\) be a given vector. Let \(r_{\varvec{p}} := \epsilon /(L\Vert \varvec{x}^* - \varvec{p}\Vert )\). Then,
where the function \(\tau (r, d, D)\) for \(0<r<1\) and \(1 \le d < D\) is defined as
Here, \(\left( {\begin{array}{c}i\\ j\end{array}}\right) \) denotes the general binomial coefficient defined in (3.9).
Proof
Let \(\alpha ^*_{\varvec{p}} = \arcsin (r_{\varvec{p}})\) and let C denote \({{\,\mathrm{Circ}\,}}_D(\alpha ^*_{\varvec{p}})\) for notational convenience. First, note that by (3.8) and (3.11), \(\tau (r, d, D) = 2v_{D-d+1}({{\,\mathrm{Circ}\,}}_D(\arcsin (r)))\). Thus, all we need to show is that \({\mathbb {P}}[({\hbox {RP}\mathcal {X}}) \ \text {is }\epsilon \text{- }\hbox {successful}]\) is lower bounded by \(2v_{D-d+1}(C)\).
By (4.2) and the Crofton formula (3.12), we have
where the inequality follows from the fact that \(v_k(C)\)’s are all nonnegative (see (3.2)). \(\square \)
Theorem 4.3 provides us with a first lower bound on the probability of success of (\(\hbox {RP}\mathcal {X}\)); recall that this is a bound on the probability of the random subspace to intersect a ball of \(\epsilon \)-minimizers. In its current form, this bound is not much useful, for two reasons. Firstly, it depends on \(\varvec{p}\); we would like to remove this dependency to be able to use the bound in our convergence analysis in Sect. 6. Secondly, the integral in (4.5) is difficult to interpret. These two issues are addressed below, in Theorem 4.4 and Sect. 4.2, respectively.
Let us explain why we choose to bound the \(\epsilon \)-success of (\(\hbox {RP}\mathcal {X}\)) in (4.6) by a multiple of \(v_{D-d+1}(C)\) in particular, whereas we could have chosen any other intrinsic volume or the entire sum of these volumes. Our reason for such a choice for the lower bound is underpinned by the following observation: using the formulae (3.8) and (3.11) for the intrinsic volumes, one can verify that \(v_{D-d+i}(C)/v_{D-d+1}(C) = \mathcal {O}(D^{(1-i)/2})\) for \(i = 1,2,\dots ,d\) as \(D \rightarrow \infty \) with other parameters kept fixedFootnote 6. Hence,
Therefore, approximating the sum by its leading term \(v_{D-d+1}(C)\) is reasonable for large values of D.
Letting \(\varvec{x}^*\) be the point in Assumption FeasBall, and \(R_{\max }\) be a positive constant, the following result provides a lower bound on the probability of \(\epsilon \)-success of (\(\hbox {RP}\mathcal {X}\)) that holds for all \(\varvec{p} \in \mathcal {X}\) satisfying \(\Vert \varvec{x}^* - \varvec{p}\Vert \le R_{\max }<\infty \). Note that, in contrast with the last theorem, this result holds for \(\varvec{p}\) arbitrarily close to \(\varvec{x}^*\); as such, it will be crucial to the convergence of our algorithmic proposals in Sect. 6. The existence of such a \(R_{\max }\), crucial for our convergence analysis, is naturally guaranteed in some cases:
-
If a sequence of reduced problems (\(\hbox {RP}\mathcal {X}\)) is being considered such that the random subspaces are drawn at the same \(\varvec{p} \in \mathcal {X}\), on can simply take \(R_{\max }=\Vert \varvec{x^*}-\varvec{p}\Vert \).
-
If the sequence of reduced problems (\(\hbox {RP}\mathcal {X}\)) corresponds to a bounded parameter sequence \(\{\varvec{p}^0, \varvec{p}^1, \dots \}\), one can choose \(R_{\max }\) to be the (finite) supremum over the sequence \(\{\Vert \varvec{x}^*-\varvec{p}^i\Vert \}\) for \(i\ge 0\).
-
If \(\mathcal {X}\) is bounded, since \(\varvec{p}\in \mathcal {X}\) and \(\varvec{x}^*\in \mathcal {X}\), one can simply let \(R_{\max }\) be the diameter of \(\mathcal {X}\).
Note that when \(\mathcal {X}\) is not bounded, it is in general difficult to derive a uniform lower bound on the probability of \(\epsilon \)-success of (\(\hbox {RP}\mathcal {X}\)) that is valid for all \(\varvec{p} \in \mathcal {X}\) (if \(\Vert \varvec{p}^k\Vert _2 \rightarrow \infty \) then the lower bound goes to zero). The above list provides two examples of rules for selecting \(\varvec{p}\) that guarantee that the result below holds even in the case \(\mathcal {X}\) bounded. Other examples are given in Sect. 5.
Theorem 4.4
(A uniform lower bound on the success probability) Let Assumption LipC hold. Let \(\varvec{A}\) be a \(D \times d\) Gaussian matrix, \(\epsilon > 0\) an accuracy tolerance, and \(\varvec{x}^*\) the point in Assumption FeasBall. For all \(\varvec{p} \in \mathcal {X}\) satisfying \(\Vert \varvec{p} - \varvec{x}^* \Vert < R_{\max }\) for some suitably chosen constant \(R_{\max }\), we have
where \(\tau (\cdot , \cdot , \cdot )\) is defined in (4.5) and \(r_{min} := \epsilon /(L R_{\max })\).
Proof
Let \(r_{\varvec{p}}\) be defined in Theorem 4.3 and let \(\alpha ^*_{\varvec{p}} = \arcsin (r_{\varvec{p}})\). We consider the two cases \(\varvec{p} \in \mathcal {X}\setminus G_{\epsilon }\) and \(\varvec{p}\in G_{\epsilon }\) separately.
First, let \(\varvec{p}\) be any point in \( \mathcal {X}\setminus G_{\epsilon }\). Then,
Now, define \(C_{min}:= {{\,\mathrm{Circ}\,}}_D(\alpha ^*_{min})\). By (4.8) and Lemma 3.7, it follows that \(C_{min} \subseteq {{\,\mathrm{Circ}\,}}_D(\alpha ^*_{\varvec{p}})\). Using Corollary 4.2, we then obtain
where the last inequality follows from the same line of argument as in (4.6). Using (3.8) and (3.11), it is easy to verify that \(2v_{D-d+1}(C_{min}) = \tau (r_{min}, d, D)\). We have shown (4.7) for \(\varvec{p} \in \mathcal {X}\setminus G_{\epsilon }\).
For \(\varvec{p} \in G_{\epsilon }\), (4.7) holds trivially, since if \(\varvec{p} \in G_{\epsilon }\), (\(\hbox {RP}\mathcal {X}\)) is \(\epsilon \)-successful with probability 1. As a sanity check, \(1 \ge 2v(C_{min}) = \tau (r_{min}, d, D)\) where the inequality is implied by the Gauss-Bonnet formula (3.4). \(\square \)
Unfortunately, the formula defining \(\tau (r, d, D)\) is not easy to interpret. To better understand the dependence of the lower bounds (4.4) and (4.7) on the parameters of the problem, we now analyse the behaviour of \(\tau (r, d, D)\) in the asymptotic regime.
4.2 Asymptotic expansions
We establish the asymptotic behaviour of \(\tau (r, d, D)\) for large D. The other parameters are kept fixed except for r which we allow to decrease with D. Note indeed that \(r_{\varvec{p}}\) in Theorem 4.3 is inversely proportional to \(\Vert \varvec{x}^* - \varvec{p} \Vert \), which typically increases with D. Before we begin, we first need to establish the following lemma.
Lemma 4.5
Let \(0< \alpha < \pi /2\) be either a fixed angle or a function of D that tends to 0 as \(D \rightarrow \infty \). Then, as \(D \rightarrow \infty \),
Proof
We write
Integration by parts with \(u = \sin (x)/(D\cos (x))\) and \(dv = D \cos (x) \sin ^{D-1}(x) dx\) yields
Let I denote \(\int _0^{\alpha } \frac{\sin ^D(x)}{\cos ^2(x)}dx\). It remains to show that \(I = O(\sin ^{D+1}(\alpha )/D)\). We express I as
We integrate I by parts with \(u = \sin (x)/(D\cos ^3(x))\) and \(dv = D\cos (x)\sin ^{D-1}(x) dx\) to obtain
Since the latter integral is positive, we have
Since I is positive for any \(0< \alpha < \pi /2\), (4.15) implies that \(I = O(\sin ^{D+1}(\alpha )/D)\). \(\square \)
We establish the asymptotic behaviours of \(\tau (r_{\varvec{p}},d,D)\) and \(\tau (r_{min},d,D)\) by analysing the asymptotics of \(\tau (r,d,D)\) defined in (4.5) and later substituting \(r_{\varvec{p}}\) and \(r_{min}\) for r in \(\tau (r,d,D)\).
Theorem 4.6
Let \(\tau (r,d,D)\) be defined in (4.5). Let d be fixed and let r be either fixed or tend to zero as \(D \rightarrow \infty \). Then, as \(D \rightarrow \infty \),
and the constants in \(\Theta (\cdot )\) are independent of D.
Proof
We prove (4.16) for \(d=1\) and \(1<d<D\) separately.
First, assume that \(d > 1\). By definition of \(\tau (r,d,D)\), we have
Let us first determine the asymptotic behaviour of the binomial coefficient. Using the fact that \(\Gamma (z+a)/\Gamma (z+b) = \Theta ( z^{a-b})\) for large z (see, e.g., [62]), we obtain
To obtainFootnote 7 (4.16), we substitute (4.18) into (4.17). Note that \((1-r^2)^{\frac{d-2}{2}}\) is bounded above and bounded away from zero by constants independent of D; thus, it can be absorbed into the constants of \(\Theta \).
Let us now prove (4.16) for \(d=1\). We have
where, by (4.18),
and, by Lemma 4.5,
By substituting (4.20) and (4.21) into (4.19), we obtain (4.16) for \(d = 1\). For similar reasons as stated above, we can relegate the term \(1/\sqrt{1-r^2}\) in (4.21) into the constants of \(\Theta \). \(\square \)
Now, to obtain the asymptotics for \(\tau (r_{\varvec{p}},d,D)\) and \(\tau (r_{\min },d,D)\), we simply apply Theorem 4.6 for \(r = r_{\varvec{p}} = \epsilon /(L\Vert \varvec{x}^* - \varvec{p} \Vert )\) and \(r = r_{\min } = \epsilon /(L R_{\max })\), respectively.
Corollary 4.7
Let d, \(\epsilon \), L be fixed and let \(\Vert \varvec{x}^* - \varvec{p}\Vert \) be either fixed or tend to infinity as \(D \rightarrow \infty \). Then the lower bounds (4.4) and (4.7) satisfy
with \(r_{\varvec{p}} = \epsilon /(L \Vert \varvec{x}^* - \varvec{p} \Vert )\) and where the constants in \(\Theta (\cdot )\) are independent of D. Similarly,
with \(r_{\min } = \epsilon /(L R_{\max })\).
Proof
Note that \(r_{\varvec{p}} = \epsilon /(L\Vert \varvec{x}^* - \varvec{p} \Vert )\) is either fixed or tends to zero as \(D \rightarrow \infty \). Then, the result follows from Theorem 4.6. \(\square \)
Corollary 4.7 shows that for any \(\varvec{p}\) not in \(G_{\epsilon }\), the lower bounds in Theorems 4.3 and 4.4 decrease exponentially with D, which is as expected since problem (P) is generally NP-hard. Note that this decrease is slower for larger values of d or \(\varvec{p}\) closer to \(\varvec{x}^*\), which is reassuring.
4.3 Comparing (\(\hbox {RP}\mathcal {X}\)) to simple random search
Using the above lower bounds on the probability of \(\epsilon \)-success of the reduced problem (\(\hbox {RP}\mathcal {X}\)), we now compare (\(\hbox {RP}\mathcal {X}\)) to a simple random search method to understand the relative performance of (\(\hbox {RP}\mathcal {X}\)) and when it is beneficial to use it for general functions. As a baseline for comparison, we use Uniform Sampling (US) and we restrict ourselves, in this section, to the specific case \(\mathcal {X} = [-1,1]^D\) (as this will allow us to estimate the probability of success of US). We start off with the derivation of a lower bound for the probability of \(\epsilon \)-success of US and the computation of its asymptotics.
Note that if a uniformly sampled point falls inside \(B_{\epsilon /L}(\varvec{x}^*)\) then US is \(\epsilon \)-successful. This implies that
where we have used the fact that \({{\,\mathrm{Vol}\,}}(B_{\epsilon /L}(\varvec{x^*})) = \frac{\pi ^{D/2}}{\Gamma (\frac{D}{2}+1)}\left( \frac{\epsilon }{L} \right) ^{D}\) (see [52, Equation 5.19.4]) and that \({{\,\mathrm{Vol}\,}}(\mathcal {X}) = 2^D\).
Using Stirling’s approximation, it is straightforward to establish the asymptotic behaviour of the lower bound \(\tau _{us}\).
Lemma 4.8
Let \(\tau _{us}\) be defined in (4.24) and let \(\epsilon \) and L be fixed. Then,
Proof
By Stirling’s approximation (see [52, Equation 5.11.7]),
By substituting (4.26) into (4.24), we obtain the desired result. \(\square \)
Let us now compare the lower bound \(\tau _{us}\) of US to the lower bound \(\tau (r_{\varvec{p}}, d, D)\) for (\(\hbox {RP}\mathcal {X}\)). It is clear from the analysis of \(\tau (r_{\varvec{p}}, d, D)\) in Sect. 4.2 that the probability of \(\epsilon \)-success of (\(\hbox {RP}\mathcal {X}\)) is higher if \(\varvec{p}\) is closer to the set of global minimizers. In the next theorem, we determine a threshold distance \(\Delta _0\) between \(\varvec{p}\) and a global minimizer \(\varvec{x}^*\) such that \(\tau (r_{\varvec{p}}, d, D)\) and \(\tau _{us}\) are approximately equal to each other. This would tell us how close \(\varvec{p}\) should be to \(\varvec{x}^*\) for (\(\hbox {RP}\mathcal {X}\)) to have a larger lower bound for the probability of success than that of US. The analysis is done in the asymptotic regime.
Theorem 4.9
Let Assumption LipC hold, let \(\mathcal {X} = [-1,1]^D\) and \(\varvec{x}^*\) be the point in Assumption FeasBall. Let \(\tau (r_{\varvec{p}}, d, D)\) and \(\tau _{us}\) be defined in Theorem 4.3 and (4.24), respectively. Let \(\epsilon \), L, d be fixed and let \(\Delta _0 = \sqrt{\frac{2D}{\pi e}}\). Then,
-
a)
If \(\displaystyle \lim \nolimits _{D\rightarrow \infty }\frac{\Delta _0 }{\Vert \varvec{x}^* - \varvec{p}\Vert } = \psi > 1\), then \(\tau (r_{\varvec{p}}, d, D)/\tau _{us} \rightarrow \infty \) as \(D \rightarrow \infty \).
-
b)
If \(\displaystyle \lim \nolimits _{D\rightarrow \infty }\frac{\Delta _0 }{\Vert \varvec{x}^* - \varvec{p}\Vert } = \psi < 1\), then \(\tau (r_{\varvec{p}}, d, D)/\tau _{us} \rightarrow 0\) as \(D \rightarrow \infty \).
Proof
From (4.23) and (4.25), we have

Footnote 8Note that in the second line there is a term \(\left( \frac{\epsilon }{L}\right) ^{-d}\left( \frac{2}{\pi e}\right) ^{d/2}\) missing inside \(\Theta \), which we removed as it is independent of D. Now, by definition of \(\Theta \), (4.27) implies that there exist positive constants \(M_1\) and \(M_2\) such that
as \(D \rightarrow \infty \). Note that \(D^{\frac{2d-1}{2(D-d)}} \rightarrow 1\) as \(D \rightarrow \infty \). Hence, if \(\Delta _0/\Vert \varvec{x}^* - \varvec{p} \Vert \rightarrow \psi > 1\) then both lower and upper bounds in (4.28) tend to infinity implying that \(\tau (r_{\varvec{p}}, d, D)/\tau _{us} \rightarrow \infty \). On the other hand, if \(\Delta _0/\Vert \varvec{x}^* - \varvec{p} \Vert \rightarrow \psi < 1\) then both lower and upper bounds in (4.28) tend to zero implying that \(\tau (r_{\varvec{p}}, d, D)/\tau _{us} \rightarrow 0\). \(\square \)
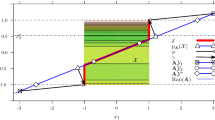
Theorem 4.9 shows that the distance between \(\varvec{p}\) and \(\varvec{x}^*\) (in the asymptotic setting) must be no greater than \(\Delta _0 \approx 0.48\sqrt{D}\) for \(\tau (r_{\varvec{p}}, d, D)\) to be larger than \(\tau _{us}\) in the case \(\mathcal {X} = [-1,1]^D\). Note that, since the distance between the origin and a corner of \(\mathcal {X}\) is equal to \(\sqrt{D}\) (\(> 0.48\sqrt{D}\)), there is no point \(\varvec{p}\) such that the ball of radius \(\Delta _0\) centred at \(\varvec{p}\) covers all points in \(\mathcal {X}\). In other words, in the specific case \(\mathcal {X} = [-1,1]^D\), for any \(\varvec{p}\) in \(\mathcal {X}\), there always exists \(\varvec{x}^*\) for which \(\tau (r_{\varvec{p}}, d, D)\) is smaller than \(\tau _{us}\). Note also that \(\Delta _0\) has no dependence on the embedding subspace dimension d. This is due to the asymptotic nature of the analysis: in (4.28), we see that both inequalities depend on d, but the dependence diminishes as \(D \rightarrow \infty \) since d is kept fixed. Although the asymptotic analysis shows no significant dependence on the subspace dimension, numerical experiments show that the value of d has a notable effect on success of (\(\hbox {RP}\mathcal {X}\)). In Fig. 3, we plot \(\tau (r_{\varvec{p}}, d, D)\) as a function of \(\Vert \varvec{x}^* - \varvec{p} \Vert \) for different values of d with D fixed at 200. The lower bound \(\tau _{us}\) of US is represented by a black horizontal line. We see that, for larger d, \(\tau (r_{\varvec{p}}, d, D)\) decreases at a slower rate and has greater threshold distance before becoming smaller than \(\tau _{us}\).

A plot of \(\tau (r_{\varvec{p}})\) versus \(\Vert \varvec{x}^* - \varvec{p} \Vert \) for different values of the subspace embedding dimension d. The lower bound \(\tau _{us}\) of US does not depend on \(\Vert \varvec{x}^* - \varvec{p} \Vert \) and, thus, it is displayed as a straight horizontal line
Remark 4.10
An important distinction must be made between the implications of the \(\epsilon \)-success of (\(\hbox {RP}\mathcal {X}\)) and the \(\epsilon \)-success of US in solving the original problem (P). Note that the \(\epsilon \)-success of US means that US has sampled a point that lies in \(G_{\epsilon }\), which in turn implies that US has successfully (approximately) solved (P). This is not the case for (\(\hbox {RP}\mathcal {X}\)). Recall that \(\epsilon \)-success of (\(\hbox {RP}\mathcal {X}\)) by definition means that there is an approximate solution \(\varvec{x}^*\) to (P) that lies in the embedded d-dimensional subspace. One needs to perform an additional global search over the subspace to locate \(\varvec{x}^*\). Therefore, for an entirely fair comparison between the two approaches, this additional computational complexity should be taken into account.
5 X-REGO: an algorithmic framework for global optimization using random embeddings
This section presents the proposed algorithmic framework for global optimization using random embeddings, named X-REGO by analogy with [20] (see the Introduction for distinctions between these variants). X-REGO is a generic algorithmic framework that replaces the high-dimensional original problem (P) by a sequence of low-dimensional random problems of the form (\(\hbox {RP}\mathcal {X}\)); these reduced random problems can then be solved using any global — and in practice, even a local — optimization solver.
Note that the kth embedding in X-REGO is determined by a realization \(\tilde{\varvec{A}}^k = \varvec{A}^k(\varvec{\omega }^k)\) of the random Gaussian matrix \(\varvec{A}^k \in \mathbb {R}^{D \times d^{k}}\), for some (deterministic) \(d^k \in \{1, \dots ,D-1\}\). For generality of our analysis, we also assume that the parameter \(\varvec{p}\) in (\(\hbox {RP}\mathcal {X}\)) is a random variable. The kth embedding is drawn at the point \(\tilde{\varvec{p}}^{k-1} = \varvec{p}^{k-1}(\varvec{\omega }^{k-1})\), a realization of the random variable \(\varvec{p}^{k-1}\), assumed to have support included in \(\mathcal {X}\). Note that this definition includes deterministic choices for \(\varvec{p}^{k-1}\), by writing it as a random variable with support equal to a singleton (deterministic and stochastic selection rules for the \(\varvec{p}\) are given below).

Each iteration of X-REGO solves – approximately and possibly, with a certain probability – a realization (\(\widetilde{\text {RP}\mathcal {X}^k}\)) of the random problem

As such, X-REGO can be seen as a stochastic process: additionally to \(\tilde{\varvec{p}}^k\), and \(\tilde{\varvec{A}}^k\), each algorithm realization provides sequences \(\tilde{\varvec{x}}^k = \varvec{x}^k(\varvec{\omega }^k)\), \(\tilde{\varvec{y}}^k = \varvec{y}^k(\varvec{\omega }^k)\) and \(\tilde{f}_{min}^k = f_{min}^k(\varvec{\omega }^k)\), for \(k \ge 1\), that are realizations of the random variables \(\varvec{x}^k\), \(\varvec{y}^k\) and \(f_{min}^k\), respectively. To calculate \(\tilde{\varvec{y}}^k\), (\(\widetilde{\text {RP}\mathcal {X}^k}\)) may be solved to some required accuracy using a deterministic global optimization algorithm that is allowed to fail with a certain probability; or employing a stochastic algorithm, so that \(\tilde{\varvec{y}}^k\) is only guaranteed to be an approximate global minimizer of (\(\widetilde{\text {RP}\mathcal {X}^k}\)) (at least) with a certain probability. This allows us to account for solvers having some stochastic component (such as multistart methods, genetic algorithms), or deterministic solvers that may fail in some cases due, for example, to a computational budget.
Note also that the choice of the random variable \(\varvec{p}^k\) and of the subspace dimension \(d^k\) provide some flexibility in the algorithm. For \(\varvec{p}^k\), possibilities include:
-
\(\varvec{p}^k = \varvec{p}\): all the random embeddings explored are drawn at the same point (in case \(\varvec{p}\) is a fixed vector in \(\mathcal {X}\)), or according to the same distribution (if \(\varvec{p}\) is a random variable),
-
the sequence \(\varvec{p}^0, \varvec{p}^1, \dots \) can be constructed dynamically during the optimization, e.g., based on the information gathered so far on the objective. For example, one may choose \(\varvec{p}^k = \varvec{x}_{opt}^k\), where \(\varvec{x}_{opt}^k\) is the best point found up to the kth embedding:
$$\begin{aligned} \varvec{x}_{opt}^k := \arg \min \{ f(\varvec{x}^1), f(\varvec{x}^2), \dots , f(\varvec{x}^k)\}. \end{aligned}$$(5.2)
Note that (\(\widetilde{\text {RP}\mathcal {X}^k}\)) is always feasible for all choices of \(\varvec{p}^k\) (\(\varvec{y} = 0\) is feasible since \(\tilde{\varvec{p}}^k \in \mathcal {X}\)). However, it may happen that this is the only feasible point of (\(\widetilde{\text {RP}\mathcal {X}^k}\)); to avoid this situation we may assume that \(\varvec{p}^k\) is in the interior of \(\mathcal {X}\). This latter assumption is not needed for our convergence results to hold, but it is a desirable feature from a numerical point of view. We expect this assumption to be satisfied in most problems of interest.
Regarding the subspace dimension \(d^k\), one can for example choose a fixed value based on the computational budget available for the reduced problem, or \(d^k\) can be progressively increased, using a warm start in each embedding. We refer the reader to Sect. 8 for a numerical comparison of some of those strategies.
The termination Line 2 could be set to a given maximum number of embeddings, or could check that no significant progress in decreasing the objective function has been achieved over the last few embeddings, compared to the value \(f(\tilde{\varvec{x}}^k_{opt})\). For generality, we leave it unspecified here.
6 Global convergence of X-REGO to a set of global \(\epsilon \)-minimizers
The convergence results presented in this paper extend the ones given in [20], in which X-REGO (with fixed subspace dimension \(d^k = d \ge d_e\) for all k) is proven to converge for functions with low-effective dimension \(d_e\). Section 6.1 is devoted to a generic convergence analysis of X-REGO, under generic assumptions on the probability of \(\epsilon \)-success of (\(\text {RP}\mathcal {X}^k\)) and on the probability of success of the solver to find an approximate minimizer of its realisation (\(\widetilde{\text {RP}\mathcal {X}^k}\)), while Sect. 6.2 presents the application of these results to arbitrary Lipschitz-continuous objectives, building on the results presented in the previous sections to show the validity of the \(\epsilon \)-success assumption.
6.1 A general convergence framework for X-REGO
This section recalls results in [20] that are needed for our main convergence results in the next section. We show that \(\varvec{x}^k_{opt}\) defined in (5.2) converges to the set of \(\epsilon \)-minimizers \(G_{\epsilon }\) almost surely as \(k \rightarrow \infty \) (see Theorem 6.3). Intuitively, our proof relies on the fact that any vector \(\tilde{\varvec{x}}^k\) defined in (5.1) belongs to \(G_\epsilon \) if the following two conditions hold simultaneously:
-
(a)
the reduced problem (\(\text {RP}\mathcal {X}^k\)) is \((\epsilon - \lambda )\)-successful in the sense of Definition 1.1, namely,
$$\begin{aligned} f_{min}^k \le f^* + \epsilon -\lambda ; \end{aligned}$$(6.1) -
(b)
the reduced problem (\(\widetilde{\text {RP}\mathcal {X}^k}\)) is solved (by a deterministic/stochastic algorithm) to an accuracy \(\lambda \in (0,\epsilon )\) in the objective function value, namely,
$$\begin{aligned} f(\varvec{A}^k \varvec{y}^k + \varvec{p}^{k-1}) \le f_{min}^k + \lambda \end{aligned}$$(6.2)holds (at least) with a certain probability, that is independent of k.
Note that in order to prove convergence of X-REGO to (global) \(\epsilon \)-minimizers, the value of \(\epsilon \) in the success probability of the reduced problem (\(\hbox {RP}\mathcal {X}\)) needs to be replaced by \((\epsilon -\lambda )\). This change is motivated by the fact that we allow inexact solutions (up to accuracy \(\lambda \)) of the reduced problem (\(\widetilde{\text {RP}\mathcal {X}^k}\)). We also emphasize that, according to the discussion in Sect. 5, and for the sake of generality, the parameter \(\varvec{p}^k\) in (\(\text {RP}\mathcal {X}^k\)) is now a random variable (in contrast with Sect. 4 where it was assumed to be deterministic).
Let us introduce two additional random variables that capture the conditions in (a) and (b) above,
where \(\mathbbm {1}\) is the usual indicator function for an event.
Let \(\mathcal {F}^k = \sigma (\varvec{A}^1, \dots , \varvec{A}^k, \varvec{y}^1, \dots , \varvec{y}^k, \varvec{p}^0, \dots , \varvec{p}^k)\) be the \(\sigma \)-algebra generated by the random variables \(\varvec{A}^1, \dots , \varvec{A}^k, \varvec{y}^1, \dots , \varvec{y}^k, \varvec{p}^0, \dots , \varvec{p}^k\) (a mathematical concept that represents the history of the X-REGO algorithm as well as its randomness until the kth embedding)Footnote 9, with \(\mathcal {F}^0 = \sigma (\varvec{p}^0)\). We also construct an ‘intermediate’ \(\sigma \)-algebra, namely,
with \(\mathcal {F}^{1/2} = \sigma (\varvec{p}^0, \varvec{A}^{1})\). Note that \(\varvec{x}^k\), \(R^k\) and \(S^k\) are \(\mathcal {F}^{k}\)-measurableFootnote 10, and \(R^k\) is also \(\mathcal {F}^{k-1/2}\)-measurable; thus they are well-defined random variables.
Remark 6.1
The random variables \(\varvec{A}^1, \dots , \varvec{A}^k\), \(\varvec{y}^1, \dots , \varvec{y}^k\), \(\varvec{x}^1, \dots , \varvec{x}^k\), \(\varvec{p}^0, \varvec{p}^1, \dots , \varvec{p}^k\), \(R^1\), \(\dots \), \(R^k\), \(S^1, \dots , S^{k}\) are \(\mathcal {F}^{k}\)-measurable since \(\mathcal {F}^0 \subseteq \mathcal {F}^1 \subseteq \cdots \subseteq \mathcal {F}^{k}\). Also, \(\varvec{A}^1, \dots , \varvec{A}^k\), \(\varvec{y}^1, \dots , \varvec{y}^{k-1}\), \(\varvec{x}^1, \dots , \varvec{x}^{k-1}\), \(\varvec{p}^0, \varvec{p}^1, \dots , \varvec{p}^{k-1}\), \(R^1\), \(\dots \), \(R^k\), \(S^1, \dots , S^{k-1}\) are \(\mathcal {F}^{k-1/2}\)-measurable since \(\mathcal {F}^0 \subseteq \mathcal {F}^{1/2} \subseteq \mathcal {F}^1 \subseteq \cdots \subseteq \mathcal {F}^{k-1} \subseteq \mathcal {F}^{k-1/2}\).
We introduce the following (weak) assumption on the solver. Namely, we require that the reduced problem (\(\text {RP}\mathcal {X}^k\)) needs to be solved to required accuracy with some positive probability.
Assumption Success-Solv For all \(k \ge 1\), there exists \(\rho ^k \in [\rho _{lb},1]\), with \(\rho _{lb} > 0\) such thatFootnote 11
i.e., with (conditional) probability at least \(\rho ^k \ge \rho _{lb}\), the solution \(\varvec{y}^k\) of (\(\text {RP}\mathcal {X}^k\)) satisfies (6.2).Footnote 12
Remark 6.2
If a deterministic (global optimization) algorithm is used to solve (\(\widetilde{\text {RP}\mathcal {X}^k}\)), then \(S^k\) is always \(\mathcal {F}_k^{k-1/2}\)-measurable and Assumption Success-Solv is equivalent to \(S^k\ge \rho ^k>0\). Since \(S^k\) is an indicator function, this further implies that \(S^k\equiv 1\).
The next assumption says that the drawn subspaces are \((\epsilon - \lambda )\)-successful with a positive probability.
Assumption Succes-Emb For all \(k \ge 1\), there exists \(\tau ^k \in [\tau _{lb},1]\), with \(\tau _{lb} > 0\) such that
i.e., with (conditional) probability at least \(\tau ^k \ge \tau _{lb} >0\), (\(\text {RP}\mathcal {X}^k\)) is (\(\epsilon - \lambda \))-successful.
Note that Assumption Success-Solv and Assumption Succes-Emb have been slightly modified compared to [20]: here, the dimension of the reduced problem is varying, so in general the probabilities of success of the solver and embedding depend on k as well. Under Assumption Success-Solv and Assumption Succes-Emb, the following result shows the convergence of X-REGO to the set of \(\epsilon \)-minimizers.
Theorem 6.3
(Global convergence) Suppose Assumption Success-Solv and Succes-Emb hold. Then,
where \(\varvec{x}^k_{opt}\) and \(G_{\epsilon }\) are defined in (5.2) and (2.1), respectively. Furthermore, for any \(\xi \in (0,1)\),
where \(K_\xi := \displaystyle \bigg \lceil \frac{|\log (1-\xi )|}{\tau _{lb} \rho _{lb}}\bigg \rceil \).
Proof
The proof is a straightforward extension of the one given in [20], and can be found in the preprint version of this work, see [19, Appendix B]. \(\square \)
Remark 6.4
If the original problem (P) is convex (and known a priori to be so), then clearly, a local (deterministic or stochastic) optimization algorithm may be used to solve (\(\widetilde{\text {RP}\mathcal {X}^k}\)) and achieve (6.2). Apart from this important speed-up and simplification, it seems difficult at present to see how else problem convexity could be exploited in order to improve the success bounds and convergence of X-REGO.
6.2 Global convergence of X-REGO for general objectives
The previous section provides a convergence result, with associate convergence rate, that depends on some parameters \(\rho _{lb}\) and \(\tau _{lb}\) defined in Assumption Success-Solv and Succes-Emb. The former intrinsically depends on the solver used to solve the reduced subproblems, and will not be discussed further here. However, the latter parameter \(\tau _{lb}\) can be estimated for general Lipschitz-continuous objectives using the results derived in Sect. 4. We also introduce some parameter \(d_{lb}\), which is simply a lower bound on the subspace dimension explored in the algorithm (i.e., \(d^k \ge d_{lb}\) for all k). If the subspace dimensions are chosen arbitrarily, simply set \(d_{lb} = 1\).
Corollary 6.5
Let Assumption LipC hold, \(\varvec{x}^*\) be the point in Assumption FeasBall (replacing \(\epsilon \) by \(\epsilon -\lambda \) in Assumption FeasBall), \(\tilde{\varvec{p}}^k\) satisfy \(\Vert \tilde{\varvec{p}}^k - \varvec{x}^*\Vert \le R_{\max }\) for all k and for some suitably chosen \(R_{\max }\), and \(d^k \ge d_{lb}\) for some \(d_{lb}>0\). Then, Assumption Succes-Emb holds with
with \(r_{\min } = (\epsilon -\lambda )/(L R_{\max })\).
Proof
Let us first recall that for all k, there holds by Corollary 4.2:
where \(\varvec{Q}\) is a \(D \times D\) random orthogonal matrix drawn uniformly from the set of all \(D \times D\) real orthogonal matrices, \(\mathcal {L}_{d^k}\) a \(d^k\)-dimensional linear subspace, and \(\alpha _{\tilde{\varvec{p}}^{k-1}}^* :=\arcsin ((\epsilon -\lambda )/\Vert \varvec{x}^*-\tilde{\varvec{p}}^{k-1}\Vert )\). Let \(\alpha ^*_{\min } := \arcsin ((\epsilon -\lambda )/(L R_{\max }))\), and note that \(\alpha ^*_{\min } \le \alpha ^*_{\tilde{\varvec{p}}^{k-1}}\) for all k. By Lemma 3.7, for any \(\alpha ^*_{\min } \le \alpha \le \pi /2\), there holds \({{\,\mathrm{Circ}\,}}_D(\alpha ^*_{\min }) \subseteq {{\,\mathrm{Circ}\,}}_D(\alpha )\) so that
for all k. By the Crofton formula, there holds
By [3, Prop. 5.9], \(h_k \ge h_{k+1}\) for all \(k = 0, \dots , D-1\). We deduce that
Using the fact that the intrinsic volumes are all non-negative, and the definition of \(h_k\), we get:
Note finally that, in terms of conditional expectation, we can write \(\mathbb {E}[R^k | \mathcal {F}^{k-1}] = 1 \cdot {\mathbb {P}}[ R^k = 1 | \mathcal {F}^{k-1}] + 0 \cdot {\mathbb {P}}[ R^k = 0 | \mathcal {F}^{k-1} ] \ge \tau _{lb}\). This shows that (6.5) in Assumption Succes-Emb holds. \(\square \)
We now estimate the rate of convergence of X-REGO for Lipschitz continuous functions using the estimates for \(\tau \) provided in Corollary 4.7.
Theorem 6.6
Let Assumptions LipC and Success-Solv hold, \(\varvec{x}^*\) be the point in Assumption FeasBall (replacing \(\epsilon \) by \(\epsilon -\lambda \) in Assumption FeasBall), \(\tilde{\varvec{p}}^k\) satisfy \(\Vert \tilde{\varvec{p}}^k - \varvec{x}^*\Vert \le R_{\max }\) for all k and for some suitably chosen \(R_{\max }\), and \(d^k \ge d_{lb}\) for some \(d_{lb}>0\). Then, \(\varvec{x}_{opt}^k\) defined in (5.2) converges to the set of \(\epsilon \)-minimizers \(G_{\epsilon }\) almost surely as \(k \rightarrow \infty \), and
with
Proof
The result follows from Theorem 6.3, Corollary 6.5 and Corollary 4.7. \(\square \)
6.3 Ensuring boundedness of \(\tilde{\varvec{p}}^k\)
So far, our convergence results rely on the assumption that, for each k, \(\Vert \tilde{\varvec{p}}^k-\varvec{x}^*\Vert \le R_{\max }\) for some suitably chosen \(R_{\max }\) and for some global minimizer \(\varvec{x}^*\) surrounded by a ball of radius \((\epsilon -\lambda )\) of feasible solutions, see Assumption FeasBall. We show in this section that the following strategies for choosing the random variable \(\varvec{p}^k\) guarantee that \(\varvec{x}_{opt}^k\) defined in (5.2) converges to the set of \(\epsilon \)-minimizers \(G_{\epsilon }\) almost surely as \(k \rightarrow \infty \).
-
1.
\(\varvec{p}^k\) is deterministic and does not vary with k (e.g., \(\varvec{p}^k = \varvec{0}\) for all k).
-
2.
\((\varvec{p}^k)_{k = 1, 2, \dots }\) is a bounded sequence of deterministic values.
-
3.
\(\varvec{p}^k\) is any random variable with support contained in \(\mathcal {X}\), and \(\mathcal {X}\) is bounded.
-
4.
\(\varvec{p}^{k}\) is a random variable defined as \(\varvec{p}^{k} = \varvec{x}^k_{opt}\), where \(\varvec{x}_{opt}^k\) is the best point found over the k first embeddings, see (5.2), and the objective is coercive.
Note that for the strategies 6.3, 6.3 and 6.3, the validity of Theorem 6.6 follows simply from the triangular inequality:
and the fact that \( \Vert \tilde{\varvec{p}}^k \Vert \) is bounded. We prove next that \(\varvec{x}_{opt}^k\) defined in (5.2) converges to the set of \(\epsilon \)-minimizers \(G_{\epsilon }\) almost surely as \(k \rightarrow \infty \) for strategy 6.3 if the objective is coercive.
Assumption 6.7
(Coerciveness, see [6]) When \(\mathcal {X}\) is unbounded, the (continuous) function \(f : \mathcal {X} \rightarrow \mathbb {R}\) in (P) satisfies
Corollary 6.8
Let Assumption 6.7 hold, and let \(\varvec{x}^*\) be a global minimizer of (P). Let \(\varvec{p}^k = \varvec{x}_{opt}^k\) for \(k \ge 1\), with \(\varvec{x}_{opt}^k\) defined in (5.2), and let \(\varvec{p}^0 \in \mathcal {X}\) be such that \(f(\tilde{\varvec{p}}^0)<\infty \). Then, there exists \(R_{\max } < \infty \) such that, for all k,
Proof
Note that the sequence \((f(\tilde{\varvec{p}}^k))_{k = 0, 1, 2, \dots }\) is decreasing by definition of the random variable \(\varvec{x}_{opt}^k\). Therefore, for all k there holds
By coerciveness of f, there exists \(R < \infty \) such that for any deterministic vector \(\varvec{y} \in \mathcal {X}\), \(\Vert \varvec{y} \Vert > R\) implies \(f(\varvec{y}) > f(\tilde{\varvec{p}}^0)\). We deduce that \(\Vert \tilde{\varvec{p}}^k \Vert < R\) for all k, so that \(\Vert \tilde{\varvec{p}}^k - \varvec{x}^*\Vert \le \Vert \tilde{\varvec{p}}^k \Vert + \Vert \varvec{x}^* \Vert \le R + \Vert \varvec{x}^*\Vert \). The result follows by writing \(R_{\max } = R + \Vert \varvec{x}^* \Vert \). \(\square \)
Corollary 6.9
Let Assumptions LipC, Success-Solv and 6.7 hold, \(\varvec{x}^*\) be the point in Assumption FeasBall (replacing \(\epsilon \) by \(\epsilon -\lambda \) in Assumption FeasBall), and \(\varvec{p}^k = \varvec{x}_{opt}^k\) for \(k \ge 1\), with \(\varvec{x}_{opt}^k\) defined in (5.2), and let \(\varvec{p}^0 \in \mathcal {X}\) be such that \(f(\tilde{\varvec{p}}^0)<\infty \). Let \(d^k \ge d_{lb}\) for some \(d_{lb}>0\). Then, \(\varvec{x}_{opt}^k\) converges to the set of \(\epsilon \)-minimizers \(G_{\epsilon }\) almost surely as \(k \rightarrow \infty \), and there exists \(R_{\max }\) such that
with
Proof
The result follows from Theorem 6.6 and Corollary 6.8. \(\square \)
Note that Corollary 6.9 provides us with a worst case convergence bound, as for each iteration k, the random subspace dimension \(d^k\) and the probability to solve to \(\lambda \)-accuracy the reduced problem (\(\text {RP}\mathcal {X}^k\)) have been lower bounded by \(d_{lb}\) and \(\rho _{lb}\), respectively. We also remind the reader that this rate involves a lower bound, derived in Sect. 4, on the probability of (\(\text {RP}\mathcal {X}^k\)) to be \(\epsilon \)-successful, which is in general not tight either.
Remark 6.10
Note that our convergence results still hold if we relax the global Lipschitz continuity requirement, and assume instead that f is Lipschitz continuous in a sufficiently large neighbourhood of an arbitrary global minimizer \(\varvec{x^*}\) of (P). Indeed, if f is Lipschitz continuous, with constant L, in an open ball of radius \(\delta > \epsilon /L\) centered at \(\varvec{x}^*\), and where \(\varvec{x}^*\) is the point in Assumption FeasBall. One can check that Proposition 2.2, and consequently, our convergence analysis, hold.
7 Applying X-REGO to functions with low effective dimensionality
Recent papers [15, 20] explore random embedding algorithms for functions with low effective dimension, that only vary over a subspace of dimension \(d_e<D\), and address respectively the case \(\mathcal {X} = \mathbb {R}^D\) and \(\mathcal {X} = [-1,1]^D\). Both papers assume that the dimension of the random subspace d in (\(\hbox {RP}\mathcal {X}\)) is the same or exceeds the effective dimension \(d_e\), and derive bounds on the probability of (\(\hbox {RP}\mathcal {X}\)) to be \(\epsilon \)-successful in that setting; these bounds are then used to prove convergence of respective random subspace methods. For the remainder of this paper, we explore the use of X-REGO for unconstrained global optimization of functions with low effective dimension, for any random subspace dimension d, thus removing the assumption \(d \ge d_e\). To prove convergence of X-REGO in that setting, we rely on the results derived in Sect. 4.
7.1 Definitions and existing results
Definition 7.1
(Functions with low effective dimensionality, see [68]) A function \(f : \mathbb {R}^D \rightarrow \mathbb {R}\) has effective dimension \(d_e < D\) if there exists a linear subspace \(\mathcal {T}\) of dimension \(d_e\) such that for all vectors \(\varvec{x}_{\top }\) in \(\mathcal {T}\) and \(\varvec{x}_{\perp }\) in \(\mathcal {T}^{\perp }\) (the orthogonal complement of \(\mathcal {T}\)), we have
and \(d_e\) is the smallest integer satisfying (7.1).
The linear subspaces \(\mathcal {T}\) and \(\mathcal {T}^{\perp }\) are respectively named the effective and constant subspaces of f. In this section, we make the following assumption on the function f.
Assumption LowED The function \(f:\mathbb {R}^D \rightarrow \mathbb {R}\) has effective dimensionality \(d_e \) with effective subspaceFootnote 13\(\mathcal {T}\) and constant subspace \(\mathcal {T}^{\perp }\) spanned by the columns of the orthonormal matrices \(\varvec{U} \in \mathbb {R}^{D \times d_e}\) and \(\varvec{V} \in \mathbb {R}^{D\times (D-d_e)}\), respectively. We write \(\varvec{x}_\top = \varvec{U} \varvec{U}^T \varvec{x}\) and \(\varvec{x}_\perp = \varvec{V} \varvec{V}^T \varvec{x}\), the unique Euclidean projections of any vector \(\varvec{x} \in \mathbb {R}^D\) onto \(\mathcal {T}\) and \(\mathcal {T}^\perp \), respectively.
As discussed in [20], functions with low effective dimension have the nice property that their global minimizers are not isolated: to any global minimizer \(\varvec{x}^*\) of (P), with Euclidean projection \(\varvec{x}_\top ^*\) on the effective subspace \(\mathcal {T}\), one can associate a subspace \(\mathcal {G}^*\) on which the objective reaches its minimal value. Indeed, writing
Assumption LowED implies that \(f(\varvec{x}) = f^*\) for all \(\varvec{x} \in \mathcal {G}^*\).
In the unconstrained case \(\mathcal {X} = \mathbb {R}^D\), the exact global solution of a single reduced problem (\(\hbox {RP}\mathcal {X}\)) with subspace dimension \(d \ge d_e\) provides an exact global minimizer of the original problem (P) with probability one, see [68, Theorem 2], [53, Rem. 2.22]. In the next section, we address the case \(d < d_e\); in other words, \(d_e\) is unknown/not known a priori.
7.2 Probability of success of the reduced problem for lower dimensional embeddings
When \(d < d_e\), we quantify the probability of the random embedding to contain a (global) \(\epsilon \)-minimizer. Similarly to the definition of \(\mathcal {G}^*\) above, one may associate to any global minimizer \(\varvec{x}^*\) of (P) a connected set \(\mathcal {G}_\epsilon ^*\) of \(\epsilon \)-minimizers. Denoting the Euclidean projection of \(\varvec{x}^*\) on the effective subspace by \(\varvec{x}_\top ^*\), under Assumption LipC (Lipschitz continuity of f), \(\mathcal {G}_\epsilon ^*\) is the Cartesian product of a \(d_e\)-dimensional ball (contained in the effective subspace) by the constant subspace \(\mathcal {T}^\perp \) (see Assumption LowED):
where L is the Lipschitz constant of f. Indeed, let \(\varvec{x} := \varvec{x}^*_\top + \varvec{U} \varvec{g} + \varvec{V} \varvec{h} \in \mathcal {G}_{\epsilon }^*\), for some \(\varvec{g}\in \mathbb {R}^{d_e}\) satisfying \(\Vert \varvec{g}\Vert \le \epsilon /L\) and for some \(\varvec{h}\in \mathbb {R}^{D-d_e}\). Then, \(f(\varvec{x}) = f(\varvec{x}^*_\top + \varvec{U} \varvec{g})\) by Assumption LowED, since \(\varvec{V} \varvec{h} \in \mathcal {T}^\perp \). By Lipschitz continuity of f, we get:
As already discussed in Sect. 2, the reduced problem (\(\hbox {RP}\mathcal {X}\)) is \(\epsilon \)-successful if the random subspace \(\varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A})\) intersects the set of approximate global minimizers, which by Lemma 7.2 contains any connected components \(\mathcal {G}_\epsilon ^*\) defined in (7.3) for some global minimizer \(\varvec{x}^*\) of (P). Figure 4 shows an abstract representation of the situation where the random subspace \(\varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A}_1)\) intersects the connected component \(\mathcal {G}_\epsilon ^*\), the corresponding embedding is therefore \(\epsilon \)-successful; conversely, the random subspace \(\varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A}_2)\) does not intersect \(\mathcal {G}_\epsilon ^*\). If \(\mathcal {G}_\epsilon ^* = G_\epsilon \) defined in (2.1), this implies that the corresponding embedding is not \(\epsilon \)-successful.

Abstract illustration of embeddings for functions with low effective dimension. The reduced problem is \(\epsilon \)-successful if the random subspace intersects the connected component \(\mathcal {G}_{\epsilon }^*\)
The following result further characterizes the probability of success of (\(\hbox {RP}\mathcal {X}\)).
Theorem 7.2
Let \(\mathcal {X} = \mathbb {R}^D\), and let Assumptions LipC and LowED hold. Let \(\varvec{A}\) be a \(D \times d\) Gaussian matrix, \(\varvec{p} \in \mathbb {R}^D\) be a fixed vector, \(\epsilon >0\) an accuracy tolerance and \(\varvec{x}^*\) any global minimizer of (P) with associate connected component \(\mathcal {G}_\epsilon ^*\) as in (7.3). Then,
where \(\varvec{U}\) is an orthonormal matrix whose columns span the effective subspace \(\mathcal {T}\) (see Assumption LowED), \(\varvec{B} := \varvec{U}^T \varvec{A}\), a \(d_e \times d\) Gaussian matrix and \(B_{\epsilon /L}(\varvec{U}^T\varvec{x}^*)\), the \(d_e\)-dimensional ball of radius \(\epsilon /L\) centered at \(\varvec{U}^T\varvec{x}^*\).
Proof
The first inequality simply follows from (2.2) and from the fact that \(\mathcal {G}_\epsilon ^* \subseteq G_\epsilon \), see (7.4). For the second relationship, since the matrix \(\varvec{Q} := \begin{bmatrix} \varvec{U} &{} \varvec{V} \\ \end{bmatrix}\) (with \(\varvec{V}\) defined in Assumption LowED) is orthogonal, for all \(\varvec{y} \in \mathbb {R}^{d}\)
Writing \(\varvec{B} := \varvec{U}^T \varvec{A} \in \mathbb {R}^{d_e \times d}\) and \(\varvec{C} := \varvec{V}^T \varvec{A} \in \mathbb {R}^{(D-d_e) \times d}\), we get for any global minimizer \(\varvec{x}^*\) of (P) (with associate Euclidean projection \(\varvec{x}_\top ^*\) on the effective subspace)
By definition of \(\mathcal {G}_\epsilon ^*\), there follows that \(\varvec{A} \varvec{y} + \varvec{p} \in \mathcal {G}_\epsilon ^*\) if and only if \( \varvec{B} \varvec{y} + \varvec{U}^T \varvec{p} \in B_{\epsilon /L}(\varvec{U}^T \varvec{x}^*)\). By Theorem A.2, \(\varvec{B}\) is a \(d_e \times d\) Gaussian matrix, which completes the proof. \(\square \)
The probability of \(\epsilon \)-success of (\(\hbox {RP}\mathcal {X}\)) can thus be lower bounded by the probability of the d-dimensional random subspace \({{\,\mathrm{range}\,}}(\varvec{B})+ \varvec{U}^T \varvec{p}\) intersecting the ball \(B_{\epsilon /L}(\varvec{U}^T \varvec{x}^*)\) in \(\mathbb {R}^{d_e}\). We now estimate the latter probability using the conic integral geometry results presented in Sects. 3 and 4: the next result can be seen as the immediate counterpart of Theorems 4.3 and 4.4 for functions with low effective dimensionality.
Corollary 7.3
Let \(\mathcal {X} = \mathbb {R}^D\), and let Assumptions LipC and LowED hold, with effective dimension \(d_e > d\). Let \(\varvec{A}\) be a \(D \times d\) Gaussian matrix and \(\epsilon >0\) an accuracy tolerance. The following claims hold.
-
Let \(\varvec{p} \in \mathbb {R}^D \setminus G_{\epsilon }\) be a given vector, let \(r_{\varvec{p}}^{\mathrm {eff}} := \epsilon / \left( L \Vert \varvec{U}^T \varvec{x}^* - \varvec{U}^T \varvec{p} \Vert \right) \), where \(\varvec{x}^*\) is any global minimizer of (P). Then,
$$\begin{aligned} {\mathbb {P}}[({\hbox {RP}\mathcal {X}}) \text { is }\epsilon \text{- }\hbox {successful}] \ge \tau (r_{\varvec{p}}^{\mathrm {eff}},d,d_e), \end{aligned}$$(7.7)where the function \(\tau (r,d,d_e)\) for \(0<r<1\) is defined in (4.5).
-
Let \(\varvec{p} \in \mathbb {R}^D\) be a given vector that satisfies \(\Vert \varvec{U}^T \varvec{p} - \varvec{U}^T \varvec{x}^*\Vert \le R_{\max }\), for some suitably chosen \(R_{\max }\), and let \(r_{\min }^{\mathrm {eff}} := \epsilon / \left( L R_{\max } \right) \). Then
$$\begin{aligned} {\mathbb {P}}[({\hbox {RP}\mathcal {X}}) \text { is }\epsilon \text{- }\hbox {successful}] \ge \tau (r_{\min }^{\mathrm {eff}},d,d_e). \end{aligned}$$(7.8)
Proof
This result is a direct extension of the analysis in Sect. 4, and more precisely, of Theorem 4.3 and Theorem 4.4, and is obtained by replacing \(\varvec{A}\) by \(\varvec{B}\), \(\varvec{x}^*\) by \(\varvec{U}^T \varvec{x}^*\), \(\varvec{p}\) by \(\varvec{U}^T \varvec{p}\) and D by \(d_e\). \(\square \)
Note that adding some constraints (setting \(\mathcal {X} \subset \mathbb {R}^D\)) makes the analysis much more complicated as even if a random subspace \(\varvec{p}+{{\,\mathrm{range}\,}}(\varvec{A})\) intersects \(\mathcal {G}_{\epsilon }^*\), this intersection may be outside the feasible domain; we therefore restrict ourselves to the unconstrained case in this paper.
7.3 X-REGO for functions with low effective dimension
We present an X-REGO variant dedicated to the optimization of functions with low effective dimension. This algorithm starts by exploring an embedding of low dimension \(d_{lb}\), assuming \(d_{lb} \le d_e\), and the dimension is progressively increased until capturing the effective dimension of the problem, see Algorithm 2. Note that Line 3 to Line 6 are exactly the same as in Algorithm 1. Recall that [68, Theorem 2] guarantees that the algorithm finds the global minimum of (P) with probability one if the reduced problem is solved exactly and if \(d^k \ge d_e\), so that in this ideal case we can terminate the algorithm after \(d_e - d_{lb} + 1\) random embeddings; thus, Algorithm 2 terminates in finitely many random embeddings. Since the effective dimension is unknown, we typically terminate the algorithm when no progress is observed in the objective value, see Sect. 8 for numerical illustrations.

7.4 Convergence of X-REGO for functions with low effective dimension
Similarly to Sects. 5 and 6, for each k, \(\varvec{p}^k\) is a random variable. The particular case of a deterministic \(\varvec{p}^k\) is represented using a random variable whose support is a singleton. To prove convergence of Algorithm 2 to an \(\epsilon \)-minimizer while allowing the reduced problems to be solved approximately, we again require the reduced problems to be \((\epsilon -\lambda )\)-successful, see Assumption Success-Solv and Assumption Succes-Emb. Note that unlike Sect. 6.2, the results below are finite termination results, as we know that with an ideal solver, Algorithm 2 finds an \(\epsilon \)-minimizer after at most \(d_e-d_{lb}+1\) embeddings. Let us first show that Assumption Succes-Emb holds, and derive the value of \(\tau _{lb}\).
Corollary 7.4
Let \(\mathcal {X} = \mathbb {R}^D\), and let Assumptions LipC and LowED hold. Let \(\tilde{\varvec{p}}^k\) satisfy \(\Vert \varvec{U}^T \tilde{\varvec{p}}^k - \varvec{U}^T \varvec{x}^*\Vert \le R_{\max }\) for all k and for some suitably chosen \(R_{\max }\) and let \(d_{lb} < d_e\). Then, Assumption Succes-Emb holds with
with \(r_{\min }^{\mathrm {eff}} = (\epsilon -\lambda )/(L R_{\max })\) and \(\tau (\cdot ,\cdot ,\cdot )\) defined in (4.5).
Proof
For all embeddings such that \(d^k < d_e\), the proof is the same as for Corollary 6.5, replacing D by \(d_e\) and \(r_{\min }\) by \(r_{\min }^{\mathrm {eff}}\). Note that if \(d^k \ge d_e\), (\(\hbox {RP}\mathcal {X}\)) is successful with probability one according to [68, Theorem 2]. The result follows then simply from the fact that \(1 \ge \tau (r_{\min },d_{lb},d_e) = 2 v_{d_e-d_{lb}+1}\) (see the Gauss-Bonnet formula (3.4), and the fact that the intrinsic volumes are nonnegative). \(\square \)
The following result proves convergence of Algorithm 2 to the set of \(\epsilon \)-minimizers almost surely after at most \(d_e - d_{lb} +1\) random embedding. Note in particular that this convergence result has no dependency on D.
Corollary 7.5
(Global convergence of X-REGO for functions with low effective dimension) Let \(\mathcal {X} = \mathbb {R}^D\), and let Assumptions LipC, Success-Solv and LowED hold. Let \(\tilde{\varvec{p}}^k\) satisfy \(\Vert \varvec{U}^T \tilde{\varvec{p}}^k - \varvec{U}^T \varvec{x}^*\Vert \le R_{\max }\) for all k and for some suitably chosen \(R_{\max }\). Let \(\epsilon > 0\) be an accuracy tolerance.
-
If \(d_{lb} \ge d_e\),
$$\begin{aligned} {\mathbb {P}}[f(\varvec{x}_{opt}^{1}) \le f^* + \epsilon ] > \rho ^{1}, \end{aligned}$$where \(\varvec{x}_{opt}^k\) is defined in (5.2) and \(\rho ^k\) is the probability of success of the solver for (\(\widetilde{\text {RP}\mathcal {X}^k}\)) (see Assumption Success-Solv). In particular, if the reduced problem is solved exactly, then \(f(\varvec{x}_{opt}^{k_{\max }}) \le f^* + \epsilon \) with probability one.
-
If \(d_{lb} < d_e\), let \(k_{\max } = d_e-d_{lb}+1\) be the index of the first embedding with dimension \(d_e\). Then
$$\begin{aligned} {\mathbb {P}}[f(\varvec{x}_{opt}^{k_{\max }}) \le f^* + \epsilon ] > \rho ^{k_{\max }}. \end{aligned}$$ -
If \(d_{lb} < d_e\), let \(k_{\max } = d_e-d_{lb}+1\). For \(1 \le k < k_{\max }\), we have
$$\begin{aligned} {\mathbb {P}}[f(\varvec{x}_{opt}^{k}) \le f^* + \epsilon ] \ge 1 - (1-\rho _{lb} \tau _{lb})^k \end{aligned}$$where \(\tau _{lb} = \tau (r_{\min }^{\mathrm {eff}},d_{lb},d_e)\), with \(\tau (\cdot ,\cdot ,\cdot )\) defined in (4.5) and \(r_{\min }^{\mathrm {eff}} = (\epsilon -\lambda )/(L R_{\max })\).
Proof
Note that, by Corollary 7.4, Theorem 6.3 applies. However, since we are interested in finite termination results, we do not directly use Theorem 6.3; instead, we extract the following claim from its convergence proof, see [19, Appendix B]. For all \(K\ge 1\),
It follows that
where \(\tau _{lb}\) and \(\rho _{lb}\) are computed/defined in Corollary 7.4 and Assumption Success-Solv, respectively. Finally, if \(K \ge k_{\max }\), it follows that \(d^K \ge d_e\), so that the probability of (\(\text {RP}\mathcal {X}^k\)) to be \((\epsilon -\lambda )\)-successful is equal to one according to [68, Theorem 2]. So, if \(K \ge k_{\max }\),
which concludes the proof. \(\square \)
8 Numerical experiments
Let us illustrate the behavior of X-REGO on a set of benchmark global optimization problems whose objectives have low effective dimension. We show empirically that Algorithm 2 simultaneously manages to accurately estimate the effective dimension of the problem, and outperforms significantly (and especially in the high-dimensional regime) the no-embedding framework, in which the original problem (P) is solved directly, with no exploitation of the special structure.
8.1 The set-up of the numerical experiments
Test set. Our synthetic test set is very similar to the one we used in [15, 20], and contains a set of benchmark global optimization problems adapted to have low effective dimensionality in the objective as explained in Appendix B. Our test set is made of 18 D-dimensional functions with low effective dimension, with \(D =10, 100\) and 1000. These D-dimensional functions are constructed from 18 low-dimensional global optimization problems with known global minima (some of which are in the Dixon-Szego test set [24]), by artificially adding coordinates and then applying a rotation so that the effective subspace is not aligned with the coordinate axes.
Solver. The reduced problems are solved using the KNITRO solver [13]. Note that, by default, KNITRO is a local solver, but switches to a global solver by activating its multistart feature. We therefore consider three “KNITRO”-type solvers: local KNITRO (no multistart used, referred to as KNITRO), and multistart KNITRO with a low/high number of starting points (cheap or expensive versions of multistart KNITRO, referred to here as ch-mKNITRO and exp-mKNITRO, respectively). The higher the number of starting points, the more likely the solver is to find a global minimizer of the reduced problem. See Table 1 for a detailed description of the settings of the different solvers.
Algorithms using a global solver (ch-mKNITRO and exp-mKNITRO). We test two different instances of the algorithmic framework presented in Algorithm 2 against the no-embedding framework, in which (P) is solved directly without using any random embedding and with no explicit exploitation of its special structure. For each instance, we let \(d_{lb} = 1\). Since the effective dimension of the problem is assumed to be unknown, termination in Algorithm 2 is defined as the first embedding on which either stagnation is observed in the computed optimal cost of the reduced problem (\(\widetilde{\text {RP}\mathcal {X}^k}\)), or if not, until \(d^k = D\). Objective stagnation is measured as follows: stop after \(k_f\) embeddings, where \(k_f\) is the smallest \(k \ge 2\) that satisfies
If \(k_f \le D\), we let \(d_e^{\mathrm {est}} := k_f-1\) be our estimate of the effective dimension of the problem. Indeed, it follows from the paragraph after (7.2) that, two randomly-reduced problems of dimension d and \(d+1\) with \(d \ge d_e\) have the same optimal cost with probability one, so that the left-hand side of (8.1) would be zero if the reduced problems were solved exactly (i.e., under the assumption of an ideal solver). We argue that, on the other hand, it is very unlikely that two randomly-reduced problems of dimension d and \(d+1\) with \(d < d_e\) have the same optimal cost.Footnote 14 We therefore terminate the algorithm after either \(k = k_f\) (if there exists \(k_f\le D\) satisfying (8.1)), or else \(k = D\) random embeddings. Regarding the choice of \(\varvec{p}^k\), we consider two possibilities: either \(\varvec{p}^k\) is a vector that does not depend on k, or \(\varvec{p}^k\) is the best point found over the k first embeddings (i.e., \(\varvec{p}^k = \varvec{x}_{opt}^k\)).
Algorithms relying on a local solver (KNITRO) and a resampling strategy. We also compare several instances of Algorithm 2 with the no-embedding framework when the reduced problem is solved using a local solver. Note that due to the possible nonconvexity of the problem, running a local solver on the original problem is not expected to find the global minimizer; results combining the no-embedding framework with a local solver are thus only reported for comparison. Recall also that our convergence analysis requires the solver to be able to find an approximate global minimizer of the subproblem with a sufficiently high probability. We show numerically that local solvers can be used when the points \(\varvec{p}^{k}\) are suitably chosen to globalize the search; we typically let \(\varvec{p}^{k}\), for some indices k, be a random variable with a sufficiently large support to contain a global minimizer of (P). Similarly as with global solvers, let \(k_f\) be the smallest \(k \ge 2\) that satisfies (8.1), and, if \(k_f \le D\), let \(d_e^{\mathrm {est}} := k_f-1\) be our estimate of the effective dimension of the problem. However, since the solver is local, we cannot assume that (8.1) implies that we found an approximate global minimizer of the original problem (P). We therefore continue the optimization, fixing the subspace dimension: \(d^k = d_e^{\mathrm {est}}\) for all \(k > k_f\), and assuming that \(\varvec{p}^k\) will be such that the next random subspace will leave the basin of attraction of the actual local minimizer. To prevent against local solutions, we use a stronger stopping criterion: the algorithm is stopped either after D embeddings, or earlier, when \(k > k_f\) and when the computed optimal cost of the reduced problem did not change significantly over the last \(n_{\mathrm {stop}}\) random embeddings, i.e., if
In our experiments, we considered two possibilities: \(n_{\mathrm {stop}} = 3\) or \(n_{\mathrm {stop}} = 5\). Here again, we consider two main strategies for choosing \(\varvec{p}^k\): either \(\varvec{p}^k\) does not depend on k (e.g., \(\varvec{p}^k\) is an identically distributed random variable, for all k), or \(\varvec{p}^k\) is the best point found over the past embeddings (\(\varvec{p}^k = \varvec{x}_{opt}^k)\), resampling \(\varvec{p}^k\) at random in a sufficiently large domain for some values of k, see below.
Summary of the algorithms: In total, we compare four instances of Algorithm 2, that correspond to specific choices of \(\varvec{p}^k\), \(k \ge 0\), and on the choice of a local/global solver.
-
Adaptive X-REGO (A-REGO). In Algorithm 2, the reduced problem is solved using a global solver and the point \( \varvec{p}^k\) is chosen as the best point foundFootnote 15 up to the kth embedding: \(\varvec{p}^{k} := \varvec{A}^k \varvec{y}^k+\varvec{p}^{k-1}\).
-
Local adaptive X-REGO (LA-REGO). In Algorithm 2, the reduced problem (\(\widetilde{\text {RP}\mathcal {X}^k}\)) is solved using a local solver (instead of global as in A-REGO). Until we find the effective dimension (i.e., for \(k < k_{f}\)), we use the same update rule for \(\varvec{p}^k\) as in A-REGO: \(\varvec{p}^{k} := \varvec{A}^k \varvec{y}^k+\varvec{p}^{k-1}\). For the remaining embeddings, the point \(\varvec{p}^k\) is chosen as follows: \(\varvec{p}^k = \varvec{A}^k \varvec{y}^k + \varvec{p}^{k-1}\) if \(|f(\varvec{A}^k \varvec{y}^k + \varvec{p}^{k-1}) - f(\varvec{p}^{k-1})| > \gamma = 10^{-5}\), and \(\varvec{p}^k\) is draw uniformly in \([-1,1]^D\) otherwise, to compensate for the local behavior of the solverFootnote 16.
-
Nonadaptive X-REGO (N-REGO). In Algorithm 2, the reduced problem is solved globally, and all the random subspaces are drawn at some fixed point: \(\varvec{p}^k = \varvec{a}\). The fixed value \(\varvec{a}\) is simply defined as a realization of a random variable uniformly distributed in \([-1,1]^D\).Footnote 17
-
Local nonadaptive X-REGO (LN-REGO). In Algorithm 2, the reduced problem (\(\widetilde{\text {RP}\mathcal {X}^k}\)) is solved using a local solver. Until we find the effective dimension (i.e., for \(k < k_f\)), we set \(\varvec{p}^{k} = \varvec{a}\), with \(\varvec{a}\) as in N-REGO. For \(k \ge k_f\), \(\varvec{p}^k\) is a random variable distributed uniformly in \([-1,1]^D\) (and resampled at each embedding), to compensate for the local behavior of the solver.
Note that, regarding the choice of \(\varvec{p}^k\) when using a local solver, we typically have two phases. In the first phase, we apply the same selection rules for \(\varvec{p}^k\), \(k < k_f\), as when using a global solver. For \(k \ge k_f\), we allow resampling to avoid the algorithm to be trapped at a local minimizer. We do not introduce some resampling in the first phase, because then stochasticity would impact the criterion (8.1) and our estimate of the effective dimension of the problem.
Experimental setup. For each algorithm described above, we solve the entire test set three times. For each problem in the test set, we note whether a true global minimum was found and record the number of function evaluations used (the termination criterion is described above). Note that from the four algorithms described above, we get six different algorithms, since algorithms A-REGO and N-REGO are endowed with two different global solvers: exp-mKNITRO and ch-mKNITRO, corresponding respectively to a low and large number of starting points. To compare with ‘no-embedding’, we solve the full-dimensional problem (P) directly with the corresponding solver with no use of random embeddings. The budget and termination criteria used to solve (\(\widetilde{\text {RP}\mathcal {X}^k}\)) within X-REGO or to solve (P) in the ‘no-embedding’ framework are the default ones, summarized in Table 1.
Remark 8.1
The experiments were coded and run in MATLAB on the 16 cores (\(2 \times 8\) Intel with hyper-threading) Linux machines with 256GB RAM and 3300 MHz speed.
We present the main numerical results using Dolan and Moré’s performance profile [26] — a popular framework to compare the performance of optimization algorithms applied to a given test set. For a given algorithm \(\mathcal {A}\), and for each function f in the test set \(\mathcal {S}\), we define

If \(\mathcal {A}\) fails to successfully converge to a \(\epsilon \)-minimizer of f, with \(\epsilon = 10^{-3}\), within the maximum computational budget, we set \(N_f(\mathcal {A}) = \infty \). We further define
as the minimal computational cost required by any algorithm to optimize f. We normalize all the computational costs by \(N_f^*\) and, for each \(\mathcal {A}\), we plot a function \(\pi _{\mathcal {A}}(\alpha )\) that computes the proportion of f’s in the test set \(\mathcal {S}\), for which the normalized computational effort spent by \(\mathcal {A}\) was less than \(\alpha \). Mathematically speaking,
where \(|\cdot |\) denotes the cardinality of a set. The algorithm \(\mathcal {A}\) is considered to have achieved better performance if it produces higher values for \(\pi _{\mathcal {A}}(\alpha )\) for lower values of \(\alpha \), i.e., on figures, the curve \(\pi _{\mathcal {A}}(\alpha )\) is higher and lefter.
8.2 Numerical results
Comparison of X-REGO with the no-embedding framework. The comparison between the above-mentioned instances of X-REGO and the no-embedding framework is given in Fig. 5. A-REGO and N-REGO clearly outperform the no-embedding framework in terms of accuracy vs computational cost, especially for large D. Reducing the number of starting points in the multistart strategy (i.e., replacing exp-mKNITRO by ch-mKNITRO) allows to further significantly improve the performance, though the total proportion of problems ultimately solved is slightly decreased compared to exp-mKNITRO. Note also that the use of a local solver (LA-REGO and LN-REGO) outperforms both global X-REGO instances and the no-embedding framework, especially for large D. They find the global minimizer in a significantly higher number of subproblems than when directly addressing the original high-dimensional problem with the local solver: the resampling strategy for \(\varvec{p}^{k}\) described above helps to globalize the search. Table 2 contains the average, over the test problems, of the number of embeddings used per algorithm; note that for (approximately) global solvers, and especially using \(\varvec{p}^{k} = \varvec{x}_{opt}^k\), the average number of embeddings is very close to the ideal \(k_f\). Indeed, the average effective dimension on our problem sets is equal to 3.7, so the ideal average number of embeddings should be 4.7, as we need an additional embedding for the stopping criterion (8.1) to be satisfied. For local solvers, the average number of embeddings is slightly higher due to the need to resample candidate solutions to globalize the search and due to the stronger stopping criterion.

Comparison between the X-REGO algorithms and ‘no-embedding’ with KNITRO. Each algorithm was run three times on the whole dataset; since all three runs returned similar curves, we display only one of them
Estimation of the effective dimension. As described earlier, instances of X-REGO naturally provide an estimate \(d_e^{\mathrm {est}}\) of the effective dimension of the problem: \(d_e^{\mathrm {est}} = k_f-1\), where \(k_f\) is the smallest integer that satisfies (8.1). In case there exists no \(k_f \le D\) satisfying (8.1), we set \(d_e^{\mathrm {est}} = D\). For several instances of Algorithm 2, Table 3 reports the number of problems of the data set on which \(d_e^{\mathrm {est}} \in [d_e, d_e+2]\), where \(d_e\) is the exact effective dimension of the problem, for \(D = 10\), \(D = 100\) and \(D = 1000\). Typically, adaptive choices of \(\varvec{p}^k\) result in a slightly larger estimate of the effective dimension; we expect this to be a consequence of the fact that \(\varvec{p}^k\) is varying, inducing more variability when evaluating criterion (8.1) than for non-adaptive variants, for which case \(\varvec{p}^k\) is fixed. We also note that the use of a local solver is comparable to a global one regarding the ability of the algorithm to estimate the effective dimension on this problem set when \(\varvec{p}^k\) is chosen adaptively, and significantly lower otherwise (Table 5 and 6). The values given in Table 3,5 and 6 have been averaged over three independent runs of our experiment, on the whole dataset, to account for randomness in the algorithms.
What if we know the effective dimension of the problem? In the favorable situation when the effective dimension \(d_e\) of each problem is known, we can set \(d_{lb} = d_e\) in Algorithm 2, and theoretically, for an ideal global solver, Algorithm 2 is guaranteed to solve exactly the original problem using one embedding. Figure 6 explores numerically the validity of this claim. We compare several instances of X-REGO with corresponding counterparts, where the effective dimension is known. When using an (approximately) global solver (ch-mKNITRO or exp-mKNITRO), we stop Algorithm 2 after one embedding of dimension \(d_e\). When the solver is local (KNITRO), we let Algorithm 2 explore several embeddings of dimension \(d_e\), and stop the algorithm when (8.2) is satisfied, with \(n_{\mathrm {stop}} = 3\), or otherwise after 50 embeddings. Figure 6 shows the corresponding performance profiles, when comparing these strategies with the ones presented on Fig. 4, and the corresponding no-embedding algorithms. In general, and except when using local solvers, knowing \(d_e\) allows to solve a significant proportion of the problems in a considerably smaller time. Admittedly, these conclusions strongly depend on the probability of the solver to be successful, i.e., of the number of starting points of the multistart procedure. Note also than in our test set, the effective dimension is typically low (average value is 3.7), which might also decrease the benefit of knowing the effective dimension and thus avoiding to explore lower-dimensional subspaces; we expect the gap between Algorithm 2 and algorithms where \(d_e\) is known to increase with the effective dimension of the problem.

Comparison of X-REGO with no-embedding, and variants of X-REGO in which the random subspace dimension is equal to the effective dimension (assumed to be known)
8.3 Conclusions to numerical experiments
We have compared several instances of Algorithm 2 with the no-embedding framework, where the original problem is addressed directly, with no use of random embeddings nor exploitation of the special structure. Overall, Algorithm 2 outperforms the no-embedding framework, and this observation becomes more and more apparent when the dimension of the original problem increases. We have also combined Algorithm 2 with a local solver; though our convergence theory does not cover this situation, we have shown that the resulting algorithm can outperform both the no-embedding framework and instances of Algorithm 2 relying on global solver when the parameters \(\varvec{p}^k\) are sampled at random in a sufficiently large domain to “globalize” the search. Regarding the estimation of the effective dimension, we noticed that instances of Algorithm 2 relying on adaptive rules for selecting \(\varvec{p}^k\) (A-REGO and LA-REGO) significantly outperform their fixed \(\varvec{p}^{k}\) counterparts. Finally, we have shown that, in the favourable case when the effective dimension is known, letting \(d_{lb} \ge d_e\) in Algorithm 2 leads to a substantial improvement in performance.
9 Conclusions and future work
We explored a generic algorithmic framework, X-REGO, for global optimization of Lipschitz-continuous functions. X-REGO is based on successively generating reduced problems (\(\hbox {RP}\mathcal {X}\)), where there is flexibility in the choice of the parameter \(\varvec{p}\). Flexibility in choosing \(\varvec{p}\) allows the user to calibrate the level of exploration of \(\mathcal {X}\).
Our central result is the proof of global convergence of X-REGO, that heavily relies on an estimate of the probability of the reduced problem (\(\hbox {RP}\mathcal {X}\)) to be \(\epsilon \)-successful. By looking at the reduced problem through the prism of conic geometry, we have developed a new type of analysis to bound the probability of \(\epsilon \)-success of (\(\hbox {RP}\mathcal {X}\)). The bounds are expressed in terms of the so-called conic intrinsic volumes of circular cones which have exact formulae and thus are quantifiable. Using these formulae, we analysed the asymptotic behaviour of the bounds for large D. The analysis suggests that the success rate of (\(\hbox {RP}\mathcal {X}\)) (as expected) decreases exponentially with growing D. Confirming our intuition, the analysis also shows that (\(\hbox {RP}\mathcal {X}\)) has a high success rate for larger d and smaller distances between the location where subspaces are embedded (i.e., the point \(\varvec{p}\)) and the location of a global minimizer \(\varvec{x}^*\). This latter property of (\(\hbox {RP}\mathcal {X}\)) for general Lipschitz continuous functions is remindful of the dependence of the success rates of (\(\hbox {RP}\mathcal {X}\)) for functions with low effective dimensionality on the distance between \(\varvec{p}_{\top }\) and \(\varvec{x}_{\top }^*\), see [20]. Furthermore, to understand the relative performance of (\(\hbox {RP}\mathcal {X}\)), we compared it with a uniform sampling technique. We looked at lower bounds for the probability of \(\epsilon \)-success of the two techniques and found that the lower bound \(\tau (r_{\varvec{p}},d,D)\) for (\(\hbox {RP}\mathcal {X}\)) is greater than the lower bound \(\tau _{us}\) for uniform sampling if the distance \(\Vert \varvec{x}^* - \varvec{p} \Vert \) is smaller than \(0.48\sqrt{D}\) in the asymptotic regime (\(D \rightarrow \infty \)). In the asymptotic analysis, the embedding subspace d was kept fixed. The analysis showed that in this regime d has no significant effect on the relative performance of (\(\hbox {RP}\mathcal {X}\)). Future research may involve comparison of the performances of (\(\hbox {RP}\mathcal {X}\)) and uniform sampling in different asymptotic settings, for example, when \(d = \beta D\) for some fixed constant \(\beta \).
Our derivations are conceptual in nature, exploring new connections of global optimization to other areas such as conic integral geometry. As an illustration, in the second part of the paper, we used our analysis to obtain lower bounds — that are independent of D — for the probability of \(\epsilon \)-success of (\(\hbox {RP}\mathcal {X}\)) for functions with low effective dimensionality in the case \(d < d_e\). This analysis is exploited algorithmically and allows lifting the restriction of needing to know \(d_e\) for random embeddings algorithms for functions with low effective dimensionality. We tested the effectiveness of X-REGO numerically using global and local KNITRO for solving the reduced problem on a set of benchmark global optimization problems modified to have low effective dimensionality. We proposed different variants of X-REGO each corresponding to a specific rule for choosing \(\varvec{p}\)’s and contrasted them against each other and against the ‘no-embedding’ framework in which the solvers were applied to (P) directly with no use of subspace embeddings. The results of the experiments showed that the difference in performance between X-REGO and ‘no-embedding’ becomes more prominent for larger D, in favour of X-REGO. The results further suggest that the effectiveness of X-REGO, just like of REGO in [15], is solver-dependent. In our experiments, the best results were achieved by the local solver. In the future, we plan to investigate the performance of X-REGO when applied to general objectives and compare it with popular global optimization solvers.
Notes
Note that this is not the first work applying conic integral geometry to optimization, see [1] for an application to the study of phase transitions in random convex optimization problems.
Throughout the paper, we assume that the objective function f is globally Lipschitz continuous on \(\mathcal {X}\). However, our convergence analysis (see Remark 6.10) still holds if we assume that f is Lipschitz continuous in a neighbourhood of a global minimizer \(\varvec{x}^*\), and that the ball \(B_{\epsilon /L}\) in Assumption FeasBall, centred at \(\varvec{x}^*\), is a subset of the neighbourhood where f is Lipschitz continuous.
The formal definition of relative interior of a set S is as follows: \({{\,\mathrm{relint}\,}}(S):=\{ \varvec{x} \in S: \exists \delta >0, B_{\delta }(\varvec{x}) \cap {{\,\mathrm{aff}\,}}(S) \subseteq S \}\), where the affine hull \({{\,\mathrm{aff}\,}}(S)\) is the smallest affine set containing S. For example, the relative interior of a line segment [A, B] \(\subset \) \(\mathbb {R}^2\) is (A, B); the relative interior of a two-dimensional square in \(\mathbb {R}^3\) is the square without its boundary.
A random vector for which each entry is an independent standard normal variable.
The term \(v_{D-d+1}(C)\) is dominant also in the scenario when \(\Vert \varvec{x}^* - \varvec{p} \Vert \rightarrow \infty \) as \(D\rightarrow \infty \) with other parameters fixed. In this case, \(v_{D-d+i}(C)/v_{D-d+1}(C) = \mathcal {O}((r_{\varvec{p}}/\sqrt{D})^{i-1})\) for \(i = 1,2,\dots ,d\) as \(D \rightarrow \infty \).
Here, we have also used the fact that if functions f(x), \(f'(x)\), g(x) and \(g'(x)\) satisfy \(f(x) = \Theta (g(x))\) and \(f'(x) = \Theta (g'(x))\) (as \(x \rightarrow \infty \)), then \(f(x)f'(x) = \Theta (g(x)g'(x))\).
Here, we use the fact that if functions f(x), \(f'(x)\), g(x) and \(g'(x)\) satisfy \(f(x) = \Theta (g(x))\) and \(f'(x) = \Theta (g'(x))\) (as \(x \rightarrow \infty \)), then \(f(x)/f'(x) = \Theta (g(x)/g'(x))\).
It would be possible to restrict the definition of the \(\sigma \)-algebra \(\mathcal {F}^k\) so that it contains strictly the randomness of the embeddings \(\varvec{A}^i\) and \(\varvec{p}^i\) for \(i\le k\); then we would need to assume that \(\varvec{y}^k\) is \(\mathcal {F}^k\)-measurable, which would imply that \(R^k\), \(S^k\) and \(\varvec{x}^k\) are also \(\mathcal {F}^k\)-measurable. Similar comments apply to the definition of \(\mathcal {F}^{k-1/2}\).
The equality in the displayed equation follows from \(\mathbb {E}[S^k | \mathcal {F}^{k-1}] = 1 \cdot {\mathbb {P}}[ S^k = 1 | \mathcal {F}^{k-1}] + 0 \cdot {\mathbb {P}}[ S^k = 0 | \mathcal {F}^{k-1} ]\).
In general, \(\rho ^k\) will depend on the dimension \(d^k\) of the kth random embedding.
Note that \(\mathcal {T}\) in Assumption LowED may not be aligned with the standard axes.
Admittedly, when optimizing difficult functions, for example that are flat almost everywhere and very steep around the minimizer, it could happen that two successive reduced problems of dimension d and \(d+1\), with \(d < d_e\), have the same optimal cost though none of them intersects the set of \(\epsilon \)-minimizers.
If the reduced problem (\(\widetilde{\text {RP}\mathcal {X}^k}\)) is solved using a global solver, then \(f( \varvec{\tilde{p}}^k) \le f(\varvec{\tilde{p}}^{k-1})\) since \(\varvec{\tilde{p}}^{k-1}\) belongs to the search space of (\(\widetilde{\text {RP}\mathcal {X}^k}\)), so that we are indeed keeping the best point found so far. If we are using a local solver, we always initialize \(\varvec{y} = \varvec{0}\) when solving (\(\widetilde{\text {RP}\mathcal {X}^k}\)), so that the same conclusion holds.
We know, from the way we have constructed the test set, that for each problem there exists a global minimizer that belongs to \([-1,1]^D\).
One could take simply \(\varvec{p} = \varvec{0}\), but due to the way we have constructed the problem set, setting \(\varvec{p} = \varvec{0}\) may give some advantage to the algorithm, so we let \(\varvec{p}^k = \varvec{a}\) instead, where \(\varvec{a}\) is a random variable drawn once at the beginning of the algorithm.
References
Amelunxen, D.: Geometric analysis of the condition of the convex feasibility problem. PhD thesis, University of Paderborn (2011)
Amelunxen, D., Lotz, M.: Intrinsic volumes of polyhedral cones: a combinatorial perspective. Discrete Comput. Geom. 58(2), 371–409 (2017)
Amelunxen, D., Lotz, M., McCoy, M.B., Tropp, J.A.: Living on the edge: phase transitions in convex programs with random data. Inf. Inference J. IMA 3(3), 224–294 (2014)
Bach, F., Jenatton, R., Mairal, J., Obozinski, G.: Optimization with sparsity-inducing penalties. Found. Trends Mach. Learn. 4, 1–106 (2011)
Bandeira, A.S., Scheinberg, K., Vicente, L.N.: Convergence of trust-region methods based on probabilistic models. SIAM J. Optim. 24(3), 1238–1264 (2014)
Beck, A.: Introduction to Nonlinear Optimization: Theory, Algorithms, and Applications with MATLAB. Society for Industrial and Applied Mathematics, MOS-SIAM Series on Optimization (2014)
Ben-Tal. A, Nemirovski, A.: Lectures on Modern Convex Optimization. Society for Industrial and Applied Mathematics (2001)
Berahas, A.S., Bollapragada, R., Nocedal, J.: An investigation of Newton-sketch and subsampled Newton methods. Optim. Methods Softw. 35(4), 661–680 (2020)
Bergou, E.H., Gorbunov, E., Richtárik, P.: Stochastic three points method for unconstrained smooth minimization. SIAM J. Optim. 30(4), 2726–2749 (2020)
Binois, M., Ginsbourger, D., Roustant, O.: A warped kernel improving robustness in Bayesian optimization via random embeddings. arXiv e-prints, page. arXiv:1411.3685 (2014)
Binois, M., Ginsbourger, D., Roustant, O.: On the choice of the low-dimensional domain for global optimization via random embeddings. arXiv e-prints, page. arXiv:1704.05318 (2017)
Boyd, S., Vandenberghe, L.: Convex Optimization. Cambridge University Press, New York, NY, USA (2004)
Byrd, R.H., Nocedal, J., Waltz, R.A.: Knitro: An Integrated Package for Nonlinear Optimization, pp. 35–59. Springer, US, Boston, MA (2006)
Cai, H., Mckenzie, D., Yin, W., Zhang, Z.: Zeroth-order regularized optimization (ZORO): approximately sparse gradients and adaptive sampling. arXiv e-prints, page. arXiv:2003.13001 (2020)
Cartis, C., Otemissov, A.: A dimensionality reduction technique for unconstrained global optimization of functions with low effective dimensionality. Inf. Inference J. IMA 11(1), 167–201 (2022)
Cartis, C., Roberts, L.: Scalable subspace methods for derivative-free nonlinear least-squares optimization. arXiv e-prints, page. Math. Program. (2022). https://doi.org/10.1007/s10107-022-01836-1
Cartis, C., Scheinberg, K.: Global convergence rate analysis of unconstrained optimization methods based on probabilistic models. Math. Program. 169(2), 337–375 (2018)
Cartis, C., Fiala, J., Shao, Z.: Hashing embeddings of optimal dimension, with applications to linear least squares. arXiv e-prints, page. arxiv:2105.11815 (2021a)
Cartis, C., Massart, E., Otemissov, A.: Global optimization using random embeddings. arXiv e-prints, page. arxiv:2107.12102 (2021b)
Cartis, C., Massart, E., Otemissov, A.: Bound-constrained global optimization of functions with low effective dimensionality using multiple random embeddings. Math. Program. (2022). https://doi.org/10.1007/s10107-022-01812-9
Chen, J., Zhu, G., Gu, R., Yuan, C., Huang, Y.: Semi-supervised embedding learning for high-dimensional Bayesian optimization. arXiv e-prints, page. arXiv:2005.14601 (2020)
Constantine, P.: Active Subspaces. SIAM, Philadelphia, PA (2015)
Demo, N., Tezzele, M., Rozza, G.: A supervised learning approach involving active subspaces for an efficient genetic algorithm in high-dimensional optimization problems. arXiv e-prints, page. arXiv:2006.07282 (2020)
Dixon, L.C.W., Szegö, G.P.: Towards Global Optimization. Elsevier, New York (1975)
Djolonga, J., Krause, A., Cevher, V.: High-dimensional gaussian process bandits. In: Proceedings of the 26th International Conference on Neural Information Processing Systems, NIPS’13, pp. 1025–1033 (2013)
Dolan, E.D., Moré, J.J.: Benchmarking optimization software with performance profiles. Math. Program. 91(2), 201–213 (2002)
Eriksson, D., Dong, K., Lee, E.H., Bindel, D., Wilson, A.G.: Scaling Gaussian process regression with derivatives. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems, NIPS’18, pp. 6868–6878 (2018)
Ernesto,P.A., Diliman, U.P.: MVF—multivariate test functions library in C for unconstrained global optimization (2005)
Fornasier, M., Schnass, K., Vybiral, J.: Learning functions of few arbitrary linear parameters in high dimensions. Found. Comput. Math. 12(2), 229–262 (2012)
Garnett, R., Osborne, M.A., Hennig, P:. Active learning of linear embeddings for gaussian processes. In: Proceedings of the Thirtieth Conference on Uncertainty in Artificial Intelligence, UAI’14, pp. 230–239 (2014)
Gavana, A.: Global optimization benchmarks and AMPGO. Available at http://infinity77.net/global_optimization/
Gendreau, M., Potvin, J.-Y.: Handbook of Metaheuristics (International Series in Operations Research & Management Science), 2nd edn. Springer, US (2010)
Goldstein, L., Nourdin, I., Peccati, G.: Gaussian phase transitions and conic intrinsic volumes: steining the Steiner formula. Ann. Appl. Probab. 27(1), 1–47 (2017)
Golovin, D., Karro, J., Kochanski, G., Lee, C., Song, X., Zhang, Q.: Gradientless descent: high-dimensional zeroth-order optimization. In: Proceedings of the Sixth International Conference on Learning Representations, ICLR’20 (2020)
Gower, R., Koralev, D., Lieder, F., Richtárik, P.: Rsn: randomized subspace Newton. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems, NIPS’19 (2019)
Gratton, S., Royer, C.W., Vicente, L.N., Zhang, Z.: Direct search based on probabilistic descent. SIAM J. Optim. 25(3), 1515–1541 (2015)
Gratton, Serge, Royer, Clément. W., Vicente, Luís. N., Zhang, Zaikun: Direct search based on probabilistic feasible descent for bound and linearly constrained problems. Comput. Optim. Appl. 72(3), 525–559 (2019)
Grishchenko, D., Iutzeler, F., Malick, J.: Proximal gradient methods with adaptive subspace sampling. Math. Oper. Res. 46(4), 1303–1323 (2021)
Gupta, A.K., Nagar, D.K.: Matrix Variate Distributions. Chapman and Hall/CRC, New York (2000)
Hanzely, F., Doikov, N., Richtárik, P., Nesterov, Y.: Stochastic subspace cubic Newton method. In: Proceedings of the 37th International Conference on Machine Learning, ICML’20 (2020)
Holland, J.H.: Genetic algorithms and the optimal allocation of trials. SIAM J. Comput. 2(2), 88–105 (1973)
Izmailov, P., Maddox, W.J., Kirichenko, P., Garipov, T., Vetrov, D., Wilson, A.G.: Subspace inference for Bayesian deep learning. In: Proceedings of the Conference on Uncertainty in Artificial Intelligence (UAI’19) (2019)
Kirschner, J., Mutny, M., Hiller, N., Ischebeck, R., Krause, A.: Adaptive and safe Bayesian optimization in high dimensions via one-dimensional subspaces. In: Proceedings of the 36th International Conference on Machine Learning, ICML’19 (2019)
Kozak, D., Becker, S., Doostan, A., Tenorio, L.: Stochastic subspace descent. arXiv e-prints, page. arXiv:1904.01145 (2019)
Lacotte, J., Pilanci, M.: Effective dimension adaptive sketching methods for faster regularized least-squares optimization. In: Proceedings of the 34th Conference on Neural Information Processing Systems, NIPS’20 (2020)
Lacotte, J., Pilanci, M., Pavone, M.: High-dimensional optimization in adaptive random subspaces. In: Proceedings of the 33rd Conference on Neural Information Processing Systems, NIPS’19 (2019)
Li, C., Farkhoor, H., Liu, R., Yosinski, J.: Measuring the intrinsic dimension of objective landscapes. In: Proceedings of the Sixth International Conference on Learning Representations, ICLR’18 (2018)
Liberti, L., Poirion, P.-L., Vu, K.: Random projections for conic programs. Linear Algebra Appl. 626, 204–220 (2021)
McCoy, M.B., Tropp, J.A.: From Steiner formulas for cones to concentration of intrinsic volumes. Discrete Comput. Geom. 51(4), 926–963 (2014)
Nesterov, Y.: Efficiency of coordinate descent methods on huge-scale optimization problems. SIAM J. Optim. 22(2), 341–362 (2012)
Nesterov, Y., Spokoiny, V.: Random gradient-free minimization of convex functions. Found. Comput. Math. 17, 527–566 (2017)
NIST. NIST Digital Library of Mathematical Functions, 2020. Available at https://dlmf.nist.gov
Otemissov, A.: Dimensionality reduction techniques for global optimization. PhD thesis, University of Oxford (2021)
Pilanci, M., Wainwright, M.J.: Newton sketch: a near linear-time optimization algorithm with linear-quadratic convergence. SIAM J. Optim. 27(1), 205–245 (2017)
Qian, H., Hu, Y.Q., Yu, Y.: Derivative-free optimization of high-dimensional non-convex functions by sequential random embeddings. In: Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, IJCAI’16 (2016)
Richtárik, P., Takáč, M.: Parallel coordinate descent methods for big data optimization. Math. Program. 156, 433–484 (2015)
Roosta-Khorasani, F., Mahoney, M.W.: Sub-sampled Newton methods. Math. Program. 174(1), 293–326 (2019)
Schneider, R., Weil, W.: Stochastic and Integral Geometry. Springer series in statistics: Probability and its applications. Springer (2008)
Solis, F.J., Wets, R.J.-B.: Minimization by random search techniques. Math. Oper. Res. 6(1), 19–30 (1981)
Stich, S.U., Müller, C.L., Gärtner, B.: Optimization of convex functions with random pursuit. SIAM J. Optim. 23(2), 1284–1309 (2013)
Surjanovic, S., Bingham, D.: Virtual library of simulation experiments: test functions and datasets, 2013. Available at https://www.sfu.ca/~ssurjano/
Tricomi, F.G., Erdélyi, A.: The asymptotic expansion of a ratio of gamma functions. Pacific J. Math. 1, 133–142 (1951)
Tyagi, H., Cevher, V.: Learning non-parametric basis independent models from point queries via low-rank methods. Appl. Comput. Harmon. Anal. 37(3), 389–412 (2014)
Ughi, G., Abrol, V., Tanner, J.: An empirical study of derivative-free-optimization algorithms for targeted black-box attacks in deep neural networks. Optim. Eng. 23, 1–28 (2021)
Vershynin, R.: High-Dimensional Probability: An Introduction with Applications in Data Science. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press (2018)
Vu, K., Poirion, P.-L., Liberti, L.: Random projections for linear programming. Math. Oper. Res. 43(4), 1051–1071 (2018)
Wang, Y., Du, S.S., Balakrishnan, S., Singh, A.: Stochastic zeroth-order optimization in high dimensions. In: International Conference on Artificial Intelligence and Statistics, AISTATS’18 (2018)
Wang, Z., Hutter, F., Zoghi, M., Matheson, D., De Freitas, N.: Bayesian optimization in a billion dimensions via random embeddings. J. Artif. Intell. Res. 55(1), 361–387 (2016)
D. P. Woodruff. Sketching as a tool for numerical linear algebra. Found. Trends® Theor. Comput. Sci. 10(1–2), 1–157 (2014)
Wright, S.J.: Coordinate descent algorithms. Math. Program. 151, 3–34 (2015)
Zhang, M., Li, H., Su, S.: High dimensional Bayesian optimization via supervised dimension reduction. In: Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI’19 (2019)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was supported by The Alan Turing Institute under The Engineering and Physical Sciences Research Council (EPSRC) grant EP/N510129/1 and under the Turing project scheme.
The second author’s work was supported by the National Physical Laboratory.
Appendices
A Technical definitions and results
1.1 A.1 Gaussian random matrices
Definition A.1
(Gaussian matrix) A Gaussian (random) matrix is a matrix whose each entry is an independent standard normal random variable.
Gaussian matrices have been well-studied with many results available at hand; here, we mention the following result that we use in the analysis; for a collection of results pertaining to Gaussian matrices and other related distributions refer to [39, 65].
Theorem A.2
(see [39, Theorem 2.3.10]) Let \(\varvec{A}\) be a \(D \times d\) Gaussian random matrix. If \(\varvec{U} \in \mathbb {R}^{D \times p}\), \(D \ge p \), and \(\varvec{V} \in \mathbb {R}^{d \times q}\), \(d \ge q\), are orthonormal, then \(\varvec{U}^T\varvec{A}\varvec{V}\) is a Gaussian random matrix.
B Problem set
Table 4 contains the name, domain and global minimum of the functions used to generate the high-dimensional test set. Similarly as in [15, 20], the problem set contains 18 problems taken from [28, 31, 61]. To generate this problem set, we transformed each of the 18 functions in Table 4 into a high-dimensional function with low-effective dimension, by adapting the method proposed by Wang et al. [68]. Let \(\bar{g}(\bar{\varvec{x}})\) be any function from Table 4, with dimension \(d_e\) and let the given domain be scaled to \([-1, 1]^{d_e}\). We create a D-dimensional function \(g(\varvec{x})\) by adding \(D-d_e\) fake dimensions to \(\bar{g}(\bar{\varvec{x}})\), \( g(\varvec{x}) = \bar{g}(\bar{\varvec{x}}) + 0\cdot x_{d_e+1} + 0 \cdot x_{d_e+2} + \cdots + 0\cdot x_{D}\). We further rotate the function by applying a random orthogonal matrix \(\varvec{Q}\) to \(\varvec{x}\) to obtain a nontrivial constant subspace. The final form of the function we test is
Note that the first \(d_e\) rows of \(\varvec{Q}\) now span the effective subspace \(\mathcal {T}\) of \(f(\varvec{x})\).
For each problem in the test set, we generate three functions f according to (B.1), one for each \(D = 10\), 100, 1000. Note that the range of effective dimension covered by our test set is slightly larger than in [15, 20], to better assess the ability of the algorithm to learn \(d_e\) (Tables 5, 6).
C Additional numerical experiments
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Cartis, C., Massart, E. & Otemissov, A. Global optimization using random embeddings. Math. Program. 200, 781–829 (2023). https://doi.org/10.1007/s10107-022-01871-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10107-022-01871-y
Keywords
- Global optimization
- Random subspaces
- Conic integral geometry
- Dimensionality reduction techniques
- Functions with low effective dimensionality