
Abstract
This paper introduces a multi-objective variant of the marine predators algorithm (MPA) called the multi-objective improved marine predators algorithm (MOIMPA), which incorporates concepts from Quantum theory. By leveraging Quantum theory, the MOIMPA aims to enhance the MPA’s ability to balance between exploration and exploitation and find optimal solutions. The algorithm utilizes a concept inspired by the Schrödinger wave function to determine the position of particles in the search space. This modification improves both exploration and exploitation, resulting in enhanced performance. Additionally, the proposed MOIMPA incorporates the Pareto dominance mechanism. It stores non-dominated Pareto optimal solutions in a repository and employs a roulette wheel strategy to select solutions from the repository, considering their coverage. To evaluate the effectiveness and efficiency of MOIMPA, tests are conducted on various benchmark functions, including ZDT and DTLZ, as well as using the evolutionary computation 2009 (CEC’09) test suite. The algorithm is also evaluated on engineering design problems. A comparison is made between the proposed multi-objective approach and other well-known evolutionary optimization methods, such as MOMPA, multi-objective ant lion optimizer, and multi-objective multi-verse optimization. The statistical results demonstrate the robustness of the MOIMPA approach, as measured by metrics like inverted generational distance, generalized distance, spacing, and delta. Furthermore, qualitative experimental results confirm that MOIMPA provides highly accurate approximations of the true Pareto fronts.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Over the past decade, there has been a considerable surge in the popularity and usage of evolutionary algorithms (EAs). These algorithms have proven to be effective in solving a wide range of real-world optimization problems in engineering and scientific research fields. Among the notable meta-heuristic approaches, the genetic algorithm (GA) stands out as the pioneering stochastic algorithm initially introduced by John Holland in 1960 (Holland 1975). Another important algorithm is simulated annealing (SA), which was proposed by Kirkpatrick et al. (1983). In 1995, Kennedy and Eberhart introduced the particle swarm optimization (PSO) algorithm (Kennedy and Eberhart 1995). Additionally, numerous other approaches have been developed subsequently, such as ant bee colony (ABC) (Karaboga and Basturk 2007), Chernobyl disaster optimizer (CDO) (Shehadeh 2023), biology migration algorithm (BMA) (Zhang et al. 2019), RIME algorithm (RIME) (Su et al. 2023), spider wasp optimization (SWO) (Abdel-Basset et al. 2023), Siberian tiger optimization (STO) (Trojovský et al. 2022), predator–prey optimization (PPO) (Mohammad Hasani Zade and Mansouri 2022), Kepler optimization algorithm (KOA) (Abdel-Basset et al. 2023), leader-advocate-believer-based optimization (LAB) (Reddy et al. 2023), past present future (PPF) (Naik and Satapathy 2021), artificial neural networks (ANNs) (D’Angelo et al. 2022), genetic programming (GP) (D’Angelo et al. 2023), and so on. Although these intelligent algorithms offer benefits, they require enhancements to accommodate the diverse characteristics of complex real-world applications. This implies that no single approach is capable of adequately solving the wide range of optimization problems. Real-world issues often exhibit various challenging features, such as uncertainty, dynamicity, combinatorial complexity, multiple objectives, and constraints. In line with this, the no-free lunch (NFL) theorem (Wolpert and Macready 1997) confirms that no optimization approach can effectively address all types of problems. Alongside the development of novel algorithms, certain researchers have explored general improvement strategies to enhance the performance of meta-heuristic algorithms. Examples of these general improvement strategies include Lévy flight (Viswanathan et al. 1996), quantum behavior (Feynman 1986), chaotic behavior (Kaplan 1979), opposition-based learning (Tizhoosh 2005), Gaussian mutation (Liu 2012), and so on. Driven by the researchers’ statements and the principles of the no-free-lunch theorem, in this paper, the quantum behavior was adopted in order to enhance the performance of the marine predators algorithm. This novel modification enhances the marine predators algorithm to effectively explore and exploit the search space and empowers the capability to balance between exploration and exploitation. Many optimization approaches typically encountered are single-objective in nature and do not adequately address the diverse features of complex real-world applications, specifically the ability to optimize many objectives simultaneously (Andersson 2000; Coello et al. 2002). This includes the challenge of optimizing multiple objectives simultaneously, which is the second principle focus of this paper. In fact, multi-objective evolutionary algorithms (MOEAs) have gained significant attention from researchers in engineering fields. These algorithms have been continually developed and improved. However, solving multi-objective optimization problems (MOPs) remains a difficult and challenging task. Among the influenced multi-objective algorithms: multi-objective particle swarm optimization (MOPSO) (Coello et al. 2004), multi-objective evolutionary algorithm based on decomposition (MOEA/D) (Zhang and Li 2007), non-dominated sorting genetic algorithm (NSGA) (Srinivas and Deb 1994), and strength Pareto evolutionary algorithm (SPEA) (Zitzler and Thiele 1999).
The classification of MOEAs can be divided into three different classes: a priori (Kim and de Weck 2005), posterior (Branke et al. 2001), and interactive (Shin and Ravindran 1991). The priori technique combines the objectives into a single one using a set of weights by aggregation and requires a decision-maker that furnishes some preferences according to how important the objectives are. For a posteriori technique, the Pareto optimal set is determined in just one run antithesis the priori method that should be run multiple times. Besides, this method benefits from maintaining the multi-objective formulation, finding out all kinds of Pareto front, and the decision-maker is required after the optimization process. In the third class, the interactive technique maintains the multi-objective formulation and considers the decision maker during the optimization procedure, thus, this method necessitates a higher execution time and computational cost to obtain accurate Pareto optimal solutions. Along these lines, this work focuses on the algorithms-based posteriori method, and most existing multi-objective evolutionary algorithms follow this technique. Many researchers have been recently reported various multi-objective approaches, for instance: multi-objective slime mould algorithm (MOSMA) (Premkumar et al. 2021), non-sorted harris hawks optimizer (NSHHO) (Jangir et al. 2021), multi-objective bonobo optimizer-based decomposition (MOBO) (Das et al. 2020), multi-objective forensic-based investigation (MOFBI) (Chou and Truong 2022), multi-objective thermal exchange optimization (MOTEO) (Kumar et al. 2022), multi-objective ant lion optimizer (MOALO) (Mirjalili et al. 2017), non-dominated sorting manta ray foraging optimization (NSMRFO) (Daqaq et al. 2022), multi-objective multi-verse optimization (MOMVO) (Mirjalili et al. 2017), multi-objective adaptive guided differential evolution (MOAGDE) (Duman et al. 2021), multi-objective backtracking search algorithm (MOBSA) (Daqaq et al. 2021), and so on. However, the main contribution of this paper could be summarized as:
-
Introduction of MOIMPA: a multi-objective variant of the marine predators algorithm (MPA) that incorporates concepts from Quantum theory is presented.
-
Enhancing exploration and exploitation: MOIMPA aims to improve the MPA’s ability to balance between exploration and exploitation by using a modified Schrödinger wave function to determine particle positions in the search space.
-
Incorporation of Pareto dominance mechanism: MOIMPA includes a repository to store non-dominated Pareto optimal solutions and utilizes a roulette wheel strategy for solutions selected based on coverage.
-
Evaluation of benchmark functions: MOIMPA is tested on benchmark functions such as ZDT and DTLZ, as well as the CEC’09 test suite, to assess its effectiveness and efficiency.
-
Comparison with other optimization methods: A comparison is made between MOIMPA and other evolutionary optimization methods like MOMPA, MOALO, and MOMVO.
-
Statistical results: Statistical metrics such as inverted generational distance (IGD), generalized distance (GD), spacing, and delta are used to demonstrate the robustness of MOIMPA.
-
Accurate approximations of Pareto front: Qualitative experimental results confirm that MOIMPA provides highly accurate approximations of the true Pareto front.
The study is structured as follows: Sect. 2 reviews previous research conducted by other researchers on the marine predators approach. Section 3 presents the mathematical formulations and definitions related to multi-objective optimization, along with the basic MPA approach and the proposed MO version, MOIMPA. Section 4 presents the findings, analysis, and discussions. Lastly, Sect. 5 concludes the paper and outlines potential avenues for future research.
2 Related works
As aforementioned, a new multi-objective version of the marine predators approach (MPA) is suggested in this work to address multi-objective problems. MPA was primarily initiated by Faramarzi et al. (2020), and existing literature demonstrates that MPA has successfully tackled various problems and outperformed several established approaches. Hence, researchers have followed the No Free Lunch theorem (NFL) and improved MPA based on the complexity and nature of their specific problems, and several studies have investigated the effectiveness of their improved approach. Among the research studies that investigate its effectiveness: Aydemir and Onay improved MPA by integrating and combining the elite natural evolution, elite random mutation, and Gaussian mutation strategies Aydemir and Kutlu Onay (2023). In Ferahtia et al. (2022) utilized the MPA approach to minimize the operating costs of the energy management strategy for the microgrid. In another work (Dinh 2022), the standard MPA was applied for medical image fusion and a better MPA performance is proven. According to Al-qaness et al. (2022) the MPAmu as a new variant of MPA was introduced using additional mutation operators for the purpose of improving its premature convergence, this algorithm was used to introduce an effective prediction tool to estimate wind power employing time-series datasets. A hybrid MPA was invented by Abdel-Basset et al. (2022), the authors suggest a novel image segmentation algorithm according to the HMPA, in which the approach was enhanced using the linearly increased worst solutions improvement strategy (LIS). Further, to find out the optimum multilevel threshold image segmentation, the authors in Abualigah et al. (2022) hybridized the marine predators and salp swarm algorithms in view of improving the standard MPA. In an effort to resolve the optimal reactive power dispatch issue integrating the uncertainties of solar and wind energy, an improved MPA is suggested in Habib Khan et al. (2022), the IMPA is based on enhancing the exploitation stage. Moreover, (Sun and Gao 2021) presented three concepts that were introduced to enhance the performance of MPA. The first concept was to construct the initial population utilizing the cubic mapping in order to enhance the diversity, the second was to adapt the estimation distribution algorithm for modifying the evolutionary direction and improving the convergence performance, whereas the last was to avoid stagnation in local optima applying the Gaussian random walk strategy. The experiments resulted in Abd Elaziz et al. (2022) indicating that the sine-cosine algorithm improved the MPA in terms of the search ability which works as a local search of the MPA. In another study (Houssein et al. 2021), a grey wolf optimizer with an opposition-based learning strategy was integrated into MPA with the aim of obtaining a faster convergence rate and avoiding being trapped in local solutions. Furthermore, a new MPA-based multi-group mechanism was proposed to optimize the economic load dispatch problem (Pan et al. 2022).
However, few scholars investigate its performance on multi-objective problems. On this basis, multi-objective MPA (MOMPA) based on crowding distance and elitist non-dominated sorting mechanisms was presented by Jangir et al. in (2023), this approach was run on some constrained, unconstrained benchmark problems and engineering design applications. (Wang et al. 2023) introduced the concept of quantity into the deep learning model to examine a wind speed integrated probability predictive approach, utilizing a multi-objective marine predators algorithm. Additionally, according to (Hassan et al. 2022), a modified version of MPA including a comprehensive learning approach was investigated to handle the multiobjective combined economic emission dispatch (CEED) optimization problem. Finally, according to the recent study (Yousri et al. 2022), another enhanced MPA named MOEMPA was suggested to manage the sharing energy in an interconnected micro-grid with a utility network in India by optimizing the emission and operating cost. Along these lines, the significant powerful features of MPA and its borrowed evolutionary algorithms mentioned above, motivated us to improve a novel multi-objective variant of marine predators algorithm in this study, named multi-objective improved marine predators algorithm (MOIMPA). The outstanding search mechanism in MPA is kept similar to the MOIMPA approach.
3 Background
This section presents a comprehensive introduction to optimization (MO) and its essential mathematical definitions, which is a foundational problem-solving technique utilized to discover the optimal solutions from a range of alternatives. In the context of multi-objective optimization, the primary aim is to concurrently optimize multiple objectives that often conflict with one another, a common occurrence in real-world decision-making situations. To gain a deeper understanding of the concepts and methods employed in this field, it is crucial to explore the marine predators approach and its multi-objective counterpart. Inspired by the efficient foraging strategies of marine predators like sharks and dolphins, the marine predators approach adopts a population-based search algorithm that emulates the movement and behavior of these creatures to solve optimization problems. By modeling the search process based on the natural behavior of marine predators, this approach seeks to enhance the efficiency and effectiveness of the optimization process. Additionally, this study also incorporates the multi-objective variant of the marine predators approach. Multi-objective optimization expands upon the traditional optimization framework by incorporating multiple conflicting objectives. The goal of the multi-objective variant is to explore and identify a set of solutions that represent trade-offs between these objectives, rather than finding a single optimal solution. This approach empowers decision-makers to gain insights into the trade-offs involved and make well-informed decisions based on the available options. First, we’ll outline key mathematical definitions in the field of optimization (MO) before discussing and reviewing the marine predators approach and its multi-objective variant.
3.1 Multi-objective optimization
As its name signifies, multi-objective optimization is the subject of addressing various conflicting objectives concurrently. Thus, the arithmetic relational operators are not efficacious in comparing different solutions. Therefore, the Pareto optimal dominance concept is utilized to determine which solution is better than another.
The MOPs mathematical formulation as a minimization problem is given as follows:
where \(O(\vec {x})\) is the objective function to be minimized. \(h_{j}(\vec {x})\) and \(g_{j}(\vec {x})\) are the equality and inequality constraints. \(N_\textrm{obj}\), n, m, and p are the numbers of objective functions, variables, inequality, and equality constraints. \(X^\textrm{min}_{j}\) and \(X^\textrm{max}_{j}\) are the boundaries of the jth variable.
The essential relationships that are able to take into account all objectives concurrently are defined as follows (Pareto 1964; Coello Coello 2009):
Let us take two vectors \(\vec {x}=\left( x_{1}, x_{2}, \ldots , x_{n}\right) \) and \(\vec {y}=\left( y_{1}, y_{2}, \ldots , y_{n}\right) \)
Definition 1
(Pareto dominance) \(\vec {x}\) is said to dominate \(\vec {y}\) if and only if \(\vec {x}\) is partially less than \(\vec {y}\) (i.e., \(\vec {x} \le \vec {y}\)):
Definition 2
(Pareto optimality) \(\vec {x} \in X\) is called a Pareto optimal solution iff:
Definition 3
(Pareto optimal set) The Pareto optimal set is a set that comprises all Pareto optimal solutions (neither \(\vec {x}\) dominates \(\vec {y}\) nor \(\vec {y}\) dominates \(\vec {x}\)):
Definition 4
(Pareto optimal front) The Pareto optimal front is defined as:
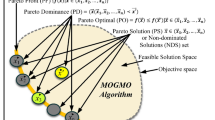
The optimal non-dominated outputs set, which represents the set of solutions for each multi-objective optimization problem, plays a significant role in evaluating and comparing different solution options. Figure 1 provides a visual representation of this concept, illustrating the relationship between the objective space and the corresponding Pareto optimal front. As depicted in Fig. 1, the red shapes represent the solutions in the objective space, while their projection onto the objective space is known as the Pareto optimal front. The Pareto optimal front consists of solutions that are not dominated by any other solution in terms of all the objectives under consideration. In other words, these solutions represent the best possible trade-offs between conflicting objectives, where improving one objective would result in a deterioration of at least one other objective. By examining the solutions depicted in both spaces, it becomes evident that the star shape in Fig. 1 dominates all the other shapes. Domination refers to a solution being superior to another solution in terms of at least one objective, without being worse in any other objective. In this case, the star shape outperforms all other shapes across all objectives, making it the most desirable solution within the given optimization problem. The visualization provided by Fig. 1 highlights the importance of identifying the Pareto optimal front and understanding the dominant relationship between solutions. This knowledge enables decision-makers to make informed choices by considering the trade-offs associated with different solutions and selecting the most appropriate one based on their preferences and constraints.

Search and objective spaces
3.2 Marine predators algorithm
The principle phases of the MPA approach are introduced in the following subsection.
3.2.1 Description of MPA
MPA is a population-based approach, inspired by the widespread foraging in ocean predators, and the optimal encounter rate in biological interaction between predator and prey, by Faramarzi et al. (2020). Like other meta-heuristics, in which the initial solution \(X_{0}\) is uniformly distributed throughout the search area as:
where \(X_\textrm{min}\) is the lower bound, \(X_\textrm{max}\) is the upper bound for variables, and rand is a uniform random vector in the range of 0–1.
According to the survival of the fittest theory, top predators in nature are better at hunting. As a result, the fittest solution is designated as a top predator to form a matrix known as the Elite. This matrix arrays looking for and locating prey depending on information about the prey’s location.
where \(\overrightarrow{X^t}\) denotes the top predator vector, which is copied n times to create the Elite matrix. n denotes the number of search agents, whereas d denotes the number of dimensions. Prey is another matrix with the same dimension as Elite, and it is used by predators to update their locations.
The MPA optimization method is separated into three primary phases, each of which takes into account a particular velocity ratio while simulating the whole life of a predator and prey as follows:
3.2.2 High velocity ratio
This situation occurs when the prey moves faster than the predator, or during the early stages of optimization, when exploration is important. In a high-velocity ratio (v 10) situation, the optimum predator tactic is to stay still. This rule’s mathematical model is as follows:
where \(R_B\) is a vector of random integers from the Normal distribution that reflect Brownian motion. The notation \(\otimes \) depicts entry-by-entry multiplications. Prey movement is simulated by multiplying \(R_B\) by Prey. \(P = 0.5\) is a constant, and R is a vector of uniform random values in the range [0,1]. This situation occurs during the first third of iterations when the step size or velocity of movement is large, indicating a high level of exploratory ability. iter is the current iteration while \(iter_\textrm{max}\) is the maximum one.
3.2.3 Unit velocity ratio
When both the predator and the prey are running at about the same speed, it suggests that both are seeking their prey. This portion happens during the intermediate phase of optimization when exploration attempts to be transiently transformed into exploitation. Exploration and exploitation are important at this stage. As a result, half of the population is earmarked for exploration and the other half for exploitation. During this stage, the prey is in charge of exploitation while the predator is in charge of exploration. As a result, if prey travels in Lévy, the best predator tactic is Brownian.
For the first half of the population
The second half of the population
where CF is an adjustable parameter that is used to track the step size.
3.2.4 Low velocity ratio
During this particular phase, a low-velocity ratio occurs when the predator’s speed surpasses that of the prey. This situation occurs near the end of the optimization process, which is typically associated with high exploitation capability. Lévy is the best predator approach for low-velocity ratios \((v = 0.1)\). This stage is depicted as:
In the Lévy method, multiplying \(R_L\) and Elite mimics predator movement, whereas adding the step size to Elite position simulates predator movement to aid in the updating of prey location.

The flowchart of the original Marine Predators Algorithm (MPA)
The additional feature of MPA is that it simulates predator behavior, increasing the chances of escape from local optima. This advantage stems from the fact that factors such as eddy formation and fish aggregating devices (FADs) can influence predator behavior. As a consequence, the predators would jump into other locations with abundant prey \(20\%\) of the time, while searching for their prey in the local area the rest of the time. FADs can be made in the following way:
where FADs = 0.2 denotes the probability of FADs influencing the optimization process. U is a binary vector containing arrays of zero and one and built by creating a random vector in the range [0, 1] and setting its array to zero if it is less than 0.2 and one if it is larger than 0.2. r is the uniform random number in the range [0,1]. The subscripts \(r_{1}\) and \(r_{2}\) are random prey matrix indexes.

The flowchart of the proposed Improved Marine Predators Algorithm (IMPA)
The main steps followed in MPA are demonstrated in Fig. 2. This flow chart depicted in Fig. 2 illustrates the step-by-step process of the MPA algorithm employed in this study. The algorithm presents a clear and structured approach to solving the optimization problem at hand. The flow chart provides a visual representation of the algorithm’s structure and the sequence of operations involved. It serves as a valuable tool for understanding the algorithm’s inner workings and aids in analyzing its efficiency and effectiveness in solving complex optimization problems.
4 The proposed algorithm
In this subsection, quantum mechanics is used to develop the original MPA technique. This quantum model of the MPA technique is named the IMPA algorithm. Quantum algorithm (QA) was first proposed in Benioff (1980). It was declared that QA could solve many difficulties based on the concepts and principles of quantum theory, including the superposition of quantum states, entanglement, and intervention. Quantum-Inspired Evolutionary Algorithm (QEA) is one of the developing algorithms which was inspired by the concept of quantum computing (Han and Kim 2002). This algorithm was successfully applied to solve several combinational optimization problems. The good performance of the QEA algorithm for finding a global best solution in a short time has attracted the attention of researchers to use quantum computing to develop algorithms such as quantum genetic algorithm (QGA) (Vlachogiannis and Østergaard 2009), multiscale quantum harmonic oscillator algorithm (MQHOA) (Wang et al. 2018), quantum Runge Kutta algorithm (QRUN) (Abd El-Sattar et al. 2022), quantum salp swarm algorithm (QSSA) (Niazy et al. 2020), quantum chaos game optimizer (QCGO) (Elkasem et al. 2022), Quantum marine predators algorithm (QMPA) (Abd Elaziz et al. 2021), and Quantum Henry gas solubility optimization algorithm (QHGSO) (Mohammadi et al. 2021). Quantum mechanics were employed to improve the PSO algorithm in dos Santos Coelho (2008). In the quantum model, by employing the Monte Carlo method, the solution \(\textrm{Prey }_{i}\) is calculated as follows:
Where \(x_\textrm{best}\) denotes the best solution, \(\alpha \) is a design parameter, u and w represent uniform probability distribution in the range [0,1], h is the random value ranging from 0 to 1. Mbest is the mean best of the population and it is defined as the mean of the \(x_\textrm{best}\) positions and it is calculated as follows:
The flow chart of the proposed IMPA technique is shown in Fig. 3, which showcases the flow chart depicting the revised steps and procedures implemented to enhance the optimization process. This modified approach aims to overcome the limitations or shortcomings of the original algorithm, offering improved performance, convergence, and solution quality. The flow chart serves as a valuable reference to analyze and evaluate the efficacy of the modified algorithm in solving multi-objective optimization problems.
4.1 Description of the proposed algorithm MOIMPA
Based on the mathematical emulation explained above, the swarm behaviors of preys can be simulated clearly. When dealing with multi-objective problems, two issues need to be adjusted for the IMPA algorithm. First, the MOIMPA needs to store multiple solutions as the optimal solutions for a multi-objective problem. Second, in each iteration, IMPA updates the preys source with the best solution, but in the multi-objective problem, single best solutions do not exist. In MOIMPA, the first issue is settled by equipping the IMPA technique with a repository of preys sources. The repository can store a limited number of non-dominated solutions. In the process of optimization, each prey is compared with all the residents in the repository using the Pareto dominance operators. If a prey dominates only one solution in the repository, it will be swapped. If a prey dominates a set of solutions in the repository, they all should be removed from the repository and the prey should be added to the repository. If at least one of the repository residents dominates prey in the new population, it should be discarded straight away. If the prey is non-dominated in comparison with all repository residents, it has to be added to the archive. If the repository becomes full, we need to remove one of the similar non-dominated solutions in the repository. For the second issue, an appropriate way is to select it from a set of non-dominated solutions with the least crowded neighborhood. This can be done using the same ranking process and roulette wheel selection employed in the repository maintenance operator. The pseudo-code of the MOIMPA algorithm is shown in Algorithm 1: The included Algorithm 1 provides a step-by-step framework for the MOIMPA algorithm. Step 1: In this step, the prey positions are updated based on Equ (11). This equation defines the update rule for the prey in the first phase of the algorithm, which occurs during the initial one-third of the maximum iterations.
Step 2 and Step 3: During the second phase of the algorithm (between one-third and two-thirds of the maximum iterations), the prey positions are updated differently for the first half and the other half of the population. Step 2 involves updating the positions of the prey in the first half of the population using Equation (14). Similarly, Step 3 updates the positions of the prey in the other half of the population using Equ (16).
Step 4: In the final phase of the algorithm (when the iteration count exceeds two-thirds of the maximum iterations), the prey positions are updated using Equ (20). This equation defines the update rule for the prey during this phase.
Step 5: Applying the effect of eddy formation and fish aggregation devices (FADs) on the prey positions is done in this step. The positions of the prey are adjusted according to Equ (21), which incorporates the influence of FADs.
Step 6: The prey positions are updated further using Equ (23). This equation specifies the position update rule for the prey, enhancing their exploration and exploitation capabilities.
Step 7: The fitness of the new solution is calculated in this step. The fitness represents the quality or objective value associated with the current solution.
Step 8: Finally, the non-dominated solutions obtained are updated in the archive, ensuring the preservation of the best solutions throughout the iterations.
These step-by-step explanations provide a clear understanding of the work performed and the variables involved at each stage of the MOIMPA algorithm presented in Algorithm 1.

4.2 Performance metrics
With a view to affirm the effectiveness of such a multiobjective algorithm, three main principles must be proved: convergence, distribution, and coverage. On this basis, to compare the MOIMPA reliability and efficiency with other competitive algorithms, four performance indicators were considered such as generation distance (GD) (Van Veldhuizen and Lamont 1998), inverse generation distance (IGD) (Sierra and Coello 2005), spacing (SP) (Schott 1995), and the delta metrics. The IGD and GD indicators are employed to evaluate the approximations to the Pareto front in relation to diversity and convergence. The spacing indicator evaluates the space between the non-dominated solutions (coverage). It is worth noting that the smaller the metric output, the higher the quality of obtained solutions. The mathematical formulations of these metrics are described as follows:
where \(d_{i}\) is the Euclidean distance between the \(i^{th}\) Pareto optimal solution attained and the true Pareto optimal solution in the reference set. \(n_\textrm{pf}\) indicates the obtained Pareto optimal solutions number.
where \(d_{i}^{\prime }\) is the Euclidean distance between the \(i^\textrm{th}\) true Pareto optimal solution and the Pareto optimal solution obtained in the reference set. \(n_\textrm{tpf}\) indicates the number of true Pareto optimal solutions.
where \({\bar{d}}\) is the average of all \(d_{i}\).
5 Experimental results and analysis
To validate the efficiency of the suggested algorithm MOIMPA, a set of test functions with diverse characteristics (various forms of Pareto front) were investigated notably five bi-objective ZDT Zitzler et al. (2000), six three-objective DTLZ (Deb et al. 2002) functions, and the CEC’09 (Zhang et al. 2008) multi-objective problem that contains ten UF functions with bi- and three-objective functions, in addition to the weld beam issue, which is listed in Table 1. Thus, four popular indicator metrics were considered namely: generation distance (GD), spacing (SP), inverse generation distance (IGD), spacing (SP), and the delta metrics as presented in the "Performance Metrics" section. On the other hand, three significant multi-objective optimization algorithms were re-implemented for comparison with a view to affirming the effectiveness of the MOIMPA approach called multiobjective marine predator algorithm (MOMPA) (Jangir et al. 2023), multiobjective ant lion optimization (MOALO) (Mirjalili et al. 2017), and multiobjective multi-verse optimization (MOMVO) (Mirjalili et al. 2017), their control parameters are listed in Table 2. However, these selected parameters are the best in most of the cases in their original papers and are kept as suggested. Thus, for ensuring fair comparison, all multi-objective approaches were executed 20 times and the maximum number of iterations is 300. The detailed settings of the system utilized in this article are presented in Table 3. The outcomes are illustrated qualitatively and quantitatively.
The experimental findings based on the average and standard deviation of the 20 runs are listed in Tables 4, 5, 6 and 7. It is worth noting here that the better approach is the one with the lower metric value, and the optimized solutions were highlighted in boldface. Further, the best Pareto optimal fronts attained were depicted in Figs. 4, 5, 6 and 7. On all twenty benchmark test suites under consideration, the MOIMPA reaches statistically significant values in most case studies. Hence, this proposed approach outstrip all five ZDT test problem, in which, four functions on IGD, three on GD, three on SP, and four on delta out of five functions in total. Besides, the MOIMPA also ranks first in the DTLZ problem on four functions out of five on each IGD, GD, SP, and delta metrics. According to the MOMVO algorithm, it outperforms the MOIMPA on UF benchmark test suites in all indicator metrics except the Spacing one, but it does not show any accuracy in terms of std performance compared to MOIMPA. However, the MOALO and the MOMPA obtained the lowest performance. Additionally, it can be seen from Figs. 4, 5, 6 and 7 that the MOIMPA yields better coverage, convergence, and well spread through the true Pareto front for all case studies. The MOMPA approach also provides a good Pareto front on ZDT except for the ZDT6 function. By contrast, the MOMVO and MOALO competitor approaches show the worst Pareto front. To sum up, the suggested optimizer MOIMPA managed to significantly outperform the competitors even on its multi-objective variant MOMPA, which means that the MOIMPA diversity and convergence are improved. The lowest values of all metrics were obtained by MOIMPA optimizer in almost case studies, it outstrips on 11 cases for IGD, 10 for GD, 13 for SP, and 11 for delta metrics out of 20. These comparison results reveal that both the convergence and coverage of the achieved outcomes by MOIMPA toward the true PF are higher than those obtained by its competing approaches and that the MOIMPA has significant stability.

Comparison of obtained Pareto fronts on ZDT functions


Comparison of obtained Pareto fronts on UF functions

Comparison of obtained Pareto fronts on DTLZ functions

Comparison of obtained Pareto fronts on weld beam function
6 Conclusion
This study has presented a modified version of the marine predators approach (MPA) that incorporates quantum optimization techniques and a multi-objective strategy. While the basic MPA is effective in solving various global and engineering problems, it has certain limitations that affect its optimization process and compromises the balance between exploitation and exploration phases, as well as the convergence towards the global solution. To overcome these limitations, quantum mechanics has been integrated into the MPA. The performance of the NSMRFO approach has been evaluated using various test functions, including ZDT, DTLZ, CEC’09 (Completions on Evolutionary Computation 2009), and several engineering problems, providing a comprehensive assessment from different perspectives. The proposed approach has undergone quantitative evaluation using four performance indicators: inverted generational distance (IGD), spacing metric (SP), generational distance (GD), and delta metric. The evaluation was conducted over 20 runs. Comparative analysis was carried out by comparing the results of the MOIMPA optimizer with other algorithms such as MOMPA, MOALO, and MOMVO. Additionally, various engineering design problems were examined to assess the efficiency of MOIMPA. The results demonstrate that the developed optimizer is more efficient based on the outcomes of the evaluation. In our future work, we plan to extend the application of the proposed algorithm to solve more multi-objective engineering problems. This includes optimizing power flow and economic emission dispatch while considering renewable energy resources. By testing the algorithm on these real-world engineering problems, we aim to validate its effectiveness and practicality in solving complex optimization challenges.
Data availability
Data sharing is not applicable to this article as no new data were created or analyzed in this study.
References
Abd Elaziz M, Mohammadi D, Oliva D, Salimifard K (2021) Quantum marine predators algorithm for addressing multilevel image segmentation. Appl Soft Comput 110:107598. https://doi.org/10.1016/j.asoc.2021.107598
Abd Elaziz M, Ewees AA, Yousri D, Abualigah L, Al-qaness MAA (2022) Modified marine predators algorithm for feature selection: case study metabolomics. Knowl Inf Syst 64(1):261–287. https://doi.org/10.1007/s10115-021-01641-w
Abd El-Sattar H, Kamel S, Hassan MH, Jurado F (2022) Optimal sizing of an off-grid hybrid photovoltaic/biomass gasifier/battery system using a quantum model of Runge Kutta algorithm. Energy Convers Manag 258:115539. https://doi.org/10.1016/j.enconman.2022.115539
Abdel-Basset M, Mohamed R, Abouhawwash M (2022) Hybrid marine predators algorithm for image segmentation: analysis and validations. Artif Intell Rev 55(4):3315–3367. https://doi.org/10.1007/s10462-021-10086-0
Abdel-Basset M, Mohamed R, Azeem SAA, Jameel M, Abouhawwash M (2023) Kepler optimization algorithm: a new metaheuristic algorithm inspired by kepler’s laws of planetary motion. Knowl Based Syst 268:110454. https://doi.org/10.1016/j.knosys.2023.110454
Abdel-Basset M, Mohamed R, Jameel M, Abouhawwash M (2023) Spider wasp optimizer: a novel meta-heuristic optimization algorithm. Artif Intell Rev. https://doi.org/10.1007/s10462-023-10446-y
Abualigah L, Al-Okbi NK, Elaziz MA, Houssein EH (2022) Boosting marine predators algorithm by salp swarm algorithm for multilevel thresholding image segmentation. Multimed Tools Appl 81(12):16707–16742. https://doi.org/10.1007/s11042-022-12001-3
Al-qaness MA, Ewees AA, Fan H, Abualigah L, Elaziz MA (2022) Boosted ANFIS model using augmented marine predator algorithm with mutation operators for wind power forecasting. Appl Energy 314:118851. https://doi.org/10.1016/j.apenergy.2022.118851
Andersson J (2000) A survey of multiobjective optimization in engineering design
Aydemir SB, Kutlu Onay F (2023) Marine predator algorithm with elite strategies for engineering design problems. Concurr Comput Pract Exp 35(7):e7612. https://doi.org/10.1002/cpe.7612
Benioff P (1980) The computer as a physical system: a microscopic quantum mechanical Hamiltonian model of computers as represented by turing machines. J Statistical Phys 22(5):563–591. https://doi.org/10.1007/BF01011339
Branke J, Kaußler T, Schmeck H (2001) Guidance in evolutionary multi-objective optimization. Adv Eng Softw 32(6):499–507. https://doi.org/10.1016/S0965-9978(00)00110-1
Chou J-S, Truong D-N (2022) Multiobjective forensic-based investigation algorithm for solving structural design problems. Autom Constr 134:104084. https://doi.org/10.1016/j.autcon.2021.104084
Coello C Carlos A, Gary LB, David VVA (2002) Evolutionary algorithms for solving multiobjective problems 623–800 https://doi.org/10.1007/978-0-387-36797-2
Coello Coello CA (2009) Evolutionary multi-objective optimization: some current research trends and topics that remain to be explored. Front Comput Sci China 3(1):18–30. https://doi.org/10.1007/s11704-009-0005-7
Coello C, Pulido G, Lechuga M (2004) Handling multiple objectives with particle swarm optimization. IEEE Trans Evolut Comput 8(3):256–279. https://doi.org/10.1109/TEVC.2004.826067
D’Angelo G, Palmieri F, Robustelli A (2022) Artificial neural networks for resources optimization in energetic environment. Soft Comput 26(4):1779–1792. https://doi.org/10.1007/s00500-022-06757-x
D’Angelo G, Della-Morte D, Pastore D, Donadel G, De Stefano A, Palmieri F (2023) Identifying patterns in multiple biomarkers to diagnose diabetic foot using an explainable genetic programming-based approach. Future Gener Comput Syst 140:138–150. https://doi.org/10.1016/j.future.2022.10.019
Daqaq F, Ouassaid M, Ellaia R (2021) A new meta-heuristic programming for multi-objective optimal power flow. Electric Eng 103(2):1217–1237. https://doi.org/10.1007/s00202-020-01173-6
Daqaq F, Kamel S, Ouassaid M, Ellaia R, Agwa AM (2022) Non-dominated sorting manta ray foraging optimization for multi-objective optimal power flow with wind/solar/small- hydro energy sources. Fractal Fract 6(4):194. https://doi.org/10.3390/fractalfract6040194
Das AK, Nikum AK, Krishnan SV, Pratihar DK (2020) Multi-objective bonobo optimizer (mobo): an intelligent heuristic for multi-criteria optimization. Knowl Inf Syst 62(11):4407–4444. https://doi.org/10.1007/s10115-020-01503-x
Deb K, Thiele L, Laumanns M, Zitzler E (2002) Scalable multi-objective optimization test problems vol 1, pp. 825–830. https://doi.org/10.1109/CEC.2002.1007032
Dinh P-H (2022) An improved medical image synthesis approach based on marine predators algorithm and maximum gabor energy. Neural Comput Appl 34(6):4367–4385. https://doi.org/10.1007/s00521-021-06577-4
dos Santos Coelho L (2008) A quantum particle swarm optimizer with chaotic mutation operator. Chaos Solitons Fractals 37(5):1409–1418. https://doi.org/10.1016/j.chaos.2006.10.028
Duman S, Akbel M, Kahraman HT (2021) Development of the multi-objective adaptive guided differential evolution and optimization of the mo-acopf for wind/pv/tidal energy sources. Appl Soft Comput 112:107814. https://doi.org/10.1016/j.asoc.2021.107814
Elkasem AH, Khamies M, Hassan MH, Agwa AM, Kamel S (2022) Optimal design of TD-TI controller for LFC considering renewables penetration by an improved chaos game optimizer. Fractal Fract 6(4):220. https://doi.org/10.3390/fractalfract6040220
Faramarzi A, Heidarinejad M, Mirjalili S, Gandomi AH (2020) Marine predators algorithm: a nature-inspired metaheuristic. Expert Syst Appl 152:113377. https://doi.org/10.1016/j.eswa.2020.113377
Ferahtia S, Rezk H, Djerioui A, Houari A, Fathy A, Abdelkareem MA, Olabi A (2022) Optimal heuristic economic management strategy for microgrids based PEM fuel cells. Int J Hydrog Energy. https://doi.org/10.1016/j.ijhydene.2022.02.231
Feynman RP (1986) Quantum mechanical computers. Found Phys 16(6):507–531. https://doi.org/10.1007/BF01886518
Habib Khan N, Jamal R, Ebeed M, Kamel S, Zeinoddini-Meymand H, Zawbaa HM (2022) Adopting scenario-based approach to solve optimal reactive power dispatch problem with integration of wind and solar energy using improved marine predator algorithm. Ain Shams Eng J 13(5):101726. https://doi.org/10.1016/j.asej.2022.101726
Han K-H, Kim J-H (2002) Quantum-inspired evolutionary algorithm for a class of combinatorial optimization. IEEE Trans Evolut Comput 6(6):580–593. https://doi.org/10.1109/TEVC.2002.804320
Hassan MH, Yousri D, Kamel S, Rahmann C (2022) A modified marine predators algorithm for solving single- and multi-objective combined economic emission dispatch problems. Comput Ind Eng 164:107906. https://doi.org/10.1016/j.cie.2021.107906
Holland JH (1975) Adaptation in natural and artificial systems: an introductory analysis with applications to biology, control, and artificial intelligence. U Michigan Press, Michigan
Houssein EH, Mahdy MA, Fathy A, Rezk H (2021) A modified marine predator algorithm based on opposition based learning for tracking the global MPP of shaded PV system. Expert Syst Appl 183:115253. https://doi.org/10.1016/j.eswa.2021.115253
Jangir P, Heidari AA, Chen H (2021) Elitist non-dominated sorting harris hawks optimization: framework and developments for multi-objective problems. Expert Syst Appl 186:115747. https://doi.org/10.1016/j.eswa.2021.115747
Jangir P, Buch H, Mirjalili S, Manoharan P (2023) Mompa: multi-objective marine predator algorithm for solving multi-objective optimization problems. Evolut Intell 16(1):169–195. https://doi.org/10.1007/s12065-021-00649-z
Kaplan J (1979) Jayorke in chaotic behavior of multidimensional difference equations. Springer-Verlag, Berlin, pp 204–227
Karaboga D, Basturk B (2007) A powerful and efficient algorithm for numerical function optimization: artificial bee colony (abc) algorithm. J Global Optim 39(3):459–471. https://doi.org/10.1007/s10898-007-9149-x
Kennedy J, Eberhart R (1995) Particle swarm optimization vol 4, pp 1942–1948. https://doi.org/10.1109/ICNN.1995.488968
Kim I, de Weck O (2005) Adaptive weighted-sum method for bi-objective optimization: pareto front generation. Struct Multidiscip Optim 29(2):149–158. https://doi.org/10.1007/s00158-004-0465-1
Kirkpatrick S, Gelatt CD, Vecchi MP (1983) Optimization by simulated annealing. Science 220(4598):671–680. https://doi.org/10.1126/science.220.4598.671
Kumar S, Jangir P, Tejani GG, Premkumar M (2022) Moteo: a novel physics-based multiobjective thermal exchange optimization algorithm to design truss structures. Knowl Based Syst 242:108422. https://doi.org/10.1016/j.knosys.2022.108422
Liu F-B (2012) Inverse estimation of wall heat flux by using particle swarm optimization algorithm with gaussian mutation. Int J Therm Sci 54:62–69. https://doi.org/10.1016/j.ijthermalsci.2011.11.013
Mirjalili S, Jangir P, Saremi S (2017) Multi-objective ant lion optimizer: a multi-objective optimization algorithm for solving engineering problems. Appl Intell 46(1):79–95. https://doi.org/10.1007/s10489-016-0825-8
Mirjalili S, Jangir P, Mirjalili SZ, Saremi S, Trivedi IN (2017) Optimization of problems with multiple objectives using the multi-verse optimization algorithm. Knowl Based Syst 134:50–71. https://doi.org/10.1016/j.knosys.2017.07.018
Mohammad Hasani Zade B, Mansouri N (2022) Ppo: a new nature-inspired metaheuristic algorithm based on predation for optimization. Soft Comput 26(3):1402. https://doi.org/10.1007/s00500-021-06404-x
Mohammadi D, Abd Elaziz M, Moghdani R, Demir E, Mirjalili S (2021) Quantum henry gas solubility optimization algorithm for global optimization. Eng Comput. https://doi.org/10.1007/s00366-021-01347-1
Naik A, Satapathy SC (2021) Past present future: a new human-based algorithm for stochastic optimization. Soft Comput 12915–12976(25):20. https://doi.org/10.1007/s00500-021-06229-8
Niazy N, El-Sawy A, Gadallah M (2020) A hybrid chicken swarm optimization with tabu search algorithm for solving capacitated vehicle routing problem. Int J Intell Eng Syst 13(4):237–247. https://doi.org/10.22266/IJIES2019.1231.22
Pan J-S, Shan J, Chu S-C, Jiang S-J, Zheng S-G, Liao L (2022) A multigroup marine predator algorithm and its application for the power system economic load dispatch. Energy Sci Eng 10(6):1840–1854. https://doi.org/10.1002/ese3.957
Pareto V (1964) Cours d’economie politique. Librairie droz
Premkumar M, Jangir P, Sowmya R, Alhelou HH, Heidari AA, Chen H (2021) Mosma: multi-objective slime mould algorithm based on elitist non-dominated sorting. IEEE Access 9:3229–3248. https://doi.org/10.1109/ACCESS.2020.3047936
Reddy R, Kulkarni AJ, Krishnasamy G, Shastri AS, Gandomi AH (2023) Lab: a leader-advocate-believer-based optimization algorithm. Soft Comput 27(11):7209–7243. https://doi.org/10.1007/s00500-023-08033-y
Schott J. (1995) Fault tolerant design using single and multicriteria genetic algorithm optimization, dtic document
Shehadeh HA (2023) Chernobyl disaster optimizer (cdo): a novel meta-heuristic method for global optimization. Neural Comput Appl 35(15):10733–10749. https://doi.org/10.1007/s00521-023-08261-1
Shin WS, Ravindran A (1991) Interactive multiple objective optimization: survey i-continuous case. Comput Oper Res 18(1):97–114. https://doi.org/10.1016/0305-0548(91)90046-T
Sierra MR, Coello Coello CA (2005) Improving pso-based multi-objective optimization using crowding, mutation and \(\in \)-dominance pp. 505–519 https://doi.org/10.1007/978-3-540-31880-4_35
Srinivas N, Deb K (1994) Multiobjective optimization using nondominated sorting in genetic algorithms. Evolut Comput 2(3):221–248. https://doi.org/10.1162/evco.1994.2.3.221
Su H, Zhao D, Heidari AA, Liu L, Zhang X, Mafarja M, Chen H (2023) Rime: a physics-based optimization. Neurocomputing 532:183–214. https://doi.org/10.1016/j.neucom.2023.02.010
Sun C-J, Gao F (2021) A tent marine predators algorithm with estimation distribution algorithm and gaussian random walk for continuous optimization problems. Comput Intell Neurosci 2021:7695596. https://doi.org/10.1155/2021/7695596
Tizhoosh H (2005) Opposition-based learning: a new scheme for machine intelligence vol 1, pp. 695–701. https://doi.org/10.1109/CIMCA.2005.1631345
Trojovský P, Dehghani M, Hanuš P (2022) Siberian tiger optimization: a new bio-inspired metaheuristic algorithm for solving engineering optimization problems. IEEE Access 10:132396–132431. https://doi.org/10.1109/ACCESS.2022.3229964
Van Veldhuizen DA, Lamont GB (1998) Multi-objective evolutionary algorithm research: A history and analysis, Evolutionary Computation 8(2)
Viswanathan GM, Afanasyev V, Buldyrev SV, Murphy EJ, Prince PA, Stanley HE (1996) Lévy flight search patterns of wandering albatrosses. Nature 381(6581):413–415. https://doi.org/10.1038/381413a0
Vlachogiannis JG, Østergaard J (2009) Reactive power and voltage control based on general quantum genetic algorithms. Expert Syst Appl 36(3):6118–6126. https://doi.org/10.1016/j.eswa.2008.07.070
Wang P, Cheng K, Huang Y, Li B, Ye X, Chen X (2018) Multiscale quantum harmonic oscillator algorithm for multimodal optimization. Comput Intell Neurosci. https://doi.org/10.1155/2018/8430175
Wang J, Guo H, Li Z, Song A, Niu X (2023) Quantile deep learning model and multi-objective opposition elite marine predator optimization algorithm for wind speed prediction. Appl Math Modell 115:56–79. https://doi.org/10.1016/j.apm.2022.10.052
Wolpert D, Macready W (1997) No free lunch theorems for optimization. IEEE Trans Evolut Comput 1(1):67–82. https://doi.org/10.1109/4235.585893
Yousri D, Ousama A, shaker Y, Fathy A, Babu TS, rezk H, Allam D (2022) Managing the exchange of energy between microgrid elements based on multi-objective enhanced marine predators algorithm. Alex Eng J 61(11):8487–8505. https://doi.org/10.1016/j.aej.2022.02.008
Zhang Q, Li H (2007) Moea/d: a multiobjective evolutionary algorithm based on decomposition. IEEE Trans Evolut Comput 11(6):712–731. https://doi.org/10.1109/TEVC.2007.892759
Zhang Q, Wang R, Yang J, Lewis A, Chiclana F, Yang S (2019) Biology migration algorithm: a new nature-inspired heuristic methodology for global optimization. Soft Comput 23(16):7333–7358. https://doi.org/10.1007/s00500-018-3381-9
Zhang Q, Zhou A, Zhao S, Suganthan PN, Liu W, Tiwari S (2008) Multiobjective optimization test instances for the CEC 2009 special session and competition
Zitzler E, Thiele L (1999) Multiobjective evolutionary algorithms: a comparative case study and the strength pareto approach. IEEE Trans Evolut Comput 3(4):257–271. https://doi.org/10.1109/4235.797969
Zitzler E, Deb K, Thiele L (2000) Comparison of multiobjective evolutionary algorithms: empirical results. Evolut Comput 8(2):173–195. https://doi.org/10.1162/106365600568202
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Contributions
MHH: Conceptualization, Methodology, Software. FD: Conceptualization, Methodology, Writing Original draft preparation. AS: Data curation, Writing–Original draft preparation. JLD-G: Visualization, Writing Original draft preparation, Investigation. SK: Conceptualization, Software, Writing–Reviewing and Editing.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no conflict of interest regarding the publication of this manuscript.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Informed Consent
Not Applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hassan, M.H., Daqaq, F., Selim, A. et al. MOIMPA: multi-objective improved marine predators algorithm for solving multi-objective optimization problems. Soft Comput 27, 15719–15740 (2023). https://doi.org/10.1007/s00500-023-08812-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-023-08812-7