
Abstract
We study a discrete-time Markov process on triangular arrays of matrices of size \(d\ge 1\), driven by inverse Wishart random matrices. The components of the right edge evolve as multiplicative random walks on positive definite matrices with one-sided interactions and can be viewed as a d-dimensional generalisation of log-gamma polymer partition functions. We establish intertwining relations to prove that, for suitable initial configurations of the triangular process, the bottom edge has an autonomous Markovian evolution with an explicit transition kernel. We then show that, for a special singular initial configuration, the fixed-time law of the bottom edge is a matrix Whittaker measure, which we define. To achieve this, we perform a Laplace approximation that requires solving a constrained minimisation problem for certain energy functions of matrix arguments on directed graphs.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In the last few decades, we have witnessed a surge of research on stochastic integrable models, often motivated by problems in mathematical physics and enriched by deep connections with algebraic combinatorics, representation theory, symmetric functions, and integrable systems [9, 10]. Some of the most intensively studied models are interacting particle systems and stochastic growth processes in the Kardar–Parisi–Zhang (KPZ) universality class [15, 45].
From a mathematical perspective, it is natural to consider noncommutative versions of these models, which have very recently received some attention. In [33] a system of interacting Brownian particles in the space of positive definite matrices was considered and shown to have an integrable structure, related to the non-Abelian Toda chain and Whittaker functions of matrix arguments (the latter introduced in that article). In the discrete-time setting, [1] proved Matsumoto-Yor and Dufresne type theorems for a random walk on positive definite matrices.
On the other hand, from the theoretical physics point of view, such matrix models may find interesting applications in quantum stochastic dynamics, as set out in [20]. In particular, [20] introduced a matrix generalisation of the classical Kesten recursion and studied a related quantum problem of interacting fermions in a Morse potential. Quoting the authors, their initial motivation was “to explore possible matrix (non-commuting) generalizations of the famous directed polymer problem (which is related to the KPZ stochastic growth equation)”.
The subject of the present article is an integrable model of random walks on positive definite matrices with local interactions. This constitutes, on the one hand, a discrete-time analogue of the matrix-valued interacting diffusions studied in [33] and, on the other hand, a matrix generalisation of the log-gamma polymer model.
To motivate the contributions of this article, let us first define a discrete-time exclusion process \(\mathcal {Z}\) of \(N\ge 1\) ordered particles \(\mathcal {Z}^1\le \mathcal {Z}^2 \le \dots \le \mathcal {Z}^N\) on \(\mathbb {Z}\) moving to the right. Let \((\mathcal {V}^1(n), \dots , \mathcal {V}^N(n))_{n\ge 1}\) be a collection of independent random variables supported on \(\mathbb {Z}_{\ge 0}\). At each time n, the particle positions are updated sequentially from the 1-st one to the Nth one, as follows. The 1-st particle simply evolves as a random walk on \(\mathbb {Z}\) with time-n increment \(\mathcal {V}^1(n)\). Once the positions of the first \(i-1\) particles have been updated, if the \((i-1)\)th particle has overtaken the ith particle, then the latter is pushed forward to a temporary position to maintain the ordering; next, to complete its update, the ith particle takes \(\mathcal {V}^i(n)\) unit jumps to the right. The particle locations then satisfy the recursive relations
If one considers the initial state
then the following last passage percolation formula holds:
where the maximum is over all directed lattice paths \(\pi \) in \(\mathbb {Z}^2\) (i.e., at each lattice site (m, k), \(\pi \) is allowed to head either rightwards to \((m+1,k)\) or upwards to \((m,k+1)\)) that start from (1, 1) and end at (n, i). As a process of last passage percolation times, \(\mathcal {Z}\) can be also associated with the corner growth process with step (or ‘narrow wedge’) initial configuration. Remarkable integrable versions of this model are those with geometrically and exponentially distributed jumps, first studied in [24].
A positive temperature version of \(\mathcal {Z}\) can be obtained by formally replacing the operations \((\max ,+)\) with \((+,\times )\) in the relations (1.1)–(1.2). Namely, given a collection of independent positive random variables \((V^1(n), \dots , V^N(n))_{n\ge 1}\), we can consider the discrete-time Markov process Z defined by
Considering the initial configuration
we have the closed-form expression
where the sum is over all directed lattice paths \(\pi \) in \(\mathbb {Z}^2\) from (1, 1) to (n, i). The variables (1.7) can be regarded as partition functions of the \((1+1)\)-dimensional directed polymer, an intensively studied model of statistical mechanics. Of particular importance is the model with inverse gamma distributed weights \(V^i(n)\), known as the log-gamma polymer, first considered in [39]. In [16] it was shown that the laws of log-gamma polymer partition functions are marginals of Whittaker measures; the latter are defined in terms of \(\textrm{GL}_d(\mathbb {R})\)-Whittaker functions and were introduced in that article.
In this article, we study a noncommutative generalisation of the above Markov process of log-gamma polymer partition functions. The ‘particles’ of this process live in \(\mathcal {P}_d\), the set of \(d\times d\) positive definite real symmetric matrices. The random weights \(V^i(n)\) are now independent inverse Wishart matrices (a matrix generalisation of inverse gamma random variables; see Sect. 1.2). We define Z by setting
where, for \(a\in \mathcal {P}_d\), \(a^{1/2}\) denotes the unique \(b\in \mathcal {P}_d\) such that \(b^2=a\). The above matrix products are symmetrised to ensure that, starting from any initial configuration \(Z^i(0)\in \mathcal {P}_d\), each \(Z^i(n)\) still belongs to \(\mathcal {P}_d\) for all \(n\ge 1\). The 1-st particle (1.8) evolves as a (\(\textrm{GL}_d\)-invariant) multiplicative random walk on \(\mathcal {P}_d\); on the other hand, the other particles (1.9) can be viewed as analogous random walks with one-sided interactions. From this point of view, the Markov process as a whole can be also regarded as a noncommutative version of the exclusion process \(\mathcal {Z}\) defined in (1.1)–(1.2). The natural generalisation of the initial configuration (1.6) is
where \(I_d\) and \(0_d\) are the \(d\times d\) identity and zero matrices, respectively. Notice that, although all but the first particle are initially zero, the process Z starting from (1.10) lives in \(\mathcal {P}_d^N\) at all times \(n\ge 1\).

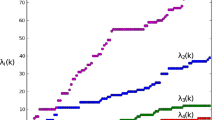
Graphical representation of a ’triangular’ array \(x\in \mathcal {T}^{N}_{d}\) as in (2.1), for \(N=4\). Each row \(x^i\), \(1\le i\le N\), consists of the matrices \((x^i_1,\dots ,x^i_i)\), read from right to left. The arrows refer to the energy function \(\Phi ^N(x)\) in (2.3), where every summand \({{\,\textrm{tr}\,}}[ab^{-1}]\) corresponds to an arrow pointing from a to b in the figure
In Sect. 3, we introduce a Markov process \(X{=}(X(n))_{n{\ge } 0}\), \(X(n) {=} (X^i_j(n))_{1{\le } j{\le } i{\le } N}\), on triangular arrays of positive definite matrices whose ‘right edge’, namely \((X^1_1,\dots ,X^N_1)\), equals Z. The evolution of X may be viewed as a noncommutative version of the dynamics on Gelfand-Tsetlin patterns with blocking and pushing interactions, studied in various contexts in [7, 8, 11, 31, 43, 44]. We refer to Fig. 1 for a graphical representation of such a triangular array. Moreover, as we detail in Remark 3.4, the ‘left edge’ of X may be regarded as a noncommutative generalisation of the strict-weak polymer studied in [17, 34].
The first main result of this article (Theorem 3.10) states that, for certain special (random) initial configurations X(0), the ‘bottom edge’ \(X^N = (X^N_1,\dots ,X^N_N)\) of X also has an autonomous Markovian evolution. The transition kernel of \(X^N\) is explicit and has an interpretation as a Doob \( h \)-transform with \( h \)-function given by a Whittaker function of matrix arguments. To obtain this, we prove certain intertwining relations between kernels associated to the process X and use the theory of Markov functions (reviewed in Appendix B). Another consequence of these intertwinings is that Whittaker functions are eigenfunctions of certain integral operators and possess a Feynman–Kac type interpretation.
Next, in Sect. 4, we define matrix Whittaker measures on \(\mathcal {P}_d^N\) after proving an integral identity of Whittaker functions of matrix arguments (Theorem 4.1), analogous to the well-known Cauchy–Littlewood identity for Schur functions. The second main result of this article (Theorem 4.8) states that, for a special initial state, the fixed-time law of the bottom edge \(X^N\) of X is a matrix Whittaker measure on \(\mathcal {P}_d^N\). Such an initial state, designed to match (1.10), is singular, in the sense that the particles are at the ‘boundary’ of \(\mathcal {P}_d\).
Due to the singularity of the initial configuration, the proof of Theorem 4.8 will be based on a suitable limiting procedure and a careful integral approximation via Laplace’s method. This will require a digression on a constrained minimisation problem for certain energy functions of matrix arguments. We chose to include this analysis in a separate section and to present it in the more general framework of directed graphs, as it may be of independent interest; see Sect. 5. For us, the main application will be the asymptotic formula (4.8) for Whittaker functions of matrix arguments.
From our main results we deduce (see Corollary 4.10) that, under the initial configuration (1.10), the particles of the process Z defined in (1.8)–(1.9) have a fixed-time law given by the first marginal of a matrix Whittaker measure on \(\mathcal {P}_d^N\). In the scalar \(d=1\) case, we recover the aforementioned result of [16] for the law of the log-gamma polymer partition functions. In Corollary 4.10, we also obtain an analogous result concerning the fixed-time law of the ‘left edge’ of the triangular array X.
It is worth mentioning that the log-gamma polymer partition functions (1.7) were also studied in [16] as embedded in a dynamic on triangular arrays. However, such a dynamic was constructed via the combinatorial mechanism of the geometric Robinson–Schensted–Knuth correspondence; in particular, at each time step, the right edge is updated using N new (independent) random variables, whereas all the other components are updated via deterministic transformations of the current state and the newly updated right edge. It turns out that, for \(d=1\), the processes considered in [16] and in the present article have an identical right edge and, under the special initial configuration of Theorem 3.10, also a bottom edge process with the same Markovian evolution. However, even in the \(d=1\) case, the two processes, as a whole, differ. The dynamic introduced in this article is driven by random updates with \(N(N+1)/2\) degrees of freedom, since each particle of the triangular array is driven by an independent source of randomness (as well as by local interactions with the other particles).
1.1 Organisation of the article
In Sect. 2, we define Whittaker functions of matrix arguments. In Sect. 3, we introduce a Markov dynamic on triangular arrays of matrices and study the evolution of its bottom edge, using the theory of Markov functions; we also obtain a Feynman–Kac interpretation of Whittaker functions. In Sect. 4, we define matrix Whittaker measures (through a Whittaker integral identity) and prove that they naturally arise as fixed-time laws in the aforementioned triangular process under a singular initial configuration. To do so, we need a Laplace approximation of Whittaker functions, which can be justified by solving a constrained minimisation problem for certain energy functions of matrix arguments on directed graphs: this is the content of Sect. 5. In Appendix A, we give a proof of the Cauchy–Littlewood identity for Schur functions that resembles our proof of the Whittaker integral identity. In Appendix B, we review the theory of Markov functions for inhomogeneous discrete-time Markov processes. Finally, in Appendix C, we prove a convergence lemma related to weak convergence of probability measures.
1.2 Notation and preliminary notions
Here we introduce some notation and preliminary notions that we use throughout this work. For background and proofs, we refer to [23, 42].
1.2.1 Positive definite matrices
Let \(\mathcal {P}_d\) be the set of all \(d\times d\) positive definite matrices, i.e. \(d\times d\) real symmetric matrices with positive eigenvalues. Throughout this article, for \(x\in \mathcal {P}_d\), we denote by \(\left|x\right|\) the determinant of x and by \({{\,\textrm{tr}\,}}[x]\) its trace.
The following properties hold:
-
\(x\in \mathcal {P}_d\) if and only if \(x^{-1} \in \mathcal {P}_d\);
-
if \(x\in \mathcal {P}_d\) and \(\lambda >0\), then \(\lambda x \in \mathcal {P}_d\);
-
if \(x,y\in \mathcal {P}_d\), then \(x+y\in \mathcal {P}_d\) (but in general \(xy\notin \mathcal {P}_d\));
-
\(x-y\in \mathcal {P}_d\) if and only if \(y^{-1} - x^{-1} \in \mathcal {P}_d\).
For \(x\in \mathcal {P}_d\), there exists a unique \(y\in \mathcal {P}_d\) such that \(y^2 = x\); we denote such a y by \(x^{1/2}\).
For any \(y\in \mathcal {P}_d\), we define the (noncommutative) ‘multiplication operation’ by y as
Such a symmetrised product will be used to construct a multiplicative random walk on \(\mathcal {P}_d\) (see Definition 3.1 and Remark 3.2 below).
We also denote by \(I_d\) and \(0_d\) the \(d\times d\) identity matrix and zero matrix, respectively.
1.2.2 Measure and integration on \(\mathcal {P}_d\)
Let \(\textrm{GL}_d\) be the group of \(d\times d\) invertible real matrices. Define the measure \(\mu \) on \(\mathcal {P}_d\) by
where \(\mathop {}\!\textrm{d}x_{i,j}\) is the Lebesgue measure on \(\mathbb {R}\) in the variable \(x_{i,j}\). Such a measure is the \(\textrm{GL}_d\)-invariant measure on \(\mathcal {P}_d\), in the sense that
for all \(a\in \textrm{GL}_d\) and for all suitable functions f. In other words, \(\mu \) is invariant under the group action of \(\textrm{GL}_d\) on \(\mathcal {P}_d\)
Furthermore, the measure \(\mu \) is preserved under the involution \(x\mapsto x^{-1}\).
1.2.3 Wishart distributions and gamma functions
For \(\alpha > \frac{d-1}{2}\), we will refer to the (d-variate) Wishart distribution with parameter \(\alpha \) as the probability measure
on \(\mathcal {P}_d\), where \(\Gamma _{d}(\alpha )\) is the d-variate gamma function, i.e.
The inverse of a Wishart matrix with parameter \(\alpha \) has the distribution
on \(\mathcal {P}_d\). We will refer to the latter as the (d-variate) inverse Wishart distribution with parameter \(\alpha \).
1.2.4 Kernels and integral operators
Let \((S, \mathcal {S})\) and \((T, \mathcal {T})\) be two measurable spaces. Let \(\mathfrak {m} {\mathcal {S}}\) denote the set of complex-valued measurable functions on \((S, \mathcal {S})\). For our purposes, a kernel from T to S will be a map \(L :T\times \mathcal {S}\rightarrow \mathbb {C}\) such that, for each \(t\in T\), \(L(t;\cdot )\) is a (complex) measure on \((S,\mathcal {S})\) and, for each \(A\in \mathcal {S}\), \(L(\cdot ; A)\) is an element of \(\mathfrak {m} {\mathcal {T}}\). The kernel L can be also, alternatively, thought of as an integral operator
whenever the integral is well defined. Clearly, the composition of kernels/operators yields another kernel/operator; such a composition is associative but, in general, not commutative. When the complex measure \(L(t; \cdot )\) is a probability measure for all \(t\in T\), we will talk about Markov kernels/operators.
Throughout this article, the measurable spaces will be usually Cartesian powers of \(\mathcal {P}_d\) (which we denote by \(\mathcal {P}_d^k\), \(k\ge 1\)), with their Borel sigma-algebras. Moreover, for a kernel L from \(\mathcal {P}_d^k\) to \(\mathcal {P}_d^\ell \), the measure \(L(t; \cdot )\) will be, in most cases, absolutely continuous with respect to the reference product measure \(\mu ^{\otimes \ell }\) on \(\mathcal {P}_d^\ell \), for any \(t\in \mathcal {P}_d^k\); with a little abuse of notation, we will then also write \(s\mapsto L(t;s)\) for the corresponding density (a measurable function on \(\mathcal {P}_d^\ell \)).
2 Whittaker functions
In this section we define Whittaker functions of matrix arguments following [33], and then extend them to a further level of generality. Notice also that the kernels (2.8) and (2.15) defined below are matrix versions of certain kernels defined in [16, Sect. 3.1] and [35, Sect. 2] (see also references therein).
2.1 Whittaker functions of matrix arguments
We define Whittaker functions of matrix arguments as integrals over ‘triangular arrays’ of \(d\times d\) positive definite matrices. For \(N\ge 1\), denote by \(\mathcal {T}^{N}_{d}:= \mathcal {P}_d \times \mathcal {P}_d^2 \times \dots \times \mathcal {P}_d^{N}\) the set of height-N triangular arrays
where \(x^i=(x^i_1, \dots , x^i_i)\in \mathcal {P}_d^i\) will be referred to as the ith row of x, for \(1\le i\le N\). For \(\lambda =(\lambda _1,\dots ,\lambda _N) \in \mathbb {C}^N\) and \(x\in \mathcal {T}^{N}_{d}\), let
For a graphical representation of the array (2.1) and of the ‘energy function’ \(\Phi ^N\), see Fig. 1. For \(z=(z_1,\dots ,z_N)\in \mathcal {P}_d^N\), let \(\mathcal {T}^{N}_{d}(z) \subset \mathcal {T}^{N}_{d}\) be the set of all height-N triangular arrays x with Nth row \(x^N = z\). We define the Whittaker function \(\psi ^N_{\lambda }(z)\) with argument \(z\in \mathcal {P}_d^N\) and parameter \(\lambda \in \mathbb {C}^N\) as
Notice that, for \(N=1\), the expression above reduces to \(\psi ^1_{\lambda }(z) = \left|z\right|^{-\lambda }\). As proved in [33], the integral (2.4) is absolutely convergent for all \(\lambda \in \mathbb {C}^N\), so that Whittaker functions are well defined.
For our purposes, it is convenient to rewrite Whittaker functions in terms of certain kernels that we now introduce. For \(N\ge 1\), \(\lambda \in \mathbb {C}^N\) and \(x\in \mathcal {T}^{N}_{d}\), define the kernel
where, as always from now on, i : j denotes the tuple \((i,i+1,\dots ,j-1, j)\) for \(i\le j\), so that \(x^{1:(N-1)}\in \mathcal {T}^{N-1}_{d}\) is the triangular array consisting of the first \(N-1\) rows of x. Notice that, for \(N=1\), (2.5) reduces to \(\Sigma ^1_{\lambda }(z; \varnothing ) = \left|z\right|^{-\lambda }=\psi ^1_{\lambda }(z)\). For \(z\in \mathcal {P}_d^N\), let us also define the kernel
where \(\delta \) is the Dirac delta kernel on \(\mathcal {P}_d^N\). Then, the Whittaker function (2.4) can be written as
Moreover, for \(N\ge 2\), \(b\in \mathbb {C}\), \(z=(z_1,\dots ,z_N)\in \mathcal {P}_d^N\), and \(y=(y_1,\dots ,y_{N-1}) \in \mathcal {P}_d^{N-1}\), let
We will usually regard (2.8) as a kernel by setting \(K^N_b(z;\mathop {}\!\textrm{d}y):= K^N_b(z;y) \mu ^{\otimes (N-1)}(\mathop {}\!\textrm{d}y)\). We then have, for \(\lambda \in \mathbb {C}^N\), \(z\in \mathcal {P}_d^N\), and \(x\in \mathcal {T}^{N-1}_{d}\),
This yields a recursive definition of Whittaker functions:
2.2 A generalisation of Whittaker functions
We now introduce a generalisation of Whittaker functions of matrix arguments, which will naturally emerge in Sect. 4.3 and, in the scalar case \(d=1\), corresponds to the one considered in [35]. These generalised Whittaker functions are integrals over trapezoidal arrays of positive definite matrices, similarly to how the Whittaker functions of Sect. 2.1 are defined as integrals over triangular arrays.
Let \(n\ge N\ge 1\) and denote by
the set of trapezoidal arrays
with ith row \(x^i=(x^i_1, \dots , x^i_{i \wedge N})\in \mathcal {P}_d^{i \wedge N}\), for \(1\le i\le n\) (here \(i \wedge N\) denotes the minimum between i and N). For \(\lambda \in \mathbb {C}^n\), \(x\in \mathcal {T}^{N,n}_{d}\) and \(s\in \mathcal {P}_d\), let

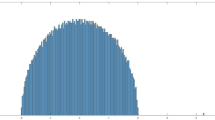
Graphical representation of a trapezoidal array \(x\in \mathcal {T}^{N,n}_{d}\) as in (2.11), for \(N=3\) and \(n=5\). The additional variable s appears in the definition (2.13) of the energy function \(\Phi ^{N,n}_s(x)\), in which every summand \({{\,\textrm{tr}\,}}[ab^{-1}]\) corresponds to an arrow pointing from a to b in the figure
See Fig. 2 for a graphical representation of the array (2.11) and of the energy function \(\Phi ^{N,n}_s\). For \(z\in \mathcal {P}_d^N\), let \(\mathcal {T}^{N,n}_{d}(z) \subset \mathcal {T}^{N,n}_{d}\) be the set of all trapezoidal arrays x with nth row \(x^n = z\). For \(n\ge N\), \(\lambda \in \mathbb {C}^n\), \(s\in \mathcal {P}_d\) and \(z\in \mathcal {P}_d^N\), we define
Notice that, if \(s=0_d\) and \(n=N\), \(\psi ^{N,N}_{\lambda ;0}= \psi ^N_{\lambda }\) corresponds to the Whittaker function defined in (2.4). The absolute convergence of the integral in (2.14), for all \(\lambda \in \mathbb {C}^n\), can be shown by adapting the proof of [33, Prop. 6-(i)].
Let us now give an equivalent representation of these generalised Whittaker functions. The following kernel will play a central role in this work. For \(a\in \mathbb {C}\) and \(z,\tilde{z}\in \mathcal {P}_d^N\), set
We will see \(P^N_{a}(z;\tilde{z})\) as a measure in either of the two arguments, defining

We then have

We also record here two relations between the kernels (2.8) and (2.15), which follow directly from the definitions:
for \(y=(y_1,\dots ,y_{N-1})\in \mathcal {P}_d^{N-1}\), \(s\in \mathcal {P}_d\), and \(z=(z_1,\dots ,z_N) \in \mathcal {P}_d^N\). Taking \(a=\lambda _N\) in (2.19), multiplying both sides by \(\psi ^{N-1}_{(\lambda _1,\dots ,\lambda _{N-1})}(y)\), integrating over \(\mathcal {P}_d^{N-1}\) with respect to \(\mu ^{\otimes (N-1)}(\mathop {}\!\textrm{d}y)\), and using (2.10) and (2.17), we obtain the identity
Remark 2.1
Let us mention that we anticipate the function \(\psi ^{N,n}_{\lambda ;s}\) to be symmetric in the parameters \(\lambda _1,\dots , \lambda _n\). This is not obvious from the definition, but it is suggested by an integral identity of Whittaker functions of matrix arguments that will be proven later on (see (4.1)). As argued in [33, § 7.1], this symmetry is true at least in the case \(N=n=2\). Moreover, it is known for \(d=1\) and arbitrary n, N; see, for example, [27, 21] and [35, pp. 369–370].
3 Markov dynamics
In this section, we define a Markov process X on triangular arrays, which can be viewed as a system of interacting random walks on \(\mathcal {P}_d\). Next, we prove intertwining relations between certain transition kernels related to this process. This implies, via the theory of Markov functions, that, under certain random initial configurations, the bottom edge of the triangular process X has an autonomous stochastic evolution. A consequence of these results is that Whittaker functions of matrix arguments are eigenfunctions of certain integral operators and, thereupon, admit a Feynman–Kac interpretation.
3.1 Interacting Markov dynamics on triangular arrays
Let \(\mathcal {O}_d\) be the real orthogonal group in dimension d. Recall that a random matrix Y in \(\mathcal {P}_d\) is said to be \(\mathcal {O}_d\)-invariant (or orthogonally invariant) if \(k^{\top } Y k\) has the same distribution of Y, for every \(k\in \mathcal {O}_d\).
Definition 3.1
Let \((W(n))_{n\ge 1}\) be a family of independent and \(\mathcal {O}_d\)-invariant random matrices in \(\mathcal {P}_d\). The \(\textrm{GL}_d\)-invariant random walk on \(\mathcal {P}_d\) with initial state \(r\in \mathcal {P}_d\) and increments \((W(n))_{n\ge 1}\) is the \(\mathcal {P}_d\)-valued process \(R=(R(n))_{n\ge 0}\) such that \(R(0)=r\) and
Remark 3.2
The random walk R of Definition 3.1 is indeed \(\textrm{GL}_d\)-invariant, in the sense that the conjugated walk \((g^{\top } R(n) g)_{n\ge 0}\) has the same transition kernels for any choice of \(g\in \textrm{GL}_d\) (cf. [1, § 3]). Instead of (3.1), one could consider a different process through the alternative symmetrisation
One can check that the resulting random walk \(R'\) is \(\mathcal {O}_d\)-invariant, but in general not \(\textrm{GL}_d\)-invariant. In principle, one could proceed to obtain analogous results to those presented in the present article using this alternative symmetrisation (for a similar approach in the continuous Brownian setting, see [33, Prop. 3.5]). However, from our point of view, the choice (3.1) is the most natural and leads to more explicit transition kernels throughout.
It is well known that the Wishart distribution (1.13) and the inverse Wishart distribution (1.14) are \(\mathcal {O}_d\)-invariant. In this article, we will focus on \(\textrm{GL}_d\)-invariant random walks with inverse Wishart increments.
Recall from definition (2.15) that \(P^1_a(z;\mathop {}\!\textrm{d}\tilde{z})= \big |z\tilde{z}^{-1}\big |^{a} {{\,\mathrm{\textrm{e}}\,}}^{-{{\,\textrm{tr}\,}}[z\tilde{z}^{-1}]} \mu (\mathop {}\!\textrm{d}\tilde{z})\) for \(a\in \mathbb {C}\). Using a straightforward change of variables, we see that, if \(\Re (a)>\frac{d-1}{2}\),
Define then the renormalised kernel
It is immediate to see that the (time-homogeneous) \(\textrm{GL}_d\)-invariant random walk on \(\mathcal {P}_d\) with inverse Wishart increments of parameter \(a>\frac{d-1}{2}\) has transition kernel \(\overline{P}^1_a\).
We now define a discrete-time Markov process \(X=(X(n))_{n\ge 0}\) on the set \(\mathcal {T}^{N}_{d}\) of height-N triangular arrays whose components are elements of \(\mathcal {P}_d\).
Definition 3.3
Fix a sequence of real parameters \(\alpha =(\alpha (n))_{n\ge 1}\), an integer \(N\ge 1\), and a real N-tuple \(\beta =(\beta ^1,\dots ,\beta ^N)\) such that \(\alpha (n) + \beta ^i >(d-1)/2\) for all n, i. Denote by \(\alpha (n)+\beta \) the N-tuple \((\alpha (n)+\beta ^1,\dots ,\alpha (n)+\beta ^N)\). For \(n\ge 1\) and \(1\le j\le i\le N\), let \(W^i_j(n)\) be an inverse Wishart random matrix with parameter \(\alpha (n)+\beta ^i\) (the same parameter across j); assume further that all these random matrices are independent of each other. We define the process \(X=(X(n))_{n\ge 0}\), where \(X(n) = (X^i_j(n))_{1\le j\le i\le N}\) is a random element of \(\mathcal {T}^{N}_{d}\), as follows: given an initial state X(0) in \(\mathcal {T}^{N}_{d}\), for \(n\ge 1\) we set recursively
The i-tuple \(X^i:=(X^i_1,\dots ,X^i_i)\) will be referred to as the ith row of X.
The fact that each \(X^i_j(n)\) takes values in \(\mathcal {P}_d\) follows by standard properties of positive definite matrices (cf. Sect. 1.2). Notice that, adopting the convention \(X^i_0(n)^{-1} = X^i_{i+1}(n)=0_d\) for all \(i\ge 0\) and \(n\ge 0\), then the last formula in (3.4) can be taken as the definition of \(X^i_j(n)\) for all \(1\le j\le i\le N\).
The dynamic on \(\mathcal {T}^{N}_{d}\) defined by (3.4) implies that the ‘top particle’ \(X^1_1\) evolves as a \(\textrm{GL}_d\)-invariant random walk in \(\mathcal {P}_d\) with inverse Wishart increments \((W^1_1(n))_{n\ge 1}\).
Furthermore, the ‘right edge’ process \((X^1_1,X^2_1,\dots ,X^N_1)\) equals the system \((Z^1,\dots ,Z^N)\) of random particles in \(\mathcal {P}_d\) with one-sided interactions defined in (1.8)–(1.9), where the random weight \(V^i(n)\) equals \(W^i_1(n)\).
The ‘left edge’ process \((X^1_1,X^2_2,\dots ,X^N_N)\) also evolves as a system of particles in \(\mathcal {P}_d\) with one-sided interactions, as we now explain. Set \(L^i(n):= X^i_i(n)^{-1}\) and \(U^i(n):= W^i_i(n)^{-1}\) for all \(1\le i\le N\) and \(n\ge 0\). Then, \(U^i(n)\) has the Wishart distribution with parameter \(\alpha (n)+\beta ^i\), and the process \(L=(L^1,\dots ,L^N)\) satisfies the recursions
Under the (singular) initial configuration
one can see by induction that \(L^i(n)=0_d\) for all \(n<i-1\) and \(L^i(i-1)=I_d\), while \(L^i(i)\) reduces to a sum of independent Wishart matrices:
In particular, \(L^i(i)\) has the Wishart distribution with parameter \(\sum _{j=1}^i(\alpha (j)+\beta ^j)\).
Remark 3.4
We make a few remarks about various specialisations of the process X and related Markov dynamics:
-
(i)
The interacting diffusion model on positive definite matrices studied in [33] (see also [32, § 9] for the \(d=1\) case) can be regarded as a continuous-time analogue of the process X defined in (3.4).
-
(ii)
It seems that even the \(d=1\) case of the dynamic (3.4) has not been explicitly considered elsewhere. It is related, even though not identical, to the process constructed in [16] via the geometric Robinson–Schensted–Knuth correspondence; see the discussion in the introduction for further details.
-
(iii)
For \(d=1\), under the ‘step’ initial configuration, the right edge can be regarded as a process of log-gamma polymer partition functions; see (1.6)–(1.7) and the discussion therein.
-
(iv)
For \(d=1\), under the ‘step’ initial configuration (3.7), the left edge can be regarded as a process of strict-weak polymer partition functions in a gamma environment, studied in [17, 34]. A strict-weak path is a lattice path \(\pi \) that, at each lattice site (m, k), is allowed to head either horizontally to the right to \((m+1,k)\) or diagonally up-right to \((m+1,k+1)\). It is easily seen that the process L defined in (3.5)–(3.6), in the \(d=1\) case, takes the closed form expression
$$\begin{aligned} L^i(n) = \sum _\pi \prod _{e\in \pi } d_e \,, \end{aligned}$$(3.8)where the sum is over all strict-weak paths \(\pi \) from (0, 1) to (n, i), the product is over all edges e in the path \(\pi \), and \(d_e\) is a weight attached to the edge e and defined as follows: \(d_e:=1\) if e is a diagonal edge from (m, k) to \((m+1,k+1)\); \(d_e:=U^{k}(m+1)\) (gamma distributed with parameter \(\alpha (m+1)+\beta ^k\)) if e is a horizontal edge from (m, k) to \((m+1,k)\). Formula (3.8) defines the strict-weak polymer partition function.
-
(v)
The \(d=1\) case of (3.4) is a ‘positive temperature’ analogue (equivalently, a \((+,\times )\) version) of the process defined by
$$\begin{aligned} \mathcal {X}^i_j(n):= \min \left( \mathcal {X}^{i-1}_{j-1}(n-1), \max \left( \mathcal {X}^{i-1}_j(n),\mathcal {X}^i_j(n-1)\right) +\mathcal {W}^i_j(n)\right) \,, \end{aligned}$$where \(\mathcal {W}^i_j(n)\) are non-negative random variables representing jumps to the right (see e.g. [44]). Roughly speaking, particle \(\mathcal {X}^i_j\) performs a random walk subject to certain interactions with other particles: it is pushed by \(\mathcal {X}^{i-1}_j\) and blocked by \(\mathcal {X}^{i-1}_{j-1}\).
-
(vi)
Besides [44], other works [7, 8, 11, 31, 43] studied, in various discrete and continuous settings, similar push-and-block dynamics on Gelfand–Tsetlin patterns driven by random updates with \(N(N+1)/2\) degrees of freedom. In particular, again in the case \(d=1\), the process X should correspond to a certain \(q\rightarrow 1\) scaling limit of the q-Whittaker processes studied in [7, 11].
Motivated to obtain the explicit Markovian evolution of X, we now introduce the following kernels. For \(a\in \mathbb {C}\), \(y=(y_1,\dots ,y_{N-1})\in \mathcal {P}_d^{N-1}\), \(\tilde{y}=(\tilde{y}_1,\dots ,\tilde{y}_{N-1})\in \mathcal {P}_d^{N-1}\), \(z=(z_1,\dots ,z_N)\in \mathcal {P}_d^N\), and \(\tilde{z}=(\tilde{z}_1,\dots ,\tilde{z}_N) \in \mathcal {P}_d^N\), we set
with the convention \(y_0^{-1}=\tilde{y}_N=0\). Moreover, for \(\lambda =(\lambda _1,\dots ,\lambda _N) \in \mathbb {C}^N\), we set
where \(x \in \mathcal {T}^{N}_{d}\) (resp., \(\tilde{x} \in \mathcal {T}^{N}_{d}\)) is a height-N triangular array of \(d\times d\) positive definite matrices with ith row \(x^i \in \mathcal {P}_d^i\) (resp., \(\tilde{x}^i \in \mathcal {P}_d^i\)), according to the notation of Sect. 2.1. One can show (an analogous computation is made in the proof of Prop. 3.6) that, if \(\Re (a)>(d-1)/2\),
Using (3.2) and (3.11), we see that, if \(\Re (\lambda _i)>(d-1)/2\) for all i, then
Therefore, under the above conditions on the parameters, one can renormalise these kernels, so that they integrate to 1:
The following result can be easily verified using the construction of X in Definition 3.3.
Proposition 3.5
Let X as in Definition 3.3. Then, the conditional distribution of \(X^N(n)\) given \(X^{N-1}(n-1)=y\), \(X^{N-1}(n)=\tilde{y}\) and \(X^N(n-1)=z\), is \(\overline{Q}^N_{\alpha (n)+\beta ^N}(y,\tilde{y},z; \cdot )\). Consequently, the process \(X=(X(n))_{n\ge 0}\) is a time-inhomogeneous Markov process with state space \(\mathcal {T}^{N}_{d}\) and time-n transition kernel \(\overline{\Pi }^N_{\alpha (n)+\beta }\).
3.2 Intertwining relations
We will now show that the Markov dynamic on X (see Definition 3.3), when started from an appropriate random initial state, induces an autonomous Markov dynamic on the Nth row, or ‘bottom edge’, of X. This will be a consequence of an intertwining relation between kernels through the theory of Markov functions, which is reviewed in Appendix B for the reader’s convenience.
Let \(N\ge 2\) and \(a,b\in \mathbb {C}\). Recalling the definitions (2.8) and (2.15) of the kernels \(K^N_b\) and \(P^N_a\), respectively, and denoting by \(\delta \) the Dirac delta kernel on \(\mathcal {P}_d^N\), let us set
for \(z,\tilde{z}\in \mathcal {P}_d^N\) and \(y, \tilde{y}\in \mathcal {P}_d^{N-1}\). We then have the following intertwining relation.
Proposition 3.6
Let \(N\ge 2\) and \(a,b\in \mathbb {C}\) such that \(\Re (a+b)> (d-1)/2\). Then,
holds as an equality between kernels from \(\mathcal {P}_d^N\) to \(\mathcal {P}_d^{N-1}\times \mathcal {P}_d^N\).
Proof
We have to prove that \(\tilde{K}^N_{b} \Lambda ^N_{a,b} f(z) = \Gamma _d(a+b)^{N-1} P^N_{a} \tilde{K}^N_{b} f(z)\), for any suitable test function \(f:\mathcal {P}_d^{N-1}\times \mathcal {P}_d^N \rightarrow \mathbb {R}\) and any \(z\in \mathcal {P}_d^N\). Using (3.15), we see that this is equivalent to the identity
Using the definitions of \(K^N_{b}\) and \(\Lambda ^N_{a,b}\), we obtain, after some rearrangements and cancellations, that the left-hand side of (3.18) equals
with the usual convention \(\tilde{y}_N=0\). By interchanging the order of integration, we see that the latter display equals
where \(\mathfrak {J}:\mathcal {P}_d^3 \rightarrow \mathbb {C}\) is defined by
By the properties of positive definite matrices (see Sect. 1.2), we have that \(w^{-1} - s^{-1} \in \mathcal {P}_d\) if and only if \(s - w \in \mathcal {P}_d\); moreover, for \(w\in \mathcal {P}_d\), the latter condition is stronger than \(s\in \mathcal {P}_d\). We then make the change of variables \(s':= s - w\), which preserves the Lebesgue measure on the ‘independent’ entries of the symmetric matrix s, so that
Therefore, we have
After the further, this time \(\mu \)-preserving, change of variables \(s'':= T_{u^{-1} + v^{-1}}(s')\), we obtain
where the gamma function is well defined since by hypothesis \(\Re (a+b)>(d-1)/2\). After a few cancellations, we then see that the left-hand side of (3.18) equals
It now follows from the definitions that this equals the right-hand side of (3.18), thus concluding the proof. \(\square \)
A simple inductive argument shows that the intertwining (3.17) can be extended to an intertwining that involves the \(\Pi \)-kernel (3.10) and the \(\tilde{\Sigma }\)-kernel (2.6). From now on, we fix \(N\ge 1\), \(a\in \mathbb {C}\) and \(\lambda =(\lambda _1,\dots ,\lambda _N)\in \mathbb {C}^N\) such that \(\Re (a+\lambda _i)> (d-1)/2\) for all i. As usual, we also use the notation \(a+\lambda := (a+\lambda _1,\dots ,a+\lambda _N)\).
Corollary 3.7
The intertwining relation
holds as an equality between kernels from \(\mathcal {P}_d^N\) to \(\mathcal {T}^{N}_{d}\).
Proof
Taking into account (2.6), it is immediate to see that (3.19) is equivalent to
for all \(z\in \mathcal {P}_d^N\) and test function \(f:\mathcal {T}^{N-1}_{d}\times \mathcal {P}_d^N \rightarrow \mathbb {R}\), where we set
To prove (3.20), we proceed by induction. For \(N=1\), (3.20) amounts to the identity
for \(z\in \mathcal {P}_d\) and \(f:\mathcal {P}_d\rightarrow \mathbb {R}\). Using (2.10) and (2.15), one can easily verify that the latter is true, as both sides equal \(\left|z\right|^a \int _{\mathcal {P}_d} \mu (\mathop {}\!\textrm{d}\tilde{z}) \left|\tilde{z}\right|^{-a-\lambda } {{\,\mathrm{\textrm{e}}\,}}^{-{{\,\textrm{tr}\,}}[z \tilde{z}^{-1}]} f(\tilde{z})\).
Let now \(N\ge 2\) and \(\tilde{\lambda } = (\lambda _1,\dots ,\lambda _{N-1})\). Assume by induction that
for any \(y\in \mathcal {P}_d^{N-1}\) and any test function \(g:\mathcal {T}^{N-2}_{d}\times \mathcal {P}_d^{N-1}\rightarrow \mathbb {R}\). Fix \(z\in \mathcal {P}_d^N\) and \(f:\mathcal {T}^{N-1}_{d}\times \mathcal {P}_d^N \rightarrow \mathbb {R}\) (which we view as \(f:\mathcal {T}^{N-2}_{d}\times \mathcal {P}_d^{N-1}\times \mathcal {P}_d^N \rightarrow \mathbb {R}\)). Choosing
in (3.21) and integrating both sides with respect to the measure \(K^N_{\lambda _N}(z; \cdot )\), we obtain
Using (2.9) and (3.10) for the left-hand side and (3.16) for the right-hand side, and interchanging the integration order, we then have
where the latter two equalities follow from (3.18) and (2.9), respectively. The identification \(\mathcal {T}^{N-2}_{d} \times \mathcal {P}_d^{N-1} = \mathcal {T}^{N-1}_{d}\) concludes the proof of (3.20). \(\square \)
Recall now that the \(\tilde{\Sigma }\)-kernels generate Whittaker functions of matrix arguments, in the sense of (2.7). By integrating the intertwining relation (3.19) and using (3.12), we immediately deduce that Whittaker functions are eigenfunctions of the integral P-operators:
Corollary 3.8
We have
We note that this complements the interpretation of the Whittaker functions \(\psi ^N_{\lambda }\), given in [33], as eigenfunctions of a differential operator, namely the Hamiltonian of a quantisation in \(\mathcal {P}_d^N\) of the N-particle non-Abelian Toda chain.
For \(x\in \mathcal {T}^{N}_{d}\) and \(z, \tilde{z}\in \mathcal {P}_d^N\), we now define
It follows from (2.7) and (3.22) that the above kernels are normalised; therefore, they are Markov kernels when the parameters \(a,\lambda _1,\dots ,\lambda _N\) are real. Notice that (3.24) may be seen as a Doob \( h \)-transform of the P-kernel (2.15). It is now immediate to deduce a renormalised version of (3.19):
Corollary 3.9
The intertwining relation
holds as an equality between kernels from \(\mathcal {P}_d^N\) to \(\mathcal {T}^{N}_{d}\).
From a probabilistic point of view, (3.25) states that, for any fixed \(z\in \mathcal {P}_d^N\), the two following update rules are equivalent: (i) starting the process X from a (random) initial configuration dictated by the intertwining kernel \(\overline{\Sigma }(z; \cdot )\) and letting it evolve according to the dynamic \(\overline{\Pi }\); and (ii) running the dynamic \({\varvec{P}}\) on the bottom edge (started at z) and then updating the whole triangular array according to the intertwining kernel \(\overline{\Sigma }\). The main result of this section is a precise account of this interpretation.
Theorem 3.10
Let \(X=(X(n))_{n\ge 0}\) be the Markov process on \(\mathcal {T}^{N}_{d}\) as in Definition 3.3. Assume that, for an arbitrary \(z\in \mathcal {P}_d^N\), the initial state X(0) of X is distributed according to the measure \(\overline{\Sigma }^N_{\beta }(z;\cdot )\). Then, the Nth row \(X^N = (X^N(n))_{n\ge 0}\) is a time-inhomogeneous Markov process (in its own filtration) on the state space \(\mathcal {P}_d^N\), with initial state z and time-n transition kernel \({\varvec{P}}^N_{\alpha (n), \beta }\). Moreover, for any bounded measurable function \(f:\mathcal {T}^{N}_{d} \rightarrow \mathbb {R}\) and \(n\ge 0\), we have
Proof
The statement is an application of Theorem B.1, where the state spaces are \(S = \mathcal {T}^{N}_{d}\) and \(T=\mathcal {P}_d^N\), and the function \(\varphi :\mathcal {T}^{N}_{d} \rightarrow \mathcal {P}_d^N\) is the projection \(\varphi (x):= x^N\) onto the Nth row of x, so that \(X^N(n)= \varphi (X(n))\). Hypothesis (i) of Theorem B.1, i.e. the fact that \(\overline{\Sigma }_{\beta }(z; \varphi ^{-1}\{z\})=1\) for any \(z\in \mathcal {P}_d^N\), holds because, by definition, the measure \(\overline{\Sigma }_{\beta }(z;\cdot )\) is supported on the set \(\mathcal {T}^{N}_{d}(z)\) of height-N triangular arrays with Nth row equal to z. On the other hand, by Prop. 3.5, the time-n transition kernel of X is \(\overline{\Pi }^N_{\alpha (n)+\beta }\). Therefore, in this case, hypothesis (ii) of Theorem B.1 reads as the set of intertwining relations
These follow from Corollary 3.9. \(\square \)
Remark 3.11
By letting N vary, it is immediate to deduce from Theorem 3.10 that every row of X evolves as a Markov process in its own filtration, under an appropriate (random) initial configuration on the previous rows. Therefore, the focus on the Nth row should only be seen as a convenient choice.
3.3 Feynman–Kac interpretation
Here we provide a Feynman–Kac type interpretation of Whittaker functions based on the eigenfunction equation (3.22). Our result should be compared to the one obtained in [33, Prop. 9] in the continuous setting of Brownian particles.
Definition 3.12
Let \(\lambda \in \mathbb {R}^N\) with
Let \(y\in \mathcal {P}_d^N\). We define \(Y=(Y(n))_{n\ge 0}=(Y_1(n),\dots ,Y_N(n))_{n\ge 0}\) to be a process in \(\mathcal {P}_d^N\) with independent components, such that each component \(Y_i=(Y_i(n))_{n\ge 0}\) is a \(\textrm{GL}_d\)-invariant random walk on \(\mathcal {P}_d\) with initial state \(Y_i(0)=y_i\) and inverse Wishart increments with parameter \(\lambda _i\).
Recalling (3.3), Y is then a time-homogeneous Markov process starting at y with transition kernel
For \(z,\tilde{z}\in \mathcal {P}_d^N\), define the sub-Markov kernel
where V is the ‘killing potential’
Denote by \(\mathbb {P}_{y}\) and \(\mathbb {E}_{y}\) the probability and expectation, respectively, with respect to the law of Y with initial state y.
Theorem 3.13
For all \(y\in \mathcal {P}_d^N\), we have
The main purpose of this subsection is to prove (3.29). In a nutshell, using a fairly standard martingale argument, we will show that the expectation in (3.29) is the unique solution to an eigenproblem; the latter is also, essentially, solved by Whittaker functions.
Lemma 3.14
Fix an integer \(\ell \ge 0\). For any \(y\in \mathcal {P}_d^N\), we have
Remark 3.15
In particular Lemma 3.14 with \(\ell =1\) implies that the infinite series inside the expectation in (3.29) converges \(\mathbb {P}_y\)-a.s.
Proof of Lemma 3.14
Since
it suffices to show that, for each \(1\le i\le N-1\),
Let us record the following properties, which hold for any \(a,b\in \mathcal {P}_d\):
-
\({{\,\textrm{tr}\,}}[ab]\le {{\,\textrm{tr}\,}}[a]{{\,\textrm{tr}\,}}[b]\) (submultiplicativity of the trace);
-
\({{\,\textrm{tr}\,}}[a]\le d\, \lambda _{\max }(a)\);
-
\(\lambda _{\max }(a^{-1}) = \lambda _{\min }(a)^{-1}\).
Here, \(\lambda _{\max }\) and \(\lambda _{\min }\) denote the maximum and minimum eigenvalue, respectively. Using these facts, we have, for \(1\le i\le N-1\):
Now, using for example [1, Corollary B.4], we have
\(\mathbb {P}_y\)-a.s., where \(\psi \) is the digamma function. These are the maximum (respectively, minimum) Lyapunov exponent of a \(\textrm{GL}_d\)-invariant random walk with inverse Wishart increments of parameter \(\lambda _{i+1}\) (respectively, \(\lambda _i\)). We then obtain
since the digamma function is strictly increasing and, by Definition 3.12, \(\lambda _{i+1}-\lambda _i>(d-1)/2\). \(\square \)
Lemma 3.16
Let \(u:\mathcal {P}_d^N\rightarrow \mathbb {R}\) be a measurable function such that
-
(i)
\(\hat{\Theta }^N_{\lambda } u = u\) (eigenfunction equation);
-
(ii)
u is bounded (boundedness property);
-
(iii)
\(u(y) \rightarrow 1\) as \(V(y;y)\rightarrow 0\) (boundary condition).
Then, for all \(y\in \mathcal {P}_d^N\),
Proof
Consider the process Y as in Definition 3.12, with initial state \(y\in \mathcal {P}_d^N\) and transition kernel \(\Theta ^N_{\lambda }\). Denote by \((\mathcal {F}(k))_{k\ge 0}\) its natural filtration. It follows from the eigenfunction equation that
Therefore, the process \(M=(M(k))_{k\ge 0}\) defined by
is an \((\mathcal {F}(k))_{k\ge 0}\)-martingale. By the boundedness property, M is uniformly bounded and, thus, a uniformly integrable martingale. Therefore, M converges \(\mathbb {P}_y\)-a.s. and in 1-norm to a certain limit \(M(\infty )\) and, for all \(k\ge 0\), we have \(M(k)=\mathbb {E}_{y}\left[ M(\infty ) \;\big |\; \mathcal {F}(k)\right] \). By Lemma 3.14 (with \(\ell =0\)), we have \(\lim _{k\rightarrow \infty }V(Y(k);Y(k))= 0\), \(\mathbb {P}_y\)-a.s. The boundary condition then implies \(\lim _{k\rightarrow \infty } u(Y(k)) =1\), \(\mathbb {P}_y\)-a.s., whence
We conclude that, for any \(y\in \mathcal {P}_d^N\),
\(\square \)
Proof of Theorem 3.13
It was proven in [33, proof of Prop. 9] that the function
is bounded and satisfies
By Lemma 3.16, it then remains to prove that \(\hat{\Theta }^N_{\lambda } v = v\). It follows from the definition (2.15) of the kernel \(P^N_a\) that
for \(z\in \mathcal {P}_d^N\). Using the eigenfunction equation (3.22), we see that the right-hand side above equals v(z), as desired. \(\square \)
Corollary 3.17
Under \(\mathbb {P}_y\), we have the distributional equality
where \(a:= y_1^{-1}y_2y_1^{-1/2}\) and Z has the inverse Wishart distribution of parameter \(\lambda _2-\lambda _1\).
Proof
We may assume that \(N=2\), so that \(Y=(Y_1,Y_2)\) starts at \(y=(y_1,y_2)\). Using Theorem 3.13 and the definition of Whittaker functions, we compute the Laplace transform of the left-hand side of (3.31) as
for \(s\in \mathbb {R}\), where we used the change of variables \(z=y_1^{1/2}x^{-1}y_1^{1/2}\). The last integral equals \(\mathbb {E}{{\,\mathrm{\textrm{e}}\,}}^{-s {{\,\textrm{tr}\,}}[aZ]}\), where Z is inverse Wishart of parameter \(\lambda _2-\lambda _1\). We conclude that the two sides of (3.31) have the same Laplace transform and, hence, the same law. \(\square \)
Remark 3.18
Up to some technical details, identity (3.31) may be also deduced from the Dufresne type identity for a random walk on \(\mathcal {P}_d\) proved in [1]. Let \((R(n))_{n\ge 0}\) be a \(\textrm{GL}_d\)-invariant random walk on \(\mathcal {P}_d\) whose initial state R(0) is an inverse Wishart matrix with parameter \(\lambda _2\) and whose increments are Beta type II matrices with parameters \(\lambda _1\) and \(\lambda _2\) (see [1] for more details). It is then natural to expect that the eigenvalue processes of the two processes \((Y_1(n)^{-1/2}Y_2(n+1)Y_1(n)^{-1/2})_{n\ge 0}\) and \((a^{1/2}R(n)a^{1/2})_{n\ge 0}\), where \(a=y_1^{-1}y_2y_1^{-1/2}\), have the same law; this is certainly true at least in the case \(d=1\). By summing the traces of these two processes over all \(n\ge 0\), [1, Theorem 4.10] would then immediately provide a proof of (3.31) that does not rely upon the Feynman–Kac formula (3.29). See [33, Lemma 8] for an analogous argument in the Brownian setting.
4 Fixed-time laws and matrix Whittaker measures
In this section, we first prove a Whittaker integral identity that allows us to introduce matrix Whittaker measures. We then obtain an asymptotic formula for a Whittaker function whose arguments go to zero or infinity in norm. Using the latter result, we next show that, for a certain singular initial state, matrix Whittaker measures appear naturally as the fixed-time laws of the bottom edge of the triangular process X introduced in Sect. 3.1. Finally, under the same singular initial state, we study the fixed-time law of the right edge and of the left edge of X.
4.1 Matrix Whittaker measures
Whittaker functions of matrix arguments satisfy a remarkable integral identity:
Theorem 4.1
Let \(n\ge N \ge 1\). Let \(\lambda =(\lambda _1,\dots ,\lambda _n)\in \mathbb {C}^n\) and \(\varrho =(\varrho _1,\dots ,\varrho _N)\in \mathbb {C}^N\) such that \(\Re (\lambda _\ell + \varrho _i) > \frac{d-1}{2}\) for all \(1\le \ell \le n\), \(1\le i\le N\). Let \(s\in \mathcal {P}_d\). Then,
The case \(N=n\) of (4.1) was noted in [33, Prop. 10]; however, the identity did not play a key role in that article, and the details of the proof were not provided therein. Below we provide a proof of the general case \(n\ge N\) that involves the generalised Whittaker functions introduced in Sect. 2.2.
In the scalar \(d=1\) setting, (4.1) goes back to [35, Corollary 3.5]. For \(d=1\) and \(N=n\), it is equivalent to an identity that was originally found in the number theoretic literature [12, 40].
Theorem 4.1 can be also seen as an analogue, in the context of Whittaker functions, of the celebrated Cauchy–Littlewood identity for Schur functions. In the literature on symmetric functions, the latter is usually proved using either the determinantal structure of Schur functions (see [29, I-(4.3)]) or the Robinson–Schensted–Knuth correspondence, a combinatorial bijection (see [41, Theorem 7.12.1]). None of these tools is available, so far, in our context. To prove (4.1), we will rather proceed inductively, using the recursive definition of Whittaker functions and the eigenfunction equation (3.22). For the reader’s convenience, we also include in Appendix A a proof of the classical Cauchy–Littlewood identity that similarly relies on an eigenfunction equation for Schur functions (which can be seen as a version of the so-called Pieri rule).
Proof of Theorem 4.1
We will prove (4.1) by induction on n. For a fixed integer \(n\ge 1\), let \(\textrm{S}(n)\) be the statement that (4.1) holds for all N such that \(n\ge N\ge 1\) and for any choice of \(\lambda \) and \(\varrho \) satisfying the assumptions of the theorem.
For \(n=N=1\) we have
where we have used the definitions of Whittaker functions and gamma functions and the \(\mu \)-preserving change of variables \(\tilde{z} = T_{s^{-1}}(z)\). This proves the base case \(\textrm{S}(1)\).
Suppose now by induction that \(\textrm{S}(n-1)\) holds for some fixed \(n\ge 2\). To prove that \(\textrm{S}(n)\) holds, let us first prove that (4.1) is valid for all N such that \(n>N\ge 1\). It follows from (2.17), Fubini’s theorem, (2.16) and (3.22), that

Since \(n-1\ge N\), using the assumption \(\textrm{S}(n-1)\) in the latter integral we obtain (4.1).
To conclude \(\textrm{S}(n)\), we are left to prove the case \(N=n\). Using (2.17), (2.10), Fubini’s theorem, (2.18), (3.22), and (2.20), we have
Recall that we have already proved (4.1) for all N such that \(n>N\ge 1\). Applying this, for \(N=n-1\), to the latter integral, we conclude that (4.1) holds also for \(N=n\). \(\square \)
Definition 4.2
For \(n\ge N\ge 1\). Let \(\lambda =(\lambda _1,\dots ,\lambda _n)\in \mathbb {R}^n\) and \(\varrho =(\varrho _1,\dots ,\varrho _N)\in \mathbb {R}^N\) such that \(\lambda _\ell + \varrho _i > \frac{d-1}{2}\) for all \(1\le \ell \le n\), \(1\le i\le N\). We call matrix Whittaker measure with parameters \(\lambda \) and \(\varrho \) the measure on \(\mathcal {P}_d^N\) that is absolutely continuous with respect to \(\mu ^{\otimes N}(\mathop {}\!\textrm{d}z)\) with density
where \(I_d\) is the \(d\times d\) identity matrix. According to the usual convention, we also denote by \(W^{N,n}_{\lambda ,\varrho }(\mathop {}\!\textrm{d}z)\) the measure itself.
By Theorem 4.1, (4.2) defines a probability distribution on \(\mathcal {P}_d^N\). This extends the definition of matrix Whittaker measures given in [33, § 7.4], which corresponds to the case \(n=N\):
4.2 Asymptotics of Whittaker functions
For any real \(k>0\), let
and let \(r^i(k):= (r^i_1(k), \dots , r^i_i(k))\). Our ultimate goal is to obtain the \(k\rightarrow \infty \) leading order approximation of the Whittaker function \(\psi _{\lambda }^N(r^N(k))\).
We rely on some results (Theorem 5.13 and Prop. 5.14) that we will prove, in a more general setting, in Sect. 5. With this purpose in mind, we use the graphical representations of the set of height-N triangular arrays \(\mathcal {T}^{N}_{d}\) and of the energy function \(\Phi ^N\), both involved in the definition of the Whittaker function (2.4) (see Fig. 1). Given \(N\ge 2\), we set
and consider the finite graph \({\varvec{G}}=({\varvec{V}},{\varvec{E}})\), where \({\varvec{E}}\) consists of all (directed) edges \((i,j)\rightarrow (i+1,j)\) and \((i+1,j+1)\rightarrow (i,j)\), for \(1\le j\le i\le N-1\). Then, \(\mathcal {T}^{N}_{d}\) may be identified as the set \(\mathcal {P}_d^{{\varvec{V}}}\) of arrays \(x=(x_v)_{v\in {\varvec{V}}}\), where each \(x_v\in \mathcal {P}_d\). Let also
We may thus identify \(z\in \mathcal {P}_d^N\) with \(z\in \mathcal {P}_d^{{\varvec{\Gamma }}}\), so that the set \(\mathcal {T}^{N}_{d}(z)\) of all height-N triangular arrays whose Nth row equals z coincides with the set \(\mathcal {P}_d^{{\varvec{V}}}(z)\), according to the notation (5.4). Furthermore, the energy function (2.3) can be equivalently rewritten as
All the results of Sect. 5 hold for the above ‘triangular graph’ structure, since:
-
\({\varvec{G}}=({\varvec{V}},{\varvec{E}})\) is an acyclic finite directed graph;
-
\({\varvec{\Gamma }}\) is a proper subset of \({\varvec{V}}\) containing the only source (N, N) and sink (N, 1) of \({\varvec{G}}\);
-
the energy function \(\Phi ^N\) is of the form (5.9).
We first prove a property of the critical points of \(\Phi ^N\) that, in the scalar \(d=1\) setting, was observed in [32].
Lemma 4.3
Let \(z\in \mathcal {P}_d^N\). Let x be any critical point of \(\Phi ^N\) on \(\mathcal {T}^{N}_{d}(z)\). For all \(1\le i\le N\), let \(p_i:= \big |x^i_1 \cdots x^i_i \big |\) be the determinant of the product of the ith row of x. Then,
Proof
The critical point equations of the energy function \(\Phi ^N\) are
with the convention \(x^{i-1}_i=(x^{i-1}_0)^{-1}=0\) for all \(1\le i<N\) (these correspond to (5.15) in the case of the triangular graph \({\varvec{G}}\)). Taking determinants of both sides, we obtain
Taking the product over j in the latter, many terms cancel out, yielding
By definition of \(p_1,\dots , p_N\), the latter can be written as
with the convention \(p_0:=1\). Finally, it is straightforward to see that equations (4.6) are equivalent to (4.5). \(\square \)
Let now
As the components of \(I_d^N\) are scalar matrices, Theorem 5.13 implies:
Corollary 4.4
The function \(\Phi ^N\) on \(\mathcal {T}^{N}_{d}(I_d^N)\) has a unique global minimiser, at which the Hessian is positive definite. Moreover, each component \(m^i_j\) of the minimiser \(m=(m^i_j)_{1\le j\le i\le N}\) is a positive scalar matrix.
Throughout this subsection, m will always denote the above minimiser.
Corollary 4.5
We have \(m^1_1=I_d\) and
Proof
Since \(m\in \mathcal {T}^{N}_{d}(I_d^N)\), we have \(m^N_j = I_d\) for all \(j=1,\dots ,N\), hence \(\big |m^N_1 \cdots m^N_N \big |= 1\). On the other hand, as a minimiser, m is a critical point of \(\Phi ^N\) on \(\mathcal {T}^{N}_{d}(I_d^N)\), hence (4.7) follows from Lemma 4.3. Furthermore, since \(m^1_1\) is a multiple of \(I_d\) with determinant 1, we have \(m^1_1=I_d\). \(\square \)
Theorem 4.6
For any \(\lambda \in \mathbb {C}^N\), we have

where \(\left|\mathcal {H}(m)\right|>0\) is the Hessian determinant of \(\Phi ^N\) at m.
The case \(d=1\), \(N=2\) of this asymptotic result is classical; the case \(d=1\) and general N can be found in [32, eq. 20]. Finally, the case \(d>1\), \(N=2\) may be inferred from the Laplace approximation of Bessel functions of matrix arguments studied in [14] (see also [22, Appendix B] and [33, Section 2.6]).
An important feature of (4.8) is that the leading order asymptotics does not depend on the parameter \(\lambda \). This was already remarked in [13] in the special case \(d=1\) and \(N=3\), for which the full asymptotic expansion was obtained.
Proof of Theorem 4.6
By (2.4), we have
Recalling (4.4), let us change variables by setting
One can then easily verify, using also the invariance property of the measure \(\mu \), that
Applying Prop. 5.14 with \(g:=\Delta ^N_{\lambda }\), we obtain

since the number of vertices of \({\varvec{G}}\) that do not belong to \({\varvec{\Gamma }}\) is \(N(N-1)/2\). The claim then follows from Corollary 4.5 (which, in particular, implies that \(\Delta ^N_{\lambda }(m)=1\)). \(\square \)
Recall now the definition (2.6) of the \(\tilde{\Sigma }\)-kernel.
Corollary 4.7
Let \(f:\mathcal {T}^{N}_{d} \rightarrow \mathbb {R}\) be a bounded and continuous function and let
Assume that \(f_k \xrightarrow {k\rightarrow \infty } f_{\infty }\) uniformly on any compact subsets of \(\mathcal {T}^{N}_{d}(I_d^N)\). Then, for any \(\lambda , \varrho \in \mathbb {R}^N\),
Proof
As the leading order asymptotics of the Whittaker function \(\psi ^N_{\lambda }(r^N(k))\) does not depend on \(\lambda \) by Theorem 4.6, we have
Therefore, it suffices to prove (4.12) for \(\varrho =\lambda \).
Note that, using (4.10) and the fact that \(\lambda \in \mathbb {R}^N\), the measure \(\mu ^N_k\) defined by
is a probability measure on \(\mathcal {T}^{N}_{d}(I_d^N)\). By definition of \(\tilde{\Sigma }_{\lambda }\), we then have
where in the integral we performed the change of variables (4.9). Since f is bounded and continuous, the functions \(\{f_k\}_{k>0}\) are uniformly bounded and continuous; moreover, by assumption, they converge as \(k\rightarrow \infty \) to \(f_{\infty }\) uniformly on any compact subsets of \(\mathcal {T}^{N}_{d}(I_d^N)\). Therefore, by Lemma C.1, it is now enough to show that \(\mu ^N_k\) converges weakly as \(k\rightarrow \infty \) to the Dirac measure \(\delta _m\), i.e. that
for every bounded and continuous function \(g:\mathcal {T}^{N}_{d}(I_d^N) \rightarrow \mathbb {R}\). This claim, in turn, follows readily from Prop. 5.14, since, without loss of generality, one can assume \(g(m)\ne 0\). \(\square \)
4.3 Fixed-time law of the ‘bottom edge’ process
Let us now go back to the Markov process X on \(\mathcal {T}^{N}_{d}\) from Definition 3.3. Recall that, under the hypotheses of Theorem 3.10, the Nth row \(X^N\) of the process X has an autonomous Markov evolution with time-n transition kernel \({\varvec{P}}^N_{\alpha (n),\beta }\) (cf. (3.24)). The transition kernel of \(X^N\) from time 0 to time n is then given by the composition
Thus, if the initial state of \(X^N\) is \(X^N(0)=z\), then the law of \(X^N(n)\) is \(U^{N,n}_{\alpha ,\beta }(z; \cdot )\).
Let now \(\lambda = (\lambda _1,\dots ,\lambda _N) \in \mathbb {C}^N\) such that \(\alpha (\ell ) + \Re (\lambda _i) > \frac{d-1}{2}\) for all \(1\le \ell \le n\) and \(1\le i\le N\). Iterating the eigenfunction equation (3.22) n times, we obtain the following eigenfunction equation for \(U^{N,n}_{\alpha ,\beta }\):
Consider now the initial state \(X^N(0)=r^N(k)\) (cf. (4.4)), which becomes singular in the limit as \(k\rightarrow \infty \). We will show that the measure \(U^{N,n}_{\alpha ,\beta }(r^N(k); \cdot )\) converges, as \(k\rightarrow \infty \), to the matrix Whittaker measure with parameters \((\alpha (1),\dots ,\alpha (n))\) and \(\beta \). An intuition about this fact is provided by (4.14). It follows from Theorem 4.6 that the ratio of Whittaker functions on the right-hand side of (4.14), evaluated at \(r^N(k)\), converges to 1 as \(k\rightarrow \infty \). It is then easy to see that, if the convergence to matrix Whittaker measures holds as claimed above, then (4.14) reduces to the Whittaker integral identity proved in Sect. 4.1.
Theorem 4.8
Let \(n\ge N\). As \(k\rightarrow \infty \), the distribution \(U^{N,n}_{\alpha ,\beta }(r^N(k); \cdot )\) converges in total variation distance (and, hence, weakly) to the matrix Whittaker measure with parameters \((\alpha (1), \dots , \alpha (n))\) and \(\beta \) (which we denote by \(W^{N,n}_{\alpha ,\beta }\) for simplicity). Namely, we have
where the supremum is taken over all measurable sets \(A \subseteq \mathcal {P}_d^N\).
Proof
We will prove that
This statement is stronger than (4.15), as the supremum in (4.15) is clearly bounded from above by the integral in (4.16).
Let us fix N and prove (4.16) by induction on \(n\ge N\). Before proving the base case, let us verify the (simpler) induction step. Assume that (4.16) holds for a certain \(n\ge N\). Using (4.2), (3.24), (2.16) and (2.17), we obtain

for \(z\in \mathcal {P}_d^N\). On the other hand, by (4.13) we have \(U^{N,n+1}_{\alpha ,\beta } = U^{N,n}_{\alpha ,\beta } {\varvec{P}}^N_{\alpha (n+1),\beta }\). Applying Fubini’s theorem and recalling that \({\varvec{P}}^N_{\alpha (n+1),\beta }\) is a Markov kernel, we then obtain
The latter expression vanishes as \(k\rightarrow \infty \) by the induction hypothesis, thus proving the induction step.
It remains to prove the base case, i.e. (4.16) for \(n=N\). Recall that the measures \(U^{N,N}_{\alpha ,\beta }(r^N(k); \cdot )\), for any \(k>0\), and \(W^{N,N}_{\alpha ,\beta }\) have the same finite total mass, since they are all probability distributions, and are absolutely continuous with respect to \(\mu ^{\otimes N}\). By Scheffé’s theorem (see e.g. [4, Theorem 16.12]), it then suffices to show the convergence of the densities:
Fix \(z\in \mathcal {P}_d^N\) once for all. Using (4.13), we write
Define now
for \(z^0, z^N\in \mathcal {P}_d^N\), with the usual conventions \(z^i_{N+1}:=0\) for all \(i=0,\dots ,N\). Using the definition (3.24) of the \({\varvec{P}}\)-kernels, we then have
Comparing (4.19) with (4.3), we are reduced to show that
Let us relabel the variables in the integral (4.18) by setting

Graphical representation of the set of variables \(z^i_j\), \(0\le i\le N\) and \(1\le j\le N\) (here \(N=4\)) appearing in (4.18). Each arrow \(a\rightarrow b\) corresponds to the term \({{\,\mathrm{\textrm{e}}\,}}^{-{{\,\textrm{tr}\,}}[ab^{-1}]}\) in the integral. Relabelling the \(z^i_j\) as in (4.21)–(4.22) yields two triangular arrays x (coloured in red) and y (coloured in blue) (colour figure online)
This relabelling yields two triangular arrays \(x,y\in \mathcal {T}^{N}_{d}\). See Fig. 3 for a graphical representation of the variables \(z^i_j\) and the corresponding arrays x and y. Recalling the definition (2.6) of the \(\tilde{\Sigma }\)-kernel, we have
where \(\hat{\alpha }(1:N):= (-\alpha (N),\dots ,-\alpha (1))\) and the function \(f:\mathcal {T}^{N}_{d}\rightarrow \mathbb {R}\) is defined by
Here, each term \({{\,\mathrm{\textrm{e}}\,}}^{-{{\,\textrm{tr}\,}}\left[ x^{N-i+1}_1 (y^i_i)^{-1} \right] }\) corresponds, graphically, to a bold arrow in Fig. 3.
We now wish to apply Corollary 4.7. Notice first that f is a continuous function of x; moreover, it is bounded below by 0 and above by \(\psi ^N_{\alpha (1:N)}(z)\) (cf. (2.4)). The associated functions \(f_k\) defined in (4.11) are
By dominated convergence and by the definition (2.4) of Whittaker function, we have the pointwise convergence
Notice that \(\{f_k\}_{k>0}\) is a collection of continuous functions, increasing with k, that converges pointwise to a continuous limit; hence, by Dini’s theorem (see e.g. [38, Theorem 7.13]), the convergence is uniform on compacts. Then, the assumptions of Corollary 4.7 are satisfied and we have
where m is the unique global minimiser of \(\Phi ^N\) on \(\mathcal {T}^{N}_{d}(I_d^N)\) (cf. Corollary 4.4). Since \(m^1_1=I_d\) by Corollary 4.5, we have
This yields the desired limit (4.20). \(\square \)
4.4 Fixed-time laws of the ‘right edge’ and ‘left edge’ processes
Throughout this subsection, it will be convenient to work with the space of \(d\times d\) positive semidefinite matrices, i.e. \(d\times d\) real symmetric matrices with nonnegative eigenvalues; such a space is the closure of \(\mathcal {P}_d\) under the standard Euclidean topology, and we thus denote it by \(\overline{\mathcal {P}}_d\).
It is clear from the definition given in Sect. 3.1 that the ‘right edge’ \(X_1=(X^1_1,\dots ,X^N_1)\) of X is a Markov process in its own filtration. Furthermore, as mentioned before, \(X_1\) equals the system \(Z=(Z^1,\dots ,Z^N)\) of random particles in \(\mathcal {P}_d\) with one-sided interactions defined in (1.8)–(1.9), where the random weight \(V^i(n)\) equals \(W^i_1(n)\), an inverse Wishart random matrix with parameter \(\alpha (n)+\beta ^i\). If the initial state Z(0) of this process is in \(\mathcal {P}_d^N\) (respectively, \(\overline{\mathcal {P}}_d^N\)), then clearly Z evolves as a process in \(\mathcal {P}_d^N\) (respectively, \(\overline{\mathcal {P}}_d^N\)).
Analogously, the ‘left edge’ of X is a Markov process in its own filtration. Its ‘inverse’ \(L=(L^1,\dots ,L^N):=((X^1_1)^{-1},\dots ,(X^N_N)^{-1})\) is given by (3.5)–(3.6), where \(U^i(n):=(W^i_i(n))^{-1}\) is a Wishart random matrix with parameter \(\alpha (n)+\beta ^i\). If the initial state L(0) of this process is in \(\mathcal {P}_d^N\) (respectively, \(\overline{\mathcal {P}}_d^N\)), then clearly L evolves as a process in \(\mathcal {P}_d^N\) (respectively, \(\overline{\mathcal {P}}_d^N\)).
As the next lemma shows, the singular initial state of the bottom edge of X considered in Sect. 4.3 induces (through Theorem 3.10) the initial state (1.10) on the right edge \(X_1\), which resembles the step or ‘narrow wedge’ initial configuration in systems of interacting particles/random walks. A similar statement holds for the left edge.
Lemma 4.9
Let X(0) be distributed according to \(\overline{\Sigma }_{\beta }(r^N(k);\cdot )\). Then, on the space \(\overline{\mathcal {P}}_d^N\), both \((X^1_1(0),\dots ,X^N_1(0))\) and \(((X^1_1(0))^{-1},\dots ,(X^N_N(0))^{-1})\) converge in law, as \(k\rightarrow \infty \), to \((I_d,0_d,\dots ,0_d)\).
Proof
We prove the claim about \((X^1_1(0),\dots ,X^N_1(0))\), as the proof of the claim about \(((X^1_1(0))^{-1},\dots ,(X^N_N(0))^{-1})\) is completely analogous.
Let \(g:\overline{\mathcal {P}}_d^N \rightarrow \mathbb {R}\) be a bounded and continuous test function. We need to prove that
Let \(f:\mathcal {T}^{N}_{d} \rightarrow \mathbb {R}\), \(f(x):= g(x_1) = g(x^1_1,\dots ,x^N_1)\) for all \(x\in \mathcal {T}^{N}_{d}\). By definition (3.23) of \(\overline{\Sigma }_{\beta }\), we then have
We now wish to apply Corollary 4.7. Since g is bounded and continuous, f also is. The associated functions \(f_k\) defined in (4.11) are
These functions converge as \(k\rightarrow \infty \) to \(f_{\infty }(x):= g(x^1_1,0_d,\dots ,0_d)\) uniformly on compacts, since g is continuous on \(\overline{\mathcal {P}}_d^N\). Therefore, by Corollary 4.7, \(\mathbb {E}\left[ g(X_1(0)) \right] \) converges as \(k\rightarrow \infty \) to \(g(m^1_1,0_d,\dots ,0_d)\), where m is the minimiser of \(\Phi ^N\) on \(\mathcal {T}^{N}_{d}(I_d^N)\). By Corollary 4.5 we have \(m^1_1=I_d\), and the claim (4.23) follows. \(\square \)
As a consequence of Theorem 4.8 and Lemma 4.9, we obtain:
Corollary 4.10
As above, let \(Z=(Z^1,\dots ,Z^N)\) and \(L=(L^1,\dots ,L^N)\) be the right edge process and the (inverse) left edge process, respectively, with initial states \(Z(0)=L(0)=(I_d,0_d,\dots ,0_d)\in \overline{\mathcal {P}}_d^N\). Then, for \(n\ge N\), \(Z^N(n)\) and \(L^N(n)\) are distributed as the first marginal and the Nth marginal, respectively, of the matrix Whittaker measure with parameters \((\alpha (1), \dots , \alpha (n))\) and \(\beta \).
Proof
Again, we only prove the claim about the right edge, as the proof of the claim about the left edge is completely analogous.
Let the process X be as in Definition 3.3, with initial state X(0) distributed according to \(\overline{\Sigma }_{\beta }(r^N(k);\cdot )\). It is clear from the definition that \(X^N_1(n)\) can be written as a continuous, deterministic function of the right edge initial state \(X_1(0)\) and of the collection of random matrices \((W^1_1(\ell ),\dots ,W^N_1(\ell ))_{1\le \ell \le n}\). Therefore, by Lemma 4.9 and the continuous mapping theorem [5, Theorem 2.7], \(X^N_1(n)\) converges in law as \(k\rightarrow \infty \) to \(Z^N(n)\).
On the other hand, by Theorem 4.8, for \(n\ge N\), \(X^N_1(n)\) converges in law as \(k\rightarrow \infty \) to the first marginal of a matrix Whittaker measure with parameters \((\alpha (1), \dots , \alpha (n))\) and \(\beta \). \(\square \)
Remark 4.11
The following generalisation of Corollary 4.10 is immediate: under the same hypotheses, for every \(1\le i\le N\) and \(n\ge i\), \(Z^i(n)\) is distributed as the first marginal of the matrix Whittaker measure with parameters \((\alpha (1), \dots , \alpha (n))\) and \((\beta ^1,\dots ,\beta ^i)\). This is due to the fact that, by definition, for any fixed \(i\ge 1\), the process \((Z_1,\dots ,Z_i)\) has both an initial configuration \((I_d,0_d,\dots ,0_d)\) and a Markov evolution that do not depend on the choice of \(N\ge i\). Analogously, for every \(1\le i\le N\) and \(n\ge i\), \(L^i(n)\) is distributed as the ith marginal of the same matrix Whittaker measure.
5 Minimisation of energy functions and Laplace approximations
In this section, we study minimisation problems for certain energy functions of matrix arguments on directed graphs. As a consequence, we obtain Laplace approximations for integrals of exponentials of these energy functions. For our purposes, the most important application of such results consists in certain asymptotics of Whittaker functions of matrix arguments; see Sect. 4.2. However, the results of this section may be of independent interest. For instance, the general framework we work with may be applied to obtain analogous asymptotics for orthogonal Whittaker functions, which also appeared in the study of stochastic systems—see [2, 6].
5.1 Energy functions on directed graphs
Let us recall some terminology of graph theory that will be useful throughout this section. A finite directed graph \(G=(V,E)\) is a pair consisting of a nonempty finite set V of vertices and a set \(E \subset \{(v,w)\in V^2:v\ne w\}\) of edges. Note that edges connecting a vertex to itself are not allowed, nor are multiple edges. The direction of an edge (v, w) connecting v to w is given by the ordering of the pair. For the sake of notational convenience, we also write \(v\rightarrow w\) when \((v,w)\in E\), and \(v \not \rightarrow w\) when \((v,w)\notin E\). A vertex v is called a sink if it has no outcoming edges (i.e. if \(v \not \rightarrow w\) for all \(w\in V\)) and a source if it has no incoming edges (i.e. if \(w \not \rightarrow v\) for all \(w\in V\)). For any \(v,w\in V\) and \(0\le l< \infty \), we call path of length l in G from v to w any sequence \((v_0, v_1,\dots ,v_l)\) such that \(v_0=v\), \(v_l = w\), and \(v_{i-1}\rightarrow v_i\) for all \(1\le i\le l\). A cycle is any path \((v_0, v_1,\dots ,v_l)\) such that \(v_0 = v_l\) and any other two vertices are distinct. We say that G is acyclic if it has no cycles. From now on, throughout the whole section, \(G=(V,E)\) will always be an acyclic finite directed graph.
Lemma 5.1
For all \(v\in V\), there exists a path in G from v to a sink; moreover, there exists a path in G from a source to v.
Proof
We will prove the existence of the first path only, as the existence of the second path follows from a similar argument. We construct the path algorithmically. Set \(v_0:= v\). For all \(i=0,1,2,\dots \), we proceed as follows: if \(v_i\) is a sink, then we stop the algorithm; otherwise, we pick \(v_{i+1}\) to be any vertex such that \(v_i \rightarrow v_{i+1}\). If the algorithm never terminates, then there exist two distinct indices i, j with \(v_i=v_j\), since G is finite; this implies that G has a cycle, against the hypotheses. Therefore, the procedure must stop in a finite number l of steps, thus yielding a path \((v_0, v_1, \dots , v_l)\) from \(v_0=v\) to a sink \(v_l\). \(\square \)
For any integer \(d\ge 1\), let \(\textrm{Sym}_d\), \(\textrm{Diag}_d\), and \(\textrm{Scal}_d\) be the sets of \(d\times d\) real symmetric matrices, real diagonal matrices, and real scalar matrices (i.e. multiples of the \(d\times d\) identity matrix \(I_d\)), respectively. We will write \(\textrm{Sym}_d^V\) for the set of arrays \(x = (x_v)_{v\in V}\), where each \(x_v\in \textrm{Sym}_d\). We will use the notations \(\textrm{Diag}_d^V\) and \(\textrm{Scal}_d^V\) in a similar way.
Let us define the ‘energy functions’
where \({{\,\mathrm{\textrm{e}}\,}}^a\) denotes the usual exponential of the matrix a. The Golden-Thompson inequality (see e.g. [3]) states that \({{\,\textrm{tr}\,}}[{{\,\mathrm{\textrm{e}}\,}}^a {{\,\mathrm{\textrm{e}}\,}}^b] \ge {{\,\textrm{tr}\,}}[{{\,\mathrm{\textrm{e}}\,}}^{a+b}]\) if a and b are symmetric matrices. It follows that
However, the two energy functions are identical only for \(d=1\).
Notice that, by Lemma 5.1, G has at least one sink and one source, possibly coinciding. Throughout, we also assume that there exists at least one vertex of G that is neither a source nor a sink. We can thus fix a subset \(\Gamma \subset V\) that contains all the sinks and sources and such that \(\Gamma ^{\textsf{c}}\), the complement of \(\Gamma \) in V, is nonempty. For any set S and any fixed array \(z = (z_v)_{v\in \Gamma } \in S^{\Gamma }\), let
Our first result concerns the asymptotic behaviour of the energy functions on \(\textrm{Sym}_d^V(z)\). Let \(\Vert \cdot \Vert \) denote any norm on \(\textrm{Sym}_d^V\).
Proposition 5.2
Let \(z\in \textrm{Sym}_d^\Gamma \). For \(x\in \textrm{Sym}_d^V(z)\), we have \(\varphi _d(x) \rightarrow \infty \) and \(\chi _d(x) \rightarrow \infty \) as \(\Vert x\Vert \rightarrow \infty \).
Proof
By inequality (5.3), it suffices to prove the claim for \(\chi _d\). As all norms on a finite-dimensional space are equivalent, we may arbitrarily take
where \(\varrho (a)\) denotes the spectral radius of a symmetric matrix a (i.e. the largest absolute value of its eigenvalues). As the spectral radius is a norm on \(\textrm{Sym}_d\), it can be easily verified that (5.5) defines a norm on \(\textrm{Sym}_d^V\). We will show that, for any sequence \((x^{(n)})_{n\ge 1} \subseteq \textrm{Sym}_d^V(z)\) such that \(\Vert x^{(n)}\Vert \rightarrow \infty \) as \(n\rightarrow \infty \), we have \(\chi _d(x^{(n)})\rightarrow \infty \) as \(n\rightarrow \infty \). For the sake of notational simplicity, we will drop the superscript of \(x^{(n)}\) and leave the dependence on n implicit.
By contradiction, assume that there exists a positive constant C such that, along a subsequence, \(\chi _d(x)\le C\). Since \(\Vert x\Vert \rightarrow \infty \), there exists \(w\in \Gamma ^{\textsf{c}}\) such that, along a further subsequence, \(\varrho (x_w)\rightarrow \infty \). This implies that, passing to a final subsequence, either \(\lambda _{\max }(x_w) \rightarrow \infty \) or \(\lambda _{\max }(-x_w) \rightarrow \infty \), where \(\lambda _{\max }(a)\) denotes the maximum eigenvalue of a symmetric matrix a. As \(w\in \Gamma ^{\textsf{c}}\), it is neither a source nor a sink. By Lemma 5.1, there exists a path \((v_0, v_1, \dots , v_l)\) of length \(l\ge 1\) in G from \(v_0=w\) to a sink \(v_l \in \Gamma \). Since G has no cycles, we have \(v_i \ne v_j\) for all \(i\ne j\); therefore, all directed edges \(v_{i-1} \rightarrow v_i\) (\(1\le i\le d\)) are distinct. We thus have
where we used the bounds \({{\,\textrm{tr}\,}}[{{\,\mathrm{\textrm{e}}\,}}^y] \ge \lambda _{\max }({{\,\mathrm{\textrm{e}}\,}}^y) = {{\,\mathrm{\textrm{e}}\,}}^{\lambda _{\max }(y)}\) for \(y\in \textrm{Sym}_d\) and \({{\,\mathrm{\textrm{e}}\,}}^\alpha \ge \alpha \) for \(\alpha \in \mathbb {R}\). Recall now that, for any \(a,b\in \textrm{Sym}_d\),
By iterating (5.7) several times and using (5.6), we obtain
By considering a path \((u_0, u_1, \dots , u_m)\) of length \(m\ge 1\) from a source \(u_0\in \Gamma \) to \(u_m=w\) (which again exists by Lemma 5.1) and using similar bounds, we also have
Since either \(\lambda _{\max }(x_w) \rightarrow \infty \) or \(\lambda _{\max }(-x_w) \rightarrow \infty \), it follows that either \(\lambda _{\max }(x_{v_l}) \rightarrow \infty \) or \(\lambda _{\max }(-x_{u_0}) \rightarrow \infty \). This contradicts the fact that \(x_{v_l} = z_{v_l}\) and \(x_{u_0} = z_{u_0}\) are both fixed for all \(x\in \textrm{Sym}_d^V(z)\), since \(v_l, u_0 \in \Gamma \). \(\square \)
Remark 5.3
Above we have assumed that \(G=(V,E)\) is acyclic and that \(\Gamma \) is a subset of V containing all the sinks and sources of G. We stress that both hypotheses are necessary for Prop. 5.2 to hold. As a counterexample, let G be the cycle graph with n vertices and let \(\Gamma =\varnothing \). If \(a\in \textrm{Sym}_d\) and \(x=(x_v)_{v\in V}\) is the array with \(x_v =a\) for all v, then
is constant in a; however, for the norm \(\Vert \cdot \Vert \) defined in (5.5), if \(\varrho (a)\rightarrow \infty \), then \(\Vert x\Vert \rightarrow \infty \).
5.2 Minima of energy functions
We now study the minima of the functions (5.1)–(5.2) on the set \(\textrm{Sym}_d^V(z)\), where \(z\in \textrm{Sym}_d^\Gamma \). In words, we wish to minimise the energy functions subject to the constraint that some of the entries of the input array (precisely, those indexed by the vertices of the subset \(\Gamma \)) are fixed.
We start with the simplest case \(d=1\), in which \(\textrm{Sym}_1 = \textrm{Diag}_1 = \textrm{Scal}_1 = \mathbb {R}\) and the two energy functions coincide:
We denote by \(\partial _v\) the partial derivative of a function on \(\mathbb {R}^V\) with respect to the variable \(x_v\).
Lemma 5.4
Let \(z\in \mathbb {R}^\Gamma \). The Hessian matrix of \(\varphi _1\) on \(\mathbb {R}^V(z)\) is positive definite everywhere. In particular, \(\varphi _1\) is strictly convex on \(\mathbb {R}^V(z)\).
Proof
On \(\mathbb {R}^V(z)\) the variables indexed by \(\Gamma \) are fixed to the assigned values z, hence we can consider \(\varphi _1\) and its Hessian as functions of \((x_v)_{v\in \Gamma ^{\textsf{c}}}\). For \(v,w\in \Gamma ^{\textsf{c}}\), we have
Thus, the quadratic form of the Hessian of \(\varphi _1\) on \(\mathbb {R}^V(z)\), as a function of \(\alpha = (\alpha _v)_{v\in \Gamma ^{\textsf{c}}}\), is
Setting \(\alpha _v:=0\) for all \(v\in \Gamma \), it is easy to see that the latter expression equals
Therefore, the Hessian is positive semidefinite everywhere. To prove that it is in fact positive definite, we will show that, if the quadratic form of the Hessian vanishes at \(\alpha \), then \(\alpha =0\). If the above expression vanishes, then \(\alpha _v = \alpha _w\) for all \(v,w\in V\) such that \(v\rightarrow w\). Let \(v \in \Gamma ^{\textsf{c}}\). By Lemma 5.1, there exists a path from v to a sink \(s\in \Gamma \). The value \(\alpha _w\) is then the same for all the vertices w along such a path. We then have \(\alpha _{v} = \alpha _s = 0\), since \(s\in \Gamma \). As \(v\in \Gamma ^{\textsf{c}}\) was arbitrary, it follows that \(\alpha =(\alpha _v)_{v\in \Gamma ^{\textsf{c}}} =0\). \(\square \)
Proposition 5.5
The function \(\varphi _1=\chi _1\) has a unique (global) minimiser on \(\mathbb {R}^V(z)\).
Proof
By Lemma 5.4, \(\varphi _1\) is a strictly convex function over the convex set \(\mathbb {R}^V(z)\); therefore, it has at most one minimiser. It remains to show the existence of a minimiser. Since \(\varphi _1\) is a continuous function, it admits at least one minimiser on every closed ball \(B_r:= \{ x\in \mathbb {R}^V(z):\Vert x\Vert \le r\}\). By Prop. 5.2, for r large enough, the minimiser on \(B_r\) is also a (global) minimiser on \(\mathbb {R}^V(z)\). \(\square \)
The case \(d>1\) is much more challenging, and we are able to deal with it only under rather strong assumptions on the fixed array z. Nonetheless, this is sufficient for our ultimate purposes.
We will be using the fact that the relation between the eigenvalues and the diagonal entries of a symmetric matrix is completely characterised by the majorisation relation. Let us briefly explain this statement, referring to [23, § 4.3] for proofs and details. For any \(\alpha = (\alpha _1, \dots , \alpha _d)\in \mathbb {R}^d\), let us denote by \(\alpha ^{\downarrow } = (\alpha ^{\downarrow }_1, \dots , \alpha ^{\downarrow }_d)\) its nonincreasing rearrangement, i.e. the permutation of the coordinates of \(\alpha \) such that \(\alpha ^{\downarrow }_1 \ge \alpha ^{\downarrow }_2 \ge \dots \ge \alpha ^{\downarrow }_d\). Given \(\alpha , \beta \in \mathbb {R}^d\), we say that \(\alpha \) majorises \(\beta \), and write \(\alpha \succ \beta \), if
Theorem 5.6
([23, Theorem 4.3.45]) Let \(x\in \textrm{Sym}_d\). Let \(\lambda = (\lambda _1, \dots \lambda _d)\) be the vector of the (real) eigenvalues of x, taken in any order. Let \(\delta _i:= x(i,i)\) for \(1\le i\le d\), so that \(\delta = (\delta _1, \dots , \delta _d)\) is the vector of the diagonal entries of x. Then we have \(\lambda \succ \delta \), and the equality \(\lambda ^{\downarrow } = \delta ^{\downarrow }\) holds if and only if x is a diagonal matrix.
We now briefly introduce the concept of Schur convexity and state the criterion that is useful for our purposes, referring e.g. to [30, Ch. I.3] for more details. A function \(H:\mathbb {R}^d \rightarrow \mathbb {R}\) is called Schur-convex if \(H(\alpha ) \ge H(\beta )\) for all \(\alpha ,\beta \in \mathbb {R}^d\) such that \(\alpha \succ \beta \). In particular, for all \(\alpha ,\beta \) such that \(\alpha ^{\downarrow } = \beta ^{\downarrow }\), we have \(\alpha \succ \beta \succ \alpha \), hence \(H(\alpha ) = H(\beta )\); in other words, every Schur-convex function is a symmetric function. Additionally, H is called strictly Schur-convex if \(H(\alpha ) > H(\beta )\) for all \(\alpha ,\beta \in \mathbb {R}^d\) such that \(\alpha \succ \beta \) and \(\alpha ^{\downarrow } \ne \beta ^{\downarrow }\).
Theorem 5.7
([30, Ch. I.3, § C]) Let \(h:\mathbb {R}\rightarrow \mathbb {R}\) and
If h is convex, then H is Schur-convex. If h is strictly convex, then H is strictly Schur-convex.
As a consequence of the results just stated, we obtain:
Proposition 5.8
Suppose that \(x\in \textrm{Sym}_d\) and \(y\in \textrm{Diag}_d\) have the same diagonal entries. Then \({{\,\textrm{tr}\,}}[{{\,\mathrm{\textrm{e}}\,}}^x] \ge {{\,\textrm{tr}\,}}[{{\,\mathrm{\textrm{e}}\,}}^y]\), and the equality holds if and only if \(x=y\).
Proof
Let \(\lambda = (\lambda _1,\dots ,\lambda _d)\) be the vector of the eigenvalues of x, taken in any order. Let \(\delta =(\delta _1,\dots ,\delta _d)\) be the vector of (common) diagonal entries of x and y, i.e. \(\delta _i = x(i,i) = y(i,i)\) for all \(1\le i\le d\). Since y is diagonal, notice that the \(\delta _i\)’s are also its eigenvalues. Therefore, the claimed inequality \({{\,\textrm{tr}\,}}[{{\,\mathrm{\textrm{e}}\,}}^x] \ge {{\,\textrm{tr}\,}}[{{\,\mathrm{\textrm{e}}\,}}^y]\) reads as \(H(\lambda ) \ge H(\delta )\), where
The function H is strictly Schur-convex by Theorem 5.7, since the exponential function is strictly convex. Since \(\lambda \succ \delta \) by Theorem 5.6, we then have \(H(\lambda ) \ge H(\delta )\), as required. Moreover, assume that \(H(\lambda ) = H(\delta )\). Then, by strict Schur-convexity of H, we have \(\lambda ^{\downarrow } = \delta ^{\downarrow }\). Again by Theorem 5.6, we conclude that x is diagonal, which in turn implies \(x=y\). \(\square \)
From the latter proposition we deduce the existence and uniqueness of a minimiser of \(\chi _d\) on \(\textrm{Sym}_d^V(z)\), under the assumption that all the ‘fixed’ entries z are diagonal matrices.
Theorem 5.9
Let \(z= (z_v)_{v\in \Gamma } \in \textrm{Diag}^{\Gamma }_d\) and set \(z(i,i):= (z_v(i,i))_{v\in \Gamma } \in \mathbb {R}^{\Gamma }\) for all \(1\le i\le d\). Then, the function \(\chi _d\) admits a unique minimiser on \(\textrm{Sym}_d^V(z)\). Such a minimiser is of the form \(m=(m_v)_{v\in V} \in \textrm{Diag}_d^V(z)\), where \(m(i,i):= (m_v(i,i))_{v\in V} \in \mathbb {R}^V\) denotes the unique minimiser of \(\chi _1\) on \(\mathbb {R}^V(z(i,i))\) for all i.
Proof
The claim will immediately follow from the two following facts:
-
(i)
for any \(x\in \textrm{Sym}_d^V(z)\), there exists \(y\in \textrm{Diag}_d^V(z)\) such that \(\chi _d(x)\ge \chi _d(y)\), with equality if and only if \(x=y\);
-
(ii)
there exists \(m\in \textrm{Diag}_d^V(z)\) (as in the statement of the theorem) such that \(\chi _d(x) \ge \chi _d(m)\) for any \(x\in \textrm{Diag}_d^V(z)\), with equality if and only if \(x=m\).
Proof of (i). Fix any \(x\in \textrm{Sym}_d^V(z)\). Define \(y=(y_v)_{v\in V}\) so that, for all \(v\in V\), \(y_v\) is the diagonal matrix with the same diagonal entries as x, i.e. \(y_v(i,i) = x_v(i,i)\) for \(1\le i\le d\). Since each \(z_v\) (for \(v\in \Gamma \)) is diagonal by hypothesis, we have \(y\in \textrm{Diag}_d^V(z)\). For any \(v,w\in V\), the matrices \(x_v-x_w\in \textrm{Sym}_d\) and \(y_v-y_w\in \textrm{Diag}_d\) have the same diagonal entries, hence \({{\,\textrm{tr}\,}}[{{\,\mathrm{\textrm{e}}\,}}^{x_v - x_w}] \ge {{\,\textrm{tr}\,}}[{{\,\mathrm{\textrm{e}}\,}}^{y_v - y_w}]\) by Prop. 5.8; summing over \(v\rightarrow w\), we obtain that \(\chi _d(x) \ge \chi _d(y)\). Assume now that \(\chi _d(x) = \chi _d(y)\). Then, \({{\,\textrm{tr}\,}}[{{\,\mathrm{\textrm{e}}\,}}^{x_v - x_w}] = {{\,\textrm{tr}\,}}[{{\,\mathrm{\textrm{e}}\,}}^{y_v - y_w}]\) whenever \(v\rightarrow w\). Again by Prop. 5.8, we then have \(x_v-y_v= x_w - y_w\) for all \(v\rightarrow w\). For any \(v\in V\), by Lemma 5.1 there exists a path \((v_0,v_1,\dots ,v_l)\) in G from \(v_0=v\) to a sink \(v_l\). Since all sinks are in \(\Gamma \) by assumption (see Sect. 5.1) and both x and y are in \(\textrm{Sym}_d^V(z)\), we have \(x_{v_l}=z_{v_l}=y_{v_l}\). Therefore, \(x_v - y_v = x_{v_1} - y_{v_1} = \cdots = x_{v_l} - y_{v_l} =0\); in particular, \(x_v=y_v\). As \(v\in V\) is arbitrary, we conclude that \(x=y\).
Proof of (ii). For \(x\in \textrm{Diag}_d^V(z)\), set \(x(i,i):=(x_v(i,i))_{v\in V} \in \mathbb {R}^V\). As each \(x_v\) is diagonal, we have
By Prop. 5.5, for all i, \(\chi _1\) has a unique minimiser m(i, i) on \(\mathbb {R}^V(z(i,i))\). Therefore, we have
and the inequality is strict whenever \(x\ne m\). \(\square \)
In the case where the ‘fixed’ entries z are scalar matrices, the inequality (5.3) immediately implies the existence and uniqueness of a minimiser of \(\varphi _d\).
Corollary 5.10
Let \(z= (z_v)_{v\in \Gamma } \in \textrm{Scal}^{\Gamma }_d\), so that \(z_v = \zeta _v I_d\) for all \(v\in \Gamma \) and for a certain \(\zeta = (\zeta _v)_{v\in V} \in \mathbb {R}^{\Gamma }\). Then, the function \(\varphi _d\) admits a unique minimiser on \(\textrm{Sym}_d^V(z)\). Such a minimiser is of the form \(m=(m_v)_{v\in V} = (\mu _v I_d)_{v\in V} \in \textrm{Scal}_d^V(z)\), where \(\mu = (\mu _v)_{v\in V} \in \mathbb {R}^V\) is the unique minimiser of \(\varphi _1\) on \(\mathbb {R}^V(\zeta )\).
Proof
Since \(\textrm{Scal}_d^{\Gamma } \subseteq \textrm{Diag}_d^{\Gamma }\), it follows from Theorem 5.9 that \(\chi _d\) has a unique minimiser m on \(\textrm{Sym}_d^V(z)\), which is of the form specified above. Since the scalar matrices \(m_v\) and \(m_w\) commute for any \(v,w\in V\), we have \({{\,\mathrm{\textrm{e}}\,}}^{m_v} {{\,\mathrm{\textrm{e}}\,}}^{-m_w} = {{\,\mathrm{\textrm{e}}\,}}^{m_v-m_w}\), hence \(\varphi _d(m) = \chi _d(m)\). By (5.3), we then have
where the second inequality is strict if \(x\ne m\). It follows that m is also the unique minimiser of \(\varphi _d\) on \(\textrm{Sym}_d^V(z)\). \(\square \)
5.3 Energy functions in logarithmic variables
It is a well-known fact that the functions
namely the matrix exponential and the matrix logarithm, are both bijections on the stated domains and inverse to each other. From now on, for any set S, we will use the following compact notations: \(\log x:= (\log x_v)_{v\in S} \in \textrm{Sym}_d^S\) for \(x=(x_v)_{v\in S}\in \mathcal {P}_d^S\), and \({{\,\mathrm{\textrm{e}}\,}}^{x}:= ({{\,\mathrm{\textrm{e}}\,}}^{x_v})_{v\in S} \in \mathcal {P}_d^S\) for \(x=(x_v)_{v\in S}\in \textrm{Sym}_d^S\).
Let us consider the analogue of \(\varphi _d\) ‘in logarithmic variables’, that is the energy function \(\Phi _d(x):= \varphi _d(\log x)\) for \(x\in \mathcal {P}_d^V\). More explicitly, recalling (5.1), we define
Take now \(z = (z_v)_{v\in \Gamma }\) such that each \(z_v\) is a positive multiple of \(I_d\), or equivalently \(\log z \in \textrm{Scal}^{\Gamma }_d\). By Corollary 5.10, \(\Phi _d\) has a unique minimiser m on \(\mathcal {P}_d^V(z)\), where \(\log m\) is the unique minimiser of \(\varphi _d\) on \(\textrm{Sym}_d^V(\log z)\). This implies that, on \(\mathcal {P}_d^V(z)\), the Hessian of \(\Phi _d\) at m is positive semidefinite. We now aim to prove the stronger statement that the Hessian of \(\Phi _d\) at m is positive definite.
As in the previous subsections, we first work with \(d=1\). Recall that, by Lemma 5.4, \(\varphi _1\) is strictly convex on \(\mathbb {R}^V(\log z)\), for \(z \in \mathcal {P}_1^{\Gamma }\). The analogous statement does not hold for \(\Phi _1\) on \(\mathcal {P}_1^V(z)\); however, the following is still true:
Lemma 5.11
For \(z\in \mathcal {P}_1^{\Gamma }\), the Hessian of \(\Phi _1\) on \(\mathcal {P}_1^V(z)\) is positive definite at any critical point.
Proof
We prove the claim by simply expressing the derivatives of \(\Phi _1\) in terms of the derivatives of \(\varphi _1\). For \(v\in \Gamma ^{\textsf{c}}\), the first partial derivative of \(\Phi _1\) w.r.t. \(x_v\) is
Therefore, for \(v,w\in \Gamma ^{\textsf{c}}\),
Assume now that x is a critical point of \(\Phi _1\) on \(\mathcal {P}_1^V(z)\), i.e. that both sides of (5.10) vanish for all \(v\in \Gamma ^{\textsf{c}}\). Then, we have
As the Hessian of \(\varphi _1\) on \(\mathbb {R}^V(\log z)\) is positive definite everywhere by Lemma 5.4, it follows that the Hessian of \(\Phi _1\) on \(\mathcal {P}_1^V(z)\) is positive definite at x. \(\square \)
To compute the Hessian in the general case \(d\ge 1\), we will use the following basic formulas (see e.g. [36]) that hold for any \(a,b\in \mathcal {P}_d\), \(1\le i\le j\le d\), and \(1\le k\le \ell \le d\):




where \(\delta (i,j)\) is 1 if \(i=j\) and 0 otherwise. In (5.12),  denotes the preceding expression with the indices i and j swapped. Notice that (5.12) and (5.14) can be deduced from (5.11).
denotes the preceding expression with the indices i and j swapped. Notice that (5.12) and (5.14) can be deduced from (5.11).
Let \(\textrm{Scal}_d^+\) be the set of positive definite scalar matrices, i.e. positive multiples of \(I_d\).
Lemma 5.12
Let \(z\in (\textrm{Scal}_d^+)^{\Gamma }\). Then, the Hessian of \(\Phi _d\) on \(\mathcal {P}_d^V(z)\) is positive definite at any critical point x such that \(x \in (\textrm{Scal}_d^+)^{V}(z)\).
Proof
We will prove that, under the stated assumptions, the Hessian of \(\Phi _d\) (for \(d\ge 1\)) can be expressed in terms of the Hessian of \(\Phi _1\); the claim will then follow from Lemma 5.11.
For ease of notation, given any \(v\in V\) and \(1\le i\le j\le d\), we will denote by \(\partial _{v;i,j}\) the partial derivative of a function of \(x\in \mathcal {P}_d^V\) with respect to the real variable \(x_v(i,j)\).
It follows from the definition (5.9) and from the formulas (5.13)–(5.14) that
for \(v\in \Gamma ^{\textsf{c}}\) and \(1\le i\le j\le d\). The critical point equations of \(\Phi _d\) on \(\mathcal {P}_d^V(z)\) are then
We will now compute the second derivatives at any critical point \(x=(x_v)_{v\in V} \in \mathcal {P}_d^V(z)\). Using (5.12) and (5.15), we have

for \(v\in \Gamma ^{\textsf{c}}\), \(1\le i\le j\le d\), and \(1\le k\le \ell \le d\). Recall now that the acyclic structure of the underlying graph guarantees that, if \(v\rightarrow w\), then \(w\not \rightarrow v\). Therefore, for \(v,w\in \Gamma ^{\textsf{c}}\) such that \(v\rightarrow w\), \(1\le i\le j\le d\), and \(1\le k\le \ell \le d\), we have
On the other hand, the second derivative w.r.t. \(x_v(i,j)\) and \(x_w(k,\ell )\) vanishes for all \(v,w\in \Gamma ^{\textsf{c}}\) such that \(v\not \rightarrow w\) and \(w\not \rightarrow v\).
According to the hypotheses of the theorem, we further assume from now on that there exists \(\zeta = (\zeta _v)_{v\in V} \in \mathcal {P}_1^{\Gamma }\) such that \(z_v = \zeta _v I_d\) for all \(v\in \Gamma \), and there exists \(\xi = (\xi _v)_{v\in V} \in \mathcal {P}_1^V\) such that \(x_v = \xi _v I_d\) for all \(v\in V\). Using the identity
we see that the second derivatives at x factorise as
Here, \(g_{\xi }(v,w)\) is an explicit function of \(\xi \), v and w; we stress that it is the same function for all \(d\ge 1\). It follows from (5.15) that, since \(x=(\xi _v I_d)_{v\in V}\) is a critical point of \(\Phi _d\) on \(\mathcal {P}_d^V(z)\), \(\xi \) is a critical point of \(\Phi _1\) on \(\mathcal {P}_1^V(\zeta )\). Therefore, the matrix
(with ‘row index’ v and ‘column index’ w), which is the Hessian matrix of \(\Phi _1\) on \(\mathcal {P}_1^V(\zeta )\) at \(\xi \), is positive definite by Lemma 5.11. On the other hand, the matrix \(f((i,j),(k,\ell ))\) (with ‘row index’ (i, j) and ‘column index’ \((k,\ell )\)) is clearly positive definite as a diagonal matrix with positive diagonal entries. Therefore, the Hessian of \(\Phi _d\) on \(\mathcal {P}_d^V(z)\) at x is positive definite, as it can be written as a Kronecker product of two positive definite matrices. \(\square \)
As any minimiser is a critical point, the main result of this section follows immediately from Corollary 5.10 and Lemma 5.12.
Theorem 5.13
Let \(z\in (\textrm{Scal}_d^+)^{\Gamma }\). Then, the function \(\Phi _d\) on \(\mathcal {P}_d^{V}(z)\) has a unique (global) minimiser m, at which the Hessian is positive definite. Moreover, we have \(m\in (\textrm{Scal}_d^+)^{V}(z)\).
5.4 Laplace approximation
We will now use Theorem 5.13 to study the asymptotic behaviour of integrals of exponentials of \(\Phi _d\), via Laplace’s approximation method. Recall the definition (1.12) of the measure \(\mu \) on \(\mathcal {P}_d\).
Proposition 5.14
Let \(z\in (\textrm{Scal}_d^+)^{\Gamma }\) and let m be the unique global minimiser of \(\Phi _d\) on \(\mathcal {P}_d^{V}(z)\) (see Theorem 5.13). Let \(g:\mathcal {P}_d^V(z) \rightarrow \mathbb {C}\) be a continuous function in a neighbourhood of m, with \(g(m)\ne 0\), and such that
Then

where \(\left|\mathcal {H}(m)\right|>0\) is the Hessian determinant of \(\Phi _d\) at m and \(\big |\Gamma ^{\textsf{c}}\big |\) is the number of vertices in \(\Gamma ^{\textsf{c}}\).
We start by stating the Laplace approximation integral formula in the multivariate context, which can be found e.g. in [19].
Theorem 5.15
([19, Theorem 4.14]) Let A be an open subset of the p-dimensional space \(\mathbb {R}^p\). Let \(h:A \rightarrow \mathbb {C}\) and \(\varrho :A\rightarrow \mathbb {R}\) be functions such that
-
(i)
\(\int _{A} \left|h(x)\right| {{\,\mathrm{\textrm{e}}\,}}^{-k \varrho (x)} \mathop {}\!\textrm{d}x < \infty \) for some \(k>0\).
-
(ii)
\(\varrho \) has a global minimiser \(x_0\in A\) such that, for every \(\varepsilon >0\),
$$\begin{aligned} \inf \{\varrho (x)-\varrho (x_0) :x\in A, \, \left|x-x_0\right| \ge \varepsilon \} >0 \,. \end{aligned}$$(5.17) -
(iii)
h is continuous in a neighbourhood of \(x_0\) and \(h(x_0) \ne 0\).
-
(iv)
\(\varrho \) is twice continuously differentiable on A and its Hessian matrix \(\mathcal {H}(x_0)\) at \(x_0\) is positive definite (in particular, its determinant \(\left|\mathcal {H}(x_0)\right|\) is positive).
Then,

Proof of Prop. 5.14
We will apply Theorem 5.15 with
The set \(\mathcal {P}_d^V(z)\) can be clearly viewed as an open subset of \(\mathbb {R}^p\), where \(p=\big |\Gamma ^{\textsf{c}}\big |d(d+1)/2\) is the number of ‘free’ real variables in A and d is the dimension of each matrix in the array. The extra product in the definition of h is the density of the measure \(\prod _{v\in \Gamma ^{\textsf{c}}} \mu (\mathop {}\!\textrm{d}x_v)\) with respect to the Lebesgue measure on \(\mathcal {P}_d^V(z)\).
Hypothesis (ii) of Theorem 5.15 is satisfied due to Theorem 5.13 and Prop. 5.2. Hypotheses (i) and (iii) are matched by the assumptions of Prop. 5.14. Finally, hypothesis (iv) also holds because of Theorem 5.13. The asymptotic formula (5.16) then follows from (5.18). \(\square \)
References
Arista, J., Bisi, E., O’Connell, N.: Matsumoto-Yor and Dufresne type theorems for a random walk on positive definite matrices. Ann. Inst. H. Poincaré (B) Probab. Statist. (2023+). arXiv: 2112.12558
Barraquand, G., Wang, S.: An identity in distribution between full-space and half-space log-gamma polymers. Int. Math. Res. Not. (2023+). arXiv:2108.08737
Bhatia, R.: Matrix Analysis Graduate. Texts in Mathematics. Springer, New York (1997)
Billingsley, P.: Probability and Measure. Wiley Series in Probability and Mathematical Statistics, 3rd ed. Wiley, Hoboken (1995)
Billingsley, P.: Convergence of Probability. Measures Wiley Series in Probability and Statistics, 2nd ed. Wiley, Hoboken (1999)
Bisi, E., Zygouras, N.: Point-to-line polymers and orthogonal Whittaker functions. Trans. Am. Math. Soc. 371(12), 8339–8379 (2019)
Borodin, A., Corwin, I.: Macdonald processes. Probab. Theory Relat. Fields 158(1–2), 225–400 (2014)
Borodin, A., Ferrari, P.L.: Anisotropic growth of random surfaces in 2+1 dimensions. Commun. Math. Phys. 325, 603–684 (2014)
Borodin, A., Gorin, V.: Lectures on integrable probability. In: Sidoravicius, V., Smirnov, S. (eds.) Probability and Statistical Physics in St. Petersburg, Vol. 91. Proceedings of Symposia in Pure Mathematics. AMS, pp. 155– 214 (2016)
Borodin, A., Petrov, L.: Integrable probability: from representation theory to Macdonald processes. Probab. Surveys 11, 1–58 (2014)
Borodin, A., Petrov, L.: Nearest neighbor Markov dynamics on Macdonald processes. Adv. Math. 300, 71–155 (2016)
Bump, D.: The Rankin-Selberg method: a survey. In: Aubert, K.E., Bombieri, E., Goldfeld, D. (eds.) Number Theory, Trace Formulas and Discrete Groups, pp. 49–109. Academic Press, London (1989)
Bump, D., Huntley, J.: Unramified Whittaker functions for \(GL(3,\mathbb{R} )\). J. Anal. Math. 65, 19–44 (1995)
Butler, R.W., Wood, A.T.A.: Laplace approximation for Bessel functions of matrix argument. J. Comput. Appl. Math. 155(2), 359–382 (2003)
Corwin, I.: Kardar–Parisi–Zhang Universality. Not. Am. Math. Soc. 63(3), 230–239 (2016)
Corwin, I., O’Connell, N., Seppäläinen, T., Zygouras, N.: Tropical combinatorics and Whittaker functions. Duke Math. J. 163(3), 513–563 (2014)
Corwin, I., Seppäläinen, T., Shen, H.: The strict-weak lattice polymer. J. Stat. Phys. 160, 1027–1053 (2015)
Dynkin, E.B.: Non-negative eigenfunctions of the Laplace-Beltrami operator and Brownian motion in certain symmetric spaces. Dokl. Akad. Nauk SSSR 141(2), 288–291 (1961)
Evans, M., Swartz, T.: Approximating Integrals via Monte Carlo and Deterministic Methods. Oxford Statistical Science Series, Oxford Univ Press, Oxford (2000)
Gautié, T., Bouchaud, J.-P., Le Doussal, P.: Matrix Kesten recursion, inverse-Wishart ensemble and fermions in a Morse potential. J. Phys. A: Math. Theor. 54(25), 255201 (2021)
Gerasimov, A., Lebedev, D., Oblezin, S.: Baxter operator and Archimedean Hecke algebra. Commun. Math. Phys. 284(3), 867–896 (2008)
Grabsch, A.: Théorie des matrices aléatoires en physique statistique: théorie quantique de la diffusion et systèmes désordonnés. PhD thesis. Université Paris- Saclay (2018)
Horn, R.A., Johnson, C.R.: Matrix Analysis, 2nd ed Cambridge University Press, Cambridge (2013)
Johansson, K.: Shape fluctuations and random matrices. Commun. Math. Phys. 209(2), 437–476 (2000)
Kelly, F.P.: Markovian Functions of a Markov Chain. Sankhyā: Indian J. Stat. Ser. A 44(3), 372–379 (1982)
Kemeny, J.G., Snell, J.L.: Finite Markov Chains. Undergraduate Texts in Mathematics, Springer-Verlag, New York (1976)
Kharchev, S., Lebedev, D.: Integral representations for the eigenfunctions of quantum open and periodic Toda chains from the QISM formalism. J. Phys. A 34(11), 2247–2258 (2001)
Kurtz, T.: Martingale problems for conditional distributions of Markov processes. Electron. J. Probab. 3, 1–29 (1998)
Macdonald, I.G.: Symmetric Functions and Hall Polynomials. Oxford Univ. Press, London (1979)
Marshall, A.W., Olkin, I., Arnold, B.C.: Inequalities: Theory of Majorization and its Applications. Springer Series in Statistics, 2nd ed. Springer, New York (2011)
Nordenstam, E.: On the shuffling algorithm for domino tilings. Electron. J. Probab. 15, 75–95 (2010)
O’Connell, N.: Directed polymers and the quantum Toda lattice. Ann. Probab. 40(2), 437–458 (2012)
O’Connell, N.: Interacting diffusions on positive definite matrices. Probab. Theory Relat. Fields 180, 679–726 (2021)
O’Connell, N., Ortmann, J.: Tracy-Widom asymptotics for a random polymer model with gamma-distributed weights. Electron. J. Probab. 20(25), 1–18 (2015)
O’Connell, N., Seppäläinen, T., Zygouras, N.: Geometric RSK correspondence, Whittaker functions and symmetrized random polymers. Invent. Math. 197(2), 361–416 (2014)
Petersen, K.B., Pedersen, M.S.: The Matrix Cookbook (2012). http://www2.imm.dtu.dk/pubdb/pubs/3274-full.html
Rogers, L.C.G., Pitman, J.W.: Markov functions. Ann. Probab. 9(4), 573–582 (1981)
Rudin, W.: Principles of Mathematical Analysis, 3rd edn. McGraw-Hill, New York (1976)
Seppäläinen, T.: Scaling for a one-dimensional directed polymer with boundary conditions. Ann. Probab. 40(1), 19–73 (2012)
Stade, E.: Archimedean L-factors on \(GL(n) \times GL(n)\) and generalized Barnes integrals. Israel J. Math. 127(1), 201–219 (2002)
Stanley, R. P.: Enumerative Combinatorics: volume 2. Vol. 62. Cambridge Studies in Advanced Mathematics. Cambridge University Press, Cambridge (1999)
Terras, A.: Harmonic Analysis on Symmetric Spaces-Higher Rank Spaces, Positive Definite Matrix Space and Generalizations, 2nd edn. Springer, New York (2016)
Warren, J.: Dyson’s Brownian motions, intertwining and interlacing. Electron. J. Probab. 12, 573–590 (2007)
Warren, J., Windridge, P.: Some examples of dynamics for Gelfand-Tsetlin patterns. Electron. J. Probab. 14, 1745–1769 (2009)
Zygouras, N.: Some algebraic structures in the KPZ universality. Probab. Surv. 19, 590–700 (2022)
Acknowledgements
The authors thank the anonymous referees for their helpful comments and suggestions, which have led to a much improved version of the paper.
Funding
Open access funding provided by TU Wien (TUW).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Research supported by the European Research Council (Grant 669306).
Appendices
Appendix A: A proof of the Cauchy–Littlewood identity
In this appendix we include a proof of the classical Cauchy–Littlewood identity for Schur functions that is based on a version of the Pieri rule. The proof of the Whittaker integral identity (4.1) is based, mutatis mutandis, on the same line of reasoning.
For any two integer partitions \(\mu =(\mu _1\ge \mu _2\ge \cdots )\) and \(\lambda =(\lambda _1\ge \lambda _2\ge \cdots )\), we write \(\mu \prec \lambda \) if \(\lambda _i\ge \mu _i\ge \lambda _{i+1}\) for all \(i\ge 1\). The size of \(\lambda \) is \(\left|\lambda \right|:=\lambda _1+\lambda _2+\dots \), while its length is the smallest \(i\ge 0\) such that \(\lambda _{i+1}=0\). We will adopt the following recursive definition of Schur polynomials: for a partition \(\lambda \) of length \(\le n\), we set
For the sake of convenience, we also set \(s_{\lambda }(x_1,\dots ,x_n):=0\) if the length of \(\lambda \) exceeds n. This definition is easily seen to be equivalent to the classical combinatorial definition of Schur polynomials as generating functions of semistandard Young tableaux.
We will use the following version of the Pieri rule:
The latter can be deduced from the usual Pieri rule (see e.g. [29, I-(5.16)])
by summing over all \(r\ge 0\). Notice that (A.2) can be read as an eigenfunction equation for the operator defined through the kernel \(I(\mu ;\lambda ):= \mathbb {1}_{\mu \prec \lambda }\), with the Schur function \(s_{\mu }\) (viewed as a function of the partition \(\mu \)) as an eigenfunction.
Theorem A.1
(Cauchy–Littlewood identity) For any \(n,N\ge 1\), we have
where the sum is over all integer partitions \(\lambda \).
Proof
Note first that we can restrict the sum on the left-hand side of (A.3) to the partitions \(\lambda \) with length \(\le \min (n,N)\). When \(N=n=1\), the identity reduces to a geometric sum:
We can then proceed by induction on \(n+N\).
Let \(n+N> 2\) and assume, without loss of generality, that \(n>1\). Using the definition (A.1), the fact that \(s_{\lambda }\) is a homogeneous polynomial of degree \(\left|\lambda \right|\), and identity (A.2), we obtain
The claim then follows from the induction hypothesis applied to the latter sum. \(\square \)
Appendix B: Markov functions and intertwinings
In this appendix we review the theory of Markov functions, in the case of inhomogeneous discrete-time Markov processes, which we are concerned with in the present article.
Let \((S, \mathcal {S})\) and \((T, \mathcal {T})\) be measurable spaces and \(\varphi :S\rightarrow T\) be a measurable function. Let \(X=(X(n))_{n\ge 0}\) be a time-inhomogeneous Markov process with state space S, time-n transition kernel \(\Pi _n\) and any initial distribution on X(0). Defining \(Z(n):=\varphi (X(n))\) for all \(n\ge 0\), we will give conditions under which the transformed process \(Z=(Z(n))_{n\ge 0}\) with state space T is still Markov in its own filtration. The well-known Dynkin criterion [18] ensures that Z satisfies the Markov property for any possible initial distribution on X. On the other hand, the theory of Markov functions (developed at various levels of generality in [25, 26, 28, 37]) provides a more subtle criterion, in which the Markov property of Z is guaranteed only under certain specific initial states of X.
Let \(\mathfrak {b} {\mathcal {S}}\) be the space of bounded measurable functions from \((S, \mathcal {S})\) to \(\mathbb {R}\).
Theorem B.1
Let \(X=(X(n))_{n\ge 0}\) be a time-inhomogeneous Markov process on S with time-n transition kernel \(\Pi _n\). Let \(\varphi :S\rightarrow T\) be a measurable function. Let \(Z=(Z(n))_{n\ge 0}\), where \(Z(n)=\varphi (X(n))\) for all \(n\ge 0\). Assume that \(\mathcal {T}\) contains all the singleton sets \(\{z\}\). Let \(\Sigma \) be a Markov kernel from T to S and, for all \(n\ge 1\), let \(P_n\) be a Markov kernel from T to T. Suppose:
-
(i)
\(\Sigma \left( z; \varphi ^{-1}\{z\}\right) =1\) for every \(z\in T\);
-
(ii)
\(\Sigma \Pi _n = P_n \Sigma \) for all \(n\ge 1\).
Assume that, for an arbitrary \(z\in T\), the initial state X(0) of X is distributed according to the measure \(\Sigma (z;\cdot )\). Then, Z is a time-inhomogeneous Markov process (in its own filtration), with initial state z and time-n transition kernel \(P_n\). Moreover, for all \(f\in \mathfrak {b} {\mathcal {S}}\) and \(n\ge 0\), we have
Proof
This proof is an inhomogeneous discrete-time version of the argument given for continuous-time Markov processes in [37]. Note that (i) implies
for all \(g\in \mathfrak {b} {\mathcal {T}}\), \(f\in \mathfrak {b} {\mathcal {S}}\), and \(z\in T\). Letting \(\Phi :\mathfrak {b} {\mathcal {T}} \rightarrow \mathfrak {b} {\mathcal {S}}\) be the Markov operator defined by \(\Phi g:= g\circ \varphi \) for \(g\in \mathfrak {b} {\mathcal {T}}\), we may rewrite the above identity as
Here, as in the following, the operations should be read from right to left, prioritising the brackets (for example, on the left-hand side of (B.2), one first multiplies the two functions f and \(\Phi g\) and then applies the operator \(\Sigma \) to the resulting function). Applying \(P_i\) to both sides of (B.2) and using hypothesis (ii), we have
Consider now test functions \(g_{0},\dots ,g_{n}\) in \(\mathfrak {b} {\mathcal {T}}\) and \(f\in \mathfrak {b} {\mathcal {S}}\). Using (B.2) and (B.3) several times, we obtain
Fix now an arbitrary \(z\in T\) and assume that X(0) is distributed according to \(\Sigma (z;\cdot )\). Then, (B.4) yields
Taking \(f\equiv 1\), we deduce that Z is a Markov process started at z with time-n transition kernel \(P_n\). For general f, the right-hand side of the equation above agrees with
This, by definition of conditional expectation, proves (B.1). \(\square \)
Remark B.2
Taking \(f\equiv 1\) in (B.2), we see that \(\Sigma \Phi \) is the identity on \(\mathfrak {b} {\mathcal {T}}\). Combining this with hypothesis (ii) of Theorem B.1, it is immediate to deduce that every kernel \(P_n\) is uniquely determined by the relation \(P_n =\Sigma \Pi _n\Phi \).
Appendix C: A convergence lemma
Here we state a useful convergence lemma. For completeness we also include its proof, which follows from the properties of weak convergence and standard estimates.
Lemma C.1
Let S be a locally compact metric space equipped with its Borel \(\sigma \)-algebra. Let \((\mu _k)_{k>0}\) be a collection of probability measures on S that converges weakly, as \(k\rightarrow \infty \), to a Dirac measure \(\delta _s\) for some \(s\in S\). Let \((f_k)_{k>0}\) be a uniformly bounded collection of continuous functions \(S\rightarrow \mathbb {R}\) such that \(f_k \xrightarrow {k\rightarrow \infty } f_{\infty }\) uniformly on any compact subset of S. Then
Proof
Fix \(\varepsilon >0\). For any Borel set \(U\subset S\), we may write
where \(\overline{U}\) and \(U^{\textsf{c}}\) are the closure and the complement of U, respectively. Since \(f_{\infty }\) is continuous (as a uniform limit of continuous functions) and S is a locally compact metric space, we can choose U to be a precompact open neighbourhood of s such that \(\left|f_{\infty }(x) - f_{\infty }(s)\right| \le \varepsilon \) for all \(x\in U\). Moreover, as \(\overline{U}\) is compact, for k large enough we have \(\left|f_k(x) - f_{\infty }(x)\right|\le \varepsilon \) for all \(x\in \overline{U}\). Finally, the Portmanteau theorem (see [5, § 2]) yields
since \(\mu _k\) converges weakly to \(\delta _s\), \(U^{\textsf{c}}\) is closed, and \(s\notin U^{\textsf{c}}\); therefore, for large enough k we also have \(\mu _k(U^{\textsf{c}}) \le \varepsilon \). By the hypothesis of uniform boundedness, there exists \(M>0\) such that \(\left|f_k(x)\right|\le M\) for all \(x\in S\) and \(k>0\). Hence, we have
for k large enough. As \(\varepsilon >0\) is arbitrary, the claim follows. \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Arista, J., Bisi, E. & O’Connell, N. Matrix Whittaker processes. Probab. Theory Relat. Fields 187, 203–257 (2023). https://doi.org/10.1007/s00440-023-01210-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00440-023-01210-y
Keywords
- Whittaker functions of matrix arguments
- Intertwining relations
- Interacting Markov dynamics
- Noncommutative polymer models
- Constrained minimisation
- Directed graphs