
Abstract
Macdonald processes are probability measures on sequences of partitions defined in terms of nonnegative specializations of the Macdonald symmetric functions and two Macdonald parameters \(q,t \in [0,1)\). We prove several results about these processes, which include the following. (1) We explicitly evaluate expectations of a rich family of observables for these processes. (2) In the case \(t=0\), we find a Fredholm determinant formula for a \(q\)-Laplace transform of the distribution of the last part of the Macdonald-random partition. (3) We introduce Markov dynamics that preserve the class of Macdonald processes and lead to new “integrable” 2d and 1d interacting particle systems. (4) In a large time limit transition, and as \(q\) goes to 1, the particles of these systems crystallize on a lattice, and fluctuations around the lattice converge to O’Connell’s Whittaker process that describe semi-discrete Brownian directed polymers. (5) This yields a Fredholm determinant for the Laplace transform of the polymer partition function, and taking its asymptotics we prove KPZ universality for the polymer (free energy fluctuation exponent \(1/3\) and Tracy-Widom GUE limit law). (6) Under intermediate disorder scaling, we recover the Laplace transform of the solution of the KPZ equation with narrow wedge initial data. (7) We provide contour integral formulas for a wide array of polymer moments. (8) This results in a new ansatz for solving quantum many body systems such as the delta Bose gas.
Similar content being viewed by others


1 Introduction
The principal goal of the present paper is to develop a formalism of Macdonald processes—a class of probability measures on Gelfand-Tsetlin patterns—and to apply it to studying interacting particle systems and directed random polymers.
Our inspiration comes from three sides: the well-known success of the determinantal point processes in general, and the Schur processes in particular, in analyzing totally asymmetric simple exclusion processes (TASEPs) and last passage percolation problems (in one space dimension); the recent breakthrough [4, 97] in finding exact solutions to the Kardar-Parisi-Zhang stochastic nonlinear PDE (KPZ equation, for short), based either on Tracy-Widom’s integrability theory for the partially asymmetric simple exclusion process (PASEP) or on the replica trick coupled with Bethe ansatz solutions of the quantum delta Bose gas; and O’Connell’s description of a certain random directed polymers in terms of eigenfunctions of the quantum Toda lattice known as class one Whittaker functions (for root systems of type A).
The present work ties these developments together.
The Macdonald processes are defined in terms of the Macdonald symmetric functions, a remarkable two-parameter family of symmetric functions discovered by Macdonald in the late 1980s [79]. The parameters are traditionally denoted by \(q,t\). On the diagonal \(q=t\), the Macdonald symmetric functions turn into the Schur functions, and the Macdonald processes turn into the Schur processes of [91, 92]. The key feature that makes the Schur processes very useful is the determinantal structure of their correlation functions. This feature is not present in the general Macdonald case, which is one reason why Macdonald processes have not been extensively studied yet (see, however, [48, 111]). We find a way of utilizing the Macdonald operators—a sequence of difference operators that are diagonalized by Macdonald symmetric functions—for explicit evaluations of averages for a rich class of observables of Macdonald processes.
In the case \(t=0\), these averages lead us to a Fredholm determinant representation of a \(q\)-Laplace transform of the distribution of the last part of a Macdonald-random partition. The appearance of the Fredholm determinant seems remarkable. As to our best knowledge, the Macdonald symmetric functions (either general ones or those for \(t=0\)) do not carry natural determinantal structures (as opposed to the Schur functions).
In a different direction, we exhibit a family of Markov chains that preserve the class of Macdonald processes. The construction is parallel to that of [18, 26] in the Schur case, and it is based on a much earlier idea of [43]. In the case \(t=0\), the continuous time version of these stochastic dynamics can be viewed as an interacting particle system in two space dimensions (whose Schur degeneration was studied in [26]). A certain one dimensional Markovian subsystem has a particularly simple description – it is a \(q\)-deformation of TASEP where a particle’s jump rate equals \(1-q^{gap}\), with ‘gap’ being the number of open spaces to the right of the particle; we call it \(q\)-TASEP. The Macdonald formalism thus provides explicit expressions for averages of many observables of these interacting particle systems started from certain special initial conditions. In particular, we obtain a Fredholm determinant formula for the \(q\)-Laplace transform of the distribution of any particle in \(q\)-TASEP started from the so-called step initial condition.
We then focus on asymptotic behavior of certain specializations of the Macdonald processes. In what follows, the parameter \(t\) is assumed to be 0.
We find that as \(q\rightarrow 1\), in the so-called Plancherel specialization, the particles in the Macdonald-random Gelfand-Tsetlin pattern crystalize onto a perfect lattice (law of large numbers behavior). The scaled fluctuations of particles around this limiting lattice converge to the Whittaker process introduced by O’Connell [86] as the image of the O’Connell-Yor semi-discrete directed polymer under a continuous version of the tropical RSK correspondence. The process is supported on triangular arrays of real numbers. (This degeneration is parallel to the recently discovered degeneration of the Macdonald symmetric functions to the class one Whittaker function, see [51].) The Markov dynamics on Macdonald processes converge to dynamics on these triangular arrays which are not the same as those induced by the tropical RSK correspondence, but which were also introduced in [86] as a geometric version of Warren’s process [113]. For a different choice of specialization, the fluctuations above converge to another version of the Whittaker process introduced in [39] as the image of Seppäläinen’s log-gamma discrete directed polymer under the tropical RSK correspondence of A.N. Kirillov [71].
Under the scalings to Whittaker processes, the Fredholm determinant formulas converge to similar formulas for the Laplace transform of the partition functions for these polymers (hence characterizing the free energy fluctuations). As one application of these new Fredholm determinant formulas we prove (via steepest descent analysis) that as time \(\tau \) goes to infinity, these polymers are in the KPZ universality class, i.e., their free energy fluctuates like \(\tau ^{1/3}\) with limiting law given by the Tracy-Widom GUE distribution. Under a different scaling, known as intermediate disorder scaling, we show how to recover the Laplace transform for the partition function of the point-to-point continuum directed random polymer, i.e., the solution to the stochastic heat equation with delta initial data, or the exponential of the solution to the KPZ equation with narrow wedge initial data. Those familiar with the non-rigorous replica approach of [45] or [33] may observe that the unjustifiable analytic continuations and rearrangements necessary to sum the divergent moment series in those works (a.k.a. the replica trick), can be seen as shadows of the rigorous manipulations and calculations performed at the higher level of the Macdonald processes.
From the point of view of the KPZ equation, we observe that the \(q\)-TASEP may now be used as its ‘integrable discretization’ in a similar way as PASEP has been used, and we expect to present more results in this direction in future works.
It has been known for a while that moments of exactly solvable polymer models solve certain quantum many body systems with delta interactions. This fact, together with Bethe ansatz computations, has been widely used in physics literature to analyze the polymers. The formalism of the Macdonald processes results in certain explicit integral formulas for those moments, that are thus solutions of the quantum many-body systems.
Those contour integral solutions provide a new and seemingly robust ansatz for solving such systems without appealing to the Bethe ansatz. As one application we provide new formulas for the solution to the delta Bose gas, with the difference between attractive and repulsive interactions only coming in as a sign change in the denominator of our contour integral integrand—a striking contrast with the Bethe ansatz approach, where the two cases lead to very different sets of eigenfunctions. The range of potential applications of these new formulas remains to be investigated.
The introduction below provides a more detailed description of our results. We would like to note that on many occasions, because of space considerations, the introduction will only give a sample statement, and for the full scale of the result the reader is encouraged to look into the body of the paper (we provide exact references to relevant statements throughout the introduction).
Outline
This paper is split into six chapters:
-
Chapter one is the introduction. We have attempted to make this fairly self-contained (at the cost of repeating certain definitions, discussions and results again in the main parts of the paper).
-
Chapter two contains the definition of Macdonald processes, the calculation of certain observables as contour integrals, and the development of dynamics which preserve these processes. Additionally, a review of properties of Macdonald symmetric functions is provided in this part for the readers’ convenience.
-
Chapter three takes the Macdonald parameter \(t=0\) (resulting in \(q\)-Whittaker processes) and contains the basic result that \(q\)-Laplace transforms of certain elements of these processes are Fredholm determinants. Specializing the \(q\)-Whittaker functions and focusing on a certain projection of the dynamics on the processes results in \(q\)-TASEP whose one-particle transition probabilities are characterized by a Fredholm determinant.
-
Chapter four includes the weak (in the sense of distribution) limit \(q\rightarrow 1\) of \(q\)-Whittaker processes. Two \(q\)-Whittaker specializations (called Plancherel and pure alpha) are focused on. They lead to Whittaker processes which were previously discovered by O’Connell [86] and Corwin, O’Connell, Seppäläinen and Zygouras [39]. Laplace transforms for certain elements of those are now given by Fredholm determinants, and exponential moments are given by contour integrals of a particularly simple form. Using the Fredholm determinant, a limit theorem is proved showing Tracy-Widom GUE fluctuations.
-
Chapter five uses the connection developed in [39, 86] to relate the above mentioned formulas to the study of directed polymers in random media and via another limiting procedure, to the continuum directed random polymer and the KPZ equation.
-
Chapter six shows how the contour integral formulas developed here provide a new ansatz for solving a certain class of integrable quantum many body systems such as the delta Bose gas.
1.1 Macdonald processes
The ascending Macdonald process \(\mathbf{M }_{asc}(a_1,\ldots ,a_N;\rho )\) is the probability distribution on sequences of partitions
(equivalently Gelfand-Tsetlin patterns, or column-strict Young tableaux) indexed by positive variables \(a_1,\ldots , a_N\) and a single Macdonald nonnegative specialization \(\rho \) of the algebra of symmetric functions, with
Here by a partition \(\lambda \) we mean an integer sequence \(\lambda =(\lambda _1\ge \lambda _2\ge \cdots \ge 0)\) with finitely many nonzero entries \(\ell (\lambda )\), and we say that \(\mu \prec \lambda \) if the two partitions interlace: \(\mu _i\le \lambda _i \le \mu _{i-1}\) for all meaningful \(i\)’s. In standard terminology, \(\mu \prec \lambda \) is equivalent to saying that the skew partition \(\lambda /\mu \) is a horizontal strip.
The functions \(P\) and \(Q\) are Macdonald symmetric functions which are indexed by (skew) partitions and implicitly depend on two parameters \(q,t\in (0,1)\). Their remarkable properties are developed in Macdonald’s book [79, Section VI] and reviewed in Sect. 2.1 below. The evaluation of a Macdonald symmetric function on a positive variable \(a\) (as in \(P_{\lambda /\mu }(a)\)) means to restrict the function to a single variable and then substitute the value \(a\) in for that variable. This is a special case of a Macdonald nonnegative specialization \(\rho \) which is an algebra homomorphism of the algebra of symmetric functions \(\mathrm{Sym }\) to \(\mathbb{C }\) that takes skew Macdonald symmetric functions to nonnegative real numbers (notation: \(P_{\lambda /\mu }(\rho )\ge 0\) for any partitions \(\lambda \) and \(\mu \)). Restricting the Macdonald symmetric functions to a finite number of variables (i.e., considering Macdonald polynomials) and then substituting nonnegative numbers for these variables constitutes such a specialization.
We will work with a more general class which can be thought of as unions of limits of such finite length specializations as well as limits of finite length dual specializations. Let \(\{\alpha _i\}_{i\ge 1}, \{\beta _i\}_{i\ge 1}\), and \(\gamma \) be nonnegative numbers, and \(\sum _{i=1}^\infty (\alpha _i+\beta _i)<\infty \). Let \(\rho \) be a specialization of \(\mathrm{Sym }\) defined by
Here \(u\) is a formal variable and \(g_n=Q_{(n)}\) is the \((q,t)\)-analog of the complete homogeneous symmetric function \(h_n\). Since \(g_n\) forms a \(\mathbb{Q }[q,t]\) algebraic basis of \(\mathrm{Sym }\), this uniquely defines the specialization \(\rho \). This \(\rho \) is a Macdonald nonnegative specialization (see Sect. 2.2.1 for more details).
Finally, the normalization for the ascending Macdonald process is given by
as follows from a generalization of Cauchy’s identity for Schur functions. It is not hard to see that the condition of the partition function \(\Pi (a_1,\ldots ,a_N;\rho )\) being finite is equivalent to \(a_i\alpha _j<1\) for all \(i,j\), and hence we will always assume this holds.
The projection of \(\mathbf{M }_{asc}\) to a single partition \(\lambda ^{(k)}, k=1,\ldots ,N\), is the Macdonald measure
Macdonald processes (which receive a complete treatment in Sect. 2.2.2) were first introduced and studied by Vuletic [111] in relation to a generalization of MacMahon’s formula for plane partitions (see also the earlier work of Forrester and Rains [48] in which a Macdonald measure is introduced). Setting \(q=t\), both \(P\) and \(Q\) become Schur functions and the processes become the well-known Schur processes introduced in [91, 92]. One may similarly degenerate the Macdonald symmetric functions to Hall-Littlewood and Jack functions (and similarly for processes). In what follows, we will focus on a less well-known degeneration to Whittaker functions.
1.2 Computing Macdonald process observables
Assume we have a linear operator \(\mathcal{D }\) in the space of functions in \(N\) variables whose restriction to the space of symmetric polynomials diagonalizes in the basis of Macdonald polynomials: \(\mathcal{D } P_\lambda =d_\lambda P_\lambda \) for any partition \(\lambda \) with \(\ell (\lambda )\le N\). Then we can apply \(\mathcal{D }\) to both sides of the identity
Dividing the result by \(\Pi (a_1,\ldots ,a_N;\rho )\) we obtain
where \(\langle \cdot \rangle _{\mathbf{MM }(a_1,\ldots ,a_N;\rho )}\) represents averaging \(\cdot \) over the specified Macdonald measure. If we apply \(\mathcal{D }\) several times we obtain
If we have several possibilities for \(\mathcal{D }\) we can obtain formulas for averages of the observables equal to products of powers of the corresponding eigenvalues. One of the remarkable features of Macdonald polynomials is that there exists a large family of such operators for which they form the eigenbasis (and this fact can be used to define the polynomials). These are the Macdonald difference operators.
In what follows we fix the number of independent variables to be \(N\in \mathbb{Z _{>0}}\). For any \(u\in \mathbb{R }\) and \(1\le i\le N\), define the shift operator \(T_{u,x_i}\) by
For any subset \(I\subset \{1,\ldots ,N\}\), define
Finally, for any \(r=1,2,\ldots ,n\), define the Macdonald difference operators
Proposition 1.1
[79, VI,(4.15)] For any partition \(\lambda =(\lambda _1\ge \lambda _2\ge \cdots )\) with \(\lambda _m=0\) for \(m>N\)
Here \(e_r\) is the elementary symmetric function, \(e_r(x_1,\ldots ,x_N) =\sum _{1\le i_1<\cdots <i_r\le N} x_{i_1}\cdots x_{i_r}\).
Although the operators \(D_N^r\) do not look particularly simple, they can be represented by contour integrals by properly encoding the shifts in terms of residues (see Sect. 2.2.3 for proofs and more general results and discussion).
Proposition 1.2
Assume that \(F(u_1,\ldots ,u_N)=f(u_1)\cdots f(u_N)\). Take \(x_1,\ldots ,x_N>0\) and assume that \(f(u)\) is holomorphic and nonzero in a complex neighborhood of an interval in \(\mathbb{R }\) that contains \(\{x_j,qx_j\}_{j=1}^N\). Then for \(r=1,2,\ldots ,N\)
where each of \(r\) integrals is over positively oriented contour encircling \(\{x_1,\ldots ,x_N\}\) and no other singularities of the integrand.
Observe that \(\Pi (a_1,\ldots ,a_N;\rho )=\prod _{i=1}^N \Pi (a_i;\rho )\). Hence, Proposition 1.2 is suitable for evaluating the right-hand side of equation (1.3). Observe also that for any fixed \(z_1,\ldots ,z_r\), the right-hand side of equation (1.4) is a multiplicative function of \(x_j\)’s. This makes it possible to iterate the procedure. The simplest case is below (the fully general case can be found in Proposition 2.16).
Proposition 1.3
Fix \(k\ge 1\). Assume that \(F(u_1,\ldots ,u_N)=f(u_1)\cdots f(u_N)\). Take \(x_1,\ldots ,x_N >0\) and assume that \(f(u)\) is holomorphic and nonzero in a complex neighborhood of an interval in \(\mathbb{R }\) that contains \(\{q^ix_j\mid i=0,\ldots ,k,j=1\ldots ,N\}\). Then
where the \(z_c\)-contour contains \(\{qz_{c+1},\ldots ,qz_k,x_1,\ldots ,x_N\}\) and no other singularities for \(c=1,\ldots ,k\).
In Proposition 2.17 we describe another family of difference operators that are diagonalized by Macdonald polynomials.
1.3 The emergence of a Fredholm determinant
Macdonald polynomials in \(N\) variables with \(t=0\) are also known of as \(q\)-deformed \(\mathfrak{gl }_{N}\) Whittaker functions [51]. We now denote the ascending Macdonald process with \(t=0\) as \(\mathbf{M }_{asc,t=0}(a_1,\ldots ,a_N;\rho )\) and the Macdonald measure as \(\mathbf{MM }_{t=0}(a_1,\ldots ,a_N;\rho )\). In the paper we refer to these as \(q\)-Whittaker processes and \(q\)-Whittaker measures, respectively.
The partition function for the corresponding \(q\)-Whittaker measure \(\mathbf{MM }_{t=0}(a_1,\ldots ,a_N;\rho )\) simplifies as
where \(\rho \) is determined by \(\{\alpha _j\}, \{\beta _j\}\), and \(\gamma \) as before, and we assume \(\alpha _i a_j<1\) for all \(i,j\) so that the series converge.
Let us take the limit \(t\rightarrow 0\) of Proposition 1.3. For the sake of concreteness let us focus on a particular Plancherel specialization in which the parameter \(\gamma >0\) but all \(\alpha _i\equiv \beta _i\equiv 0\) for \(i\ge 1\). Let us also assume that all \(a_i\equiv 1\). For compactness of notation, in this case we will replace \(\mathbf{MM }_{t=0}(a_1,\ldots ,a_N;\rho )\) with \(\mathbf{MM }_{Pl}\). Similar results for general specializations and values of \(a_i\), as well as the exact statements and proofs of the results given below can be found in Sect. 3.1.
Write \(\mu _k=\left\langle q^{k\lambda _N}\right\rangle _{\mathbf{MM }_{Pl}}\). Then
where \(f(z) = (1-z)^{-N} \exp \{(q-1)\gamma z\}\) and where the \(z_j\)-contours contain \(\{q z_{j+1},\ldots , q z_k, 1\}\) and not 0. For example when \(k=2, z_2\) is integrated along a small contours around 1, and \(z_1\) is integrated around a slightly larger contour which includes 1 and the image of \(q\) times the \(z_2\) contour.
We may combine these \(q\)-moments into a generating function
where \(k_q!= (q;q)_n/(1-q)^n\) and \((a;q)_k=(1-a)\cdots (1-aq^{k-1})\) (when \(k=\infty \) the product is infinity, though convergent since \(|q|<1\)). This generator function is, via the \(q\)-Binomial theorem, a \(q\)-Laplace transform in terms of the \(e_q q\)-exponential function which can be inverted to give the distribution of \(\lambda _N\) (see Proposition 3.1). As long as \(|\zeta |<1\) the convergence of the right-hand side above follows readily, and justifies the interchanging of the summation and the expectation.
Remark 1.4
It is this sort interchange of summation and expectation which can not be justified when trying to recover the Laplace transform of the partition function of the continuum directed random polymer from its moments. In what follows we show how this generating function can be written as a Fredholm determinant. The non-rigorous replica approach manipulations of Dotsenko [45] and Calabrese et al. [33] can be seen as a shadow of the rigorous calculations we now detail (in this way, some of what follows can be thought of as a rigorous version of the replica approach).
We can now describe how to turn the above formulas for \(q\)-moments of \(\lambda _N\) into a Fredholm determinant for the \(q\)-Laplace transform. To our knowledge there is no a priori reason as to why one should expect to find a nice Fredholm determinant for the transform (and all of its subsequent degenerations). In Sect. 3.2 we provide similar statements for general specializations and values of \(a_i\), as well as the exact statements and proofs of the results given below.
In order to turn the series of contour integrals (1.5) into a Fredholm determinant, it would be nice if all contours were the same. This can be achieved by either shrinking all contours to a single small circle around 1, or blowing all contours up to a single large circle containing 0 and 1. We focus here on the small contour formulas and resulting Fredholm determinant (in Sect. 3.2.3 we provide a large contour Fredholm determinant as well, which has a very familiar form for those readers familiar with Tracy and Widom’s ASEP formulas [108]).
It follows by careful residue book-keeping (see Proposition 3.8) that
where the \(w_j\) are all integrated over the same small circle \(C_w\) around 1 (not including 0 and small enough so as no to include \(qC_w\)). The notation \(\lambda \vdash k\) means that \(\lambda \) partitions \(k\) [i.e., if \(\lambda =(\lambda _1,\lambda _2,\ldots )\) then \(k=\sum \lambda _i\)], and the notation \(\lambda = 1^{m_1}2^{m_2}\cdots \) means that \(i\) shows up \(m_i\) times in the partition \(\lambda \).
Before stating our first Fredholm determinant, recall its definition. Fix a Hilbert space \(L^2(X,\mu )\) where \(X\) is a measure space and \(\mu \) is a measure on \(X\). When \(X=\Gamma \), a simple (anticlockwise oriented) smooth contour in \(\mathbb{C }\), we write \(L^2(\Gamma )\) where for \(z\in \Gamma , d\mu (z)\) is understood to be \(\tfrac{dz}{2\pi \iota }\). When \(X\) is the product of a discrete set \(D\) and a contour \(\Gamma , d\mu \) is understood to be the product of the counting measure on \(D\) and \(\frac{dz}{2\pi \iota }\) on \(\Gamma \). Let \(K\) be an integral operator acting on \(f(\cdot )\in L^2(X,\mu )\) by \(Kf(x) = \int _{X} K(x,y)f(y) d\mu (y)\). \(K(x,y)\) is called the kernel of \(K\). One way of defining the Fredholm determinant of \(K\), for trace class operators \(K\), is via the series
By utilizing the small contour formula for the \(\mu _k\) given in (1.6) we can evaluate the generating function as a Fredholm determinant (see Proposition 3.15 for a more general statement). Specifically, for all \(|\zeta |\) close enough to zero (and by analytic continuation for \(\zeta \in \mathbb{C }\setminus q^{\mathbb{Z _{\le 0}}}\)),
where \(K\) is defined in terms of its integral kernel
with \(f(w) = (1-w)^{-N} \exp \{(q-1)\gamma w\}\) and \(C_{w}\) a small circle around 1 (as above).
By using a Mellin-Barnes type integral representation (Lemma 3.20) we can reduce our Fredholm determinant to that of an operator acting on a single contour. The above developments all lead to the following result (Theorem 3.18).
Theorem 1.5
Fix \(\rho \) a Plancherel nonnegative specialization of the Macdonald symmetric functions (i.e., \(\rho \) determined by (1.2) with \(\gamma >0\) but all \(\alpha _i\equiv \beta _i\equiv 0\) for \(i\ge 1\)). Then for all \(\zeta \in \mathbb{C }\setminus \mathbb{R _{+}}\)
where \(C_w\) is a positively oriented small circle around 1 and the operator \(K_{\zeta }\) is defined in terms of its integral kernel
where
The operator \(K_{\zeta }\) is trace-class for all \(\zeta \in \mathbb{C }\setminus \mathbb{R _{+}}\).
Note also the following (cf. Proposition 3.1).
Corollary 1.6
We also have that
where \(C_{n,q}\) is any simple positively oriented contour which encloses the poles \(\zeta =q^{-M}\) for \(0\le M\le n\) and which only intersects \(\mathbb{R _{+}}\) in finitely many points.
A similar result can be found when \(\rho \) is given by a pure alpha specialization (\(\gamma =0\) and \(\beta _i\equiv 0\) for all \(i\ge 1\)) in the form of Theorem 4.62.
1.4 New “integrable” interacting particle systems
The Macdonald processes can be seen as fixed time measures on Gelfand-Tsetlin patterns evolving according to a certain class of dynamics (see Fig. 1 for various degenerations of these measures and dynamics). Discrete and continuous versions of these dynamics are constructed (see Sect. 2.3) for general parameters \(t,q\in (0,1)\) via an approach of Borodin and Ferrari [26], that in its turn was based on an idea of Diaconis and Fill [43]. Other examples of such dynamics can be found in [13, 18, 25, 27–30]. Presently we will focus on the continuous time Markov dynamics in the case \(t=0\) as this degeneration results in simple, local updates.

A flowchart for Macdonald processes and some of their specializations and limits. Taking \(t\rightarrow 0\) we focus on two specializations: Plancherel (primarily) and pure alpha. The pure alpha case degenerates to the Plancherel as the number of alpha variables grows to infinity. In the Plancherel case we define \(q\)-Whittaker process and measures. Natural dynamics on Gelfand Tsetlin patterns which preserve these processes are given by the \(q\)-Whittaker 2d-growth model. A marginal of these dynamics is the \(q\)-TASEP. Taking \(q\rightarrow 0\) yields the Whittaker processes (from the Plancherel specialization) and the \(\alpha \)-Whittaker processes (from the pure alpha specialization). Again, taking \(n\rightarrow \infty \) takes the \(\alpha \)-Whittaker processes to the Whittaker processes. These processes now encode the partition functions of directed polymers – the O’Connell-Yor semi-discrete polymer and Seppäläinen’s log-gamma polymer (respectively). There are two natural scaling limits for these polymers. The first is the intermediate disorder scaling in which the polymer inverse temperature is taken to zero as the other parameters go to infinity. In both cases, the polymer converge to the continuum directed random polymer, whose free energy is the solution to the Kardar-Parisi-Zhang stochastic PDE. The other scaling limit is the strong disorder scaling in which inverse temperature is fixed and positive and the other parameters are taken to infinity. Now the polymer free energy converges to the Tracy-Widom GUE statistics of the Kardar-Parisi-Zhang universality class fixed point
The \(q\)-Whittaker 2d-growth model is a continuous time Markov process on the space of Gelfand-Tsetlin patterns defined by (1.1). Each of the coordinates \(\lambda _k^{(m)}\) has its own independent exponential clock with rate
(the factors above for which the subscript exceeds the superscript, or either is zero must be omitted). When the \(\lambda _k^{(m)}\)-clock rings we find the longest string \(\lambda _k^{(m)}= \lambda _k^{(m+1)}=\cdots = \lambda _k^{(m+n)}\) and move all the coordinates in this string to the right by one. Observe that if \(\lambda _k^{(m)}=\lambda _{k-1}^{(m-1)}\) then the jump rate automatically vanishes (Fig. 2c).

a First few steps of \(q\)-Whittaker 2d-growth model written in variables \(x_{k}^{(m)} = \lambda _k^{(m)}-k\). b The rate at which \(x_k^{(m)}\) moves is influenced by three neighbors. The dotted arrows indicate whether the neighbor’s influence increases (arrow to the right) or decreases (arrow to the left) the jumping rate. c Projecting onto the left edge leads to \(q\)-TASEP in which particle jump rates are only affected by the number of consecutive empty sites to their right
A natural initial condition for these dynamics is the zero pattern in which \(\lambda _k^{(m)}\equiv 0\). When started from the zero pattern, and run for time \(\gamma \) (with \(a_1=a_2=\cdots =1\)), the marginal distribution of the entire GT pattern is given by the Plancherel specialization of the \(t=0\) Macdonald (a.k.a. \(q\)-Whittaker) process \(\mathbf{M }_{Pl}\) (this follows from the more general result of Proposition 2.24).
When \(k\!=\!m\), the rates given above simplify to \((1\!-\!q^{\lambda _{k-1}^{(k-1)}\!-\!\lambda _k^{(k)}})\). This implies that the edge of the GT pattern \(\{\lambda _k^{(k)}\}_{1\le k\le N}\) evolves marginally as a Markov process. If we set \(x_k=\lambda _k^{(k)}-k\) for \(k=1,2,\ldots \), then the state space consists of ordered sequences of integers \(x_1\!>\!x_2\!>\!x_3\!>\!\cdots \). The time evolution is given by a variant on the classical totally asymmetric simple exclusion process (TASEP) which we call \(q\)-TASEP (note that \(q=0\) reduces \(q\)-TASEP to TASEP). Now each particle \(x_i\) jumps to the right by 1 independently of the others according to an exponential clock with rate \(1-q^{x_{i-1}\!-\!x_i-1}\) (here \(x_{i-1}\!-\!x_i\!-\!1\) can be interpreted at the number of empty spaces before the next particle to the right). The zero GT pattern corresponds to the step initial condition where \(x_n(0)\!=\!-n, n\!=\!1,2,\dots \) (see Sect. 3.3.3 for an interacting particle systems perspective on \(q\)-TASEP). The gaps of \(q\)-TASEP evolve according to a certain totally asymmetric zero range process which we will call \(q\)-TAZRP. The \(q\)-TAZRP and its quantum version under the name “\(q\)-bosons” were introduced in [98] where their integrability was also noted. A stationary version of \(q\)-TAZRP was studied in [11] and a cube root fluctuation result was shown.
The moment and Fredholm determinant formulas apply to give statistics of the 2d-growth model and \(q\)-TASEP, and in this sense these models are integrable. For example, Theorem 1.5 should enable a proof that \(q\)-TASEP, for \(q\) fixed, is in the KPZ universality class. For TASEP this was shown by Johansson [64] for step initial condition, and for ASEP by Tracy and Widom [108]. Additionally, for ASEP, there is a weakly asymmetric scaling limit which converges to the KPZ equation with narrow wedge initial data [4, 15]—a connection which enables the calculation of one-point exact statistics for its solution [4, 97]. For \(q\)-TASEP there should be such a limit as \(q\rightarrow 1\) in which one sees the KPZ equation (see Sect. 5.4.4 for a heuristic argument providing scalings). Such direct asymptotics of these models will be pursued elsewhere. Instead, we make an intermediate scaling limit which leads us first to the Whittaker processes and directed polymers, and then to the KPZ equation and universality class.
1.5 Crystallization and Whittaker process fluctuations
The class-one \(\mathfrak{gl }_{N}\)-Whittaker functions are basic objects of representation theory and integrable systems [46, 73]. One of their properties is that they are eigenfunctions for the quantum \(\mathfrak{gl }_{N}\)-Toda chain (see Sect. 4.1.1 for various other properties including orthogonality and completeness relations). As showed by Givental [55], they can also be defined via the following integral representation, which is a degeneration of (3.7) for \(q\)-Whittaker functions or the combinatorial formula (2.14,2.15) for Macdonald polynomials:
where \(\lambda =(\lambda _1,\ldots ,\lambda _N)\) and
It was observed in [51] and proved below in Theorem 4.7 (along with uniform tail estimates) that Macdonald symmetric functions with \(t=0\) (called here \(q\)-Whittaker functions), when restricted to \(N\) variables, converge to class-one \(\mathfrak{gl }_{N}\)-Whittaker functions as \(q\rightarrow 1\) (and the various other parameters at play are properly scaled).
It is not just Macdonald symmetric functions which converge to Whittaker functions. The \(q\)-Whittaker process (Macdonald process as \(t=0\)) converges to the following measure on \(\mathbb{R }^{\frac{N(N+1)}{2}}\) which was first introduced and studied by O’Connell [86] (see Sect. 4.1.3 for a more general definition).
For any \(\tau >0\) set
with the Skylanin measure
and define the following Whittaker process as a measure on \(\mathbb{R }^{\frac{N(N+1)}{2}}\) with density function (with respect to the Lebesgue measure) given by
The nonnegativity of the density follows from definitions. Integrating over the variables \(T_{k,i}\) with \(k<N\) yields the following Whittaker measure with density function given by
The fact that this measure integrates to one follows from the orthogonality relation for Whittaker functions given in Sect. 4.1.1. Note that the particles under this measure are no longer restricted to form GT patterns (i.e., lie on \(\mathbb{Z _{\ge 0}}\) and interlace).
Let us return to the \(q\)-Whittaker process. Introduce a scaling parameter \(\epsilon \) and set \(q=e^{-\epsilon }\). Then for time \(\gamma = \epsilon ^{-2} \tau \) one finds that as \(\epsilon \rightarrow 0\) (hence \(q\rightarrow 1\) and \(\gamma \rightarrow \infty \)) the \(q\)-Whittaker process on GT patterns crystalizes onto a regular lattice. The fluctuations of the pattern around this limiting lattice converge under appropriate scaling to the above defined Whittaker process (see Sect. 4.1.3 for a more general statement and proof of this result).
Theorem 1.7
Fix \(\rho \) a Plancherel nonnegative specialization of the Macdonald symmetric functions [i.e., \(\rho \) determined by (1.2) with \(\gamma >0\) but all \(\alpha _i\equiv \beta _i\equiv 0\) for \(i\ge 1\)] and write \(\mathbf{M }_{Pl}\) for the \(q\)-Whittaker process \(\mathbf{M }_{asc,t=0}(1,\ldots ,1;\rho )\). In the limit regime
\(\mathbf{M }_{Pl}\) converges weakly, as \(\epsilon \rightarrow 0\), to the Whittaker process \(\mathbf{W }_{(\tau )}\bigl (\{T_{k,i}\}_{1\le i\le k\le N}\bigr )\).
The dynamics of the \(q\)-Whittaker 2d-growth model also have a limit as the following Whittaker 2d-growth model (see Sect. 4.1.3 for a general definition). This is a continuous time (\(\tau \ge 0\)) Markov diffusion process \(T(\tau )=\{T_{k,j}(\tau )\}_{1\le j\le k\le N}\) with state space \(\mathbb{R }^{\frac{N(N+1)}{2}}\) which is given by the following system of stochastic (ordinary) differential equations: Let \(\{W_{k,j}\}_{1\le j\le k \le N}\) be a collection of independent standard one-dimensional Brownian motions. The evolution of \(T\) is defined recursively by \(dT_{1,1} = dW_{1,1}\) and for \(k=2,\ldots , N\),
It follows from Theorem 1.7 and standard methods of stochastic analysis that the above \(q\)-Whittaker 2d-growth model initialized with zero initial GT pattern converges (under scalings as in (1.14)) to the Whittaker 2d-growth model with entrance law for \(\{T_{k,j}(\delta )\}_{1\le j\le k\le N}\) given by the density \(\mathbf{W }_{(\delta )}\left( \{T_{k,j}\}_{1\le j\le k\le N}\right) \) for \(\delta >0\). Let us briefly describe this limit result for the \(N=2\) dynamics. Under the specified \(q\)-Whittaker dynamics, the particle \(\lambda _1^{(1)}\) evolves as a rate one Poisson jump process. In time \(\tau \epsilon ^{-2}, \lambda _1^{(1)}\) is macroscopically at \(\tau \epsilon ^{-2}\). In an \(\epsilon ^{-1}\) scale, the particle’s dynamics converge (as \(\epsilon \rightarrow 0\)) to that of a standard Brownian motion \(W_{1,1}\). Turning to \(\lambda _2^{(2)}\), the entrance law provided by Theorem 1.7 shows that
Thus the jump rate for \(\lambda _2^{(2)}\) is given by
In the time scale \(\epsilon ^{-2}, T_{2,2}\) behaves like a Brownian motion \(W_{2,2}\) plus a drift due to this perturbation of \(-\epsilon e^{T_{2,2}(\tau ) - T_{1,1}(\tau )}\) – exactly as given by the Whittaker 2d-growth model. The argument for \(\lambda _2^{(1)}\) is similar.
O’Connell proved ([86] Section 9) that the projection of the Whittaker 2d-growth model onto \(\{T_{N,j}(\tau )\}_{1\le j\le N}\) is itself a Markov diffusion process with respect to its own filtration with entrance law given by density \(\mathbf{WM }_{(\tau )}\left( \{T_{N,j}\}_{1\le j\le N}\right) \) and infinitesimal generator given by
where \(H\) is the quantum \(\mathfrak{gl }_{N}\)-Toda lattice Hamiltonian
The \(q\)-Laplace transform generating function and Fredholm determinant of Theorem 1.5 has a limit under the \(q\rightarrow 1\) scalings (see Sect. 4.1.6 for a more general statement and proof)
Theorem 1.8
For any \(u\ge 0\),
where \(C_\delta \) is a positively oriented contour containing the origin of radius less than \(\delta /2\) with any \(0< \delta <1\). The operator \(K_u\) is defined in terms of its integral kernel
1.6 Tracy-Widom asymptotics for polymer free energy
O’Connell [86] introduced the Whittaker process to describe the free energy of a semi-discrete directed polymer in a random media (see Sect. 5.1 for general background on directed polymers or Sect. 5.2 for more on this particular model). We refer to this as the O’Connell-Yor semi-discrete directed polymer, as it was introduced in [89]. Define an up/right path in \(\mathbb{R }\times \mathbb{Z }\) as an increasing path which either proceeds to the right (along a copy of \(\mathbb{R }\)) or jumps up (in \(\mathbb{Z }\)) by one unit. For each sequence \(0<s_1<\cdots <s_{N-1}<\tau \) we can associate an up/right path \(\phi \) from \((0,1)\) to \((\tau ,N)\) which jumps between the points \((s_i,i)\) and \((s_{i},i+1)\), for \(i=1,\ldots , N-1\), and is continuous otherwise. The polymer paths will be such up/right paths, and the random environment will be a collection of independent standard Brownian motions \(B(s) = (B_1(s),\ldots , B_N(s))\) for \(s\ge 0\) (see Fig. 3 for an illustration of this polymer). The energy of a path \(\phi \) is given by
The (quenched) partition function \(\mathbf{Z }^{N}(\tau )\) is given by averaging over the possible paths:
where the integral is with respect to Lebesgue measure on the Euclidean set of all up/right paths \(\phi \) (i.e., the simplex of jumping times \(0<s_1<\cdots <s_{N-1}<\tau \)). One can similarly introduce a hierarchy of partition functions \(\mathbf{Z }^{N}_{n}(\tau )\) for \(0\le n\le N\) by setting \(\mathbf{Z }^{N}_{0}(\tau )=1\) and for \(n\ge 1\),
where the integral is now with respect to the Lebesgue measure on the Euclidean set \(D_n(\tau )\) of all \(n\)-tuples of non-intersecting (disjoint) up/right paths with initial points \((0,1),\ldots , (0,n)\) and endpoints \((\tau ,N-n+1),\ldots , (\tau ,N)\).

The O’Connell-Yor semi-discrete directed polymer is a reweighting of Poisson jump process space-time trajectories (in bold) with respect to Boltzmann weights given by exponentiating a Hamiltonian givne by the path integral along the trajectory through a field of independent 1-dimensional white noises. The (quenched) partition function is the normalizing constant to make this reweighting into a probability measure
The hierarchy of free energies \(\mathbf{F }^{N}_{n}(\tau )\) for \(1\le n\le N\) if defined as
Among these, \(\mathbf{F }^{N}_{1}(\tau )\) is the directed polymer free energy.
It is shown in [86] Theorem 3.1 that as a process of \(\tau , (-\mathbf{F }^{N}_{N}(\tau ),\ldots , -\mathbf{F }^{N}_{1}(\tau ))\) is given by the Markov diffusion process with entrance law given by density \(\mathbf{WM }_{(\tau )}\left( -\mathbf{F }^{N}_{N}(\tau ),\ldots , -\mathbf{F }^{N}_{1}(\tau )\right) \) and infinitesimal generator given by (1.15). Note that this means that \(\mathbf{F }_{1}^{N}(\tau )\) and \(-T_{N,N}(\tau )\) are equal in law and thus we may apply Theorem 1.8 to characterize the distribution of the free energy \(\mathbf{F }_{1}^{N}(\tau )\) of the O’Connell-Yor polymer. The form of the Fredholm determinant is such that we may also calculate a limit theorem for the free energy fluctuations as \(\tau \) and \(N\) go to infinity.
Before taking these asymptotics, let us motivate the limit theorem we will prove. Since the noise is Brownian, scaling time is the same as introducing a prefactor \(\beta \) in front of \(E(\phi )\) above. Generally, \(\beta \) is called the inverse temperature, and taking time to infinity is like taking \(\beta \) to infinity (or temperature to zero). The limit of the free energy hierarchy (divided by \(\beta \)) as \(\beta \) goes to infinity and time is fixed, is described by a coupled set of maximization problems. In particular, regarding \(\mathbf{F }^{N}_{1}(\tau )\),
As recorded in [86] Theorem 1.1 (see the references stated therein), \(M^N_1(1)\) is distributed as the largest eigenvalue of an \(N\times N\) GUE random matrix (in fact the limit of the entire free energy hierarchy has the law of the standard Dyson Brownian motion). It follows from the original work of Tracy and Widom [105] and also [47, 84] that
The polymer universality belief (see [41]) holds that all polymers in one space and one time dimension (with homogeneous and light-tailed noise) should have the same asymptotic scaling exponent (\(1/3\)) and limit law (\(F_{\mathrm{GUE}})\).
In order to state our result here, recall the Digamma function \(\Psi (z) = [\log \Gamma ]^{\prime }(z)\). Define for \(\kappa >0\)
and let \({\bar{t}_{\kappa }}\) denote the unique value of \(t\) at which the minimum is achieved. Finally, define the positive number (scaling parameter) \({\bar{g}_{\kappa }}= -\Psi ^{\prime \prime }({\bar{t}_{\kappa }})\).
Then by taking rigorous asymptotics of the Fredholm determinant of Theorem 1.8 (for a proof see Theorem 4.47) we have
Theorem 1.9
For all \(N\), set \(t=N\kappa \). For \(\kappa >0\) large enough,
The condition on \(\kappa \) being large is artificial and presently comes out of technicalities in performing the steepest descent analysis of the Fredholm determinant of Theorem 1.8. In [20] the above technical issues are overcome and the theorem is extended to all \(\kappa >0\). Note that the double exponential on the left-hand side of (1.16) becomes an indicator function (and hence its expectation becomes a probability) since \(e^{-e^{c(x-a)}}\rightarrow \mathbf{1}_{x<a}\) as \(c\rightarrow \infty \). The law of large numbers with the constant \({\bar{f}_{\kappa }}\) was conjectured in [89] and proved in [82]. A tight one-sided bound on the fluctuation exponent for \(\mathbf{F }^{N}_1(t)\) was determined in [102]. Taking \(\kappa \rightarrow \infty \) one recovers (1.18). Spohn [104] has recently described how the above theorem fits into a general physical KPZ scaling theory.
There exists a similar story to that presented above when the O’Connell-Yor polymer is replaced by the log-gamma discrete directed polymer introduced by Seppäläinen [101]. Using Kirillov’s [71, 85] tropical RSK correspondence, Corwin et al. [39] introduce a different Whittaker process to describe the free energy hierarchy for this polymer (see Sect. 5.3 for more on this). Presently we call this the \(\alpha \)-Whittaker process (see Sect. 4.2) and it arises as the limit of the Macdonald process when \(\rho \) is a pure alpha specialization (some \(\alpha _i>0, \beta _i=0\) for all \(i\ge 1\) and \(\gamma =0\)).
1.7 Solvability of the KPZ equation
The continuum directed random polymer (CDRP) is the universal scaling limit for discrete and semi-discrete polymers when the inverse-temperature \(\beta \) scales to zero in a critical manner (called intermediate disorder scaling) as the system size goes to infinity (this was observed independently by Calabrese et al. [33] and by Alberts et al. [1] and is proved in [2] for discrete polymers and in [81] for the O’Connell-Yor semi-discrete polymer). In the CDRP, the polymer path measure is the law of a Brownian bridge and the random media is given by Gaussian space time white noise.
The CDRP partition function is written as (see [4, 37])
where \(\mathbb{E }\) is the expectation of the law of the Brownian bridge \(b(\cdot )\) starting at \(X\) at time 0 and ending at \(0\) at time \(T\). The Gaussian heat kernel is written as \(p(T,X)=(2\pi )^{-1/2}e^{-X^2/T}\). The expression \(:\mathrm{exp}:\) is the Wick exponential and can be defined either through a limiting smoothing procedure as in [14] or via Weiner-Itô chaos series [4]. Via a version of the Feynman-Kac formula, \(\mathcal{Z }(T,X)\) solves the well-posed stochastic heat equation with multiplicative noise and delta function initial data:
Due to a result of Mueller [83], almost surely \(\mathcal{Z }(T,X)\) is positive for all \(T>0\) and \(X\in \mathbb{R }\), hence we can take its logarithm:
This is called the Hopf-Cole solution to the Kardar-Parisi-Zhang (KPZ) equation with narrow wedge initial data [4, 15, 67]. Formally (though it is ill-posed due to the non-linearity) the KPZ equation is written as
We may perform an intermediate disorder scaling limit of the Fredholm determinant of Theorem 1.8. Under this scaling, the double exponential in the left-hand side of (1.16) is preserved, giving us a Laplace transform of \(\mathcal{Z }\). For \(u=s \exp \left\{ -N-\tfrac{1}{2}\sqrt{TN}-\tfrac{1}{2}N\log (T/N)\right\} \),
where the operator \(K_{s}\) is defined in terms of its integral kernel
where \(\kappa _T= 2^{-1/3}T^{1/3}\) and \(\mathrm{Ai}\) is the Airy function.
This is shown in Sect. 5.4.3 by expanding around the critical point of the kernel in Theorem 1.8 (under the above scalings). A rigorous proof of this result (which requires more than just a critical point analysis) is provided in [20].
The equality of the left-hand and right-hand sides of (1.19) is already known. It follows from the exact formulas for the probability distribution for the solution to the KPZ equation which was simultaneously and independently discovered in [4, 97] and proved rigorously in [4]. Those works took asymptotics of Tracy and Widom’s ASEP formulas [106–108] and rely on the fact that weakly scaled ASEP converges to the KPZ equation [4, 15]. It has been a challenge to expand upon the solvability of ASEP as necessary for asymptotics (see [109] for the one such extension to half-Bernoulli initial conditions and [40] for the resulting formula for the KPZ equation with half-Brownian initial data). The many parameters (the \(a_i\)’s, \(\alpha _i\)’s, and \(\beta _i\)’,s) we have suppressed in this introduction can be used to access statistics for the KPZ equation with other types of initial data, which will be a subject of subsequent work (cf. [20]).
Soon after, Calabrese et al. [33] and Dotsenko [45] derived the above Laplace transform through a non-rigorous replica approach. There, the Laplace transform is written as a generating function in the moments of \(\mathcal{Z }(T,0)\). The \(N\)-th such moment grows like \(e^{cN^{3}}\) and hence this generating function is widely divergent. By rearranging terms and analytically continuing certain functions off integers, this divergent series is summed and the Laplace transform formula results. These manipulations can actually be seen as shadows of the rigorous manipulations performed at the Macdonald process level.
1.8 Moment formulas for polymers
We previously saw that due to the large family of difference operators diagonalized by the Macdonald symmetric functions, we can derive contour integral formulas for a rich family of observables for Macdonald processes (in this introduction, Propositions 1.1 and 1.2 as well as more general statements in Sects. 2.2.3 and 3.1.3). The limit which takes Macdonald processes (and \(q\)-Whittaker processes) to Whittaker processes turns these observables into moments of the partition function hierarchy [e.g., (1.17)].
Let us focus on Proposition 1.2 and its limit. This proposition calculated the Macdonald process expectation of \(q^{k\lambda _N^N}\). In the scalings of Theorem 1.7, this becomes the Whittaker process expectation of \(e^{-k T_{N,N}}\) (see Sect. 4.1.4 for general precise statements of this sort). It follows from the above discussed connection between Whittaker processes and the O’Connell-Yor semi-discrete polymer that (see Sect. 5.2.2 for more general statements and a proof of this result which appears as Proposition 5.8).
Proposition 1.10
For any \(N\ge 1, k\ge 1\) and \(\tau \ge 0\),
where the \(w_j\)-contour contains \(\{w_{j+1}+1,\ldots ,w_k+1,0\}\) and no other singularities for \(j=1,\ldots ,k\).
An intermediate disorder scaling limit of this result leads to contour integral formulas for moments of the CDRP (see Sect. 5.4.2 for more general statements).
Proposition 1.11
For \(k\ge 1\) and \(T>0\),
where the \(z_A\)-contour is along \(C_A+\iota \mathbb{R }\) for any \(C_1>C_2+1>C_3+2>\cdots >C_k+(k-1)\).
Note that since \(\mathcal{Z }(T,X)/p(T,X)\) is a stationary process in \(X\) [4], this likewise gives formulas for all values of \(X\in \mathbb{R }\).
Let us work out the \(k=1\) and \(k=2\) formulas explicitly. For \(k=1\), the above formula gives \(\langle \mathcal{Z }_1(T,X)^k\rangle = (2\pi T)^{-1/2}\) which matches \(p(T,0)\) as one expects. When \(k=2\) we have (see Remark 5.23)
where
This formula for \(k=2\) matches formula (2.27) of [14] where it was rigorously derived via local time calculations.
1.9 A contour integral ansatz for some quantum many body systems
Moments of the exactly solvable polymer models studied above solve certain quantum many body systems with delta interactions. This fact is the basis for the replica approach employed in this area since the work of Kardar [66]. Let us focus on the moments of the CDRP (details and discussion are in Sect. 6.2, whereas Sect. 6.1 deals with the O’Connell-Yor semi-discrete polymer).
Let \(\mathbb{W }^{N}=\{X_1<X_2<\cdots <X_N\}\) be the Weyl chamber. We say that a function \(u:\mathbb{W }^{N}\times \mathbb{R _{+}}\rightarrow \mathbb{R }\) solves the delta Bose gas with coupling constant \(\kappa \in \mathbb{R }\) and delta initial data if:
-
For \(X\in \mathbb{W }^{N}\),
$$\begin{aligned} \partial _T u = \tfrac{1}{2}\Delta u, \end{aligned}$$ -
On the boundary of \(\mathbb{W }^{N}\),
$$\begin{aligned} (\partial _{X_{i}}-\partial _{X_{i+1}}-\kappa )u \big \vert _{X_{i+1}=X_{i}+0} = 0, \end{aligned}$$ -
and for any \(f\in L^{2}(\mathbb{W }^{N})\cap C_b(\overline{\mathbb{W }^{N}})\), as \(t\rightarrow 0\)
$$\begin{aligned} N! \int _{\mathbb{W }^{N}} f(x) u(X;t) dX \rightarrow f(0). \end{aligned}$$
When \(\kappa >0\) this is called the attractive case, whereas when \(\kappa <0\) this is the repulsive case.
Note that the boundary condition is often included in PDE so as to appear as
The relevance of the delta Bose gas for the CDRP is that
solves the attractive delta Bose gas with coupling constant \(\kappa =1\) (attractive) and delta initial data.
Inspired by the simplicity of Proposition 1.11 which gives \(u(X;T)\) when \(X_i\equiv 0\), we propose and verify the following contour integral ansatz for the solution to this many body problem.
Proposition 1.12
Fix \(N\ge 1\). The solution to the delta Bose gas with coupling constant \(\kappa \in \mathbb{R }\) and delta initial data can be written as
where the \(z_j\)-contour is along \(\alpha _j+\iota \mathbb{R }\) for any \(\alpha _1>\alpha _2+\kappa >\alpha _3+2\kappa >\cdots >\alpha _N+(N-1)\kappa \).
The proof of this result (given in Sect. 6.2) is straightforward. In particular, it is easy to check that as \(T\rightarrow 0\) this provides the correct delta initial data.
One should note that the above proposition deals with both the \(\kappa >0\) (attractive) and \(\kappa <0\) (repulsive) delta Bose gas. Looking in the arguments of Section 4 of [59] (where they were proving the Plancherel theory for the delta Bose gas) it is possible to extract the formula of the above proposition. This type of formula reveals a symmetry between the two cases which is not present in the eigenfunctions.
An alternative and much earlier taken approach to solving the delta Bose gas is by demonstrating a complete basis of eigenfunctions (and normalizations) which diagonalize the Hamiltonian and respect the boundary condition. The eigenfunctions were written down in 1963 for the repulsive delta interaction by Lieb and Liniger [75] by Bethe ansatz. Completeness was proved by Dorlas [44] on \([0,1]\) and by Heckman and Opdam [59] and then recently by Prolhac and Spohn (using formulas of Tracy and Widom [110]) on \(\mathbb{R }\) (as we are considering presently). For the attractive case, McGuire [80] wrote the eigenfunctions in terms of string states in 1964. As opposed to the repulsive case, the attractive case eigenfunctions are much more involved and are not limited to bound state eigenfunctions (hence a lack of symmetry with respect to the eigenfunctions). The norms of these states were not derived until 2007 in [32] using ideas of algebraic Bethe ansatz. Dotsenko [45] later worked these norms out very explicitly through combinatorial means. Completeness in the attractive case was shown by Oxford [93], and then by Heckman and Opdam [59], and recently by Prolhac and Spohn [95].
The work [33, 45, 75, 95, 110] provide formulas for the propagators (i.e., transition probabilities) for the delta Bose gas with general initial data. These formulas involve either summations over eigenstates or over the permutation group. In the repulsive case it is fairly easy to see how the formula of Proposition 1.12 is recovered from these formulas.
For the attractive case we can use a degeneration of the identity given in (1.6) to turn the moment formulas of Proposition 1.12 into the formulas given explicitly in Dotsenko’s work [45]. The reason why the symmetry, which is apparent in Proposition 1.12, is lost in the eigenfunction expansion is due to the constraint on the contours. In the repulsive case \(\kappa <0\) and the contours are given by having the \(z_j\)-contour along \(\alpha _j+\iota \mathbb{R }\) for any \(\alpha _1>\alpha _2+\kappa >\alpha _3+2\kappa >\cdots >\alpha _N+(N-1)\kappa \). The contours, therefore, can be taken to be all the same. It is an easy calculation to turn the Bethe ansatz eigenfunction expansion into the contour integral formula we provide. The attractive case leads to contours which are not the same. In making the contours coincide we encounter a sizable number of poles which introduces many new terms which agrees with the fact that there are many other eigenfunctions coming from the Bethe ansatz in this case.
The ansatz applies in greater generality (revealing the role of each part of the contour integrals, see Remark 6.15) and is useful in solving many body systems which arise in the study of other polymers (e.g., for semi-discrete polymers such as the O’Connell-Yor or discrete parabolic Anderson models see Sect. 6.1).
1.10 Further developments
Since this work was posted we have developed a few of the directions of research coming from the theory of Macdonald processes. We briefly recount the main points of these developments below.
In joint work with Ferrari [20] we consider two models for directed polymers in space-time independent random media (the O’Connell-Yor semi-discrete directed polymer and the continuum directed random polymer) at positive temperature and prove their KPZ universality via asymptotic analysis of exact Fredholm determinant formulas for the Laplace transform of their partition functions. In particular, we show that for large time \(\tau \), the probability distributions for the free energy fluctuations, when rescaled by \(\tau ^{1/3}\), converges to the GUE Tracy-Widom distribution. This completes Theorem 4.47 to all \(\kappa >0\).
We also consider the effect of boundary perturbations to the quenched random media on the limiting free energy statistics. For the semi-discrete directed polymer, when the drifts of a finite number of the Brownian motions forming the quenched random media are critically tuned, the statistics are instead governed by the limiting Baik-Ben Arous-Péché distributions [8] from spiked random matrix theory. For the continuum polymer, the boundary perturbations correspond to choosing the initial data for the stochastic heat equation from a particular class, and likewise for its logarithm—the KPZ equation. The Laplace transform formula we prove can be inverted to give the one-point probability distribution of the solution to these stochastic PDEs for the class of initial data.
In joint work with Ferrari and Veto [22] we further extend the class of initial data for which we can compute exact statistics so as to include the equilibrium initial data for the KPZ equation. That is to say, we are able to exactly characterize the distribution of the solution to the KPZ equation when started with a two-sided Brownian motion and prove that as \(t\) goes to infinity and under \(t^{1/3}\) scaling, the one-point probability distribution converges to the \(F_0\) distribution of Baik and Rains. The \(t^{1/3}\) scaling for fluctuations associated with this initial data was previously shown in [9].
In joint work with Remenik [23] we prove that under \(n^{1/3}\) scaling, the limiting distribution as \(n\rightarrow \infty \) of the free energy of Seppäläinen’s log-Gamma discrete directed polymer is GUE Tracy-Widom. The main technical innovation we provide is a general identity between a class of \(n\)-fold contour integrals and a class of Fredholm determinants. Applying this identity to the integral formula proved in [39] for the Laplace transform of the log-Gamma polymer partition function, we arrive at a Fredholm determinant which lends itself to asymptotic analysis (and thus yields the free energy limit theorem). The Fredholm determinant was anticipated via the formalism of Macdonald processes yet its rigorous proof was so far lacking because of the nontriviality of certain decay estimates required by that approach (see Theorem 4.55).
In joint work with Sasamoto [24] we prove duality relations for two interacting particle systems: \(q\)-TASEP and ASEP. Expectations of the duality functionals correspond to certain joint moments of particle locations or integrated currents, respectively. Duality implies that they solve systems of ODEs. These systems are integrable and for particular step and half stationary initial data we use a nested contour integral ansatz to provide explicit formulas for the systems’ solutions and hence also the moments.
We form Laplace transform like generating functions of these moments and via residue calculus we compute two different types of Fredholm determinant formulas for such generating functions. For ASEP, the first type of formula is new and readily lends itself to asymptotic analysis (as necessary to reprove GUE Tracy-Widom distribution fluctuations for ASEP), while the second type of formula is recognizable as closely related to Tracy and Widom’s ASEP formula [106–109]. For \(q\)-TASEP both formulas coincide with those computed via the theory of Macdonald processes (in particular see Sects. 3.2 and 3.3 below).
Both \(q\)-TASEP and ASEP have limit transitions to the free energy of the continuum directed polymer, the logarithm of the solution of the stochastic heat equation, or the Hopf-Cole solution to the Kardar-Parisi-Zhang equation. Thus, \(q\)-TASEP and ASEP are integrable discretizations of these continuum objects; the systems of ODEs associated to their dualities are deformed discrete quantum delta Bose gases; and the procedure through which we pass from expectations of their duality functionals to characterizing generating functions is a rigorous version of the replica trick in physics.
In joint work with Gorin and Shakirov [21] we extend many of the algebraic results developed here. In particular, using a certain operator diagonalized by the Macdonald polynomials, we generalize Theorem 1.5 by showing that even when \(t\ne 0\), the expectation of a certain observable of the Macdonald process is written in terms of a similar type of Fredholm determinant formula. We also extend the moment computation of Sect. 2.2.3 to multilevel moment formulas. As a consequence we can compute joint moments for \(\{q^{\lambda ^{N_i}_{N_i}}\}\) as \(i\) varies (when the Macdonald parameter \(t=0\)). Via the connection to \(q\)-TASEP, this provides a purely algebraic derivation of the multipoint formulas for \(q\)-TASEP found in [24] via duality.
2 Macdonald processes
2.1 Definition and properties of Macdonald symmetric functions
So as to make our work self-contained we provide a brief review of all of the properties and concepts related to Macdonald symmetric functions which we will be utilizing. Our main reference for this material is the book of Macdonald [79].
2.1.1 Partitions, Young diagrams and tableaux
A partition is a sequence \(\lambda = (\lambda _1,\lambda _2,\ldots )\) of nonnegative integers such that \(\lambda _1\ge ~\lambda _2\ge ~\cdots \). The length \(\ell (\lambda )\) is the number of non-zero \(\lambda _i\) and the weight \(|\lambda |=\lambda _1+\lambda _2+\cdots \). If \(|\lambda |=n\) then \(\lambda \) partitions \(n\). An alternative notation is \(\lambda = 1^{m_1}2^{m_2}\cdots \) where \(m_i\) represents the multiplicity of \(i\) in the partition \(\lambda \). The natural (partial) ordering on the space of partitions is called the dominance order and is given by \(\lambda \ge \mu \) if and only if
A partition \(\lambda \) can be graphically represented as a Young diagram with \(\lambda _1\) left justified boxes in the top row, \(\lambda _2\) in the second row, and so on. Thus \(m_i\) represents the number of rows with exactly \(i\) boxes. Define \(\mathbb{Y }\) to be the set of all partitions. The transpose of a Young diagram is denoted \(\lambda ^{\prime }\) and defined by the property \(\lambda _i^{\prime } = |\{j:\lambda _j\ge i\}|\). Some of these concepts are illustrated in Fig. 4.

The Young diagram \(\lambda =(5,3,2,2)\) and its transpose (not shown) \(\lambda ^{\prime }=(4,4,2,1,1)\). The length \(\ell (\lambda )=4\) and weight \(|\lambda |=12\). The Young diagram \(\mu =(3,2,2,1)\) is such that \(\lambda \supset \mu \). The skew Young diagram \(\lambda -\mu \) is shown in black thick lines and is a horizontal 4-strip.
Given two diagrams \(\lambda \) and \(\mu \) such that \(\lambda \supset \mu \) (as a set of boxes), we call the set-difference \(\theta = \lambda -\mu \) a skew Young diagram. A skew Young diagram \(\theta \) is a horizontal \(m\) strip if \(|\theta |=m\) and if in each column, \(\theta \) has at most one box (Fig. 4).
A column-strict (skew) Young tableaux \(T\) is a sequence of partitions \(\lambda ^{(i)}\):
such that \(\theta ^{(i)} = \lambda ^{(i)}-\lambda ^{(i-1)}\) are all horizontal strips (For such a pair of partitions we also write \(\lambda ^{(i-1)}\prec \lambda ^{(i)}\) ). If \(\mu =\varnothing \) then this is also known of as a semi-standard Young tableaux and if one fills each skew diagram \(\theta ^{(i)}\) with the label \(i\), then these numbers must be strictly increasing in each column and weakly increasing in each row. The shape of \(T\) is \(\lambda -\mu \), and \((|\theta ^{(1)}|,|\theta ^{(2)}|,\ldots , |\theta ^{(r)}|)\) is the weight of \(T\). One may likewise define a vertical \(m\) strip and row-strict (skew) Young tableaux by transposing the role of rows and columns.
We occasionally will use the notation \(\lambda \cup \square _k\) which is the Young diagram formed by appending an additional square to row \(k\) of \(\lambda \).
2.1.2 Symmetric functions
The ring of polynomials in \(n\) independent variables with rational coefficients is denoted \(\mathbb{Q }[x_1,\ldots , x_n]\). The symmetric group \(S_n\) acts on such polynomials by permuting the variable labels. A symmetric polynomial is any polynomial in \(\mathbb{Q }[x_1,\ldots , x_n]\) which is invariant under this action. The symmetric polynomials form a subring and additionally have the structure of a graded ring
where \(\mathrm{Sym }_n^k\) consists of all homogeneous symmetric polynomials of degree \(k\).
For \(\alpha = (\alpha _1,\ldots ,\alpha _n)\in \mathbb{Z _{\ge 0}}^n\) we write \(x^{\alpha } = x_1^{\alpha _1}\cdots x_n^{\alpha _n}\). A permutation \(\pi \in S_n\) acts on a vector \(\alpha \) by permuting its indices. For any partition \(\lambda \) such that \(\ell (\lambda )\le n\), the monomial symmetric polynomial \(m_{\lambda }\) is defined as
where the summation is over all \(\pi \in S_n\) yielding unique monomials \(x^{\pi (\lambda )}\). The collection of \(m_{\lambda }\), for \(\lambda \) running over all partitions of length less than or equal to \(n\), form a \(\mathbb{Q }\)-basis for \(\mathrm{Sym }_n\). Restricting to \(\lambda \) such that \(|\lambda |=k\), the \(m_{\lambda }\) form a \(\mathbb{Q }\)-basis of \(\mathrm{Sym }_n^k\).
It is often more convenient to work with an infinite number of independent variables. This is achieved [79, I.2] in the following way: for \(m\ge n, \rho _{m,n}\) is a homomorphism from \(\mathrm{Sym }_m\) to \(\mathrm{Sym }_n\) (here \(m\ge n\)) defined by taking a symmetric polynomial \(f(x_1,\ldots ,x_n,\ldots , x_m)\) to \(f(x_1,\ldots ,x_n,0,\ldots ,0)\). Restricted to the monomial symmetric polynomial basis, \(\rho _{m,n}\) takes \(m_{\lambda }(x_1,\ldots ,x_m)\) to \(m_{\lambda }(x_1,\ldots ,x_n)\) if \(\ell (\lambda )\le n\) and to 0 otherwise. The homomorphism is surjective, as is its restriction \(\rho ^{k}_{m,n}\) from \(\mathrm{Sym }^k_m\) to \(\mathrm{Sym }^k_{n}\).
We form the inverse limit \(\mathrm{Sym }^k = \lim _{\leftarrow } \mathrm{Sym }^k_n\) of the \(\mathbb{Q }\)-modules \(\mathrm{Sym }^k_n\) relative to the homomorphisms \(\rho ^k_{m,n}\). \(\mathrm{Sym }^k\) has a \(\mathbb{Q }\)-basis consisting of the monomial symmetric functions \(m_{\lambda }\) (for all \(\lambda \) such that \(|\lambda |=k\)) defined by \(\rho ^k_{n}(m_{\lambda }) = m_{\lambda }(x_1,\ldots ,x_n)\) for all \(n\ge k\).
We define \(\mathrm{Sym }= \bigoplus _{k\ge 0} \mathrm{Sym }^k\) to be the ring of symmetric functions in countably many independent variables \(x_1,x_2,\ldots \). There exist surjective homomorphisms \(\rho _n\) from \(\mathrm{Sym }\) to \(\mathrm{Sym }_n\) which act by restricting \(m_{\lambda }\) to \(m_{\lambda }(x_1,\ldots , x_n)\) if \(|\lambda |\le n\), or otherwise zero. These are ring homomorphisms and thus give \(\mathrm{Sym }\) the structure of a graded ring. We will use the term symmetric function when dealing with elements of \(\mathrm{Sym }\) (as they are not, in fact, polynomials but rather formal infinite sums of monomials) and polynomial when dealing with elements of \(\mathrm{Sym }_n\) for some \(n\).
Besides the monomial symmetric functions, there exist a number of other bases for \(\mathrm{Sym }\). The most simple among these are:
-
The elementary symmetric functions \(e_r:= m_{1^{r}}\) (recall that \(1^r\) represents the partition \((1,1,\ldots , 1)\) with \(r\) entries). Then \(\mathrm{Sym }=\mathrm{span}(e_{\lambda }|\lambda \in \mathbb{Y })\) with \(e_{\lambda } = e_{\lambda _1}e_{\lambda _2} \cdots \).
-
The complete homogeneous symmetric functions \(h_r:=\sum _{|\lambda |=r} m_{\lambda }\). Then setting \(h_{\lambda } = h_{\lambda _1}h_{\lambda _2} \cdots \), \(\mathrm{Sym }=\mathrm{span}(h_{\lambda }|\lambda \in \mathbb{Y })\).
-
The power sum symmetric functions \(p_r:=m_{r}\). Since \(r\) represents the partition \(\lambda =(r)\) this translates formally into \(p_r=\sum x_i^r\). From power sums we form \(p_{\lambda }=\prod _{i=1}^{\ell (\lambda )} p_{\lambda _i}\). Then \(\mathrm{Sym }=\mathrm{span}(p_{\lambda }|\lambda \in \mathbb{Y })\).
Less obvious symmetric functions include those of Schur, Hall-Littlewood, and Jack. They are all indexed by partitions and share the characteristic that they can be uniquely defined (via Gram-Schmidt—although the existence of the needed basis is nontrivial as we use partial order) from the following two properties: (a) They can be expressed in terms of the monomial symmetric functions via a strictly upper unitriangular transition matrix (for instance the Schur functions \(s_{\lambda }=m_{\lambda } + \sum _{\mu <\lambda \in \mathbb{Y }} K_{\lambda \mu }m_{\mu }\) where \(K_{\lambda \mu }\) are the Kostka numbers); (b) They are pairwise orthogonal with respect to a scalar product under which the power sum symmetric functions are orthogonal. The specific scalar product differs between the functions. For the Schur functions it is defined by \(\langle p_{\lambda }, p_{\mu }\rangle = \delta _{\lambda \mu } z_{\lambda }\) where \(z_{\lambda } = \prod _{i\ge 1}i^{m_{i}}(m_i)!\) (here \(\lambda = 1^{m_1}2^{m_2}\cdots \)) and where \(\delta _{\lambda \mu }\) is the indicator function that \(\lambda =\mu \). For the Hall-Littlewood functions \(z_{\lambda }\) is replaced by \(z_{\lambda }(t) = z_{\lambda } \prod _{i=1}^{\ell (\lambda )} (1-t^{\lambda _i-1})\), where \(t\in (0,1)\) – and now the coefficients are in \(\mathbb{Q }[t]\). For Jack’s symmetric functions \(z_{\lambda }\) is replaced by \(z_{\lambda }\alpha ^{\ell (\lambda )}\) for \(\alpha >0\) – and now the coefficients are in \(\mathbb{Q }[\alpha ]\).
In fact, the symmetric functions of Schur, Hall-Littlewood, and Jack are all generalized by the symmetric functions of Macdonald [79, Section VI].
2.1.3 Macdonald symmetric functions
We now introduce the Macdonald symmetric functions and identify a number of relevant properties which we will appeal to in our development of the Macdonald process. Macdonald symmetric functions are indexed by partitions and denoted \(P_{\lambda }(x;q,t)\) where \(q,t\in (0,1)\). The coefficients for the symmetric functions are now in \(\mathbb{Q }[q,t]\). We will generally suppress the \(q\) and \(t\) and write \(P_{\lambda }(x)\) or \(P_{\lambda }\) unless their presence is pertinent. \(P_{\lambda }\) can be uniquely defined from the following two properties [79, VI,(4.7)]: (a) They can be expressed in terms of the monomial symmetric functions via a strictly upper unitriangular transition matrix:
where \(R_{\lambda \mu }\) are functions of \(q,t\). (b) They are pairwise orthogonal with respect to a scalar product which can be defined on the power sum symmetric functions (since they form a linear basis for the symmetric functions) via
for \(\lambda =1^{m_1}2^{m_2}\cdots \). Along with \(P_{\lambda }\) one defines
so that \(P_{\lambda }\) and \(Q_{\mu }\) are orthonormal.
Specializing \(q=t\) recovers the Schur symmetric functions, \(q=0\) recovers the Hall-Littlewood symmetric functions with parameter \(t\), and taking \(q=t^{\alpha }\) with \(t\rightarrow 1\) recovers the Jack symmetric functions with parameter \(\alpha \).
The complete homogeneous symmetric function \(h_{r}\) has a \((q,t)\)-analog which is denoted \(g_r=Q_{(r)}\) and can be expressed as \(g_r = \sum _{|\lambda |=r} z_{\lambda }(q,t)^{-1}p_{\lambda }\) (this is analogous in the sense that \(h_{r} = s_{(r)}\)). These also form an algebraic basis for \(\mathrm{Sym }\) [79, VI,(2.19)].
The Macdonald symmetric polynomial is defined as the restriction of \(P_{\lambda }\) onto a finite number of variables \(x_1,\ldots , x_m\). Formally, since \(P_{\lambda }\in \mathrm{Sym }^{|\lambda |}\), for any \(m\ge 0\), the Macdonald polynomial in \(m\) variables is written as \(P_{\lambda }(x_1,\ldots , x_m)\) and is the projection of \(P_{\lambda }\) into \(\mathrm{Sym }^{|\lambda |}_{m}\). If \(m<\ell (\lambda )\) then \(P_{\lambda }(x_1,\ldots , x_m)=0\).
Macdonald symmetric polynomials demonstrate the following index shift property [79, VI,(4.17)]:
Owing to this property we can extend Macdonald symmetric polynomials so as to be defined for arbitrary integer values of \(\lambda _1\ge \lambda _2\ge \cdots \lambda _\ell (\lambda )\) via iterating the above relation. For negative values of \(\lambda _j\)’s, \(P_{\lambda }\) becomes a Laurent polynomial in the \(x\)’s.
For \(u,v\in (0,1)\) define a \(\mathbb{Q }[q,t]\)-algebra endomorphism \(\omega _{u,v}\) on \(\mathrm{Sym }\) in terms of its action on power sums [79, VI,(2.14)]:
Clearly \(\omega _{v,u}w_{u,v}\) is the identity on \(\mathrm{Sym }\). Moreover, \(\omega _{u,v}\) acts on Macdonald symmetric functions as [79, VI,(5.1)]
This endomorphism takes \(g_r\) to \(e_r\), the (usual) elementary symmetric functions.
2.1.4 Cauchy identity
For any two sequences of independent variables \(x_1,x_2,\ldots \) and \(y_1,y_2,\ldots \) define
Then [79, VI,(2.5)],
where \((a;q)_{\infty }=(1-a)(1-aq)(1-aq^2)\cdots \) is the \(q\)-Pochhammer symbol (see Sect. 3.1.1). Additionally,
If the \(P_{\lambda }\) and \(Q_{\lambda }\) are considered as symmetric functions variables \(x_1,x_2,\ldots \) and \(y_1,y_2,\ldots \) (respectively) then the above identities are as formal powers. If both sides can be evaluated as absolutely convergent series, then the identities are as numeric equalities. In particular if all but a finite number of the variables are finite (i.e., the case of Macdonald symmetric polynomials), the identities are necessarily numeric equalities. For symmetric functions there exists an extension to the concept of evaluating at an infinite sequence of variables. This is called specializing the functions and in Sect. 2.2.1 we will show how the Cauchy identity extends to this context. This will necessitate extending the notation \(\Pi (x;y)\) to \(\Pi (\rho _1,\rho _2)\) where \(\rho _1\) and \(\rho _2\) are specializations. When the specialization reduces to evaluation as here, the definition likewise reduces. Thus there should be no ambiguity in our usage of the symbol \(\Pi \) in this context.
Note that applying the endomorphism \(\omega _{q,t}\) to \(\Pi (x;y)\) gives
2.1.5 Torus scalar product
The Macdonald symmetric polynomials in \(N\) independent variables are orthogonal under another scalar product which is called the torus scalar product and denoted by \(\langle \cdot ,\cdot \rangle _N^{\prime }\). It is defined [79, VI,(9.10)] as
where \(\mathbb{T }^N\) is the \(N\)-fold product of the torus \(\{z=e^{2\pi \iota \theta }\}\).
Under this scalar product we can compute \(\langle P_{\lambda }, P_{\lambda } \rangle _N^{\prime }\) where we interpret \(P_{\lambda }\) as the Macdonald symmetric polynomial with \(N\) variables [79, VI,(9, Ex 1d)]
It follows from equation (2.5) that
where the dot represents that the inner product is applied to the function which takes \(z\mapsto \Pi (z;x)\). Note that above \(z\) represents a \(N\)-vector \((z_1,\ldots ,z_N)\).
2.1.6 Pieri formulas for Macdonald symmetric functions
Recall that \(g_r=Q_{(r)}\) is the \((q,t)\)-analog of the complete homogeneous symmetric function, while \(e_r\) is the (usual) elementary symmetric function. Since the Macdonald symmetric functions form a basis for \(\mathrm{Sym }\) it follows that for each \(\mu \) and \(r\) there exist constants (depending on \(q,t\)) \(\varphi _{\lambda /\mu }, \psi _{\lambda /\mu }, \varphi _{\lambda /\mu }^{\prime }\) and \(\psi _{\lambda /\mu }^{\prime }\) such that:
Define \(f(u) = (tu;q)_{\infty }/(qu;q)_{\infty }\). The coefficients above have exact formulas as follows [79, VI,(6.24)]: If \(\lambda - \mu \) is a horizontal \(r\)-strip then
otherwise the coefficient is zero; Applying the endomorphism \(\omega _{q,t}\) implies that the coefficients \(\varphi _{\lambda /\mu }^{\prime }(q,t) = \varphi _{\lambda /\mu }(t,q)\) and \(\psi _{\lambda /\mu }^{\prime }(q,t) = \psi _{\lambda /\mu }(t,q)\). These coefficients are zero unless \(\lambda -\mu \) is a vertical \(r\)-strip.
The expressions above can be reduced significantly. For example, given \(\lambda -\mu \) a vertical \(r\)-strip,
2.1.7 Skew Macdonald symmetric functions
Similar to equation (2.9), for two partitions \(\mu ,\nu \) one can expand the product \(P_{\mu }P_{\nu } = \sum _{\lambda \in \mathbb{Y }} f_{\mu \nu }^{\lambda } P_{\lambda }\). By consideration of degree, \(f_{\mu \nu }^{\lambda }\) may only be non-zero if \(|\lambda |=|\mu |-|\nu |, \lambda \supset \mu \) and \(\lambda \supset \nu \). When \(q=t\) these are called Littlewood-Richardson coefficients; when \(q=0\) these are Hall polynomials in \(t\) [79, VI,(7.2)]. Alternatively, one can extract these coefficients via \(f_{\mu \nu }^{\lambda } = \langle Q_{\lambda },P_{\mu }P_{\nu }\rangle \).
A skew Macdonald symmetric function is defined as [79, VI,(7.5,7.6)]
By linearity this implies that \(\langle Q_{\lambda /\mu },f\rangle = \langle Q_{\lambda },P_{\mu } f\rangle \) for all \(f\in \mathrm{Sym }\). These functions are zero unless \(\lambda \supset \mu \), in which case \(Q_{\lambda /\mu }\) is homogeneous of degree \(|\lambda |-|\mu |\).
Likewise, we can define \(P_{\lambda /\mu }\) so that \(\langle P_{\lambda /\mu },Q_{\nu }\rangle = \langle P_{\lambda },Q_{\mu }Q_{\nu }\rangle \). Owing to the relationship \(Q_{\lambda }=\langle ~P_{\lambda },P_{\lambda }\rangle ^{-1}P_{\lambda }\) it follows that
It is possible to express skew Macdonald symmetric functions in terms of the \(\varphi \) and \(\psi \) of equations (2.10) and (2.11). Specifically let \(T\) represent a column-strict (skew) tableaux of shape \(\lambda -\mu \) given by a sequence of \(\lambda ^{(i)}\) as in equation (2.1). Let \(\alpha \) be the weight of \(T\) (i.e., \(\alpha _i = |\lambda ^{(i)}-\lambda ^{(i-1)}|\)) and define \(x^T\) as \(x^{\alpha }= x_1^{\alpha _1}x_2^{\alpha _2}\cdots \). Then we have the following combinatorial formula expansion [79, VI,(7.13)]
and the summation is over all \(T\) which are column-strict (skew) tableaux of shape \(\lambda -\mu \).
Likewise
and the summation is over all \(T\) which are column-strict (skew) tableaux of shape \(\lambda -\mu \).
If we restrict the Macdonald symmetric functions to Macdonald polynomials in a single variable \(x_1\), then the above expansions imply
if \(\lambda -\mu \) is a horizontal strip, and zero otherwise. Likewise
if \(\lambda -\mu \) is a horizontal strip, and zero otherwise.
Finally, we recount a few pertinent formulas involving these skew functions [79, VI.7]:
With regards to the last equations, the argument \((x,y)\) simply means the union of the two sets of variables. The function therefore is symmetric with respect to any permutation of the variables in this union. A consequence of this is that to evaluate a symmetric function \(f\) at \((x,y)\) one can alternatively expand \(f\) in terms of power sum symmetric functions and set \(p_n(x,y) = p_n(x)+p_n(y)\). In Sect. 2.2.1 below we consider general specializations of symmetric functions for which one must take this power sum equality as the definition of the union of two specializations.
Similar to equation (2.4), the endomorphism \(\omega _{q,t}\) acts on skew Macdonald symmetric functions as [79, VI,(7.16)]
2.2 The Macdonald processes
2.2.1 Macdonald nonnegative specializations of symmetric functions
A specialization \(\rho \) of \(\mathrm{Sym }\) is an algebra homomorphism of \(\mathrm{Sym }\) to \(\mathbb{C }\). We denote the application of \(\rho \) to \(f\in \mathrm{Sym }\) as \(f(\rho )\). The trivial specialization \(\varnothing \) takes value 1 at the constant function \(1\in \mathrm{Sym }\) and takes value \(0\) at any homogeneous \(f\in \mathrm{Sym }\) of degree \(\ge 1\). For two specializations \(\rho _1\) and \(\rho _2\) we define their union \(\rho =(\rho _1,\rho _2)\) as the specialization defined on power sum symmetric functions via
and extended to \(\mathrm{Sym }\) by linearity. Also, for \(a>0\) define \(a\cdot \rho \) as the specialization which takes homogeneous functions \(f\in \mathrm{Sym }\) to \(a^{\mathrm{degree}(f)} f(\rho )\), which we write as \(f(a\cdot \rho )\).
An example of a specialization is the homomorphism which can be written as \(f(x_1,\ldots , x_n)\). This represents restricting \(f\) to \(\mathrm{Sym }_n\) and then evaluating the resulting polynomial at the values \(x_1,\ldots , x_n\). We call this a finite length specialization. Not all specializations are finite length. The class with which we work will contain more general specializations which can be thought of as unions of limits of such finite length specializations as well as limits of finite length dual specializations. A finite length dual specialization is obtained by a finite length specialization composed with the endomorphism \(\omega _{q,t}\). All of the formulas involving finite length specializations from Sect. 2.1 likewise hold for general specializations.
Let \(t\) and \(q\) be two parameters in \((0,1)\), and let \(\{P_\lambda \}\) be the corresponding Macdonald symmetric functions (see Sect. 2.1.3).
Definition 2.1
We say that a specialization \(\rho \) of \(\mathrm{Sym }\) is Macdonald nonnegative (or just ‘nonnegative’) if it takes nonnegative values on the skew Macdonald symmetric functions: \(P_{\lambda /\mu }(\rho )\ge 0\) for any partitions \(\lambda \) and \(\mu \).
There is no known classification of the nonnegative specializations. The classification is known in the case of nonnegative specializations of Jack’s symmetric functions [69] and in the subcase of Schur symmetric functions this is a classical statement known as “Thoma’s theorem” (see [68] and references therein). In the Macdonald case, however, it is not hard to come up with a class of examples. In fact, Kerov conjectured that the following class completely classifies all nonnegative specializations ([68], section II.9)—though this has not been proved.
Let \(\{\alpha _i\}_{i\ge 1}, \{\beta _i\}_{i\ge 1}\), and \(\gamma \) be nonnegative numbers, and \(\sum _{i=1}^\infty (\alpha _i+\beta _i)<\infty \). Let \(\rho \) be a specialization of \(\mathrm{Sym }\) defined by
Here \(u\) is a formal variable and \(g_n=Q_{(n)}\) is the \((q,t)\)-analog of the complete homogeneous symmetric function \(h_n\). Since \(g_n\) forms a \(\mathbb{Q }[q,t]\) basis of \(\mathrm{Sym }\), this uniquely defines the specialization \(\rho \). The expression in equation (2.23) which we write as \(\Pi (u;\rho )\) is a special case of equation (2.27) for \(\rho _1\) equal to the finite length specialization to a single variable \(u\).
Notice also that if \(\rho \) is specified by nonnegative numbers \(\{\alpha _i\}_{i\ge 1}, \{\beta _i\}_{i\ge 1}\), and \(\gamma \), then \(a\cdot \rho \) is likewise specified by \(\{a\alpha _i\}_{i\ge 1}, \{a\beta _i\}_{i\ge 1}\), and \(a\gamma \) as follows from the calculation
Proposition 2.2
For any nonnegative \(\{\alpha _i\}_{i\ge 1}, \{\beta _i\}_{i\ge 1}\), and \(\gamma \) such that \(\sum _{i=1}^\infty (\alpha _i+\beta _i)~<~\infty \), the specialization \(\rho \) is Macdonald nonnegative.
Proof
It suffices to verify the statement for finitely many nonzero \(\alpha _i\)’s and \(\beta _i\)’s. One then obtains infinitely many ones by a limit transition, and also produces a nontrivial \(\gamma \) by taking \(M\) of the \(\beta _i\)’s equal to \(\gamma /M\) and sending \(M\) to infinity.
By using the fact that
which follows from equation (2.21), we reduce the statement to \(\rho \)’s with finitely many nontrivial \(\alpha _i\)’s or finitely many nontrivial \(\beta _i\)’s. Applying the endomorphism \(\omega _{q,t}\) given in equation (2.3) we see that by virtue of equations (2.7), (2.13) and (2.22), we only need to consider one of these two cases.
On the other hand, if we only have finitely many positive \(\alpha _j\)’s, \(P_{\lambda /\mu }\) are simply skew Macdonald polynomials in variables \(\alpha _1,\alpha _2,\ldots \). The tableaux expansion of equation (2.15) then allows us to conclude the proof. \(\square \)
We name a few particularly useful specializations:
Definition 2.3
A Macdonald nonnegative specialization \(\rho \) is called
-
Plancherel if \(\alpha _i=\beta _i=0\) for all \(i\) and \(\gamma >0\);
-
Pure alpha if \(\beta _i=0\) for all \(i, \gamma =0\) and at least one \(\alpha _i>0\);
-
Pure beta if \(\alpha _i=0\) for all \(i, \gamma =0\) and at least one \(\beta _i>0\).
For a nonnegative specialization \(\rho \), denote by \(\mathbb{Y }(\rho )\) the set of partitions (or Young diagrams) \(\lambda \) such that \(P_\lambda (\rho )>0\). We also call \(\mathbb{Y }(\rho )\) the support of \(\rho \) (recall the set of all partitions is denoted as \(\mathbb{Y }\)).
Using the combinatorial formula for the Macdonald symmetric functions in equation (2.14) and the endomorphism \(\omega _{q,t}\), it is not hard to show that if a nonnegative specialization \(\rho \) is defined as in equation (2.23) with \(\gamma =0, p<\infty \) nonzero \(\alpha _j\)’s and \(q<\infty \) nonzero \(\beta _j\)’s, then \(\mathbb{Y }(\rho )\) consists of the Young diagrams that fit into the \(\Gamma \)-shaped figure with \(p\) rows and \(q\) columns. Otherwise it is easy to see that \(\mathbb{Y }(\rho )=\mathbb{Y }\).
In particular, if in equation (2.23) all \(\beta _j\)’s and \(\gamma \) vanish, and there are \(p\) nonzero \(\alpha _j\)’s, then \(\mathbb{Y }(\rho )\) consists of Young diagrams with no more than \(p\) rows. Such a finite length specialization consists in assigning values \(\alpha _j\) to \(p\) of the symmetric variables used to define \(\mathrm{Sym }\), and \(0\)’s to all the other symmetric variables.
2.2.2 Definition of Macdonald processes
Fix a natural number \(N\) and nonnegative specializations \(\rho _0^+,\ldots ,\rho _{N-1}^+, \rho _1^-,\ldots ,\rho _N^-\) of \(\mathrm{Sym }\). For any sequences \(\lambda =(\lambda ^{(1)},\ldots ,\lambda ^{(N)})\) and \(\mu =(\mu ^{(1)},\ldots ,\mu ^{(N-1)})\) of partitions satisfying
define their weight as
There is one factor for any two neighboring partitions in equation (2.25). The fact that all the specializations are nonnegative implies that all the weights are nonnegative.
For any two specializations \(\rho _1,\rho _2\) set
provided that the series converge. This extends the definition of \(\Pi (x;y)\) given in Sect. 2.1.4 and of \(\Pi (u;\rho )\) in Sect. 2.2.1.
Proposition 2.4
Assuming \(\Pi (\rho _i^+;\rho _j^-)<\infty \) for all \(i,j\), we have
Proof
The proposition follows from repeated use of the identity in equation (2.24) and
which extend equations (2.19) and (2.20) to general specializations. \(\square \)
Definition 2.5
The Macdonald process \(\mathbf{M }(\rho _0^+,\ldots ,\rho _{N-1}^+;\rho _1^-,\ldots ,\rho _N^-)\) is the probability measure on sequences \((\lambda ,\mu )\) as in equation (2.25) with
The Macdonald process with \(N=1\) is called the Macdonald measure and written as \(\mathbf{MM }(\rho ^+;\rho ^-)\).
We write the probability distribution and expectation with respect to the Macdonald process (measure) as \(\mathbb{P }_{\mathbf{M }(\rho _0^+,\ldots ,\rho _{N-1}^+;\rho _1^-,\ldots ,\rho _N^-)}, \mathbb{E }_{\mathbf{M }(\rho _0^+,\ldots ,\rho _{N-1}^+;\rho _1^-,\ldots ,\rho _N^-)}\) or \(\langle \cdot \rangle _{\mathbf{M }(\rho _0^+,\ldots ,\rho _{N-1}^+;\rho _1^-,\ldots ,\rho _N^-)}\) (\(\mathbb{P }_{\mathbf{MM }(\rho ^+;\rho ^-)}, \mathbb{E }_{\mathbf{MM }(\rho ^+;\rho ^-)}\) or \(\langle \cdot \rangle _{\mathbf{MM }(\rho ^+;\rho ^-)}\)).
Using equations (2.24), (2.28) and (2.29) it is not difficult to show that a projection of the Macdonald process to any subsequences of \((\lambda ,\mu )\) is a also a Macdonald process. In particular, the projection of \(\mathbf{M }\bigl (\rho _0^+,\ldots ,\rho _{N-1}^+;\rho _1^-,\ldots ,\rho _N^-\bigr )\) to \(\lambda ^{(j)}\) is the Macdonald measure \(\mathbf{MM }\bigl (\rho ^+_{[0,j-1]};\rho ^-_{[j,N]}\bigr )\), and its projection to \(\mu ^{(k)}\) is a slightly different Macdonald measure \(\mathbf{MM }\bigl (\rho ^+_{[0,k-1]};\rho ^-_{[k+1,N]}\bigr )\). Here we used the notation \(\rho ^\pm _{[a,b]}\) to denote the union of specializations \(\rho ^\pm _m, m=a,\ldots ,b\).
Proposition 2.6
Under the probability distribution given by the Macdonald process, the random variables \(|\lambda ^{(1)}|, |\lambda ^{(2)}-\mu ^{(1)}|, \ldots , |\lambda ^{(N)}-\mu ^{(N-1)}|\) are independent. Likewise \(|\lambda ^{(1)}-\mu ^{(1)}|,|\lambda ^{(2)}-\mu ^{(2)}|,\ldots , |\lambda ^{(N)}|\) are independent. Moreover these random variables have generating functions given by
Proof
Observe that for \(a_0^+,a_1^+,\ldots , a_{N-1}^+\) and \(a_1^{-},\ldots ,a_N^{-}\) positive numbers, (suppressing the Macdonald process subscript in the expectation), \(\mathbb{E }\left[ \!(a_{0}^+)^{|\lambda ^{(1)}|}(a_1^{-})^{|\lambda ^{(1)}-\mu ^{(1)}|}\right. \left. (a_1^+)^{|\lambda ^{(2)}-\mu ^{(1)}|}\cdots \right] \) is given by
where \(Z=\prod _{0\le i<j\le N}\Pi (\rho _i^+;\rho _j^-)\). Setting \(a_i^+\equiv 1\) or \(a_j^-\equiv 1\) and observing the way the generating function factors gives the desired independence, and likewise setting all variables to 1 except one gives the generation function formula. \(\square \)
We will mainly focus on a special case of the Macdonald process.
Definition 2.7
The ascending Macdonald process \(\mathbf{M }_{asc}(a_1,\ldots ,a_N;\rho )\) is the probability measure on sequences
(or equivalently column-strict Young tableaux) indexed by positive variables \(a_1,\ldots , a_N\) and a single nonnegative specialization \(\rho \), with
Here \(\Pi (a_1,\ldots ,a_N;\rho ) = \Pi (a_1;\rho )\cdots \Pi (a_N;\rho )\) with the terms \(\Pi (u;\rho )\) as defined in (2.23).
The ascending Macdonald process is a special case of Macdonald processes with \(\rho _j^+\) being specializations into a single positive variable \(a_{j+1}, j=1,\ldots ,N\), the specializations \(\rho _1^-,\ldots ,\rho _{N-1}^-\) being trivial, and the only remaining free specialization \(\rho _N^-\) being written simply as \(\rho \). Then \(\mu ^{(k)}=\lambda ^{(k)}\) for all \(k\), and the process lives on sequences as in equation (2.30) and is given by equation (2.31).
If \(\rho \) corresponds to parameters \(\{\alpha _i\}, \{\beta _i\}, \gamma \) as in the previous section, it is not hard to see that the condition of the partition function \(\Pi (a_1,\ldots ,a_N;\rho )\) being finite is equivalent to \(a_i\alpha _j<1\) for all \(i,j\).
Observe that the projection of \(\mathbf{M }_{asc}\) to \(\lambda ^{(k)}, k\!=\!1,\ldots ,N\), is the Macdonald measure
2.2.3 Difference operators and integral formulas
The relevance of this section to the study of Macdonald processes is explained by the following observation. Assume we have a linear operator \(\mathcal{D }\) in the space of functions in \(n\) variables whose restriction to the space of symmetric polynomials diagonalizes in the basis of Macdonald polynomials: \(\mathcal{D } P_\lambda =d_\lambda P_\lambda \) for any partition \(\lambda \) with \(\ell (\lambda )\le n\). Then we can apply \(\mathcal{D }\) to both sides of the identity
Dividing the result by \(\Pi (a_1,\ldots ,a_n;\rho )\) we obtain
where \(\langle \cdot \rangle _{\mathbf{MM }(a_1,\ldots ,a_n;\rho )}\) represents averaging \(\cdot \) over the specified Macdonald measure. If we apply \(\mathcal{D }\) several times we obtain
If we have several possibilities for \(\mathcal{D }\) we can obtain formulas for averages of the observables equal to products of powers of the corresponding eigenvalues. The goal of this section is to provide a few variants for such operators.
In what follows we fix the number of independent variables to be \(n\in \mathbb{Z _{>0}}\).
Definition 2.8
For any \(u\in \mathbb{R }\) and \(1\le i\le n\), define the shift operator \(T_{u,x_i}\) by
For any subset \(I\subset \{1,\ldots ,n\}\), define
Finally, for any \(r=1,2,\ldots ,n\), define the Macdonald difference operator
Proposition 2.9
[79, VI(4.15)] For any partition \(\lambda \) with \(\ell (\lambda )\le n\)
Here \(e_r\) is the elementary symmetric function, \(e_r(x_1,\ldots ,x_n) = \sum _{1\le i_1<\cdots <i_r\le n} x_{i_1} \cdots x_{i_r}\).
Although the operators \(D_n^r\) do not look particularly simple, they can be represented by contour integrals, which will later be helpful for evaluating the right-hand side of equation (2.32).
Remark 2.10
In the below propositions the desired contours always exist under the hypothesis that the parameter \(t\) is sufficiently small and the ratios \(x_i/x_j\) are sufficiently close to 1. This will suffice for our purposes. Extending validity of these formulas to the full set of parameters may require more work.
Proposition 2.11
Assume that \(F(u_1,\ldots ,u_n)=f(u_1)\cdots f(u_n)\). Take \(x_1,\ldots ,x_n>0\) and assume that \(f(u)\) is holomorphic and nonzero in a complex neighborhood of an interval in \(\mathbb{R }\) that contains \(\{x_j,qx_j\}_{j=1}^n\). Then for \(r=1,2,\ldots ,n\)
where each of \(r\) integrals is over positively oriented contour encircling \(\{x_1,\ldots ,x_n\}\) and no other singularities of the integrand.
Proof
First note that since \(t\) and \(q\) are assumed to be in \((0,1)\) it is always possible to find contours of integration as desired by the statement of the proposition we are proving. We assume now that the \(x_i\) are pairwise disjoint. By continuity of both sides of the formula in the \(x\) variables, this suffices to prove the general result. Now use the Cauchy determinant identity
and compute the residues at \(z_j=x_{m_j}\). Thanks to the Vandermonde determinants in the numerator, one gets zero contributions if \(m_j\)’s are not pairwise distinct, and if they are distinct one easily verifies that the contribution corresponds to the summand in \(D_n^r\) with \(I=\{x_{m_1},\ldots ,x_{m_r}\}\). The \(r!\) factor is responsible for permutations of the elements of \(I\). \(\square \)
Remark 2.12
We define a useful analog to the Macdonald operator \(D_n^r\) to be the operator
where the operator \(T_{q^{-1}}\) multiplies all variables by \(q^{-1}\). Observe that
and
Observe that
Applying this to a function \(F(u_1,\ldots , u_n)=f(u_1)\cdots f(u_n)\) as in Proposition 2.11 we obtain an analogous integral formula
where the contours include the poles \(z_j=x_m\) and no other singularities. Under the change of integration variables \(z_j=1/w_j\) for \(j=1,\ldots , r\) we have
where the contours now include the poles \(w_j=x_m^{-1}\) and no other singularities. The formula is exactly as in Proposition 2.11 with an extra factor of \(t^{r(n-1)}\), the \(x_m\)’s replaced by their inverses, and \(f(u)\) replaced by \(f(u^{-1})\). Iterating these operators will lead to very similar formulas to the ones we now obtain for powers of \(D_n^r\).
Remark 2.13
Recall that \(\Pi (a_1,\ldots ,a_n;\rho )=\prod _{i=1}^n \Pi (a_i;\rho )\). Hence, Proposition 2.11 is suitable for evaluating the right-hand side of equation (2.32). We will not rewrite these formulas as they are immediate.
Observe also that for any fixed \(z_1,\ldots ,z_r\), the right-hand side of equation (2.33) is a multiplicative function of \(x_j\)’s. This makes it possible to iterate the procedure. Let us do that in the simplest case first, then the full case below in Proposition 2.16.
Proposition 2.14
Fix \(k\ge 1\). Assume that \(F(u_1,\ldots ,u_n)=f(u_1)\cdots f(u_n)\). Take \(x_1,\ldots ,x_n >0\) and assume that \(f(u)\) is holomorphic and nonzero in a complex neighborhood of an interval in \(\mathbb{R }\) that contains \(\{q^ix_j\mid i=0,\ldots ,k,j=1\ldots ,n\}\). Then
where the \(z_c\)-contour contains \(\{qz_{c+1},\ldots ,qz_k,x_1,\ldots ,x_n\}\) and no other singularities for \(c=1,\ldots ,k\).
Proof
This follows from sequential application of Proposition 2.11. For \(k=1\) the statement coincides with Proposition 2.11. We call the integration variable \(z_1\) and deform the integration contour to contain \(\{x_j,qx_j\}_{j=1}^n\). Then the \(x\)-dependent part of the integrand satisfies the assumption of Proposition 2.11 with \(\tilde{f}(u)=f(u)(tz_1-u)/(z_1-u)\), and we apply Proposition 2.11 to the integrand. Call the new integration variable \(z_2\) and iterate the procedure. \(\square \)
Remark 2.15
In the Schur measure case, one can apply products of operators \(D_n^1\) with different values of \(q=t\). This would allow to derive a formula for the correlation functions of the Schur measure. Specifically observe that when \(q=t\)
Calling \((\lambda _1+n-1,\ldots , \lambda _n) = (\ell _1,\ldots , \ell _n)\) we thus have
where \(\rho _1\) is the first correlation function. We likewise find that
is easily expressible via the first \(s\) correlation. From this one might recover all of the correlation functions of the Schur measure.
Proposition 2.16
Fix \(k\ge 1\) and \(r_{\alpha }\ge 1\) for \(1\le \alpha \le k\). Assume that \(F(u_1,\ldots ,u_n)=f(u_1)\cdots f(u_n)\). Take \(x_1,\ldots ,x_n >0\) and assume that \(f(u)\) is holomorphic and nonzero in a complex neighborhood of an interval in \(\mathbb{R }\) that contains \(\{q^i x_j\mid i=0,\ldots ,k;\,j=1\ldots ,n\}\). Then
where the \(z_{\alpha ,j}\)-contour contains \(\{qz_{\beta ,i}\}\) for all \(i\in \{1,\ldots , r_{\beta }\}\) and \(\beta >\alpha \), as well as \(\{x_1,\ldots ,x_n\}\) and no other singularities.
The proof is similar to those of Propositions 2.11 and 2.14.
Let us describe another family of difference operators that are diagonalized by Macdonald polynomials.
Proposition 2.17
With the notation \(y_m=x_mq^{\eta _m}\) for \(m=1,\ldots ,n, (a)_{\infty } = (a;q)_{\infty }\) and \(x=(x_1,\ldots , x_n), y=(y_1,\ldots , y_n)\) we have
Here \(z\) is a formal variable, and the formula can be viewed as an identity of formal power series in \(z\).
The coefficient of \(z^r\) in the right-hand side is the polynomial \(g_r=Q_{(r)}\) evaluated at the variables \(\left\{ q^{\lambda _i}t^{n-i}\right\} _{i=1}^n\). The formula is dual to the first Pieri formula of equation (2.9) in the same way as Proposition 2.9 is dual to the last Pieri formula of equation (2.9) (see Sect. 2.1.6 or [79, VI,(6.7)] for detailed explanations). While the left-hand side can be viewed as an application of a \(q\)-integral operator to \(P_\lambda \), the coefficient of \(z^r\) constitutes a difference operator of order \(r\).
Remark 2.18
We were unable to find this formula in the literature. It is similar to Theorem I in [90], however, that theorem increases the number of variables in the polynomial. It is plausible that one can recover Proposition 2.17 from Okounkov’s raising operator, but we chose to give a direct proof.
Proof of Proposition 2.17
Following [79, VI.6] for each partition \(\mu \) of length less than or equal to \(n\), define a homomorphism (i.e. specialization)
We extend \(u_\mu \) to rational functions in \(x_1,\ldots , x_n\) for which the specialized denominator does not vanish. It follows from equation (2.6) that
hence the coefficient of \(z^m\) on the right-hand side of our desired identity is \(u_{\lambda }(g_m)P_{\lambda }(x_1,\ldots , x_n)\).
It suffices to prove the identity under application of \(u_{\mu }\) to both sides for arbitrary \(\mu \). For the right-hand side we obtain \(u_{\lambda }(g_m)u_{\mu }(P_{\lambda })\) as the coefficient of \(z^m\).
Using [79, VI,(6.6)] we have the index-variable duality relation
Hence using the first of the Pieri formulas (2.18)
The sum over \(\nu \) can be restricted to those for which \(\nu /\mu \) is a horizontal strip.
Set \(n(\lambda ) = \sum _{i=1}^{\ell (\lambda )} (i-1)\lambda _i\). What remains then is to show that for \(\eta _i = \nu _i-\mu _i\) we have the following identity
Following [79, VI,(6.11)] we find that if we set
then
Recall the formula for \(\varphi _{\nu /\mu }\) given in (2.10). By evaluating the first ratio of \(f\)’s when \(i=j\) and then shifting indices for the second ratio we find that
where \(f(u) = (tu)_{\infty } / (qu)_{\infty }\).
We can, however, recognize that the product of \(i<j\) can be written as
One now immediately sees that the required identity follows by substituting \(y_m=x_m q^{\eta _m}\) as necessary. \(\square \)
2.3 Dynamics on Macdonald processes
2.3.1 Commuting Markov operators
Let \(y,z,v\) be Macdonald nonnegative specializations of \(\mathrm{Sym }\). Set
where recall \(\mathbb{Y }(\rho )=\{\kappa \in \mathbb{Y }\mid P_\kappa (\rho )>0\}\), and for the first definition we assume that \(\Pi (y;z)=\sum _{\kappa \in \mathbb{Y }} P_\kappa (y)Q_\kappa (z)<\infty \).
Equations (2.24) and (2.28) imply that the matrices
are stochastic:
It also follows from equations (2.24), (2.28) and (2.29) that \(p^\uparrow \) and \(p^\downarrow \) act well on the Macdonald measures:
Observe that \(\mathbf{MM }(\rho _1;\rho _2)=\mathbf{MM }(\rho _2;\rho _1)\), so the parameters of the Macdonald measures in these relations can also be permuted.
Proposition 2.19
Let \(y,z,z_1,z_2,v_1,v_2\) be nonnegative specializations of \(\mathrm{Sym }\). Then we have the commutativity relations
where for the first relation we assume \(\Pi (y;z_1,z_2)<\infty \), and for the third relation we assume \(\Pi (y,v;z)<\infty \).
Proof
The arguments for all three identities are similar; we only give a proof of the third one (which is in a way the hardest and will be used later on). We have
where along the way we extended the summation in \(\mu \) from \(\mathbb{Y }(y,v)\) to \(\mathbb{Y }\) because \(P_\nu (y)P_{\mu /\nu }(v)>0\) implies \(P_\mu (y,v)>0\) by equation (2.24); we used equation (2.28) to switch from \(\mu \) to \(\kappa \), and finally we restricted the summation in \(\kappa \) from \(\mathbb{Y }\) to \(\mathbb{Y }(y)\) because \(P_{\nu }(y)Q_{\nu /\kappa }(z)>0\) implies \(\kappa \subset \nu \) and \(P_{\kappa }(y)>0\). \(\square \)
For a Macdonald nonnegative specialization \(y\) define a matrix \(q^\uparrow =[q^\uparrow _{\lambda \mu }]_{\lambda ,\mu \in \mathbb{Y }(y)}\) by
where \(\varphi _{\lambda /\mu }\) is defined in Sect. 2.1.6. Then the off-diagonal entries of this matrix are nonnegative and \(\sum _{\mu }q_{\lambda \mu }^\uparrow (y)=0\), hence \(q^\uparrow \) could serve as a matrix of transition rates for a continuous time Markov process.
Corollary 2.20
Let \(y,v\) be nonnegative specializations of \(\mathrm{Sym }\). Then
Proof
Consider the third relation of Proposition 2.19 and take \(z\) to be the specialization into a single variable \(\epsilon \). Using equation (2.16) to collect the linear terms in \(\epsilon \) we obtain the desired equality. \(\square \)
2.3.2 A general construction of multivariate Markov chains
Let \((\mathcal{S }_1,\ldots ,\mathcal{S }_n)\) be an \(n\)-tuple of discrete countable sets, and \(P_1,\ldots ,P_n\) be stochastic matrices defining Markov chains \(\mathcal{S }_j\rightarrow \mathcal{S }_j\). Also let \(\Lambda _1^2,\ldots , \Lambda _{n-1}^n\) be stochastic links between these sets:
Assume that these matrices satisfy the commutation relations
We will define a multivariate Markov chain with transition matrix \(P^{(n)}\) on the state space
The transition probabilities for the Markov chain with transition matrix \(P^{(n)}\) are defined as [we use the notation \(X_n=(x_1,\ldots ,x_n), Y_n=(y_1,\ldots ,y_n)\)]
if \(\prod _{k=2}^n\Delta ^k_{k-1}(x_k,y_{k-1})>0\), and \(0\) otherwise.
One way to think of \(P^{(n)}\) is as follows: Starting from \(X=(x_1,\ldots ,x_n)\), we first choose \(y_1\) according to the transition matrix \(P_1(x_1,y_1)\), then choose \(y_2\) using \(\frac{P_2(x_2,y_2)\Lambda _{1}^2(y_2,y_1)}{\Delta ^2_{1}(x_2,y_1)}\), which is the conditional distribution of the middle point in the successive application of \(P_2\) and \(\Lambda ^2_1\) provided that we start at \(x_2\) and finish at \(y_1\), after that we choose \(y_3\) using the conditional distribution of the middle point in the successive application of \(P_3\) and \(\Lambda ^3_2\) provided that we start at \(x_3\) and finish at \(y_2\), and so on. Thus, one could say that \(Y\) is obtained from \(X\) by sequential update.
Proposition 2.21
Let \(m_n\) be a probability measure on \(\mathcal{S }_n\). Let \(m^{(n)}\) be a probability measure on \(\mathcal{S }^{(n)}\) defined by
Set \(\tilde{m}_n=m_nP_n\) and
Then \(m^{(n)}P^{(n)}= \tilde{m}^{(n)}\).
Proof
The argument is straightforward. Indeed,
Extending the sum to \(x_1\in \mathcal{S }_1\) adds 0 to the right-hand side. Then we can use equation (2.35) to compute the sum over \(x_1\), removing \(\Lambda ^2_1(x_2,x_1), P_1(x_1,y_1)\) and \(\Delta ^2_1(x_2,y_1)\) from the expression. Similarly, we sum consecutively over \(x_2,\ldots ,x_n\), and this gives the needed result. \(\square \)
A generalization of Proposition 2.21 can be found in ([26], Proposition 2.7). A continuous time variant of the above construction, which is not as straightforward, can be found in ([30] Section 8).
2.3.3 Markov chains preserving the ascending Macdonald processes
For any \(k=1,2,\dots \), denote by \(\mathbb{Y }(k)\) the set of Young diagrams with at most \(k\) rows.
For a nonnegative specialization \(\rho \) and a positive number \(a\) such that \(\Pi (\rho ;a)<\infty \), and for two partitions \(\lambda \in \mathbb{Y }(n-1)\) and \(\mu \in \mathbb{Y }(n)\), we define a probability distribution on \(\mathbb{Y }(n)\) via
Here we assume that the set of \(\nu \)’s giving nonzero contributions to the right-hand side is nonempty. Then equation (2.28) implies the existence of the normalizing constant.
Example 2.22
-
1. If \(\rho \) is a specialization into a single variable \(\alpha >0\), then equations (2.16) and (2.17) enable us to rewrite \(P_{a,\rho }\) in the form
$$\begin{aligned} \!\!\!\!\!\!\!\!P_{a,\alpha }(\nu \,\Vert \,\lambda ,\mu )={\left\{ \begin{array}{ll} const\cdot \varphi _{\nu /\mu } \psi _{\nu /\lambda } (\alpha a)^{|\nu |},&{} \nu /\lambda \,\mathrm{and}\, \nu /\mu \,{\text{ are } \text{ horizontal } \text{ strips }},\\ 0&{} \mathrm{otherwise}, \end{array}\right. } \end{aligned}$$where \(\varphi \) and \(\psi \) are defined in Sect. 2.1.6 and explicit formulas for them are given in equations (2.10) and (2.11). Note that the constant is independent of \(\nu \) but does depend on all other variables.
-
2. If \(\rho \) is a specialization into a single dual variable \(\beta >0\), i.e. the right-hand side of (2.23) has the form \(1+\beta u\), then equation (2.22) implies
$$\begin{aligned}&P_{a,\hat{\beta }}(\nu \,\Vert \,\lambda ,\mu )\\&\quad ={\left\{ \begin{array}{ll} const\cdot \psi ^{\prime }_{\nu /\mu } \psi _{\nu /\lambda } (\beta a)^{|\nu |},&{} \nu /\lambda \, \text{ and } \, \nu ^{\prime }/\mu ^{\prime } \, \text{ are } \text{ horizontal } \text{ strips },\\ 0&{} \text{ otherwise }, \end{array}\right. } \end{aligned}$$where \(\psi ^{\prime }\) is defined in Sect. 2.1.6 and given by an explicit formula in equation (2.12). We have used the notation \(\hat{\beta }\) above to distinguish the \(\beta \) specialization from the \(\alpha \) specialization in the previous example.
-
3. The first two terms in Taylor expansions of \(P_{a,\alpha }\) and \(P_{a,\hat{\beta }}\) as \(\alpha ,\beta \rightarrow 0\) are
$$\begin{aligned}&P_{a,\alpha }(\nu \,\Vert \,\lambda ,\mu )\sim \mathbf{1 }_{\nu =\mu }\\&\quad +\,\alpha a{\left\{ \begin{array}{ll} \frac{\psi _{\nu /\lambda }}{ \psi _{\mu /\lambda }}\,\varphi _{\nu /\mu } &{} \nu /\mu \,\mathrm{is\,a\,single\,box},\\ 0,&{} \nu \ne \mu \,\,\mathrm{and }\,\,\nu \ne \mu \cup \{\square \},\\ -\sum _{\kappa =\mu \cup \{\square \}} \frac{\psi _{\kappa /\lambda }}{\psi _{\mu /\lambda }}\,\varphi _{\kappa /\mu },&{}\nu =\mu , \end{array}\right. } \end{aligned}$$and
$$\begin{aligned}&P_{a,\hat{\beta }}(\nu \,\Vert \,\lambda ,\mu )\sim \mathbf{1 }_{\nu =\mu }\\&\quad +\,\beta a {\left\{ \begin{array}{ll} \frac{\psi _{\nu /\lambda }}{ \psi _{\mu /\lambda }}\,\psi ^{\prime }_{\nu /\mu } &{} \nu /\mu \, \mathrm{is\,a\,single\,box},\\ 0,&{} \nu \ne \mu \,\,\mathrm{and }\,\,\nu \ne \mu \cup \{\square \},\\ -\sum _{\kappa =\mu \cup \{\square \}} \frac{\psi _{\kappa /\lambda }}{\psi _{\mu /\lambda }}\,\psi ^{\prime }_{\kappa /\mu },&{}\nu =\mu . \end{array}\right. } \end{aligned}$$From definitions of \(\varphi \) and \(\psi ^{\prime }\) one immediately sees that the coefficient of \(\alpha \) in \(P_{a,\alpha }\) is \(\frac{1-t}{1-q}\) times the coefficient of \(\beta \) in \(P_{a,\hat{\beta }}\).
Fix \(N\ge 1\), and denote
The ascending Macdonald process \(\mathbf{M }_{asc}(a_1,\ldots ,a_N;\rho )\) defined in Sect. 2.2.2 is a probability measure supported on \(\mathcal{X }^{(N)}\).
Let \(\sigma \) be a nonnegative specialization with \(\Pi (\sigma ;a_j)<\infty \) for \(j=1,\ldots ,N\). Define a matrix \(\mathfrak{P }_\sigma \) with rows and columns parameterized by \(\mathcal{X }^{(N)}\) via
The structure of \(\mathfrak{P }_\sigma \) is such that to compute the entry with row indexed by \((\lambda ^{(1)},\ldots ,\lambda ^{(N)})\) and column \((\mu ^{(1)},\ldots , \mu ^{(N)})\), one first computes the probability of \(\mu ^{(1)}\) given \(\lambda ^{(1)}\), then \(\mu ^{(2)}\) given \(\lambda ^{(2)}\) and \(\mu ^{(1)}\), then \(\mu ^{(3)}\) given \(\lambda ^{(3)}\) and \(\mu ^{(2)}\), and so on.
Proposition 2.23
The matrix \(\mathfrak{P }_\sigma \) is well-defined and it is stochastic. Moreover,
Proof
This is a special case of Proposition 2.21. We specialize the notation of Sect. 2.3.2 as follows: \(n=N, \mathcal{S }_k=\mathbb{Y }(k), k=1,\ldots ,N\),
The commutation relation of equation (2.35) follows from the third identity in Proposition 2.19. One further takes \(m_n\) to be the Macdonald measure \(\mathbf{MM }(a_1,\ldots ,a_n;\rho )\). This immediately implies
cf. equation (2.34), and the statement follows. \(\square \)
A continuous time analog
Define a matrix \(\mathfrak{q }\) with rows and columns parameterized by \(\mathcal{X }^{(N)}\) as follows. For the off-diagonal entries, for any triple of integers \((A,B,C)\) such that
set
if [we use the notation \(\lambda ^{(j)} = (\lambda ^{(j)}_1 \ge \cdots \ge \lambda ^{(j)}_{j})\)]
\(\mu _k^{(m)}=\lambda _k^{(m)}\) for all other values of \((k,m)\), and
if a suitable triple does not exist. The diagonal entries of \(\mathfrak{q }\) are then defined so that the sum of entries in every row is zero.
Less formally, this continuous time Markov chain can be described as follows. Each of the coordinates \(\lambda _k^{(m)}\) has its own exponential clock with rate
where all clocks are independent. Here \(\square _k\) denotes a box of a Young diagram that is located in the \(k\)th row. When the \(\lambda _A^{(B)}\)-clock rings, the coordinate checks if its jump by one to the right would violate the interlacing condition. If no violation happens, that is, if
then this jump takes place. This means that we find the longest string \(\lambda _A^{(B)}=\lambda _A^{(B+1)}=\dots =\lambda _A^{(B+C)}\) and move all the coordinates in this string to the right by one. If a jump would violate the interlacing condition, then no action is taken.
The reason to define \(\mathfrak{q }\) in this way is that it is the linear term in \(\epsilon \) of the matrix \(\mathfrak{P }_\sigma \) defined earlier, when \(\sigma \) is the specialization into a single dual variable \(\epsilon \), cf. Example 2.22 above.
From the definition of \(\psi ,\psi ^{\prime }\) via products over boxes in equations (2.11) and (2.12), it is obvious that the off-diagonal matrix elements of \(\mathfrak{q }\) are nonnegative and uniformly bounded. Also, the definition of \(\mathfrak{q }\) implies that in each row, at most \(N(N+1)/2\) entries of \(\mathfrak{q }\) are nonzero. Thus, \(\mathfrak{q }\) uniquely defines a Feller Markov process on \(\mathcal{X }^{(N)}\) that has \(\mathfrak{q }\) as its generator, cf. [76]. For any \(\tau \ge 0\), the matrix of transition probabilities for this process after time \(\tau \) is \(\mathfrak{Q }_\tau =\exp (\tau \mathfrak{q })\).
Proposition 2.24
For any \(\tau \ge 0\) we have
where \(\rho _\tau \) is the Plancherel specialization afforded by equation (2.23) with \(\gamma =\tau \) and all other parameters equal to zero.
Proof
We start with Proposition 2.23 and take \(\sigma =\hat{\epsilon }\) to be the specialization into a single dual variable \(\epsilon \). Noting that \(\mathfrak{P }_{\hat{\epsilon }}\) is a triangular matrix whose entries are polynomials in \(\epsilon \) of degree at most \(N(N+1)/2\), we conclude that
entry-wise (recall that \(\mathfrak{q }\) is the coefficient of \(\epsilon \) in \(\mathfrak{P }_{\hat{\epsilon }}\)). On the other hand, Proposition 2.23 implies that
where \(\sigma _{\tau ,\epsilon }\) is the specialization into \([\tau \epsilon ^{-1}]\) dual variables equal to \(\epsilon \). Since for any \(\tau \ge 0\), we have that \(\lim _{\epsilon \rightarrow 0}~f(\sigma _{\tau ,\epsilon })~=f(\rho _\tau )\) for any symmetric function \(f\), and since also \(\lim _{N\rightarrow \infty } \Pi (a_1,\ldots , a_N;\rho ,\sigma _{\tau ,\epsilon }) = \Pi (a_1,\ldots , a_N;\rho ,\rho _{\tau })\), it follows that \(\mathbf{M }_{asc}(a_1,\ldots ,a_N;\rho ,\sigma _{\tau ,\epsilon })\) weakly converges to \(\mathbf{M }_{asc}(a_1,\ldots ,a_N;\rho ,\rho _\tau )\), and the proof is complete. \(\square \)
Remark 2.25
One could construct \(\mathfrak{q }\) starting from matrices \(q^\uparrow \) introduced at the end of Sect. 2.3.1 by using the formalism of [30], Section 8. The needed commutativity relations follow from Corollary 2.20.
3 q-Whittaker processes
3.1 The q-Whittaker processes
3.1.1 Useful q-deformations
We record some \(q\)-deformations of classical functions and transforms. Section 10 of [6] is a good references for many these definitions and statements. We assume throughout that \(|q|<1\). The classical functions are recovered in all cases in the \(q\rightarrow 1\) limit, though the exact nature of this convergence will be relevant (and discussed) later.
q-deformations of classical functions
The \(q\)-Pochhammer symbol is written as \((a;q)_{n}\) and defined via the product (infinite convergent product for \(n=\infty \))
The \(q\)-factorial is written as either \([n]_{q}!\) or just \(n_q!\) and is defined as
The \(q\)-binomial coefficients are defined in terms of \(q\)-factorials as
The \(q\)-binomial theorem ([6] Theorem 10.2.1) says that for all \(|x|<1\) and \(|q|<1\),
Two corollaries of this theorem ([6] Corollary 10.2.2a/b) which will be used later is that under the same hypothesis on \(x\) and \(q\),
For any \(x\) and \(q\) we also have ([6] Corollary 10.2.2.c)
There are two different \(q\)-exponential functions. The first (which we will use extensively) is denoted \(e_q(x)\) and defined as
while the second is defined as
For compact sets of \(x\), both \(e_q(x)\) and \(E_q(x)\) converge uniformly to \(e^{x}\) as \(q\rightarrow 1\). In fact, the convergence of \(e_q(x)\rightarrow e^{x}\) is uniform over \(x\in (-\infty ,0)\) as well.
The \(q\)-gamma function is defined as
For \(x\) in compact subsets of \(\mathbb{C }\setminus \{0,-1,\cdots \}, \Gamma _q(x)\) converges uniformly to \(\Gamma (x)\) as \(q\rightarrow 1\).
q-Laplace transform
Define the following transform of a function \(f\in \ell ^1(\{0,1,\ldots \})\):
where \(z\in \mathbb{C }\).
Proposition 3.1
One may recover a function \(f\in \ell ^1(\{0,1,\ldots \})\) from its transform \(\widehat{f}^{q}(z)\) with \(z\in \mathbb{C }\setminus \{q^{-k}\}_{k\ge 0}\) via the inversion formula
where \(C_n\) is any positively oriented contour which encircles the poles \(z=q^{-M}\) for \(0\le M \le n\).
Remark 3.2
This statement can be viewed as an inversion formula for the Laplace transform with \(e_q(x)\) replacing the exponential function. An inversion of the Laplace transform with \(E_q(x)\) replacing the exponential function goes back to [57]. However, for the \(e_q(x)\) Laplace transform, it appears that the recent manuscript of Bangerezako [12] contains the first inversion formula (as well as many other properties of the transform and worked out examples). We were initially unaware of this manuscript and thus produced our own inversion formula and the proof below.
Proof
Observe that the residue of \(\widehat{f}^{q}\) at \(z=q^{-M}\) can be easily calculated for any \(M\ge 0\) with the outcome
Alternatively this can be written in terms of matrix multiplication. Let \(A=[A_{k,\ell }]_{k,\ell \ge 0}\) be an upper triangular matrix defined via its entries
Then we have
where \(\vec {f}\) is the row vector \(\vec {f}=\{f(0),f(1),\ldots \}\). Since \(A\) is upper triangular, it has a unique inverse which is also upper triangular and can be readily calculated to find that \(A^{-1} = B = [B_{k,\ell }]_{k,\ell \ge 0}\) is given by
Therefore
Expressing this in terms of a contour integral yields the desired result of equation (3.5). \(\square \)
3.1.2 Definition and properties of q-Whittaker functions
q-deformed Givental integral and recursive formula
Macdonald polynomials in \(\ell +1\) variables with \(t=0\) are also known of as \(q\)-deformed \(\mathfrak{gl }_{\ell +1}\) Whittaker functions [51]. We denote the \(P\) version of the \(q\)-Whittaker function as \({\Upsilon }\) and define it by
where \(\underline{p}_{\ell +1} = \{p_{\ell +1,1},\ldots , p_{\ell +1,\ell +1}\}\). In [51] the \(Q\) version of the \(q\)-Whittaker function is considered. It is denoted by \({\Psi }\) and defined by
The two functions are related by
where \(\Delta (\underline{p}_{(}{ell+1})\) is defined in (3.9). We will focus on the \({\Upsilon }\) function here which accounts for slight changes between what we write and what one finds in [51]. Note that the Pieri formulas for Sect. 2.1.6 become, in this limit, the Hamiltonians for the quantum \(q\)-deformed \(\mathfrak{gl }_{\ell +1}\)-Toda chain (see e.g. [46, 96] or [51]).
These \(q\)-Whittaker functions can be expressed in terms of a combinatorial formula which follows from the combinatorial formula (2.15) for Macdonald polynomials. To state the combinatorial formula let us denote \(\mathbb{GT }^{(\ell +1)}(\underline{p}_{\ell +1})\) to be the set of triangular arrays of integers \(p_{k,i}\) for \(1\le i\le k\le \ell \) satisfying the interlacing condition that \(p_{k+1,i}\ge p_{k,i}\ge ~p_{k+1,i+1}\). One can also think of this set as those interlacing triangular arrays of height \(\ell +1\) with a fixed top row given by \(\underline{p}_{\ell +1}\). Also let \(\mathbb{GT }_{\ell +1,\ell }(\underline{p}_{\ell +1})\) be a set \(\underline{p}_{\ell } = \{p_{\ell ,1},\ldots , p_{\ell ,\ell }\}\) of integers satisfying the interlacing condition \(p_{\ell +1,i}\ge p_{\ell ,i}\ge p_{\ell +1,i+1}\). Then
For \(\underline{p}_{\ell +1}\) which is not ordered, we define the \(q\)-Whittaker function as zero (see Example 1.1 of [51]). Equation (3.7) follows from (3.6) and the combinatorial formula (2.15) for the Macdonald polynomials.
It follows from the combinatorial formula that the \(q\)-Whittaker functions satisfy a defining recursive relation:
where
This recursive formula will play a prominent role later when we prove that the \(t=0\) ascending Macdonald process converges to the Whittaker process. It is easy to see that a similar formula exists for \({\Psi }\), as one finds in [51].
3.1.3 Difference operators and integral formulas
The present goal is to take limits \(t\rightarrow +0\) in some of the previously stated results.
The nonnegative specializations in this case are described by the degeneration of equation (2.23):
When \(t=0\) we call the ascending Macdonald process \(\mathbf{M }_{asc,t=0}(a_1,\ldots ,a_N;\rho )\) the \(q\)-Whittaker process and the Macdonald measure \(\mathbf{MM }_{t=0}(a_1,\ldots ,a_N;\rho )\) the \(q\)-Whittaker measure.
The partition function for the corresponding \(q\)-Whittaker measure \(\mathbf{MM }_{t=0} (a_1,\ldots ,a_N;\rho )\) is given by
where \(\rho \) is determined by \(\{\alpha _j\}, \{\beta _j\}\), and \(\gamma \) as before, and we assume \(\alpha _i a_j<1\) for all \(i,j\) so that the series converge.
Taking the limit of Proposition 2.11 yields
Proposition 3.3
For any \(1\le r\le N\), and assuming \(\alpha _i a_j<1\) for all \(i,j\),
where the \(z_j\)-contours contain \(\{a_1,\ldots , a_N\}\) and no other poles.
Proof
We have
Proposition 2.11 and relation (2.32) conclude the proof. \(\square \)
Remark 3.4
One may also take the \(t\rightarrow 0\) limit of the operator \(\tilde{D}_N^r\) defined in Remark 2.12. Doing so we see that \(\tilde{D}_n^r t^{rn-r(r+1)/2}\) converges to an operator whose eigenvalue at \(P_{\lambda }\) is equal to \(q^{-\lambda _1-\cdots - \lambda _r}\). Just as above, we may likewise take a limit of the contour integral formula for expectations.
Let us take the limit \(t\rightarrow 0\) of Proposition 2.14 along the same lines.
Proposition 3.5
For any \(k \ge 1\), and assuming \(\alpha _i a_j<1\) for all \(i,j\),
where \(z_j\)-contour contains \(\{qz_{j+1},\ldots ,qz_k,a_1,\ldots ,a_N\}\) and no other singularities for \(j=1,\ldots ,k\).
Proof
Straightforward limit \(t\rightarrow 0\) of Proposition 2.14. \(\square \)
Likewise we take the limit \(t\rightarrow 0\) of Proposition 2.16.
Proposition 3.6
Fix \(k\ge 1\) and \(r_{\kappa }\ge 1\) for \(1\le \kappa \le k\). Then assuming \(\alpha _i a_j<1\) for all \(i,j\),
where the \(z_{\kappa _1,j}\)-contour contains \(\{qz_{\kappa _2,i}\}\) for all \(i\in \{1,\ldots , r_{\kappa _2}\}\) and \(\kappa _2>\kappa _1\), as well as \(\{a_1,\ldots ,a_N\}\) and no other singularities.
Proof
Straightforward limit \(t\rightarrow 0\) of Proposition 2.16. \(\square \)
Finally, let us take the limit \(t\rightarrow 0\) in Proposition 2.17.
Proposition 3.7
With the notation \(b_m=a_mq^{\eta _m}\) for \(m=1,\ldots ,N\), we have
Here \(u\) is a formal variable, and the formula can be viewed as an identity of formal power series in \(u\).
Proof
The only part in the identity of Proposition 2.17 that does not have an obvious limit is
We have
as \(t\rightarrow 0\). Multiplying over all \(1\le j<k\le N\) we obtain the result. \(\square \)
3.2 Moment and Fredholm determinant formulas
3.2.1 Moment formulas
Recall the \(q\)-factorial \(n_q! = \frac{(1-q)(1-q^2)\cdots (1-q^n)}{(1-q)(1-q)\cdots (1-q)}\) (see also Sect. 3.1.1).
Proposition 3.8
For a meromorphic function \(f(z)\) and \(k\ge 1\) set \(\mathbb{A }\) to be a fixed set of singularities of \(f\) (not including 0) and assume that \(q^m\mathbb{A }\) is disjoint from \(\mathbb{A }\) for all \(m\ge 1\). Then setting
we have
where the \(z_p\)-contours contain \(\{q z_j\}_{j> p}\), the fixed set of singularities \(\mathbb{A }\) of \(f(z)\) but not 0, and the \(w_j\) contours contain the same fixed set of singularities \(\mathbb{A }\) of \(f\) and no other poles.
As a quick example consider \(f(z)\) which has a pole at \(z=1\). Then the \(z_k\)-contour is a small circle around 1, the \(z_{k-1}\)-contour goes around \(1\) and \(q\), and so on until the \(z_1\)-contour encircles \(\{1,q,\ldots , q^{k-1}\}\) (see Fig. 5 for example). All the \(w\) contours are small circles around 1 and can be chosen to be the same.

Possible contours when \(k=3\) for the \(z_j\) contour integrals in Proposition 3.8
Proof
This proposition amounts to book-keeping of the residues of \(\prod \frac{z_A-z_B}{z_A - qz_B}\) and can be proved by considering a rich enough class of “dummy” functions \(f(z)\). Assume that \(f(z)\) has poles at \(\mathbb{A }:=\{a_j\}_{j\in J}\) (where \(J=\{1,\ldots , |\mathbb{A }|\}\) is an index set) inside the integration contour.
When we evaluate \(\mu _k\) as the sum of residues in (3.11), for each \(\lambda \vdash k\) we have to sum over \(\{a_{j_i}\}_{i=1}^{\ell (\lambda )}\) with \(a_{j_i}\in \mathbb{A }\) referring to the pole of \(f(w_i)\). Because of the determinant, we get nonzero contributions only when all \(a_{j_i}\) are mutually distinct. Also, if \(\lambda _{i}=\lambda _{i^{\prime }}\) then permuting \(j_i\) and \(j_{i^{\prime }}\) does not affect the contribution. This symmetry allows us to cancel the prefactor \((m_1!m_2!\cdots )^{-1}\) and replace the summation over \(\lambda \) by a summation over disjoint subsets of \(J\) of size \(m_1,m_2,\) and so on. Hence we can evaluate expression (3.11) for \(\mu _k\) as a sum over sets \(S=(S_1,S_2,\ldots ,)\) of size \(m_1,m_2,\ldots \) such that \(S_i\subset \mathbb{A }, |S_i|=m_i, m_1+2m_2+3m_3+\cdots =k\) and the \(S_i\) are disjoint. Call \(\mathcal S \) the set of all such sets \(S=(S_1,S_2,\ldots )\). It is also convenient to index the elements of \(S\) as
where the first \(m_1\) elements are in \(S_1\), the next \(m_2\) are in \(S_2\) and so on. For a given \(b\in S\) we denote by \(\lambda (b)\) the index of the \(S_i\) such that \(b\in S_i\). Then by expanding into residues equation (3.11) takes the form
We will prove our identity [the equivalence of (3.10) and (3.11)] via induction on \(k\). The case \(k=1\) is immediately checked. Let \(k\) be general, and assume we already have a proof for \(k-1\). In (3.10) we can evaluate the integral over \(z_k\) as a sum of residues involving \((k-1)\)-fold integral:
Now apply the induction hypothesis to the \((k-1)\)-fold integral in the right-hand side above with \(\tilde{f}_j(z) = f(z)\frac{z-a_j}{z-qa_j}\) and the set of poles \(\tilde{\mathbb{A }}_j = (\mathbb{A }\backslash \{a_j\})\cup \{qa_j\}\). We note two useful facts: For \(\ell \ne j\)
and
By induction, the integral in the right-hand side of (3.13) can be written (according to the discussion at the beginning of this proof) as a sum over non-intersecting subsets \(\tilde{S}_j =(\tilde{S}_{j,1},\tilde{S}_{j,2}\ldots )\) with \(\tilde{S}_{j,\ell }\subset \tilde{\mathbb{A }}_j, |\tilde{S}_{j,\ell }|=\tilde{m}_{\ell }\) and \(\tilde{m}_1+2\tilde{m}_2+3\tilde{m}_3+\cdots = k-1\) (let \(\tilde{\mathcal{S }}_j\) be the set of all such \(\tilde{S}_j\)). Thus from (3.12) the right-hand side of (3.13) can be expanded as
where \(\tilde{\lambda }(\tilde{b})\) is the index of the set \(\tilde{S}_{i,\cdot }\) that contains \(\tilde{b}\).
It will be more convenient to map these subsets and \(a_j\) onto a new set of subsets. From \(a_j\in \mathbb{A }\) and the collection \((\tilde{S}_{j,1},\tilde{S}_{j,2},\ldots )\) we now construct a collection \((S_1,S_2,\ldots )\) of disjoint subsets of \(\mathbb{A }\) with \(|S_i|=m_i\) and \(m_1+2m_2+3m_3+\cdots = k\). If \(qa_j\in \tilde{S}_{j,\ell }\) for some \(\ell \) then
If \(qa_j\notin \cup _{\ell \ge 1} \tilde{S}_{j,\ell }\) then
Then using (3.14) for the second line of (3.16) and (3.15) for the third line we find that for a given collection \((S_1,S_2,\ldots )\), the associated term in equation (3.16) is given by
where \(\tilde{b}_i=b_i q^{\delta _{ij}}\) and \(\delta _{ij}=1\) if \(i=j\) and zero otherwise. Note that although the above expression makes sense literally only for \(\lambda (b_j)>1\), the natural limit \(\lambda (b_j)\rightarrow 1\) gives the correct contribution for those \(b\in S_1\). In that case the factor \(b_j(q^{\lambda (b_j)-1}-1)q^{2-\lambda (b_j)}\) disappears and the \(j^{th}\) row and column of the matrix whose determinant we compute is removed.
To prove the induction step, we need to show that the sum above equals the analogous term in (3.12), which is
The contribution of \(f\) can be canceled right away. Recalling the \(q\)-factorial definition and gathering factors of \(q\) we are thus lead to prove the following identity
Abbreviating \(\lambda (b_i)=:\lambda _i\) and evaluating the Cauchy determinants via
[where \(V(x_i)= \prod _{i<j} (x_i-x_j)\) is the Vandermonde determinant] we obtain
Equivalently, the desired identity reduces to showing that
The left-hand side of the above formula is the sum of the residues of the function
at the points \(z=b_{\ell }\) for \(\ell \ge 1\). On the other hand \(-(1-q^{\sum \lambda _\ell })\) is the difference of residues of the same function at \(z=\infty \) and \(z=0\). This completes the proof. \(\square \)
We state an analogous formula to the one contained in Proposition 3.8 which now involves integrating around zero and over large contours.
Proposition 3.9
For any continuous function \(f(z)\) and \(k\ge 1\),
where the \(z_j\)-contours and \(w_j\)-contours are all the same.
Remark 3.10
Assuming \(\mathbb{A }\) is inside a small enough neighborhood of \(z=1\), the integration contours of Proposition 3.8 with additional small circles around \(z_j=0, j=1,\ldots , k\) (cf. Proposition 3.12 below) can be deformed without passing through singularities to the same circle of the form \(|z_j|=R>1\).
Proof
The following is a useful combinatorial identity from which the result readily follows. This identity can be derived using Proposition 3.8 by choosing \(f\) with exactly \(k\) poles and then evaluating both sides via residues. It can also be shown through induction.
Lemma 3.11
[79, III,(1.4)] Set \(c_{q,k} = (q^{-1}-1)\cdots (q^{-k}-1)\) then
We may use this to symmetrize the integrand in the right-hand side of (3.17). The only non-symmetric term is the product over \(A<B\). However, using the above combinatorial identity we find that (recall the \(k!\) came from symmetrizing)
It is now straightforward to check that the prefactors of the integral are as desired. \(\square \)
Proposition 3.12
For simplicity assume \(f(0)=1\). Recall \(\mu _j\) from (3.10) (with \(\mu _0=1\) for convenience) and define \(\tilde{\mu }_j\) by adding a small circle around 0 to each of the \(z_j\) contours in (3.10). Then
Proof
Define a triangular array of integrals \(\nu _{j,k}\) by
where the contours for \(z_{1},\ldots , z_{j}\) do not contain 0, whereas the contours for \(z_{j+1},\ldots , z_{k+j}\) do contain 0.
By shrinking the contour \(z_{j+1}\) without crossing through 0 we can establish the recurrence relation
This can be solved to find that
from which the proposition follows by relating \(\nu _{j,0}\) to \(\mu _j\) and \(\nu _{0,k}\) to \(\tilde{\mu }_k\). \(\square \)
3.2.2 General Fredholm determinant formula
In this section we state certain formal identities between power series and Fredholm determinant expansions. Later we specialize our choice of functions and show that these formal identities then hold numerically as well. We should first, however, specify what we mean by a formal identity versus a numerical identity, and also what is a Fredholm determinant (in both contexts).
Background and definitions for Fredholm determinants
For a general overview of the theory of Fredholm determinants, the reader is referred to [56, 74, 103]. However, for our purposes, the below definition will suffice and no further properties of the determinants will be needed.
Definition 3.13
Fix a Hilbert space \(L^2(X,\mu )\) where \(X\) is a measure space and \(\mu \) is a measure on \(X\). When \(X=\Gamma \), a simple (anticlockwise oriented) smooth contour in \(\mathbb{C }\), we write \(L^2(\Gamma )\) where for \(z\in \Gamma , d\mu (z)\) is understood to be \(\tfrac{dz}{2\pi \iota }\). When \(X\) is the product of a discrete set \(D\) and a contour \(\Gamma , d\mu \) is understood to be the product of the counting measure on \(D\) and \(\frac{dz}{2\pi \iota }\) on \(\Gamma \).
Let \(K\) be an integral operator acting on \(f(\cdot )\in L^2(X,\mu )\) by \(Kf(x) = \int _{X} K(x,y)f(y) d\mu (y)\). \(K(x,y)\) is called the kernel of \(K\) and we will assume throughout that \(K(x,y)\) is continuous in both \(x\) and \(y\). A formal Fredholm determinant expansion of \(I+K\) is a formal series written as
In other words, it is the formal power series in \(z\) of \(\det (I+zK)_{L^2(X)}\) with \(z\) set to 1.
If \(K\) is a trace-class operator then the terms in the above expansion can be evaluated and form a convergent series. This is called the numerical Fredholm determinant expansion as it actually takes a numerical value. Note that it is not necessary that \(K\) be trace-class for the series to be absolutely convergent.
The following is a useful criteria for an operator to be trace-class (see [74] page 345 or [17]).
Lemma 3.14
An operator \(K\) acting on \(L^2(\Gamma )\) for a simple smooth contour \(\Gamma \) in \(\mathbb{C }\) with integral kernel \(K(x,y)\) is trace-class if \(K(x,y):\Gamma ^2\rightarrow \mathbb{R }\) is continuous as well as \(K_2(x,y)\) is continuous in \(y\). Here \(K_2(x,y)\) is the derivative of \(K(x,y)\) along the contour \(\Gamma \) in the second entry.
A formal power series in a variable \(\zeta \) and a formal Fredholm determinant expansion whose kernel \(K(x,y)\) depends implicitly on \(\zeta \) are formally equal (or their equality is a formal identity) if they are equal as formal power series in \(\zeta \).
Fredholm determinant formulas
Proposition 3.15
Consider \(\mu _k\) as in equation (3.11) defined with respect to the same set of poles \(\mathbb{A }\) for \(k=1,2,\ldots \), and set the \(w_j\)-contours all to be \(C_{w}\) such that \(C_{w}\) contains the set of poles \(\mathbb{A }\) of the meromorphic function \(f(w)\). Then the following formal equality holds
where \(\det (I+K)\) is a formal Fredholm determinant expansion and the operator \(K\) is defined in terms of its integral kernel
The above identity is formal, but also holds numerically if the following is true: There exists a positive constant \(M\) such that for all \(w\in C_{w}\) and all \(n\ge 0, |f(q^n w)|\le M\) and \(\zeta \) is such that \(|(1-q)\zeta | <M^{-1}\); and \(1/|q^n w -w^{\prime }|\) is uniformly bounded from zero for all \(w,w^{\prime }\in C_{w}\) and \(n\ge 1\).
Proof
All contour integrals in this proof are along \(C_{w}\). Observe that we can rewrite the summation in the definition of \(\mu _k\) so that
where \(w=(w_1,\ldots , w_L), \lambda =(\lambda _1,\ldots , \lambda _L)\) and is specified by \(\lambda =1^{m_1}2^{m_2}\cdots \), and where the integrand is
The term \(\tfrac{(m_1+m_2+\cdots )!}{m_1! m_2! \cdots }\) is a multinomial coefficient and can be removed by replacing the inner summation by
with \(n=(n_1,\ldots ,n_L)\) and where \(\mathcal L _{k,m_1,m_2,\ldots } = \{n_1,\ldots ,n_L\ge 1: \sum n_i = k\quad \mathrm{and\,for\,each }\quad j\ge 1, m_j\quad \mathrm{of\,the\,}\quad n_i \mathrm{\,equal } j\}\). This gives
Now we may sum over \(k\) which removes the requirement that \(\sum n_i = k\). This yields that the left-hand side of equation (3.19) can be expressed as
This is the definition of the formal Fredholm determinant expansion \(\det (I+K)_{L^2(\mathbb{Z _{>0}}\times C_{w})}\), as desired.
We turn now to the additional conditions for numerical equality. In order to justify the rearrangements in the above argument, we must know that the double summation of (3.20) is absolutely convergent. By the conditions stated and Hadamard’s bound we find that:
for some constant \(B\) large enough and a positive constant \(r<1\) (such that \(|(1-q)\zeta C|\le ~r~<1\)). This bound may be plugged into the summation in \(L\) and in \(n_1,\ldots , n_{L}\) and evaluating the geometric sums we arrive at
which is finite due to the \(L!\) in the denominator. This absolute convergence means we can permute terms any way we want, and hence justifies the earlier calculations as being numerical identities (and not just formal manipulations). \(\square \)
Proposition 3.16
For
cf. Proposition 3.9 and Remark 3.10, with \(k\ge 1\) and integrals along a fixed contour \(\tilde{C}_w\), the following formal identity holds
where \(\det (I+\tilde{K})\) is a formal Fredholm determinant expansion and the operator \(\tilde{K}\) is defined in terms of its integral kernel
The above identity is formal, but also holds numerically for \(\zeta \) such that the left-hand side converges absolutely and the right-hand side operator \(\tilde{K}\) is trace-class.
Proof
Observe that \(\tilde{\mu }_k\) coincides with the left-hand side of Proposition 3.9. Rewriting it as in the right-hand side and plugging this formula into the power series gives (absorbing the \(2\pi \iota \) into \(dw\)):
Given the additional convergence, the numerical equality is likewise clear. \(\square \)
3.2.3 q-Whittaker process Fredholm determinant formulas
We may apply the general theory above to the special case given by Proposition 3.5 to compute the \(q\)-Laplace transform of \(\lambda _N\) under the measure \(\mathbf{MM }_{t=0}(a_1,\ldots ,a_N;\rho )\).
Small contour formulas
Corollary 3.17
There exists a positive constant \(C\ge 1\) such that for all \(|\zeta |<C^{-1}\) the following numerical equality holds
where the operator \(K\) is defined in terms of its integral kernel
with
and \(C_{a,\rho }\) is a positively oriented contour containing \(a_1,\ldots , a_N\) and no other singularities of \(f\).
Proof
Observe that using the corollary of the \(q\)-binomial theorem recorded in equation (3.1), for \(|\zeta |<1\) we may expand
The convergence of the right-hand side above follows from the fact that \(q^{k\lambda _N}\le 1\) and
which shows geometric decay for large enough \(k\).
In Propositions 3.8 and 3.15 we may choose \(f\) as in equation (3.23) and choose contours so as to enclose only the \(a_1,\ldots , a_m\) singularities of \(f\). The result is the kernel of equation (3.22). Proposition 3.15 now applies (since the constant \(C\) in the statement of the result can be chosen such that for all \(w\!\in \! C_{a,\rho }\) and for all \(n\!\ge \! 0, |f(q^n w)|\!<\!C\), the equality in that proposition is numerical). Finally Proposition 3.5 shows that \(\left\langle q^{k\lambda _N}\right\rangle _{\mathbf{MM }_{t=0}(a_1,\ldots ,a_N;\rho )}\!=\!\mu _k\) as defined by the \(f\) above, and thus the corollary follows. \(\square \)
Theorem 3.18
Fix \(\rho \) a Plancherel (see Definition 2.3) Macdonald nonnegative specialization. Fix \(0<\delta <1\) and \(a_1,\ldots , a_N\) such that \(|a_i -1|\le d\) for some constant \(d <\frac{1-q^{\delta }}{1+q^{\delta }}\). Then for all \(\zeta \in \mathbb{C }\setminus \mathbb{R _{+}}\)
where \(C_a\) is a positively oriented circle \(|w-1|=d\) and the operator \(K_{\zeta }\) is defined in terms of its integral kernel
where
The operator \(K_{\zeta }\) is trace-class for all \(\zeta \in \mathbb{C }\setminus \mathbb{R _{+}}\).
The above theorem should be contrasted with Proposition 3.7 which gives an \(N\)-fold summation formula for the left-hand side of (3.24). Note also the following (cf. Proposition 3.1).
Corollary 3.19
We also have that
where \(C_{n,q}\) is any simple positively oriented contour which encloses the poles \(\zeta =q^{-M}\) for \(0\le M\le n\) and which only intersects \(\mathbb{R _{+}}\) in finitely many points.
Proof of Theorem 3.18
The starting point for this proof is Corollary 3.17. There are, however, two issues we must deal with. First, the operator in the corollary acts on a different \(L^2\) space; second, the equality is only proved for \(|\zeta |<C^{-1}\). We split the proof into three steps. Step 1: We present a general lemma which provides an integral representation for an infinite sum. Step 2: Assuming \(\zeta \in \{\zeta :|\zeta |<C^{-1}, \zeta \notin \mathbb{R _{+}}\}\) we derive equation (3.24). Step 3: A direct inspection of the left-hand side of that equation shows that for all \(\zeta \ne q^{-M}\) for \(M\ge 0\) the expression is well-defined and analytic. The right-hand side expression can be analytically extended to all \(\zeta \notin \mathbb{R _{+}}\) and thus by uniqueness of the analytic continuation, we have a valid formula on all of \(\mathbb{C }\setminus \mathbb{R _{+}}\).
-
Step 1: The purpose of the next lemma is to change that \(L^2\) space we are considering and to replace the summation in Corollary 3.17 by a contour integral.
Lemma 3.20
For all functions \(g\) which satisfy the conditions below, we have the identity that for \(\zeta \in \{\zeta :|\zeta |<1, \zeta \notin \mathbb{R _{+}}\}\):
where the infinite contour \(C_{1,2,\ldots }\) is a negatively oriented contour which encloses \(1,2,\ldots \) and no singularities of \(g(q^s)\) (e.g. \(C_{1,2,\ldots }=\iota \mathbb{R }+\delta \) oriented from \(-\iota \infty +\delta \) to \(\iota \infty +\delta \)), and \(z^s\) is defined with respect to a branch cut along \(z\in \mathbb{R }^{-}\). For the above equality to be valid the left-hand-side must converge, and the right-hand-side integral must be able to be approximated by integrals over a sequence of contours \(C_{k}\) which enclose the singularities at \(1,2,\ldots , k\) and which partly coincide with \(C_{1,2,\ldots }\) in such a way that the integral along the symmetric difference of the contours \(C_{1,2,\ldots }\) and \(C_{k}\) goes to zero as \(k\) goes to infinity.
Proof
The identity follows from \(\mathrm{Res}\Gamma _{s=k}(-s)\Gamma (1+s) = (-1)^{k+1}\). \(\square \)
Remark 3.21
Let us briefly illustrate the application of Lemma 3.20 which is similar to Mellin-Barnes type integral representations for hypergeometric functions. Consider
By including the pole at 0 in Lemma 3.20 one readily checks that for \(\zeta \in \{\zeta :|\zeta |<1, \zeta \notin \mathbb{R _{+}}\}\)
and thus for \(\zeta \in \{\zeta :|\zeta |<1, \zeta \notin \mathbb{R _{+}}\}\)
The left-hand side is analytic for all \(\zeta \ne q^{-M}, M\ge 0\), while the right-hand side is analytic for \(\zeta \notin \mathbb{R _{+}}\). By analytic continuation, the above equality holds for all \(\zeta \notin \mathbb{R _{+}}\). Analytic continuation of the right-hand side to the whole domain of analyticity would require additional means.
-
Step 2: For this step let us assume that \(\zeta \in \{\zeta :|\zeta |<C^{-1}, \zeta \notin \mathbb{R _{+}}\}\). We may rewrite equation (3.22) as
$$\begin{aligned} K(n_1,w_1;n_2,w_2) = \zeta ^{n_1} g_{w_1,w_2}(q^{n_1}) \end{aligned}$$where \(g\) is given in equation (3.25).
Writing out the \(M\)th term in the Fredholm expansion we have (\(C_{a,\rho }\) of Corollary 3.17 are chosen to be \(C_a\) of the statement of Theorem 3.18)
In order to apply Lemma 3.20 to the inner summations consider contours \(\{C_{k}\}_{k\ge 1}\) which are negatively oriented semi-circles that contain the right half of a circle centered at \(\delta \) and of radius \(k\). The infinite contour \(C_{1,2,\ldots } = \delta + \iota \mathbb{R }\). By the condition on the contour \(C_{a}\) we are assured that these finite semi-circles \(C_k\) do not contain any poles beyond those of the Gamma function \(\Gamma (-s)\). The only other possible poles as \(s\) varies is when \(q^s w_j -w_{\sigma (j)} =0\). However, the conditions on \(C_{a}\) and on the contours on which \(s\) varies show that these poles are not present in the semi-circles \(C_{k}\).
In order to apply the above lemma we must also estimate the integral along the symmetric difference. Identify the part of the symmetric difference given by the semi-circle arc as \(C^{arc}_k\) and the part given by \(\{\iota y + \delta : |y|>k\}\) as \(C^{seg}_k\). Since \(\mathrm{Re }(s)\ge \delta \) it is straight-forward to see that \(g_{w_1,w_2}(q^s)\) stays uniformly bounded as \(s\) varies along these contours. Consider then \((-\zeta )^s\). This is defined by writing \(-\zeta = r e^{i\theta }\) for \(\theta \in (-\pi ,\pi )\) and \(r>0\), and setting \((-\zeta )^s =r^s e^{\iota s\theta }\). Writing \(s=x+\iota y\) we have \(|(-\zeta )^s| = r^{x}e^{-y\theta }\). Note that our assumption on \(\zeta \) corresponds to \(r<1\) and \(\theta \in (-\pi ,\pi )\). Concerning the product of Gamma functions, recall Euler’s Gamma reflection formula
One readily confirms that for all \(s\): \(\mathrm{dist}(s,\mathbb{Z })>c\) for some \(c>0\) fixed,
for a fixed constant \(c^{\prime }>0\) which depends on \(c\). Therefore, along the \(C^{seg}_k\) contour,
and since \(\theta \in (-\pi ,\pi )\) is fixed, this product decays exponentially in \(|y|\) and the integral goes to zero as \(k\) goes to infinity. Along the \(C^{arc}_k\) contour, the product of Gamma functions still behaves like \(c^{\prime }e^{-\pi |y|}\) for some fixed \(c^{\prime }>0\). Thus along this contour
Since \(r<1\) and \(-(\pi +\theta )<0\) these terms behave like \(e^{-c^{\prime \prime }(x+|y|)}\) (\(c^{\prime \prime }>0\) fixed) along the semi-circle arc. Clearly, as \(k\) goes to infinity, the integrand decays exponentially in \(k\) (versus the linear growth of the length of the contour) and the conditions of the lemma are met.
Applying Lemma 3.20 we find that the \(M\)th term in the Fredholm expansion can be written as
Therefore the determinant can be written as \(\det (I+K_{\zeta })_{L^2(C_{a})}\) as desired.
-
Step 3: In order to analytically extend our formula we must prove two facts. First, that the left-hand side of equation (3.24) is analytic for all \(\zeta \notin \mathbb{R _{+}}\); and second, that the right-hand side determinant is likewise analytic for all \(\zeta \notin \mathbb{R _{+}}\) (and in doing so that the operator is trace class on that set of \(\zeta \)).
Expand the left-hand side of equation (3.24) as
where \(\mathbb{P }=\mathbb{P }_{\mathbf{MM }_{t=0}(a_1,\ldots ,a_N;\rho )}\).
Observe that for any \(\zeta \notin \{q^{-M}\}_{M=0,1,\ldots }\), within a neighborhood of \(\zeta \) the infinite products are uniformly convergent and bounded away from zero. As a result the series is uniformly convergent in a neighborhood of any such \(\zeta \) which implies that its limit is analytic, as desired.
Turning to the Fredholm determinant, let us first check that we are, indeed, justified in writing the infinite series as a Fredholm determinant (i.e., the \(K_{\zeta }\) is trace-class). We use the conditions given in Lemma 3.14 which requires that we check that \(K_{\zeta }(w,w^{\prime })\) is continuous simultaneously in both \(w\) and \(w^{\prime }\), as well as that the derivative of \(K_{\zeta }(w,w^{\prime })\) in the second entry is continuous in \(w^{\prime }\). Both of these facts are readily checked. In fact, since we have a uniformly and exponentially convergent elementary integral, it and all its derivatives in \(w\) and \(w^{\prime }\) are continuous. This is because differentiation does not affect the exponential decay.
In order to establish that the Fredholm determinant \(\det (I+K_{\zeta })_{L^2(C_{a})}\) is an analytic function of \(\zeta \) away from \(\mathbb{R _{+}}\) we appeal to the Fredholm expansion and the same criteria that limits of uniformly absolutely convergent series of analytic functions are themselves analytic. There exist theorems (such as in [56] Section IV.1, Property 8, or in the appendix of [4]) which show that if a trace-class operator is an analytic function of a parameter \(\zeta \), then so if the determinant. However, the analyticity of the operator must be shown in the trace-class norm which tends to be involved. Since we are already dealing directly with Fredholm series expansions, we find it more natural to prove analyticity directly from the series rather than try to appeal to these results.
Returning to the issue at hand, recall that
It is clear from the definition of \(K_{\zeta }\) that \(\det (K_{\zeta }(w_i,w_j))_{i,j=1}^{n}\) is analytic in \(\zeta \) away from \(\mathbb{R _{+}}\). Thus any partial sum of the above series is analytic in the same domain. What remains is to show that the series is uniformly absolutely convergent on any fixed neighborhood of \(\zeta \) not including \(\mathbb{R _{+}}\). Towards this end consider the \(n\)th term in the Fredholm expansion:
We wish to bound the absolute value of this. Observe that uniformly over \(s_j\) and \(w_j\) the term
for some fixed constant \(const_1>0\). Now consider the determinant. Along the contours for \(s\) and \(w\) the ratio \(\frac{1}{q^{s_i}w_i -w_j}\) is uniformly bounded in absolute value by a constant \(const_2\). By Hadamard’s bound
Taking the absolute value of (3.29) and bringing the absolute value all the way inside the integrals, we find that after plugging in the results of (3.30) and (3.31)
For \(\zeta \notin \mathbb{R _{+}}\) it is then easy to check (using decay properties) that in a neighborhood of \(\zeta \) which does not touch \(\mathbb{R _{+}}\), the expression
is uniformly bounded by a fixed constant \(const_3>0\). Thus we have
which is uniformly convergent as a series in \(n\), just as was desired to prove analyticity in \(\zeta \). \(\square \)
Proof of Corollary 3.19
By virtue of the fact (given in Step 3 of the proof of Theorem 3.18) that \(\langle \frac{1}{\left( \zeta q^{\lambda _N};q\right) _{\infty }}\rangle \) is analytic away from \(\zeta = q^{-M}\), for integers \(M\ge 0\), it follows that even though the Fredholm determinant \(\det (I+K_{\zeta })_{L^2(C_{a})}\) is not defined for \(\zeta \in \mathbb{R _{+}}\) we may still integrate along a contour which intersects \(\mathbb{R _{+}}\) only a finite number of times. We may then apply the inversion formula of Proposition 3.1 to conclude our corollary. \(\square \)
Large contour formulas
Definition 3.22
A closed simple contour \(C\) is star-shaped with respect to a point \(p\) if it strictly contains \(p\) and every ray from \(p\) crosses \(C\) exactly once.
Theorem 3.23
Fix \(\rho \) a Macdonald nonnegative specialization, defined as in equation (2.23) in terms of nonnegative numbers \(\{\alpha _i\}_{i\ge 1}, \{\beta _i\}_{i\ge 1}\) and \(\gamma \). Also fix \(a_1,\ldots , a_N\) positive numbers such that \(\alpha _i a_j<1\) for all \(i,j\). Then for all \(\zeta \in \mathbb{C }\)
where \(\det (I+\zeta \tilde{K})\) is an entire function of \(\zeta \) and the operator \(\tilde{K}\) is defined in terms of its integral kernel
with
and \(\tilde{C}_{a,\rho }\) a positively oriented star-shaped (with respect to 0) contour containing \(a_1,\ldots , a_N\) and no other singularities of \(f\).
Proof
Observe first that both sides of equation (3.32) are analytic functions of \(\zeta \). The right-hand side is clear since \(\det (I+\zeta K)_{L^2(\tilde{C}_{a,\rho })}\) is always an entire function of \(\zeta \) for \(K\) trace-class. The left-hand side is analytic as can be seen from considering its series expansion:
where \(\mathbb{P }=\mathbb{P }_{\mathbf{MM }_{t=0}(a_1,\ldots ,a_N;\rho )}\). The products above are clearly converging uniformly to non-trivial limits in any fixed neighborhood of \(\zeta \) and hence the series is likewise uniformly convergent in any neighborhood defining an analytic function. One similarly shows the (real) analyticity of both sides of (3.32) in \(a_1,\ldots , a_N\).
It remains to prove equation (3.32) for \(|\zeta |<1\) and \(a_i\)’s in a small enough neighborhood of \(1\). Define \(\tilde{\mu }_k\) by the left-hand side of (3.21) with \(f\) as defined in the statement of the theorem and \(\tilde{C}_w\) equal to \(\tilde{C}_{a,\rho }\) likewise defined in the statement of the theorem. By Remark 3.10 and Proposition 3.12 we can rewrite \(\tilde{\mu }_k\) via an expansion into \(\mu _j\) as \(j\) varies between \(0\) and \(k\) and where \(\mu _j\) is defined as in (3.10) with \(f\) as in the statement of the theorem and with nested contours not including 0. By Proposition 3.5, we can recognize that \(\mu _k = \left\langle q^{k\lambda _N}\right\rangle _{\mathbf{MM }_{t=0}(a_1,\ldots ,a_N;\rho )}\).
Summing up these deductions we have found that
By (3.2) we get
From the above it is clear that \(|\tilde{\mu }_k|\le 1\). Observe that due to the \(q\)-Binomial theorem and this a priori bound, for \(|\zeta |<1\)
On the other hand, replacing \(\zeta \) by \(\zeta /(1-q)\) in Proposition 3.16, we find that the left-hand side above is equal to the Fredholm determinant in equation (3.32). Thus for \(|\zeta |<1\) and \(a_i\)’s in a small enough neighborhood of \(1\) we have proved the desired result. The full result follows by the earlier mentioned analyticity. \(\square \)
Note also the following (cf. Proposition 3.1),
Corollary 3.24
Under the assumptions of Theorem 3.23 one has
where the integration is along any positively oriented contour which encloses the poles \(\zeta =q^{-M}\) for \(0\le M\le n\).
Remark 3.25
The above, simple, formula for the probability density is highly reminiscent of the initial Fredholm determinant expression of Tracy and Widom [108] in the context of the ASEP. While simple, it is not obvious how to take asymptotics of this formula. The approach of [108] may serve as a guide and one might try to factor the kernel so as to cancel the denominator product and then re-express the resolvent as a kernel written in terms of a separate integration. We, however, make no attempt at this presently, as we already have a different Fredholm determinant expression which is more readily studied asymptotically.
3.3 q-TASEP and the q-Whittaker 2d-growth model
3.3.1 The q-Whittaker 2d-growth model
Let us now look at the limits as \(t\rightarrow 0\) of the transition rates of the continuous time Markov process from Sect. 2.3.3.
Lemma 3.26
For \(t=0\) we have
Proof
Substitution \(t=0\) into the formulas of Sect. 2.1.6. \(\square \)
Lemma 3.26 enables us to compute the limits of the matrix elements of the generator \(\mathfrak q \). The off-diagonal entries are either 0 or
for suitable \(1\le k\le m\).
Lemma 3.27
For any \(1\le k\le m, \lambda ^{(m-1)}\in \mathbb{Y }(m-1), \lambda ^{(m)}\in \mathbb{Y }(m), \lambda ^{(m-1)}\prec \lambda ^{(m)}\), we have
If \(k=m=1\), the right-hand side is 1. If \(k=1\) and \(m>1\) the right-hand side should be read as \({(1-q^{\lambda _{1}^{(m)}-\lambda _{2}^{(m)}+1})}/{(1-q^{\lambda _{1}^{(m)}-\lambda _1^{(m-1)}+1})}\). Finally, if \(k=m\) the right-hand side is equal to \((1-q^{\lambda _{m-1}^{(m-1)}-\lambda _m^{(m)}})\).
Proof
We will do the computation for \(m>1\) and \(1<k<m\). The three cases listed separately are obtained by omitting suitable factors in the expressions below. From the formula of Lemma 3.26 we have
Since \(\psi ^{\prime }_{(\lambda \cup \square _k)/\lambda }=(1-q^{\lambda _{k-1}-\lambda _k})\), we arrive at the result. \(\square \)
We may now make the following definition.
Definition 3.28
The \(q\)-Whittaker 2d-growth model with drift \(a=(a_1,\ldots , a_N)\in \mathbb{R }^N\) is a continuous time Markov process on the space \(\mathcal{X }^{(N)}\) of Sect. 2.3.3, whose transition rates depend on \(q\) and the set of parameters \(a_1\ldots , a_N\) and are as follows: Each of the coordinates \(\lambda _k^{(m)}\) has its own independent exponential clock with rate
(as in Lemma 3.27 the factors that do not make sense must be omitted). When the \(\lambda _A^{(B)}\)-clock rings we find the longest string \(\lambda _A^{(B)}=\lambda _A^{(B+1)}=\dots =\lambda _A^{(B+C)}\) and move all the coordinates in this string to the right by one. Observe that if \(\lambda _A^{(B)}=\lambda _{A-1}^{(B-1)}\) then the jump rate automatically vanishes.
We will sometimes call the above dynamics the q-Whittaker 2d-dynamics. To visualize this process it is convenient to set \(x_{k}^{(m)} = \lambda _k^{(m)}-k\). These dynamics are illustrated in Fig. 2a, b.
Remark 3.29
It follows immediately from Proposition 2.24 that if the \(q\)-Whittaker 2d-growth model is initialized according to \(\mathbf{MM }_{t=0}(a_1,\ldots ,a_N;\rho )\) with \(\rho \) a Plancherel specialization with \(\gamma =0\) (i.e., initially \(\lambda _k^{(m)}\equiv 0\)), then after time \(\tau \), the entire GT pattern is distributed according to \(\mathbf{MM }_{t=0}(a_1,\ldots ,a_N;\rho )\) with \(\rho \) a Plancherel specialization with \(\gamma =\tau \).
Remark 3.30
Even though the above 2d-growth model is initially defined on the state space \(\mathcal{X }^{(N)}\) for a fixed number of layers \(N\), it is possible to extend these dynamics to the space of infinite Gelfand-Tsetlin patterns \(\mathcal{X }^{(\infty )}\) – one can find constructions of such Markov dynamics on infinite schemes in the Schur case in [27, 30].
Remark 3.31
Proposition 2.6 implies that for \(k\) fixed, the sum \(\sum _{i=1}^{k} \lambda ^{(k)}_{i}\) evolve under the \(q\)-Whittaker 2d-dynamics as a Poisson processes, and at a fixed time moment, these quantities for different \(k\) are distributed jointly as independent Poisson random variables.
3.3.2 q-TASEP formulas
The projection of the \(q\)-Whittaker 2d-growth model dynamics to the set of smallest coordinates \(\{\lambda _k^{(k)}\}_{k\ge 1}\) is also Markovian. If we set \(x_k=\lambda _k^{(k)}-k\) for \(k=1,2,\ldots \), then the state space consists of ordered sequences of integers \(x_1>x_2>x_3>\cdots \). The time evolution is given by a variant on the classical totally asymmetric simple exclusion process (TASEP) which we call \(q\)-TASEP and define as follows [see Fig. 2c]:
Definition 3.32
The \(q\)-TASEP is a continuous time interacting particle system on \(\mathbb{Z }\) where each particle \(x_i\) jumps to the right by 1 independently of the others according to an exponential clock with rate \(a_i(1-q^{x_{i-1}-x_i-1})\), where \(a_i\)’s are positive and \(0<q<1\). A particular initial condition of interest is that of the step initial condition where \(x_n(0)=-n, n=1,2,\dots \).
As long as there is a finite number of particles to the right of the origin initially, this process is well-defined since only particles to the right affect a particle’s evolution. In Sect. 3.3.3 below we briefly discuss two approaches which may be used to construct \(q\)-TASEP for any initial condition.
The exponential moment formulas of Sect. 3.1.3 and the Fredholm determinant formula of Sect. 3.2.3 translate immediately into formulas for \(q\)-TASEP since \(x_n+n = \lambda ^{(n)}_{n}\). In particular, Theorem 3.18 gives the distribution of \(x_n\) in terms of a Fredholm determinant, from which one could extract asymptotics.
3.3.3 Properties of the q-TASEP
We now briefly study the properties of the \(q\)-TASEP from the perspective of interacting particle systems. We assume here that the jump rate parameters \(a_m\equiv 1\). We also indicate a few results one might hope to extend from the usual TASEP setting. The totally asymmetric simple exclusion process (TASEP) corresponds to the \(q=0\) limit of \(q\)-TASEP in which particles jump right at rate 1 if the destination is unoccupied (this is the exclusion rule).
When initialized with a finite number of particles to the right of the origin it is easy to construct the \(q\)-TASEP, as we did in the previous section. This approach fails when there are an infinite number of particles because we can not simply construct the process from the right-most particle on. There are two approaches one employs to prove the existence of such infinite volume dynamics: Markov generators, and graphical constructions. Both of these approaches work for the \(q\)-TASEP though we will mainly present the graphical construction.
Proposition 3.33
For any (possibly random) initial condition \(x^0=\{x_{i}(0)\}\) of particles, there exists a \(q\)-TASEP process \(x(t)\) for \(t\ge 0\) with \(x(0)=x^0\) almost surely.
Proof
Assume there is an infinite number of particles to the right of the origin (otherwise the dynamics have already been constructed). The graphical construction (and idea going back to Harris in 1978 [58]) enables us to construct the dynamics simultaneous for all initial conditions (and hence provides the basic coupling of \(q\)-TASEP). We only consider a finite time interval \([0,T]\) but because of the Markov property, we can extend our construction to all \(t\ge 0\). The key idea is to prove that the dynamics split into finite (random) pieces on which the construction is trivially that of a continuous Markov chain on a finite state space.
Above every site of \(\mathbb{Z }\) draw half-infinite time lines and throw independent Poisson point processes of intensity 1 along these lines. To every point associate a random variable uniformly distributed on \([0,1]\). Particles move up along these time lines until they encounter a Poisson point at which time they compare the point’s random variable \(r\) with the quantity \(r^{\prime }\!=\!1\!-q^{d-1}\) where \(d\) is the distance to the next particle to the right. If \(r\!<\!r^{\prime }\) then the particle jumps one space to the right, otherwise it makes no action.
This process exists for the following reason: for any fixed time \(T>0\) there almost surely exists a site \(n\) (which depends on the initial data and the Poissonian environment) such that there is initially a particle at site \(n\) and such that in the time interval \([0,T]\) there are no Poisson points above \(n\) (i.e., the particle at \(n\) never moves). This ensures that the process to the left of \(n\) evolves independently of the process to the right and hence ensures the existence of the process to the left. There will be infinitely many such special separation points to the right of the origin and hence the process can be constructed in a consistent way in every compact set and hence the infinite volume limit dynamics exists. \(\square \)
In particular it is worth noting that \(q\)-TASEP falls into a category of exclusion processes which are known as speed-changed simple exclusion processes (\(q\)-TASEP, however, does not satisfy the gradient condition and has a speed function which is not a local function of the occupation variables—see for instance [42] for more on speed-changed exclusion).
Remark 3.34
Without getting into the technicalities, the generator construction deals not with particles but rather with occupation variables \(\eta \in \{0,1\}^{\mathbb{Z }}\) where \(\eta (z)=1\) corresponds to having a particle at \(z\) and \(\eta (z)=0\) corresponds to having a hole there. The generator for \(q\)-TASEP is denoted by \(L^{q-TASEP}\) and is defined by its action on local (i.e., depending only on a finite number of occupation variables) functions \(f:\{0,1\}^{\mathbb{Z }}\rightarrow \mathbb{R }\) by
where \(g_x(\eta )\) is the number of 0’s in \(\eta \) to the right of \(x\) until the first 1, and where \(\eta ^{x,x+1}\) is the configuration in which the occupation variables at \(x\) and \(x+1\) have been switched. One readily checks the conditions for Theorem 1.3.9 of [77] are satisfied, hence the above generator gives rise to a Feller Markov process as desired (condition 1.3.3 is clearly satisfied, whereas 1.3.8 is satisfied since \(\sum _{u} \gamma (x,u)\) is bounded by a geometric series with parameter \(q\) for \(u>x\)).
Instead of keeping track of particle locations or occupation variables, one could alternatively consider the gaps between consecutive particles. Let \(y_i=x_i-x_{i+1} -1\) represent the number of holes between particle \(i\) and particle \(i+1\) (which recall is to its left). The evolution of the collection of \(\{y_i\}\) also has a nice description in terms of a zero range process.
Definition 3.35
The totally asymmetric (nearest neighbor) zero range process (TAZRP) on \(\mathbb{Z }\) with rate function \(g:\mathbb{Z _{>0}}\rightarrow [0,\infty )\) is a Markov process with state space \(\{0,1,\ldots \}^{\mathbb{Z }}\). For a state \(y\in \{0,1,\ldots \}^{\mathbb{Z }}\) one says there are \(y_i\) particles at site \(i\). The dynamics of TAZRP are given as follows: in each site \(i, y_i\) decreases by 1 and \(y_{i+1}\) increase by 1 (simultaneously) in continuous time at rate given by \(g(y_i)\). We fix throughout that \(g(0)=0\).
We record a few pertinent facts about TAZRP proved in the literature on the subject (see the book of Kipnis and Landim [72] for additional discussion).
Proposition 3.36
-
1.
Assume \(g(k)>0\) for all \(k\ge 1\) and \(\sup _{k\ge 0} | g(k+1)-g(k)|<\infty \) then TAZRP is a well-defined Markov process.
-
2.
The set of invariant distributions for TAZRP which are also translation-invariant (with respect to translations of \(\mathbb{Z }\)) are generated by the following extremal invariant distributions \(\mu _\alpha \) on \(y(0)\), for \(\alpha \in [0,\sup g(k))\): \(\mu _\alpha \) is the product measure with each \(y_i(0)\) distributed according to
$$\begin{aligned} \mu _{\alpha }(y(0): y_i(0)=k) = {\left\{ \begin{array}{ll} Z_{\alpha } \frac{ \alpha ^k}{g(1)\cdots g(k)}, &{} \mathrm{if }\, k>0,\\ Z_\alpha &{} \mathrm{if }\,k=0.\end{array}\right. } \end{aligned}$$ -
3.
If \(g(k+1)>g(k)\) for \(k\ge 1\) (the attractive case) then for two initial conditions \(y(0)\le y^{\prime }(0)\) (i.e. \(y_i(0)\le y^{\prime }(0)\) for all \(i\in \mathbb{Z }\)) there exists a monotone coupling of the dynamics such that almost surely under the coupled measure, \(y(t)\le y^{\prime }(t)\) for all \(t\).
Proof
The existence of the dynamics is proved in [78]. The invariant distributions and monotone coupling is shown in [5]. Recall that a measure \(\mu \) is invariant for a Markov chain given by a semi-group \(S(t)\) if the push-forward of \(\mu \) under \(S(t)\), written as \(\mu S(t)\) is equal to \(\mu \) for all \(t\). \(\square \)
From the above theorem we conclude the following immediate corollary.
Corollary 3.37
The TAZRP associated to \(q\)-TASEP started with an infinite number of particles to the left and right of the origin is given by a rate function \(g(k)=1-q^k\) is a well-defined Markov process. Its translation invariant extremal invariant distributions are given by product measure \(\mu _\alpha \) for \(\alpha \in [0,1)\) with each \(y_i(0)\) distributed according to the marginal distribution
We call this distribution the \(q\)-Geometric distribution of parameter \(\alpha \). In the \(q=0\) (TASEP) limit, the \(q\)-Geometric distributions converge to standard geometric distributions with probability of \(k\) given by \((1-\alpha )\alpha ^k\).
It is an easy application of the \(q\)-Binomial theorem (see Sect. 3.1.1) that for a random variable \(r\) given by a \(q\)-Geometric distribution of parameter \(\alpha \)
In the case of \(q\)-TASEP with only a finite number of particles to the left of or right of the origin, the TAZRP is no longer on \(\mathbb{Z }\) but rather an interval (possibly half-infinite) of \(\mathbb{Z }\). At the boundaries one must put a source and a sink, but let us not go into that in detail.
Remark 3.38
In the case \(a_i\equiv 1\), the TAZRP associated with \(q\)-TASEP and its quantum version under the name “\(q\)-bosons” were introduced in [98] where their integrability was also noted. A stationary version of \(q\)-TAZRP was studied in [11] and a cube root fluctuation result was shown as a consequence of a more general theory of cube root fluctuations for TAZRPs.
Second class particles play an important role in the study of ASEP and can be studied here as well. For ASEP started with invariant distribution initial data, second class particles macroscopically follow characteristic lines for the conservative Hamilton-Jacobi PDE which governs the limiting shape of the height function associated to this particle system. Using couplings, this approach was employed to prove general hydrodynamic theories [100]. Finer scale properties of second class particles can be related to two-point functions for ASEP as well as to the current of particles crossing a characteristic. These relations have been useful in establishing tight bounds on scaling exponents for the height function evolution of the ASEP [10]. It would be certainly very interesting to see if these approaches still apply for \(q\)-TASEP.
One of the key pieces in determining the associated hydrodynamic PDE for a particle system is to develop an expression for the flux in equilibrium. We now provide a heuristic computation for what the flux through the bond between 0 and 1 should be per unit time (i.e., \(\mathbb{E }[N_t]/t\) where \(N_t\) is defined as the number of particles to cross from site 0 to site 1 in time \(t\)). In order for a particle to move from site 0 to 1, there must be a particle at site 0 at time \(t\) and hole at 1 at time \(t\). First consider the probability of having site 1 occupied. If we can determine the overall density of particles for a given parameter \(\alpha \), then the probability of a particle at 0 should equal that density. This density is given by \((1+\mathbb{E }[r])^{-1}\) where \(r\) is given by a \(q\)-Geometric distribution of parameter \(\alpha \). In order to calculate \(\mathbb{E }[r]\) observe that
where we used the \(q\)-Binomial theorem in the second equality.
Now given a particle at 0, the probability of a jump occurring in a unit time \(dt\) is given by
where the last equality is from shifting the indices and recognizing the sum as \(\sum _k \mathbb{P }(r=k)\). Putting these two pieces together we find that (at least in this heuristic way)
where \(N_t\) is defined as the number of particles to cross from 0 to 1 in time \(t\). We do not have a nicer form than this for the flux, though when \(q=0\) this reduces to \(\alpha (1-\alpha )\) as expected.
4 Whittaker processes
4.1 The Whittaker process limit
4.1.1 Definition and properties of Whittaker functions
Givental integral and recursive formula
The class-one \(\mathfrak{gl }_{\ell +1}\)-Whittaker functions are basic objects of representation theory and integrable systems [46, 73]. One of their properties is that they are eigenfunctions for the quantum \(\mathfrak{gl }_{\ell +1}\)-Toda chain. As showed by Givental [55], they can also be defined via the following integral representation
\(\underline{x}_{\ell +1} = \{x_{\ell +1,1},\ldots , x_{\ell +1,\ell +1}\}\in \mathbb{R }^{\ell +1}, \underline{\lambda }_{\ell +1}=\{\lambda _{1},\ldots ,\lambda _{\ell +1}\}\in \mathbb{C }^{\ell +1}\) and
Note \(e^{-e^{const\cdot M}}\)-type decay of the integrand outside a box of size \(M\).
Remark 4.1
Despite notational similarity, these are different than the \(\psi _{\lambda /\mu }\) functions which arise in the Pieri formulas. The letter \(\psi \) is used for both functions so as to be consistent with the literature. The Whittaker functions will always be written with both a subscript and an argument, while the \(\psi \) from the Pieri formula appears with only a subscript.
The Givental integral representation has a recursive structure. The resulting recursive formula for the Whittaker functions plays a significant role in estimating bounds on the growth of Whittaker functions in the \(\underline{x}_{\ell +1}\) variables. It says that [50]
where we have a base case \(Q^{1\rightarrow 0}_{\lambda _1}(x_{1,1})=e^{\iota \lambda _1 x_{1,1}}\) and for \(\ell >0\)
The operator \(Q^{\ell +1\rightarrow \ell }_{\lambda _{\ell +1}}\) is known of as a Baxter operator.
Orthogonality and completeness relations
The Whittaker functions have many remarkable properties. Let us note the orthogonality and completeness relations which can be found in [99, 112] or [52] Theorem 2.1: For any \(\ell \ge 0\) and \(\underline{\lambda }_{\ell +1},\underline{\tilde{\lambda }}_{\ell +1},\underline{x}_{\ell +1},\underline{y}_{\ell +1}\in \mathbb{R }^{\ell +1}\),.
where the Skylanin measure \(m_{\ell +1}(\underline{\lambda }_{\ell +1})\) is defined by
These identities should be understood in a weak sense and show that the transform defined by integration against Whittaker functions is an isometry from \(L^2(\mathbb{R }^{\ell +1},d\underline{x}_{\ell +1})\) to \(L^{2,sym}(\mathbb{R }^{\ell +1},m_{\ell +1} d\underline{\lambda }_{\ell +1})\) where the sym implies that functions are invariant in permuting their entries.
Mellin Barnes integral representation and recursion
There exists a dual integral representation to that of Givental which was discovered in [70] and goes by the name of a Mellin Barnes representation. Following [50] (\(q\)-Whittaker functions also have an analogous representation [54], as do Macdonald polynomials [7]) we have
where, just for the purpose of this representation we write \(\underline{\lambda }_{n} = \{\lambda _{n,1},\ldots , \lambda _{n,n}\}\in \mathbb{C }^{n}\) and where the domain of integration \(S\) is defined by the conditions \(\max _j \left\{ \mathrm{Im }\lambda _{k,j}\right\} <\min _m \left\{ \mathrm{Im }\lambda _{k+1,m}\right\} \) for all \(k=1,\ldots ,\ell \). Recall that we assumed \(\lambda _{n,j}=0\) for \(j>n\).
The Mellin Barnes integral representation has a recursive structure. The resulting recursive formula for the Whittaker functions plays a significant role in estimating bounds for the growth of Whittaker functions in the \(\underline{\lambda }_{\ell +1}\) indices:
where we have for \(\ell \ge 1\)
and where the domain of integration \(S_{\ell }\) is defined by the conditions \(\max _j \left\{ \mathrm{Im }\lambda _{\ell ,j}\right\} <\min _{m}\left\{ \mathrm{Im }\lambda _{\ell +1,m}\right\} \).
The operator \(\hat{Q}^{\ell +1\rightarrow \ell }_{x_{\ell +1}}\) is known of as a dual Baxter operator.
Controlled decay of Whittaker functions
Definition 4.2
For \(\underline{x}_{\ell +1}\in \mathbb{R }^{\ell +1}\) define the set-valued function
Proposition 4.3
Fix \(\ell \ge 0\). Then for each \(\sigma \subseteq \{1,\ldots ,\ell \}\) there exists a polynomial \(R_{\ell +1,\sigma }\) of \(\ell +1\) variables such that for all \(\underline{\lambda }_{\ell +1}\in \mathbb{R }^{\ell +1}\) and for all \(\underline{x}_{\ell +1}\) with \(\sigma (\underline{x}_{\ell +1})=\sigma \) we have the following estimate:
The idea here is that double exponentials serve as softened versions of indicator functions. If the double exponentials were replaced by indicator functions, and if the \(\lambda \) were set to zero, then the integral (4.1) could easily be evaluated and found equal to a constant times the Vandermonde determinant of the vector \(\underline{x}_{\ell +1}\) when the vector entries are ordered, and zero otherwise. This is certainly of the type of bound given above. The purpose of the bound above is to show that the softening does not greatly change such an upper bound.
The proof of this Proposition relies on the following.
Lemma 4.4
For all \(m\!\ge \! 0\) there exists constants \(c\!=\!c(m)\!\in \! (0,\infty )\) such that for \(a\!\le \! 0\)
Proof
Let \(x^*\) by the largest \(x\le -1\) such that the following inequality holds: \(e^{-x}\ge ~m~\log |x-1|-x\). Clearly for \(x\) negative enough this will hold, though \(x^*\) will depend on \(m\). Now split the integral between \(-\infty \) and \(x^*\) and \(x^*\) and 0. Observe that when the inequality holds, so does \(e^{-x}\ge e^{a} m \log |x-1| - x\) (since \(a<0\) implies \(e^{a}<1\) and \(\log |x-1|\) is positive on \(x<0\)) and hence
Therefore the first integral (between \(-\infty \) and \(x^*<-1\)) can be majorized by the integral of \((e^{e^{-a}})^x\) which is certainly bounded by a constant time \(e^{-e^{-a}}\). For the second integral, we can upper-bound \(e^{-e^{-(a+x)}}\) by \(e^{-e^{-a}}\) so that the integral is bounded by that times the integral of \(|x|^m\) from \(x^*\) to 0, which is simply a constant depending on \(m\), as desired. \(\square \)
Proof of Proposition 4.3
The proof of this Proposition is instructive since it underlies the idea of the proof of the analogous upper bound in Theorem 4.7. We prove this by induction on \(\ell \). The base case is \(\ell \!=\!0\). Then \(\psi _{\lambda _{1,1}}(x_{1,1})\!=\! e^{\iota \lambda _{1,1}x_{1,1}}\) and it is clear that the proposition’s claim is satisfied by letting the polynomial be a constant exceeding one.
Now assume that we have proved the induction up to \(\ell -1\) and we will prove it for \(\ell \). The key here is the recursive formula for the Whittaker functions given in equation (4.2).
Consider \(\underline{x}_{\ell +1}\in \mathbb{R }^{\ell +1}\) and call \(\sigma =\sigma (\underline{x}_{\ell +1})\). We do not, in fact, need to use the double exponential decay of the Whittaker function (given by the inductive hypothesis), but rather just that its absolute value is bounded by a polynomial of its arguments. Actually, by dropping this double exponential term (which is after all bounded by 1) we can expand the bounding polynomial into monomials and then factor the integration into one-dimensional integrals. These integrals are of the form
We must consider separately the case \(x_{\ell +1,i}-x_{\ell +1,i+1} \ge 0\) and \(x_{\ell +1,i}-x_{\ell +1,i+1} \le 0\). The first case, where \(x_{\ell +1,i}-x_{\ell +1,i+1} \ge 0\), corresponds to \(i\notin \sigma (\underline{x}_{\ell +1})\). We would like to show, therefore, that (4.6) is bounded by a polynomial. We may split the integral in (4.6) into three parts:
On the first integration we bound \(\exp \{-e^{-(x_{\ell +1,i}-x_{\ell ,i})}\}\) by 1. We then perform a change of variables \(\tilde{x}_{\ell ,i}= x_{\ell ,i} - x_{\ell +1,i+1}\) and the bound on this integration becomes
By expanding this as a polynomial in \(\tilde{x}_{\ell ,i}\) we can apply Lemma 4.4 to each term separately to see that the first part of (4.7) is bounded by a polynomial in \(\underline{x}_{\ell +1}\) as desired. The bound for the third part goes similarly. For the second part of the integral, we bound both double exponential terms by one and then note that the remaining integral is clearly a polynomial. Summing up, when \(x_{\ell +1,i}-x_{\ell +1,i+1} \ge 0\), we find a polynomial bound for (4.6), as desired.
We turn to the case \(x_{\ell +1,i}-x_{\ell +1,i+1} \le 0\), which corresponds to \(i\in \sigma (\underline{x}_{\ell +1})\). We would like to show that in this case, (4.6) is bounded by a polynomial times a double exponential factor. We can split (4.6) into two parts:
Let us focus on just the first part of the integral, since the second part is analogously bounded. On the first part of the integration we bound \(\exp \{-e^{-(x_{\ell +1,i}-x_{\ell ,i})}\}\) by one and perform a change of variables \(\tilde{x}_{\ell ,i} = x_{\ell ,i} - (x_{\ell +1,i}+x_{\ell +1,i+1})/2\). The result is a bound on that part of the integral by
By expanding the polynomial \(\left( \tilde{x}_{\ell ,i}+\frac{x_{\ell +1,i}+x_{\ell +1,i+1}}{2}\right) ^m\) into monomials we may apply Lemma 4.4 with \(a= (x_{\ell +1,i}-x_{\ell +1,i+1})/2\). The result is that we find that (4.9) is bounded by a polynomial in \(\underline{x}_{\ell +1}\) times the double exponential factor \(\exp \{-e^a\}\) with \(a\) as above. This, however, is exactly the desired bound.
By combining the results for each monomial of the form of (4.6) we get the desired bound for level \(\ell +1\), thus completing the inductive step. \(\square \)
Remark 4.5
Fix any compact set \(D\subset \mathbb{R }^{\ell +1}\). Then for all \(c<\pi /2\) there is a constant \(C\) such that
for all \(\underline{x}_{\ell +1}\in D\).
Let us briefly sketch how this is shown. This estimate relies on the recursive version of the Mellin Barnes representation for Whittaker functions given in Sect. 4.1.1. By induction on \(\ell \), and by replacing Gamma functions by their asymptotic exponential behavior, one can bound \(|\psi _{\underline{\lambda }_{\ell +1}}(\underline{x}_{\ell +1})|\) in terms of the integral
By studying the critical points of the function being exponentiated, one sees that the integral is bounded as desired.
4.1.2 Whittaker functions as degenerations of q-Whittaker functions
In order to relate \(q\)-Whittaker functions to classical Whittaker functions we must take certain rescalings and limits.
Definition 4.6
We introduce the following scalings:
Furthermore, define the rescaling of the \(q\)-Whittaker function \({\Upsilon }_{\underline{z}_{\ell +1}}(\underline{p}_{\ell +1})\) (defined in Sect. 3.1.2) as
We are now in a position to state our main result concerning the controlled convergence of \(q\)-Whittaker functions to Whittaker functions.
Theorem 4.7
For all \(\ell \ge 1\) and all \(\underline{\nu }_{\ell +1}\in \mathbb{R }^{\ell +1}\) we have the following:
-
1.
For each \(\sigma \subseteq \{1,\ldots ,\ell \}\) there exists a polynomial \(R_{\ell +1,\sigma }\) of \(\ell +1\) variables (chosen independently of \(\nu \) and \(\epsilon \)) such that for all \(\underline{x}_{\ell +1}\) with \(\sigma (\underline{x}_{\ell +1})=\sigma \) [recall the function \(\sigma (\cdot )\) from equation (4.2)] we have the following estimate: for some \(c^*>0\)
$$\begin{aligned} |\psi ^{\epsilon }_{\underline{\nu }_{\ell +1}}(\underline{x}_{\ell +1})| \le R_{\ell +1,\sigma (\underline{x}_{\ell +1})}(\underline{x}_{\ell +1}) \prod _{i\in \sigma (\underline{x}_{\ell +1})} \exp \{-c^* e^{-(x_{\ell +1,i}-x_{\ell +1,i+1})/2}\}.\nonumber \\ \end{aligned}$$(4.10) -
2.
For \(\underline{x}_{\ell +1}\) varying in a compact domain, \(\psi ^{\epsilon }_{\underline{\nu }_{\ell +1}}(\underline{x}_{\ell +1})\) converges (as \(\epsilon \) goes to zero) uniformly to \(\psi _{\underline{\nu }_{\ell +1}}(\underline{x}_{\ell +1})\).
This theorem is proved in Sect. 4.1.2 and follows a similar, albeit more involved, route as the proof of Proposition 4.3 for Whittaker functions. Prior to commencing that proof it is necessary to record and prove a few precise estimates about asymptotics of \(q\)-factorials.
Remark 4.8
In [51] a non-rigorous derivation of a point-wise version of part 2 of the above convergence result is given. Through careful considerations of uniformity and tail bounds we prove the above theorem.
Asymptotics and bounds on a certain q-Pochhammer symbol
Recall that we have defined \(\mathcal{A }(\epsilon ) = -\frac{\pi ^2}{6} \frac{1}{\epsilon } -\frac{1}{2}\log \frac{\epsilon }{2\pi }, m(\epsilon ) = -[\epsilon ^{-1}\log \epsilon ], q=e^{-\epsilon }\) and \(f_{\alpha }(y,\epsilon ) = (q;q)_{\epsilon ^{-1}y_{\alpha ,\epsilon }}\), where \(y_{\alpha ,\epsilon }=y+\epsilon \alpha m(\epsilon )\). Throughout this section we will always assume that \(y\) is such that \(\epsilon ^{-1}y_{\alpha ,\epsilon }\) is a nonnegative integer.
Proposition 4.9
Assume \(\alpha \ge 1\), then for all \(y\) such that \(\epsilon ^{-1}y_{\alpha ,\epsilon }\) is a nonnegative integer,
where \(c=c(\epsilon )>0\) is independent of all variables besides \(\epsilon \) and can be taken to go to zero with \(\epsilon \).
On the other hand for all \(b^*<1\) and for all \(y\) such that \(\epsilon ^{-1}y_{\alpha ,\epsilon }\) is a nonnegative integer,
where \(c=c(y_{\alpha ,\epsilon })<C\) for \(C<\infty \) fixed and independent of all variables, and where \(c(y_{\alpha ,\epsilon })\) can be taken as going to zero as \(y_{\alpha ,\epsilon }\) increases.
The following is then an immediate consequence of combining the above asymptotics:
Corollary 4.10
Assume \(\alpha \ge 1\), then for any \(M>0\) and any \(\delta >0\), there exists \(\epsilon _0>0\) such that for all \(\epsilon <\epsilon _0\) and all \(y\ge -M\) such that \(\epsilon ^{-1}y_{\alpha ,\epsilon }\) is a nonnegative integer,
Proof of Proposition 4.9
Let us first introduce the plan of this proof. There are three steps. In the first step we consider \(\log f_{\alpha }(y,\epsilon )\) as \(y\) goes to infinity and compute its limit. In the second step we take the derivative of this expression in \(y\) and notice that this is a much more manageable series (the logarithms disappear) so that we can approximate it to any degree of accuracy we need. Finally, in the third step, we write out the bounds from below and above and integrate them to obtain the claimed estimates.
-
Step 1: First observe that for any fixed \(\epsilon , \lim _{y\rightarrow \infty } \log f_{\alpha }(y,\epsilon )\) exists and (by dominated convergence) is given by
$$\begin{aligned} \lim _{y\rightarrow \infty } \log f_{\alpha }(y,\epsilon ) \!=\! -\!\sum _{r=1}^{\infty } \frac{1}{r} \left( \frac{e^{-r\epsilon }}{1\!-\!e^{-r\epsilon }}\right) \!=\! \!-\!\sum _{n=1}^{\infty } \sum _{r=1}^{\infty } \frac{1}{r} e^{-nr\epsilon } \!=\!\log \prod _{n=1}^{\infty } (1\!-\!e^{-n\epsilon }).\nonumber \\ \end{aligned}$$(4.14)We may say even more.
Lemma 4.11
For all \(\alpha \ge 1\) and all \(\delta >0\) there exists \(\epsilon _0>0\) such that for all \(\epsilon <\epsilon _0\)
Proof
The Dedekind eta function
has the modular property that
Taking \(\tau = \tfrac{\iota \epsilon }{2\pi }\) and recalling the definition of \(f_{\alpha }\) we have
Note that the second equality follows from the modular property of the Dedekind eta function.
This implies that
All that remains, therefore, is to show that for any \(\delta \) we can choose \(\epsilon _0\) such that for all \(\epsilon <\epsilon _0\)
The upper bound is clear. For the lower bound we use the following inequality
Applying this inequality shows that
which, for \(\epsilon \) small enough is certainly above \(-\delta \). \(\square \)
-
Step 2: Let us first note the identity which holds for \(q<1\)
$$\begin{aligned} \log \prod _{n=1}^{N}(1-q^n) = \sum _{n=1}^{N} \log (1-q^n) = -\sum _{n=1}^{N}\sum _{r=1}^{\infty } \frac{1}{r} q^{nr} = -\sum _{r=1}^{\infty } \frac{q^r}{r} \left( \frac{1-q^{Nr}}{1-q^r}\right) . \end{aligned}$$
Now set \(q=e^{-\epsilon }\) and \(N = \epsilon ^{-1} y_{\alpha ,\epsilon }\) to obtain
Observe that since \(y_{\alpha ,\epsilon }\ge 0\), each term in the summation above is positive. This expression becomes more manageable if we differentiate both sides.
Lemma 4.12
For all \(y_{\alpha ,\epsilon }\ge 0\)
Proof
It suffices that for \(\epsilon >0\) fixed and \(y_{\alpha ,\epsilon }\ge 0\), we prove that (a) there exists \(\eta >0\) such that the right-hand side of (4.16) is uniformly convergent (in \(r\)) in \([y_{\alpha ,\epsilon }-\eta ,y_{\alpha ,\epsilon }+\eta ]\), (b) each term in the series has a continuous derivative, and (c) the term-wise differentiated series given on the right-hand side of equation (4.17) is also uniformly convergent (in \(r\)) in \([y_{\alpha ,\epsilon }-\eta ,y_{\alpha ,\epsilon }+\eta ]\).
It is clear that (b) is true. To prove (a) and (c) consider the tail of the series. Let us focus on (a) for the moment. As observed already, the summands in equation (4.16) are all positive. Since \(\epsilon \) is fixed, assume that we only consider tail terms for which \(r\ge \lceil \epsilon ^{-1}\log 2 \rceil \). This means that we can bound \(1-e^{-r\epsilon }\ge 1/2\). Therefore it suffices to show the following converges uniformly for \(x\) varying in \([y_{\alpha ,\epsilon }-\eta ,y_{\alpha ,\epsilon }+\eta ]\)
Since we could choose \(\eta \) small enough so that \(\epsilon +x> 0\) for all \(x\in [y_{\alpha ,\epsilon }-\eta ,\eta +y_{\alpha ,\epsilon }]\) it is clear that this positive series is bounded above by a convergent geometric series and hence is uniformly convergent in \(r\). For (c) a similar logic applies. \(\square \)
-
Step 3: We immediately get an upper bound on the derivative of the logarithm
$$\begin{aligned} \frac{\partial }{\partial y} \log f_{\alpha }(y,\epsilon ) \le -\frac{e^{-(\epsilon +y_{\alpha ,\epsilon })}}{\epsilon }. \end{aligned}$$(4.18)
This is easy to see since each term of the summation in (4.17) is positive. This bound comes from taking only the \(r=1\) term and using the inequality \(1-e^{-a}\le a\) for \(a\ge 0\).
In order to get a lower bound on the derivative of the logarithm we must work a little harder. Fix \(b^*<1\) and note that there exists an \(a^*>0\) such that
Lemma 4.13
Define \(r^*=\lfloor \epsilon ^{-1}a^*\rfloor \) with \(a^*\) as above. Then
Proof
Start by splitting (4.17) into three parts as
The first term is controlled by the following bound:
from which it follows that
For the second term we may apply inequality (4.19) which gives
For the third term we use the fact that \(1-e^{-a}\) is increasing for \(a\ge 0\), which gives
Combining these three bounds gives the lemma. \(\square \)
The upper bound of (4.18) and the lower bound of Lemma 4.13 we have shown deal with the derivative of \(\log f_{\alpha }(y,\epsilon )\). In order to conclude information about \(\log f_{\alpha }(y,\epsilon )\) itself we employ the following:
Lemma 4.14
Consider \(a\in \mathbb{R }\) and \(y_0<\infty \), and a continuous differentiable function \(g(y)\) such that \(\lim _{y\rightarrow \infty }g(y)\) exists and equals \(g^{\infty }\in \mathbb{R }\). Then if
then (respectively)
Proof
First observe that if \(h(y)\) has a limit \(h^{\infty }\) at \(y=\infty \), then
Thus if \(\frac{\partial }{\partial y} h(y)\le 0\) for all \(y\ge y_0\) then also
Applying this and noting that \(e^{-y} \!=\! \frac{\partial }{\partial y} \left( - e^{-y}\right) \), we find that by taking \(h(y)\!=\! g(y)\!-\! e^{-y}a\) we get (since \(e^{-\infty }\!=\!0\)) the desired inequality (1). Similarly we derive (2). \(\square \)
Now we can complete the proof of Proposition 4.9. From equation (4.14) of Step 1 we know that a limit exists for \(\log f_{\alpha }(y,\epsilon )\) as \(y\) goes to infinity. Thus we may apply case (1) of Lemma 4.14 and using the lower bound in Lemma 4.11 along with the upper bound on the derivative given in (4.18), we immediately conclude the desired lower bound of equation (4.11).
To get the upper bound of equation (4.12) we apply case (2) of Lemma 4.14 and using the upper bound in Lemma 4.11 along with the lower bound on the derivative given in (4.13), we find that
The last summation above can be bounded using the value of \(r^*\) as
which is itself bounded by a constant \(c\) uniformly in \(\epsilon \) and \(y_{\alpha ,e}\ge 0\). Moreover, this constant can be taken to be going to zero as \(y_{\alpha ,\epsilon }\) increases. Putting this bound back into (4.24) gives equation (4.14) and hence concludes the proof of Proposition 4.9. \(\square \)
Inductive proof of Theorem 4.7
Let us first explain the plan of the proof. We prove the statement of Theorem 4.7 by induction on \(\ell \). Step 1 is to restate in (4.25) the recursion equation (3.8) given the scaling we are now considering. The base case \(\ell =0\) for the inductive proof we give is trivially satisfied. Step 2 is to record uniform bounds on the terms in (4.25). Here we make critical use of Proposition 4.9. Finally, Step 3 is to prove the inductive hypothesis. To prove the bounds in part 1 of the theorem we can employ the bounds from Step 2 to reduce the problem to a similar consideration as in the proof of Proposition 4.3. The proof of the convergence result in part 2 of the theorem follows from the inductive hypothesis along with the uniformity of the bounds given in Proposition 4.9.
-
Step 1: Let us recall the recursion equation (3.8), which can be rewritten (see [51]) as
$$\begin{aligned}&\psi ^{\epsilon }_{\underline{\nu }_{\ell +1}}(\underline{x}_{\ell +1})\nonumber \\&\quad = \sum ^{\qquad \epsilon }_{\underline{x}_{\ell +1}\in R_{\epsilon }(\underline{x}_{\ell +1})} \Delta ^{\epsilon }(\underline{x}_{\ell }) e^{\iota \nu _{\ell +1}\left( \sum _{i=1}^{\ell +1} x_{\ell +1,i} - \sum _{i=1}^{\ell } x_{\ell ,i}\right) } Q^{\epsilon }_{\ell +1,\ell }(\underline{x}_{\ell +1},\underline{x}_{\ell })\psi ^{\epsilon }_{\underline{\nu }_{\ell }}(\underline{x}_{\ell })\nonumber \\ \end{aligned}$$(4.25)where
$$\begin{aligned} \sum ^{\qquad \epsilon }_{\underline{x}_{\ell }\in R_{\epsilon }(\underline{x}_{\ell +1})}&= \sum _{x_{\ell ,1}\in R^{\epsilon }_1} \epsilon \cdots \sum _{x_{\ell ,\ell }\in R^{\epsilon }_\ell } \epsilon \\ R^{\epsilon }_i&= \{x_{\ell ,i}\in \epsilon \mathbb{Z }: -\epsilon m(\epsilon ) +x_{\ell +1,i+1} \le x_{\ell ,i} \le \epsilon m(\epsilon ) +x_{\ell +1,i}\} \end{aligned}$$and where
$$\begin{aligned} \!\!\!\Delta ^{\epsilon }(\underline{x}_{\ell })&= \prod _{i=1}^{\ell -1} e^{-\mathcal{A }(\epsilon )}f_2(x_{\ell ,i} - x_{\ell ,i+1},\epsilon ),\\ \!\!\!Q^{\epsilon }_{\ell +1,\ell }(\underline{x}_{\ell +1},\underline{x}_{\ell })&= \prod _{i=1}^{\ell } e^{\mathcal{A }(\epsilon )}f_1(x_{\ell +1,i}-x_{\ell ,i},\epsilon )^{-1}e^{\mathcal{A }(\epsilon )}f_1(x_{\ell ,i}-x_{\ell +1,i+1},\epsilon )^{-1}. \end{aligned}$$
When \(\ell =0\), we have
This actually is equal to \(\psi _{\nu _1}(x_{1,1})\) for all \(\epsilon \), hence part 2 of the Theorem is satisfied. Moreover, since \(\ell =0\), part 1 is trivially satisfied by taking the polynomial to be a constant greater than 1. Therefore we have established the \(\ell =0\) base case of the theorem. The rest of the proof is devoted to proving the induction step.
-
Step 2: Assume now that we have proved the theorem for \(\ell -1\) and we will show how the theorem for \(\ell \) follows. From the inductive hypothesis we have the following bounds which are valid for \(\underline{x}_{\ell }\in R_{\epsilon }(\underline{x}_{\ell +1})\) and for \(\epsilon \) sufficiently small (here \(c\) is a positive constant which varies between lines and \(b^*\) is arbitrary but strictly bounded above by 1):
$$\begin{aligned} |\psi ^{\epsilon }_{\underline{\nu }_{\ell }}(\underline{x}_{\ell })|&\le R_{\ell ,\sigma (\underline{x}_{\ell })}(\underline{x}_{\ell }) \prod _{i\in \sigma (\underline{x}_{\ell })} \exp \{-e^{-(x_{\ell ,i}-x_{\ell ,i+1})/2}\}\nonumber \\ x|\Delta ^{\epsilon }(\underline{x}_{\ell })|&\le \exp \left\{ \sum _{i=1}^{\ell -1} \left( c + (b^*)^{-1} \sum _{r=1}^{\infty } \frac{\epsilon ^{2r-1}e^{-r(x_{\ell ,i}-x_{\ell ,i+1})}}{r^2}\right) \right\} \nonumber \\ |Q^{\epsilon }_{\ell +1,\ell }(\underline{x}_{\ell +1},\underline{x}_{\ell })|&\le e^{c} \exp \left\{ \sum _{i=1}^{\ell } \left( -e^{-(x_{\ell +1,i}-x_{\ell ,i})} - e^{-(x_{\ell ,i}-x_{\ell +1,i+1})}\right) \right\} \!. \end{aligned}$$(4.26)
The first inequality is directly from part 1 of the theorem, for \(\ell -1\). The second inequality relies on the bound given in equation (4.12) when \(\alpha =2\). The domain \(R_{\epsilon }(\underline{x}_{\ell +1})\) for \(\underline{x}_{\ell }\) corresponds to the condition that \(y_{2,\epsilon }\ge 0\). The exact statement of the inequality uses the fact that
for \(b^{*}<1\) fixed and \(\epsilon \) small enough; it also uses the fact that \(e^{-r\epsilon }<1\). The third inequality comes immediately from equation (4.11).
Observe that the \(\Delta ^{\epsilon }\) term has the potential to become large. This occurs when \(x_{\ell ,i}-x_{\ell ,i+1}\) approaches the lower bound of its values on the domain for \(\underline{x}_{\ell }\) which corresponds to \(x_{\ell ,i}-x_{\ell ,i+1} = -2\log \epsilon ^{-1}\). This bound on the domain is due to the fact that in Definition 4.6, \(p_{\ell ,k}\) satisfied the interlacing condition. The growth of \(\Delta ^{\epsilon }\) is, however, canceled by the rapid decay of the \(Q^{\epsilon }\) term, as we now show:
Lemma 4.15
Consider \(\underline{x}_{\ell +1}\) such that \(x_{\ell +1,i}-x_{\ell +1,i+1}\ge -2\log \epsilon ^{-1}, \underline{x}_{\ell }\in R_{\epsilon }(\underline{x}_{\ell +1})\) and \(b^*\) close to (though less than) one. Then there exist constants \(c^*\in (0,1)\) and \(C>0\) such that
Proof
Using the bounds of (4.26) showing this suffices to proving that for each \(1\le i\le \ell \),
with \(\underline{x}_{\ell +1}\) and \(\underline{x}_{\ell }\) as specified in the statement of the lemma. Call \(a=x_{\ell +1,i}-x_{\ell ,i} + \log \epsilon ^{1}\) and \(b=x_{\ell ,i}-x_{\ell +1,i+1}+\log \epsilon ^{-1}\). Observe that the conditions on \(\underline{x}_{\ell +1}\) and \(\underline{x}_{\ell }\) then reduce to the condition that \(a,b\ge 0\) and the desired inequality reduces to proving that
for all \(a,b\ge 0\). It is now straightforward to prove the above inequality. For \(a=b=0\) this reduces to showing that
which follows for \(b^*\) close enough to 1 and \(c^*\) close enough to 0 [since \(\zeta (2)=\pi ^2/6<2\)]. To extend the proof to all \(a,b\) simply observe that the derivative of the left-hand side in any positive direction in the \((a,b)\) plane, is less than the corresponding derivative of the right-hand side. Showing this [which only uses the inequality \(\log (1-x)\le -x\) for \(x<1\)] completes the proof of the lemma. \(\square \)
-
Step 3: We may now prove that given the inductive hypothesis for \(\ell -1\), the theorem is satisfied for \(\ell \). Let us start with part 1 of the theorem. By the recursive formula (4.25), the triangle inequality and Lemma 4.15 we have
$$\begin{aligned} |\psi ^{\epsilon }_{\underline{\nu }_{\ell +1}}(\underline{x}_{\ell +1})|\le \sum ^{\qquad \epsilon }_{\underline{x}_{\ell }\in R_{\epsilon }(\underline{x}_{\ell +1})} |Q^{\epsilon }_{\ell +1,\ell }(\underline{x}_{\ell +1},\underline{x}_{\ell })|^{c^*} |\psi ^{\epsilon }_{\underline{\nu }_{\ell }}(\underline{x}_{\ell })| \end{aligned}$$(4.27)for the constant \(c^*\in (0,1)\) given in Lemma 4.15. From the inductive hypothesis, \(|\psi ^{\epsilon }_{\underline{\nu }_{\ell }}(\underline{x}_{\ell })|\) is bounded by a polynomial in \(\underline{x}_{\ell }\) times a collection of double exponential terms. The double exponential terms are bounded by 1, so let us bound \(|\psi ^{\epsilon }_{\underline{\nu }_{\ell }}(\underline{x}_{\ell })|\) by just a polynomial. Splitting that polynomial into monomials and using the bound given in (4.26) for \(Q^\epsilon \) we find that the summation in (4.27) factors into a product of terms like
$$\begin{aligned} \sum _{x_{\ell ,i}\in R^{\epsilon }_i} \epsilon (x_{\ell ,i})^m \exp \{-c^* e^{-(x_{\ell +1,i}-x_{\ell ,i})}\}\exp \{- c^* e^{-(x_{\ell ,i}-x_{\ell +1,i+1})}\}, \end{aligned}$$where \(m\in \mathbb{Z _{\ge 0}}\).
This summation can be bounded by the integral it converges to which is
Using the exact same argument as in the inductive step in the proof of Proposition 4.3, we can now complete the proof of part 1 of the theorem by bounding this integral, and then recombining all of the monomial terms. The only change between that proof and this is the factor of \(c^*\) in the exponential. However, as one readily seems from Lemma 4.4, this factor just carries through to the final formula and accounts for the \(c^*\) in (4.10).
We turn now to proving part 2 in this inductive step. Fix a compact domain \(D_{\ell +1}\) in which \(\underline{x}_{\ell +1}\) may vary. We wish to show that on \(D_{\ell +1}, \psi ^{\epsilon }_{\underline{\nu }_{\ell +1}}(\underline{x}_{\ell +1})\) converges uniformly as \(\epsilon \) goes to zero and \(\underline{x}_{\ell +1}\) is varied in \(D\) to \(\psi _{\underline{\nu }_{\ell +1}}(\underline{x}_{\ell +1})\). By Lemma 4.15, for any fixed \(\eta >0\) we can find a compact domain \(D_{\ell }\) for the \(\underline{x}_{\ell }\) variables, outside of which the summation in equation (4.25) is bounded in absolute value by \(\eta \), uniformly over \(\underline{x}_{\ell +1}\) varying in \(D_{\ell +1}\).
On the domain \(D_{\ell }\) we have uniform convergence of the summand of (4.25) to the analogous integrand of equation (4.2). This can be seen by combining the inductive hypothesis for \(\ell -1\) and equation (4.13) of Corollary 4.10. It follows then that the Riemann sum of the summand of (4.25) over the domain \(D_{\ell }\) converges to the integral over the domain \(D_{\ell }\) in the recursive formula for the Whittaker functions, given in equation (4.2). Moreover, this convergence is uniform as \(\underline{x}_{\ell +1}\in D_{\ell +1}\).
All that remains to finish the proof is to note that by Proposition 4.3, by taking \(D_{\ell }\) large enough we can ensure an upper bound of \(\eta \) on the absolute value of the contribution of the integral in (4.2) outside of \(D_{\ell }\). Moreover, this upper bound is uniform over \(\underline{x}_{\ell +1}\in D_{\ell +1}\). Since \(\eta \) was arbitrary, this completes the inductive step for uniform convergence, and hence completes the proof of Theorem 4.7.
4.1.3 Weak convergence to the Whittaker process
We start by defining the Whittaker process and measure as introduced and first studied by O’Connell [86] in relation to the image of the O’Connell-Yor semi-discrete directed polymer under a continuous version of the tropical Robinson-Schensted-Knuth correspondence (see Sect. 5.2).
Definition 4.16
For any \(\tau >0\) set
For any \(N\)-tuple \(a=(a_1,\ldots ,a_N)\in \mathbb{R }^N\) and \(\tau >0\), define the Whittaker process as a measure on \(\mathbb{R }^{\frac{N(N+1)}{2}}\) with density function (with respect to the Lebesgue measure) given by
The nonnegativity of the density follows from definitions. Integrating over the variables \(T_{k,i}\) with \(k<N\) yields the following Whittaker measure with density function given by
Remark 4.17
The form of the Whittaker measure and the Macdonald measure may appear different. The Macdonald \(P\) polynomial has degenerated into the Whittaker function \(\psi \), the normalizing constant has become the Gaussian prefactor. The specialization of the Macdonald \(Q\) function which degenerates to the measure we are presently studying is the Plancherel specialization. Whittaker functions only arise as limits of pure alpha Macdonald polynomials. In order to find the limit of the Placherel specialized Macdonald \(Q\) function we use the fact that it can be represented via the torus inner product in terms of the Macdonald \(P\) polynomial and the normalizing constant. This torus integral limits to the expression \(\theta _{\tau }(\underline{x}_{N})\) above. The Whittaker measure we are considering is, perhaps, more appropriately called the Plancherel Whittaker measure, as we will introduce in Sect. 4.2 the \(\alpha \)-Whittaker measure.
The Whittaker measure is a probability measure
It is not clear, a priori, that these measures integrate to 1, however we have the following:
Proposition 4.18
Fix \(N\ge 1\). For all \(a=(a_1,\ldots , a_N)\in \mathbb{R }^N \),
Proof
Formally this fact follows immediately by applying the orthogonality relations for Whittaker functions given in Sect. 4.1.1. That relation, however, is only necessarily true when the index, here written as \(\iota a\) is purely real. Thus, in order to justify this identity for indices \((a_1,\ldots , a_N)\) not all identically 0, we must perform an analytic continuation of the orthogonality relation (when \(a_i\equiv 0\) this continuation is not needed and the result follows immediately). This analytic continuation relies on a Paley-Weiner type super-exponential decay estimate for \(\theta _{\tau }(\underline{x}_{N})\) which is given in Proposition 4.20.
A less direct proof that the Whittaker measure integrates to 1 comes from the fact that the Whittaker process/measure arise as the law of the image of a directed polymer model (studied in [86]) under a continuous version of the tropical Robinson-Schensted-Knuth correspondence (see Remark 5.5).
For the direct proof we now give, define a function
for \((a_1,\ldots , a_N)\in \mathbb{C }^N\). When restricted to the complex axes \((a_1,\ldots ,a_N)\in \iota \mathbb{R }^N\), the orthogonality of Whittaker functions readily implies that
We wish to analytically continue this result to all of \(\mathbb{C }^N\) and hence show that \(f\) is everywhere identically 1. This requires us to show that \(f(a_1,\ldots , a_N)\) is analytic. The Whittaker function \(\psi _{\iota a}(\underline{x}_{N})\) is known to be entire with respect to its index (see the discussion in [86]) as well as continuous in its variable. On account of this, analyticity of \(f(a_1,\ldots , a_N)\) will follow if we can show that for any compact region \(A\subset \mathbb{C }^N\) and any \(\epsilon >0\), there exists a compact region \(X\in \mathbb{R }^N\) such that
for all \((a_1,\ldots ,a_N)\in A\).
This claim relies on two pieces. The first is a lemma about the growth of Whittaker functions with imaginary index and the second (a more sizable result) is about the super-exponential decay of \(\theta _{\tau }\).
Lemma 4.19
For any positive real numbers \(y_1,\ldots , y_N\) there exist \(c_0, C_0>0\) such that
Proof
This follows easily by induction from the Givental recursive formula (4.2) for the Whittaker functions. \(\square \)
The second estimate is given by the following:
Proposition 4.20
Fix \(N\ge 1\). For any constant \(R\ge 0\), there exists a constant \(C>0\) such that for all \(\underline{x}_{N}\in \mathbb{R }^N\),
By combining this proposition with the above lemma we see that by choosing \(R\) to exceed the \(c_0\), we can ensure exponential decay in \((x_1,\ldots , x_N)\) and hence prove the bound (4.31). This completes the proof of analyticity of \(f(a_1,\ldots , a_N)\) and hence by analytic continuation, \(f(a_1,\ldots , a_N)\equiv 1\) for all \((a_1,\ldots , a_N)\in \mathbb{C }^N\) as desired.
All that remains, therefore, is to prove Proposition 4.20.
Proof of Proposition 4.20
The case of \(N=1\) is standard, yet instructive. In this case, \(\psi _{\nu }(x) = e^{-i\nu x}\) and \(m_N\) is just \(1/(2\pi )\). The idea now is to shift the contour of integration in (4.28) from \(\mathbb{R }\) to \(\mathbb{R }+\iota y\). This is justified by Cauchy’s theorem and the fact that the integrand decays suitably fast along every horizontal contour. Changing variables to absorb this shift into \(x\) yields
Since the final integral above is bounded in absolute value by a constant, this yields the inequality
where \(C_y>0\) depends on \(y\). By taking \(y=R\) when \(x<0\) and \(y=-R\) when \(x>0\), we arrive at the claimed inequality of the proposition.
The case of \(N\ge 2\) is more subtle and relies on a series expansion for the Whittaker function. We work out the calculation explicitly for \(N=2\). For general \(N\ge 2\) a similar series expansion into fundamental Whittaker functions exists (combining Theorem 18 of [63] and Proposition 3 of [87]) for which the argument presented below can readily be adapted.
In the case \(N=2\) the Whittaker functions can be expressed explicitly in terms of the Bessel-K function (sometimes also called the Macdonald function—not to be confused with the Macdonald symmetric function):
where
and the Bessel-K function is given by
Thus we can write
This double integral factors as
We may compute the first integral as
Turning to the second integral, let us call
If we can show that for any \(R>0, |F_2(y_2)| \le \exp (-R |y_2|)\) then Proposition 4.20 will be proved. This is because we already know (from the above computation) that \(|F_1(y_1)|\le \exp (-R|y_1|)\) for all \(R>0\). The claimed result of the proposition follows by the triangle inequality (\(|y_1|+|y_2| \ge |x_1|+|x_2|\)) and the relation \(|\theta _{\tau }(x)| = |F_1(y_1)||F_2(y_2)|\).
In order to show \(|F_2(y_2)| \le \exp (-R |y_2|)\) we should consider two cases: (1) when \(y_2\le 0\), and (2) when \(y_2\ge 0\). In case (1) we use the uniform asymptotics that as \(z\rightarrow \infty \), for all \(v\in \mathbb{R }\),
The exponential decay is the important part here and we can bound the right-hand side above by \(Ce^{-cz}\) for some \(C\!>\!0\) and any \(c\!<\!1\). This allows us to show that for \(y_2\!\le \! 0\),
The remaining integral is independent of \(y_2\) and clearly converges due to the Gaussian decay in \(\kappa _2\). Thus, for \(y_2\le 0\)
It is clear that this double exponential decay can be bounded by exponential decay to any order \(R\), at the cost of prefactor constant to account for \(y_0\) near 0. This completes the desired estimate in case (1).
Turning to case (2), where \(y_2\ge 0\), we will first utilize the fact that the Bessel-K function can be rewritten as a Bessel-I function in such a way as to cancel the \(\sinh \) term. This expansion and cancelation is important and a similar phenomena occurs for general \(N\ge 2\) (see Proposition 3 of [87]). In particular
where the Bessel-I function has the following convergent Taylor series expansion around \(z=0\).
Plugging this in (and absorbing numerical constants as \(c\))
We wish to cut the series expansion for Bessel-I at a particular level \(\ell ^*\) and estimate the remainder term.
Use the Gamma functional equation to rewrite this as
where \((v+1)\cdots (v+\ell )\) for \(\ell =0\) is just interpreted as \(1\). For all \(z\in \mathbb{R }\) and \(v\in \iota \mathbb{R }\) it follows that
for the constant \(C(\ell ^*)\) depending on \(\ell ^*\) but independent of \(z\) and \(v\).
Thus we can show that
where
Note that III contains the remainder term estimate from both the \(I_{-\iota \kappa _2}\) and \(I_{\iota \kappa _2}\) terms, with \(z=2 e^{-y_2/2}\).
It remains to show that each of these terms can be bounded by \(Ce^{-R|y_2|}\) for \(y_2\ge 0\) and \(C\) depending on \(R\) but not on \(y_2\). As noted before, this will complete the proof of the proposition. Consider III first. By taking \(\ell ^*+1 \ge R\) the desired bound \(III\le C e^{-Ry_2}\) immediately follows. I and II can be dealt with in the same manner, thus let us just consider I. We will bound each term in I separately and call them \(I_{\ell }\). Recall that \(1/\Gamma (w)\) is an entire function in \(w\). It follows from Cauchy’s theorem and the Gaussian decay of the integrand, that for any \(b\in \mathbb{R }\),
The shift by \(\iota b\) of the contour can be removed via a change of variables which yields
Take \(b=-2R\) and bound the integral above as
where we have used \(e^{-y_2\ell } \le 1\) since \(y_2\ge 0\), and where the constant \(C\) is thus independent of \(y_2\). This means that for \(y_2\ge 0\)
which is exactly as necessary. This estimate can be made for each term in I and likewise for each term in II and hence completes the proof of Proposition 4.20. \(\square \)
As we have proved Proposition 4.20 above, the proof of Proposition 4.18 is also completed. \(\square \)
Weak convergence statement and proof
Theorem 4.21
In the limit regime
the \(q\)-Whittaker process \(\mathbf{M }_{asc,t=0}(A_1,\ldots ,A_N;\rho )\) with \(t=0\) and a Plancherel specialization \(\rho \) determined by \(\gamma \) (and \(\alpha _i,\beta _i=0\) for all \(i\ge 0\)) as in equation (2.23), weakly converges, as \(\epsilon \rightarrow 0\), to the Whittaker process \(\mathbf{W }_{(a,\tau )}\bigl (\{T_{k,i}\}_{1\le i\le k\le N}\bigr )\).
Remark 4.22
The \(q\)-Whittaker process induces a measure on \(\{T_{k,j}\}_{1\le j\le k\le N}\) through the scalings given above. It is this measure which has a limit as \(\epsilon \) goes to zero.
Proof
Recall definition (2.31) which says
It suffices to control the convergence for \(\{T_{k,i}\}\) varying in any given compact set. This is due to the positivity of the measure and because we can see independently that the limiting expression integrates to 1. However, since we wish to prove weak convergence of this measure to the limiting measure, it is crucial that all of our estimates (with respect to convergence as \(\epsilon \) goes to zero) are suitably uniform over the given compact set. As such, for the rest of the proof fix a compact set for the \(\{T_{k,i}\}\).
We consider the right-hand side of equation (4.33) in three lemmas which, when combined, prove the theorem: (1) The product of skew Macdonald polynomials \(P_{\lambda /\mu }\), (2) The \(\Pi \) factor in the denominator, (3) The \(Q\) Macdonald symmetric function. The first of these lemmas relies on the asymptotics developed in Proposition 4.9, the second is simply a matter of Taylor approximation. The third lemma is more involved and employs the torus scalar product. The full strength of Theorem 4.7 is utilized in the proof of this third lemma.
Before commencing the proof, let us recall the notation introduced in Sect. 4.1.2: \(\mathcal{A }(\epsilon ) = -\frac{\pi ^2}{6} \frac{1}{\epsilon } -\frac{1}{2}\log \frac{\epsilon }{2\pi }\) and \(f_{\alpha }(y,\epsilon )~=~(q;q)_{\epsilon ^{-1}y_{\alpha ,\epsilon }}\) where \(y_{\alpha ,\epsilon }=y+\epsilon \alpha m(\epsilon )\), and \(m(\epsilon )= -[\epsilon ^{-1}\log \epsilon ]\).
Let us start by considering the skew Macdonald polynomials with \(t=0\).
Lemma 4.23
Fix any compact subset \(D\subset \mathbb{R }^{N(N+1)/2}\). Then
where the \(o(1)\) error goes uniformly (with respect to \(\{T_{k,i}\}_{1\le i\le k\le N}\in D\)) to zero as \(\epsilon \) goes to zero.
Proof
From equation (2.17) we have that when restricted to one variable, \(P_{\lambda /\mu }(A)=\psi _{\lambda /\mu } A^{|\lambda -\mu |}\), with \(\psi _{\lambda /\mu }\) as in Lemma 3.26. From that we may express
Now observe that given the scalings we have chosen, we have
Noting that
it follows from the estimates of Corollary 4.10 and scalings of the \(A_i\) that we may rewrite equation (4.35) as
where the \(o(1)\) error goes uniformly (with respect to \(\{T_{k,i}\}_{1\le i\le k\le N}\in D\)) to zero as \(\epsilon \) goes to zero.
Applying this to each of the skew Macdonald polynomials we arrive at the claimed result. \(\square \)
Now turn to the \(\Pi \) factor.
Lemma 4.24
We have
where the \(o(1)\) error goes to zero as \(\epsilon \) goes to zero.
Proof
Observe that by the definition of \(\Pi \) and \(A\), and simple Taylor approximation
\(\square \)
Finally turn to the \(Q_{\lambda ^{(N)}}(\rho )\) factor.
Lemma 4.25
Fix any compact subset \(D\subset \mathbb{R }^{N(N+1)/2}\). Then
where the \(o(1)\) error goes uniformly (with respect to \(\{T_{k,i}\}_{1\le i\le k\le N}\in D\)) to zero as \(\epsilon \) goes to zero.
Proof
We employ the torus scalar product (see Sect. 2.1.5) with respect to which the Macdonald polynomials are orthogonal (we keep \(t=0\)):
Note that taking \(t=0\) in equation (2.8) yields
Recalling the definition of \(\Pi \) from equation (2.27) we may write
Let us break up the study of the asymptotics of \(Q\) into a few steps.
-
Step 1: We show that
$$\begin{aligned} \langle P_{\lambda ^{(N)}},P_{\lambda ^{(N)}}\rangle ^{\prime }_N = e^{o(1)}, \end{aligned}$$where the \(o(1)\) error goes (with respect to \(\{T_{k,i}\}_{1\le i\le k\le N}\in D\)) to zero as \(\epsilon \) goes to zero.
Since
and \(q=e^{-\epsilon }\) we find that
Now consider (taking \(b=e^{T_{N,i+1}-T_{N,i} + \epsilon }\))
where the last approximation is valid uniformly for \(b\) bounded (as is our case). Thus, summing the geometric series, we find that
Since \(\log (\langle P_{\lambda ^{(N)}},P_{\lambda ^{(N)}}\rangle ^{\prime }_N) = \sum _{i=1}^{N-1} \log (q^{\lambda ^{(N)}_{i} - \lambda ^{(N)}_{i+1} +1};q)_{\infty }\), the desired result immediately follows.
The next three steps deal with the convergence of the integrand of the torus scalar product, and then the convergence of the integral itself. We introduce the change of variables \(z_j= \exp \{\iota \epsilon \nu _j\}\).
-
Step 2: Fix a compact subset \(V\subset \mathbb{R }^N\). Then
$$\begin{aligned} \Pi (z_1,\ldots , z_N;\rho ) = E_{\Pi } e^{-\tau \sum _{k=1}^{N} \nu _k^2/2} e^{o(1)},\quad E_{\Pi }= e^{\tau N \epsilon ^{-2}} e^{\tau \epsilon ^{-1} \iota \sum _{k=1}^{N} \nu _k}, \end{aligned}$$and
$$\begin{aligned} P_{\lambda ^{(N)}}(z_1,\ldots , z_N)&= E_{P}\psi _{\nu _1,\ldots , \nu _N}(T_{N,1},\ldots , T_{N,N}) e^{o(1)},\quad \\ E_{P}&= \epsilon ^{-\frac{N(N-1)}{2}} e^{-\frac{(N-1)(N+2)}{2}\mathcal{A }(\epsilon )}e^{\tau \epsilon ^{-1}\iota \sum _{k=1}^{N} \nu _k}, \end{aligned}$$where the \(o(1)\) error goes uniformly (with respect to \(\{T_{k,i}\}_{1\le i\le k\le N}\in D\) and \(\{\nu _i\}_{1\le i\le N}\in V\)) to zero as \(\epsilon \) goes to zero.
The \(\Pi \) asymptotics follows just as in the proof of Lemma 4.24. For \(P_{\lambda ^{(N)}}(z_1,\ldots , z_N)\), using the shift property of equation (2.2) for Laurent Macdonald polynomials we may remove the \(\gamma \) factor out of each term of \(\lambda ^{(N)}\) at the cost of introducing the prefactor of \((z_1\cdots z_N)^{\gamma } = e^{\tau \epsilon ^{-1}\iota \sum _{k=1}^{N} \nu _k}\). Theorem 4.7 applies to \(P_{\lambda ^{(N)}-(\gamma ,\ldots , \gamma )}(z_1,\ldots , z_N)\) and allows us to deduce the uniform estimate above (recall Macdonald symmetric functions with \(t=0\) are \(q\)-Whittaker functions with variable and index switched).
-
Step 3: Fix a compact subset \(V\subset \mathbb{R }^N\). Then
$$\begin{aligned} m_N^{q}(z)\prod _{i=1}^{N} \frac{ dz_i}{z_i} = E_m m_N(\underline{\nu }_{N}) \prod _{i=1}^{N} d\nu _i e^{o(1)},\quad E_{m}=\epsilon ^{N^2}e^{N(N-1)\mathcal{A }(\epsilon )}, \end{aligned}$$(4.36)where the \(o(1)\) error goes uniformly (with respect to \(\{\nu _i\}_{1\le i\le N}\in V\)) to zero as \(\epsilon \) goes to zero.
Set \(x=\iota (\nu _j-\nu _i)\), so that \(q^x = z_i z_j^{-1}\). Then recalling the \(q\)-gamma function defined in equation (3.3), we find that the left-hand side of equation (4.36) equals
Note that the term \(\iota (\nu _j-\nu _i)\) can be removed from the exponent of \((1\!-\!q)\) due to cancelation over the full product \(i\!\ne \! j\). Also note that \((q;q)_{\infty } \!=\! e^{\mathcal{A }(\epsilon )} e^{o(1)}\). Lastly, recall that \(\Gamma _q\) converges to \(\Gamma \) as \(\epsilon \!\!\rightarrow \! 0\) uniformly on compact sets bounded from \(\{0,-1,\ldots \}\). Combine these observations we recover the right-hand side of equation (4.36).
-
Step 4: We have
$$\begin{aligned}&\langle \Pi (z_1,\ldots , z_N;\rho ),P_{\lambda }(z_{1},\ldots , z_{N})\rangle ^{\prime }_N \nonumber \\&\quad = \left( e^{\frac{(N-1)(N-2)}{2}\mathcal{A }(\epsilon )} e^{\tau N \epsilon ^{-2}} \epsilon ^{\frac{N(N+1)}{2}}\right) \theta _{\tau }(T_{N,1},\ldots ,T_{N,N}) e^{o(1)}, \end{aligned}$$(4.37)where the \(o(1)\) error goes uniformly (with respect to \(\{T_{k,i}\}_{1\le i\le k\le N}\in D\)) to zero as \(\epsilon \) goes to zero.
Steps 2 and 3 readily show that the integrand of the scalar product on the left-hand side of equation (4.37) converges to the integrand of \(\theta _{\tau }\) on the right-hand side times \(E_{\Pi }\overline{E_{P}} E_m\) (recall that we must take the complex conjugate of \(P_{\lambda }\) and hence also \(E_{P}\)). These three terms combine to equal the prefactor of \(\theta _{\tau }\) above. This convergence, however, is only on compact sets of the integrand variables \(\nu \). In order to conclude convergence of the integrals we must show suitable tail decay for large \(\nu \).
In particular, we need to show that if we define
then
with the limits uniform with respect to \(\{T_{k,i}\}_{1\le i\le k\le N}\in D\).
First consider \(\left| \frac{\Pi (z_1,\ldots , z_N;\rho )}{E_{\Pi }}\right| \). For \(x\in [-\pi ,\pi ], \cos (x)-1 \le -x^2/6\) (this is not sharp but will do). This shows that
for \(\nu _k\in [-\epsilon ^{-1}\pi ,\epsilon ^{-1}\pi ]\) (which are the bounds of integration in \(\nu _k\)). This implies that for all \(\nu _k\in [-\epsilon ^{-1}\pi ,\epsilon ^{-1}\pi ]\),
Turning now to \(\left| \frac{\overline{P_{\lambda ^{(N)}}(z_1,\ldots , z_N)}}{\overline{E_{P}}}\right| \), we see that by applying the first part of Theorem 4.7, this term can be bounded by a constant, uniformly with respect to \(\{T_{k,i}\}_{1\le i\le k\le N}\in D\).
Finally, consider
The prefactors are independent of \(\nu \) and we have already determined that they go to 1 suitably as \(\epsilon \) goes to zero. Thus we can focus entirely on the term \(\frac{1}{\Gamma _{q}(\iota (\nu _j-\nu _i))}\). For this we use the fact that there exist constant \(c,c^{\prime }\) such that for all \(a\in [-2\pi \epsilon ^{-1},2\pi \epsilon ^{-1}]\),
From this inequality, it follows that on the whole domain of integration for the \(\nu _k\in [-\epsilon ^{-1}\pi ,\epsilon ^{-1}\pi ]\) we may bound this part of the integrand by
This growth bound can be compared to the decay bound of equation (4.39). There exists an \(M_0>0\) and \(c^{\prime \prime }>0\) such that for all \(M>M_0\), for \(\nu \in D_M\)
Therefore, on this domain, we have been able to bound our integrand by a constant times \(e^{-c^{\prime }\sum _{k=1}^{N} \nu _k^2}\). Moreover, this bound is uniform in \(\epsilon \) small enough and in \(\{T_{k,i}\}_{1\le i\le k\le N}\in D\). Thus we can take \(\epsilon \) to zero and we are left with an integral which has Gaussian decay in the \(\nu _k\). Therefore, as \(M\rightarrow \infty \), the integrand goes to zero as desired, thus proving equation (4.38) and completing this step of the proof and hence the proof of Lemma 4.25. \(\square \)
Having proved Lemmas 4.23, 4.24 and 4.25 we can combine the three factors along with a Jacobian factor of \(\epsilon ^{-\frac{N(N+1)}{2}}\) which comes from our rescaling of the \(q\)-Whittaker process. Combining these factors, and noting both the cancelation of the prefactors and uniformity of the convergence of each term, we find our desired limit and thus conclude the proof of Theorem 4.21. \(\square \)
Whittaker 2d-growth model
Definition 4.26
Fix \(N\ge 1\), and \(a=(a_1,\ldots , a_N)\in \mathbb{R }^N\). The Whittaker 2d-growth model with drift \(a\) is a continuous time Markov diffusion process \(T(\tau )=\{T_{k,j}(\tau )\}_{1\le j\le k\le N}\) with state space \(\mathbb{R }^{N(N+1)/2}\) and \(\tau \) representing time, which is given by the following system of stochastic (ordinary) differential equations: Let \(\{W_{k,j}\}_{1\le j\le k \le N}\) be a collection of independent standard one-dimensional Brownian motions. The evolution of \(T\) is defined recursively by \(dT_{1,1} = dW_{1,1}+a_1 dt\) and for \(k=2,\ldots , N\),
The Whittaker 2d-growth model coincides with “symmetric dynamics” of [86] Section 9.
Theorem 4.27
Fix \(N\ge 1\), and \(a=(a_1,\ldots , a_N)\in \mathbb{R }^N\). Consider the \(q\)-Whittaker 2d-growth model with drifts \((A_1,\ldots , A_N)\) (Definition 3.28) initialized with \(\lambda ^{(k)}_{j}=0\) for all \(1\le j\le k\le N\). Let \(\lambda ^{(k)}_j(\tau )\) represent the value at time \(\tau \ge 0\) of \(\lambda ^{(k)}_j\). For \(\epsilon >0\) set
Then, for each \(0< \delta \le t, T(\cdot ) = \{T_{k,j}(\cdot )\}_{1\le j\le k\le N}\) converges in the topology of \(C([\delta ,t],\mathbb{R }^{N(N+1)/2})\) (i.e., continuous trajectories in the space of triangular arrays \(\mathbb{R }^{N(N+1)/2}\) with the uniform topology) to the Whittaker 2d-growth model with drift \((-a_1,\ldots ,-a_N)\) and the entrance law for \(\{T_{k,j}(\delta )\}_{1\le j\le k\le N}\) given by the density \(\mathbf{W }_{(a;\delta )}\left( \{T_{k,j}\}_{1\le j\le k\le N}\right) \).
Proof
The entrance law follows immediately from the weak convergence of the \(q\)-Whittaker process to the Whittaker process (i.e., the single time convergence of the 2d-growth processes) which is given by Theorem 4.21. The convergence of the dynamics of the Markov processes follows by induction on the level \(k\) and standard methods of stochastic analysis. \(\square \)
Remark 4.28
Given the Whittaker 2d-growth model dynamics \(T(\tau )\) with drift \((-a_1,\ldots ,-a_N)\) there are two projections which are themselves (i.e., with respect to their own filtration) Markov diffusion processes. It is easy to see that \(\{T_{k,k}\}_{1\le k\le N}\) evolves autonomously of the other coordinates. This is the continuous space limit of the \(q\)-TASEP process.
A less obvious second case is proved in Section 9 of [86]: The projection onto \(\{T_{N,j}(\tau )\}_{1\le j\le N}\) is a Markov diffusion process with entrance law given by the density \(\mathbf{WM }_{(a;\tau )}\left( \{T_{N,j}\}_{1\le j\le N}\right) \), i.e., for \(x=(x_1,\ldots ,x_N)\)
The infinitesimal generator for the diffusion is given by
where \(H\) is the quantum \(\mathfrak{gl }_{n}\)-Toda lattice Hamiltonian
4.1.4 Integral formulas for the Whittaker process
By applying the scalings of Theorem 4.21 we may deduce integral formulas for the Whittaker measure which are analogous to those of Propositions 3.3, 3.5, 3.6 and 3.7.
The limiting form of Proposition 3.3 is the following:
Proposition 4.29
For any \(1\le r\le N\),
where the contours include all the poles of the integrand.
The limiting form of Proposition 3.5 is the following:
Proposition 4.30
For any \(k \ge 1\),
where the \(w_j\)-contour contains \(\{w_{j+1}-1,\cdots ,w_k-1,-a_1,\cdots ,-a_N\}\) and no other singularities for \(j=1,\ldots ,k\).
The limiting form of Proposition 3.6 can be generalized to the following most general moment expectation:
Proposition 4.31
Fix \(k\ge 1, N\ge N_1\ge N_2 \cdots \ge N_k\), and \(1\le r_{\alpha }\le N_{\alpha }\) for \(1\le \alpha \le k\). Then
where the \(w_{\alpha ,j}\)-contour contains \(\{w_{\beta ,i}-1\}\) for all \(i\in \{1,\ldots ,r_{\beta }\}\) and \(\beta >\alpha \), as well as \(\{-a_1,\ldots ,-a_N\}\) and no other singularities.
Remark 4.32
Since the Whittaker measure is supported on all of \(\mathbb{R }^N\), it is clear that the above formulas can not be proved from the weak convergence result of Theorem 4.21. One could attempt to strengthen that result so as to imply the above formulas via a limiting procedure. One can alternatively derive the formulas by developing an analogous (degeneration) theory for Whittaker processes as we have done for Macdonald symmetric functions. After stating and proving the limit of Proposition 3.7 momentarily, we will use this approach to prove Proposition 4.31 (and hence also 4.29 and 4.30). Another rigorous alternative to prove the above results is to pursue the method of replicas. In Part 6 we develop this replica approach which, among other things, gives an independent check of the formula of Proposition 4.30 above.
The methods we develop below in Sect. 4.1.5 allow us to prove integral formulas for joint exponential moments at different times that do not have obvious Macdonald analogs. We will just give one of those here.
Proposition 4.33
Fix \(N\ge 1\) and \(a=(a_1,\ldots , a_N)\in \mathbb{R }^N\). Consider the Whittaker 2d-growth model with drift \(-a\), denoted by \(T(\tau )\) for \(\tau \ge 0\). For times \(\tau _1\le \tau _2\le \cdots \le \tau _k\),
where the \(w_{A}\) contour contains only the poles at \(\{w_B-1\}\) for \(B>A\) as well as \(\{-a_1,\ldots , -a_N\}\), and where the expectation is with respect to the growth model evolution.
Remark 4.34
The proofs of Propositions 4.31 and 4.33 use spectral representations for relevant Markov kernels that were pointed out to us by O’Connell.
The following Proposition is likely to be a limiting form of Proposition 3.7. It is a generalization of [86] Corollary 4.2, and follows in a similar manner.
Proposition 4.35
([86] Corollary 4.2) For any \(u\in \mathbb{C }\) with \(\mathrm{Re }(u)>0\) we have
where the integral is taken over lines parallel to the real axis with \(\mathrm{Im }(\nu _j)<\min _{i=1}^{N}(a_i)\).
4.1.5 Whittaker difference operators and integral formulas
The Macdonald operator of rank \(r\) with \(t=0\) is given by (see Sect. 2.2.3)
Take the limit as in Definition 4.6 – i.e.,
Under this scaling
and
The conclusion is that
Lemma 4.36
([70], 5.3(c)) We have
By orthogonality of Whittaker functions, the following identity holds:
where \(e_I = (\mathbf{1 }_{k\in I})_{k=1,\ldots ,n}\) is the vector with ones in the slots of label \(I\) and zeros otherwise. This identity should be understood in a weak sense, in that it holds when both sides are integrated against \(m_{n}(\lambda )W(\lambda )\) for \(W(\lambda )\) such that
decays super-exponentially in \(x\) and \(W(\lambda )\) is analytic in \(\lambda \) in at least a neighborhood of radius 1 around \(\mathbb{R }^n\).
Remark 4.37
Note that if for \(m\) fixed, \(\lambda = \nu + \iota e_m\) then
This equality agrees with the fact that if we conjugate both sides of (4.43) then \(\lambda \) and \(\nu \) switch places [note that \(m_n(\lambda )\) and \(m_n(\nu )\) are real if we assume that \(\lambda ,\nu \in \mathbb{R }^n\)].
Recall the Baxter operator (4.3) \(Q^{N\rightarrow N-1}_{\kappa }\) which was defined via its integral kernel
where \(x\in \mathbb{R }^N\) and \(y\in \mathbb{R }^{N-1}\). Set
Also, recall that Givental’s integral representation of the Whittaker functions leads to the recursive formula
where \(\lambda =(\lambda _1,\ldots ,\lambda _{N-1})\) and \((\lambda ,\kappa ) = (\lambda _1,\ldots , \lambda _{N-1},\kappa )\). By using the orthogonality of Whittaker functions we obtain from this
Further utilizing the orthogonality we compute the convolutions as
where \(x\in \mathbb{R }^N\) and \(y\in \mathbb{R }^{N-k}\). Also set \(Q^{m\rightarrow m}(x,y) = \delta (x-y)\) for any \(m\ge 1\).
Proof of Proposition 4.31
Recall that by Theorem 4.27, \(T(\tau )\) has an entrance law \(\mathbf{W }_{(a;\tau )}\). The density of the marginal distribution of the Whittaker process \(\mathbf{W }_{(a;\tau )}(\{x^k_j\}_{1\le j\le k \le N})\) restricted to levels \(x^{N_1},\ldots , x^{N_k}\) [(where \(N\ge N_1\ge N_2\ge \cdots \ge N_k\) and \(x^{N_k}=(x^{N_k}_1,\ldots ,x^{N_k}_{N_k})\)] has the form
where \(a^M=(a_1,\ldots , a_M)\). Note that the term above in the large parentheses is just \(\mathbf{WM }_{(a^{N_1};\tau )}\). By canceling \(\psi _{\iota a^j}\) factors and using the spectral representation (4.44) for the Baxter operators, we may rewrite this expression as
Let us multiply this expression by
and integrate over all the \(x\)-variables using (4.43). We start the integration with \(x^{N_k}\), then go to \(x^{N_{k-1}}\) and so on. The decay estimate of Proposition 4.20 is needed at this place to make sure that the integrals converge and that we may apply the identity (4.43). We obtain
Above, the subscript around the parentheses as in \((a^{N_1}+e_{I_2}+\cdots +e_{I_k})_{i_1}\) refers to the \(i_1\) entry of the vector in the parentheses. For a sequence \(b=\{b_1,\ldots ,b_n\}\) and a subset \(J\) of its indices denote
Then we may write
Using the above we may rewrite (4.45) as
The interior sums over \(I_{j}\) have the exact same structure as the sum over \(I_k\) but with \(k\) replaced by \(j\) and the sequence \((a_1,\ldots , a_{N_1})=a^{N_1}\) replaced by \(a^{N_1}+e_{I_{j+1}}+\cdots +e_{I_k}\).
Lemma 4.38
Let \(f(u)\) be an analytic function in a sufficiently large neighborhood of \(x_1,\ldots , x_n\in \mathbb{C }\). Then
where the contours for the \(w_j\) are such that they only include the poles \(w_j=x_m\) for all \(j,m\).
Proof
This follows by a straightforward computation of residues. If different \(w_j\)’s pick the same pole \(x_m\), the contribution is zero because of the Vandermonde factor. There are \(r!\) ways to match \(\{w_1,\ldots , w_r\}\) to \(\{x_i\}_{i\in I}\), thus the \(1/r!\). \(\square \)
Using this lemma we can compute the inner most sum over \(I_1\) in (4.46) taking \(n=N_1, x~=~a^{N_1}+e_{I_2}+\cdots +e_{I_k}\), and \(f(u) = e^{\frac{\tau }{2}u}\). This gives
We now want to do the same summation over \(I_2\) with \(\tilde{n}= N_2, \tilde{x} = a^{N_2}+e_{I_3}+\cdots + e_{I_k}\). Note that
Thus we take
and obtain
where the \(w^{(2)}\) contours contain only \(\tilde{x}_{m_2}\) as poles, while \(w^{(1)}\) contours also contain the poles at points given by \(w^{(2)}+1\). Iterating this procedure shows that (4.46) can be rewritten as
where the \(w^{(\alpha )}_j\) contour contains the poles \(\{a_1,\ldots , a_{N_{\alpha }}\}\) and also the poles \(\{w^{(\beta )}_{i}+1\}\) for all \(i\in ~\{1,\ldots ~r_{\beta }\}\) and \(\beta >\alpha \). Proposition 4.31 follows by taking \(w^{(\alpha )}_i = -w_{\alpha ,i}. \square \)
Proof of Proposition 4.33
The evolution over time \(\tau \) is given by the semi-group [recall Definition (4.41)]
Since \(H\) is diagonalized by \(\{\psi _{b}\}_{b\in \mathbb{R }^N}\) with eigenvalues given by \(H\psi _{b} = (-\sum _{j=1}^{N} b_j^2)\) \(\psi _{b}\) we can write the kernel of the semi-group \(e^{\frac{1}{2}tH}\) as
We will focus on the case \(k=2\) (i.e., the two time case) as the general case follows similarly. The above considerations show that the two-time distribution for our diffusion is
We multiply this expression by \(e^{-x_N-y_N}\) and integrate over \(x,y\in \mathbb{R }^N\). Doing this amounts to computing \(\left\langle e^{-\sum _{i=1}^{2} T_{N,N}(\tau _i)} \right\rangle \) as desired. Using (4.43) we obtain, by first integrating over \(y\) then over \(x\) (the convergence of the integrals is justified by the decay of Proposition 4.20), that \(\left\langle e^{-\sum _{i=1}^{2} T_{N,N}(\tau _i)} \right\rangle \) equals
where the \(w_2\) contour contains \(\{a_1,\ldots , a_N\}\) and the \(w_1\) contour contains \(\{w_2+1,a_1,\ldots ,a_N\}\). \(\square \)
4.1.6 Fredholm determinant formulas for the Whittaker process
Convergence lemmas
We introduce two probability lemmas. The first will be useful when we perform asymptotics on the Whittaker process Fredholm determinant, whereas the second (proved similarly) will be useful presently.
Lemma 4.39
Consider a sequence of functions \(\{f_n\}_{n\ge 1}\) mapping \(\mathbb{R }\rightarrow [0,1]\) such that for each \(n, f_n(x)\) is strictly decreasing in \(x\) with a limit of \(1\) at \(x=-\infty \) and \(0\) at \(x=\infty \), and for each \(\delta >0\), on \(\mathbb{R }\setminus [-\delta ,\delta ] f_n\) converges uniformly to \(\mathbf{1 }(x\le 0)\). Define the \(r\)-shift of \(f_n\) as \(f^r_n(x) = f_n(x-r)\). Consider a sequence of random variables \(X_n\) such that for each \(r\in \mathbb{R }\),
and assume that \(p(r)\) is a continuous probability distribution function. Then \(X_n\) converges weakly in distribution to a random variable \(X\) which is distributed according to \(\mathbb{P }(X\le r) = p(r)\).
Proof
Consider \(s<t<u\). By the conditions on \(f_n\) it follows that for all \(\epsilon >0\) there exists \(n_0>0\) such that for all \(n>n_0\)
The above fact follows from the uniform convergence outside of any fixed interval of the origin. By the convergence of \(\mathbb{E }[f^s_n(X_n)]\rightarrow p(s)\) as \(n\rightarrow \infty \), it follows further that there also exists \(n_1>n_0\) such that for all \(n>n_1\)
This implies that
The above is established for arbitrary \(\epsilon \) and thus
The above is also established for arbitrary \(s<t<u\) and by taking \(s\) and \(u\) to \(t\) it follows that
Since \(p(\cdot )\) is continuous it follows that the left and right bounds are identical, hence
which is exactly as desired. \(\square \)
Lemma 4.40
Consider a sequence of functions \(\{f_n\}_{n\ge 1}\) mapping \(\mathbb{R }\rightarrow [0,1]\) such that for each \(n, f_n(x)\) is strictly decreasing in \(x\) with a limit of \(1\) at \(x=-\infty \) and \(0\) at \(x=\infty \), and \(f_n\) converges uniformly on \(\mathbb{R }\) to \(f\). Consider a sequence of random variables \(X_n\) converging weakly in distribution to \(X\). Then
Proof
Follows from a similar sandwiching approach as above. \(\square \)
Asymptotics of the q-Whittaker process Fredholm determinant formulas
Theorem 4.41
Fix \(0<\delta _2<1\), and \(\delta _1<\delta _2 /2\); also fix \(a_1,\ldots , a_N\) such that \(|a_i|<\delta _1\). Then for all \(u\in \mathbb{C }\) such that \(\mathrm{Re }(u)>0\)
where \(C_a\) is a positively oriented contour containing \(a_1,\ldots , a_N\) and such that for all \(v,v^{\prime }\in C_a, |v-v^{\prime }|~<~\delta _2\). The operator \(K_u\) is defined in terms of its integral kernel
Proof
The proof splits into two pieces. Step 1: We prove that the left-hand side of equation (3.24) of Theorem 3.18 converges to \(\left\langle e^{-u e^{-T_{N,N}}} \right\rangle _{\mathbf{WM }_{(a_1,\ldots ,a_N;\tau )}}\). This relies on combining Theorem 4.21 (which provides weak convergence of the \(q\)-Whittaker process to the Whittaker process) with Lemma 4.40 and the fact that the \(q\)-Laplace transform converges to the usual Laplace transform. Step 2: We prove that the Fredholm determinant expression coming from the right-hand side of Theorem 3.18 converges to the Fredholm determinant given in the theorem we are presently proving. This convergence is done via the Fredholm expansion and uniformly controlled term by term asymptotics.
We scale the parameters of Theorem 3.18 as
-
Step 1: Rewrite the left-hand side of equation (3.24) in Theorem 3.18 as
$$\begin{aligned} \left\langle \frac{1}{\left( \zeta q^{\lambda _N};q\right) _{\infty }}\right\rangle _{\mathbf{MM }_{t=0}(A_1,\ldots ,A_N;\rho )} = \left\langle e_q(x_q)\right\rangle _{\mathbf{MM }_{t=0}(A_1,\ldots ,A_N;\rho )} \end{aligned}$$where
$$\begin{aligned} x_q=(1-q)^{-1}\zeta q^{\lambda _N} =-ue^{-T_N} \epsilon /(1-q) \end{aligned}$$and \(e_q(x)\) is as in Sect. 3.1.1. Combine this with the fact that \(e_q(x)\rightarrow e^{x}\) uniformly on \(x\in ~(-\infty ,0)\) to show that, considered as a function of \(T_N, e_q(x_q)\rightarrow e^{-u e^{-T_N}}\) uniformly for \(T_N\in \mathbb{R }\). By Theorem 4.21, the measure on \(T_N\) (induced from the \(q\)-Whittaker measure on \(\lambda _N\)) converges weakly in distribution to the Whittaker measure \(\mathbf{WM }_{(a_1,\ldots ,a_N;\tau )}\). Combining this weak convergence with the uniform convergence of \(e_q(x_q)\) and Lemma 4.40 gives that
$$\begin{aligned} \left\langle \frac{1}{\left( \zeta q^{\lambda _N};q\right) _{\infty }}\right\rangle _{\mathbf{MM }_{t=0}(A_1,\ldots ,A_N;\rho )} \rightarrow \left\langle e^{-u e^{-T_{N}}} \right\rangle _{\mathbf{WM }_{(a_1,\ldots ,a_N;\tau )}} \end{aligned}$$as \(q\rightarrow 1\) (i.e., \(\epsilon \rightarrow 0\)).
-
Step 2: Recall the kernel in the right-hand side of equation (3.24) in Theorem 3.18. It can be rewritten as a Fredholm determinant of a kernel in \(v\) and \(v^{\prime }\) (recall \(w=q^v\)) as follows
$$\begin{aligned} K^{q}(v,v^{\prime }) = \frac{1}{2\pi \iota }\int _{-\iota \infty + \delta }^{\iota \infty +\delta }h^q(s) ds, \end{aligned}$$where
$$\begin{aligned} h^q(s)&= \Gamma (-s)\Gamma (1+s)\left( \frac{-\zeta }{(1-q)^N}\right) ^s \frac{q^v \log q}{q^s q^v - q^{v^{\prime }}}\\&\times \prod _{m=1}^{N} \frac{\Gamma _q(\log _q(q^v/A_m))}{\Gamma _q(\log _q(q^s q^v/A_m))} \exp \{\gamma q^v(q^{s}-1)\} \end{aligned}$$where the new term \(q^v \log q\) came from the Jacobian of changing \(w\) to \(v\).
Let us first demonstrate the point-wise limit before turning to the necessary uniformity to prove convergence of the Fredholm determinant. Consider the behavior of each term as \(q\rightarrow 1\) (or equivalently as \(\epsilon \rightarrow 0\)):
Combining these point-wise limits together gives the kernel (4.47). However, in order to prove convergence of the determinants, or equivalently the Fredholm expansion series, one needs more than just point-wise convergence.
In fact, we require three lemmas to complete the proof:
Lemma 4.42
Fix any compact subset \(D\) of the interval \(\iota \mathbb{R }+ \delta \). Then the following convergence as \(q\rightarrow 1\) is uniform over all \(s\in D\) and \(v,v^{\prime }\in C_{a}\):
Proof
This strengthened version of the above point-wise convergence follows from the uniform convergence of the \(\Gamma _q\) function to the \(\Gamma \) function on compact regions away from the poles, as well as standard Taylor series estimates. \(\square \)
Lemma 4.43
There exists a constant \(C\) such that for all \(s\in \iota \mathbb{R }+ \delta \), and all \(q\in (1/2,1)\)
Proof
Though not exactly, the left-hand side above is very close to a periodic function of \(\mathrm{Im }(s)\) of fundamental domain \([-\pi \epsilon ^{-1},\pi \epsilon ^{-1}]\). Observe that, as in equation (4.40),
where \(c,c^{\prime }\) are positive constants independent of \(\epsilon \) (or equivalently \(q\)) and \(f^{\epsilon } = \mathrm{dist}(\mathrm{Im }(s),2\pi \epsilon ^{-1} \mathbb{Z })\).
The other terms are periodic in \(s\) of fundamental domain \([-\pi \epsilon ^{-1},\pi \epsilon ^{-1}]\). In order to control their absolute value we look to upper-bound the real part of their logarithm and find that for \(s\in \iota \mathbb{R }+ \delta _2\):
This bound follows from careful Taylor series estimation and the bound that for \(x\in [-\pi ,\pi ], \cos (x)-1\le -x^2/6\). These two bounds shows that
which is easily bounded by a constant for all \(s\). \(\square \)
Lemma 4.44
For all \(q\in (1/2,1), |K^q(v,v^{\prime })|\le C\) for a fixed constant \(C>0\) and all \(v,v^{\prime }\in C_{a}\).
Proof
Combine the tail decay estimate of Lemma 4.43 with the decay in \(s\) [uniform over \(q\in (1/2,1)\) and \(v,v^{\prime }\in C_a\)] of the other terms of the integrand of \(K^{q}(v,v^{\prime })\). This shows that for any constant \(C>0\), there exists another constant \(c>0\) such that for all \(s, |s|>C\) we have \(h^q(s)\le e^{-c|s|}\), uniformly over over \(q\in (1/2,1)\) and \(v,v^{\prime }\in C_a\). By Lemma 4.42, for \(s\) such that \(|s|\le C\), there is uniform convergence to the right-hand side of equation (4.48). Since the right-hand side of equation (4.48) is uniformly bounded in \(s\) and \(v,v^{\prime }\in C_{a}\), it follows that \(h^q(s)\) is likewise bounded on the compact set of \(s\) such that \(|s|\le C\). Combining this with the decay for large \(s\) proves the lemma. \(\square \)
Now combine the lemmas to finish the proof. By Lemma 4.44 and Hadamard’s bound, in order to proof convergence of the Fredholm expansion of \(\det (I+K_{\zeta })\) to \(\det (I+K_{u})\), it suffices to consider only a finite number of terms in the expansion (as the contribution of the later terms can be bounded arbitrarily close to zero by going out far enough in the expansion). By the tail bounds of Lemma 4.43 along with bounds for the other terms (which are uniform in \(q,v,v^{\prime }\)) one shows that the integrals in \(s\) variables in the Fredholm expansion can likewise be restricted to compact sets (as the contribution to the integrals from outside these set can be bounded arbitrarily close to zero by choosing large enough compact sets). Finally, restricted to compact sets, the uniform convergence result of Lemma 4.42 implies convergence of the remaining (compactly supported) integrals as \(q\) goes to 1. This completes the proof of convergence of the Fredholm determinants. \(\square \)
4.1.7 Tracy-Widom asymptotics
In performing steepest descent analysis on Fredholm determinants, the following proposition allows one to deform contours to descent curves.
Lemma 4.45
(Proposition 1 of [108]) Suppose \(s\rightarrow C_s\) is a deformation of closed curves \(C_s\) and a kernel \(L(\eta ,\eta ^{\prime })\) is analytic in a neighborhood of \(C_s\times C_s\subset \mathbb{C }^2\) for each \(s\). Then the Fredholm determinant of \(L\) acting on \(C_s\) is independent of \(s\).
Definition 4.46
The Digamma function \(\Psi (z) = [\log \Gamma ]^{\prime }(z)\). Define for \(\kappa >0\)
and let \({\bar{t}_{\kappa }}\) denote the unique value of \(t\) at which the minimum is achieved. Finally, define the positive number (scaling parameter) \({\bar{g}_{\kappa }}= -\Psi ^{\prime \prime }({\bar{t}_{\kappa }})\).
Theorem 4.47
There exists a \(\kappa ^*>0\) such that for \(\kappa >\kappa ^*\) and \(\tau = \kappa N\)
Remark 4.48
This result should hold for all \(\kappa ^*>0\). However there are certain technical challenges which must be overcome to get the full set of \(\kappa \). At the level of a critical point analysis, the results works equally well for all \(\kappa ^*>0\). The challenge comes in proving the negligibility of integrals away from the critical point. This is accomplished in [20] and the result is shown for all \(\kappa ^*>0\). The law of large numbers with the constant \({\bar{f}_{\kappa }}\) was conjectured in [89] and proved in [82]. A tight one-sided bound on the fluctuation exponent for \(\mathbf{F }^{N}_1(t)\) was determined in [102] Spohn [104] has recently described how the above theorem fits into a general physical KPZ scaling theory.
Proof of Theorem 4.47
The starting point of our proof is the Fredholm determinant formula given in Theorem 4.41 for the expectation of \(e^{-ue^{-T_{N,N}}}\) over Whittaker measure \(\mathbf{WM }_{(0,\ldots ,0;\tau )}\). Consider the function \(f_N(x) = e^{-e^{N^{1/3}x}}\) and define \(f_N^r(x) = f_N(x-r)\). Observe that this sequence of functions meets the criteria of Lemma 4.39. Setting
observe that
By Lemma 4.39, if for each \(r\in \mathbb{R }\) we can prove that
for \(p_{\kappa }(r)\) a continuous probability distribution function, then it will follow that
as well.
In light of the above observations, it remains for us to analyze the asymptotics of the Fredholm determinant formula given in Theorem 4.41 for the case \(a_m\equiv 0\). The result of that theorem is that
where \(C_0\) is positively oriented contour containing \(0\) such that for all \(v,v^{\prime }\in C_{0}, |v-v^{\prime }|<\delta _2\) where \(\delta _2\) is any fixed real number in \((0,1)\). The operator \(K_{u(N,r,\kappa )}\) is defined in terms of its integral kernel via
Let us first provide a critical point derivation of the asymptotics. We will then provide the rigorous proof. Besides standard issues of estimation, we must be very careful about manipulating contours due to a mine-field of poles (this ultimately leads to our present technical limitation that \(\kappa >\kappa ^*\)).
We start by making a change of variables in the integral defining the kernel \(K_{u(N,r,\kappa )}(v,v^{\prime })\). Set \(\zeta = s + v\) and rewrite
where
and where we have also replaced \(\Gamma (-s)\Gamma (1+s) = \pi / \sin (-\pi s)\). The problem is now prime for steepest descent analysis of the integral defining the kernel above.
The idea of steepest descent is to find critical points for the function being exponentiated, and then to deform contours so as to go close to the critical point. The contours should be engineered such that away from the critical point, the real part of the function in the exponential decays and hence as \(N\) gets large, has negligible contribution. This then justifies localizing and rescaling the integration around the critical point. The order of the first non-zero derivative (here third order) determines the rescaling in \(N\) (here \(N^{1/3}\)) which in turn corresponds with the scale of the fluctuations in the problem we are solving. It is exactly this third order nature that accounts for the emergence of Airy functions and hence the Tracy Widom (GUE) distribution.
The critical point equation for \(G\) is given by \(G^{\prime }(z)=0\) where
The Digamma function \(\Psi (z)\) is given in Definition 4.46 as is \({\bar{t}_{\kappa }}\), which clearly satisfies \(G^{\prime }({\bar{t}_{\kappa }}) = 0\) and hence is a critical point. We will Taylor expand around this point \(z={\bar{t}_{\kappa }}\). Consider the second and third derivatives of \(G(z)\):
By the definition of \({\bar{t}_{\kappa }}\) as the argmin of \(\kappa t - \Psi (t)\), it is clear that \(G^{\prime \prime }({\bar{t}_{\kappa }})=0\), and recalling the definition of \({\bar{g}_{\kappa }}\) we have that \(G^{\prime \prime \prime }({\bar{t}_{\kappa }}) = -{\bar{g}_{\kappa }}\). This indicates that near \(z={\bar{t}_{\kappa }}\),
plus lower order terms. This cubic behavior suggests rescaling around \({\bar{t}_{\kappa }}\) by the change of variables
Clearly the steepest descent contour for \(v\) from \({\bar{t}_{\kappa }}\) departs at an angle of \(\pm 2\pi /3\) whereas the contour for \(\zeta \) departs at angle \(\pm \pi /3\). The \(\zeta \) contour must lie to the right of the \(v\) contour (so as to avoid the pole from \(1/(\zeta -v^{\prime })\)). As \(N\) goes to infinity, neglecting the contribution away from the critical point, the point-wise limit of the kernel becomes
where the kernel acts on the contour \(\pm 2\pi / 3\) (oriented from negative imaginary part to positive imaginary part) and the integral in \(\tilde{\zeta }\) is on the contour \(\pm \pi /3 + \delta \) for any \(\delta >0\) (likewise oriented). This is owing to the fact that
where the \(N^{-1/3}\) comes from the Jacobian associated with the change of variables in \(v\) and \(v^{\prime }\).
Another change of variables to rescale by \((\tilde{g}_{\kappa }/2)^{1/3}\) results in
Noting that \(\mathrm{Re }(\tilde{\zeta }-\tilde{v}^{\prime })>0\) we can linearize
This allows us to factor the kernel into the composition of three operators \(ABC\) and by the cyclic nature of the Fredholm determinant, \(\det (I+ABC) = \det (I+CAB)\). This reordering allows us to evaluate the Airy integrations and we find the standard form of the Airy kernel. This shows that the limiting expectation \(p_{\kappa }(r)= F_{\mathrm{GUE}}\left( ({\bar{g}_{\kappa }}/ 2)^{-1/3}r\right) \) which shows that it is a continuous probability distribution function and thus Lemma 4.39 applies. This completes the critical point derivation.
The challenge now is to rigorously prove that \(\det (I+K_{u(N,r,\kappa )})\) converges to \(\det (I+K_{r,\kappa })\) where the two operators act on their respective \(L^2\) spaces and are defined with respect to the kernels above in (4.49) and (4.51). In fact, everything done above following this convergence claim is rigorous.
We will consider the case where \(\kappa >\kappa ^*\) for \(\kappa ^*\) large enough and perform certain estimates given that assumption. Let us record some useful such estimates:
For \(z\) close to zero we also have (\(\gamma \) is the Euler Mascheroni constant \(\sim 0.577\))
Now consider replacing \(z= \kappa ^{-1/2}\tilde{z}\,\):
where the error is uniform for \(\tilde{z}\) in any compact domain and
Our approach will be as follows: Step 1: We will deform the contour \(C_{0}\) on which \(v\) and \(v^{\prime }\) are integrated as well as the contour on which \(\zeta \) is integrated so that they both locally follow the steepest descent curve for \(G(z)\) coming from the critical point \({\bar{t}_{\kappa }}\) and so that along them there is sufficient global decay to ensure that the problem localizes to the vicinity of \({\bar{t}_{\kappa }}\). Step 2: In order to show this desired localization we will use a Taylor series with remainder estimate in a small ball of radius approximately \(1/\sqrt{\kappa }\) around \({\bar{t}_{\kappa }}\), and outside that ball we will use the estimate (4.52) for the \(v\) and \(v^{\prime }\) contour, and a similarly straight-forward estimate for the \(\zeta \) contour. Step 3: Given these estimates we can show convergence of the Fredholm determinants as desired.
-
Step 1: Define the contour \(C_{f}\) which corresponds to a steep (not steepest though) descent contour of the function \(f(\tilde{z})\) leaving \(\tilde{z}=1\) at an angle of \(2\pi /3\) and returning to \(\tilde{z}=1\) at an angle of \(-2\pi /3\), given a positive orientation. In particular we will take \(C_{f}\) to be composed of a line segment from \(\tilde{z}=1\) to \(\tilde{z}=1 + e^{\iota 2\pi /3}\), then a circular arc (centered at 0) going counter-clockwise until \(\tilde{z}=1+e^{-\iota 2\pi /3}\) and then a line segment back to \(\tilde{z}=1\). It is elementary to confirm that along \(C_f, \mathrm{Re }(f)\) achieves its maximal value of 0 at the unique point \(\tilde{z}=1\) and is negative everywhere else.
-
Now we can define the \(v\) contour \(C_{G,\kappa ,c}\) which will serve as our steep descent contour for \(G(v)\) (see Fig. 6). The contour \(C_{G,\kappa ,c}\) starts at \(v={\bar{t}_{\kappa }}\) and departs at an angle of \(2\pi /3 + O(\kappa ^{-1})\) along a straight line of length \(c/\sqrt{\kappa }\) where the angle is chosen so that the endpoint of this line-segment touches the scaled contour \(\kappa ^{-1/2}C_{f}\) given above. The contour then continues along \(\kappa ^{-1/2}C_{f}\). The contour in the lower half plane is defined via reflecting through the real axis. That the error to the angle is \(O(\kappa ^{-1})\) is readily confirmed due to the \(O(\kappa ^{-3/2})\) error between \({\bar{t}_{\kappa }}\) and \(1/\sqrt{\kappa }\). The constant \(c>0\) will be fixed soon as needed for the estimates. One should note that for \(\kappa \) large, the contour \(C_{G,\kappa ,c}\) is such that for \(v\) and \(v^{\prime }\) along it, \(|v-v^{\prime }|<\delta _2\) where \(\delta _2\) can be chosen as any real number in \((0,1)\). By virtue of this fact, we may employ Proposition 4.45 to deform our initial contour \(C_{0}\) (given from Theorem 4.41) to the contour \(C_{G,\kappa ,c}\) without changing the value of the Fredholm determinant.
Fig. 6 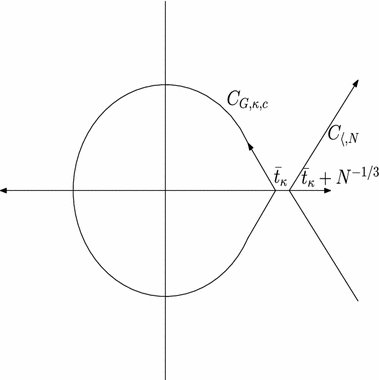
Steep descent contours
-
Likewise, we must deform the contour along which the \(\zeta \) integration in (4.50) is performed. Given that \(v,v^{\prime }\in C_{G,\kappa ,c}\) now, we may again use Proposition 4.45 to deform the \(\zeta \) integration to a contour \(C_{\langle ,N}\) which is defined symmetrically over the real axis by a ray from \({\bar{t}_{\kappa }}+N^{-1/3}\) leaving at an angle of \(\pi /3\) (again, see Fig. 6). It is easy to see that this deformation does not pass any poles, and with ease one confirms that due to the quadratic term in \(G(\zeta )\) the deformation of the infinite contour is justified by suitable decay bounds near infinity between the original and final contours. Thus, the outcome for this first step is that the \(v,v^{\prime }\) contour is now given by \(C_{G,\kappa ,c}\) and the \(\zeta \) contour is now given by \(C_{\langle ,N}\) which is independent of \(v\).
-
Step 2: We will presently provide two types of estimates for our function \(G\) along the specified contours: those valid in a small ball around the critical point and those valid outside the small ball. Let us first focus on the small ball estimate.

Lemma 4.49
There exists a constant \(c\) and \(\kappa ^*>0\) such that for all \(\kappa >\kappa ^*\) the following two facts hold:
-
(1)
There exists a constant \(c^{\prime }>0\) such that for all \(v\) along the line segments of length \(c/\sqrt{\kappa }\) in the contour \(C_{G,\kappa ,c}\):
$$\begin{aligned} \mathrm{Re }\left[ G(\zeta )-G({\bar{t}_{\kappa }})\right] \le \mathrm{Re }\left[ -c^{\prime }\kappa ^{3/2}(v-{\bar{t}_{\kappa }})^3 \right] . \end{aligned}$$ -
(2)
There exists a constant \(c^{\prime }>0\) such that for all \(\zeta \) along the line segments of length \(c/\sqrt{\kappa }\) in the contour \(C_{\langle ,N}\):
$$\begin{aligned} \mathrm{Re }\left[ G(v)-G({\bar{t}_{\kappa }})\right] \ge \mathrm{Re }\left[ -c^{\prime }\kappa ^{3/2}(\zeta -{\bar{t}_{\kappa }})^3 \right] . \end{aligned}$$
Proof
Recall the Taylor expansion remainder estimate for a function \(F(z)\) expanded around \(z^*\),
We may apply this to our function \(G(z)\) around the point \({\bar{t}_{\kappa }}\) giving
As before let \(z=\kappa ^{-1/2}\tilde{z}\) and also let \(w=\kappa ^{-1/2}\tilde{w}\). Note that for \(\kappa \) large,
This implies the key estimate
Both parts of the lemma follow readily from this estimate. \(\square \)
We may now turn to the estimate outside the ball of size \(c/\sqrt{\kappa }\).
Lemma 4.50
For every constant \(c\in (0,1)\) there exists \(\kappa ^*>0\) and \(c^{\prime }>0\) such that for all \(v\) along the circular part of the contour \(C_{G,\kappa ,c}\), the following holds:
Proof
Writing \(v=\kappa ^{-1/2}\tilde{v}\) we may appeal to the estimate (4.52) and the fact that along the circular part of the contour \(C_{G,\kappa ,c}\), the function \(f(\tilde{v})\) is strictly negative and the error in the estimate is \(O(\kappa ^{-1/2})\). \(\square \)
The above bound suffices for the \(v\) contour since it is finite. However, the \(\zeta \) contour is infinite so our estimate must be sufficient to ensure that the contour’s tails do not play a role.
Lemma 4.51
For every constant \(c\in (0,1)\) there exists \(\kappa ^*>0\) and \(c^{\prime }>0\) such that for all \(\zeta \) along the contour \(C_{\langle ,N}\) of distance exceeding \(c/\sqrt{\kappa }\) from \({\bar{t}_{\kappa }}\), the following holds:
Proof
This estimate is best established in three parts. We first estimate for \(\zeta \) between distance \(c/\sqrt{\kappa }\) and distance \(c_1/\sqrt{\kappa }\) from \({\bar{t}_{\kappa }}\) (\(c_1\) large). Second we estimate for \(\zeta \) between distance \(c_1/\sqrt{\kappa }\) and distance \(c_2\) from \({\bar{t}_{\kappa }}\). Finally we estimate for all \(\zeta \) yet further. This third estimate is immediate from the first line of (4.52) in which the quadratic term in \(z\) clearly exceeds the other terms for \(\kappa \) large enough and \(|z|>c_2\).
To make the first estimate we use the bottom line of (4.52). The function \(f(\tilde{z})\) has growth along this contour sufficient to overwhelm the terms \(\gamma \kappa ^{-1/2}(1-\tilde{z}) + O(\kappa ^{-1})\) as long as \(\kappa \) is large enough. The \(O(\kappa ^{-1})\) error in (4.52) is only valid for \(\tilde{z}\) in a compact domain though. So for the second estimate we must use the cruder bound that \(G(z)-G({\bar{t}_{\kappa }}) = f(\tilde{z}) +O(1)\) for \(z\) along the contour and of size less than \(c_2\) from \({\bar{t}_{\kappa }}\). Since in this regime of \(z, f(\tilde{z})\) behaves like \(-\kappa z^2/2\), one sees that for \(\kappa \) large enough, this \(O(1)\) error is overwhelmed and the claimed estimate follows. \(\square \)
-
Step 3: We now employ the estimates given above to conclude that \(\det (I+K_{u(N,r,\kappa )})\) converges to \(\det (I+K_{r,\kappa })\) where the two operators act on their respective \(L^2\) spaces and are defined with respect to the kernels above in (4.49) and (4.51). The approach is standard so we just briefly review what is done. Convergence can either be shown at the level of Fredholm series expansion or trace-class convergence of the operators. Focusing on the Fredholm series expansion, the estimates provided in Step 2, along with Hadamard’s bound show that for any \(\epsilon \), there is a \(k\) large enough such that for all \(N\), the contribution of the terms of the Fredholm series expansion past index \(k\) can be bounded by \(\epsilon \). This localizes the problem of asymptotics to a finite number of integrals involving the kernels. The estimates of Step 2 then show that these integrals can be localized in a large window of size \(N^{-1/3}\) around the critical point \({\bar{t}_{\kappa }}\). The cost of throwing away the portion of the integrals outside this window can be uniformly (in \(N\)) bounded by \(\epsilon \), assuming the window is large enough. Finally, after a change of variables to rescale this window by \(N^{1/3}\) we can use the Taylor series with remainder to show that as \(N\) goes to infinity, the integrals coming from the kernel \(K_{u(N,r,\kappa )}\) converge to those coming from \(K_{r,\kappa }\). This last step is essentially the content of the critical point computation given earlier. \(\square \)
4.2 The \(\alpha \)-Whittaker process limit
4.2.1 Weak convergence to the \(\alpha \)-Whittaker process
We start by defining the \(\alpha \)-Whittaker process and measure as introduced and first studied in [39] in relation to the image of the log-gamma discrete directed polymer under the tropical Robinson-Schensted-Knuth correspondence (see Sect. 5.3).
Definition 4.52
Fix integers \(n\ge N\ge 1\) and vectors \(\alpha = (\alpha _1,\ldots , \alpha _n)\) and \(a=(a_1,\ldots , a_N)\) such that \(\alpha _i>0\) for all \(1\le i\le n\) and \(\alpha _i+a_j>0\) for all combinations of \(1\le i\le n\) and \(1\le j\le N\). Define the \(\alpha \)-Whittaker process as a probability measure on \(\mathbb{R }^{\frac{N(N+1)}{2}}\) with the density function given by
where
Remark 4.53
As explained in Remark 4.17, the difference in appearance between this measure and the Macdonald measure is due to the use of the torus product representation for the Macdonald \(Q\) function. However, since we are dealing with finite pure-alpha specializations for the \(Q\) function, it should be possible to write the \(\alpha \)-Whittaker process in terms of the product of two Whittaker functions. Such a formula when \(N=n\) can be found in [39].
The nonnegativity of the density is not obvious but it does follow from Theorem 4.55 below. To see that the total integral is equal to 1, one first integrates over the variables \(T_{k,i}\) with \(k<N\), which yields the following \(\alpha \)-Whittaker measure
and then over the remaining variables, using the orthogonality of the Whittaker functions.
Remark 4.54
In order to make use of the orthogonality we need to justify the analytic continuation of this relation off the real axis. As in Sect. 4.1.3 this requires strong decay estimates for \(\theta _{\alpha ,n}\) which presently we do not make.
Theorem 4.55
(Modulo decay estimates) In the limit regime
the \(q\)-Whittaker process \(\mathbf{M }_{asc,t=0}(A_1,\ldots ,A_N;\rho )\) with pure alpha specialization \(\rho \) determined by \(\alpha =(\alpha _1,\ldots ,\alpha _n)\) (and \(\gamma =0, \beta _i=0\) for all \(i\ge 0\)) as in equation (2.23), weakly converges to the \(\alpha \)-Whittaker process \({\varvec{\alpha } \mathbf W }_{(a;\alpha ,n)}\bigl (\{T_{k,i}\}_{1\le i\le k\le N}\bigr )\).
Proof, modulo decay estimates
The proof of this result follows along the same lines as the proof of Theorem 4.21. As such, we provide the main steps only, and forgo repeating arguments when they remain unchanged.
As before, recall that by definition
where \(t=0\) in the Macdonald symmetric functions.
It suffices to control the convergence for \(\{T_{k,i}\}\) varying in any given compact set—thus for the rest of the proof fix a compact set for the \(\{T_{k,i}\}\). Again we provide three lemmas which combine to the result. Recall also the notation \(\mathcal{A }(\epsilon ) = -\frac{\pi ^2}{6} \frac{1}{\epsilon } -\frac{1}{2}\log \frac{\epsilon }{2\pi }\).
Let us start by considering the skew Macdonald polynomials with \(t=0\).
Lemma 4.56
Fix any compact subset \(D\subset \mathbb{R }^{N(N+1)/2}\). Then
where the \(o(1)\) error goes uniformly (with respect to \(\{T_{k,i}\}_{1\le i\le k\le N}\in D\)) to zero as \(\epsilon \) goes to zero.
Proof
This is proved exactly as in Lemma 4.23 by making the replacement \(\tau = \epsilon n \log \epsilon ^{-1}\). \(\square \)
Lemma 4.57
We have
where the \(o(1)\) error goes to zero as \(\epsilon \) goes to zero.
Proof
Note that
From the definition of the \(q\)-Gamma function and its convergence to the usual Gamma function as \(q\rightarrow 1\), we have
where the \(o(1)\) term goes to zero as \(\epsilon \) goes to zero. Recalling the scalings we have, and using this convergence, the lemma follows. \(\square \)
Lemma 4.58
(Modulo decay estimate in Step 4) Fix any compact subset \(D\subset \mathbb{R }^{N(N+1)/2}\). Then
where the \(o(1)\) error goes uniformly (with respect to \(\{T_{k,i}\}_{1\le i\le k\le N}\in D\)) to zero as \(\epsilon \) goes to zero.
Proof
We employ the torus scalar product, see Sect. 2.1.5, with respect to which the Macdonald polynomials are orthogonal (we keep \(t=0\)):
Recalling the definition of \(\Pi \) from equation (2.27) we may write
Let us break up the study of the asymptotics of \(Q\) into a few steps. The first three steps follow easily, while the fourth requires a strong decay estimate which we presently do not give.
-
Step 1: Just as in Lemma 4.25
$$\begin{aligned} \langle P_{\lambda ^{(N)}},P_{\lambda ^{(N)}}\rangle ^{\prime }_N = e^{o(1)}, \end{aligned}$$where the \(o(1)\) error goes to zero as \(\epsilon \) goes to zero. The next three steps deal with the convergence of the integrand of the torus scalar product, and then the convergence of the integral itself. We introduce the change of variables \(z_j= \exp \{\iota \epsilon \nu _j\}\).
-
Step 2: Fix a compact subset \(V\subset \mathbb{R }^N\). Then
$$\begin{aligned} \Pi (z_1,\ldots , z_N;\rho ) = E_{\Pi } \prod _{i=1}^{n}\prod _{k=1}^{N} \Gamma ({\alpha }_i - \iota \nu _k)e^{o(1)}, \quad E_{\Pi } = \prod _{i=1}^{n}\prod _{k=1}^{N}\frac{1}{e^{\mathcal{A }(\epsilon )} \epsilon ^{1-{\alpha }_i + \iota \nu _j}}, \end{aligned}$$and
$$\begin{aligned}&P_{\lambda ^{(N)}}(z_1,\ldots , z_N) =E_{P}\psi _{\nu _1,\ldots , \nu _N}(T_{N,1},\ldots , T_{N,N}) e^{o(1)}, \\&\quad E_{P} = \epsilon ^{-\frac{N(N-1)}{2}} e^{-\frac{(N-1)(N+2)}{2}\mathcal{A }(\epsilon )}\epsilon ^{-n\iota \sum _{k=1}^{N} \nu _k}, \end{aligned}$$where the \(o(1)\) error goes uniformly (with respect to \(\{T_{k,i}\}_{1\le i\le k\le N}\in D\) and \(\{\nu _i\}_{1\le i \le N}\in V\)) to zero as \(\epsilon \) goes to zero.
-
Step 3: Fix a compact subset \(V\subset \mathbb{R }^N\). Then
$$\begin{aligned} m_N^{q}(z)\prod _{i=1}^{N} \frac{dz_i}{z_i} = E_{m} m_N(\nu ) \prod _{i=1}^{N} d\nu _i e^{o(1)}, \qquad E_m= \epsilon ^{N^2}e^{N(N-1)\mathcal{A }(\epsilon )} \end{aligned}$$where the \(o(1)\) error goes uniformly (with respect to \(\{\nu \}_{1\le N}\in V\)) to zero as \(\epsilon \) goes to zero.
-
Step 4: We have
$$\begin{aligned}&\langle \Pi (z_1,\ldots , z_N;\rho ),P_{\lambda }(z_{1},\ldots , z_{N})\rangle ^{\prime }_N \nonumber \\&\quad = \left( e^{\frac{(N-1)(N-2)}{2}\mathcal{A }(\epsilon )} \epsilon ^{\frac{N(N+1)}{2}}\prod _{i=1}^{n}\prod _{k=1}^{N}\frac{1}{\epsilon ^{1-\alpha _i}}\right) \theta _{{\alpha },n}(T_{N,1},\ldots ,T_{N,N}) e^{o(1)}\qquad \qquad \end{aligned}$$(4.56)where the \(o(1)\) error goes uniformly (with respect to \(\{T_{k,i}\}_{1\le i\le k\le N}\in D\)) to zero as \(\epsilon \) goes to zero. The proof of this step is involved and relies on precise asymptotic estimates involving the tails of the \(q\)-Whittaker functions. We presently forgo this estimate. Steps 2 and 3 readily show that the integrand of the scalar product on the left-hand side of equation (4.56) converges to the integrand of \(\theta _{\alpha ,n}\) on the right-hand side times \(E_{\Pi }\overline{E_{P}} E_m\) (recall that we must take the complex conjugate of \(P_{\lambda }\) and hence also \(E_{P}\)). These three terms combine to equal the prefactor of \(\theta _{\alpha ,n}\) above. This convergence, however, is only on compact sets of the integrand variables \(\nu \). In order to conclude convergence of the integrals we must show suitable tail decay for large \(\nu \). In particular, the estimate we need to show is that if we define
$$\begin{aligned} V_M = \{(z_1,\ldots , z_N): \forall 1\le k\le N, z_k=e^{\iota \epsilon \nu _k}\quad \mathrm{and }\quad |\nu _k|>M\}, \end{aligned}$$then
$$\begin{aligned} \lim _{M\rightarrow \infty } \lim _{\epsilon \rightarrow 0}\int _{\nu \in V_{M}} \frac{\Pi (z_1,\ldots , z_N;\rho )}{E_{\Pi }} \frac{\overline{P_{\lambda ^{(N)}}(z_1,\ldots , z_N)}}{\overline{E_{P}}} \frac{m_N^q(z)}{E_m} \prod _{i=1}^{N} \frac{ dz_i}{z_i}=0 \end{aligned}$$with the limits uniform with respect to \(\{T_{k,i}\}_{1\le i\le k\le N}\in D\). Such an estimate (which would complete the proof of this lemma) uses the Mellin Barnes integral representation for Whittaker functions in Sect. 4.1.1 and an analogous representation for the \(q\)-Whittaker functions. \(\square \)
We may combine the above lemmas, just as in the proof of Theorem 4.21, to complete the proof Theorem 4.55, modulo the above decay estimates which we do not presently make. \(\square \)
4.2.2 Integral formulas for the \(\alpha \)-Whittaker process
Similarly to Sect. 4.1.4, the moment formulas for the \(q\)-Whittaker processes give rise to moment formulas for the \(\alpha \)-Whittaker processes. The proof of the following statements follows the same path as that for Propositions 4.29, 4.30, 4.31 and use decay noted in Remark 4.54 in replacement of the decay estimate of Proposition 4.20.
Proposition 4.59
(Modulo decay assumption in Remark 4.54) For any \(1\le r\le N\),
where the contours include all the poles of the integrand.
The limiting form of Proposition 3.5 is the following:
Proposition 4.60
(Modulo decay assumption in Remark 4.54) For any \(k \ge 1\),
where the \(w_j\)-contour contains \(\{w_{j+1}-1,\cdots ,w_k-1,-a_1,\cdots ,-a_N\}\) and no other singularities for \(j=1,\ldots ,k\).
The limiting form of Proposition 3.6 is the following:
Proposition 4.61
(Modulo decay assumption in Remark 4.54) Fix \(k\ge 1\) and \(r_{\kappa }\ge 1\) for \(1\le \kappa \le k\). Then
where the \(w_{\kappa _1,j}\)-contour contains \(\{w_{\kappa _2,i}-1\}\) for all \(i\in \{1,\ldots ,r_{\kappa _2}\}\) and \(\kappa _2>\kappa _1\), as well as \(\{-a_1,\ldots ,-a_N\}\) and no other singularities.
A statement similar to Proposition 4.35 and Proposition 3.7 can be found in [39].
4.2.3 Fredholm determinant formulas for the \(\alpha \)-Whittaker process
Let us first write the analog to Theorem 3.18 (which was done for Plancherel specializations) in the case of pure alpha specializations.
Theorem 4.62
Fix \(\rho \) a pure alpha (see Definition 2.3) Macdonald nonnegative specialization determined by positive numbers \(\hat{\alpha }=(\hat{\alpha }_1,\ldots ,\hat{\alpha }_n)\). Fix \(0<\delta <1\) and \(A_1,\ldots , A_N\) such that \(|A_i -1|\le d\) for some constant \(d <\frac{1-q^{\delta }}{1+q^{\delta }}\). Then for all \(\zeta \in \mathbb{C }\setminus \mathbb{R _{+}}\)
where \(C_A\) is a positively oriented circle \(|w-1|=d\) and the operator \(K_{\zeta }\) is defined in terms of its integral kernel
where
The operator \(K_{\zeta }\) is trace-class for all \(\zeta \in \mathbb{C }\setminus \mathbb{R _{+}}\).
Proof
The proof of this result is a straightforward modification of that of Theorem 3.18. \(\square \)
From this we can prove the analog of Theorem 4.41.
Theorem 4.63
(Modulo decay estimates of Theorem 4.55) Recall the conditions of Definition 4.52. Fix \(0<\delta _2<1\), and \(\delta _1<\delta _2 /2\). Fix \(a_1,\ldots , a_N\) such that \(|a_i|<\delta _1\). Then
where \(C_a\) is a positively oriented contour containing \(a_1,\ldots , a_N\) such that for all \(v,v^{\prime }\in C_a, |v-v^{\prime }|<\delta _2\). The operator \(K_u\) is defined in terms of its integral kernel
Proof
The proof of this result is a straightforward modification of that of Theorem 4.41. The proof relies on the weak convergence result of Theorem 4.55 which is proved modulo certain decay estimates. \(\square \)
5 Directed polymer in a random media
5.1 General background
In this section we will focus on a class of models introduced first by Huse and Henley [61] which we will call directed polymers in a random media (DPRM). Such polymers are directed in what is often referred to as a time direction, and then are free to configure themselves in the remaining \(d\) spatial dimensions. The probability of a given configuration of the polymer is then given [relative to an underlying path measure on paths \(\pi (\cdot )\)] as a Radon Nikodym derivative which is often written as a Boltzmann weight involving a Hamiltonian which assigns an energy to the path:
In the above equation \(dP_0\) represents the underlying path measure (which is independent of the Hamiltonian and its randomness). The parameter \(\beta \) is known as the inverse temperature since modifying its value changes the balance between underlying path measure (entropy) and the energetic rewards presented by the disordered or random media in which the path lives. The term \(H_{Q}\) represents the Hamiltonian which assigns an energy to a given path. The subscript \(Q\) stands for quenched which means that this \(H_{Q}(\pi (\cdot ))\) is actually a random function of the disorder \(\omega \) which we think of as an element of a probability space. Finally, \(Z^{\beta }_{Q}\) is the quenched partition function which is defined as necessary to normalize \(dP_{Q}^{\beta }\) as a probability measure:
The measure \(dP_{Q}^{\beta }\) is a quenched polymer measure since it is still random with respect to the randomness of the Hamiltonian \(H_{Q}\). This is to say that \(dP_{Q}^{\beta }\) is also a function of the disorder \(\omega \). We denote averages with respect to the disorder \(\omega \) by \(\langle \cdot \rangle \), so that \(\langle Z^{\beta }_Q\rangle \) represents the averaged value of the partition function. We use \(\mathbb{P }\) for the probability measure for the disorder \(\omega \) and denote the variance with respect to the disorder as \(\mathrm{var}{\cdot }\).
At infinite temperature, \(\beta =0\), and under standard hypotheses on \(dP_0\) (i.e., i.i.d. finite variance increments) the measure \(dP^{\beta }_{Q}(\pi (\cdot ))\) rescales diffusively to that of a Brownian motion and thus the polymer is purely maximizing entropy. At zero temperature, \(\beta =\infty \), the polymer measure concentrates on the path (or paths) \(\pi \) which maximize the polymer energy \(H_Q(\pi )\). A well studied challenge is to understand the effect of quenched disorder at positive \(\beta \) on the behavior of a \(dP^{\beta }_{Q}\)-typical path of the free energy \(F^\beta _{Q}:=\beta ^{-1} \log (Z^{\beta }_Q)\). A rough description of the behaviour is given by the transversal fluctuation exponent \(\xi \) and the longitudinal fluctuation exponent \(\chi \). There are many different ways these exponents have been defined, and it is not at all obvious that they exist for a typical polymer model – though it is believed that they do. As \(n\) goes to infinity, the first exponent describes the fluctuations of the endpoint of the path \(\pi \): typically \(|\pi (n)| \approx n^{\xi }\). The second exponent describes the fluctuations of the free energy: \(\mathrm{var}{F_{\beta ,Q}} \approx n^{2\chi }\). Assuming the existence of these exponents, in order to have a better understanding of the system it is of essential interest to understand the statistics for the properly scaled location of the endpoint and fluctuations of the free energy.
We will now focus entirely on Hamiltonians which take the form of a path integral through a space-time independent noise field. In the discrete setting of \(dP_0\) as SSRW of length \(n\), the noise field can be chosen as IID random variables \(w_{i,x}\) and then \(H_{Q}(\pi (\cdot )) = \sum _{i=0}^{n} w_{i,\pi (i)}\).
The first rigorous mathematical work on directed polymers was by Imbrie and Spencer [62] in 1988 where (by use of an elaborate expansion) they proved that in dimensions \(d\ge 3\) and with small enough \(\beta \), the walk is diffusive (\(\xi =1/2\)). Bolthausen [16] strengthened the result (under same same \(d\ge 3, \beta \) small assumptions) to a central limit theorem for the endpoint of the walk. His work relied on the now fundamental observation that renormalized partition function (for \(dP_0\) a SSRW of length \(n\)) \(W_n=Z^{\beta }_{Q} /\langle Z^{\beta }_Q\rangle \) is a martingale.
By a zero-one law, the limit \(W_\infty =\lim _{n\rightarrow \infty } W_n\) is either almost surely \(0\) or almost surely positive. Since when \(\beta =0\), the limit is 1, the term strong disorder has come to refer to the case of \(W_{\infty }=0\) since then the disordered noise has, indeed, a strong effect. The case \(W_{\infty }>0\) is called weak disorder.
There is a critical value \(\beta _c\) such that weak disorder holds for \(\beta <\beta _c\) and strong for \(\beta >\beta _c\). It is known that \(\beta _c=0\) for \(d\in \{1,2\}\) [35] and \(0<\beta _c\le \infty \) for \(d\ge 3\). In \(d\ge 3\) and weak disorder the walk converges to a Brownian motion, and the limiting diffusion matrix is the same as for standard random walk [36].
On the other hand, in strong disorder it is known (see [35]) that there exist (random) points at which the path \(\pi \) has a positive probability (under \(dP_{Q}^{\beta }\)) of ending. This is certainly different behavior than that of a Brownian motion.
The behavior of directed polymer when restricted to \(d=1\) has drawn significant attention and the scaling exponents \(\xi ,\chi \) and fluctuation statistics are believed to be universal with respect to the underlying path measure and underlying random Hamiltonian. Establishing such universality has proved extremely difficult (see [101] for a review of the progress so far in this direction).
The KPZ universality belief is that in \(d=1\), for all \(\beta >0\) and all distributions for \(w_{i,j}\) (up to certain conjectural conditions on finite moments) the exponents \(\xi =2/3\) and \(\chi =1/3\). A stronger form of this conjecture is that, up to centering and scaling, there exists a unique limit
where \(Z^{\beta }(t,x)\) is the point to point partition function of polymers ending at \(x\) at time \(t\). The operator \(R_{\epsilon }\) is the KPZ renormalization operator and acts on a space-time function as \((R_{\epsilon } f)(t,x) = \epsilon f(\epsilon ^{-3}t,\epsilon ^{-2}x)\) minus the necessary centering. This limit point is described in [41] where it is called the KPZ renormalization fixed point. Information about this fixed point (such as the fact that for a fixed \(t\), it is spatially distributed as an Airy\(_2\) process [94]) has generally come from studying ground-state, or zero temperature models such as last passage percolation, TASEP or PNG (see the review [37]).
It has only been very recently that exactly solvable finite temperature polymer models have been discovered and analyzed. In the following sections we introduce these models, provide background as to what was previously known about their solvability and then demonstrate how the methods developed in this paper enhance the solvability.
5.2 The O’Connell-Yor semi-discrete directed polymer
5.2.1 Definitions and results from [86]
Definition 5.1
An up/right path in \(\mathbb{R }\times \mathbb{Z }\) is an increasing path which either proceeds to the right or jumps up by one unit. For each sequence \(0<s_1<\cdots <s_{N-1}<t\) we can associate an up/right path \(\phi \) from \((0,1)\) to \((t,N)\) which jumps between the points \((s_i,i)\) and \((s_{i},i+1)\), for \(i=1,\ldots , N-1\), and is continuous otherwise. Fix a real vector \(a=(a_1,\ldots , a_N)\) and let \(B(s) = (B_1(s),\ldots , B_N(s))\) for \(s\ge 0\) be independent standard Brownian motions such that \(B_i\) has drift \(a_i\). Define the energy of a path \(\phi \) to be
Then the semi-discrete directed polymer partition function \(\mathbf{Z }^{N}(t)\) is given by
where the integral is with respect to Lebesgue measure on the Euclidean set of all up/right paths \(\phi \) (i.e., the simplex of jumping times \(0<s_1<\cdots <s_{N-1}<t\)). One can introduce the hierarchy of partition functions \(\mathbf{Z }^{N}_{n}(t)\) for \(0\le n\le N\) via \(\mathbf{Z }^{N}_{0}(t)=1\) and for \(n\ge 1\),
where the integral is with respect to the Lebesgue measure on the Euclidean set \(D_n(t)\) of all \(n\)-tuples of non-intersecting (disjoint) up/right paths with initial points \((0,1),\ldots , (0,n)\) and endpoints \((t,N-n+1),\ldots , (t,N)\).
The hierarchy of free energies \(\mathbf{F }^{N}_{n}(t)\) for \(1\le n\le N\) is defined via
The triangular array
can be recognized as being almost surely (path-wise) equal to the trajectories of a certain diffusion Markov process. In order to state this result we define an auxiliary diffusion Markov process
recursively as follows: Let \(d\mathbf{G }^{1}_{1} = d\tilde{B}_1\) and, for \(k=2,\ldots ,N\)
where the \(\tilde{B}_{k}=-B_k\) and \(B_k\) are the independent standard Brownian motions with drifts \(a_k\) which serve as the inputs for the polymer model.
It is shown in [86] that:
Theorem 5.2
Fix \(N\ge 1\) and a vector of drifts \(a=(a_1,\ldots , a_N)\), then:
-
1.
If we define \(\mathbf{G }\) in terms of \(\mathbf{F }\) via
$$\begin{aligned} \left\{ \mathbf{F }^{k}_j(\cdot )\right\} _{1\le j\le k\le N}=\left\{ -\mathbf{G }^{k}_{k-j+1}(\cdot )\right\} _{1\le j\le k\le N} \end{aligned}$$then, almost surely, \(\mathbf{G }\) satisfies the diffusion Markov process defined in (5.1).
-
2.
\(\left\{ \mathbf{G }^N_n(\cdot )\right\} _{1\le n\le N}\) evolves as a diffusion Markov process in \(\mathbb{R }^N\) (with respect to its own filtration) with infinitesimal generator given by
$$\begin{aligned} \mathcal L _{a} = \tfrac{1}{2} \psi _{\iota a}^{-1} \left( H-\sum _{i=1}^{N} a_i^2\right) \psi _{\iota a} = \tfrac{1}{2}\Delta + \nabla \log \psi _{\iota a} \cdot \nabla \end{aligned}$$where \(\psi _{\iota a}(x) = \psi _{\iota a_1,\ldots , \iota a_N}(x_1,\ldots , x_N)\) is the Whittaker functions (see Sect. 4.1.1 and note the difference between the given definition and that of [86]), where \(H\) is the quantum \(\mathfrak{gl }_N\) Toda lattice Hamiltonian
$$\begin{aligned} H=\Delta - 2\sum _{i=1}^{N-1} e^{x_{i+1}-x_i}. \end{aligned}$$The entrance law at time \(t\) for this diffusion is given by the Whittaker measure \(\mathbf{WM }_{(a;t)}\) of (4.30).
-
3.
For each \(t>0\), the conditional law of \(\mathbf{G }(t)=\left\{ \mathbf{G }^{k}_{j}(t)\right\} _{1\le j\le k \le N}\) given
$$\begin{aligned} \left\{ \left\{ \mathbf{G }^{N}_n(s)\right\} _{1\le n\le N}:s\le t, \left\{ \mathbf{G }^{N}_n(t)\right\} _{1\le n\le N} = x\right\} \end{aligned}$$is given by the density
$$\begin{aligned} \psi _{\iota a}(x)^{-1} \exp (\mathcal{F _{\iota a}(\mathbf{G }(t))}). \end{aligned}$$
Remark 5.3
It is useful to note the following symmetry: The transformation \(T_{k,i}\leftrightarrow -T_{k,k+1-i}\) maps \(\mathbf{W }_{(a;\tau )}\) to \(\mathbf{W }_{(-a;\tau )}\) (the sign of \(a_j\)’s changes). This easily follows from the definition of \(\mathbf{W }_{(a;\tau )}\).
Corollary 5.4
Fix \(N\ge 1\) and a vector of drifts \(a=(a_1,\ldots , a_N)\), then \(\mathbf{F }(t)=\left\{ \mathbf{F }^{k}_j(\cdot )\right\} _{1\le j\le k\le N}\) is distributed according to the Whittaker process \(\mathbf{W }_{(-a;t)}\) defined in (4.29).
Remark 5.5
As mentioned in the proof of Proposition 4.18, the above result provides probabilistic means to seeing that the Whittaker measure is a probability measure.
Remark 5.6
As a corollary of the above result and the Bump-Stade identity O’Connell [86] derived a integral formula for the Laplace transform of \(\mathbf{Z }^{N}_{1}(t)\) (see Proposition 4.35). In [23] we proved an identity which shows that this integral formula is equivalent to the Fredholm determinant formula we derived earlier (in the polymer context see in Sect. 5.2.3).
The dynamics given by the coupled stochastic ODEs in (5.1) do not correspond to the Whittaker 2d-growth model given in Sect. 4.1.3. For instance, one readily sees that the dynamics of (5.1) is driven by \(N\) noises, whereas that of the Whittaker 2d-growth model is driven by \(N(N+1)/2\) noises. O’Connell does consider the Whittaker 2d-growth model and refers to it as a “symmetric” version of the dynamics of (5.1)—see Remark 4.28. Restricted to the top level, both processes are Markovian with generator \(\mathcal L \). Also, restricted to the edge of the triangular array, the dynamics of \(\{T^{k}_{k}(\cdot )\}_{1\le k\le N}\) and of \(\{\mathbf{G }^{k}_{k}(\cdot )\}_{1\le k\le N}\) coincide and are both Markov processes. These edge dynamics correspond to the limit of the \(q\)-TASEP process.
5.2.2 Integral formulas
The following result follows from Theorem 5.2 and Proposition 4.29.
Proposition 5.7
Fix \(N\ge 1\) and a drift vector \(a=(a_1,\ldots ,a_N)\). Then for \(1\le r\le N\) and \(t\ge 0\)
where the contours include all the poles of the integrand.
The following result follows from Theorem 5.2 and Proposition 4.30. We give an independent check of this result in Part 6 using the replica approach (see Proposition 6.4).
Proposition 5.8
Fix \(N\ge 1\) and a drift vector \(a=(a_1,\ldots ,a_N)\). Then for \(k\ge 1\) and \(t\ge 0\)
where the \(w_{A}\) contour contains only the poles at \(\{w_B+1\}\) for \(B>A\) as well as \(\{a_1,\ldots , a_N\}\).
The following more general statement follows from Theorem 5.2 and Proposition 4.31.
Proposition 5.9
Fix \(N\ge 1\) and a drift vector \(a=(a_1,\ldots ,a_N)\). Then for \(k\ge 1, r_{\alpha }\ge 1\) for \(1\le \alpha \le k, N\ge N_1\ge N_2\ge \cdots \ge N_k\), and \(t\ge 0\),
where the \(w_{\alpha ,j}\)-contour contains \(\{w_{\beta ,i}+1\}\) for all \(i\in \{1,\ldots ,r_{\beta }\}\) and \(\beta >\alpha \), as well as \(\{a_1,\ldots ,a_N\}\) and no other singularities.
The following result follows from Theorem 5.2 and Proposition 4.33.
Proposition 5.10
Fix \(N\ge 1\) and a drift vector \(a=(a_1,\ldots ,a_N)\). Then for \(k\) time moments \(0\le t_1\le t_2\le \cdots \le t_k\),
where the \(w_{A}\) contour contains only the poles at \(\{w_B+1\}\) for \(B>A\) as well as \(\{a_1,\ldots , a_N\}\).
5.2.3 Fredholm determinant formula
The following result follows from Theorem 4.41, Corollary 5.4 and Remark 5.3.
Theorem 5.11
Fix \(N\ge 1\) and a drift vector \(a=(a_1,\ldots ,a_N)\). Fix \(0<\delta _2<1\), and \(\delta _1<\delta _2 /2\) such that \(|a_i|<\delta _1\). Then for \(t\ge 0\),
where \(C_{a}\) is a positively oriented contour containing \(a_1,\ldots , a_N\) and such that for all \(v,v^{\prime }\in C_{a}\), we have \(|v-v^{\prime }|<\delta _2\). The operator \(K_u\) is defined in terms of its integral kernel
The following result follows from Theorem 5.2 and Theorem 4.47. Recall Definition 4.46.
Theorem 5.12
Fix drifts \(a_i\equiv 0\) and for all \(N\), set \(t=N\kappa \). Then there exists \(\kappa ^*>0\) such that for \(\kappa >\kappa ^*\),
Remark 5.13
This result should hold for all \(\kappa ^*>0\). See Remark 4.48 for further developments achieve this.
5.2.4 Parabolic Anderson model
Consider an infinitesimal generator \(L\) for a continuous time Markov process on \(\mathbb{Z }\) with potential \(V:\mathbb{R _{+}}\times \mathbb{Z }\rightarrow \mathbb{R }\). Then, under fairly general conditions on \(L\) and \(V\), the initial value problem
has a unique solution which can be written via the Feynman-Kac representation as
where \(X(\cdot )\) is a diffusion with infinitesimal generator \(L\) and \(\mathbb{E }_x\) represents the expectation over trajectories of such a diffusion started from \(x\) [34].
This average over paths integrals can be thought of as a polymer (in the potential \(V\)) started at \(x\), ending according to a potential given by \(\log (f(y))\) and evolving according to the underlying path measure given by the Markov process with generator \(L\). When \(f(y)=\delta _{y=j}\) (the Kronecker delta) and \(\tilde{L}\) is the time reversal of \(L\), then there is an alternative representation as
where \(\tilde{\mathbb{E }}_{j}\) is the expectation of the time reversed process \(\tilde{X}\) started at \(j\) at time 0 in time reversed potential \(\tilde{V}(s,i) = \tilde{V}(t-s,i)\). Often it is interesting to consider potentials \(V\) which are random.
The O’Connell-Yor semi-discrete directed polymer partition function \(\mathbf{Z }^{N}(t)\) with drift vector \(\{a_1,\ldots , a_N\}\) fits into this framework. Let the time reversed generator \(\tilde{L}\) be a Poisson jump process \(\tilde{X}(t)\) which increases from \(i\) to \(i+1\) at rate one, let \(f(y)=\delta (y=1)\), and let \(V(s,i) = dW(s,i)+a_i\) where \(dW(\cdot ,i)\) are independent identically distributed 1-dimensional white noises (i.e., distributional derivatives of independent Brownian motions). Let the integral \(\int _0^t V(s,\tilde{X}(s))ds\) be treated as the Itô integral \(\int _0^t dW(s,\tilde{X}(s))\) for a given realization of \(\tilde{X}(s)\). Then the partition function \(\mathbf{Z }^{N}(t)=e^{t} u(t,N)\). The reason for the \(e^t\) factor comes from the fact that a Poisson point process with exactly \(N-1\) jumps on the time interval \([0,t]\) is distributed according to the uniform density \(e^{-t}t^{N-1}/(N-1)!\) on the simplex of jump times \(0<s_1<\cdots <s_{N-1}<t\). This differs by the \(e^t\) factor from the measure we integrated against when defining \(\mathbf{Z }^{N}(t)\).
The symmetric parabolic Anderson model on \(\mathbb{R _{+}}\times \mathbb{Z }\) fits into the same setup but has a generator corresponding to that of a simple symmetric continuous time random walk. The analysis performed in [86] does not seem to extend to this model or to any other generators \(L\) than that of the Poisson jump process described above. However, in Part 6 we will demonstrate a new ansatz for computing polymer moments which applies to some degree to the symmetric parabolic Anderson model as well (cf. Remark 6.6).
5.3 Log-gamma discrete directed polymer
We presently follow the notation of [39].
Definition 5.14
Fix \(N\ge 1\) and a semi-infinite matrix \(d=(d_{ij}: i\ge 1, 1\le j\le N)\) of positive real weights \(d_{ij}\in \mathbb{R }^{>0}\). For each \(n\ge 1\) form the \(n\times N\) matrix \(d^{[1,n]}=(d_{ij}: 1\le i\le n, 1\le j\le N) \). For \(1\le \ell \le k\le N\) let \(\Pi _{n,k}^{\ell }\) denote the set of \(\ell \)-tuples \(\pi =(\pi _1,\ldots , \pi _\ell )\) of non-intersecting lattice paths in \(\mathbb{Z }^2\) such that, for \(1\le r\le \ell , \pi _{r}\) is a lattice path from \((1,r)\) to \((n,k+r-\ell )\). A lattice path only takes unit steps in the coordinate directions between nearest-neighbor lattice points of \(\mathbb{Z }^2\) (i.e., up or right); non-intersecting means that paths do not touch. The weight of an \(\ell \)-tuple \(\pi = (\pi _1,\ldots , \pi _\ell )\) of such paths is
Let us assume \(n\ge N\) (otherwise some additional case must be taken—see [39]). Then for \(1\le \ell \le k\le N\), let
Define the free energy hierarchy \(f(n)=\{f^{k}_{\ell }(n): 1\le \ell \le k\le N\}\) via
We express the mapping (5.2) that defines \(f(n)\) from \(d^{[1,n]}\) as
This corresponds to the tropical P tableaux of the image of \(d^{[1,n]}\) under Kirillov’s tropical Robinson-Schensted-Knuth correspondence [71].
Definition 5.15
Let \(\theta \) be a positive real. A random variable \(X\) has inverse-gamma distribution with parameter \(\theta >0\) if it is supported on the positive reals where it has distribution
We abbreviate this as \(X\sim \Gamma ^{-1}(\theta )\).
Definition 5.16
An inverse-gamma weight matrix, with respect to a parameter matrix \(\gamma =(\gamma _{i,j}>0: i\ge 1, 1\le j\le N)\), is a matrix of positive weights \((d_{i,j}: i\ge 1, 1\le j\le N)\) such that the entries are independent random variables \(d_{i,j}\sim \Gamma ^{-1}(\gamma _{i,j})\). We call a parameter matrix \(\gamma \) solvable if \(\gamma _{i,j} = \hat{\theta }_i+ \theta _j>0\) for real parameters \((\hat{\theta }_i: i\ge 1)\) and \((\theta _j: 1\le j\le N)\). In this case we also refer to the associated weight matrix as solvable.
Remark 5.17
The weights \(d_{i,j}\) can be considered as \(e^{-\tilde{d}_{i,j}}\) where \(\tilde{d}_{i,j}\) are distributed as log-gamma random variables. Since traditionally one identified the distribution of the weights of the Hamiltonian for a directed polymer this is the origin of the name (see [101]).
From now on we will fix that the weight matrix \(d\) is an inverse-gamma weight matrix with a solvable parameter matrix. Analogously to the O’Connell-Yor semi-discrete polymer, the hierarchy \(f(n)\) evolves as a Markov chain in \(n\) with state space in \(\mathbb{R }^{N(N+1)/2}\). An explicit construction of this Markov chain as a function of the weights \(d\) is given in [39] (appealing to the recursive formulation of the tropical RSK correspondence which is given in [85]). We will not restate the kernel of this Markov chain on \(\mathbb{R }^{N(N+1)/2}\), but only remark that it is not the same as the limiting Markov chain which corresponds to the scaling limit of the dynamics given in Proposition 2.23. However, we have the following:
Remark 5.18
The marginal distribution of \(\{f^{N}_{\ell }(n)\}_{1\le \ell \le N}\) is given by the \(\alpha \)-Whittaker measure \({\varvec{\alpha } \mathbf WM }_{(a;\alpha ,n)}\) with \(a_j=\theta _j\) for \(1\le j\le N\) and \(\alpha _i= \hat{\theta }_i\) for \(1\le i\le n\). The formulas given in Sect. 4.2.2 provide formulas for the moments of certain terms in the hierarchy of free energies. The Fredholm determinant formula in Sect. 4.2.3 provides a formula for the expectation of \(\exp (-se^{f^N_N(n)})\). It should be noted that this is not the single path free energy of the model, but rather the free energy for a dual single path polymer model. Remark 2.12, however, provides the necessary formulas which when developed in the manner of this paper should yield a Fredholm determine for \(f^{N}_1(n)\) as well.
5.4 Continuum directed random polymer and Kardar-Parisi-Zhang stochastic PDE
Definition 5.19
O’Connell and Warren introduced the partition function hierarchy for the continuum directed random polymer (CDRP). It is a continuous function \(\mathcal{Z }_{n}(T,X)\) of \((n,T,X)\) varying over \((\mathbb{Z _{>0}},\mathbb{R _{+}},\mathbb{R })\), which is formally written as
where \(\mathbb{E }\) is the expectation of the law on \(n\) independent Brownian bridges \(\{b_i\}_{i=1}^{n}\) starting at \(0\) at time 0 and ending at \(X\) at time \(T\). The \(:\mathrm{exp}:\) is the Wick exponential and \(p(T,X)=(2\pi )^{-1/2}e^{-X^2/T}\) is the standard heat kernel. Intuitively these path integrals represent energies of non-intersecting paths, and thus the expectation of their exponential represents the partition function for this multiple path directed polymer model. The Wick exponential must be carefully defined and one approach to doing this is via Weiner-Itô chaos series: For \(n\in \mathbb{Z _{>0}}, T\ge 0\) and \(X\in \mathbb{R }\) define [88]
where \(\Delta _k(T) = \{0<t_1<\cdots <t_k<T\}\), and \(R_k^{(n)}\) is the \(k\)-point correlation function for a collection of \(n\) non-intersecting Brownian bridges which all start at \(0\) at time \(0\) and end at \(X\) at time \(T\). For notational simplicity set \(\mathcal{Z }_0(T,X)\equiv 1\). These series are convergent in \(L^2(\dot{{\fancyscript{W}}})\). For \(n=1\) one readily observes that the above series satisfies the well-posed stochastic heat equation with multiplicative noise and delta function initial data:
In light of this, the Wick exponential provides a generalization of the Feynman-Kac representation. There are other equivalent approaches to defining the Wick exponential (see [37]).
The entire set of \(\mathcal{Z }_{n}(T,X)\) are almost surely everywhere positive for \(T>0\) fixed as one varies \(n\in \mathbb{Z _{>0}}\) and \(X\in \mathbb{R }\) [38]. Hence it is justified to define, for each \(T>0\) the \(KPZ_T\) line ensemble which is a continuous \(\mathbb{Z _{>0}}\)-indexed line ensemble \(\mathcal{H }^T = \left\{ {\mathcal{H }}^T_{n}\right\} _{n\in \mathbb{Z _{>0}}}: \mathbb{Z _{>0}}\times \mathbb{R }\rightarrow \mathbb{R }\) given by
Taking \(n=1, \mathcal{H }^{T}_1(\cdot )\) is the Hopf-Cole solution to the Kardar-Parisi-Zhang stochastic PDE. Formally, the KPZ stochastic PDE is given by
This is an ill-posed equation—hence its interpretation as the logarithm of the stochastic heat equation. The delta initial data for the stochastic heat equation is called narrow wedge initial data for KPZ.
The CDRP can be thought of in terms of the general directed polymer framework. The CDRP defined corresponds to an underlying path measure of Brownian bridge which starts at \(0\) at time \(0\) and ends at \(X\) at time \(T\), an inverse temperature \(\beta =1\) (\(\beta \) can be scaled into \(T\) in fact) and a quenched Hamiltonian given by
The reason for the Wick exponential is due to the roughness of the potential as well as the Brownian path.
5.4.1 CDRP as a polymer scaling limit
The CDRP occurs as limits of discrete and semi-discrete polymers under what has been called intermediate disorder scaling. This means that the inverse temperature should be scaled to zero in a critical way as the system size scales up. For the discrete directed polymer it was observe independently by Calabrese, Le Doussal and Rosso [33] and by Alberts, Khanin and Quastel [1] that if one scaled \(\beta \) as \(n^{-1/4}\) and the end point of an \(n\)-step simple walk as \(n^{1/2}y\) then the properly scaled partition function converges to CDRP partition function. Using convergence of discrete to continuum chaos series, [2] provide a proof of this result that is universal with respect to the underlying IID random variables which form the random environment (subject to certain moment conditions).
Concerning the O’Connell-Yor semi-discrete directed polymer, a similar approach to that of [2] is used in [81] to prove convergence of the entire partition function hierarchy. Define a scaling coefficient
Then for any \(n\) fixed, consider (for \(N\ge n\)), the scaled partition functions
In the next section we will provide evidence that as \(N\rightarrow \infty \), this rescaled polymer partition function hierarchy converges to that of the CDRP hierarchy \(\mathcal{Z }_n(T,X)\). This evidence is at the level of showing that various moment formulas converge to their analogous CDRP formulas. A proof of the convergence of this collection of space-time stochastic processes will appear in forthcoming work [81].
5.4.2 Integral formulas for the CDRP
The convergence result of [81] mentioned in Sect. 5.4.1 shows that the semi-discrete polymer partition function hierarchy converges weakly to that of the CDRP. This convergence does not imply convergence of moments (though one might attempt to strengthen it). Without reference to the convergence, it is fairly easy to see the scalings under which to take asymptotics of the moment expressions given in Sect. 5.2.2. One can check, after the fact, that these agree with the intermediate disorder scaling of [81] which strongly suggests that these limits provide expressions for the moments of the CDRP hierarchy. By using replica methods we can confirm this fact for some of these formulas.
In what follows we specialized to zero drifts (i.e., \(a_i\equiv 0\)). Analogous formulas can be written down for general drifts.
Proposition 5.20
Fix \(T>0, X\in \mathbb{R }\), and a drift vector \(a=(a_1,\ldots ,a_N)=(0,\ldots , 0)\). Then for \(r\ge ~1\),
where the contours can all be taken to be \(\iota \mathbb{R }\).
Proof
This follows from a simple asymptotic analysis of the formula of Proposition 5.7. Changing variables \(w_j\) to \(-w_j\) and replacing \(\prod _{1\le k\le \ell \le r} (w_k-w_\ell )^2\) by \(\prod _{k\ne \ell }^r (w_k-w_\ell )\) clears the powers of \(-1\). Under the above scaling, \(t=\sqrt{TN}+X\) so that the \(e^{rt/2}\) term cancels the analogous term in the denominator of the left-hand side of (5.10). The function \(e^{tw}/w^N\) which shows up in the integrand can be written as \(e^{tw-N\log w}\). This function \(tw-N\log w\) has a critical point at \(N/t\). Let \(w_c\) correspond to the critical point when \(X=0\), i.e, \(w_c= T^{-1/2} N^{1/2}\). Set \(w=w_c+z\) and observe that
By plugging in the value of \(t\) and \(w_c\), and expanding \(\log (1+z/w_c)\) around \(z/w_c=0\) we find
By deforming the integration contours so as to be \(w_c+\iota \mathbb{R }\) and by standard estimates on the decay of \(tw-N\log w\) away from the critical point along said contours, we find that in the \(N\rightarrow \infty \) limit, we are left with \(e^{\frac{T}{2}z^2+X z}\) (that is after canceling the diverging prefactor with the rest of the denominator on the left-hand side of (5.10)). The only other term left to consider is the Vandermonde determinant, but since it involves differences of variables, it remains unchanged aside for having \(z\)’s substituted for \(w\)’s. This proves the limiting formula. \(\square \)
Remark 5.21
The above limit result along with the scalings of Sect. 5.4.1 suggest the following formula: For \(T>0\) and \(r\ge 1\),
where the contours can all be taken to be \(\iota \mathbb{R }\).
Proposition 5.22
Fix \(T>0, X\in \mathbb{R }\), and a drift vector \(a=(a_1,\ldots ,a_N)=(0,\ldots , 0)\). Then for \(k\ge 1\),
where the \(z_A\)-contour is along \(C_A+\iota \mathbb{R }\) for any \(C_1>C_2+1>C_3+2>\cdots >C_k+(k-1)\).
Proof
This follows immediately from the same type of argument as used in the proof of Proposition 5.20 but with the role of Proposition 5.7 replaced by Proposition 5.8. The only change is that the contours must be ordered correctly in the asymptotics, which introduces the ordering above. \(\square \)
Remark 5.23
In Sect. 6.2 we will prove that the above asymptotics correctly gives the moments of the CDRP suggested by Sect. 5.4.1: for \(T>0\),
where the \(z_A\)-contour is along \(C_A+\iota \mathbb{R }\) for any \(C_1>C_2+1>C_3+2>\cdots >C_k+(k-1)\). Note that the above formula agrees with the fact that \(\mathcal{Z }_n(T,X)/p(T,X)^n\) is a stationary process in \(X\). The stationarity was observed for \(n=1\) in [4] as a result of the invariance of space time white noise under affine shift. This argument extends to general \(n\ge 1\).
Let us work out the \(k=1\) and \(k=2\) formulas explicitly. For \(k=1\), the above formula gives \(\langle \mathcal{Z }_1(T,0)\rangle = (2\pi T)^{-1/2}\) which matches \(p(T,0)\) as on expects. When \(k=2\) we have
where
and where to get from the second to third lines we used that since \(\mathrm{Re }(z_1-z_2-1)>0\) we may use the linearization formula
This formula for \(k=2\) matches formula (2.27) of [14] where it was rigorously proved via local time calculations.
Proposition 5.24
Fix \(T>0, X\in \mathbb{R }\), and a drift vector \(a=(a_1,\ldots ,a_N)=(0,\ldots , 0)\). Then for \(k\ge 1, r_{\alpha }\ge 1\) for \(1\le \alpha \le k\), and \(s_1\le s_2\le \cdots \le s_k\),
where \(N_{\alpha }=(N^{1/2} - s_{\alpha }T^{1/2})^2\) and the \((z_{\alpha ,j}-s_{\alpha })\)-contour is along \(C_{\alpha }+\iota \mathbb{R }\) for any \(C_1>C_2+1>C_3+2>\cdots > C_k+(k-1)\), for all \(j\in \{1,\ldots , r_\alpha \}\).
Proof
Follows by asymptotic analysis along the same lines as the above results using Proposition 5.9. \(\square \)
Remark 5.25
The above limit result along with the scalings of Sect. 5.4.1 suggest the following formula: fix \(T>0\). Then for \(k\ge 1, r_{\alpha }\ge 1\) for \(1\le \alpha \le k\), and \(X_1\le ~X_2\le ~\cdots ~\le ~X_k\),
where the \(z_{\alpha ,j}\)-contour is along \(C_{\alpha }+\iota \mathbb{R }\) for any \(C_1>C_2+1>C_3+2>\cdots > C_k+(k-1)\), for all \(j\in \{1,\ldots , r_\alpha \}\). The moment is, of course, symmetric in the order of the \(X_\alpha \)’s – the integral however, is not (due to the ordering of the contours in the integral).
Proposition 5.26
Fix \(T>0\) and a drift vector \(a=(a_1,\ldots ,a_N)=(0,\ldots , 0)\). Then for \(k\) real numbers \(X_1\le X_2\le \cdots \le X_k\),
where the \(z_{A}\)-contour is along \(C_{A}+\iota \mathbb{R }\) for any \(C_1>C_2+1>C_3+2>\cdots >C_k+(k-1)\).
Proof
Follows by asymptotic analysis along the same lines as the above results using Proposition 5.10. \(\square \)
Remark 5.27
In Sect. 6.2 we will prove that the above asymptotics correctly gives the moments of the CDRP suggested by Sect. 5.4.1: for \(T>0\), and \(X_1\le X_2\le \cdots \le X_k\),
where the \(z_A\)-contour is along \(C_A+\iota \mathbb{R }\) for any \(C_1>C_2+1>C_3+2>\cdots > C_k+(k-1)\).
For example, when \(k=2\) this formula leads to the spatial two point function
or equivalently,
5.4.3 Fredholm determinant formula for the CDRP
We present a critical point asymptotic analysis of our Fredholm determinant formula. The critical scaling makes the analysis more involved and we do not attempt a rigorous proof presently but note that in [20] this derivation is rigorously performed.
Critical point derivation 5.28
Fix \(T>0\) and a drift vector \(a=(a_1,\ldots ,a_N)=(0,\ldots , 0)\). Then, for \(u=s \exp \{-N-\tfrac{1}{2} \sqrt{TN} - \tfrac{1}{2} N \log (T/N)\}\),
where the operator \(K_s\) is defined via is integral kernel
where \(\kappa _T= 2^{-1/3}T^{1/3}\).
Remark 5.29
The above critical point derivation is made rigorous in [20]. Assuming the above result it follows rigorously from the results of [81] explained in Sect. 5.4.1 that
This Laplace transform can be inverted and doing so one recovers the exact solution to the KPZ equation which was simultaneously and independently discovered in [4, 97] and proved rigorously in [4]. Soon after, [33] derived this same Laplace transform through a non-rigorous replica approach. From [4] one can easily provide a rigorous proof of the above stated formula. The \(T/24\) which shows up is the law of large numbers term for the KPZ equation.
Derivation
It may be helpful to the reader to first study the proof of Theorem 4.47, especially the critical point derivation which can be found at the beginning of the proof. The mine-field of poles (coming from the \(\Gamma (-s)\Gamma (1+s)\) term) which one encountered in performing the asymptotics does not get scaled away. In the GUE asymptotics, only the pole at zero remained relevant in the scaling limit. In the present limit the poles at every integer contribute non-trivially in the limit as we will see.
The idea will be to manipulate the kernel of the Fredholm determinant into a form which is good for asymptotics and then to (näively) take those asymptotics, disregarding a plethora of mathematical issues (such as poles and tail decay bounds).
We will start from the formula given by Theorem 5.11 with all \(a_m=0\) and \(u\) as specified in the statement of the result we seek to prove. The first manipulation is to change variables to set \(w=v+s\). This changes the contour of integration for \(s\) to a somewhat odd contour for \(w\). As this is a formal derivation, we will disregard restrictions on how this contour can be deformed and hence not specify it.
Now recall the identity
which, for instance, can be found in [4] page 19. Of course one must restrict the set of \(z\) for which this holds, but again we proceed formally, so let us not. Using this we can rewrite our formula in terms of the kernel
where
Let \(T=\beta ^4\) in what follows. Perform the change of variables \(v=N^{1/2}\tilde{v}\) and likewise for \(v^{\prime }, w\), and \(t\). This yields, after taking into account the effect on the determinant \(L^2\) space,
where
For \(z\) near infinity we have the asymptotics
Plugging in this expansion to our formula for \(G\) it follows that
Observe that \(z\log z + z\log \beta ^2 - \tfrac{\beta ^2}{2}z^2\) has a critical point at \(z=\beta ^{-2}\) at which the second derivative also disappears. Therefore we expand each grouping of terms in \(G(z)\) around this point. Call all order 1 terms \(G_1(z)\), all order \(N^{-1/2}\) terms \(G_2(z)\), and the \(N^{-1}\) term \(G_3(z)\). Observe then that
Now make the change of variables \(\hat{z} = N^{1/2}(z-\beta ^{-2})\) and we find
where
The constant \(c\) can be explicitly written, but is inconsequential as we ultimately have a ratio of \(G\) functions and hence this cancels.
Returning to \(\tilde{K}\) we perform the change of variables \(\hat{w} =N^{1/2}(\tilde{w} - \beta ^{-2})\) and likewise for \(\hat{v}\) and \(\hat{v}^{\prime }\). This yields (after an additional change of variables in the \(t\) integral)
Let us momentarily consider the contours. The \(\hat{w}\) and \(\hat{v}\) contours about should be such that \(\mathrm{Re }(\hat{w}-\hat{v})\in (0,1)\). In the limit we would like them to become infinite lines parallel to the imaginary axis, such that \(\mathrm{Re }(\hat{w}-\hat{v})\in (0,1)\).
Taking stock of what we have done so far, our Laplace transform is given by \(\det (I+\hat{K})\) with the contours and kernels as specified above. Let us no longer write the terms in the exponent which go to zero, and rewrite our kernel without any hats or tildes as
where
If we replace \(w\) by \(w+\tfrac{1}{2}\) and likewise for \(v\) and \(v^{\prime }\) the formula for \(F\) reduces to
so that we get
Since \(\mathrm{Re }(w-v^{\prime })>0\) we can substitute
Inserting this in, we find that the kernel \(\hat{K}\) is given by
This can be factored as \(\hat{K}=ABC\) where
are integral operators given by their kernels
The \(C_{w}\) and \(C_{v}\) represent the contours on which these act.
Now observe that \(\det (I+ABC)=\det (I+BCA)\), where \(BCA(r,r^{\prime })\) acts on \(L^2(0,\infty )\) with kernel
These two interior integrals can be expressed as Airy functions after a change of variables. After recalling that \(T=\beta ^4\), the resulting expression is exactly that of the kernel \(K_{se^{-T/24}}(r,r^{\prime })\). \(\square \)
5.4.4 CDRP directly from \(q\)-TASEP
We present a soft argument for why \(q\)-TASEP should be related to the stochastic heat equation.
Recall that that particles of \(q\)-TASEP evolve according to a Markov chain with the rate of increase of \(x_N\) by 1 equal to \((1-q^{x_{N-1}-x_N-1})\). We assume that initially \(x_1>x_2>\cdots \). Then the update rule will preserve the order. Consider the scaling
In a time interval \(dt= \epsilon ^{-2} d\tau \) (small in the rescaled time \(\tau \) but large in \(q\)-TASEP time \(t\)). Then the change in \(x_N\) over the time interval \(dt\) is equal to the jump rate
that remains approximately constant over \(dt\), multiplied by the number of Poisson jumps over \(dt\). The latter can be thought of as approximately \(\epsilon ^{-2} d\tau + \epsilon ^{-1} (B_N(\tau +d\tau )-B_N(d\tau ))\), where \(B_N\) is a Brownian motion which comes from the limit of the centered Poisson jumps of the clock from particle \(N\). Thus,
Terms of order \(\epsilon ^{-2}\) cancel, and collecting \(\epsilon ^{-1}\) terms gives
or after rearranging and taking \(d\tau \rightarrow 0\),
Note that this equation is satisfied by the O’Connell-Yor partition function by setting \(e^{y_N}(\tau )= \mathbf{Z }^{N}(\tau )\). If we pass to \(\tilde{\mathbf{Z }}^N =e^{-\tau } \mathbf{Z }^N\), which means that \(\tilde{\mathbf{Z }}^N\) is the expectation of Poisson point paths taking \(N-1\) jumps from time 0 to \(\tau \), then
This is a discretized version of the stochastic heat equation with multiplicative noise, and a further limit reproduces the continuum stochastic heat equation.
This also suggests the existence of a microscropic Hopf-Cole transform for \(q\)-TASEP, similar to that of [49] for ASEP. This transform and the analog to the work of [4, 15] will be the subject of a subsequent work.
At this point, however, we would like to figure out the scaling that takes \(q\)-TASEP to the stochastic heat equation. This can be done by studying under what scalings the integral representations for moments of \(q\)-TASEP converge to those for the stochastic heat equation. Recall that \(x_N(t)=\lambda ^{(N)}_N-N\) is the location of particle \(N\) at time \(t\) where initially for \(N\ge 1, x_N(0)=-N\). Let us assume all \(q\)-TASEP speeds \(a_k\equiv 1\).
Proposition 5.30
Consider the following scaling limit of \(q\)-TASEP. Let \(q=e^{-\epsilon }\) and \(\tau := \epsilon ^4 t^2/N\). Let \(\epsilon \rightarrow 0, t\rightarrow \infty \) and \(N\rightarrow \infty \) so that \(\epsilon ^{-2} \ll t\ll \epsilon ^{-3}, N\ll \epsilon ^{-2}\), and \(\tau \) has a limit. Define \(\ell ^{(N)}_N(\tau )\) by
Then for any \(k\ge 0\),
where the \(z_A\)-contour is along \(C_A+\iota \mathbb{R }\) for any \(C_1>C_2+1>C_3+2>\cdots >C_k+(k-1)\). Note that the right-hand side is as in Remark 5.23 or Proposition 6.10 (with all \(x\)’s set to 0).
Proof
We start with Proposition 3.5 which shows
where \(z_j\)-contour contains \(\{qz_{j+1},\ldots ,qz_k,1\}\) and no other singularities, and where
We will perform steepest descent analysis. The exponential function \(F(z)\) has a critical point at \(z_c\) such that \(F^{\prime }(z_c)=0\). This is solved by
With our assumptions we have
whence \(\epsilon \ll 1-z_c \ll 1\). We will deform the contours to form longer (in \(\epsilon \) scale) stretches of vertical lines near \(z_c\) with distance of order \(\epsilon \) between the lines. The standard steepest descent type arguments allow to estimate away the contributions away from \(z_c\). Let us do the change of variables
Note that under this change, \(\frac{dz_j}{z_j}\) goes to \(\frac{\epsilon dw_j}{\epsilon w_j +z_c}\) which behaves like \(\epsilon dw_j\) for \(\epsilon \) small. This account for the \(\epsilon ^{-1}\log \epsilon ^{-1}\) term in the scalings. We have
(where \(\mathrm{lot}\) represents lower order terms) and finally
Hence,
and substituting into the formula for \(\langle q^{k\lambda ^{(N)}_N}\rangle \) and changing the signs of the integration variables \(\{w_j\}\), we obtain the desired relation. \(\square \)
The above proposition provides the time and fluctuation scaling for \(q\)-TASEP to the stochastic heat equation, however it does not give the spatial scaling. For the stochastic heat equation we have joint moments, but not for \(q\)-TASEP, so a similar calculation can not presently be made. The spatial scaling should also come up naturally from the rescaling of the \(q\)-TASEP dynamics (after the microscopic Hopf-Cole transform) necessary to converge to the stochastic heat equation. We pursue this in a subsequent work.
6 Replicas and quantum many body systems
6.1 Replica analysis of semi-discrete directed polymers
6.1.1 The many body system
Consider an infinitesimal generator \(L\) for a continuous time autonomous (time-homogeneous) Markov process on \(\mathbb{Z }\) and independent \(\mathbb{Z }\)-indexed one dimensional white noises \(\{W(\cdot ,i)\}_{i\in \mathbb{Z }}\) where the \(\cdot \) represents time (which varies over \(\mathbb{R _{+}}\)). We can define a directed polymer partition function \(Z_{L,\beta }(t,x)\) as
where \(\delta \) is the Kronecker delta, and the expectation is with respect to the path measure on \(\pi (\cdot )\) given by the trajectories of the continuous Markov process started at 0 with infinitesimal generator given by \(L\). There is a polymer measure for which this is the partition function—it is the reweighting of the above mentioned path measure with respect to the Boltzmann weights given by \(\exp \left\{ \int _{0}^{t} \beta W(s,\pi (s))\right\} \). In Sect. 5.2.4 we saw that, via the Feynman-Kacs representation and time reversal, this provides a solution to an initial value problem \(\partial _t u = L^* u - Vu\) with \(L^*\) the adjoint of \(L\) (resulting from the time-reversal).
Define
where \(\langle \cdot \rangle \) denotes the average with respect to the white noises.
Define \(\Omega ^k_{\vec {x};t}\) to be the set of all \(k\) paths \(\vec {\pi }=\{\pi _i(\cdot )\}_{i=1}^{k}\) which, at time \(t\) are such that \(\pi _i(t)=x_i\) and \(\pi _i(0)=0\) for all \(1\le i\le k\). Denote \(W(s,\vec {\pi }(s)) = \sum _{i=1}^{k} W(s,\pi _i(s))\). Then
The outer integral is with respect to the Lebesgue measure on \(\Omega ^k_{\vec {x};t}\).
Remark 6.1
Any finite range generator \(L\) can be written (possibly, using time homothety) via its action on functions \(f:\mathbb{Z }\rightarrow \mathbb{R }\) as
where \(p_i>0, \sum _{i\in I} p_i=1\), and \(I\) is a finite set such that \(p_i=0\) for \(i\notin I\). These \(p_i\) represent the jump rates of the process from \(x\) to \(x+i\). The adjoint of \(L\) is denoted by \(L^*\) and given by
so that \((Lf,g)\!=\!(f,L^* g)\) where \((f,g) \!=\!\sum _{x\in \mathbb{Z }} f(x)g(x)\). The adjoint generator corresponds to running the process backwards and accounts for the reversal in the jump directions: \(p_i\) is now the jump rates of the process from \(x\) to \(x\!-\!i\). The \(k\)-fold tensor product of the adjoint generator \(L^*\) is defined by its action on functions \(g:\mathbb{Z }^k\!\rightarrow \! \mathbb{R }\) via
The O’Connell-Yor semi-discrete directed polymer corresponds to the generator
whereas the parabolic Anderson model corresponds to the generator
That is to say, in the first case, the continuous time random walk only increases at rate one, whereas in the second case, the continuous time random walk is simple and symmetric.
Remark 6.2
The following result is not new (cf. [34] Theorem 2.3.2) but we include a proof below for completeness.
Proposition 6.3
Assume \(L\) is of the form (6.2). For \(k\ge 1\) and \(\vec {x}\in \mathbb{Z }^k, \bar{Z}_{L,\beta }(\vec {x};t)\) is a solution to the following many-body system:
with \(L^{*,k}\) is the k-fold tensor product of the adjoint of \(L\), subject to the initial condition
and the symmetry condition that \(u(\sigma \vec {x};t) = u(\vec {x};t)\) for any permutation \(\sigma \in S_k\).
Proof
This result relies heavily on the fact that the random environment given by the white noises \(W(\cdot ,i)\) is Gaussian. It is the Gaussian nature of the noise which makes the interaction term \(\sum _{a,b=1}^{K} \delta (x_a-x_b)\) only two-body (i.e., only involving pairs of two variables rather than more). The essence of the proof is to consider a small change in the time and to derive the differential effect of this \(dt\) change on \(\bar{Z}_{L,\beta }(\vec {x};t)\). Since the jumps of \(\pi (\cdot )\) are determined by Poisson events at rates \(p_i\), the probability of multiple jumps is sufficiently unlikely. This makes the analysis easy since we can separately consider the small \(p_i dt\) probability of different jumps, without considering the effect of their joint occurrence.
The symmetry condition is clear. In order to prove the evolution equation, consider the differential increment of time \(dt\) and for simplicity of notation we will now write [recalling the notation \(\Omega ^k_{\vec {x};t}\) introduced after (6.1)]
The set \(A\) represents paths which are at \(\vec {x}\) at time \(t\) and at time \(t+dt\); set \(B\) represents paths at \(\vec {x}\) at time \(t\) but not at time \(t+dt\); and set \(C\) represents paths at \(\vec {x}\) at time \(t+dt\) but not at time \(t\). Observe then that
Therefore
where
Now we use the independence of the intervals of the white-noise as well as the fact that
The first term of the four above can be rewritten as
The last part of the above expression deserves explanation: On the event \(A\), all particles stay in the same place for the time \(dt\). This means that the contribution from the exponential of the integral of the white noise from \(t\) to \(t+dt\) needs to take into account how many particles are at the same place. The contribution we get is the square of this number, summed over all clusters of particles. The above expression in terms of \(\delta (x_a-x_b)\) is conveniently the same as this. This is why Gaussian noise produces two-body interactions, and no more.
Thus, up to an \(O(dt^2)\) correction, the first term is
Turn now to the third term and likewise express it as
Thus
The second term can be expressed as
where \(\vec {x}_{j,i} = (x_1,\ldots , x_{j-1},x_{j}+i,x_{j+1},\ldots ,x_k)\) and \(B_{j,i}\) is the event that \(\vec {\pi }(t) = \vec {x}_{j,i}\) and \(\vec {\pi }(t+dt) = \vec {x}\) (which partitions \(B\) up to an error of \(O(dt^2)\) which comes from two jumps in the interval \(dt\)). Now observe that
due to the fact that up jumps from \(x_j-i\) to \(x_j\) occur at rate \(p_i\) and in a short interval \(dt\) by probability of more than one such jump is \(O(dt^2)\). Therefore we have
where the exponential term also disappeared since it was \(1+O(dt)\). The minus sign in front of \(i\) above is where the adjoint \(L^*\) comes in. Likewise one shows that
Combining \((1)+(2)-(3)-(4)\) shows that
As \(dt\) goes to zero (due to a priori boundedness of \(\bar{Z}_{L,\beta }(\vec {x};t)\)) and hence this converges to the desired relation \(\partial _t \bar{Z}_{L,\beta }(\vec {x};t) = H\bar{Z}_{L,\beta }(\vec {x};t)\), This proves the proposition. \(\square \)
6.1.2 Solving the semi-discrete quantum many body system
Proposition 6.3 gives us a way to check the previously derived formula (5.8) for the \(k\)-th moment of the O’Connell-Yor semi-discrete directed polymer: \(\left\langle \prod _{i=1}^k \mathbf{Z }^{N_i}_{1}(t) \right\rangle \). Observe that for the generator \(L\) in (6.3), and \(\beta =1\)
The reason for the \(e^{-kt}\) factor is that in the definition of \(\bar{Z}_{L,1}(\vec {N};t)\), the averaging is with respect to a Poisson process \(\pi (\cdot )\) whereas in \(\mathbf{Z }^{N_i}_{1}(t)\) the averaging is over the simplex of volume \(t^{N-1}/(N-1)!\), not \(e^{-t}t^{N-1}/(N-1)!\) as the Poisson process dictates.
Inspired by the form of Proposition 5.8 one may write down an ansatz for the solution to the many body problem in Proposition 6.3 which will give us a formula for \(\bar{Z}_{L,1}(\vec {N};t)\).
Proposition 6.4
Fix \(L\) as in (6.3) and \(k\ge 1\). For \(\vec {N}=(N_1,\ldots ,N_k)\) such that \(N_1\ge N_2\ge \cdots \ge N_k\), the following integral solves the many body problem given in Proposition 6.3 but with initial condition given by delta functions at \(1\) rather than 0:
where the \(w_j\)-contour contains \(\{w_{j+1}+1,\cdots ,w_k+1,0\}\) and no other singularities for \(j=1,\ldots ,k\).
Remark 6.5
This integral formula is only valid on the subspace where \(N_1\ge N_2\ge \cdots \ge N_k\) and must be extended outside that subspace by symmetry. Its value when the \(N_j\) are unordered does not give the polymer moment. By taking all of the \(N_j=N\) we recover a proof of Proposition 5.8.
Remark 6.6
One might hope that the solution to the many body system which corresponds to the moments of the general nearest neighbor parabolic Anderson model (continuous time, discrete space) with delta function initial data can also be written in terms of the above ansatz. In [19] this is accomplished for the second moment and thus yields an exact contour integral formula for the second moment.
Proof
We need to check the initial condition and the evolution equation. Let us start with the initial condition. When \(t=0\) the formula gives
The contour for \(w_1\) can be expanded to infinity without crossing any poles except possibly at infinity. If \(N_1=1\) there is a first order pole at infinity for \(w_1\), and for \(N_1>1\) there is no pole. Thus if \(N_1>1, \bar{Z}_{L,1}(\vec {N};0)=0\). This shows \(N_1\le 1\). Likewise, we can collapse \(w_k\) to zero. Doing this we find the \(\bar{Z}_{L,1}(\vec {N};0)=0\) unless \(N_k\ge 1\). Combined this implies \(N_1=\cdots =N_k=1\) gives the only nonzero contribution to \(\bar{Z}_{L,1}\) (which can be checked to equal 1).
We now turn to the proof that the evolution equation is satisfied by this integral formula. Let us first assume all \(N_j\) are distinct. Taking the time derivative of \(\bar{Z}_{L,1}(\vec {N};t)\) we can bring the differentiation inside the integrals to show that
On the other hand, one immediately checks that the effect of applying the discrete derivatives to \(\bar{Z}_{L,1}(\vec {N};t)\) also brings down a factor of \(w_j-1\) for each \(j=1,\ldots , k\). Summing these factors up gives \(w_1+\cdots +w_k - k\). From this we must subtract \(\tfrac{1}{2}k\) due to the fact that the \(k\) of the terms in the delta interaction are 1 (i.e., when \(a=b\)). Thus the effect of applying the Hamiltonian \(H\) to \(\bar{Z}_{L,1}(\vec {N};t)\) is to introduce a factor of \(w_1+\cdots +w_k-\tfrac{k}{2}\) in the integral. This, however, matches with the formula we got from taking a time derivative, and hence implies the evolution equation holds.
When the \(N_j\) are not all distinct, the argument becomes slightly more involved. Assume that the \(N_j\) form several groups within which each \(N_j\) has the same value. Each group can be treated similarly so let us consider the group of \(N_1\): \(N_1=N_2=\cdots = N_m=n\) for some \(1\le m\le k\). We now make a basic observation:
Lemma 6.7
For any \(i=1,\ldots , k-1\), and any function of \(k\) variables \(f(w_1,\ldots , w_k)\) such that \(f(w_1,\ldots , w_i,w_{i+1},\ldots w_k)=f(w_1,\ldots , w_{i+1},w_{i},\ldots w_k)\) (i.e., symmetric in the \(i\) variable),
where the \(w_j\)-contour contains \(\{w_{j+1}+1,\cdots ,w_k+1,0\}\) and no other singularities for \(j=1,\ldots ,k\).
Proof
The \(w_{i}-w_{i+1}-1\) factor cancels with one term in the denominator of the product over \(A<B\). This kills the pole for \(w_{i}\) associated with \(w_{i+1}+1\). This means that we can deform the \(w_i\) contour to the \(w_{i+1}\) contour. We can then relabel to switch the labels of \(w_{i}\) and \(w_{i+1}\). This does not change the value of \(f\) (due to its symmetry). On the other hand, due to the anti-symmetry of the Vandermonde determinant, this results in sign change and nothing more. The upshot of the asymmetry is that this shows that the integral we are considering is equal to its negative, and hence zero. \(\square \)
Applying this lemma, it follows that multiplying the integrand by \(w_{1}+\cdots + w_{m}\) has the same effect as multiplying it by
Multiplication by \(w_m\) is equivalent to reducing one of the number \(N_1,\ldots , N_m\) by one. One the other hand, letting \(\nabla _j f(N) = f(N-1)-f(N)\), one sees that applying \(\nabla _j+1\) for \(1\le j \le m\) also has the effect of reducing one of \(N_1,\ldots , N_m\) by one. Thus, multiplication of the integrand by \((w_1+\cdots + w_m)\) is equivalent to
In addition to the sum \(w_1+\cdots + w_m\), differentiation with respect to \(t\) also introduces an additional \(-\tfrac{m}{2}\) (for each grouping of equal \(N\)’s). Thus we get
Note that for a grouping of size \(m\) of equal \(N\)’s, the term \(\sum _{a,b} \delta (N_a-N_b) = m^2\). Thus, summing these over each grouping of each \(N\)’s we find that this is equivalent to \(H\bar{Z}_{L,1}(\vec {N};t)\), as desired. \(\square \)
6.2 Delta Bose gas and the continuum directed polymer
Let \(\mathbb{W }^{N}=\{x_1<x_2<\cdots <x_N\}\) be the Weyl chamber.
Definition 6.8
A function \(u:\mathbb{W }^{N}\times \mathbb{R _{+}}\rightarrow \mathbb{R }\) solves the delta Bose gas with coupling constant \(\kappa \in \mathbb{R }\) and delta initial data if:
-
For \(x\in \mathbb{W }^{N}\),
$$\begin{aligned} \partial _t u = \tfrac{1}{2}\Delta u, \end{aligned}$$ -
On the boundary of \(\mathbb{W }^{N}\),
$$\begin{aligned} (\partial _{x_{i}}-\partial _{x_{i+1}}-\kappa )u \big \vert _{x_{i+1}=x_{i}+0} = 0, \end{aligned}$$ -
and for any \(f\in L^{2}(\mathbb{W }^{N})\cap C_b(\overline{\mathbb{W }^{N}})\), as \(t\rightarrow 0\)
$$\begin{aligned} N! \int _{\mathbb{W }^{N}} f(x) u(x;t) dx \rightarrow f(0). \end{aligned}$$
When \(\kappa >0\) this is called the attractive case, whereas when \(\kappa <0\) this is the repulsive case. By scaling one can assume \(\kappa =\pm 1\).
Note that the boundary condition is often included in PDE so as to appear as
Remark 6.9
It is widely accepted in the physics literature that the moments of the CDRP correspond to the solution of the attractive delta Bose gas. We will state this correspondence below, but note that we do not know of a rigorous mathematical treatment of this fact. One approach to such a rigorous proof would be to smooth out the white noise in space and then observe that the moments solve the Lieb-Liniger many body problem with smoothed delta potential. It then suffices to prove that the smoothed moments converge to the moments without smoothing and likewise for the solutions to the Lieb-Liniger many body problem. In the case \(N=2\) this is treated in [3], Section I.3.2.
Fix \(N\!\ge \! 1\) and fix \(x\!=\!(x_1,\ldots , x_N)\!\in \! \mathbb{R }^N\). From the above discussion we expect that
solves the attractive delta Bose gas with coupling constant \(\kappa =1\) and delta initial data. This fact can be checked when \(N=1,2\) from [14] as we did in Remark 5.23.
From the moments of the CDRP one might hope to recover the polymer partition function’s distribution function. However, the moments grow far too fast to uniquely characterize the distribution hence no such approach could be mathematically rigorous. The same issue occurs at the level of the O’Connell-Yor polymer. Nevertheless, by summing strongly divergent series coming from moment formulas, [33] and [45] were able to recover the formulas of [4, 97]. In some sense, \(q\)-TASEP provides a regularization of these models at which level the analogous series are convergent and the moment problems are well-posed.
Proposition 6.10
Fix \(N\ge 1\). The solution to the delta Bose gas with coupling constant \(\kappa \in \mathbb{R }\) and delta initial data can be written as
where the \(z_j\)-contour is along \(\alpha _j+\iota \mathbb{R }\) for any \(\alpha _1>\alpha _2+\kappa >\alpha _3+2\kappa >\cdots >\alpha _N+(N-1)\kappa \).
Proof
We will first check the PDE for \(x=(x_1<x_2<\cdots <x_N)\) (i.e., \(x\in \mathbb{W }^{N}\)) and \(t>0\), and then the boundary condition and finally the initial condition. For \(x\in \mathbb{W }^{N}\) we may compute \(\partial _t u(x;t)\) by bring the differentiation inside the \(dz\) integrals (as is justified by the ample Gaussian decay). This has the effect of introducing a new multiplicative factor of \(\tfrac{1}{2}\sum _{j=1}^{N} z_j^2\) in the integrand. Likewise we may compute \(\tfrac{1}{2}\Delta u(x;t)\) by differentiating inside the integral which also leads to a factor of \(\tfrac{1}{2}\sum _{j=1}^{N} z_j^2\) in the integrand. Since the two resulting expressions coincide, the PDE is satisfied.
In order to check the boundary condition observe that if we apply \((\partial _{x_{i}}-\partial _{x_{i+1}}-\kappa )\) to \(u(x;t)\) this introduces a factor of \((z_i-z_{i+1}-\kappa )\) in the integrand and the remaining argument is as in the proof of Lemma 6.7 above.
The initial condition requires a little more work to prove. Fix a function \(f\in L^{2}(\mathbb{W }^{N})\cap ~C_b(\overline{\mathbb{W }^{N}})\), (and set \(f(x)=f(\sigma x)\) for all permutations \(\sigma \in S_N\)) and assume \(t>0\). Compute
where \(\hat{f}(z_1,\ldots ,z_N)\) is the Fourier transform
Observe that
This product can be expanded, and there is a single term which has no denominator and is just \(1\). That term leads to
As there are no poles in \(z_j\) we can deform all contours back to \(\iota \mathbb{R }\) and then take \(t=0\) which results in
This is just the integral of the Fourier transform and therefore equals \(f(0)\). Since we are trying to show that \(\int _{\mathbb{R }^N} f(x) u(x;t) dx \rightarrow f(0)\) as \(t\rightarrow 0\), it now suffices to prove that all of the other terms in the expansion of the product (6.7) have contribution which goes to zero as \(t\rightarrow 0\). We will do this for \(u(x;t)\) directly (rather than its Fourier transform).
Besides the term \(1\) dealt with above, the expansion of (6.7) involves terms
where \(K\) is a non-empty subset of \(\{(A,B): 1\le A<B\le N\}\) and \(k=|K|\). Let \(v=x/||x||\) be the unit vector in the direction of \(x\). Deform the \(z_j\)-contours to lie along \(-t^{-1/2}v_j + \iota \mathbb{R }\) (due to the ordering of coordinates of \(x\) and the Gaussian decay near infinity, this deformation can be made as long as \(t\) is small enough so that no poles are crossed in deforming). Change variables so that \(w_j=t^{1/2}z_j\). Thus
Due to the choice of \(w_j\)-contours, \(\mathrm{Re }(x\cdot w) = -||x||\) and so by taking absolute values we get
Since the integral is now clearly convergent and independent of \(x\) we get
for some constant \(C>0\).
For any function \(f\in L^{2}(\mathbb{W }^{N})\cap C_b(\overline{\mathbb{W }^{N}})\) we may compute the integral against \(u^{K}\). The conditions on \(f\) imply that \(|f(x)|<M\) for some constant \(M\) as \(x\) varies in \(\overline{\mathbb{W }^{N}}\). By the triangle inequality
The second inequality follows by substituting (6.8) and performing the change of variables \(y_i=t^{-1/2} x_i\) in order to bounding the resulting integral (this change of variables results in the cancelation of the \(t^{-N/2}\) term). Observe that since \(k=|K|\ge 1\), as \(t\rightarrow 0\) these terms disappear for all non-empty \(K\). Since these terms account for the other terms in the expansion of the right-hand side of (6.7) this shows that only the delta function coming from the empty \(K\) plays a role as \(t\rightarrow 0\). This completes the proof of the initial conditions. \(\square \)
Remark 6.11
Inserting a symmetric factor \(F(z_1,\ldots ,z_N)\) into the integrand of the right-hand side of (6.6) preserves the evolution equation and boundary condition, but leads to different initial conditions.
Remark 6.12
One should note that the above proposition deals with both the \(\kappa >0\) (attractive) and \(\kappa <0\) (repulsive) delta Bose gas. Looking in the arguments of Section 4 of [59] (where they were proving the Plancherel theory for the delta Bose gas) it is possible to extract the formula of the above proposition. This type of formula reveals a symmetry between the two cases which is not present in the Bethe Ansatz eigenfunctions.
An alternative and much earlier taken approach to solving the delta Bose gas is by demonstrating a complete basis of eigenfunctions (and normalizations) which diagonalize the Hamiltonian and respect the boundary condition. The eigenfunctions were written down in 1963 for the repulsive delta interaction by Lieb and Liniger [75] by Bethe ansatz. Completeness was proved by Dorlas [44] on \([0,1]\) and by Heckman and Opdam [59] and then recently by Prolhac and Spohn (using formulas of Tracy and Widom [110]) on \(\mathbb{R }\) (as we are considering presently). For the attractive case, McGuire [80] wrote the eigenfunctions in terms of string states in 1964. As opposed to the repulsive case, the attractive case eigenfunctions are much more involved and are not limited to bound state eigenfunctions (hence a lack of symmetry with respect to the eigenfunctions). The norms of these states were not derived until 2007 in [32] using ideas of algebraic Bethe ansatz. Dotsenko [45] later worked these norms out very explicitly through combinatorial means. Completeness in the attractive case was shown by Oxford [93], and then by Heckman and Opdam [59], and recently by Prolhac and Spohn [95].
The work [33, 45, 75, 95, 110] provide formulas for the propagators (i.e., transition probabilities) for the delta Bose gas with general initial data. These formulas involve either summations over eigenstates or over the permutation group. In the repulsive case it is fairly easy to see how the formula of Proposition 6.10 is recovered from these formulas.
Remark 6.13
The reason why the symmetry which is apparent in Proposition 6.10 is lost in the eigenfunction expansion is due to the constraint on the contours. In the repulsive case \(\kappa <0\) and the contours are given by having the \(z_j\)-contour along \(\alpha _j+\iota \mathbb{R }\) for any \(\alpha _1>\alpha _2+\kappa >\alpha _3+2\kappa >\cdots >\alpha _N+(N-1)\kappa \). The contours, therefore, can be taken to be all the same. It is a straight-forward calculation to turn the Bethe ansatz eigenfunction expansion into the contour integral formula we provide. The attractive case leads to contours which are not the same. In making the contours coincide we encounter a sizable number of poles which introduces many new terms which coincide with the fact that there are many other eigenfunctions coming from the Bethe ansatz in this case.
For the attractive case, the following proposition (which is a degeneration of Proposition 3.8 and can be proved similarly) provides a way to turn the moment formula of Proposition 6.10 into the formula given explicitly in Dotsenko’s work [45].
Proposition 6.14
For an entire function \(f(z)\) and \(k\ge 1\), setting
we have
where the \(z_j\)-contour is along \(\alpha _j+\iota \mathbb{R }\) for any \(\alpha _1>\alpha _2+1>\alpha _3+2>\cdots >\alpha _k+(k-1)\)
Remark 6.15
The contour integral formulas used to solve the quantum many body systems in Proposition 6.10 and Proposition 6.4 should be understood as coming about from a more general contour integral ansatz. The correspondence is as follows. Consider a many body system which evolves in a Weyl chamber according to a certain PDE and has delta function initial condition. Assume it also has a boundary condition on the boundary of the Weyl chamber involving consecutively labeled particles. Then an ansatz for the solution is an \(N\)-dimensional contour integral in \(z_1,\ldots , z_N\) which involves three terms. The first term is \(\exp (z\cdot x)\); the second term is the exponential of the Fourier transform of the PDE generator applied to \(z\); the third term is a product for \(1\le A<B\le N\) of \((z_A-z_B)\) divided by a term which is chosen to cancel for \(i, i+1\) when the corresponding boundary condition is checked.
References
Alberts, T., Khanin, K., Quastel, J.: The intermediate disorder regime for directed polymers in dimension \(1+1\). Phys. Rev. Lett. 105, 090603 (2010)
Alberts, T., Khanin, K., Quastel, J.: Intermediate disorder regime for \(1+1\) dimensional directed polymers. arXiv:1202.4398
Albeverio, S., Gesztesy, F., Høegh-Krohn, R., Holden, H.: Solvable models in quantum mechanics, 2nd edn. AMS, Providence (2005)
Amir, G., Corwin, I., Quastel, J.: Probability distribution of the free energy of the continuum directed random polymer in \(1+1\) dimensions. Commun. Pure Appl. Math. 64, 466–537 (2011)
Andjel, E.D.: Invariant measures for the zero range process. Ann. Probab. 10, 525–547 (1982)
Andrews, G., Askey, R., Roy, R.: Special functions. Cambridge University Press, Cambridge (2000)
Awata, H., Odake, S., Shiraishi, J.: Integral representations of the Macdonald symmetric functions. Commun. Math. Phys. 179, 666–747 (1996)
Baik, J., Ben Arous, G., Péché, S.: Phase transition of the largest eigenvalue for non-null complex sample covariance matrices. Ann. Probab. 33, 1643–1697 (2005)
Balázs, M., Quastel, J., Seppäläinen, T.: Scaling exponent for the Hopf-Cole solution of KPZ/stochastic Burgers. J. Am. Math. Soc. 24, 683–708 (2011)
Balazs, M., Seppalainen, T.: Order of current variance and diffusivity in the asymmetric simple exclusion process. Ann. Math. 171, 1237–1265 (2010)
Balázs, M., Komjáthy, J., Seppäläinen, T.: Microscopic concavity and fluctuation bounds in a class of deposition processes. Ann. Inst. H. Poincaré B 48, 151–187 (2012)
Bangerezako, G.: An introduction to q-difference equations. http://perso.uclouvain.be/alphonse.magnus/gbang/qbook712.pdf. Accessed Oct 2011
Betea, D.: Elliptically distributed lozenge tilings of a hexagon. arXiv:1110.4176
Bertini, L., Cancrini, N.: The stochastic heat equation: Feynman-Kac formula and intermittence. J. Stat. Phys. 78, 1377–1401 (1995)
Bertini, L., Giacomin, G.: Stochastic Burgers and KPZ equations from particle systems. Commun. Math. Phys. 183, 571–607 (1997)
Bolthausen, E.: A note on diffusion of directed polymers in a random environment. Commun. Math. Phys. 123, 529–534 (1989)
Bornemann, F.: On the numerical evaluation of Fredholm determinants. Math. Comp. 79, 871–915 (2010)
Borodin, A.: Schur dynamics of the Schur processes. Adv. Math. 228, 2268–2291 (2011)
Borodin, A., Corwin, I.: On moments of the parabolic Anderson model. arXiv:1211.7125
Borodin, A., Corwin, I., Ferrari, P.L.: Free energy fluctuations for directed polymers in random media in \(1+1\) dimension. arXiv:1204.1024
Borodin, A., Corwin, I., Gorin, V., Shakirov, S.: (2013)
Borodin, A., Corwin, I., Ferrari, P.L., Veto, B.: (2013)
Borodin, A., Corwin, I., Remenik, D.: Log-Gamma polymer free energy fluctuations via a Fredholm determinant, identity. arXiv:1206.4573
Borodin, A., Corwin, I., Sasamoto, T.: From duality to determinants for q-TASEP and ASEP. arXiv:1207.5035
Borodin, A., Duits, M.: Limits of determinantal processes near a tacnode. Ann. Inst. H. Poincare B 47, 243–258 (2011)
Borodin, A., Ferrari, P.L.: Anisotropic growth of random surfaces in \(2+1\) dimensions. arXiv:0804.3035
Borodin, A., Gorin, V.: Markov processes of infinitely many nonintersecting random walks. Probab. Theory Relat. Fields. doi:10.1007/s00440-012-0417-4 (2013)
Borodin, A., Gorin, V.: Shuffling algorithm for boxed plane partitions. Adv. Math. 220, 1739–1770 (2009)
Borodin, A., Kuan, J.: Random surface growth with a wall and Plancherel measures for O(infinity). Commun. Pure Appl. Math. 63, 831–894 (2010)
Borodin, A., Olshanski, G.: Markov processes on the path space of the Gelfand-Tsetlin graph and on its boundary. arXiv:1009.2029
Borodin, A., Rains, E.: Eynard-Mehta theorem, Schur process, and their Pfaffian analogs. J. Stat. Phys. 121, 291–317 (2005)
Calabrese, P., Caux, J.S.: Dynamics of the attractive 1D Bose gas: analytical treatment from integrability. J. Stat. Mech. P08032 (2007)
Calabrese, P., Le Doussal, P., Rosso, A.: Free-energy distribution of the directed polymer at high temperature. Euro. Phys. Lett. 90, 20002 (2010)
Carmona, R., Molchanov, S.: Parabolic Anderson problem and intermittency. Memoirs of AMS, vol. 518 (1994)
Comets, F., Shiga, T., Yoshida, N.: Probabilistic analysis of directed polymers in a random environment: a review. In: Funaki, T., Osada, H. (eds.) Stochastic Analysis on Large Scale Interacting Systems, pp. 115–142. Math. Soc. Japan, Tokyo (2004)
Comets, F., Yoshida, N.: Directed polymers in random environment are diffusive at weak disorder. Ann. Probab. 5, 1746–1770 (2006)
Corwin, I.: The Kardar-Parisi-Zhang equation and universality class. arXiv:1106.1596
Corwin, I., Hammond, A.: The H-Brownian Gibbs property of the KPZ line ensemble (2013)
Corwin, I., O’Connell, N., Seppäläinen, T., Zygouras, N.: Tropical combinatorics and Whittaker functions. arXiv:1110.3489
Corwin, I., Quastel, J.: Crossover distributions at the edge of the rarefaction fan. Ann. Probab. (to appear)
Corwin, I., Quastel, J.: Renormalization fixed point of the KPZ universality class. arXiv:1103.3422
De Masi, A., Presutti, E., Spohn, H., Wick, W.D.: Asymptotic equivalence of fluctuation fields for reversible exclusion processes with speed change. Ann. Probab. 14, 409–423 (1986)
Diaconis, P., Fill, J.A.: Strong stationary times via a new form of duality. Ann. Probab. 18, 1483–1522 (1990)
Dorlas, T.C.: Orthogonality and completeness of the Bethe ansatz eigenstates of the nonlinear Schroedinger model. Comm. Math. Phys. 154, 347–376 (1993)
Dotsenko, V.: Bethe ansatz derivation of the Tracy-Widom distribution for one-dimensional directed polymers. Euro. Phys. Lett. 90, 20003 (2010)
Etingof, P.: Whittaker functions on quantum groups and q-deformed Toda operators. Amer. Math. Soc. Transl. Ser.2, vol. 194, pp. 9–25. AMS, Providence (1999)
Forrester, P.J.: The spectrum edge of random matrix ensembles. Nucl. Phys. B 402, 709–728 (1993)
Forrester, P.J., Rains, E.: Interpretations of some parameter dependent generalizations of classical matrix ensembles. Probab. Theo. Rel. Fields 131, 1–61 (2005)
Gärtner, J.: Convergence towards Burgers equation and propagation of chaos for weakly asymmetric exclusion process. Stoch. Proc. Appl. 27, 233–260 (1988)
Gerasimov, A., Kharchev, S., Lebedev, D., Oblezin, S.: On a Gauss-Givental representation for quantum Toda chain wave function. Int. Math. Res. Notices 96489 (2006)
Gerasimov, A., Lebedev, D., Oblezin, S.: On a classical limit of q-deformed Whittaker functions. arXiv:1101.4567
Gerasimov, A., Lebedev, D., Oblezin, S.: Baxter operator and Archimedean Hecke algebra. Commun. Math. Phys. 284, 867–896 (2008)
Gerasimov, A., Lebedev, D., Oblezin, S.: On q-deformed \({\mathfrak{gl}}_{\ell +1}\)-Whittaker function I. Commun. Math. Phys. 294, 97–119 (2010)
Gerasimov, A., Lebedev, D., Oblezin, S.: On q-deformed \({\mathfrak{gl}}_{\ell +1}\)-Whittaker function III arXiv:0805.3754
Givental, A.: Stationary phase integrals, quantum Toda lattices, flag manifolds and the mirror conjecture. Topics in Singularity Theory., AMS Transl. Ser. 2, vol. 180, pp. 103–115, AMS, Providence (1997)
Gohberg, I.C., Krein, M.G.: Introduction to the theory of linear nonselfadjoint operators in Hilbert space. AMS Transl. (1969)
Hahn, W.: Beiträge zur Theorie der Heineschen Reihen. Die 24 Integrale der hypergeometrischen q-Differenzengleichung. Das q-Analogon der Laplace-Transformation. Mathematische Nachrichten 2, 340–379 (1949)
Harris, T.E.: Additive set-valued Markov processes and graphical methods. Ann. Probab. 6, 355–378 (1978)
Heckman, G.J., Opdam, E.M.: Yang’s system of particles and Hecke algebras. Ann. Math. 145, 139–173 (1997)
Hille, E.: Analytic function theory, vol. II. Giin and Co., Chelsea New York (1977). Republished
Huse, D.A., Henley, C.L.: Pinning and roughening of domain walls in Ising systems due to random impurities. Phys. Rev. Lett. 54, 2708–2711 (1985)
Imbrie, J.Z., Spencer, T.: Diffusion of directed polymers in a random environment. J. Stat. Phys. 52, 609–626 (1988)
Ishii, T., Stade, E.: New formulas for Whittaker functions on \(GL(n, \mathbb{R})\). J. Funct. Anal. 244, 289–314 (2007)
Johansson, K.: Shape fluctuations and random matrices. Commun. Math. Phys. 209, 437–476 (2000)
Johansson, K.: Random growth and random matrices. European Congress of Mathematics, vol. I (Barcelona, 2000), 445–456, Progr. Math., vol. 201, Birkhäuser, Basel (2001)
Kardar, M.: Replica-Bethe Ansatz studies of two-dimensional interfaces with quenched random impurities. Nucl. Phys. B 290, 582–602 (1987)
Kardar, K., Parisi, G., Zhang, Y.Z.: Dynamic scaling of growing interfaces. Phys. Rev. Lett. 56, 889–892 (1986)
Kerov, S.: Asymptotic representation theory of the symmetric group and its applications in analysis. Translations of mathematical monographs, vol. 219, AMS, Providence (2003)
Kerov, S., Okounkov, A., Olshanski, G.: The boundary of the Young graph with Jack edge multiplicities. Int. Math. Res. Notices 173–199 (1998)
Kharchev, S., Lebedev, D.: Integral representations for the eigenfunctions of quantum open and periodic Toda chains from the QISM formalism. J. Phys. A 34, 2247–2258 (2001)
Kirillov, A.N.: Introduction to tropical combinatorics. In: Kirillov, A.N., Liskova, N. (eds.) Physics and Combinatorics. Proc. Nagoya 2000 2nd Internat. Workshop. World Scientific, Singapore, 82–150, (2001)
Kipnis, C., Landim, C.: Scaling limits of interacting particle systems. Spinger, Berlin (1999)
Kostant, B.: Quantisation and representation theory. In: Proc. SRC/LMS Research Symposium on Representation Theory of Lie Groups, Oxford. LMS Lecture Notes 34, pp. 287–316. Cambridge University Press, Cambridge (1977)
Lax, P.D.: Functional analysis. Wiley, Newyork (2002)
Lieb, E.H., Liniger, W.: Exact Analysis of an Interacting Bose Gas. I. The General Solution and the Ground State. Phys. Rev. Lett. 130, 1605–1616 (1963)
Liggett, T.: Continuous time Markov processes: an introduction. In: Graduate Studied in Mathematics, vol. 113, AMS, Providence (2010)
Liggett, T.: Interacting particle systems. Spinger, Berlin (2005)
Liggett, T.: An infinite particle system with zero range interactions. Ann. Probab. 1, 240–253 (1973)
Macdonald, I.G.: Symmetric functions and hall polynomials, 2nd edn. Oxford University Press, New York (1999)
McGuire, J.B.: Study of exactly soluble one-dimensional N-body problems. J. Math. Phys. 5, 622 (1964)
Moreno Flores, G., Quastel, J.: Intermediate disorder for the O’Connell-Yor model (2013)
Moriarty, J., O’Connell, N.: On the free energy of a directed polymer in a Brownian environment. Markov Process Relat. Fields 13, 251–266 (2007)
Mueller, C.: On the support of solutions to the heat equation with noise. Stochastics 37, 225–246 (1991)
Nagao, T., Wadati, M.: Eigenvalue distribution of random matrices at the spectrum edge. J. Phys. Soc. Jpn. 62, 3845–3856 (1993)
Noumi, M., Yamada, Y.: Tropical Robinson-Schensted-Knuth correspondence and birational Weyl group actions. Representation theory of algebraic groups and quantum groups. In: Adv. Stud. Pure Math., vol. 40, pp. 371–442. Math. Soc. Japan, Tokyo (2004)
O’Connell, N.: Directed polymers and the quantum Toda lattice. Ann. Probab. 40, 437–458 (2012)
O’Connell, N.: Whittaker functions and related stochastic processes. arXiv:1201.4849
O’Connell, N., Warren, J.: A multi-layer extension of the stochastic heat equation arXiv:1104.3509
O’Connell, N., Yor, M.: Brownian analogues of Burke’s theorem. Stoch. Proc. Appl. 96, 285–304 (2001)
Okounkov, A.: (Shifted) Macdonald polynomials: q-Integral representation and combinatorial formula. Compos. Math. 112, 147–182 (1998)
Okounkov, A., Reshetikhin, N.: Correlation function of Schur process with application to local geometry of a random 3-dimensional Young diagram. J. Am. Math. Soc. 16, 581–603 (2003)
Okounkov, A.: Infinite wedge and random partitions. Selecta Math. 7, 57–81 (2001)
Oxford, S.: The Hamiltonian of the quantized nonlinear Schrödinger equation. Ph.D. thesis, UCLA, (1979)
Prähofer, M., Spohn, H.: Scale invariance of the PNG droplet and the Airy process. J. Stat. Phys. 108, 1071–1106 (2002)
Prolhac, S., Spohn, H.: The propagator of the attractive delta-Bose gas in one dimension. J. Math. Phys. 52, 122106 (2011)
Ruijsenaars, S.N.M.: Relativistic Toda systems. Commun. Math. Phys. 133, 217–247 (1990)
Sasamoto, T., Spohn, H.: One-dimensional KPZ equation: an exact solution and its universality. Phys. Rev. Lett. 104, 23 (2010)
Sasamoto, T., Wadati, M.: Exact results for one-dimensional totally asymmetric diffusion models. J. Phys. A 31, 6057–6071 (1998)
Semenov-Tian-Shansky, M.: Quantisation of open Toda lattices. Dynamical systems VII: integrable systems, nonholonomic dynamical systems. In: Arnol’d, V.I., Novikov, S.P. (eds.) Encyclopaedia of mathematical sciences, vol. 16. Springer, Berlin (1994)
Seppäläinen, T.: Existence of hydrodynamics for the totally asymmetric simple K-exclusion process. Ann. Probab. 27, 361–415 (1999)
Seppäläinen, T.: Scaling for a one-dimensional directed polymer with boundary conditions. Ann. Probab. 40, 19–73 (2012)
Seppäläinen, T., Valko, B.: Bounds for scaling exponents for a 1+1 dimensional directed polymer in a Brownian environment. Alea 7, 451–476 (2010)
Simon, B.: Trace ideals and their applications. AMS, Providence (2005)
Spohn, H.: KPZ scaling theory and the semi-discrete directed polymer model. arXiv:1201.0645
Tracy, C., Widom, H.: Level-spacing distributions and the Airy kernel. Commun. Math. Phys. 159, 151–174 (1994)
Tracy, C., Widom, H.: Integral formulas for the asymmetric simple exclusion process. Commun. Math. Phys. 279, 815–844 (2008) (Erratum. Commun. Math. Phys. 304, 875–878 (2011))
Tracy, C., Widom, H.: A Fredholm determinant representation in ASEP. J. Stat. Phys. 132, 291–300 (2008)
Tracy, C., Widom, H.: Asymptotics in ASEP with step initial condition. Commun. Math. Phys. 290, 129–154 (2009)
Tracy, C., Widom, H.: Formulas for ASEP with two-sided Bernoulli initial condition. J. Stat. Phys. 140, 619–634 (2010)
Tracy, C., Widom, H.: The dynamics of the one-dimensional delta-function Bose gas. J. Phys. A 41, 485204 (2008)
Vuletic, M.: A generalization of MacMahon’s formula. Trans. Am. Math. Soc. 361, 2789–2804 (2009)
Wallach, N.: Real reductive groups II. Academic Press, San Diego (1992)
Warren, J.: Dyson’s Brownian motions, intertwining and interlacing. Electr. J. Probab. 12, 573–590 (2007)
Acknowledgments
The authors would like to thank P.L. Ferrari, V. Gorin, A. Okounkov, G. Olshanski, J. Quastel, E. Rains, T. Sasamoto, T. Seppäläinen and H. Spohn for helpful discussions pertaining to this paper. We are particularly grateful to N. O’Connell for generously sharing his insights on this subject with us through this project. Additional thanks go out to the participants of the American Institute of Mathematics workshop on the “Kardar-Parisi-Zhang equation and universality class” where AB first spoke on these results. AB was partially supported by the NSF grant DMS-1056390. IC recognizes support and travel funding from the NSF through the PIRE grant OISE-07-30136 and grant DMS-1208998; as well as support from the Clay Mathematics Institute through a Clay Research Fellowship and Microsoft Research through the Schramm Memorial Fellowship.