
Abstract
Age estimation based on DNA methylation (DNAm) can be applied to children, adolescents and adults, but many CG dinucleotides (CpGs) exhibit different kinetics of age-associated DNAm across these age ranges. Furthermore, it is still unclear how growth disorders impact epigenetic age predictions, and this may be particularly relevant for a forensic application. In this study, we analyzed buccal mucosa samples from 95 healthy children and 104 children with different growth disorders. DNAm was analysed by pyrosequencing for 22 CpGs in the genes PDE4C, ELOVL2, RPA2, EDARADD and DDO. The relationship between DNAm and age in healthy children was tested by Spearman’s rank correlation. Differences in DNAm between the groups “healthy children” and the (sub-)groups of children with growth disorders were tested by ANCOVA. Models for age estimation were trained (1) based on the data from 11 CpGs with a close correlation between DNAm and age (R ≥ 0.75) and (2) on five CpGs that also did not present significant differences in DNAm between healthy and diseased children. Statistical analysis revealed significant differences between the healthy group and the group with growth disorders (11 CpGs), the subgroup with a short stature (12 CpGs) and the non-short stature subgroup (three CpGs). The results are in line with the assumption of an epigenetic regulation of height-influencing genes. Age predictors trained on 11 CpGs with high correlations between DNAm and age revealed higher mean absolute errors (MAEs) in the group of growth disorders (mean MAE 2.21 years versus MAE 1.79 in the healthy group) as well as in the short stature (sub-)groups; furthermore, there was a clear tendency for overestimation of ages in all growth disorder groups (mean age deviations: total growth disorder group 1.85 years, short stature group 1.99 years). Age estimates on samples from children with growth disorders were more precise when using a model containing only the five CpGs that did not present significant differences in DNAm between healthy and diseased children (mean age deviations: total growth disorder group 1.45 years, short stature group 1.66 years). The results suggest that CpGs in genes involved in processes relevant for growth and development should be avoided in age prediction models for children since they may be sensitive for alterations in the DNAm pattern in cases of growth disorders.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Age estimation based on DNA methylation (DNAm) is about to become firmly established in the forensic methodical repertoire [1,2,3]. Current research questions particularly concern methodical aspects, the accuracy of age estimates and age-independent factors that may influence DNAm [4,5,6].
More and more studies focus on DNAm in children and adolescents. Many CpGs in genes that are comprised in models for forensic age estimation exhibit different kinetics of DNAm in children/adolescents, as compared to adults [7,8,9,10]. Most probably, this has to be attributed to molecular processes related to growth and development; an “accelerated” epigenetic aging goes along with faster physical development [11]. Despite these differences between non-adults and adults, the data published so far indicate that the relationship between DNAm and age may nevertheless be close within the group of healthy children and adolescents [7,8,9,10]. This comparably close relationship is surprising, considering that the complex processes of growth and development during childhood and adolescence are subdued to numerous influences, e.g. genetics, the individual constitutional disposition, endocrinologic factors, diet and diseases [12].
Furthermore, the question arises, if models for age estimation based on DNAm data from healthy children and adolescents can also be applied to young individuals with growth disorders.
“Growth disorders” is a generic term that encompasses many different syndromic and non-syndromic phenotypes. “Short stature” and “tall stature” are defined as height below the 2.5th or above the 97.5th percentile of a population [13]. It has been reported that more than 3200 genetic variants at more than 700 genomic loci influence growth and adult stature in subjects of European ancestry [14, 15]. These variants usually involve noncoding DNA intergenic or intronic sequences. The intergenic nucleotide variants often are the sites of epigenetic regulation of the expression of the associated genes [12, 14, 16]. Identified height-influencing genes are, for example, involved in cellular function and metabolic processes at the growth plate or are being assigned to the growth hormone axis; gene variants that affect stature in normal subjects include intracellular signalling, transcription, DNA repair, chromatin remodelling, collagen formation or paracrine signalling [14, 16, 17].
To what extent (epigenetic) alterations of one or more of these genomic loci affect growth and development remains subject of extensive research. For children with idiopathic short stature (ISS), a higher methylation status of the promoter region of the insulin like growth factor 1 gene has been detected and discussed as a contributor to the reduced body length [18]. DNAm profiling of children with short stature that were born small for gestational age revealed differentially methylated DNA regions that are said to be associated with imprinting disorders also affecting growth [19]. Studies on such developmental disorders that go along with alterations in body length demonstrate a crucial pathogenetic role for DNAm; in fact, typical methylation signatures have been identified that enable the diagnosis of these disorders on an epigenetic basis [20,21,22].
Therefore, it appeared even more relevant to test whether the age-dependent patterns of DNAm of genes that are used in models for forensic age estimation may be altered in children with growth disorders.
We investigated DNAm in buccal mucosa samples from 104 children and adolescents with growth disorders and compared the results with DNAm data from 95 healthy young individuals. DNAm analysis by pyrosequencing was performed for amplicons of the genes PDE4C, ELOVL2, RPA2, EDARADD and DDO. Furthermore, an epigenetic age-prediction model was trained for 11 age-associated CpGs for healthy children and adolescents, which was subsequently applied to the young individuals with growth disorders.
Material and methods
Analysed samples
A detailed list of the study participants can be found in the supplementary material. Children/adolescents were only included after written informed consent of their legal guardians.
Buccal mucosa samples were collected from 95 healthy children/adolescents (healthy group: ages between 0.42 and 18 years; 51 females, 44 males) and 104 children/adolescents that were patients of the paediatric clinic of the University Hospital Düsseldorf, suffering from a growth disorder (growth disorder group: ages between 1 and 17 years; 48 females, 56 males). The only condition for inclusion into the study was the diagnosis “growth disorder”, independent of the specific clinical diagnosis/aetiology; however, the collective comprised predominantly cases with short stature.
In detail, the growth disorder group is composed of the following subgroups:
-
76 children/adolescents with short stature (short stature group, body length under the 2.5th percentile: ages between 1 and 15 years; 28 females, 48 males)
-
33 children/adolescents with idiopathic short stature (idiopathic short stature group: ages between 2 and 15 years; 11 females, 22 males)
-
29 children/adolescents with short stature of endocrinologic aetiology (endocrinologic group: ages between 3 and 15 years; 8 females, 21 males)
-
14 children/adolescents with short stature of genetic aetiology (genetic group: ages between 1 and 11 years; 9 females, 5 males)
-
-
28 children/adolescents without short stature (body length between 2.5th and 97.5th percentiles or over 97.5th percentile), comprising clinical diagnoses like precocious puberty, tall stature, failure to thrive (non-short stature group: ages between 1 and 17 years; 20 females, 8 males).
DNA extraction, quantification and bisulphite conversion
Genomic DNA was extracted from buccal swab samples of both groups using the NucleoSpin® Tissue Kit from Macherey–Nagel (North Rhine-Westfalia/Germany) according to the manufacturer’s protocol. Lysis was performed overnight at 56 °C. Elution of DNA was performed in 100 µl BE buffer (part of the extraction kit). Quantification was performed according to the manufacturer’s protocol using either the Applied Biosystems™ 7500 Real-Time PCR System and Quantiplex® Pro Kit (Qiagen, North Rhine-Westfalia/Germany) or the QuantiFluor dsDNA Sample Kit (Promega, Wisconsin/USA) and Quantus Fluorometer (Promega, Wisconsin/USA).
For bisulphite conversion of DNA, either the EZ DNA Methylation-Gold™ Kit (Zymo Research, California/USA) or the EpiTect Fast DNA Bisulphite Kit (Qiagen, North Rhine-Westfalia/Germany) was used according to the manufacturer’s protocol. Positive controls that were included in each analysis did not reveal relevant differences with regard to the utilized kit. Since buccal swabs from children often contain only little amounts of DNA, the analysis parameters were adapted according to the kits’ manuals. If possible, the optimal amount of 200 to 500 ng of input DNA was used; in some cases, lower amounts had to be accepted, but in no case less than 10 ng per reaction volume was used, which is a critical threshold [23].
DNA methylation analysis by pyrosequencing (22 CpGs located in the genes PDE4C, RPA2, ELOVL2, DDO and EDARADD)
For amplification, CpG-specific PCRs were performed using either the HotStar-Taq kit (Qiagen, North Rhine-Westfalia/Germany) or the PyroMark PCR kit (Qiagen, North Rhine-Westfalia/Germany) according to the manufacturer’s protocol. Primer sequences for 22 CpG sites that were already successfully used in a preceding project [24] and that are reported to show an age-correlated DNAm status in cells obtained by buccal swabs were taken from the original papers [25,26,27]. Information about the primer sequences, the chromosome location of the CpG sites and the PCR conditions can be found in the supplementary material. For subsequent pyrosequencing, 10–20 µl of the biotinylated PCR product was immobilized on 1 μl streptavidin Sepharose™HP beads (GE Healthcare, Illinois/USA). Sequencing primers were designed as previously described [25,26,27]. Pyrosequencing was performed using the PyroMark Q24 Advanced CpG Reagents Kit (Qiagen, North Rhine-Westfalia/Germany) and the PyroMark Q24 Advanced System (Qiagen, North Rhine-Westfalia/Germany). Positive and negative controls were also included and evaluated after each run, and agarose gels were checked for the presence and the right length of PCR products. Pyrosequencing was considered reliable when sequencing was correct (e.g. peaks not too small or missing), and pyrograms reached a pre-defined threshold.
Twenty-six samples of the healthy group (and 109 samples of a previous study) were analysed at least twice. The difference between the obtained DNAm did not exceed 3% as long as the pyrograms did not contain error messages. With regard to costs and practicability, the remaining samples were therefore analysed only once.
Relationship between DNAm and age for 22 CpG sites in healthy children and adolescents
The relationship between DNAm and age in the healthy group was tested by Spearman’s rank correlation. For all CpGs (located in the genes PDE4C, ELOVL2, RPA2, EDARADD and DDO), Spearman’s correlation coefficients (R) were calculated. CpGs revealing a close correlation between DNAm and age (R > 0.75) were used for the development of age prediction models (so called “11 CpGs models”, see below).
Testing for differences in DNAm between individuals with and without growth disorders
DNAm differences between the investigated groups of children/adolescents were tested by ANCOVA; at a p-value < 0.05, results were considered significant. In detail, the growth disorder group (n = 104), the short stature group (n = 76) and the non-short stature group (n = 28) were each tested versus the healthy group (n = 95). We also tested for differences between male (n = 54) and female (n = 48) individuals within the growth disorder group.
Though it is well known that BMI can influence DNAm [28], we refrained from testing for differences between children/adolescents with under-, over- or normal weight, since these data were only available for the growth disorder group resulting in numbers too small for an adequate calculation (underweight n = 17, overweight n = 14, normal weight n = 73; see also supplementary material).
Age estimation, model validation and group comparison
The key challenge for the current investigation was to reconcile training of the predictive models in the available cohort of healthy children while at the same time comparing their performance between (also) healthy children and those with growth disorders. In this context, it is important to stress that testing the trained models in the same subjects that were used for training is invalid, as model training and evaluation need to be strictly separated. In addition, we note that the age and sex distribution of the target groups (growth disorder and short stature) deviated from the available controls, representing a potential confound for the interpretation of any difference in predicted age.
To overcome these challenges, we used a matched subsampling approach with Matlab® 2021 and the “Statistics and Machine-Learning Toolbox”. In particular, we drew 25,000 (unique) paired subsamples from the reference cohort and one target cohort, respectively, which were well matched to each other in terms of age and sex (both p > 0.3). Per cohort, the number of individuals drawn for these subsamples represented 10% (rounded upwards) of the smaller of the two sets, i.e. reference and target. The selected subsamples were then set aside as the test data so that the subjects drawn from the reference cohort were not used for training but remained unseen to the algorithm in the same way as the (matched) subsample from the target cohort. That is, we drew from each cohort the same number of subjects in such a way that the two selected subsamples were closely matched for age and gender while ensuring that at least 90% of the reference cohort was available for training.
Repeating this setup 25,000 times then allows deriving distributions of prediction accuracy (how well did models trained on the remaining reference cohort generalize to the unseen reference subjects and those with a growth disorder) and bias (systematic difference in predicted age). The former was evaluated by the mean absolute errors (MAEs). The results for the healthy children test samples were then compared against those for the growth disorder test samples that were matched regarding the number of samples, age and sex. The latter, biases resulting in a systematic over- or underestimation of the growth disorder test samples, was quantified by the mean age gap (i.e. the difference between the estimated and the chronological age) and again compared across groups.
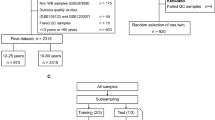
This approach was applied to all growth disorder (sub-)groups. For a graphic illustration of modelling and performance procedures, see Fig. 1.

Illustration of age predictor modelling and performance procedure. Training of 25.000 models and performance testing on extracted healthy children test samples as well as on matched test samples from diseased children was performed in the same way for all growth disorder (sub-)groups. MAE mean absolute error
The age prediction models themselves were trained on the part of the healthy reference cohort that was not set aside for testing, using a random forest algorithm using (chronological) age as the continuous target variable as well as the CpG information and sex as features for prediction. In a first step, we trained 11 CpGs models; in a second step, “robust” models were trained by using only the robust 5 CpG sites that did not present significant differences between healthy children and children with growth disorders (so called “5 CpGs models”). The prediction forest consisted of 1000 individual trees that were built from bootstrap-samples of the training dataset using the curvature test. This test selected the split predictor that minimizes the p-value of chi-square tests of independence between each predictor, i.e. feature, and the response, i.e. age.
The detailed set parameters were as follows:
mdl = TreeBagger(trees,data(testFold(i,:) = = 0,:),Target(testFold(i,:) = = 0),'CategoricalPredictors',1,'Method','regression','Surrogate','all','MinLeafSize',1,…
'PredictorSelection','curvature','options',statset('useparallel',true),'OOBPrediction','on');
Minimum Leaf Size 1.
Split selection: Curvature test—selects the split predictor that minimizes the p-value of chi-square tests of independence between each predictor and the response.
With regard to single missing values: surrogate splits—when the value of the optimal split predictor for an observation is missing; if you specify to use surrogate splits, the software sends the observation to the left or right child node using the best surrogate predictor.
Results
Close correlations between DNAm and age at 11 of 22 CpG sites in the healthy group
The analysis of DNAm levels at the 22 CpG sites in the healthy group resulted in correlation coefficients (Spearman R) between − 0.44 (DDO) and 0.87 (ELOVL2/CpG3 and 6) (Table 1). For half of the 22 CpG sites, R was lower than 0.75; these sites were excluded from further analysis, i.e. age estimation modelling. The remaining 11 CpGs with a close correlation between DNAm and age were included in the11 CpGs models. Figures depicting analysis results versus donors’ age sorted by (sub-)groups from these 11 CpGs are provided in the supplementary material.
Significant differences in DNAm between individuals with and without growth disorders
ANCOVA revealed significant differences (with α < 0.05) at 11 CpG sites in all genes between the healthy group and the total growth disorder group, and at 12 CpG sites in all genes between the healthy group and the short stature subgroup; in the non-short stature group, only 3 CpG sites in the genes PDE4C, ELOVL2 and RPA2 presented significant differences. The lowest p-values were found for RPA2/CpG3, ELOVL2/CpG7 and ELOVL2/CpG3 (Table 2). No significant differences were found when testing male vs female individuals within the growth disorder group.
Six of the 11 CpG sites that showed significant differences in DNAm when comparing the healthy group with the growth disorder (sub-)groups are among those with a close correlation between DNAm and age (R > 0.75); the remaining 5 sites with a close correlation between DNAm and age (CpG1, CpG2, CpG5, CpG8 and CpG9 in ELOVL2) appear to be robust by exhibiting no significant differences between the two groups. These five CpGsites were comprised in the 5 CpGs models.
Age prediction by models based on healthy children training data (“11 CpGs models”) reveal a tendency for overestimating the ages of children with growth disorders, as compared to age- and sex-matched healthy children test samples
The means and medians of the MAEs of age estimation based on the 11 CpGs models calculated in 25,000 runs for the test samples of the growth disorder group (mean 2.21 years, median 2.19 years) were slightly higher than those for the age- and sex-matched healthy children test samples (mean 1.79 years, median 1.77 years). With regard to the 25,000 runs for test samples of the short stature group (mean 2.34 years, median 2.32 years), the differences were even slightly higher when compared to age- and sex-matched healthy children test samples (mean 1.79 years, median 1.76 years). Means and medians of the MAEs of the 5 CpGs models that were calculated in the same way showed comparable values (Fig. 2). The same accounts for the results of the subgroups idiopathic short stature, genetic aetiology, endocrinologic aetiology and non-short stature: the calculated means and medians did not show obvious differences (Table 3).

Mean absolute errors (MAE, in years) of 25,000 age estimations based on healthy children training samples (90% of the total healthy group sample number each) and performed on healthy children test samples (healthy group: extracted 10% of the total healthy group samples) as well as on test samples of the growth disorder group and the short stature group (each matched regarding sample number, age and sex). A, B 11 CpGs models. C, D 5 CpGs models
The mean deviations of the age gaps (the differences between estimated and chronological ages) revealed a clear tendency for overestimation of ages in the growth disorder group (mean 1.85 years, median 1.84 years; healthy group mean 0.28 years and median 0.27 years) as well as in the short stature group (mean 1.99, median 1.99 years; healthy group mean 0.52 years and median 0.51 years) in the 11 CpGs models. In the 5 CpG models, on the other hand, the age gaps were clearly smaller for the growth disorder group (mean 1.45 years, median 1.45 years; healthy group mean 0.21 years, median 0.20 years) and the short stature group (mean 1.66, median 1.66; healthy group mean 0.68, median 0.68) (Fig. 3). The same accounts for the growth disorder subgroups (Table 3).

Mean deviation of the age gaps (difference between estimated and chronological ages in years) of 25,000 age estimations based on healthy children training samples (90% of the total healthy group sample number each) and performed on healthy children test samples (healthy group: extracted 10% of the total healthy group samples) as well as on test samples of the growth disorder group and the short stature group (each matched regarding sample number, age and sex). A, B 11 CpGs models. C, D 5 CpGs models
Discussion
Methodical aspects
Since DNA samples of young individuals with growth disorders are difficult to obtain, we had to work with a rather small (n = 104 in the growth disorder group) and heterogeneous sample collection.
To tackle this challenge, we calculated numerous models when testing the performance of age prediction on the healthy group and the growth disorder group, as well as its subgroups. Twenty-five thousand models were calculated which were then used for age prediction on matching test samples of the total healthy group and one of the 6 growth disorder (sub-)groups. The resulting mean and median MAEs of the prediction runs provide a reliable impression of how well DNAm-based age predictors that have been trained on data derived from healthy children/adolescents work on test samples of individuals with growth disorders.
The study at hand was conducted with the primary aim to test the influence of growth disorders on DNAm and, in a forensic context, on DNAm-based age estimation in children and adolescents. We did not intend to establish a new final model for forensic age estimation. The calculated models only serve the purpose to test and illustrate the alleged influence.
Biological aspects
Eleven of the 22 analysed CpGs in the genes PDE4C, ELOVL2 and RPA2 exhibited significant differences between young, healthy individuals and age- and sex-matched individuals with growth disorders. A final biological interpretation of the significant differences in 7 of these 11 CpGs when comparing individuals with and without growth disorders is, of course, not possible solely based on the presented data. However, it can be stated that the findings are in line with publications that focus on (epi)genetic factors in the pathophysiology of growth disorders.
It has been proposed that genes involved in fundamental cellular processes like intracellular signalling, transcription, DNA repair or chromatin remodelling play an important role in growth and in the pathophysiology of growth disorders [14, 29]. Against this background, it might not be too surprising that the analysed CpGs in the genes PDE4C and ELOVL2 show a different methylation level in young individuals with growth disorders when compared to healthy children/adolescents, since both genes take part in such processes: PDE4C is a member of the phosphodiesterase superfamily and insofar involved in the control of intracellular levels of cyclic nucleotides, underlying a vast number of physiologic processes (e.g. [30]); ELOVL2 belongs to a group of enzymes that are vital for the elongation of fatty acids resulting in very long–chain fatty acids, major building blocks for various molecules (e.g. [31]). The finding of differences in DNAm patterns of the RPA2 gene is even more interesting: RPA is a multifunctional protein that plays a role in DNA replication, repair, recombination and beyond [32], being essential for cell cycle progression. Upon DNA damage, RPA gains negative charges through phosphorylation at the N-terminus of RPA2 that carries the phosphorylation motif. If this gene would be regulated epigenetically and DNAm would play a role, it would be plausible that altered DNAm patterns may result in disorders of growth. But of course, this is merely a highly speculative hypothesis which is based only on the analytical results of single CpGs and which cannot be further substantiated.
Forensic aspects
Our study proofs age-related DNAm at certain CpG sites in young individuals, meaning that DNAm-based age estimation can also be applied for children and adolescents and thus confirms results of other studies [7, 8].
However, our 11 CpGs models included 6 CpGs with significant differences in DNAm between healthy children and children with growth disorders. These differences were less obvious in the MAEs but presented themselves as a systemic upward “shift” in the age gaps. As a consequence, there was a clear tendency to overestimate the ages of children with growth disorders, with mean deviations of about + 1.85 years. That means, the inclusion of (too many of) such “sensible” CpGs in age predictors may lead to systematic errors in age estimation. Taking into account that, for example, about 3% of children in Germany meet the diagnostic requirements of short stature [33], these findings cannot be neglected in forensic practice. Optimized models for age estimation should aim at the inclusion of as many robust CpGs as possible; for growth disorders, such robust CpGs are for example CpG1, CpG2, CpG5, CpG8 and CpG9 in ELOVL2. Our 5 CpGs models which contained only these robust CpGs obviously performed somewhat better on test samples of diseased children (Fig. 3; Table 3).
In this respect, CpGs in genes involved in processes relevant for growth and development are more likely to be unsuitable for age prediction models since they seem to be especially sensitive for alterations in the DNAm pattern in cases of growth/developmental disorders.
References
Böhme P, Reckert A, Becker J, Ritz-Timme S (2021) Molecular methods for age estimation. Rechtsmedizin. https://doi.org/10.1007/s00194-021-00490-9
Freire-Aradas A, Phillips C, Lareu MV (2017) Forensic individual age estimation with DNA: From initial approaches to methylation tests. Forensic Sci Rev 29:121–144
Hanafi M, Soedarsono N, Auerkari E (2021) Biological age estimation using DNA methylation analysis: a systematic review. Sci Dent J 5:1–11. https://doi.org/10.4103/sdj.Sdj_27_20
Han Y, Franzen J, Stiehl T et al (2020) New targeted approaches for epigenetic age predictions. BMC Biol 18:71. https://doi.org/10.1186/s12915-020-00807-2
Koop BE, Reckert A, Becker J, Han Y, Wagner W, Ritz-Timme S (2020) Epigenetic clocks may come out of rhythm-implications for the estimation of chronological age in forensic casework. Int J Legal Med 134:2215–2228. https://doi.org/10.1007/s00414-020-02375-0
Pfeifer M, Bajanowski T, Helmus J, Poetsch M (2020) Inter-laboratory adaption of age estimation models by DNA methylation analysis-problems and solutions. Int J Legal Med 134:953–961. https://doi.org/10.1007/s00414-020-02263-7
Freire-Aradas A, Phillips C, Giron-Santamaria L et al (2018) Tracking age-correlated DNA methylation markers in the young. Forensic Sci Int Genet 36:50–59. https://doi.org/10.1016/j.fsigen.2018.06.011
Wu X, Chen W, Lin F et al (2019) DNA methylation profile is a quantitative measure of biological aging in children. Aging (Albany NY) 11: 10031–51. https://doi.org/10.18632/aging.102399
Alisch RS, Barwick BG, Chopra P et al (2012) Age-associated DNA methylation in pediatric populations. Genome Res 22:623–632. https://doi.org/10.1101/gr.125187.111
Almstrup K, Lindhardt Johansen M, Busch AS et al (2016) Pubertal development in healthy children is mirrored by DNA methylation patterns in peripheral blood. Sci Rep 6:28657. https://doi.org/10.1038/srep28657
Binder AM, Corvalan C, Mericq V et al (2018) Faster ticking rate of the epigenetic clock is associated with faster pubertal development in girls. Epigenetics 13:85–94. https://doi.org/10.1080/15592294.2017.1414127
Muthuirulan P, Capellini TD (2019) Complex phenotypes: mechanisms underlying variation in human stature. Curr Osteoporos Rep 17:301–323. https://doi.org/10.1007/s11914-019-00527-9
Barstow C, Rerucha C (2015) Evaluation of short and tall stature in children. Am Fam Physician 92:43–50
AW Root 2020 Genetic Regulation of adult stature in humans J ClinEndocrinol Metab 105. https://doi.org/10.1210/clinem/dgaa210
Yengo L, Sidorenko J, Kemper KE et al (2018) Meta-analysis of genome-wide association studies for height and body mass index in approximately 700000 individuals of European ancestry. Hum Mol Genet 27:3641–3649. https://doi.org/10.1093/hmg/ddy271
M Guo Z Liu J Willen et al 2017 Epigenetic profiling of growth plate chondrocytes sheds insight into regulatory genetic variation influencing height Elife 6. https://doi.org/10.7554/eLife.29329
Jee YH, Andrade AC, Baron J, Nilsson O (2017) Genetics of short stature. Endocrinol Metab Clin North Am 46:259–281. https://doi.org/10.1016/j.ecl.2017.01.001
Ouni M, Castell AL, Rothenbuhler A, Linglart A, Bougneres P (2016) Higher methylation of the IGF1 P2 promoter is associated with idiopathic short stature. Clin Endocrinol (Oxf) 84:216–221. https://doi.org/10.1111/cen.12867
S Peeters K Declerck M Thomas et al 2020 DNA methylation profiling and genomic analysis in 20 children with short stature who were born small for gestational age J ClinEndocrinol Metab 105. https://doi.org/10.1210/clinem/dgaa465
Aref-Eshghi E, Rodenhiser DI, Schenkel LC et al (2018) Genomic DNA methylation signatures enable concurrent diagnosis and clinical genetic variant classification in neurodevelopmental syndromes. Am J Human Gene 102:156–174. https://doi.org/10.1016/j.ajhg.2017.12.008
Sadikovic B, Aref-Eshghi E, Levy MA, Rodenhiser D (2019) DNA methylation signatures in mendelian developmental disorders as a diagnostic bridge between genotype and phenotype. Epigenomics 11:563–575. https://doi.org/10.2217/epi-2018-0192
Hood RL, Schenkel LC, Nikkel SM et al (2016) The defining DNA methylation signature of Floating-Harbor syndrome. Sci Rep 6:38803. https://doi.org/10.1038/srep38803
Naue J, Hoefsloot HCJ, Kloosterman AD, Verschure PJ (2018) Forensic DNA methylation profiling from minimal traces: how low can we go? Forensic Sci Int Genet 33:17–23. https://doi.org/10.1016/j.fsigen.2017.11.004
Becker J, Böhme P, Reckert A et al (2021) Evidence for differences in DNA methylation between Germans and Japanese. Int J Legal Med. https://doi.org/10.1007/s00414-021-02736-3
Naue J, Hoefsloot HCJ, Mook ORF et al (2017) Chronological age prediction based on DNA methylation: massive parallel sequencing and random forest regression. Forensic Sci Int Genet 31:19–28. https://doi.org/10.1016/j.fsigen.2017.07.015
Weidner CI, Lin Q, Koch CM et al (2014) Aging of blood can be tracked by DNA methylation changes at just three CpG sites. Genome Biol 15:R24. https://doi.org/10.1186/gb-2014-15-2-r24
Bekaert B, Kamalandua A, Zapico SC, Van de Voorde W, Decorte R (2015) Improved age determination of blood and teeth samples using a selected set of DNA methylation markers. Epigenetics 10:922–930. https://doi.org/10.1080/15592294.2015.1080413
Sun D, Zhang T, Su S et al (2019) Body Mass Index Drives Changes in DNA Methylation: A Longitudinal Study. Circ Res 125:824–833. https://doi.org/10.1161/CIRCRESAHA.119.315397
Fan X, Zhao S, Yu C et al (2021) Exome sequencing reveals genetic architecture in patients with isolated or syndromic short stature. J Genet Genomics 48:396–402. https://doi.org/10.1016/j.jgg.2021.02.008
Azevedo MF, Faucz FR, Bimpaki E et al (2014) Clinical and molecular genetics of the phosphodiesterases (PDEs). Endocr Rev 35:195–233. https://doi.org/10.1210/er.2013-1053
Jakobsson A, Westerberg R, Jacobsson A (2006) Fatty acid elongases in mammals: their regulation and roles in metabolism. Prog Lipid Res 45:237–249. https://doi.org/10.1016/j.plipres.2006.01.004
Dueva R, Iliakis G (2020) Replication protein A: a multifunctional protein with roles in DNA replication, repair and beyond. NAR Cancer 2: zcaa022. https://doi.org/10.1093/narcan/zcaa022
E Keller W Kiess R Pfäffle A Keller 2007 Kleinwuchs Kinder- und Jugendmedizin 7 209 216. https://doi.org/10.1055/s-0038-1625650
Funding
Open Access funding enabled and organized by Projekt DEAL. This work was funded by Deutsche Forschungsgemeinschaft (DFG, RI 704/4–1 and WA 1706/8–1).
Author information
Authors and Affiliations
Contributions
F.M. and S.R.-T. wrote the draft of this paper. S.R.-T. provided the idea and the concept of this work and gave support and guidance in all project phases. J.Be. analyzed the samples, evaluated the data and performed the statistical evaluation. P.B. gave technical advice and was responsible for troubleshooting. S.B.E. developed the model for age prediction. B.K., J.Bl. and T.G. collected and analyzed the samples. C.R. helped with the study design and the sample collection. W.W. supported the study design and gave technical advice. All the authors contributed to the interpretation of data and gave their consent for the final version of the manuscript.
Corresponding author
Ethics declarations
Ethics approval
All procedures performed in studies involving human tissue were in concordance with the ethical standards of the institutional and/ or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards (approved by Ethics Committee at the Medical Faculty of Heinrich-Heine University: HEBE-project, study number 5049). This article does not contain any studies with animals performed by any of the authors.
Consent to participate
Informed consent was obtained from all individual participants included in the study and/ or from legal guardians.
Conflict of interest
W.W. is cofounder of Cygenia GmbH (www.cygenia.com) that may provide service for analysis of epigenetic age. Apart from this, the authors have no conflict of interest to declare that are relevant to the content of this article.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mayer, F., Becker, J., Reinauer, C. et al. Altered DNA methylation at age-associated CpG sites in children with growth disorders: impact on age estimation?. Int J Legal Med 136, 987–996 (2022). https://doi.org/10.1007/s00414-022-02826-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00414-022-02826-w