
Abstract
Parkinson’s disease (PD), Parkinson’s disease with dementia (PDD) and dementia with Lewy bodies (DLB) are three clinically, genetically and neuropathologically overlapping neurodegenerative diseases collectively known as the Lewy body diseases (LBDs). A variety of molecular mechanisms have been implicated in PD pathogenesis, but the mechanisms underlying PDD and DLB remain largely unknown, a knowledge gap that presents an impediment to the discovery of disease-modifying therapies. Transcriptomic profiling can contribute to addressing this gap, but remains limited in the LBDs. Here, we applied paired bulk-tissue and single-nucleus RNA-sequencing to anterior cingulate cortex samples derived from 28 individuals, including healthy controls, PD, PDD and DLB cases (n = 7 per group), to transcriptomically profile the LBDs. Using this approach, we (i) found transcriptional alterations in multiple cell types across the LBDs; (ii) discovered evidence for widespread dysregulation of RNA splicing, particularly in PDD and DLB; (iii) identified potential splicing factors, with links to other dementia-related neurodegenerative diseases, coordinating this dysregulation; and (iv) identified transcriptomic commonalities and distinctions between the LBDs that inform understanding of the relationships between these three clinical disorders. Together, these findings have important implications for the design of RNA-targeted therapies for these diseases and highlight a potential molecular “window” of therapeutic opportunity between the initial onset of PD and subsequent development of Lewy body dementia.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The Lewy body diseases (LBDs) comprise three neurodegenerative diseases, which are characterised by accumulation of Lewy bodies (α-synuclein-containing aggregates) in neurons and neuronal processes [55, 84]. These disorders, which include Parkinson’s disease (PD), Parkinson’s disease with dementia (PDD) and dementia with Lewy bodies (DLB), have a prevalence in the general population aged ≥ 65 years of 2–3% [87], 0.3–0.5% [3] and 1–2% [55], respectively. Together, PDD and DLB are collectively known as the Lewy body dementias and they are second only to Alzheimer’s disease (AD) in prevalence among people with dementia [4]. All three LBDs are associated with disability and reduced quality of life; DLB is associated with earlier mortality and a higher cost of care compared with AD [18, 83, 107]. With no disease-modifying therapies available for any of the LBDs, these diseases present a major unmet clinical need [95].
While a variety of mechanisms, including mitochondrial and lysosomal dysfunction, oxidative stress, α-synuclein misfolding and neuroinflammation, have been implicated in PD pathogenesis [17, 87], less is known about the mechanisms underlying PDD and DLB. Elucidating these mechanisms could provide a biological basis for the clinical distinction between PDD and DLB, which remains controversial in the field [14, 55, 56, 89, 112]. Clinically, PDD and DLB are arbitrarily separated by the diagnostic "1-year rule": if dementia is diagnosed before or within 1 year of the onset of parkinsonism, it is considered to represent DLB, whereas PDD is defined by dementia first presenting more than 1 year after the onset of parkinsonism [38, 74]. Thus, PDD and DLB are clinically distinguished based only on the relative timing of motor and cognitive impairments, despite sharing many symptoms (e.g. dementia, depression, parkinsonism, REM sleep behaviour disorder and visual hallucinations). Arguably, two of the core clinical features of DLB, fluctuating cognition and visual hallucinations, are more prevalent in DLB compared with PD/PDD [39, 81], suggesting two separate disorders. However, the overlap of these core clinical features could also be evidence that the disorders are on a spectrum of disease, where DLB represents a more severe form of PDD.
Neuropathologically, all three LBDs are classed as synucleinopathies, but at the end stage of disease they often present with concomitant pathologies, such as tau neurofibrillary tangles and amyloid-β [44, 92, 99]. PD and PDD are thought to be purer synucleinopathies, whereas over 90% of DLB cases have some, often substantial, AD pathology [38, 52, 71, 74, 92, 99]. While some neuropathological differences have been reported between the Lewy body dementias and PD (e.g. tau and amyloid-β pathology at a more advanced stage in the Lewy body dementias [99]), these differences do not permit confident distinction between the LBDs when no clinical diagnosis is present. Genetically, the differences between PDD and DLB are not well-characterised, although APOE, GBA and SNCA mutations have been implicated in both [2, 112]. More is known about the genetic risk factors contributing to PD and DLB, which share some risk loci (GBA, TMEM175 and SNCA) and pathways (lysosomal and endocytic pathways) [21, 29, 50, 77, 93]. However, there is also evidence that association signals at SNCA may be distinct in PD and DLB (i.e. located at the 3’ and 5’ end of the SNCA gene, respectively) [21, 29, 48, 50], and while risk pathways are shared, PD genetic risk factors only explain a small portion of DLB phenotypic variance [29, 49].
Identifying therapeutic targets that could modify the development of PDD or DLB requires an understanding of the cellular and molecular features of these diseases. Transcriptomic profiling, through RNA-sequencing of patient-derived tissue, would aid in the identification of such targets, but remains limited in all three LBDs. Of all transcriptomic studies of PD and Lewy body dementia highlighted in two recent systematic reviews (33 and 31 gene expression studies in brain, respectively [17, 30]), only 5 used RNA-sequencing. Furthermore, among transcriptomic studies of the three LBDs, few have addressed possible alternative splicing or the confounding of bulk-tissue transcriptomic profiling by differences in cellular composition.
Here, we pair bulk-tissue and single-nucleus RNA-sequencing to gain a comprehensive view of cell-type-specific transcriptional changes in the LBDs. This combined approach is used, because, while single-nucleus RNA-sequencing can address confounding by cellular composition, providing previously unattainable insight into cell-type-specific transcriptomic pathology [60, 61], compared with bulk-tissue RNA-sequencing it has little ability to resolve transcriptomic diversity via splicing. This limitation arises due to the trade-off that exists between choosing a single-nucleus RNA-sequencing protocol that has high throughput but only sequences 3′ ends of transcripts versus a protocol whose library construction permits sequencing full-length transcripts but has reduced throughput [27]. Using this combined sequencing approach, we found transcriptional changes in multiple cortical cell types across the LBDs, with more differentially expressed genes and pathways identified in PDD and DLB than in PD. We also observed widespread alternative splicing, particularly in PDD and DLB, with evidence suggesting that specific splicing factors play a role in orchestrating the disease-related splicing changes. Collectively, these results identify common and distinct molecular pathology in the LBDs across several cell types and provide insight into the extent to which the LBDs represent discrete diseases with unique pathogenic processes.
Results
Paired single-nucleus and bulk-tissue RNA sequencing of anterior cingulate cortex in individuals with Lewy body disease
We applied single-nucleus and bulk-tissue RNA-sequencing to adjacent anterior cingulate cortex tissue sections from 28 individuals, including non-neurological control individuals and individuals with Lewy body disease (Fig. 1). The latter were split into three disease groups, consisting of PD, PDD and DLB, based on clinical assessments of retrospectively reviewed case records (n = 7 per group). We sampled from the anterior cingulate cortex, as it is one of the first cortical areas to be affected by α-synuclein pathology [6, 105] and a region where Lewy body densities correlate with cognitive impairment in PD [59]. Although selected individuals were matched, where possible, for demographic and pathologic factors, there were significant differences in the proportions of sexes between the groups in keeping with previous literature describing a male bias in DLB [78] (proportion female: control = 1/7, PD = 5/7, PDD = 2/7, DLB = 0/7; p value = 0.020; Chi-squared test; Supplementary Fig. 1, Supplementary Table 1). Disease duration also differed significantly between groups, with DLB cases having a shorter duration of disease before death, reflecting the fact that PDD cases have PD motor symptoms for several years before development of dementia (median disease duration in years: PD = 12, PDD = 11, DLB = 6; p value = 0.0099; Kruskal–Wallis rank sum test; Supplementary Fig. 1, Supplementary Table 1). Using this sample set, we report a total of 205,948 droplet-based single-nucleus and 24 bulk-tissue transcriptomic profiles, with an average of 1,398 genes per nucleus and 27,802 genes per bulk-tissue sample detected, respectively (Supplementary Fig. 2, Supplementary Fig. 3, Supplementary Table 1).

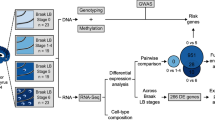
Overview of approach. In this study, anterior cingulate cortex was sampled from a cohort of 28 individuals divided equally between four groups: non-neurological controls; Parkinson’s disease without cognitive impairment (PD); Parkinson’s disease with dementia (PDD); and dementia with Lewy bodies (DLB) (Supplementary Fig. 1, Supplementary Table 1). For each individual, a frozen tissue block derived from the anterior cingulate was sectioned (sectioned area indicated with green shaded box), with adjacent sections used for single-nucleus or bulk-tissue RNA-sequencing (Supplementary Fig. 2, Supplementary Fig. 3, Supplementary Table 1). Following data pre-processing, single-nucleus RNA-sequencing data was used to generate cell-type-specific differential gene expression profiles and to deconvolute bulk-tissue RNA-sequencing data. Bulk-tissue RNA-sequencing was used in differential gene expression and splicing analyses, with cell-type proportions included as model covariates in both analyses. Results from single-nucleus RNA-sequencing and bulk-tissue RNA-sequencing were used in downstream gene set enrichment analyses to identify disease-relevant pathways. Furthermore, common risk variants for Alzheimer’s disease (AD), PD risk and PD age of onset (PD AOO) were mapped to cell-type-specific expression profiles and cell-type-specific differential expression. The image of the human brain displays a coronal section cut at the level of nucleus accumbens. RNA-seq RNA-sequencing, UMI unique molecular identifier
Increased proportions of microglia and vascular cells across Lewy body diseases
Quality control, clustering and classification of major cell types in the anterior cingulate cortex was first performed on nuclear RNA from each of the 28 individuals, after which we used the Conos framework to generate a joint graph of nuclei across all individuals [13]. Clusters were assigned to 7 broad cell types by significant overlap (Fisher’s exact test, p value < 2.2 × 10–16) with a merged list of marker genes derived from two human single-cell datasets (Supplementary Fig. 2) [61, 109]. In total, we identified 75,826 excitatory neurons, 26,467 inhibitory neurons, 46,662 oligodendrocytes, 25,726 astrocytes, 13,788 microglia, 12,497 oligodendrocyte precursors (OPCs), and 4532 vascular cells (which represented a merge of endothelial cells and pericytes), with each cell type consistently identified across all individuals in each disease group (Fig. 2a, Supplementary Fig. 4a, b).

Cellular diversity of the anterior cingulate cortex across disease states. a Joint graph of all nuclei derived from all individuals visualised using UMAP embedding. Nuclei are coloured by cell type. b Cell-type proportions derived from Scaden deconvolution (available in Supplementary Table 2). Cell-type proportions (upper panel) are grouped by cell type and disease status and displayed relative to the median of controls (within a cell type). Significant differences in cell-type proportions between disease groups (lower panel) were determined using the Wilcoxon rank sum test, with FDR correction for multiple testing. Non-significant results (FDR > 0.1) were coloured white; **FDR < 0.05; *FDR ≤ 0.1. OPC oligodendrocyte precursor cell, UMAP uniform manifold approximation and projection
Next, we sought to identify significant changes in the proportions of these major cell types across all disease groups. Although single-nucleus RNA-sequencing shows less sampling bias than single-cell sequencing [10], its suitability for estimation of cell-type proportions remains in question [33]. Thus, we used Scaden [76], a deep-learning-based deconvolution algorithm that can train on artificial bulk-tissue RNA-sequencing samples simulated from tissue-matched single-nucleus RNA-sequencing data, to estimate cell-type proportions across disease groups. Importantly, Scaden permitted pairing of our single-nucleus and bulk-tissue transcriptomic profiles and modelling of inter-subject variability. We observed a low overall correlation between single-nucleus-estimated and Scaden-predicted cell-type proportions (Spearman’s ρ = 0.25, p value = 0.0009), although per-cell-type correlations were higher for some cell types (highest in microglia, Spearman’s ρ = 0.79, p value = 8.2 × 10–6; Supplementary Fig. 4c).
Using Scaden predictions, we identified a significantly increased proportion of microglia in all disease groups compared with the control group, and a significantly increased proportion of OPCs and vascular cells in DLB cases compared with controls (Fig. 2b, FDR-corrected p < 0.05, Wilcoxon rank sum test). In addition, we observed a nominally significant increase in vascular proportions in PDD and PD cases compared with controls (FDR-corrected p < 0.1, Fig. 2b). By applying Scaden to a second, larger independent PD case–control bulk-tissue RNA-sequencing dataset [37], we were able to replicate the observed increase in microglial and vascular proportions in PD cases compared with controls (FDR-corrected p < 0.05, Supplementary Fig. 5).
Differential gene expression analysis highlights transcriptional alterations in multiple cell types and differentiates Lewy body dementias from PD
Differential gene expression analyses were separately performed with bulk-tissue and single-nucleus RNA-sequencing data to characterise molecular changes across the disease groups (“Materials and methods”). Following correction for changes in Scaden-predicted cell-type proportions in bulk-tissue gene expression, only 60 genes (53 unique genes) were found differentially expressed (DE) across the six pairwise comparisons (FDR < 0.05, Supplementary Table 3). Despite the low number of bulk-tissue DE genes identified, we noted that gene expression adjusted for cell type and experimental covariates resulted in much clearer clustering of samples by disease group (as determined through visual inspection) compared with uncorrected gene expression and gene expression adjusted for experimental covariates alone (Supplementary Fig. 6a–c). Notably, separation of disease groups was primarily observed on the same axis of variation (i.e. the first principal component, PC1), suggesting that (i) the genes contributing most to variation between groups are similar across disease groups, and thus PD, PDD and DLB may represent a neuropathological continuum and (ii) that there are gene expression changes between disease groups that are independent of differences in cell-type proportions (Supplementary Fig. 6a–c). Using pathway enrichment, we found that the top 100 genes contributing to PC1 were associated with immune-related GO terms (e.g. peptide antigen binding and MHC protein complex), as well as terms relating to endocytic vesicles and unfolded protein binding (Supplementary Fig. 6d, Supplementary Table 4).
Consistent with the view that gene expression changes exist between disease groups independent of differences in cell-type proportions, using single-nucleus RNA-sequencing data, 9,242 unique genes were found DE across cell-type-specific pairwise comparisons (all six pairwise comparisons, |log2(fold change)|> log2(1.5), FDR < 0.05, Supplementary Table 5). Focusing only on comparisons with the control group, these analyses highlighted three main themes.
First, differential gene expression was widespread and involved glia and neurons. While we found that DE genes were detected across all three case–control comparisons and across all major cell types, the largest numbers of DE genes were observed in excitatory neurons, followed by oligodendrocytes (Fig. 3a). In fact, across case–control comparisons, the number of DE genes identified in oligodendrocytes exceeded that in inhibitory neurons by a factor of up to 11.4-fold (depending on the case–control comparison; Fig. 3a). Comparison of the Lewy body diseases to each other yielded similar results; that is, transcriptional alterations across all major cell types, but with the largest number of DE genes observed in excitatory neurons, followed by oligodendrocytes (Supplementary Fig. 7).

Cell-type-specific gene expression changes and pathway enrichments across disease states. a Number of differentially expressed (DE) genes across each cell type in pairwise comparisons of disease groups to the control group (|log2(fold change)|> log2(1.5), FDR < 0.05). The intensity of the grey colour is proportional to the number of DE genes. b Binary plot indicating with bars whether a gene (column) is down-regulated (upper panel) or up-regulated (lower panel) in a given cell type (rows). Number of DE genes in each comparison indicated on the x-axis. c Reduced gene ontology (GO) terms associated with cell-type-specific down- and up-regulated DE genes identified across pairwise comparisons of disease groups with the control group. Due to the magnitude of pathway enrichments, original GO term enrichments (referred to as “child terms”) were grouped using semantic similarity. The number of enriched child GO terms assigned to each reduced parent term across all cell types and comparisons in the panel is indicated in parentheses on the y-axis. Reduced GO terms were ordered on the y-axis by the number of cell types and comparisons in which the term was found enriched. The fill of each tile indicates the − log10(FDR) of the most significant child term associated with the parent term within that comparison/cell type. Non-significant results (FDR > 0.05) were coloured white. Results for pairwise comparisons between disease groups are displayed in Supplementary Fig. 7. All cell-type-specific DE genes and pathway enrichments are available in Supplementary Table 5 and Supplementary Table 6, respectively. DEG differentially expressed gene, OPC oligodendrocyte precursor cell
Second, DE genes were commonly specific to a cell type. Indeed, of the 1131, 2535 and 4816 down-regulated DE genes identified across comparisons of PD, PDD and DLB with control, 79%, 66% and 67%, respectively, were DE in only one cell type (Fig. 3b). Among up-regulated DE genes, these percentages ranged from 74 to 76% across the three case–control comparisons.
Third, the Lewy body dementias, as distinct from PD, were characterised by the predominant down-regulation of gene expression relative to control in most cell types; the only exception were inhibitory neurons in PDD, where the number of up-regulated DE genes exceeded the number of down-regulated DE genes (Fig. 3a, b). Furthermore, the transcriptomic profile of the two Lewy body dementias was very similar, with 303 down-regulated and 87 up-regulated DE genes identified in a comparison of DLB with PDD (Supplementary Fig. 7). In contrast, comparisons of the two Lewy body dementias with PD identified > 2000 down-regulated and > 1000 up-regulated DE genes, suggesting that while there are transcriptional commonalities between PDD and DLB, PD is transcriptionally distinct from the Lewy body dementias in the anterior cingulate cortex.
Pathway enrichment was used to explore the biological implications of cell-type-specific differential gene expression. Focusing on case–control comparisons, we found that down- and up-regulated DE gene sets were enriched for 306 and 272 GO terms, respectively (each pathway was only counted once, even if it appeared across > 1 case–control comparison). Using measures of semantic similarity to cluster GO terms, and thus reduce pathway redundancy, we identified 29 down-regulated and 27 up-regulated GO terms (Fig. 3c, Supplementary Table 6). Despite the high proportion of cell-type-specific DE genes, we identified GO terms that were perturbed across multiple cell types in a given case–control comparison. For example, in comparisons of PD with control, terms related to glutamatergic synapses, the mitochondrial inner membrane, and post-translational protein modification were enriched across ≥ 5 cell types. These commonalities in GO term enrichment were a feature of both down- and up-regulated DE gene sets but were more apparent among (i) down-regulated DE gene sets and (ii) comparisons of PDD and DLB with control, with pathway perturbations affecting a median of 3–5 cell types, as compared with 1–3 in comparisons of PD with control (Supplementary Fig. 8a). Furthermore, we noted that consistent with the high number of DE genes detected for excitatory neurons, a high number of enriched pathways were observed in this cell type across all case–control comparisons, particularly in PDD and DLB (Supplementary Fig. 8b). This observation was even more pronounced in comparisons of the Lewy body dementias with PD, where the number of enriched pathways identified in excitatory neurons was almost twofold higher than the second most-affected cell type. Overall, this analysis served to highlight disproportionately large transcriptional differences in PDD and DLB, as compared with PD, particularly in excitatory neurons and, to a lesser extent, oligodendrocytes.
Genes and pathways genetically associated with PD implicate physiological variability of SNCA expression in selective vulnerability of neurons
Many of the GO terms enriched among down- and up-regulated genes, such as receptor-mediated endocytosis, have been previously implicated in PD. With this in mind, we narrowed our focus to the cell-type-specific expression of genes and pathways genetically associated with PD pathogenesis [12, 16].
PD-associated genes were derived from a recent review of mutations that have been reported to cause PD, including well-known examples, such as SNCA [16]. Of the 21 genes considered, 13 were DE in at least one major cell type and one case–control comparison (Fig. 4a). For example, excitatory neurons, inhibitory neurons, astrocytes and oligodendrocytes all showed significant up-regulation of SNCA in PD cases when compared with controls (fold change: 0.64–1.30; FDR: 2.6 × 10–7–7.2 × 10–157, Fig. 4a).

Cell-type-specific alterations of PD-associated genes and pathways. a Differential expression of PD-associated genes (associated by mutations reported to cause PD) across cell types and pairwise comparisons of disease groups with the control group. Fill of the tile indicates the log2(fold change), with non-significant results (FDR > 0.05) coloured grey. b UMAP plot of excitatory and inhibitory neurons (upper panel, 102,293 nuclei), with SNCA expression levels (lower panel). c Ridgeline plot of distribution of SNCA expression levels in excitatory neurons across disease groups. Distributions have been split into 3 cumulative quantiles, highlighting, where 0–50%, 50–90% and 90–100% of the nuclei in each disease group lie. d Number of enriched pathways (FDR < 0.05) identified using cell-type-specific down- and up-regulated DE genes from each pairwise comparison together with 46 PD-associated pathways (associated in a large-scale polygenic risk score-based assessment of 2199 gene sets). DEG differentially expressed gene, GO gene ontology, OPC oligodendrocyte precursor cell, UMAP uniform manifold approximation and projection. PD-associated genes and pathways were derived from references [12, 16], respectively
There is robust genetic evidence linking increased SNCA dosage to PD pathogenesis, including (i) duplication and triplication events in the SNCA gene that underlie autosomal dominant forms of PD [26, 97] and (ii) the association of PD risk loci with increased SNCA expression [66, 100]. In view of this evidence, we further explored SNCA expression, finding that, while SNCA expression was up-regulated in PD in all four cell types with a similar fold change (Fig. 4a), SNCA expression in control individuals was highly variable across cell types (Supplementary Fig. 9). This variability in control SNCA expression extended to (i) the proportion of nuclei expressing SNCA, with 61% of excitatory neurons expressing SNCA, as compared with < 22% across all other cell types and (ii) the range of observed SNCA expression, which was wider in excitatory neurons compared with all other cell types (Supplementary Fig. 9). These differences in cell-type-specific SNCA expression were particularly apparent between inhibitory and excitatory neurons, irrespective of disease group, with a higher proportion of excitatory neurons expressing SNCA (Fig. 4b, Supplementary Fig. 9). Furthermore, these differences were visible in a cell type across disease groups. Indeed, SNCA expression in excitatory neurons from the Lewy body dementias, as compared with the control group, was marked by (i) a decrease in the proportion of SNCA-expressing nuclei in PDD and (ii) a shift in the expression range of the top 10% highest expressing nuclei to lower levels of SNCA expression (Fig. 4c). This was not, however, the case for PD, which maintained a similar distribution of SNCA expression to the control group, with a slight shift in the expression range of the top 10% highest expressing nuclei to higher levels of SNCA expression. The absence of a population of cells expressing higher levels of SNCA suggests that variability in SNCA expression within control ranges may contribute to the selective vulnerability of subpopulations of excitatory neurons to Lewy body pathology.
PD-associated pathways were leveraged from a recent study identifying 46 pathways implicated in PD through pathway-specific polygenic risk score and rare variant burden analyses [12]. Based on case–control comparisons, we found that pathways that have been genetically associated with PD causation (such as terms related to synaptic transmission and vesicle-mediated transport) were dysregulated in all major cell types, with the exception of vascular cells, wherein only 3 pathways were implicated (Fig. 4d, Supplementary Fig. 10, Supplementary Table 7). We noted that the number of dysregulated pathways tended to increase with increasing clinical disease severity (i.e. PD < PDD < DLB) in excitatory neurons and glia, but not inhibitory neurons and vascular cells, supporting the notion of a disease spectrum. In general, fewer pathways were dysregulated in inhibitory neurons, with 12 of 46 pathways dysregulated in at least one case–control comparison, as compared with excitatory neurons, astrocytes and oligodendrocytes (23–27 of 46 pathways).
Differentially expressed genes in glia enrich for heritability of PD age of onset and risk
To identify cell types through which common genetic variants associated with PD risk and dementia may be acting, we used Hi–C-coupled Multi-marker Analysis of GenoMic Annotation (H-MAGMA) [96] and stratified LD score regression (sLDSC) [41]. As age of PD onset is correlated with clinical progression [34, 58, 85], and there is a significant negative genetic correlation between the GWAS for PD age of onset (AOO) and PD risk [15], we included both GWASs in our analysis. Furthermore, given the potential cooccurrence of Alzheimer’s disease (AD) pathology in the Lewy body dementias, we used a recent late-onset AD GWAS [54].
Genetic association analyses with H-MAGMA and sLDSC were run with two sets of annotations: (i) the top 10% most cell-type-specific genes from each disease group and (ii) cell-type-specific DE genes (|log2(fold change)|> log2(1.5), FDR < 0.05). The latter were tested on the basis that DE genes better capture gene expression signatures representative of a given disease state. Using the top 10% most cell-type-specific genes, we observed a significant association between AD genetic risk and genes highly expressed in microglia derived from control, PD and PDD groups (control, FDRLDSC = 0.038; PD, FDRLDSC = 0.019; PDD, FDRLDSC = 0.035; Fig. 5a; Supplementary Table 8), replicating previous literature [5, 22, 54]. Furthermore, we observed a significant association between genetic determinants of PD age of onset and genes highly expressed in OPCs derived from the DLB group (FDRHMAGMA = 0.022) and PD genetic risk and genes highly expressed in oligodendrocytes (a cell type of increasing interest to the PD field [5, 22]) derived from the control group (FDRHMAGMA = 0.013).

Genetic associations with top 10% most cell-type-specific genes and cell-type-specific differentially expressed genes. Genetic associations using a top 10% most cell-type-specific genes in each disease group and b cell-type-specific differentially expressed genes in disease comparisons with controls. Two methods were used to identify associations: Hi–C-coupled MAGMA (H-MAGMA) and stratified LD score regression (sLDSC). The heatmap is coloured by degree of significance with both or either method, with * and ** indicating nominal significance (unadjusted p value < 0.05) or significance (FDR-corrected p value < 0.05; corrected for number of cell types tested). Results available in Supplementary Table 8. AD Alzheimer’s disease, OPC oligodendrocyte precursor cell
Using cell-type-specific DE genes, we identified a significant association between genetic determinants of PD age of onset and genes found DE in astrocytes and OPCs from comparisons of PD with control (astrocytes, FDRLDSC = 0.0085; OPCs, FDRLDSC = 0.0085; Fig. 5b). Splitting differentially expressed genes by their direction of effect showed that this signal was driven by up-regulated genes (Supplementary Fig. 11). In addition, we identified a nominal association using both methods between PD genetic risk and genes found DE in oligodendrocytes from comparisons of PD with control (PHMAGMA = 0.011, PLDSC = 0.041; Fig. 5b), which was driven by up-regulated genes (FDRHMAGMA = 0.013, PLDSC = 0.044; Supplementary Fig. 11). Finally, we noted that genes up-regulated in excitatory neurons from comparisons of PDD with control were significantly associated with PD genetic risk (FDRLDSC = 0.040; Supplementary Fig. 11).
Differential splicing distinguishes PDD from DLB and highlights the role of specific RNA-binding proteins
Given the limitations of single-nucleus RNA-sequencing in the detection of splicing, we applied Leafcutter to our bulk-tissue RNA-sequencing to assess differential splicing (DS) [65]. Leafcutter captures changes in local splicing events through construction of intron clusters, wherein overlapping introns are connected by the splice junction(s) they share. We identified a total of 4656 DS intron clusters in 3751 genes (FDR < 0.05, |∆PSI|≥ 0.1; Supplementary Table 9) across all pairwise comparisons, with the highest number identified in comparisons of DLB with control or PD (Supplementary Fig. 12a). Notably, between 28 and 32% of DS events were partially annotated with respect to the reference transcriptome, with splicing events including novel donor or acceptor splice sites, novel exon skip and novel combination events (Supplementary Fig. 13a, b). We were, however, able to detect these events in larger control cohorts suggesting that they represent biologically relevant splicing (Supplementary Note, Supplementary Fig. 13c, d).
DS genes showed a significant enrichment in oligodendrocytes across comparisons of all disease groups with the control group (i.e. these genes had higher expression in oligodendrocytes than expected by chance), an observation that we replicated using the same external PD case–control bulk-tissue RNA-sequencing dataset used in replication of deconvolution results (Fig. 6a, Supplementary Note, Supplementary Fig. 15a, Supplementary Table 10). In contrast, enrichments in other cell types appeared to be disease specific (Fig. 6a). For example, only genes found DS in comparisons of PD with control or DLB with PD enriched in astrocytes. Notably, as the only pairwise comparison, DS genes from DLB compared with PDD consistently enriched in all excitatory neuron annotations. Pathway enrichments were observed across 4 of 6 pairwise comparisons (no enrichments were observed in comparisons of PD or PDD with control; Supplementary Fig. 12b, Supplementary Table 11). Pathways that were shared across comparisons of DLB with control, PD and PDD, included terms related to endosomes and enzyme activity (in particular, GTPase activity), mirroring terms highlighted both by replication analyses and by pathway analysis of single-nucleus DE genes (Fig. 6b, Supplementary Note, Supplementary Fig. 12b, Supplementary Fig. 15b).

Cell-type enrichments of differentially spliced genes and pathway sharing across analyses. a Enrichment of the top 100 differentially spliced genes (FDR < 0.05, |∆PSI| ≥ 0.1, with rank determined by |∆PSI|) in cell types derived from each disease group. Enrichments were determined using expression-weighted cell-type enrichment (EWCE). The x-axis denotes the disease status of the cell type in question, while the y-axis denotes the groups compared in the differential splicing analysis. Pairwise comparisons have been grouped by whether diseased individuals are compared with control individuals (Ref: control) or other diseased individuals (Ref: disease). Tiles were coloured by standard deviations (s.d.) from the mean, which indicate the distance (in s.d.) of the target list from the mean of the bootstrapped samples. Multiple test correction was performed across EWCE results using FDR. Non-significant results (FDR > 0.05) were coloured white. ***FDR < 0.001; **FDR < 0.01; *FDR < 0.05. All results available in Supplementary Table 10. b Clustering of shared pathway enrichments using genes identified across the three main analyses (represented by grey bar entitled, “Analysis”). These included: bulk-tissue differential splicing (“Bulk DS”, Supplementary Fig. 12); gene contributions to bulk-tissue gene expression PC1 (“Bulk PC”, Supplementary Fig. 6); and single-nucleus differential expression (“snRNA DEG”, Fig. 3). Pathways (in rows) from all three analyses were filtered to include only those that appear across more than one type of analysis. Pathways are ordered from highest to lowest by the number of gene sets in which they are enriched (as displayed in the bar plot on the right-hand side). Gene sets (in columns) are clustered using hierarchical clustering on the Pearson correlation between gene sets (pathways were encoded with a binary 1 for “Present” or 0 for “Absent”, represented on the plot by black and white, respectively). Gene sets derived from differential splicing (Bulk DS) were collapsed across our own dataset and the replication dataset, resulting in one gene set (column) per pairwise comparison. Likewise, gene sets derived from up- and down-regulated single-nucleus DE gene sets were collapsed across cell types (represented by the coloured bar entitled, “Cell type”), such that each cell type was represented by a single column. Pathway overlaps using pairwise comparisons between disease groups are displayed in Supplementary Fig. 16. ∆PSI delta percent spliced in, GO gene ontology, OPC oligodendrocyte precursor cell
Visualisation of pathway sharing across gene sets derived from the three analyses (bulk-tissue differential splicing, gene contributions to bulk-tissue gene expression PC1 and single-nucleus differential expression) demonstrated limited sharing between the two bulk-tissue analyses (the exceptions being “presynapse”, “transport vesicle”, “coated vesicle”, and “endosome membrane”; Fig. 6b; Supplementary Fig. 16). Notably, pathway analysis of DS genes from DLB compared with PDD implicated a much wider breadth of pathways compared with pathway analysis of single-nucleus DE genes from the same comparison, and indeed, no pathways overlapped between the two analyses in this pairwise comparison (Supplementary Fig. 16). This observation suggests that differences between PDD and DLB are not sufficiently captured by consideration of gene expression alone.
Patterns of pathway sharing between each of the bulk-tissue analyses and single-nucleus differential expression highlighted highly shared terms related to synaptic function, unfolded protein binding, and vesicle transport. Of note, RNA splicing was (i) jointly implicated by differential splicing and single-nucleus differential expression derived from excitatory neurons, oligodendrocytes, astrocytes and microglia in comparisons of DLB with control and (ii) separately implicated by single-nucleus differential expression derived from excitatory neurons and oligodendrocytes in comparisons of PDD with control (Fig. 6b). Together with the abundant differential splicing observed, these results indicated that dysregulation of splicing factors may play a role in the pathogenesis of LBDs.
To further investigate this observation, we used a catalogue of known RNA-binding protein (RBP) binding motifs from the ATtRACT database [45], and defined introns by their proximal intronic regions (the 50 nt of an exon and 500 nt of an intron flanking the 5′ and 3′ splice sites), which are an important region for splicing regulation [80]. Proximal intronic regions from DS introns were compared with non-DS introns across each pairwise comparison, identifying a total of 4 RBP binding motifs with a significant enrichment in DS proximal intronic regions from at least one pairwise comparison (Supplementary Table 12). Among these was the consensus sequence GGGGGGG in DS proximal intronic regions from PDD comparisons with control (Bonferroni-adjusted p value = 0.000601; Supplementary Table 12). This sequence is targeted by 17 RBPs from the ATtRACT database (including several members of the hnRNP family, such as HNRNPC and FUS), as well as RBPs not included in the database, such as RBM25 [25, 36]. Notably, RBM25 was found DS across comparisons of PDD with control in our own dataset and the replication dataset (in-house, clu_26788, FDR-adjusted p value = 0.00653; SRP058181, clu_12260, FDR-adjusted p value = 0.0499; Supplementary Table 9). Furthermore, the consensus sequence GAAGGAA, targeted by HNRNPM, was enriched in DS proximal intronic regions from comparisons of DLB with control and PD (Bonferroni-adjusted p values, control vs DLB = 0.0141, PD vs DLB = 0.00133). Finally, two consensus sequences, CUGGAUU and CUAACCCUAA targeted by SRSF9 and PCBP2, respectively, were enriched in DS proximal intronic regions from comparisons of DLB with PDD (Bonferroni-adjusted p values, CUGGAUU = 0.000958, CUAACCCUAA = 0.0174). Of note, SRp30c (encoded by SRSF9) has been shown to interact with hTRA2-β (encoded by TRA2B) [110, 113], which targets the consensus sequence AAGAAGAAGAA, which we also found to be nominally enriched in DS proximal intronic regions from comparisons of DLB with PDD (Bonferroni-adjusted p value = 0.0865).
Overall, these results highlighted (i) the abundant levels of alternative splicing, particularly in PDD and DLB, with evidence to suggest that certain splicing factors may play a role in orchestrating these disease-related splicing changes and (ii) that differential splicing, particularly in comparisons of DLB with PDD, captures additional features of disease-related perturbations, which were not captured by single-nucleus differential gene expression.
Discussion
Here, we applied paired bulk-tissue and single-nucleus RNA-sequencing to transcriptomically profile PD, PDD and DLB. Using this approach, we (i) found transcriptional differences relative to controls for multiple cell types across the LBDs, with PDD and DLB more severely affected than PD; (ii) observed high levels of alternative splicing, particularly in PDD and DLB; and (iii) identified splicing factors, with links to other dementia-related neurodegenerative diseases, that may coordinate these disease-related splicing changes. Together, these results highlight transcriptomic commonalities and distinctions between the LBDs, which can be used to inform our understanding of the relationship between these three clinical disorders.
Existing transcriptomic studies of the LBDs have relied on bulk-tissue analyses and profiled each disease separately, limiting our understanding of the molecular landscape of these diseases individually and in relation to one another. In addition, few initiatives have addressed genome-wide assessment of splicing in this context, despite studies implicating alternative splicing as a disease mechanism in monogenic and sporadic forms of PD [31, 66], and complex disease, in general [64]. Using multiple sequencing and analytic approaches, our analyses had the potential to identify differences between the LBDs attributable to changes in cell-type proportions, cell-type-specific gene expression and bulk-tissue splicing. While we found that increases in microglial and vascular cell-type proportions were a feature of LBDs, these increases did not distinguish among the LBDs. Importantly, the observed microglial increase was consistent with results from: (i) an RNA-sequencing-based study of PD modelling cellular composition in the frontal cortex, where microglial and oligodendrocyte marker gene profiles were increased in PD compared to control [79] and (ii) a study of cell numbers and DNA content in LBD-affected brain regions, which showed an increased number of large-sized and all nuclei (implying gliosis) in the anterior cingulate cortex of LBD cases compared to controls [82]. In contrast to cell-type proportions, cell-type-specific differential gene expression and bulk-tissue differential splicing distinguished PD from the Lewy body dementias, with PDD and DLB demonstrating a higher degree of commonality. These results suggest that irrespective of when dementia onset occurs in the disease process it gives rise to similar end-stage, post-mortem transcriptomic signatures in the anterior cingulate cortex.
It is notable that bulk-tissue differential splicing (i) was a prominent feature of the LBDs; (ii) discriminated between PD and the Lewy body dementias; and (iii) provided evidence of relationships with other neurodegenerative diseases clinically associated with dementia. Enrichment analyses using DS genes associated with each of the three LBDs revealed shared cell-type associations, such as the differential splicing of genes highly expressed in oligodendrocytes, as well as disease-specific cell type and pathway associations. Indeed, splicing analyses highlighted pathways relating to GTPase activity and regulation across several pairwise comparisons involving DLB, perhaps due to their role in a range of cellular processes that have been implicated in PD, such as clearance of Golgi-derived vesicles through the autophagy–lysosome system, mitochondrial fission and fusion, and p38 MAPK signalling [12, 82]. RNA splicing was additionally associated with the Lewy body dementias, by both differential splicing and single-nucleus differential expression. To further investigate these observations, we assessed RBP binding motif enrichment to identify potential upstream regulators of splicing. All four significantly enriched RBP binding motifs were targeted by RBPs that have been implicated to varying degrees in neurodegenerative diseases, with HNRNPC implicated in AD [90], and FUS, HNRNPC, HNRNPM and PCBP2 associated with frontotemporal dementia (FTD) [11]. Furthermore, not only has PCBP2 (encoding hnRNP E2) been found to colocalise with TDP-43 pathology in specific pathological subtypes of FTD [57], but SRSF9 together with TRA2B are implicated in tau splicing [110]. Given that both Lewy body dementias are characterised by co-pathology [92, 99], including tau and TDP-43 pathology, we speculate whether dysregulation of splicing might be one of the drivers of this co-pathology. Further studies will be required to understand whether this is the case.
Looking at cell-type-specific differential gene expression, the most prominent difference between the LBDs was the widespread down-regulation of genes and pathways in the Lewy body dementias, as compared with PD. In genetic association analyses, these genes did not enrich for genetic determinants of PD age of onset or PD risk, suggesting that this down-regulation is a consequence of the disease process, as opposed to a cause. In contrast, up-regulated genes (identified primarily in comparisons of PD with control) enriched for genetic determinants of PD age of onset and PD risk, highlighting known (OPCs/oligodendrocytes [5, 22]) and new (astrocytes) cell types in PD pathogenesis. In fact, common to all three LBDs was the presence of transcriptional alterations across multiple cell types. While DE genes were found to be largely cell-type-specific (i.e. DE in only one cell type), these genes converged on similar pathways, with GO terms found to be perturbed across multiple cell types in a given case–control comparison. Restricting to genes and pathways genetically associated with PD (which arguably are more likely to be causal), we similarly saw multiple cell-type involvement across all three LBDs, albeit with some suggestion of a hierarchy of increasing perturbation in excitatory neurons and glia (i.e. PD < PDD < DLB). Together, these results suggest the involvement of multiple cell types in LBD pathogenesis, and potentially indicate a common regulatory response across cell types in each disease.
While we observed transcriptional alterations in multiple cell types, some cell types, such as excitatory neurons and oligodendrocytes, were more strongly impacted than others (most notably, excitatory neurons), implying some degree of selective vulnerability. In support of this observation, expression of SNCA (encoding α-synuclein, the major component of Lewy bodies [102]) in excitatory neurons from the Lewy body dementias, as compared with the control group, was marked by a decrease in the proportion of SNCA-expressing nuclei in PDD and a shift in the expression range of the top 10% highest expressing nuclei to lower values. While we recognise that this is an observational study, it is tempting to speculate that (i) variability in physiological levels of SNCA may impact on pathogenesis, an area of research that has received far less attention as compared with increased SNCA dosage [26, 66, 97, 100] and (ii) that the absence of cells expressing high physiological levels of SNCA may contribute to the selective vulnerability of subpopulations of excitatory neurons to Lewy body pathology.
There are several limitations to this work. Some of these, including the use of post-mortem tissue and the subsequent inability to distinguish differences that arise early in the disease course from those that arise later, are natural limitations. Others, however, emphasise key areas for future work; the most important are the study of one brain region in diseases that gradually affect multiple brain regions and the small size of the cohort used. Where possible, we attempted to validate results in larger independent control and case–control studies, but larger studies covering more brain regions will be needed in the continuing assessment of the LBDs.
Among technological limitations, a known issue in single-nucleus RNA-sequencing is the depletion of transcripts that preferentially enrich in the cytoplasmic compartment, such as transcripts that localise to neuronal dendrites [10] and signatures of microglial activation [104]. This limitation has implications both for differential gene expression, but also downstream deconvolution and indeed, the use of single-nucleus RNA-sequencing as a reference was found to decrease the performance of three deconvolution algorithms (including Scaden) on post-mortem human brain data [76]. This limitation stresses the importance of relating cell types defined by single-nucleus RNA-sequencing back to their spatial phenotypes, a process for which the emerging field of spatial transcriptomics will be instrumental in resolving [70]. Our results provide clear hypotheses to test using spatial transcriptomics both for cell-type-specific DE analysis and analysis of differential cell-type proportions.
Among methodological limitations, we recognise that RBP binding motif enrichment oversimplifies the biology of RBPs. A common feature of RBPs is the presence of multiple RNA-binding domains, which are thought to interact with repeating motifs spaced apart on pre-mRNA transcripts [36, 43]; this feature is not captured in the current analysis. Similarly, our analyses do not account for sequence context [36] (e.g. flanking nucleotide composition, repeated motifs, RNA structure) and thus cannot distinguish between RBPs that bind similar motifs. Developing tools that could address this in silico represents an opportunity to identify additional regulators of splicing in the LBDs.
In summary, our comprehensive transcriptomic analysis of all three LBDs highlights the complex, multi-cell-type transcriptional response to Lewy body pathology and LBD co-pathologies. Furthermore, it identifies post-mortem molecular signatures in the anterior cingulate cortex that distinguish PD from the two Lewy body dementias, such as perturbation of RNA splicing, a mechanism linked to several dementia-related neurodegenerative diseases. Together, these findings have important implications for the design of RNA-targeted therapies for these diseases and highlight a potential molecular “window” of therapeutic opportunity between the initial onset of PD and subsequent development of Lewy body dementia.
Materials and methods
Sample selection
Individuals with clinical parkinsonism and/or dementia with Lewy bodies (DLB) and pathologically confirmed PD were obtained from the Parkinson’s UK Tissue Bank. Clinical assessment of individuals was carried out on clinical notes collated retrospectively using records from movement disorder neurologists, neurosurgeons, psychiatrists, geriatricians, PD nurse specialists and general practitioners. Clinical parkinsonism was defined using the current MDS task force criteria [88] and Lewy body dementia by the most recent clinical diagnostic criteria for PDD and DLB [38, 74]. The 1-year rule, alongside positive clinical features for DLB (spontaneous parkinsonism, REM sleep behaviour disorder, fluctuating cognition and complex visual hallucinations) were used to separate individuals with PDD and DLB. Pathologic assessment was performed on representative tissue sections from recommended brain regions in the Braak α-synuclein [20] and Braak tau [19] staging systems as part of the routine diagnostic process for the Parkinson’s UK Tissue Bank. A maximum Braak tau stage of 3 was used to filter out individuals with excessive Alzheimer’s pathology, thus ensuring that dementia in these individuals arose from α-synucleinopathy. PD without cognitive impairment was defined either by (i) a lack of evidence of positive cognitive features, such as memory impairment, executive dysfunction and visuo-spatial dysfunction in retrospective clinical case notes or (ii) where positive cognitive features were reported present, cognitive impairment was ruled out based on objective cognitive testing or positive cognitive features were proven to be adverse effects of medication. In addition, where possible, individuals were selected based on a post-mortem interval of less than 24 h to ensure optimal tissue quality for nuclear extraction. In total, 7 PD, 7 PDD and 7 DLB individuals were selected, matched where possible for demographic and pathologic factors, along with 7 age-matched non-neurological control individuals. Control individuals were defined by a lack of clinical neurological features and no definitive pathological diagnoses. To ensure consistency, a cutoff of Braak tau stage 3 was also used for control individuals. The severity of α-synuclein pathology in the anterior cingulate was graded semi-quantitatively from 0 to 3 based on the validated scoring system from Alafuzoff et al. [6] Furthermore, Lewy pathology (i.e. Lewy bodies and Lewy neurites) was scored using the most recent LP consensus criteria [9]. For each individual, a tissue block of cortical grey matter from the anterior cingulate was sectioned at 80 µm thickness. Adjacent sections were subsequently used for bulk-tissue RNA isolation (2 sections per sample) or isolation of nuclei for single-nuclei RNA-sequencing. Clinical, pathological and sample measures for the cohort are available in Supplementary Table 1.
Isolation of nuclei
Nuclei were isolated using buffers prepared as in Krishnaswami et al. [60], including nuclei isolation medium #1 (NIM1), nuclei isolation medium #2 (NIM2), Homogenisation Buffer (HB), 29% and 50% vol/vol iodixanol dilutions. Briefly, brain tissue sections were suspended in 800 µL HB and homogenised in a pre-cooled 2 mL dounce homogeniser, with five strokes of the loose pestle, followed by 10–15 strokes with the tight pestle. The homogenate was filtered through a BD Falcon tube with a cell strainer cap (35 µm) and centrifuged at 1000g for 8 min. Thereafter, nuclei were subjected to an additional clean-up step (density gradient centrifugation), as detailed in Krishnaswami et al., albeit with centrifugation of the layered nuclei/29% iodixanol solution at 13,000g for 40 min at 4 °C. The supernatant was carefully removed, and the nuclei pellet washed with PBS buffer (PBS + 1% BSA + 0.2 U/ml RNAseIn), filtered through a BD Falcon tube with a cell strainer cap, centrifuged at 500g for 5 min at 4 °C and washed again. Nuclei were counted using an LUNA-FL Dual Fluorescence Cell Counter (Logos Biosystems, L20001) using Acridine orange dye to stain nuclei.
Nuclei encapsulation and single-nucleus RNA-sequencing data generation
All samples were processed as per 10× Genomics Chromium Single Cell Reagent Kits Protocol (chemistry: Single Cell 3′ v2). Following manufacturer’s guidelines, the samples were processed to target 10,000 nuclei per sample. Briefly, we performed 8 cycles of cDNA amplification and 14 cycles of final indexing PCR. cDNA concentrations were measured using Qubit dsDNA HS Assay Kit (ThermoFisher, Q32851), and cDNA and library preparations were assessed using the Bioanalyzer High-Sensitivity DNA Kit (Agilent, 5067-4627). All samples were pooled to equimolar concentration and sequenced together across 28 lanes on an Illumina Hi-Seq 4000.
Single-nucleus RNA-sequencing data processing
Sequenced reads were demultiplexed and processed using Cell Ranger (v 3.0.2) and thereafter mapped to the GRCh38 human reference genome using gene annotations from Ensembl v93 [35, 116]. Across each of the 28 sequenced samples, reads mapped to primary transcripts were summarised as counts. Droplets containing nuclei were distinguished from empty droplets (containing ambient RNA) using the EmptyDrops algorithm, as implemented in the R package DropletUtils (v 1.6.1) [69]. An ambient profile threshold of 300 UMI was used to determine the background RNA content of the empty droplets. Thereafter we removed nuclei with > 5% mitochondrial content and genes expressed in < 5 nuclei. Once low-quality nuclei had been filtered out, the dataset was normalised using the NormalizeData() function in Seurat (v 3.2.0) [103]. The default normalising method used by Seurat (version 3) is a global-scaling normalisation method, “LogNormalize”. The method normalises the gene expression values in each cell (n) by multiplying n by the total expression of the cell (a size factor of 10,000 for each cell is used by default) and log-transforming the result. After this normalisation step, we used Seurat’s pipeline to cluster the nuclei. First, distances were calculated between two nuclei with similar gene expression patterns using Euclidean algorithm and edges were drawn. Second, a Louvain algorithm was used to cluster the nuclei. Finally, clustering was carried out using the FindClusters() function using 30 principal components (PCs) and a resolution parameter of 2. The clustered cells were tested to remove barcodes with more than 1 nuclei encapsulated in the droplet using DoubletFinder (v 2.0.2), with the expected proportion of doublets set at ~ 7% [72].
Cell-type identification
The remaining nuclei were visualised using a non-linear dimensionality reduction algorithm known as Uniform Manifold Approximation and Projection (UMAP, v 0.1.10) [73]. We then used the Wilcoxon rank sum test (FDR < 0.05) implemented in the Seurat function FindAllMarkers() to identify genes differentially expressed in one cluster compared with all other clusters. Cell types were assigned by testing genes differential to a particular cell type for enrichment (Fisher’s exact test) for cell-type markers from two human single-cell datasets [61, 109]. Nuclei classified as endothelial cells and pericytes were merged into one class referred to as vascular cells.
A joint graph of 205,498 nuclei from across all individuals from each of their respective filtered datasets (referred to as the panel of datasets) was generated using the R package, Clustering On Network Of Samples (Conos, v 1.1.2) [13]. This was done to bring panel datasets into a common expression space accounting for technical differences between datasets, which could be used for downstream cell-type-specific differential expression analyses between disease groups. buildGraph() was used to construct a graph with parameters for nearest neighbour parameters set at k = 30, k.self = 5, in space of 30 CPCA (common principal component). The embedGraph() function was used to partition cells into 7 clusters for the 7 broad cell types.
Bulk-tissue RNA-sequencing data generation
RNA isolation was performed by the commercial company, BioXpedia A/S. Samples were lysed with QIAzol and RNA extracted using the RNeasy 96 Kit (Qiagen) with an optional on-membrane DNase treatment, as per manufacturer instructions. Samples were thereafter quantified by absorption on the QIAxpert (Qiagen) and their RNA integrity number (RIN) assessed using the Agilent 4200 Tapestation (Agilent). RIN ranged from 1.6 to 7.8, with a median of 6.5. Only samples derived from tissue-sections with a RIN ≥ 4.2 were included in downstream RNA sequencing. As a result, only 24 samples were sequenced (5 controls, 7 PD, 6 PDD and 6 DLB; Supplementary Table 1). 250 ng of total RNA was used as input for cDNA library construction with the TruSeq Stranded mRNA Sample Preparation Kit (Illumina), as per manufacturer instructions. To minimise read mis-assignment in downstream sample de-multiplexing, xGen UDI-UMI Adapters (Integrated DNA Technologies, Inc.) were used. Libraries were multiplexed on the NovaSeq S2 Flow Cell (the same 24 libraries were run across both lanes) for paired-end 100 bp sequencing on the NovaSeq 6000 Sequencing System (Illumina) to obtain an average read depth of ~ 180 M paired-end reads per sample.
Bulk-tissue RNA-sequencing data processing
Fastp (v 0.20.0), a fast all-in-one FASTQ pre-processor, was used for adapter trimming, read filtering and base correction [28]. Fastp default settings were used for quality filtering and base correction. Processed reads were mapped to the GRCh38 human reference genome via STAR (v 2.7.0a) using gene annotations from Ensembl v97 [35, 116]. Multi-sample 2-pass mapping was used, wherein two rounds of mapping were performed to improve the sensitivity of novel splice junction detection. ENCODE standard options for long RNA-seq were used, with the exception of (i) -outFilterMultimapNmax, which was set to 1, thus retaining only uniquely mapped reads and (ii) -alignSJDBoverhangMin, which was set to the STAR default of a minimum 3 bp overhang required for an annotated spliced alignment. Processed reads were also quantified with Salmon (v 0.14.1) using the mapping-based mode, with sequence-specific, fragment GC-content and positional bias correction options enabled (-seqBias, -gcBias, -posBias) [86]. A decoy-aware transcriptome file based on GRCh38 and Ensembl v97 was generated using MashMap2 (v 2.0) [53] and used as a reference together with the appropriate option for the sequencing library type (-libType ISF). The R package tximport (v 1.14.2) was used to transform Salmon transcript-level abundance estimates to gene-level abundance estimates [101]. Genes found to overlap ENCODE blacklist regions were removed from downstream analyses (“Key resources”) [7]. Pre-alignment quality control metrics were generated using Fastp and FastQC (v 0.11.8) [8], and post-alignment quality control metrics using RSeQC (v 2.6.4) [111]. Pipeline source code can be found in https://github.com/RHReynolds/RNAseqProcessing.
Processing of PD case–control replication dataset
Replication of several downstream bulk-tissue RNA-sequencing analyses were performed using a PD case–control bulk-tissue RNA-sequencing dataset provided by Dumitriu et al. [37] and processed for re-use by recount2 [32]. The dataset was accessed via recount2 (recount accession ID: SRP058181). The original study contained RNA-sequencing of prefrontal cortical samples (Brodmann Area 9) derived from 44 control individuals and 29 individuals with PD. Paired-end 101-bp sequencing was applied to each sample, with a mean depth of 83.3 million read pairs per sample. All samples were of a reasonably high quality, with RIN values ranging from 5.8 to 9.1 and a median of 7.6. Accessed samples were checked for any mismatch between the reported sex of brain donors and the sex as determined by the expression of sex-specific genes (XIST and DDX3Y). As a result, one control sample was removed (recount sample ID: SRR2015746; study sample ID: C0061); the sample was reported to be male, but notable expression of XIST was observed. Furthermore, as sample demographics from the original study included whether PD patients were diagnosed with dementia, the 29 PD cases were split into those with and without dementia (PD, n = 18; PDD, n = 11).
Deconvolution
Cell-type proportions in bulk-tissue RNA-sequencing samples were estimated using Scaden (v 0.9.2), a deep-learning-based deconvolution algorithm [76]. Unlike linear-regression-based deconvolution algorithms, Scaden does not require cell-type-specific gene expression profiles. Instead, Scaden trains on artificial bulk-tissue RNA-sequencing samples simulated from tissue-specific single-cell RNA-sequencing data, after which the model is used to predict cell-type proportions from real bulk-tissue RNA-sequencing samples. In this study, training data was generated separately for each individual with paired single-nucleus RNA- and bulk-tissue RNA-sequencing, allowing Scaden to capture cross-subject heterogeneity. This yielded a total of 24,000 artificial bulk-tissue RNA-sequencing samples (1000 samples per individual). Prior to generation of training data, single-nucleus RNA-sequencing counts per cell were normalised using the total counts over all genes, ensuring that every cell had the same total count after normalisation. Thereafter, artificial bulk-tissue RNA-sequencing samples were simulated using the Scaden bulk_simulation.py script, which sub-samples cells from input single-nucleus RNA-sequencing data and then aggregates expression across sub-sampled cells. Here, 1000 cells were used per simulated sample. Artificial bulk-tissue RNA-sequencing samples were combined and stored in a h5ad file, using the Scaden create_h5ad_file.py script. To ensure generated training data and bulk-tissue RNA-sequencing samples (in the form of counts normalised by library size) for prediction shared the same features (genes) and feature scale, both datasets were pre-processed with scaden process (the two datasets shared a total of 13,191 genes following processing). Following this, each of the three Scaden ensemble models was independently trained (scaden train) for 5000 steps, as recommended by the developers to prevent overfitting, using the default values for batch size and learning rate [76]. Finally, predictions for cell-type proportions were made with scaden predict.
Replication of predicted cell-type proportions was performed using a second independent PD case–control dataset accessed from recount2 (see “Processing of PD case–control replication dataset”). As the Scaden algorithm requires that training data and prediction data have a perfect overlap of features, it was necessary to re-perform pre-processing with scaden process (using library-normalised counts from the replication dataset; the two datasets shared a total of 14,094 genes following processing) and to train a new model (using the same parameters as previously). In both datasets, significant differences in cell-type proportions between disease groups were a two-sided Wilcoxon rank sum test, with FDR-correction for multiple testing.
Bulk-tissue RNA-sequencing covariate selection
Sources of variation in bulk-tissue RNA-sequencing data were identified using principal component analysis (PCA) performed on gene-level expression filtered to include only genes with count > 0 in all samples (28,692 genes) and transformed with DESeq2’s vst(), which applies a variance stabilising transformation. RIN and age of death were significantly correlated with the first and second PC, respectively. Furthermore, cell-type proportions for excitatory and inhibitory neurons, microglia and astrocytes were significantly correlated with the first, third and fourth PC, respectively. Thus, the final model for differential expression and splicing (referred to as the “cell-type- and covariate-corrected” model) consisted of the disease group and the top 4 PCs (which collectively explained 52.6% of the total variance).
To explore the effect of accounting for cell-type proportions, vst-transformed gene expression was batch-corrected using the final “cell-type- and covariate-corrected” model or a minimised “covariate-corrected” model consisting of disease group, age of death, RIN and sex. Samples were thereafter plotted by their first two principal components to determine how well disease groups separated (Supplementary Fig. 6). Batch correction was performed using the removeBatchEffect() function from the R package, limma (v 3.42.2) [91]. Prior to correction, covariates to be used in the model were scaled to ensure that variables that are measured on different scales (e.g. age of death vs RIN) are comparable.
As in the original study [37], the final model for the replication dataset (see “Processing of PD case–control replication dataset”) included disease group and the covariates age of death, RIN and post-mortem interval (PMI). In addition, cell-type proportions for all cell types were included in the final model, as these were significantly correlated with several of the top 8 PCs.
Differential gene expression
Single-nucleus RNA-sequencing
We used Model-based Analysis of Single-cell Transcriptomics (MAST, v 1.12.0), a method specifically designed to carry out differential expression analysis, on our single-nucleus RNA-sequencing data [40]. MAST is a two-part, generalised linear model. The first part of the model uses logistic regression to model whether a gene is expressed i.e. the discrete rate of expression of each gene over the background of other transcripts. The second part of the model models the level of expression (conditional on whether a gene is expressed in a cell) using a Gaussian linear model. Information from both parts of the model are combined to model changes in gene expression levels and with control for multiple sources of variation, such as cell–cell variation. MAST also models the cellular detection rate, which is defined as the fraction of genes that are detectably expressed in each cell. The cellular detection rate acts as a substitution for both technical and biological factors, such as dropout, cell volume and other extrinsic factors that could influence gene expression. Controlling for the cellular detection rate improves the sensitivity (true positive rate) and specificity (true negative rate) of MAST in the presence of confounding between the cellular detection rate and true biological signals.
To perform differential expression, cell-type-specific nuclei from each of the 28 filtered sample count matrices (see “Single-nucleus RNA-sequencing data processing”) were merged to create 7 cell-type count matrices. Genes that were expressed in ≤ 3 nuclei were removed from the analysis. Following this, differential expression analysis was performed separately for each cell type, across all pairwise combinations of the disease groups (n = 6). A likelihood ratio test was used, with age of death, post-mortem interval (PMI), and sex included as covariates. Genes with FDR < 0.05 and absolute fold-change > 1.5 were considered significant.
Bulk-tissue RNA-sequencing
Bulk-tissue differential gene expression was assessed using the DESeq2 R package (v 1.26.0) and gene-level expression filtered to include only genes with count > 0 in all samples (28,692 genes) [68]. With one exception (the maximum number of iterations allowed for convergence, maxit = 1000), default parameters were used, including the default Wald test of significance. Differentially expressed genes were identified in a pairwise manner, controlling for covariates identified using gene-level expression (see “Bulk-tissue RNA-sequencing covariate selection”). Multiple testing was performed by FDR-correction, with a cutoff of FDR < 0.05 applied for significance.
Differential splicing analysis
Differential splicing was assessed using Leafcutter (v 0.2.8), which detects splicing variation using sequencing reads with a gapped alignment to the genome (here, termed junction reads) [65]. Junction reads, which are presumed to represent intron excision events, are used to quantify intron usage across samples without any reliance on existing reference annotation. Importantly, Leafcutter does not estimate isoform abundance or exon inclusion levels, but rather captures changes in local splicing events through construction of intron clusters, wherein overlapping introns are connected by the splice junction(s) they share. As input, splice junctions outputted by STAR (SJ.out.tab) were first filtered to remove any regions that overlapped ENCODE blacklist regions (“Key resources”) [7] and thereafter converted to the .junc files used by Leafcutter for intron clustering. The conversion was performed using custom R code (convert_STAR_SJ_to_junc() in https://github.com/RHReynolds/RNAseqProcessing). Intron clusters were defined using Leafcutter’s leafcutter_cluster.py with thresholds ensuring the removal of: (i) introns supported by < 30 junction reads across all 24 samples or < 0.1% of the total number of junction read counts for the entire cluster and (ii) introns of more than 1 Mb. This yielded a total of 43,544 clusters encompassing 152,298 introns that were used for further analysis. Differentially spliced (DS) clusters were identified in a pairwise manner, controlling for covariates identified using gene-level expression (see “Bulk-tissue RNA-sequencing covariate selection”), and annotated to genes using exon files generated from GRch38 Ensembl v97 (with the Leafcutter helper script gtf_to_exons.R). As per Leafcutter default filters, only introns detected in ≥ 5 samples were tested and an intron cluster was only tested if detected in ≥ 3 individuals in each comparison group with an overall coverage of ≥ 20 junction reads. p values were FDR-corrected for multiple testing and an intron cluster and its overlapping gene were considered differentially spliced if (i) FDR < 0.05 and (ii) the intron cluster contained at least one intron with an absolute delta percent-spliced-in value (|∆PSI|) ≥ 0.1. The latter filter was applied to improve the specificity of Leafcutter [106].
Annotation of differential splicing events
Introns within intron clusters were annotated using annotate_junc_ref() from the R package Detecting Aberrant Splicing Events from RNA-sequencing (dasper, v 1.1.4) [117], which categorises junctions based on (i) whether the junction is present within the entire set of annotated introns or (ii) whether both, one of, or neither the donor and acceptor splice site precisely overlap the boundary of a known exon. For both checks, Ensembl v97 was used. When defining and clustering introns, leafcutter_cluster.py adds 1 bp to the end of a junction read; thus, to ensure optimal mapping to reference annotation, 1 bp was removed from all intron ends prior to use of annotate_junc_ref() using custom code (convert_leafcutter.R from https://github.com/RHReynolds/LBD-seq-bulk-analyses). Junctions (and the introns they represent) were then classified into one of the following categories: annotated, novel exon skip, novel combination, novel acceptor, novel donor, ambiguous gene and unannotated (“none”) (Supplementary Fig. 13). Annotated junctions are those that match the boundaries of an existing intron. Unannotated junctions have neither end overlapping a known exon. Novel acceptors and novel donors are junctions, where one end (acceptor or donor) matches the boundary of a known exon. Novel exon skip and novel combination junctions have both ends overlapping known exon boundaries, which are not part of the set of annotated introns. They are distinguished by whether their start or end overlaps exons derived from the same transcript. That is, for an event to be a novel exon skip, both the start and end must overlap an exon contained in the same transcript, whereas to be a novel combination, the start and end overlap exons are from different transcripts. Junctions that mapped to more than one gene (“ambiguous gene”) were not considered in downstream analyses.
Gene set enrichment
Functional enrichment of cell-type-specific differentially expressed genes
Functional term enrichment analysis for cell-type-specific differentially expressed genes from each pairwise comparison was performed using the overrepresentation analysis module from the R package implementation of WEB-based Gene SeT AnaLysis Toolkit (WebGestaltR, v 0.4.4) [67]. Two separate analyses were performed using (i) only non-redundant Gene Ontology (GO) terms (which are generated by selecting the most general terms in each branch of the GO directed acyclic graph structure from all terms with 20–500 genes) and (ii) 46 biological pathways associated with PD risk in a large-scale pathway-specific polygenic risk analysis [12]. For both analyses, default values for WebGestalt parameters were used, which include a minimum and maximum overlap of 10 and 500, respectively. FDR-correction for multiple testing was performed, and significant pathways were those with FDR < 0.05.
Functional enrichment of differentially spliced genes
Gene set enrichment for GO terms was performed using enrichGO() and clusterCompare() from clusterProfiler (v 3.14.3), which permit GO enrichment analysis (based on a hypergeometric distribution) and comparison across multiple gene lists [115]. Two separate analyses were run using (i) all differentially spliced genes (FDR < 0.05, |∆PSI|> = 0.1) across each pairwise comparison in the discovery dataset and (ii) genes overlapping validated intron clusters with ≥ 1 intron that shared the same direction of effect. In both analyses, default parameters were used; these included FDR-correction for multiple testing and filtering for terms with FDR < 0.05.
Functional enrichment of genes associated with bulk-tissue gene expression principal components
Genes contributing to PC1, following batch correction of cell-type proportions (as described in “Bulk-tissue RNA-sequencing covariate selection”), were extracted using get_pva_var() from the R package, factoextra (v 1.0.7). The top 100 genes contributing to gene-expression-derived PC1 were used for gene set enrichment with enrichGO() from clusterProfiler [115]. Default parameters were used, which included FDR-correction for multiple testing and filtering for terms with FDR < 0.05.
Visualisation of GO term overlaps between analyses
Overlapping GO-derived pathway enrichments from each of the three analyses (i.e. single-nucleus differential expression, bulk-tissue differential splicing, and gene expression contributions to bulk-tissue PC1) were visualised using the ComplexHeatmap R package (v 2.7.7) [47]. Pathways from all three analyses were filtered to include only those that were shared across more than one type of analysis. Pathways were encoded by a binary 1 and 0 for present and absent, respectively, permitting clustering of gene sets by Pearson correlation. Gene sets derived from differential splicing were collapsed across our own dataset and the replication dataset, resulting in one gene set per pairwise comparison. Likewise, gene sets derived from up- and down-regulated single-nucleus DE gene sets were collapsed across cell types, resulting in 7 gene sets per pairwise comparison.
Reduction of GO terms using semantic similarity
To reduce redundancy across GO-derived pathway enrichment analyses derived from various analyses (i.e. single-nucleus differential expression, bulk-tissue differential splicing, genes contributing to bulk-tissue PC1), two steps were taken. First, GO terms were filtered to exclude terms with ≥ 20 genes or ≤ 2000 genes. Second, semantic similarity of all enriched GO terms was calculated using mgoSim() from the GOSemSim R package (v 2.17.1) [114] and a graph-based measure of semantic similarity (measure = “Wang”) [108]. Thereafter, reduceSimMatrix() from the rrvgo R package (v 1.1.4) was used to reduce terms [94]. This function reduces terms by generating a distance matrix from the semantic similarity scores, which is hierarchically clustered using complete linkage (a “bottom-up” clustering approach). Both steps were combined into the function go_reduce(), available at: https://github.com/RHReynolds/rutils. The hierarchical tree was then cut at a threshold of 0.9 (leading to fewer groups), and the term with the highest semantic similarity score was used to represent each group of terms. This reduction was performed separately for each of the three analyses.
Cell-type enrichment of differentially spliced genes
Expression-weighted cell-type enrichment (v 0.99.2) was used to determine whether differentially spliced genes demonstrate higher expression in certain cell types than would be expected by chance [98]. EWCE requires two inputs: a gene list and gene cell-type specificity values derived from single-cell/nucleus data (here, termed a specificity matrix). Two sets of gene lists were run. The first set of gene lists included the top 100 differentially spliced genes (FDR < 0.05, |∆PSI|> = 0.1, ranked by p value) across each pairwise comparison in the discovery dataset. In the case, where a gene had multiple significant intron clusters, the most significant cluster with the highest |∆PSI| was used for ranking. The second set of gene lists included genes overlapping validated intron clusters with ≥ 1 intron that shared the same direction of effect. Both sets of gene lists were run together with gene cell-type specificity values separately derived from each disease group (i.e. control, PD, PDD and DLB); specificity matrices were generated for cell types in each disease group using the generate.cell.data() function of the EWCE package. For each combination of gene list and specificity matrix, 100,000 bootstrap replicates were used. Transcript length and GC-content biases were controlled by selecting bootstrap replicates with comparable properties to the target gene lists. Data are displayed as standard deviations from the mean, which indicate the distance of the mean expression of the target gene list from the mean expression of the bootstrap replicates.
RNA-binding protein binding motif analysis
Generating sequences
Two sets of sequences were generated per pairwise comparison. These sets included all differentially spliced introns (FDR < 0.05, |∆PSI|) and non-differentially spliced introns (FDR > 0.05), as defined by their 5′ and 3′ proximal intronic regions (500 nucleotides of proximal intron and 50 nucleotides of exon flanking the 5′ and 3′ splice sites). A 5′ or 3′ splice site could be associated with more than one intron (e.g. in the case of two introns with the same 5′ splice site, but varying 3′ splice sites), and thus could be associated with more than one |∆PSI| value. In these cases, the highest |∆PSI| was assigned to the proximal intronic region.
Enrichment of RBP binding motifs
The position weight matrices (PWMs) of RBP binding motifs in humans were collected from the ATtRACT database (v 0.99β) [45]. Motifs < 7 nucleotides in length and with a quality score of < 1 were removed to reduce false positives in the motif matches (quality score estimates the binding affinity between RBPs and binding sites). Furthermore, to remove redundancy between multiple motifs for one RBP, the longest available motif was selected. Finally, RBPs that had a median TPM of 0 in GTEx (v 8) anterior cingulate cortex samples were removed (e.g. RBMY1A1) [46]. This resulted in 82 unique PWMs, which were used to identify enrichment of RBP binding motifs. Analysis of Motif Enrichment (AME, v 5.1.1) [75] was used with default parameters (-scoring avg) to compare enrichment of RBP binding motifs between differentially spliced and non-differentially spliced proximal intronic regions. RBP binding motifs with an enrichment-optimised and Bonferroni-adjusted p < 0.05 were considered to be significantly over-represented in differentially spliced proximal intronic regions compared with non-differentially spliced proximal intronic regions.
Integration with GWAS
To test for enrichment of genetic association of a gene set to a trait we employed two orthogonal methods, Hi–C-coupled Multi-marker Analysis of GenoMic Annotation (H-MAGMA) [96] and stratified LD score regression (sLDSC) [41]. Both methods were run with two sets of annotations: (i) the top 10% most cell-type-specific genes, as determined using specificity values derived from EWCE (see “Cell-type enrichment of differentially spliced genes”) and (ii) cell-type-specific differentially expressed genes (FDR < 0.05, |log2(fold change)|> log2(1.5)). These annotations were run with 3 genome-wide association studies (GWASs), including Alzheimer’s disease (AD), Parkinson’s disease (PD) and Parkinson’s disease Age of Onset (PD AOO) (Table 1) [15, 54, 77] In both analyses, p values were FDR-corrected for the number of cell types tested.
H-MAGMA
Hi–C-coupled MAGMA (H-MAGMA) (v 1.08b of MAGMA [63]) was used to carry out gene-set enrichment analysis using three GWAS summary statistics. Gencode v26 (“Key resources”) was used to assign exonic SNPs and promoter SNPs, which is defined as 2 kb upstream of the transcription start site (TSS), to their target genes based on their genomic location. Chromatin interactions to exons and promoters generated from Hi–C performed on adult dorsolateral prefrontal cortex, were used to assign intergenic and intronic SNPs to their cognate genes [96]. Gene-level association statistics were computed using window coordinates of 10 kb downstream and 35 kb upstream.
sLDSC
Stratified LDSC (v 1.0.1) was used to test whether cell-type-specific DE genes or the top 10% most cell-type-specific genes contributed to the common SNP heritability of AD, PD or PD AOO [24, 42]. To ensure gene lists were sufficiently large, only gene lists with more than 20 genes were run. Gene coordinates (Ensembl v97, GRCh38) were extended by 100 kb upstream and downstream of their transcription start and end site, to capture regulatory elements that might contribute to disease heritability [42]. All annotations were constructed in a binary format (1 if the SNP was present within the annotation and 0 if not), using all SNPs with a minor allele frequency > 5%. Annotations were then added individually to the baseline model of 53 annotations provided by Finucane et al. (v 1.2, GRCh38), comprising genome-wide annotations reflecting genetic architecture. As annotations and the baseline model were mapped to GRCh38, all GWAS summary statistics were converted from GRCh37 to GRCh38 using the R implementation of the LiftOver tool, which is available from the rtracklayer package (v 1.46.0) [62]. HapMap Project Phase 3 (HapMap3) SNPs and 1000 Genomes Project Phase 3 European population SNPs were used for the regression and LD reference panels, respectively [1, 51]. The MHC region (chr6: 25,000,000–34,000,000, GRCh38) was excluded from all analyses owing to the complex and long-range LD patterns in this region. For all stratified LDSC analyses, we report a one-tailed p value (coefficient p value) based on the coefficient z-score outputted by stratified LDSC. A one-tailed test was used as we were only interested in annotation categories with a significantly positive contribution to trait heritability, conditional upon the baseline model.
Key resources
Resource | Source/reference | Identifier/URL |
|---|---|---|
Biological Samples | ||
Frozen human anterior cingulate cortex samples | Parkinson’s UK Tissue Bank | |
Critical Commercial Assays | ||
Chromium Single Cell 3’ Gene Expression Kit, v2 | 10 × Genomics | PN-120237 |
Qubit dsDNA HS Assay Kit | ThermoFisher | Q32851 |
Bioanalyzer High-Sensitivity DNA Kit | Agilent | 5067-4627 |
QIAzol | Qiagen | 79306 |
RNeasy 96 Kit | Qiagen | 74181 |
TruSeq Stranded mRNA Library Prep Kit | Illumina | 20020594 |
xGen UDI-UMI Adapters, 1–96 | Integrated DNA Technologies | 10005903 |
Deposited Data | ||
ATtRACT database (v 0.99β) | Giudice et al., 2016 [45] | |
Cell-type marker genes | Wang et al., 2018 | http://resource.psychencode.org/ (DER-21_Single_cell_markergenes_UMI.xlsx) |
ENCODE blacklist regions (v 2) | Amemiya et al., 2019 [7] | https://github.com/Boyle-Lab/Blacklist/blob/master/lists/hg38-blacklist.v2.bed.gz |
Ensembl GRCh38 Ensembl v97 | Ensembl genome browser | ftp://ftp.ensembl.org/pub/release-97/gtf/homo_sapiens/Homo_sapiens.GRCh38.97.gtf.gz |
H-MAGMA: Hi-C gene-SNP pairs for adult dorsolateral prefrontal cortex | Sey et al., 2020 [96] | https://github.com/thewonlab/H-MAGMA/blob/master/Input_Files/Adult_brain.genes.annot |
Gencode v26 | ||
GTEx portal (v 8) | GTEx Consortium, 2015 [46] | |
LDSC baseline annotations (v 1.2) | Finucane et al., 2015 [41] | |
PD-associated genes | Blauwendraat et al., 2020 [16] | |
PD-associated pathways | Bandres-Ciga et al., 2020 [12] | |
Recount2 | Collado-Torres et al., 2015 [32] | |
Software and Algorithms | ||
Analysis of Motif Enrichment (AME, v 5.1.1) | McLeay et al., 2010 [75] | |
Bulk-tissue RNA-sequencing pipeline | ||
Cell Ranger (v 3.0.2) | 10 × Genomics | https://support.10xgenomics.com/single-cell-gene-expression/software/pipelines/latest/installation |
clusterProfiler (v 3.14.3) | Yu et al., 2012 [115] | |
Conos (v 1.1.2) | Barkas et al., 2019 [13] | |
ComplexHeatmap (v 2.7.7) | Gu et al., 2016 [47] | |
DESeq2 (v 1.26.0) | Love et al., 2014 [68] | |
Detecting Aberrant Splicing Events from RNA-sequencing (dasper, v 1.1.4) | Zhang et al., 2021 [117] | |
DoubletFinder (v 2.0.2) | McGinnis et al., 2019 [72] | |
DropletUtils (v 1.6.1) | Lun et al., 2019 [69] | |
EWCE (v 0.99.2) | Skene et al., 2016 [98] | |
Factoextra (v 1.0.7) | ||
Fastp (v 0.20.0) | Chen et al., 2018 [28] | |
FastQC (v 0.11.8) | Andrews et al., 2010 [8] | |
GoSemSim (v 2.17.0) | Yu et al., 2010 [114] | |
ggplot2 (v 3.3.2) | ||
LDSC (v 1.0.1) | Bulik-Sullivan et al., 2015 [23] | |
Leafcutter (v 0.2.8) | Li et al., 2018 [65] | |
Limma (v 3.42.2) | Ritchie et al., 2015 [91] | |
MAGMA (v 1.0.8b) | de Leeuw et al., 2015 [63] | |
MashMap2 (v 2.0) | Jain et al., 2018 [53] | |
MAST (v 1.12.0) | Finak et al., 2015 [40] | |
recount (v 1.11.8) | Collado-Torres et al., 2015 [32] | |
rrvgo (v 1.1.4) | Sayols et al., 2020 [94] | |
RSeQC (v 2.6.4) | Wang et al., 2012 [111] | |
rtracklayer (v 1.46.0) | Lawrence et al., 2009 [62] | |
rutils (v 0.99.2) | ||
Salmon (v 0.14.1) | Patro et al., 2017 [86] | |
Seurat (v 3.2.0) | Stuart et al. 2019 [103] | |
Scaden (v 0.9.2) | Menden et al., 2020 [76] | |
STAR (v 2.7.0a) | Dobin et al., 2013 [35] | |
Tximport (v 1.14.2) | Soneson et al., 2015 [101] | |
UMAP (v 0.1.10) | McInnes et al., 2018 [73] | |
WebGestaltR (v 0.4.4) | Liao et al. [67] | |
Data availability
Bulk-tissue RNA-sequencing data can be accessed through the European Genome–phenome Archive (study ID: EGAS00001005305). Single-nucleus RNA-sequencing can be accessed through the Gene Expression Omnibus (accession ID: GSE178146).
Code availability
Code used to process and analyse bulk-tissue RNA-sequencing data, to generate sLDSC outputs, and to generate figures for the manuscript is available at: https://rhreynolds.github.io/LBD-seq-bulk-analyses/. Code used to process and analyse single-nucleus RNA-sequencing data and to generate H-MAGMA outputs is available at: https://github.com/rahfel/snRNAseqProcessingSteps. All other open source software used in this paper is available for all tools used (see “Key resources”).
References
1000 Genomes Project Consortium, Abecasis GR, Auton A, Brooks LD, DePristo MA, Durbin RM et al (2012) An integrated map of genetic variation from 1,092 human genomes. Nature 491:56–65
Aarsland D, Creese B, Politis M, Chaudhuri KR, Ffytche DH, Weintraub D et al (2017) Cognitive decline in Parkinson disease. Nat Rev Neurol 13:217–231
Aarsland D, Kurz MW (2010) The epidemiology of dementia associated with Parkinson’s disease. Brain Pathol 20:633–639
Aarsland D, Rongve A, Nore SP, Skogseth R, Skulstad S, Ehrt U et al (2008) Frequency and case identification of dementia with Lewy bodies using the revised consensus criteria. Dement Geriatr Cogn Disord 26:445–452
Agarwal D, Sandor C, Volpato V, Caffrey T, Monzon-Sandoval J, Bowden R et al (2020) A single-cell atlas of the human substantia nigra reveals cell-specific pathways associated with neurological disorders. Nat Commun 11(1):4183. https://doi.org/10.1038/s41467-020-17876-0
Alafuzoff I, Ince PG, Arzberger T, Al-Sarraj S, Bell J, Bodi I et al (2009) Staging/typing of Lewy body related α-synuclein pathology: a study of the BrainNet Europe Consortium. Acta Neuropathol 117:635–652
Amemiya HM, Kundaje A, Boyle AP (2019) The ENCODE blacklist: identification of problematic regions of the genome. Sci Rep 9:1–5
Andrews S, Krueger F, Segonds-Pichon A, Biggins L, Krueger C, Wingett S (2010) FastQC: a quality control tool for high throughput sequence data. Babraham Institute. http://www.bioinformatics.babraham.ac.uk/projects/fastqc
Attems J, Toledo JB, Walker L, Gelpi E, Gentleman S, Halliday G et al (2021) Neuropathological consensus criteria for the evaluation of Lewy pathology in post-mortem brains: a multi-centre study. Acta Neuropathol 141:159–172. https://doi.org/10.1007/s00401-020-02255-2
Bakken TE, Hodge RD, Miller JA, Yao Z, Nguyen TN, Aevermann B et al (2018) Single-nucleus and single-cell transcriptomes compared in matched cortical cell types. PLoS ONE 13:e0209648. https://doi.org/10.1371/journal.pone.0209648
Bampton A, Gittings LM, Fratta P, Lashley T, Gatt A (2020) The role of hnRNPs in frontotemporal dementia and amyotrophic lateral sclerosis. Acta Neuropathol 140:599–623. https://doi.org/10.1007/s00401-020-02203-0
Bandres-Ciga S, Saez-Atienzar S, Kim JJ, Makarious MB, Faghri F, Diez-Fairen M et al (2020) Large-scale pathway specific polygenic risk and transcriptomic community network analysis identifies novel functional pathways in Parkinson disease. Acta Neuropathol 140:341–358
Barkas N, Petukhov V, Nikolaeva D, Lozinsky Y, Demharter S, Khodosevich K et al (2019) Joint analysis of heterogeneous single-cell RNA-seq dataset collections. Nat Methods 16:695–698. https://doi.org/10.1038/s41592-019-0466-z
Berg D, Postuma RB, Bloem B, Chan P, Dubois B, Gasser T et al (2014) Time to redefine PD? Introductory statement of the MDS Task Force on the definition of Parkinson’s disease. Mov Disord 29:454–462. https://doi.org/10.1002/mds.25844
Blauwendraat C, Heilbron K, Vallerga CL, Bandres-Ciga S, von Coelln R, Pihlstrøm L et al (2019) Parkinson’s disease age at onset genome-wide association study: defining heritability, genetic loci, and α-synuclein mechanisms. Mov Disord 34:866–875. https://doi.org/10.1002/mds.27659
Blauwendraat C, Nalls MA, Singleton AB (2020) The genetic architecture of Parkinson’s disease. Lancet Neurol 19:170–178. https://doi.org/10.1016/S1474-4422(19)30287-X
Borrageiro G, Haylett W, Seedat S, Kuivaniemi H, Bardien S (2018) A review of genome-wide transcriptomics studies in Parkinson’s disease. Eur J Neurosci 47:1–16
Boström F, Jönsson L, Minthon L, Londos E (2007) Patients with Lewy body dementia use more resources than those with Alzheimer’s disease. Int J Geriatr Psychiatry 22:713–719
Braak H, Alafuzoff I, Arzberger T, Kretzschmar H, Tredici K (2006) Staging of Alzheimer disease-associated neurofibrillary pathology using paraffin sections and immunocytochemistry. Acta Neuropathol 112:389–404
Braak H, Del Tredici K, Rüb U, de Vos RAI, Jansen Steur ENH, Braak E (2003) Staging of brain pathology related to sporadic Parkinson’s disease. Neurobiol Aging 24:197–211
Bras J, Guerreiro R, Darwent L, Parkkinen L, Ansorge O, Escott-Price V et al (2014) Genetic analysis implicates APOE, SNCA and suggests lysosomal dysfunction in the etiology of dementia with Lewy bodies. Hum Mol Genet 23:6139–6146
Bryois J, Skene NG, Hansen TF, Kogelman LJA, Watson HJ, Liu Z et al (2020) Genetic identification of cell types underlying brain complex traits yields insights into the etiology of Parkinson’s disease. Nat Genet 52:482–493
Bulik-Sullivan B, Finucane HK, Anttila V, Gusev A, Day FR, Loh PRR et al (2015) An atlas of genetic correlations across human diseases and traits. Nat Genet 47:1236–1241. https://doi.org/10.1038/ng.3406
Bulik-Sullivan BK, Loh P-R, Finucane HK, Ripke S, Yang J, Schizophrenia Working Group of the Psychiatric Genomics Consortium et al (2015) LD Score regression distinguishes confounding from polygenicity in genome-wide association studies. Nat Genet 47:291–295. https://doi.org/10.1038/ng.3211
Carlson SM, Soulette CM, Yang Z, Elias JE, Brooks AN, Gozani O (2017) RBM25 is a global splicing factor promoting inclusion of alternatively spliced exons and is itself regulated by lysine mono-methylation. J Biol Chem 292:13381–13390
Chartier-Harlin MC, Kachergus J, Roumier C, Mouroux V, Douay X, Lincoln S et al (2004) α-synuclein locus duplication as a cause of familial Parkinson’s disease. Lancet 364:1167–1169
Chen X, Teichmann SA, Meyer KB (2018) From tissues to cell types and back: single-cell gene expression analysis of tissue architecture. Annu Rev Biomed Data Sci 1:29–51
Chen S, Zhou Y, Chen Y, Gu J (2018) Fastp: an ultra-fast all-in-one FASTQ preprocessor. Bioinformatics 34:i884–i890
Chia R, Sabir MS, Bandres-Ciga S, Saez-Atienzar S, Reynolds RH, Gustavsson E et al (2021) Genome sequencing analysis identifies new loci associated with Lewy body dementia and provides insights into its genetic architecture. Nat Genet. 53(3):294–303. https://doi.org/10.1038/s41588-021-00785-3
Chowdhury A, Rajkumar AP (2020) Systematic review of gene expression studies in people with Lewy body dementia. Acta Neuropsychiatr 32(6):281–292
La Cognata V, D’Agata V, Cavalcanti F, Cavallaro S (2015) Splicing: is there an alternative contribution to Parkinson’s disease? Neurogenetics 16:245–263
Collado-Torres L, Nellore A, Kammers K, Ellis SE, Taub MA, Hansen KD et al (2017) Reproducible RNA-seq analysis using recount2. Nat Biotechnol 35:319–321. https://doi.org/10.1038/nbt.3838
Denisenko E, Guo BB, Jones M, Hou R, de Kock L, Lassmann T et al (2020) Systematic assessment of tissue dissociation and storage biases in single-cell and single-nucleus RNA-seq workflows. Genome Biol 21:130
Diederich NJ, Moore CG, Leurgans SE, Chmura TA, Goetz CG (2003) Parkinson disease with old-age onset: a comparative study with subjects with middle-age onset. Arch Neurol 60:529–533
Dobin A, Davis CA, Schlesinger F, Drenkow J, Zaleski C, Jha S et al (2013) STAR: Ultrafast universal RNA-seq aligner. Bioinformatics 29:15–21
Dominguez D, Freese P, Alexis MS, Su A, Hochman M, Palden T et al (2018) Sequence, structure, and context preferences of human RNA binding proteins. Mol Cell 70:854-867.e9
Dumitriu A, Golji J, Labadorf AT, Gao B, Beach TG, Myers RH et al (2016) Integrative analyses of proteomics and RNA transcriptomics implicate mitochondrial processes, protein folding pathways and GWAS loci in Parkinson disease. BMC Med Genom 9:5. https://doi.org/10.1186/s12920-016-0164-y
Emre M, Aarsland D, Brown R, Burn DJ, Duyckaerts C, Mizuno Y et al (2007) Clinical diagnostic criteria for dementia associated with Parkinson’s disease. Mov Disord 22:1689–1707 (quiz 1837)
Eversfield CL, Orton LD (2019) Auditory and visual hallucination prevalence in Parkinson’s disease and dementia with Lewy bodies: a systematic review and meta-analysis. Psychol Med 49:2342–2353
Finak G, McDavid A, Yajima M, Deng J, Gersuk V, Shalek AK et al (2015) MAST: a flexible statistical framework for assessing transcriptional changes and characterizing heterogeneity in single-cell RNA sequencing data. Genome Biol 16:1–13. https://doi.org/10.1186/s13059-015-0844-5
Finucane HK, Bulik-Sullivan B, Gusev A, Trynka G, Reshef Y, Loh P-R et al (2015) Partitioning heritability by functional annotation using genome-wide association summary statistics. Nat Genet 47:1228–1235
Finucane HK, Reshef YA, Anttila V, Slowikowski K, Gusev A, Byrnes A et al (2018) Heritability enrichment of specifically expressed genes identifies disease-relevant tissues and cell types. Nat Genet 50:621–629
Gerstberger S, Hafner M, Tuschl T (2014) A census of human RNA-binding proteins. Nat Rev Genet 15:829–845
Geut H, Hepp DH, Foncke E, Berendse HW, Rozemuller JM, Huitinga I et al (2020) Neuropathological correlates of parkinsonian disorders in a large Dutch autopsy series. Acta Neuropathol Commun 8:39
Giudice G, Sánchez-Cabo F, Torroja C, Lara-Pezzi E (2016) ATtRACT-a database of RNA-binding proteins and associated motifs. Database 2016:1–9
GTEx Consortium (2015) Human genomics. The Genotype-Tissue Expression (GTEx) pilot analysis: multitissue gene regulation in humans. Science 348:648–660
Gu Z, Eils R, Schlesner M (2016) Complex heatmaps reveal patterns and correlations in multidimensional genomic data. Bioinformatics 32:2847–2849
Guella I, Evans DM, Szu-Tu C, Nosova E, Bortnick SF et al (2016) α-synuclein genetic variability: a biomarker for dementia in Parkinson disease. Ann Neurol 79:991–999
Guerreiro R, Escott-Price V, Hernandez DG, Kun-Rodrigues C, Ross OA, Orme T et al (2019) Heritability and genetic variance of dementia with Lewy bodies. Neurobiol Dis 127:492–501
Guerreiro R, Ross OA, Kun-Rodrigues C, Hernandez DG, Orme T, Eicher JD et al (2018) Investigating the genetic architecture of dementia with Lewy bodies: a two-stage genome-wide association study. Lancet Neurol 17:64–74
International HapMap 3 Consortium, Altshuler DM, Gibbs RA, Peltonen L, Altshuler DM, Gibbs RA et al (2010) Integrating common and rare genetic variation in diverse human populations. Nature 467:52–58. https://doi.org/10.1038/nature09298
Irwin DJ, Grossman M, Weintraub D, Hurtig HI, Duda JE, Xie SX et al (2017) Neuropathological and genetic correlates of survival and dementia onset in synucleinopathies: a retrospective analysis. Lancet Neurol 16:55–65
Jain C, Koren S, Dilthey A, Phillippy AM, Aluru S (2018) A fast adaptive algorithm for computing whole-genome homology maps. Bioinformatics 34:i748–i756
Jansen IE, Savage JE, Watanabe K, Bryois J, Williams DM, Steinberg S et al (2019) Genome-wide meta-analysis identifies new loci and functional pathways influencing Alzheimer’s disease risk. Nat Genet 51:404–413
Jellinger KA (2018) Dementia with Lewy bodies and Parkinson’s disease-dementia: current concepts and controversies. J Neural Transm 125:615–650. https://doi.org/10.1007/s00702-017-1821-9
Jellinger KA, Korczyn AD (2018) Are dementia with Lewy bodies and Parkinson’s disease dementia the same disease? BMC Med 16:34
Kattuah W, Rogelj B, King A, Shaw CE, Hortobágyi T, Troakes C (2019) Heterogeneous nuclear ribonucleoprotein e2 (hnrnp e2) is a component of tdp-43 aggregatesspecifically in the a and c pathological subtypes of frontotemporal lobar degeneration. Front Neurosci 13:1–11
Kempster PA, O’Sullivan SS, Holton JL, Revesz T, Lees AJ (2010) Relationships between age and late progression of Parkinson’s disease: a clinico-pathological study. Brain 133:1755–1762
Kövari E, Gold G, Herrmann FR, Canuto A, Hof PR, Bouras C et al (2003) Lewy body densities in the entorhinal and anterior cingulate cortex predict cognitive deficits in Parkinson’s disease. Acta Neuropathol 106:83–88
Krishnaswami SR, Grindberg RV, Novotny M, Venepally P, Lacar B, Bhutani K et al (2016) Using single nuclei for RNA-seq to capture the transcriptome of postmortem neurons. Nat Protoc 11:499–524
Lake BB, Chen S, Sos BC, Fan J, Kaeser GE, Yung YC et al (2018) Integrative single-cell analysis of transcriptional and epigenetic states in the human adult brain. Nat Biotechnol 36:70–80
Lawrence M, Gentleman R, Carey V (2009) rtracklayer: an R package for interfacing with genome browsers. Bioinformatics 25:1841–1842
de Leeuw CA, Mooij JM, Heskes T, Posthuma D (2015) MAGMA: generalized gene-set analysis of GWAS data. PLoS Comput Biol 11:1–19
Li YI, van de Geijn B, Raj A, Knowles DA, Petti AA, Golan D et al (2016) RNA splicing is a primary link between genetic variation and disease. Science 352:600–604
Li YI, Knowles DA, Humphrey J, Barbeira AN, Dickinson SP, Im HK et al (2018) Annotation-free quantification of RNA splicing using LeafCutter. Nat Genet 50:151–158
Li YI, Wong G, Humphrey J, Raj T (2019) Prioritizing Parkinson’s disease genes using population-scale transcriptomic data. Nat Commun 10:994. https://doi.org/10.1038/s41467-019-08912-9
Liao Y, Wang J, Jaehnig EJ, Shi Z, Zhang B (2019) WebGestalt 2019: gene set analysis toolkit with revamped UIs and APIs. Nucleic Acids Res 47:W199-205
Love MI, Huber W, Anders S (2014) Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2. Genome Biol 15:1–21
Lun ATL, Riesenfeld S, Andrews T, Dao TP, Gomes T, Marioni JC (2019) EmptyDrops: Distinguishing cells from empty droplets in droplet-based single-cell RNA sequencing data. Genome Biol 20:1–9
Marx V (2021) Method of the year: spatially resolved transcriptomics. Nat Methods 18:9–14. https://doi.org/10.1038/s41592-020-01033-y
McAleese KE, Colloby SJ, Thomas AJ, Al-Sarraj S, Ansorge O, Neal J et al (2021) Concomitant neurodegenerative pathologies contribute to the transition from mild cognitive impairment to dementia. Alzheimers Dement. https://doi.org/10.1002/alz.12291
McGinnis CS, Murrow LM, Gartner ZJ (2019) DoubletFinder: doublet detection in single-cell RNA sequencing data using artificial nearest neighbors. Cell Syst 8:329-337.e4
McInnes L, Healy J, Melville J (2018) UMAP: uniform manifold approximation and projection for dimension reduction. arXiv: 1802.03426
McKeith IG, Boeve BF, Dickson DW, Halliday G, Taylor J-P, Weintraub D et al (2017) Diagnosis and management of dementia with Lewy bodies: fourth consensus report of the DLB Consortium. Neurology 89:88–100
McLeay RC, Bailey TL (2010) Motif Enrichment Analysis: a unified framework and an evaluation on ChIP data. BMC Bioinform 11:165. https://doi.org/10.1186/1471-2105-11-165
Menden K, Marouf M, Oller S, Dalmia A, Magruder DS, Kloiber K et al (2020) Deep learning–based cell composition analysis from tissue expression profiles. Sci Adv 6:eaba2619. https://doi.org/10.1126/sciadv.aba2619
Nalls MA, Blauwendraat C, Vallerga CL, Heilbron K, Bandres-Ciga S, Chang D et al (2019) Identification of novel risk loci, causal insights, and heritable risk for Parkinson’s disease: a meta-analysis of genome-wide association studies. Lancet Neurol 18:1091–1102
Nelson PT, Schmitt FA, Jicha GA, Kryscio RJ, Abner EL, Smith CD et al (2010) Association between male gender and cortical Lewy body pathology in large autopsy series. J Neurol 257:1875–1881
Nido GS, Dick F, Toker L, Petersen K, Alves G, Tysnes O et al (2020) Common gene expression signatures in Parkinson’s disease are driven by changes in cell composition. Acta Neuropathol Commun 8:55
Van Nostrand EL, Pratt GA, Yee BA, Wheeler EC, Blue SM, Mueller J et al (2020) Principles of RNA processing from analysis of enhanced CLIP maps for 150 RNA binding proteins. Genome Biol Genome Biol 21:1–26
O’Dowd S, Schumacher J, Burn DJ, Bonanni L, Onofrj M, Thomas A et al (2019) Fluctuating cognition in the Lewy body dementias. Brain 142:3338–3350
Obergasteiger J, Frapporti G, Pramstaller PP, Hicks AA, Volta M (2018) A new hypothesis for Parkinson’s disease pathogenesis: GTPase-p38 MAPK signaling and autophagy as convergence points of etiology and genomics. Mol Neurodegener 13:40
Oesterhus R, Soennesyn H, Rongve A, Ballard C, Aarsland D, Vossius C (2014) Long-term mortality in a Cohort of home-dwelling elderly with mild Alzheimer’s disease and Lewy body dementia. Dement Geriatr Cogn Disord 38:161–169
Outeiro TF, Koss DJ, Erskine D, Walker L, Kurzawa-Akanbi M, Burn D et al (2019) Dementia with Lewy bodies: an update and outlook. Mol Neurodegener 14:1–18
Pagano G, Ferrara N, Brooks DJ, Pavese N (2016) Age at onset and Parkinson disease phenotype. Neurology 86:1400–1407
Patro R, Duggal G, Love MI, Irizarry RA, Kingsford C (2017) Salmon provides fast and bias-aware quantification of transcript expression. Nat Methods 14:417–419. https://doi.org/10.1038/nmeth.4197
Poewe W, Seppi K, Tanner CM, Halliday GM, Brundin P, Volkmann J et al (2017) Parkinson disease. Nat Rev Dis Prim 3:17013
Postuma RB, Berg D, Stern M, Poewe W, Marek K, Litvan I (2015) CME MDS clinical diagnostic criteria for Parkinson’s disease. Mov Disord 30:1591–1599
Postuma RB, Berg D, Stern M, Poewe W, Olanow CW, Oertel W et al (2016) Abolishing the 1-year rule: how much evidence will be enough? Mov Disord 31:1623–1627
Raj T, Li YI, Wong G, Humphrey J, Wang M, Ramdhani S et al (2018) Integrative transcriptome analyses of the aging brain implicate altered splicing in Alzheimer’s disease susceptibility. Nat Genet 50:1584–1592. https://doi.org/10.1038/s41588-018-0238-1
Ritchie ME, Phipson B, Wu D, Hu Y, Law CW, Shi W et al (2015) Limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res 43:e47
Robinson JL, Lee EB, Xie SX, Rennert L, Suh E, Bredenberg C et al (2018) Neurodegenerative disease concomitant proteinopathies are prevalent, age-related and APOE4-associated. Brain 141:2181–2193
Rongve A, Witoelar A, Ruiz A, Athanasiu L, Abdelnour C, Clarimon J et al (2019) GBA and APOE ε4 associate with sporadic dementia with Lewy bodies in European genome wide association study. Sci Rep 9:7013
Sayols S (2020) rrvgo: a Bioconductor package to reduce and visualize Gene Ontology terms. Bioconductor. https://ssayols.github.io/rrvgo
Schapira AHV, Chaudhuri KR, Jenner P (2017) Non-motor features of Parkinson disease. Nat Rev Neurosci 18:435–450
Sey NYA, Hu B, Mah W, Fauni H, McAfee JC, Rajarajan P et al (2020) A computational tool (H-MAGMA) for improved prediction of brain-disorder risk genes by incorporating brain chromatin interaction profiles. Nat Neurosci 23:583–593. https://doi.org/10.1038/s41593-020-0603-0
Singleton AB, Farrer M, Johnson J, Singleton A, Hague S, Kachergus J et al (2003) alpha-Synuclein locus triplication causes Parkinson’s disease. Science 302:841
Skene NG, Grant SGN (2016) Identification of vulnerable cell types in major brain disorders using single cell transcriptomes and expression weighted cell type enrichment. Front Neurosci 10:1–11
Smith C, Malek N, Grosset K, Cullen B, Gentleman S, Grosset DG (2019) Neuropathology of dementia in patients with Parkinson’s disease: a systematic review of autopsy studies. J Neurol Neurosurg Psychiatry 90:1234–1243
Soldner F, Stelzer Y, Shivalila CS, Abraham BJ, Latourelle JC, Barrasa MI et al (2016) Parkinson-associated risk variant in distal enhancer of α-synuclein modulates target gene expression. Nature 533:95–99
Soneson C, Love MI, Robinson MD (2015) Differential analyses for RNA-seq: transcript-level estimates improve gene-level inferences. F1000Research 4:1521
Spillantini MG, Schmidt ML, Lee VM-Y, Trojanowski JQ, Jakes R, Goedert M (1997) Alpha-synuclein in Lewy bodies. Nature 388:839–840
Stuart T, Butler A, Hoffman P, Hafemeister C, Papalexi E, Mauck WM et al (2019) Comprehensive integration of single-cell data. Cell 177:1888-1902.e21
Thrupp N, Sala Frigerio C, Wolfs L, Skene NG, Fattorelli N, Poovathingal S et al (2020) Single-nucleus RNA-Seq is not suitable for detection of microglial activation genes in humans. Cell Rep 32(13):108189
Del Tredici K, Braak H (2016) Review: sporadic Parkinson’s disease: development and distribution of α-synuclein pathology. Neuropathol Appl Neurobiol 42:33–50. https://doi.org/10.1016/j.nbd.2015.03.003
Vaquero-Garcia J, Norton S, Barash Y (2018) LeafCutter vs. MAJIQ and comparing software in the fast moving field of genomics. bioRxiv 463927. http://biorxiv.org/content/early/2018/11/08/463927.abstract
Vossius C, Rongve A, Testad I, Wimo A, Aarsland D (2014) The use and costs of formal care in newly diagnosed dementia: a three-year prospective follow-up study. Am J Geriatr Psychiatry 22:381–388
Wang JZ, Du Z, Payattakool R, Yu PS, Chen CF (2007) A new method to measure the semantic similarity of GO terms. Bioinformatics 23:1274–1281
Wang D, Liu S, Warrell J, Won H, Shi X, Navarro FCP et al (2018) Comprehensive functional genomic resource and integrative model for the human brain. Science 362(6420):eaat8464
Wang Y, Wang J, Gao L, Lafyatis R, Stamm S, Andreadis A (2005) Tau exons 2 and 10, which are misregulated in neurodegenerative diseases, are partly regulated by silencers which bind a SRp30c·SRp55 complex that either recruits or antagonizes htra2β1. J Biol Chem 280:14230–14239
Wang L, Wang S, Li W (2012) RSeQC: quality control of RNA-seq experiments. Bioinformatics 28:2184–2185
Weil RS, Lashley TL, Bras J, Schrag AE, Schott JM (2017) Current concepts and controversies in the pathogenesis of Parkinson’s disease dementia and dementia with Lewy bodies. F1000Research 6:1604
Young PJ, DiDonato CJ, Hu D, Kothary R, Androphy EJ, Lorson CL (2002) SRp30c-dependent stimulation of survival motor neuron (SMN) exon 7 inclusion is facilitated by a direct interaction with hTra2β1. Hum Mol Genet 11:577–587
Yu G, Li F, Qin Y, Bo X, Wu Y, Wang S (2010) GOSemSim: an R package for measuring semantic similarity among GO terms and gene products. Bioinformatics 26:976–978
Yu G, Wang LG, Han Y, He QY (2012) ClusterProfiler: an R package for comparing biological themes among gene clusters. Omi A J Integr Biol 16:284–287
Zerbino DR, Achuthan P, Akanni W, Amode MR, Barrell D, Bhai J et al (2018) Ensembl 2018. Nucleic Acids Res 46:D754–D761
Zhang D, Reynolds RH, Garcia-Ruiz S, Gustavsson EK, Sethi S, Aguti S et al (2021) Detection of pathogenic splicing events from RNA-sequencing data using dasper. bioRxiv 2021.03.29.437534. http://biorxiv.org/content/early/2021/03/30/2021.03.29.437534.abstract
Acknowledgements
RF, DRO, MRJ and PKS were supported through the UKRI Medical Research Council (MRC grant code, DRO: MR/N008219/1; RF, MRJ and PKS: MR/S02638X/1). MRJ was also separately supported through the Imperial College NIHR Biomedical Research Centre (BRC) Scheme. RHR was supported through the award of a Leonard Wolfson Doctoral Training Fellowship in Neurodegeneration and through the Signe og Peter Gregersens Mindefond. AMS was supported through the UK Dementia Research Institute. SAGT acknowledges support from a Junior 1 award from the Fonds de recherche du Québec—Santé (FRQS). JH was supported through the UKRI Medical Research Council (MRC Grant Code: MR/N026004/), the UK Dementia Research Institute, The Wellcome Trust (202903/Z/16/Z), the Dolby Family Fund, and the NIHR. PMM was supported through the Imperial College NIHR Biomedical Research Centre (BRC) and the UK Dementia Research Institute and gratefully acknowledges personal funding from the Edmond Safra Foundation and Lily Safra. He is an NIHR Senior Investigator. SG is director of the Parkinson’s UK Tissue Bank, funded by Parkinson’s UK, a charity registered in England and Wales (258197) and in Scotland (SC037554). MR was supported through the award of a UKRI Medical Research Council Clinician Scientist Fellowship (MRC Grant Code: MR/N008324/1).
Author information
Authors and Affiliations
Contributions
RF processed and analysed single-nucleus RNA-sequencing data and assisted with preparation of the manuscript. RHR processed and analysed bulk-tissue RNA-sequencing data, integrated bulk-tissue and single-nucleus RNA-sequencing data, and together with MR, prepared the first draft of the manuscript. AMS generated tissue sections, isolated nuclei and was involved in quality control of single-nucleus and bulk-tissue RNA-sequencing data generation. BT assisted with access to tissue samples and performed the neuropathological assessment of all samples. SAGT assisted with genetic enrichment analyses. SG enabled access to tissue samples and supervised their neuropathological assessment. MRJ and PKS supervised processing and analysis of single-nucleus RNA-sequencing data and genetic enrichment analyses. MR supervised processing and analysis of bulk-tissue RNA-sequencing data and integration with single-nucleus RNA-sequencing data. AMS, JH, PMM, SG, DRO, MRJ, PKS and MR conceived and designed the study. All authors contributed to the interpretation, critical review and final approval of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
RHR, RF, AMS, BT, SAGT, JH, SG, DRO, MRJ, PKS and MR declare that they have no relevant financial or non-financial interests to disclose. PMM has received honoraria or consulting fees from Biogen, Novartis, Ipsen Pharmaceuticals, NodThera and Celgene. He receives research funding from Biogen, Merck, Celgene and Bristol Myers Squibb.
Ethics approval
Ethics approval for the work carried out on the tissue from the Multiple Sclerosis and Parkinson’s Tissue Bank was given by Wales REC3 ethic committee, REC reference 18/WA/0238.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Feleke, R., Reynolds, R.H., Smith, A.M. et al. Cross-platform transcriptional profiling identifies common and distinct molecular pathologies in Lewy body diseases. Acta Neuropathol 142, 449–474 (2021). https://doi.org/10.1007/s00401-021-02343-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00401-021-02343-x