
Abstract
A theory for diffusivity estimation for spatially extended activator–inhibitor dynamics modeling the evolution of intracellular signaling networks is developed in the mathematical framework of stochastic reaction–diffusion systems. In order to account for model uncertainties, we extend the results for parameter estimation for semilinear stochastic partial differential equations, as developed in Pasemann and Stannat (Electron J Stat 14(1):547–579, 2020), to the problem of joint estimation of diffusivity and parametrized reaction terms. Our theoretical findings are applied to the estimation of effective diffusivity of signaling components contributing to intracellular dynamics of the actin cytoskeleton in the model organism Dictyostelium discoideum.
Similar content being viewed by others

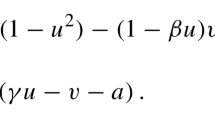

Avoid common mistakes on your manuscript.
1 Introduction
The purpose of this paper is to develop the mathematical theory for statistical inference methods for the parameter estimation of stochastic reaction–diffusion systems modeling spatially extended signaling networks in cellular systems. Such signaling networks are one of the central topics in cell biology and biophysics as they provide the basis for essential processes including cell division, cell differentiation, and cell motility (Peter 2017). Nonlinearities in these network may cause rich spatiotemporal behavior including the emergence of oscillations and waves (Beta and Kruse 2017). Furthermore, alterations and deficiencies in the network topology can explain many pathologies and play a key role in diseases such as cancer (Condeelis et al. 2005). Here we present a method to estimate both diffusivity and reaction terms of a stochastic reaction–diffusion system, given space–time structured data of local concentrations of signaling components. We mainly focus on the estimation of diffusivity, whose precision can be increased by simultaneous calibration of the reaction terms.
To test this approach, we use fluorescence microscopy recordings of the actin dynamics in the cortex of cells of the social amoeba Dictyostelium discoideum, a well-established model organism for the study of a wide range of actin-dependent processes (Annesley and Fisher 2009). A recently introduced stochastic reaction–diffusion model could reproduce many features of the dynamical patterns observed in the cortex of these cells including excitable and bistable states (Alonso et al. 2018; Flemming et al. 2020; Moreno et al. 2020). In combination with the experimental data, this model will serve as a specific test case to exemplify our mathematical approach. Since in real-world applications the available data will not allow for calibrating and validating detailed mathematical models, in this paper we will be primarily interested in minimal models that are still capable of generating all observed dynamical features at correct physical magnitudes. The developed estimation techniques should in practice be as robust as possible w.r.t. uncertainty and even misspecification of the unknown real dynamics.
The impact of diffusion and reaction in a given model will be of fundamentally different structure and it is one of the main mathematical challenges to separate these impacts in the data in order to come to valid parameter estimations. On the more mathematical side, diffusion corresponds to a second-order partial differential operator—resulting in a strong spatial coupling in the given data, whereas the reaction corresponds to a lower order, in fact 0 order, in general resulting in highly nonlinear local interactions in the data. For introductory purposes, let us assume that our data is given in terms of a space- and time-continuous field X(t, x) on \([0,T]\times {\mathcal {D}}\), where T is the terminal time of our observations and \({\mathcal {D}}\subset {\mathbb {R}}^2\) a rectangular domain that corresponds to a chosen data segment in a given experiment. Although in practice the given data will be discrete w.r.t. both space and time, we will be interested in applications where the resolution is high enough in order to approximate the data by such a continuous field. Our standing assumption is that X(t, x) is generated by a dynamical system of the form
where \(\Delta \) is the Laplacian, given by \(\Delta X(t, x) = \partial _{x_1}^2X(t, x) + \partial _{x_2}^2X(t, x)\), \(x=(x_1,x_2)\), which captures the diffusive spreading in the dynamics of X(t, x). The intensity of the diffusion is given by the diffusivity \(\theta _0\). Finally, \({\mathcal {F}}\) is a generic term, depending on the solution field X(t, x), which describes all non-diffusive effects present in X(t, x), whether they are known or unknown. A natural approach to extract \(\theta _0\) from the data is to use a “cutting-out estimator” of the form
where Y(t, x) is a suitable test function. In the second fraction of (2), we use the functional form for readability. In particular, we write \(X=X(t, x)\) for the solution field. We will also write \(X_t = X(t, \cdot )\) for the (spatially varying) solution field at a fixed time t. In order to ease notation, we will use this functional form from now on throughout the paper. It is possible to derive (2) from a least squares approach by minimizing \(\theta \mapsto \Vert \partial _tX-\theta \Delta X\Vert ^2\) with a suitably chosen norm. If the non-diffusive effects described by \({\mathcal {F}}\) are negligible, we see by plugging (1) into (2) that \({{\hat{\theta }}}_0\) is close to \(\theta _0\). If a sound approximation \(\overline{{\mathcal {F}}}\) to \({\mathcal {F}}\) is known, the estimator can be made more precise by substituting \(\partial _tX\) by \(\partial _tX-\overline{{\mathcal {F}}}_X\) in (2). A usual choice for Y is a reweighted spectral cutoff of X, which leads to the spectral approach described below.
Under additional model assumptions, e.g., if (1) is in fact a stochastic partial differential equation (SPDE) driven by Gaussian white noise, a rather developed parameter estimation theory for \(\theta _0\) has been established in Pasemann and Stannat (2020) on the basis of maximum likelihood estimation (MLE).
In this paper, we are interested in further taking into account also those parts of \({\mathcal {F}}_X\) corresponding to local nonlinear reactions. As a particular example, we will focus on a recently introduced stochastic reaction–diffusion system of FitzHugh–Nagumo type that captures many aspects of the dynamical wave patterns observed in the cortex of motile amoeboid cells (Flemming et al. 2020),
Here, we identify \(\theta _0=D_U\) and the only observed data is the activator variable, i.e., \(X=U\).
Therefore, in this example the non-diffusive part of the dynamics will be further decomposed as \({\mathcal {F}} = F + \xi \), where \(\xi \) is Gaussian white noise and \(F=F(U)\) encodes the non-Markovian reaction dynamics of the activator. The inhibitor component V in the above reaction–diffusion system is then incorporated for minimal modeling purposes to allow the formation of traveling waves in the activator variable U that are indeed observed in the time evolution of the actin concentration. This model and its dynamical features is explained in detail in Sect. 2.1.1.
As noted before, it is desirable to include this additional knowledge into the estimation procedure (2) by subtracting a suitable approximation \(\overline{{\mathcal {F}}}\) of the—in practice—unknown \({\mathcal {F}}\). Although (3), (4) suggest an explicit parametric form for \(\overline{{\mathcal {F}}}\), it is a priori not clear how to quantify the nuisance parameters appearing in the system. Thus, an (approximate) model for the data is known qualitatively, based on the observed dynamics, but not quantitatively. In order to resolve this issue, we extend (2) and adopt a joint maximum likelihood estimation of \(\theta _0\) and various nuisance parameters.
The field of statistical inference for SPDEs is rapidly growing, see Cialenco (2018) for a recent survey. The spectral approach to drift estimation was pioneered by Hübner et al. (1993), Huebner and Rozovskii (1995) and subsequently extended by various works, see, e.g., Huebner et al. (1997), Lototsky and Rosovskii (1999), Lototsky and Rozovskii (2000) for the case of non-diagonalizable linear evolution equations. In Cialenco and Glatt-Holtz (2011), the stochastic Navier–Stokes equations have been analyzed as a first example of a nonlinear evolution equation. This has been generalized by Pasemann and Stannat (2020) to semilinear SPDEs. Joint parameter estimation for linear evolution equations is treated in Huebner (1993), Lototsky (2003), see also Piterbarg and Rozovskii (1996) for a discussion. Besides the spectral approach, other measurement schemes have been studied. See, e.g., Pospíšil and Tribe (2007), Bibinger and Trabs (2020), Bibinger and Trabs (2019), Chong (2019a), Chong (2019b), Khalil and Tudor (2019), Cialenco and Huang (2019), Cialenco et al. (2020), Cialenco and Kim (2020), Kaino and Uchida (2019) for the case of discrete observations in space and time. Recently, the local approach has been worked out in Altmeyer and Reiß (2020) for linear equations, was subsequently generalized in Altmeyer et al. (2020b) to the semilinear case and applied to a stochastic cell repolarization model in Altmeyer et al. (2020a).
The paper is structured as follows: In Sect. 2, we give a theory for joint diffusivity and reaction parameter estimation for a class of semilinear SPDEs and study the spatial high-frequency asymptotics. Special emphasis is put on the FitzHugh–Nagumo system. In Sect. 3, the biophysical context for these models is discussed. The performance of our method on simulated and real data is evaluated in Sect. 4.
2 Maximum Likelihood Estimation for Activator–Inhibitor Models
In this section, we develop a theory for parameter estimation for a class of semilinear SPDE using a maximum likelihood ansatz. The application we are aiming at is an activator–inhibitor model as in Flemming et al. (2020). More precisely, we show under mild conditions that the diffusivity of such a system can be identified in finite time given high spatial resolution and observing only the activator component.
2.1 The Model and Basic Properties
Let us first introduce the abstract mathematical setting in which we are going to derive our main theoretical results. We work in spatial dimension \(d\ge 1\). Given a bounded domain \({\mathcal {D}}=[0,L_1] \times \dots \times [0,L_d] \subset {\mathbb {R}}^d\), \(L_1,\dots ,L_d>0\), we consider the following parameter estimation problem for the semilinear SPDE
with periodic boundary conditions for \(\Delta \) on the Hilbert space \(H={{\bar{L}}}^2({\mathcal {D}}) = \{u \in L^2 ({\mathcal {D}}) |\int _{\mathcal {D}} u\mathrm {d}x=0\}\), together with initial condition \(X_0\in H\). We allow the nonlinear term F to depend on additional (nuisance) parameters \(\theta _1,\dots ,\theta _K\) and write \(\theta =(\theta _0,\dots ,\theta _K)^T\), \(\theta _{1:K}=(\theta _1,\dots ,\theta _K)\) for short. Without further mentioning it, we assume that \(\theta \in \Theta \) for a fixed parameter space \(\Theta \), e.g., \(\Theta ={\mathbb {R}}_+^K\). Next, W is a cylindrical Wiener process modeling Gaussian space–time white noise, that is, \({\mathbb {E}}[\dot{W}(t, x)]=0\) and \({\mathbb {E}}[\dot{W}(t, x)\dot{W}(s, y)]=\delta (t-s)\delta (x-y)\). In order to introduce spatial correlation, we use a dispersion operator of the form \(B=\sigma (-\Delta )^{-\gamma }\) with \(\sigma >0\) and \(\gamma >d/4\), describing spectral decay of the noise intensity. Here, \(\sigma \) is the overall noise intensity, and \(\gamma \) quantifies the decay of the noise for large frequencies in Fourier space. In addition, \(\gamma \) determines the spatial smoothness of X, see Sect. 2.1.2. The condition \(\gamma >d/4\) ensures that the covariance operator \(BB^T\) is of trace class, which is a standard assumption for well-posedness of (5), cf. Liu and Röckner (2015).
Denote by \((\lambda _k)_{k\ge 0}\) the eigenvalues of \(-\Delta \), ordered increasingly, with corresponding eigenfunctions \((\Phi _k)_{k\ge 0}\). It is well known (Weyl 1911; Shubin 2001) that \(\lambda _k\asymp \Lambda k^{2/d}\) for a constant \(\Lambda >0\), i.e., \(\lim _{k\rightarrow \infty }\lambda _k/(\Lambda k^{2/d})=1\). The proportionality constant \(\Lambda \) is known explicitly [see, e.g., Shubin (2001, Proposition 13.1)] and depends on the domain \({\mathcal {D}}\). Let \(P_N:H\rightarrow H\) be the projection onto the span of the first N eigenfunctions, and set \(X^N:=P_NX\). For later use, we denote by I the identity operator acting on H. For \(s\in {\mathbb {R}}\), we write \(H^s:=D((-\Delta )^{s/2})\) for the domain of \((-\Delta )^{s/2}\), which is given by
and abbreviate \(|\cdot |_s:=|\cdot |_{H^s}\) for the norm on that space whenever convenient. We assume that the initial condition \(X_0\) is regular enough, i.e., it satisfies \({\mathbb {E}}[|X_0|_{s}^p]<\infty \) for any \(s\ge 0\), \(p\ge 1\), without further mentioning it in the forthcoming statements. We will use the following general class of conditions with \(s\ge 0\) in order to describe the regularity of X:
- \((A_s)\):
-
For any \(p\ge 1\), it holds
$$\begin{aligned} {\mathbb {E}}\left[ \sup _{0\le t\le T}|X_t|_{s}^p\right] < \infty . \end{aligned}$$(6)
Our standing assumption is that X is well posed in the sense that there exists a probabilistically and analytically weak solution \(X\in C(0,T;H)\) to (5), unique in the sense of probability law, such that \((A_0)\) holds. This is a consequence, for example, of the assumptions from Liu and Röckner (2015, Theorem 5.1.3).
2.1.1 An Activator–Inhibitor Model
An important example for our analysis is given by the following FitzHugh–Nagumo type system of equations in \(d\le 2\) [cf. Flemming et al. (2020)]:
together with sufficiently smooth initial conditions. Here, f is a bistable third-order polynomial \(f(x, u) = u(u_0-u)(u - a(x)u_0)\), and \(a\in C^1_b ({\mathbb {R}},{\mathbb {R}})\) is a bounded and continuously differentiable function with bounded derivative. The boundedness condition for a is not essential to the dynamics of U and can be realized in practice by a suitable cutoff function.
The FitzHugh–Nagumo system Fitzhugh (1961), Nagumo et al. (1962) originated as a minimal model capable of generating excitable pulses mimicking action potentials in neuroscience. Its two components U and V are called activator and inhibitor, respectively.
The spatial extension of the Fitzhugh–Nagumo system, obtained via diffusive coupling, is used to model propagation of excitable pulses and two-phase dynamics. In the case of the two phases, low and high concentration of the activator U are realized as the stable fixed points of the third-order polynomial f at 0 and \(u_0\). The unstable fixed point \(a u_0\), \(a\in (0,1)\), separates the domains of attraction of the two stable fixed points. The interplay between spatial diffusion, causing a smoothing out of concentration gradients with rate \(D_U\), and the local reaction forcing f, causing convergence of the activator to one of the stable phases with rate \(k_1\), leads to the formation of transition phases between regions with low or high concentration of U. The parameters determine shape and velocity of the transition phases, e.g., low values of a enhance the growth of regions with high activator concentration. This corresponds to the excitable regime, as explained in Flemming et al. (2020).
Conversely, a high concentration of the inhibitor V leads to a decay in the activator U, with rate \(k_2\). In the excitable regime, this mechanism leads to moving activator wave fronts. The inhibitor is generated with rate \(\epsilon b\) in the presence of U and decays at rate \(\epsilon \). Its spatial evolution is determined by diffusion with rate \(D_V\). Finally, choosing a as a functional depending on the total activator concentration introduces a feedback control that allows to stabilize the dynamics.
A detailed discussion of the relevance for cell biology is given in Sect. 3. More information on the FitzHugh–Nagumo model and related models can be found in Ermentrout and Terman (2010).
For this model, we can find a representation of the above type (5) as follows: Using the variation of constants formula, the solution V to (8) with initial condition \(V_0=0\) can be written as \(V_t=\epsilon b\int _0^te^{(t-r)(D_V\Delta -\epsilon I)}U_r\mathrm {d}r\). Inserting this representation into (7) yields the following reformulation
of the activator–inhibitor model (7), (8) by setting \(\theta _0 = D_U\), \(\theta _1 = k_1u_0{{\bar{a}}}\), \(\theta _2=k_1\), \(\theta _3 = k_2\epsilon b\), \({{\overline{F}}}=0\) for some \({{\bar{a}}}>0\) and
Here \(e^{D_V\Delta -\epsilon I}\) is the semigroup generated by \(D_V\Delta -\epsilon I\). Note that \(F_3\) now depends on the whole trajectory of U, so that the resulting stochastic evolution Eq. (9) is no longer Markovian.
For the activator–inhibitor system (7), (8), we can verify well-posedness directly. For completeness, we state the optimal regularity results for both U and V, but our main focus lies on the observed variable \(X=U\).
Proposition 1
Let \(\gamma >d/4+1/2\). Then there is a unique solution (U, V) to (7), (8). Furthermore, U satisfies \((A_s)\) for any \(s<2\gamma -d/2+1\), and V satisfies \((A_s)\) for any \(s<2\gamma -d/2+3\).
The proof is deferred to “Appendix A.1.”
2.1.2 Basic Regularity Results
In the semilinear SPDE model (5), the nonlinear term F is assumed to satisfy [cf. Altmeyer et al. (2020b)]:
- \((F_{s,\eta })\):
-
There is \(b>0\) and \(\epsilon >0\) such that
$$\begin{aligned} |(-\Delta )^{\frac{s-2+\eta +\epsilon }{2}}F_{\theta _{1:K}}(Y)|_{C(0,T;H)} \le c(\theta _{1:K})(1+|(-\Delta )^{\frac{s}{2}}Y|_{C(0,T;H)})^b \end{aligned}$$for \(Y\in C(0,T;H^s)\), where c depends continuously on \(\theta _{1:K}\).
In particular, if \(F(Y)(t) = F(Y_t)\), this simplifies to
for \(Y\in H^s\). In order to control the regularity of X, we apply a splitting argument (see also Cialenco and Glatt-Holtz 2011; Pasemann and Stannat 2020; Altmeyer et al. 2020b) and write \(X={{\overline{X}}}+{{\widetilde{X}}}\), where \({{\overline{X}}}\) is the solution to the linear SPDE
where W is the same cylindrical Wiener process as in (5), and \({{\widetilde{X}}}\) solves a random PDE of the form
Lemma 2
The process \({{\overline{X}}}\) is Gaussian, and for any \(p\ge 1\), \(s<2\gamma -d/2+1\):
Proof
This is classical, see, e.g., Da Prato and Zabczyk (2014), Liu and Röckner (2015). \(\square \)
Proposition 3
-
(1)
Let \((A_{s})\) and \((F_{s, \eta })\) hold. Then for any \(p\ge 1\):
$$\begin{aligned} {\mathbb {E}}\left[ \sup _{0\le t\le T}|{{\widetilde{X}}}_t|_{s+\eta }^p\right] <\infty . \end{aligned}$$(17)In particular, if \(s+\eta <2\gamma -d/2+1\), then \((A_{s+\eta })\) is true.
-
(2)
Let \(G:C(0,T;H)\supset D(G)\rightarrow C(0,T;H)\) be any function such that \((F_{s,\eta })\) holds for G. Then for \(s < 2\gamma -d/2+1\) and \(p\ge 1\):
$$\begin{aligned} {\mathbb {E}}\left[ \sup _{0\le t\le T}|G(X)(t)|_{s+\eta -2}^p\right] < \infty . \end{aligned}$$(18)In particular,
$$\begin{aligned} {\mathbb {E}}\int _0^T|G(X)(t)|_{s+\eta -2}^2\mathrm {d}t < \infty . \end{aligned}$$(19)
Proof
-
(1)
For \(t\in [0,T]\) and \(\epsilon >0\),
$$\begin{aligned} |{{\widetilde{X}}}_t|_{s+\eta }&\le |S(t)X_0|_{s+\eta } + \int _0^t|S(t-r)F_{\theta _{1:K}}(X)(t)|_{s+\eta }\mathrm {d}r \\&\le |X_0|_{s+\eta } + \int _0^t(t-r)^{-1+\epsilon /2}|F_{\theta _{1:K}}(X)(t)|_{s-2+\eta +\epsilon }\mathrm {d}r \\&\le |X_0|_{s+\eta } + \frac{2}{\epsilon }T^\frac{\epsilon }{2}\sup _{0\le t\le T}|F_{\theta _{1:K}}(X)(t)|_{s-2+\eta +\epsilon } \\&\le |X_0|_{s+\eta } + \frac{2}{\epsilon }T^\frac{\epsilon }{2}c(\theta _{1:K})(1+|X|_{C(0,T;H^s)})^b, \end{aligned}$$where \(\theta _1,\dots ,\theta _K\) are the true parameters. This implies (17). If \(s+\eta < 2\gamma -d/2+1\), then a bound as in (17) holds for \({{\overline{X}}}\) by Lemma 2, and the claim follows.
-
(2)
This follows from
$$\begin{aligned} {\mathbb {E}}\left[ \sup _{0\le t\le T}|G(X)(t)|_{s+\eta -2}^p\right]&\le c{\mathbb {E}}\left[ \left( 1+\sup _{0\le t\le T}|X_t|_s\right) ^{bp}\right] < \infty . \end{aligned}$$(20)
\(\square \)
These regularity results form the basis for the asymptotic analysis of diffusivity estimation, as explained in the next section.
2.2 Statistical Inference: The General Model
The projected process \(P_NX\) induces a measure \({\mathbb {P}}_\theta \) on \(C(0,T;{\mathbb {R}}^N)\). Heuristically [see Liptser and Shiryayev (1977, Section 7.6.4)], we have the following representation for the density with respect to \({\mathbb {P}}_{{{\overline{\theta }}}}^N\) for an arbitrary reference parameter \({{\overline{\theta }}}\in \Theta \):
By setting the score (i.e., the gradient with respect to \(\theta \) of the log likelihood) to zero, and by formally substituting the (fixed) parameter \(\gamma \) by a (free) parameter \(\alpha \), we get the following maximum likelihood equations:
Any solution \(({{\hat{\theta }}}^N_0,\dots ,{{\hat{\theta }}}^N_K)\) to these equations is a (joint) maximum likelihood estimator (MLE) for \((\theta _0,\dots ,\theta _K)\). W.l.o.g. we assume that the MLE is unique, otherwise fix any solution. We are interested in the asymptotic behavior of this estimator as \(N\rightarrow \infty \), i.e., as more and more spatial information (for fixed \(T>0\)) is available. While identifiability of \(\theta _1,\dots ,\theta _K\) in finite time depends in general on additional structural assumptions on F, the diffusivity \(\theta _0\) is expected to be identifiable in finite time under mild assumptions. Indeed, the argument is similar to Cialenco and Glatt-Holtz (2011), Pasemann and Stannat (2020), but we have to take into account the dependence of \({{\hat{\theta }}}^N_0\) on the other estimators \({{\hat{\theta }}}^N_1,\dots ,{{\hat{\theta }}}^N_K\). Note that the likelihood equations give the following useful representation for \({{\hat{\theta }}}^N_0\):
By plugging in the dynamics of X according to (5), we obtain the following decomposition:
The right-hand side vanishes whenever for large N the denominator grows faster than the numerator in each of the three fractions. In principle, strong oscillation of the reaction parameter estimates \({{\hat{\theta }}}^N_{1:K}\) may influence the convergence rate for the first term, so in order to exclude undesirable behavior, we assume that \({{\hat{\theta }}}^N_{1:K}\) is bounded in probabilityFootnote 1. This is a mild assumption which is in particular satisfied if the estimators for the reaction parameters are consistent. In Sect. 2.3, we verify this condition for the case that F depends linearly on \(\theta _{1:K}\). Regarding the third term, we exploit the martingale structure of the noise in order to capture the growth in N. Different noise models may be used in (5) without changing the result, as long as the numerator grows slower than the denominator. For example, the present argument directly generalizes to noise of martingale typeFootnote 2. Now, the growth of the denominator can be quantified as follows:
Lemma 4
Let \(\alpha >\gamma -d/4-1/2\), let further \(\eta ,s_0>0\) such that \((A_s)\) and \((F_{s,\eta })\) are true for \(s_0\le s < 2\gamma +1-d/2\). Then
in probability, with
Proof
Using Proposition 3 (i), the proof is exactly as in Pasemann and Stannat (2020, Proposition 4.6). \(\square \)
Theorem 5
Assume that the likelihood equations are solvable for \(N\ge N_0\), assume that \(({{\hat{\theta }}}^N_i)_{N\ge N_0}\) is bounded in probability for \(i=1,\dots ,K\). Let \(\alpha >\gamma -d/4-1/2\) and \(\eta , s_0>0\) such that \((A_s)\) and \((F_{s, \eta })\) hold for any \(s_0\le s < 2\gamma +1-d/2\). Then the following is true:
-
(1)
\({{\hat{\theta }}}^N_0\) is a consistent estimator for \(\theta _0\), i.e., \({{\hat{\theta }}}^N_0\xrightarrow {{\mathbb {P}}}\theta _0\).
-
(2)
If \(\eta \le 1 + d/2\), then \(N^{r}({{\hat{\theta }}}^N_0-\theta _0)\xrightarrow {{\mathbb {P}}}0\) for any \(r<\eta /d\).
-
(3)
If \(\eta > 1+d/2\), then
$$\begin{aligned} N^{\frac{1}{2}+\frac{1}{d}}({{\hat{\theta }}}^N_0-\theta _0)\xrightarrow {d}{\mathcal {N}}(0, V), \end{aligned}$$(26)with \(V = 2\theta _0(4\alpha -4\gamma +d+2)^2 / (Td\Lambda ^{2\alpha -2\gamma +1}(8\alpha -8\gamma +d+2))\).
Proof
By means of the decomposition (22), we proceed as in Pasemann and Stannat (2020). Denote by \({{\hat{\theta }}}^{\mathrm {full},N}_0\) the estimator which is given by (21) if the \({{\hat{\theta }}}^N_1,\dots ,{{\hat{\theta }}}^N_K\) are substituted by the true values \(\theta _1,\dots ,\theta _K\). In this case, the estimation error simplifies to
with
By Lemma 4, the rescaled prefactor \(c_N N^{1/2+1/d}\) converges in probability to \(\sqrt{C_{2\alpha -\gamma }} / C_\alpha \). The second factor converges in distribution to a standard normal distribution \({\mathcal {N}}(0,1)\) by the central limit theorem for local martingales (see Liptser and Shiryayev 1989, Theorem 5.5.4 (I); Jacod and Shiryaev 2003, Theorem VIII.4.17). This proves (26) for \({{\hat{\theta }}}^{\mathrm {full},N}_0\). To conclude, we bound the bias term depending on \({{\hat{\theta }}}^N_1,\dots ,{{\hat{\theta }}}^N_K\) as follows, using \(|P_NY|_{s_2}\le \lambda _N^{(s_2-s_1)/2}|P_NY|_{s_1}\) for \(s_1<s_2\): Let \(\delta >0\). Then
so using \((F_{2\gamma +1-d/2-\delta ,\eta })\),
As \(c({{\hat{\theta }}}^N_{1:K})\) is bounded in probability and \(\delta >0\) is arbitrarily small, the claim follows. The remaining term involving the true parameters \(\theta _1,\dots ,\theta _K\) is similar. This concludes the proof. \(\square \)
It is clear that a Lipschitz condition on F with respect to \(\theta _{1:K}\) allows to bound \({{\hat{\theta }}}^N_0-{{\hat{\theta }}}^{\mathrm {full},N}_0\) in terms of \(|{{\hat{\theta }}}^N_{1:K}-\theta _{1:K}|N^{-(\eta -\delta )/d}\) for \(\delta >0\), using the notation from the previous proof. In this case, consistency of \({{\hat{\theta }}}^N_i\), \(i=1,\dots ,K\), may improve the rate of convergence of \({{\hat{\theta }}}^N_0\). However, as noted before, in general we cannot expect \({{\hat{\theta }}}^N_i\), \(i=1,\dots ,K\), to be consistent as \(N\rightarrow \infty \).
2.3 Statistical Inference: The Linear Model
We put particular emphasis on the case that the nonlinearity F depends linearly on its parameters:
This model includes the FitzHugh–Nagumo system in the form (9). We state an additional verifiable condition, depending on the contrast parameter \(\alpha \in {\mathbb {R}}\), which guarantees that the likelihood equations are well posed, among others.
- \((L_\alpha )\):
-
The terms \(F_1(Y),\dots ,F_K(Y)\) are well defined as well as linearly independent in \(L^2(0,T;H^{2\alpha })\) for every non-constant \(Y\in C(0,T;C({\mathcal {D}}))\).
In particular, condition \((L_\alpha )\) implies for \(i=1,\dots ,K\) that
For linear SPDEs, similar considerations have been made first in Huebner (1993), Chapter 3. The maximum likelihood equations for the linear model (28) simplify to
where
for \(i,j=1,\dots ,K\), and
for \(i=1,\dots ,K\).
In order to apply Theorem 5, we need that the estimators \({{\hat{\theta }}}^N_1,\dots ,{{\hat{\theta }}}^N_K\) are bounded in probability.
Proposition 6
In the setting of this section, let \(\eta ,s_0>0\) such that \((A_s)\) and \((F_{s,\eta })\) are true for \(s_0\le s < 2\gamma +1-d/2\). For \(\gamma -d/4-1/2<\alpha \le \gamma \wedge (\gamma -d/4-1/2+\eta /2)\wedge (\gamma -d/8-1/4+\eta /4)\), let \((L_\alpha )\) be true. Then the \({{\hat{\theta }}}^N_i\), \(i=0,\dots ,K\), are bounded in probability.
The proof of Proposition 6 is given in “Appendix A.2.” We note that the upper bound on \(\alpha \) can be relaxed in general, depending on the exact asymptotic behavior of \(A_N(X)_{i,i}\), \(i=1,\dots ,K\). Proposition 6 together with Theorem 5 gives conditions for \({{\hat{\theta }}}^N_0\) to be consistent and asymptotically normal in the linear model (28). In particular, we immediately get for the activator–inhibitor model (7), (8), as the linear independency condition \((L_\alpha )\) is trivially satisfied and \(\eta \) can be chosen arbitrarily close to 2:
Theorem 7
Let \(\gamma >d/4\). Then \({{\hat{\theta }}}^N_0\) has the following properties in the activator–inhibitor model (7), (8):
-
(1)
In \(d=1\), let \(\gamma -3/4<\alpha \le \gamma \). Then \({{\hat{\theta }}}^N_0\) is a consistent estimator for \(\theta _0\), which is asymptotically normal as in (26).
-
(2)
In \(d=2\), let \(\gamma -1<\alpha < \gamma \). Then \({{\hat{\theta }}}^N_0\) is a consistent estimator for \(\theta _0\) with optimal convergence rate, i.e., \(N^r({{\hat{\theta }}}^N_0-\theta _0)\xrightarrow {{\mathbb {P}}}0\) for any \(r<1\).
So far, we have presented a theory of parameter estimation for stochastic reaction–diffusion models, with special emphasis on activator–inhibitor systems. In the next chapter, the context of this class of models for intracellular actin dynamics is discussed.
3 Application to Activator–Inhibitor Models of Actin Dynamics
The actin cytoskeleton is a dense polymer meshwork at the inner face of the plasma membrane that determines the shape and mechanical stability of a cell. Due to the continuous polymerization and depolymerization of the actin filaments, it displays a dynamic network structure that generates complex spatiotemporal patterns. These patterns are the basis of many essential cellular functions, such as endocytic processes, cell shape changes, and cell motility (Blanchoin et al. 2014). The dynamics of the actin cytoskeleton is controlled and guided by upstream signaling pathways, which are known to display typical features of non-equilibrium systems, such as oscillatory instabilities and the emergence of traveling wave patterns (Peter 2017; Beta and Kruse 2017). Here we use giant cells of the social amoeba D. discoideum that allow us to observe these cytoskeletal patterns over larger spatial domains (Gerhardt et al. 2014). Depending on the genetic background and the developmental state of the cells, different types of patterns emerge in the cell cortex. In particular, pronounced actin wave formation is observed as the consequence of a mutation in the upstream signaling pathway—a knockout of the RasG-inactivating RasGAP NF1—which is present for instance in the commonly used laboratory strain AX2 (Veltman et al. 2016). Giant cells of NF1-deficient strains thus provide a well-suited setting to study the dynamics of actin waves and their impact on cell shape and division (Flemming et al. 2020).

Actin waves in experiments (top) and model simulations (bottom). a Normal-sized cell with a circular actin wave. b Giant cell with several fragmented actin waves. c Subsection of the cortical area of the giant cell shown in (b), indicated as dotted green rectangle. Experimental images are confocal microscopy recordings of mRFP-LimE\(\Delta \) expressing D. discoideum AX2 cells, see Gerhardt et al. (2014). (Bottom) Simulations of the stochastic reaction–diffusion model (3), (4) in a (d) small and e large domain, defined by a dynamically evolving phase field and f with periodic boundary conditions. For details on the phase field simulations, see Flemming et al. (2020). (Scale bars, \(10\,\upmu \hbox {m}\)) Details on the numerical implementation can be found in “Appendix B”
In Fig. 1a, b, we show a normal-sized and a giant D. discoideum cell in the wave-forming regime for comparison. Images were recorded by confocal laser scanning microscopy and display the distribution of mRFP-LimE\(\Delta \), a fluorescent marker for filamentous actin, in the cortex at the substrate-attached bottom membrane of the cell. As individual actin filaments are not resolved by this method, the intensity of the fluorescence signal reflects the local cortical density of filamentous actin. Rectangular subsections of the inner part of the cortex of giant cells as displayed in panel (C) were used for data analysis in Sect. 4.
Many aspects of subcellular dynamical patterns have been addressed by reaction–diffusion models. While some models rely on detailed modular approaches (Beta et al. 2008; Peter 2017), others have focused on specific parts of the upstream signaling pathways, such as the phosphatidylinositol lipid signaling system (Arai et al. 2010) or Ras signaling (Fukushima et al. 2019). To describe wave patterns in the actin cortex of giant D. discoideum cells, the noisy FitzHugh–Nagumo type reaction–diffusion system (3), (4), combined with a dynamic phase field, has been recently proposed (Flemming et al. 2020).
In contrast to the more detailed biochemical models, the structure of this model is rather simple. Waves are generated by noisy bistable/excitable kinetics with an additional control of the total amount of activator U. This constraint dynamically regulates the amount of U around a constant level in agreement with the corresponding biological restrictions. Elevated levels of the activator represent typical cell front markers, such as active Ras, PIP3, Arp2/3, and freshly polymerized actin that are also concentrated in the inner part of actin waves. On the other hand, markers of the cell back, such as PIP2, myosin II, and cortexillin, correspond to low values of U and are found outside the wave area (Schroth-Diez et al. 2009). Tuning of the parameter b allows to continuously shift from bistable to excitable dynamics, both of which are observed in experiments with D. discoideum cells. In Fig. 1d–f, the results of numerical simulations of this model displaying excitable dynamics are shown. Examples for bounded domains that correspond to normal-sized and giant cells are shown, as well as results with periodic boundary conditions that were used in the subsequent analysis.
Model parameters, such as the diffusivities, are typically chosen in an ad hoc fashion to match the speed of intracellular waves with the experimental observations. The approach introduced in Sect. 2 now allows us to estimate diffusivities from data in a more rigorous manner. On the one hand, we may test the validity of our method on in silico data of model simulations, where all parameters are predefined. On the other hand, we can apply our method to experimental data, such as the recordings of cortical actin waves displayed in Fig. 1c. This will yield an estimate of the diffusivity of the activator U, as dense areas of filamentous actin reflect increased concentrations of activatory signaling components. Note, however, that the estimated value of \(D_U\) should not be confused with the molecular diffusivity of a specific signaling molecule. It rather reflects an effective value that includes the diffusivities of many activatory species of the signaling network and is furthermore affected by the specific two-dimensional setting of the model that neither includes the kinetics of membrane attachment/detachment nor the three-dimensional cytosolic volume.
4 Diffusivity Estimation on Simulated and Real Data
In this section, we apply the methods from Sect. 2 to synthetic data obtained from a numerical simulation and to cell data stemming from experiments as described in Sect. 3. We follow the formalism from Theorem 5 and perform a Fourier decomposition on each data set. Set \(\phi _k(x) = \cos (2\pi k x)\) for \(k\le 0\) and \(\phi _k(x)=\sin (2\pi k x)\) for \(k>0\), then \(\Phi _{k,l}(x, y)=\phi _k(x/L_1)\phi _l(y/L_2)\), \(k,l\in {\mathbb {Z}}\), form an eigenbasis for \(-\Delta \) on the rectangular domain \({\mathcal {D}}=[0,L_1]\times [0,L_2]\). The corresponding eigenvalues are given by \(\lambda _{k,l}=4\pi ^2((k/L_1)^2+(l/L_2)^2)\). As before, we choose an ordering \(((k_N,l_N))_{N\in {\mathbb {N}}}\) of the eigenvalues (excluding \(\lambda _{0,0}=0\)) such that \(\lambda _N = \lambda _{k_N,l_N}\) is increasing.
In the sequel, we will use different versions of \({{\hat{\theta }}}^N_0\) which correspond to different model assumptions on the reaction term F, concerning both the effects included in the model and a priori knowledge on the parametrization. While all of these estimators enjoy the same asymptotic properties as \(N\rightarrow \infty \), it is reasonable to expect that they exhibit huge qualitative differences for fixed \(N\in {\mathbb {N}}\), depending on how much knowledge on the generating dynamics is incorporated. In order to describe the model nonlinearities that we presume, we use the notation \(F_1,F_2,F_3\) as in (10), (11), (12). As a first simplification, we substitute \(F_1\) by \({{\widetilde{F}}}_1\) given by
in all estimators below. This corresponds to an approximation of the function a by an effective average value \({{\bar{a}}}>0\). While this clearly does not match the full model, we will see that it does not pose a severe restriction as a(U) tends to stabilize in the simulation. Recall the explicit representation (21) of \({{\hat{\theta }}}^N_0\). As before, K is the number of nuisance parameters appearing in the nonlinear term F. We construct the following estimators which capture qualitatively different model assumptions:
-
(1)
The linear estimator \({\hat{\theta }}^{\mathrm {lin},N}_0\) results from presuming \(K=0\) and \(F=0\).
-
(2)
The polynomial or Schlögl estimator \({{\hat{\theta }}}^{\mathrm {pol},N}_0\), where \(K=0\) and
$$\begin{aligned} F(u)&=k_1u(u_0-u)(u-{{\bar{a}}}u_0)\\&=-k_1{{\bar{a}}}u_0u(u_0-u)+k_1u^2(u_0-u) \\&= \theta _1{{\widetilde{F}}}_1(u)+\theta _2F_2(u) \end{aligned}$$for known constants \(k_1,u_0,{{\bar{a}}}>0\), \(\theta _1 = k_1u_0{{\bar{a}}}\), \(\theta _2=k_1\). The corresponding SPDE (5) is called stochastic Nagumo equation or stochastic Schlögl equation and arises as the limiting case \(\epsilon \rightarrow 0\) of the stochastic FitzHugh–Nagumo system.
-
(3)
The full or FitzHugh–Nagumo estimator \({{\hat{\theta }}}^{\mathrm {full},N}_0\), where \(K=0\) and
$$\begin{aligned} F(u)&=k_1u(u_0-u)(u-{{\bar{a}}} u_0)-k_2v\nonumber \\&= \theta _1{{\widetilde{F}}}_1(u)+\theta _2F_2(u)+\theta _2F_3(u) \end{aligned}$$(32)with \(\theta _1 = k_1u_0{{\bar{a}}}\), \(\theta _2=k_1\) and \(\theta _3 = k_2\epsilon b\), where v is given by \(v_t=\int _0^te^{(t-r)(D_V\Delta -\epsilon I)}u_r\mathrm {d}r\). As before, \(k_1,k_2,u_0,{{\bar{a}}},D_v,\epsilon >0\) are known.
Furthermore, we modify \({{\hat{\theta }}}^{\mathrm {full},N}_0\) in order to estimate different subsets of model parameters at the same time. We use the notation \({{\hat{\theta }}}^{i,N}_0\), where i is the number of simultaneously estimated parameters. More precisely, we set \({{\hat{\theta }}}^{1,N}_0={{\hat{\theta }}}^{\mathrm {full},N}_0\), and additionally:
-
(1)
The estimator \({{\hat{\theta }}}^{2,N}_0\) results from \(K=1\) and \(F_{\theta _1}\) given by (32) for known \(\theta _2,\theta _3>0\). This corresponds to an unknown \(\bar{a}\).
-
(2)
The estimator \({{\hat{\theta }}}^{3,N}_0\) results from \(K=2\) and \(F_{\theta _1,\theta _2}\) given by (32). Only \(\theta _3\) is known.
-
(3)
The estimator \({{\hat{\theta }}}^{4,N}_0\) results from \(K=3\) and \(F_{\theta _1,\theta _2,\theta _3}\) given by (32). All three parameters \(\theta _1,\theta _2,\theta _3\) are unknown.
In all estimators in this section, we set the regularity adjustment \(\alpha =0\). This is a reasonable choice if the driving noise in (7), (8) is close to white noise.
It is worthwhile to note that \({\hat{\theta }}^{\mathrm {lin},N}_0\) is invariant under rescaling the intensity of the data, i.e., substituting X by cX, \(c>0\). This has the advantage that we do not need to know the physical units of the data. In fact, the intensity of fluorescence microscopy data may vary due to different expression levels of reporter proteins within a cell population, or fluctuations in the illumination. While invariance under intensity rescaling is a desirable property, the fact that nonlinear reaction terms are not taken into account may outweigh this advantage, especially if the SPDE model is close to the true generating process of the data. This is the case for synthetic data. The discussion in Sect. 4.1 shows that even if the model specific correction terms in (21) vanish asymptotically, their effect on the estimator may be huge in the non-asymptotic regime, especially at low resolution level. However, real data may behave differently, and a detailed nonlinear model may not reveal additional information on the underlying diffusivity, see Sect. 4.4.

Performance of diffusivity estimators on simulated data under different model assumptions in the spatial high-frequency regime. Solid black line is plotted at the true parameter \(\theta _0=1\times 10^{-13}\), dashed black line is plotted at zero. In all displays, we restrict to \(N\ge 25\) in order to avoid artifacts stemming from low resolution
4.1 Performance on Synthetic Data
First, we study the performance of the mentioned estimators on simulations. The numerical scheme is specified in “Appendix B.” While we have perfect knowledge on the dynamical system which generates the data in this setting, it is revelatory to compare the different versions of \({{\hat{\theta }}}^N_0\) which correspond to varying levels of model misspecification. The simulation shows that \(a(|U_t|_{L^2})\) fluctuates around a value slightly larger than 0.15. We demonstrate the effect of qualitatively different model assumptions on our method in Fig. 2 (top left) by comparing the performance of \({\hat{\theta }}^{\mathrm {lin},N}_0\), \({{\hat{\theta }}}^{\mathrm {pol},N}_0\), and \({{\hat{\theta }}}^{\mathrm {full},N}_0\). The result can be interpreted as follows: As \({\hat{\theta }}^{\mathrm {lin},N}_0\) does not see any information on the wave fronts, the steep gradient at the transition phase leads to a low diffusivity estimate. On the other hand, \({{\hat{\theta }}}^{\mathrm {pol},N}_0\) incorporates knowledge on the wave fronts as they appear in the Schlögl model, but the decay in concentration due to the presence of the inhibitor is mistaken as additional diffusion. Finally, \({{\hat{\theta }}}^{\mathrm {full},N}_0\) contains sufficient information on the dynamics to give a precise estimate. In Fig. 2 (top right), we show the effect of wrong a priori assumptions on \({{\bar{a}}}\) in \({{\hat{\theta }}}^{\mathrm {full},N}_0\). Even for \(N=800\), the precision of \({{\hat{\theta }}}^{\mathrm {full},N}_0\) clearly depends on the choice of \(\bar{a}\). Remember that there is no true \({{\bar{a}}}\) in the underlying model, rather, \({{\bar{a}}}\) serves as an approximation for \(a(|U_t|_{L^2})\). Better results can be achieved with \({{\hat{\theta }}}^{2,N}_0, {{\hat{\theta }}}^{3,N}_0\), and \({{\hat{\theta }}}^{4,N}_0\), see Fig. 2 (bottom left): \({{\hat{\theta }}}^{2,N}_0\) has no knowledge on \({{\bar{a}}}\) and recovers the diffusivity precisely, and even \({{\hat{\theta }}}^{4,N}_0\) performs better than the misspecified \({{\hat{\theta }}}^{\mathrm {full},N}_0\) from the top right panel of Fig. 2.
4.2 Discussion of the Periodic Boundary
In Fig. 2 (bottom right), we sketch how the assumption of periodic boundary conditions influences the estimate. While \({{\hat{\theta }}}^{2,N}_0\) works very well on the full domain of \(200\times 200\) pixels with periodic boundary conditions, it decays rapidly if we just use a square section of \(75\times 75\) pixels. In fact, the boundary conditions are not satisfied on that square section. This leads to the presence of discontinuities at the boundary. These discontinuities, if interpreted as steep gradients, lower the observed diffusivity. Hence, a first guess to improve the quality is to mirror the square section along each axis and glue the results together. In this manner, we construct a domain with \(150\times 150\) pixels, on which \({{\hat{\theta }}}^{2,N}_0\) performs well. We emphasize that, while this periodification procedure is a natural approach, its performance will depend on the specific situation, because the dynamics at the transition edges will still not obey the true underlying dynamics. Furthermore, by modifying the data set as explained, we change its resolution, and consequently, a different amount of spectral information may be included into \({{\hat{\theta }}}^{2,N}_0\) for interpretable results.

Sensitivity of (left) \({\hat{\theta }}^{\mathrm {lin},N}_0\) and (right) \({{\hat{\theta }}}^{2,N}_0\) to different noise levels. Solid black line is plotted at \(\theta _0=1\times 10^{-13}\), and dashed black line is plotted at zero. As before, we restrict to \(N\ge 25\) in the plots
4.3 Effect of the Noise Intensity
In Fig. 3, we study the effect of varying the noise level in the simulation. We compare \({\hat{\theta }}^{\mathrm {lin},N}_0\), which is agnostic to the reaction model, to \({{\hat{\theta }}}^{2,N}_0\), which incorporates a detailed reaction model. While \({{\hat{\theta }}}^{2,N}_0\) performs well regardless of the noise level, the quality of \({\hat{\theta }}^{\mathrm {lin},N}_0\) tends to improve for larger \(\sigma \). In this sense, a large noise amplitude hides the effect of the nonlinearity. This is in line with the observations made in Pasemann and Stannat (2020, Section 3). We note that the dynamical features of the process change for \(\sigma =0.2\): In this case, due to the strong fluctuations stemming from the noise, the model is no longer capable of generating traveling waves.

In all displays, we restrict to \(N\ge 25\) in order to avoid artifacts stemming from low resolution. Dashed black line is plotted at zero (top). Performance of different diffusivity estimators on (top left) cell data and (top right) periodified cell data (bottom). The effects of applying a kernel with bandwidth \({{\bar{\sigma }}}\) is shown for (bottom left) not periodified and (bottom right) periodified data
4.4 Performance on Real Data
A description of the experimental setup can be found in “Appendix B.” The concentration in the data is represented by grey values ranging from 0 to 255 at every pixel. This range is standardized to the unit interval [0, 1], in order to match the stable fixed points of the bistable polynomial f in the reference case \(u_0=1\). Note that this is necessary for all estimators except \({\hat{\theta }}^{\mathrm {lin},N}_0\). We compare \({\hat{\theta }}^{\mathrm {lin},N}_0\) with \({{\hat{\theta }}}^{2,N}_0\), \({{\hat{\theta }}}^{3,N}_0\), and \({{\hat{\theta }}}^{4,N}_0\), which are more flexible than \({{\hat{\theta }}}^{\mathrm {pol},N}_0\) and \({{\hat{\theta }}}^{\mathrm {full},N}_0\). In Fig. 4 (top left) the behavior of these four estimators on a sample cell is shown. Interestingly, the model-free linear estimator \({\hat{\theta }}^{\mathrm {lin},N}_0\) is close to \({{\hat{\theta }}}^{3,N}_0\) and \({{\hat{\theta }}}^{4,N}_0\), which impose very specific model assumptions. This pattern can be observed across different cell data sets. In particular, this is notably different from the performance of these three estimators on synthetic data. This discrepancy seems to indicate that the lower-order reaction terms in the activator–inhibitor model are not fully consistent with the information contained in the experimental data. This can have several reasons; for example, it is possible that a more detailed model reduction of the known signaling pathway inside the cell is needed. On the contrary, \({{\hat{\theta }}}^{2,N}_0\) seems to be comparatively rigid due to its a priori choices for \(\theta _2\) and \(\theta _3\), but it eventually approaches the other estimators. Variations in the value of \(u_0\) have an impact on the results for small N but not on the asymptotic behavior. In Fig. 4 (top right), the cell from Fig. 4 (top left) is periodified before evaluating the estimators. As expected from the discussion in Sect. 4.2, the estimates rise, but the order of magnitude does not change drastically.
4.5 Invariance under Convolution
Given a function \(k\in L^1({\mathcal {D}})\), define \(T_k:H^s({\mathcal {D}})\rightarrow H^s({\mathcal {D}})\), \(s\in {\mathbb {R}}\), via \(u\mapsto k*u=\int _{\mathcal {D}}k(\cdot -x)u(x)\mathrm {d}x\), where k and u are identified with their periodic continuation. It is well known that \(T_k\) commutes with \(\Delta \), i.e., \(T_k\circ \Delta =\Delta \circ T_k\). Thus, if X is a solution to a semilinear stochastic PDE with diffusivity \(\theta \), the same is true for \(T_kX\): While the nonlinearity and the dispersion operator may be changed by \(T_k\), the diffusive part is left invariant, in particular the diffusivity of X and \(T_kX\) is the same. Based on this observation, a comparison between the effective diffusivity of X and \(T_kX\) for different choices of k may serve as an indicator if the assumption that a data set X is generated by a semilinear SPDE (5) is reasonable in the first place, and if the diffusion indeed can be considered to be homogeneous and isotropic. We use a family of periodic kernels \(k=k_{{{\bar{\sigma }}}}\), \({{\bar{\sigma }}}>0\), which are normed in \(L^1({\mathcal {D}})\) and coincide on the reference rectangle \([-L_1/2,L_1/2]\times [-L_2/2,L_2/2]\) with a Gaussian density with standard deviation \({{\bar{\sigma }}}\). In Fig. 4 (bottom), the effects of applying \(T_{k_{{{\bar{\sigma }}}}}\) for different bandwidths \({{\bar{\sigma }}}\) are shown for one data set and its periodification. While the diffusivity of the data without periodification on the left-hand panel is slightly affected by the kernel, more precisely, its tendency to fall is enlarged, the graphs for the effective diffusivity of the periodified data are virtually indistinguishable. Periodification seems to be compatible with the expected invariance under convolution, even if the periodified data are not generated by a semilinear SPDE but instead by joining smaller patches of that form. In total, these observations are in accordance with the previous sections and suggest that the statistical analysis of the data based on a semilinear SPDE model is reasonable.
4.6 The Effective Diffusivity of a Cell Population

The samples are evaluated (top) without or (bottom) with periodification. \({{\hat{\theta }}}^{3, N}_0\) with (left) \(N=N_\mathrm {const}\) or (right) \(N=N_\mathrm {stop}\) is plotted against \(N_\mathrm {stop}\). The least squares fit is shown in red. The p value in each plot corresponds to a t-test whose null hypothesis states that the slope of the regression line is zero. Clearly, the slope is more notable in the case \(N=N_{\mathrm {const}}\)
We compare the estimated diffusivity for a cell population consisting of 36 cells. The boundaries in space and time of all samples are selected in order to capture only the interior dynamics within a cell, and consequently, the data sets differ in their size. On the one hand, the estimated diffusivity tends to stabilize in time, i.e., the number of frames in a sample, corresponding to the final time T, does not affect the result much. On the other hand, the size of each frame, measured in pixels, determines the number of eigenfrequencies that carry meaningful information on the process. Thus, we expect that N can be chosen larger for samples with high spatial resolution. We formalize this intuition with the following heuristic: Let \(r_x\) and \(r_y\) denote the number of pixels in each row and column, resp., of every frame in a sample. Let \(N_\mathrm {stop}=\lfloor 4r_xr_y/M^2\rfloor \), where \(M\in {\mathbb {N}}\) is a parameter representing the number of pixels needed for a sine or cosine to extract meaningful information. That is, a square of dimensions \(r_x\times r_y = M\times M\) leads to \(N_\mathrm {stop}=4\), so in this case only the eigenfunctions \(\Phi _{k,l}\), \(k,l\in \{-1,1\}\) are taken into account, whose period length is M in both dimensions. In our evaluations, we choose \(M=12\) for the data without periodification and \(M=24\) for the periodified data sets. We mention that the cells are also heterogeneous with respect to their characteristic length \({\overline{\hbox {d}x}}\) and time \({\overline{\hbox {d}t}}\), given in meters per pixel and seconds per frame for each data set.Footnote 3 However, a detailed quantitative analysis of the resulting discretization error is beyond the scope of our work. In Fig. 5, we compare the results for \({{\hat{\theta }}}^{3,N_\mathrm {stop}}_0\) with \({{\hat{\theta }}}^{3,N_\mathrm {const}}_0\) within the cell population, where \(N_\mathrm {const}=899\) is independent of the sample resolution. Evaluating the estimator at \(N_\mathrm {stop}\) decorrelates the estimated diffusivity from the spatial extension of the sample. The results for different cells have the same order of magnitude, which indicates that the effective diffusivity can be used for statistical inference for cells within a population or between populations in future research.

Estimation of the reaction parameter \(\theta _1\) on (left) simulated data and (right) cell data. All times are given in seconds, relative to the first frame. As before, we restrict to \(N\ge 25\)
4.7 Estimating \(\theta _1\)
When solving the linear MLE equations in order to obtain \({{\hat{\theta }}}^{2,N}_0\), we simultaneously get an estimate \({{\hat{\theta }}}_1^{2,N}\) for \(\theta _1=k_1u_0{{\bar{a}}}\). Note that \(u_0=1\) by convention, and \(\theta _2=k_1=1\) is treated as known quantity in this case. Thus, \(\theta _1\) can be identified with \({{\bar{a}}}\). In Fig. 6 we show the results for \({{\hat{\theta }}}_1^{1,N}\) on simulated data (left) and on a cell data sample (right). Note that in general, we cannot expect to observe increased precision for \({{\hat{\theta }}}_1^{2,N}\) as N grows, because the reaction term is of order zero.Footnote 4 However, it is informative to consider also the large time regime \(T\rightarrow \infty \), i.e., to include more and more frames to the estimation procedure. In the case of simulated data, a oscillates around an average value close to 0.15, which should be considered to be the ground truth for \({{\bar{a}}}\). This effective value \({{\bar{a}}}\) is recovered well, even for small T, with increasing precision as T grows. Clearly, this depends heavily on the model assumptions. In the case of cell data, the results are rather stable. This indicates that it may be reasonable to use the concept of an “effective unstable fixed point \({{\bar{a}}}\) of the reaction dynamics, conditioned on the model assumptions included in \({{\hat{\theta }}}^{2,N}_0\),” when evaluating cell data statistically.

As before, we restrict to \(N\ge 25\). (left) Effective diffusivity outside the cell, plot for one data set. Dashed line is plotted at zero. (right) Comparison of the energy inside and outside the cell. Both data sets have the same spatial and temporal extensions
4.8 The Case of Pure Noise Outside the Cell
If the data set does not contain parts of the cell but rather mere noise, the estimation procedure still returns a value. This “observed diffusivity” (see Fig. 7) originates completely from white measurement noise. More precisely, the appearance and vanishing of singular pixels is interpreted as instantaneous (i.e., within the time between two frames) diffusion to the steady state. Thus, the observed diffusivity in this case can be expected to be even larger than the diffusivity inside the cell. In this section, we give a heuristical explanation for the order of magnitude of the effective diffusivity outside the cell.
We work in dimension \(d=2\). Assume that a pixel has width \(x>0\). This value is determined by the spatial resolution of the data. For simplicity, we approximate it by a Gaussian density \(\phi _0(y)\) with standard deviation \(\sigma _0 = \frac{x}{2}\). This way, the inflection points of the (one-dimensional marginal) density match the sharp edges of the pixel. Now, using \(\phi _0\) as an initial condition for the heat equation on the whole space \({\mathbb {R}}^2\), the density \(\phi _t\) after time t is also a Gaussian density, with standard deviation \(\sigma _t=\sqrt{\sigma _0^2+2\theta t}\), obtained by convolution with the heat kernel. The maximal value \(f_\mathrm {max}^t\) of \(\phi _t\) is attained at \(y=0\) with \(f_\mathrm {max}^t = (2\pi \sigma _t^2)^{-1} = (2\pi (\sigma _0^2 + 2\theta t))^{-1}\). Now, if we observe after time \(t>0\) at the given pixel an intensity decay by a factor \(b>0\), i.e.,
this leads to an estimate for the diffusivity of the form
For example, set \(t = 0.97s\) and \(x=2.08\times 10^{-7}\) m, as in the data set from Fig. 7 (left). The intensity decay factor varies between different pixels in the data set, reasonable values are given for \(b\le 30\). If \(b=30\), we get \(\theta \ge 1.6\times 10^{-13}\,\hbox {m}^2/\hbox {s}\), for \(b = 20\), we get \(\theta \ge 1\times 10^{-13}\,\hbox {m}^2/\hbox {s}\), and for \(b=15\), we have \(\theta \ge 7.8\times 10^{-14}\,\hbox {m}^2/\hbox {s}\). This matches the observed diffusivity outside the cell from Fig. 7, which is indeed of order \(1\times 10^{-13}\,\hbox {m}^2/\hbox {s}\): For example, with \(N=N_\mathrm {stop}=\lfloor 4r_xr_y/M^2\rfloor \) and \(M=12\), as in Sect. 4.6, we get \(N_\mathrm {stop}=165\) and \({{\hat{\theta }}}^{\mathrm {lin}, N_\mathrm {stop}}_0=1.36\times 10^{-13}\,\hbox {m}^2/\hbox {s}\) for this data set consisting of pure noise. In total, this gives a heuristical explanation for the larger effective diffusivity outside the cell compared to the estimated values inside the cell.
It is important to note that even if the effective diffusivity outside the cell is larger, this has almost no effect on the estimation procedure inside the cell. This is because the total energy \(A_N(X)_{0, 0}\) of the noise outside the cell is several orders of magnitude smaller than the total energy of the signal inside the cell, see Fig. 7 (right).
5 Discussion and Further Research
In this paper, we have extended the mathematical theory of parameter estimation of stochastic reaction–diffusion system to the joint estimation problem of diffusivity and parametrized reaction terms within the variational theory of stochastic partial differential equations. We have in particular applied our theory to the estimation of effective diffusivity of intracellular actin cytoskeleton dynamics.
Traditionally, biochemical signaling pathways were studied in a purely temporal manner, focusing on the reaction kinetics of the individual components and the sequential order of the pathway, possibly including feedback loops. Relying on well-established biochemical methods, many of these temporal interaction networks could be characterized. However, with the recent progress in the in vivo expression of fluorescent probes and the development of advanced live cell imaging techniques, the research focus has increasingly shifted to studying the full spatiotemporal dynamics of signaling processes at the subcellular scale. To complement these experiments with modeling studies, stochastic reaction–diffusion systems are the natural candidate class of models that incorporate the relevant degrees of freedom of intracellular signaling processes. Many variants of this reaction–diffusion framework have been proposed in an empirical manner to account for the rich plethora of spatiotemporal signaling patterns that are observed in cells. However, the model parameters in such studies are oftentimes chosen in an ad hoc fashion and tuned based on visual inspection, so that the patterns produced in model simulations agree with the experimental observations. A rigorous framework that allows to estimate the parameters of stochastic reaction–diffusion systems from experimental data will provide an indispensable basis to refine existing models, to test how well they perform, and to eventually establish a new generation of more quantitative mathematical models of intracellular signaling patterns.
The question of robustness of the parameter estimation problem with respect to specific modeling assumptions of the underlying stochastic evolution equation is an important problem in applications that needs to be further investigated in future research. In particular, this applies to the dependence of diffusivity estimation on the domain and its boundary. In this work, we based our analysis on a Fourier decomposition on a rectangular domain with periodic boundary conditions. A natural, boundary-free approach is using local estimation techniques as they have been developed and used in Altmeyer and Reiß (2020), Altmeyer et al. (2020b), Altmeyer et al. (2020a). An additional approach aiming in the same direction is the application of a wavelet transform.
It is a crucial task to gather further information on the reaction term from the data. Principally, this cannot be achieved in a satisfactory way on a finite time horizon, so the long-time behavior of maximum likelihood-based estimators needs to be studied in the context of stochastic reaction–diffusion systems. We will address this issue in detail in future work.
To conclude, statistical inference for stochastic partial differential equations is an emerging field, which increasingly attracts the attention of mathematical research. When applied to experimental data coming from microscopy observation, it will provide a beneficial tool for the quantitative analysis of subcellular pattern formation.
Notes
A sequence of estimators \(({{\hat{\theta }}}^N)_{N\in {\mathbb {N}}}\) is called bounded in probability (or tight) if \(\sup _{N\in {\mathbb {N}}}{\mathbb {P}}(|{{\hat{\theta }}}^N|>M)\rightarrow 0\) as \(M\rightarrow \infty \).
Further tests indicate that the estimated diffusivity correlates with the characteristic diffusivity \({\overline{\hbox {d}x}}^2/{\overline{\hbox {d}t}}\). A more detailed examination of the discretization effects and other dependencies which are not directly related to the underlying process is left for future research. Also, it would be interesting to understand the extent to which the effective diffusivity in the data is scale dependent.
According to Huebner and Rozovskii (1995), the maximum likelihood estimator for the coefficient of a linear-order zero perturbation to a heat equation with known diffusivity converges only with logarithmic rate in \(d=2\).
References
Altmeyer, R., Bretschneider, T., Janák, J., Reiß, M.: Parameter estimation in an SPDE model for cell repolarization. Preprint: arXiv:2010.06340 [math.ST] (2020)
Altmeyer, R., Cialenco, I., Pasemann, G.: Parameter estimation for semilinear SPDEs from local measurements. Preprint: arXiv:2004.14728 [math.ST] (2020)
Adams, R.A., Fournier, J.J.F.: Sobolev Spaces, second ed., Pure and Applied Mathematics, vol. 140. Elsevier/Academic Press, Cambridge (2003)
Annesley, Sarah J., Fisher, Paul R.: Dictyostelium discoideum—a model for many reasons. Mol. Cell. Biochem. 329(1–2), 73–91 (2009)
Altmeyer, R., Reiß, M.: Nonparametric estimation for linear SPDEs from local measurements. Ann. Appl. Probab. (2020) (to appear)
Alonso, Sergio, Stange, Maike, Beta, Carsten: Modeling random crawling, membrane deformation and intracellular polarity of motile amoeboid cells. PLoS ONE 13(8), e0201977 (2018)
Arai, Yoshiyuki, Shibata, Tatsuo, Matsuoka, Satomi, Sato, Masayuki J., Yanagida, Toshio, Ueda, Masahiro: Self-organization of the phosphatidylinositol lipids signaling system for random cell migration. Proc. Natl. Acad. Sci. 107(27), 12399–12404 (2010)
Beta, Carsten, Amselem, Gabriel, Bodenschatz, Eberhard: A bistable mechanism for directional sensing. New J. Phys. 10(8), 083015 (2008)
Blanchoin, Laurent, Boujemaa-Paterski, Rajaa, Sykes, Cécile, Plastino, Julie, Dynamics, Actin: Architecture, and mechanics in cell motility. Physiol. Rev. 94(1), 235–263 (2014)
Beta, Carsten, Kruse, Karsten: Intracellular oscillations and waves. Ann. Rev. Condens. Matter Phys. 8(1), 239–264 (2017)
Bibinger, M., Trabs, M.: On central limit theorems for power variations of the solution to the stochastic heat equation. In: Steland, A., Rafajłowicz, E., Okhrin, O. (eds.) Stochastic Models, Statistics and Their Applications. Springer Proceedings in Mathematics and Statistics, vol. 294, pp. 69–84. Springer, Berlin (2019)
Bibinger, M., Trabs, M.: Volatility estimation for stochastic PDEs using high-frequency observations. Stochast. Process. Their Appl. 130(5), 3005–3052 (2020)
Cialenco, I., Delgado-Vences, F., Kim, H.-J.: Drift estimation for discretely sampled SPDEs, stochastics and partial differential equations: analysis and computations (2020) (to appear)
Cialenco, I., Glatt-Holtz, N.: Parameter estimation for the stochastically perturbed Navier–Stokes equations. Stochast. Process. Appl. 121(4), 701–724 (2011)
Cialenco, I., Huang, Y.: A Note on parameter estimation for discretely sampled SPDEs. Stochast. Dyn. (2019). https://doi.org/10.1142/S0219493720500161 (to appear)
Chong, C.: High-frequency analysis of parabolic stochastic PDEs. Ann. Stat. (2019) (to appear)
Chong, C.: High-frequency analysis of parabolic stochastic PDEs with multiplicative noise: part I. Preprint: arXiv:1908.04145 [math.PR] (2019)
Cialenco, Igor: Parameter estimation for SPDEs with multiplicative fractional noise. Stoch. Dyn. 10(4), 561–576 (2010)
Cialenco, I.: Statistical inference for SPDEs: an overview. Stat. Inference Stoch. Process. 21(2), 309–329 (2018)
Cialenco, I., Kim, H.-J.: Parameter estimation for discretely sampled stochastic heat equation driven by space-only noise revised. Preprint: arXiv:2003.08920 [math.PR] (2020)
Cialenco, Igor, Lototsky, Sergey V.: Parameter estimation in diagonalizable bilinear stochastic parabolic equations. Stat. Inference Stoch. Process. 12(3), 203–219 (2009)
Condeelis, John, Singer, Robert H., Segall, Jeffrey E.: THE GREAT ESCAPE: when cancer cells hijack the genes for chemotaxis and motility. Annu. Rev. Cell Dev. Biol. 21(1), 695–718 (2005)
Devreotes, P.N., Bhattacharya, S., Edwards, M., Iglesias, P.A., Lampert, T., Miao, Y.: excitable signal transduction networks in directed cell migration. Ann. Rev. Cell Dev. Biol. 33(1), 103–125 (2017)
Da Prato, G., Zabczyk, J.: Stochastic Equations in Infinite Dimensions, Encyclopedia of Mathematics and its Applications, vol. 152, 2nd edn. Cambridge University Press, Cambridge (2014)
Ermentrout, G.B., Terman, D.H.: Mathematical Foundations of Neuroscience, Interdisciplinary Applied Mathematics, vol. 35. Springer, New York (2010)
Flemming, Sven, Font, Francesc, Alonso, Sergio, Beta, Carsten: How cortical waves drive fission of motile cells. Proc. Natl. Acad. Sci. 117(12), 6330–6338 (2020)
Fitzhugh, R.: Impulses and physiological states in theoretical models of nerve membrane. Biophys. J. 1, 445–466 (1961)
Fukushima, S., Matsuoka, S., Ueda, M.: Excitable dynamics of Ras triggers spontaneous symmetry breaking of PIP3 signaling in motile cells. J. Cell Sci. 132, 1–12 (2019)
Gerhardt, Matthias, Ecke, Mary, Walz, Michael, Stengl, Andreas, Beta, Carsten, Gerisch, Günther: Actin and PIP3 waves in giant cells reveal the inherent length scale of an excited state. J. Cell Sci. 127(20), 4507–4517 (2014)
Hübner, M., Khasminskii, R., Rozovskii, B.L.: In: Cambanis, S., Ghosh, J.K., Karandikar, R.L., Sen, P.K. (eds) Two Examples of Parameter Estimation for Stochastic Partial Differential Equations, Stochastic Processes, pp. 149–160. Springer, New York (1993)
Huebner, M., Lototsky, S., Rozovskii, B.L.: Asymptotic Properties of an Approximate Maximum Likelihood Estimator for Stochastic PDEs, Statistics and Control of Stochastic Processes (Y. M. Kabanov, B. L. Rozovskii, and A. N. Shiryaev, eds.), World Sci. Publ., (1997), pp. 139–155
Huebner, M., Rozovskii, B.L.: On asymptotic properties of maximum likelihood estimators for parabolic stochastic PDE’s. Probab. Theory Related Fields 103(2), 143–163 (1995)
Huebner, M.: Parameter Estimation for Stochastic Differential Equations, ProQuest LLC, Ann Arbor (1993). Thesis (Ph.D.)–University of Southern California
Jacod, J., Shiryaev, A.N.: Limit Theorems for Stochastic Processes, Grundlehren der Mathematischen Wissenschaften, vol. 288. Springer, Berlin (2003)
Khalil, Z.M., Tudor, C.: Estimation of the drift parameter for the fractional stochastic heat equation via power variation. Mod. Stoch. Theory Appl. 6(4), 397–417 (2019)
Kaino, Y., Uchida, M.: Parametric estimation for a parabolic linear SPDE model based on sampled data. Preprint: arXiv:1909.13557 [math.ST] (2019)
Lototsky, S.: Parameter Estimation for Stochastic Parabolic Equations: Asymptotic Properties of a Two-Dimensional Projection-Based Estimator. Stat. Inference Stoch. Process. 6(1), 65–87 (2003)
Lototsky, S.V., Rosovskii, B.L.: Spectral asymptotics of some functionals arising in statistical inference for SPDEs. Stoch. Process. Appl. 79(1), 69–94 (1999)
Lototsky, S., Rozovskii, B.L.: In: Korolyuk, V., Portenko, N., Syta, H. (eds) Parameter Estimation for Stochastic Evolution Equations with Non-Commuting Operators, Skorokhod’s Ideas in Probability Theory, Institute of Mathematics of the National Academy of Science of Ukraine, Kiev, pp. 271–280 (2000)
Liu, W., Röckner, M.: Stochastic Partial Differential Equations: An Introduction. Universitext. Springer, New York (2015)
Liptser, R.S., Shiryayev, A.N.: Statistics of Random Processes I (General Theory), Applications of Mathematics, vol. 5. Springer, New York (1977)
Sh, R., Liptser, A., Shiryayev, N.: Theory of Martingales, Mathematics and its Applications (Soviet Series), vol. 49. Kluwer Academic Publishers Group, Dordrecht (1989)
Moreno, E., Flemming, S., Font, F., Holschneider, M., Beta, C., Alonso, S.: Modeling cell crawling strategies with a bistable model: From amoeboid to fan-shaped cell motion. Physica D Nonlinear Phenomena 412, (2020)
Nagumo, A., Arimoto, S., Yoshizawa, S.: An active pulse transmission line simulating nerve axon. Proc. IRE 50(10), 2061–2070 (1962)
Piterbarg, L., Rozovskii, B.: Maximum likelihood estimators in the equations of physical oceanography. In: Adler, R.J., Młuller, P., Rozovskii, B.L. (eds.) Stochastic Modelling in Physical Oceanography, Progress in Probability vol. 39, pp. 397–421. Birkhäuser Boston, Boston (1996)
Pasemann, G., Stannat, W.: Drift estimation for stochastic reaction–diffusion systems. Electron. J. Stat. 14(1), 547–579 (2020)
Pospíšil, Jan, Tribe, Roger: Parameter estimates and exact variations for stochastic heat equations driven by space–time white noise. Stoch. Anal. Appl. 25(3), 593–611 (2007)
Schroth-Diez, Britta, Gerwig, Silke, Ecke, Mary, Hegerl, Reiner, Diez, Stefan, Gerisch, Günther: Propagating waves separate two states of actin organization in living cells. HFSP J. 3(6), 412–427 (2009)
Shubin, M.A.: Pseudodifferential Operators and Spectral Theory, 2nd edn. Springer, Berlin (2001)
Veltman, Douwe M., Williams, Thomas D., Bloomfield, Gareth, Chen, Bi-Chang, Betzig, Eric, Insall, Robert H., Kay, Robert R.: A plasma membrane template for macropinocytic cups. Elife 5, e20085 (2016)
Weyl, H.: Über die asymptotische Verteilung der Eigenwerte. Nachrichten von der Gesellschaft der Wissenschaften zu Göttingen, Mathematisch-Physikalische Klasse 110–117 (1911)
Acknowledgements
This research has been partially funded by Deutsche Forschungsgemeinschaft (DFG)—SFB1294/1-318763901. SA acknowledges funding from MCIU and FEDER—PGC2018-095456-B-I00.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Philipp M Altrock.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A. Additional Proofs
1.1 Proof of Proposition 1
We prove Proposition 1 by a series of lemmas. First, we show that (7), (8) is well posed in \({\mathcal {H}} = L^2\times L^2\). First note that for any \(u,v\in L^2({\mathcal {D}})\) and \(x\in {\mathbb {R}}\):
as \(\partial f(x, u)\) is bounded from above uniformly in x and u.
Lemma 8
There is a unique \({\mathcal {H}}\)-valued solution (U, V) to (7), (8), and
for any \(p\ge 1\).
In particular,
for any \(p\ge 1\).
Proof of Lemma 8
This follows from Liu and Röckner (2015, Theorem 5.1.3). In order to apply this result, we have to test the conditions (H1), \((H2')\), (H3), \((H4')\) (i.e., hemicontinuity, local monotonicity, coercivity, and growth) therein. Set \({\mathcal {V}} = H^1\times H^1\). Define \(A(U, V) = (A_1(U, V), A_2(U, V))\) with
As \(B=(-\Delta )^{-\gamma }\) is constant and of Hilbert–Schmidt type, we can neglect it in the estimates. In order to check the conditions , we have to look separately at \(A_1\) and \(A_2\). The statements for \(A_2\) is trivial by linearity, so we test the parts of the conditions corresponding to \(A_1\). (H1) is clear as f(x, u) is a polynomial in u and continuous in x. (H2) follows from (35) via
for some \({{\tilde{x}}}\in {\mathbb {R}}\) and \(\widetilde{V}:{\mathcal {D}}\rightarrow {\mathbb {R}}\), and \(|\partial _x f({{\tilde{x}}}, U_2)|_{L^2} = |u_0a'({{\tilde{x}}})U_2(u_0-U_2)|_{L^2}\lesssim |U_2|_{L^2}+|U_2^2|_{L^2}\). With \(|U_2^2|_{L^2} = |U_2|_{L^4}^2\lesssim |U_2|_{H^1}^2\), we see that local monotonicity as in (H2) is satisfied by taking \(\rho ((u,v)) = c|u|_{H^1}^2\le c|(u,v)|_{{\mathcal {V}}}^2\). Now, for (H3),
for some \({{\widetilde{V}}}:{\mathcal {D}}\rightarrow {\mathbb {R}}\), again using (35). Finally,
so it remains to control \(|f(|U|_{L^2},U)|_{H^{-1}}^2\lesssim |f(|U|_{L^2},U)|_{L^1}^2\lesssim |U|_{L^1}^2+|U^2|_{L^1}^2+|U^3|_{L^1}^2\), and we have \(|U|_{L^1}^2\lesssim |U|_{L^2}^2\) as well as \(|U^2|_{L^1}^2=|U|_{L^2}^4\) and \(|U^3|_{L^1}^2 = |U|_{L^3}^6\lesssim |U|_{H^{1/3}}^6\lesssim |U|_{H^1}^2|U|_{L^2}^4\). Thus, (H4) is true. Putting things together, we get that Liu and Röckner (2015) is applicable for sufficiently large \(p\ge 1\), and the claim follows. \(\square \)
In order to improve (37) to the \(H^1\)-norm, it suffices to prove coercivity, i.e., (H3) from Liu and Röckner (2015), for the Gelfand triple \(H^2\subset H^1\subset L^2\).
Lemma 9
The solution (U, V) to (7), (8) satisfies \((A_1)\), i.e., for any \(p\ge 1\):
Proof
This is done by
where (35) has been used componentwise. By Liu and Röckner (2015, Lemma 5.1.5) we immediately obtain (40). \(\square \)
Remember that by integrating (8), we can write (7) as
where we adopted the notation from (10), (11), (12).
Lemma 10
The process (U, V) satisfies \((A_s)\) for some \(s>1\).
Proof
Let \(U={{\overline{U}}}+{{\widetilde{U}}}\) be the decomposition of U into its linear and nonlinear part as in (14),(15). We will prove
for any \(p,q\ge 1\) and \(s<2\). As \(\gamma >d/4\) in \(d\le 2\), there is \(s>1\) such that (42) is true for \({{\overline{U}}}\) with \(q=2\), and the claim follows. Let us now prove (42). First, note that by Lemma 9 and the Sobolev embedding theorem in dimension \(d\le 2\), (42) is true for \(U_t\) with any \(p,q\ge 1\) and \(s=0\). For \(k\in {\mathbb {N}}\), by \(|U_t^k|_{L^q}^p = |U_t|_{L^{kq}}^{kp}\), we see that polynomials in U satisfy (42) with \(s=0\), too. In particular, using that a is bounded,
for \(i=1,2\) and \(p,q\ge 1\). A simple calculation shows that the same is true for \(F_3\). As in the proof of Proposition 3, we see that
with \(\eta <2\), \(q\ge 1\) and \(\epsilon =2-\eta \), and the proof is complete. \(\square \)
Proof of Proposition 1
In \(d\le 2\), \(H^s\) is an algebra for \(s>1\), i.e., \(uv\in H^s\) for \(u,v\in H^s\) Adams and Fournier (2003). Together with the assumption that a is bounded, it follows immediately that \((F_{s, \eta })\) holds for \(F_1\), \(F_2\) separately (with \(K=0\)) for any \(s>1\) and \(\eta < 2\). For \(F_3\), we have for any \(\delta >0\):
so \(F_3\) satisfies \((F_{s, \eta })\) even with \(s\in {\mathbb {R}}\), \(\eta <4\). It is now clear that the \((F_{s, \eta })\) holds for \(F = \theta _1F_1+\theta _2F_2+\theta _3F_3\) for any \(s>1\) and \(\eta < 2\) (with \(K=3\)). The claim follows from Proposition 3 (i) for U and (ii) for V, noting that \(V = \epsilon b F_3(U)\). \(\square \)
1.2 Proof of Proposition 6
This section is devoted to proving Proposition 6. A similar argument can be found in Huebner (1993), Chapter 3 for linear SPDEs. We start with an auxiliary statement, which characterizes the rate of \(\det (A_N(X))\). For simplicity of notation, we abbreviate \(a^N_i:=A_N(X)_{i,i}\) for \(i=0,\dots , K\). While there is a trival upper bound \(\det (A_N(X))\lesssim a^N_0\dots a^N_K\) obtained by the Cauchy–Schwarz inequality, the corresponding lower bound requires more work. Our argument is geometric in nature: A Gramian matrix measures the (squared) volume of a parallelepiped spanned by the vectors defining the matrix. The argument takes place in the separable Hilbert space \(L^2(0,T;H^{2\alpha })\), and we find a (uniform in N) lower bound on the \((K+1)\)-dimensional volume of the parallelepiped spanned by the vectors \(P_N(-\Delta )X, P_NF_1(X), \dots , P_NF_K(X)\). While the latter K components (and thus their K-dimensional volume) converge, the first component gets eventually orthogonal to the others as N grows. This is formalized as follows:
Lemma 11
Let \(\eta ,s_0>0\) such that \((A_s)\) and \((F_{s,\eta })\) are true for \(s_0\le s < 2\gamma +1-d/2\). Let \(\gamma -d/4-1/2<\alpha \le \gamma -d/4-1/2+\eta /2\). Under assumption \((L_\alpha )\), we have
In particular, \(A_N(X)\) is invertible if N is large enough.
Proof
The argument is pathwise, so we fix a realization of X. We abbreviate \(\langle \cdot ,\cdot \rangle _\alpha :=\langle \cdot ,\cdot \rangle _{L^2(0,T;H^{2\alpha })}\) and \(\Vert \cdot \Vert _\alpha :=|\cdot |_{L^2(0,T;H^{2\alpha })}\); further, we write \(F_0(X) = \Delta X\) in order to unify notation. By a simple normalization procedure, it suffices to show that
Let \(\epsilon >0\) and choose \(N_0,N_1\in {\mathbb {N}}\) with \(N_0\le N_1\) such that:
-
\(\Vert P_NF_i(X)-F_i(X)\Vert _\alpha <\epsilon \Vert F_i(X)\Vert _\alpha \) and \(\Vert F_i(X)\Vert _\alpha / \Vert P_NF_i(X)\Vert _\alpha < 2\) for \(i=1,\dots ,K\) and \(N\ge N_0\). This is possible due to \(\alpha \le \gamma -d/4-1/2+\eta /2.\)
-
\(\Vert P_{N_0}F_0(X) \,/\, \Vert P_{N}F_0(X)\Vert _\alpha \,\Vert _\alpha <\epsilon \) for \(N\ge N_1\). This is possible as \(\Vert P_NF_0(X)\Vert _\alpha \) diverges due to \(\alpha > \gamma -d/4-1/2\).
Now one performs a Laplace expansion of (48) in the first column. Each entry of the matrix in (48) can be bounded by 1 trivially, but we can say more:
for \(N\ge N_1\) with \(i=1,\dots ,K\), where we used the Cauchy–Schwarz inequality and the choice of \(N_0\), \(N_1\). Consequently, in order for (48) to be true, it suffices to show for the (0, 0)-minor:
By \((L_\alpha )\), we have
so (49) holds true by continuity for \(i=1,\dots ,K\). \(\square \)
Proof of Proposition 6
As before, we formally write \(F_0(X) = \Delta X\) in order to unify notation. By plugging in the dynamics of X, we see that for \(i=0,\dots ,K\),
Thus, with \({{\bar{b}}}_N(X)_{i} = \int _0^T\langle (-\Delta )^{2\alpha -\gamma }P_NF_i(X),\mathrm {d}W^N_t\rangle \) and \(\theta = (\theta _0,\dots ,\theta _K)^T\), this read as
i.e.,
Using the explicit representation for the inverse matrix \(A_N(X)^{-1}\), we have
where \({{\overline{A}}}^{(i,j)}_N(X)\) results from \(A_N(X)\) by erasing the ith row and the jth column. Remember that by Lemma 4, \(a^N_0\asymp C_\alpha N^{\frac{2}{d}(2\alpha -2\gamma +1)+1}\). Further, due to \(\alpha \le \gamma -d/4-1/2+\eta /2\), \(a^N_i / a^N_0 \rightarrow 0\) in probability for all \(i=1,\dots ,K\). Now, by the Cauchy–Schwarz inequality, each summand in the numerator can be bounded by terms of the form
for \(i,j=0,\dots ,K\). Thus, by Lemma 11, in order to prove the claim it remains to find a uniform bound in probability for the terms of the form \(|{{\bar{b}}}_N(X)_i| / \sqrt{a^N_ia^N_j}\). Now, for \(i=1,\dots ,K\),
uniformly in N as \(\alpha < \gamma - d/8 - 1/4 + \eta /4\). Further, \((a^N_0)^{-1/2}\) converges to zero in probability, while \((a^N_i)^{-1/2}\) converges to a positive constant for \(i=1,\dots ,K\). For \(i=0\), the reasoning is similar: By Proposition 3 and Lemma 4, we have
Together with \(a_0^N\sim N^{\frac{2}{d}(2\alpha -2\gamma +1)+1}\) and \(\alpha \le \gamma \), this yields that \({{\bar{b}}}_N(X)_0^2/a^N_0\) (and consequently \(|{{\bar{b}}}_N(X)_0|/\sqrt{a^N_0a^N_j}\) for \(j=0,\dots ,K\)) is bounded in probability. The claim follows. \(\square \)
Appendix B. Methods
1.1 Numerical Simulation
For the evaluation in Sect. 4 and Fig. 1f, we simulated (7), (8) on a square with side \(L=75\), with spatial increment \(\mathrm {d}x=0.375\), for \(t\in [T_0, T_1)\), \(T_0=500\), \(T_1=700\), with temporal increment \(\mathrm {d}t=0.01\), using an explicit finite difference scheme, of which we recorded every 100th frame. We choose \(T_0=500\) in order to avoid artifacts stemming from zero initial conditions at \(T=0\). We set \(b=0.2\), \(\gamma =0\), \(\sigma =0.1\) and \(a(x) = 0.5-b+0.5(x/(0.33u_0L^2)-1)\). In Sect. 4.3, we use additional simulations with \(\sigma =0.05\) and \(\sigma =0.2\).
For single and giant cell simulations in Fig. 1d, e, we solve (7), (8) on a square with side \(L=75\), with spatial increment \(\mathrm {d}x=0.15\), for \(t\in [0,T]\), \(T=1000\), with temporal increment \(\mathrm {d}t=0.002\), using an explicit finite difference scheme together with a phase field model Flemming et al. (2020) to account for the interior of the single and giant cells, corresponding, respectively, to an area of \(\hbox {A}_0=113\,\upmu m^2\) and \(\hbox {A}_0=2290\,\upmu m^2\). We used \(b=0.4\) and \(a(x) = 0.5-b+0.5(x/(0.25u_0A_0)-1)\). The noise terms are chosen as in Flemming et al. (2020), with \(\sigma =0.1\) and \(k_\eta =0.1\) in the notation therein.
For both simulations, the remaining parameters are \(D_U=0.1, D_V=0.02, k_1=k_2=1, u_0=1, \epsilon =0.02\). The unit length is \(1\,\upmu \hbox {m}\), and the unit time is 1s.
1.2 Experimental Settings
For experiments, D. discoideum AX2 cells expressing mRFP-LimE\(\Delta \) as a marker for F-actin were used. Cell culture and electric pulse-induced fusion to create giant cells were performed as described in Gerhardt et al. (2014), Flemming et al. (2020). For live cell imaging, an LSM 780 (Zeiss, Jena) with a 63x objective lens (alpha Plan-Apochromat, NA 1.46, Oil Korr M27, Zeiss Germany) was used. The spatial and temporal resolution was adjusted for each individual experiment to acquire image series with the best possible resolution, while protecting the cells from photodamage. Images series were saved as 8-bit tiff files. For image series where the full range of 256 pixel values was not utilized, the image histograms were optimized in such a way that the brightest pixels corresponded to a pixel value of 255.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Pasemann, G., Flemming, S., Alonso, S. et al. Diffusivity Estimation for Activator–Inhibitor Models: Theory and Application to Intracellular Dynamics of the Actin Cytoskeleton. J Nonlinear Sci 31, 59 (2021). https://doi.org/10.1007/s00332-021-09714-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00332-021-09714-4
Keywords
- Parametric drift estimation
- Stochastic reaction–diffusion systems
- Maximum likelihood estimation
- Actin cytoskeleton dynamics