
Abstract
Soft sensors are data-driven devices that allow for estimates of quantities that are either impossible to measure or prohibitively expensive to do so. DL (deep learning) is a relatively new feature representation method for data with complex structures that has a lot of promise for soft sensing of industrial processes. One of the most important aspects of building accurate soft sensors is feature representation. This research proposed novel technique in automation of manufacturing industry where dynamic soft sensors are used in feature representation and classification of the data. Here the input will be data collected from virtual sensors and their automation-based historical data. This data has been pre-processed to recognize the missing value and usual problems like hardware failures, communication errors, incorrect readings, and process working conditions. After this process, feature representation has been done using fuzzy logic-based stacked data-driven auto-encoder (FL_SDDAE). Using the fuzzy rules, the features of input data have been identified with general automation problems. Then, for this represented features, classification process has been carried out using least square error backpropagation neural network (LSEBPNN) in which the mean square error while classification will be minimized with loss function of the data. The experimental results have been carried out for various datasets in automation of manufacturing industry in terms of computational time of 34%, QoS of 64%, RMSE of 41%, MAE of 35%, prediction performance of 94%, and measurement accuracy of 85% by proposed technique.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Soft sensor is a virtual inferential prediction method that uses easily measured variables to forecast process variables that are difficult to measure directly due to technological, economic constraints as well as a complex environment. Soft sensor attempts to construct a regression prediction method between easily measured variables as well as difficultly measured variables, which is used to address issue that hinders measurements from being used as feedback signals in quality control methods [1]. For at least 10 years, there has been a growing trend in use of data-driven AI (artificial intelligence) approaches to enhance machines, processes, and products across several industrial domains [2]. In recent years, reducing emissions as a result of stronger environmental restrictions has also been a major motivator [3]. However, gathering the data required for such approaches is fraught with difficulties, one of which is the long life of industrial gear. Official depreciation estimates range from (rarely) 6 to more than 30 years, depending on the country, type of machinery, and industrial sector [4]. Experience suggests that, particularly in small and medium-sized businesses, resilient equipment can last even longer in regular usage. Soft sensor approaches are used more widely in industrial processes, and they have become a key emerging trend in both academics as well as industry [5]. Early academics proposed model predictive control like generalized predictive control, dynamic matrix predictive control and model control method, in light of model prediction in industrial production process [6]. However, these soft sensor prediction approaches have several flaws. ANN (Artificial neural networks), rough set, SVM (support vector machine) and hybrid techniques are some AI and ML methods based on data-driven technologies that have been proposed to solve issues where it is difficult to measure key processes as well as quality variables for soft sensor methods as a result of DL in soft sensor control method as well as continuous progress in engineering technology [7].
The contribution of this research is as follows:
-
To design novel techniques in automation of manufacturing industry where the dynamic soft sensors are used in feature representation and classification of the data
-
To collect the data cloud storage and create the virtual sensors dataset based on gear fault detection, spindle fault detection, and bearing fault detection in automation industry
-
To represent the feature using fuzzy logic-based stacked data driven auto-encoder (FL_SDDAE) where the features of input data have been identified with general automation problems.
-
Then, the features have been classified using least square error backpropagation neural network (LSEBPNN) in which the mean square error while classification will be minimized with loss function of the data
-
Here the experimental results have been carried out in terms of QoS, measurement accuracy, RMSE, MAE, prediction performance, and computational time.
Research organization is as follows. In Section 2, related works are described. Section 3 gives details of proposed method. proposed method performance, and the results are present in Section 4. Finally, Section 5 concludes the work.
2 Related works
DL-based techniques are recently exhibited solid representation competency and success in a variety of computer science domains, including image processing, computer vision, NLP, and more [8]. Stack autoencoder (SAE) [9], DBN (deep belief network) [10], CNN [11], and LSTM [12] are some of widely utilized deep network architectures. Greedy layer-wise unsupervised pre-training, as well as supervised fine-tuning, are highly important for DL architectures like SAE. The SAE weights evaluated during unsupervised pre-training step are used in supervised fine-tuning stage, which is a more significant method than random weight initialization [13]. As a result, various industrial applications of soft sensors based on SAE [14] are presented. Same authors improved this result significantly by utilizing a TDNN in [15].Mean error dropped to just 1.14 to 1.32% and 1.65° to 3.08°, in the same conditions utilized in [16, 17]. As a result, the type of network used in these two papers had a significant impact on the algorithms’ performance. In [18], an RNN is presented that collects information regarding air–fuel ratio λ, ignition angle, and turbocharger boost pressure in addition to rotational speed signal. Focus was on neural network design, which had a significant impact on the algorithm’s performance. To estimate cylinder pressure curves, [19] uses a NN with RBF (radial basis functions) as well as consequently no recurrence. Authors of [20] presents a novel convolutional, BiGRU, and Capsule network-based deep learning model, HCovBi-Caps, to classify the hate speech and authors of [21] introduce BiCHAT: a novel BiLSTM with deep CNN and hierarchical attention-based deep learning model for tweet representation learning toward hate speech detection. Authors of [15] do not use raw rotational speed signal, but instead translate it into frequency domain as well as process only first 20 harmonics, to earlier research are used an RBF network. They also employ structure-borne sound signal’s 21st–50th harmonics. As a result, the preparation of the given data is the most important aspect of this project. The typical errors for pMax as well as its position in crank angle range are 3.4% and 1.5°, respectively. Using a multi-layer perceptron, [22] predicts combustion parameters directly from crankshaft’s rotational speed as well as acceleration data, in contrast to the previous studies (MLP). The mean error lies between 1.38° and 9.1°, with a range of 4.1 to 8.0%. A deep learning-based R2DCNNMC model is proposed for detection and classification of COVID-19 employed chest X-ray images data [23]. Privacy of data driven uses on the k-anonymity and l-diversity supervised models classifies the healthcare data [24]. Virtualization for dynamics on cloud for network operation and management is discussed in [25] and proposed hybrid model on cloud ensures the maximum benefits from virtualization.
The effective implementations of SAE-based DL listed above reveal a significant capacity to extract features. Deep structures exceed typical soft-sensing prediction performance thanks to unsupervised layer-wise pre-training as well as supervised fine-tuning processes. Proposed industrial soft sensors are static methods based on notion of a static process as well as steady-state. However, the inherently dynamic nature of industrial processes cannot be neglected. Chemical processes, for example, are highly dynamic, with current state being linked to earlier ones. As a result, time-related characteristics of time-series recorded data are important.
3 System model
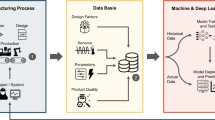
This section discusses the proposed design in automation of manufacturing industry based on dynamic soft sensors. Here the data has been processed to recognize the missing value and usual problems like hardware failures, incorrect readings, communication errors, process working conditions. Then their features have been represented in module 1 and the represented feature has been classified in module 2 using deep learning techniques. The overall research architecture is given in Fig. 1.

Overall Proposed diagram for virtual sensor-based fault detection in automation industry
3.1 Feature representation using fuzzy logic based stacked data driven auto-encoder (FL_SDDAE)
ENotice is replaced Eq. (2) represents overall input–output transfer function about general autoencoder (AE) structure. The input \(\left({x}^{\left[\alpha \right]}\in {\mathcal{R}}^{d}\right)\) is supplied to hidden layer, whose output is utilized to reconstruct \(\left({\stackrel{\backprime}{x}}^{\left|\alpha \mathrm{\rfloor}\right.}\right)\) input through output layer (y) as shown in Eq. (1).
An encoder or recognition model is another name for this approach. Optimize variational parameters φ such that as shown in Eq. (2):
As stated in Eq. (3), inference models are any directed graphical model.
In the directed graph, \(Pa\left({\mathbf{z}}_{j}\right)\) is set of parent variables of variable \({\mathbf{z}}_{j}\).
The non-negative Kullback–Leibler (KL) divergence between \({q}_{\phi }\left(\left.\mathbf{z}\right|\mathbf{x}\right)\) and \({p}_{{\varvec{\theta}}}\left(\left.\mathbf{z}\right|\mathbf{x}\right)\) is the second term in Eq. (5):
The variational lower bound, commonly known as ELBO, is the first term in Eq. (6):
Because the KL divergence is non-negative, ELBO shows a lower bound on data’s log-likelihood, as demonstrated in Eq. (7).
Because the ELBO’s expectation is taken \({q}_{\phi }\left(\left.\mathbf{z}\right|\mathbf{x}\right)\), which is a function of φby Eq. (9):
Apply a reparameterization approach to compute unbiased estimates of \({\nabla }_{\phi }{\mathcal{L}}_{\theta ,\phi }\left(\mathbf{x}\right)\), in case of continuous latent variables.
Replace an expectation w.r.t. \({q}_{\phi }\left(\left.\mathbf{z}\right|\mathbf{x}\right)\) with one w.r.t. \({p}_{{\varvec{\theta}}}\) via reparameterization given by Eq. (10).
A simple factorized vGaussian encoder by Eq. (12)
The log determinant of the Jacobian is given by Eq. (13):
and the posterior density is given by Eq. (14):
From Eq. (15)
Let Gx be defined: X ⊂ Rn → R, that is, a function on compact set X = α1,1 × … × [αn,βn] and analytic formula of Gx be unknown.
Define \({N}_{j}\left(j=\mathrm{1,2},\dots ,n\right)\) fuzzy sets \({A}_{j}^{1},{A}_{j}^{2},\dots ,{A}_{j}^{{N}_{j}}\in \left[{\alpha }_{j},{\beta }_{j}\right]\), which are normal, consistent, and complete with triangular MFs \({\mu }_{{A}_{j}^{1}}\left({x}_{j};{a}_{j}^{1},{b}_{j}^{1},{c}_{j}^{1}\right),\dots ,{{\mu }_{{A}_{j}}}^{{N}_{j}}\left({x}_{j};{a}_{j}^{{N}_{j}},{{b}_{j}}^{{N}_{j}},{{c}_{j}}^{{N}_{j}}\right)\), and \({A}_{j}^{1}<{A}_{j}^{2}<\cdots <{A}_{j}^{{N}_{j}}\) with \({a}_{j}^{1}={b}_{j}^{1}={\alpha }_{j}\) and \({b}_{j}^{{N}_{j}}={c}_{j}^{{N}_{j}}={\beta }_{j}\), which,
-
\({e}_{1}^{1}={\alpha }_{1},{e}_{1}^{{N}_{1}}={\beta }_{1}\), and \({e}_{1}^{j}={b}_{1}^{j}\) for \(j=\mathrm{2,3},\dots ,{N}_{1}-1\), -\({e}_{2}^{1}={\alpha }_{2},{e}_{2}^{{N}_{2}}={\beta }_{2}\), and \({e}_{1}^{j}={b}_{2}^{j}\) for \(j=\mathrm{2,3},\dots ,{N}_{2}-1\),:\({e}_{n}^{1}={\alpha }_{n},{e}_{n}^{{N}_{n}}={\beta }_{n}\), and \({e}_{1}^{j}={b}_{1}^{\mathrm{^{\prime}}}\) for \(j=\mathrm{2,3},\dots ,{N}_{n}-1.\)
-
Construct \(I={N}_{1}\times {N}_{2}\times \dots \times {N}_{n}\) fuzzy if–then rules in following form:
-
\({R}_{X}^{{j}_{1}-{j}_{n}}:\mathrm{IF}{x}_{1}\) is \({A}_{1}^{{j}_{1}}\) and \({x}_{2}\) is \({A}_{2}^{{j}_{2}}\) and … and \({x}_{n}\) is \({A}_{n}^{{j}_{n}}\) Then \(y\) is \({B}^{{j}_{1}-{j}_{n}}\), where \({j}_{1}=\mathrm{1,2},\dots ,{N}_{1},{j}_{2}=\mathrm{1,2},\dots ,{N}_{2},\dots ,{j}_{n}=\mathrm{1,2},\dots ,{N}_{n}\), and center of the fuzzy set \({B}^{{j}_{1}\dots {/}_{n}}\), denoted by \({\overset{\leftharpoonup}{y} }^{{\mathrm{^{\prime}}}_{1}\cdots {/}_{n}}\), is chosen as Eq. (16):
-
\({\overset{\leftharpoonup}{y} }^{{j}_{1}\dots /n}=G\left({e}_{1}^{{j}_{1}},\dots ,{e}_{n}^{{j}_{n}}\right)\)
$${\vartheta }_{l}=\tau \left({\mu }_{{A}_{1}^{1-j-in,i}}\left({x}_{1}\right),{\mu }_{{A}_{2}^{1-jn,i}}\left({x}_{2}\right),\dots ,{\mu }_{{A}_{n}^{j1-jn,i}}\left({x}_{n}\right)\right)$$(16)
Therefore, from \({\mu }_{\overline{{B }^{4}}}\left(y\right)=t\left({\vartheta }_{i},{\mu }_{{B}^{i}}\left(y\right)\right),\forall y\in R\), fuzzy inference produces fuzzy set of output by: \({\mu }_{\stackrel{-}{B/1-jn,A}}\left(y\right)=t\left({\vartheta }_{i},{\mu }_{{B}^{j1-jn,i}}\left(y\right)\right)\forall y\in R\).\(t\left({\vartheta }_{i},{\mu }_{{B}^{j1-jn,i}}\left(y\right)\right)\forall y\in R\). \({\mu }_{\overset{\leftharpoonup}{B}/1-/n}(y)=s\left({\mu }_{B/1-1n,1}(y),{\mu }_{B/1-jn,2}\left(y\right),\dots ,{\mu }_{B/1-jn,}(y)\right)\).
 , where \({a}_{j}^{i}\) are parameters, and are evaluated by LSM.
, where \({a}_{j}^{i}\) are parameters, and are evaluated by LSM.
Since the fuzzy sets \({A}_{j}^{1},\dots ,{A}_{j}^{{N}_{j}}\) are complete at every \(x\in X\), then there exist \({j}_{1},{j}_{2},\dots ,{j}_{n}\) such that: \(\mathrm{min}\left({\mu }_{{{A}_{1}}^{^{\prime}}}\left({x}_{1}\right),{\mu }_{{A}_{2}^{\mathrm{^{\prime}}2}}\left({x}_{2}\right),\dots ,{\mu }_{{{A}_{n}}^{n}}\left({x}_{n}\right)\right)\ne 0.\) Let \(f\left(x\right)\) be fuzzy system in (13) and \(G\left(x\right)\) be unknown function in (18). If \(G\left(x\right)\) is continuously differentiable on \(X=\left[{\alpha }_{1},{\beta }_{1}\right]\times \left[{\alpha }_{2},{\beta }_{2}\right]\times \dots \times \left[{\alpha }_{n},{\beta }_{n}\right]\), then:
where infinite norm \({\left|\left|.\right|\right|}_{\infty }\) is given as: \({\left|\left|d\left(x\right)\right|\right|}_{\infty }={\mathrm{sup}}_{x\in X} \left|d\left(x\right)\right|\) and \({h}_{j}={\mathrm{max}}_{1\le k\le {N}_{j}} \left|{e}_{j}^{k+1}-{e}_{j}^{k}\right|,(j=\mathrm{1,2},\dots ,n\). \(\underset{\_}{\mathrm{Let }{X}^{j1}\dots {/}_{n}}=\left[{e}_{1}^{{j}_{1}},{e}_{1}^{{j}_{1}+1}\right]\times \left[{e}_{2}^{{j}_{2}},{e}_{2}^{{j}_{2}+1}\right]\times \dots \times \left[{e}_{n}^{{j}_{n}},{e}_{n}^{{j}_{n}+1}\right]\), where \({j}_{1}=\mathrm{1,2},\dots ,{N}_{1}-1,{j}_{2}=\mathrm{1,2},\dots ,{N}_{2}-1,\dots\), \({j}_{n}=\mathrm{1,2},\dots ,{N}_{n}-1.\) Since \(\left[{\alpha }_{j},{\beta }_{j}\right]=\left[{e}_{j}^{1},{e}_{j}^{2}\right]\cup \left[{e}_{j}^{2},{e}_{j}^{3}\right]\cup \dots \cup \left[{e}_{j}^{{N}_{j}-1},{e}_{j}^{{N}_{j}}\right],j=\mathrm{1,2},\dots ,n.\) From Eq. (19):
From (20), (21), (22), we obtain:
From the Mean Value \({}^{{k}_{n}={f}_{n}:{/}_{n}+1}\)
From the Mean Value model is given (23) as:
Since \(x\in {X}^{{j}_{1}-{j}_{n}}\), means that \({x}_{1}\in \left[{e}_{1}^{j1},{e}_{1}^{j1+1}\right],{x}_{2}\in \left[{e}_{2}^{j2},{e}_{2}^{j2+1}\right]\dots {x}_{n}\in \left[{e}_{n}^{jn},{e}_{n}^{jn+1}\right]\), have by Eq. (24),
Then, (25) becomes:
From (26), conclude that fuzzy systems in form.
\({\left|\left|\frac{\partial G}{\partial {x}_{1}}\right|\right|}_{\infty },{\left|\left|\frac{\partial G}{\partial {x}_{2}}\right|\right|}_{\infty },\dots ,{\left|\left|\frac{\partial G}{\partial {x}_{n}}\right|\right|}_{\infty }\) are finite numbers for any given \(\varepsilon >0\), select \({h}_{1},{h}_{2},\dots ,{h}_{n}\) small enough such that \({\left|\left|\frac{\partial G}{\partial {x}_{1}}\right|\right|}_{\infty }{h}_{1}+{\left|\left|\frac{\partial G}{\partial {x}_{2}}\right|\right|}_{\infty }{h}_{2}+\cdots +{\left|\left|\frac{\partial G}{\partial {x}_{n}}\right|\right|}_{\infty }{h}_{n}<\varepsilon\). Hence from (27):
We can see from (28) that we need to know the boundaries of the derivatives of G(x) about \({x}_{1},{x}_{2},\dots ,{x}_{n}\) to represent a fuzzy system with a pre-specified accuracy.
Select a fuzzy method with a MIS, an SF, a CADand a Triangular MF, which then derive using Eq. (29).
The more rules you have, the more parameters you will have and the more computation you will have to do, but you will get better accuracy. When initial parameters yi (0), aji (0), bji (0), cji (0) are specified, the fuzzy system becomes by Eq. (30).
for a sigmoid activation function, it gives by Eq. (31):
Thus, if consider \(\overset{\leftharpoonup}{X }={\left(0,\dots ,0\right)}^{^{\prime}},{b}_{l}^{\left[\gamma \right]\left(t\right)}=0\forall t\in \left\{1,\dots ,T\right\}\), the Taylor series expansion of \({h}_{l}^{\left[\gamma \right]\left(t\right)}\) is given by Eq. (32):
with w′ l u, given by Eq. (33), and \({X}^{\left(t\right)}={\left({x}_{\varphi \left(1\right)}^{\left(t\right)},\dots ,{x}_{\varphi \left(d,\right)}^{\left(t\right)}\right)}^{\mathrm{^{\prime}}}\) being a column vector of the input at time t. Let \(H={\left({h}^{\left[\gamma \right](1)},\dots ,{h}^{\left[\gamma \right]\left(T\right)}\right)}^{\mathrm{^{\prime}}},\mathrm{ for }X=\overset{\leftharpoonup}{X }\) then:
where s is number of hidden neurons. Taylor series expansion of Ψk T isgiven by Eq. (34):
By replacing \({h}_{u}^{\left[\gamma \right]\left(t\right)}\) of Eq. (35) with \({h}_{l}^{\left[\gamma \right]\left(t\right)}\) of Eq. (36):
Finally, by substituting
derived features \({{w}_{l,\nu }^{\mathrm{^{\prime}}\mathrm{^{\prime}}}}^{\left(t\right)}\) through summations on indexes f, p, and q combine features \(\left(\left({w}_{l,\nu }^{\left[\gamma \right]}\right.\right.\) and \(\left.{w}_{l,k}^{\left[\rho \right]}\right)\) extracted from both Fuzzy based SAEs and gives compact representation of input over time.
3.2 Least square error back propagation neural network (LSEBPNN)
Let, training set in a C-class issue contains vector pairs \(\left\{\left(\stackrel{\backprime}{{x}_{1}},{y}_{1}\right),\left({{\varvec{x}}}_{2},{{\varvec{y}}}_{2}\right),\dots ,\left({{\varvec{x}}}_{P},{{\varvec{y}}}_{P}\right)\right\}\) where \({{\varvec{x}}}_{p}\in {\mathbb{R}}^{N}\) refers to pth input pattern and \({{\varvec{y}}}_{p}\in \left\{\left.{{\varvec{t}}}_{c}\right|,\stackrel{\backprime}{c}=\mathrm{1,2},\dots ,C;{{\varvec{t}}}_{c}\in {\mathbb{R}}^{c}\right\}\) refers to target output of c network corresponding to this input.
All weights and bias terms are included in LSEBPNN’s adaptive parameters. The training phase’s main aim is to establish the best weights and bias terms for minimizing difference between network output as well as target output. The difference is referred regarded as the network’s training error. MSE for pth input pattern in the traditional BP technique is \({E}_{p}=\frac{1}{2}{\sum }_{k=1}^{C} {\left({t}_{pk}-{o}_{pk}^{\circ }\right)}^{2}\). It shows that an input pattern’s target value could be several. To put it another way, any input pattern can have any target value with any membership value. To put it another way, the training problem can be thought of as a fuzzy constraint fulfillment problem.Suggested network modifies parameters throughout training phase to ensure that these limitations are overcome as efficiently as possible. The constraints for pth input pattern are stated mathematically as fuzzy MSE term, which is given by Eq. (38)
The learning laws for networks are derived using same approach as traditional BP technique. Suppose that the weight update, Dw, happens after each input pattern has been presented. Assuming that all weight changes in network are made with same learning-rate parameter h, weight changes applied to weights w and w are k j ji determined according to the gradient-descent rules by Eq. (39), (40):
where by Eq. (41)
Again, from Eq. (42),
where by Eq. (43)
In many circumstances, the traditional BP technique may not converge quickly, when classes overlap. Because ambiguous vectors are assigned full weightage in one class, this is case. In suggested version, error to be back propagated is given more weight in the case of nodes with higher membership values.
The learning algorithm’s purpose is to reduce the squared error cost function, which is given by Eq. (44)
Equation (45), where m is total number of vectors in training data set given by
Partial derivative about w i (s) and equate it to zero to determine weight vector that minimizes cost function given by Eq. (46).
In vector matrix form, Eq. (48) are rearranged as
\({w}_{i}^{\left(s\right)}\) is weight vector to ith linear combiner in sth layer, Eq. (49) is given as deterministic normal equation
By equating partial derivative of performance index \({\mathbf{w}}_{i}^{\left(k\right)}(n)\) and setting it equal to zero, the performance index is minimised (50)
Equation (51), (52) is set to the following
where by Eq. (53)
Now, define a matrix operation for simplicity \(A\odot B\doteq {A}_{R}{B}_{R}+\jmath {A}_{I}{B}_{I}\). The flow chart for LSEBPNN is represented in Fig. 2.

The flow chart for LSEBPNN
4 Performance analysis
Proposed method is implemented into a prototype software system utilizing Python 3.7 to evaluate and assess potential contribution of proposed strategy for future real-world applications. Resources utilized to combine proposed method were an Intel i7 processor (Intel(R) Core(TM) i7-3770 CPU @3.40 GHz 3.80 Ghz) and an eight (8) gigabyte RAM (Intel, Santa Clara, CA, USA) (Samsung, Seoul, Korea). Microsoft Windows 10 was the operating system on which the suggested system was hosted and tested.
Table 1 shows comparative analysis for various fault situations for proposed and existing techniques. Here the fault situation has been detected by virtual sensor-based datasets of automation industry. The parametric analysis has been carried out in terms of QoS, measurement accuracy, RMSE, MAE, prediction performance, and computational time.\
Figures 3, 4, and 5 show comparative analysis for various virtual sensor-based datasets from automation industry. The dataset collected from cloud is based on spindle fault detection-based data, gear fault detection-based data, and bearing fault detection-based data. For spindle fault detection data, the proposed technique obtained computational time of 34%, QoS of 64%, RMSE of 41%, MAE of 35%, prediction performance of 94%, measurement accuracy of 85%.The proposed technique obtained computational time of 43%, QoS of 67%, RMSE of 43%, MAE of 39%, prediction performance of 79%, and measurement accuracy of 85% by gear-based fault detection dataset. For bearing fault detection data, the proposed technique obtained computational time of 49%, QoS of 68%, RMSE of 45%, MAE of 41%, prediction performance of 86%, and measurement accuracy of 84%. From the above analysis, proposed technique obtained optimal results for all the fault detection based on automation industry data.

Comparative analysis of spindle-based dataset in terms of a computational time, b QoS, c RMSE, d MAE, e prediction performance, f measurement accuracy

Comparative analysis of gear-based dataset in terms of a computational time, b QoS, c RMSE, d MAE, e prediction performance, f measurement accuracy

Comparative analysis of bearing-based dataset in terms of a computational time, b QoS, c RMSE, d MAE, e prediction performance, f measurement accuracy
The fundamental challenge in dealing with soft sensor principles is a lack of understanding due to their novelty and, as a result, a lack of typical mathematical descriptions or structure. On the other hand, it allows for more creative expression. In general, vast arrays of statistics for calculations are required when working with soft sensors. It is vital to have a thorough understanding of the controlled process’s principles, physical characteristics, and the parameters’ relationships.
5 Conclusion
This research propose novel technique in virtual soft sensor-based fault detection in automation industry using deep learning technique integrated with cloud module. Here the aim is to design novel techniques in automation of manufacturing industry where the dynamic soft sensors are used in feature representation and classification of the data. The data has been collected from cloud storage and created the virtual sensors dataset based on gear fault detection, spindle fault detection, and bearing fault detection in automation industry. Then to represent the feature using fuzzy logic-based stacked data-driven auto- encoder (FL_SDDAE) where the features of input data have been identified with general automation problems. Then the features have been classified using least square error back propagation neural network (LSEBPNN) in which the mean square error while classification will be minimized with loss function of the data. Here the experimental results have been carried out in terms of computational time of 34%, QoS of 64%, RMSE of 41%, MAE of 35%, prediction performance of 94%, and measurement accuracy of 85% has been obtained by proposed technique. One is that nonlinear systems’ predictive control cannot be solved successfully. Another issue is that stability as well as resilience of multivariable predictive control algorithms must be addressed, and accurate principle models for complex systems are extremely difficult to construct. Despite the contributions made so far, there are still areas where future work might be improved. On the loss function, targeted-output regularizes would extract even better features, improving the suggested work. Another future intervention would be to use approaches on the unsupervised pre-training to identify dynamic-related aspects. In addition, industrial research scenarios were used to apply the proposed method, however developing a soft sensor proposal for a real-world industrial scenario could be challenging. Non-linearities, abnormalities, and highly complex ecosystems must all be taken into account. The industrial study cases have shown to be suitable and widely used in the implementation and evaluation of models, and they serve as the foundation for many contributions in this field of research.
References
Savytskyi O, Tymoshenko M, Hramm O, Romanov S (2020) Application of soft sensors in the automated process control of different industries. In E3S Web of Conferences (Vol. 166, p 05003). EDP Sciences. https://doi.org/10.1051/e3sconf/202016605003
Sun Q, Ge Z (2021) A survey on deep learning for data-driven soft sensors. IEEE Transactions on Industrial Informatics 17(9):5853–5866
Andronie M, Lăzăroiu G, Iatagan M, Uță C, Ștefănescu R, CocoȘatu M (2021) Artificial intelligence-based decision-making algorithms, internet of things sensing networks, and deep learning-assisted smart process management in cyber-physical production systems. Electronics 10(20):2497
Kovacova M, Lăzăroiu G (2021) Sustainable organizational performance, cyber-physical production networks, and deep learning-assisted smart process planning in Industry 4.0-based manufacturing systems. Econ Manag Fin Markets 16(3):41–54
Bibi R, Saeed Y, Zeb A, Ghazal TM, Rahman T, Said RA, ... Khan MA (2021) Edge AI-based automated detection and classification of road anomalies in VANET using deep learning. Comput Intell Neurosci 2021:1–16
Valaskova K, Ward P, Svabova L (2021) Deep learning-assisted smart process planning, cognitive automation, and industrial big data analytics in sustainable cyber-physical production systems. J Self-Governance Manag Econ 9(2):9–20
Hndoosh RW, Kumar S, Saroa MS (2014) Fuzzy mathematical models for the analysis of fuzzy systems with application to liver disorders. IOSR J Comput Eng 16(5):71–85
Kingma DP, Welling M (2019) An introduction to variational autoencoders. Foundations and Trends® in Machine Learning 12(4):307–392
D’Angelo G, Palmieri F (2021) A stacked autoencoder-based convolutional and recurrent deep neural network for detecting cyberattacks in interconnected power control systems. Int J Intell Syst 36(12):7080–7102
Abrar S, Zerguine A, Bettayeb M (2002) Recursive least-squares backpropagation algorithm for stop-and-go decision-directed blind equalization. IEEE Trans Neural Netw 13(6):1472–1481
Bargellesi N, Beghi A, Rampazzo M, Susto GA (2021) AutoSS: a deep learning-based soft sensor for handling time-series input data. IEEE Robot Autom Lett 6(3):6100–6107
Thomopoulos SC (2021) Risk assessment and automated anomaly detection using a deep learning architecture. IntechOpen. https://doi.org/10.5772/intechopen.96209
Senthilkumar P, Rajesh K (2021) Design of a model based engineering deep learning scheduler in cloud computing environment using Industrial Internet of Things (IIOT). J Ambient Intell Humanized Comput 1–9
Yao L, Ge Z (2021) Dynamic features incorporated locally weighted deep learning model for soft sensor development. IEEE Trans Instrum Meas 70:1–11
Moreira de Lima JM, Ugulino de Araújo FM (2021) Industrial semi-supervised dynamic soft-sensor modeling approach based on deep relevant representation learning. Sensors 21(10):3430
Sahoo SR, Gupta BB (2021) Multiple features based approach for automatic fake news detection on social networks using deep learning. Appl Soft Comput 100:106983
Fazil M, Khan S, Albahlal BM, Alotaibi RM, Siddiqui T, Shah MA (2023) Attentional multi-channel convolution with bidirectional LSTM cell toward hate speech prediction. IEEE Access 11:16801–16811. https://doi.org/10.1109/ACCESS.2023.3246388
Zhang J, Gao RX (2021) Deep learning-driven data curation and model interpretation for smart manufacturing. Chin J Mech Eng 34(1):1–21
Xia K, Sacco C, Kirkpatrick M, Saidy C, Nguyen L, Kircaliali A, Harik R (2021) A digital twin to train deep reinforcement learning agent for smart manufacturing plants: environment, interfaces and intelligence. J Manuf Syst 58:210–230
Khan S et al (2022) HCovBi-caps: hate speech detection using convolutional and Bi-directional gated recurrent unit with Capsule network. IEEE Access 10:7881–7894
Khan S et al (2022) BiCHAT: BiLSTM with deep CNN and hierarchical attention for hate speech detection. J King Saud Univ-Comput Inform Sci 34(7):4335–4344
Maschler B, Ganssloser S, Hablizel A, Weyrich M (2021) Deep learning based soft sensors for industrial machinery. Procedia CIRP 99:662–667
Khan S, Saravanan V, Lakshmi TJ, Deb N, Othman NA (2022) Privacy protection of healthcare data over social networks using machine learning algorithms. Comput Intell Neurosci 2022(9985933):8
Haq AU, Li JP, Ahmad S, Khan S, Alshara MA, Alotaibi RM (2021) Diagnostic approach for accurate diagnosis of COVID-19 employing deep learning and transfer learning techniques through chest X-ray images clinical data in E-healthcare. Sensors 21(24):8219
Khan S, Al-Mogren AS, AlAjmi MF (2015) Using cloud computing to improve network operations and management. 2015 5th National Symposium on Information Technology: Towards New Smart World (NSITNSW), Riyadh, Saudi Arabia, 2015, pp. 1–6. https://doi.org/10.1109/NSITNSW.2015.7176418
Funding
The authors extend their appreciation to the Deanship of Scientific Research at Imam Mohammad Ibn Saud Islamic University (IMSIU) for funding and supporting this work through Research Partnership Program no. RP-21-07-06. The authors acknowledge the support from Princess Nourah Bint Abdulrahman University Researchers Supporting Project number (PNURSP2023R440), Princess Nourah Bint Abdulrahman University, Riyadh, Saudi Arabia.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Ethical approval
This article does not contain any studies with animals performed by any of the authors.
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Khan, S., Siddiqui, T., Mourade, A. et al. Manufacturing industry based on dynamic soft sensors in integrated with feature representation and classification using fuzzy logic and deep learning architecture. Int J Adv Manuf Technol 128, 2885–2897 (2023). https://doi.org/10.1007/s00170-023-11602-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00170-023-11602-y