
Abstract
Purpose
To predict the occurrence of calcium oxalate kidney stones based on clinical and gut microbiota characteristics.
Methods
Gut microbiota and clinical data from 180 subjects (120 for training set and 60 for validation) attending the West China Hospital (WCH) were collected between June 2018 and January 2021. Based on the gut microbiota and clinical data from 120 subjects (66 non-kidney stone individuals and 54 kidney stone patients), we evaluated eight machine learning methods to predict the occurrence of calcium oxalate kidney stones.
Results
With fivefold cross-validation, the random forest method produced the best area under the curve (AUC) of 0.94. We further applied random forest to an independent validation dataset with 60 samples (34 non-kidney stone individuals and 26 kidney stone patients), which yielded an AUC of 0.88.
Conclusion
Our results demonstrated that clinical data combined with gut microbiota characteristics may help predict the occurrence of kidney stones.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Nephrolithiasis is a common urological disease, with a constantly increasing prevalence in recent years. Calcium oxalate stones, which accounts for about 80% of kidney stone types, is the most common category of kidney stones [1]. The calcium oxalate stone pathogenesis often includes a high concentration of oxalate ions, which, by combining with calcium ions or other cations in the urine produces small crystals that adhere to the renal tubular epithelial cells of the kidney, cause a series of reactions, such as inflammation and oxidative stress. These crystals crystallize, nucleate and grow into kidney stones. Among them, oxalic acid increases urinary calcium oxalate saturation about ten times more than calcium, and a mild increase in urinary oxalate can significantly increase the risk of nephrolithiasis [2]. Urinary citrate binds to calcium and inhibits crystallization, thus reducing stone formation. Urine composition can be used to assess stone risk and monitor treatment response in patients with kidney stones [3].
The gut microbiota is crucial in maintaining environmental homeostasis in the gut. 16S ribosomal RNA(rRNA) sequencing offers more possibilities to reveal the diversity of microbes, as several studies have shown significant differences in the gut microbiota between patients with and without kidney stones [4, 5]. Short-chain fatty acids (SFCA) are health-friendly metabolites, produced by the gut microbiota [6] and through different metabolic pathways [7, 8], that provide an ideal environment for the production of acetate, propionate and butyrate [9]. Huang [10] found that short-chain fatty acids have an inhibitory effect on the oxidative stress and inflammatory response of glomerular lineage membrane cells, and that oxidative stress and inflammatory response is involved in stone formation.
Machine learning has been used to analyze microbiome data to identify disease-related biomarkers. Some well-known machine learning algorithms include k-nearest neighbors, random forest, support vector machines, and linear discriminant analysis, and have found applications in genomics, proteomics, systems biology and many other fields [11]. Some studies have developed predictive models for kidney stone recurrence, but with moderate predictive accuracy [12, 13]. With a total of 806 Chinese patients, Wu [14] identified 300 biomarkers from the microbiome and built a predictive model with a moderate predictive accuracy. Overall, there is a lack of works on prediction of calcium oxalate kidney stones, especially based on Chinese patients. Moreover, it is unclear what methods would be most suitable for the prediction of kidney stones, given a variety of available machine learning methods.
To address these questions, we collected microbial data and clinical data from 180 Chinese patients and explored a variety of machine learning methods for predicting the occurrence of calcium oxalate stones. Applications of machine learning methods may help compare their predictiveness using the criterion of area under the curve (AUC) and identify biomarkers that can inform treatment decisions for calcium oxalate stones.
Materials and methods
Subject
Our study was in a case–control setting with subjects recruited by the West China Hospital (WCH) from June 2018 to January 2021. Patients were diagnosed with kidney stones by renal ureteral X-ray, urinary ultrasound or abdominal CT examination, while controls were those without renal colic or subclinical retained stone attacks by abdominal ultrasound. All patients received percutaneous nephroscopic lithotripsy or flexible ureteroscopy, with stone composition confirmed by infrared spectroscopy.
The study was approved by the Research Ethics Committee of the WCH, and informed consent was obtained from each participant. The following types of kidney stone patients were excluded: the main component is not calcium oxalate, calcium oxalate is mixed with other components of stones (such as infectious stones or uric acid stones), urinary tract abnormalities, metabolic diseases (including metabolic syndrome), hyperthyroidism, hyperparathyroidism, and long-term use of drugs that may cause kidney stones. Participants were also excluded if they used antibiotics or immunosuppressants three months prior to stool sampling, or had inflammatory bowel disease, irritable bowel syndrome, gastrointestinal tract infections or digestive tumors, bowel surgery, diarrhea and constipation within one month before stool sampling.
A total of 66 non-kidney stone individuals (NS) and 54 patients with kidney stone (KS) were included in this study as training samples, while additional 60 subjects (34 NS and 26 KS) were sampled for validation. Thus, a total of 180 samples were included for this study.
Data preparation
Microbial DNA extracted from fecal samples was sequenced with 16S rRNA. OTU analysis was performed on 180 samples using Usearch (version 7.0, http://drive5.com/uparse/), and the RDP classifier algorithm was used to annotate taxonomic information. Following the filtering processes as in [15], we excluded samples which were less than 100 reads and OTUs were less than 10 reads, and discarded OTUs which happened < 1% of all the samples. We calculated the relative abundance of each OTU by dividing its value by the total number of reads per sample. Stool SCFA was determined using gas chromatography–mass spectrometry, and urinary oxalate was tested using liquid chromatography–mass spectrometry.
Feature selection
With the 16 s rRNA data, we collapsed OTUs to the genus level based on a commonly used approach: we first sum their relative abundances respectively, and then drop any OTUs which cannot be annotated at the genus level. The genera selected by both the LDA effect size (LEfSe) (LDA score > 1, P < 0.05) [16] and the hierarchical feature engineering (HFE) [17] were used as candidate features. We performed univariate analysis, including Chi-squared test, t-test and Wilcoxon rank sum test, for feature selection.
Machine learning
On the training set, we used fivefold cross validation to compare the average AUC in order to assess the predictive performance of support vector machines (SVM), random forest (RF), gradient boosted trees (Gboost), lasso, ridge, elastic net (Enet), k-nearest neighbor (KNN) and linear discriminant analysis (LDA). Using the average AUC as the criterion, we found that RF performed the best. We further used the independent validation set to validate the model performance of RF. Analysis was conducted by Python (version 2.7) and R (version 3.6).
Results
Taxonomic analysis of microbiota between NS controls and KS patients
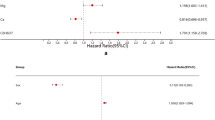
The 16S rRNA sequencing data were processed to obtain 5868 OTUs. LEfSe and HFE analysis yielded 243 genera and 14 genera, respectively. The three common genera were: g__Flavobacterium, g__Rhodobacter, g__Gordonia (Fig. 1). Predictive models were built using only these three genus, with AUCs ranging from 0.682 to 0.763 across the eight models (Fig. 2a).

Intersection of genus of LEfSe and HFE

Receiver operating characteristic (ROC) curves were utilized to evaluate the performance of eight methods for predicting kidney stone occurrence (a using three genera b using five clinical information c using three genera plus five clinical indicators). d receiver-operating characteristic (ROC) curves were utilized to evaluate the performance of RF for predicting kidney stone occurrence using three genera plus five clinical indicators
Clinical characteristics of NS controls and KS patients
In our descriptive analyses, we presented means and standard deviations for continuous variables which were approximately normally distributed; otherwise, we used medians and quartiles. Univariate association analyses revealed no significant differences in age, sex, BMI, propionic acid concentration, isobutyric acid concentration, isovaleric acid concentration, valeric acid concentration, hexanoic acid concentration, calcium concentration and uric acid concentration between NS and KS (Table 1). However, there were significant differences in oxalate concentration, acetic acid concentration, citrate concentration, phosphorus concentration and urinary PH between NS and KS (all P < 0.05).
The predictive models were built based on five clinical characteristics: oxalate concentration, acetic acid concentration, citrate concentration, phosphorus concentration and urinary PH. The random forest model had the highest AUC value of 0.902, while the other models presented AUCs around 0.89 (Fig. 2b).
Comparisons of prediction models of Genus plus clinical data
We next combined three genus and four clinical indicators for prediction and found the AUC in general improved for all of the methods. Indeed, the AUCs of Gboost, ridge, Enet, LDA and SVM were all above 0.89, except for lasso(0.884) and KNN(0.879), and the RF had the highest AUC of 0.936 (Fig. 2c).
In summary, we found that using the genera data combined with the clinical data produced a more accurate prediction than using the genera or clinical data alone, and random forest produced the best predictive models (Table 2). We next use the validation dataset to further evaluate random forest, which gave an AUC of 0.88 (Fig. 2d).
Discussion
Comparing eight machine learning methods, we found that random forest outperformed the other machine learning algorithms. Moreover, genera combined with clinical features improved prediction, which suggested that renal stone disease could be diagnosed with clinical indicators in conjunction with gut microbiota data.
Our study identified three disease-related bacteria, among which g__Flavobacterium belongs to Flavobacteriaceae. The relative abundance of Flavobacterium was reduced in obese patients compared to healthy controls [18]. The other two bacteria, g__Rhodobacter and g__Gordonia, belong to the Rhodobacterace and Nocardiaceae, respectively. It was reported that some genera of Rhodobacterace and Nocardiaceae Nocardiaceae can cause infection in humans [19].
Included in our models were oxalate concentration, acetic acid concentration, citrate concentration, phosphorus concentration and urinary pH. Oxalate and acetic acid concentrations are also important indicators of kidney stone occurrence, and higher oxalate is related with a higher risk of calcium oxalate stone [20]. Reducing dietary intake or body synthesis of oxalate is effective in preventing and treating calcium oxalate stones. Acetate is the most abundant SCFA and is an important cofactor for bacterial growth [21, 22]. Citrate can inhibit the formation of CaOx stones [23]. In addition, the pH of urine has been reported to alter several types of stones, including calcium oxalate, calcium phosphate, and uric acid [3]. A study [24] has suggested that urinary phosphorus may play a role in the formation of kidney stones, but not urinary calcium, which agreed to our results that calcium does not differ between patients with stones and healthy individuals.
Random forest is commonly used as an effective classification method in microbiome prediction models. Statnikov [25] used OTUs to perform different classification tasks on eight datasets and found that random forest and support vector machines are the most effective machine learning techniques for performing accurate classification from these microbiome data. Duvallet [15] used the random forest method to classify the 10 diseases and found that for the CRC (colorectal cancer) dataset, the random forest The AUC reached 0.92. Bacteria associated with CRC include Fusobacterium, Porphyromonas, Peptostreptococcus, Parvimonas, and Enterobacter genera. Pasolli [26] used the microbiota as features to classify five diseases, including cirrhosis, colorectal cancer, and inflammatory bowel disease (IBD), using a random forest classifier. In the cirrhosis dataset, using Veillonella and Streptococcus genera as features, random forest had AUC of 0.945. In the CRC dataset, P. stomatitis, Fusobacterium nucleatum and Streptococcus salivarius correlated with CRC, the AUC of random forest was 0.873. In the IBD dataset, the AUC was 0.89.
Using discriminant analysis, Chiang [27] utilized 151 calcium oxalate stones patients and 105 healthy controls of four genetic polymorphisms: vascular endothelial growth factor (VEGF), E-calcine adhesion, urokinase, and cytochrome p450c17, as well as relevant environmental factors (milk, water, outdoor activity and coffee consumption), presented a prediction model of kidney stones. The results showed that when only genetic factors were considered, the classification success rate of DA was 64%; but with all relevant factors considered (genetic and environmental factors), the classification success rate for DA was 74%. In [28], an SVM model for detecting kidney stone types by using 42 features of 936 kidney stone patients, including sex, acid urine status, calcium levels, back pain and urinary tract infection, reached an AUC of 86.9%.
To our knowledge, no research has been done to combine gut microbiota with clinical characteristics to predict the occurrence of kidney stones. Filling this gap, we constructed a prediction model of calcium oxalate kidney stones using microbiota, metabolites of microbiota and urinary parameters. Our machine learning results may provide new and non-invasive potential diagnostic biomarkers for calcium oxalate kidney stones.
References
Khan SR (1997) Animal models of kidney stone formation: an analysis. World J Urol 15(4):236–243
Li H, Ye ZQ, He W et al (2012) Screening of differentially expressed genes in the jejunum of rats with idiopathic hyperoxaluria. Chin Med J 125:312–315
Grases F, Costa-Bauza A, Prieto RM (2006) Renal lithiasis and nutrition. Nutr J 6(5):23
Mulder IE, Schmidt B, Stokes CR et al (2009) Environmentally-acquired bacteria influence microbial diversity and natural innate immune responses at gut surfaces. BMC Biol 7:79
Tang RQ, Jiang YH, Tan AH et al (2018) 16S rRNA gene sequencing reveals altered composition of gut microbiota in individuals with kidney stones. Urolithiasis 46:503–514
Felizardo RJF, Watanabe IKM, Dardi P, Rossoni LV, Câmara NOS (2019) The interplay among gut microbiota, hypertension and kidney diseases: the role of short-chain fatty acids. Pharmacol Res 141:366–377
Miller TL, Wolin MJ (1996) Pathways of acetate, propionate, and butyrate formation by the human fecal microbial flora. Appl Environ Microbiol 62:1589–1592
Morrison DJ, Preston T (2016) Formation of short chain fatty acids by the gut microbiota and their impact on human metabolism. Gut Microbes 7:189–200
Guarner F, Malagelada JR (2003) Gut flora in health and disease. Lancet 361:512–519
Huang W, Guo HL, Deng X et al (2017) Short-chain fatty acids inhibit oxidative stress and inflammation in mesangial cells induced by high glucose and lipopolysaccharide. Exp Clin Endocrinol Diabetes 125:98–105
Larrañaga P, Calvo B, Santana R et al (2006) Machine learning in bioinformatics. Brief Bioinform 7:86–112
Vaughan LE, Enders FT, Lieske JC et al (2019) Predictors of symptomatic kidney stone recurrence after the first and subsequent episodes. Mayo Clin Proc 94:202–210
D’Costa MR, Haley WE, Mara KC et al (2019) Symptomatic and radiographic manifestations of kidney stone recurrence and their prediction by risk factors: a prospective cohort study. J Am Soc Nephrol 30:1251–1260
Wu HL, Cai LH, Li DF et al (2018) Metagenomics biomarkers selected for prediction of three different diseases in Chinese population. Biomed Res Int 2018:2936257
Duvallet C, Gibbons SM, Gurry T, Irizarry RA, Alm EJ (2017) Meta-analysis of gut microbiome studies identifies disease-specific and shared responses. Nat Commun 8:1784
Segata N, Izard J, Waldron L, Gevers D et al (2011) Metagenomic biomarker discovery and explanation. Genome Biol 12:R60
Oudah M, Henschel A (2018) Taxonomy-aware feature engineering for microbiome classification. BMC Bioinformatics 19:227
Nistal E, Sáenz de Miera LE, Ballesteros Pomar M et al (2019) An altered fecal microbiota profile in patients with non-alcoholic fatty liver disease (NAFLD) associated with obesity. Rev Esp Enferm Dig 111(4):275–282
Castellani A, Chalmers AJ (1919) Manual of tropical medicine, 3rd edn. Williams Wood and Co, New York
Taylor EN, Curhan GC (2007) Oxalate intake and the risk for nephrolithiasis. J Am Soc Nephrol 18:2198–2204
Macfarlane GT, Gibson GR, Cummings JH (1992) Comparison of fermentation reactions in different regions of the human colon. J Appl Bacteriol 72:57–64
Duncan SH, Holtrop G, Lobley GE, Calder AG, Stewart CS, Flint HJ (2004) Contribution of acetate to butyrate formation by human faecal bacteria. Br J Nutr 91:915–923
Barbas C, García A, Saavedra L, Muros M (2002) Urinary analysis of nephrolithiasis markers. J Chromatogr B Analyt Technol Biomed Life Sci 781(1–2):433–455
Berkemeyer S, Bhargava A, Bhargava U (2007) Urinary phosphorus rather than urinary calcium possibly increases renal stone formation in a sample of Asian Indian, male stone-formers. Br J Nutr 98(6):1224–1228
Statnikov A, Henaff M, Narendra V et al (2013) A comprehensive evaluation of multicategory classification methods for microbiomic data. Microbiome 1(1):11
Pasolli E, Truong DT, Malik F, Waldron L, Segata N (2016) Machine learning meta-analysis of large metagenomic datasets: tools and biological insights. PLoS Comput Biol 12(7):e1004977
Chiang D, Chiang HC, Chen WC, Tsai FJ (2003) Prediction of stone disease by discriminant analysis and artificial neural networks in genetic polymorphisms: a new method. BJU Int 91(7):661–666
Kazemi Y, Mirroshandel SA (2018) A novel method for predicting kidney stone type using ensemble learning. Artif Intell Med 84:117–126
Acknowledgements
The authors thank Tiffany T. Li, a native English speaker, for proofreading and polishing the manuscript.
Funding
This study was supported by The National Natural Science Fund of China (81770703, 81970602); Project of Science and Technology Department of Sichuan Province (2021YFS0116); 1.3.5 project for disciplines of excellence, West China Hospital (ZYJC18015, ZYGD18011, ZY2016104); and the Post-Doctor Research Project, West China Hospital [2019HXBH087].
Author information
Authors and Affiliations
Contributions
LYX and XJ conceived and designed the study, analyzed the data, and wrote the first draft of the manuscript. YL conducted the sample collection, and gathered data. YCM, ZTW and ZYJ conducted the laboratory experiments. HL participated in manuscript revision. YL and KJW participated in designing the study and revising the manuscript. YL critiqued statistical results and interpretation.
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Ethical approval
This study was approved by the West China Hospital of Sichuan University Medical Research Ethics Committee (2018182), and informed consents were obtained from each participant.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Liyuan Xiang and Xi Jin are co-first authors.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xiang, L., Jin, X., Liu, Y. et al. Prediction of the occurrence of calcium oxalate kidney stones based on clinical and gut microbiota characteristics. World J Urol 40, 221–227 (2022). https://doi.org/10.1007/s00345-021-03801-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00345-021-03801-7