
Abstract
Background
Identification of genetic variants that are associated with fatty acid composition in beef will enhance our understanding of host genetic influence on the trait and also allow for more effective improvement of beef fatty acid profiles through genomic selection and marker-assisted diet management. In this study, 81 and 83 fatty acid traits were measured in subcutaneous adipose (SQ) and longissimus lumborum muscle (LL), respectively, from 1366 purebred and crossbred beef steers and heifers that were genotyped on the Illumina BovineSNP50 Beadchip. The objective was to conduct genome-wide association studies (GWAS) for the fatty acid traits and to evaluate the accuracy of genomic prediction for fatty acid composition using genomic best linear unbiased prediction (GBLUP) and Bayesian methods.
Results
In total, 302 and 360 significant SNPs spanning all autosomal chromosomes were identified to be associated with fatty acid composition in SQ and LL tissues, respectively. Proportions of total genetic variance explained by individual significant SNPs ranged from 0.03 to 11.06 % in SQ, and from 0.005 to 24.28 % in the LL muscle. Markers with relatively large effects were located near fatty acid synthase (FASN), stearoyl-CoA desaturase (SCD), and thyroid hormone responsive (THRSP) genes. For the majority of the fatty acid traits studied, the accuracy of genomic prediction was relatively low (<0.40). Relatively high accuracies (> = 0.50) were achieved for 10:0, 12:0, 14:0, 15:0, 16:0, 9c-14:1, 12c-16:1, 13c-18:1, and health index (HI) in LL, and for 12:0, 14:0, 15:0, 10 t,12c-18:2, and 11 t,13c + 11c,13 t-18:2 in SQ. The Bayesian method performed similarly as GBLUP for most of the traits but substantially better for traits that were affected by SNPs of large effects as identified by GWAS.
Conclusions
Fatty acid composition in beef is influenced by a few host genes with major effects and many genes of smaller effects. With the current training population size and marker density, genomic prediction has the potential to predict the breeding values of fatty acid composition in beef cattle at a moderate to relatively high accuracy for fatty acids that have moderate to high heritability.
Similar content being viewed by others


Background
Dietary fats influence risks for developing cardiovascular disease, obesity and various forms of cancer, and have led to recommendations to limit consumption of some foods including beef [1]. Recommendations to limit beef consumption are mainly related to its relatively high content of saturated fatty acids (SFAs) as SFA consumption is believed to have negative effects on human health [2, 3]. Beef, however, is also a natural source of polyunsaturated fatty acid (PUFA) biohydrogenation intermediates (BHI) including vaccenic acid (11 t-18:1) and conjugated linoleic acids (CLAs), which have a number of purported health benefits [4–6]. In addition, beef is rich in monounsaturated fatty acids (MUFAs), in particular oleic acid 9c-18:1, which is the main fatty acid found in healthy Mediterranean diets, and may also contribute positively to beef flavour and tenderness [7]. Considerable efforts have, therefore, gone into improving beef fatty acid profiles in beef to meet the consumers’ growing demand for more nutritious, healthier and more palatable meat. Diet is known to have a major influence on beef fatty acid composition [8], but the use of genomic technologies to improve beef fatty acid profiles have not been thoroughly investigated [9].
The fatty acid composition of beef is a complex trait with heritability estimates ranging from near 0 to 0.73, depending on populations and the types of fatty acid [10–18]. To further elucidate the genetic control of host animals on fatty acid composition, chromosomal regions or quantitative trait loci (QTL) and candidate genes that are associated with fatty acid composition in beef cattle have been identified on multiple chromosomes based on low density DNA markers [19–21], and based on candidate gene DNA marker association analyses [22–36]. Genome-wide association studies (GWAS) using a relatively high density of single nucleotide polymorphism (SNP) markers (e.g. Illumina BovineSNP50 Beadchip) in recent years have assisted in the search for DNA markers associated with the fatty acid composition of beef, but studies are limited to a small number of fatty acids in certain beef breeds [7, 37, 38]. Saatchi et al. [16] analyzed 49 fatty acid traits in steaks of Angus beef cattle and reported results of GWAS and genomic prediction of direct genomic breeding values of the fatty acid traits. Onogi et al. [39] also reported genomic prediction for 8 fatty acid traits in Japanese Black cattle. Many fatty acids with potential health value (i.e. PUFA-BHI) were, however, not reported in those studies. In this study, we comprehensively analyzed fatty acid profiles and report GWAS and genomic prediction of breeding values for 81 and 83 individual and grouped fatty acids in subcutaneous adipose (SQ) and longissimus lumborum muscle (LL), respectively, in Canadian beef cattle populations.
Results and discussion
Descriptive statistics and genomic heritability estimates
Summary statistics and genomic heritability estimates for the 81 fatty acid traits of SQ and 83 fatty acid traits of LL are presented in Table 1. In general, the estimates of heritability for the same fatty acids are comparable in both the adipose and muscle tissues, with a correlation coefficient of 0.61. Relatively higher (>0.40) heritability estimates were found for 10:0, 12:0, 18:0, ai15:0, 9c-14:1, 9c-16:1, 13c-18:1, 18:3n-3, 18:2n-6, n-3, n-6, sumtrans 18:1, total PUFA, P/S, and P/(S + B) in the SQ tissue, and for 12:0, 14:0, 16:0, 9c-14:1, 9c-16:1, 12c-16:1, 9c-18:1, 13c-18:1, SFA, SFA + BFA, MUFA, n-6/n-3, and health index (HI) in the LL muscle, which suggests greater direct host genetic effects on these traits in the corresponding tissues. Very low (<0.05) or zero heritability were observed for 22:0, 7c-17:1, 12 t-18:1, 15 t-18:1, 6 t,8 t:18:2, 7 t,9 t-18:2, 9 t,11 t-18:2, 10 t,12 t-18:2, 12 t,14 t-18:2, and n-6/n-3 in the SQ tissue, and for 7c-17:1, 15 t-18:1, 6 t,8 t-18:2, 7 t,9 t-18:2, 7 t,9c-18:2, 8 t,10 t-18:2, 12 t,14 t-18:2 in the LL muscle, which indicates weak host direct genetic control on these traits. In general, the heritability estimates for the fatty acids in this study are in line with those reported in other studies [10, 12, 15]. Therefore, the genomic estimated additive genetic variance and heritability for the fatty acid traits were further used in the calculation of total genetic variance explained by significant markers identified in GWAS and in the derivation of realised accuracy of genomic prediction in this study.
Genome-wide association study
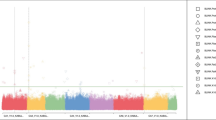
In total, 302 and 360 significant SNPs spanning all autosomal chromosomes were identified to be associated with one or more fatty acid traits in the SQ and LL tissues, respectively, at the genome-wise empirical significance threshold at α = 0.05. Significant SNPs and their distributions over the genome varied for different fatty acid traits. Manhattan plots of posterior probability of inclusion (PPI) were provided in Additional file 1 for all fatty acid traits in the two tissues. Proportions of genotypic variance explained by individual significant SNPs ranged from 0.03 to 11.06 % in SQ, and from 0.005 to 24.28 % in LL. Among these, 28 and 41 SNPs individually explained greater than 1 % of total genetic variance for at least one fatty acid trait in the SQ and LL tissues, respectively. Figures 1 and 2 showed these SNPs and their associated traits in SQ and LL, respectively. Of these SNPs, SNP rs41921177 at the location of BTA19:51326750 had the largest effects on multiple fatty acid traits in both tissues, followed by SNP rs42714483 at BTA29:18090509 and SNP rs42090719 at BTA26:20903573. Details of all significant SNPs including SNP name, chromosome position, allele substitution effect, percentage of total genetic variance explained, and PPI were also provided in additional files (Additional file 2 for SQ and Additional file 3 for LL). Candidate genes within 1 mega base pair (Mb) region centering the significant SNPs were provided separately (Additional file 4).

Summary of fatty acid trait associations across genomic regions (SNPs) and percentage of genetic variance explained by significant SNPs in the subcutaneous adipose tissue (SQ). Each row represents a trait and each column represents a SNP. Only traits with at least one significant SNP explaining greater than 1 % of genetic variance were listed, and only SNPs that explain greater than 1 % of genetic variance for at least one trait were shown. The top of the figure shows the chromosome and position and the bottom shows the name of the SNP. Va %: percentage of genetic variance

Summary of fatty acid trait associations across genomic regions (SNPs) and percentage of genetic variance explained by significant SNPs in longissimus lumborum muscle (LL). Each row represents a trait and each column represents a SNP. Only traits with at least one significant SNP explaining greater than 1 % of genetic variance were listed, and only SNPs that explain greater than 1 % of genetic variance for at least one trait were shown. The top of the figure shows the chromosome and position and the bottom shows the name of the SNP. Va %: percentage of genetic variance
SNP rs41921177 was significantly associated with 19 individual and grouped fatty acids in the LL muscle including SFAs 10:0, 12:0, 13:0, 14:0, 15:0, 16:0, 18:0, branched fatty acids (BFAs) ai 15:0 and iso 18:0, MUFAs 9c-14:1, 9c-15:1, 9c-16:1, 12c-16:1, 9c-18:1, 11c-20:1, grouped fatty acids total SFA, SFA + BFA, total MUFA and HI, with genetic variance explained from 1.37 % (18:0) to 24.28 % (14:0). The same SNP also showed significant associations with 11 of the above fatty acids in SQ including saturated fatty acids 12:0, 14:0, 15:0, 16:0, SFA, monounsaturated fatty acids 9c-14:1, 9c-15:1, 9c-16:1, 9c-18:1, 12c-16:1 and HI, explaining 0.33 % (SFA) to 11:06 % (14:0) of the genetic variance (also see Additional file 2). This chromosomal region was previously identified to be associated with 14:0, 16:0, 16:1 and 18:1 in adipose and muscle tissues of a Jersey and Limousin crossbred beef cattle [21], with 9c-18:1, and 14:0, 14:1, 16:0, 16:1 in intramuscular fat of Japanese Black cattle [7, 37], with 14:0, 16:0, 9c-14:1 and 9c-18:1 in adipose tissue of an Australian multi-breed beef population [38], with 14:0, 14:1, 16:0, 16:1, 9c-18:1, MUFA, SFA, and Atherogenic index (AI, the inverse of HI) in muscle of American Angus beef cattle [16]. The association of this chromosomal region with the fatty acid traits was therefore confirmed in both the SQ and LL tissues of a Canadian beef population of diverse breed compositions, indicating a strong host genetic effect on the fatty acid composition in beef tissues. Multiple genes are within 1 Mb region centering the SNP (see Additional file 4), with FASN being a strong candidate gene due to its function in fatty acid synthesis [40, 41]. Different SNPs of the FASN gene have also been reported to be associated with concentrations of saturated and monounsaturated fatty acids in various beef and dairy cattle populations [7, 16, 18, 22, 37, 38, 40–45].
SNP rs42714483 showed significant associations with concentrations of 15 fatty acids in the LL tissue and 10 fatty acids in SQ including 10:0, 12:0, 13:0, 14:0, 15:0, 9c-14:1, 12c-16:1, 13c-18:1, 9c,15c-18:2, and HI in both the tissues, and 16:0, 18:0, 9c-15:1, 9c-16:1, and 9c-18:1 in the LL tissue. Saatchi et al. [16] also identified the same chromosomal region associated with fatty acids 14:0, 9c-14:1, 16:0, 16:1, 18:0, 9c-18:1, and AI, and Kelly et al. [38] found SNPs in the same chromosomal region that were associated with fatty acids 14:0, 9c-14:1 in subcutaneous adipose tissue of an Australian multi-breed beef population [38]. These results strongly support that the chromosome region on BTA 29 harbors host genes that influence fatty acid composition of beef tissues. In this study, the SNP at BTA29:18090509 is a missense mutation (T/C) of the thyroid hormone responsive gene (THRSP), causing amino acid change from isoleucine to valine (I16V). Recently THRSP has been considered as a candidate gene for fatty acid composition in beef [16, 46]. Substitution of allele T with C of this missense mutation was associated with decrease of 10:0, 12:0, 13:0, 14:0, 15:0, 16:0, 9c-14:1, 9c-15:1, 9c-16:1, 12c-16:1, 13c-18:1, 9c,15c-18:2, and increase of 18:0, 9c-18:1, and HI (see Additional files 2 and 3). The direction of the allele substitution effect on different fatty acid traits also coincided with that of SNP rs41921177, which is close to FASN gene, suggesting possible co-ordinations between THRSP and FASN genes in fatty acid synthesis.
SNP rs42090719 at BTA26: 20903573 was found to be significantly associated with 9c-14:1, 12c-16:1, 13c-18:1 in both the LL and SQ tissues, 9c,15c-18:2 and CLA isomers 11 t,13c + 11c,13 t-18:2 (also see Additional file 3) in the LL tissue. In addition, SNP rs41646463 at BTA26:21258113 also showed significant associations with 13c-18:1 in both the LL and SQ tissues. In the nearby chromosomal region of BTA26:18994785, SNP rs109465094 was significantly associated with 9c-14:1, 12c-16:1, 13c-18:1 and 9c,15c-18:2 in LL. The chromosomal regions on BTA 26 were previously found associated with a variety of fatty acids in muscle of American Angus and in adipose tissue in an Australian multi-breed beef population, and stearoyl-CoA desaturase gene (SCD) was suggested as a candidate gene [16, 38]. The two SNPs, rs42090719 and rs41646463, are within 250 kilo base pairs (Kb) of SCD. The other SNP rs109465094 is more than 2 Mb distant from SCD, indicating a possible alternative candidate gene or its association could merely be due to LD with SCD. Linkage disequilibrium between SNPs around the SCD gene were analysed and visualised using the Haploview software [47] and results are shown in Additional file 5. Indeed, the three significant SNPs are in moderate to high LD with SNPs in a LD block containing the SCD gene. The SCD gene is involved in the synthesis of particular MUFA and CLA isomers, in creating a double bond at the Δ9 position of fatty-acyl CoA [48, 49]. SCD has been reported to be associated with both meat and milk fatty acid composition in cattle [7, 16, 18, 32, 34, 37, 38, 42, 50–56]. The present study showed that SNPs close to the SCD gene were associated with many MUFAs and several CLA isomers but none of the SFAs, which supports the proposed role of SCD in fatty acid composition in beef. However, in this study none of the SNPs around SCD were associated with oleic acid, 9c-18:1, the most abundant MUFA in beef. This could be partly due to lack of SNPs in the current panel that are in a high LD with SCD to capture all its effects. Interestingly, several other studies also showed no associations between SCD and oleic acid in various beef and dairy cattle populations, using different SNP panels or SCD gene SNP [7, 16, 38, 50, 51, 57], although two other studies have reported significant associations between SCD SNP variants and oleic acid concentrations in Japanese Black cattle [18, 32]. The role of SCD on the concentration of oleic acid in beef is worthy of further investigation.
Other SNPs on BTA 1, 3, 4, 5, 6, 7, 10, 16, 20, 23, 24, 25, 28 and on 1, 2, 4, 5, 6, 8, 10, 13, 14, 16, 23, 24, 25, 27, 28 were found significantly associated with one or more fatty acid concentrations in the SQ and LL, respectively, but with relatively smaller effects (Figs. 1 and 2). The SNP rs41642879 at BTA23:6760915 was associated with 12:0, 14:0, and HI of both the LL and SQ, and with 16:0, 9c-14:1 in LL tissue. There are several genes within the 1 Mb window centering the SNP. One possible candidate gene is the glutamate-cysteine ligase catalytic subunit gene (GCLC), which is involved in the synthesis of glutathione (GSH) [58]. Glutathione has an antioxidant function by oxidizing itself into Glutathione disulfide (GSSG), which in turn is reduced to GSH at the expense of nicotinamide adenine dinucleotide phosphate (NADPH) oxidase [58]. The latter is essential for fatty acid synthesis [40]. The SNP rs41574597 at BTA23:25956421 was found to be associated with 11c-20:1 in both tissues. Several genes belonging to the butyrophilin family are located nearby. Butyrophilin is the major protein associated with milk fat droplets and has been reported to be related to milk quality in cattle [59]. However, it was suggested that butyrophilin is specific to mammary tissue [60] hence its role in meat fatty acid production remains unclear.
Fewer SNPs were identified for PUFAs (90 in SQ and 87 in LL) in comparison to the number of significant SNPs for SFAs (121 in SQ and 117 in LL) and MUFAs (174 in SQ and 120 in LL). One SNP rs41582945 at BTA2:50069820 explained 2.45 % of genetic variance for dihomo-gamma-linolenic acid (Dihomo-GLA, 20:3n-6) in LL. However, no known genes exist in the 1 Mb region of this SNP. Several SNPs were also found to be associated with the intermediate product of Dihomo-GLA, arachidomic acid in LL (20:4n-6). The most significant SNP rs110776216 on BTA2:131968682 explained 1.91 % of total genetic variance of 20:4n-6 and was located within the endothelin converting enzyme 1 gene (ECE1) which encodes the enzyme that converts big endothelin-1 to endothelin-1. Endothelin-1 was previously found to stimulate arachidonic acid release in human pericardial smooth muscle cells [61, 62]. In this study, no significant SNPs were found to be associated with iso14:0, 7c-17:1, 15 t-18:1, 9c-20:1, 6 t,8 t-18:2, 7 t,9c-18:2, 9 t,11 t-18:2, 8 t,10 t-18:2, 7 t,9 t-18:2, 20:5n3 in LL and 22:0, 7c-17:1, 11c-18:1, 12 t-18:1, 15 t-18:1, 6 t,8 t-18:2, 10 t,12 t-18:2, 9 t,11 t-18:2, 8 t,10 t-18:2, 7 t,9 t-18:2, 18:3n6, 20:3n9, and n-6/n-3 in SQ. These fatty acid traits had very low or near zero heritability estimates (Table 1), therefore their concentrations were less likely influenced by host direct genetic effects.
Genomic prediction
Realized accuracies of genomic prediction measured as the Pearson’s correlation coefficients between genomic estimated breeding values (GEBV) and adjusted phenotypic values of fatty acid traits divided by square root of heritability are presented in Table 2. Accuracies of breeding values estimated from the pedigree-based BLUP method (PBLUP) are also presented in Table 2 as comparisons. The realized accuracy of genomic prediction ranged from −0.05 for 15 t-18:1 to 0.73 for 14:0 in the LL muscle, and varied from −0.05 for 20:3n-9 to 0.65 for 16 t-18:1 in the SQ tissue. Averaged across all traits, accuracies from PBLUP, GBLUP, and the Bayesian method were 0.23, 0.32, and 0.35, respectively, in SQ, and 0.17, 0.39, and 0.46, respectively, in LL. These results suggested the effectiveness of genomic prediction using either GBLUP or the Bayesian method. However, the incompleteness of the pedigree (only one generation) may largely contribute to the low accuracy for the PBLUP method. It should be noted that the realized accuracy could be overestimated when heritability is underestimated as pointed out by Lourenco et al. [63]. Accuracies that were substantially overestimated tended to have relatively large SE (>0.10) as shown in Table 2. Additionally, Pearson’s correlation coefficient between estimated breeding values and adjusted phenotypes, and regression coefficient by regressing adjusted phenotypes on estimated breeding values were also calculated and provided in Additional file 6. The correlation coefficients averaged 0.11, 0.15, and 0.15 for PBLUP, GBLUP, and the Bayesian method, respectively, in SQ, and averaged 0.08, 0.14, and 0.16, respectively in LL. The average regression coefficients in SQ were 1.02, 0.77, and 0.92, and were 1.04, 0.90, and 0.83 in LL for PBLUP, GBLUP, and the Bayesian method, respectively. The regression coefficient is expected to be 1 if the estimated breeding values were unbiased predictions of the true breeding values. Nevertheless, for most of the fatty acid traits, the accuracy of genomic prediction were relatively low (<0.40), which was expected given the low heritability estimates and the small sample size used in this study [64]. Relatively higher accuracy (r (GEBV,y)/h ≥ 0.50 with SE < 0.10) were achieved for 10:0 (0.53), 12:0 (0.53), 14:0 (0.73), 15:0 (0.69), 16:0 (0.50), 9c-14:1 (0.55), 12c-16:1 (0.55), 13c-18:1 (0.51), and HI (0.59) in LL, and for 12:0 (0.58), 14:0 (0.61), 15:0 (0.62), 10 t,12c-18:2 (0.52), and 11 t,13c + 11c,13 t-18:2 (0.56) in SQ. The relatively higher accuracy for certain saturated and monounsaturated fatty acids, and HI, and relatively lower accuracy for CLAs and other PUFAs in muscle were compatible with the magnitude of their estimated heritability (Table 1). The correlations between heritability estimates and realised accuracy of genomic prediction in LL were 0.61 and 0.39 for Bayesian and GBLUP methods, respectively. However, in SQ such correlations were only 0.10 for GBLUP and 0.23 for the Bayesian method, which is likely due to many overestimations of realised accuracy for traits with low and inaccurate heritability estimates. Genomic prediction from the Bayesian method performed similarly as GBLUP for most of the traits, but substantially better for several traits in LL muscle such as 10:0 (0.37 for GBLUP vs 0.53 for BayesCπ), 12:0 (0.31 vs 0.53), 14:0 (0.45 vs 0.73), 15:0 (0.57 vs 0.69), 16:0 (0.36 vs 0.50), 9c-14:1 (0.34 vs 0.55), 9c-16:1 (0.37 vs 0.49), 12c-16:1 (0.32 vs 0.55), 9c-18:1 (0.27 vs 0.37), 13c-18:1 (0.36 vs 0.51), and HI (0.41 vs 0.59), and for traits in SQ including 12:0 (0.42 vs 0.58), 14:0 (0.39 vs 0.61), and 9c-14:1 (0.31 vs 0.43). These traits have been shown to have SNPs with larger effects from GWAS results (Figs. 1 and 2). The Bayesian method adopted in this study allows a fraction of SNPs to take relatively large effects, which may better characterize the genetic architecture of traits that have QTL of larger effects than the GBLUP method [65], which assumes all SNPs have the same genetic variance.
Fatty acid composition is a complex trait and it is difficult and expensive to measure, making it a good candidate trait for genomic selection. To date, genomic prediction for fatty acid composition in beef cattle has only been reported by Saatchi et al. [16] for 24 individual and grouped/ratio of fatty acids in steaks of American Angus beef cattle, and by Onogi et al. [39] for 8 fatty acid traits in musculus trapezius of Japanese Black cattle. Relatively higher prediction accuracies were found for 14:0 (0.57), 16:0 (0.53), total long chain saturated fatty acids (0.57), total medium chain saturated fatty acids (0.57), 9c-18:1 (0.35), 12c-18:1 (0.35), total MUFA (0.38), (14:0 + 16:0)/all (0.55), and AI (0.56) in Saatchi’s study, compared to other fatty acid traits. In this study, relatively higher accuracies were also obtained for SFAs 12:0, 14:0, and 15:0 in both the LL and SQ tissues, and for 10:0, 16:0, 9c-14:1, 12c-16:1, 13c-18:1, and HI in LL (Table 2), suggesting strong host genetic controls on synthesis of these SFAs and MUFAs. Saatchi et al. [16] reported genomic prediction accuracies for 12 PUFAs and all were very low (<0.30). In this study, we analyzed 32 and 34 PUFAs and PUFA-BHI (including CLAs and 11 t-18:1) in the adipose and muscle tissues, respectively, and found moderate accuracies (between 0.30 and 0.45) for 11 t-18:1, 9c,13 t + 8 t,12c-18:2, 9c,15c-18:2, 8 t,13c-18:2, 11 t,15c-18:2, 18:2n-6, 18:3n-3, n-3, n-6, and total PUFA in both the adipose and muscle tissues, moderate accuracies for 20:3n-6, 20:3n-9, 22:4n-6, 22:6n-3 in the muscle, and relatively high accuracies (>0.50) for 12 t,14c + 12c,14 t-18:2, and 11 t,13c + 11c,13 t-18:2 in the adipose tissue, suggesting considerable host genetic influence on these fatty acids. Different beef cattle populations, environments where the animals were raised, sample sizes and statistical models may also contribute to the differences of genomic prediction accuracy observed between different studies. Although most dietary PUFAs are biohydrogenated by rumen bacteria [66], a portion of PUFAs and PUFA-BHI may escape and deposit into body fat of beef. In addition, some PUFAs can be endogenously synthesized, for example CLAs can be synthesized from one of the PUFA-BHI, vaccenic acid (11 t-18:1) by the host [67]. Therefore, contents of both PUFAs and PUFA-BHI are potentially influenced by host genetics and thus predictable by genomic prediction. Onogi et al. [39] also reported a relatively high accuracy (0.56) for PUFA C18:2 in Japanese Black cattle. Although it would be worthwhile to further verify the genomic prediction accuracy in other beef cattle populations, the moderate to relatively high genomic prediction accuracies achieved in this study for the HI, several individual SFAs, MUFAs, PUFAs and PUFA-BHI suggest that genomic selection is a promising tool for genetic improvement of fatty acid profiles in beef cattle to produce healthier meat. Therefore, as consumers’ demand for healthier meat continues to grow, beef producers may get more premiums by producing meat with enhanced fatty acid profiles, which can be achieved by incorporating fatty acid composition traits into a multi-trait selection index for selection and/or by genetic based diet management.
Conclusions
Fatty acid composition in beef tissues is a polygenic trait that is controlled by a few major host genes and many genes of small effects. Several genes, including FASN, SCD, and THRSP, are major candidate genes for variations of fatty acid contents in beef cattle. Accuracy of genomic prediction was low for most of the fatty acid traits investigated. Moderate accuracy was obtained for SFAs 10:0, 12:0, 13:0, 14:0, 15:0, 16:0, MUFAs 9c-14:1, 12c-16:1, 13c-18:1, and HI in LL, and for SFAs 12:0, 14:0, 15:0, and CLA isomers 10 t,12c-18:2, and 11 t,13c + 11c,13 t-18:2 in SQ. The Bayesian method performed similarly as GBLUP for most of the traits, but substantially better for fatty acid traits that are influenced by QTL of larger effects. The moderate genomic prediction accuracy achieved in this study for HI in LL and several individual fatty acids in LL and SQ tissue suggest that it is possible to genetically improve fatty acid profiles in beef cattle to produce healthier meat through genomic selection. Further investigations on the identification of causal mutations for variations of fatty acid contents in beef tissues and on improvement of genomic prediction accuracy are required.
Methods
Animal populations, tissue collection and fatty acid analyses
A total of 1366 steers and heifers born between 2008 and 2011 were used in this study. The animals were from four different herds including three commercial herds and one experimental herd located in Alberta of Canada. All dietary treatments and experimental procedures were approved by the AAFC Lacombe Research Centre Animal Care Committee and animals were cared for as outlined under the guidelines established by the Canadian Council on Animal Care [68]. Breed compositions of the 1366 steers and heifers were represented by purebred Angus (ANAN, n = 6), Hereford-Angus crossbreds (HEAN, n = 120), Charolais-Red Angus crossbreds (CHAR, n = 93), crossbreds produced by mating Hereford-Angus to Gelbvieh-Angus crossbreds (HEANGV, n = 209), and calves produced from crosses between a composite terminal bull strain which was derived from Hereford, Black Angus, Red Angus, and Limousin, and crossbred cows with a mixed background of Angus, Red Angus, Hereford, Simmental, Charolais, Limousin and Gelbvieh (TXX, n = 938). A more detailed description of breeding and management of the herds have been described previously [69–71]. A written consent from the owner of the commercial herds was obtained for the use of cattle data in this study. After weaning, animals were raised under one of four production systems: (1) calf-fed, growth implant; (2) calf-fed; no growth implant; (3) yearling-fed, growth implant; (4) yearling-fed, no growth implant [70, 72]. All animals were fed high concentration diets for finishing and were targeted to be slaughtered at a constant back fat thickness of 9 to 10 mm measured between the 12th and 13th ribs.
After slaughter, the longissimus luborum muscle (LL) of each animal was taken from the left striploin at 48 h post-mortem, vacuum packed and then chilled at 2 °C. The striploin samples were then transported by a refrigerated truck to a meat lab of the AAFC Lacombe Research Centre where a sub-sample of approximately 10 grams of LL muscle and 5 grams of subcutaneous adipose (SQ) tissue from the side of the striploin of each animal was taken, vacuum packed and frozen at −80 °C for subsequent fatty acid analyses. The two tissues have distinct metabolism roles involving fat usage: muscle is mainly for energy expenditure to produce force and motion while adipose including intramuscular fat within muscle is the main tissue for fat storage [73]. The two tissues were selected mainly because they are major parts of carcass that are consumed as beef products by humans. Fatty acid analyses of LL and SQ tissues were based on the protocols described previously with some modifications [10]. Briefly, lipid was extracted from the LL muscle tissue using Folch’s method [74] as outlined by Cruz-Hernandez et al. [75] and from the SQ tissue based on the procedures described in [75] and [76]. Fatty acid methyl esters (FAME) were then derivatized using sodium methoxide from the lipid extracts for quantification of fatty acid composition. Gas chromatography (GC) and silver-ion high performance liquid chromatography (Ag + HPLC) analyses were conducted to separate and quantify individual fatty acids as outlined in [77] using a two-step GC procedure and in [75] using Ag + HPLC. Individual fatty acids were expressed as a percentage of the total FAME. Concentrations of groups of fatty acids, including total saturated fatty acids (SFA), branched fatty acids (BFA), sum of SFA and BFA (SFA + BFA), mono-unsaturated fatty acids (MUFA), poly-unsaturated fatty acids (PUFA), sum of trans 18:1 fatty acids (sumtrans18:1), total conjugated linoleic acid (Total CLA), n-3, and n-6, were measured by summing up the percentages of individual fatty acids within the fatty acid group. Ratios between PUFA and SFA (P/S), PUFA and sum of SFA and BFA (P/(S + B)), and between n-6 and n-3 (n-6/n-3) were also calculated. A health index (HI), proposed in [35], was computed as HI = (MUFA + PUFA) / (4 × 14:0 + 16:0). A total of 83 individual and grouped/ratio fatty acid traits in the LL muscle and 81 in the SQ tissue were quantified. Two fatty acids, 20:5n3 and 22:6n3 were not detected in SQ in this study due to their extremely low concentrations in the tissue.
Single nucleotide polymorphism genotyping
All animals were genotyped on the Illumina BovineSNP50 Beadchip comprised of 54,609 SNP markers. Markers with minor allele frequency less than 0.05, missing rate greater than 0.20, extremely deviated from Hardy-Weinberg equilibrium test (P < 10−6), or in high correlation with another SNP (r ≥ 0.95) were removed. After filtering, 35,446 SNPs were kept for analyses. Sporadically missing genotypes represented 0.14 % of the total genotypes and were imputed via Beagle 3.3.2 [78].
Genome-wide association study
Phenotypic values were adjusted for fixed effects and random contemporary group effects using a linear mixed model which included fixed effects of breed type, gender, production system, linear covariates of animal’s age at slaughter, days between slaughter and fatty acid extraction, and metabolic energy of diet, and random effects of contemporary groups defined as combinations of feedlot location and year, additive genetic effects and residual errors. Fatty acid traits in LL muscle were also adjusted for intramuscular fat content by including the marbling score as an additional fixed linear covariate. A genomic relationship matrix for additive genetic effects was constructed from SNP marker genotypes using the first method of VanRaden [79]. Variance components and heritability were estimated using the above model and average-information REML algorithm implemented via ASReml v3.0 software package [80].
The adjusted phenotypes were subsequently analysed using the BayesCπ method [81] for genome-wide association studies. The model can be described as follows:
where y i is the adjusted phenotypic value of the i th animal, μ is the general mean, x ij is the j th SNP genotype of animal i and was coded as 0, 1 or 2 depending on copies of an arbitrarily specified allele, M is the total number of SNP markers, a j is the allele substitution effect of SNP j, and e i is the random residual effect.
A mixture distribution was assumed for a j so that (a j |π, σ 2 a ) ~ (1 − π)N(0, σ 2 a ) + πδ 0(a j ), where N(0, σ 2 a ) is a normal distribution with mean 0 and variance σ 2 a , and δ 0(a j ) denotes a distribution concentrated at zero, and (1 − π) and π are the weights for the two distributions. A latent indicator variable γ j was introduced for each SNP so that when γ j = 1, a j ~ N(0, σ 2 a ), and when γ j = 0, a j = 0. Prior distribution for γ j follows a Bernoulli distribution with probability (1 − π), and the joint prior density for γ is \( f\left(\gamma \Big|\pi \right) = {\prod}_j{\pi}^{\left(1-{\gamma}_j\right)}{\left(1-\pi \right)}^{\gamma_j}. \) Residual error e i was assumed from a normal distribution N(0, σ 2 e ). The prior distribution for σ 2 a (or σ 2 e ) is a scaled inverse Chi-square distribution with degree of freedom v a (or v e ) and a scale parameter S 2 a (or S 2 e ). The hyper-parameter v a (or v e) was arbitrarily set to 4 (or 10), and S 2 a (or S 2 e ) was set to \( {\widehat{\sigma}}_u^2\left({v}_a-2\right)/\left[{v}_a\left(1-\pi \right)\sum 2{p}_j\left(1-{p}_j\right)\right] \) (or \( {\widehat{\sigma}}_0^2\left({v}_e-2\right)/{v}_e \)), where p j is allele frequency for marker j, \( {\widehat{\sigma}}_u^2 \) and \( {\widehat{\sigma}}_0^2 \) were total additive genetic and residual variances obtained from the analyses described previously. A Gibbs sampling algorithm was used for generating samples for unknown parameters from their joint posterior distribution. The computer program was self-written in C language using the computing algorithm as described by Chen et al. [82]. The Gibbs chain length was 45,000 with the first 5000 discarded as burn-in. Posterior inclusion probability for each SNP was estimated as sample mean of the latent indicator variable for that SNP, and was used as a signal of association. To declare the significance of a SNP effect, empirical genome-wise significance threshold at α = 0.05 was determined by 1000 permutation analyses according to the procedure of Churchill and Doerge [83]. Briefly, the adjusted phenotype values of each fatty acid were randomly shuffled and assigned back to the animals for the BayesCπ analyses while the genotype data remained intact. The process was repeated 1000 times and the largest SNP posterior inclusion probability from each permutation analysis was kept and ordered in ascending order, and the 950th value was defined as the genome-wise significance threshold. Candidate genes in the window of 1 Mb centering the significant SNPs were obtained by querying the Ensemble gene database using SNP locations from the bovine UMD3.1 genome assembly via the SNP annotation tool in the NGS-SNP suite [84].
Genomic prediction
Genomic best linear unbiased prediction (GBLUP) and BayesCπ methods were used for genomic prediction. A ten-fold cross validation was used to evaluate the accuracy of genomic prediction. The data was first split into 10 approximately equal-sized groups according to sires of the animals so that no sire families overlapped between any two groups. For each breed type, the number of animals in each cross-validation group was kept approximately the same so that each breed in the validation group was also represented in the training population. For each cross validation, nine groups were used for training and the remaining one was used as the validation population. For GBLUP, animals in the validation population were assumed with no phenotypic values, and the animals in the training and validation populations were then combined to estimate the breeding values for animals in the validation population using a linear animal model, which can be written as:
Where y* is the vector of adjusted fatty acid phenotypic values from animals in the training population, μ is the overall mean, a is the vector of breeding values for all animals, e is the vector of random residuals and Z is the incidence matrix relating a to y*. The additive genomic relationship matrix for all animals was derived from the SNP markers using the first method of VanRaden [79], and ASReml 3.0 [80] was used to estimate the breeding values. For the BayesCπ method, SNP effects were estimated based on the training population using the statistical model as described in the GWAS analyses. The GEBV for animal i in the validation population was predicted by summing up SNP effects over all loci as follows:\( {\mathrm{GEBV}}_i={\displaystyle {\sum}_{j=1}^M{x}_{ij}{a}_j} \), where a j is the estimated effect for SNP j. For comparisons, a pedigree based BLUP method (PBLUP) was also used to estimate the breeding values, assuming no phenotypic values for validation animals. However, only one generation of the pedigree was available for construction of the additive genetic relationship matrix. Realized accuracy of genomic prediction was measured as the correlation between estimated breeding values and the adjusted phenotype in the validation groups divided by square root of heritability and was averaged across the ten cross-validations.
Availability of supporting data
The data sets supporting the results of this article are included within the article and its additional files. The original data sets used in this study are available upon request as part of the data is not public.
Abbreviations
- AAFC:
-
Agriculture and Agri-food Canada
- Ag + HPLC:
-
silver-ion high performance liquid chromatography
- AI:
-
atherogenic index
- BFA:
-
branched fatty acid
- BHI:
-
biohydrogenation intermediates
- BTA:
-
Bos taurus autosome
- CLA:
-
conjugated linoleic acid
- FAME:
-
fatty acid methyl esters
- GBLUP:
-
genomic best linear unbiased prediction
- GC:
-
gas chromatography
- GEBV:
-
genomic estimated breeding value
- GWAS:
-
genome-wide association study
- HI:
-
health index
- LD:
-
linkage disequilibrium
- LL:
-
Longissimus lumborum muscle
- MME:
-
mixed model equations
- MUFA:
-
monounsaturated fatty acid
- PBLUP:
-
pedigree-based best linear unbiased prediction
- PPI:
-
posterior probability of inclusion
- PUFA:
-
polyunsaturated fatty acid
- QTL:
-
quantitative trait loci
- SFA:
-
saturated fatty acid
- SNP:
-
single nucleotide polymorphism
- SQ:
-
subcutaneous adipose
References
Pan A, Sun Q, Bernstein AM, Schulze MB, Manson JE, Stampfer MJ, et al. Red meat consumption and mortality results from 2 prospective cohort studies. Arch Intern Med. 2012;172(7):555–63.
Gormley TR, Downey G, O’Beirne D. Food, health and the consumer. London: Elsevier Applied Science Publishers Ltd.; 1987.
Raes K, de Smet S, Demeyer D. Effect of double-muscling in Belgian Blue young bulls on the intramuscular fatty acid composition with emphasis on conjugated linoleic acid and polyunsaturated fatty acids. Anim Sci. 2001;73:253–60.
Bassett CMC, Edel AL, Patenaude AF, McCullough RS, Blackwood DP, Chouinard PY, et al. Dietary vaccenic acid has antiatherogenic effects in LDLr(−/−) mice. J Nutr. 2010;140(1):18–24.
Corl BA, Barbano DM, Bauman DE, Ip C. Cis-9, trans-11 CLA derived endogenously from trans-11 18:1 reduces cancer risk in rats. J Nutr. 2003;133(9):2893–900.
Wijendran V, Hayes KC. Dietary n-6 and n-3 fatty acid balance and cardiovascular health. Annu Rev Nutr. 2004;24:597–615.
Uemoto Y, Abe T, Tameoka N, Hasebe H, Inoue K, Nakajima H, et al. Whole-genome association study for fatty acid composition of oleic acid in Japanese Black cattle. Anim Genet. 2011;42(2):141–8.
De Smet S, Raes K, Demeyer D. Meat fatty acid composition as affected by fatness and genetic factors: a review. Anim Res. 2004;53(2):81–98.
Vahmani P, Mapiye C, Prieto N, Rolland DC, McAllister TA, Aalhus JL, et al. The scope for manipulating the polyunsaturated fatty acid content of beef: a review. J Anim Sci Biotechnol. 2015;6(1):1–13.
Ekine-Dzivenu C, Chen L, Vinsky M, Aldai N, Dugan M, McAllister T, et al. Estimates of genetic parameters for fatty acids in brisket adipose tissue of Canadian commercial crossbred beef steers. Meat Sci. 2014;96(4):1517–26.
Inoue K, Kobayashi M, Shoji N, Kato K. Genetic parameters for fatty acid composition and feed efficiency traits in Japanese Black cattle. Animal. 2011;5(07):987–94.
Kelly M, Tume R, Newman S, Thompson J. Genetic variation in fatty acid composition of subcutaneous fat in cattle. Anim Prod Sci. 2013;53(2):129–33.
Malau‐Aduli A, Edriss M, Siebert B, Bottema C, Pitchford W. Breed differences and genetic parameters for melting point, marbling score and fatty acid composition of lot-fed cattle. J Anim Physiol Anim Nutr. 2000;83(2):95–105.
Nogi T, Honda T, Mukai F, Okagaki T, Oyama K. Heritabilities and genetic correlations of fatty acid compositions in longissimus muscle lipid with carcass traits in Japanese Black cattle. J Anim Sci. 2011;89(3):615–21.
Pitchford W, Deland M, Siebert B, Malau-Aduliand A, Bottema C. Genetic variation in fatness and fatty acid composition of crossbred cattle. J Anim Sci. 2002;80(11):2825–32.
Saatchi M, Garrick DJ, Tait RG, Mayes MS, Drewnoski M, Schoonmaker J, et al. Genome-wide association and prediction of direct genomic breeding values for composition of fatty acids in Angus beef cattle. BMC Genomics. 2013;14(1):730.
Tait Jr RG, Zhang S, Knight T, Bormann JM, Strohbehn DR, Beitz DC, et al. Heritability estimates for fatty acid concentration in Angus beef. Anim Industry Rep. 2007;653(1):17.
Yokota S, Sugita H, Ardiyanti A, Shoji N, Nakajima H, Hosono M, et al. Contributions of FASN and SCD gene polymorphisms on fatty acid composition in muscle from Japanese Black cattle. Anim Genet. 2012;43(6):790–2.
Alexander L, MacNeil M, Geary T, Snelling W, Rule D, Scanga J. Quantitative trait loci with additive effects on palatability and fatty acid composition of meat in a Wagyu–Limousin F2 population. Anim Genet. 2007;38(5):506–13.
Gutierrez-Gil B, Wiener P, Richardson R, Wood J, Williams J. Identification of QTL with effects on fatty acid composition of meat in a Charolais × Holstein cross population. Meat Sci. 2010;85(4):721–9.
Morris C, Bottema C, Cullen N, Hickey S, Esmailizadeh A, Siebert B, et al. Quantitative trait loci for organ weights and adipose fat composition in Jersey and Limousin back-cross cattle finished on pasture or feedlot. Anim Genet. 2010;41(6):589–96.
Abe T, Saburi J, Hasebe H, Nakagawa T, Misumi S, Nade T, et al. Novel mutations of the FASN gene and their effect on fatty acid composition in Japanese Black beef. Biochem Genet. 2009;47(5–6):397–411.
Bartoň L, Kott T, Bureš D, Řehák D, Zahradkova R, Kottova B. The polymorphisms of stearoyl-CoA desaturase (SCD1) and sterol regulatory element binding protein-1 (SREBP-1) genes and their association with the fatty acid profile of muscle and subcutaneous fat in Fleckvieh bulls. Meat Sci. 2010;85(1):15–20.
Han C, Vinsky M, Aldai N, Dugan MER, McAllister TA, Li C. Association analyses of DNA polymorphisms in bovine SREBP-1, LXR alpha, FADS1 genes with fatty acid composition in Canadian commercial crossbred beef steers. Meat Sci. 2013;93(3):429–36.
Hoashi S, Ashida N, Ohsaki H, Utsugi T, Sasazaki S, Taniguchi M, et al. Genotype of bovine sterol regulatory element binding protein-1 (SREBP-1) is associated with fatty acid composition in Japanese Black cattle. Mamm Genome. 2007;18(12):880–6.
Hoashi S, Hinenoya T, Tanaka A, Ohsaki H, Sasazaki S, Taniguchi M, et al. Association between fatty acid compositions and genotypes of FABP4 and LXR-alpha in Japanese Black cattle. BMC Genet. 2008;9(1):84.
Oh D, La B, Lee Y, Byun Y, Lee J, Yeo G, et al. Identification of novel single nucleotide polymorphisms (SNPs) of the lipoprotein lipase (LPL) gene associated with fatty acid composition in Korean cattle. Mol Biol Rep. 2013;40(4):3155–63.
Oh D, Lee Y, Lee C, Chung E, Yeo J. Association of bovine fatty acid composition with missense nucleotide polymorphism in exon7 of peroxisome proliferator-activated receptor gamma gene. Anim Genet. 2012;43(4):474.
Oh DY, Lee YS, La BM, Lee JY, Park YS, Lee JH, et al. Identification of exonic nucleotide variants of the thyroid hormone responsive protein gene associated with carcass traits and fatty acid composition in Korean cattle. Asian Austral J Anim. 2014;27(10):1373–80.
Oh DY, Lee YS, La BM, Yeo JS. Identification of the SNP (single nucleotide polymorphism) for fatty acid composition associated with beef flavor-related FABP4 (fatty acid binding protein 4) in Korean cattle. Asian Austral J Anim. 2012;25(7):913–20.
Oh DY, Lee YS, Yeo JS. Identification of the SNP (single necleotide polymorphism) of the stearoyl-CoA desaturase (SCD) associated with unsaturated fatty acid in Hanwoo (Korean cattle). Asian Austral J Anim. 2011;24(6):757–65.
Ohsaki H, Tanaka A, Hoashi S, Sasazaki S, Oyama K, Taniguchi M, et al. Effect of SCD and SREBP genotypes on fatty acid composition in adipose tissue of Japanese Black cattle herds. Anim Sci J. 2009;80(3):225–32.
Orru L, Cifuni G, Piasentier E, Corazzin M, Bovolenta S, Moioli B. Association analyses of single nucleotide polymorphisms in the LEP and SCD1 genes on the fatty acid profile of muscle fat in Simmental bulls. Meat Sci. 2011;87(4):344–8.
Taniguchi M, Utsugi T, Oyama K, Mannen H, Kobayashi M, Tanabe Y, et al. Genotype of stearoyl-CoA desaturase is associated with fatty acid composition in Japanese Black cattle. Mamm Genome. 2004;15(2):142–8.
Zhang S, Knight TJ, Reecy JM, Wheeler TL, Shackelford SD, Cundiff LV, et al. Associations of polymorphisms in the promoter I of bovine acetyl-CoA carboxylase-alpha gene with beef fatty acid composition. Anim Genet. 2010;41(4):417–20.
Sevane N, Armstrong E, Cortés O, Wiener P, Wong RP, Dunner S, et al. Association of bovine meat quality traits with genes included in the PPARG and PPARGC1A networks. Meat Sci. 2013;94(3):328–35.
Ishii A, Yamaji K, Uemoto Y, Sasago N, Kobayashi E, Kobayashi N, et al. Genome-wide association study for fatty acid composition in Japanese Black cattle. Anim Sci J. 2013;84(10):675–82.
Kelly MJ, Tume RK, Fortes M, Thompson JM. Whole-genome association study of fatty acid composition in a diverse range of beef cattle breeds. J Anim Sci. 2014;92(5):1895–901.
Onogi A, Ogino A, Komatsu T, Shoji N, Shimizu K, Kurogi K, et al. Whole-genome prediction of fatty acid composition in meat of Japanese Black cattle. Anim Genet. 2015;46(5):557-559.
Menendez JA, Lupu R. Fatty acid synthase and the lipogenic phenotype in cancer pathogenesis. Nat Rev Cancer. 2007;7(10):763–77.
Morris CA, Cullen NG, Glass BC, Hyndman DL, Manley TR, Hickey SM, et al. Fatty acid synthase effects on bovine adipose fat and milk fat. Mamm Genome. 2007;18(1):64–74.
Matsuhashi T, Maruyama S, Uemoto Y, Kobayashi N, Mannen H, Abe T, et al. Effects of bovine fatty acid synthase, stearoyl-coenzyme a desaturase, sterol regulatory element-binding protein 1, and growth hormone gene polymorphisms on fatty acid composition and carcass traits in Japanese Black cattle. J Anim Sci. 2011;89(1):12–22.
Oh D, Lee Y, La B, Yeo J, Chung E, Kim Y, et al. Fatty acid composition of beef is associated with exonic nucleotide variants of the gene encoding FASN. Mol Biol Rep. 2012;39(4):4083–90.
Roy L. Association of polymorphisms in the bovine FASN gene with milk-fat content (vol 37, pg 215, 2006). Anim Genet. 2009;40(1):126.
Schennink A, Bovenhuis H, Leon-Kloosterziel KM, van Arendonk JAM, Visker MHPW. Effect of polymorphisms in the FASN, OLR1, PPARGC1A, PRL and STAT5A genes on bovine milk-fat composition. Anim Genet. 2009;40(6):909–16.
La B, Oh D, Lee Y, Shin S, Lee C, Chung E, et al. Association of bovine fatty acid composition with novel missense nucleotide polymorphism in the thyroid hormone-responsive (THRSP) gene. Anim Genet. 2013;44(1):118.
Barrett JC, Fry B, Maller J, Daly MJ. Haploview: Analysis and visualization of ld and haplotype maps. Bioinformatics. 2005;21(2):263–5.
Kim Y-C, Ntambi JM. Regulation of stearoyl-CoA desaturase genes: role in cellular metabolism and preadipocyte differentiation. Biochem Biophys Res Commun. 1999;266(1):1–4.
Bauman D, Baumgard L, Corl B, Griinari dJ. Biosynthesis of conjugated linoleic acid in ruminants. Proc Am Soc Anim Sci. 1999;1999:1–14.
Li C, Aldai N, Vinsky M, Dugan MER, McAllister TA. Association analyses of single nucleotide polymorphisms in bovine stearoyl-CoA desaturase and fatty acid synthase genes with fatty acid composition in commercial cross-bred beef steers. Anim Genet. 2012;43(1):93–7.
Maharani D, Jung Y, Jung WY, Jo C, Ryoo SH, Lee SH, et al. Association of five candidate genes with fatty acid composition in Korean cattle. Mol Biol Rep. 2012;39(5):6113–21.
Mele M, Conte G, Castiglioni B, Chessa S, Macciotta NPP, Serra A, et al. Stearoyl-coenzyme a desaturase gene polymorphism and milk fatty acid composition in Italian Holsteins. J Dairy Sci. 2007;90(9):4458–65.
Milanesi E, Nicoloso L, Crepaldi P. Stearoyl CoA desaturase (SCD) gene polymorphisms in Italian cattle breeds. J Anim Breed Genet. 2008;125(1):63–7.
Moioli B, Contarini G, Avalli A, Catillo G, Orru L, De Matteis G, et al. Short communication: effect of stearoyl-coenzyme A desaturase polymorphism on fatty acid composition of milk. J Dairy Sci. 2007;90(7):3553–8.
Narukami T, Sasazaki S, Oyama K, Nogi T, Taniguchi M, Mannen H. Effect of DNA polymorphisms related to fatty acid composition in adipose tissue of Holstein cattle. Anim Sci J. 2011;82(3):406–11.
Rincon G, Islas-Trejo A, Castillo AR, Bauman DE, German BJ, Medrano JF. Polymorphisms in genes in the SREBP1 signalling pathway and SCD are associated with milk fatty acid composition in Holstein cattle. J Dairy Res. 2012;79(1):66–75.
Bouwman AC, Bovenhuis H, Visker MH, van Arendonk JA. Genome-wide association of milk fatty acids in Dutch dairy cattle. BMC Genet. 2011;12(1):43.
Lu SC. Glutathione synthesis. Bba-Gen Subjects. 2013;1830(5):3143–53.
Bhattacharya TK, Misra SS, Sheikh FD, Sukla S, Kumar P, Sharma A. Effect of butyrophilin gene polymorphism on milk quality traits in crossbred cattle. Asian Austral J Anim. 2006;19(7):922–6.
Franke WW, Heid HW, Grund C, Winter S, Freudenstein C, Schmid E, et al. Antibodies to the major insoluble milk fat globule membrane-associated protein: Specific location in apical regions of lactating epithelial cells. J Cell Biol. 1981;89(3):485–94.
Simonson M, Dunn M. The molecular mechanisms of cardiovascular and renal regulation by endothelin peptides. J Lab Clin Med. 1992;119(6):622–39.
Wu-Wong JR, Dayton BD, Opgenorth TJ. Endothelin-1-evoked arachidonic acid release: a Ca (2+)-dependent pathway. Am J Physiol Cell Physiol. 1996;271(3):C869–77.
Lourenco D, Tsuruta S, Fragomeni B, Masuda Y, Aguilar I, Legarra A, et al. Genetic evaluation using single-step genomic best linear unbiased predictor in American Angus. J Anim Sci. 2015;93(6):2653–62.
Goddard M. Genomic selection: Prediction of accuracy and maximisation of long term response. Genetica. 2009;136(2):245–57.
Hayes BJ, Pryce J, Chamberlain AJ, Bowman PJ, Goddard ME. Genetic architecture of complex traits and accuracy of genomic prediction: coat colour, milk-fat percentage, and type in Holstein cattle as contrasting model traits. PLoS Genet. 2010;6(9):e1001139.
Harfoot C, Hazlewood G: Lipid metabolism in the rumen. In: The rumen microbial ecosystem. London: Blackie Academic & Professional; 1997: 382–426.
Grinari J, Bauman DE. Biosynthesis of conjugated linoleic acid and its incorporation into meat and milk in ruminants. Adv Conjugated Linoleic Acid Res. 1999;1:180–200.
Canadian Council on Animal Care. Guide to the care and use of experimental animals. Olfert EB, Cross BM and McWilliam AA, eds. Vol. 1, 2nd ed. Ottawa, ON: CCAC; 1993.
Basarab J, Colazo M, Ambrose D, Novak S, McCartney D, Baron V. Residual feed intake adjusted for backfat thickness and feeding frequency is independent of fertility in beef heifers. Can J Anim Sci. 2011;91(4):573–84.
Basarab J, McCartney D, Okine E, Baron V. Relationships between progeny residual feed intake and dam productivity traits. Can J Anim Sci. 2007;87(4):489–502.
López-Campos Ó, Aalhus JL, Okine EK, Baron VS, Basarab JA. Effects of calf-and yearling-fed beef production systems and growth promotants on production and profitability. Can J Anim Sci. 2013;93(1):171–84.
Akanno E, Plastow G, Li C, Miller S, Basarab J. Accuracy of molecular breeding values for production and efficiency traits of Canadian crossbred beef cattle using a cross-validation approach. In: 10th World Congress on Genetics Applied to Livestock Production: August 17-22 2014; Vancouver, BC, Canada: Asas; 2014.
Lee H-J, Park H-S, Kim W, Yoon D, Seo S. Comparison of metabolic network between muscle and intramuscular adipose tissues in Hanwoo beef cattle using a systems biology approach. Int J Genomics. 2014;2014.
Folch J, Lees M, Stanley GHS. A simple method for the isolation and purification of total lipids from animal tissues. J Biol Chem. 1957;226(1):497–509.
Cruz-Hernandez C, Deng ZY, Zhou JQ, Hill AR, Yurawecz MP, Delmonte P, et al. Methods for analysis of conjugated linoleic acids and trans-18: 1 isomers in dairy fats by using a combination of gas chromatography, silver-ion thin-layer chromatography/gas chromatography, and silver-ion liquid chromatography. J AOAC Int. 2004;87(2):545–62.
Dugan MER, Kramer JKG, Robertson WM, Meadus WJ, Aldai N, Rolland DC. Comparing subcutaneous adipose tissue in beef and muskox with emphasis on trans 18:1 and conjugated linoleic acids. Lipids. 2007;42(6):509–18.
Kramer JKG, Hernandez M, Cruz-Hernandez C, Kraft J, Dugan MER. Combining results of two GC separations partly achieves determination of all cis and trans 16:1, 18:1, 18:2 and 18:3 except CLA isomers of milk fat as demonstrated using Ag-Ion SPE fractionation. Lipids. 2008;43(3):259–73.
Browning SR, Browning BL. Rapid and accurate haplotype phasing and missing-data inference for whole-genome association studies by use of localized haplotype clustering. Am J Hum Genet. 2007;81(5):1084–97.
VanRaden PM. Efficient methods to compute genomic predictions. J Dairy Sci. 2008;91(11):4414–23.
Gilmour AR, Gogel BJ, Cullis BR, Thompson R. ASREML user guide release 3.0. In. Hemel Hempstead, HP1 1ES, UK: VSN International Ltd.; 2009. www.vsni.co.uk.
Habier D, Fernando RL, Kizilkaya K, Garrick DJ. Extension of the Bayesian alphabet for genomic selection. BMC Bioinformatics. 2011;12.
Chen L, Li C, Schenkel F. An alternative computing strategy for genomic prediction using a Bayesian mixture model. Can J Anim Sci. 2015;95(1):1–11.
Churchill GA, Doerge RW. Empirical threshold values for quantitative trait mapping. Genetics. 1994;138(3):963–71.
Grant JR, Arantes AS, Liao X, Stothard P. In-depth annotation of SNPs arising from resequencing projects using NGS-SNP. Bioinformatics. 2011;27(16):2300–1.
Acknowledgements
The authors thank Ivy Larsen for assistance on beef tissue collection, Shurong Xiong for fatty acid analyses, Ereddad Kharraz and Jonathan Curtis for assistance on fatty acid analyses. This work was supported by the Alberta Livestock and Meat Agency (ALMA) (2010R038R). Support (in kind) from Beefbooster Inc., Alberta, Canada to the project was also highly appreciated. This research has been enabled by the use of computing resources provided by WestGrid and Compute/Calcul Canada.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
CL conceived, designed and oversaw the study. LC performed statistical analyses. LC and CL wrote the paper. CED participated in data analyses. MV carried out quantification of fatty acids. JB, JA, MD, CF participated in the design of the study and contributed to acquisition of data. PS performed SNP and gene annotation. All authors read, commented and approved the final manuscript.
Additional files
Additional file 1:
Manhattan plot of posterior probability of inclusion of single nucleotide polymorphisms (SNP) for 81 fatty acid composition traits in subcutaneous adipose (SQ) and 83 traits in longissimus lumborum muscle (LL). Dashed line indicates the significance threshold at genome-wise empirical threshold at α = 0.05 determined from a 1000 permutation analysis. (PDF 13567 kb)
Additional file 2:
List of significant single nucleotide polymorphisms (SNP) for 81 fatty acid composition traits in subcutaneous adipose (SQ). Results include trait name, SNP name, chromosome, position on the UMD3.1 genome assembly, alleles, allele substitution effect, percentage of total genetic variance explained, and posterior probability of inclusion of SNP. (CSV 24 kb)
Additional file 3:
List of significant single nucleotide polymorphisms (SNP) for 81 fatty acid composition traits in longissimus lumborum muscle (LL). Results include trait name, SNP name, chromosome, position on the UMD3.1 genome assembly, alleles, allele substitution effect, percentage of total genetic variance explained, and posterior probability of inclusion of SNP. (CSV 27 kb)
Additional file 4:
Genes within 1 Mb region centering significant single nucleotide polymorphisms (SNP). Candidate genes were obtained from the Ensemble database by querying the SNP locations against the bovine UMD3.1 genome assembly using the SNP annotation tool in the NGS-SNP suite. (CSV 1037 kb)
Additional file 5:
Linkage disequilibrium (LD) beween single nucleotide polymorphisms (SNP) around the SCD gene. Linkage disequilibrium was measured as D prime. The red triangle indicates the location of the SCD gene. An LD block was shown surrounding the SCD gene. Names of the SNPs significantly associated with fatty acid composition were highlighted in green. (PDF 971 kb)
Additional file 6:
Pearson’s correlation coefficients between estimated breeding values and adjusted phenotypes and regression coefficients of adjusted phenotypes on estimated breeding values. (DOCX 35 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Chen, L., Ekine-Dzivenu, C., Vinsky, M. et al. Genome-wide association and genomic prediction of breeding values for fatty acid composition in subcutaneous adipose and longissimus lumborum muscle of beef cattle. BMC Genet 16, 135 (2015). https://doi.org/10.1186/s12863-015-0290-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12863-015-0290-0