
Abstract
The present study performs landcover modelling using the SLEUTH model. The urban land use changing factors are calibrated to predict the Land Use Land Cover (LULC) for a densely populated and developing smart city, Prayagraj, India. This research aims to use the SLEUTH model for simulating the future urban growth with the help of historical LULC (1990–2020), road network and elevation data. The influence of road gravity and slope resistant coefficients is very significant in this study's outcome. The built-up area of the region increased from 40.22 km2 (5.10% of total area) in 1990 to 85.89 km2 (10.89%) in 2020. According to prediction results, in the next 20 years, the built-up growth rate would be 1.9% and approximated built-up area would be 118.66 km2 (14.98%) in the year 2040. The quality of the result has been quantified in terms of best fit value of Optimal SLEUTH Metric (OSM) and validated against the existing LULC. The study utilises a spatially explicit urban growth model with 30 m resolution remote sensing data and provides future landuse of Prayagraj city.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The anthropogenic activities have been intensified in the last three decades with technological enhancements. The geographic processes accelerate the human population surge (Mosammam et al. 2017; Franco et al. 2017). The low-density urban areas become high density urban regions along with the expansion of the city boundaries worldwide. The human population is expected to shoot up and migrate to urban regions (Kar et al. 2018). Today, 56.2% of the world’s population is living in cities and according to the United Nations (UN) report, this figure is expected to reach 60.04% by the year 2030 (United Nations 2019). In India, the urban population in 2015 was 429,069 thousand (32.8%); this figure raised to 483,099 thousand (34.9%) in 2020 and by the year 2030, it is expected to reach 607,342 thousand (40.1%) (United Nations 2020). The significant urban population increment is predicted to occur in the lesser developed regions of East Asia, South Asia and Africa, whereas 35% of the total increased population will reside in India, China and Nigeria only (United Nations, 2020). In this scenario, smart urban land use planning is essential for socio-economic and sustainable development.
The Land Use Land Cover (LULC) pattern changes as the infrastructure grows for human needs. These changes are usually manifest as the forest and vegetation get converted into built-up LULC like residential building, commercial complex, industrial plant, transportation infrastructure etc. (Kassawmar et al. 2018; Kumar and Agrawal 2019). The scenario worsens when these activities grow irregularly, leading to the loss of natural resources and ecological imbalance. Despite the devastating impact of the COVID-19 pandemic, it has been proven that behavioural changes can retard carbon emission and improve air quality in cities globally (United Nations 2020; Muhammad et al. 2020). The government's development and environmental policies could help to reduce the impact of rapid urbanization. The simulation and modelling of the urban growth patterns can help in the monitoring of the complex urbanisation process (Megahed et al. 2015). Accurate temporal monitoring can help to control the irregular developments and can support stakeholders in sustainable development planning (Kar et al. 2018). Various remote sensing data with Geographic Information System (GIS) technology ease the information gathering. Due to abundant remote sensing data availability, spatial assessment of urban sprawl patterns is possible (Deep and Saklani 2014; Mishra et al. 2020). The frequent simulations of urban growth were carried out at the micro-level due to the availability of open-access spatial data and satellite images. Urban growth dynamics and behaviour is varied according to various geographical features and usually shows a nonlinear growth pattern (Deep and Saklani 2014).
Urban growth prediction and its impact on other natural LULC has been trending for the last two decades. The projection and revitalisation of land use development and conversion monitoring helped in the agricultural and economic output prediction (Yang et al. 2021), flood-prone area detection (Al Rifat and Liu 2022), scenario impact assessment (Alay et al. 2021), calculation of environmental indicators (Singh et al. 2022) and various other applications worldwide (Nwaogu and Pechanec 2018; Shukla and Jain 2020). The urban growth modelling is further enhanced by linking the image spectral information to the independent variables and ancillary data through machine learning. The machine learning approaches use the temporal LULC information to calibrate the spatial parameters and changing fashion of urbanisation. Many models simulate the urban growth in past, mainly using Cellular Automata (CA) (Shafizadeh-Moghadam et al. 2017; Lu et al. 2019), fractal analysis (Rastogi and Jain 2018), Artificial Neural Network (ANN) (Fattah et al. 2021), spatial statistics (Abdullahi et al. 2015) etc. CA has been extensively used in past studies. CA-based modelling was applied in environmental monitoring and now it is used ubiquitously in urban growth modelling (Guzman et al. 2020). CA is suitable for the complex model, which compiles elements showing nonlinear variation and widely used in urban sprawl detection analysis (Kantakumar et al. 2019; Lu et al. 2019; Faichia et al. 2020). CA integrated with LULC data and neighbourhood information has given accurate spatial data simulation results in the past (Saxena et al. 2021a). The neural network models are now trending as they have provided satisfactory results in recent years (Li et al. 2019). The composite technology such as MLP-ANN and MC-CA techniques also applied to get more accurate prediction results (Yang et al. 2019).
The researchers used models that included the multi-temporal LULC information along with geographical and socio-economical urban growth driving variables such as elevation, slope, distance from roads, population and other geographic components. In the recent past, some popular static and dynamic models such as Multi-Layer perceptron (MLP) using Land Change Modular (LCM) (Megahed et al. 2015; Vinayak et al. 2021), CA-Markov (Nath et al. 2020; Khwarahm et al. 2021a, b), ANN-based prediction (Rahman et al. 2017; Anand and Oinam 2020), SLEUTH urban growth model (Ilyassova et al. 2021; Alay et al. 2021) and ANN-Markov chain-based model (Al Rifat and Liu 2022) were used by different researchers globally. These models are compared in Table 1.
Compared to other urban growth prediction approaches like ANN, regression tree and Markov chain, it is found that the SLEUTH model has provided greater accuracy to urban variation (Berberoğlu et al. 2016). The urban prediction models such as the Markov chain are static where the growth could be known in a quantitative transition of LULC classes but unable to give a spatial output of future urbanisation. SLEUTH model overcomes such limitations and provides the prediction output spatially based on several factors like slope, road transportation network etc., including LULC (Alay et al. 2021). The SLEUTH model works well even for the medium resolution images as it can achieve a good model of fit value on data of up to 30 m resolution (Eyelade et al. 2021).
Keith Clarke developed the SLEUTH model in Santa Barbara at the University of California (Clarke et al. 1997). SLEUTH is an acronym of Slope, Landuse, Exclusion, Urban, Transportation and Hillshade (Ilyassova et al. 2021). These are the name of the input layers of this model. SLEUTH is a CA-based forecasting model used for Urban Growth Modelling (UGM) and land use modelling by using the Deltatron Model. The UGM application of the model is more popular. There are recent researches held on urban growth prediction using SLUETH model globally (Hossain Shubho and Islam 2020). There are four growth rules in SLEUTH: spontaneous growth rule, spreading centre growth rule, edge growth rule and road influenced growth rule (Saxena and Jat 2020a). All these four growth rules are related with five coefficients named Dispersion Coefficient (Diff), Breed Coefficient (Brd), Spread Coefficient (Sprd), Slope Resistance Coefficient (Slp) and Road Gravity Coefficient (RG). The description of these growth rules and their relation with corresponding coefficients is given in Table 4. Along with these growth rules, secondary ‘self-modification rules’ are applied in this model, which is used to alter the value of growth coefficients to achieve a typical S-curve for urban expansion growth rate (Jawarneh 2021). Self-modification rules like boom, bust, critical low and critical high constants are responsible for the nonlinear simulation of urban growth patterns (Saxena and Jat 2019). The urban cells are the living organisms which are regulated through transition rules that train within CA as nested loops set. The outer loop performs the Monte Carlo iterations and the inner loop executes the growth rule (Capan 2019; Saxena and Jat 2020b).
Land use change models were started from 1973 Markov inter-temporal change simulation model. The CA-based models were most frequently used by different researchers. CA Markov model has been applied maximum times for simulation using historical LULC data such as CA Markov, CA SLEUTH, Logistic CA, or separately CA. SLEUTH model was applied in land use change simulation popularly as it proves the better identification of new isolated growth centres (Mondal et al. 2020). SLEUTH model is implemented globally in different cities by different researchers and planners (Li et al. 2021; Jayasinghe et al. 2021; Alay et al. 2021). There is an urgent requirement for studies that can simulate and predict urban growth. The SLEUTH model was initially developed for the San Francisco Bay area (Şevik 2006). Over the time, it was repeatedly used for North America and Europe (Peiman and Clarke 2014; Berberoğlu et al. 2016; Liu et al. 2019). Some Indian subcontinent studies were carried out using the SLEUTH model (Kantakumar et al. 2011; Chaudhuri and Clarke 2019; Saxena and Jat 2020a, b; Vani and Prasad 2021), but they are mainly focused on the metropolitan cities. This work attempts to fill these gaps by implementing the SLEUTH model for the urban growth of Prayagraj city of India, an emerging smart city.
Urban centres that experience continued demand for more development and so wish to grow further, typically an increase in built-up areas or both horizontally and vertically expansion since these are the only options with limited suitable land availability. Prayagraj is the rapidly growing city of India which has education and religious significance. Urban agglomeration is developing here at the cost of natural landcover. It is hypothesised that the SLEUTH model will help to understand the urban dynamics here and predict the future LULC. This simulation and perdition would be done up to the year 2040 on the basis of input data of the past three decades with the help of the SLEUTH model. However, a high growth rate and too far future prediction would be the challenges for the results of this model.
In the present study, built-up land density is considered to be proportional to the relative probability of the development of a particular area or location having a higher developmental potential resulting in a possible increase in built-up area vertically and horizontally per unit area of land. This is reflected in terms of the desire of more people to use that location for various built-up activities (residential, commercial, infrastructure, industries, etc.). This research aims to project the urban growth of Prayagraj city in India. To achieve this aim, following research objectives have been formulated: (1) To identify the LULC and its temporal variation for the study area. (2) To check the efficiency of the SLEUTH model and validation of its results (3) To predict the LULC dynamics for the year 2040 based on the data of the past three decades. (4) To identify the major drivers for LULC change and urban growth.
The research paper is segmented into four main sections. The first section introduces the study, including some research background, problem statement and objectives. The second section is of material and methods which describes the details and geographical significance of the study area along with the data used and methodology. The methodology includes prepossessing of data as input required for the model, calibration and validation of the SLEUTH model. Section three presents the results of classification, calibration, prediction and validation. It includes a brief discussion of the research corollary with the help of critical graphs and quantity matrices of spatial parameters. Finally, in the last section conclusion and limitations and future scope are covered. The research was performed at the GIS Cell of Motilal Nehru National Institute of Technology Allahabad, Prayagraj, India, from May 2020 to November 2021.
Materials and methods
Study area
The study area for urban growth analysis is Prayagraj city which is located in the Uttar Pradesh state of India. It is a tier-II type developing city and was selected for the Smart City Mission of India. According to the census 2011, the total population was 1,117,094 (Census of India 2011). The climate of the region is tropical and has a high-temperature variation from 2 °C in the winter months (December–January) to 45 °C in the summer months (June–July). The city is situated at the 98 m elevation above mean sea level (Ministry of Urban Development 2014).
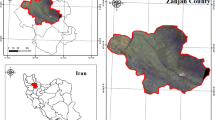
The Municipal Corporation Area (MCA) of Prayagraj city contains 82 km2 area and is divided into 80 municipal wards (Government of UP 2012). The municipal ward boundary shapefile of the city was constructed through the digitisation process. A 5 km buffer was created outside the municipal ward boundary region, which is facing transformation due to high built-up construction and public settlement. Eventually, a square area extent which includes the municipal administrative wards of the Prayagraj city and a 5 km buffer area around the municipal boundary was selected as the study area, as illustrated in Fig. 1. The geographical extent of the study area is from 81̊ 40''51'E to 81 ̊ 57" 31' E longitude and from 25̊ 19" 49' N to 25̊ 35" 6' N latitude. The total study area is of 785.12 km2.

The study area containing the city ward boundary and 5 km buffer region
The city has a significant share in the economic and cultural development of the country. The city is situated at the confluence of two sacred rivers: Ganges and Yamuna. The renowned Kumbh fair is celebrated every six years at rivers' confluence (Sangam). One of the largest mass gatherings in the world takes place in this fair. In 2019, over 240 million pilgrims visited the fair during 55 days event (Agrawal and Bapurao 2021). The open land for the Kumbh recreational activities is preserved as ground, covering 16.02% of the total MCA. The study area includes various real state projects, central and state government offices, industries and renowned educational institutions. According to Sarif and Gupta (2021, 2022) the built-up land in the city was 18.54 km2 in 1988, which increased up to 47.15 km2 in the year 2018 at the cost of agriculture and forest land.
Data used
The present analysis work was performed in two stages, stage I and stage II. Stage I analysis was performed to validate the model and included input datasets from 1990 to 2010. Stage II was the prediction stage, which gave the prediction output of urban growth and used input data from 1990 to 2020. To prepare input data for the SLEUTH model, the opensource datasets of a fixed time interval were collected. The datasets details are listed in Table 2.
The city ward map was collected through Prayagraj Nagar Nigam's official website. The Survey of India (SOI) topographical maps were downloaded through its respective official websites. The study area is covered in four SOI topographical sheets, i.e. G44P10, G44P11, G44P14 and G44P15. The Landsat images of 1990, 1995, 2000, 2010 and 2020 were acquired through the USGS Earth Explorer portal to generate the LULC maps. Stacking was performed to obtain the composite images since the images were in a sequential band format. To prepare slope and hillshade data, an open-source Digital Elevation Model (DEM) was acquired from Shuttle Radar Topographic Mission (SRTM) data. Afterwards, the transportation road network data collection was done with the help of OpenStreetMap, which was validated and corrected through a digitised road map of Prayagraj city. The projection system of all the images was set to World Geodetic System 1984 (WGS84) and Universal Transverse Mercator (UTM) zone 44 north. Google Earth historical time series data were used for ground-truthing and validation for LULC changes.
Methodology
Input layer preparation
Six input layers are required in the SLEUTH model. These layers were slope, landuse, exclusion, urban, transportation and hillshade. The methodology for the preparation of these input data layers is given in Fig. 2.

Methodology for input layer creation
The landuse layer is prepared through supervised classification of Landsat satellite images. Supervised classification is used to obtain the landuse layer, a user-controlled process that involves training sample collection for signature identification of a particular feature. These signatures are the spectral reflectance range for a specific element and were further used to assign the LULC class to each pixel (Nguyen et al. 2020). There are various classification techniques which give excellent accuracies such as Random Forests (RF), Support Vector Machine (SVM) and Maximum Likelihood Classifier (MLC) (Alshari and Gawali 2021). Among these techniques, MLC is the most commonly used classification technique for various remote sensing applications (Allam et al. 2019; Chughtai et al. 2021).
The LULC features, i.e. fallow land, sand, urban, vegetation and water were extracted through MLC supervised classification method. The description of LULC classes is given in Table 3. In the landuse layer generation, at least 15 training samples dispersed in the whole image were taken for each category. After the spectral signature preparation, the image pixels were sorted into a given number of feature classes by using some mathematical algorithms known as decision rules.
After the image classification, an accuracy assessment was performed with the help of confusion matrix generation. Two hundred fifty stratified random points were compared with the ground truth data and the kappa coefficient was computed for the classified image. The high-resolution Google Earth time series data, SOI toposheets and ancillary data were used as reference data. The classification accuracy was affected by classes' heterogeneous behaviour and spectral signatures' overlapping ranges (DN values) into different spectral bands.
A minimum of nine multitemporal layers are required to perform one set of analyses in the SLEUTH model: four urban layers of different years, one slope layer, one hillshade layer, one exclusion layer and two road networks layers. For the analysis of a stage-I, total of twelve input layers were taken in this work, which included four urban layers (1990, 1995, 2000 and 2010), three road layers (1990, 2000 and 2010), two landuse layers (1990 and 2010), one slope percent layer, one hillshade layer and one exclusion layer. In stage-II, total of thirteen input layers were taken, which included four urban layers (1990, 2000, 2010 and 2020), four road layers (1990, 2000, 2010 and 2020), two landuse layers (1990 and 2020), one slope per cent layer, one hillshade layer and one exclusion layer. These layers were prepared in true greyscale Graphics Interchange Format (GIF) image type.
The urban layers were extracted through multitemporal LULC maps. The landuse images of different years were reclassified and assigned a value of one to the urban class and zero to all other pixels for creating urban layers. The LULC layer was then prepared into greyscale image for the input into the SLEUTH model. Therefore, LULC maps were reclassified into a range from one to five and converted into a greyscale image. Transportation networks and junctions significantly influenced urbanisation (Chaudhuri and Clarke 2019). The road network of the region was captured from OpenStreetMap in shapefile format. The polyline road shapefile was converted into a raster image with pixel size 30 m × 30 m and the same extent as the urban layer. All the road pixels were assigned a value of 100 and the remaining pixels were set to 0. The road network layer formed through digitisation of the city's arterial and sub-arterial roads from the road map of the Public Work Department (PWD) was used as reference data for validating OpenStreetMap data. The road network of the year 1990, 2000 and 2010 was obtained with the help of satellite data and Google Earth historical imagery. The slope percent and hillshade layers were generated with the help of the SRTM DEM. The SRTM DEM of 1-arc second resolution was downloaded and reprojected as the existing input layers. It was clipped by the study area boundary for making slope percentage and hillshade layers. The exclusion input layer represented the area where urban settlement and development was either forbidden or not possible such as a waterbody or government restricted area. River and cantonment areas were considered in the exclusion layer obtained from the city ward map. This layer can be modified as per local criteria that ultimately alter the prediction results (Liu et al. 2019). Afterwards, all the input layers datasets were resampled for all three calibration phases, i.e. 120 m for coarse calibration, 60 m for fine calibration and 30 m for final calibration. For the SLEUTH model, all data were converted into a true greyscale 8-bit GIF file format. The naming convention described on the SLEUTH website was followed before placing the data into the input directory of the model.
SLEUTH modelling
SLEUTH is a modified CA that predicts urban growth according to the type of growth pattern in the past and through four growth rules stimulated by controlling factors. These rules were spontaneous growth, spreading centre growth, edge growth and road influenced growth. These rules are governed by five coefficients, i.e. dispersion, breed, spread, slope and road gravity coefficient. A short description of these rules and the relative coefficient is given in Table 4. All these coefficients were initialised with value zero at coarse calibration which limits up to value 100. The change in the coefficient values in different phase impacts the growth rules (Harb et al. 2020).
The SLEUTH model was executed in this study using the brute force method. The structure of the model is given in Fig. 3.

Methodology for executing the SLEUTH model
This model has been completed in three phases: test, calibration and prediction (Berberoğlu et al. 2016). The test mode run ensured the accuracy of input data preparation and if any remaining error, it showed the relative error statements. The calibration phase of the model was the most crucial phase, which involved training the model to achieve the best fit values of growth coefficients (Peiman and Clarke 2014). There were three modes of calibration, i.e. coarse, fine and final calibration. In particular analysis, the dataset with a spatial resolution of 120 m, 60 m and 30 m were used for coarse, fine and final calibration, respectively. The calibration refined and narrowed down the limits of the coefficient from coarse to final calibration. Eventually, the coefficients and best-fit parameters defined from the calibration were used in the prediction phase. This phase was carried out in a single run with 100 Monte Carlo iterations. The mean coefficient values of all Monte Carlo iterations were used to predict urban growth. The prediction results were the probabilistic map of landuse growth based on growth rules and coefficients defined (Agyemang et al. 2022). Each coefficient set replicated the historical urban growth pattern regarding the urban extent's initial seed layer (urban layer of 1990). The subsequent input layers of later years (1995, 2000, 2010 and 2020) were used as control points.
The prediction output has been assessed through statistical data generated in the form of 13 metrics. These metrics are (1) ‘product’ statics represents the product of all matrices, (2) ‘compare’ statistic that shows the urban growth pattern, (3) ‘population’ that represents the number of urban pixels, (4) ‘edge’ represents the peripheral urban pixel count, (5) ‘cluster’ that shows urban cluster edge cells, (6) ‘cluster size’ that represents mean, (7) ‘Lee-Sallee’ is a shape index and represents the fitness of models between the given input year data, (8) ‘Slope’ compare the slope of given and modelled slope through least square regression, (9) ‘% urban’ shows a least square regression value comparing from modelled and given urban cells, (10) ‘Xmean’ represents the x coordinate of cluster radius, (11) ‘Ymean’ represents y coordinate of cluster radius, (12) ‘Radius’ is a standard normalised radius extracted from Xmean and Ymean, and (13) ‘F-match’ represents the fitness of landuse (Dietzel and Clarke 2007; Capan 2019).
The Lee-Sallee statistic was used for shape measurement and showed the pattern of urban growth (Lee and Sallee 1970). Many researchers used Lee-Sallee to sort the best-fit range of coefficient in the calibration process, but in 2007 (Dietzel and Clarke 2007) published the concept of Optimum SLEUTH Metric (OSM). The OSM is the product of seven metrics, i.e. compare, population, edges, clusters, slope, Xmean and Ymean. The top 20 coefficients corresponding to OSM were used to select the range of coefficients in the subsequent calibration phase. After the final calibration, the best fit values of all coefficients came in the forecasting calibration step's output. The next phase was a prediction that used these best-fit values of coefficients and simulates the results in the output folder. The output includes statistical and image data, including average, standard deviation, log file, cumulative urban maps, animated land urban maps, etc., for modelled years (Jantz et al. 2010).
The results of stage-I prediction have been validated quantitatively as well as visually. The prediction results for the year 2020 were validated with actual urban growth data. The validation of the model was necessary to assess the model capability of urban behaviour simulation.
Results and discussion
Input layers
LULC classification
The first objective of this work was to identify the LULC of the study area. The Landsat images of 1990, 1995, 2000, 2010 and 2020 were classified using the MLC technique. All five classified maps are shown in Fig. 4, and the area of classes in different years is mentioned in Table 5. The majorly existing LULC defined the characteristics of that area. There were five dominant LULC classes in the study area: fallow land, sand, urban, vegetation and water. Fallow land was present in the surrounding area of the city. It contained new alluvial soil at river banks, non-agricultural lands, land acquired for industries, construction sites, unmetalled roadwork, etc.

LULC maps of the study area
In year 1990, the fallow land area was 430.59 km2 (54.61% of total study area) which remained only 343.52 km2 (43.56%). This decreasing trend indicates the increased anthropogenic activities in the area and urban sprawl. The second most found feature was vegetation. Vegetation class included the groups of tree canopy, farmland, green foliage, dense green scrubs, etc. The decreasing vegetation trend indicated the loss of flora and fauna in the region over the years. The area of sand was large (10.11% of total) due to the confluence of two major rivers. The increasing trend of sand area between year 1990 and 2000 has occurred due to river meandering and was verified through previous studies (Sarif and Gupta 2022).The sand was spread on the river banks. The built-up or urban area has increased consistently in the last three decades. The urban class included concrete roads, buildings, impervious constructions, etc. Initially, in the year 1990, it was 5.1% of the total area, whereas, in the year 2020, it reached up to 10.89%. This increase in the urban area has affected the natural land cover patterns like vegetation and fallow land. Water bodies were shrinking in the region. Although, according to Saha and Agrawal (2020) in the monsoon season comparatively larger area came under the waterlogged region. The percentage of water was 12.39% in 1990 which reduced to 5.26% in 2020. Vegetation and fallow land area have been reduced in the last three decades.
The validation of the classification results was carried out with the help of ground truth data. The historical images of Google Earth had been used to collect some ground control points for reference. Accuracy assessment of each classified map was performed through an error matrix which includes the User Accuracy (UA), Producer's Accuracy (PA), overall accuracy and kappa coefficient. These are mentioned in Table 6. The overall accuracy of all the classified maps was above 90% and the kappa coefficient values were above 0.85.
Over three decades, several LULC transitions took place. Figure 5 depicts the major LULC transitions. These transitions are further illustrated with the help of Google Earth images. From these transitions, it is clear that the natural land cover is losing at the cost of anthropogenic activities.

Major LULC transitions in Prayagraj from 1990 to 2020
SLEUTH input layers
The input data layers of SLEUTH were in raster format with identical numbers of rows and columns. The input layers had WGS 84 datum and UTM zone 44 north projection. All the layers had a cell size of 30 m. The images were resampled into GIF greyscale format in three spatial resolution sets, i.e. 30 m, 60 m and 120 m. The prepared layers are shown in Fig. 6.

The input data layers of the SLEUTH model
The temporal urban layers depict the sprawl of built-up activities in the city's outer area over the years. The city's ward boundary only covers approximately half of the urban region. The exclusion input layer represents the area that was not available or prohibited for performing construction activities. In this layer, the mainstream river area and restricted military area (cantonment) were included. Slope and hillshade layers were generated from the same SRTM DEM image. The slope layer represents the slope of the region in percentage, whereas the hillshade layer shows the sunlit and shadowed areas. The road network data collection and creation were a complex process. The OpenStreetMap road data had been downloaded. It was corrected with the help of the digitised map to generate a road network for the year 2020. Due to past road network data unavailability, Google Earth time-series images were used to extract roads from 1990, 2000 and 2010. The road network highly influences the development of new urban settlements (Parchianloo et al. 2021). The development rate of roads has increased with the urban sprawl simultaneously with the state and national highway projects in the last three decades. Lastly, the LULC images of 1990, 2010 and 2020 are converted in greyscale GIF format for input in SLEUTH.
Model calibration and validation
This study has used the brute force calibration method. 'Brute force calibration' means checking every possibility. In the calibration phase, the coefficient range limit for the data was decided by three resolutions, i.e. coarse, fine and final spatial resolution. Generally, coarse spatial resolution was taken four times of actual resolution, whereas fine data had resolution two times coarser than real data. The calibration phase was used to find the best fit values of five coefficients, i.e. dispersion, breed, spread, slope and road gravity. The convergence of these coefficients from the range of 0–100 to a single best fit value was carried out in the coarse, fine and final calibration. For coarse calibration, the 120 m spatial resolution dataset was selected as input data, the range of coefficients was selected from 0 to 100, and the step value was selected as 25. The upper 20 OSM metrics values and their corresponding coefficients values were selected to converge the coefficients range for the next calibration, i.e. fine calibration. The values of metrics generated after coarse calibration of stage-I corresponding to the top 20 OSM values are given in Table 7. For the fine calibration, the dataset of 60 m layers was selected. The narrow-downed range through OSM had been used in the final calibration. The final calibration was the most time taking process of all the processes. The step values had narrowed down to 1 in the final calibration and only a single value was coming as output for each coefficient. These values were further put in the forecasting step and found the best fit values for each coefficient.
It can be noticed in Table 7 that the value of compare metric was 0.55 for the top OSM values which was satisfactory. This value further varied between 0.55 and 0.59 in all three calibrations that indicated good comparison between modelled and actual urban extent. The least square regression value of population varied from 0.98 to 1 that showed a greater similarity between actual and modelled growth. The regression values of edge and cluster were also lied in satisfactory range in all three calibration phases. It represented the comparison between shape and form of the modelled and actual urban growth. The Lee-Sallee values of more than 0.4 are acceptable and indicates near perfection calibration (Chandan et al. 2020). The results of calibration indicated that the coefficients for growth modelling characterises matched with the actual growth pattern and could be used for the further prediction for LULC of the Prayagraj. The values and statistics for the stage-I calibration process are mentioned in Table 8.
The best fit values express the influence of the coefficient during the prediction process. The obtained dispersion, breed and spread values were less (best-fit = 1), showing lesser spontaneous growth. It depicted that the development of new urban centres was significantly less during the study period. The results were verified through the previous urban growth analysis carried out by Sarif and Gupta (2021) for Prayagraj city. They also concluded that the urban growth was more concentrated to the city centre. The slope gradient and road gravity coefficients were 49 and 17, respectively. It showed that the road influenced growth was dominating in this region. The results were validated through temporal LULC maps where the built-up change was clearly visible in the linear patterns alongside the roads. The optimum values of self-modifying parameters were taken as suggested by previous researches (Saxena et al. 2021b). The values of boom, bust critical low and critical high were taken as 1.3, 0.10, 0.90 and 1.25, respectively, whereas critical slope value was taken as 15. The procedure followed in stage-I has been used again in stage II. For the stage-II calibration, the layers of the years 1990, 2000, 2010 and 2020 were used to predict the output landuse till 2040. The values of statistical parameters are mentioned in Table 9.
After calibration, the validation of the model was carried out with the actually observed classification of 2020. Figure 7 shows the comparison between actual and modelled urban landuse areas. Although the landuse pattern of both images was the same, some spatial disparity was established between them. The modelled and real built-up area came as 75.34 km2 and 85.89 km2, respectively. This difference was occurring because of two major regions. First was the government policies that promoted the development along the highways. The impact of this can be seen on the actual urban area. The modelled urban area missed this development. Another cause of mismatch was the exclusion river layer. Over time, unplanned urbanisation took place in this region because of haphazard development and change in the river coast, which the modelled results could not capture.

Modelled and actual landuse image of 2020
Model prediction
SLEUTH model can forecast a future urban settlement by calculating appropriate calibration. Prayagraj city has a plane topography, but the region of rivers contains slopes and is less affected by settlement. The growth might be observed in new locations away from the existing urban centres. The best fit values express the influence of the coefficient during the prediction process. The obtained dispersion, breed and spread values were less (best-fit = 1), indicating lesser spontaneous growth. According to Aithal et al. (2019), the values of dispersion and breed coefficients for major four Indian cities Delhi, Mumbai, Kolkata and Hyderabad was found to be low. This similar behaviour specifies the lesser chances of outward dispersive growth and formation of new urban centres on its own. Road gravity's most significant influence was shown as the road gravity (best fit value 17 after stage II), which shows the growth alongside the roads and development of change during the last three decades. The economic activities and other social factors are directly related with growth and are highly influenced by transportation network (Liu et al. 2020). The prediction result of the LULC for the year 2040 is given in Fig. 8.

Modelled LULC for the year 2040
The modelled 2040 urban region is matching with the urban growth trend. The extension of urban areas in the last three decades and predicted expansion for 2040 is shown in Fig. 9. The new spontaneous urban growth depends on the existing transportation network. The area of urban is expanded around highways prominently.

Urban area expansion in Prayagraj from 1990 to 2040
The urban settlement in Prayagraj city is seen in all four directions (Fig. 9). The National Highway (NH-2) went from east to west and passed by centre of the city. Major construction network temporally increasing over the time along with NH-2. The trans-river development was shown mainly after 2000 to 2020 which is indicated by dark green and red colours, respectively. Over the time, the densification of city taken place and construction and development of new road were found in the outskirts of city. New built-up region found along the national and states highways which passes from rural area and connects other cities through them. This indicates the increment of people settlement on the outer city region at the cost of agriculture and fallow land (Mekonnen and Ghosh 2020). Various analysis took place regarding sensitivity and other calibration best fit values over the years (Saxena et al. 2021b; Sarica et al. 2021; Zhang et al. 2021; Jat and Saxena 2021). The road network gravity factor was also prominent for horizontal urban growth development. Researchers had achieved good results while validating the model from observed results.
Conclusion
Urban areas have been proliferated in developing countries. The urban dwellers' demands may become a severe burden on natural resources in the near future. LULC prediction models are a valuable tool to counter the urbanisation challenges as they will help decide the development policies. This study investigates the LULC trend and predicts the future LULC using the SLEUTH model. The study aims to predict urban expansion and its impact on other LULC for the smart city region of Prayagraj. For this purpose, Landsat images, OpenStreetMap, SRTM DEM, Google Earth and topographic maps are used. Firstly, LULC of the years 1990, 1995, 2000, 2010 and 2020 is generated using the supervised image classification. The results have shown the trend of LULC change. The most prominent among them is the continuous growth of urban/ built-up areas, which increased from 40.22 km2 to 85.89 km2.
In order to study and predict urban sprawl, SLEUTH model has been used. It ran for coarse, fine and final calibrations. The value of the five coefficients ranges from 0 to 100 and converges to best-fit values after these calibrations. The road gravity coefficient is proven as the most affecting driver of landuse change. To better understand the urban growth drivers, the best fit values of coefficients have helped. The influence of slope gradient and road gravity is strong rather than other drivers. The least-square regression metrics have shown satisfactory values, indicating that the model has properly captured the historical growth. SLEUTH model has forecasted the growth in urban areas to 118.65 km2 by 2040. In the past three decades, the urban growth rate was 3.78%, whereas, in the upcoming 20 years, the growth rate will be 1.9%. This would take place at the cost of natural land cover and open land. The results have been validated with respect to the LULC maps, topographic maps and Google Earth images. Although the results are satisfactory, but the analysis using this model included a tedious calibration process.
SLEUTH is a sophisticated model that yields correct results in a complex problem. The results will help the city planners, administrators and government in making appropriate plans and policies. More sustainable growth plans could be made based on the predicted 2040 LULC results. There is an alarming situation for the natural and agricultural land alongside the state and national highways outside the existing cities. The policymakers should plan to ameliorate the current situation. The model considered a number of input datasets to simulate landuse change and urban growth. However, it did not take crucial socio-economic factors, which is one of the limitations.
Data availability
The authors are thankful to USGS Earth Explorer for freely available Landsat datasets for study area region.
Code availability
Not applicable.
References
Abdullahi S, Pradhan B, Mansor S, Shariff ARM (2015) GIS-based modeling for the spatial measurement and evaluation of mixed land use development for a compact city. Giscience Remote Sens 52:18–39. https://doi.org/10.1080/15481603.2014.993854
Agrawal S, Bapurao KG (2021) Cloud-based geospatial mapping and analysis of prayagraj kumbh mela of India: The UNESCO intangible cultural heritage. In: Geo-intelligence for sustainable development. pp 17–33
Agyemang FSK, Silva E, Fox S (2022) Modelling and simulating ‘informal urbanization’: An integrated agent-based and cellular automata model of urban residential growth in Ghana. Environ Plan B Urban Anal City Sci. https://doi.org/10.1177/23998083211068843
Aithal BH, Chandan MC, Nimish G (2019) Assessing land surface temperature and land use change through spatio-temporal analysis: a case study of select major cities of India. Arab J Geosci. https://doi.org/10.1007/s12517-019-4547-1
Al Rifat SA, Liu W (2022) Predicting future urban growth scenarios and potential urban flood exposure using Artificial Neural Network-Markov Chain model in Miami Metropolitan Area. Land Use Policy 114:105994. https://doi.org/10.1016/j.landusepol.2022.105994
Alay AM, Tunçay HE, Clarke KC (2021) SLEUTH modeling informed by landscape ecology principles: case study using scenario-based planning in Sariyer, Istanbul. Turkey J Urban Plan Dev 147:05021043. https://doi.org/10.1061/(ASCE)UP.1943-5444.0000746
Allam M, Bakr N, Elbably W (2019) Multi-temporal assessment of land use/land cover change in arid region based on landsat satellite imagery: Case study in Fayoum Region. Egypt Remote Sens Appl Soc Environ 14:8–19. https://doi.org/10.1016/j.rsase.2019.02.002
Alshari EA, Gawali BW (2021) Development of classification system for LULC using remote sensing and GIS. Glob Transitions Proc 2:8–17. https://doi.org/10.1016/j.gltp.2021.01.002
Anand V, Oinam B (2020) Future land use land cover prediction with special emphasis on urbanization and wetlands. Remote Sens Lett 11:225–234. https://doi.org/10.1080/2150704X.2019.1704304
Berberoğlu S, Akın A, Clarke KC (2016) Cellular automata modeling approaches to forecast urban growth for adana, Turkey: A comparative approach. Landsc Urban Plan 153:11–27. https://doi.org/10.1016/j.landurbplan.2016.04.017
Çapan, H (2019) Evaluating urban growth trends by using SLEUTH model: a case study in Adana (Master's thesis, Middle East Technical University)
Census of India (2011) Office of the Registrar General of India and Census Commissioner. Government of India
Chandan MC, Nimish G, Bharath HA (2020) Analysing spatial patterns and trend of future urban expansion using SLEUTH. Spat Inf Res 28:11–23. https://doi.org/10.1007/s41324-019-00262-4
Chaudhuri G, Clarke KC (2019) Modeling an Indian megalopolis– A case study on adapting SLEUTH urban growth model. Comput Environ Urban Syst 77:101358. https://doi.org/10.1016/j.compenvurbsys.2019.101358
Chughtai AH, Abbasi H, Karas IR (2021) A review on change detection method and accuracy assessment for land use land cover. Remote Sens Appl Soc Environ 22:100482. https://doi.org/10.1016/j.rsase.2021.100482
Clarke KC, Hoppen S, Gaydos L (1997) A self-modifying cellular automaton model of historical urbanization in the San Francisco Bay area. Environ Plan B Plan Des 24:247–261. https://doi.org/10.1068/b240247
Deep S, Saklani A (2014) Urban sprawl modeling using cellular automata. Egypt J Remote Sens Sp Sci 17:179–187. https://doi.org/10.1016/j.ejrs.2014.07.001
Dietzel C, Clarke KC (2007) Toward optimal calibration of the SLEUTH land use change model. Trans GIS 11:29–45. https://doi.org/10.1111/j.1467-9671.2007.01031.x
Eyelade D, Clarke KC, Ijagbone I (2021) Impacts of spatiotemporal resolution and tiling on SLEUTH model calibration and forecasting for urban areas with unregulated growth patterns. Int J Geogr Inf Sci. https://doi.org/10.1080/13658816.2021.2011292
Faichia C, Tong Z, Zhang J et al (2020) Using RS data-based CA–markov model for dynamic simulation of historical and future LUCC in Vientiane. Laos Sustainability 12:8410. https://doi.org/10.3390/su12208410
Fattah MA, Morshed SR, Morshed SY (2021) Multi-layer perceptron-Markov chain-based artificial neural network for modelling future land-specific carbon emission pattern and its influences on surface temperature. SN Appl Sci 3:359. https://doi.org/10.1007/s42452-021-04351-8
Franco S, Mandla VR, Ram Mohan Rao K (2017) Trajectory of urban growth and its socioeconomic impact on a rapidly emerging megacity. J Urban Plan Dev 143:04017002. https://doi.org/10.1061/(ASCE)UP.1943-5444.0000378
Government of UP UD (2012) Comprehensive mobility Plan Allahabad
Guzman LA, Escobar F, Peña J, Cardona R (2020) A cellular automata-based land-use model as an integrated spatial decision support system for urban planning in developing cities: the case of the Bogotá region. Land Use Policy 92:104445. https://doi.org/10.1016/j.landusepol.2019.104445
Harb M, Garschagen M, Cotti D et al (2020) Integrating data-driven and participatory modeling to simulate future urban growth scenarios: findings from Monastir. Tunisia Urban Sci 4:10. https://doi.org/10.3390/urbansci4010010
Hossain Shubho MT, Islam I (2020) An integrated approach to modeling urban growth using modified built-up area extraction technique. Int J Environ Sci Technol 17:2793–2810. https://doi.org/10.1007/s13762-020-02623-1
Ilyassova A, Kantakumar LN, Boyd D (2021) Urban growth analysis and simulations using cellular automata and geo-informatics : comparison between Almaty and Astana in Kazakhstan. Geocarto Int 36:520–539. https://doi.org/10.1080/10106049.2019.1618923
Jantz CA, Goetz SJ, Donato D, Claggett P (2010) Designing and implementing a regional urban modeling system using the SLEUTH cellular urban model. Comput Environ Urban Syst 34:1–16. https://doi.org/10.1016/j.compenvurbsys.2009.08.003
Jat MK, Saxena A (2021) SLEUTH model sensitivity testing: game of life, cellular neighborhood, and diffusivity. Arab J Geosci 14:2014. https://doi.org/10.1007/s12517-021-08380-w
Jawarneh RN (2021) Modeling past, present, and future urban growth impacts on primary agricultural land in greater Irbid municipality, Jordan Using SLEUTH (1972–2050). ISPRS Int J Geo-Information 10:212. https://doi.org/10.3390/ijgi10040212
Jayasinghe P, Kantakumar LN, Raghavan V, Yonezawa G (2021) Comparative evaluation of open source urban simulation models applied to Colombo City and Environs in Sri Lanka. Int J Geoinformatics 17:49–60. https://doi.org/10.52939/ijg.v17i3.1897
Kantakumar NL, Sawant NG, Kumar S (2011) Forecasting urban growth based on GIS, RS and SLEUTH model in Pune metropolitan area. Int J Geomatics Geosci 2:568–579
Kantakumar LN, Kumar S, Schneider K (2019) SUSM: a scenario-based urban growth simulation model using remote sensing data. Eur J Remote Sens 52:26–41. https://doi.org/10.1080/22797254.2019.1585209
Kar R, Obi Reddy GP, Kumar N, Singh SK (2018) Monitoring spatio-temporal dynamics of urban and peri-urban landscape using remote sensing and GIS – A case study from Central India. Egypt J Remote Sens Sp Sci 21:401–411. https://doi.org/10.1016/j.ejrs.2017.12.006
Kassawmar T, Eckert S, Hurni K et al (2018) Reducing landscape heterogeneity for improved land use and land cover (LULC) classification across the large and complex Ethiopian highlands. Geocarto Int 33:53–69. https://doi.org/10.1080/10106049.2016.1222637
Khwarahm NR, Najmaddin PM, Ararat K, Qader S (2021a) Past and future prediction of land cover land use change based on earth observation data by the CA–Markov model: a case study from Duhok governorate. Iraq Arab J Geosci 14:1544. https://doi.org/10.1007/s12517-021-07984-6
Khwarahm NR, Qader S, Ararat K, Fadhil Al-Quraishi AM (2021b) Predicting and mapping land cover/land use changes in Erbil /Iraq using CA-Markov synergy model. Earth Sci Informatics 14:393–406. https://doi.org/10.1007/s12145-020-00541-x
Kumar V, Agrawal S (2019) Agricultural land use change analysis using remote sensing and gis: a case study of Allahabad, India. Int Arch Photogramm Remote Sens Spat Inf Sci XLII-3/W6:397–402. https://doi.org/10.5194/isprs-archives-XLII-3-W6-397-2019
Lee DR, Sallee GT (1970) A method of measuring shape. Geogr Rev 60:555–563
Li C, Gao X, Wu J, Wu K (2019) Demand prediction and regulation zoning of urban-industrial land: Evidence from Beijing-Tianjin-Hebei Urban Agglomeration. China Environ Monit Assess 191:412. https://doi.org/10.1007/s10661-019-7547-4
Li N, Miao S, Wang Y (2021) The future urban growth under policies and its ecological effect in the Jing-Jin-Ji area. China Heliyon 7:e06786. https://doi.org/10.1016/j.heliyon.2021.e06786
Liu Y, Id LL, Chen L et al (2019) Urban growth simulation in different scenarios using the SLEUTH model : A case study of Hefei. East China. https://doi.org/10.1371/journal.pone.0224998
Liu D, Clarke KC, Chen N (2020) Integrating spatial non stationarity into SLEUTH for urban growth modelling: A case study in the Wuhan metropolitan area. Comput Environ Urban Syst 84:101545. https://doi.org/10.1016/j.compenvurbsys.2020.101545
Lu Y, Wu P, Ma X, Li X (2019) Detection and prediction of land use/land cover change using spatiotemporal data fusion and the Cellular Automata–Markov model. Environ Monit Assess 191:68. https://doi.org/10.1007/s10661-019-7200-2
Megahed Y, Cabral P, Silva J, Caetano M (2015) Land cover mapping analysis and urban growth modelling using remote sensing techniques in greater Cairo Region—Egypt. ISPRS Int J Geo-Information 4:1750–1769. https://doi.org/10.3390/ijgi4031750
Mekonnen Y, Ghosh SK (2020) Urban growth and land use simulation using SLEUTH model for Adama City, Ethiopia. pp 279–293
Ministry of Urban Development GoI (2014) Slum Free City Plan of Action - Allahabad. Prayagraj
Mishra PK, Rai A, Rai SC (2020) Land use and land cover change detection using geospatial techniques in the Sikkim Himalaya, India. Egypt J Remote Sens Sp Sci 23:133–143. https://doi.org/10.1016/j.ejrs.2019.02.001
Mondal B, Chakraborti S, Das DN et al (2020) Comparison of spatial modelling approaches to simulate urban growth: a case study on Udaipur city, India. Geocarto Int 35:411–433. https://doi.org/10.1080/10106049.2018.1520922
Mosammam HM, Nia JT, Khani H et al (2017) Monitoring land use change and measuring urban sprawl based on its spatial forms. Egypt J Remote Sens Sp Sci 20:103–116. https://doi.org/10.1016/j.ejrs.2016.08.002
Muhammad S, Long X, Salman M (2020) COVID-19 pandemic and environmental pollution: A blessing in disguise? Sci Total Environ 728:138820. https://doi.org/10.1016/j.scitotenv.2020.138820
Nath B, Wang Z, Ge Y et al (2020) Land use and land cover change modeling and future potential landscape risk assessment using Markov-CA model and analytical hierarchy process. ISPRS Int J Geo-Inf 9:134. https://doi.org/10.3390/ijgi9020134
Nguyen HTT, Pham TA, Doan MT, Tran PTX (2020) Land use/land cover change prediction using multi-temporal satellite imagery and multi-layer perceptron Markov model. Int Arch Photogramm Remote Sens Spat Inf Sci XLIV-3/W1-:99–105. https://doi.org/10.5194/isprs-archives-XLIV-3-W1-2020-99-2020
Nwaogu C, Pechanec V (2018) Dynamics in gIscience. Springer International Publishing, Cham
Parchianloo R, Rahimi R, Kiani Sadr M et al (2021) Integrated CA model and remote sensing approach for simulating the future development of a city. Int J Environ Sci Technol 18:1465–1478. https://doi.org/10.1007/s13762-020-02942-3
Peiman R, Clarke K (2014) The impact of data time span on forecast accuracy through calibrating the SLEUTH Urban Growth Model. Int J Appl Geospatial Res 5:21–35. https://doi.org/10.4018/ijagr.2014070102
Rahman MTU, Tabassum F, Rasheduzzaman M et al (2017) Temporal dynamics of land use/land cover change and its prediction using CA-ANN model for southwestern coastal Bangladesh. Environ Monit Assess 189:565. https://doi.org/10.1007/s10661-017-6272-0
Rastogi K, Jain G V (2018) Urban sprawl analysis using shannon ’ s entropy and fractal analysis : A case study on Tiruchirappalli city, India. In: The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Volume. Dehradun, India, pp 20–23
Saha AK, Agrawal S (2020) Mapping and assessment of flood risk in Prayagraj district, India: a GIS and remote sensing study. Nanotechnol Environ Eng 5:11. https://doi.org/10.1007/s41204-020-00073-1
Sarica GM, Zhu T, Jian W et al (2021) Spatio-temporal dynamics of flood exposure in Shenzhen from present to future. Environ Plan B Urban Anal City Sci 48:1011–1024. https://doi.org/10.1177/2399808321991540
Sarif MO, Gupta RD (2021) Comparative evaluation between Shannon’s entropy and spatial metrics in exploring the spatiotemporal dynamics of urban morphology: a case study of Prayagraj City, India (1988–2018). Spat Inf Res 29:961–979. https://doi.org/10.1007/s41324-021-00406-5
Sarif MO, Gupta RD (2022) Spatiotemporal mapping of land use/land cover dynamics using remote sensing and GIS approach: a case study of Prayagraj City, India (1988–2018). Environ Dev Sustain 24:888–920. https://doi.org/10.1007/s10668-021-01475-0
Saxena A, Jat MK (2019) Capturing heterogeneous urban growth using SLEUTH model. Remote Sens Appl Soc Environ 13:426–434. https://doi.org/10.1016/j.rsase.2018.12.012
Saxena A, Jat MK (2020a) Analysing performance of SLEUTH model calibration using brute force and genetic algorithm – based methods. Geocarto Int 35:256–279. https://doi.org/10.1080/10106049.2018.1516242
Saxena A, Jat MK (2020b) Land suitability and urban growth modeling: development of SLEUTH-suitability. Comput Environ Urban Syst 81:101475. https://doi.org/10.1016/j.compenvurbsys.2020.101475
Saxena A, Jat MK, Clarke KC (2021a) Development of SLEUTH-Density for the simulation of built-up land density. Comput Environ Urban Syst 86:101586. https://doi.org/10.1016/j.compenvurbsys.2020.101586
Saxena A, Jat MK, Kumar S (2021b) Sensitivity analysis and retrieval of optimum SLEUTH model parameters. Geocarto Int. https://doi.org/10.1080/10106049.2021.1974957
Şevik, Ö. (2006). Application of SLEUTH model in Antalya (Master's thesis, Middle East Technical University)
Shafizadeh-Moghadam H, Asghari A, Taleai M et al (2017) Sensitivity analysis and accuracy assessment of the land transformation model using cellular automata. Giscience Remote Sens 54:639–656. https://doi.org/10.1080/15481603.2017.1309125
Shukla A, Jain K (2020) Comparison of spatial modelling approaches to predict urban growth of Lucknow City, India. In: IGARSS 2020 - 2020 IEEE international geoscience and remote sensing symposium. IEEE, pp 4267–4270
Singh VG, Singh SK, Kumar N, Singh RP (2022) Simulation of land use/land cover change at a basin scale using satellite data and markov chain model. Geocarto Int. https://doi.org/10.1080/10106049.2022.2052976
United Nations (2019) The sustainable development goals report 2019. United Nations publication issued by the Department of Economic and Social Affairs
United Nations (2020) World Cities Report 2020 The Value of Sustainable Urbanisation. Nairobi, Kenya
Vani M, Prasad PRC (2021) Modelling urban expansion of a south-east Asian city, India: comparison between SLEUTH and a hybrid CA model. Model Earth Syst Environ. https://doi.org/10.1007/s40808-021-01150-3
Vinayak B, Lee HS, Gedem S (2021) Prediction of land use and land cover changes in Mumbai city, India, using remote sensing data and a multilayer perceptron neural network-based markov chain model. Sustainability 13:471. https://doi.org/10.3390/su13020471
Yang J, Guo A, Li Y et al (2019) Simulation of landscape spatial layout evolution in rural-urban fringe areas: a case study of Ganjingzi District. Giscience Remote Sens 56:388–405. https://doi.org/10.1080/15481603.2018.1533680
Yang J, Yang R, Chen M-H et al (2021) Effects of rural revitalization on rural tourism. J Hosp Tour Manag 47:35–45. https://doi.org/10.1016/j.jhtm.2021.02.008
Zhang Y, Zhao L, Zhao H, Gao X (2021) Urban development trend analysis and spatial simulation based on time series remote sensing data: A case study of Jinan. China Plos One 16:e0257776. https://doi.org/10.1371/journal.pone.0257776
Acknowledgments
The authors wish to thank all who assisted in conducting this work.
Funding
Not applicable.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing interests that could have appeared to influence the work reported in this paper.
Consent to participate
The authors are unanimously agreed to participate in study.
Consent for publication
The authors are agreed for publication of this work.
Ethics approval
The manuscript has been read and approved for submission by all the named authors.
Additional information
Editorial responsibility: Shahid Hussain.
Rights and permissions
About this article

Cite this article
Kumar, V., Agrawal, S. Urban modelling and forecasting of landuse using SLEUTH model. Int. J. Environ. Sci. Technol. 20, 6499–6518 (2023). https://doi.org/10.1007/s13762-022-04331-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13762-022-04331-4