
Abstract
Scour depth downstream of weirs is considered one of the most important hydraulic problems, which greatly influences the stability of weirs. Recently, artificial intelligence (AI) methods have become increasingly popular in modeling hydraulic variables, especially scour depth, because they can capture nonlinear relationships between input variables and their associated objectives. Despite their importance, these models have problems with hyperparameter tuning in scour depth modeling due to their structures, so algorithms must be used to tune the hyperparameters. Moreover, these algorithms are usually tuned by using the trial-and-error method to select the hyperparameters such as the number of hidden nodes, transfer function, and learning rate, and in this case, the main problem is overfitting during the training phase. To solve these problems, the high-order response surface method (HORSM), an improved version of the response surface method (RSM), is used as an alternative approach for the first time in this study to predict the scour depth. The HORSM model is based on high-order polynomial functions (from two to six) compared with the artificial neural network model (ANN). The findings indicate that the fifth order of the HORSM polynomial function yields the most precise predictions, with a higher coefficient of determination (R2) of 0.912 and Willmott Index (WI) of 0.972 compared to the values obtained using ANN (R2 = 0.886 and WI = 0.927). Moreover, the accuracy of the predictions is represented by a reduction of the mean square error by up to 44.17 and 29.01% compared to the classical RSM and ANN, respectively. The suggested model established an excellent correlation and accuracy with experimental values.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Weir is one of the oldest structures of low-water hydraulics. It was built in watercourses for numerous reasons, such as to measure water flow, lift water upstream, and control flow velocity (Razmi et al. 2022). In the case of weirs, local scour downstream is an important topic for researchers and has been the subject of numerous studies in recent decades (Bormann and Julien 1991; Gaudio et al. 2000; Lenzi et al. 2002; D’Agostino and Ferro 2004; Lu et al. 2013; Pagliara and Kurdistani 2013). Scouring is the process by which turbulent water flow removes sediment around the structure (Habib et al. 2021), exposing the structure to corrosion and possible failure. Scouring begins upstream of the downstream edge when the water stream creates a shear stress greater than the critical shear stress of the sediment downstream of the weir. In addition, the hole dimensions of the vertical scour change much faster than those of the horizontal (Salih et al. 2020). Moreover, sediment suspension is the only way to transport sediment in the initial stage. Moreover, sediment transport becomes part of the combination of bottom and suspended load as the diameters of the vertical scour holes change. Asymptotically, the criterion of equilibrium is reached when the scour rate increases to zero. This process is influenced by the flow properties of the water and the physical properties of the soil.
Construction of adequate protection measures is only possible if the location and depth of scour downstream are accurately estimated and understood (Guven and Gunal 2008a; Deng and Cai 2010; Carvalho et al. 2019). However, the correct estimation of scour depth, \({D}_{s}\), is a difficult process due to the complexity of water flow patterns around hydraulic structures. Therefore, in recent decades, scour processes have been modeled using deterministic models of varying complexity and precision (Sharafati et al. 2020c). Considering the different flow, time, and material properties in field and laboratory tests, several empirical equations have been developed to predict \({D}_{s}\) (Bormann and Julien 1991), (D’Agostino and Ferro 2004), (Chee and Padiyar 1969; Mossa 1998; Olsen and Kjellesvig 1998; Marion et al. 2004). However, these studies mostly rely on traditional scouring based on physical models, which in turn limits the understanding of the overall scouring process. In addition, the use of empirical equations leads to under- or overestimation of scour depth (Goel and Pal 2009; Tafarojnoruz 2012; Sharafati et al. 2021).
Another way to predict scour depth is to use a numerical model. Different types of numerical techniques have been used to evaluate the scour process by solving the formula for sediment transport and the equations of Navier–Stokes (Sharafati et al. 2020b). The advancement of numerical models (Mohd Yusof et al. 2023) (e.g., Flow3D, ANSYS-FLUENT, and OpenFoam) has made them an effective option for modeling scour depth (Sharafati et al. 2020b). However, due to the high-computational cost for complicated problems, the use of numerical models is limited (Tafarojnoruz 2012). On the other hand, soft computing approaches (SC) provide appealing features for simulating complicated relationships between input and output variables. Based on observational data, the approaches of SC mimic the desired trends, unlike empirical calculations that may not reflect the complexity of the scouring process (Sharafati et al. 2021) (Najafzadeh et al. 2017; Sharafati et al. 2020b). In the approach of SC, the predictive modeling is automatically generated and does not rely on the user's knowledge. In addition, the models in the approach of SC can recognize implicit relationships between features (Bagheri et al. 2024), while empirical equations rely on explicit data before building models to explore the relationships between different parameters. Moreover, the models of SC provide less expensive and more flexible methods for studying complicated issues (Gholami et al. 2016). The ability of the models of SC, to simulate \({D}_{s}\) problems, has been effectively implemented in many studies in the last decades (Sharafati et al. 2021), (Azamathulla et al. 2008a, b; Guven and Gunal 2008a; Altan and Hacıoğlu 2020). Table 1 provides some examples of the application of various SC models to predict \({{\text{D}}}_{{\text{s}}}\).
Accurately predicting scour depth is crucial for the longevity of water infrastructures. Yet, the task is difficult (Abudallah Habib et al. 2021) due to factors like complex shapes, water behavior, and sediment motion (Tao et al. 2021). The limitations of existing models and traditional equations, which result in inaccuracies (Fuladipanah et al. 2023; Le and Thu Hien 2024), emphasize the necessity for the development of better approaches to guide sustainable and safe hydraulic design. Therefore, researchers developed in previous works several statistical and AI-based models to predict the scour depth (Marulasiddappa et al. 2024). As shown in Table 1, several bio-inspired algorithms have been used to hybridize AI models to capture the nonlinear relationship between the input variables and the associated targets by adjusting the parameters that have a large impact on model accuracy in the most efficient way (Moayedi et al. 2019; Xu et al. 2020; Zhou et al. 2020). Although predictive models have made significant progress, their structure is becoming more complicated due to the incorporation of AI techniques with complicated algorithms, which makes it more difficult to understand their results and behavior. In addition to the complexity of the applied models, some machine learning-based models have several shortcomings, such as generalization problems and difficulties in understanding and explaining the decisions. Moreover, machine learning models usually require multiple techniques to determine and select their hyperparameters (Mohammadi 2023), such as the type of transfer function, the number of hidden neurons, the learning rate, and kernel function, so these parameters were usually determined by trial and error (Wang et al. 2018; Liu et al. 2020; Panda and Panda 2020). These problems can be solved by the novel and alternative model of high-order response surface method (HORSM) for predicting the scour depth. It is important to note that HORSM is an improved version of the classic response surface methodology model. Numerous researchers have used the traditional response surface methodology (RSA) to efficiently develop predictive models to solve many problems in various fields such as construction and materials (Hameed et al. 2021a), water resources (Keshtegar et al. 2018), and hydrology (Keshtegar and Kisi 2017). In addition, an improved version of RSA called HORMS has been introduced in recent years to solve challenging environmental and water resources problems (Keshtegar and Kisi 2017), (Keshtegar et al. 2019). Despite the successes achieved with HORMS, its applications in solving civil engineering problems in hydraulic and hydrology are still limited to the best of the author's knowledge. Therefore, in this study, HORSM models based on different polynomial functions are used to predict scour depth downstream of weirs. Moreover, the reported results are validated and compared with the models from ANN to investigate the performance of the applied methodology in solving a significant hydraulic problem.
The rest structure of the paper is organized as follows. In Sect. “Methodology,” there is a detailed description of the experimental data, applied models (HORSM and ANN), and statistical measures. Evaluating and analyzing the obtained results from HORSM model and other comparable models are further discussed in Sect. “Results and discussion.” Finally, the conclusion and research recommendations are provided in Sect. “Conclusion.”
Methodology
Data collection
Several factors influence scour development downstream of weirs, e.g., flow conditions, bed material, tailwater depth, and weir geometry (Goel and Pal 2009), (Najafzadeh 2015). Therefore, it is possible to estimate scour depth using the following relationship:
where \(v\) is the kinematic viscosity of the fluid, \(\rho\) is the water density, \(g\) is the acceleration, \({h}_{o}\) is the average approximation of the flow depth, \({h}_{t}\) is the depth of embodied tailwater, \({\cup }_{o}\) is the average approach of the flow velocity, \({\rho }_{s}\) is the particle density at the bed, \({d}_{50}\) is the mean value of the particle size at the bed, \({\sigma }_{g}\) is the standard deviation of the particle size at the bed, \({\cup }_{c}\) is the average approximation of the critical flow velocity, z is the weir height, and b is the weir depth. The influence of non-dimensional parameters such as \(\frac{{\cup }_{o}}{{\cup }_{c}}\), \(\frac{{d}_{50}}{{h}_{t}}\), \(\frac{z}{{h}_{t}}\) has been investigated in many studies. These studies found that the non-dimensional parameters performed better than the dimensional parameters in estimating the scour depth (Karbasi and Azamathulla 2017), (Najafzadeh 2015). Other studies show that variations in approach flow and tailwater have a significant effect on scour depth (Guven 2011), (Najafzadeh 2015), (Onen 2014). Gunan et al. (Guan et al. 2016) find that decreasing tailwater depth (\(\frac{z}{{h}_{t}}\)) and increasing flow intensity (\(\frac{{\cup }_{o}}{{\cup }_{c}}\)) increases scour depth. In addition, other studies have shown that the width of the weir (\(\frac{b}{{h}_{t}})\) has a large effect on scour depth (Najafzadeh 2015), (Roushangar et al. 2016). Therefore, based on the dimensional analysis, the following equation is used (Guan et al. 2016).
where \(\frac{{d}_{50}}{{h}_{t}}\) represents the effect of particle size in the bed, \(\frac{z}{{h}_{t}}\) represents tailwater depth, and \(\frac{z}{{h}_{t}}\) represents flow conditions.
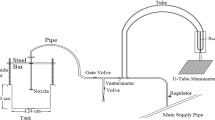
Data from four published studies (D’Agostino and Ferro 2004), (D’agostino 1994), (Veronese 1937), (Falciai and Giacomin 1978) with different acquisition conditions were combined into a dataset of 186 experimental data to evaluate the capabilities of the high-order response surface in predicting scour depth. The statistical description of the data used can be found in Table 2 and Fig. 1. Furthermore, the data utilized in this research have been gathered and can be located in supplementary file accompanying this study (Appendix 1).

The correlation matrix of the used variables
High-order response surface method (HORSM)
In general, response surface approach (RSA) is an empirical, mathematical, and statistical modeling approach used to study multiple regressions (MR) by using quantitative data from specific observations to simultaneously solve multivariate equations. RSA quantifies the relationships between one or more measured variables and three input variables that primarily influence the response. Moreover, RSA uses a simple and explicit function to approximate an originally complicated and implicit limit state function. However, the correctness of the results strongly depends on how the properties of the original boundary condition are correctly represented by the approximation function. The adequacy of the generated RSA depends mainly on the appropriate positioning of the so-called sample points that approximate the response function using a typical regression approach. In general, the RSA uses a second-order polynomial form with cross terms. By including cross terms in the RSA second-order polynomial, a reasonable prediction for the time series can be achieved. Since the prediction of the scour downstream (\({D}_{s}\)) is a complex and highly nonlinear process, and using a second-order RSA polynomial may not provide reliable prediction (Keshtegar et al. 2016), a new version of RSA is proposed based on a high-order polynomial function mixed with the extremely nonlinear cross term to form the method high-order response surface (HORSM). The HORSM can be represented in Eq. (3), considering several independent variables \({\varvec{R}}\left\{{r}_{1},{r}_{2},{r}_{3},\dots \right\}\)
\({\check{S} }\left( v \right)\) represent high-order calculated RSA for ….., \(n\) is the input predictor number, \({\gamma }_{0}\), \({\gamma }_{i}\), \({\gamma }_{ij}\), \({\alpha }_{ij}\), \({b}_{ij}\), \({d}_{ij}\), and \({g}_{ij}\) represent the unknown coefficients which can be determined using Eq. (4) as follows (Keshtegar et al. 2016):
Here, \(\mu\) is the order of RSA, ranging from 2 to 6 in this study. Calibration of multiple experimental designs is considered in the calculation of coefficients. In general, the unknown RSM coefficients in Eq. (1) are calculated using the least-squares error approach by minimizing the error between the actual \(S\left( r \right)\) and the calculated \({\check{S} }(r)\)=\(P{(r)}^{T}a)\) for \({D}_{s}\) values. Equation (5) represents the error as follows:
where \({\varvec{S}}\left(r\right)=[{S}_{1}, {S}_{2}, {S}_{3}, \ldots , {S}_{NI}]\) is the actual value and \(P{(r)}^{T}=\left[P\left({S}_{1}\right), P\left({S}_{2}\right), P\left({S}_{3}\right), \ldots , P\left({S}_{NI}\right)\right]\) is the predicted value based on a high-order polynomial for \(NI\) number of observed data. Equation (6) shows the predicted scour depth downstream in weirs using 6th order RSA considering several variables (assume 3 variables).
A system in linear form can be obtained by minimizing the error function in Eq. (6) for the unknown coefficients \(a\), also the value of \({D}_{s}\) can be predicted using Eq. (7) as follows:
As mentioned earlier, using high-order polynomial RSA can produce a more accurate prediction of \({D}_{s}\) than the use of second-order polynomials in a strongly nonlinear process. The prediction of \({D}_{s}\) using HORSM can be summarized as follows:
-
Set the input data for \({D}_{s}\) with the predictors \({r}_{1},{r}_{2},{r}_{3},\dots\).
-
Set the order of RSA and use Eqs. (2) and (4) to estimate the predicted value for training the model \(P\left(S\right)\) from the data.
-
Fix the predicted vector for all samples (\(P\left({r}_{all}\right)\)) for both training and test data.
-
Use Eq. (8) to obtain the predicted \({D}_{s}\)\(\left( {\check{S} (r)} \right)\)
$${\check{S} }\left( r \right) = P\left( {r_{all} } \right)^{T} \left[ {P\left( r \right)^{T} P\left( r \right)} \right]^{ - 1} \left[ {P\left( r \right)^{T} P\left( r \right)} \right]$$(8)
In this study, the HORSM software code was built using the MATLAB language based on four prior phases. Figure 2 illustrates the framework of the proposed HORSM model.

The structure of HORSM
Feedforward neural network
Feedforward neural network (FFNN) is an algorithm that has layers comparable to the processing unit for human neurons. Each unit (node) in the FFNN layer is connected to all other units in the layers (Hameed et al. 2021b). These connections with the layers are not all identical, as the weight and strength of each connection can change (see Fig. 3). Processing of information in a neural network (NN) involves input of data by the input units and movement from one layer to the next through the network until it reaches the output units (Hagan and Menhaj 1994; Üstün et al. 2020). In FFNN, the data are transmitted only in one direction from the input nodes, if any, to the hidden nodes and then to the output nodes (Hertz 2018). The output values are computed by the neural network based on the input values, while the intermediate results of the computations are associated with the hidden layer nodes.

The structure of FFNN
Each j-node receives input from each i-node in the previous layer and each input signal (\({X}_{i}\)) is associated with a weight (\({R}_{ij}\)). The incoming signal (\({E}_{j})\) is the sum of all incoming signals plus the neuron's threshold (\({t}_{j})\).
To generate the node's outgoing signal (\({y}_{i})\), the incoming signal (\({E}_{j})\) is passed through a nonlinear activation function. The logistic sigmoid function is the most commonly used of this type of networks. The function of this transmission is continuously differentiated, monotonic, symmetric and bounded from 0 to 1 (Hecht-Nielsen 1990). The function can be mathematically expressed by the following equation (see Eq. 10) (Lipu et al. 2021). However, in this study, we use a linear transfer function for the output layer. It is important to mention that the ANN has been trained using the Marquardt algorithm, which allows for effective optimization and learning.
Model development
In this study, classical RSM models and four models based on HORSM supported by polynomial functions ranging from 3 to 6 orders, as well as ANN models, have been constructed to predict the depth of scour downstream of weirs. For constructing the models, 186 experimental samples were used. Out of these samples, 66% (123 samples) were randomly selected for training the models, and the remaining 63 samples were used for testing the models. It is worth noting that the MATLAB programming language was used to develop all the prediction models. During this work, the training samples were used to adjust the models' parameters. For ANN models, the Levenberg–MarquardIn hydraulic engineering, it is importantt algorithm was chosen to train the models, and hidden nodes within the range of 2 to 15 were used. The testing data were used to evaluate the efficiency of predicting based on several statistical metrics and graphical figures. Finally, sensitivity analysis is also executed to select the most effective predictors that have a large impact on depth of scour.
Performance evaluation
Several statistical parameters, such as the coefficient of determination (\({R}^{2}\)), root mean square error (RMSE), mean absolute error (MAE), correlation coefficient (R), root mean square relative error (RMSRE), Willmott index (WI), mean absolute percentage error (MAPE), and relative root mean square error (RRMSE), are used to investigate the accuracy of the proposed models. The following mathematical formulas describe each parameter (Hameed et al. 2022).
where \({D}_{s}^{r,m}\) and \({\overline{{D}_{s}}}^{r,m}\) are the actual value and the mean of the actual value of the scour depth (\({D}_{s})\) at the \({r}^{{\text{th}}}\) sample. \({D}_{s}^{r,c}\) and \({\overline{{D}_{s}}}^{r,c}\) are the predicted and the mean of the predicted value of \({D}_{s}\) at the \({r}^{{\text{th}}}\) sample, respectively. The mentioned metrics are commonly employed for model validation (Mamata et al. 2023). Some of these metrics, such as RMSE, RMSRE, MAPE, RRMSE, and MAE, are utilized to account for prediction errors. When the model produces a minimum value close to zero, it serves as a positive indicator that the model has a precise prediction. On the other hand, metrics such as R, R2, and WI are used to assess how well the predicted values align with the observed values during validation. The ideal value for these metrics is one (Hameed et al. 2024), indicating a perfect match between the model's predictions and the observed values. Therefore, a higher value close to one for these metrics signifies a good model.
Results and discussion
Two models were created to predict the maximum scour depth \(\frac{ds}{ht}\) downstream of the weirs, namely the high-order response surface method model (HORSM) and the ANN model. As for the structure of HORSM models, different high-order polynomial functions (second, third, fourth, and fifth-order) were tested to find the best predictive model. For model construction, 66% of the samples are used to train the proposed models, and the rest are proposed for testing. Finally, sensitivity analysis is also performed to select the most effective predictors that have a large impact on the \(\frac{ds}{ht}\).
Graphical representations and statistical measures were used to evaluate the performance of each model to assess predictive ability. The performance of the applied models in the training phase is shown in Table 3. Overall, most of the applied models achieved good predictions for \(\frac{ds}{ht}\), with the exception of the classical RSA (RMS2) and ANN models, respectively. For example, the ANN and the classical RSM models were founded with a higher prediction error: MAE of 0.121 and 0.141; RMSE of 0.176 and 0.194; MAPE of 0.237 and 0.269; RRMSE of 29.163 and 32.077; R of 0.825 and 0.781; and WI of 0.902 and 0.867. On the other hand, the \({{\text{HORSM}}}_{5}\), and \({{\text{HORSM}}}_{6}\) provided excellent predictions with lower MAE (0.090, 0.087), RMSE (0.133, 0.131), MAPE (0.188, 0.184), RRMSE (22.018, 21.709), R (0.904, 0.906), and WI (0.948, 0.949). Also, based on the results presented in Table 3, both HORMSM3 and HORSM4 exhibit a relatively similar performance in predicting the depth of scour. The MAE is 1.04/0.097, RMSE is 1.47/1.38, RRMSE is 24.57/22.752, R is 0.881/0.897, MAPE is 0.216/0.202, and WI is 0.934/0.943, respectively, for HORSM3/HORSM4. Thus, the statistical analysis shows that the performance of \({{\text{HORSM}}}_{5},\) and \({{\text{HORSM}}}_{6}\) is very similar in the training phase.
In this study, a visualization comparison is also performed to visually analyze the performance of each proposed model compared to the observed targets. The scatter plots shown in Fig. 4 provide further information on both the performance of the applied model and the deviation between predicted and observed ds/ht in the training phase. The graphs visually display the relationship between predicted and measured values of depth scour. These figures help to assess the accuracy of the prediction model and understand how closely the predicted values align with the actual measurements. They also indicate the variability in the model's predictions by showing how the predicted points are spread out around the measured values. Additionally, scatter plots provide the value of R2, which is a statistical measure of how well the model fits the data. It can be observed that the classical RSM and ANN models provide poor predictions that are further away from the corresponding (actual) values. Moreover, the classical RSM and ANN models have a significantly low predictive capacity in terms of the coefficient of determination of the correlation (\({R}^{2}\)). Upon observation, it is evident that both the classical RSM and the generated predicted samples deviate significantly from the fit line in the scatter plot. The respective values of R2 for these models are 0.611 and 0.680. In contrast, the applied models such as \({{\text{HORSM}}}_{3}\), \({{\text{HORSM}}}_{4}\), and \({{\text{HORSM}}}_{5}\), as well as \({{\text{HORSM}}}_{6}\), provide a good and higher value of \({R}^{2}\). Additionally, the estimated points of both models show less scattering around the ideal line (1:1), indicating a higher quality of prediction. Moreover, the HORSM6 model exhibits the highest accuracy with an R2 value of 0.822, followed by HORSM5 with an R2 value of 0.817, HORSM4 with an R2 value of 0.804, and HORSM3 with an R2 value of 0.775.

A comparison between the predictions of the applied model and the actual values of \(\frac{ds}{ht}\) during the training phase
To further visually examine the performance of the model, we constructed both a Taylor plot (Taylor 2001) and a violin plot (Hintze and Nelson 1998). Three statistics, namely the Root Mean Square Difference (RMSD), the normalized standard deviation, and the correlation coefficient, are used to create the Taylor plot, which is a polar plot. The higher the power of the model in the Taylor plot, the closer the model values are to the observed values (Sigaroodi et al. 2014). A violin plot is a boxplot that is combined with a kernel density plot to show the distribution of the data. From Fig. 5, it can be seen that the classical RSM and ANN models have a major problem in predicting \(\frac{ds}{ht}\). However, the HORSM models with high-order polynomial functions provide satisfactory predictions. From Fig. 6, it can be seen that the \({{\text{HORSM}}}_{4}\), \({{\text{HORSM}}}_{5}\), and \({{\text{HORSM}}}_{6}\) models are very close to the location of the observed \(\frac{ds}{ht}\), which means that there is a very good agreement between the predicted and observed values. Furthermore, from the figure, it can be observed that both \({{\text{HORSM}}}_{5}\) and \({{\text{HORSM}}}_{6}\) models are the closest to the benchmark value (represented by the measured point). These models also exhibit the highest correlation, the fewest RMSD, and a closer standard deviation to the observed measured point according to the Taylor diagram. Overall, the \({{\text{HORSM}}}_{5}\) and \({{\text{HORSM}}}_{6 }\) models are the best models according to the quantitative and visual analysis. Moreover, the performance of these models in the training phase is very similar.

Violin plots showing visual comparison between actual and predicted values of \(\frac{ds}{ht}\) during the training phase

The Taylor diagram shows the similarity between the applied model predictions and the observed values of \(\frac{ds}{ht}\) during the training phase
In order to select the best and most reliable predictive models, some recent studies have shown that the training step is not sufficient and may lead to misleading judgments due to different conditions that may occur in the calibration processes (Alomar et al. 2020; Hameed et al. 2021c, a). Therefore, the testing phase is crucial for identifying the most accurate model. Moreover, the best model is able to perform well in both the training and testing phases. The quantitative evaluation of all applied models in the testing phase is summarized in Table 4. According to Table 4, the \({{\text{HORSM}}}_{5}\) model has the lowest prediction error (MAE = 0.083, MAPE = 0.135, RMSE = 0.115 and RRMSE = 18.079) and the highest similarity with the observed scour values (R = 0.955, and WI = 0.972) compared to the other models. Similar to the training phase, both HORSM3 and HORSM4 exhibit similar performance in the testing phase, as shown in Table 4. However, HORSM4 demonstrates slightly better accuracy. The statistical performance for HORSM3 and HORSM4 includes lower prediction error with MAE (0.097 and 0.095), RMSE (0.139 and 0.134), MAPE (0.156 and 0.164), and RRMSE (21.818 and 21.036). Additionally, both models achieve good accuracy with R (0.954 and 0.935) and WI (0.954 and 0.962). Overall, the excellent ability of the \({{\text{HORSM}}}_{5}\) model shows in the reduction of RMSE values by 44.17%, 17.27%, 14.18%, 36.46% and 29.01% compared to the classical RMS,\({{\text{HORSM}}}_{3}\), \({{\text{HORSM}}}_{4}\), \({{\text{HORSM}}}_{6}\), and ANN models, respectively. Moreover, the evaluation of the visualization in scatter plots (see Fig. 7) shows that the \({{\text{HORSM}}}_{5}\) model has the highest similarity of predictions with the actual values with an \({R}^{2}\) is 0.912, followed by \({{\text{HORSM}}}_{3}\)(\({R}^{2}\) = 0.894), ANN (\({R}^{2}\) = 0.886), \({{\text{HORSM}}}_{4}\)(\({R}^{2}\) = 0.874), the classical RMSE model (\({R}^{2}\) = 0.810), and \({{\text{HORSM}}}_{6}\) (\({R}^{2}\) = 0.874).

A comparison between applied model predictions and actual values of \(\frac{ds}{ht}\) during the testing phase
On the other hand, Fig. 7 shows that although the \({{\text{HORSM}}}_{6}\) model has excellent accuracy in the training phase, it has the lowest predictive capacity in the testing phase. In addition to its poor prediction, \({{\text{HORSM}}}_{6}\) also provides negative estimates. The situation can be interpreted that this model suffers from overfitting in the training phase and therefore has shown its weaknesses in providing more reliable estimates in the testing phase. The violin diagram (Fig. 8) shows the ability of each model to predict scour depth. Some of the applied models provided very poor estimates, such as \({{\text{HORSM}}}_{6}\), and ANN. The model ANN is not able to efficiently estimate the higher value of scour depth. On the other hand, the \({{\text{HORSM}}}_{6}\) model fails to simulate the lower value of scour depth. However, the \({{\text{HORSM}}}_{5}\) model is superior compared to the other models and manages to simulate the highest and the lowest value of the scour depth.

Violin plots showing a visual comparison between actual and predicted values of \(\frac{ds}{ht}\) during the testing phase
Finally, as can be seen in Fig. 9, a Taylor diagram is created for the test data set to allow a more comprehensive evaluation and to select the best predictive models. As for the best predictive model, the results from Fig. 9 are consistent with previous evaluations, whether quantitative, visual, or both. It can be seen that the \({{\text{HORSM}}}_{5}\) model is the best model because it has a very good agreement between its predictions and the observed values. Moreover, all previous evaluations have shown that HORSM is very sensitive to the order of the polynomial degree. Thus, it can be seen that HORSM with a fifth-degree polynomial gives the best predictions and outperforms the AI model (ANN).

The Taylor diagram shows the similarity between the applied model predictions and the observed values of \(\frac{ds}{ht}\) during the testing phase
Comparison of the attained results to sophisticated models and empirical relations
The obtained results from the best predictive model in this study (\({{\text{HORSM}}}_{5})\) are validated against well-established empirical equations and other AI models. Comparing the performance of the proposed model in predicting the scour depth with models developed in the literature may give a clear and important impression about the efficiency and validity of the proposed model.
Sharafati et al. (Sharafati et al. 2020a) developed a hybrid model based on the integration of the bio-inspirited algorithm (invasive weed optimization (IWO)) and adaptive neuro-fuzzy inference system (ANFIS) to estimate the souring depth. The applied model (ANFIS-IWO) managed to provide satisfactory accuracy of prediction (R = 0.932), and however, this model also generated relatively higher prediction error (RMSE = 0.148, and MAE = 0.108). Furthermore, an empirical equation-based model is created by (Guan et al. 2016; Sharafati et al. 2020a) to predict the souring depth. The results showed the accuracy of the model was not accurate as expected, providing a higher prediction error with RMSE = 0.447, and MAE = 0.395. Based on the reported results from both models, it can be concluded that the pattern of the scouring depth is complicated and the existing model could not efficiently capture the underlying relations between predictors and scouring depth.
For further quantitative comparison, the accuracy of the proposed model of this study compared with more and advanced models developed in previous studies (Elkiki 2018; Guven and Gunal 2008b; Goel and Pal 2009; Guven 2011; Najafzadeh 2015; Sattar et al. 2018) in terms of correlation coefficient (R). Figure 10 summarizes the prediction accuracies of eight different AI modeling techniques. The reviewed models yielded good estimates, having higher similarity between their targets and the actual scouring depth. Besides, the correlation coefficient of these models varies between 0.905 and 0.948, while the proposed model (\({{\text{HORSM}}}_{5})\) showed the highest accuracy (R = 0.955). Lastly, the validation illustrates that the \({{\text{HORSM}}}_{5}\) model achieved higher prediction accuracy compared to other models.

Comparison between the accuracy of the proposed model and other models developed in the previous study throughout the testing stage
Sensitivity analysis
In hydraulic engineering, it is important to determine which parameters have a significant effect on scour depth (\(\frac{ds}{ht}\)). In this section, we explain the approach used to select the most important predictors. After selecting the best predictive model (\({{\text{HORSM}}}_{5}\)), different input combinations were used to train the model. All possible input combinations were considered when performing the sensitivity analysis (see Table 5). It is important to mention that the model is trained with 66% of the data and the remaining data are used for testing. According to the results of the testing phase (see Fig. 11), the most important critical case is the second case (combination II). The most important indication is that the prediction accuracy decreases drastically when the factor (z/ht) is not present. Moreover, the factor z/ht is very important for the dynamics of the scour depth compared to other factors. The second and third important parameters are Uo/Uc, and d50/ht, respectively.

Results of sensitivity analysis for different combinations
Discussion
The primary focus of this paper is to explore the possibility of utilizing a suitable and efficient prediction model for accurately estimating the depth of scouring downstream of weirs. The accurate estimation of scouring depth holds significant importance in the field of water resources as it ensures the sustainability of hydraulic structures. However, predicting the depth of scouring poses a considerable challenge in the hydraulic discipline due to the involvement of various complex parameters, such as irregular geometry, the natural characteristics of water flow dynamics, and the nonlinear movement of sediments. The limitations of existing empirical formulas necessitate the development of advanced models capable of accurately predicting the impact of these parameters on scouring patterns. Additionally, a reliable predictive model would greatly assist in the sustainable design of hydraulic structures. In this study, the HORSM was employed, equipped with different orders of high-order polynomial functions ranging from two to six. The findings of this research indicate that HORSM5 is the most effective model, demonstrating superior performance compared to AI-based models (ANN). The fifth order of the HORSM polynomial function provides the most precise predictions, exhibiting a higher R2 of 0.912 and WI of 0.972 when compared to the values obtained using ANN (R2 = 0.886 and WI = 0.927). Furthermore, the accuracy of the predictions is evidenced by a reduction in mean square error of up to 44.17% and 29.01% in comparison with classical RSM and ANN, respectively.
In addition, the proposed model, HORSM5, was validated against various sophisticated models and empirical models developed in previous works, including DNN, hybrid model (GMDP-PSO), SVR, and other ML-based models (refer to Fig. 10) (Elkiki; Guven and Gunal 2008b; Goel and Pal 2009; Guven 2011; Najafzadeh 2015; Sattar et al. 2018). The correlation coefficients of these models ranged from 0.905 to 0.948, while the HORSM5 model demonstrated the highest accuracy, with a correlation coefficient of approximately 0.955. The validation results clearly indicate that the HORSM5 model outperforms other models in terms of prediction accuracy.
In the comparative analysis, HORSM5 outshined ANN by reducing the RMSE by a notable 29%, showcasing its robust capability to discern complex patterns and interdependencies within the data, which translated into enhanced prediction precision. On the other hand, ANN's performance was less effective when compared to HORSM5. The diminished accuracy of ANN may be linked to a confluence of issues. Firstly, the training data may have lacked quality or been an ill fit for the model's learning process. Secondly, there may have been difficulties in fine-tuning the hyperparameters effectively. Thirdly, the algorithm might have encountered obstacles in avoiding local minima. Finally, the limited number of training samples for ANN could have hindered its performance. More training samples would have allowed ANN to efficiently learn and improve its predictive capabilities by increasing its capacity to capture underlying patterns and relationships in the data. Collectively, these factors played a part in undermining the ANN's predictive performance as observed in the research.
Conclusion
In this study, an improved version of the RSM model was used as a predictive model for predicting scour depth downstream of weirs, which is considered one of the most important parameters in the hydraulic field. The traditional RSM was developed using high-order polynomial functions with two to six polynomial degrees, which gave rise to the HORSM approach. The traditional RSM and HORSM models were trained and validated using 186 experimental data. In addition, these models were validated using the ANN model as an efficient form of artificial intelligence model. The experimental samples were randomly divided into training and testing sets, with a ratio of 66% for training and 34% for testing. Various statistical metrics, including RMSE, R, MAE, R2, MAPE, WI, and RRMSE, were employed to evaluate the prediction accuracy. The study found that the HORSM equipped with fifth-order polynomial functions provided the best prediction accuracy and outperformed the standard RSM and ANN models. The proposed model demonstrated a reduced prediction error for scour depth compared to other models, with values of MAE = 0.083, RMSE = 0.115, and MAPE = 0.135. Additionally, it exhibited high accuracy, as reflected in R = 0.955, and WI = 0.972, indicating superior performance. Also, a sensitivity analysis was performed to assess the impact of various hydraulic and geometric parameters on scour depth prediction. The absence of the factor (z/ht) significantly decreased prediction accuracy, highlighting its crucial role in scour depth dynamics. Additionally, Uo/Uc and d50/ht were identified as the second and third most important parameters, respectively. The proposed model can be used to estimate the marginal power functions in reliability planning and to predict other parameters in the hydraulic domain, such as the discharge coefficient and scour depth around bridge piers. Moreover, the proposed approach is very powerful for large data sets. However, when few or small data points are available (\(N<\frac{(n+1)(n+2)}{2}+\left(Q-2\right)*{n}^{2}\)), the HORSM may not provide satisfactory predictions, which in turn limits its use. Therefore, it is important for the future to improve the HORSM approach to solve various engineering problems with few samples (observations) and large input vectors. Thus, this study proposes the following recommendations:
-
1.
Employing principal component analysis (PAC) to decrease the dimensionality of the processed data for higher-order response surface methodology (HORSM).
-
2.
Utilizing a regularization parameter to improve the performance of the HORSM model.
Data availability
Data are available upon request from the corresponding author. Also, the data are provided in supplementary file.
Abbreviations
- \({R}^{2}\) :
-
Coefficient of determination.
- MAE:
-
Mean absolute error
- RMSE:
-
Root mean square error
- NSE:
-
Nash–Sutcliffe efficiency
- WI:
-
Willmott index
- R :
-
Correlation coefficient
- VAF:
-
Variant analysis frequency
- SI:
-
Scatter index
- MSE:
-
Mean squared error
- AIC:
-
Akaike’s information criterion
- RE:
-
Relative error
- PE:
-
Percentage error
- MPE:
-
Mean percentage error
- MAPE:
-
Mean absolute percentage error
- \({E}_{{\text{sn}}}\) :
-
Coefficient of efficiency
- RAE:
-
Relative absolute error
- D :
-
Index of agreement
- SVR:
-
Support vector regression
- Tbpso:
-
Binary particle swarm optimization
- LR:
-
Linear regression
- DT:
-
Decision tree
- DNN:
-
Multi-output descriptive neural network
- ANFIS:
-
Adaptive neuro-fuzzy inference systems
- BBO:
-
Biogeography-based optimization
- IWO:
-
Invasive weed optimization
- TLBO:
-
Teaching–learning-based optimization
- GA:
-
Genetic algorithm optimizer
- XGBoost:
-
Extreme gradient boosting
- ANN:
-
Artificial neural network
- GEP:
-
Gene expression program
- MLR:
-
Multiple linear regression
- NF-GMDH:
-
Neuro-fuzzy based-group method of data handling
- PSO:
-
Particle swarm optimization
- EPR:
-
Evolutionary polynomial regression
- ENNF:
-
Explicit neural networks formulation
- GP:
-
Genetic programming
- SVMs:
-
Support vector machines
- RBF:
-
Radial basis kernel
- FNN:
-
Feedforward neural networks
- \(v\) :
-
Kinematic viscosity
- \(\rho\) :
-
Water density
- \(g\) :
-
Acceleration
- \({h}_{o}\) :
-
Average approximation of the flow depth
- \({h}_{t}\) :
-
Depth of embodied tailwater
- \({\cup }_{o}\) :
-
Average approach of the flow velocity
- \({\rho }_{s}\) :
-
Particle density at the bed
- \({d}_{50}\) :
-
Mean value of the particle size
- \({\sigma }_{g}\) :
-
Standard deviation of the particle size
- \({\cup }_{c}\) :
-
Average approximation of the critical flow velocity
- \(z\) :
-
Weir height
- \(b\) :
-
Weir depth
References
Abudallah Habib I, Wan Mohtar WHM, Muftah Shahot K et al (2021) Bridge failure prevention: an overview of self-protected pier as flow altering countermeasures for scour protection. Civ Eng Infrastructures J 54:1–22. https://doi.org/10.22059/ceij.2020.292296.1627
Alomar MK, Hameed MM, Al-Ansari N, Alsaadi MA (2020) Data-driven model for the prediction of total dissolved gas: robust artificial intelligence approach. Adv Civ Eng. https://doi.org/10.1155/2020/6618842
Altan A, Hacıoğlu R (2020) Model predictive control of three-axis gimbal system mounted on UAV for real-time target tracking under external disturbances. Mech Syst Signal Process 138:106548
Azamathulla HM, Deo MC, Deolalikar PB (2008a) Alternative neural networks to estimate the scour below spillways. Adv Eng Softw 39:689–698
Azamathulla HM, Ghani AA, Zakaria NA et al (2008b) Genetic programming to predict ski-jump bucket spill-way scour. J Hydrodyn Ser B 20:477–484
Bagheri A, Bordbar A, Heidarnejad M, Masjedi A (2024) In-depth simulation of netted collars on scour depth control using machine-learning models. Results Eng 21:101820. https://doi.org/10.1016/j.rineng.2024.101820
Bormann NE, Julien PY (1991) Scour downstream of grade-control structures. J Hydraul Eng 117:579–594
Carvalho TP, Soares FA, Vita R et al (2019) A systematic literature review of machine learning methods applied to predictive maintenance. Comput Ind Eng 137:106024
Chee SP, Padiyar PV (1969) Erosion at the base of flip buckets. Eng J, Can 52(11):22–24
D’agostino V (1994) Indagine sullo scavo a valle di opere trasversali mediante modello fisico a fondo mobile. L’energia Elettr 71:37–51
D’Agostino V, Ferro V (2004) Scour on alluvial bed downstream of grade-control structures. J Hydraul Eng 130:24–37
Deng L, Cai CS (2010) Bridge scour: prediction, modeling, monitoring, and countermeasures. Pract Period Struct Des Constr 15:125–134
Elkiki M (2018) Estimation of scour depth downstream the skew V-notch weirs using artificial neural network and gene expression program. Int Water Technol J 8(1):1–14
Falciai M, Giacomin A (1978) Indagine sui gorghi che si formano a valle delle traverse torrentizie. Ital for Mont 23:111–123
Fuladipanah M, Hazi MA, Kisi O (2023) An in-depth comparative analysis of data-driven and classic regression models for scour depth prediction around cylindrical bridge piers. Appl Water Sci 13:231. https://doi.org/10.1007/s13201-023-02022-0
Gaudio R, Marion A, Bovolin V (2000) Morphological effects of bed sills in degrading rivers. J Hydraul Res 38:89–96
Gholami A, Bonakdari H, Zaji AH et al (2016) Improving the performance of multi-layer perceptron and radial basis function models with a decision tree model to predict flow variables in a sharp 90 bend. Appl Soft Comput 48:563–583
Goel A, Pal M (2009) Application of support vector machines in scour prediction on grade-control structures. Eng Appl Artif Intell 22:216–223
Guan D, Melville B, Friedrich H (2016) Local scour at submerged weirs in sand-bed channels. J Hydraul Res 54:172–184. https://doi.org/10.1080/00221686.2015.1132275
Guven A (2011) A multi-output descriptive neural network for estimation of scour geometry downstream from hydraulic structures. Adv Eng Softw 42:85–93
Guven A, Gunal M (2008a) Prediction of scour downstream of grade-control structures using neural networks. J Hydraul Eng 134:1656–1660
Guven A, Gunal M (2008b) Genetic programming approach for prediction of local scour downstream of hydraulic structures. J Irrig Drain Eng 134:241–249
Habib I, Wan Mohtar WHM, El-Shafie A, Sharil S (2021) Potential of epoxidised natural rubber alumina nanoparticles (ENRAN) sheet as local bridge pier scour countermeasure. Ain Shams Eng J 12:1255–1265
Hagan MT, Menhaj MB (1994) Training feedforward networks with the marquardt algorithm. IEEE Trans Neural Networks 5:989–993
Hameed MM, AlOmar MK, Baniya WJ, AlSaadi MA (2021a) Prediction of high-strength concrete: high-order response surface methodology modeling approach. Eng Comput. https://doi.org/10.1007/s00366-021-01284-z
Hameed MM, AlOmar MK, Baniya WJ, AlSaadi MA (2021b) Incorporation of artificial neural network with principal component analysis and cross-validation technique to predict high-performance concrete compressive strength. Asian J Civ Eng 22:1019–1031. https://doi.org/10.1007/s42107-021-00362-3
Hameed MM, Alomar MK, Mohd Razali SF et al (2021c) Application of artificial intelligence models for evapotranspiration prediction along the southern coast of turkey. Complexity 2021:1–20. https://doi.org/10.1155/2021/8850243
Hameed MM, Abed MA, Al-Ansari N, Alomar MK (2022) Predicting compressive strength of concrete containing industrial waste materials: novel and hybrid machine learning model. Adv Civ Eng 2022:5586737. https://doi.org/10.1155/2022/5586737
Hameed MM, Razali SFM, Mohtar WHMW et al (2024) Deep learning versus hybrid regularized extreme learning machine for multi-month drought forecasting: a comparative study and trend analysis in tropical region. Heliyon 10
Hecht-Nielsen R (1990) Solution for a distributed hydrological model and applications. Neurocomputing 89–93
Hertz JA (2018) Introduction to the theory of neural computation. CRC Press
Hintze JL, Nelson RD (1998) Violin plots: a box plot-density trace synergism. Am Stat 52:181–184
Karbasi M, Azamathulla HM (2017) Prediction of scour caused by 2D horizontal jets using soft computing techniques. Ain Shams Eng J 8:559–570
Keshtegar B, Kisi O (2017) Modified response-surface method: new approach for modeling pan evaporation. J Hydrol Eng 22:4017045
Keshtegar B, Allawi MF, Afan HA, El-Shafie A (2016) Optimized river stream-flow forecasting model utilizing high-order response surface method. Water Resour Manag 30:3899–3914
Keshtegar B, el Seghier M, Ben A (2018) Modified response surface method basis harmony search to predict the burst pressure of corroded pipelines. Eng Fail Anal 89:177–199
Keshtegar B, Heddam S, Kisi O, Zhu S-P (2019) Modeling total dissolved gas (TDG) concentration at columbia river basin dams: high-order response surface method (H-RSM) vs. M5Tree, LSSVM, and MARS. Arab J Geosci 12:1–15
Le X-H, Thu Hien LT (2024) Predicting maximum scour depth at sluice outlet: a comparative study of machine learning models and empirical equations. Environ Res Commun. https://doi.org/10.1088/2515-7620/ad1f94
Lenzi MA, Marion A, Comiti F, Gaudio R (2002) Local scouring in low and high gradient streams at bed sills. J Hydraul Res 40:731–739
Lipu MSH, Miah MS, Hannan MA et al (2021) Artificial intelligence based hybrid forecasting approaches for wind power generation: progress, challenges and prospects. IEEE Access 9:102460–102489. https://doi.org/10.1109/ACCESS.2021.3097102
Liu DR, Lee SJ, Huang Y, Chiu CJ (2020) Air pollution forecasting based on attention-based LSTM neural network and ensemble learning. Expert Syst 37:e12511. https://doi.org/10.1111/exsy.12511
Lu J, Hong J, Chang K, Lu T (2013) Evolution of scouring process downstream of grade-control structures under steady and unsteady flows. Hydrol Process 27:2699–2709
Mamata RC, Ramlia A, Rosyidib SAP (2023) Shear strength prediction of treated soft clay with sugarcane bagasse ash using artificial intelligence methods. J Kejuruter 35:597–605
Marion A, Lenzi MA, Comiti F (2004) Effect of sill spacing and sediment size grading on scouring at grade-control structures. Earth Surf Process Landforms J Br Geomorphol Res Gr 29:983–993
Marulasiddappa SB, Patil AP, Kuntoji G et al (2024) Prediction of scour depth around bridge abutments using ensemble machine learning models. Neural Comput Appl 36:1369–1380. https://doi.org/10.1007/s00521-023-09109-4
Moayedi H, Tien Bui D, Gör M et al (2019) The feasibility of three prediction techniques of the artificial neural network, adaptive neuro-fuzzy inference system, and hybrid particle swarm optimization for assessing the safety factor of cohesive slopes. ISPRS Int J Geo-Information 8:391
Mohammadi B (2023) Modeling various drought time scales via a merged artificial neural network with a firefly algorithm. Hydrology 10(3):58
Mohd Yusof MA, Sharil S, Wan Mohtar WHM et al (2023) The application of OpenFOAM in modelling flow for vegetated channel. J Kejuruter 35:961–973. https://doi.org/10.17576/jkukm-2023-35(4)-19
Mossa M (1998) Experimental study on the scour downstream of grade-control structures. Proc, 26th Convegno di Idraul e Costr Idraul 581–594
Najafzadeh M (2015) Neuro-fuzzy GMDH based particle swarm optimization for prediction of scour depth at downstream of grade control structures. Eng Sci Technol an Int J 18:42–51
Najafzadeh M, Tafarojnoruz A, Lim SY (2017) Prediction of local scour depth downstream of sluice gates using data-driven models. ISH J Hydraul Eng 23:195–202
Olsen NRB, Kjellesvig HM (1998) Three-dimensional numerical flow modeling for estimation of maximum local scour depth. J Hydraul Res 36:579–590
Onen F (2014) Prediction of scour at a side-weir with GEP, ANN and regression models. Arab J Sci Eng 39:6031–6041
Pagliara S, Kurdistani SM (2013) Scour downstream of cross-vane structures. J Hydro-Environment Res 7:236–242
Panda S, Panda G (2020) Fast and improved backpropagation learning of multi-layer artificial neural network using adaptive activation function. Expert Syst 37:e12555. https://doi.org/10.1111/exsy.12555
Razmi M, Saneie M, Basirat S (2022) Estimating discharge coefficient of side weirs in trapezoidal and rectangular flumes using outlier robust extreme learning machine. Appl Water Sci 12:176. https://doi.org/10.1007/s13201-022-01698-0
Roushangar K, Akhgar S, Erfan A, Shiri J (2016) Modeling scour depth downstream of grade-control structures using data driven and empirical approaches. J Hydroinformatics 18:946–960
Salih SQ, Habib M, Aljarah I et al (2020) An evolutionary optimized artificial intelligence model for modeling scouring depth of submerged weir. Eng Appl Artif Intell 96:104012
Sattar AMA, Plesiński K, Radecki-Pawlik A, Gharabaghi B (2018) Scour depth model for grade-control structures. J Hydroinformatics 20:117–133
Sharafati A, Haghbin M, Haji Seyed Asadollah SB et al (2020a) Scouring depth assessment downstream of weirs using hybrid intelligence models. Appl Sci 10(11):3714
Sharafati A, Tafarojnoruz A, Shourian M, Yaseen ZM (2020b) Simulation of the depth scouring downstream sluice gate: the validation of newly developed data-intelligent models. J Hydro-Environ Res 29:20–30
Sharafati A, Tafarojnoruz A, Yaseen ZM (2020c) New stochastic modeling strategy on the prediction enhancement of pier scour depth in cohesive bed materials. J Hydroinformatics 22:457–472
Sharafati A, Haghbin M, Motta D, Yaseen ZM (2021) The application of soft computing models and empirical formulations for hydraulic structure scouring depth simulation: a comprehensive review, assessment and possible future research direction. Arch Comput Methods Eng 28:423–447
Sigaroodi SK, Chen Q, Ebrahimi S et al (2014) Long-term precipitation forecast for drought relief using atmospheric circulation factors: a study on the Maharloo Basin in Iran. Hydrol Earth Syst Sci 18:1995–2006
Tafarojnoruz A (2012) Discussion of “genetic programming to predict bridge pier scour” by H. Md. Azamathulla, Aminuddin Ab Ghani, Nor Azazi Zakaria, and Aytac Guven. J Hydraul Eng 138:669–671
Tao H, Habib M, Aljarah I et al (2021) An intelligent evolutionary extreme gradient boosting algorithm development for modeling scour depths under submerged weir. Inf Sci 570:172–184. https://doi.org/10.1016/j.ins.2021.04.063
Taylor KE (2001) Summarizing multiple aspects of model performance in a single diagram. J Geophys Res Atmos 106:7183–7192
Üstün O, Bekiroğlu E, Önder M (2020) Design of highly effective multilayer feedforward neural network by using genetic algorithm. Expert Syst 37:e12532. https://doi.org/10.1111/exsy.12532
Veronese A (1937) Erosion of a bed downstream from an outlet. Color A M Coll Fort Collins, USA
Wang J, Zhong D, Adeli H et al (2018) Smart bacteria-foraging algorithm-based customized kernel support vector regression and enhanced probabilistic neural network for compaction quality assessment and control of earth-rock dam. Expert Syst 35:e12357. https://doi.org/10.1111/exsy.12357
Xu C, Amar MN, Ghriga MA, et al (2020) Evolving support vector regression using Grey Wolf optimization; forecasting the geomechanical properties of rock. Eng Comput 1–15
Zhou G, Moayedi H, Bahiraei M, Lyu Z (2020) Employing artificial bee colony and particle swarm techniques for optimizing a neural network in prediction of heating and cooling loads of residential buildings. J Clean Prod 254:120082
Acknowledgements
The author would like to thank Al-Maarif University College for supporting this research.
Funding
Not applicable.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
We acknowledge that the present research has been conducted ethically, and the final form of this research has been agreed by all author.
Consent to participate
The authors consent to participate in this research study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix 1
Appendix 1
Data set | |||
|---|---|---|---|
d50/ht | Z/ht | Uo/Uc | ds/ht |
0.014964 | 2.591241 | 0.059048 | 0.405109 |
0.010123 | 1.012346 | 0.270565 | 0.654321 |
0.01 | 1.731707 | 0.110377 | 0.45122 |
0.039806 | 6.893204 | 0.041109 | 0.825243 |
0.142 | 10.18 | 0.022517 | 1.3 |
0.014336 | 1.433566 | 0.156566 | 0.681818 |
0.025949 | 4.493671 | 0.076923 | 0.537975 |
0.021505 | 1.344086 | 0.233766 | 0.752688 |
0.13125 | 6.63125 | 0.024586 | 0.5625 |
0.15 | 7.371429 | 0.028686 | 0.857143 |
0.107335 | 2.415027 | 0.073342 | 0.447227 |
0.013355 | 2.312704 | 0.170093 | 0.732899 |
0.014388 | 0.179856 | 0.921769 | 0.719424 |
0.013355 | 2.312704 | 0.093661 | 0.521173 |
0.086061 | 6.739394 | 0.010863 | 0.333333 |
0.053097 | 1.769912 | 0.132716 | 0.973451 |
0.157778 | 10.91111 | 0.034682 | 2.222222 |
0.016942 | 2.933884 | 0.141784 | 0.764463 |
0.02971 | 5.144928 | 0.041109 | 0.471014 |
0.016803 | 2.909836 | 0.140845 | 0.79918 |
0.049569 | 1.767241 | 0.125436 | 0.668103 |
0.010789 | 1.868421 | 0.140845 | 0.552632 |
0.011748 | 2.034384 | 0.041109 | 0.30086 |
0.154043 | 4.757447 | 0.02501 | 0.468085 |
0.10101 | 2.020202 | 0.092297 | 0.589226 |
0.03268 | 0.653595 | 0.37377 | 0.588235 |
0.017316 | 0.692641 | 0.454545 | 0.606061 |
0.031944 | 1.138889 | 0.186174 | 0.375 |
0.013758 | 2.38255 | 0.041148 | 0.369128 |
0.124481 | 1.244813 | 0.148036 | 1.037344 |
0.029487 | 1.051282 | 0.173434 | 0.487179 |
0.009762 | 1.690476 | 0.170093 | 0.666667 |
0.025786 | 2.578616 | 0.070915 | 0.691824 |
0.052036 | 1.855204 | 0.108619 | 0.678733 |
0.11194 | 1.865672 | 0.098458 | 0.652985 |
0.017647 | 1.823529 | 0.179104 | 0.382353 |
0.161538 | 8.130769 | 0.016129 | 0.5 |
0.142 | 10.08 | 0.027136 | 1.7 |
0.015 | 1.25 | 0.294118 | 0.4 |
0.011714 | 2.028571 | 0.141784 | 0.485714 |
0.084 | 4.564 | 0.026251 | 0.44 |
0.022905 | 3.96648 | 0.076923 | 0.642458 |
0.010789 | 1.078947 | 0.181087 | 0.592105 |
0.025381 | 1.42132 | 0.209581 | 0.203046 |
0.031507 | 1.123288 | 0.070972 | 0.273973 |
0.016078 | 1.607843 | 0.156566 | 0.647059 |
0.049398 | 8.554217 | 0.021134 | 0.686747 |
0.228261 | 11.30435 | 0.010142 | 0.543478 |
0.249655 | 7.262069 | 0.019036 | 0.413793 |
0.019712 | 3.413462 | 0.07685 | 0.552885 |
0.068047 | 2.426036 | 0.070972 | 0.532544 |
0.010789 | 1.868421 | 0.07685 | 0.342105 |
0.01038 | 1.037975 | 0.249503 | 0.632911 |
0.058974 | 2.102564 | 0.186174 | 0.846154 |
0.009762 | 0.97619 | 0.270565 | 0.619048 |
0.017826 | 1.782609 | 0.102145 | 0.630435 |
0.021552 | 2.586207 | 0.112637 | 0.560345 |
0.091 | 10.46 | 0.01416 | 1 |
0.00988 | 1.710843 | 0.156514 | 0.578313 |
0.009425 | 1.632184 | 0.170093 | 0.655172 |
0.041667 | 1.369048 | 0.188366 | 0.238095 |
0.362 | 10.25 | 0.014493 | 0.65 |
0.202857 | 14.54286 | 0.012181 | 1.428571 |
0.01025 | 1.025 | 0.102145 | 0.35 |
0.016129 | 0.16129 | 0.86692 | 0.376344 |
0.03605 | 1.285266 | 0.173434 | 0.673981 |
0.038206 | 1.362126 | 0.050107 | 0.282392 |
0.012733 | 2.204969 | 0.110377 | 0.512422 |
0.031579 | 1.473684 | 0.194203 | 0.263158 |
0.031944 | 1.138889 | 0.108619 | 0.402778 |
0.017982 | 3.114035 | 0.110377 | 0.657895 |
0.019431 | 3.364929 | 0.041109 | 0.450237 |
0.019011 | 1.064639 | 0.319149 | 0.494297 |
0.006098 | 1.585366 | 0.321569 | 0.487805 |
0.15 | 7.3 | 0.032713 | 1 |
0.021466 | 3.717277 | 0.021134 | 0.340314 |
0.023599 | 1.179941 | 0.267157 | 0.589971 |
0.016803 | 2.909836 | 0.021134 | 0.368852 |
0.019231 | 1.076923 | 0.308383 | 0.576923 |
0.012853 | 2.225705 | 0.110377 | 0.489028 |
0.157778 | 11.34444 | 0.017341 | 1.333333 |
0.00988 | 0.987952 | 0.205411 | 0.537349 |
0.1 | 5.457143 | 0.012456 | 0.261905 |
0.011615 | 1.161473 | 0.070915 | 0.396601 |
0.084559 | 3.014706 | 0.125436 | 0.691176 |
0.034743 | 1.238671 | 0.026753 | 0.135952 |
0.018667 | 1.066667 | 0.315657 | 0.933333 |
0.010123 | 1.012346 | 0.227545 | 0.580247 |
0.012424 | 2.151515 | 0.041109 | 0.30303 |
0.01025 | 1.775 | 0.156514 | 0.6375 |
0.012349 | 1.23494 | 0.038382 | 0.271084 |
0.0875 | 4.741667 | 0.02381 | 0.4375 |
0.074194 | 2.645161 | 0.049356 | 0.387097 |
0.016078 | 2.784314 | 0.093661 | 0.568627 |
0.022654 | 1.553398 | 0.198044 | 0.809061 |
0.016803 | 1.680328 | 0.129949 | 0.594262 |
0.014236 | 1.423611 | 0.181087 | 0.642361 |
0.009425 | 1.632184 | 0.140845 | 0.471264 |
0.016598 | 0.373444 | 0.687943 | 0.497925 |
0.117417 | 1.604697 | 0.115204 | 1.272016 |
0.030263 | 1.078947 | 0.159059 | 0.460526 |
0.012577 | 2.177914 | 0.021134 | 0.276074 |
0.010649 | 1.844156 | 0.041109 | 0.246753 |
0.014778 | 0.8867 | 0.377224 | 0.246305 |
0.021026 | 3.641026 | 0.110377 | 0.717949 |
0.155365 | 4.746781 | 0.02794 | 0.515021 |
0.010513 | 1.051282 | 0.156566 | 0.512821 |
0.039423 | 3.942308 | 0.070915 | 0.980769 |
0.07 | 8.053846 | 0.026192 | 1.230769 |
0.190526 | 5.642105 | 0.026448 | 0.421053 |
0.089686 | 1.943199 | 0.100633 | 0.822123 |
0.022989 | 0.804598 | 0.371287 | 0.689655 |
0.0568 | 4.572 | 0.029395 | 0.44 |
0.047674 | 8.255814 | 0.041109 | 0.697674 |
0.084559 | 3.014706 | 0.026753 | 0.330882 |
0.012275 | 2.125749 | 0.110377 | 0.449102 |
0.1222 | 1.466395 | 0.125691 | 0.305499 |
0.042424 | 1.575758 | 0.162921 | 0.787879 |
0.284 | 20.28 | 0.006981 | 1.6 |
0.021354 | 3.697917 | 0.041109 | 0.40625 |
0.012615 | 2.184615 | 0.07685 | 0.4 |
0.034431 | 1.227545 | 0.125436 | 0.329341 |
0.038679 | 6.698113 | 0.041148 | 0.566038 |
0.039048 | 3.904762 | 0.038382 | 0.619048 |
0.011389 | 1.972222 | 0.093661 | 0.472222 |
0.011081 | 1.108108 | 0.102145 | 0.418919 |
0.168372 | 5.274419 | 0.014638 | 0.27907 |
0.011233 | 1.945205 | 0.110377 | 0.410959 |
0.01025 | 1.775 | 0.059048 | 0.3 |
0.011081 | 1.918919 | 0.126177 | 0.548649 |
0.168372 | 5.32093 | 0.012129 | 0.395349 |
0.011748 | 1.174785 | 0.227545 | 0.630372 |
0.010789 | 1.868421 | 0.140845 | 0.565789 |
0.112994 | 1.883239 | 0.097125 | 0.847458 |
0.010033 | 1.839465 | 0.216828 | 0.568562 |
0.105634 | 0.96831 | 0.196783 | 1.144366 |
0.034454 | 5.966387 | 0.041109 | 0.697479 |
0.011714 | 2.028571 | 0.076923 | 0.377143 |
0.031944 | 1.138889 | 0.142164 | 0.472222 |
0.032394 | 1.15493 | 0.049356 | 0.239437 |
0.121704 | 1.37931 | 0.134323 | 0.811359 |
0.084 | 4.544 | 0.028232 | 0.48 |
0.017012 | 2.946058 | 0.07685 | 0.60166 |
0.010649 | 1.844156 | 0.140845 | 0.454545 |
0.110577 | 3.942308 | 0.050107 | 0.528846 |
0.055288 | 1.971154 | 0.090268 | 0.504808 |
0.033333 | 3.333333 | 0.070915 | 0.813008 |
0.023563 | 2.356322 | 0.102145 | 0.747126 |
0.010933 | 1.893333 | 0.171188 | 0.586667 |
0.22625 | 6.6 | 0.022363 | 0.4375 |
0.02157 | 0.560828 | 0.48264 | 0.474547 |
0.037217 | 1.326861 | 0.159059 | 0.582524 |
0.041667 | 1.485507 | 0.142164 | 0.623188 |
0.006 | 1.06 | 0.461783 | 0.28 |
0.009647 | 1.670588 | 0.126177 | 0.458824 |
0.091 | 10.37 | 0.017532 | 1.2 |
0.010847 | 1.084656 | 0.129949 | 0.462963 |
0.014437 | 1.443662 | 0.102145 | 0.528169 |
0.012166 | 2.106825 | 0.140845 | 0.563798 |
0.142 | 10 | 0.0306 | 1.8 |
0.119522 | 1.294821 | 0.143762 | 0.896414 |
0.155556 | 7.762963 | 0.021159 | 0.592593 |
0.012934 | 2.239748 | 0.076923 | 0.425868 |
0.011905 | 0.992063 | 0.410646 | 0.793651 |
0.101111 | 10.96667 | 0.037812 | 2.444444 |
0.034328 | 1.223881 | 0.188615 | 0.656716 |
0.017155 | 2.970711 | 0.021134 | 0.359833 |
0.030667 | 1.093333 | 0.188615 | 0.541333 |
0.075833 | 8.541667 | 0.03228 | 1.5 |
0.011582 | 2.00565 | 0.110377 | 0.437853 |
0.012424 | 1.242424 | 0.205411 | 0.69697 |
0.01025 | 1.775 | 0.093661 | 0.4375 |
0.096154 | 1.442308 | 0.13689 | 1.041667 |
0.012424 | 2.151515 | 0.126177 | 0.590909 |
0.160889 | 4.968889 | 0.022129 | 0.444444 |
0.032578 | 1.161473 | 0.125436 | 0.453258 |
0.011233 | 1.123288 | 0.205411 | 0.575342 |
0.011233 | 1.945205 | 0.059048 | 0.342466 |
0.035019 | 1.478599 | 0.179907 | 0.700389 |
0.009951 | 1.723301 | 0.041109 | 0.276699 |
0.047674 | 8.255814 | 0.021134 | 0.697674 |
0.032764 | 1.168091 | 0.090268 | 0.353276 |
0.015873 | 0.904762 | 0.233062 | 0.603175 |
0.076757 | 6 | 0.018244 | 0.513514 |
0.05291 | 2.010582 | 0.113953 | 0.687831 |
0.103806 | 1.038062 | 0.185418 | 1.124567 |
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hameed, M.M., Khaleel, F., AlOmar, M.K. et al. Introducing high-order response surface method for improving scour depth prediction downstream of weirs. Appl Water Sci 14, 120 (2024). https://doi.org/10.1007/s13201-024-02181-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13201-024-02181-8