
Abstract
Learning from data streams in the presence of concept drift is among the biggest challenges of contemporary machine learning. Algorithms designed for such scenarios must take into an account the potentially unbounded size of data, its constantly changing nature, and the requirement for real-time processing. Ensemble approaches for data stream mining have gained significant popularity, due to their high predictive capabilities and effective mechanisms for alleviating concept drift. In this paper, we propose a new ensemble method named Kappa Updated Ensemble (KUE). It is a combination of online and block-based ensemble approaches that uses Kappa statistic for dynamic weighting and selection of base classifiers. In order to achieve a higher diversity among base learners, each of them is trained using a different subset of features and updated with new instances with given probability following a Poisson distribution. Furthermore, we update the ensemble with new classifiers only when they contribute positively to the improvement of the quality of the ensemble. Finally, each base classifier in KUE is capable of abstaining itself for taking a part in voting, thus increasing the overall robustness of KUE. An extensive experimental study shows that KUE is capable of outperforming state-of-the-art ensembles on standard and imbalanced drifting data streams while having a low computational complexity. Moreover, we analyze the use of Kappa versus accuracy to drive the criterion to select and update the classifiers, the contribution of the abstaining mechanism, the contribution of the diversification of classifiers, and the contribution of the hybrid architecture to update the classifiers in an online manner.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The data revolution over the last two decades has changed almost every aspect of data analytics. One must take into account the fact that the size of data is constantly growing and one cannot store all of it. Data is in motion, constantly expanding, and changing its properties (Morales et al. 2016). Additionally, data may come from many sources at the same time, calling for efficient preprocessing and standardization (Ramirez-Gallego et al. 2017). Such changes affected various real-life applications, including social media (Miller et al. 2014), medicine (Triantafyllopoulos et al. 2016), and security (Faisal et al. 2015) to name a few. This poses challenges for learning systems that must accommodate all these properties, while maintaining a high predictive power and capabilities of operating in real-time (Marrón et al. 2017; Ramírez-Gallego et al. 2017; Cano and Krawczyk 2018, 2019).
The velocity of data gave rise to the notion of data streams, potentially unbounded collections of data that continuously flood the system. As new data is continuously arriving, storing a data stream is not a viable option. One needs to analyze new instances on-the-fly, incorporate the useful information into the classifier, and discard them. Both the prediction and classifier update steps cannot be of a high complexity, as instances arrive rapidly and bottlenecks must be avoided. Data streams are also subject to a phenomenon known as concept drift (Gama et al. 2014; Žliobaite et al. 2015a; Barddal et al. 2017), where the properties of the stream are subject to a change over time. This includes not only the discriminatory power of features but also the size of the feature space, ratios of instances among classes, as well as the emergence and disappearance of classes.
In order to accommodate such characteristics, data streams inspired the development of new families of algorithms capable of continuous integration of new data, while providing robustness to its evolving nature. These include concept drift detectors for creating alarms when the change takes place, and incremental or online algorithms that are capable of processing new instances as they arrive and discarding them right after (Pears et al. 2014). Ensemble techniques, one of the most promising directions in standard machine learning, have been successfully applied to the both former (Woźniak et al. 2016) and the latter domains (Krawczyk et al. 2017). In this paper, we will focus on data streams classification. Although there is a plethora of existing ensemble methods for drifting data streams, none of the existing algorithms offers a stable performance over a high variety of potential streaming problems (Krawczyk et al. 2017; Gomes et al. 2017a). This calls for the development of new ensemble classifiers that will be characterized by a lower variance in the results when subject to varying types of complex data.
Furthermore, existing ensemble techniques are dedicated to either standard or imbalanced datasets but not to both of them (Hoens et al. 2012; Ren et al. 2018b). Standard ensembles fail when dealing with skewed data (Krawczyk 2016), while ensembles dedicated to imbalanced data streams perform sub-par to standard methods when the number of instances among classes is roughly equal (Krawczyk et al. 2017). Additionally, one may not know beforehand that the analyzed data stream is imbalanced, or data stream may become periodically imbalanced due to variations in ratios of arriving instances. This calls for developing a more robust approach that can work efficiently in both scenarios.
This paper proposes a new ensemble learning algorithm for drifting data streams, named Kappa Updated Ensemble (KUE). It addresses the discussed shortcomings of existing ensemble methods, offering a stable and efficient classification approach over a wide set of data stream problems. Additionally, it displays an improved robustness to class imbalance without any need for applying preprocessing or specialized base classifiers. KUE achieves this by guiding its learning process using the Kappa statistic and utilizing it for the calculation of weights assigned to base classifiers. KUE offers a combination of online and block-based approaches, both continuously updating its base classifiers and replacing them with new ones when necessary. What is important, KUE adds new classifiers only when they improve the ensemble performance, while maintaining the previous learners in opposite cases. Base classifiers used by KUE are diversified by using random feature subsets and updated with new instances with probability derived from Poisson distribution. The wider exploration of feature subspaces leads to improved generalization capabilities and better anticipation of potential concept drifts. Finally, base classifiers in KUE may abstain from voting, reducing the chance of incompetent classifiers affecting the final decision. Despite its various characteristics, KUE displays low decision and update times, as well as low computational resources consumption.
To summarize, the main contributions of this work are as follow:
-
KUE, a new ensemble classification algorithm for drifting data streams that uses the Kappa statistic for selecting and weighting its base classifiers.
-
Hybrid architecture, that updates base classifiers in an online manner, while changing the ensemble set-up in a block-based mode.
-
Diversification techniques for base learners that combine online bagging with using random feature subspaces.
-
Abstaining of base classifiers that reduces the impact of non-competent base learners.
-
Achieving stable performance over a variety of streaming problems, while maintaining robustness to drift and class imbalance, and displaying low computational complexity.
-
A thorough experimental study, comparing KUE to 15 state-of-the-art ensemble methods over 60 standard and 33 imbalanced data stream benchmarks.
-
An analysis of the contribution and impact of each of the algorithm’s mechanisms individually.
The rest of the paper is organized as follows. Section 2 presents an overview of data stream mining and related works in ensemble learning and imbalanced classification for data streams. Section 3 provides a detailed description of the proposed Kappa Updated Ensemble algorithm, its architecture, and principles. Section 4 presents a thorough experimental study on a large set of data streams, including imbalanced streams with concept drift and varying imbalance ratio. Moreover, the contribution of each of the algorithm’s mechanisms is individually analyzed to evaluate their impact in the quality of the predictions. Experimental results are also validated through non-parametric statistical analysis. Finally, Sect. 5 summarizes the concluding remarks and discusses future lines of work.
2 Data stream mining
This section presents a comprehensible overview of data stream mining, concept drift, ensemble classifiers for data streams, and introduces the challenge of imbalanced learning in data stream mining.
2.1 Overview
A data stream can be seen as a sequence \(<S_1, S_2, \ldots , S_n,\ldots>\), in which each element \(S_j\) is a set of instances (or a single instance in a case of online learning) (Gaber 2012). Each instance is independent and randomly generated using a stationary probability distribution \(D_j\). In this paper, we consider the supervised learning scenario that allows us to define each element as:
where \(p_j(\mathbf {x},y)\) is a joint distribution of jth instance, defined by d-dimensional feature space and belonging to class y. Each instance in the stream is independent and randomly drawn from a stationary probability distribution \(\varPsi _j (\mathbf {x},y)\).
If a transition \(\hbox {S}_j \rightarrow \hbox {S}_{j+1}\) (where \(\hbox {D}_j = \hbox {D}_{j+1}\)) holds, then we deal with a stationary data stream. However, real-life problems are usually subject to a change over time, where the characteristics and definitions of a stream evolve. This phenomenon is known as concept drift (Brzeziński and Stefanowski 2013; Gama et al. 2014; Balle et al. 2014; Webb et al. 2016, 2018).
We will now present main aspects related to concept drift and other difficulties present in evolving data streams:
-
Influence on decision boundaries There is a distinction between real and virtual concept drifts (Sobolewski and Woźniak 2013). The former influences previously learned decision rules or classification boundaries, increasing the error on instances coming from the current stream concept. Real drift affects posterior probabilities \(p_j(y|\mathbf {x})\) and additionally may impact unconditional probability density functions. It poses a significant threat to the learning system and must be tackled as soon as it appears. Virtual concept drift affects only the distribution of features \(\mathbf {x}\) over time:
$$\begin{aligned} \widehat{p}_j(\mathbf {x}) = \sum _{y \in Y} p_j(\mathbf {x},y), \end{aligned}$$(2)where Y is a set of possible values taken by \(S_j\). As only the values of features change, this type of drift does not force us to adapt the used classification model. However, it may trigger false change alarms and thus force unnecessary and costly adaptations.
-
Locality of changes We distinguish between global and local concept drifts (Gama and Castillo 2006). The former one affects the entire stream, while the latter one affects only certain parts of it (e.g., selected regions of the feature space or subsets of classes). These types of drifts should be distinguished, as often rebuilding the entire classification model is not necessary and one may concentrate in updating only the part of the learning system that has been subject to a local concept drift.
-
Speed of changes We distinguish between sudden, gradual, and incremental concept drifts (Gama et al. 2014).
Sudden concept drift describes a scenario in which underlying instance distribution abruptly changes with tth example arriving from the stream:
$$\begin{aligned} p_j(\mathbf {x},y) = {\left\{ \begin{array}{ll} D_0 (\mathbf {x},y), &{} \quad \text {if } j < t\\ D_1 (\mathbf {x},y), &{} \quad \text {if } j \ge t \end{array}\right. } \end{aligned}$$(3)Incremental concept drift can be seen as a steady progression from one concept to another (thus consisting on multiple intermediate concepts in between), such that the distance from the old concept is increasing, while the distance to the new concept is increasing:
$$\begin{aligned} p_j(\mathbf {x},y) = {\left\{ \begin{array}{ll} D_0 (\mathbf {x},y), &{} \text {if } j< t_1\\ (1 - \alpha _j) D_0 (\mathbf {x},y) + \alpha _j D_1 (\mathbf {x},y), &{}\text {if } t_1 \le j < t_2\\ D_1 (\mathbf {x},y), &{} \text {if } t_2 \le j \end{array}\right. } \end{aligned}$$(4)where
$$\begin{aligned} \alpha _j = \frac{j - t_1}{t_2 - t_1}. \end{aligned}$$(5)Gradual concept drift stands for a situation where over a given period of time instances arriving from the stream oscillate between two distributions:
$$\begin{aligned} p_j(\mathbf {x},y) = {\left\{ \begin{array}{ll} D_0 (\mathbf {x},y), &{} \text {if } j< t_1\\ D_0 (\mathbf {x},y), &{} \text {if } t_1 \le j< t_2 \wedge \delta > \alpha _j\\ D_1 (\mathbf {x},y), &{} \text {if } t_1 \le j < t_2 \wedge \delta \le \alpha _j\\ D_1 (\mathbf {x},y), &{} \text {if } t_2 \le j, \end{array}\right. } \end{aligned}$$(6)where \(\delta \in [0,1]\) is a random variable. This models the decreasing probability of old concept occurrence with increasing probability of the new concept occurrence.
-
Recurrence In many scenarios it is possible that a previously seen concept from kth iteration may reappear D\(_{j+1}\) = D\(_{j-k}\), once or periodically (Gama and Kosina 2014). This is known as recurring concept drift.
-
Presence of noise Apart from concept drift, one may encounter other types of changes in data. They are connected with the potential appearance of incorrect information in the stream, and known as blips and noise (Zhu et al. 2008; Chandola et al. 2009). Blips are random changes in stream characteristics that should be ignored (may be seen as outliers). Noise represents significant fluctuations in feature values or class labels, representing some corruption in received instances. While the classification model should adapt to concept drift, these types of changes should not influence the underlying model, as they will have a negative impact.
-
Feature drift This is a type of change in data streams that happens when a subset of features becomes, or stops to be, relevant to the learning task (Barddal et al. 2017). Additionally, new features may emerge (thus extending the feature space), while the old ones may cease to arrive (Barddal et al. 2019a). Therefore, classifiers need to adapt to these changes in feature space (Barddal et al. 2016) by performing a dynamic feature selection (Yuan et al. 2018; Barddal et al. 2019b), using randomness in selected features (Abdulsalam et al. 2011), or employing a sliding window and feature space transformation (Nguyen et al. 2012).
We must note that in most real-world problems the nature of changes is far from being well-defined or known, and we must be able to deal with hybrid changes through time, known as mixed concept drift. Moreover, this becomes even more challenging when access to the labels is unavailable (Sethi and Kantardzic 2017).
The simplest solution for handling concept drift is to rebuild the classification model whenever new data becomes available. Such an approach has a prohibitive computational cost and it is not feasible for any real-life applications (Žliobaite et al. 2015b; Matuszyk and Spiliopoulou 2017; Srinivasan and Bain 2017). This has led to the development of specialized methods for this problem. There are two main approaches for tackling concept drift:
-
Explicit drift handling This approach is based on using an external tool, called detector, that monitors specific characteristics of a data stream (Kuncheva 2013; Barros and Santos 2018). Most typical ones include changes in classification errors (Pesaranghader and Viktor 2016), statistical distribution variations (Sobolewski and Woźniak 2017), or density changes (Liu et al. 2018). Detectors output two types of information: warning and detection. A warning signal is being raised when a start of potential changes is being observed and informs the learning system to start training a new classifier on recent instances. A detection signal is being emitted when the magnitude of changes reaches a certain threshold and informs the learning system to replace the old classifier with a new one.
-
Implicit drift handling Here, we assume that the used classification model inherently adapts itself to changes. One of the earliest approaches was to use a sliding window of fixed size that stores most recent instances from the stream (Zhang et al. 2017). By incorporating new instances and discarding old ones, this solution achieves an adaptation to drifts in streams. A problem of proper window size setting is predominant here. Too small window will adapt swiftly even to small changes but may lead to overfitting on a small training sample. A large window will capture a more global outlook on the stream but may mix instances coming from different concepts. Recent works in this area propose to use multiple windows or to dynamically adapt the window size (Mimran and Even 2014). Another approach lies in using online learners, capable of processing instances from the stream one by one, thus focusing its learning procedure on the most recent ones (Vicente et al. 1998). Online learners are characterized by high processing speed and low computational complexity and must process each instance only once. Some standard classifiers (i.e., neural networks) are capable of working in an online mode but there is a plethora of specialized classifiers that use modified learning schemes to cope with drift presence (Zhang et al. 2016).
Please note that only explicit methods actually detect the moment of drift, are capable of pinpointing the moment of change, and acting accordingly. They return information about the change and thus can be seen as actual detection. Implicit methods follow the data and inherently adapt to changes, but they (in vast majority of cases) do not return any information on when the change took place, what was the nature of change, etc. Therefore, they cannot be considered as “detection” methods. Thus, we refer to them both as explicit and implicit drift handling methods.
2.2 Ensemble learning for data stream mining
Ensemble learning has gained significant attention in machine learning and data mining over the last two decades. Combining multiple classifiers is capable of returning an improved predictive performance over any single learner in the pool. For an ensemble to work, it must be formed from mutually complementary and individually competent classifiers. This is the problem of diversity—a combination of accurate, yet similar learners will contribute no new knowledge, while a combination of different, yet inaccurate classifiers will create a weak ensemble. Therefore, various techniques for controlled diversity creation has been proposed, with the most popular ones being Bagging, Boosting, and Random Forest (Bertini and Nicoletti 2019; Van Rijn et al. 2018; Bertini and Nicoletti 2019).
Ensemble approaches are very popular in data stream mining, which can be contributed to their flexible set-up, capabilities of changing the importance of base classifiers, as well as natural mechanisms for incorporating new information (Krawczyk et al. 2017; Gomes et al. 2017a; Dong and Japkowicz 2018). Additionally, new incoming data can be seen as an attractive way to maintain diversity among ensemble members (Minku et al. 2010). We may distinguish three main approaches for learning ensemble classifiers over data streams:
-
Weight modifications This approach focuses on modifying the weights assigned to classifiers in the ensemble, in order to reflect their current competencies over the data stream (Kolter and Maloof 2007; Ren et al. 2018a). The basic idea lies in having a diverse pool of classifiers and monitoring their performance in a dynamic way (e.g., instance by instance). Classifiers that make correct predictions can be deemed as better adapted to the current concept and thus their weights should be increased. Classifiers making incorrect decisions are penalized in a similar manner (Mejri et al. 2018). More advanced solutions take into an account the presence of concept drift that should strongly affect the weights, especially in case of sudden changes (Krawczyk et al. 2017). The weight adaptation speed after a concept drift must be much more rapid to reflect the new state of the environment.
-
Dynamic ensemble line-up This approach focuses on dynamically replacing the classifiers in the pool. After a new chunk of data becomes available, a new classifier is being trained on it and added to the ensemble (Brzeziński and Stefanowski 2014b). If a certain ensemble size has been reached, a pruning mechanism is applied to remove irrelevant learners (Ditzler et al. 2013). Usually, the oldest or weakest performing classifier is being discarded. This mechanism implements both incremental learning of new concepts, as well as gradual forgetting of old ones, thus naturally tackling the evolving nature of data streams. Dynamic ensemble set-up is usually connected with specific weighting mechanisms that promote the newest ensemble members and reduce the weights as time passes (Jackowski 2014). Recent proposals postulate to boost the weights of classifiers if they are performing well on current instances even if these learners are trained on older concepts (Woźniak et al. 2013).
-
Online ensemble update This approach focuses on maintaining a pool of online classifiers that are updated with incoming instances (Pietruczuk et al. 2017; Zhai et al. 2017; Pesaranghader et al. 2018). Here the set-up is stable and learners adapt to drifts by updating them with new data (Olorunnimbe et al. 2018; Bonab and Can 2018). Additionally, this is used to maintain diversity among base classifiers, as if each of them would be updated with the same set of instances, they would all converge to similar models (Minku et al. 2010). Dynamic classifier selection is a specific case of online approach, as a pool of online learners is being maintained but only the most competent ones are being selected for the decision making process (Almeida et al. 2016).
Apart from these main trends, there exist a plethora of hybrid solutions that merge the mentioned techniques. Often dynamic ensemble line-ups are combined with online learners to achieve faster response rates (Brzeziński and Stefanowski 2014a), or online ensembles incorporate a pruning mechanism to discard classifiers that would be too difficult to properly adapt to the current state of the stream (Bifet et al. 2010b).
2.3 Imbalanced data streams
Imbalanced distribution of instances among data classes poses a significant problem for learning systems (Krawczyk 2016). This issue becomes even more challenging when being present in a data stream mining scenario (Chen and He 2013; Wang et al. 2018). Here, we must accommodate not only for skewed classes but also for the evolving nature of data. Main issues related to imbalanced data streams include (Chen and He 2013; Fernández et al. 2018):
-
Simultaneous concept and imbalance ratio drift The proportions of objects among classes may change along the presence of concept drift. Therefore, classes are not permanently associated with their minority or majority roles, as these may change over time.
-
Evolving data characteristics Minority instances may have a different level of hardness associated with them. This information may be used to improve the learning process by concentrating on the most difficult instances. However, in data streams these properties may change dynamically, forcing an adaptation of imbalance handling techniques.
-
Emergence and disappearance of new classes Over time, new classes may emerge and old ones disappear. As this is usually a gradual process, it will affect the class imbalance ratios, which must be accounted for.
A real-world example of such a problem is a network of sensors that collectively work towards recognizing activities or object position. Here, the number of observations recorded by each sensor will change over time, as well as the environmental conditions in the network area. Novel activities may appear, increasing the number of classes to be recognized, as well as further changing the minority-majority relationships among classes.
Ensemble algorithms have been applied to learning from imbalanced data streams with great success. They usually aim at balancing data in every arriving chunk (Wang and Pineau 2016), or in case of online learning employing incremental sampling solutions to balance the stream instance by instance (Wang et al. 2015).
These solutions have been applied to problems that are known beforehand as imbalanced ones. However, one must note that in the data stream domain one usually does not know beforehand what characteristics of data are to be expected. While these specific solutions are effective for imbalanced streams, they are easily outperformed by other models on balanced streams (Krawczyk 2017). Class imbalance may appear periodically, e.g., after a concept drift when instances from a new concept still appear less frequently (Sun et al. 2016). Therefore, in many real-time scenarios one cannot predict if and when the stream will output imbalanced distributions. This requires classification algorithms that are able to handle effectively balanced data streams, while at the same time displaying increased robustness to class imbalance.
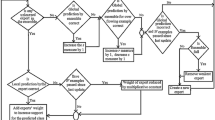
3 Kappa Updated Ensemble
This section presents the Kappa Updated Ensemble (KUE) algorithm, the learning model and its components, its computational and memory complexity, and its advantages as compared with state-of-the-art ensembles for data streams. KUE is detailed in Algorithm 1. The main idea of KUE is to integrate the advantages already demonstrated in the data stream mining literature of incremental learning, varying-size random subspaces, online bagging (Bifet et al. 2010b), and dynamic weighted voting (Kolter and Maloof 2007), into a single algorithm driven by the Kappa statistic while keeping a simple, effective, and computationally efficient algorithm capable of quickly self-adapting to drifts in features and data classes distribution without requiring an explicit drift detector. KUE maintains a weighted pool of diverse component classifiers and predicts the class of incoming examples by aggregating the predictions of components using weighted voting with possible abstention.

3.1 Ensemble structure and initialization
Let \(\mathcal {E}\) be an ensemble classifier comprised by k components of \(\gamma \) base classifiers such that \(\gamma _j\)\(\in \)\(\mathcal {E}\) (\(j = 1, 2, \dots , k\)). The components of the ensemble are initialized when the first data chunk \(\mathcal {S}_1\) in the data stream \(\mathcal {S}\) arrives. In order to promote the diversity of the ensemble components exploring feature subspaces of varied dimensionality, each base classifier \(\gamma _j\) is built on a different r-dimensional random subspace \(\varphi _j\), where \(1 \le r \le f\) from the original f-dimensional space in S. Importantly, the dimensionality and the subspace of features for each component are both randomized. This is a significant difference as compared to Adaptive Random Forest (Gomes et al. 2017b) which selects a fixed subspace dimensionality for all the components. We consider that allowing a different subspace dimensionality per ensemble component provides better flexibility to identify and explore more diverse random feature subspaces.
On the other hand, online bagging is applied to weight and resample with replacement instances within the subspace using the Poisson(1) distribution. It has been shown that this online bagging approach improves the performance of data stream classifiers, particularly OzaBag (Oza 2005), Leverage Bagging (Bifet et al. 2010b), and Adaptive Random Forest (Gomes et al. 2017b) follow this approach.
This way, the algorithm randomizes and diversifies the input (both instances and features) for the internal construction of the ensemble components. Once the base classifiers are trained on such data, their Kappa performances are used as weights on the voting for the class prediction of new instances.
Kappa statistic has been commonly used in imbalanced classification (Ferri et al. 2009; Jeni et al. 2013; Brzeziński et al. 2018). It evaluates the competence of a classifier by measuring the inter-rater agreement between the successful predictions and the statistical distribution of the data classes, correcting agreements that occur by mere statistical chance (Cano et al. 2013). Kappa statistic ranges from \(-100\) (total disagreement) through 0 (default probabilistic classification) to 100 (total agreement), and it is computed as in Eq. 7:
where \(x_{ii}\) is the count of cases in the main diagonal of the confusion matrix (successful predictions), n is the number of examples, c is the number of classes, and \(x_{.i}\), \(x_{i.}\) are the column and row total counts, respectively. Importantly, Kappa penalizes all-positive or all-negative predictions, which is especially useful in multi-class imbalanced data. Moreover, since the data classes distributions may change through the progress of the stream, Kappa provides better insight than other metrics to detect changes in the performance of the algorithms due to drifts in the data classes distribution.
3.2 Ensemble model update
Every time a new data chunk \(\mathcal {S}_i\)\(\in \)\(\mathcal {S}\) arrives, data is projected on the existing random subspaces for each of the ensemble components and instances are weighted through online bagging using the Poisson(1) distribution (Bifet et al. 2010b). This way, the existing components of the ensemble are incrementally updated using the new data input diversified for each member, similar to Adaptive Random Forest (Gomes et al. 2017b). The competence of the updated components is evaluated on the most current data and their Kappa are updated. This is similar to the Accuracy Updated Ensemble (Brzeziński and Stefanowski 2011) but using the Kappa statistic rather than accuracy to drive the competence of classifiers.
Two scenarios may occur here when updating the competence of the components. In case of receiving a chunk maintaining a similar data distribution than previous chunks, the performance of each of the components is expected to be stable. The components will update and refine their learned model. However, in case of a drift in the concepts, features, data classes, or noise, the performance of the components may significantly decrease, especially in the event of a sudden drift. Therefore, in order to preemptively anticipate any possible drifts of unknown nature, a new set of q classifiers are trained and evaluated each in a new r-dimensional random subspace on the most recent chunk. The variable random nature of the feature projections in the building of the new components helps to overcome drifts and noise on an undetermined sets of features. If the Kappa statistic of each of the new classifiers improves the Kappa statistic of the weakest existing component, then it replaces such component as it demonstrates to be most up to date. By replacing the weakest components with the newest classifiers, the algorithm balances the learning of new classification models and the forgetting of old classifiers which are no longer valid due to the drift in the data. This way, there is no need for an explicit drift detector as the self-update mechanism is intrinsic to the design of the ensemble update model.
3.3 Weighted voting
The class prediction \(\hat{y}\) of an instance x is conducted through weighted majority voting of each of the ensemble components using their Kappa on the most current chunk. The weighted aggregated voting is defined in Eq. 8:
This simplifies the ensemble weighting mechanism while reflecting the most up to date competence of the components. Importantly, components participate in the class voting only when their Kappa \(\ge \) 0, i.e., those components whose competence is clearly not good enough abstain from the vote. Abstaining classifiers have demonstrated to improve the performance of online ensembles for drifting and noisy data streams (Błaszczyński et al. 2009; Krawczyk and Cano 2018). On the other hand, in the unlikely case of all classifiers having a Kappa value < 0 means that no classifier was able to model the data better than a default-hypothesis classifier based on the data class distribution. Therefore, in such cases the class prediction is returned according to a roulette selector given the class distribution frequencies.
3.4 Complexity analysis
Let us now analyze the time and memory complexity of the KUE algorithm. The algorithm receives a data chunk \(\mathcal {S}_i\)\(\in \)\(\mathcal {S}\) of \(|\mathcal {S}_i|\) instances. The ensemble comprises k base classifiers. The base classifier for KUE is HoeffdingTree, also known as VFDT, which builds a decision tree with a constant time and constant memory per instance (Hulten et al. 2001). Therefore, the ensemble initialization on the first chunk \(\mathcal {S}_1\) has a time complexity of \(\mathcal {O}(k|\mathcal {S}_1|)\). The ensemble model update on a subsequent chunk \(\mathcal {S}_i\) has a time complexity of \(\mathcal {O}(k|\mathcal {S}_i|)\) to update the k existing components. Moreover, the algorithm trains \(q \le k\) new components on the chunk \(\mathcal {S}_i\) potentially replacing the weakest members, which has a time complexity of \(\mathcal {O}(q|\mathcal {S}_i|)\). Consequently, the time complexity of KUE is \(\mathcal {O}((k + q)|\mathcal {S}_i|)\).
The memory complexity of the base classifier HoeffdingTree is \(\mathcal {O}(fvlc)\) where f is the number of features, v is the maximum number of values per feature, l is the number of leaves in the tree, and c is the number of classes (Hulten et al. 2001). However, KUE performs r-dimensional random subspace projections for each of the k and q components, where \(r \le f\), then effectively reducing the memory complexity of HoeffdingTree to \(\mathcal {O}(rvlc)\). Therefore, the memory complexity of KUE comprising k components plus one new trained at a time is \(\mathcal {O}((k+1)rvlc)\).
3.5 Contribution, novelty, and advantages over existing ensembles
Initialization of components KUE initializes the k components using data from the first chunk \(\mathcal {S}_1\) projected on different random feature subspaces. On the contrary, Accuracy Updated Ensemble and Accuracy Weighted Ensemble initialize only one component in each of the initial k chunks and on whole of the feature set. This makes KUE more accurate and reliable at the beginning of the stream sequence since the k diverse components exist from the very first chunk.
Impact of learning in subspaces Online bagging and random subspaces have demonstrated to improve the performance of ensembles for online data streams, inspired by Random Forests alike methods such as Adaptive Random Forest (Gomes et al. 2017b). However, the traditional approach is to build the ensemble components on random subspaces of the same fixed dimensionality. This raises important concerns on whether this approach is the best for data streams subject to concept drifts. First, the optimal subspace size cannot be predetermined apriori as it depends on the dataset distribution and on the relevance, redundancy, or noise in the features. Second, the dimensionality of the subspace should not be constant since features and noise are subject to drift with time, making it necessary to dynamically adapt as the stream evolves. One may think about a scenario in which noise is propagating from none to all features as the stream progresses, making fixed size subspaces incapable of dynamically adapting. Therefore, the dynamic and variable size of the random subspaces in KUE constitutes a significant advantage to adapt to such scenarios. Moreover, exploring random small subspaces allows for faster model training and better classifier generalization while keeping competitive accuracy.
Kappa metric for classifier weighting Use of Kappa rather than accuracy for evaluating the competence of a data stream classifier in an ensemble is beneficial in three ways. First, there is a clear threshold for Kappa > 0 in which one can determine whether a classifier is positively contributing to the ensemble by making a likely a correct prediction. Components whose Kappa < 0 are discarded as they actually introduce misleading predictions. However, when using accuracy this is not possible since the mere accuracy value is not informative enough as it does not take into account the data classes distribution. Second, Kappa is a strict measure that will quickly drop in case of incorrect predictions, making it much more useful for weighting components rather than using accuracy that would only introduce small changes in weights. Third, the data classes distribution may drift as the stream progresses. Kappa is capable of capturing the competence of the components reflecting the possibly varying data classes distribution with time. Therefore, this is a significant advantage in KUE as compared with existing ensembles driven by accuracy such as Dynamic Weighted Majority (Kolter and Maloof 2007), Accuracy Updated Ensemble (Brzeziński and Stefanowski 2011), or Accuracy Weighted Ensemble (Wang et al. 2003).
Incorporating new classifiers Accuracy Updated Ensemble (Brzeziński and Stefanowski 2011) treats the newly trained classifier for each chunk as perfect and its predictions are not weighted. However, this may not be the best option, especially on complex data where high accuracy is difficult to get, making the new classifier overconfident. On the other hand, in KUE the weights of the new classifier are taken into account as soon as the classifier joins the ensemble, reflecting its most current competence.
Moreover, KUE is designed to train and replace q classifiers at a time, replacing many base classifiers if needed due to extreme drifts of the stream where all previous base classifiers would become immediately outdated. However, according to the experiments in Sect. 4.5, it is shown that training one new base classifier per chunk is sufficient to achieve competitive results while keeping the lowest computational complexity.
Abstaining classifiers Abstaining classifiers in the weighted voting is a significant advantage as compared to similar existing ensemble methods (Krawczyk and Cano 2018), especially in the case of a sudden drift where many of the components are suddenly no longer competent. In such a scenario, block-based ensembles may not react sufficiently fast to changes and it takes few iterations to learn new correct models in the new data distribution. Traditional block-based ensembles may react too slowly as classifiers generated from outdated blocks still remain valid components even though they have inaccurate weights. On the contrary, by allowing a classifier to abstain in KUE, only the components that correctly reflect the current concepts of the stream will participate in the vote, avoiding misleading predictions from outdated components.
In this work, we propose to combine them all along with the Kappa metric to lead the selection and update of the base classifiers.
4 Experimental study
This section presents the algorithms, datasets, and experiments designed to evaluate and compare the performance of the proposed method with state-of-the-art ensembles for data streams.
4.1 Algorithms
The KUE algorithm has been implemented in the Massive Online Analysis (MOA) software (Bifet et al. 2010a, 2018), which includes a collection of generators, algorithms, and performance metrics for data streams. The proposal is compared with 15 other ensemble classifiers for data stream mining available in MOA, all using a single-thread implementation in Java. These comprise a diverse set of methods including block-based, bagging, boosting, random forest, and weighted ensembles (Gama et al. 2013).
Table 1 lists the algorithms, their base learners, and their main parameters, which were selected according to the recommended values reported by their authors and other studies in this area. The KUE algorithm’s source code, an executable version, and the datasets along with detailed results for the experimental analysis are available online to facilitate the reproducibility of results and future comparisons.Footnote 1 Experiments were run on an Intel Xeon CPU E5-2690v4 with 384 GB of memory on a Centos 7 \( \times \, 86-64\) system.
4.2 Datasets
The experimental study comprises 60 standard and 33 imbalanced data stream benchmarks to evaluate the performance of algorithms. Properties of the data stream benchmarks are presented in Tables 2 and 3. We have selected a diverse set of benchmarks reflecting various possible drifts (no drift, gradual drift, recurring drift, sudden drift), including 13 real datasets, and a variety of stream generators (RBF, RandomTree, Agrawal, AssetNegotiation, LED, Hyperplance, Mixed, SEA, Sine, STAGGER, Waveform) with different properties concerning speed and number of concept drifts. Moreover, for imbalanced datasets, we analyze the impact of the imbalance ratio (IR), including scenarios where the imbalance ratio dynamically changes through the progress of the stream. The imbalance ratio represents the relation between the number of instances of the majority class and the minority class. In the case of multi-class imbalanced dataset it is reported as the relation between the most frequent class and the least frequent class. For the sake of conducting a fair comparison, the chunk size is set to 1000 instances for all algorithms, which is the default setup in the chunk evaluation of data stream mining algorithms and it also the default value provided by MOA (Bifet et al. 2010a, 2018). To the best of our knowledge, this is one of the biggest experimental setups conducted so far as most papers in data streams are based on 8-16 benchmarks (Krawczyk et al. 2017; Gomes et al. 2017a).
4.3 Experiment 1: Evaluation on standard data streams
Table 4 shows the average performance and ranks of the classifiers on the 60 standard data streams. Results are provided for accuracy, Kappa, model update (train time), prediction (test time), and memory consumption (RAM-Hours). Different metrics provide complementary perspectives of the predictive power of the classifiers. Ranks of the classifiers according to Friedman are reported for each metric. Finally, the meta-rank shows the average rank across all metrics.
Table 5 shows the accuracy for each of the 60 standard data streams. The accuracy is averaged through all the instances of the stream. Detailed results for all metrics and datasets are available online (see footnote 1) including plots with the variation of the performance metrics through the progress of the stream.
Table 6 presents the outcomes of Wilcoxon statistical test (García and Herrera 2008; García et al. 2010) where the lower the p value the bigger differences between the algorithms, while Figs. 1 and 2 depict the visualizations of ranks according to the Bonferroni–Dunn test. Figure 3 presents the pairwise comparison between KUE and reference methods with the respect to the number of wins, ties, and loses on all datasets. Figure 4 depicts the distribution of the frequencies of ranks achieved by all of the ensemble classifiers over all datasets.
Finally, Figs. 5, 6 and 7 present detailed results over all processed instances in the stream for three selected datasets with respect to accuracy, Kappa, chunk update time, and memory consumption.
Comparison with other ensembles KUE has been compared with 15 other ensemble classifiers on 60 standard data stream benchmarks. KUE is capable of outperforming in a statistically significant manner 11 out of 15 reference classifiers on more than 45 datasets each. Therefore, we will focus on a detailed analysis of the top 4 reference methods, which are OBAD, LB, AUE2, and ARF.
OBAD returns the best performance on average among all classifiers for both accuracy and Kappa metrics. From Fig. 3 one can see that OBAD returns better results than KUE on 15 datasets, and ties with KUE on 20 datasets. Figure 4 shows that OBAD does not score the first rank as frequently as LB or KUE but at the same time is rarely in a lower position than 5th. This makes it the most challenging reference method for KUE, as OBAD proves to be a good all-purpose classifier. However, the superiority of KUE can be seen on Fig. 4, as KUE never achieves a lower rank than 6th, while for certain datasets OBAD can position itself on as low ranks as 9th or 10th. Additionally, the pairwise statistical analysis proves that differences between KUE and OBAD are statistically significant.
LB is another challenging reference classifier. It is interesting to see that according to Fig. 3, LB wins with KUE on a higher number of datasets than OBAD. At the same time, KUE wins with LB more frequently than with OBAD, as ties here are very rare. This shows that LB delivers unstable results that are highly dependent on the datasets. Analyzing Fig. 4, we can see that LB scores a similar number of first positions as KUE, and more than OBAD. At the same time, there are certain datasets on which LB achieves much lower scores, ultimately leading to its lower overall average ranking. This shows that LB is not as data-invariant as KUE, making it less reliable for general data stream mining purposes.
AUE2 is a natural counterpart of KUE, as they share similar roots in how to expand the ensemble and use a predictive metric for weighting. Results clearly point to the superiority of KUE over AUE2, which can be contributed to our proposed mechanisms. By using random feature subsets we achieved a better multi-view grasp of data stream characteristics, and by adding new classifiers only when they contribute to the ensemble we are able to avoid updating the ensemble set-up when not necessary. Figure 3 shows that KUE outperforms AUE2 on a similar number of datasets as it outperforms OBAD but is much more likely to tie with AUE2 than lose to it. When analyzing the rank frequencies, one can see that AUE2 often scores as the second best classifier, incapable of securing the first rank on most of the datasets.

Bonferroni–Dunn test for accuracy on standard data

Bonferroni–Dunn test for Kappa on standard data

Comparison of KUE and reference ensemble classifiers with respect to the number of wins (green), ties (yellow), and losses (red) over 60 standard data stream benchmarks datasets. A tie was considered, when the difference in obtained metric values were \(\le 0.05\) (Color figure online)

Frequencies of ranks scored by ensemble classifiers on 60 standard data stream benchmarks

Performance of top 5 ensemble methods according to their prequential accuracy, prequential Kappa, chunk update time, and memory consumption on LED generator with sudden concept drift

Performance of top 5 ensemble methods according to their prequential accuracy, prequential Kappa, chunk update time, and memory consumption on RBF generator with gradual concept drift

Performance of top 5 ensemble methods according to their prequential accuracy, prequential Kappa, chunk update time, and memory consumption on Agrawal generator with recurrent sudden concept drift
ARF is surprisingly the weakest of all top four methods. It wins with KUE on the same number of datasets as AUE2 but is less likely to tie with it. Therefore, ARF loses to KUE most frequently of all four top performing classifiers. Analyzing its rank frequencies shows that they are evenly distributed between second and 11th rank, proving that ARF is subject to the highest variance in its performance.
These results allow us to conclude that KUE is a suitable choice for a wide array of data stream mining problems, always returning a satisfactory performance. Additionally, the analysis of rank frequencies shows its high stability over all datasets, making KUE an excellent off-the-shelf algorithm.
Computational complexity KUE offers both better predictive power and lower time complexity. Not only does KUE outperform in both accuracy and Kappa metrics the top four reference ensemble methods (OBAD, LB, AUE2, and ARF), but it is also characterized by up to 10 times faster update time per chunk and using an order of magnitude less memory. This shows that the proposed components of KUE are not only lightweight themselves but also lead to gaining an advantage over reference ensembles.
Using feature subspaces speeds up the training of new classifiers, as the models are fitted in a lower dimensional space. Additionally, the classifier selection procedure does not impose any additional cost, as it simply measures the Kappa metric returned by new and existing classifiers.
Figures 5, 6 and 7 allow us to analyze the time and memory requirements of KUE in more details over three selected data streams. KUE displays a very stable utilization of computational resources that does not display any significant variations over time. Furthermore, KUE complexity is not influenced by the sudden presence of concept drift as can be seen for LED and Agrawal streams.
All these characteristics show that KUE combines an accurate predictive power with low computational resource consumption, making it a suitable choice for high-speed data stream mining, as well as for applications in environments with constrained resources, like edge computing on mobile devices.
Recovery rates after concept drift Recovery after a concept drift is crucial in every data stream mining algorithm. It can be seen as a period of time (or a number of instances) after which a classifier is capable of returning a stable performance, i.e., capturing the properties of a new concept. This is especially important in case of a sudden change where base classifiers need to be trained from scratch. The recovery period is a time in which classifiers cannot be treated as a competent and thus the risk of making an incorrect prediction is increased.
A popular way of analyzing the recovery rates is a visual analysis of error rates by plotting the performance over an entire stream. This can be seen in Figs. 5, 6 and 7 for three selected datasets: LED and Agrawal with a sudden concept drift, and RBF with a gradual concept drift. Each of these datasets was prepared in such a way that clearly emphasizes the point of change. LED has a single drift after 500,000 instances, Agrawal has 5 drifts after 175,000 instances each, and RBF has a drift present through the entire time. This allows us to analyze the behavior of KUE and the top 4 reference ensembles on these challenging scenarios.
One can see that in all three cases KUE is capable of reducing its error in the smallest amount of time. AUE2 and ARF are capable of satisfactory drift recovery, yet still being slower than KUE in most of the cases. OBAD and LB require the highest number of instances to reduce their error, invalidating them for high-speed data streams with frequent rapid changes.
The excellent adaptability of KUE can be contributed to two factors: usage of feature subspaces by each classifier, and weighting base classifiers according to Kappa metric. The former property offers interesting behavior on drifting streams, as only certain features may be affected by concept drift. KUE holds a pool of diverse base classifiers, each using a different subset of features. This allows them to better anticipate the direction of changes and improves the probability of having a classifier that uses features less (or not at all) affected by concept drift. The latter property offers capabilities for boosting the importance of the most competent classifiers after concept drift presence. The Kappa metric promotes classifiers that are most different from random decisions, thus allowing to assign them the highest weight in the class prediction. This naturally combines with the fact that classifiers use different features, allowing KUE to focus on classifiers that were least affected by concept drift, or that are achieving the best recovery rates using new instances.
4.4 Experiment 2: Evaluation on imbalanced data streams
The aim of the second experiment was to examine the robustness of KUE to class imbalance, as compared to the reference ensemble algorithms. While KUE was not specifically designed for the imbalanced data stream mining, we wanted to evaluate how KUE will respond to skewed class distributions, especially when combined with the concept drift. We do not compare KUE with specific methods designed for imbalanced data streams (Brzeziński and Stefanowski 2018), as our work does not focus on this issue. We wanted to check if, by simple alteration of the general streaming ensemble scheme and the Kappa statistic, we are able to improve the performance on imbalanced data without using dedicated sampling or algorithm-level modifications.
Table 7 shows the average performance and ranks of the classifiers on the 33 imbalanced data streams. Results are provided for accuracy, AUC, Kappa, G-Mean, model update (train time), prediction (test time), and memory consumption (RAM-Hours). Different metrics provide complementary perspectives of the predictive power of the classifiers. Ranks of the classifiers according to Friedman are reported for each metric. Finally, the meta-rank shows the average rank across all metrics.
Table 8 shows the Kappa for each of the 33 standard data streams. The Kappa is averaged through all the instances of the stream. Detailed results for all metrics and datasets are available online\(^{1}\) including plots with the variation of the performance metrics through the progress of the stream.
Table 9 presents the outcomes of Wilcoxon test (García and Herrera 2008; García et al. 2010) where the lower the p value the bigger differences between the algorithms, while Figs. 8, 9, 10 and 11 depict the visualizations of ranks according to the Bonferroni–Dunn test. Figure 12 presents the pairwise comparison between KUE and reference methods with the respect to the number of wins, ties, and loses on all datasets. Figure 13 depicts the distribution of the frequencies of ranks achieved by all of the ensemble classifiers over all imbalanced datasets.

Bonferroni–Dunn test for accuracy on imbalanced data

Bonferroni–Dunn test for AUC on imbalanced data

Bonferroni–Dunn test for Kappa on imbalanced data

Bonferroni–Dunn test for G-Mean on imbalanced data

Comparison of KUE and reference ensemble classifiers with respect to the number of wins (green), ties (yellow), and losses (red) over 33 imbalanced data stream benchmarks. A tie was considered, when the difference in obtained metric values were \(\le 0.05\) (Color figure online)

Frequencies of ranks scored by ensemble classifiers on 33 imbalanced data stream benchmarks

Performance of top 5 ensemble methods according to their prequential AUC, prequential Kappa, chunk update time, and memory consumption on Hyperplane generator with imbalance ratio drift (1:1 to 1:20)

Performance of top 5 ensemble methods according to their prequential AUC, prequential Kappa, chunk update time, and memory consumption on Hyperplane generator with imbalance ratio drift (1:10 to 1:1 to 10:1)

Performance of top 5 ensemble methods according to their prequential AUC, prequential Kappa, chunk update time, and memory consumption on Agrawal generator with sudden concept drift and imbalance ratio drift (1:1 to 1:20)
Finally, Figs. 14, 15 and 16 present detailed results over all processed instances in the stream for three selected datasets with respect to AUC, Kappa, chunk update time, and memory consumption.
The role of class imbalance in data stream mining While this work does not focus on imbalanced data stream mining, one must be aware that the issue of skewed class distributions may appear in any data stream problem. As instances arrive over time and we have no control over the source of data, periodically we may obtain more instances from one of the classes. Such local class imbalance is usually not taken into account by the current solutions that either assume that the stream is always roughly balanced or that the class imbalance is embedded in the nature of the analyzed problem. However, such local distribution fluctuations may be harmful to a classifier and lead to creating a bias towards one of the classes that will propagate to new instances (even if they will not be imbalanced) and will be difficult to remove. As local imbalance will affect all the classifiers in the ensemble, one cannot deal with it by simply discarding one of the classifiers. Additionally, after a bias has been created, updating classifiers with new balanced distributions will not instantly remove it. Therefore, even shortly appearing imbalanced distributions may have long-term effects on any ensemble algorithm. That is why we postulate that even general-use data stream mining methods should display a high robustness to skewed class distributions.
Performance comparison using skew-insensitive metrics As accuracy is not a proper metric for evaluating imbalanced problems, we have selected three skew-insensitive prequential measures: AUC, Kappa, and G-mean (Jeni et al. 2013; Brzeziński et al. 2018). For the purpose of evaluation, we have created 33 imbalanced benchmarks without and with concept drift, as well as with static or changing class imbalance ratios.
For the AUC metric, KUE offers the highest average performance, with OBASHT and OBAD following closely (87.86 vs. 87.39 and 87.37 respectively). This is confirmed by the rank test, where KUE scores 2.80, OBASHT 4.12 and OBAD 3.17. It is interesting to highlight that while the average AUC is higher for OBASHT, OBAD achieves a much better rank. This shows that OBASHT is not stable and displays a high variance among different datasets. On the contrary, KUE returns highly stable performance over all 33 benchmarks, always achieving both high AUC values and high positions in rankings. All other ensemble methods performed inferior to these three methods, showing that they are highly susceptible to skewed class distributions. It is interesting to see that AUE1 and AUE2, very well performing methods for standard data streams, return sub-par performance when handling skewed classes. Therefore, the only competitor for KUE is OBAD. While their AUC performance is similar, OBAD is a much slower and computationally expensive method than KUE, as proven by training time (0.4967 s vs. 0.0554 s) and memory consumption (5.43E−3 vs. 4.33E−4 RAM-Hours). This shows that when considering AUC as a metric, KUE offers an excellent performance both in predictive power and computational complexity.
For the Kappa metric, we achieve the highest differences between KUE and reference ensembles, which is to be expected as KUE optimizes this metric directly. Here, the three follow-up performers to KUE are OBAD, LB, and HEB (67.32, 64.84, and 67.85 vs. 69.84). OBAD once again offers a stable performance when taking ranks into an account but at the cost of increased resource consumption.
Finally, for the G-mean metric, we observe a different behavior. KUE is still the best performing ensemble on average but OBASHT is not performing well for G-mean (with a rank of 9.32). The best performing reference methods are OCB, OBAD, and HEB, following closely the performance of KUE (75.89, 75.05, and 76.72 vs 77.18). However, this can be perceived differently, when analyzing the ranks of these algorithms (6.24, 3.83 and 5.89 vs 3.59). Once again, we can see that among the top-performing reference methods only OBAD offers a coherent performance between average G-mean and ranks but again at the cost of higher computational resource consumption than KUE.
To summarize, KUE offers the most stable performance on imbalanced data on all the three skew-insensitive metrics. This proves its increased robustness to imbalanced distributions as compared to reference ensemble methods. This is important from the perspective of potential periodical (or local) imbalance appearing in standard data streams, as one cannot anticipate them and thus cannot employ efficiently dedicated algorithms to combat skewed classes. KUE combines excellent performance on standard data streams while being more robust to class imbalance, making it a highly attractive off-the-shelf algorithm for a diverse set of data stream problems.
Role of Kappa statistic KUE derives its good performance from the usage of Kappa statistic for both classifier selection and weighting. The advantage of Kappa lies in its applicability to both standard and imbalanced problems, as it can handle multi-class datasets and displays skew-insensitive characteristics. Therefore, contrary to other metrics, it can be seen as a more universal tool for monitoring the ensemble performance and a good choice when one requires an ensemble algorithm that can tackle a vast variety of data stream mining problems.
Role of feature subsets Another characteristic of KUE that improves its performance on imbalanced data streams is the usage of feature subsets for each base classifier. In the case of imbalanced problems, not only the imbalance ratio itself is a source of learning difficulty but also the instance-level characteristics. Even if the imbalance ratio is high but classes are easily separable, there will be no bias towards the majority class. The problem appears when instances are borderline or overlapping. These properties may be bounded with the features, as some of them will be characterized by lower or higher probability of correct separation. Therefore, base classifiers used in KUE have the possibility of discarding some of the more difficult features in used subspaces and thus reducing the bias towards the majority class. As our procedure for subspace creation is random, we cannot guide this as we would with a feature selection approach. At the same time, the random subspace creation does not impose additional computational costs on KUE, contrary to any feature selection. Therefore, using random feature subsets offers a good trade-off between improved robustness to skew-sensitive features and applicability to high-speed data streams.
4.5 Experiment 3: Analysis of Kappa Updated Ensemble properties
The third and final experiment aimed at investigating the specific properties of KUE and showcasing that our choice of its principles, components, and parameters is a valid one. We investigate the impact of the six most important aspects of the KUE algorithm on its performance: (1) the influence of Kappa vs accuracy to drive the ensemble components weighting and selection, (2) the contribution of the abstaining mechanism, (3) the contribution of the feature subspaces diversification, (4) the influence of the hybrid online architecture, (5) the number of classifiers that are trained on each new data chunk, and (6) the size of feature subsets that are used by each base classifier.

Comparison between KUE and its individualized mechanisms on accuracy, Kappa, and AUC
Influence of Kappa, abstaining, feature subspace diversification, and online architecture In order to evaluate the impact of the four discussed mechanisms on KUE performance, we have curated a set of experiments comparing different versions of KUE with one of the mechanisms being switched off. This allows us to compare their individual contributions to the KUE architecture. Figure 17 shows the comparison of performance among five different versions of KUE, using five data streams and three performance metrics.
From the results one can see that the discussed complete KUE architecture obtains the best performance, showcasing gains from embedding all four mechanisms into the learning process. There is not a single case when switching off any of the mechanisms would lead to an improvement in performance. There is a case for each mechanism showing that it contributes in a significant manner to overall KUE performance. Therefore, having all of them turned on allows for KUE to return excellent performance on a wide range of data stream problems. Thus, KUE can be seen as an off-the-shelf solution that could handle diverse classification problems without a need for any tedious parameter tuning or selecting which mechanisms should be switched off.
As for contributions of individual mechanisms, one can see that using online architecture leads to greatest improvements on all of metrics. This shows that combining block-based training of a new classifier with online updating of the ensemble members allows for better capturing both short-term and long-term changes, as well as adapting to local data characteristics without losing generalization capabilities. Diversity (i.e., using random feature subspaces of varying sizes) and Kappa-based weighting schemes are another big contributors, leading to better anticipation of drifts and faster recovery after change a (as seen on Aggrawal and Hyperplane datasets). Finally, abstaining is the least frequently used mechanism, but offers significant benefit to KUE in specific scenarios (as seen in Aggrawal datasets). Therefore, it protects KUE from relying its decision on non-competent classifiers in the ensemble, if such would ever appear.

Influence of the number of new classifiers trained for each new batch of instances on the KUE predictive power and update time

Comparison between the proposed random feature subspace used in KUE (black line) and fixed size feature subspace (blue points), results averaged over all 93 data stream benchmarks (Color figure online)
Role of the number of base classifiers trained on each chunk We investigate if training more classifiers on each new chunk will lead to a predictive improvement in KUE. As we are using random feature subspaces for each classifier, the intuition dictates that such an approach should be fruitful. We examined the impact of training 1 (default parameter used in KUE) to 10 (equal to the full KUE pool) classifiers whenever new data becomes available. The trade-off between accuracy and computational cost averaged over all 93 used benchmarks is depicted in Fig. 18. Surprisingly, providing more classifiers for the KUE selection procedure does not lead to significant improvements in accuracy or Kappa for standard data streams, as regardless of the number of components the gains were statistically insignificant. At the same time, training each new classifiers and thus extending the KUE selection procedure leads to a significant increase in the update time for each batch. For imbalanced data streams and four different performance metrics used one can observe the same time dependencies as for standard streams. However, we observe even smaller, if any, gains in performance when more than a single classifier is trained per each chunk.
This may be explained by the fact that KUE does not forces addition of a new classifier to the ensemble for every chunk if it does not positively contribute to the ensemble. Therefore, with even a single classifier being trained, if the randomly selected features are of low quality, then it is not incorporated into the ensemble. At the same time, as each base classifier in KUE works in an online mode, each of them is updated with new instances, thus not losing the information coming from the new batch. This allows us to conclude that training a single new classifier on each batch of data leads to the best trade-off between predictive accuracy and required update time.
Impact of the feature sampling on the base classifiers We investigate if our proposed varying size of the feature subspace is better than a fixed size subspace. Figure 19 depicts the differences between the used sampling and fixed subspaces for each of metric and independently for standard and imbalanced data streams. We can see that the randomization in the size of feature subspaces always works better than using a fixed subspace size. We can explain this by the presence of feature drifts and the fact that the relevance of features evolves over time. Thus, a fixed feature subspace size is not capable of adapting to such dynamics, leading to either omitting important features (subspace too small) or incorporating too many redundant ones (subspace too big). KUE employs a classifier selection mechanism that adds a new base classifier to the ensemble only when it improves it. This indirectly alleviates the effects of incorrectly sampled feature subspace size, as such a classifier will be discarded. This can be seen as reducing the negative impact of variance in our randomized approach on the KUE performance.
5 Conclusions and future works
In this work, we have presented KUE, a new ensemble classification algorithm for drifting data streams. KUE offered a hybrid architecture, combining the advantages of online adaptation of base classifiers and block-based updating of the ensemble line-up. KUE used the Kappa statistic for simultaneous selection and weighting of base classifiers, which allowed to achieve a robust performance on standard and imbalanced data streams without the need for dedicated skew-insensitive mechanisms. KUE offered a better predictive power and adaptation to concept drift by training base classifiers on random subsets of features, which increased the diversity and capabilities for handling feature-based drifts. In order to reduce the impact of incompetent classifiers at a given state of the stream, KUE was empowered with an abstaining mechanism that removed selected classifiers from the voting procedure.
KUE was evaluated against 15 state-of-the-art ensemble algorithms on a wide set of 60 standard and 33 imbalanced data stream benchmarks. Such a wide-range study, backed-up with a statistical analysis of results, showed that KUE offers most the stable performance of all examined methods, regardless of data type and the metric used. Additionally, KUE was characterized by a low decision and update times, as well as memory consumption, making it a suitable choice for high-speed data stream mining. We showed an analysis of the KUE’s main mechanisms and how the individually contribute to improving the predictive power.
We plan to continue our works on KUE and extend it to multi-label data streams, as well as to implement it on Apache Spark to learn from multiple parallel data streams in a distributed environment. Moreover, the exploration of the ROC metric for leading the selection, weighting of the classifiers, and heterogeneous ensemble schemes are promising lines for future research.
Notes
KUE source code, datasets, detailed results, and visualizations available at: http://doi.org/10.17605/OSF.IO/6H438.
References
Abdulsalam, H., Skillicorn, D. B., & Martin, P. (2011). Classification using streaming random forests. IEEE Transactios on Knowledge and Data Engineering, 23(1), 22–36.
Almeida, P., Oliveira, L., de Souza, A., & Sabourin, R. (2016). Handling concept drifts using dynamic selection of classifiers. In IEEE international conference on tools with artificial intelligence (pp. 989–995).
Balle, B., Castro, J., & Gavaldà, R. (2014). Adaptively learning probabilistic deterministic automata from data streams. Machine Learning, 96(1), 99–127.
Barddal, J. P., Enembreck, F., Gomes, H. M., Bifet, A., & Pfahringer, B. (2019a). Boosting decision stumps for dynamic feature selection on data streams. Information Systems, 83, 13–29.
Barddal, J. P., Enembreck, F., Gomes, H. M., Bifet, A., & Pfahringer, B. (2019b). Merit-guided dynamic feature selection filter for data streams. Expert Systems with Applications, 116, 227–242.
Barddal, J. P., Gomes, H. M., Enembreck, F., & Pfahringer, B. (2017). A survey on feature drift adaptation: Definition, benchmark, challenges and future directions. Journal of Systems and Software, 127, 278–294.
Barddal, J. P., Gomes, H. M., Enembreck, F., Pfahringer, B., & Bifet, A. (2016). On dynamic feature weighting for feature drifting data streams. In European conference on machine learning (pp. 129–144).
Barros, R. S. M., & Santos, S. G. T. C. (2018). A large-scale comparison of concept drift detectors. Information Sciences, 451, 348–370.
Bertini, J. R., & Nicoletti, M. (2019). An iterative boosting-based ensemble for streaming data classification. Information Fusion, 45, 66–78.
Bifet, A., & Gavaldà, R. (2007). Learning from time-changing data with adaptive windowing. In SIAM international conference on data mining (pp. 443–448).
Bifet, A., Gavaldà, R., Holmes, G., & Pfahringer, B. (2018). Data stream mining: With practical examples in MOA. Cambridge: MIT Press.
Bifet, A., Holmes, G., Kirkby, R., & Pfahringer, B. (2010). MOA: Massive online analysis. Journal of Machine Learning Research, 11, 1601–1604.
Bifet, A., Holmes, G., & Pfahringer, B. (2010). Leveraging bagging for evolving data streams. In European conference on machine learning (pp. 135–150).
Bifet, A., Holmes, G., Pfahringer, B., Kirkby, R., & Gavaldà, R. (2009). New ensemble methods for evolving data streams. In ACM SIGKDD international conference on knowledge discovery and data mining (pp. 139–148).
Błaszczyński, J., Stefanowski, J., & Zajac, M. (2009). Ensembles of abstaining classifiers based on rule sets. In International symposium on methodologies for intelligent systems (pp. 382–391).
Bonab, H. R., & Can, F. (2018). GOOWE: Geometrically optimum and online-weighted ensemble classifier for evolving data streams. ACM Transactions on Knowledge Discovery from Data, 12(2), 25.
Brzeziński, D., & Stefanowski, J. (2011). Accuracy updated ensemble for data streams with concept drift. In International conference on hybrid artificial intelligence systems (pp. 155–163).
Brzeziński, D., & Stefanowski, J. (2013). Classifiers for concept-drifting data streams: Evaluating things that really matter. In ECML PKDD workshop on real-world challenges for data stream mining (pp. 10–14).
Brzeziński, D., & Stefanowski, J. (2014a). Combining block-based and online methods in learning ensembles from concept drifting data streams. Information Sciences, 265, 50–67.
Brzeziński, D., & Stefanowski, J. (2014b). Reacting to different types of concept drift: The accuracy updated ensemble algorithm. IEEE Transactions on Neural Networks and Learning Systems, 25(1), 81–94.
Brzeziński, D., & Stefanowski, J. (2018). Ensemble classifiers for imbalanced and evolving data streams. Data Mining in Time Series and Streaming Databases, 83(1), 44–68.
Brzeziński, D., Stefanowski, J., Susmaga, R., & Szczȩch, I. (2018). Visual-based analysis of classification measures and their properties for class imbalanced problems. Information Sciences, 462, 242–261.
Cano, A., & Krawczyk, B. (2018). Learning classification rules with differential evolution for high-speed data stream mining on GPUs. In IEEE congress on evolutionary computation (pp. 197–204).
Cano, A., & Krawczyk, B. (2019). Evolving rule-based classifiers with genetic programming on GPUs for drifting data streams. Pattern Recognition, 87, 248–268.
Cano, A., Zafra, A., & Ventura, S. (2013). Weighted data gravitation classification for standard and imbalanced data. IEEE Transactions on Cybernetics, 43(6), 1672–1687.
Chandola, V., Banerjee, A., & Kumar, V. (2009). Anomaly detection: A survey. ACM Computing Surveys, 41(3), 15.
Chen, S., & He, H. (2013). Nonstationary stream data learning with imbalanced class distribution. In H. He & Y. Ma (Eds.), Imbalanced learning: Foundations, algorithms, and applications (pp. 151–186).
Ditzler, G., Rosen, G., & Polikar, R. (2013). Discounted expert weighting for concept drift. In IEEE symposium on computational intelligence in dynamic and uncertain environments (pp. 61–67).
Dong, Y., & Japkowicz, N. (2018). Threaded ensembles of autoencoders for stream learning. Computational Intelligence, 34(1), 261–281.
Elwell, R., & Polikar, R. (2011). Incremental learning of concept drift in nonstationary environments. IEEE Transactions on Neural Networks, 22(10), 1517–1531.
Faisal, M. A., Aung, Z., Williams, J. R., & Sanchez, A. (2015). Data-stream-based intrusion detection system for advanced metering infrastructure in smart grid: A feasibility study. IEEE Systems Journal, 9(1), 31–44.
Fernández, A., García, S., Galar, M., Prati, R. C., Krawczyk, B., & Herrera, F. (2018). Learning from imbalanced data sets. Berlin: Springer. https://doi.org/10.1007/978-3-319-98074-4.
Ferri, C., Hernández-Orallo, J., & Modroiu, R. (2009). An experimental comparison of performance measures for classification. Pattern Recognition Letters, 30(1), 27–38.
Gaber, M. M. (2012). Advances in data stream mining. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 2(1), 79–85.
Gama, J., & Castillo, G. (2006). Learning with local drift detection. In Advanced data mining and applications (pp. 42–55).
Gama, J., & Kosina, P. (2014). Recurrent concepts in data streams classification. Knowledge and Information Systems, 40(3), 489–507.
Gama, J., Sebastião, R., & Rodrigues, P. P. (2013). On evaluating stream learning algorithms. Machine Learning, 90(3), 317–346.
Gama, J., Žliobaite, I., Bifet, A., Pechenizkiy, M., & Bouchachia, A. (2014). A survey on concept drift adaptation. ACM Computing Surveys, 46(4), 44:1–44:37.
García, S., Fernández, A., Luengo, J., & Herrera, F. (2010). Advanced nonparametric tests for multiple comparisons in the design of experiments in computational intelligence and data mining: Experimental analysis of power. Information Sciences, 180(10), 204–2064.
García, S., & Herrera, F. (2008). An extension on statistical comparisons of classifiers over multiple data sets for all pairwise comparisons. Journal of Machine Learning Research, 9, 2677–2694.
Gomes, H. M., Barddal, J. P., Enembreck, F., & Bifet, A. (2017). A survey on ensemble learning for data stream classification. ACM Computing Surveys, 50(2), 23.
Gomes, H. M., Bifet, A., Read, J., Barddal, J. P., Enembreck, F., Pfharinger, B., et al. (2017). Adaptive random forests for evolving data stream classification. Machine Learning, 106(9–10), 1469–1495.
Gomes, H. M., & Enembreck, F. (2014). SAE2: Advances on the social adaptive ensemble classifier for data streams. In ACM symposium on applied computing (pp. 798–804).
Hoens, T. R., Polikar, R., & Chawla, N. V. (2012). Learning from streaming data with concept drift and imbalance: An overview. Progress in Artificial Intelligence, 1(1), 89–101.
Hulten, G., Spencer, L., & Domingos, P. (2001). Mining time-changing data streams. In ACM SIGKDD international conference on knowledge discovery and data mining (pp. 97–106).
Jaber, G., Cornuéjols, A., & Tarroux, P. (2013). A new on-line learning method for coping with recurring concepts: The ADACC system. In International conference on neural information processing (pp. 595–604).
Jackowski, K. (2014). Fixed-size ensemble classifier system evolutionarily adapted to a recurring context with an unlimited pool of classifiers. Pattern Analysis and Applications, 17(4), 709–724.
Jeni, L. A., Cohn, J. F., & De La Torre, F. (2013). Facing imbalanced data–recommendations for the use of performance metrics. In Humaine association conference on affective computing and intelligent interaction (pp. 245–251).
Kolter, J. Z., & Maloof, M. A. (2007). Dynamic weighted majority: An ensemble method for drifting concepts. Journal of Machine Learning Research, 8, 2755–2790.
Krawczyk, B. (2016). Learning from imbalanced data: Open challenges and future directions. Progress in Artificial Intelligence, 5(4), 221–232.
Krawczyk, B. (2017). Active and adaptive ensemble learning for online activity recognition from data streams. Knowledge-Based Systems, 138, 69–78.
Krawczyk, B., & Cano, A. (2018). Online ensemble learning with abstaining classifiers for drifting and noisy data streams. Applied Soft Computing, 68, 677–692.
Krawczyk, B., Minku, L. L., Gama, J., Stefanowski, J., & Woźniak, M. (2017). Ensemble learning for data stream analysis: A survey. Information Fusion, 37, 132–156.
Kuncheva, L. I. (2013). Change detection in streaming multivariate data using likelihood detectors. IEEE Transactions on Knowledge and Data Engineering, 25(5), 1175–1180.
Liu, A., Lu, J., Liu, F., & Zhang, G. (2018). Accumulating regional density dissimilarity for concept drift detection in data streams. Pattern Recognition, 76, 256–272.
Marrón, D., Ayguadé, E., Herrero, J. R., Read, J., & Bifet, A. (2017). Low-latency multi-threaded ensemble learning for dynamic big data streams. In IEEE international conference on big data (pp. 223–232).
Matuszyk, P., & Spiliopoulou, M. (2017). Stream-based semi-supervised learning for recommender systems. Machine Learning, 106(6), 771–798.
Mejri, D., Limam, M., & Weihs, C. (2018). A new dynamic weighted majority control chart for data streams. Soft Computing, 22(2), 511–522.
Miller, Z., Dickinson, B., Deitrick, W., Hu, W., & Wang, A. H. (2014). Twitter spammer detection using data stream clustering. Information Sciences, 260, 64–73.
Mimran, O., & Even, A. (2014). Data stream mining with multiple sliding windows for continuous prediction. In European conference on information systems (pp. 1–15).
Minku, L. L., White, A. P., & Yao, X. (2010). The impact of diversity on online ensemble learning in the presence of concept drift. IEEE Transactions on Knowledge and Data Engineering, 22(5), 730–742.
Morales, G. D. F., Bifet, A., Khan, L., Gama, J., & Fan, W. (2016). IoT big data stream mining. In ACM SIGKDD international conference on knowledge discovery and data mining (pp. 2119–2120).
Nguyen, H. L., Woon, Y. K., Ng, W. K., & Wan, L. (2012). Heterogeneous ensemble for feature drifts in data streams. In Pacific-Asia conference on knowledge discovery and data mining (pp. 1–12).
Olorunnimbe, M. K., Viktor, H., & Paquet, E. (2018). Dynamic adaptation of online ensembles for drifting data streams. Journal of Intelligent Information Systems, 50(2), 291–313.
Oza, N. C. (2005). Online bagging and boosting. In IEEE international conference on systems, man and cybernetics (pp. 2340–2345).
Pears, R., Sakthithasan, S., & Koh, Y. S. (2014). Detecting concept change in dynamic data streams. Machine Learning, 97(3), 259–293.
Pelossof, R., Jones, M., Vovsha, I., & Rudin, C. (2009). Online coordinate boosting. In IEEE international conference on computer vision (pp. 1354–1361).
Pesaranghader, A., & Viktor, H. (2016). Fast hoeffding drift detection method for evolving data streams. In European conference on machine learning and knowledge discovery in databases (pp. 96–111).
Pesaranghader, A., Viktor, H., & Paquet, E. (2018). Reservoir of diverse adaptive learners and stacking fast hoeffding drift detection methods for evolving data streams. Machine Learning, 107(11), 1711–1743.
Pietruczuk, L., Rutkowski, L., Jaworski, M., & Duda, P. (2017). How to adjust an ensemble size in stream data mining? Information Sciences, 381, 46–54.
Ramírez-Gallego, S., Krawczyk, B., García, S., Woźniak, M., Benítez, J., & Herrera, F. (2017). Nearest neighbor classification for high-speed big data streams using spark. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 47(10), 2727–2739.
Ramirez-Gallego, S., Krawczyk, B., Garcia, S., Woźniak, M., & Herrera, F. (2017). A survey on data preprocessing for data stream mining: Current status and future directions. Neurocomputing, 239, 39–57.
Ren, S., Liao, B., Zhu, W., & Li, K. (2018). Knowledge-maximized ensemble algorithm for different types of concept drift. Information Sciences, 430, 261–281.
Ren, S., Liao, B., Zhu, W., Li, Z., Liu, W., & Li, K. (2018). The gradual resampling ensemble for mining imbalanced data streams with concept drift. Neurocomputing, 286, 150–166.
Sethi, T. S., & Kantardzic, M. (2017). On the reliable detection of concept drift from streaming unlabeled data. Expert Systems with Applications, 82, 77–99.
Sobolewski, P., & Woźniak, M. (2013). Comparable study of statistical tests for virtual concept drift detection. In International conference on computer recognition systems (pp. 329–337).
Sobolewski, P., & Woźniak, M. (2017). SCR: Simulated concept recurrence—A non-supervised tool for dealing with shifting concept. Expert Systems, 34(5), 1–12.
Srinivasan, A., & Bain, M. (2017). An empirical study of on-line models for relational data streams. Machine Learning, 106(2), 243–276.
Sun, Y., Tang, K., Minku, L. L., Wang, S., & Yao, X. (2016). Online ensemble learning of data streams with gradually evolved classes. IEEE Transactions on Knowledge and Data Engineering, 28(6), 1532–1545.
Triantafyllopoulos, D., Korvesis, P., Mporas, I., & Megalooikonomou, V. (2016). Real-time management of multimodal streaming data for monitoring of epileptic patients. Journal of Medical Systems, 40(3), 45:1–45:11.
Van Rijn, J. N., Holmes, G., Pfahringer, B., & Vanschoren, J. (2018). The online performance estimation framework: Heterogeneous ensemble learning for data streams. Machine Learning, 107(1), 149–176.
Vicente, R., Kinouchi, O., & Caticha, N. (1998). Statistical mechanics of online learning of drifting concepts: A variational approach. Machine Learning, 32(2), 179–201.
Wang, B., & Pineau, J. (2016). Online bagging and boosting for imbalanced data streams. IEEE Transactions on Knowledge and Data Engineering, 28(12), 3353–3366.
Wang, H., Fan, W., Yu, P. S., & Han, J. (2003). Mining concept-drifting data streams using ensemble classifiers. In ACM SIGKDD international conference on knowledge discovery and data mining (pp. 226–235).
Wang, S., Minku, L. L., & Yao, X. (2015). Resampling-based ensemble methods for online class imbalance learning. IEEE Transactions on Knowledge and Data Engineering, 27(5), 1356–1368.
Wang, S., Minku, L. L., & Yao, X. (2018). A systematic study of online class imbalance learning with concept drift. IEEE Transactions on Neural Networks and Learning Systems, 29(10), 4802–4821.
Webb, G. I., Hyde, R., Cao, H., Nguyen, H. L., & Petitjean, F. (2016). Characterizing concept drift. Data Mining and Knowledge Discovery, 30(4), 964–994.
Webb, G. I., Lee, L. K., Goethals, B., & Petitjean, F. (2018). Analyzing concept drift and shift from sample data. Data Mining and Knowledge Discovery, 32(5), 1179–1199.
Woźniak, M., Kasprzak, A., & Cal, P. (2013). Weighted aging classifier ensemble for the incremental drifted data streams. In International conference on flexible query answering systems (pp. 579–588).
Woźniak, M., Ksieniewicz, P., Cyganek, B., & Walkowiak, K. (2016). Ensembles of heterogeneous concept drift detectors—Experimental study. In Computer information systems and industrial management (pp. 538–549).
Yuan, L., Pfahringer, B., & Barddal, J. P. (2018). Iterative subset selection for feature drifting data streams. In 33rd annual ACM symposium on applied computing (pp. 510–517).
Zhai, T., Gao, Y., Wang, H., & Cao, L. (2017). Classification of high-dimensional evolving data streams via a resource-efficient online ensemble. Data Mining and Knowledge Discovery, 31(5), 1242–1265.
Zhang, L., Lin, J., & Karim, R. (2017). Sliding window-based fault detection from high-dimensional data streams. IEEE Transactions on Systems, Man, and Cybernetics: Systems, 47(2), 289–303.
Zhang, Q., Zhang, P., Long, G., Ding, W., Zhang, C., & Wu, X. (2016). Online learning from trapezoidal data streams. IEEE Transactions on Knowledge and Data Engineering, 28(10), 2709–2723.
Zhu, X., Zhang, P., Wu, X., He, D., Zhang, C., & Shi, Y. (2008). Cleansing noisy data streams. In IEEE international conference on data mining (pp. 1139–1144).
Žliobaite, I., Bifet, A., Read, J., Pfahringer, B., & Holmes, G. (2015). Evaluation methods and decision theory for classification of streaming data with temporal dependence. Machine Learning, 98(3), 455–482.
Žliobaite, I., Budka, M., & Stahl, F. T. (2015). Towards cost-sensitive adaptation: When is it worth updating your predictive model? Neurocomputing, 150, 240–249.
Acknowledgements
This research was partially supported by the 2018 VCU Presidential Research Quest Fund and an Amazon AWS Machine Learning Research award.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Editor: João Gama.
Rights and permissions
About this article

Cite this article
Cano, A., Krawczyk, B. Kappa Updated Ensemble for drifting data stream mining. Mach Learn 109, 175–218 (2020). https://doi.org/10.1007/s10994-019-05840-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10994-019-05840-z