
Abstract
Data streams are potentially unbounded sequences of instances arriving over time to a classifier. Designing algorithms that are capable of dealing with massive, rapidly arriving information is one of the most dynamically developing areas of machine learning. Such learners must be able to deal with a phenomenon known as concept drift, where the data stream may be subject to various changes in its characteristics over time. Furthermore, distributions of classes may evolve over time, leading to a highly difficult non-stationary class imbalance. In this work we introduce Robust Online Self-Adjusting Ensemble (ROSE), a novel online ensemble classifier capable of dealing with all of the mentioned challenges. The main features of ROSE are: (1) online training of base classifiers on variable size random subsets of features; (2) online detection of concept drift and creation of a background ensemble for faster adaptation to changes; (3) sliding window per class to create skew-insensitive classifiers regardless of the current imbalance ratio; and (4) self-adjusting bagging to enhance the exposure of difficult instances from minority classes. The interplay among these features leads to an improved performance in various data stream mining benchmarks. An extensive experimental study comparing with 30 ensemble classifiers shows that ROSE is a robust and well-rounded classifier for drifting imbalanced data streams, especially under the presence of noise and class imbalance drift, while maintaining competitive time complexity and memory consumption. Results are supported by a thorough non-parametric statistical analysis.
Similar content being viewed by others


1 Introduction
Modern data is characterized by two crucial factors: volume (massive size) and velocity (ever-growing speed and changing nature of data). The combination of these two factors gave rise to the notion of data streams (Bahri et al., 2021; Bifet et al., 2019; Gomes et al., 2019b). Streaming scenarios pose unique challenges to machine learning algorithms, as we are not only concerned about their predictive power, but also about their computational complexity, response latency, and capability of adapting to and incorporating new data. Additionally, data streams evolve over time and their characteristics and definitions are subject to change. This is known as concept drift, which forces classifiers to constantly update and adapt to the current state of data (Gama et al., 2014; Lu et al., 2019a). Furthermore, challenges present in static classification can emerge in streaming environments. Class imbalance is one of the most relevant challenges (Branco et al., 2016). When combined with concept drift, no longer only the disproportions among classes pose a learning difficulty, class roles and imbalance ratio may change dynamically. This renders the majority of traditional algorithms dedicated to countering imbalanced distributions inadequate for data streams (Fernández et al., 2018). All of those mentioned challenges have led to intensive research on algorithms capable of thriving in such difficult environments. Ensembles emerged as the most powerful solutions (Krawczyk et al., 2017).
In this paper we introduce Robust Online Self-Adjusting Ensemble (ROSE), a novel online ensemble architecture dedicated to mining imbalanced and drifting data streams. It incorporates four primary features that allow ROSE to handle any type of data stream and concept drift and offer robustness to variable class imbalance over time. ROSE employs adaptive self-tuning, adjusting its parameters and ensemble line-up dynamically on the go for best performance, without the need for human supervision or ad-hoc solutions. The main contributions of this paper are:
-
Novel online ensemble architecture on dynamic feature subspaces ROSE is an online self-adjusting ensemble for exploring variable-size feature subspaces to adapt to concept drift and dynamic class imbalance ratios in non-stationary data streams.
-
Background ensemble for concept drift adaptation ROSE monitors the base classifiers for detecting concept drift within each of the feature subspaces. If a drift warning is emitted, the algorithm learns a new ensemble on the background on a new set of feature subspaces. The performance of base classifiers in the current and background ensemble are compared, selecting the top performing ones to replace the ensemble. This allows for adding new classifiers to the ensemble that are specialized on the current concept and discarding outdated models adapting to changes in the feature space.
-
Automatic handling of class imbalance ROSE holds a sliding window buffer per class to keep a representation of the most recent instances on which to build new background base learners. This counters class imbalance, as the buffer enforces an undersampling of majority classes.
-
Enhancing the exposure to minority class instances In order to further make ROSE skew-insensitive, we propose a self-adjusting \(\lambda\) for bagging to reflect the evolving distribution of the data classes and enforce the Hoeffding bound to improve the classification performance on minority classes.
-
Extensive and reproducible experimental framework The performance of ROSE is examined based on a comprehensive experimental study and comparison with 30 state-of-the-art ensembles. We present seven different sets of experiments on imbalanced streams, artificial stream generators, noisy streams, and real-world data streams. This makes the present study one of the most thorough and reproducible experimental analysis of ensemble performance with concept drift and class imbalance.
The rest of the paper is organized as follows. Section 2 presents an overview of data streams and related works in ensemble learning. Section 3 discusses the challenges and approaches for imbalanced data streams. Section 4 presents the proposed ROSE algorithm and its features. Section 5 presents a thorough experimental study on a large set of data streams, including imbalanced streams with concept drift, varying imbalance ratio, and noise, as well as an ablation study. Experimental results are also validated through non-parametric statistical analysis. Finally, Sect. 6 summarizes the concluding remarks and discusses future lines of work.
2 Learning from data streams
Preliminaries We define a data stream as a sequence \(<S_1, S_2, \ldots , S_n,\ldots>\), in which each element \(S_j\) is a collection of instances (batch scenario) or a single instance (online scenario). Each instance is independent and randomly generated using a stationary probability distribution \(D_j\). In this paper, we consider the supervised online learning scenario that allows us to define each element as \(S_j \sim p_j(x^1,\ldots ,x^d,y) = p_j({\mathbf {x}},y)\), where \(p_j({\mathbf {x}},y)\) is a joint distribution of j-th instance, defined by d-dimensional feature space and belonging to class y. Each instance in the stream is independent and randomly drawn from a stationary probability distribution \(\varPsi _j ({\mathbf {x}},y)\).
Concept drift Whenever a new instance (or batch of instances) arrives, we refer to the progression of the data stream. If S\(_j\) \(\rightarrow\) S\(_{j+1}\) (where D\(_j\) = D\(_{j+1}\)) is true, then we deal with a stationary data stream and no changes occur. However, real-life problems are very frequently subject to concept drift, where the characteristics and definitions of a stream change. Drifts can be of various characteristics and understanding what type of change is currently affecting the stream helps to better adapt to it (Lu et al., 2019a). Concept drift taxonomy analyzes two factors: (1) influence on the decision boundaries; and (2) speed of change. The former divides concept drift into virtual and real. Virtual concept drift affects only the distribution of feature values within each class, but does not affect posterior probabilities. Real concept drift affects the decision boundaries of a classifier, increasing the error of the underlying classifier. This type of drift enforces an adaptation of a classifier in order to maintain high predictive power. When looking at the speed of changes, one may distinguish three types of concept drift. Sudden drift takes place instantaneously, switching to a new distribution at a given point. Gradual drift interleaves instances from old and new concepts. Incremental concept drift can be seen as a transition between two states with multiple intermediate concepts between them. Additionally, we distinguish recurring concept drift, where previously seen concepts may reemerge.
There are two potential ways of addressing concept drift: explicit and implicit (Lu et al., 2019a). Explicit drift detection is based on the assumption that we are capable of recognizing when drift is taking place. This is achieved by combining classifiers with an external tool, called drift detectors (de Barros & de Carvalho Santos, 2018). Such detectors are capable of continuous stream monitoring and raising an alarm when it is highly probable that stream is subject to a drift. Various factors are taken into an account, such as classifier’s error, statistical distribution of data, similarity metrics, etc. When drift is detected, the classifier is replaced with a new one trained on the most recent instances. The main drawback of drift detectors lies in their requirements for labeled instances (semi-supervised and unsupervised detectors also exist, although they are less accurate) and in the cost paid for false alarms (unnecessary replacement of a competent classifier). Implicit drift detection methods assume that the classifier is capable of self-adjusting to new instances coming from the stream while forgetting the old information (Liu et al., 2016). This way, new information is constantly incorporated into the learner, which should allow for adapting to evolving concepts (Kozal et al., 2021). Drawbacks of implicit methods lie in their parametrization - establishing proper learning and forgetting rates, as well as the size of a sliding window.
Ensemble learning for data streams Ensemble learning has proven itself to be one of the most effective solutions for data streams (Ghomeshi et al., 2019; Krawczyk et al., 2017). It maintains all of the advantages of this approach for static scenarios, such as improved predictive power, increased robustness and stability. Additionally, ensembles can naturally manage concept drift by incorporating new base learners trained on most recent data and discarding outdated ones (Cano & Krawczyk, 2020). New concepts offer a natural way of maintaining diversity among ensemble members, allowing them to continuously be mutually complementary (Gomes et al., 2019a). When looking at the possible approaches to ensemble learning for data streams, three main paths exist (Krawczyk et al., 2017): (1) dynamic combiners; (2) dynamic ensemble setup; and (3) dynamic ensemble updating. Combiners assume that we focus on adapting the combination rule (e.g., weights in voting) to promote classifiers that are best adapted to the current state of the stream. Dynamic ensemble setup assumes that the pool of classifiers should be constantly updated with new ones and pruned to remove its weakest members. Dynamic ensemble updating assumes that classifiers in the ensemble should not be discarded, but continuously updated with new instances, while maintaining their diversity. ROSE proposed in this paper is a hybrid approach that combines the advantages of adaptive online update of base classifiers with dynamic ensemble setup with online pruning, while managing per-class balanced instance buffers.
Continual learning and data stream mining Continual learning is one of the recently emerged paradigms in deep learning that focuses on building models that can accumulate new knowledge without forgetting the previously learned one (Parisi et al., 2019). While the majority of the works in this domain focus purely on deep neural networks and image-based benchmarks, we should note that the general idea of continual learning is not reserved only to them. There exist interesting similarities between continual learning and data stream mining, as both focus on incorporating new information into the model (Krawczyk, 2021). Data stream mining puts emphasis on adaptation to changes (i.e., handling concept drift), while continual learning puts emphasis on retaining knowledge (i.e., avoiding catastrophic forgetting). Recent works point to the potential of combining these two domains, offering learning systems capable of being robust to both catastrophic forgetting and concept drift affecting previously learned knowledge (Cano & Krawczyk, 2019; Korycki & Krawczyk, 2021a). Furthermore, the setting of data stream mining is identical to task-free (Aljundi et al., 2019) or task-agnostic (He et al., 2019) continual learning, where classes arrive mixed with each other and are not separated into pre-defined tasks. In this paper we discuss that data stream mining tools can be beneficial to continual learning scenarios and we show that having a per class buffer allows it to retain knowledge and is parallel to experience replay approaches used to avoid catastrophic forgetting (Buzzega et al., 2020).
3 Imbalanced data streams
Challenges in imbalanced data stream mining Skewed class distributions are a common problem in data stream mining (Aminian et al., 2020; Gao et al., 2008; Wu et al., 2014). When combined with concept drift novel learning difficulties arise. Imbalance ratio is no longer static and will change with the progress of the stream (Brzeziński & Stefanowski, 2017). Classes may switch their roles over time, with minority transitioning to be majority and vice versa. This is known as imbalance ratio drift and poses a significant challenge to the majority of the existing algorithms that need to have a pre–defined minority class in order to effectively balance distributions (Korycki & Krawczyk, 2021b). This drift can be independent from or connected with concept drift, where class definitions will change over time (Wang & Minku, 2020). Therefore, one must not only monitor each class for changes in its properties, but also for changes in its frequency. New classes may appear and old ones disappear, leading to oscillations between binary and multi-class imbalanced (Krawczyk, 2016). In most real-life scenarios, streams are not predefined as balanced or imbalanced, they may be imbalanced only temporarily (Wang et al., 2018). Examples of dynamic class imbalance include evolving user interests over time (where new topics emerge and old ones dynamically change their relevance) (Wang et al., 2014), social media analysis (where new events may take place and existing events may appear with fluctuating frequency) (Liu et al., 2020), or medical data streams (where patient records continually evolve over time and we observe changing ratios of admission reasons) (Al-Shammari et al., 2019).
Data-level approaches for imbalanced data streams While resampling approaches are very popular for standard imbalanced problems, they cannot be trivially adapted to streaming setting. Here, we need to keep track of which class to dynamically resample, to avoid enhancing class imbalance instead of countering it. Modifications of SMOTE algorithm for drifting data streams are popular (Bernardo et al., 2020b), with the most recent versions working with any number of classes and under limited supervision (Korycki & Krawczyk, 2020). Other popular methods include Incremental Oversampling for Data Streams (IOSDS) (Anupama & Jena, 2019) that focus on replicating instances that are not identified as noisy or overlapping; and undersampling via Selection-Based Resampling (SRE) (Ren et al., 2019) that iteratively removes the safe instances from majority class without introducing reverse bias towards the minority class. Some studies report the usefulness of combining multiple resampling approaches together in order to obtain a more diverse representation of the minority class (Bobowska et al., 2019). Drawbacks of existing data-level approaches lie in their high memory requirements (for oversampling) or possibility of removing instances from older concepts that are still relevant (for undersampling).
Algorithm-level approaches for imbalanced data streams As an alternative to resampling incoming data, one may modify the streaming classifier itself to make it skew-insensitive. This can be done either via cost-sensitive adaptation or by modifying the underlying learning mechanisms (Loezer et al., 2020). The cost-sensitive method has been applied successfully to streaming decision trees, where their leaves have been replaced with perceptrons that use threshold adjustment of their decision outputs (Krawczyk & Skryjomski, 2017). Their cost matrix is updated using the current imbalance ratio and the local difficulty factors of incoming instances. Another approach uses Online Multiple Cost-Sensitive Learning (OMCSL) (Yan et al., 2017) where cost matrices for all classes are adjusted incrementally according to a sliding window. Among algorithm-level modifications, the most popular one is the combination of Hoeffding Decision Trees with Hellinger splitting criteria to make them robust to imbalanced distributions (Lyon et al., 2014). Another approach uses online one-class Support Vector Machines to track minority classes (Klikowski & Wozniak, 2020). Nearest neighbor classifiers have been used efficiently for imbalanced data streams, by modifying their sliding-window approaches with a reactive memory mechanism (Abolfazli & Ntoutsi, 2020; Roseberry et al., 2019, 2021). Drawbacks of algorithm-level solutions lie in their lack of flexibility (as they can be used only with a specific type of classifier) and in their reliance on either external drift detectors (that are either biased towards majority class or sensitive to false alarms) or implicit online adaptation (that may be delayed with respect to drift occurrence).
Ensemble learning for imbalanced data streams Combining multiple classifiers offers a very powerful way of tackling imbalanced data streams, as combining base classifiers with different skew-insensitive solutions allows for increased robustness and diversity that allows additionally to effectively handle concept drifts (Brzeziński & Stefanowski, 2018; Du et al., 2021; Grzyb et al., 2021; Krawczyk et al., 2017). The most popular approach is to combine either under- or oversampling with Online Bagging (Wang etal., 2015). Similar approaches can be applied to either Adaptive Random Forest (Ferreira et al., 2019), Online Boosting (Wang & Pineau, 2016), Random Subspaces (Klikowski & Wozniak, 2019), Dynamic Weighted Majority (Lu et al., 2017), Kappa Updated Ensemble (Cano & Krawczyk, 2020) or any ensemble that can incrementally update its base learners (Li et al., 2020). Robustness of ensembles to class imbalance can also be increased by using dedicated combination schemes or adaptive chunk-based learning (Lu et al., 2019b). Alternatively, one may see preprocessing approaches as a way of ensuring diversity among base classifiers (Korycki & Krawczyk, 2021c). This allows for anticipating the direction of concept drift and choosing the most suitable learner by dynamic classifier (or ensemble) selection (Zyblewski et al. 2021). Finally, abstaining mechanisms can be introduced into ensembles to temporarily remove most uncertain classifiers from contributing to the collective decision–making process (Korycki et al., 2019). The drawback of existing ensemble solutions lies in their specialization to imbalanced streams—they do not perform well when handling balanced streams. As in real-world applications imbalance may be a temporal characteristic of the analyzed stream, their practical applicability is severely limited.
4 ROSE: robust online self-adjusting ensemble
This section presents the ROSE features and algorithm, a robust and well-rounded ensemble classifier that is flexible to various imbalanced data stream mining scenarios. ROSE aims at improving the effectiveness and latency in the response to fast concept drift and varying class imbalance. We will use the notation of an ensemble \({\mathcal {E}}\) of k \(\gamma\) base classifiers such that \({\mathcal {E}} = \{ \gamma _1 , \gamma _2 , \dots \gamma _k \}\) are built on the data stream S.
4.1 ROSE features
The main features are: (1) online training of base classifiers on variable size random subsets of features; (2) online detection of concept drift and creation of a background ensemble for faster adaptation to changes; (3) sliding window per class to create skew-insensitive classifiers regardless of the current imbalance ratio; and (4) self-adjusting bagging to enhance the exposure of difficult instances from minority classes.
Variable size random feature subspaces ROSE builds each base classifier \(\gamma _j\) on a random r-dimensional feature subspace \(\varphi _j\), where \(1 \le r \le f\) from the original f-dimensional space in the data stream S. The r dimensionality and the \(\varphi _j\) subset of features are both randomly generated for each base learner. It allows to generate diverse feature subspaces of variable size. This is a significant difference when compared to Adaptive Random Forest (Gomes et al., 2017) which selects a static subspace dimensionality for all the base classifiers. Diverse feature subspaces of random size have demonstrated to improve the performance of the ensemble in KUE (Cano & Krawczyk, 2020). However, while KUE follows a uniform probability distribution to pick the subspace size in the range [1,f] (leading to a wide range of sizes), ROSE follows a normal distribution for subspace sizes as in Eq. 1:
where \(\mu\) is 0.7 by default and ranged [0,1] (leading to a more centered subspace size close to the mean), giving the end-user a better control on the feature subspace sizes centered around the desired mean. This allows to maintain a higher diversity of the ensemble and make base classifiers locally specialized in varying regions of the decision space. Using feature subsets offers two additional advantages—reduced effects of noise and allows for a faster adaptation to local concept drifts that affect only certain features. These advantages of this diverse ensemble architecture were demonstrated in KUE (Cano & Krawczyk, 2020).
Detection of concept drift and background ensemble ROSE monitors the base classifiers for detecting concept drift on the respective feature subspaces. Since they exploit different feature subspaces, drift may occur on one or several of the subspaces. Some features may become relevant while others may lose discriminatory power in the classification over time. If a drift warning is emitted by any of the drift detectors (we use the ADWIN drift detector), ROSE starts training another ensemble in the background. Building ensembles in the background is a successful strategy due to the different capabilities that their base classifiers have in adapting to concept drift (Minku & Yao, 2011) as the new ensemble will not be influenced by old concepts which no longer present in the current state of the data stream. ROSE combines this with the different feature subspaces used by the background ensemble, leading to enhanced diversity of individual classifiers and better adaptation to concept drift.
The background ensemble is initialized using a sliding window per class with the most recent instances, providing a solid foundation to learn the most recent decision boundaries. Newly trained base classifiers do not carry any previous history, so when old concepts become irrelevant they will offer better adaptation than their older counterparts. Additionally, new base classifiers are trained using different feature subsets than the ones already in the pool, hence offering ROSE the option to explore new areas of the decision space that may become relevant after a drift. The background ensemble continues learning instance by instance after the first drift warning was emitted, adapting to the new data distribution. After a certain number of instances, which by default is the total window size of 1000 instances, the performance of the current ensemble and the background ensemble can be compared. The novelty compared to other approaches such as (Brzeziński & Stefanowski, 2014a) is the replacement of multiple base classifiers at once. The k base classifiers of the current ensemble and the k base classifiers of the background ensemble compete to select the k best performing classifiers that will replace and become the new ensemble. The weakest worst performing classifiers are discarded. The selection of the best classifiers is driven by the maximization of the product of their accuracy and Kappa metrics.
Kappa is commonly used in imbalanced classification (Brzeziński et al., 2018, 2019). It evaluates the competence of a classifier by measuring the inter-rater agreement between the successful predictions and the statistical distribution of the data classes, correcting agreements that occur by mere statistical chance. Kappa ranges from \(-100\) (total disagreement) through 0 (default probabilistic classification) to 100 (total agreement). Kappa penalizes all-positive or all-negative predictions. Moreover, Kappa provides better insight than other metrics in detecting changes in the distribution of the classes in multi-class imbalanced data. However, Kappa may be too drastic in penalizing misclassifications on difficult data. Therefore, we propose the product of accuracy and Kappa to drive the selection and weighting of the classifiers.
This strategy allows for a two-way adaptation to drift: (1) existing base classifiers are updated in an online manner; (2) a new background ensemble is trained on the most recent data per class and on new subset of features. We combine the online incremental learning with the dynamic ensemble setup approach, allowing the addition of new classifiers to the ensemble and removal of the least accurate ones.
Sliding window per class Similar approaches in the literature employ one buffer of 1000 instances as a sliding window to train the base classifiers. However, since data classes are imbalanced, the sliding window will also be skewed. Class distributions may change over time and we need to be prepared to handle evolving and dynamic imbalance ratios. Our original contribution is to propose to employ one sliding window buffer per class to keep a representation of the most recent instances per class. Therefore, we create independent representations for any number of classes that can hold instances from various stages of the stream. ROSE uses this buffer of most recent instances per class to initialize a new ensemble upon drift warning. Since we employ one buffer per class, to keep a fair comparison with similar approaches, the sum of the buffers is limited to the same 1000 instances. Therefore, we define a maximum buffer size per class of 1000/number of classes. This strategy allows ROSE to perform an undersampling of majority classes, retaining only a fixed number of the most recent instances from them. This approach does not add any additional computational complexity, contrary to other methods (Wu et al., 2014). Whenever a new background ensemble is initialized, the sliding window per class provides a balanced class distribution to warm up the new base classifiers. This allows for alleviating the bias towards majority classes and handling evolving imbalance ratios. Furthermore, (Gao et al., 2008) strategies are designed for balancing chunk-based ensembles, while our sliding window strategy is designed for online training of ensembles. ROSE effectively scales up to any number of classes, while other approaches were designed for two-class problems and their chunk rebalancing strategies may suffer when handling more classes inside chunks of the same size.
Self-adjusting \(\lambda\) for bagging ROSE employs online bagging to weight and resample with replacement instances in the subspace using the \(Poisson(\lambda )\) distribution. Online bagging improves the performance of data stream ensembles and it is employed in OzaBag (Oza, 2005), Leveraging Bagging (Bifet et al., 2010b), Adaptive Random Forest (Gomes et al., 2017), and KUE (Cano & Krawczyk, 2020). However, existing approaches use a fixed value for \(\lambda\), typically 1 or 4. Consequently, the weighting and resampling will follow a static distribution for all of the instances, regardless of the imbalance ratio of the classes. Moreover, \(\lambda\) will be constant through all of the stream regardless of whether the stream is stable or recently experienced an imbalance ratio drift. On the other hand, ROSE uses a self-adjusting \(\lambda\) that dynamically changes over time to adapt to varying imbalance ratios, reflecting the increasing difficulty in classifying minority class instances. The initial value of \(\lambda\) is set as \(\lambda _{min} = 4\) when the distribution of the classes is not yet known.
Ensembles based on the idea of online bagging use the \(Poisson(\lambda )\) distribution to control how many times a given instance will be shown to each base learner. Standard online bagging uses \(\lambda = 1\) to mimic static bagging, while algorithms like Leveraging Bagging (Bifet et al., 2010b) or Adaptive Random Forest (Gomes et al., 2017) use \(\lambda = 4\) for a more aggressive exploitation of instances. ROSE proposes a dynamic self-adjusting \(\lambda\) value. We keep a histogram of the data class distribution in the window of most recent instances. The value of \(\lambda\) will be dynamically adjusted based on the most recent imbalance ratios between the instance’s class and the majority class. We propose to calculate the self-adjusting \(\lambda\) as in Eq. 2:
where \(\lambda _{min} = 4\). This self-adjusting parametrization benefits both balanced and imbalanced distributions. Under balanced data the logarithmic function makes \(\lambda = 4\), similar to Leveraging Bagging or Adaptive Random Forest. On the other hand, if the imbalance ratio is 10:1 then \(\lambda = 8\), or if the imbalance ratio is 100:1 then \(\lambda = 12\). The logarithmic function provides a more reasonable and smoother scaling of the \(\lambda\) value as the imbalance ratio increases. This strategy allows ROSE to enhance the importance of the minority class instances and use them more aggressively to train a balanced classifier. Increased exposure to minority instances will also result in faster creation of new split in decision tree-based classifiers that use Hoeffding’s bound, adapting faster to concept drift. Self-adaptive \(\lambda\) for class imbalance was also discussed in (Wang etal., 2015), but the approach proposed there was based on checking conditional clauses and switching between various formulas for lambda calculation. ROSE simplifies this by proposing a single formula for \(\lambda\) calculation, which leads to better classification performance.
4.2 ROSE algorithm
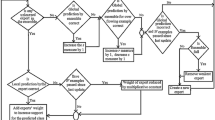
The algorithm to build the ROSE classifier comprises three main stages: (1) the ensemble initialization on a diverse set of random feature subspaces, (2) the ensemble model update per-instance adapting to class imbalance, and (3) the learning of a background ensemble and replacement of base learners to adapt to concept drift and varying properties of the stream. Algorithm 1 presents the pseudo-code of ROSE.

Ensemble initialization and diversity The main idea of the initialization phase (lines 3–8 in Algorithm 1) is to generate diverse base classifiers \(\gamma\) exploring variable r-dimensional random feature subspaces \(\varphi\). Random subspaces of varied size sample the input feature space adding diversity of the classifiers.
Ensemble update The ensemble update phase (lines 10-16 in Algorithm 1) involves the incremental learning of the base classifiers. The self-adjusting \(\lambda\) for bagging (line 10) adjusts the \(\lambda\) value according to the class of the current instance \(S_i\) and the most recent distribution of the data classes in the sliding window per class w. Next, the prequential accuracy and Kappa metrics are calculated after classifying the instance \(S_i\) (lines 13–14). Finally, the base classifiers are updated with the instance \(S_i\) and its weight according to \(Poisson(\lambda )\) (line 15).
Ensemble replacement Lines 17–40 in Algorithm 1 detail the creation and training of the background ensemble, and the replacement of base classifiers. The ensemble polls the current base classifiers for concept drift or warning detection using ADWIN on the respective feature subspaces. If a warning is detected in any of them (line 17), the algorithm starts learning an ensemble in the background on new sets of feature subspaces to early adapt to drifts. The background ensemble is initialized using the sliding window per class containing the most recent instances (lines 19–26), where instances on the sliding window are presented to the base classifiers in the order they were originally received. In the following set of instances, the background ensemble is updated on a purely online manner (lines 29–34). After a certain number of instances equal to the sliding window size of 1000 instances (line 37), the performance of the current and background base classifiers are compared to identify the best performing classifiers on their respective feature subspaces. The top performing base classifiers are selected to replace the ensemble (line 38). This strategy allows to incorporate the multiple classifiers dynamically and discard under-performing models based on outdated concepts.
Weighted voting to classify new instances ROSE combines its base classifiers using weighted voting, where weights are calculated based on the product of the accuracy and Kappa of each individual classifier, similar to the selection of the best performing classifiers in the ensemble replacement. The combination of the two metrics is preferred to the individual metrics for two main reasons: (1) not to introduce an excessive bias by having a metric too sensitive to skew class distributions (accuracy), and (2) Kappa may produce extremes while accuracy provides better continuity, which is preferred to multiply classifier weights.
Time and memory complexity analysis The primary ensemble comprises k base classifiers. The base classifier for ROSE is HoeffdingTree (Hulten et al., 2001), also known as VFDT, which builds a decision tree with a constant time and constant memory per instance. Thus, the ensemble initialization on the first instance \({\mathcal {S}}_1\) has a time complexity of \({\mathcal {O}}(k)\). The ensemble model update and incremental learning on a subsequent instance \({\mathcal {S}}_i\) has a time complexity of \({\mathcal {O}}(k \cdot \lambda )\) to update the k existing classifiers according to the current \(\lambda\). Moreover, if the algorithm trains the background ensemble of another k classifiers, it adds a time complexity of \({\mathcal {O}}(k \cdot \lambda )\) but only when a drift warning is detected. Consequently, the worst-case time complexity of ROSE is \({\mathcal {O}}(2 \cdot k \cdot \lambda \cdot |{\mathcal {S}}|)\).
The memory complexity of the base classifier HoeffdingTree is \({\mathcal {O}}(f \cdot v \cdot l \cdot c)\) where f is the number of features, v is the maximum number of values per feature, l is the number of leaves in the tree, and c is the number of classes (Hulten et al., 2001). However, ROSE performs r-dimensional random subspace projections for each of the k classifiers, where \(r \le f\), then effectively reducing the memory complexity of HoeffdingTree to \({\mathcal {O}}(r \cdot v \cdot l \cdot c)\). ROSE also needs to store a sliding window per class w of the most recent instances. Therefore, the worst-case memory complexity of ROSE comprising k classifiers in the primary ensemble plus the k classifiers in the background ensemble is \({\mathcal {O}}((2 \cdot k \cdot r \cdot v \cdot l \cdot c) + (|w| \cdot f))\). The reduction of the feature subspaces makes ROSE competitive in time and memory complexity compared to its counterparts.
4.3 Comparison between ROSE and the Kappa updated ensemble
Our previous work introduced KUE (Cano & Krawczyk, 2020), which is also driven by the Kappa metric. Therefore, it is necessary to clearly describe the major differences between KUE and ROSE, as they are both driven by the same metric for ensemble lineup management. While KUE is a chunk-based general-purpose ensemble for drifting data streams (and also happens to do well for imbalanced data), ROSE is an online ensemble specifically designed for imbalanced data streams with dynamic imbalance ratio and concept drift, offering a number of features designed specifically to tackle these challenges. We want to highlight that all of underlying ROSE features are not simple extensions of our previous work, but are novel contributions that lead to the excellent robustness to non-stationary, imbalanced, and difficult data. The detailed comparison between the two is provided in Table 1 and the differences of the experimental studies are in Table 2.
5 Experimental study
The experimental study was designed to answer the following research questions (RQ):
-
RQ1 Can ROSE outperform state-of-the-art ensemble methods under static imbalance ratios?
-
RQ2 Can ROSE outperform state-of-the-art ensemble methods under drifting imbalance ratios?
-
RQ3 Can ROSE offer better learning capabilities under instance-level difficulties?
-
RQ4 Does ROSE exhibit improved robustness to drifting noise on imbalanced streams?
-
RQ5 Does ROSE maintain its performance when handling real-world data streams?
-
RQ6 How does each of ROSE features improve the competence of the ensemble?
Experimental setup
Algorithms Table 3 enumerates the ensemble classifiers used in the experiments. Ensembles are categorized based on their general-purpose versus class-imbalance design. All ensembles are evaluated with the same parameter settings of 10 base classifiers using HoeffdingTree as the base learner. Algorithms employing a sliding window use a buffer size of 1000 instances. No individual hyperparameter optimization was conducted for any algorithm as we believe algorithms should exhibit a robust performance off the shelf. Results reported for all algorithms/benchmarks are for a single run.
The source code for ROSE and the experimental setups for the seven experiments are publicly available on GitHub.Footnote 1 All algorithms are implemented in MOA (Bifet et al., 2010a), where their source code is publicly available, and run on an Intel Xeon CPU E5-2690v4 with 384 GB memory and CentOS 8.
Experiments 1 to 5 show the detailed results for the nine most representative ensembles (ROSE, KUE, ARF, LB, SRP, OOB, UOB, OUOB, and CSMOTE). Experiment 6 shows the aggregated results for all 31 ensembles on all benchmarks. Experiment 7 presents an ablation study of ROSE’s features.
Performance evaluation Algorithms are compared using their prequential Kappa and AUC (Brzeziński & Stefanowski, 2017) metrics and their rank. The rank is calculated using the Friedman’s test rank (Demšar, 2006). Let \(r_{i}^{j}\) be the rank of the j-th of k algorithms on the i-th of N datasets. The algorithm’s rank is calculated as \(R_{j}=\frac{1}{N} \sum _{i} r_{i}^{j}\).
5.1 Experiment 1: analyzing robustness to static class imbalance
Goal of the experiment This experiment was designed to address RQ1 and evaluate the robustness of the classifiers to static class imbalance (general-purpose vs. imbalance-specific ensembles, respectively) without enforced concept drift. It is desired that any classifier designed for skewed data will display a high robustness to different levels of imbalance, i.e., output stable predictive performance regardless of the disproportion among classes. To evaluate this, we prepared six data stream benchmarks {Agrawal, AssetNegotiation, RandomRBF, SEA, Sine, Hyperplane} with static imbalance ratios of {5, 10, 20, 50, 100}. This allows us not only to gain insight into how each given classifier behaves under specific class distributions but also how it performs with increasing class imbalance. Figure 1 illustrates the performance of the selected general-purpose and imbalance-specific ensembles, respectively, with the increasing static imbalance ratio. Tables 4 and 5 present the average Kappa and AUC for each of the evaluated imbalance ratios averaged over the six data stream benchmarks, and the overall rank of the algorithms according to Friedman. Best results in the tables are presented in bold font.

Robustness to class imbalance ratios (Kappa). The first group of algorithms includes imbalanced-specific ensembles (ROSE vs. OOB, UOB, OUOB, CSMOE). The second group of algorithms includes general-purpose ensembles (ROSE vs. KUE, ARF, LB, SRP)
Comparison with class-imbalance ensembles ROSE was compared with OOB, UOB, OUOB, and CSMOTE. We can see that UOB displays the worst robustness to increasing imbalance ratio, showing significant drops in performance when IR becomes higher than 20 (with the exception of AssetNegotiation, SEA, and Sine datasets). This can be explained by the fact that with increased IR, there are increasing less minority instances in each batch. As UOB uses undersampling, it tries to reduce the size of the majority class. This leads to having a smaller training set that hinders the online learning capabilities of UOB. This is especially crucial when high imbalance ratio is combined with concept drift, since the small sample size will reduce the chances of quick recovery from changes. Even when instances from new concept will arrive their numbers will be continually reduced, leading to much more prolonged adaptation process. OOB, the counterpart of UOB, displays much better robustness and stability to varying imbalance ratio. However, especially for the hyperplane dataset, we can see a significant drop in performance when handling higher imbalance ratios. The hyperplane generator uses sudden drifts internally, which allows us to understand the reason behind such a drop. Oversampling of instances in case of high imbalance ratio, leads to an oversaturation of the classifier with instances from old concepts. This may significantly reduce the forgetting capability of any underlying classifier, thus leading to lower reactivity to concept drift. CSMOTE and OUOB display very good robustness to increasing imbalance ratio. Sadly, their predictive power is lowest from all methods, proving that robustness on its own is not enough. The proposed ROSE combines robustness with best predictive performance, showing that ROSE is capable of handling even high class imbalance. This is especially desired in various real-world continual and streaming problems, where we do not know how the imbalance ratio may change over time and we need a classifier that can offer stable performance regardless of characteristics of incoming data. ROSE is capable of outperforming all of the methods on most of the datasets. On a few of them (notably AssetNegotiation and SEA) ROSE returns comparable performance to reference methods, but never is outperformed by them.
Comparison with general-purpose ensembles ROSE was compared with KUE, ARF, LB, and SRP. Surprisingly, general-purpose ensembles display similar robustness to increasing imbalance ratio as skew-insensitive approaches discussed previously. This can be explained by the diversity of base learners employed in those ensembles. Using mutually complimentary learners leads to a reduction in bias towards the majority class and better management of even higher class disproportion. This shows that the idea of classifier diversity, strongly explored in ROSE, is a key factor in designing effective ensemble learners for imbalanced data streams. However, SRP has problems with stability on SEA, Hyperplane, and Sine datasets, where increasing imbalance ratio leads to higher variance in its results. ROSE outperforms all of the reference ensemble methods in terms of stability and predictive power on all imbalance ratios.
5.2 Experiment 2: analyzing robustness to drifting class imbalance
Goal of the experiment This experiment was designed to address RQ2 and evaluate the robustness of classifiers to a scenario with drifting imbalance ratio. Concept drift may also affect the class distributions, changing the learning difficulty over time. While many existing methods are designed to cope well with the static imbalance ratio present during the training phase, they lack effective mechanisms that allow for skew-insensitive adaptation to time-varying disproportions between classes. To evaluate this, we prepared six data stream benchmarks {Agrawal, AssetNegotiation, RandomRBF, SEA, Sine, Hyperplane} with drifting imbalance ratio representing first increasing and then decreasing imbalance ratio {5, 10, 20, 100, 20, 10, 5}. This allows us to analyze not only how each analyzed classifier is able to cope with class imbalance, but also how adaptive it is to the dynamic imbalance ratio occurrences. Figure 2 illustrates the prequential Kappa over time for the selected general-purpose and imbalance-specific ensembles. Tables 6 and 7 present the average Kappa and AUC for each of the drift types on the six generators, and the rank of the algorithms.

Prequential Kappa on drifting class imbalance ratios. The first group of algorithms includes imbalanced-specific ensembles (ROSE vs. OOB, UOB, OUOB, CSMOE). The second group of algorithms includes general-purpose ensembles (ROSE vs. KUE, ARF, LB, SRP)
Comparison with class-imbalance ensembles We can see that while all methods can handle drifting imbalance ratios, their main differences lie in how strongly imbalance drift affects them and how quickly they can recover from the imbalance drift. It is interesting to see that both over- and undersampling based ensemble methods perform significantly worse in the case of drifting imbalance ratios. While OOB (on Kappa) and UOB (on AUC) are the best performing method from all class-imbalance ensembles (despite their lack of explicit drift handling mechanisms), their hybrid OUOB counterpart often falls short to most of the methods. This can be explained by its inability to effectively switch between different resampling approaches that leads to slower recovery from changes in imbalance ratio and drifts. In all of six benchmarks CSMOTE (with ARF) shows the biggest drops in performance among all methods when imbalance ratio increases. This can be explained by the inability of the online k-nearest neighbor-based oversampling method to properly model the majority class with the increasing class disproportions. This forces CSMOTE to introduce artificial instances to wrong classes, not being able to adapt quickly enough to sudden changes. Therefore, we can conclude that SMOTE-based solutions are not suitable to handle drifting imbalance ratios in data streams, especially when imbalance ratio is increasing over time. ROSE offers superior performance to all four of class-imbalance ensembles, showing both smaller drops in performance when imbalance ratio drift occurs, but also displaying quicker recovery rates after the drift, leading to faster adaptations to new concepts with different class proportions. This shows that ROSE offers great capabilities of adaptation to drifting and imbalanced data streams, far outperforming state-of-the-art skew-insensitive solutions.
Comparison with general-purpose ensembles We can see that general-purpose ensemble approaches cannot cope with the imbalance drift and require significant time to recover from changes in class ratios and thus offer lower recovery rates than ROSE. Even if their performance on a fully learned concept is satisfactory, they require more instances than ROSE to achieve this performance and capture the properties of concept with new imbalance ratio. It is interesting to notice that in case of the Kappa metric, KUE and LB ensemble classifiers work better than skew-insensitive solutions discussed earlier. This shows that ensemble approaches can effectively utilize their diversity to offer faster adaptation to sudden changes. Skew-insensitive solutions (especially CSMOTE) do not emphasize diversity during their base classifier update, thus leading to slower adaptation to drifts. ROSE combines the advantages of both approaches, combining fast adaptation via promoted diversity of base classifiers with skew-insensitive mechanisms offering robustness to static and drifting imbalance ratios.
5.3 Experiment 3: analyzing robustness to instance-level difficulties

Robustness to borderline and rare instances under different class imbalance (Kappa). The first group of algorithms includes imbalanced-specific ensembles (ROSE vs. OOB, UOB, OUOB, CSMOE). The second group of algorithms includes general-purpose ensembles (ROSE vs. KUE, ARF, LB, SRP)
Goal of the experiment This experiment was designed to address RQ3 and evaluate the robustness of the data stream classifiers to instance-level difficulties (Brzeziński et al., 2021). We used two imbalance generatorsFootnote 2 to create scenarios with the presence of borderline or rare instances, as well as with both types at once, while experiencing a split of the cluster. Difficult instances were created for the minority class to present a significantly more challenging scenario. We evaluated their influence on classifiers on their own and combined with medium IR equal to 10 and high IR equal to 100. Borderline instances are challenging to classifiers as they lie in the uncertainty area of the decision space and strongly impact the induction of the classification border. Rare instances are overlapping with the majority class, leading to small sample and sparse subconcepts created within the minority class. So far only few works discussed the idea of analyzing the instance-level difficulty in the context of data streams and concept drift, while this issue is of crucial importance in imbalanced data domain. Figure 3 and Tables 8 and 9 show the performance of the ensemble methods on data streams with various ratios of instance-level difficulties injected into the stream.
Comparison with class-imbalance ensembles All four reference methods were designed to learn from imbalanced data stream, but only by considering the global imbalance ratio. One can see that none of the state-of-the-art skew-insensitive classifiers display any additional robustness to the increasing number of both borderline and rare instances. Out of the two types, rare instances pose much more difficulty to all methods. UOB and OOB cannot effectively handle the borderline instances, as their sampling methods only increase the overlap on the boundary, leading to a decreased certainty between the classes. This is especially visible in the case of OOB, as it may enhance the presence of borderline instances that are overlapping with the majority class, leading effectively to higher error on both classes. In case of rare instances, UOB, OOB, and OUOB cannot efficiently clean their neighborhoods or oversample them in a meaningful manner, leading to significant drops in predictive performance with an increased ratio of difficult instances. Interestingly, CSMOTE displays much better performance than random resampling approaches, which is particularly visible on the rare instances. This can be attributed to the fact that rare instances create the small sample size problem, not offering enough information for classifiers to efficiently capture their properties. CSMOTE indirectly increases the density of instances in their neighborhood, leading to their increased importance during the classifier training. ROSE can handle borderline and rare instances more effectively than those four classifiers, due to its capabilities of increased exposure to difficult instances. The proposed self-adjusting \(\lambda\) allows for displaying borderline and rare instances multiple times to base classifiers, increasing their adaptation to local data characteristics. This shows that ROSE displays high robustness not only to class imbalance, but also data irregularities and instance-level difficulties.
Comparison with general-purpose ensembles Results show that when only instance-level difficulties are present the general-purpose ensembles display performance and robustness similar to their skew-insensitive counterparts. This is a very interesting observation, as it shows that instance-level difficulties pose completely different challenges to learning systems than imbalanced data. And while they can be a part of the imbalanced problem, they can pose as a difficult problem on their own. Surprisingly, KUE which in other experiments was one of the best performing methods, here is among the most affected by increasing ratios of difficult instances. This shows that while KUE displays great performance on standard and cleaned data streams, it cannot be effectively applied to data streams with irregularities. Here the second most robust method, after the proposed ROSE, is SRP. By training classifiers on random feature subspaces, SRP alters the instance-level characteristics (by altering distances between instances), which may lead to better capturing of rare objects. This observation applies to ROSE, as our approach uses a similar mechanism. ARF also displays good robustness to instance-level difficulties. As ARF trains its base learners on both subsets of instances and features, some of the learners in its pool are going to be more affected by difficult instances than the others. However ARF, unlike ROSE, does not offer any mechanisms for increasing the exposure to difficult instances—which in the end results in it having worse predictive performance on difficult data streams than the proposed ROSE.
5.4 Experiment 4: analyzing robustness to drifting noise on imbalanced streams
Goal of the experiment This experiment was designed to address RQ4 and evaluate the robustness of classifiers to a scenario with the presence of drifting noise affecting the features. To make this scenario more realistic and at the same time challenging, we combined it with the dynamic imbalance ratio examined in Experiment 2. This way, both noise and IR drift over time. Feature distribution affects the definition of class boundaries, thus leading to a more challenging skewed learning scenario with higher degree of overlap between classes. Features affected by noise should be discarded by a classifier (Krawczyk & Cano, 2018), as they may display a highly negative impact on the learning from minority classes. We used the six generators from Experiment 2 with drifting imbalance ratio, further injecting noise into a varying ratio of features {10%, 20%, 30%, 40%}. Figure 4 shows the plots depicting robustness to increasing noise ratio and Fig. 5 depicts the comparison between ROSE and best performing ensemble methods under drifting imbalance ratio and 20% of features being subject to noise. This is further accompanied by Tables 10 and 11 showing average Kappa and AUC metrics under varying noise levels over the six data stream benchmarks.

Robustness to different levels of noise with sudden drift (Kappa). The first group of algorithms includes imbalanced-specific ensembles (ROSE vs. OOB, UOB, OUOB, CSMOE). The second group of algorithms includes general-purpose ensembles (ROSE vs. KUE, ARF, LB, SRP)
Comparison with class-imbalance ensembles We can see that the reference streaming classifiers, while able to work with class imbalance as the only learning difficulty, they do not possess any mechanisms for coping with the presence of noise in the stream. Neither over- or undersampling based solutions can remove noisy or redundant features, leading to noise significantly impairing their learning. UOB and CSMOTE are the ones that are impacted most negatively by noise. While CSMOTE performance can be easily explained (SMOTE uses Euclidean distance to generate artificial instances, thus noise decreases the quality of oversampling), the poor performance of UOB comes as a surprising observation. Random undersampling does not use any feature-based information, thus the noise must negatively impact the bagging procedure itself. UOB does not have any explicit drift handling mechanism, which may lead to performance degradation over time under non-stationary noise. At the same time, ROSE shows robustness to varying levels of noise, significantly outperforming reference solutions. It is very important to notice that the difference between ROSE and reference classifiers in terms of their predictive power (measured both as prequential Kappa and prequential AUC) is much more significant in Experiment 2 (which used the same data streams but without noise). This shows that reference skew-insensitive classifiers are strongly impacted by noise, while ROSE suffers significantly lower drops in performance regardless of the noise level present. By analyzing Fig. 5 we can see that the combination of feature noise and drifting imbalance ratio becomes even more challenging for reference classifiers. We observe that with the increasing imbalance ratio the negative impact of noise strengthens. This can be attributed to the impact of noise on both majority and minority classes. Their distributions become shifted, leading to increasing overlapping and more difficult borderline instances. With increasing imbalance ratio, we have less and less safe minority instances, thus negatively impacting the adaptation of classifiers to drifts. ROSE is capable of removing noisy features and effectively utilizing feature subspaces to train noise-insensitive classifiers that improve its adaptation to concept drift and incorporation of new, useful knowledge into ROSE ensemble.
Comparison with general-purpose ensembles While standard ensembles do not offer high robustness to class imbalance, they are capable of handling feature noise as well as skew-insensitive streaming classifiers. In some cases (e.g., Agrawal or Hyperplane generators) we observe that general-purpose ensembles display higher robustness to noise than their skew-insensitive counterparts. This can be explained by some specific mechanisms embedded in the ensembles that allow to handle implicitly some noise. KUE uses a combination of feature subspaces (like ROSE) that allow to filter out noisy features from being included in newly trained classifiers. Additionally, KUE uses an abstaining mechanism that removes the most uncertain classifiers from the voting procedure. If a classifier is highly affected by noisy features, its certainty will become closer to a random classifier. Abstaining mechanism will temporarily switch off such a classifier, leading to better a response to noisy data streams. ARF also uses feature subspaces, but in each decision tree node, leading to a reduced probability of noisy features becoming the backbone of its base classifiers. ROSE displays the highest robustness to any level of noise due to its capability of using feature subspaces combined with the use of a background ensemble to explore new random subspaces without noise.

Prequential Kappa on drifting noise (noise on 20% of the features). The first group of algorithms includes imbalanced-specific ensembles (ROSE vs. OOB, UOB, OUOB, CSMOE). The second group of algorithms includes general-purpose ensembles (ROSE vs. KUE, ARF, LB, SRP)
5.5 Experiment 5: real-world datasets
Goal of the experiment This experiment was designed to address RQ5 and evaluate the predictive power of ROSE on 24 real-world imbalanced and drifting data streams. The four previous experiments focused on analyzing the robustness of ROSE to various learning difficulties present in imbalanced data streams, allowing us to gain deeper insight into why ROSE is a highly effective and well-rounded classifier. We used data stream generators to have a full control over the created data and to simulate specific challenging scenarios. Real-world datasets pose specific challenges to classifiers, as they are not generated in a controlled environment. They are characterized by a combination of various learning difficulties that appear with varying strength or frequency. Their imbalance ratio changes over time, while concept drift may oscillate among different types with varying speed. Therefore, evaluating ROSE against reference methods on real-world data streams is a crucial step towards proving effectiveness of our classifier. The real-world data streams employed in the study are popular benchmarks for streaming classifiers. This will allow readers to position the effectiveness of the methods among other studies on data streams, even those not focusing on class imbalance. Figure 6 shows the plot depicting the prequential Kappa over time and Table 12 presents the prequential metrics (accuracy, Kappa, and AUC) averaged across all 24 datasets and the ranks.

Prequential Kappa on real-world datasets. The first group of algorithms includes imbalanced-specific ensembles (ROSE vs. OOB, UOB, OUOB, CSMOE). The second group of algorithms includes general-purpose ensembles (ROSE vs. KUE, ARF, LB, SRP)
Unique nature of real-world imbalanced data streams It is important to highlight a crucial difference between artificial and real-world imbalanced data streams. All generators are probabilistic and base the generation of instances on prior probability taken from current parametric imbalance ratio. With the change of imbalance ratio, the underlying probability of generating instance from minority and majority classes also change. Still, their appearance in the stream is dictated strictly by these priors, leading to bounded time windows within which minority and majority instances appear. This does not hold for real-world imbalanced data streams, as they were collected following some specific phenomenon observations and are not bounded with such clear probabilistic mechanisms. Therefore, there are no uniform characteristics to be observed over extended periods of time and the arrival of class-specific instances is dictated by how the observations were collected. This poses unique challenges to imbalanced data stream mining, such as latency with which instances from a specific class arrive, or extended periods of time when instances from only a single class appear. Such a formulation of data streams is much more challenging for existing streaming classifiers, as it makes blind adaptation to every new instance insufficient. Instead, it forces guided adaptation when useful knowledge is retained to avoid the forgetting of specific classes. This makes real-world imbalanced data streams akin to continual / lifelong learning, where robustness to catastrophic forgetting becomes a key issue. Such benchmarks allow us to gain additional insights into ROSE and reference classifiers, allowing to evaluate them under these unique and challenging conditions.
Comparison with class-imbalance ensembles It is very interesting to see that skew-insensitive methods deliver inferior results to ROSE on most of the datasets with respect to Kappa. This shows us that these reference methods cannot handle compound real-world problems that are characterized by mixed drifts and varying class imbalance ratios. The especially low performance of OOB and UOB can be attributed to their online nature. They adapt their resampling strategy to the newly arriving instance, not being able to retain any memory of the previously seen concepts. When subject to a high latency of instances from a certain class (i.e., one of classes not appearing for a certain period) they will become highly skewed and cannot effectively recover from such an extreme imbalance ratio. OUOB and CSMOTE display much better performance, showing that their more complex mechanisms (hybrid resampling for OUOB and guided oversampling for CSMOTE) are able to capture more compound characteristics of the real-world streams. ROSE is capable of outperforming all four reference methods, which we contribute to storing buffers for each class independently, making ROSE robust to catastrophic forgetting in such latency scenarios.
Comparison with general-purpose ensembles When analyzing prequential accuracy, we can see that SRP is the best performing method. However, when analyzing skew-insensitive metrics such as Kappa we can see that ROSE outperforms every single ensemble method. This shows how using accuracy as a metric may lead to false conclusions and how existing ensemble methods can be biased towards the majority class. This is especially visible in case of ARF and LB that achieve great prequential accuracy on all benchmarks, but a significantly lower Kappa. ROSE offers flexibility to various challenges present in real-world data, delivering stable performance. It is important to note that ROSE always achieves high ranks, while reference ensembles are characterized by a high variance in their performance, making them impractical for deployment in new, unknown domains.
5.6 Experiment 6: overall comparison and statistical analysis
Goal of the experiment The previous experiments presented a detailed evaluation of ROSE against selected reference methods on imbalanced and drifting data streams, as well as on real-world benchmarks. Due to the readability of the results, we compared ROSE with four top performing skew-insensitive ensembles and four top-performing general-purpose ensembles. However, each experiment was actually run using all 30 ensembles listed in Table 3, resulting in the biggest study of learning from imbalanced data streams conducted so far. In this section, we present the summary of results for all of 30 ensembles, including non-parametric and Bayesian statistical analyses. Tables 13 and 14 present the results for all classifiers according to prequential Kappa and AUC. Results are divided into five major groups (following the previous five experiments) and averaged over all benchmarks belonging to a given group. The meta rank represents the rank of the ranks across all of the benchmarks. Table 15 shows the averages and ranks of the runtime (seconds per 10,000 instances) and memory consumption (RAM-hours) of all algorithms.
To evaluate the statistical significance of the results over multiple datasets, Figs. 7 and 8 present the visualization of Bonferroni-Dunn tests (multiple algorithm comparison) for both metrics using a p-value of 0.01. The algorithms are sorted according to their rank. The critical distance (CD) interval indicates the difference of ranks between algorithms to be considered statistically different. Furthermore, Fig. 9 depicts the visualizations of Bayesian rank test (pairwise algorithm comparison) between ROSE and best performing skew-insensitive method (OOB) and best performing general-purpose ensemble method (LB). This test returns probabilities that one model will outperform the other based on measured performance. The top region indicates practical equivalence, while the lower right portion denotes better performance for ROSE and the remaining side for the opposing algorithm.

Bonferroni-Dunn statistical analysis on Kappa

Bonferroni-Dunn statistical analysis on AUC
Comparison with reference classifiers We observe that ROSE achieves the best performance and ranks regardless of the benchmark (from five major groups) and outperforms in a statistically significant manner all of 30 methods. It is important to note that ROSE delivers a very stable performance and high ranks over all benchmarks. This cannot be said about any of the other methods that are subject to high variation depending on the benchmark. This is further augmented by the observation of behaviors on Kappa and AUC. While ROSE always achieves best rank on both metrics, the second-best performing method for Kappa is LB, while for AUC is OOB. At the same time LB for AUC is ranked as the fourth classifier. This showcases that ROSE is a well-rounded and flexible classifier, capable of dealing with various learning challenges present in imbalanced and drifting data streams. This allows ROSE to be efficiently deployed on a data stream with no prior knowledge of its characteristics, imbalance ratio, or presence of noise. Due to its self-adjusting nature ROSE can tackle any emerging and unknown difficulties, while remaining robust to skewed distributions. ROSE exhibits a runtime similar to LB and ARF while improving the Kappa and AUC. ROSE requires additional memory compared to KUE to train and store the background ensemble. While DACC is the fastest and has the lowest memory consumption its Kappa and AUC ranks are among the worst. On the other hand, OSMOTE and OUOB show the slowest runtime and the largest demand of memory resources.

Bayesian test: ROSE versus LB and OOB on Kappa and AUC
5.7 Experiment 7: ablation study
Goal of the experiment Previous experiments allowed us to establish the effectiveness and robustness of ROSE when facing diverse benchmarks within learning from imbalanced data streams. In this final experiment, we aim at performing an ablation study to gain deeper insights into why ROSE is such an effective classifier and which of its features help to improve the accuracy and robustness to drift and class imbalance. ROSE consists of four main features. We performed an ablation study by switching off each of these features individually and seeing how they influence the performance of our ensemble. Therefore, the static lambda version uses a fixed \(\lambda = 4\), the one window version uses a single sliding window of 1000 instances regardless the number of classes, the no background ensemble skips the training of an ensemble on the background, the all features version uses all input features for learning on all base classifiers, and the none version uses none of these features. Moreover, we also compare ROSE by testing three other alternatives, replacing one classifier at a time, selecting uniform subspace distributions, and using the (Wang etal., 2015) \(\lambda\) rule. Tables 16 and 17 present the averaged results of ROSE without its features over the previous five experimental studies along with the three alternatives. Figure 10 shows the prequential performance of ROSE and its impaired versions over time for selected representative data stream benchmarks.

Contribution of each of the ROSE features in different experiments
Self-adjusting \(\lambda\) for bagging Usage of adaptive \(\lambda\) in online bagging has a significant impact on ROSE performance. This is especially visible for benchmarks with drifting imbalance ratio, instance-level difficulties, and noise. The \(\lambda\) parameter explicitly controls the Poisson distribution for online bagging, and thus implicitly moderates the exposure of instances to base classifiers of our ensemble. By presenting more difficult instances to classifiers several times, we focus their adaptation on such challenging cases. This is crucial for better adaptation to minority classes, as borderline/rare instances should be better modeled by the classifier, while safe instances do not require such an exposure. Existing methods use a fixed value of \(\lambda\), while ROSE proposes a self-adjusting modification. This is a crucial reason behind ROSE adaptation to drifting imbalance and instance-level difficulties, as the impact of most challenging instances is boosted during adaptation. At the same time, this increases the robustness of ROSE to noise, as potentially noisy instances are less exposed to ROSE and thus do not deteriorate the adaptation process.
Sliding window per class Storing individual sliding windows for each class seems to have the lowest impact on ROSE from all four features. We can see that it offers small improvements for drifting imbalance, instance-level difficulties, and noisy streams, but the gains are overshadowed by remaining features. However, for real-world data streams we can see a much higher improvement of having a sliding window per class. This is due to the nature of these benchmarks discussed in detail in Experiment 5. Artificially generated data streams follow a probabilistic distribution and thus there always will be instances from each class present in the stream (although with varying ratios). Real-world data are not bounded by such mechanisms and thus some classes may periodically disappear from the stream. This situation is identical to catastrophic forgetting in continual learning of deep architectures, where accommodation of new information leads to discarding of the previously seen one. Buffers per class in ROSE offer robustness to catastrophic forgetting, as even during periods of high latency our ensemble will have access to instances from all the classes. This makes our individual sliding windows indispensable for any real-world scenario and offers a powerful backbone for adapting ROSE to class-incremental learning problems in the future.
Background ensemble Background ensemble offers a quick and safe way for ROSE to completely restart its architecture in case of a sudden changes or a strong noise presence in the stream. While ROSE adapts its base classifiers in an online manner, in some scenarios it may be more beneficial to replace most, if not all, base classifiers with new ones trained on the most recent concept (as adaptation may be too slow to properly recover from drift.) This is a significant step further from existing adaptive ensemble architectures that train only a single background classifier and use it to replace the worst performing member of the ensemble. This limits their adaptation capabilities to sudden drifts or extreme changes in imbalance ratios, as only one classifier can be replaced at a time. The background ensemble significantly improves the robustness to noise, as if the most of the base classifiers use noisy features, then one-by-one replacement will not be enough. As each member of background ensemble is trained on a new feature subset, we limit the chances of using the same noisy features in both old and new ensembles.
Random feature subspaces The combination of feature and instance subspaces support the diversity among the base classifiers in ROSE. This factor leads to one of the most significant gains in classification accuracy for ROSE, showing the importance of using diversified subspace representations for training base learners for drifting and imbalanced data streams. When subspaces are combined with self-adjusting \(\lambda\), ROSE effectively gains a mechanism to control its own diversity. As it is known for data stream ensembles, high diversity is helpful when recovering from concept drift, while low / moderate diversity allows better exploitation of the stable concept. Furthermore, such subspaces limit the chances of using noisy features / instances to adapt the classifiers, leading to better robustness when learning from imbalanced data streams.
Alternative mechanisms Finally, we analyze the benefits of the ROSE features over the state-of-the-art existing mechanisms in the literature. This will allow us to prove that not only ROSE as whole offers superior performance to reference ensembles, but also that every mechanism introduced by ROSE is individually justified. Existing ensemble methods usually replace the single worst classifier (Brzeziński & Stefanowski, 2014a), while ROSE may replace several of them simultaneously. By offering the flexibility of replacing multiple classifiers at once, ROSE offers improved adaptability to changing and difficult data. In case of sudden drifts or evolving data complexity levels more than a single classifier can become outdated and simply replacing them one by one will lead to slower recovery rates after the change. This is most pronounced in the case of drifting IR and instance-level difficulties. When building feature subspaces for base classifiers reference approaches usually use a uniform probability to select the number of used features (Cano & Krawczyk, 2020), while ROSE replaces this with a normal distribution. We can see that this leads to most significant gain when handling instance-level difficulties and real-world datasets. This can be explained by the fact that better-defined subspaces lead to improved separation among instances, thus leading to reduction in classification difficulties and lower susceptibility to presence of noisy features. Finally, we have compared ROSE self-adaptive \(\lambda\) from Eq. 2 to the approach proposed by (Wang etal., 2015). We can see that our \(\lambda\) calculation method outperforms the reference one, especially when dealing with noisy and real-world datasets. This shows that ROSE \(\lambda\) adaptation process is less prone to temporal disturbances caused by noise, as well as can better handle diverse combinations of concept drift and imbalance ratio changes present in real-world problems.
6 Conclusions and future work
Summary In this paper, we have introduced Robust Online Self-Adjusting Ensemble (ROSE) for mining drifting and imbalanced data streams. The novelty of ROSE lies in an original ensemble architecture design with multiple features designed for a high level of interplay with each other. ROSE uses base classifiers trained on subsets of both instances and features, which allows for handling both complex and noisy data streams. ROSE offers a hybrid architecture that maintains a fixed-size pool of classifiers updated in an online manner, but is capable of automatic training of new classifiers. Drift detectors associated with each base classifier in the pool (and hence with a feature subset that it represents) control the training of a background ensemble. A Kappa-based classifier selection is used to determine if the newly trained learner should be added to the ensemble. ROSE is capable of handling both standard and imbalanced data streams without any need for switching between these modes. This is achieved by using balanced buffers per class that store instances to train new classifiers; and thanks to adaptive \(\lambda\) parameter that forces increased exposure of minority instances to all classifiers.
Main research findings The extensive experimental study on a total of five diverse benchmarks proved that ROSE not only is capable of significantly outperforming 30 state-of-the-art skew-insensitive and general-purpose ensembles, but additionally can handle a variety of difficult data stream mining scenarios (such as skewed classes, evolving class imbalance ratio, instance-level difficulties, noisy features, or binary and multi-class problems) without the need of end-user tuning or supervision. ROSE has a runtime and memory consumption comparable to reference methods such as Kappa Updated Ensemble, Leveraging Bag, and Adaptive Random Forest.
Lessons learned Experimental comparison: In order to gain a deeper insight into the performance of any algorithm for imbalanced data streams, it must be be evaluated using a diverse set of scenarios, including static and dynamic imbalance ratios paired with instance-level difficulties, noise, and concept drift, as well as real-world datasets to have a holistic comparison. Only such a thorough experimental study allows to formulate specific recommendations for applicability areas. We can conclude that ROSE is a well-rounded ensemble capable of displaying robustness under diverse difficulties present in imbalanced data streams. Handling skewed distributions: ROSE shows that robustness to class imbalance can be achieved by exploiting learning mechanisms and per-class forgetting, outperforming existing resampling approaches. Computational and memory complexity: all features of ROSE contribute to its high predictive performance (as seen during the ablation study), while being characterized by low time and memory complexities. This allows ROSE to display resource consumption on par with algorithm like Leveraging Bagging and Adaptive Random Forest. Metrics: ROSE evaluation have shown that that Kappa and AUC metrics provide complementary information about the performance of the classifiers. While Kappa strengthens the significance of the minority class under highly imbalanced datasets, AUC offers a balanced trade-off between the majority and minority classes. Therefore, a complete comparison of classifiers should include both complementary metrics.
Future works Our future works will concentrate on extending the classifier generation and selection procedure in such a way that will increase the probability of features that were marked as drifting ones to be included in the newly created feature subspaces. We will further investigate connections between data stream mining and continual learning to adapt ROSE mechanisms to create robust deep learning architectures. We will study the application to multi-label classification where labels are often highly imbalanced.
Availability of data and material
Data & materials available at https://github.com/canoalberto/ROSE.
Code availability
Source code is available at https://github.com/canoalberto/ROSE.
Notes
Source code and experimental setup available at https://github.com/canoalberto/ROSE.
Imbalance generators available at https://github.com/dabrze/imbalanced-stream-generator.
References
Abolfazli, A., & Ntoutsi, E. (2020). Drift-aware multi-memory model for imbalanced data streams. In IEEE international conference on big data (pp. 878–885).
Al-Shammari, A., Zhou, R., Naseriparsa, M., & Liu, C. (2019). An effective density-based clustering and dynamic maintenance framework for evolving medical data streams. International Journal of Medical Informatics, 126, 176–186.
Aljundi, R., Kelchtermans, K., & Tuytelaars, T. (2019). Task-free continual learning. In IEEE conference on computer vision and pattern recognition (pp. 11254–11263).
Aminian, E., Ribeiro, R. P., & Gama, J. (2020). A study on imbalanced data streams. In Machine learning and knowledge discovery in databases (pp. 380–389).
Anupama, N., & Jena, S. (2019). A novel approach using incremental oversampling for data stream mining. Evolving Systems, 10(3), 351–362.
Bahri, M., Bifet, A., Gama, J., Gomes, H. M., & Maniu, S. (2021). Data stream analysis: Foundations, major tasks and tools. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 11(3), e1405.
Bernardo, A., Della Valle, E., & Bifet, A. (2020a). Incremental rebalancing learning on evolving data streams. In International conference on data mining workshops (pp. 844–850).
Bernardo, A., Gomes, H. M., Montiel, J., Pfahringer, B., Bifet, A., & Della Valle, E. (2020b). C-SMOTE: Continuous synthetic minority oversampling for evolving data streams. In IEEE international conference on big data (pp. 483–492).
Bifet, A., Holmes, G., Pfahringer, B., Kirkby, R., & Gavaldà, R. (2009). New ensemble methods for evolving data streams. In ACM SIGKDD international conference on knowledge discovery and data mining (pp. 139–148).
Bifet, A., Holmes, G., Kirkby, R., & Pfahringer, B. (2010). MOA: Massive online analysis. Journal of Machine Learning Research, 11, 1601–1604.
Bifet, A., Holmes, G., & Pfahringer, B. (2010b). Leveraging bagging for evolving data streams. In European conference on machine learning (pp. 135–150).
Bifet, A., Hammer, B., & Schleif, F. (2019). Recent trends in streaming data analysis, concept drift and analysis of dynamic data sets. In European symposium on artificial neural networks.
Bobowska, B., Klikowski, J., & Wozniak, M. (2019). Imbalanced data stream classification using hybrid data preprocessing. Machine Learning and Knowledge Discovery in Databases, 1168, 402–413.
Bonab, H. R., & Can, F. (2018). GOOWE: Geometrically optimum and online-weighted ensemble classifier for evolving data streams. ACM Transactions on Knowledge Discovery from Data, 12(2), 25.
Branco, P., Torgo, L., & Ribeiro, R. P. (2016). A survey of predictive modeling on imbalanced domains. ACM Computing Surveys (CSUR), 49(2), 1–50.
Brzeziński, D., & Stefanowski, J. (2011). Accuracy updated ensemble for data streams with concept drift. In International conference on hybrid artificial intelligence systems (pp. 155–163).
Brzeziński, D., & Stefanowski, J. (2014). Combining block-based and online methods in learning ensembles from concept drifting data streams. Information Sciences, 265, 50–67.
Brzeziński, D., & Stefanowski, J. (2014). Reacting to different types of concept drift: The accuracy updated ensemble algorithm. IEEE Transactions on Neural Networks and Learning Systems, 25(1), 81–94.
Brzeziński, D., & Stefanowski, J. (2017). Prequential AUC: Properties of the area under the ROC curve for data streams with concept drift. Knowledge and Information Systems, 52(2), 531–562.
Brzeziński, D., & Stefanowski, J. (2018). Ensemble classifiers for imbalanced and evolving data streams. Data Mining in Time Series and Streaming Databases, Machine Perception and Artificial Intelligence, 83, 44–68.
Brzeziński, D., Stefanowski, J., Susmaga, R., & Szczȩch, I. (2018). Visual-based analysis of classification measures and their properties for class imbalanced problems. Information Sciences, 462, 242–261.
Brzeziński, D., Stefanowski, J., Susmaga, R., & Szczȩch, I. (2019). On the dynamics of classification measures for imbalanced and streaming data. IEEE Transactions on Neural Networks and Learning Systems, 31(8), 2868–2878.
Brzeziński, D., Minku, L. L., Pewinski, T., Stefanowski, J., & Szumaczuk, A. (2021). The impact of data difficulty factors on classification of imbalanced and concept drifting data streams. Knowledge and Information Systems, 63(6), 1429–1469.
Buzzega, P., Boschini, M., Porrello, A., & Calderara, S. (2020). Rethinking experience replay: A bag of tricks for continual learning. In 25th international conference on pattern recognition (pp. 2180–2187).
Cano, A., & Krawczyk, B. (2019). Evolving rule-based classifiers with genetic programming on GPUs for drifting data streams. Pattern Recognition, 87, 248–268.
Cano, A., & Krawczyk, B. (2020). Kappa updated ensemble for drifting data stream mining. Machine Learning, 109(1), 175–218.
de Carvalho Santos, S. G. T., Júnior, P. M. G., dos Santos Silva, G. D., & de Barros, R. S. M. (2014). Speeding up recovery from concept drifts. In European conference on machine learning and knowledge discovery in databases (pp. 179–194).
de Barros, R. S. M., & de Carvalho Santos, S. G. T. (2018). A large-scale comparison of concept drift detectors. Information Sciences, 451–452, 348–370.
de Barros, R. S. M., de Carvalho Santos, S. G. T., & Júnior, P. M. G. (2016). A boosting-like online learning ensemble. In International joint conference on neural networks (pp. 1871–1878).
Demšar, J. (2006). Statistical comparisons of classifiers over multiple data sets. The Journal of Machine Learning Research, 7, 1–30.
Du, H., Zhang, Y., Gang, K., Zhang, L., & Chen, Y. C. (2021). Online ensemble learning algorithm for imbalanced data stream. Applied Soft Computing, 107, 107378.
Fernández, A., García, S., Galar, M., Prati, R. C., Krawczyk, B., & Herrera, F. (2018). Learning from Imbalanced Data Sets. Springer.
Ferreira, L. E. B., Gomes, H. M., Bifet, A., & Oliveira, L. S. (2019). Adaptive random forests with resampling for imbalanced data streams. In International joint conference on neural networks (pp. 1–6).
Gama, J., $\breve{Z}$liobaitė, I., Bifet, A., Pechenizkiy, M., & Bouchachia, A. (2014). A survey on concept drift adaptation. ACM Computing Surveys, 46(4):44:1–44:37.
Gao, J., Ding, B., Fan, W., Han, J., & Yu, P. S. (2008). Classifying data streams with skewed class distributions and concept drifts. IEEE Internet Computing, 12(6), 37–49.
Ghomeshi, H., Gaber, M. M., & Kovalchuk, Y. (2019). Ensemble dynamics in non-stationary data stream classification. In Learning from data streams in evolving environments (pp. 123–153). Springer.
Gomes, H. M., & Enembreck, F. (2014). SAE2: Advances on the social adaptive ensemble classifier for data streams. In ACM symposium on applied computing (pp. 798–804).
Gomes, H. M., Bifet, A., Read, J., Barddal, J. P., Enembreck, F., Pfharinger, B., et al. (2017). Adaptive random forests for evolving data stream classification. Machine Learning, 106(9–10), 1469–1495.
Gomes, H. M., Read, J., & Bifet, A. (2019a). Streaming random patches for evolving data stream classification. In IEEE international conference on data mining (pp. 240–249). IEEE
Gomes, H. M., Read, J., Bifet, A., Barddal, J. P., & Gama, J. (2019). Machine learning for streaming data: State of the art, challenges, and opportunities. ACM SIGKDD Explorations Newsletter, 21(2), 6–22.
Grzyb, J., Klikowski, J., & Wozniak, M. (2021). Hellinger distance weighted ensemble for imbalanced data stream classification. Journal of Computational Science, 51, 101314.
He, X., Sygnowski, J., Galashov, A., Rusu, A. A., Teh, Y. W., & Pascanu, R. (2019). Task agnostic continual learning via meta learning. CoRR arXiv:abs/1906.05201
Hulten, G., Spencer, L., & Domingos, P. (2001). Mining time-changing data streams. In ACM SIGKDD international conference on knowledge discovery and data mining (pp. 97–106).
Jaber, G., Cornuéjols, A., & Tarroux, P. (2013). A new on-line learning method for coping with recurring concepts: The ADACC system. In International conference on neural information processing (pp. 595–604).
Klikowski, J., & Wozniak, M. (2019). Multi sampling random subspace ensemble for imbalanced data stream classification. In R. Burduk, M. Kurzynski, & M. Wozniak (Eds.), International conference on computer recognition systems (Vol. 977, pp. 360–369).
Klikowski, J., & Wozniak, M. (2020). Employing one-class SVM classifier ensemble for imbalanced data stream classification. International Conference on Computational Science, 12140, 117–127.
Kolter, J. Z., & Maloof, M. A. (2007). Dynamic weighted majority: An ensemble method for drifting concepts. Journal of Machine Learning Research, 8, 2755–2790.
Korycki, L., & Krawczyk, B. (2020). Online oversampling for sparsely labeled imbalanced and non-stationary data streams. In International joint conference on neural networks (pp. 1–8).
Korycki, L., & Krawczyk, B. (2021a). Class-incremental experience replay for continual learning under concept drift. In IEEE conference on computer vision and pattern recognition workshops (pp. 3649–3658).
Korycki, L., & Krawczyk, B. (2021b). Concept drift detection from multi-class imbalanced data streams. In IEEE international conference on data engineering (pp. 1068–1079).
Korycki, L., & Krawczyk, B. (2021c). Low-dimensional representation learning from imbalanced data streams. In Pacific-Asia conference on advances in knowledge discovery and data mining (Vol. 12712 LNCS, pp. 629–641).
Korycki, L., Cano, A., & Krawczyk, B. (2019). Active learning with abstaining classifiers for imbalanced drifting data streams. In IEEE international conference on big data (big data) (pp. 2334–2343).
Kozal, J., Guzy, F., & Wozniak, M. (2021). Employing chunk size adaptation to overcome concept drift. CoRR arXiv:abs/2110.12881
Krawczyk, B. (2016). Learning from imbalanced data: Open challenges and future directions. Progress in Artificial Intelligence, 5(4), 221–232.
Krawczyk, B. (2021). Tensor decision trees for continual learning from drifting data streams. Machine Learning, 110(11), 3015–3035.
Krawczyk, B., & Cano, A. (2018). Online ensemble learning with abstaining classifiers for drifting and noisy data streams. Applied Soft Computing, 68, 677–692.
Krawczyk, B., & Skryjomski, P. (2017). Cost-sensitive perceptron decision trees for imbalanced drifting data streams. Machine Learning and Knowledge Discovery in Databases, 10535, 512–527.
Krawczyk, B., Minku, L. L., Gama, J., Stefanowski, J., & Wozniak, M. (2017). Ensemble learning for data stream analysis: A survey. Information Fusion, 37, 132–156.
Li, Z., Huang, W., Xiong, Y., Ren, S., & Zhu, T. (2020). Incremental learning imbalanced data streams with concept drift: The dynamic updated ensemble algorithm. Knowledge-Based Systems, 195, 105694.
Liu, C., Feng, L., & Fujimaki, R. (2016). Streaming model selection via online factorized asymptotic bayesian inference. In IEEE international conference on data mining (pp. 271–280).
Liu, X., Fu, J., & Chen, Y. (2020). Event evolution model for cybersecurity event mining in tweet streams. Information Sciences, 524, 254–276.
Loezer, L., Enembreck, F., Barddal, J. P., & de Souza Britto Jr, A. (2020). Cost-sensitive learning for imbalanced data streams. In Proceedings of the 35th annual ACM symposium on applied computing (pp. 498–504).
Lu, J., Liu, A., Dong, F., Gu, F., Gama, J., & Zhang, G. (2019). Learning under concept drift: A review. IEEE Transactions on Knowledge and Data Engineering, 31(12), 2346–2363.
Lu, Y., Cheung, Ym., & Tang, Y. Y. (2017). Dynamic weighted majority for incremental learning of imbalanced data streams with concept drift. In International joint conference on artificial intelligence (pp. 2393–2399).
Lu, Y., Cheung, Y. M., & Tang, Y. Y. (2019). Adaptive chunk-based dynamic weighted majority for imbalanced data streams with concept drift. IEEE Transactions on Neural Networks and Learning Systems, 31(8), 2764–2778.
Lyon, R., Brooke, J., Knowles, J., & Stappers, B. (2014). Hellinger distance trees for imbalanced streams. In International conference on pattern recognition (pp. 1969–1974).
Minku, L. L., & Yao, X. (2011). DDD: A new ensemble approach for dealing with concept drift. IEEE Transactions on Knowledge and Data Engineering, 24(4), 619–633.
Oza, N. C. (2005) Online bagging and boosting. In IEEE international conference on systems, man and cybernetics (pp. 2340–2345).
Parisi, G. I., Kemker, R., Part, J. L., Kanan, C., & Wermter, S. (2019). Continual lifelong learning with neural networks: A review. Neural Networks, 113, 54–71.
Pelossof, R., Jones, M., Vovsha, I., & Rudin, C. (2009). Online coordinate boosting. In IEEE international conference on computer vision (pp. 1354–1361).
Ren, S., Zhu, W., Liao, B., Li, Z., Wang, P., Li, K., et al. (2019). Selection-based resampling ensemble algorithm for nonstationary imbalanced stream data learning. Knowledge-Based System, 163, 705–722.
Roseberry, M., Krawczyk, B., & Cano, A. (2019). Multi-label punitive kNN with self-adjusting memory for drifting data streams. ACM Transactions on Knowledge Discovery from Data, 13(6).
Roseberry, M., Krawczyk, B., Djenouri, Y., & Cano, A. (2021). Self-adjusting k nearest neighbors for continual learning from multi-label drifting data streams. Neurocomputing, 442, 10–25.
Van Rijn, J. N., Holmes, G., Pfahringer, B., & Vanschoren, J. (2015). Having a blast: Meta-learning and heterogeneous ensembles for data streams. In IEEE international conference on data mining (pp. 1003–1008).
Wang, B., & Pineau, J. (2016). Online bagging and boosting for imbalanced data streams. IEEE Transactions on Knowledge and Data Engineering, 28(12), 3353–3366.
Wang, H., Fan, W., Yu, P. S., & Han, J. (2003). Mining concept-drifting data streams using ensemble classifiers. In ACM SIGKDD international conference on knowledge discovery and data mining (pp. 226–235).
Wang, S., & Minku, L. L. (2020). AUC estimation and concept drift detection for imbalanced data streams with multiple classes. In International joint conference on neural networks (pp. 1–8).
Wang, S., Minku, L. L., & Yao, X. (2015). Resampling-based ensemble methods for online class imbalance learning. IEEE Transactions on Knowledge and Data Engineering, 27(5), 1356–1368.
Wang, S., Minku, L. L., & Yao, X. (2016). Dealing with multiple classes in online class imbalance learning. In International joint conference on artificial intelligence (pp. 2118–2124).
Wang, S., Minku, L. L., & Yao, X. (2018). A systematic study of online class imbalance learning with concept drift. IEEE Transactions on Neural Networks Learning Systems, 29(10), 4802–4821.
Wang, T., Jin, X., Ding, X., & Ye, X. (2014). User interests imbalance exploration in social recommendation: A fitness adaptation. In ACM international conference on conference on information and knowledge management (pp. 281–290).
Wu, K., Edwards, A., Fan, W., Gao, J., & Zhang, K. (2014). Classifying imbalanced data streams via dynamic feature group weighting with importance sampling. In SIAM international conference on data mining (pp. 722–730).
Yan, Y., Yang, T., Yang, Y., & Chen, J. (2017). A framework of online learning with imbalanced streaming data. In AAAI conference on artificial intelligence (pp. 2817–2823).
Zyblewski, P., Sabourin, R., & Wozniak, M. (2021). Preprocessed dynamic classifier ensemble selection for highly imbalanced drifted data streams. Information Fusion, 66, 138–154.
Acknowledgements
This research was partially supported by the 2018 VCU Presidential Research Quest Fund and an Amazon AWS Machine Learning Research award. High Performance Computing resources provided by the High Performance Research Computing (HPRC) Core Facility at Virginia Commonwealth University (https://chipc.vcu.edu) were used for conducting the research reported in this work.
Funding
This research was partially supported by the 2018 VCU Presidential Research Quest Fund (Alberto Cano) and an Amazon AWS Machine Learning Research award (Alberto Cano & Bartosz Krawczyk).
Author information
Authors and Affiliations
Contributions
AC contributed to the design of the algorithm, implementation, experimental evaluation, and manuscript preparation. BK contributed to the manuscript preparation. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Editor: Indre Zliobaite.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Cano, A., Krawczyk, B. ROSE: robust online self-adjusting ensemble for continual learning on imbalanced drifting data streams. Mach Learn 111, 2561–2599 (2022). https://doi.org/10.1007/s10994-022-06168-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10994-022-06168-x