
Abstract
In this paper we address a min–max problem of fractional quadratic (not necessarily convex) over linear functions on a feasible set described by linear and (not necessarily convex) quadratic functions. We propose a conic reformulation on the cone of completely positive matrices. By relaxation, a doubly nonnegative conic formulation is used to provide lower bounds with evidence of very small gaps. It is known that in many solvers using Branch and Bound the optimal solution is obtained in early stages and a heavy computational price is paid in the next iterations to obtain the optimality certificate. To reduce this effort tight lower bounds are crucial. We will show empirical evidence that lower bounds provided by the copositive relaxation are able to substantially speed up a well known solver in obtaining the optimality certificate.
Similar content being viewed by others

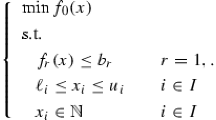
Avoid common mistakes on your manuscript.
1 Introduction and motivation
In optimization, the objective function of the underlying mathematical model represents a certain performance measure to be optimized. In many situations this performance is described as the ratio of two functions to accurately reflect the trade-off between two, sometimes competing, aspects of the system, like profit versus the number of employees or production versus consumption, mean value and variance, cost versus time or volume. Problems of this kind arise in many different activities such as financial planning (where the ratio of debt/equity must be considered), in production planning (inventory/sales or revenue/employee), health care (cost/patient), blending problems (income/quantity of raw material), in the domains of optics, engineering, or information retrieval, to name just a few. More application examples can be found in the first chapter of [25].
Sometimes the fractional relation is ignored for the sake of model simplicity and replaced by a parameterized linear function. An alternative approach introduces bounds on one of the functions as a constraint in the model. However, recent interest has focused on more realistic mathematical models, and increased research effort focuses on advanced methodologies to directly address the problem of ratio optimization, also known as fractional programming.
Consider the so called single-ratio fractional problem,
where \(\Omega \subseteq {\mathbb {R}}^n\) is a bounded convex set and it is assumed that \(g({\mathsf {x}})>0\) for \({\mathsf {x}}\in \Omega \). If f and g are affine functions and \(\Omega \) is a polyhedron, problem (1.1) is called a linear fractional optimization problem. If the functions f and g are quadratic (one of them can be affine) and \(\Omega \) is a polyhedron, we will call this problem as a quadratic fractional optimization problem on a polyhedron. If \(\Omega \) is not a polyhedron it will just be referred as a quadratic fractional optimization problem.
Fractional problems (1.1) are nonconvex in general. Under convexity and concavity assumptions for f and g respectively, and nonnegativity of f if g is not affine, (1.1) is termed a convex–concave fractional program [22], and the objective function is strictly quasi-convex. Any local solution to a convex–concave fractional program is also a global solution, as it happens for general convex programs, and in addition a solution of the Karush–Kuhn–Tucker optimality conditions is a global solution if the numerator and denominator functions are differentiable on an open set containing \(\Omega \). But the convexity and concavity assumptions are restrictive, and in many practical problems they are not valid.
As a generalization of (1.1) we can find the generalized fractional program or min–max fractional optimization problem
and as a special case the discrete case, where we have a finite set \(I=\left\{ 1, \ldots , m\right\} \) instead of U:
In the sequel we will consider the discrete case and assume that:
Note that condition (1.6) aims at ensuring that \(g_i({\mathsf {x}})\ne 0\) and so the problem is well-posed. The positivity condition is not restrictive because we can multiply both numerator and denominator by \((-1)\) ensuring this condition even if \(g_i({\mathsf {x}})<0\). We can assume (1.7) without loss of generality since we can always consider an equivalent problem adding L to \(\frac{f_i({\mathsf {x}})}{g_i({\mathsf {x}})}\) in the objective function for \(i\in I\) with \(L>0\) large enough such that the new numerator \(f_i({\mathsf {x}}) + Lg_i({\mathsf {x}})>0\) on \(\Omega \).
In this paper we are particularly interested in problems (1.3) since they are relevant for performing worst-case analysis as mentioned in [15, 20]. Indeed, suppose that the uncertainty set \(U\subset {\mathbb {R}}^p\) is a polytope with known (few) vertices \({\mathsf {v}}_1,\ldots {\mathsf {v}}_m\), so \(U=\hbox {conv }\left\{ {\mathsf {v}}_i : i\in I\right\} \), and further assume that the objective \(f({\mathsf {x}},{\mathsf {y}})/g({\mathsf {x}},{\mathsf {y}})\) depends in a quasiconvex way on \({\mathsf {y}}\) for any fixed \({\mathsf {x}}\in \Omega \). Now putting \(f_i ({\mathsf {x}}) = f({\mathsf {x}},{\mathsf {v}}_i)\) and \(g_i({\mathsf {x}}) = g({\mathsf {x}},{\mathsf {v}}_i)\), it is obvious that problems (1.2) and (1.3) are the same, so that the robust formulation can be phrased in terms of finitely many scenarios which do not affect the set \(\Omega \) representing precisely known (not uncertain, global) constraints. Closely related applications arise from goal programming and multicriteria optimization when Chebychev’s norm is used to evaluate the goals or criteria, leading to
where \(\Delta = \left\{ {\mathsf {w}}\in {\mathbb {R}}^m_+ : \sum _{i=1}^m w_i = 1\right\} \) is the standard simplex in \({\mathbb {R}}^m\). The equivalence of (1.3) and (1.8) follows as above, or else directly from the fact that the maximum of m numbers is equal to the maximum of their convex combinations [8, 13]. Problem (1.8) is particularly interesting when pooling of the rival objective functions is considered, in which case the components \(w_i\) are the pooling weights. Then the min–max solution provides a robust pooling by suggesting a strategy that does not depend on the prevailing scenario.
The solution of (1.3) allows the decision maker to compute the best strategy under the worst-case scenario. In practical terms, solving the min–max problem ensures that the solution value will not deteriorate whichever scenario turns out to be the true one. The real solution evaluation will be at least as good as the min–max value. In this context the above mentioned applications of (1.1) can be directly extended to (1.3) in cases where there is some uncertainty related to outside factors. The maximum operator can be avoided by introducing another variable; indeed, problem (1.3) is equivalent to the following problem
We will investigate (1.3) in case of quadratic functions \(f_i\) and affine \(g_i\). Problems of this type have applications in maximal predictability portfolio [11], cluster analysis [19], transportation problems with several objective functions [24], and investment allocation problems [27], to name but a few.
This paper is organized in five sections. After this introduction, Sect. 2 presents a review on some methods for addressing general min–max problems. In Sect. 3 the conic reformulation and a tractable relaxation is constructed. This section also incorporates a discussion regarding the extension of these results to the quadratic over quadratic case. Sect. 4 reports computational experience, followed by concluding remarks in the last section.
2 Short review of some traditional methods
Before we proceed we will present in this section two traditional approaches for addressing the min–max problem. Both suffer from the same drawback, namely for general matrices the subproblems are nonconvex, so most of them cannot be solved quickly and the first approach does not even guarantee optimality. Throughout this section, we assume for simplicity of exposition that \(\Omega \) is compact and all involved functions are continuous.
2.1 The minimum-regret approach
We start by introducing a naive minimax strategy based on the regret concept [20]. First, an optimal solution (which generically is unique) for each individual objective function is obtained:
Next, the impact of solution \({\mathsf {x}}_k^*\), \(k\in I\), on the other objective functions is investigated, tantamount to the loss incurred by adopting \({\mathsf {x}}_k^*\) if a scenario different from k occurs:
The best strategy \({\mathsf {x}}^*\) will be the one corresponding to the solution that would be the least damaging if a different scenario replaces the one for which the solution is optimal, i.e., select \(i\in I\) such that \(\alpha _i = \min \nolimits _{k\in I} \alpha _k \) and put \({\mathsf {x}}^*={\mathsf {x}}_i^*\).
2.2 A generalization of the Dinkelbach approach
Denote by
In [9] a method for solving (1.3) based on the Dinkelbach approach for a single ratio is presented. considering a parameterized version of problem (2.2):
and a solution of the equation \(F(\lambda ) = 0\) is sought. It is known that \(F(\lambda )\) has some important properties, namely:
- (a):
-
F is real-valued, decreasing and continuous;
- (b):
- (c):
-
\(\lambda ^*\) is finite and \(F(\lambda ) = 0\) if and only if \(\lambda =\lambda ^*\).
Algorithm 1 describes the adaptation of the single ratio Dinkelbach method to multiple ratios. The difference consists mainly in the update of the parameter \(\lambda \) in each iteration, steps (1) and (2).

The convergence of this method is linear, in contrast to the superlinear convergence in case of the Dinkelbach method for a single ratio (which follows by analogy to the Newton method). A better convergence is obtained by modifying the update of \({\mathsf {x}}^k\) to
by approximating a Newton step, and thus increasing the convergence rate to superlinearity. This method is also equivalent to the partial linearization procedure in [3]. See [9].
3 A copositive approach
Let us recall the problem (1.3) under investigation
In this work we are considering
and
with \({\mathsf {A}}\) a \(k\times n\) matrix while \({\mathsf {a}}_q\in {\mathbb {R}}^n\) and \({\mathsf {A}}_q\in {\mathcal M}_n\) for all \(q{ \in \! [{1}\! : \! {p}]}\). We write \(2{\mathsf {r}}_i\) in the linear term later in (3.2), to keep the analogy with the numerator and to allow for a simpler notation when discussing extensions to the quadratic over quadratic case. Observe that we have implicitly introduced slack variables for the linear constraints but keep quadratic inequalities as constraints. No definiteness assumptions are made on \({\mathsf {A}}_q\). Likewise, in the sequel we will make no assumptions about matrices \({\mathsf {Q}}_i\) in (3.1), other than symmetry.
Our proposal is to use copositive optimization to construct good lower bounds that can be incorporated in a global optimization method for solving this class of min–max problems. Many solvers return a feasible solution at early stages of the branch and bound tree which turns out to be optimal after a following, in many cases long, sequence of iterations, incurring heavy computational burden for obtaining an optimality certificate. Good lower bounds are crucial at this stage. We will show how the lower bounds provided by the copositive relaxation can speed up BARON to obtain this optimality certificate earlier. But before that we briefly recapitulate some essential concepts about copositive optimization.
3.1 Quick facts about copositive optimization
A conic optimization problem in the space \({\mathcal {S}}_n\) of symmetric matrices of order n consists in optimizing a linear function with linear constraints over a cone \({\mathcal {K}}\subseteq {\mathcal {S}}_n\):
where \({\mathsf {X}}\bullet {\mathsf {Y}}= \hbox {trace }({\mathsf {Y}}^\top {\mathsf {X}})=\sum _{i,j=1}^n X_{ij}Y_{ij}\). The dual of (3.4) is also a conic optimization problem of the form
which involves the dual cone
As usual, we drop sign constraints \(u_i\ge 0\) on the dual variables in case of linear equality constraints \({\mathsf {A}}_i\bullet {\mathsf {X}}= b_i\) on the primal side.
Well-investigated special matrix cones include the semidefinite cone \({\mathcal {S}}^+_n\subset {\mathcal {S}}_n \) of all positive-semidefinite symmetric \(n\times n\) matrices (i.e. those \({\mathsf {X}}\) with no negative eigenvalue, denoted by \({\mathsf {X}}\succeq {\mathsf {O}}\)), and the cone \({\mathcal {N}}_n\subset {\mathcal {S}}_n\) of symmetric \(n\times n\) matrices \({\mathsf {X}}\) with no negative entry (denoted by \({\mathsf {X}}\ge {\mathsf {O}}\)). These two cones are selfdual, \({\mathcal {S}}^+_n = {\mathcal {S}}^{+*}_n\) and \({\mathcal {N}}_n = {\mathcal {N}}_n^*\).
Combination of both properties leads to the cone of so-called doubly nonnegative matrices
The dual cone \({\mathcal {D}}_n^* = {\mathcal {S}}^+_n + {\mathcal {N}}_n\), so \({\mathcal {D}}_n\) is no longer self-dual. While all of aforementioned cones are tractable in a certain sense, there is an important intractable subcone of \({{\mathcal {D}}}_n\), namely the cone of all completely positive symmetric \(n\times n\) matrices,
with its dual cone, that of copositive matrices which are symmetric of order n:
We have \({\mathcal {CP}}_4 = {\mathcal {D}}_4\) but \({\mathcal {CP}}_n \subsetneqq {\mathcal {D}}_n\) for \(n\ge 5\).
A copositive optimization problem is a conic problem (3.4) with \({\mathcal {K}}={\mathcal {COP}}_n\), and most authors include in the definition of copositive optimization also the case \({\mathcal {K}}={\mathcal {CP}}_n\). This problem class has recognized merits since it admits reformulations of hard optimization problems, such as continuous nonconvex quadratic [4, 5, 18], mixed-integer quadratic [7], continuous [2] and mixed-integer [1] fractional quadratic problems. Basically, by lifting quadratic expressions, all constraints can be linearized, pushing the hardness entirely into the cone description. Indeed, checking that a matrix is in \({\mathcal {CP}}_n\) is NP-hard [10], and it is co-NP-complete to check whether a matrix is copositive [14]. Nevertheless it is an important feature of completely positive formulations that relaxations giving tight lower bounds can be obtained by replacing \({\mathcal {CP}}_n\) by \({\mathcal {D}}_n\), for instance. Even tighter relaxation bounds can be obtained by the so-called approximation hierarchies which replace \({\mathcal {CP}}_n\) by other tractable cones (polyhedral or expressible by linear matrix inequalities). These approximation hierarchies can be constructed using simplices [6, 23], sums-of-squares [16] or polynomials [4, 17].
3.2 Copositive reformulation
We now present a reformulation based on copositive optimization of problem (1.3) written now in a more descriptive way to facilitate further reading.
Using a Shor lifting and considering \({\mathsf {y}}^\top =\left[ 1 \; , \; {\mathsf {x}}^\top \right] \) we write \(h({\mathsf {x}})\) in (3.10) by
Next we square the homogenized linear constraints:
where
Likewise, homogenize the quadratic constraints by introducing, for all \(q{ \in \! [{1}\! : \! {p}]}\),
So, denoting
we arrive at
The linear constraints (3.11) are homogenized as inequalities instead of equivalent equalities (given that \(\widehat{{\mathsf {A}}_0}\) is pd) to simplify notation, defining all the constraints, quadratic and linear, with the same structure.
Next, borrowing from (1.9), we introduce another variable \(v \in {\mathbb {R}}\) and using hypothesis (1.6), we obtain
Now considering \({\mathsf {z}}=[ {\mathsf {y}}^\top \; v ]^\top \) and
we obtain
Now for \({\mathsf {X}}={\mathsf {z}}{\mathsf {z}}^\top \), we obtain the following reformulation of (3.14), more precisely, of \((\lambda ^*)^2\), in view of \(z_{n+1}^*\ge 0\):
where \({\mathcal {CP}}_{n+2}^{\mathrm {rk}\,1}:= \left\{ {\mathsf {X}}\in {\mathcal {CP}}_{n+2} : \hbox {rank }{\mathsf {X}}=1\right\} \). Dropping the rank constraint leads to the completely positive relaxation
with its dual
where \({\mathsf {E}}_k\bullet {\mathsf {X}}= X_{kk}\). Weak duality and rank relaxation yield immediately the relations \(\gamma ^*_{COP}\le \gamma ^*_{CP} \le \gamma ^* = (\lambda ^*)^2\). If an optimal solution of (3.16) has rank one then we have \(\gamma ^*_{CP} = \gamma ^* \) and vice versa.
Further, tractable relaxations of above conic problems may use approximation hierarchies for \({\mathcal {CP}}_{n+2}\), for instance by replacing \({\mathcal {CP}}^{rk1}_{n+2}\) by \({\mathcal {D}}_{n+2}\), the cone of doubly nonnegative matrices. In this case we obtain the following problem:
for which \(\sqrt{\delta ^*}\le \sqrt{\gamma ^*_{CP}}\le \sqrt{\gamma ^*} = \lambda ^*\).

Nonconvex quadratic over affine: Example 3.1
Example 3.1
Consider the following example:
Upon \(0\le x_2=1-\frac{x_1}{2}\), the quadratic constraints reduces to \(x_1 \ge 0\) (which is redundant) and we obtain the following one-dimensional problem
Figure 1 shows both fractions and the nonconvex objective \(h({\mathsf {x}})\). The optimal solution \({\mathsf {x}}^* =[0.8898,0.5551]^\top \) is designated by a circle. The optimal value is 0.5955 as opposed to the copositive relaxation bound 0.5141 attained at an optimal solution with a rank exceeding one. Note that as we are in dimension four, problems (3.16) and (3.18) coincide.
The next example considers a convex instance where the objective \(h({\mathsf {x}})\) is smooth at the optimal solution.

Convex quadratic over affine: Example 3.2
Example 3.2
Consider
Upon \(x_2=(10-2x_1)/5\) we obtain the following one-dimensional problem
Figure 2 shows a representation of the univariate problem, now the solution is obtained at a stationary point of one function corresponding to the optimal solution \(x_1^*= 1.0650\) and \(x_2^*= 1.5740\). The optimal value is \(\lambda ^*=2.0115\), the square of which coincides with the value \(\gamma ^*_{CP}\) at the optimal rank-one-solution \({\mathsf {z}}^*({\mathsf {z}}^*)^\top \) of the copositive relaxation (3.16) with \({\mathsf {z}}^* = [1,x_1^*,x_2^*,\lambda ^*]^\top \). Again we are in dimension four, so problems (3.16) and (3.18) coincide. Furthermore, there is neither a conic duality gap nor a relaxation gap, \(\sqrt{\delta ^*}= \sqrt{\gamma ^*_{COP}} = \sqrt{\gamma ^*_{CP}} = \sqrt{\gamma ^*} = \lambda ^*\), in this example. We will specify a more general condition for zero relaxation gap below.
Theorem 3.3
(a) For any \({\mathsf {u}}= [u_0,\ldots u_{m},\mu _0,\ldots \mu _p]^\top \in {\mathbb {R}}^{m+p+2}_+\) consider the following symmetric matrix of order \(n+2\):
where

and
If \({\mathsf {S}}_{\mathsf {u}}\) is copositive, then \(\sqrt{u_0} \le \lambda ^*\), so we get a valid lower bound for the problem (1.3) with affine-linear denominators \(g_i({\mathsf {x}})\).
(b) Now suppose that \({\mathsf {x}}^*\in \Omega \) and put \({\sqrt{u_0}}= h({\mathsf {x}}^*)\). If for this value of \(u_0\), above \({\mathsf {S}}_{\mathsf {u}}\) is copositive, then \({\mathsf {x}}^*\) solves the problem (1.3) with affine-linear denominators \(g_i({\mathsf {x}})\), and both the conic duality and relaxation gaps are zero:
Proof
(a) The matrix \({\mathsf {S}}_{\mathsf {u}}\) as defined in (3.19) coincides with the slack matrix of the dual problem (3.17), as one can easily verify. By assumption, this \({\mathsf {S}}_{\mathsf {u}}\) is feasible to (3.17), hence we obtain
(b) Now put \({\sqrt{u_0}} =h({\mathsf {x}}^*)\). If \({\mathsf {S}}_{\mathsf {u}}\) is still feasible to (3.17), we now get \(h({\mathsf {x}}^*)={\sqrt{u_0}} \le \sqrt{\gamma ^*_{COP}} \le \sqrt{\gamma ^*_{CP}} \le \sqrt{\gamma ^*} = \lambda ^* \le h({\mathsf {x}}^*)\), and all assertions are established. \(\square \)
3.3 Some considerations about the constrained min–max quadratic over quadratic case
Before presenting the computational experience we discuss some limitations regarding extensions of the previous work, on a conic reformulation, to the quadratic over quadratic case, when:
The quadratic over affine case is obtained considering \({\mathsf {T}}_i = {\mathsf {O}}\) for \(i \in I\). Knowing that it is possible to replace a quadratic expression in the objective function by an additional variable introducing this relation as a constraint of the problem, we immediately looked for the possibility of applying the same conic reformulation to this more general case but we faced strong limitations regarding the conic relaxation.
First we show that that this case can be converted to a quadratic over affine problem, as (3.10) with the introduction of additional variables, \(x_{n+i}\) replacing the quadratic expressions \({\mathsf {x}}^\top {\mathsf {T}}_i{\mathsf {x}}\) in \({g}_i({\mathsf {x}})\) and adding the quadratic constraints \({\mathsf {x}}^\top {\mathsf {T}}_i{\mathsf {x}}\ge x_{n+i}\) for \(i\in I\). A problem with an affine denominator is obtained subject to \(m+p+1\) quadratic constraints plus (linear) sign constraints. It is worth noting that additional quadratic constraints should not pose further difficulties concerning the conic reformulation. An equivalent problem is obtained as follows:
where
denoting by \({\mathsf {O}}\) zero matrices of various but suitable size
and
where we abbreviated
with \({\mathsf {e}}_i\) the \(i\hbox {th}\) column of the identity matrix \({\mathsf {I}}_m\) of order m.

Nonconvex quadratic over quadratic: Example 3.4
Example 3.4
Consider the following example
with \(\Omega = \left\{ {\mathsf {x}}\in {\mathbb {R}}^2_+ : x_1 + 2x_2=2\right\} \). Upon replacing \(x_2=1-\frac{x_1}{2}\) we obtain the following one-dimensional problem
Figure 3 shows both quadratic ratios, and the optimal value 0.4381 over [0, 2] attained at the optimal solution \({\mathsf {x}}^* =[0.9122,0.5439]^\top \) is designated by a circle. Applying above reasoning, problem (3.23) can be rewritten as
with
with the same optimal value, now attained at \([0.9122,\;0.5439,\;1.1279, \;4.3759]^\top \) with objective value \(\lambda ^* =0.4381\). Solving problem (3.16) for this instance yields an optimal solution with a relaxation bound of \(\sqrt{\delta ^*}= 0.3713\). We note that this lower bound is not as tight as in the previous examples with a relative relaxation gap \(\frac{\lambda ^*- \sqrt{\delta ^*}}{\lambda ^*} \approx 15.25\%\) as opposed to \(13.67\%\) in Example 3.1 (and zero in Example 3.2).
When observing in detail the structure of the constraints of the conic optimization relaxation for the quadratic over quadratic case we have (abbreviating \({\mathsf {Z}}={\mathsf {X}}_{n+1:n+m,n+1:n+m}\))


and

The occurrence of a sub-matrix of zeros (in the framed box) in constraints (3.24)–(3.26) contributes to a severe deterioration of the quality of the lower bounds. Further research on this topic is left for future investigation.
4 Computational experience
The numerical experiments were performed on a PC, Intel(R) Core(TM) i7-2640M, 2.80 Ghz,400 GB RAM. The software Matlab 2013Ra was used to run the global optimization solver BARON [21] and SDPT3(4.0)/Octave [26], a Matlab package for solving convex optimization problems involving linear equations and inequalities, second-order cone constraints, and semidefinite constraints (linear matrix inequalities). The interface YALMIP [12] was used to call SDPT3.
To study the empirical quality of the lower bounds provided by the relaxation (3.18) we used the global optimization solver BARON to obtain, when possible, the optimal solution to define the gaps and to provide a lower bound for comparison. It would be useless to use the last lower bound provided by BARON since in most problems it would coincide with the optimal value and it is the result of a chain of different methods (which are unknown to the user). To compare with the first lower bound of BARON would be a fair choice, but even better is to compare the performance of BARON with itself when the lower bound of relaxation \(\delta ^*\) is provided to this solver.
The formulation defined for BARON input was the following:
The software BARON does not accept, as input, an initial lower bound to start the search, but in this case, since the objective function is a single variable v and BARON accepts box bounds (lower and upper) for variables it was in fact possible to indirectly impose a lower bound by introducing the lower box bound \(v_l\) for v. This allowed to study the quality of the lower bound by solving (3.18), obtaining as optimal value \(X_{n+1,n+1}^*\) and running BARON twice, with \(v_l=-\infty \) and \(v_l=\sqrt{X_{n+1,n+1}^*}\).
The limit time ( in seconds) for the first run of BARON was set to \(\mathtt{MaxTime} = 250\) and the gap tolerance \(\mathtt{EpsA} = 10^{-4}\). On the second run of BARON, the time limit was set differently to each instance to 250 minus the run time of SDPT3 for that instance. The settings for SDPT3 were \(\mathtt{sdpt3.maxit}= 500\) for the maximal number of iterations and \({\texttt {sdpt3.gaptol}}=10^{-2}\) for the gap tolerance.
Ten test instances were randomly generated for up to ten ratios, i.e. \(m=\#I\in \{3, 5, 10\}\) in (3.18), and variable dimensions \(n\in \left\{ 5, 25, 50,75\right\} \). All experiments had one linear equality and one quadratic inequality constraint (\(k=p=1\)) with, again, randomly chosen coefficients.
4.1 Empirical study on the quality of lower bounds
In the analysis of the results we focus to answer the question whether the relaxation is more efficient than the battery of techniques used in BARON to generate lower bounds for this problem, using a first run of BARON with \(v \ge -\infty \) (RUN1) and a second run with \(v \ge \sqrt{X_{n+1,n+1}^*}\) (RUN2). We compare to the result of the SDPT3 solver for solving (3.18), designated by RUN0.
Table 1 presents results from RUN0, RUN1 and RUN2 where the columns represent:
-
Problem—Problem name ‘INSTaMbNc’ where ‘a’ is the instance number (0–9) for the same specifications: ‘b’ number of ratios and ‘c’ number of variables.
-
E1—Status of BARON RUN1 solution, ‘NorC’ means ‘textitNormal Completion’ and ‘MCPU’ stands for ‘Max. allowable CPU time exceeded’. The limit was set to 250 seconds.
-
Btime—the difference between the CPU time of RUN1 and RUN2 when the status of RUN1 was ‘Normal Completion’ or the time of RUN2 alone when RUN1 stopped because of ‘Max. allowable CPU time exceeded’. When E1 is ‘MCPU’ and Btime is 250,00 it means that also in the RUN2 the maximal CPU time was exceeded.
-
Biter—the difference between the number of iterations of RUN1 and RUN2 when the status of RUN1 was ‘Normal Completion’ or the time of RUN2 alone when RUN1 stopped because of ‘Max. allowable CPU time exceeded’.
-
BMN—the difference between the index of the best node (where the best upper bound was obtained) of RUN1 and RUN2 when the status of RUN1 was ‘textitNormal Completion’ or the best node for RUN2 alone when RUN1 stopped because of ‘Max. allowable CPU time exceeded’.
-
Baron LB—Lower Bound output for RUN1.
-
Baron UB—Upper Bound output for RUN1.
-
GAP1—\(100\frac{\mathtt{BARON}\hbox { UB}-\mathtt{BARON}\hbox { LB} }{\mathtt{BARON}\hbox { UB}}\) for RUN1
-
GAP2—\(100\frac{\mathtt{BARON}\hbox { UB}-\mathtt{BARON}\hbox { LB} }{\mathtt{BARON}\hbox { UB}}\) for RUN2
-
E2—Status of solution, 0 for ‘Successfully solved’, 3 for ‘Maximum iterations or time limit exceeded’, 4 for ‘Numerical problems’ and 5 for ‘textitLack of progress’.
-
YLB—SDPT3 RUN0 optimal value’s square root.
-
GAP0—\(100\frac{\mathtt{BARON}\hbox { UB}-\hbox {YLB} }{\mathtt{BARON}\hbox { UB}}\) for RUN0
-
Time—CPU time of RUN0
Looking at Table 1, merits of the lower bounds provided by (3.18) are clear and more pronounced for larger instances. First we should observe the resulting gaps and see that for the smaller problems the lower bound coincides with the optimal value in most instances. As the size increases, it is evident that the lower bound from (3.18) outperforms BARON’s lower bounding techniques. In some cases (INST8M5N25, INST8M5N50) only by providing the lower bound from (3.18) it was possible to obtain the optimal solution. The caveats occur for some numerical problems (\(\mathtt{E2}=4\)) encountered in some instances, and the lower bound cannot be trusted. In fact significantly negative gap values (\(<-10^{-2}\)) represent these cases while small negative gaps are just the result of error propagation. Figure 4 gives a graphical representation of these gaps. It is clear that the line for GAP1 is mostly above that of GAP2 and GAP0 due to usage of (3.18), and that the line of GAP2 lies close to that of GAP0, meaning that the proposed lower bound represents an important contribution. The decrease in each instance from GAP1 to GAP2 is the direct result of the a priori knowledge of this lower bound.

Relative gaps for the \(m=5\) instances
The next observation is related to CPU time in columns BTime and Time. Most of the time the best upper bound is achieved at an early stage and so BARON puts considerably larger effort in improving the lower bound. So, even discounting the fact that BARON time is not only related to lower bound calculations, Table 1 shows that it clearly pays to have an initial lower bound calculated by (3.18).
In just a few cases (Btime \(<0\)) it seems that it does not compensate the a priori knowledge of the lower bound given by (3.18), even if the bound in the first node is really weak. We must bear in mind that it is not clear at which stage of the procedure (if at all) BARON interprets the lower bound box constraint for variable v also as a lower bound for the optimal value. Nevertheless the overall conclusion is that it is a benefit and sometimes even crucial to have the lower bound provided by (3.18).
5 Conclusion
In this paper we make a contribution to extend the class of hard optimization problems for which a conic reformulation, based on the cone of copositive or completely positive matrices, is known. We address min–max problems of fractional quadratic (not necessarily convex) over affine functions on a feasible set described by linear and (not necessarily convex) quadratic functions. Relaxations of copositive reformulations have proved to produce tight lower bounds and empirical evidence obtained by the computational experience on this problem corroborates this statement. Relaxation of the completely positive cone by the doubly nonnegative cone led to a tractable relaxation problem providing lower bounds with very small gaps, enabling us to globally solve a difficult optimization problem. It is known that in branch and bound methods, very good, sometimes even optimal, solutions are obtained at early stages of traversing the problem tree. The effort to prove optimality or to state a safe termination criterion for the search depends on closing the gap between the lower and upper bound, so the quality of the first are crucial. In this paper we present a lower bounding procedure that justifies once more the high reputation of relaxations gained from conic reformulations.
References
Amaral, P.A., Bomze, I.M.: Copositivity-based approximations for mixed-integer fractional quadratic optimization. Pac. J. Optim. 11(2), 225–238 (2015)
Amaral, P.A., Bomze, I.M., Júdice, J.J.: Copositivity and constrained fractional quadratic problems. Math. Program. 146(1–2), 325–350 (2014)
Benadada, Y., Ferland, J.A.: Partial linearization for generalized fractional programming. Z. Oper. Res. 32, 101–106 (1988)
Bomze, I.M., de Klerk, E.: Solving standard quadratic optimization problems via linear, semidefinite and copositive programming. J. Glob. Optim. 24(2), 163–185 (2002)
Bomze, I.M., Dür, M., de Klerk, E., Roos, C., Quist, A.J., Terlaky, T.: On copositive programming and standard quadratic optimization problems. J. Glob. Optim. 18(4), 301–320 (2000)
Bundfuss, S.: Copositive matrices, copositive programming, and applications. Dissertation, Technische Universität Darmstadt, Darmstadt, Germany (2009)
Burer, S.: On the copositive representation of binary and continuous nonconvex quadratic programs. Math. Program. 120(2, Ser. A), 479–495 (2009)
Cohen, G.: An algorithm for convex constrained minimax optimization based on duality. Appl. Math. Optim. 7, 347–372 (1981)
Crouzeix, J.-P., Ferland, J.A.: Algorithms for generalized fractional programming. Math. Program. 52(1), 191–207 (1991)
Dickinson, P.J.C., Gijben, L.: On the computational complexity of membership problems for the completely positive cone and its dual. Comput. Optim. Appl. 57(2), 403–415 (2014)
Lo, A.W., MacKinlay, A.C.: Maximizing predictability in the stock and bond markets. Macroecon. Dyn. 1, 102–134 (1997)
Löfberg, J.: YALMIP: a toolbox for modeling and optimization in MATLAB. In: Proceedings of the CACSD Conference, Taipei, Taiwan (2004)
Medanić, J.V., Andjelić, M.: On a class of differential games without saddle-point solutions. J. Optim. Theory Appl. 8, 413430 (1971)
Murty, K.G., Kabadi, S.N.: Some NP-complete problems in quadratic and nonlinear programming. Math. Program. 39(2), 117–129 (1987)
Parpas, P., Rustem, B.: Algorithms for Minimax and Expected Value Optimization, pp. 121–151. Wiley, New York (2009)
Parrilo, P.A.: Structured semidefinite programs and semi-algebraic geometry methods in robustness and optimization. Ph.D. thesis, California Institute of Technology, Pasadena, CA, May (2000)
Peña, J., Vera, J., Zuluaga, L.F.: Computing the stability number of a graph via linear and semidefinite programming. SIAM J. Optim. 18(1), 87–105 (2007)
Preisig, J.C.: Copositivity and the minimization of quadratic functions with nonnegativity and quadratic equality constraints. SIAM J. Control Optim. 34(4), 1135–1150 (1996)
Rao, M.R.: Cluster analysis and mathematical programming. J. Am. Stat. Assoc. 66(335), 622–626 (1971)
Rustem, B., Howe, M.: Algorithms for Worst-case Design and Applications to Risk Management. Princeton University Press, Princeton (2002)
Sahinidis, N.V.: BARON 17.8.9: Global Optimization of Mixed-Integer Nonlinear Programs, User’s Manual (2017)
Schaible, S.: Fractional programming. I, duality. Manag. Sci. 22(8), 858–867 (1976)
Sponsel, J., Bundfuss, S., Dür, M.: An improved algorithm to test copositivity. J. Glob. Optim. 52, 537–551 (2012)
Stancu-Minasian, I.M.: On the transportation problem with multiple objective functions. Bull. Math. Soc. Sci. Math. Roum. 3(22), 315–328 (1978)
Stancu-Minasian, I.M.: Fractional Programming: Theory, Methods and Applications. Kluwer Academic Publishers, Dordrecht (1997)
Toh, K.C., Todd, M.J., Tütüncü, R.H.: SDPT3: a Matlab software package for semidefinite programming, version 1.3. Optim. Methods Softw. 11(1–4), 545–581 (1999)
Ziemba, W.T., Parkan, C., Brooks-Hill, R.: Calculation of investment portfolios with risk free borrowing and lending. Manag. Sci. 21(2), 209–222 (1974)
Acknowledgements
Open access funding provided by University of Vienna. The authors would like to thank the two anonymous reviewers for their comments and suggestions that have helped to improve the initial version of the article. This work was partially supported by the Fundação para a Ciência e a Tecnologia (Portuguese Foundation for Science and Technology) through the project UID/MAT/00297/2019 (Centro de Matemática e Aplicações).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Amaral, P.A., Bomze, I.M. Nonconvex min–max fractional quadratic problems under quadratic constraints: copositive relaxations. J Glob Optim 75, 227–245 (2019). https://doi.org/10.1007/s10898-019-00780-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10898-019-00780-3
Keywords
- Min–max fractional quadratic problems
- Conic reformulations
- Copositive cone
- Completely positive cone
- Lower bounds