
Abstract
A disease risk model is a statistical method which assesses the probability that an individual will develop one or more diseases within a stated period of time. Such models take into account the presence or absence of specific epidemiological risk factors associated with the disease and thereby potentially identify individuals at higher risk. Such models are currently used clinically to identify people at higher risk, including identifying women who are at increased risk of developing breast cancer. Many genetic and non-genetic breast cancer risk models have been developed previously. We have evaluated existing non-genetic/non-clinical models for breast cancer that incorporate modifiable risk factors. This review focuses on risk models that can be used by women themselves in the community in the absence of clinical risk factors characterization. The inclusion of modifiable factors in these models means that they can be used to improve primary prevention and health education pertinent for breast cancer. Literature searches were conducted using PubMed, ScienceDirect and the Cochrane Database of Systematic Reviews. Fourteen studies were eligible for review with sample sizes ranging from 654 to 248,407 participants. All models reviewed had acceptable calibration measures, with expected/observed (E/O) ratios ranging from 0.79 to 1.17. However, discrimination measures were variable across studies with concordance statistics (C-statistics) ranging from 0.56 to 0.89. We conclude that breast cancer risk models that include modifiable risk factors have been well calibrated but have less ability to discriminate. The latter may be a consequence of the omission of some significant risk factors in the models or from applying models to studies with limited sample sizes. More importantly, external validation is missing for most of the models. Generalization across models is also problematic as some variables may not be considered applicable to some populations and each model performance is conditioned by particular population characteristics. In conclusion, it is clear that there is still a need to develop a more reliable model for estimating breast cancer risk which has a good calibration, ability to accurately discriminate high risk and with better generalizability across populations.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Breast cancer is the most common cancer among females in high-, middle- and low-income countries and it accounts for 23% of all new female cancers globally [1, 2]. While there has been a significant reduction in mortality, incidence rates have continued to rise [3]. Breast cancer incidence rates are high in North America, Australia, New Zealand, and Western and Northern Europe. It has intermediate levels of incidence in South America, Northern Africa, and the Caribbean but is lower in Asia and sub-Saharan Africa [1].
Early detection of breast cancer improves prognosis and increases survival. Mammographic imaging is the best method available for early detection [4] contributing substantially in reducing the deaths caused by breast cancer [5]. Unfortunately mammography mass screening still leads to some levels of over-diagnosis and over-treatment [6]. As yet routine mammography screening is not readily available globally, particularly in some developing countries [7, 8]. This is supported by the observations that for every million adult women there are only four mammogram screening machines in Sudan has four mammogram machines, whereas Mexico has 37 and Canada has 72 [9]. Under these circumstances, it is clearly more appropriate to prioritize access to mammographic screening or other targeted interventions (such as tamoxifen chemoprevention) for higher-risk individuals who could be identified using a sensitive and specific risk prediction model [10]. Such risk prediction models are individualized statistical methods to estimate the probability of developing certain medical diseases. This is based on specific risk factors in currently healthy individuals within a defined period of time [11]. Such prediction models have a number of potential uses such as planning intervention trials, designing population prevention policies, improving clinical decision-making, assisting in creating benefit/risk indices and estimating the burden cost of disease in population [10].
A general case can also be made for using risk models for certain diseases. For example, their use can allow the application of risk-reducing interventions that may actually prevent the disease in question. If their application can be based on use of existing health records this will avoid increasing levels of anxiety in at least low to moderate risk individuals. The National Cancer Institute of the USA (NCI) has confirmed that the application of “risk prediction” approaches has an extraordinary chance of enhancing “The Nation’s Investment in Cancer Research” [12]. This provides an explanation for the rapid increase in the number of models now being reported in the literature [11, 13]. It is clear that not all developed models are valid or can be widely used across populations. The minimum performance measures required for a useful and robust risk prediction model in clinical decision making are discrimination and calibration [14].
We recognize that risk models are increasingly now being used as part of a “triage” assessment for mammography and/or for receipt of other more personalized medical care. There is a growing interest in applying risk prediction models as educational tools.
The models developed can differ significantly with regard to; the specific risk factors that are included; the statistical methodology used to estimate, validate and calibrate risk; in the study design used; and in the populations investigated to assess the models. These differences make it essential that any assessment of model usefulness takes into account both their internal and external validity. Here, we focus on the reliability, discriminatory accuracy and generalizability of breast cancer risk models that exclude clinical (any variable which needs physician input e.g., presence of atypical hyperplasia) and any genetic risk factors. Accurate assessment of risk using easily acquired data is essential as a first stage of tackling the rising burden of breast disease globally. Well-validated models with high predictive power are preferable although this is not the case for all models. The usability of any model is dependent on the purpose the model will be used for and its target populations [15]. Furthermore, it has been suggested that adapting existing predictive models to the local circumstances of a new population rather than developing a new model for each time is a better approach [16].
This review focuses on breast cancer risk predicting models that incorporated modifiable risk factors and/or factors that can be self-reported. Such models could be applied as an educational tool and potentially used to advice at risk individuals on appropriate behavioural changes.
Methods
Databases
The following databases were searched for all related publications (up to July 2016): PubMed (https://www.ncbi.nlm.nih.gov/pubmed/); ScienceDirect (http://www.sciencedirect.com/); the Cochrane Database of Systematic Reviews (CDSR) (http://www.cochranelibrary.com/). Terms used for the search were “assessment tool, assessment model, risk prediction model, predictive model, prediction score, risk index, breast cancer, breast neoplasm, breast index, Harvard model, Rosner and Colditz model, and Gail model”. Risk models were retrieved based on any study design, study population or types of risk factors.
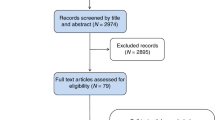
A Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) approach was applied for selecting reviewed articles [17]. A total of 61 genetic and non-genetic breast cancer risk models were identified and then filtered to include only risk models with non-clinical factors (Fig. 1). These models contain variables which are considered to be modifiable and/or self-reported by the respondents. For this review, 14 studies were eventually considered to be eligible. No literature reviews were found on breast cancer risk models solely focusing on epidemiological risk factors although all the selected reviews summarized generic composite risk models. The literature search was extended to include publications relating to systematic reviews and meta-analyses; this did not reveal any appropriate publications.

Identification of eligible risk models using PRISMA flowchart
Confidence in risk factors
Details relating to the degree of confidence in variables used as risk factors in the risk models were taken from the Harvard report [18]. The degree of confidence was categorized as either:
-
definite (an established association between outcome and exposure where chance, bias [systematic error], confounders [misrepresentation of an association by unmeasured factor/s] are eliminated with significant confidence)
-
probable (an association exists between the outcome and the exposure where chance, bias, confounders cannot be eliminated with sufficient confidence—inconsistent results found with different studies)
-
possible (inconclusive or insufficient evidence of an association between the outcome and the exposure)
Results
Potential risk factors included in breast cancer non-clinical predictive models
The variables used in the 14 models under review and specifies the degree of confidence (definite, probable or possible) in those variables as risk factors for breast cancer based on the current literature are summarized in Table 1.
Age, age at first birth, age at menarche, family history of breast cancer, and self-reported history of biopsies were the most common variables used amongst the 14 models selected. These variables are considered as definite risk factors for developing breast cancer [18]. Other additional variables were observed in fewer models. These included ethnicity (Jewish—definite), definite hormonal replacement therapy, diet (some probable and others possible), physical activity (possible), height (definite), weight (probable- for pre-menopausal women and definite for post-menopausal women). Among pre-menopausal females, weight is considered to be a protective factor [19]. In contrast amongst post-menopausal women, weight is considered to be a risk factor [20,21,22] as is parity, oral contraceptive pill use (definite), pregnancy history, timing and type of menopause (definite), menstrual regularity (possible), menstrual duration and gestation period (probable), smoking (possible), mammogram screening (probable) and age of onset of breast cancer in a relative (definite).
The largest number of definite factors included in a model (n = 10 variables) was seen in the study reported by Colditz and Rosner [18]. This was followed by studies by reported by Park [23], Novotny [24] and Rosner [25]. We evaluated the number of the definite, probable and possible variables in the models to compare their performance based on the type and number of the variable included.
Evaluation measures of the risk models
The most important measures used to assess the performance of the models were considered to be as follows:
-
Calibration (reliability): the E/O statistic measures the calibration performance of the predictive model. Calibration involves comparing the expected versus observed numbers of the event using goodness-of-fit or chi square statistics. A well-calibrated model will have a number close to 1 indicating little difference between the E and O events. If the E/O statistic is below 1.0 then the event incidence is underestimated, while if the E/O ratio is above 1.0 then incidence is overestimated [14, 26].
-
Discrimination (precision): the C statistic (Concordance statistic) measures the discrimination performance of the predictive model and corresponds to the area under a receiver operating characteristic curve. This statistic measures how efficiently the model is able to discriminate affected individuals from un-affected individuals. A C-statistic of 0.5 indicates no discrimination between individuals who go on to develop the condition and those who do not. In contrast, a C-statistic of 1 implies perfect discrimination [27, 28]. Good discrimination is important for screening individuals and for effective clinical decision making [10].
-
Accuracy: is tested by measuring of ‘sensitivity’, ‘specificity’, ‘positive predictive value’ (PPV) and negative predictive value (NPV). All of these terms are defined in Table 2. These measures indicate how well the model is able to categorize specific individuals into their real group (i.e., 100% certain to be affected or unaffected). Accuracy is equally important for both individual categorisation and for clinical decision making. Nevertheless, even with good specificity or sensitivity, low positive predictive values may be found in rare diseases [10] as the predictive values also depend on disease prevalence. With high prevalence, PPV will increase while NPV will decrease [29].
-
Utility: this evaluates the ease with which the target groups (public, clinicians, patients, policy makers) can submit the data required by the model. Utility evaluation assesses lay understanding of risk, risk perception, results interpretation, level of satisfaction and worry [30]. This evaluation usually uses surveys or interviews [26].
Calibration and discrimination were the most common measures used to assess the breast cancer risk models under review and these measures are summarized in Fig. 2. Internal calibration was performed in just three of the 14 models with values ranging from 0.92 to 1.08. These calibration values represented a good estimate of the affected cases using these models. For external calibration, six of the 14 models used an independent cohort. Rosner [25] and Pfeiffer [31] reported the highest with E/O values of 1.00 and followed by Colditz [18] with an E/O of 1.01.

Calibration and discrimination performances of the 13 breast cancer risk models
The C-Statistic values measuring internal discrimination ranged across studies from 0.61 to 0.65. The Park [23] model achieved the best outcome (C-Statistic = 0.64). Additionally, Park [23] showed the highest value with a C-Statistic of 0.89 when applied to subjects recruited from the NCC (National Cancer Centre) screening program. The lowest C-Statistic (0.56) was observed in the Gail model [32]. Overall, this demonstrates that the models have better calibration than discrimination. Accuracy was only evaluated in the Lee model [33]. Sensitivity, specificity and overall accuracy were calculated. The values indicate low accuracy with values ranging from 0.55 to 0.66 (Table 3).
In qualitative research relating to the impact and utility [34] of the Harvard Cancer Risk Index (HCRI) [18], nine focus groups (six female, three male) showed good overall satisfaction with HCRI. Participants appreciated both the detailed explanation and the updated inclusion of risk factors. On the other hand, some participants criticized the absence of what they considered to be important factors (e.g., environmental factors and poverty). Some participants believed that some of the factors on which subjects had been assessed might cause anxiety. It is also noted, however, that the case has been made that such anxiety provides motivation for action to mitigate risk [35].
Overview of current models
All the models described (except for Lee et al. 2004) [36] are extended versions of either the Gail model or the Rosner and Colditz model (Tables 4, 5). The Gail model developed in 1989 [37] was the first risk model for breast cancer and included the following variables: age, menarche age, age at first birth, breast cancer history in first-degree relatives, history of breast biopsies and history of atypical hyperplasia. The range of calibration of the Gail modified models was E/O = (0.93–1.17) and the discrimination range was C-Statistics = (0.56–0.65). This indicates that these models are well calibrated, although discrimination could be improved.
Ueda et al. [38] modified the Gail model by including age at menarche, age at first delivery, family history of breast cancer and BMI in post-menopausal women, as risk factors in his model for Japanese women. However, as with the original Gail model, no validation was performed. In the Boyle model [39], more factors were included such as alcohol intake, onset age of diagnosis in relatives, one of the two diet scores and BMI and HRT. This results in calibration with E/O close to unity and less acceptable discrimination of C-stat = 0.59. The Novotny model [24] added the number of previous breast biopsies performed on a woman and her history of benign breast disease. However, no validation assessment was performed for this model. Newer models [32, 40, 41] included the number of benign biopsies. This resulted in acceptable calibration but less acceptable discrimination (Gail [32]: E/O = 0.93; C-stat = 0.56; Matsuno: E/O = 1.17, C-statistic = 0.614; and Banegas E/O = 1.08). Park et al. [23] included menopausal status, number of pregnancies, duration of breastfeeding, oral contraceptive usage, exercise, smoking, drinking, and number of breast examinations as risk factors. This model has an E/O = 0.965; C-stat = 0.64. However, the C-statistic reported from the external validation cohort was high compared to the original C-statistic. They reported a C-statistic of 0.89 using the NCC cohort. This discrepancy was claimed to be caused by the population characteristics (participants were 30 years and above, recruited from cancer screening program, from a teaching hospital in an urban area) [23]. In the same year, Pfeiffer et al. [23] developed a model where parity was considered as a factor and had E/O of 1.00 and a C-statistic of 0.58. The later Gail model published in 2007 used logistic regression to derive relative risks. These estimates are then combined with attributable risks and cancer registry incidence data to obtain estimates of the baseline hazards [32].
The Rosner and Colditz model of 1994 [42] was based on a cohort study of more than 91,000 women. The model used Poisson regression (rather than logistic regression as in the Gail model). The variables were as follows: age, age at all births, menopause age, and menarche age. This model was not validated. A new version in 1996 [25] included one modification (current age was excluded) and gave an E/O = 1.00 and a C-statistic = 0.57. In 2000, Colditz et al. [18] modified the model with risk factors for: benign breast disease, use of post-menopausal hormones, type of menopause, weight, height, and alcohol intake. This model gave an E/O = 1.01; C-statistic = 0.64.
Lee et al. [36] used two control groups: a “hospitalised” group and a nurses and teachers group. The risk factors in the hospitalized controls were as follows: family history, menstrual regularity, total menstrual duration, age at first full-term pregnancy, and duration of breastfeeding. The risk factors in the nurses/teachers control group were as follows: age, menstrual regularity, alcohol drinking status and smoking status. This model was not based on Gail or Rosner and Colditz. Hosmer–Lemeshow goodness of fit was used to assess model fit which had a p value = 0.301 in (hospital controls) and p value = 0.871 in (nurse/teacher controls). No calibration or discrimination measures were reported.
Lee [33] used three evaluation techniques to assess the discrimination and the accuracy of their model: support vector machine, artificial neural network and Bayesian network. Of the three, support vector machine showed the best values among the Korean cohort. However, accuracy and discrimination were less acceptable in this model.
In summary, calibration performance is similar between models (Modified Gail and modified Rosner, Colditz), yet modified Gail models showed better discrimination performance with the C-statistic of the Park model being 0.89.
Discussion
There is increasing interest among clinicians, researchers and the public in the use of risk models. This makes it important that we fully evaluate model development and application. Each risk model should be assessed before it can be recommended for any clinical application. Performance assessment should involve the use of an independent population [43] separate from the population used to build the model. We have reviewed breast cancer risk models that include non-genetic and non-clinical risk factors but exclude clinical risk factors. By using PubMed, ScienceDirect, Cochrane library and other research engines, 14 models met these criteria. The most recent model examined was developed in 2015 [33]. Most models were based on two earlier risk models developed over 20 years ago—the Gail model [37] and the Rosner and Colditz model [42]. The modified versions of these two original models varied in the risk factors included and the estimation methods used. In 2012, there were two literature reviews published which analysed breast cancer risk prediction models [11, 28]; however, our review focuses particular on modifiable risk factors and/or self-reported factors and we have updated the models published after 2012 [23, 31, 33].
Most models with modifiable risk factors included report acceptable calibration, with E/O close to 1 but less acceptable discrimination with C-statistic close to 0.5. Calibration and validation were improved when more definite factors were included. A possible explanation for less acceptable discrimination performance could be the inclusion of weaker evidence-based factors (probable and possible risk factors). All the models had combinations of probable and possible factors with no single model restricted to the inclusion of the definite factors.
Various factors affect model performance. Inclusion of less significant factors is likely to occur in studies with small sample sizes [11, 28]. Some important clinical risk factors were not included and this may affect the model’s final performance [44]. Breast cancer heterogeneity may also contribute to poor performance as different cancer types may have different risk factors [11]. Most of the models included in this review did not stratify breast cancer into its subtypes during model development. Rosner and Colditz however evaluated the model’s performance based on breast cancer subtypes (ER±, PR ± or HR2±) and concluded that risk factors vary according to the subtypes [45, 46]. Finally, even when strong risk factors are included in a model, significant increases in C-statistic have not been seen [47].
Model performance statistics were affected by the criteria used to stratify the analysis. Four models were stratified by age (below 50 and above 50). One model was further stratified by menopausal status [38], one by ethnicity [41] and one by number of births [42]. Breast cancer risk models could be improved if appropriate factors were used to stratify the population. For example, pre-menopausal and post-menopausal females have different risk factors in breast cancer development. The models that applied menopausal status have some limitation in that this may not be applicable to women who have had hysterectomy. For example, in the US, hysterectomy is the second most common procedure performed and the likelihood of oophorectomy varies by age at hysterectomy [48]. Hence, completion of risk assessment outside of a clinical setting is problematic as women may be challenged to define their menopausal status. Even though the overall performance of these models appears to be moderate in differentiating between cases and non-cases, they may still serve as a good educational tool as part of cancer prevention. Utility evaluation assesses the public’s knowledge of breast cancer risk factors rather well and could be used to promote cancer risk reduction actions.
A significant limitation in the development of risk models is the absence of consensus standards for defining and classifying a model’s performance. For example what is the level of good or acceptable calibration or measures of discrimination? what are acceptable measures of specificity and sensitivity in diagnostic/prognostic/preventive models? how close to unity should calibration and discrimination be for a model to be considered valid? what is the utility cut-off in each type of model? All of these questions are hard to answer without global agreement. However, this lack of consensus is understandable as these values vary depending on the type of the model type (diagnostic, prognostic, preventive), goal (clinical tool, educational tool, screening tool), targeted audience (public, high-risk patients, patients visiting the clinic) and the disease itself and its types or subtypes (such as breast cancer, familial breast cancer, lobular/ductal/invasive/in situ carcinoma breast cancer). This suggests that the closer value of E/O and C-statistics to 1, the better model performance. Such a pragmatic attitude permits us to begin to focus on improving the availability of effective risk reduction actions.
Furthermore, some of the models reviewed cannot be applied to some of the populations as the risk factors may vary between different populations. For example, alcohol consumption would not be applicable to Muslim women. We recommend that researchers develop a more reliable and valid breast cancer risk model which has good calibration, accuracy, discrimination and utility where both internal and external validations indicate that it can be reliable for general use. In order to improve our models, the following should be considered: (1) the model type (diagnostic, prognostic, preventive), goal (clinical tool, educational tool, screening tool), targeted audience (public, high-risk patient), (2) inclusion of definite risk factors while incorporating the clinical and/or genetic risk factors where possible, (3) dividing the model into disease subtypes, age and menopausal status, (4) ensuring that a model is developed that can be validated externally.
Abbreviations
- CDSR:
-
Cochrane Database of Systematic Reviews
- ROC:
-
Area under a receiver operating characteristic curve
- AUC:
-
Area under a receiver operating characteristic curve
- NPV:
-
Negative predictive value
- PPV:
-
Positive predictive value
- TP:
-
True positive
- TN:
-
True negative
- FP:
-
False positive
- FN:
-
False negative
- NCC:
-
National Cancer Centre cohort
- KMCC:
-
Korean Multi-center Cancer Cohort
- NHW:
-
Non-Hispanic white
- NCI:
-
National Cancer Institute
- E/O:
-
Expected/observed
References
Jemal A, Bray F, Center MM, Ferlay J, Ward E, Forman D (2011) Global cancer statistics. CA: a cancer. J Clin 61(2):69–90. https://doi.org/10.3322/caac.20107
Li CI (2010) Breast cancer epidemiology. Springer, Berlin. https://doi.org/10.1007/978-1-4419-0685-4
Parkin DM, Fernández LMG (2006) Use of statistics to assess the global burden of breast cancer. Breast J 12:S70–S80. https://doi.org/10.1111/j.1075-122X.2006.00205.x
Schreer I, Lüttges J (2005) Breast cancer: early detection. In: Gourtsoyiannis NC, Ros PR (eds) Radiologic-pathologic correlations from head to toe: understanding the manifestations of disease. Springer, Berlin, pp 767–784. https://doi.org/10.1007/3-540-26664-x_35
Tabar L, Yen MF, Vitak B, Chen HHT, Smith RA, Duffy SW (2003) Mammography service screening and mortality in breast cancer patients: 20-year follow-up before and after introduction of screening. Lancet 361(9367):1405–1410. https://doi.org/10.1016/S0140-6736(03)13143-1
Gotzsche PC, Jorgensen KJ (2013) Screening for breast cancer with mammography. Cochrane Database Syst Rev. https://doi.org/10.1002/14651858.CD001877.pub5
Anderson BO, Braun S, Lim S, Smith RA, Taplin S, Thomas DB (2003) Early detection of breast cancer in countries with limited resources. Breast J 9(Suppl 2):S51–S59
Yip CH, Smith RA, Anderson BO, Miller AB, Thomas DB, Ang ES, Caffarella RS, Corbex M, Kreps GL, McTiernan A (2008) Guideline implementation for breast healthcare in low- and middle-income countries: early detection resource allocation. Cancer 113(8 Suppl):2244–2256. https://doi.org/10.1002/cncr.23842
Li J, Shao Z (2015) Mammography screening in less developed countries. SpringerPlus 4:615. https://doi.org/10.1186/s40064-015-1394-8
Freedman AN, Seminara D, Gail MH, Hartge P, Colditz GA, Ballard-Barbash R, Pfeiffer RM (2005) Cancer risk prediction models: a workshop on development, evaluation, and application. J Natl Cancer Inst 97(10):715–723. https://doi.org/10.1093/jnci/dji128
Anothaisintawee T, Teerawattananon Y, Wiratkapun C, Kasamesup V, Thakkinstian A (2012) Risk prediction models of breast cancer: a systematic review of model performances. Breast Cancer Res Treat 133(1):1–10. https://doi.org/10.1007/s10549-011-1853-z
National Cancer Institute (2005) The nation’s investment in cancer research. A plan and budget proposal for the fiscal year 2006. https://www.cancer.gov/about-nci/budget/plan/. 2018
Gerds TA, Cai T, Schumacher M (2008) The performance of risk prediction models. Biom J 50(4):457–479. https://doi.org/10.1002/bimj.200810443
Steyerberg EW, Vickers AJ, Cook NR, Gerds T, Gonen M, Obuchowski N, Pencina MJ, Kattan MW (2010) Assessing the performance of prediction models: a framework for some traditional and novel measures. Epidemiology 21(1):128–138. https://doi.org/10.1097/EDE.0b013e3181c30fb2
Moons KG, Altman DG, Vergouwe Y, Royston P (2009) Prognosis and prognostic research: application and impact of prognostic models in clinical practice. BMJ 338:b606. https://doi.org/10.1136/bmj.b606
Moons KG, Kengne AP, Grobbee DE, Royston P, Vergouwe Y, Altman DG, Woodward M (2012) Risk prediction models: II. External validation, model updating, and impact assessment. Heart 98(9):691–698. https://doi.org/10.1136/heartjnl-2011-301247
Liberati A, Altman DG, Tetzlaff J, Mulrow C, Gøtzsche PC, Ioannidis JPA, Clarke M, Devereaux PJ, Kleijnen J, Moher D (2009) The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate healthcare interventions: explanation and elaboration. BMJ 339. https://doi.org/10.1136/bmj.b2700
Colditz GA, Atwood KA, Emmons K, Monson RR, Willett WC, Trichopoulos D, Hunter DJ (2000) Harvard report on cancer prevention volume 4: Harvard Cancer Risk Index. Risk Index Working Group, Harvard Center for Cancer Prevention. Cancer Causes Control 11(6):477–488
Weiderpass E, Braaten T, Magnusson C, Kumle M, Vainio H, Lund E, Adami H-O (2004) A prospective study of body size in different periods of life and risk of premenopausal breast cancer. Cancer Epidemiol Biomark Prev 13(7):1121
Eliassen A, Colditz GA, Rosner B, Willett WC, Hankinson SE (2006) Adult weight change and risk of postmenopausal breast cancer. JAMA 296(2):193–201. https://doi.org/10.1001/jama.296.2.193
Folkerd E, Dowsett M (2013) Sex hormones and breast cancer risk and prognosis. Breast 22(Suppl 2):S38–43. https://doi.org/10.1016/j.breast.2013.07.007
Wright CE, Harvie M, Howell A, Evans DG, Hulbert-Williams N, Donnelly LS (2015) Beliefs about weight and breast cancer: an interview study with high risk women following a 12 month weight loss intervention. Hereditary Cancer Clin Pract 13(1):1. https://doi.org/10.1186/s13053-014-0023-9
Park B, Ma SH, Shin A, Chang M-C, Choi J-Y, Kim S, Han W, Noh D-Y, Ahn S-H, Kang D (2013) Korean risk assessment model for breast cancer risk prediction. PLoS ONE 8(10):e76736
Novotny J, Pecen L, Petruzelka L, Svobodnik A, Dusek L, Danes J, Skovajsova M (2006) Breast cancer risk assessment in the Czech female population—an adjustment of the original Gail model. Breast Cancer Res Treat 95(1):29–35
Rosner B, Colditz GA (1996) Nurses’ health study: log-incidence mathematical model of breast cancer incidence. J Natl Cancer Inst 88(6):359–364
Win AK, MacInnis RJ, Hopper JL, Jenkins MA (2012) Risk prediction models for colorectal cancer: a review. Cancer Epidemiol Biomark Prev 21(3):398–410
Engel C, Fischer C (2015) Breast cancer risks and risk prediction models. Breast Care 10(1):7–12
Meads C, Ahmed I, Riley R (2012) A systematic review of breast cancer incidence risk prediction models with meta-analysis of their performance. Breast Cancer Res Treat 132(2):365–377. https://doi.org/10.1007/s10549-011-1818-2
Parikh R, Mathai A, Parikh S, Chandra Sekhar G, Thomas R (2008) Understanding and using sensitivity, specificity and predictive values. Indian J Ophthalmol 56(1):45–50
Emmons KM, Wong MEI, Puleo E, Weinstein N, Fletcher R, Colditz G (2004) Tailored computer-based cancer risk communication: correcting colorectal cancer risk perception. J Health Commun 9(2):127–141. https://doi.org/10.1080/10810730490425295
Pfeiffer RM, Park Y, Kreimer AR, Lacey JV Jr, Pee D, Greenlee RT, Buys SS, Hollenbeck A, Rosner B, Gail MH (2013) Risk prediction for breast, endometrial, and ovarian cancer in white women aged 50 y or older: derivation and validation from population-based cohort studies. PLoS Med 10(7):e1001492
Gail MH, Costantino JP, Pee D, Bondy M, Newman L, Selvan M, Anderson GL, Malone KE, Marchbanks PA, McCaskill-Stevens W (2007) Projecting individualized absolute invasive breast cancer risk in African American women. J Natl Cancer Inst 99(23):1782–1792
Lee C, Lee JC, Park B, Bae J, Lim MH, Kang D, Yoo K-Y, Park SK, Kim Y, Kim S (2015) Computational discrimination of breast cancer for Korean women based on epidemiologic data only. J Korean Med Sci 30(8):1025–1034. https://doi.org/10.3346/jkms.2015.30.8.1025
Karen ME, Susan K-W, Kathy A, Lisa C, Rima R, Graham C (1999) A qualitative evaluation of the harvard cancer risk index. J Health Commun 4(3):181–193. https://doi.org/10.1080/108107399126904
Bandura A (1992) Exercise of personal agency through the self-efficacy mechanism. In: Self-efficacy: thought control of action. Hemisphere Publishing Corp, Washington, DC, pp 3–38
Lee EO, Ahn SH, You C, Lee DS, Han W, Choe KJ, Noh D-Y (2004) Determining the main risk factors and high-risk groups of breast cancer using a predictive model for breast cancer risk assessment in South Korea. Cancer Nurs 27(5):400–406
Gail MH, Brinton LA, Byar DP, Corle DK, Green SB, Schairer C, Mulvihill JJ (1989) Projecting individualized probabilities of developing breast cancer for white females who are being examined annually. J Natl Cancer Inst 81(24):1879–1886
Ueda K, Tsukuma H, Tanaka H, Ajiki W, Oshima A (2003) Estimation of individualized probabilities of developing breast cancer for Japanese women. Breast Cancer 10(1):54–62
Boyle P, Mezzetti M, La Vecchia C, Franceschi S, Decarli A, Robertson C (2004) Contribution of three components to individual cancer risk predicting breast cancer risk in Italy. Eur J Cancer Prev 13(3):183–191
Banegas MP, Gail MH, LaCroix A, Thompson B, Martinez ME, Wactawski-Wende J, John EM, Hubbell FA, Yasmeen S, Katki HA (2012) Evaluating breast cancer risk projections for Hispanic women. Breast Cancer Res Treat 132(1):347–353
Matsuno RK, Costantino JP, Ziegler RG, Anderson GL, Li H, Pee D, Gail MH (2011) Projecting individualized absolute invasive breast cancer risk in Asian and Pacific Islander American women. J Natl Cancer Inst 103(12):951–961. https://doi.org/10.1093/jnci/djr154
Rosner B, Colditz GA, Willett WC (1994) Reproductive risk factors in a prospective study of breast cancer: the Nurses’ Health Study. Am J Epidemiol 139(8):819–835
Collins GS, de Groot JA, Dutton S, Omar O, Shanyinde M, Tajar A, Voysey M, Wharton R, Yu LM, Moons KG, Altman DG (2014) External validation of multivariable prediction models: a systematic review of methodological conduct and reporting. BMC Med Res Methodol 14:40. https://doi.org/10.1186/1471-2288-14-40
Pepe MS, Janes H, Longton G, Leisenring W, Newcomb P (2004) Limitations of the odds ratio in gauging the performance of a diagnostic, prognostic, or screening marker. Am J Epidemiol 159(9):882–890. https://doi.org/10.1093/aje/kwh101
Rosner B, Glynn RJ, Tamimi RM, Chen WY, Colditz GA, Willett WC, Hankinson SE (2013) Breast cancer risk prediction with heterogeneous risk profiles according to breast cancer tumor markers. Am J Epidemiol 178(2):296–308. https://doi.org/10.1093/aje/kws457
Colditz GA, Rosner BA, Chen WY, Holmes MD, Hankinson SE (2004) Risk factors for breast cancer according to estrogen and progesterone receptor status. J Natl Cancer Inst 96(3):218–228
Cook NR (2007) Use and misuse of the receiver operating characteristic curve in risk prediction. Circulation 115(7):928–935. https://doi.org/10.1161/circulationaha.106.672402
Laughlin GA, Barrett-Connor E, Kritz-Silverstein D, von Mühlen D (2000) Hysterectomy, oophorectomy, and endogenous sex hormone levels in older women: the rancho Bernardo study. J Clin Endocrinol Metab 85(2):645–651. https://doi.org/10.1210/jcem.85.2.6405
Kim DJ, Rockhill B, Colditz GA (2004) Validation of the Harvard Cancer Risk Index: a prediction tool for individual cancer risk. J Clin Epidemiol 57(4):332–340. https://doi.org/10.1016/j.jclinepi.2003.08.013
Colditz GA, Rosner B (2000) Cumulative risk of breast cancer to age 70 years according to risk factor status: data from the Nurses’ Health Study. Am J Epidemiol 152(10):950–964
Matsuno RK, Costantino JP, Ziegler RG, Anderson GL, Li H, Pee D, Gail MH (2011) Projecting individualized absolute invasive breast cancer risk in Asian and Pacific Islander American women. J Natl Cancer Inst 103:951–961
Emmons KM, Koch-Weser S, Atwood K, Conboy L, Rudd R, Colditz G (1999) A qualitative evaluation of the Harvard Cancer Risk Index. J Health Commun 4(3):181–193. https://doi.org/10.1080/108107399126904
Pfeiffer RM, Park Y, Kreimer AR, Lacey JV, Pee D, Greenlee RT, Buys SS, Hollenbeck A, Rosner B, Gail MH, Hartge P (2013) Risk prediction for breast, endometrial, and ovarian cancer in white women aged 50 y or older: derivation and validation from population-based cohort studies. PLoS Med 10(7):e1001492
Timmers JM, Verbeek AL, IntHout J, Pijnappel RM, Broeders MJ, den Heeten GJ (2013) Breast cancer risk prediction model: a nomogram based on common mammographic screening findings. Eur Radiol 23(9):2413–2419. https://doi.org/10.1007/s00330-013-2836-8
McCowan C, Donnan PT, Dewar J, Thompson A, Fahey T (2011) Identifying suspected breast cancer: development and validation of a clinical prediction rule. Brit J Gen Pract 61 (586). https://doi.org/10.3399/bjgp11X572391
Cook NR, Rosner BA, Hankinson SE, Colditz GA (2009) Mammographic screening and risk factors for breast cancer. Am J Epidemiol 170(11):1422–1432. https://doi.org/10.1093/aje/kwp304
Tice JA, Cummings SR, Smith-Bindman R, Ichikawa L, Barlow WE, Kerlikowske K (2008) Using clinical factors and mammographic breast density to estimate breast cancer risk: development and validation of a new predictive model. Ann Intern Med 148(5):337–375. https://doi.org/10.7326/0003-4819-148-5-200803040-00004
Rosner B, Colditz GA, Iglehart JD, Hankinson SE (2008) Risk prediction models with incomplete data with application to prediction of estrogen receptor-positive breast cancer: prospective data from the Nurses’ Health Study. Breast Cancer Res 10(4):R55. https://doi.org/10.1186/bcr2110
Lee SM, Park JH, Park HJ (2008) Implications of systematic review for breast cancer prediction. Cancer Nurs 31(5):E40–E46. https://doi.org/10.1097/01.NCC.0000305765.34851.e9
Chlebowski RT, Anderson GL, Lane DS, Aragaki AK, Rohan T, Yasmeen S, Sarto G, Rosenberg CA, Hubbell FA, Women’s Health Initiative I (2007) Predicting risk of breast cancer in postmenopausal women by hormone receptor status. J Natl Cancer Inst 99(22):1695–1705. https://doi.org/10.1093/jnci/djm224
Decarli A, Calza S, Masala G, Specchia C, Palli D, Gail MH (2006) Gail model for prediction of absolute risk of invasive breast cancer: Independent evaluation in the Florence-European Prospective Investigation Into Cancer and Nutrition Cohort. J Natl Cancer I 98(23):1686–1693. https://doi.org/10.1093/jnci/djj463
Chen JB, Pee D, Ayyagari R, Graubard B, Schairer C, Byrne C, Benichou J, Gail MH (2006) Projecting absolute invasive breast cancer risk in white women with a model that includes mammographic density. J Natl Cancer I 98(17):1215–1226. https://doi.org/10.1093/jnci/djj332
Barlow WE, White E, Ballard-Barbash R, Vacek PM, Titus-Ernstoff L, Carney PA, Tice JA, Buist DS, Geller BM, Rosenberg R, Yankaskas BC, Kerlikowske K (2006) Prospective breast cancer risk prediction model for women undergoing screening mammography. J Natl Cancer Inst 98(17):1204–1214. https://doi.org/10.1093/jnci/djj331
Tice JA, Miike R, Adduci K, Petrakis NL, King E, Wrensch MR (2005) Nipple aspirate fluid cytology and the Gail model for breast cancer risk assessment in a screening population. Cancer Epidemiol Biomark Prev 14(2):324–328. https://doi.org/10.1158/1055-9965.EPI-04-0289
Taplin SH, Thompson RS, Schnitzer F, Anderman C, Immanuel V (1990) Revisions in the Risk-Based Breast-Cancer Screening-Program at Group Health Cooperative. Cancer 66 (4):812–818. https://doi.org/10.1002/1097-0142(19900815)66:4%3C812::Aid-Cncr2820660436%3E3.0.Co;2-1
Gail MH, Brinton LA, Byar DP, Corle DK, Green SB, Schairer C, Mulvihill JJ (1989) Projecting individualized probabilities of developing breast-cancer for white females who are being examined annually. J Natl Cancer Inst 81(24):1879–1886. https://doi.org/10.1093/jnci/81.24.1879
Anderson DE, Badzioch M (1984) Risk of familial breast-cancer. Lancet 1(8373):392–392
Ottman R, Pike MC, King MC, Henderson BE (1983) Practical guide for estimating risk for familial breast-cancer. Lancet 2(8349):556–558
Lee AJ, Cunningham AP, Kuchenbaecker KB, Mavaddat N, Easton DF, Antoniou AC, Modifiers CI, Consortium BCA (2014) BOADICEA breast cancer risk prediction model: updates to cancer incidences, tumour pathology and web interface. Brit J Cancer 110(2):535–545. https://doi.org/10.1038/bjc.2013.730
McCarthy AM, Armstrong K, Handorf E, Boghossian L, Jones M, Chen JB, Demeter MB, McGuire E, Conant EF, Domchek SM (2013) Incremental impact of breast cancer SNP panel on risk classification in a screening population of white and African American women. Breast Cancer Res Treat 138(3):889–898. https://doi.org/10.1007/s10549-013-2471-8
Dite GS, Mahmoodi M, Bickerstaffe A, Hammet F, Macinnis RJ, Tsimiklis H, Dowty JG, Apicella C, Phillips KA, Giles GG, Southey MC, Hopper JL (2013) Using SNP genotypes to improve the discrimination of a simple breast cancer risk prediction model. Breast Cancer Res Treat 139(3):887–896. https://doi.org/10.1007/s10549-013-2610-2
Biswas S, Atienza P, Chipman J, Hughes K, Barrera AMG, Amos CI, Arun B, Parmigiani G (2013) Simplifying clinical use of the genetic risk prediction model BRCAPRO. Breast Cancer Res Treat 139(2):571–579. https://doi.org/10.1007/s10549-013-2564-4
Sueta A, Ito H, Kawase T, Hirose K, Hosono S, Yatabe Y, Tajima K, Tanaka H, Iwata H, Iwase H, Matsuo K (2012) A genetic risk predictor for breast cancer using a combination of low-penetrance polymorphisms in a Japanese population. Breast Cancer Res Treat 132(2):711–721. https://doi.org/10.1007/s10549-011-1904-5
Huesing A, Canzian F, Beckmann L, Garcia-Closas M, Diver WR, Thun MJ, Berg CD, Hoover RN, Ziegler RG, Figueroa JD, Isaacs C, Olsen A, Viallon V, Boeing H, Masala G, Trichopoulos D, Peeters PHM, Lund E, Ardanaz E, Khaw KT, Lenner P, Kolonel LN, Stram DO, Le Marchand L, McCarty CA, Buring JE, Lee IM, Zhang SM, Lindstrom S, Hankinson SE, Riboli E, Hunter DJ, Henderson BE, Chanock SJ, Haiman CA, Kraft P, Kaaks R, Bpc3 (2012) Prediction of breast cancer risk by genetic risk factors, overall and by hormone receptor status. J Med Genet 49(9):601–608. https://doi.org/10.1136/jmedgenet-2011-100716
Darabi H, Czene K, Zhao WT, Liu JJ, Hall P, Humphreys K (2012) Breast cancer risk prediction and individualised screening based on common genetic variation and breast density measurement. Breast Cancer Res 14(1):R25. https://doi.org/10.1186/bcr3110
Dai JC, Hu ZB, Jiang Y, Shen H, Dong J, Ma HX, Shen HB (2012) Breast cancer risk assessment with five independent genetic variants and two risk factors in Chinese women. Breast Cancer Res 14(1):R17. https://doi.org/10.1186/bcr3101
Biswas S, Tankhiwale N, Blackford A, Barrera AM, Ready K, Lu K, Amos CI, Parmigiani G, Arun B (2012) Assessing the added value of breast tumor markers in genetic risk prediction model BRCAPRO. Breast Cancer Res Treat 133(1):347–355. https://doi.org/10.1007/s10549-012-1958-z
van Zitteren M, van der Net JB, Kundu S, Freedman AN, van Duijn CM, Janssens ACJW (2011) Genome-based prediction of breast cancer risk in the general population: a modeling study based on meta-analyses of genetic associations. Cancer Epidem Biomark 20(1):9–22. https://doi.org/10.1158/1055-9965.Epi-10-0329
Crooke PS, Justenhoven C, Brauch H, Dawling S, Roodi N, Higginbotham KSP, Plummer WD, Schuyler PA, Sanders ME, Page DL, Smith JR, Dupont WD, Parl FF, Consortium G (2011) Estrogen metabolism and exposure in a genotypic-phenotypic model for breast cancer risk prediction. Cancer Epidemiol Biomark 20(7):1502–1515. https://doi.org/10.1158/1055-9965.Epi-11-0060
Wacholder S, Hartge P, Prentice R, Garcia-Closas M, Feigelson HS, Diver WR, Thun MJ, Cox DG, Hankinson SE, Kraft P, Rosner B, Berg CD, Brinton LA, Lissowska J, Sherman ME, Chlebowski R, Kooperberg C, Jackson RD, Buckman DW, Hui P, Pfeiffer R, Jacobs KB, Thomas GD, Hoover RN, Gail MH, Chanock SJ, Hunter DJ (2010) Performance of common genetic variants in breast-cancer risk models. New Engl J Med 362(11):986–993. https://doi.org/10.1056/NEJMoa0907727
Antoniou AC, Cunningham AP, Peto J, Evans DG, Lalloo F, Narod SA, Risch HA, Eyfjord JE, Hopper JL, Southey MC, Olsson H, Johannsson O, Borg A, Passini B, Radice P, Manoukian S, Eccles DM, Tang N, Olah E, Anton-Culver H, Warner E, Lubinski J, Gronwald J, Gorski B, Tryggvadottir L, Syrjakoski K, Kallioniemi OP, Eerola H, Nevanlinna H, Pharoah PDP, Easton DF (2008) The BOADICEA model of genetic susceptibility to breast and ovarian cancers: updates and extensions. Brit J Cancer 98(8):1457–1466. https://doi.org/10.1038/sj.bjc.6604305
Tyrer J, Duffy SW, Cuzick J (2004) A breast cancer prediction model incorporating familial and personal risk factors. Stat Med 23(7):1111–1130. https://doi.org/10.1002/sim.1668
Evans DGR, Eccles DM, Rahman N, Young K, Bulman M, Amir E, Shenton A, Howell A, Lalloo F (2004) A new scoring system for the chances of identifying a BRCA1/2 mutation outperforms existing models including BRCAPRO. J Med Genet 41(6):474–480. https://doi.org/10.1136/jmg.2003.017996
Antoniou AC, Pharoah PPD, Smith P, Easton DF (2004) The BOADICEA model of genetic susceptibility to breast and ovarian cancer. Brit J Cancer 91(8):1580–1590. https://doi.org/10.1038/sj.bjc.6602175
Jonker MA, Jacobi CE, Hoogendoorn WE, Nagelkerke NJD, de Bock GH, van Houwelingen JC (2003) Modeling familial clustered breast cancer using published data. Cancer Epidemiol Biomark 12(12):1479–1485
Fisher TJ, Kirk J, Hopper JL, Godding R, Burgemeister FC (2003) A simple tool for identifying unaffected women at a moderately increased or potentially high risk of breast cancer based on their family history. Breast 12(2):120–127. https://doi.org/10.1016/S0960-9776(02)00285-0
Apicella C, Andrews L, Hodgson SV, Fisher SA, Lewis CM, Solomon E, Tucker K, Friedlander M, Bankier A, Southey MC, Venter DJ, Hopper JL (2003) Log odds of carrying an Ancestral Mutation in BRCA1 or BRCA2 for a defined personal and family history in an Ashkenazi Jewish woman (LAMBDA). Breast Cancer Res 5(6):R206–R216. https://doi.org/10.1186/bcr644
Frank TS, Deffenbaugh AM, Reid JE, Hulick M, Ward BE, Lingenfelter B, Gumpper KL, Scholl T, Tavtigian SV, Pruss DR, Critchfield GC (2002) Clinical characteristics of individuals with germline mutations in BRCA1 and BRCA2: Analysis of 10,000 individuals. J Clin Oncol 20(6):1480–1490. https://doi.org/10.1200/Jco.20.6.1480
de la Hoya M, Osorio A, Godino J, Sulleiro S, Tosar A, Perez-Segura P, Fernandez C, Rodriguez R, Diaz-Rubio E, Benitez J, Devilee P, Caldes T (2002) Association between BRCA1 and BRCA2 mutations and cancer phenotype in Spanish breast/ovarian cancer families: Implications for genetic testing. Int J Cancer 97(4):466–471. https://doi.org/10.1002/ijc.1627
Berry DA, Iversen ES, Gudbjartsson DF, Hiller EH, Garber JE, Peshkin BN, Lerman C, Watson P, Lynch HT, Hilsenbeck SG, Rubinstein WS, Hughes KS, Parmigiani G (2002) BRCAPRO validation, sensitivity of genetic testing of BRCA1/BRCA2, and prevalence of other breast cancer susceptibility genes. J Clin Oncol 20(11):2701–2712. https://doi.org/10.1200/Jco.2002.05.121
Antoniou AC, Pharoah PDP, McMullan G, Day NE, Stratton MR, Peto J, Ponder BJ, Easton DF (2002) A comprehensive model for familial breast cancer incorporating BRCA1, BRCA2 and other genes. Brit J Cancer 86(1):76–83. https://doi.org/10.1038/sj/bjc/6600008
Vahteristo P, Eerola H, Tamminen A, Blomqvist C, Nevanlinna H (2001) A probability model for predicting BRCA1 and BRCA2 mutations in breast and breast-ovarian cancer families. Brit J Cancer 84(5):704–708. https://doi.org/10.1054/bjoc.2000.1626
Gilpin CA, Carson N, Hunter AGW (2000) A preliminary validation of a family history assessment form to select women at risk for breast or ovarian cancer for referral to a genetics center. Clin Genet 58(4):299–308. https://doi.org/10.1034/j.1399-0004.2000.580408.x
Hartge P, Struewing JP, Wacholder S, Brody LC, Tucker MA (1999) The prevalence of common BRCA1 and BRCA2 mutations among Ashkenazi Jews. Am J Hum Genet 64(4):963–970. https://doi.org/10.1086/302320
Parmigiani G, Berry DA, Aguilar O (1998) Determining carrier probabilities for breast cancer-susceptibility genes BRCA1 and BRCA2. Am J Hum Genet 62(1):145–158. https://doi.org/10.1086/301670
Frank TS, Manley SA, Olopade OI, Cummings S, Garber JE, Bernhardt B, Antman K, Russo D, Wood ME, Mullineau L, Isaacs C, Peshkin B, Buys S, Venne V, Rowley PT, Loader S, Offit K, Robson M, Hampel H, Brener D, Winer EP, Clark S, Weber B, Strong LC, Rieger P, McClure M, Ward BE, Shattuck-Eidens D, Oliphant A, Skolnick MH, Thomas A (1998) Sequence analysis of BRCA1 and BRCA2: correlation of mutations with family history and ovarian cancer risk. J Clin Oncol 16(7):2417–2425. https://doi.org/10.1200/Jco.1998.16.7.2417
Shattuck-Eidens D, Oliphant A, Fau-McClure M, McClure M, Fau-McBride C, McBride C, Fau-Gupte J, Gupte J, Fau-Rubano T, Rubano T, Fau-Pruss D, Pruss D, Fau-Tavtigian SV, Tavtigian SV, Fau-Teng DH, Teng DH, Fau-Adey N, Adey N, Fau-Staebell M, Staebell M, Fau-Gumpper K, Gumpper K, Fau-Lundstrom R, Lundstrom R, Fau-Hulick M, Hulick M, Fau-Kelly M, Kelly M, Fau-Holmen J, Holmen J, Fau-Lingenfelter B, Lingenfelter B, Fau-Manley S, Manley S, Fau-Fujimura F, Fujimura F, Fau-Luce M, Luce M, Fau-Ward B, Ward B, Fau-Cannon-Albright L, Cannon-Albright L, Fau-Steele L, Steele L, Fau-Offit K, Offit K, Fau-Thomas A, Thomas A et al (1997) BRCA1 sequence analysis in women at high risk for susceptibility mutations. Risk factor analysis and implications for genetic testing. J Am M Assoc (0098-7484 (Print))
Couch FJ, DeShano ML, Blackwood MA, Calzone K, Stopfer J, Campeau L, Ganguly A, Rebbeck T, Weber BL, Jablon L, Cobleigh MA, Hoskins K, Garber JE (1997) BRCA1 mutations in women attending clinics that evaluate the risk of breast cancer. New Engl J Med 336(20):1409–1415. https://doi.org/10.1056/Nejm199705153362002
Claus EB, Risch N, Thompson WD (1994) Autosomal-dominant inheritance of early-onset breast-cancer—implications for risk prediction. Cancer 73 (3):643–651. https://doi.org/10.1002/1097-0142(19940201)73:3%3C643::Aid-Cncr2820730323%3E3.0.Co;2-5
Claus EB, Risch N, Thompson WD (1993) The calculation of breast-cancer risk for women with a first degree family history of ovarian-cancer. Breast Cancer Res Treat 28(2):115–120. https://doi.org/10.1007/Bf00666424
Wang S, Ogundiran T, Ademola A, Olayiwola OA, Adeoye A, Adeniji-Sofoluwe A, Morhason-Bello I, Odedina S, Agwai I, Adebamowo C, Obajimi M, Ojengbede O, Olopade OI, Huo D (2016) Abstract 2590: development and validation of a breast cancer risk prediction model for black women: findings from the Nigerian breast cancer study. Cancer Res. https://doi.org/10.1158/1538-7445.AM2016-2590
Acknowledgments
We are very grateful to Ministry of Higher Education in Oman for supporting the first author with her PhD studies without their financial support we would not be able to publish this paper.
Funding
Kenneth R. Muir and Artitaya Lophatananon were funded by ICEP (“This work was also supported by CRUK [Grant Number C18281/A19169]”).
Author information
Authors and Affiliations
Contributions
Conception and design: KM, AL and KA. Development of methodology: KM, AL and KA. Acquisition of data: KM, KA and AL. Analysis and interpretation of data (e.g., statistical analysis, biostatistics, computational analysis): KA, AL. Writing, review, and/or revision of the manuscript: KA, KM, AL, MY, WO.
Corresponding author
Ethics declarations
Conflict of interest
None of the authors have any competing interests.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Al-Ajmi, K., Lophatananon, A., Yuille, M. et al. Review of non-clinical risk models to aid prevention of breast cancer. Cancer Causes Control 29, 967–986 (2018). https://doi.org/10.1007/s10552-018-1072-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10552-018-1072-6