
Abstract
Landslides pose a significant threat to human life and infrastructure, underscoring the ongoing need for accurate landslide susceptibility mapping (LSM) to effectively assess risks. This study introduces an innovative approach that leverages multi-objective evolutionary fuzzy algorithms for landslide modeling in Khalkhal town, Iran. Two algorithms, namely the non-dominated sorting genetic algorithm II (NSGA-II) and the evolutionary non-dominated radial slots-based algorithm (ENORA), were employed to optimize Gaussian fuzzy rules. By utilizing 15 landslide conditioning factors (aspect, altitude, distance from the fault, soil, slope, lithology, rainfall, distance from the road, the normalized difference vegetation index (NDVI), land cover, plan curvature, profile curvature, topographic wetness index (TWI), stream power index (SPI), and distance from the river) and historical landslide events (153 landslide locations), we randomly partitioned the input data into training (70%) and validation (30%) sets. The training set determined the weight of conditioning factor classes using the frequency ratio (FR) approach. These weights were then used as inputs for the NSGA-II and ENORA algorithms to generate an LSM. The NSGA-II algorithm achieved a root-mean-square error (RMSE) of 0.25 during training and 0.43 during validation. Similarly, the ENORA algorithm demonstrated an RMSE of 0.28 in training and 0.48 in validation. The findings revealed that the LSM created by the NSGA-II algorithm exhibited superior predictive capabilities (area under the receiver operating characteristic curve (AUC) = 0.867) compared to the ENORA algorithm (AUC = 0.844). Additionally, a particle swarm optimization (PSO) algorithm was employed to determine the importance of conditioning factors, identifying lithology, land cover, and altitude as the most influential factors.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Natural disasters are a prominent research issue for geoscientists and engineers because of their impact on human settlements (Galli et al. 2008). Globally, landslides are typical dangerous natural disasters that frequently result in multiple fatalities (Mandal and Mandal 2018). Landslides murdered 66,438 people and cost roughly $10 billion in economic losses worldwide between 1900 and 2020, according to the Emergency Events Database (Guha-Sapir et al. 2020). Iran is situated within the seismic belt of the Alps and Himalayas, rendering it more susceptible to a range of natural disasters, such as landslides. Moreover, the Iranian Plateau is situated in southwest Asia, which is recognized as a high and mountainous region in western Asia (Farrokhnia et al. 2011). Additionally, the western and northern regions of the Iranian Plateau are home to the Zagros and Alborz Mountain Ranges. According to the reported data, from January 2003 to September 2007, Iran experienced an annual economic loss of 12.7 billion USD, attributed to 4900 landslides (Dehnavi et al. 2015; Shafizadeh-Moghadam et al. 2019). Ardabil province, situated in the northernmost region of Iran, is characterized by significant variations in altitude and slope fluctuations (Feizizadeh and Blaschke 2013; Hamedi et al. 2022). Moreover, due to its proximity to the Caspian Sea and the occurrence of heavy rainfall, the province is prone to landslides (Hamedi et al. 2022). As reported in the study on natural resources and watersheds of Ardabil province, over 6800 landslide points have been identified within the province. Notably, 52.5% of these landslides are concentrated in the Sefid-rud dam area and in Kausar and Khalkhal towns. Given the significant concentration of landslides in Khalkhal town, as highlighted by the mentioned cases, it is crucial to prioritize and implement effective management strategies to mitigate and reduce the risk of landslides in the area. Multiple variables, including severe rainfall, earthquakes, snowmelt, volcanic eruptions, and land-use changes undermining slope stability, typically trigger landslides (Marjanović et al. 2011). Therefore, land-use planners and policymakers should prioritize disaster mitigation and contingency planning research related to sustainable development and lowering the danger of potential landslide disasters (Kavzoglu et al. 2015).
Identifying landslide-prone areas is critical for studies on hazard management (Kavzoglu et al. 2019). A region's susceptibility to landslides is affected by various geo-environmental factors, including topography, weather conditions, and land properties (Guzzetti et al. 2005). Landslide susceptibility maps (LSMs) have been constructed using various data-driven and quantitative methods in recent years (Guzzetti et al. 1999). Qualitative techniques, such as the technique for order of preference by similarity to ideal solution (TOPSIS) (Aslam et al. 2022), the analytic hierarchy process (AHP) (Yalcin 2008), fuzzy logic (Ozdemir 2020), and the analytical network process (ANP) (Pham et al. 2021) are based on the expert knowledge to create LSM. Data-driven approaches include deterministic and statistical techniques. Deterministic approaches are static (Alvioli and Baum 2016), but statistical methods, such as bivariate statistical analysis (Constantin et al. 2011; Hong et al. 2018) and machine learning techniques (Merghadi et al. 2020; Razavi-Termeh et al. 2021), rely on the correlation between detected contributing factors and the occurrence of landslides. Indeed, among the bivariate statistical methods commonly employed in LSM, two main approaches are the frequency ratio (FR) and weight of evidence (WOE) methods (Shirzadi et al. 2017). Recently, several advanced machine learning techniques for constructing LSM have been identified, such as logistic regression (LR) (Wang et al. 2016), decision tree (DT) (Pradhan 2013), bagging (BA) and random subspace (RS) (Nhu et al. 2020a, b), random forest (RF) (Taalab et al. 2018), support vector machine (SVM) (Lee et al. 2017; Zhang et al. 2018), adaptive neuro-fuzzy inference system (ANFIS) (Razavi-Termeh et al. 2021), AdaBoost (AB), alternating decision tree (ADTree) (Nhu et al. 2020a, b), and artificial neural network (ANN) (Bragagnolo et al. 2020). However, each technique for machine learning has distinct advantages and disadvantages. To improve the accuracy of machine learning algorithms, hybridization of BA and logistic model trees (LMTree) (Truong et al. 2018) and the hybridization of RS and classification and regression trees (CART) (Pham et al. 2018) algorithms have been commonly used in creating LSM. Therefore, deep learning approaches have recently outperformed previous machine learning techniques and successfully created LSM (Dao et al. 2020). Various deep learning algorithms such as convolutional neural network (CNN) (Azarafza et al. 2021), recurrent neural network (RNN) (Ngo et al. 2021), and long short-term memory (LSTM) (Habumugisha et al. 2022) have used to create LSM.
Meta-heuristic algorithms have been used in recent research to fine-tune model parameters and eliminate errors to improve the performance of machine learning and deep learning algorithms (Ranjgar et al. 2021; Razavi-Termeh et al. 2022). So far, metaheuristic algorithms have been used to optimize various machine/deep learning algorithms such as ANFIS (Mehrabi et al. 2020), ANN (Mehrabi and Moayedi 2021), CNN (), and support vector regression (SVR) (Panahi et al. 2020) for landslide susceptibility modeling. In establishing LSM, metaheuristic algorithms have demonstrated acceptable accuracy when combined with machine learning or deep learning algorithms (Alqadhi et al. 2021; Hakim et al. 2022). One of the most significant advantages of this fuzzy logic theory is that it allows for the natural explanation, in linguistic terms, of issues that must be solved rather than in terms of precise numerical correlations (Huang and Sun 2013). The widespread use of fuzzy logic theory in geographic information systems (GIS) is primarily motivated by its ability to deal with complex systems straightforwardly (Yao and Jiang 2005). Fuzzy rules are used in fuzzy logic systems to infer outputs from variables that serve as inputs. The main goal of our study is to address the challenge of determining accurate and appropriate fuzzy rules, typically based on expert opinions (Bai and Wang 2006), for LSM.
We aim to fill this gap by proposing a novel approach that utilizes multi-objective evolutionary algorithms in conjunction with fuzzy logic. Specifically, our study focuses on applying multi-objective evolutionary algorithms, such as the non-dominated sorting genetic algorithm II (NSGA-II) and the evolutionary non-dominated radial slots-based algorithm (ENORA), to develop a classifier that optimizes the selection of fuzzy rules for LSM. This approach represents a significant advancement in the field, as the combination of multi-objective evolutionary algorithms and fuzzy logic has not been previously employed for LSM development. By leveraging the strengths of NSGA-II and ENORA, our study seeks to identify the best fuzzy rules for LSM, thereby enhancing the accuracy and reliability of the susceptibility mapping process. Additionally, our research contributes to the scientific literature by conducting a comparative analysis of NSGA-II and ENORA, exploring their performance and effectiveness in the context of LSM. This comparative evaluation of multi-objective evolutionary algorithms for LSM represents a novel aspect of our study.
2 Material and methods
2.1 Data preparation
2.1.1 Study area
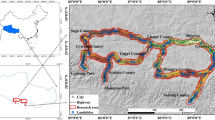
Khalkhal town, with an area of 2688 km2, is situated in the Ardabil province, Iran, between the latitudes of 37° 11′ N and 37° 51′ N, as well as the longitudes of 48° 10′ E and 48° 55′ E (Fig. 1). The altitude of the highest point of the town is 3318 m (Agh Dagh Mountain). Due to its mountainous nature, this town has long and very cold winters and mild and semi-arid summers. The average temperature in this area is less than 20 °C. The coldest and hottest months of the year in this region are January and August, respectively. Khalkhal has an average annual rainfall of 350 mm, with the most rain falling in the spring. The area's formations range from lower Paleozoic rock to Quaternary alluvial sediments, with the earliest rocks dating back to the lower Paleozoic. This town has 43,029 hectares of semi-humid and semi-dry forest. Summer pastures cover 50 to 80% of the land cover in the town. According to the reports of natural resources and watersheds of Ardabil province, more than 6800 locations experiencing landslides have been identified within the region. It is worth mentioning that the majority, accounting for 52.5% of these landslides, are concentrated in specific areas, namely the Sefid-rud dam area and the towns of Kausar and Khalkhal. Approximately 48% of the documented landslides in the study area are classified as active landslides. Among these active landslides, 53.5% exhibit rotational movement, while 17.3% demonstrate transitional activity. Due to various factors such as topography, high slope gradients, loose and non-resistant surface materials on resistant formations, and specific climatic conditions, including spring rains and snowfall, Khalkhal town is identified as an area with a high potential for landslides. It is considered the most susceptible region in Ardabil province regarding landslide occurrences. The combination of these factors contributes to the heightened risk and vulnerability of Khalkhal town to landslides. Photos of the occurrence of landslides in the study area are shown in Fig. 2.

Case study location: a Iran, b Khalkhal town, and c landslide points

Photographs of landslides occurrence within the study region
2.1.2 Landslide inventory map
Using an existing database of landslide occurrences, experts can better comprehend the relationship between affective variables and landslide occurrences in a particular region (Tsangaratos et al. 2017). Consequently, it is of the utmost importance to identify the location of past and present landslides accurately. This study created the landslide inventory map using the historical records from the National Geoscience Database of Iran (NGDIR). The data identified 153 landslide locations (centroids) throughout the region. The Holdout method was used to determine training and test data (70:30 ratio). A total of 107 landslides (70%) were randomly selected for landslide modeling, and the outcomes were subsequently validated through the utilization of 46 additional landslides (30%) (Fig. 1). The choice to utilize a 70:30 proportion for the division between the training and testing datasets in our research is underpinned by our aim to cultivate a resilient model that can effectively extrapolate insights to novel data instances. Simultaneously, this division ensures the identification and management of potential overfitting (Moayedi et al. 2020; Mehrabi 2021; Asadi Nalivan et al. 2023). A random layer of 153 non-landslide locations was also generated to train and test the modeling.
2.1.3 Landslide effective factors
It is vital to use proper landslide conditioning factors to build an accurate susceptibility map. Therefore, based on previous landslide susceptibility research (Pham et al. 2018; Pourghasemi et al. 2020; Razavi-Termeh et al. 2021) and the study in Iran, the following fifteen conditioning factors were selected for creating LSM: aspect, altitude, distance from the fault, soil, slope, lithology, rainfall, distance from the road, the normalized difference vegetation index (NDVI), land cover, plan curvature, profile curvature, topographic wetness index (TWI), stream power index (SPI), and distance from the river (Table 1 and Fig. 3). ArcGIS 10.3 and SAGA GIS 8.2.1 software created all conditioning factors as raster with a spatial resolution of 30 × 30 m.


Criteria affecting landslides: a Altitude, b Slope, c Aspect, d Plan curvature, e Profile curvature, f TWI, g SPI, h Distance to river, i Distance to fault, j Distance to road, k NDVI, l) Rainfall, m Soil, n Lithology, and o Land cover
The digital elevation model (DEM) created altitude, slope angle, slope aspect, profile/plan curvature, TWI, and SPI factors. On the Google Earth Engine (GEE) platform, shuttle radar topography mission (SRTM) images generated the DEM. TWI and SPI were computed in SAGA GIS 8.2.1 using Eqs. (1) and (2), respectively (Pham et al. 2018).
\({\mathrm{A}}_{\mathrm{s}}\) denotes the area contributing to the slope's gradient and \(\upbeta\) indicates the slope angle. The limits of \({\mathrm{A}}_{\mathrm{s}}\) will depend on the spatial resolution and extent of the topographic data being used. In most cases, slope angles are measured in degrees and range from 0° (flat terrain) to 90° (vertical terrain). The distances to rivers and roads were determined using a 1:50,000 scale National Cartographic Organization (NCO) topographic map. The 10-year average rainfall data from synoptic stations in the research area were provided by the Iranian Meteorological Organization (IMO). ArcGIS 10.3 developed a rainfall raster layer using the kriging interpolation technique. The 1:100,000 scale geological maps of Iran were used to determine the distribution of lithological units and faults. A land cover map was created by analyzing Sentinel-1 and Sentinel-2 images on the GEE platform (Ghorbanian et al. 2020). The map of land cover was created in thirteen classes. Iran's Natural Resources and Watershed Management Organization provided the soil types. The soil map was prepared in four groups. The NDVI map was created using Landsat 8 satellite imagery on the GEE platform. The NDVI was determined using Eq. (3) (Shogrkhodaei et al. 2021).
where NIR (band 5) represents the near-infrared and R (band 4) represents the red.
2.2 Methods
2.2.1 Multicollinearity analysis
Multicollinearity indicates that the qualities of at least two predicted parameters in multiple regression are substantially associated with linearity (Achour et al. 2018). Therefore, an appropriate selection of these factors is required to establish their independence from one another (Farahani et al. 2022). Multicollinearity findings were evaluated objectively using the VIF (variance inflation factor) metric. A multicollinear factor (VIF > 10) should be removed from modeling (Shogrkhodaei et al. 2021).
2.2.2 Frequency ratio (FR) method
FR can be used to estimate the likelihood of a landslide (Pham et al. 2021). The FR describes spatial correlations between landslides and their causes (Razavi-Termeh et al. 2021). The FR method for each factor class was computed using Eq. 4.
where \({\mathrm{A}}_{\mathrm{i}}^{\mathrm{j}}\) represents the number of landslide pixels in factor i's class j, and \({\mathrm{B}}_{\mathrm{i}}^{\mathrm{j}}\) represents the number of pixels in factor i's class j. To calculate the FR for a specific factor class (i.e., factor i's class j), the number of landslide pixels in that class (\({\mathrm{A}}_{\mathrm{i}}^{\mathrm{j}}\)) is divided by the total number of landslide pixels in all classes of factor i (\({\sum }_{\mathrm{J}}{\mathrm{A}}_{\mathrm{i}}^{\mathrm{j}}\)). Similarly, the number of pixels in the factor class (\({\mathrm{B}}_{\mathrm{i}}^{\mathrm{j}}\)) is divided by the total number of pixels in all classes of factor i (\({\sum }_{\mathrm{J}}{\mathrm{B}}_{\mathrm{i}}^{\mathrm{j}}\)). Specific classes and values for \({\mathrm{A}}_{\mathrm{i}}^{\mathrm{j}}\) and \({\mathrm{B}}_{\mathrm{i}}^{\mathrm{j}}\) will depend on the analyzed factors and the data used in the study. The equation can be applied to different factors by substituting the appropriate values for \({\mathrm{A}}_{\mathrm{i}}^{\mathrm{j}}\) and \({\mathrm{B}}_{\mathrm{i}}^{\mathrm{j}}\) for each factor class. The values of i and j depend on the number of factors and classes, and there is no limit to the number of these parameters.
2.2.3 Fuzzy logic
Based on fuzzy set theory, Zadeh et al. (1996) proposed fuzzy logic. Parameter standardization using a fuzzy membership function is the first step in the fuzzy model. A membership function that is normalized exists between zero and one. A mapping between an input and an output can be represented as fuzzy inference using fuzzy logic (Mohebbi Tafreshi et al. 2021). The most commonly encountered fuzzy inference approach is Mamdani fuzzy inference. The fuzzy interface model was developed using Mamdani's compositional rule of inference. The following four steps are outlined to create a Mamdani fuzzy inference system in this research (Allawi et al. 2018; Omair et al. 2021): (1) Fuzzification: The inputs are examined with membership functions after the collection of fuzzy rules has been determined. The factors of linguistic ranking assigned to corresponding fuzzy sets are high and low. The membership function for the created fuzzy interface system's input variables is determined using a Gaussian distribution. (2) In the second stage, we integrate the fuzzy inputs based on the fuzzy rules to estimate the rule strength (fuzzy operations). A set of IF–THEN rules determines the foundational laws of knowledge. (3) Fuzzy inference method: The rule's influence is finally determined in the third step, which combines the rule's strength with the output function. (4) Defuzzification: The defuzzification technique takes a fuzzy set as input (the aggregate output fuzzy set) and produces a single integer as output. According to the algorithm, the fuzzy numbers must be converted to crisp numbers using Eq. (5).
In this equation, "n" is the total number of elements in the fuzzy set. Each element, denoted as \({\mathrm{x}}_{\mathrm{i}}\), is associated with a membership value \({\upmu }_{\mathrm{i}}\).
2.2.4 Particle swarm optimization (PSO) algorithm
Based on the social behavior of birds in a flock, the PSO algorithm simulates a population-based search algorithm (Deng et al. 2019). One particle can represent the optimal solution to an optimization problem in the PSO algorithm. To find the best answer in a given search space, the particle that represents a potential solution to the optimization issue can fly around (Chen et al. 2017a, b). The following equations will be utilized to adjust each particle's velocity (v) and position (x):
Particle velocity and its current location in iteration j are given by \({v}_{ij}\left(t+1\right)\) and \({x}_{ij}\left(t+1\right)\), respectively. W represents the weight of inertia, t is the number of iterations, c1 represents the cognitive learning factor, c2 represents the social learning factor, and r1 and r2 are random values (Razavi-Termeh et al. 2020).
The PSO algorithm was used in this study to determine which factors were most important. In this study, the following objective function (Eq. 8) was utilized to determine a feature using the PSO algorithm:
where E represents the objective function to be minimized, the actual value is y, the estimated value is y', w is between 0 and 1, and n is the number of features. The percentage of frequency of each factor was utilized to estimate its importance.
2.2.5 Non-dominated sorting genetic algorithm II (NSGA-II)
NSGA-II is an enhanced form of the non-dominated sorting genetic algorithm (NSGA). The NSGA-II design is elitist and does not require sharing parameters (Verma et al. 2021). The NSGA-II algorithm, introduced by Deb et al. (2002), comprises three primary elements. The elements of the NSGA-II algorithm encompass non-dominated sorting, crowding distance, and NSGA-II operators (Cao et al. 2011; Mohammadi et al. 2015). (1) Non-dominated sorting: The dominance relationship between vector u = (u1,u2,…,uk) and vector v = (v1,v2,…,vk) holds if and only if u is partially less than v. The concept above can be mathematically expressed as Eq. 9 (Cao et al. 2011).
Solution x1 is said to dominate solution x2 when x1 is not inferior to x2 in any of the objective functions and is superior to x2 in at least one objective function. (2) Crowding distance: The purpose of crowding distance is to evaluate the density of solutions surrounding a particular solution within a population. For a given point i, the crowding distance represents the approximate size of the giant cuboid that encloses point i without including any other issues from the population. Mathematically, the crowding distance can be represented by the following equations (Cao et al. 2011).
where \({x}_{i}\) represents the solution for i, \({d}_{i}^{1}\) corresponds to the crowding distance of solution i in the first objective function, \({d}_{i}^{2}\) denotes the crowding distance of solution i in the second objective function, and \({d}_{i}\) signifies the numerical value of the crowding distance for a solution i. (3) NSGA-II Operators: The performance of NSGA-II relies on two fundamental operators, namely crossover and mutation. In the crossover operator, two chromosomes are chosen, and their genetic information is randomly exchanged to generate an improved population. Several crossover operators exist, including one-point crossover, two-point crossover, and others. Mutation serves as another operator in NSGA-II, crucial for preserving the diversity of solutions. It involves modifying one or more gene values within a chromosome from its original state. Applying the mutation operator can result in a different answer from the previous one, enhancing the exploration of the solution space and promoting diversity within the population. NSGA-II starts by creating an initial population of solutions. Then, the objective functions are evaluated for each answer and combined using a weighted sum method. The number of dominations is calculated for all solutions using non-dominated sorting. The crowding distance is computed for each key to measure its density. Answers are ranked based on non-dominated sorting and crowding distance. Fitter solutions are selected, and the next generation is created through crossover and mutation operators. This process continues until a stopping criterion is met, allowing the algorithm to converge toward optimal solutions (Yusoff et al. 2011; Cao et al. 2011).
2.2.6 Evolutionary non-dominated radial slots-based algorithm (ENORA)
ENORA is a multi-objective evolutionary algorithm that adopts an elitist Pareto-based approach. It employs a survival strategy known as (μ + λ), where μ represents the population size, and λ denotes the number of offspring produced (Jiménez et al. 2018). The (μ + λ) strategy, initially introduced by Rechenberg in 1973 as an evolution strategy, involved a population size of 1 and was referred to as (1 + 1)-ES. This approach utilized selection, adaptive mutation, and small population size. Schwefel (1981) later introduced recombination and populations of more than one individual into the (μ + λ) strategy. As an elitist method, the (μ + λ) technique enables the survival of the μ best children and parents in the population. In ENORA, a (μ + λ) survival strategy is employed, where μ is equal to λ, representing the population size. Binary tournament selection and self-adaptive crossover and mutation techniques are utilized for multi-objective evolutionary optimization (Jiménez et al. 2015). Following the initialization and evaluation of a population P consisting of N individuals, during each of the T generations, a pair of parents is selected from the population P using binary tournament selection. The algorithm selects the best from a pair of random individuals based on the rank crowding better function. In the algorithm context, an individual I is deemed superior to an individual J if the I rank in the population P is lower (i.e., better) than the rank of J. The rank of an individual I in a population P, denoted as rank(P, I), is determined by its non-domination level among the individuals J in the population P. Suppose individual I and individual J are assigned to the same radial slot (slot(I) = slot(J)), which represents a specific region of the search space. In that case, they share the same non-domination level (Eqs. 13 and 14) (Jiménez et al. 2015).
In the given Equation, \({\text{d}} = \left\lfloor {\sqrt[{n - 1}]{N}} \right\rfloor\) represents the number of objectives in the optimization problem while \({h}_{j}{\prime}\) referring to the objective function \({f}_{j}{\prime}\) normalized within the range [0, 1]. When two individuals, I and J, share the same rank in the population, the best individual is determined based on their crowding distance within their respective fronts. The individual with the greater crowding distance is considered the superior one (Jiménez et al. 2018). The algorithm selects parent individuals, performs crossover and mutation, evaluates the offspring, and adds them to an auxiliary population Q. This process repeats until Q reaches size N. P and Q are then merged to create the additional population R. Ranks are assigned to individuals in R based on their non-domination levels. Finally, the N best individuals in R, determined by the rank crowding better function, survive to the next generation (Jiménez et al. 2015).
2.2.7 Optimization model
This study employed the Gaussian fuzzy membership function with two parameters, the standard deviation and the center (Eq. 15) (Jiménez et al. 2014).
where \({c}_{ij}\) represents the center and \({\sigma }_{ij}\) represents the standard deviation. Equation 15\(\upmu {A}_{ij}({x}_{j})\) represents the degree of membership of a value \({x}_{j}\) to the fuzzy set \({A}_{ij}\).
We assess three primary criteria: accuracy, transparency, and compactness. Suitable objective functions must be used to define quantitative metrics for these objectives (Jiménez et al. 2008). (1) Accuracy: The root means squared error (RMSE) was used to measure model accuracy:
where \({y}_{i}\) represents the model's output, \({t}_{i}\) represents the desired output, and the number of samples is N. (2) Transparency: The similarity function was used for transparency. Equation 17 measures the similarity between two distinct fuzzy sets (A and B).
(3) Compactness: For the compactness of a fuzzy model, the model's rule count (M) and the number of different fuzzy sets (L) are indicators. Based on the previous discussion, the following multi-objective constrained optimization model is proposed (Eq. 18).
where \({\mathrm{g}}_{\mathrm{s}}\) [0, 1] is a similarity criterion defined (\({\mathrm{g}}_{\mathrm{s}}\) = 0.4).
2.2.8 Evaluation metrics
In this study, the RMSE index (Eq. 16) was used to evaluate the performance of the models. The LSM was tested for accuracy using the receiver operating characteristic (ROC) curve. The ROC curve is computed utilizing two TPR (true positive rate) and FPR (false positive rate) indices (Eqs. 19–20) (Razavi-Termeh et al. 2020).
The four parameters for determining ROC are true positive (TP), false positive (FP), true negative (TN), and false negative (FN) pixels (Farhangi et al. 2022). There is a y-axis and an x-axis to the ROC curve, representing TPR and FPR. According to a statistical measure called the area under the curve (AUC), an LSM accuracy can be determined by its value. The AUC index is calculated based on Eq. (21) (Pourghasemi et al. 2020).
where t represents a threshold value, AUC values less than 0.5 denote poor model performance, whereas values near 1 denote great model accuracy (Farahani et al. 2022).
2.2.9 Methodology
The methodology used in this study to model landslide susceptibility is shown in Fig. 4. The procedure begins with creating a landslide inventory and 15 conditioning factor maps. In the following stage, the input data were pre-processed using multicollinearity analysis, FR method, and PSO algorithms. The fuzzy rules were optimized using multi-objective evolutionary algorithms in the following step. Finally, the landslide susceptibility map was created using the NSGA-II and ENORA algorithms and evaluated using metric indicators.

The methodology used in the research
3 Result
3.1 Analysis of the multicollinearity of the effective factors
Multicollinearity tests were conducted on the landslide conditioning factors. The results demonstrate that rainfall (1.052) has the lowest variance inflation factor (VIF) value of landslide conditioning factors, while slope has the highest VIF value of 1.837. (Table 2). The VIF values of landslide conditioning factors are less than 10, indicating no collinearity among these factors. As a result, the 15 landslide conditioning factors chosen are suitable for modeling.
3.2 Importance of factors using the PSO algorithm
The significance of effective factors was determined utilizing the PSO algorithm. Table 3 presents the parameters used by the PSO algorithm. Considering that in this research, 15 effective criteria on landslides are considered, the PSO algorithm is run in 15 separate steps to determine the importance of the criteria. In the initial run, this algorithm computes the value of the objective function (Eq. 8) using a single criterion. Subsequently, in the following run, the algorithm calculates the objective function using a combination of two criteria. This procedure is repeated sequentially up to the 15th run, where the objective function is evaluated using a combination of 15 different criteria. Factors with the highest percentage of repetition in 15 different runs were of greater importance in landslide modeling. Figure 5 shows the objective function convergence diagram. The best value of the objective function in this algorithm was 0.133. The importance of effective criteria in this research is shown in Table 4. According to the findings, lithology, land cover, and altitude are the most significant factors, accounting for 93.3%, 86.6%, and 66.6%, respectively. Also, according to the results, the distance from the fault with, 13.3%, is the least important.

Convergence diagram of PSO algorithm
3.3 Calculate spatial relationships using the FR method
Table 5 presents the FR value for each factor that influences the likelihood of a landslide. A value close to or completely 0 for FR suggests low landslide susceptibility, whereas a value greater than 1 indicates greater. The altitude class between 1600 and 2000 m has an FR value of 1.67. With a weight of 1.31, the slope angle class 0–10 degrees has the highest FR values. North-facing slope aspect has the highest FR values in this investigation (1.76). The result indicates that the FR value of the > 0.001 class for plan curvature was 1.04. Class − 0.0006–0.002 has a higher FR weight for profile curvature, with a value of 1.14. The association between TWI and landslide occurrence revealed that class 4.8–5.7 has a high FR weight of 1.74. Regarding the SPI factor, the 0–200 class has the greatest FR value (2). Based on the distance from the river, the most likely place for landslides to happen is between 400 and 600 m (FR = 1.67). According to the distance from the fault criterion results, the class > 1200 m has the highest FR value (1.11). The value of the FR in the distance from the road criterion indicates that landslides are more frequent in lower values of this criterion (with the highest FR value = 2.75). The NDVI criterion results show that the greatest FR (2.59) is associated with a class > 0.46. According to the rainfall criterion findings, the middle class (540–640 mm) has a higher FR value (1.2). The soil criterion results show that the highest FR (1.55) is associated with the Mollisols class. The association between landslide frequency and lithology reveals that the Plms class is the most frequent, with an FR value of 3.26. According to the land cover results, the farmland class has the highest weight value of FR (1.51).
3.4 Development of evolutionary multi-objective fuzzy algorithms
The NSGA-II and ENORA hybrid algorithms were developed for landslide susceptibility analysis. A holdout sampling strategy was used to create training and test sets. Seventy percent of the landslide data (107 points) were used for model training and thirty percent for model testing (46 points). There were 153 non-landslides chosen randomly for the training and testing datasets, combined to form the training and testing datasets. The Waikato Environment for Knowledge Analysis (WEKA 3.9.5) and MATLAB R2017b software created evolutionary multi-objective fuzzy algorithms. The weights obtained in the FR method for the effective criteria were used as modeling input. Table 6 presents the parameters in the development of multi-objective evolutionary fuzzy algorithms.
The convergence function of multi-objective evolutionary fuzzy algorithms in 1000 iterations is shown in Fig. 6. Given that the objective function is to minimize the RMSE value, the values of this index for the NSGA-II and ENORA algorithms are 0.4377 and 0.4534, respectively. According to the results, the NSGA-II algorithm demonstrated a lower cost than the ENORA algorithm.

Multi-objective evolutionary algorithms convergence diagram
The optimal values for the mean and standard error of the fuzzy Gaussian function were calculated during the development of multi-objective evolutionary fuzzy algorithms. The optimal values of the fuzzy Gaussian membership function are summarized in Table 7 and were used to determine the best rules in modeling. In this research, two labels, high (high probability of landslide occurrence) and low (low probability of landslide occurrence), were used in the Gaussian membership function. Figure 7 shows the Gaussian fuzzy membership function diagram for all criteria.



Diagram of the Gaussian fuzzy membership function
The optimal combination rules in Mamdani's fuzzy technique are determined using evolutionary multi-objective algorithms based on the constructed Gaussian membership function. Based on the results, the NSGA-II algorithm gave ten rules for integrating fuzzy membership functions, whereas the ENORA algorithm presented four rules. The rules optimized by NSGA-II and ENORA algorithms are summarized in Tables 8 and 9, respectively.
Table 10 presents the performance of the multi-objective evolutionary fuzzy algorithms during training and testing datasets. The NSGA-II and ENORA algorithms generated RMSE (0.25, 0.28) in the training phase and RMSE (0.43, 0.48) in the validation phase, respectively, according to Table 10. In modeling, the NSGA-II algorithm outperformed the ENORA algorithm. The predictive ability of these two algorithms is shown in Fig. 8, utilizing the training and test datasets.

Graph of prediction ability of algorithms during training and testing datasets
3.5 Creation of maps of landslide susceptibility
After optimizing fuzzy rules using multi-objective evolutionary fuzzy algorithms, the fuzzy rules obtained were integrated using the fuzzy Mamdani approach. In an ArcGIS 10.3 platform, LSM for the two algorithms was created. LSM was produced on each grid cell using two algorithms. We divided all susceptibility maps into five categories using the natural breaks (Razavi-Termeh et al. 2021) approach. The landslide susceptibility maps generated by two multi-objective evolutionary fuzzy algorithms are shown in Fig. 9. The spatial distribution of the two algorithms is similar.

Landslide susceptibility mapping (LSM) of the study area by: a NSGA-II algorithm, and b ENORA algorithm
The percentage of different categories of landslide susceptibility maps produced with two algorithms is summarized in Fig. 10. The five landslide susceptibility classes of very low, low, medium, high, and very high in the NSGA-II covered 10.96%, 35.51%, 32.78%, 15.34%, and 5.4% of the district area, respectively. In the ENORA algorithm, the five landslide susceptibility groups of very low, low, medium, high, and very high included 17.86%, 35.99%, 27.86%, 13.65%, and 4.6%, respectively. The spatial results of LSM using NSGA-II revealed that 20.7% of the overall region exhibited susceptibility ranging from high to very high. Furthermore, the ENORA result showed that 18.3% of the general area had high to very high susceptibility.

Diagram of the percentage of different categories of LSM
3.6 Validation and comparison of algorithms
The susceptibility prediction probability was computed using the testing dataset, AUC, and statistical evaluation metrics. Figure 11 and Table 11 show the overall performance of two multi-objective evolutionary landslide susceptibility algorithms using the AUC. The AUC findings show that the NSGA-II algorithm has the greatest AUC value (0.867), followed by the ENORA algorithm (0.844). It was evident that all algorithms possess a strong capability for prediction.

ROC curve outputs for multi-objective evolutionary algorithms
The Friedman test was used at a 5% significance level to examine statistically significant differences between the two landslide susceptibility algorithms. With significance and chi-square values of 0.00001 (< 0.05) and more than 66.18, the Friedman test findings in Table 12 show that the null hypothesis was rejected.
Because the Friedman test results only show significant differences in algorithm performance, the results cannot provide comparisons between some algorithms. As a result, the Wilcoxon signed-rank test was used to determine the statistical significance of the algorithms. When the p-value is less than 0.05, and the z-value exceeds the crucial thresholds (1.96 and + 1.96), as shown in Table 13, then the Wilcoxon signed-rank test yields positive results. The results showed that the performance difference between each set of algorithms is statistically significant.
4 Discussion
4.1 Assessment of conditioning factors
Data pre-processing was performed before modeling and LSM preparation utilizing multicollinearity analysis, the FR method, and the PSO algorithm. According to multicollinearity analysis, 15 factors were independent and can be considered in the modeling. Using the PSO algorithm, the importance of criteria revealed that the lithology, land cover, and altitude criteria were the most important in modeling. One of the most notable effects of lithology is its ability to increase the hardness of rocks and speed up weathering (Pourghasemi and Rahmati 2018). The conclusions of this study are consistent with the findings of Pourghasemi et al. (2020) and Wang et al. (2019) on the significance of lithology. Slope stability and landslide occurrence are impacted by land cover via various root system mechanisms (Miller 2013). This study's findings on the importance of land cover are consistent with those of Pourghasemi et al. (2020) and Wang et al. (2019). Even though geomorphological processes and weather conditions can be affected by altitude, altitude has no direct effect on landslides (Youssef and Pourghasemi 2021). The findings of Achour and Pourghasemi (2020) and Pourghasemi and Rahmati (2018) about the significance of altitude align with this research's results.
Using the FR technique, it was found that landslides were most likely to occur at an altitude of 1600–2000 m. This is primarily due to rising rainfall and, thus, soil moisture with altitude (Bamutaze 2019). The results of the altitude criterion were consistent with the research of Pham et al. (2021). Lower slopes were found to be associated with the occurrence of landslides. The contact horizon between the overlying loess and the underlying mudstone is particularly prone to landslides; this weak plane typically has an angle of 10° to 20° (Derbyshire 2001). The slope criterion results were consistent with Wu et al. (2020). One explanation for the north aspect's higher FR value is that it receives less solar energy than other aspects, which may account for most of the wetness (Pham et al. 2017). The results of the aspect criterion were in line with those of Nohani et al. (2019). Regarding plan curvature, convex had the highest FR value, particularly when combined with faulty road design, resulting in failure slopes (Nohani et al. 2019). This criterion's results were consistent with Pham et al. (2021). The findings revealed that the risk of landslides increases with decreasing profile curvature (Pourghasemi et al. 2020). Based on the findings of this study, the lowest TWI and SPI values had the highest FR weight. Lower TWI values at higher elevations show that water penetrates soils through slopes (Achour and Pourghasemi 2020). The results showed that landslides were more likely to occur at shorter distances from the river. Slope instability is likely to occur due to the proximity of small villages to large river valleys and the accompanying lateral river erosion (Zhang and Liu 2010). According to the findings, the likelihood of a landslide rose with distance from the fault. Furthermore, according to the PSO algorithm, this criterion needed to be more important. The results of the distance from the fault in this research differed from other research, which may be due to the geographical conditions of the study area. The distance from the road revealed that landslides were more likely to occur at shorter distances. Due to human engineering activity, Loess slopes' stress balance has been altered to favor landslides near roads (Wu et al. 2020). This outcome is consistent with previously reported research (Pham et al. 2021). The results showed that in higher NDVI values, the probability of landslide occurrence was higher. This finding is consistent with previous studies (Wang et al. 2019). Rainfall is an important factor in landslide occurrence since it affects soil structure. Landslides are more likely when there has been a lot of rain, which is in line with other studies (Wang et al. 2019; Razavi-Termeh et al. 2021). The Mollisols class of soil and Plms class of lithology unit had a higher landslide probability. The results of these two criteria show that the classes in the area with higher FR values of these two criteria are affected by other factors. The findings revealed that the probability of a landslide occurring was higher in the farmland class. This is due to increased soil moisture from cultivated land. Slope material weight and pore water pressure increased in lockstep with changes in soil moisture on the slope (Wubalem 2021).
The prepared susceptibility map showed that the high-risk areas in the study area mostly correspond to the criteria of distance from the road, distance from the river, altitude, and land cover. These criteria seem to be more effective factors in the occurrence of landslides in the study area.
4.2 Assessment of modeling algorithms
Utilizing the PSO algorithm, the importance of factors was determined. So far, this algorithm has yet to be used to assess the significance of landslide-related factors. However, multiple studies have verified that when the PSO algorithm is used with machine learning algorithms, it produces satisfactory accuracy in creating LSM. These studies have explored the effectiveness of combining the PSO algorithm with various machine learning algorithms such as ANN (Moayedi et al. 2019), SVM (Zhao and Zhao 2021), ANFIS (Chen et al. 2017a, b), deep belief networks (DBN) (Li et al. 2022), random trees (RT) (Saha et al. 2022), and multi-layer perceptrons (MLP) (Li et al. 2019) in creating LSMs. The PSO algorithm contains a memory, which allows all particles to retain the knowledge of reasonable solutions. In other words, each particle in the PSO algorithm benefits from its previous information, but similar behavior and features do not exist in different evolutionary algorithms (Wang et al. 2007). One significant disadvantage of fuzzy logic systems is that they depend entirely on human knowledge and expertise (Tikk and Baranyi 2000). As a result, in this study, two multi-objective evolutionary algorithms (NSGA-II and ENORA) were employed to optimize fuzzy rules. One of their key advantages is that they are population-based, allowing them to uncover multiple intriguing solutions in a single run. Another advantage is that no preconceived notions about the nature of the problem are entertained (Pilát 2010). The results showed that these algorithms had acceptable accuracy in preparing the LSM. Based on the results, the NSGA-II algorithm was more accurate than the ENORA algorithm in optimizing the fuzzy rules and preparing the LSM. The NSGA-II algorithm's advantages include non-penalty constraint handling, rapid and efficient convergence, searching in an extensive range, and dealing with problems that begin with non-feasible solutions (Subashini and Bhuvaneswari 2012).
4.3 Future suggestion
In terms of future research directions, a dynamic approach to susceptibility mapping that considers temporal fluctuations in variables such as rainfall intensity, alterations in land cover, and urbanization dynamics can augment the model's flexibility and adaptiveness. The imperative of addressing uncertainty is underscored; therefore, conducting a comprehensive analysis of uncertainty that encompasses the reliability of input data, variations in model parameters, and the convergence behavior of the algorithm can yield insights into the resilience and stability of susceptibility mapping results. Integrating remote sensing data, encompassing resources like satellite imagery and LiDAR data presents an avenue with the potential to enhance the caliber of input data, thus refining the precision exhibited by the susceptibility model. Furthermore, delving into exploring and establishing a susceptibility assessment framework that extends its purview to encompass multiple hazards, such as floods or earthquakes, could furnish a holistic comprehension of the susceptibilities inherent in the landscape's fabric.
5 Conclusion
The primary goal of this research is to create and compare two multi-objective evolutionary fuzzy algorithms for LSM. By optimizing fuzzy rules, the proposed algorithms can reduce the uncertainty of LSM. The following conclusions can be made from the experiment results:
-
1.
The PSO algorithm determined that lithology, land cover, and height were the most important determinants of landslides in the research area.
-
2.
Based on the FR method, high altitude, low slope, north aspect, concave curvature, low TWI, low SPI, high NDVI, high rainfall, Mollisols soil type, Plms lithology unit, and land farm class of land cover were most related to the occurrence of landslides in the study area.
-
3.
The proposed algorithms optimized ten and four rules of Gaussian fuzzy using NSGA-II and ENORA, respectively.
-
4.
The proposed algorithms achieved good accuracy in LSM. For example, the prediction performance of the NSGA-II and ENORA algorithms produced AUC values of 0.867 and 0.844, respectively.
-
5.
In LSM, the NSGA-II algorithm outperformed the ENORA algorithm in accuracy.
-
6.
The information obtained from this study could be helpful for policymakers and decision-makers in areas prone to landslides.
References
Achour Y, Pourghasemi HR (2020) How do machine learning techniques help in increasing accuracy of landslide susceptibility maps? Geosci Front 11:871–883. https://doi.org/10.1016/j.gsf.2019.10.001
Achour Y, Garçia S, Cavaleiro V (2018) GIS-based spatial prediction of debris flows using logistic regression and frequency ratio models for Zêzere River basin and its surrounding area, Northwest Covilhã, Portugal. Arab J Geosci 11:1–17. https://doi.org/10.1007/s12517-018-3920-9
Allawi MF, Jaafar O, Mohamad Hamzah F, Mohd NS, Deo RC, El-Shafie A (2018) Reservoir inflow forecasting with a modified coactive neuro-fuzzy inference system: a case study for a semi-arid region. Theoret Appl Climatol 134:545–563. https://doi.org/10.1007/s00704-017-2292-5
Alqadhi S, Mallick J, Talukdar S, Bindajam AA, Saha TK, Ahmed M, Khan RA (2021) Combining logistic regression-based hybrid optimized machine learning algorithms with sensitivity analysis to achieve robust landslide susceptibility mapping. Geocarto Int. https://doi.org/10.1080/10106049.2021.2022009
Alvioli M, Baum RL (2016) Parallelization of the TRIGRS model for rainfall-induced landslides using the message passing interface. Environ Model Softw 81:122–135. https://doi.org/10.1016/j.envsoft.2016.04.002
Asadi Nalivan O, Mousavi Tayebi SA, Mehrabi M, Ghasemieh H, Scaioni M (2023) A hybrid intelligent model for spatial analysis of groundwater potential around Urmia Lake, Iran. Stoch Environ Res Risk Assess 37(5):1821–1838. https://doi.org/10.1007/s00477-022-02368-y
Aslam B, Maqsoom A, Khalil U, Ghorbanzadeh O, Blaschke T, Farooq D, Tufail RF, Suhail SA, Ghamisi P (2022) Evaluation of different landslide susceptibility models for a local scale in the Chitral District, Northern Pakistan. Sensors 22:3107. https://doi.org/10.3390/s22093107
Azarafza M, Azarafza M, Akgün H, Atkinson PM, Derakhshani R (2021) Deep learning-based landslide susceptibility mapping. Sci Rep 11:1–16. https://doi.org/10.1038/s41598-021-03585-1
Bai Y, Wang D (2006) Fundamentals of fuzzy logic control—fuzzy sets, fuzzy rules and defuzzifications. In: Advanced fuzzy logic technologies in industrial applications. Springer, pp 17–36. https://doi.org/10.1007/978-1-84628-469-4_2
Bamutaze Y (2019) Morphometric conditions underpinning the spatial and temporal dynamics of landslide hazards on the volcanics of Mt. Elgon, Eastern Uganda. Emerging Voices in Natural Hazards Research. Elsevier, pp 57–81. https://doi.org/10.1016/B978-0-12-815821-0.00010-2
Bragagnolo L, da Silva R, Grzybowski J (2020) Artificial neural network ensembles applied to the mapping of landslide susceptibility. CATENA 184:104240. https://doi.org/10.1016/j.catena.2019.104240
Cao K, Batty M, Huang B, Liu Y, Yu L, Chen J (2011) Spatial multi-objective land use optimization: extensions to the non-dominated sorting genetic algorithm-II. Int J Geogr Inf Sci 25:1949–1969. https://doi.org/10.1080/13658816.2011.570269
Chen B, Yang J, Jeon B, Zhang X (2017a) Kernel quaternion principal component analysis and its application in RGB-D object recognition. Neurocomputing 266:293–303. https://doi.org/10.1016/j.neucom.2017.05.047
Chen W, Panahi M, Pourghasemi HR (2017b) Performance evaluation of GIS-based new ensemble data mining techniques of adaptive neuro-fuzzy inference system (ANFIS) with genetic algorithm (GA), differential evolution (DE), and particle swarm optimization (PSO) for landslide spatial modelling. CATENA 157:310–324. https://doi.org/10.1016/j.catena.2017.05.034
Constantin M, Bednarik M, Jurchescu MC, Vlaicu M (2011) Landslide susceptibility assessment using the bivariate statistical analysis and the index of entropy in the Sibiciu Basin (Romania). Environ Earth Sci 63:397–406. https://doi.org/10.1007/s12665-010-0724-y
Deb K, Pratap A, Agarwal S, Meyarivan TAMT (2002) A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans Evol Comput 6:182–197. https://doi.org/10.1109/4235.996017
Dehnavi A, Aghdam IN, Pradhan B, Morshed Varzandeh MH (2015) A new hybrid model using step-wise weight assessment ratio analysis (SWARA) technique and adaptive neuro-fuzzy inference system (ANFIS) for regional landslide hazard assessment in Iran. CATENA 135:122–148. https://doi.org/10.1016/j.catena.2015.07.020
Deng W, Yao R, Zhao H, Yang X, Li G (2019) A novel intelligent diagnosis method using optimal LS-SVM with improved PSO algorithm. Soft Comput 23:2445–2462. https://doi.org/10.1007/s00500-017-2940-9
Derbyshire E (2001) Geological hazards in loess terrain, with particular reference to the loess regions of China. Earth Sci Rev 54:231–260. https://doi.org/10.1016/S0012-8252(01)00050-2
Farahani M, Razavi-Termeh SV, Sadeghi-Niaraki A (2022) A spatially based machine learning algorithm for potential mapping of the hearing senses in an urban environment. Sustain Cities Soc 80:103675. https://doi.org/10.1016/j.scs.2022.103675
Farhangi F, Sadeghi-Niaraki A, Nahvi A, Razavi-Termeh SV (2022) Spatial modelling of accidents risk caused by driver drowsiness with data mining algorithms. Geocarto Int 37:2698–2716. https://doi.org/10.1080/10106049.2020.1831626
Farrokhnia A, Pirasteh S, Pradhan B, Pourkermani M, Arian M (2011) A recent scenario of mass wasting and its impact on the transportation in Alborz Mountains, Iran using geo-information technology. Arab J Geosci 4:1337–1349. https://doi.org/10.1007/s12517-010-0238-7
Feizizadeh B, Blaschke T (2013) GIS-multicriteria decision analysis for landslide susceptibility mapping: comparing three methods for the Urmia lake basin, Iran. Nat Hazards 65:2105–2128. https://doi.org/10.1007/s11069-012-0463-3
Galli M, Ardizzone F, Cardinali M, Guzzetti F, Reichenbach P (2008) Comparing landslide inventory maps. Geomorphology 94:268–289. https://doi.org/10.1016/j.geomorph.2006.09.023
Ghorbanian A, Kakooei M, Amani M, Mahdavi S, Mohammadzadeh A, Hasanlou M (2020) Improved land cover map of Iran using Sentinel imagery within Google Earth Engine and a novel automatic workflow for land cover classification using migrated training samples. ISPRS J Photogramm Remote Sens 167:276–288. https://doi.org/10.1016/j.isprsjprs.2020.07.013
Guha-Sapir D, Below R, Hoyois P (2020) EM-DAT: the CRED/OFDA international disaster database. In: Brussels, Belgium: Centre for Research on the Epidemiology of Disasters (CRED), Université Catholique de Louvain
Guzzetti F, Carrara A, Cardinali M, Reichenbach P (1999) Landslide hazard evaluation: a review of current techniques and their application in a multi-scale study, Central Italy. Geomorphology 31:181–216. https://doi.org/10.1016/S0169-555X(99)00078-1
Guzzetti F, Reichenbach P, Cardinali M, Galli M, Ardizzone F (2005) Probabilistic landslide hazard assessment at the basin scale. Geomorphology 72:272–299. https://doi.org/10.1016/j.geomorph.2005.06.002
Habumugisha JM, Chen N, Rahman M, Islam MM, Ahmad H, Elbeltagi A, Sharma G, Liza SN, Dewan A (2022) Landslide susceptibility mapping with deep learning algorithms. Sustainability 14:1734. https://doi.org/10.3390/su14031734
Hakim WL, Rezaie F, Nur AS, Panahi M, Khosravi K, Lee CW, Lee S (2022a) Convolutional neural network (CNN) with metaheuristic optimization algorithms for landslide susceptibility mapping in Icheon, South Korea. J Environ Manag 305:114367. https://doi.org/10.1016/j.jenvman.2021.114367
Hamedi H, Alesheikh AA, Panahi M, Lee S (2022) Landslide susceptibility mapping using deep learning models in Ardabil province, Iran. Stoch Environ Res Risk Assess 36:4287–4310. https://doi.org/10.1007/s00477-022-02263-6
Hong H, Kornejady A, Soltani A, Termeh SVR, Liu J, Zhu A, Ahmad BB, Wang Y (2018) Landslide susceptibility assessment in the Anfu County, China: comparing different statistical and probabilistic models considering the new topo-hydrological factor (HAND). Earth Sci Inf 11:605–622. https://doi.org/10.1007/s12145-018-0352-8
Huang Y-C, Sun H-C (2013) Dissolved gas analysis of mineral oil for power transformer fault diagnosis using fuzzy logic. IEEE Trans Dielectr Electr Insul 20:974–981. https://doi.org/10.1109/TDEI.2013.6518967
Jiménez F, Sánchez G, Juárez JM (2014) Multi-objective evolutionary algorithms for fuzzy classification in survival prediction. Artif Intell Med 60:197–219. https://doi.org/10.1016/j.artmed.2013.12.006
Jiménez F, Martínez C, Miralles-Pechuán L, Sánchez G, Sciavicco G (2018) Multi-objective evolutionary rule-based classification with categorical data. Entropy 20:684. https://doi.org/10.3390/e20090684
Jiménez F, Sánchez G, Sánchez JF, Alcaraz JM (2008) Fuzzy classification with multi-objective evolutionary algorithms. In: International workshop on hybrid artificial intelligence systems. Springer, pp 730–738. https://doi.org/10.1007/978-3-540-87656-4_90
Jiménez F, Marzano E, Sánchez G, Sciavicco G, Vitacolonna N (2015) Attribute selection via multi-objective evolutionary computation applied to multi-skill contact center data classification. In: 2015 IEEE symposium series on computational intelligence. IEEE, pp 488–495. https://doi.org/10.1109/SSCI.2015.78
Kavzoglu T, Kutlug Sahin E, Colkesen I (2015) An assessment of multivariate and bivariate approaches in landslide susceptibility mapping: a case study of Duzkoy district. Nat Hazards 76:471–496. https://doi.org/10.1007/s11069-014-1506-8
Kavzoglu T, Colkesen I, Sahin EK (2019) Machine learning techniques in landslide susceptibility mapping: a survey and a case study. In: Landslides: theory, practice and modelling, pp 283–301. https://doi.org/10.1007/978-3-319-77377-3_13
Lee S, Hong S-M, Jung H-S (2017) A support vector machine for landslide susceptibility mapping in Gangwon Province, Korea. Sustainability 9:48. https://doi.org/10.3390/su9010048
Li D, Huang F, Yan L, Cao Z, Chen J, Ye Z (2019) Landslide susceptibility prediction using particle-swarm-optimized multilayer perceptron: Comparisons with multilayer-perceptron-only, bp neural network, and information value models. Appl Sci 9:3664. https://doi.org/10.3390/app9183664
Li J, Wang W, Chen G, Han Z (2022) Spatiotemporal assessment of landslide susceptibility in Southern Sichuan, China using SA-DBN, PSO-DBN and SSA-DBN models compared with DBN model. Adv Space Res 69:3071–3087. https://doi.org/10.1016/j.asr.2022.01.043
Mandal S, Mandal K (2018) Modeling and mapping landslide susceptibility zones using GIS based multivariate binary logistic regression (LR) model in the Rorachu river basin of eastern Sikkim Himalaya, India. Model Earth Syst Environ 4:69–88. https://doi.org/10.1007/s40808-018-0426-0
Marjanović M, Kovačević M, Bajat B, Mihalić Arbanas S, Abolmasov B (2011) Landslide assessment of the Strača basin (Croatia) using machine learning algorithms. Acta Geotech Slov 8:45–55
Mehrabi M (2021) Landslide susceptibility zonation using statistical and machine learning approaches in Northern Lecco, Italy. Nat Hazards. https://doi.org/10.1007/s11069-021-05083-z
Mehrabi M, Moayedi H (2021) Landslide susceptibility mapping using artificial neural network tuned by metaheuristic algorithms. Environ Earth Sci 80:1–20. https://doi.org/10.1007/s12665-021-10098-7
Mehrabi M, Pradhan B, Moayed H, Alamri A (2020) Optimizing an adaptive neuro-fuzzy inference system for spatial prediction of landslide susceptibility using four state-of-the-art metaheuristic techniques. Sensors 20(6):1723. https://doi.org/10.3390/s20061723
Merghadi A, Yunus AP, Dou J, Whiteley J, ThaiPham B, Bui DT, Avtar R, Abderrahmane B (2020) Machine learning methods for landslide susceptibility studies: a comparative overview of algorithm performance. Earth-Sci Rev 207:103225. https://doi.org/10.1016/j.earscirev.2020.103225
Miller A (2013) Assessing landslide susceptibility by incorporating the surface cover index as a measurement of vegetative cover. Land Degrad Dev 24:205–227. https://doi.org/10.1002/ldr.1115
Moayedi H, Mehrabi M, Mosallanezhad M, Rashid ASA, Pradhan B (2019) Modification of landslide susceptibility mapping using optimized PSO-ANN technique. Eng Comput 35:967–984. https://doi.org/10.1007/s00366-018-0644-0
Moayedi H, Mehrabi M, Bui DT, Pradhan B, Foong LK (2020) Fuzzy-metaheuristic ensembles for spatial assessment of forest fire susceptibility. J Environ Manag 260:109867. https://doi.org/10.1016/j.jenvman.2019.109867
Mohammadi M, Nastaran M, Sahebgharani A (2015) Sustainable spatial land use optimization through non-dominated sorting Genetic Algorithm-II (NSGA-II): (Case Study: Baboldasht District of Isfahan). Indian J Sci Technol 8:118–129. https://doi.org/10.17485/ijst/2015/v8iS3/60700
Mohebbi Tafreshi G, Nakhaei M, Lak R (2021) Land subsidence risk assessment using GIS fuzzy logic spatial modeling in Varamin aquifer, Iran. GeoJournal 86:1203–1223. https://doi.org/10.1007/s10708-019-10129-8
Ngo PTT, Panahi M, Khosravi K, Ghorbanzadeh O, Kariminejad N, Cerda A, Lee S (2021) Evaluation of deep learning algorithms for national scale landslide susceptibility mapping of Iran. Geosci Front 12:505–519. https://doi.org/10.1016/j.gsf.2020.06.013
Nhu V-H, Mohammadi A, Shahabi H, Ahmad BB, Al-Ansari N, Shirzadi A, Clague JJ, Jaafari A, Chen W, Nguyen H (2020a) Landslide susceptibility mapping using machine learning algorithms and remote sensing data in a tropical environment. Int J Environ Res Public Health 17:4933. https://doi.org/10.3390/ijerph17144933
Nhu V-H, Shirzadi A, Shahabi H, Chen W, Clague JJ, Geertsema M, Jaafari A, Avand M, Miraki S, Talebpour Asl D, Pham BT, Ahmad BB, Lee S (2020b) Shallow landslide susceptibility mapping by random forest base classifier and its ensembles in a semi-arid region of Iran. Forests 11:421. https://doi.org/10.3390/f11040421
Nohani E, Moharrami M, Sharafi S, Khosravi K, Pradhan B, Pham BT, Lee SM, Melesse A (2019) Landslide susceptibility mapping using different GIS-based bivariate models. Water 11:1402. https://doi.org/10.3390/w11071402
Omair M, Noor S, Tayyab M, Maqsood S, Ahmed W, Sarkar B, Habib MS (2021) The selection of the sustainable suppliers by the development of a decision support framework based on analytical hierarchical process and fuzzy inference system. Int J Fuzzy Syst 23:1986–2003. https://doi.org/10.1007/s40815-021-01073-2
Ozdemir A (2020) A comparative study of the frequency ratio, analytical hierarchy process, artificial neural networks and fuzzy logic methods for landslide susceptibility mapping: Taşkent (Konya), Turkey. Geotech Geol Eng 38:4129–4157. https://doi.org/10.1007/s10706-020-01284-8
Panahi M, Gayen A, Pourghasemi HR, Rezaie F, Lee S (2020) Spatial prediction of landslide susceptibility using hybrid support vector regression (SVR) and the adaptive neuro-fuzzy inference system (ANFIS) with various metaheuristic algorithms. Sci Total Environ 741:139937. https://doi.org/10.1016/j.scitotenv.2020.139937
Pham BT, Khosravi K, Prakash I (2017) Application and comparison of decision tree-based machine learning methods in landside susceptibility assessment at Pauri Garhwal Area, Uttarakhand, India. Environ Process 4:711–730. https://doi.org/10.1007/s40710-017-0248-5
Pham BT, Prakash I, Bui DT (2018) Spatial prediction of landslides using a hybrid machine learning approach based on random subspace and classification and regression trees. Geomorphology 303:256–270. https://doi.org/10.1016/j.geomorph.2017.12.008
Pham QB, Achour Y, Ali SA, Parvin F, Vojtek M, Vojteková J, Al-Ansari N, Achu A, Costache R, Khedher KM (2021) A comparison among fuzzy multi-criteria decision making, bivariate, multivariate and machine learning models in landslide susceptibility mapping. Geomat Nat Haz Risk 12:1741–1777. https://doi.org/10.1080/19475705.2021.1944330
Pilát M (2010) Evolutionary multiobjective optimization: a short survey of the state-of-the-art. In: Proceedings of the contributed papers part I—mathematics and computer sciences, WDS, Prague, Czech, pp 1–4
Pourghasemi HR, Rahmati O (2018) Prediction of the landslide susceptibility: which algorithm, which precision? CATENA 162:177–192. https://doi.org/10.1016/j.catena.2017.11.022
Pourghasemi HR, Kornejady A, Kerle N, Shabani F (2020) Investigating the effects of different landslide positioning techniques, landslide partitioning approaches, and presence-absence balances on landslide susceptibility mapping. CATENA 187:104364. https://doi.org/10.1016/j.catena.2019.104364
Pradhan B (2013) A comparative study on the predictive ability of the decision tree, support vector machine and neuro-fuzzy models in landslide susceptibility mapping using GIS. Comput Geosci 51:350–365. https://doi.org/10.1016/j.cageo.2012.08.023
Ranjgar B, Razavi-Termeh SV, Foroughnia F, Sadeghi-Niaraki A, Perissin D (2021) Land subsidence susceptibility mapping using persistent scatterer SAR interferometry technique and optimized hybrid machine learning algorithms. Remote Sens 13:1326. https://doi.org/10.3390/rs13071326
Razavi-Termeh SV, Khosravi K, Sadeghi-Niaraki A, Choi S-M, Singh VP (2020) Improving groundwater potential mapping using metaheuristic approaches. Hydrol Sci J 65:2729–2749. https://doi.org/10.1080/02626667.2020.1828589
Razavi-Termeh SV, Shirani K, Pasandi M (2021) Mapping of landslide susceptibility using the combination of neuro-fuzzy inference system (ANFIS), ant colony (ANFIS-ACOR), and differential evolution (ANFIS-DE) models. Bull Eng Geol Env 80:2045–2067. https://doi.org/10.1007/s10064-020-02048-7
Razavi-Termeh SV, Sadeghi-Niaraki A, Choi S-M (2022) Spatio-temporal modelling of asthma-prone areas using a machine learning optimized with metaheuristic algorithms. Geocarto Int. https://doi.org/10.1080/10106049.2022.2028903
Rechenberg I (1973) Evolutionsstrategie. Optimierung technischer Systeme nach Prinzipien derbiologischen Evolution.
Saha S, Saha A, Roy B, Sarkar R, Bhardwaj D, Kundu B (2022) Integrating the Particle Swarm Optimization (PSO) with machine learning methods for improving the accuracy of the landslide susceptibility model. Earth Sci Inf 15:2637–2662. https://doi.org/10.1007/s12145-022-00878-5
Schwefel HP (1981) Numerical optimization of computer models. Wiley, New York
Shafizadeh-Moghadam H, Minaei M, Shahabi H, Hagenauer J (2019) Big data in geohazard; pattern mining and large scale analysis of landslides in Iran. Earth Sci Inf 12:1–17. https://doi.org/10.1007/s12145-018-0354-6
Shirzadi A, Chapi K, Shahabi H, Solaimani K, Kavian A, Ahmad BB (2017) Rock fall susceptibility assessment along a mountainous road: an evaluation of bivariate statistic, analytical hierarchy process and frequency ratio. Environ Earth Sci 76:1–17. https://doi.org/10.1007/s12665-017-6471-6
Shogrkhodaei SZ, Razavi-Termeh SV, Fathnia A (2021) Spatio-temporal modeling of pm2.5 risk mapping using three machine learning algorithms. Environ Pollut 289:117859. https://doi.org/10.1016/j.envpol.2021.117859
Subashini G, Bhuvaneswari M (2012) Comparison of multi-objective evolutionary approaches for task scheduling in distributed computing systems. Sadhana 37:675–694. https://doi.org/10.1007/s12046-012-0102-4
Taalab K, Cheng T, Zhang Y (2018) Mapping landslide susceptibility and types using Random Forest. Big Earth Data 2:159–178. https://doi.org/10.1080/20964471.2018.1472392
Tikk D, Baranyi P (2000) Comprehensive analysis of a new fuzzy rule interpolation method. IEEE Trans Fuzzy Syst 8:281–296. https://doi.org/10.1109/91.855917
Truong XL, Mitamura M, Kono Y, Raghavan V, Yonezawa G, Truong XQ, Do TH, Tien Bui D, Lee S (2018) Enhancing prediction performance of landslide susceptibility model using hybrid machine learning approach of bagging ensemble and logistic model tree. Appl Sci 8:1046. https://doi.org/10.3390/app8071046
Tsangaratos P, Ilia I, Hong H, Chen W, Xu C (2017) Applying Information Theory and GIS-based quantitative methods to produce landslide susceptibility maps in Nancheng County, China. Landslides 14:1091–1111. https://doi.org/10.1007/s10346-016-0769-4
Van Dao D, Jaafari A, Bayat M, Mafi-Gholami D, Qi C, Moayedi H, Van Phong T, Ly H-B, Le T-T, Trinh PT (2020) A spatially explicit deep learning neural network model for the prediction of landslide susceptibility. CATENA 188:104451. https://doi.org/10.1016/j.catena.2019.104451
Verma S, Pant M, Snasel V (2021) A comprehensive review on NSGA-II for multi-objective combinatorial optimization problems. IEEE Access 9:57757–57791. https://doi.org/10.1109/ACCESS.2021.3070634
Wang X, Yang J, Teng X, Xia W, Jensen R (2007) Feature selection based on rough sets and particle swarm optimization. Pattern Recogn Lett 28:459–471. https://doi.org/10.1016/j.patrec.2006.09.003
Wang L-J, Guo M, Sawada K, Lin J, Zhang J (2016) A comparative study of landslide susceptibility maps using logistic regression, frequency ratio, decision tree, weights of evidence and artificial neural network. Geosci J 20:117–136. https://doi.org/10.1007/s12303-015-0026-1
Wang Y, Fang Z, Hong H (2019) Comparison of convolutional neural networks for landslide susceptibility mapping in Yanshan County, China. Sci Total Environ 666:975–993. https://doi.org/10.1016/j.scitotenv.2019.02.263
Wu Y, Ke Y, Chen Z, Liang S, Zhao H, Hong H (2020) Application of alternating decision tree with AdaBoost and bagging ensembles for landslide susceptibility mapping. CATENA 187:104396. https://doi.org/10.1016/j.catena.2019.104396
Wubalem A (2021) Landslide susceptibility mapping using statistical methods in Uatzau catchment area, Northwestern Ethiopia. Geoenviron Disasters 8:1–21. https://doi.org/10.1186/s40677-020-00170-y
Yao X, Jiang B (2005) Visualization of qualitative locations in geographic information systems. Cartogr Geogr Inf Sci 32:219–229. https://doi.org/10.1559/152304005775194683
Youssef AM, Pourghasemi HR (2021) Landslide susceptibility mapping using machine learning algorithms and comparison of their performance at Abha Basin, Asir Region, Saudi Arabia. Geosci Front 12:639–655. https://doi.org/10.1016/j.gsf.2020.05.010
Yusoff Y, Ngadiman MS, Zain AM (2011) Overview of NSGA-II for optimizing machining process parameters. Procedia Eng 15:3978–3983. https://doi.org/10.1016/j.proeng.2011.08.745
Zadeh LA, Klir GJ, Yuan B (1996) Fuzzy sets, fuzzy logic, and fuzzy systems: selected papers. World Scientific, Singapore
Zhang M-s, Liu J (2010) Controlling factors of loess landslides in western China. Environ Earth Sci 59:1671–1680. https://doi.org/10.1007/s12665-009-0149-7
Zhang T, Han L, Chen W, Shahabi H (2018) Hybrid integration approach of entropy with logistic regression and support vector machine for landslide susceptibility modeling. Entropy 20:884. https://doi.org/10.3390/e20110884
Zhao S, Zhao Z (2021) A comparative study of landslide susceptibility mapping using SVM and PSO-SVM models based on Grid and Slope Units. Math Probl Eng 2021:1–15. https://doi.org/10.1155/2021/8854606
Acknowledgements
This research was supported by the MSIT (Ministry of Science and ICT), Korea, under the ITRC (Information Technology Research Center) support program (IITP-2023-RS-2022-00156354) supervised by the IITP (Institute for Information & communications Technology Planning & Evaluation) and the Ministry of Trade, Industry and Energy (MOTIE) and Korea Institute for Advancement of Technology (KIAT) through the International Cooperative R&D program (Project No. P0016038).
Author information
Authors and Affiliations
Contributions
Seyed Vahid Razavi-Termeh (SVR-T), Javad Hatamiafkoueieh (JH), Abolghasem Sadeghi-Niaraki (AS-N), Soo-Mi (S-MC), and Khalifa M. Al-Kindi (KMA-K): Conceptualization, JH and SVR-T; Data creation, SVR-T; Formal analysis, SVR-T and JH; Funding acquisition, AS-N and S-MC; Investigation, SVR-T; Methodology, SVR-T; Project administration, AS-N and KMA-K; Resources, SVR-T and KMA-K; Software, SVR-T; Supervision, AS-N and S-MC; Validation, SVR-T and JH; Visualization, SVR-T; Writing—original draft, SVR-T; Writing—review &; editing, JH, AS-N and S-MC, and KMA-K.
Corresponding author
Ethics declarations
Competing interests
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Razavi-Termeh, S.V., Hatamiafkoueieh, J., Sadeghi-Niaraki, A. et al. A GIS-based multi-objective evolutionary algorithm for landslide susceptibility mapping. Stoch Environ Res Risk Assess (2023). https://doi.org/10.1007/s00477-023-02562-6
Accepted:
Published:
DOI: https://doi.org/10.1007/s00477-023-02562-6