
Abstract
This paper proposes an error concealment algorithm for whole frame loss for multi-view video decoding. In our proposal, the relationship between motion vectors and disparity vectors is exploited first. Based on the parallelogram-like motion relationship, the motion vectors of error frames can be indirectly derived by projecting the disparity vectors from the counterpart view. In addition, to further improve the concealing results, a joint sum of the absolute difference (SAD) minimization approach is also proposed to find the block for the purpose of concealing the current error block by jointly considering motion vectors and disparity vectors. Experimental results show that our proposed algorithm provides better video quality than previous work and reduces error propagation.
Similar content being viewed by others


1. Introduction
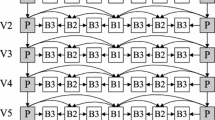
As multimedia technology has advanced in recent years, the applications of three-dimensional (3D) television and free viewpoint video (FVV) have become more attractive. To support multi-view video coding, the multi-view video coding standard has been proposed [1, 2] based on the motion-compensated prediction (MCP) technology adopted in H.264/AVC [3, 4] by incorporating the disparity-compensated prediction (DCP) technology as shown in Figure 1, to eliminate inter-view redundancy.

The prediction structure of two views.
In the error-prone network environment, packet errors or packet loss may occur very frequently due to the unpredictable interruption of noise sources, which leads to the decline of the received video quality as shown in Figure 2. Therefore, error recovering mechanisms have become an important research issue. To deal with the problem in multi-view applications, many studies have been proposed. In general, error recovery can be undertaken by two approaches called error resilience [5–9] and error concealment [10–18]. For multi-view error concealment, study [17] uses the intra-view difference, inter-view correlation, and difference of the inter-view disparity vector projections on the neighboring views to conceal the error frames. However, this requires complex computations in terms of the temporal change detection, disparity estimation, and frame difference projection which results in difficulties for real-time applications. Study [18] compares the sum of the absolute difference (SAD) between the previous two frames and the SAD between adjacent views of the previous frame to achieve error concealment. However, useful information regarding disparity vectors has not been considered to help with the error concealment process. In [17], the authors prove that the disparity vectors could significantly improve the error concealment results.

Illustration of error propagation in a multi-view application.
To deal with error problem for multi-view video coding, we propose a whole frame error concealment algorithm which applies a predictive compensation approach as well as considering the inter-view correlation to conceal the error frame of the right view. By using the disparity vectors (DVs) in the previous frame as the reference prediction DVs, the motion vectors (MVs) inside the block, referred by the reference DVs, are collected to be the candidates for our error concealment process. Finally, the candidate MV with the smallest joint SAD is chosen as the best MV to conceal the error block, once the candidate MVs have been successfully collected.
The rest of this paper is organized as follows. In Section 2, the proposed algorithm is described in detail. Section 3 shows some simulation results to demonstrate the efficiency of our proposed error concealment algorithm. The conclusion is provided in Section 4.
2. Proposed algorithm
For the single-view error concealment approach, the error concealment algorithms are only considered using the information from the spatial and temporal domains. However, since we can have the information between coding views in the multi-view video coding, we can consider that the relationship between views achieves better error concealment results compared to the single-view error concealment. Therefore, we will first observe the relationship between views and propose our error concealment algorithm based on the observation.
2.1 Observation of multi-view characteristics
To create multi-view video sources, the cameras are usually placed along a horizontal line to capture the scene at the same time. In this case, the motion vectors between different views are very similar to each other due to the identical capturing target from the perspective of the time axis. However, when observing the target from the perspective of the view axis, we can observe that the distance between the placement of the cameras will cause the appearance of objects in the scene. Therefore, the inter-view disparity vectors are usually used to describe the object relationship between views. Figure 3 gives an example to illustrate the movement between frames and views.

Illustration of real sequence with multi-views.
If we discover the multi-view sequences, we can investigate the following properties. First, for the quiescent regions which have almost zero motion behavior, the relationship between frames in single view is higher than that between views. Second, for the high-motion regions, the relationship between views is much higher than that between frames. Based on the above observation, study [17] proposes a parallelogram-like motion relationship to describe the correlation between motion vectors and disparity vectors as shown in Figure 4. From this figure, we can find that if an object has been moved from frame (f-1) to frame (f) in one view, we can also observe the same movement in another view. Similarly, if we obtain certain disparity vectors from frame (f-1), we can obtain the similar disparity vectors from frame (f) as well.

The in-view and cross-view parallelogram-like motion relationship (DV R,f-1 ≈ DV R,f , MV R,f ≈ MV L,f ).
2.2 Proposed error concealment algorithm
From the above sub-section, we observe that the motion vectors between views and disparity vectors between frames have a high degree of similarity and a close relationship. The proposed error concealment algorithm is based on this observation. Figure 5 shows the flowchart of the proposed algorithm. First, a DV set is reconstructed according to the extended window (EW). Once the EW has been decided, we check if there is any disparity vector within EW. If there is, the proposed DV-based error concealment algorithm will be applied for dealing with the error recover problem. Otherwise, the proposed MV-based error concealment algorithm will be used. The details of the proposed algorithm are described as follows:

Flowchart of the proposed error concealment algorithm.
-
1.
EW construction
In the proposed algorithm, the block size of B is adopted to conceal the erroneous frames. However, using 16 or 8 for B will obtain better concealment results since selecting 4 for B would result in a broken frame. After deciding on the block size, we extend B pixels all around the corresponding block in the previous frame to form a 3B × 3B-size EW as shown in Figure 6. The derivation process of EW can be expressed as follows:

Schematic diagram of the extended window.
-
2.
DV-based error concealment
If the EW contains any DV, we will calculate the area covered by each disparity vector in the EW and check whether any covered area has exceeded a predefined threshold. In our proposed algorithm, the default of the threshold is set to half of the EW area. If all of the covered areas pointed to by DVs in the EW are less than a predefined threshold TH, the error concealment algorithm will switch to the MV-based error concealment. Otherwise, the covered area of each DV inside the EW will be calculated and the DV with the biggest area size in the EW will be selected to conceal the error block.
-
3.
MV-based error concealment
-
(a)
Reconstruction of new extended window
The proposed MV-based error concealment algorithm will be executed by two conditions. The first condition is the switching from DV-based error concealment while the second condition is the empty EW. Therefore, based on the condition, a new extended window (NEW) will be reconstructed as follows:
where W and H mean the width and height, respectively, of the entire frame. In other words, if the MV-based error concealment process is trigged by the empty EW, the NEW will be constructed by all DVs in the entire frame. Otherwise, the NEW will be the same as the EW.
-
(b)
MV derivation process
Once the NEW has been constructed successfully, the DVs inside NEW will be considered to select the motion vectors from the left view. To derive the motion vectors corresponding to all DVs in NEW, the DVs inside NEW will be used to be projected onto the left view with a B × B window called a covered window (CW) as shown in Figure 7. After the DV projection, we will face the problem that the CW would cover more than one motion vector as shown in Figure 8. Therefore, a simple mechanism that the motion vector with the largest covered area by CW will be selected as the final motion vector in the motion vector derivation process. The motion vectors can be selected as follows:

Relationship between DVs and CWs.

Illustration of motion vectors covered by CW.
where Area(.) is the function of the area calculation according to the specific target.
-
(c)
SAD calculation according to selected MV
Based on the parallelogram-like motion relationship between inter-frame and inter-view correlation as shown in Figure 4, we can observe that the will be very similar to the and the will be very similar to the also. Therefore, when the f th frame of the right view has an error occurring, the MV obtained from the corresponding block in the left view shifted by the DV will be very similar to the original MV of the error frame if the corresponding DV in the previous frame is correct. Therefore, the SADs between B1 and B2 as shown in Figure 9 are calculated for all MVs covered by CW to determine the block for concealing the current erroneous block. However, the situation might be faced when the block has been shifted from the wrong DV and the luminance component difference between blocks pointed to by the wrong MVs is unnoticeable. To solve this problem, we further consider SADs between the left and right views in the previous frame (FL,f-1). The step-by-step block selecting procedure for computing SADs is described below.

Illustration of block relationship for computing SAD.
Step 1: The disparity vector of erroneous block B c has been selected and projected onto the left view to obtain the block B1 pointed to by .
Step 2: The motion vector with the largest area coverage by B1 will be selected and projected onto the previous frame of the right view to obtain B2.
Step 3: The corresponding block B3 pointed by from B2 will be used to calculate the SAD between B2 and B3.
Step 4: Finally, the motion vector with minimum joint SADs will be derived by the following equations to conceal the error block B c :
The notations of Equation 4 are listed as follows:
-
i and j, the horizontal and vertical indexes of the B × B block in a frame
-
a and b, the horizontal and vertical indexes of the pixel inside the block
-
FR,f, the lost frame of the right view
-
FR,f-1, the previous frame of the lost frame in the right view
-
FL,f, the current frame of the left view
-
FL,f-1, the previous frame of the lost frame in the left view
-
, the horizontal component of the n th DV in the block of the previous frame of the right view
-
, the vertical component of the n th DV in the block of the previous frame of the right view
-
, the horizontal component of the n th MV in the block of the current frame of the left view
-
, the vertical component of the n th MV in the block of the current frame of the left view
By jointly considering the SADs between views and frames, the concealing results can be further improved.
3. Simulation results
In this section, several simulation results are given to demonstrate the efficiency of our proposed MVC error concealment algorithm. The test sequences we used for simulation are Ballroom (640 × 480), Exit (640 × 480), Flamenco (640 × 480), Race1 (640 × 480), AkkoKayo (640 × 480), and Vassar (640 × 480). In our simulation, we assume that only the right view has the whole frame error while the left view has not. Study [18] is adopted for comparison in this paper, but we have made some modifications for [18] in order to allow the algorithm of [18] to be able to support whole frame loss error concealment. The simulation settings are summarized in Table 1, in which the packet loss rate (PLR) is simulated by randomly dropping a certain number of frames. For example, the 5% PLR is simulated by randomly dropping 5 frames out of 100 frames.
Tables 2 and 3 tabulate the peak signal-to-noise ratio (PSNR) comparison for our proposed algorithm with other methods under different packet error rate conditions for entire frame and error frame only cases, respectively. Frame Copy (FC), Motion Copy (MC), and the algorithm of [18] are compared. In these tables, the ΔPSNR is calculated by the PSNR values of our proposal minus the PSNR values of [18] while B is set to 8, which means that the basic error concealing block size is 8. From these tables, we can observe that our proposed algorithm outperforms other methods. Quantitatively, our proposed algorithm can achieve about 4-dB PSNR improvement compared to [18] for the high-motion sequence Race1 under the 5% packet error rate condition. However, for other sequences such as Exit and Vassar, the PSNR improvement is less significant. This situation can be explained as follows. From [18], it can be found that the MB pixels at the same spatial position from the temporal and inter-view directions are evaluated. In other words, [18] does not take the motion of the frame into account. This mechanism could be able to obtain good concealment results for low-motion sequences. However, since our proposal takes both motion vector and disparity motion into account, the proposal can obtain better concealment results for high-motion sequences. On average, our proposed algorithm can receive 1.326- and 1.421-dB PSNR improvement compared to [18] for entire frame and error frame only cases, respectively.
Tables 4 and 5 list the PSNR comparison for the case that B is 16. From these tables, we can observe that even though the basic error concealing block size has been extended to 16, our proposed algorithm can still achieve PSNR improvement when compared to [18]. On average, our proposed algorithm can receive 1.346- and 1.784-dB PSNR improvement compared to [18] for entire frame and error frame only cases, respectively. From Tables 2, 3, 4, and 5, we can observe that the PSNR improvement of smaller B is better than that of larger B. This situation can be explained as follows. In general, the larger B will contain more objects within a single block. Intuitively, it will not be easy to find a matching block from the temporal or inter-view directions which contains multiple objects. For smaller B, multiple objects can be possibly divided into multiple blocks and thus leads to the ease of finding matching blocks. Table 6 tabulates the decoding time of our proposed algorithm when compared to the error frame decoding.
Figures 10, 11, and 12 exhibit the subjective quality comparisons for our proposed algorithm with [18]. From these figures, it is very obvious that our proposed algorithm can significantly improve the subjective quality results. In general, our proposed algorithm can efficiently reduce the broken image effects.

Subjective comparison of Ballroom sequence at the 30th frame ( B = 8). (a) Error free (35.444 dB). (b) Concealed frame by [18] (19.093 dB). (c) Concealed frame by the proposed algorithm (20.134 dB).

Subjective comparison of Exit sequence at the 20th frame ( B = 8). (a) Error free (37.142 dB). (b) Concealed frame by [18] (27.040 dB). (c) Concealed frame by the proposed algorithm (28.534 dB).

Subjective comparison of Race1 sequence at the 55th frame ( B = 8). (a) Error free (36.016 dB). (b) Concealed frame by [18] (14.985 dB). (c) Concealed frame by the proposed algorithm (19.021 dB).
4. Conclusions
To deal with entire frame loss problem in multi-view video decoding, this paper proposes an error concealment algorithm by considering the relationship between motion vectors and disparity vectors. Based on the parallelogram-like motion relationship, a joint SAD minimization approach is proposed to find the best block for concealing the current error block. Through the help of the proposal, the error propagation problem can thus be reduced. Simulation results demonstrate that our proposed algorithm outperforms previous work in terms of subject and objective quality measurements.
References
Ho YS, Oh KJ: Overview of multi-view video coding. In Proceedings of International Workshop on Systems, Signals and Image Processing, 2007 and 6th EURASIP Conference focused on Speech and Image Processing, Multimedia Communications and Services. Maribor; 2007:5-12.
Vetro A, Wiegand T, Sullivan GJ: Overview of the stereo and multi-view video coding extensions of the H.264/MPEG-4 AVC standard. IEEE Proc. 2011, 99(4):626-642.
Wiegand T, Sullivan GJ, Bjontegaard G, Luthra A: Overview of the H.264/AVC video coding standard. IEEE Trans. Circ. Syst. Vid. Technol. 2003, 13(7):560-576.
Wiegand T, Sullivan G: Draft ITU-T recommendation and final draft international standard of joint video specification (ITU-T Rec. H.264/ISO/IEC 14496-10 AVC). In Joint Video Team of ISO/IEC MPEG and ITU-T VCEG, JVT-G050. Pattaya; 2003.
Wang Y, Tham JY, Lee WS, Goh KH: Pattern selection for error-resilient slice interleaving based on receiver error concealment technique. In Proceedings of IEEE International Conference on Multimedia and Expo. Barcelona; 2011.
Micallef BW, Debono CJ: An analysis on the effect of transmission errors in real-time H.264-MVC bit-streams. In Proceedings of IEEE Mediterranean Electrotechnical Conference MELECON. Valletta; 2010:1215-1220.
Dissanayake MB, De Silva DVSX, Worrall ST, Fernando WAC: Error resilience technique for multi-view coding using redundant disparity vectors. In Proceedings of IEEE International Conference on Multimedia and Expo. Suntec; 2010:1712-1717.
Xiao J, Tillo T, Lin C, Zhao Y: Joint redundant motion vector and intra macroblock refreshment for video transmission. EURASIP J. Image Vid. Process. 2011., 2011(12): doi:10.1186/1687-5281-2011-12
Ye S, Ouaret M, Dufaux F, Ebrahimi T: Improved side information generation for distributed video coding by exploiting spatial and temporal correlations. EURASIP J. Image Vid. Process. 2009, 2009: 683510. doi:10.1155/2009/683510
Xiang X, Zhao D, Ma S, Gao W: Auto-regressive model based error concealment scheme for stereoscopic video coding. In Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing. Prague; 2011:849-852.
Lee PJ, Kuo KT: An adaptive error concealment method selection algorithm for multi-view video coding. In Proceedings of IEEE International Conference on Consumer Electronics. Las Vegas; 2013:474-475.
Stankiewicz O, Wegner K, Domanski M: Error concealment for MVC and 3D video coding. In Proceedings of Picture Coding Symposium. Nagoya; 2010:498-501.
Lee SH, Lee SH, Cho NI, Yang JH: A motion vector prediction method for multi-view video coding. In Proceedings of International Conference on Intelligent Information Hiding and Multimedia Signal Processing. Harbin; 2008:1247-1250.
Liu S, Chen Y, Wang YK, Gabbouj M, Hannuksela MM, Li H: Frame loss error concealment for multi-view video coding. In Proceedings of IEEE International Symposium on Circuits and Systems. Seattle; 2008:3470-3473.
Liang L, Ma R, An P, Liu C: An effective error concealment method used in multi-view video coding. In Proceedings of International Congress on Image and Signal Processing. Shanghai; 2011:76-79.
Chung TY, Sull S, Kim CS: Frame loss concealment for stereoscopic video plus depth sequences. IEEE Trans. Consum. Electron. 2011, 57(3):1336-1344.
Chen Y, Cai C, Ma KK: Stereoscopic video error concealment for missing frame recovery using disparity-based frame difference projection. In Proceedings of IEEE International Conference on Image Processing. Cairo; 2009:4289-4292.
Zhou Y, Hou C, Pan R, Yuan Z, Yang L: Distortion analysis and error concealment for multi-view video transmission. In Proceedings of IEEE International Symposium on Broadband Multimedia Systems and Broadcasting. Shanghai; 2010:1-5.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
To view a copy of this licence, visit https://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kuan, YK., Li, GL., Chen, MJ. et al. Error concealment algorithm using inter-view correlation for multi-view video. J Image Video Proc 2014, 38 (2014). https://doi.org/10.1186/1687-5281-2014-38
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1687-5281-2014-38