
Abstract
Genetic algorithm has been used in various applications including reserve estimations in oil and gas industry for the last few decades. It is an effective stochastic inversion technique for optimization problems. The oil and gas industry is a risk based industry due to lot of uncertainties associated in each reservoir parameter used during the reserve estimation process. Detailed analysis of input data is very much important, either for the pre-bid evaluation or after the discovery of hydrocarbons. In this paper, stochastic approach in hydrocarbon resource estimation has been discussed. The algorithm starts with development of initial population and evaluation of the same. In the second step a fitness value is assigned to each individual. The best fit parents are then selected and by crossover and mutation of new populations are generated. The same process is continued until the optimum solution is reached. The efficacy of the algorithm is tested on real data set of seismic and petrophysical data from Cambay basin. The outcome is a range of resource estimates with various probability values.
Similar content being viewed by others

Introduction
Genetic algorithm (GA) is a stochastic (Jamshidi and Mostafavi 2013) global search method based on Darwin’s theory of “natural selection and survival of the fittest.” The genetic algorithm starts with no apriori knowledge of the correct solution and depends entirely on responses from its environment and evolution operators (i.e., reproduction, crossover, and mutation) to arrive at the best solution. The approach has been used in the past to characterize reservoirs and to optimize hydrocarbon production. Some examples are cited here. GA was invented by John Holland (1975). GA has been used along with Simulated annealing (SA) to generate optimum value of permeability for an Antolini Sandstone using variograms (Sen et al. 1995). GA has been applied to maximize the total Net present value (NPV) in production scheduling for a group of oil and gas field (Harding et al. 1998). Modified GA was used for reservoir characterization with the help of predefined geological data and structural model to get the best prediction of reservoir performance (Romero et al. 2000). GA was also applied to portfolio optimization in oil and gas field (Fichter 2000) and to discrete optimization too. It is not too fast good heuristic for combinatorial problems. It traditionally emphasizes combining information from good parents (crossover) with many variants, e.g., reproduction models, operators.
The major advantage that has been observed in GA is their ability to generate near optimal solutions rapidly. It is a good alternative for non-linear inverse problem. Non-linear inverse problems had at times premature convergence which resulted in due to smaller size of the population and could be overcome by increasing the size of it or by re-scaling the parameters used for the study (Gallagher et al. 1991; Gallagher and Sambridge 1994). GA has the potential to solve global optimization problems more efficiently than many other stochastic inversion techniques. This has been demonstrated while studying the feasibility of the genetic approach to geophysical optimization problems (Sambridge and Drijkoningen 1992). A genetic algorithm tries to find an optimal answer by evolving a population of trial answers in a way that mimics biological evolution. If simulated annealing “cooks” an answer, then genetic algorithm “breeds” one (Smith et al. 1992).
To predict the critical properties of heptanes-plus components in gas condensates, GA has been used as an optimization tool. Mutation, population size, number of generation, crossover, and reproduction parameters affected the evolution process. Although most of the parameters are problem dependent, the sensitivity study has shown that the number of generations should not be set too low to prevent any early break in the evolution (Sinayuc and Gumrah 2004). The minimum miscibility pressure (MMP) between the reservoir oil and carbon dioxide has been predicted by GA-based correlations in an optimal laboratory program. It was found that the data obtained for testing and fitting of quantitative models and developing correlations, and GA technique is more accurate than that obtained from similar standard experimental methods (Emera and Sarma 2008). Further, a GA-based technique has been used to develop more reliable correlations to predict the CO2 solubility, oil swelling factor, CO2-oil density, and CO2-oil viscosity for both the dead and live oils. It has been observed that GA-based correlations could predict the CO2-oil mixture physical properties more accurately including the effects of the molecular weight of the oil and the CO2 liquefaction pressure. Such correlations could be integrated into a reservoir simulation program for CO2 flooding process.
A new model has been proposed in 2007 by combining Real option theory, Genetic algorithm, and Monte Carlo simulation to find options for investment decision of an oilfield development. The above model with genetic algorithms has provided a large number of investment alternatives, avoiding the need to solve partial differential equations (Lazo et al. 2007). Reserve estimation procedures have been reviewed, and suggestions have been made for the improvements for conventional oil and gas fields. This may be considered as a standard for industry (Demirmen 2007). Genetic algorithm has been found to be suitable for the development of an Iranian oilfield and an optimum number of wells required to develop has been calculated on the basis of technical and economical aspects (Nejad et al. 2007). To estimate the gas compressibility factor, GA has been used to taking the variables like pseudo-reduced temperatures of 977 points spectrum of gas composition at wide ranges of pressure and temperature.
Genetic algorithm has been used for permeability estimation, total recovered hydrocarbon, and economic viability. The use of lognormal probability distribution for parameter/optimization provided a better mean for GA solution (Sircar et al. 2011). The values obtained by the lognormal are slightly lower than that derived from the triangular distributions which lead to a higher confidence in estimating the parameters which assure the convergence to a local optimum as well as global optimum.
Murphy (2003) used a library function to bring a variation in fitness scaling, selection, and other genetic operators such as crossover and mutation to solve the particular problem. Genetic algorithm has been used to optimize the production of oil and gas condensate (Tavakkolian et al. 2004).A system of mathematical equations has been analyzed to predict the optimum parameters of the production.
In this paper, a step by step algorithm is worked out to demonstrate how hydrocarbon resource can be evaluated using genetic algorithm. The algorithm is tested on field data set taken from North Cambay basin.
Data used for resource estimation
The reservoir data are obtained from seven wells in an oil field located in North Cambay Basin, India. The initial data set is presented herewith as Table 1.
The parameters which are required for resource estimation are areal extent of the pool, net pay thickness of the reservoir, porosity, water saturation, formation volume factor, etc. In oil industry, only a limited number of geoscientific data are available in exploration phase. Uncertainty prevails in the collected data set which warrants expansion of data size (population) by stochastic simulation process. For this simulation, various probability distribution functions are used, which are based on the histogram analysis of the collected data. In this study, triangular distribution has been chosen for the simulation purpose because of data limitation. Triangular distribution is a continuous probability distribution which works by taking the minimum, maximum, and mode value of each variable which are needed to be simulated for generating more data. To have more consistent data and to fulfill the objective of the study, the simulation algorithm is coded in such a way so that it can generate 28 numbers of data points. In order to know the variation in reservoir parameter, the percentiles of each parameter are calculated from the cumulative distribution function. The ranges for each parameter selected based on stochastic simulation are presented in Table 2. The expanded data range has been used as input parameter for G A.
Methodology
As per the AAPG guidelines, the generalized classic volumetric equation for petroleum initially in-place is (PIIP) expressed as
where,
PIIP = Petroleum initially in-place (for oil OIIP and for gas GIIP)
A = Areal extent of the reservoir pool (m2)
h = Net pay (m)
φ = Porosity (fraction)
Swi = Initial water saturation
FVF = Formation volume factor [for oil (RB/STB) or gas (Rcf/scf)]
Oil initially in-place or Gas initially in-place is measured in barrels or cubic feet.
The estimated ultimate recovery (EUR) is calculated as
where,
EUR = Estimated ultimate recovery (STB or SCF)
PIIP = Petroleum initially in-place (STB or SCF)
RE = Recovery efficiency
The data recorded at the surface of the earth are limited by number of observations, and Geology of the study area changes within a few meters due to reservoir heterogeneity as a result the input parameters of a reservoir are always uncertain.
The steps of any genetic algorithm are representation of the solutions of the problem, creation of an initial population of solutions, fitness function or evaluation function, population, and genetic operators (crossover and mutation) which change the genetic characteristics of offspring during reproduction, parent selection, and survivor selection. The best solution in each generation goes to the final population. The behavior and performance of genetic algorithm is highly inclined by the representation which is established by the previous work (Goldberg 1989; Liepins and Vose 1990). Appropriate design of representation is essential to be successful in genetic algorithm.
Before starting the genetic algorithm, the sampling interval of each reservoir parameters such as area, porosity, hydrocarbon saturation, formation volume factor, etc. is calculated using the following formula
where ∆S is the sampling interval, S max is the maximum value, S min is the minimum value of each parameter, m is the base of encoding (for binary m = 2), and n is the number of bits which represent each parameter in binary code. The population space is expressed by (m n). The reservoir parameters which are mentioned earlier cannot be estimated exactly. Therefore, sampling is required to estimate the same because the sample represents the whole population.
Let us consider the case of “oil saturation” which varies from 60 to 74 %, and each oil saturation value is binary coded with eight bits. The sampling resolution for the same is 0.05 %.
Population An initial set of population of each parameter is generated randomly (Haupt and Haupt 2004). The population size depends upon how complex the problem is. To discover the whole search space (Rezaian et al. 2010), the initial population should be a large pool of genes. So the designing of algorithm should be such that there must be enough diversity in the population to get fast and good solution otherwise the solution may fall in the local minima. In our case, the population size is 256 (28). The range of population is 255.
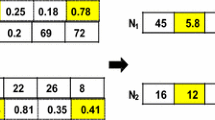
Encoding The standard binary coding is being followed. The reservoir parameters are continuous value, and they need to be converted into binary number and vice versa. As the population is eight bit, so every parameter is encoded with eight bit binary number. As for example, oil saturation value “70” is encoded as “01000110.” As the population size is 256, so for each parameter 256 strings of population will be evaluated for optimization in genetic algorithm. The manual process of full cycle of genetic algorithm for one parameter “oil saturation” is shown in Table 3. The population size is big, so only four strings have been considered for manual process, but the new algorithm has taken care of the whole 256 population.
Fitness function After creation of an initial set of population randomly, each of these population is evaluated and assigned a fitness value. Fitness is defined as the ratio of the assessment value of a particular chromosome to the average assessment of all the chromosomes. In our case, power law (Sadjadi 2004) fitness function f(x) = (x k) has been taken for fitness assessment of each population. The x value is 2 for binary representation, and the k value is problem dependent as in our case it is taken as 0.5 because the range of population is 28. This helps the algorithm to store maximum 256 bits. Hence selection of fitness scaling is an important task in genetic algorithm. If the population size is “n” then the fitness of ith chromosome is expressed as F i, and the average fitness of the population for ith generation is generally calculated using the following formula
The fitness (Chipperfield et al. 1994) probability of selection is
where P i is the fitness probability and F i is individual parameter’s fitness. The fitness calculation has been presented in Table 3. It has been observed that the fitness of fourth string is highest and fitness of second string is lowest.
Expected count If the population size is “n” then the expected count (E i ) of each string is
Suppose a string is having E i = 2.5 then this will get a two confirmed counts and other with a probability of 0.5. The lowest expected count is represented as E i = 0, and it is removed from the population. Thus, in Table 3, the lowest expected count is 0.90471 and is set as zero. On the basis of the expected count, every individual may get multiple copies.
Crossover Crossover is the process of creating new offspring of better quality by exchanging of good information from the selected parents. By this process, clone of good strings has been created instead of new generation. However, depending upon the problem complexity, a unique crossover designing is needed for the success of the problem. There are different types of crossover operators which have been used in practice such as
-
a.
Single-point crossover
-
b.
Two-point crossover
-
c.
Multi-point crossover
-
d.
Uniform crossover
The fundamental steps for all crossover operators are random selection of parents, selection of crossover point, and swapping of information between the two strings at the crossover point. Based on the objective of the problem, in the present study, single-point crossover is considered. The designed algorithm can pick a single crossover site randomly. In Table 4, the second string has been replaced by the fourth string based on the fitness value. Study suggests that there are two pairs of strings, and the first two strings are having the crossover site six, whereas the last two strings are having the crossover site two. So for the first two strings, at the crossover site, i.e., after the sixth bit, the tail bits are exchanged by crossover. Similarly for the last two strings, the tail bits are exchanged at the crossover site, i.e., after fourth bit. Thus, the summation, average, and maximum fitness of the selected oil saturation values presented in Table 3 (32.7893, 8.1973, 8.9443) have been improved by crossover operation and are presented in Table 4 (34.3016, 8.5754, 9.0554).
Crossover probability
Crossover is performed after selection of a pair of chromosomes to generate offspring. The ratio of pairs of chromosomes which will be selected for mating to the total number of pairs of chromosomes is defined as the crossover probability. The purpose of crossover is to have new chromosomes which will accomplish good qualities of the old chromosomes. In this case, based on the different experiments, the crossover probability is taken as 65 %. The meaning of 65 % crossover probability is that out of 100 pairs of strings, only 65 pairs of randomly chosen strings will have crossover and the rest of the pairs of strings will remain unchanged.
Mutation
Mutation is an important operator in genetic algorithm to generate new genes by flipping one or more gene values randomly in a chromosome. A better solution of the problem may be achieved by these new genes in the chromosome. It also helps in preventing the solution to be trapped in local minima. Sometimes it is possible to recover the lost genes through mutation. The genetic diversity in the population is maintained by mutation. Crossover operator alone cannot generate good offspring because if at any certain position, the values of all chromosomes are same then the children will also have the same value at that particular position. To avoid such kind of problem, mutation is required. There are various types of mutation in use in binary genetic algorithm depending upon the objective of the problems such as
-
(a)
Flip bit mutation
-
(b)
Interchanging mutation
-
(c)
Reversing
Based on the objective of the problem, flip bit mutation is considered. In this mutation, the values or bits (0 and 1) of the selected genes are flipped by mutation operator. The mutation operator is generated randomly. In Table 5, the first and third strings are having mutation. The last bit of the first string and the fifth bit of the third string have been flipped by mutation operator. The important thing in mutation is that the summation and average fitness values of the oil saturation are further improved from (34.3016, 8.5754) to (34.8473, 8.711825) by mutation, but the maximum fitness remains unchanged.
Mutation probability It is the ratio of the bits to be flipped randomly to the total bits of the chromosomes. Suppose, a chromosome has a length of 100 bits and mutation probability is 0.06 then only six bits chosen at random will be flipped. In our case, the mutation probability is kept as 12 % because the high mutation probability will change the maximum genes of the chromosome, and the algorithm will relapse into a random search for an optimum. Similarly, very low mutation probability will be failed to recover the lost genes. In our algorithm, every selected bit in the chromosome is checked whether it is less or equals to the mutation probability and if it is then the bit is changed otherwise it is kept as it is.
Next generation After crossover and mutation only four individuals are left in the population and only two of them are chosen for the simulation to get the solution of the problem. The four individuals comprise two parents and two children. Based on the convergence criteria, two of them are selected. The convergence criterion adopted is that if the difference between child fitness and parent fitness is less than 0.001, the program stops.
Results and discussions
The genetic algorithm software has been developed using Visual C++. The efficacy of the algorithm has also been tested and validated for hydrocarbon resource estimation using real data set. The outcomes of the study have been discussed in the following paragraphs.
From the above study, it has been observed that the summation, average, and maximum fitness of initial oil saturation values have improved through genetic algorithm. This has been achieved by the proper selection of the genetic operators such as crossover and mutation.
The simulation graphs presented in Figs 1 and 3 provide the statistics of the simulation for oil initial in-place and recoverable oil in million metric standard barrels (MMBL). Figures 2 and 4 depict the cumulative probability of the simulation for oil initially in-place and recoverable resources. The minimum, maximum, mean, median, mode, standard deviation, and range oil initial in-place are 4.639, 42.52, 34.26, 36.09, 42.44, 7.003, and 37.89, respectively. The minimum, maximum, mean, median, mode, standard deviation, and range recoverable oil are 0.9703, 6.997, 5.583, 5.904, 6.928, 1.133, and 6.027, respectively.

Simulation graph for Oil initially in-place

Cumulative probability of the simulation graph for Oil initially in-place

Simulation graph for Recoverable resource (Oil)

Cumulative probability of the simulation for Recoverable resource (Oil)
The range of the OIIP and Recoverable resource gives an idea about the spread of the data. In our study, the ranges are 37.89 and 6.027, respectively, so that the range of output is minimized. The standard errors of the mean calculated from those simulations are presented in Table 7. The standard errors of OIIP and Recoverable oil are 0.22 and 0.03, respectively. From the standard error analysis, the true mean of the population is precisely quantified. That means it can measure the accuracy with which a sample represents a population. Smaller the standard error, better the representation of the sample of the overall population. The P10, P50, and P90 values of oil initially in-place (MMSTB) and recoverable oil (MMSTB) are calculated based on the cumulative distribution function analysis and are 41.28, 34.22, 24.94, and 6.71, 5.63, 4.02, respectively (Table 6). By the help of this genetic algorithm, total 1,000 values of initial in-palace and recoverable oil have been calculated, and the percentile of the same is presented herewith as Tables 5 and 6, respectively.
References
Chipperfield A, Fleming P, Pohlheim H, Fonseca C (1994) Genetic algorithm toolbox. University of Sheffield, Sheffield, pp 1–105
Demirmen F (2007) Reserves estimation: the challenge for the industry. J Pet Technol 59(05):80–89
Emera MK, Sarma HK (2008) A genetic algorithm-based model to predict co-oil physical properties for dead and live oil. J Can Pet Technol 47(2):52–61
Fichter DP (2000) Application of genetic algorithms in portfolio optimization for the oil and gas industry. In: Paper SPE 62970 presented at the 2000 SPE annual technical conference and exhibition, Dallas, 1–4 Oct 2000
Gallagher K, Sambridge M (1994) Genetic algorithms: a powerful tool for large- scale nonlinear optimization problems. Comput Geosci 20(7/8):1229–1236
Gallagher K, Sambridge M, Drijkoningen G (1991) Genetic algorithms: an evolution from Monte Carlo methods for strongly non-linear geophysical optimization problems. Geophys Res Lett 18(12):2177–2180
Goldberg DE (1989) Genetic algorithm in search, optimization and machine learning. Addison-Wesley Publishing Company, Inc, Reading
Harding TJ, Radcliffe NJ, King PR (1998) Hydrocarbon production scheduling with genetic algorithms. In: Paper SPE-36379-PA, published at the SPE Journal, June 1998, pp 99–107
Haupt RL, Haupt SE (2004) Practical genetic algorithms, 2nd edn. Wiley Interscience Publication, Hoboken
Holland JH (1975) An introductory analysis with application to biology, control & artificial intelligence–adaptation in natural & artificial systems. The MIT Press, Cambridge
Jamshidi E, Mostafavi H (2013) Soft-computation application to optimize drilling bit selection utilizing virtual intelligence and genetic algorithms. In: Paper IPTC 16446 presented at international petroleum technology conference, Beijing, China, 26–28 Mar 2013
Lazo JGL, Pacheco MAC, Vellasco MMBR (2007) Real options and genetic algorithms to approach of the optimal decision rule for oil field development under uncertainties. In: Castillo O, Melin P, Ross OM, Cruz RS, Pedrycz W, Kacprzyk J (eds) Theoretical advances and applications of fuzzy logic and soft computing. Advances in soft computing, vol 42. Springer, Heidelberg, pp 445–454
Liepins GE, Vose MD (1990) Representational issues in genetic optimization. J Exp Theor Artif Intell 2(2):101–115
Murphy R (2003) A generic parallel genetic algorithm. Masters Thesis, Department of Mathematics, University of Dublin, Trinity College, Oct 2003
Nejad SAT, Aleagha AAV, Salari S (2007) Estimating optimum well spacing in a middle east onshore oil field using a genetic algorithm optimization approach. In: Paper SPE-105230-MS presented at SPE middle east oil and gas show and conference, Kingdom of Bahrain, 11–14 Mar 2007
Rezaian A, Alipanah M, Pour HN, Kazemi H (2010) A genetic algorithm approach to determination of optimum diameter of gas transmission pipes. In: Paper SPE-140671-MS presented at the 34th annual SPE international conference and exhibition, Tinapa–Calabar, Nigeria, 31 July–7 August 2010
Romero CE, Carter JN, Gringarten AC, Zimmerman RW (2000) A modified genetic algorithm for reservoir characterisation. In: Paper SPE 64765 presented at the 2000 SPE international oil and gas conference and exhibition, Beijing, 7–10 Nov 2000
Sadjadi FA (2004) Comparison of fitness scaling functions in genetic algorithms with applications to optical processing. In: Proceedings of SPIE (5557), SPIE, Bellingham
Sambridge MS, Drijkoningen GG (1992) Genetic algorithms in seismic waveform inversion. Geophys J Int 109:323–342
Sen MK, Datta-Gupta A, Stoffa PL, Lake LW, Pope GA (1995) Stochastic reservoir modeling using simulated annealing and genetic algorithm. In: Paper SPE 24754-PA, published at the SPE formation evaluation, March 1995, pp 49–56
Sinayuc C, Gumrah F (2004) Predicting the critical properties of heptanes-plus in gas condensates: genetic algorithms as an optimization tool. In: Paper petroleum society 2004—141 presented at the petroleum society’s 5th Canadian international petroleum conference, Calgary, Alberta, Canada, 8–10 June 2004
Sircar A, Patel HK, Sheth S, Jadvani R (2011) Application of genetic algorithm to hydrocarbon resource estimation. Journal of Petroleum and Gas Engineering 4(2):83–92
Smith ML, Scales JA, Fischer TL (1992) Global search and genetic algorithm, geophysics. Lead Edge Explor 11(1):22–26
Tavakkolian M, Jalali FF, Emadi MA (2004) Production optimization using genetic algorithm approach. In: Paper SPE 8901 presented at the 28th annual SPE international technical conference and exhibition, Abuja, Nigeria, 2–4 August 2004
Acknowledgments
We would like to express our sincere thanks and gratitude to Pandit Deendayal Petroleum University and M/s Gujarat State Petroleum Corporation Ltd. to provide encouragement, help, and support to accomplish this paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article

Cite this article
Thander, B., Sircar, A. & Karmakar, G.P. Hydrocarbon resource estimation: a stochastic approach. J Petrol Explor Prod Technol 5, 445–452 (2015). https://doi.org/10.1007/s13202-014-0144-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13202-014-0144-8