
Abstract
We propose a novel approach to the analysis of covariance operators making use of concentration inequalities. First, non-asymptotic confidence sets are constructed for such operators. Then, subsequent applications including a k sample test for equality of covariance, a functional data classifier, and an expectation-maximization style clustering algorithm are derived and tested on both simulated and phoneme data.
Article PDF
Similar content being viewed by others

Avoid common mistakes on your manuscript.
References
Abraham, C., Cornillon, P.-A., Matzner-Løber, E. and Molinari, N. (2003). Unsupervised curve clustering using b-splines. Scand. J. Stat. 30, 3, 581–595.
Arlot, S., Blanchard, G. and Roquain, E. (2010). Some nonasymptotic results on resampling in high dimension, i: Confidence regions. Ann. Stat. 38, 1, 51–82.
Bartlett, P.L. and Mendelson, S. (2003). Rademacher and Gaussian complexities: Risk bounds and structural results. J. Mach. Learn. Res. 3, 463–482.
Bartlett, P.L., Boucheron, S. and Lugosi, G. (2002). Model selection and error estimation. Mach. Learn. 48, 1–3, 85–113.
Berlinet, A., Biau, G. and Rouviere, L. (2008). Functional supervised classification with wavelets. In Annales de l’ISUP, volume 52.
Boucheron, S., Lugosi, G. and Massart, P. (2013). Concentration inequalities: A nonasymptotic theory of independence. Oxford University Press.
Cabassi, A. and Kashlak, A.B. (2016). fdcov: Analysis of Covariance Operators. R package version 1.0.0.
Casella, G. and Berger, R.L. (2002). Statistical inference, volume 2. Duxbury Pacific Grove.
Chang, C., Chen, Y. and Ogden, T. (2014). Functional data classification: a wavelet approach. Comput. Stat. 29, 6, 1497–1513.
De la Pena, V. and Giné, E. (2012). Decoupling: From dependence to independence. Springer Science & Business Media.
Delaigle, A. and Hall, P. (2012). Achieving near perfect classification for functional data. J. R. Statist. Soc. Series B (Statist. Methodol.) 74, 2, 267–286.
Fan, Z. (2011). Confidence regions for infinite-dimensional statistical parameters. Part III essay in Mathematics, University of Cambridge. http://web.stanford.edu/zhoufan/PartIIIEssay.pdf.
Ferraty, F. and Vieu, P. (2003). Curves discrimination: A nonparametric functional approach. Comput. Statist. Data Anal. 44, 1, 161–173.
Ferraty, F. and Vieu, P. (2006). Nonparametric Functional Data Analysis: Theory and Practice. Springer Science & Business Media.
Fremdt, S., Steinebach, J.G., Horváth, L. and Kokoszka, P. (2013). Testing the equality of covariance operators in functional samples. Scand. J. Stat. 40, 1, 138–152.
Giné, E. and Nickl, R. (2010). Confidence bands in density estimation. Ann. Stat. 38, 2, 1122–1170.
Giné, E. and Nickl, R. (2016). Mathematical Foundations of Infinite-Dimensional Statistical Models. Cambridge University Press.
Glendinning, R.H. and Herbert, R.A. (2003). Shape classification using smooth principal components. Pattern Recogn. Lett. 24, 12, 2021–2030.
Hall, P., Poskitt, D.S. and Presnell, B. (2001). A functional data-analytic approach to signal discrimination. Technometrics 43, 1, 1–9.
Hastie, T., Buja, A. and Tibshirani, R. (1995). Penalized discriminant analysis. Ann. Stat., 73–102.
Horváth, L. and Kokoszka, P. (2012). Inference for Functional Data with Applications, volume 200. Springer Science & Business Media.
Isserlis, L. (1918). On a formula for the product-moment coefficient of any order of a normal frequency distribution in any number of variables. Biometrika 12, 1/2, 134–139.
James, G.M. and Hastie, T.J. (2001). Functional linear discriminant analysis for irregularly sampled curves. J. R. Statist. Soc. Series B, Statist. Methodol., 533–550.
Jiang, C.-R., Aston, J.A. and Wang, J.-L. (2016). A functional approach to deconvolve dynamic neuroimaging data. J. Am. Stat. Assoc. 111, 513, 1–13.
Kerkyacharian, G., Nickl, R. and Picard, D. (2012). Concentration inequalities and confidence bands for needlet density estimators on compact homogeneous manifolds. Probab. Theory Relat. Fields 153, 1–2, 363–404.
Koltchinskii, V. (2001). Rademacher penalties and structural risk minimization. IEEE Trans. Inf. Theory 47, 5, 1902–1914.
Koltchinskii, V. (2006). Local rademacher complexities and oracle inequalities in risk minimization. Ann. Stat. 34, 6, 2593–2656.
Ledoux, M. (2001). The Concentration of Measure Phenomenon, volume 89. American Mathematical Soc.
Lounici, K. and Nickl, R. (2011). Global uniform risk bounds for wavelet deconvolution estimators. Ann. Stat. 39, 1, 201–231.
Müller, H.-G. and Stadtmüller, U. (2005). Generalized functional linear models. Ann. Statist., 774–805.
Panaretos, V.M., Kraus, D. and Maddocks, J.H. (2010). Second-order comparison of Gaussian random functions and the geometry of DNA minicircles. J. Am. Stat. Assoc. 105, 490, 670–682.
Peng, J. and Müller, H.-G. (2008). Distance-based clustering of sparsely observed stochastic processes, with applications to online auctions. Ann. Appl. Statist., 1056–1077.
Pigoli, D., Aston, J.A.D., Dryden, I.L. and Secchi, P. (2014). Distances and inference for covariance operators. Biometrika, page asu008.
Pigoli, D., Hadjipantelis, P.Z., Coleman, J.S. and Aston, J.A.D. (2015). The analysis of acoustic phonetic data: exploring differences in the spoken romance languages. arXiv:1507.07587.
Ramsay, J.O. and Silverman, B.W. (2005). Functional Data Analysis. Springer, New York.
Talagrand, M. (1996). New concentration inequalities in product spaces. Inventiones mathematicae 126, 3, 505–563.
Acknowledgements
JA is grateful that this research was supported by EPSRC grant EP/K021672/2.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: Confidence Sets for the Mean in Banach Spaces
The goal of this section is to construct a non-asymptotic confidence region in the Banach space setting. This is specialized in Section 3 to our case of interest, covariance operators, when the Xi below are replaced with \(f_{i}^{\otimes 2}\).
Let X1, … , Xn ∈ (B, ‖⋅‖B) be mean zero independent and identically distributed Banach space valued random variables with ‖Xi‖ B ≤ U for all i = 1, … , n where U is some positive constant. Furthermore, let \(\left \langle {\cdot },{\cdot }\right \rangle :B\times B^{*} \rightarrow \mathbb {R}\) such that for X ∈ B and ϕ ∈ B∗ then 〈X, ϕ〉 = ϕ(X). Define
where the supremum is taken over a countably dense subset of the unit ball of B∗. Furthermore, define vn = 2U EZ + nσ2. Then, P (Z > EZ + r) ≤ exp{−r2/(2vn + 2rU/3)}. Rewriting Z as \(n\left \lVert {\bar {X}-\mathrm {E}{ \bar {X}}}\right \rVert _{B}\) results in
where ‖Xi‖ B < U and \(v_{n} = 2nU\mathrm {E}\{\left \lVert {\bar {X}-\mathrm {E}{\bar {X}}}\right \rVert _{B}\} + n\sigma ^{2}\).
The above tail bound incorporates the unknown \(\mathrm {E}(\lVert {\bar {X}-\mathrm {E}{\bar {X}}}\rVert _{B})\). Consequently, a symmetrization technique is used. This term is replaced by the norm of the Rademacher average \( R_{n} = {n^{-1}}{\sum }_{i = 1}^{n}\varepsilon _{i}(X_{i}- \bar {X}) \) where the εi are independent and identically distributed Rademacher random variables also independent of the Xi. This substitution is justified by invoking the symmetrization inequality (Giné and Nickl, 2016, Theorem 3.1.21),
If the data are symmetric about their mean, which is when Xi −EXi and EXi − Xi are equidistributed, the coefficient of 2 is unnecessary and can be dropped. This is because Xi −EXi and ε{Xi −EXi} are also equidistributed. In practice, the data may not be symmetric. However, averaging even a moderately sized data set has a symmetrizing effect on the sample mean. Assuming the data is not highly skewed, the coefficient of 2 can be safely dropped in practice to tighten the confidence set. In fact, considering the phoneme data from Section 5.1 in this setting results in the values displayed in Table 6, which shows that in the trace norm setting, the Rademacher average is much greater than half the size of EZ, and that in the Hilbert-Schmidt and operator norm settings, the Rademacher average is actually marginally less than EZ.
This symmetrization result allows us to replace the original expectation with the expectation of the Rademacher average. Furthermore, Talagrand’s inequality also applies to Rn. Hence, the Rademacher average concentrates strongly about its expectation, which justifies dropping the expectation. In practice, one can use the intermediary Eε‖Rn‖ B, which can be approximated for reasonable sized data sets via Monte Carlo simulations of the εi. However, this is not strictly necessary, and for large data sets, a single random draw of εi will suffice (Giné and Nickl, 2016, Section 3.4.2).
The resulting (1 − α)-confidence set is
To make use of these results in practice, both the weak variance σ2 must be estimated for the data and a reasonable choice of U must be made, and a main contribution of this present paper is to propose some theoretically motivated but practically useful non-asymptotic choices for these constants that work for the functional data applications we are investigating.
Appendix B: Calculation of the Weak Variance
1.1 B.1 The Weak Variance for p ∈ [1, ∞)
To calculate the weak variance σ2, define f⊗n = f ⊗… ⊗ f to be the n-fold tensor product of f with itself and extend the definition of \( \left \langle {\cdot },{\cdot }\right \rangle : (L^{2})^{\otimes 4}\times \{(L^{2})^{\otimes 4}\}^{*}\rightarrow \mathbb {R} \) such that 〈f⊗4, ϕ⊗4〉 = 〈f⊗2, ϕ⊗2〉2 = 〈f, ϕ〉4 = ϕ(f)4. For operators π ∈ {(L2)⊗2}∗ and Ξ ∈ {(L2)⊗4}∗, the weak variance is
where the inequality stems from the fact that the supremum is being taken over a larger set. However, in the Hilbert space setting, the dual of the tensor product does coincide with the tensor product of the dual space, and thus the above inequality can be replaced with an equality if the Hilbert-Schmidt norm, 2-Schatten norm, is used. Given a bound \(\left \lVert {f_{i}}\right \rVert _{L^{2}}^{2}\le c^{2}=U\), then \( \sigma ^{2}\le \lVert { \mathrm {E}{ f^{\otimes 4}}}\rVert _{p}\le \mathrm {E}\lVert {f}\rVert _{L^{2}}^{4} \le c^{4} = U^{2}. \)
1.2 B.2 The Weak Variance for p = ∞
Let E be a countable dense subset of the unit ball of L2(I). In the case p = ∞, we cannot use duality, but can still write Z and σ2 as suprema over the countable set and achieve the same results as above.
As before, if \(\left \lVert {f_{i}^{\otimes 2}}\right \rVert _{\infty }=\left \lVert {f_{i}}\right \rVert _{L^{2}}^{2}\le c^{2}=U\), then σ2 ≤ U2.
1.3 B.3 The Weak Variance for Gaussian Data
Similarly to the bounded case, we estimate ‖Ef⊗4 −Σ⊗2‖ p for Gaussian data. Consider f from a Gaussian process with mean zero and covariance Σ. Strictly speaking these variables are not norm bounded, but similar concentration results for Gaussian processes can be derived. Indeed, let f1, … , fn be independent Gaussian processes with mean zero and covariance Σ. The empirical covariance kernel is \(\hat {c}(s,t) = n^{-1}{\sum }_{i = 1}^{n} f_{i}(s)f_{i}(t)\), which is a Gaussian polynomial. By the decoupling inequality (De la Pena and Giné, 2012, Theorem 4.2.27), there exists a κ > 0 such that
where \(\tilde {c}(s,t) = n^{-1}{\sum }_{i = 1}^{n} f_{i}(s)f_{i}^{\prime }(t)\) with \(f_{1}^{\prime },\ldots ,f_{n}^{\prime }\) independent copies of the original fi. Thus, our Gaussian polynomial can be thought of as a conditional Gaussian random variable. Now using concentration bounds for norms of Gaussian vectors (Giné and Nickl, 2016, Theorem 2.6.8) twice, an inequality similar to the one in the bounded case is obtained easily.
Defining fs = f(s), the integral kernel can be written as (Isserlis, 1918)
Hence, we have that Efsftfufv −Σs, tΣu, v = Σs, uΣt, v + Σs, vΣt, u and that the operator Ef⊗4 −Σ⊗2, which can be thought of as an Hilbert-Schmidt operator on the space Op(L2), can be represented by the integral kernel cf(s, u)cf(t, v) + cf(s, v)cf(t, u). These two terms are merely relabeled versions of Σ⊗2. Consequently, using the subadditivity of the norm, ‖Ef⊗4 −Σ⊗2‖ p ≤ ‖Σ⊗2‖ p + ‖Σ⊗2‖ p = 2 ‖Σ⊗2‖ p. For example, for the Hilbert-Schmidt norm,
Lemma 5.1 of Horváth and Kokoszka (2012) gives an explicit form of a covariance operator of Σ in terms of the eigenfunctions of Σ for Gaussian data in the Hilbert-Schmidt setting.
Given λi, the eigenvalues of Σ, the spectrum of Σ⊗2 is \(\{ \lambda _{i}\lambda _{j}\}_{i,j = 1}^{\infty }\). Hence, for any of the p-Schatten norms, \(\lVert {{\Sigma }\otimes {\Sigma }}\rVert _{p} = \lVert {\Sigma }{\rVert _{p}^{2}}\). Note that in the above calculations, the weak variance depends on the unknown Σ. In practice, this can be replaced by the empirical estimate \(\hat {\Sigma }\).
Appendix C: Heavy Tails and Noisy Measurements
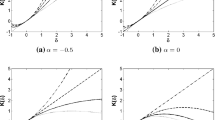
As often in practice functional data comes from noisy measurements, consider data of the form Yi = Xi + εi where Xi is a mean zero Gaussian process with covariance operator Σ and εi is Gaussian white noise with covariance c2I for some c2 > 0. Figure 5 repeats the previous power analysis for the two sample test but in the moderately noisy settings.

Similar to Figs. 3 and 4 except white noise with variance c2 = 100 is added to each functional data observation. In the top plot, the eigenvalues of Σ decay as O(k− 4) as in Fig. 3; in the bottom plot, the eigenvalues of Σ decay as O(k− 2) as in Fig. 4
Secondly, heavier tailed data, specifically t-distributed data with 6 degrees of freedom, can also be handled by this method. Figure 6 repeats the earlier two sample power analysis but with the heavier tailed distribution in place of the Gaussian. Here, the coefficient of (k + 2)/(k + 3) in Eq. 4.1 was replaced with simply 1 in order to achieve the correct empirical size. In general, given arbitrary data, one can simulate null data and adjust the tuning parameters to match the desired empirical size of the test.

A repetition of the experiments from Figs. 3 and 4 but with data simulated from a multivariate t-distribution with 6 degrees of freedom. In the top plot, the eigenvalues of Σ decay as O(k− 4) as in Fig. 3; in the bottom plot, the eigenvalues of Σ decay as O(k− 2) as in Fig. 4
Lastly, the empirical coverage of the concentration based confidence set is still comparable to the desired coverage in the heavy tailed case. Consider t-distributed data with six degrees of freedom; Nine operators were randomly generated and data was simulated from each. Figure 7 recreates the simulated confidence sets from Fig. 2, but with the t-distributed data. To achieve these empirical coverages, the Gaussian weak variance, previously calculated to be \(\sigma ^{2}= 2\left \lVert {\Sigma }\right \rVert _{p}^{2}\), is scaled by a factor of ν/(ν − 4) where ν is the degrees of freedom.

The empirical confidence level of the set from Eq. 3.1 for nine different operators given a sample size of 35 curves generated from a t-distributed process with 6 degrees of freedom. The black line is where the desired and empirical levels are equal. The desired level ranges from α = 1% to α = 10%. 10,000 replications were used to produce these curves
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Kashlak, A.B., Aston, J.A.D. & Nickl, R. Inference on Covariance Operators via Concentration Inequalities: k-sample Tests, Classification, and Clustering via Rademacher Complexities. Sankhya A 81, 214–243 (2019). https://doi.org/10.1007/s13171-018-0143-9
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13171-018-0143-9