
Abstract
Time series in the Earth Sciences are often characterized as self-affine long-range persistent, where the power spectral density, S, exhibits a power-law dependence on frequency, f, S(f) ~ f −β, with β the persistence strength. For modelling purposes, it is important to determine the strength of self-affine long-range persistence β as precisely as possible and to quantify the uncertainty of this estimate. After an extensive review and discussion of asymptotic and the more specific case of self-affine long-range persistence, we compare four common analysis techniques for quantifying self-affine long-range persistence: (a) rescaled range (R/S) analysis, (b) semivariogram analysis, (c) detrended fluctuation analysis, and (d) power spectral analysis. To evaluate these methods, we construct ensembles of synthetic self-affine noises and motions with different (1) time series lengths N = 64, 128, 256, …, 131,072, (2) modelled persistence strengths β model = −1.0, −0.8, −0.6, …, 4.0, and (3) one-point probability distributions (Gaussian, log-normal: coefficient of variation c v = 0.0 to 2.0, Levy: tail parameter a = 1.0 to 2.0) and evaluate the four techniques by statistically comparing their performance. Over 17,000 sets of parameters are produced, each characterizing a given process; for each process type, 100 realizations are created. The four techniques give the following results in terms of systematic error (bias = average performance test results for β over 100 realizations minus modelled β) and random error (standard deviation of measured β over 100 realizations): (1) Hurst rescaled range (R/S) analysis is not recommended to use due to large systematic errors. (2) Semivariogram analysis shows no systematic errors but large random errors for self-affine noises with 1.2 ≤ β ≤ 2.8. (3) Detrended fluctuation analysis is well suited for time series with thin-tailed probability distributions and for persistence strengths of β ≥ 0.0. (4) Spectral techniques perform the best of all four techniques: for self-affine noises with positive persistence (β ≥ 0.0) and symmetric one-point distributions, they have no systematic errors and, compared to the other three techniques, small random errors; for anti-persistent self-affine noises (β < 0.0) and asymmetric one-point probability distributions, spectral techniques have small systematic and random errors. For quantifying the strength of long-range persistence of a time series, benchmark-based improvements to the estimator predicated on the performance for self-affine noises with the same time series length and one-point probability distribution are proposed. This scheme adjusts for the systematic errors of the considered technique and results in realistic 95 % confidence intervals for the estimated strength of persistence. We finish this paper by quantifying long-range persistence (and corresponding uncertainties) of three geophysical time series—palaeotemperature, river discharge, and Auroral electrojet index—with the three representing three different types of probability distribution—Gaussian, log-normal, and Levy, respectively.
Similar content being viewed by others

1 Introduction
Time series can be found in many areas of the Earth Sciences and other disciplines. After obvious periodicities and trends have been removed from a time series, the stochastic component remains. This can be broadly broken up into two parts: (1) the statistical frequency-size distribution of values (how many values at a given size) and (2) the correlations between those values (how successive values cluster together, or the memory in the time series). In this paper, and because of their importance and use in the broad Earth Sciences, we will compare the strengths and weaknesses of commonly used measures for quantifying a frequently encountered type of memory, long-range persistence, also known as long-memory or long-range correlations.
This paper is organized as follows. In this introduction section we introduce long-range persistence and its importance in the Earth Sciences. We then provide in Sect. 2 a brief background to processes and time series and in Sect. 3 a more detailed background to long-range persistence. Section 4 describes the synthetic time series construction and presentation of the synthetic noises (with normal, log-normal, and Levy one-point probability distributions) that we will use for evaluating the strength of long-range persistence. This is followed in Sect. 5 (time domain techniques) and Sect. 6 (frequency-domain techniques) with a description of several prominent techniques (Hurst rescaled range analysis, semivariogram analysis, detrended fluctuation analysis, and power spectral analysis) for measuring the strength of long-range persistence. Section 7 presents the results of the performance analyses of the techniques, with in Sect. 8 a discussion of the results. In Sect. 9, benchmark-based improvements to the estimators for long-range dependence that are based on the techniques described in Sects. 5 and 6 are introduced. Section 10 is devoted to applying these tools to characterize the long-range persistence of three geophysical time series. These three time series—palaeotemperature, river discharge, and Auroral electrojet index—represent three different types of one-point probability distribution—Gaussian, log-normal, and Levy, respectively. Finally, Sect. 11 gives an overall summary and discussion.
After the paper’s main text, five appendices give details of the construction of synthetic noises used in this paper and the fitting of power laws to data. Additionally, to accompany this paper, are four sets of electronic supplementary material: (1) 1,260 synthetic fractional noise examples and an R program for creating them, (2) an R program for the user to run the five types of long-range persistence analyses described in this paper, (3) an Excel spread sheet which includes detailed summary results of the performance tests applied here to 6,500 different sets of time series parameters, and a calibration spreadsheet/graph for the user to do benchmark-based improvement techniques, and (4) a PDF file with the 41 figures from this paper at high resolution.
We now introduce the idea of long-range persistence in the context of the Earth Sciences, with many of these ideas explored in more depth in later sections. Many time series in the Earth Sciences exhibit persistence (memory) where successive values are positively correlated; big values tend to follow big and small values follow small. The correlations are the statistical dependence of directly and distantly neighboured values in the time series. Besides correlations caused by periodic components, two types of correlations are often considered in the statistical modelling of time series: short-range (Priestley 1981; Box et al. 1994) and long-range (Beran 1994; Taqqu and Samorodnitsky 1992). Short-range correlations (persistence) are characterized by a decay in the autocorrelation function that is bounded by an exponential decay for large lags; in other words, a fixed number of preceding values influence the next value in the time series. In contrast, long-range correlated time series (of which a specific subclass is sometimes referred to as fractional noises or 1/f noises) are such that any given value is influenced by ‘all’ preceding values of the time series and are characterized by a power-law decay (exact or asymptotic) of the correlation between values as a function of the temporal distance (or lag) between them.
This power-law decay of values can be better understood in the context of self-similarity and self-affinity. Mandelbrot (1967) introduced the idea of self-similarity (and subsequently fractals) in the context of the coast of Great Britain where the same approximate coastal shape is found at multiple scales. He found a power-law relationship between the total length of the coast as a function of the segment length, with the power-law exponent parameter called the fractal dimension. The concept of fractals to describe spatial objects has become widely used in the Earth Sciences (in addition to other disciplines). Mandelbrot and van Ness (1968) extended the idea of self-similarity in spatial objects to time series, calling the latter a self-affine fractal or a self-affine time series when appropriately rescaling the two axes produces a time series that is statistically similar.
In a self-affine time series, the strength of the variations at a given frequency varies as a power-law function of that frequency. Thus, a large range of frequencies are influenced. In other words, any given value in a time series is influenced by all other values preceding it, with the values themselves forming a self-similar pattern and the self-affine time series exhibiting, by definition, long-range persistence. The strength of long-range correlations can be related to the fractal dimension (Voss 1985; Klinkenberg 1994) and influences the efficacy and appropriateness of long-range persistent algorithms chosen.
Self-affine time series (long-range persistence) have been discussed and documented for many processes in the Earth Sciences. Examples include river run-off and precipitation (Hurst 1951; Mandelbrot and van Ness 1968; Montanari et al. 1996; Kantelhardt et al. 2003; Mudelsee 2007; Khaliq et al. 2009), atmospheric variability (Govindan et al. 2002), temperatures over short to very long time scales (Pelletier and Turcotte 1999; Fraedrich and Blender 2003), fluctuations of the North-Atlantic Oscillation index (Collette and Ausloos 2004), surface wind speeds (Govindan and Kantz 2004), the geomagnetic auroral electrojet index (Chapman et al. 2005), geomagnetic variability (Anh et al. 2007), and ozone records (Kiss et al. 2007).
Although long-range persistence has been shown to be a part of many geophysical records, physical explanations for this type of behaviour and geophysical models that describe this property appropriately are less common. In one example, Pelletier and Turcotte (1997) modelled long-range persistence found in climatological and hydrological time series with an advection–diffusion model of heat and water vapour in the atmosphere. In another example, Blender and Fraedrich (2003) modelled long-range persistent surface temperatures by coupled atmosphere–ocean models and found different persistence strengths for ocean and coastal areas. In a third example, Mudelsee (2007) proposed a hydrological model, where a superposition of short-range dependent processes with different model parameters results in a long-range persistent process; he modelled river discharge as the spatial aggregation of mutually independent reservoirs (which he assumed to be first-order autoregressive processes).
Long-range persistent behaviour occurs also in a few (but not in all) models of self-organized criticality (Bak et al. 1987; Turcotte 1999; Hergarten 2002; Kwapień and Drożdż 2012); as an example the Bak–Sneppen model (Bak and Sneppen 1993; Daerden and Vanderzande 1996) is a simple model of co-evolution between interacting species and has been used to describe evolutionary biological processes. The Bak–Sneppen model has also been extended to solar and geophysical phenomena such as X-ray bursts at the Sun’s surface (Bershadskii and Sreenivasan 2003), solar flares (Meirelles et al. 2010), and for Earth’s magnetic field reversals (Papa et al. 2012). Nagler and Claussen (2005) found that cellular automata models (i.e. grid-based models with simple nearest-neighbour rules of interaction) can also generate long-range persistent behaviour.
Physical explanations and models for long-range persistence are certainly a strong step forward in the published literature, rather than ‘just’ documentation of persistence (based on the statistical properties of measured data) itself. However, these physical explanations in the community are often confounded by the following: (1) a confusion of whether asymptotic or the more specific case of self-affine long-range persistence is being explored; (2) in the case of some models, such as ‘toy’ cellular automata models and some ‘philosophical’ models, a lack of sensitivity in the model itself, so that any output tends towards some sort of universal behaviour; and (3) sometimes non-rigorous and visual comparison of any model output (which itself is based on a simplification of the physical explanations) with ‘reality’. As such, these physical explanations and models are welcome, but are often met with a bit of scepticism by peers in any given community (e.g., see Frigg 2003).
Long-range correlations are also generic to many chaotic systems (Manneville 1980; Procaccia and Schuster 1983; Geisel et al. 1985, 1987), for which a large class of models in the geosciences has been designed. Furthermore, over the last decade it has become clear that long-range correlations are not only important for describing the clustering of the time series values (i.e. big or small values clustering together), but are also one of the key parameters for describing the return times of and correlations between values in a series of extremes over a given threshold (Altmann and Kantz 2005; Bunde et al. 2005; Blender et al. 2008) and for characterizing the scaling of linear trends in short segments of the considered time series (Bunde and Lennartz 2012).
Most empirical studies of self-affinity and long-range persistence compare different techniques or discuss the minimal length of the time series to ensure reliable estimates of the strength of long-range dependence. There are few (e.g., Malamud and Turcotte 1999a; Velasco 2000) systematic studies on the influence of one-point probability distributions (e.g., normal vs. other distributions) on the performance of the estimators. As many time series in the geosciences have a one-point probability density that is heavily non-Gaussian, we will in this paper systematically examine different synthetic time series with varying strengths of long-range persistence and different statistical distributions. By doing so, we will repeat and review parts of what has been found previously, confirming and/or highlighting major issues, but also systematically examine non-Gaussian time series in a manner previously not done, particularly with respect to heavy-tailed frequency-size probability distributions. We will thus establish the degree of utility of common techniques used in the Earth Sciences for examining the presence or absence, and strength, of long-range persistence, by using synthetic time series with probability distributions and number of data values similar to those commonly found in the geosciences.
2 Time Series
In this section we give a brief background to processes and time series, along with an introduction to three geophysical time series examples that we consider in this paper. Records of geophysical processes and realizations of their models can be represented by a time series, x t , t = 1, 2, …, N, with t denoting the time index of successive measurements of x t separated by a sampling interval Δ (including units), and N the number of observed data points. The (sample) mean \( \bar{x} \) and (sample) variance \( \sigma_{x}^{2} \) of a time series are as follows:
The (sample) standard deviation σ x is the square root of the (sample) variance. A table of variables used in this paper is given in Table 1.
We distinguish here between a process and a time series. An example of a stochastic process is a first-order autoregressive (AR(1)) process:
with ϕ 1 a constant (−1 < ϕ 1 < 1), ε t a white noise, and the value at time t (i.e. x t ) determined by the constant, white noise, and the value at time t–1 (i.e. x t–1). This is a very specific process given by Eq. (2). An example of a time series would be a realization of this process. We will discuss in more depth this AR(1) process in Sect. 3.1.
We can also have other processes which are not described by a simple set of equations, for example, geoprocesses (e.g., climate dynamics, plate tectonics) or a large experimental set-up where the results of the experiment are data; the process in the latter case is the physical or computational interactions in the experiment. In the geosciences, often just a single or a very few realizations of a process are available (e.g., temperature records, recordings of seismicity), unless one does extensive model simulations, where hundreds to thousands of realizations of a given process might be created. Each realization of a process is called a time series. In the geosciences, with (often) just one time series, which is itself one realization of a process, we then attempt to infer from that single realization (the time series), properties of the process. The process can be considered to be the ‘underlying’ physical mechanism or equation or theory for a given system.
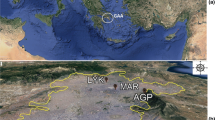
We now consider three diverse examples of time series from the Earth Sciences, which after presenting here, we will return to in Sect. 10 as geophysical examples to which we apply the long-range persistence techniques evaluated in this paper. The first time series (Fig. 1a) is the bi-decadal δ18O record of the Greenland Ice Sheet Project Two (GISP2) data (Stuiver et al. 1995) for the last 10,000 years (500 values at 20 year intervals) and shows the departure of the ratio of 18O to 16O isotopes in the core versus a standard, in parts per mil (parts per thousand or ‰). This measure is considered a proxy for Greenland air temperature (Stuiver et al. 1995). The second time series (Fig. 1b) is daily discharge from the Elkhorn River (USGS 2012) in Nebraska at Waterloo (USGS station 06800500) with a drainage area of 17,800 km2 and for the 73 year period 1 January 1929 to 30 December 2001. The third time series (Fig. 1c) is the geomagnetic auroral electrojet index (AE index) sampled per minute (Kyoto University 2012), both the original series (Fig. 1c) and the first difference (Fig. 1d), and quantifies variations of the auroral zone horizontal magnetic field activity (Davis and Sugiura 1966) of the Northern Hemisphere.

Three examples of geophysical time series exhibiting long-range persistence. a Bi-decadal oxygen isotope data set δ18O (proxy for palaeotemperature) from Greenland Ice Sheet Project Two (GISP2) for the last 10,000 years (Stuiver et al. 1995), with 500 values given at 20 year intervals. b Discharge of the Elkhorn river (at Waterloo, Nebraska, USA) sampled daily for the period from 01 January 1929 to 30 December 2001 (USGS 2012). c The geomagnetic auroral electrojet (AE) index sampled per minute for the 24 h period of 01 February 1978 (Kyoto University 2012). d The differenced AE index, \( \Delta x_{\text{AE}} (t) = x_{\text{AE}} (t) - x_{\text{AE}} (t - 1) \) from (c), with Δ = 1 min; note that the units of Δx AE are the units of x AE divided by minutes. To the right of each time series are given the normalized histograms of the data sets with best-fitting models for one-point probability densities, with those probabilities corresponding to (a) and (b) on a linear axis, and (d) the probability given on a logarithmic axis
For each of the three time series in Fig. 1a,b,d are given the data in time (left) and their respective probability densities and underlying probability distributions (right). Each time series is equally spaced in time, with respective temporal spacing as follows: palaeotemperature Δ = 20 years, river discharge Δ = 1 day, and AE index Δ = 1 min (minute). However, the visual appearance when the three time series are compared is different. These ‘time impressions’ rely on the statistical frequency-size distribution of values (how many values at a given size) and the correlation between those values (how successive values cluster together, or the memory in the time series).
Visual examination of the probability distributions (Fig. 1, right) of the three time series confirms that they capture what we see in the time series (left) and provides some insight into their statistical character. The distribution of values in the time series x temp (Fig. 1a) is broadly symmetric—with a mean value at about −34.8 [per mil] and with few extremes lower than −36 [per mil] or greater than −34 [per mil]. We see an underlying probability distribution that is symmetric, and most likely Gaussian.
The river discharge series shown in Fig. 1b consists of positive values 0 ≤ x discharge ≤ 2,656 m3 s−1. Note that two values are larger than 1,500 m3 s−1 and not shown on the graph. Its underlying probability distribution shown to the right is highly asymmetric; in other words, there are very few very large values (x discharge > 500 m3 s−1) and many smaller values, a distribution with a long tail of larger values on the right-hand side. This distribution can be approximated by a log-normal distribution.
The differenced AE index Δx AE series presented in Fig. 1d has values between −120 and 140 [W min−2] and is approximately symmetric around zero. Despite its symmetry, its underlying probability distribution is different from the Gaussian-like distributed palaeotemperature series x temp presented in Fig. 1a. Here, the fraction of values in the centre and at the very tails of the distribution is larger, showing double-sided power-law behaviour of the probability distribution (Pinto et al. 2012). These probability densities can be approximated by a Levy probability distribution.
While correlations within each of the three types of geophysical time series given in Fig. 1 (left) are more difficult to compare visually, all three time series exhibit some persistence: large values tend to follow large ones, and small values tend to follow small ones. The relative ordering of small, medium, and large values creates clusters (or lack of clusters) which we can make some attempts to observe visually. The palaeotemperature series (Fig. 1a) appears to have small clusters, contrasting with the discharge series (Fig. 1b) and the differenced AE index series (Fig. 1d), which appear to have larger clusters. One might argue, although it is difficult to do this visually, that the latter two time series therefore exhibit a higher ‘strength’ of persistence. Measures for quantifying persistence strength will be introduced formally in Sect. 3.1. We can also look at the roughness or ‘noisiness’ of the time series. The palaeotemperature series (Fig. 1a) appears to have the most scatter followed by the river discharge (Fig. 1b) and the differenced AE index (Fig. 1d), although, again, it is difficult to compare these visually, between clearly very different types of time series. These considerations show that it is sometimes difficult to grasp the strength of persistence visually from the time series itself.
One method commonly used (e.g., Tukey 1977; Andrienko and Andrienko 2005) to examine correlations between pairs of values at lag τ for a given time series is to plot x t+τ on the y-axis and x t on the x-axis, in other words lagged scatter plots. In Fig. 2, we give lagged scatter plots of the three geophysical time series shown in Fig. 1, each shown for lag τ = 1 (with units depending on the respective units of each time series). The resultant graphs give a measure of the dependence on the preceding values, with overall positive correlation given by a positive diagonal line. The ellipse-shaped scatter plots in Fig. 2b,c indicate correlations, whereas the scatter in Fig. 2a,d indicates much less dependence of a given value on its preceding value (i.e. less correlation for a lag τ = 1). However, one could consider other lags (e.g., instead of a lag of 1 day for the discharge, one might consider a lag of 1 year) or consider a range of lags together, from short-range in time to long-range. More quantitative techniques for considering the strength of correlations (persistence) will be introduced in the next section (Sect. 3), where we formally define persistence and persistence strength.

Lagged scatter plots of the three geophysical time series shown in Fig. 1. a Bi-decadal oxygen isotope data set δ18O (proxy for palaeotemperature). b Discharge of the Elkhorn river. c The geomagnetic auroral electrojet (AE) index. d The differenced geomagnetic auroral electrojet index. For each time series from Fig. 1, on the y-axis are shown x t+1 values and on the x-axis x t , giving their dependence on the preceding values
3 Long-Range Persistence
In this section we first introduce a general quantitative description of correlations in the context of the autocorrelation function and with examples from short-range persistent models (Sect. 3.1). We then give a formal definition of long-range persistence along with a discussion of stationarity (Sect. 3.2), examples of long-range persistent time series and processes from the social and physical sciences (Sect. 3.3), a discussion of asymptotic long-range persistence versus self-affinity (Sect. 3.4), and a brief theoretical overview of white noise and Brownian motion (Sect. 3.5) and conclude with a discussion and overview of fractional noises and motions (Sect. 3.6).
3.1 Correlations
As introduced in Sects. 1 and 2, correlations describe the statistical dependence of directly and distantly neighboured values in a process. These statistical dependencies can be assessed in many different ways, including joint probability distributions between neighbouring values that are separated by a given lag and quantitative measures for the strength of interdependence, such as mutual information (e.g., Shannon and Weaver 1949) or correlation coefficients (e.g., Matheron 1963). In the statistical modelling of time series (realizations of a process), two types of correlations (persistence) can be considered:
-
1.
Short-range correlations where values are correlated to other values that are in a close temporal neighbourhood with one another, that is, values are correlated with one another at short lags in time (Priestley 1981; Box et al. 1994).
-
2.
Long-range correlations where all or almost all values are correlated with one another, that is, values are correlated with one another at very long lags in time (Beran 1994; Taqqu and Samorodnitsky 1992).
Persistence is where large values tend to follow large ones, and small values tend to follow small ones, on average more of the time than if the time series were uncorrelated. This contrasts with anti-persistence, where large values tend to follow small ones and small values large ones. For both persistence and anti-persistence, one can have a strength that varies from weak to very strong. We will consider in this paper models (processes) for both persistence and anti-persistence.
One technique by which the persistence (or anti-persistence) of a time series can be quantified is the autocorrelation function. The autocorrelation function C(τ), for a given lag τ, is defined as follows (Box et al. 1994):
where again \( \bar{x} \) is the sample mean, \( \sigma_{x}^{2} \) the sample variance (Eq. 1), and N the number of values in the time series. Here one multiples a given value of the time series x t (mean removed) with the value x t+τ (mean removed), for τ steps later (the lag), sums them up, and then normalizes appropriately. The autocorrelation function of a process is the ensemble average of the autocorrelation function applied to each of many time series (realizations of the process).
For zero lag (τ = 0 in Eq. 3), and using the definition for variance (Eq. 1), the autocorrelation function is C(0) = 1.0. For processes considered in this paper, we find that as the lag, τ, increases, τ = 1, 2, …, (N − 1), the autocorrelation function C(τ) decreases and the correlation between x t+τ and x t decreases. Positive values of C(τ) indicate persistence, negative values indicate anti-persistence, and zero values indicate no correlation. Various statistical tests exist (e.g., the Q K statistic, Box and Pierce 1970) that take into account the sample size of the time series, and values of C(τ) for those τ calculated, to determine the significance of rejecting the time series as being correlated. A plot of C(τ) versus τ is known as a correlogram. A rapid decay of the correlogram indicates short-range correlations, and a slow decay indicates long-range correlations.
A number of fields use time series models based on short-range persistence (e.g., hydrology, Bras and Rodriguez-Iturbe 1993). As an illustration of the autocorrelation function, we will apply it to a short-range persistent model. Several empirical models have been used to generate time series with short-range correlations (persistence) (Thomas and Hugget 1980; Box et al. 1994). Here we use the AR(1) (autoregressive order 1) process introduced in Eq. (2). In Fig. 3 we give four realizations of an AR(1) process for four different values of the constant ϕ 1 = 0.0, 0.2, 0.4, 0.8. With increasing values of ϕ 1, the persistence (and clustering) becomes stronger, as evidenced by large values becoming more likely to follow large ones, and small values followed by small ones; we also observe for increasing ϕ 1 that the variance of the values in each realization increases. We apply the autocorrelation function C(τ) (Eq. 3) to each time series given in Fig. 3 and give the resulting correlograms in Fig. 4.


Correlograms of four AR(1) time series. The autocorrelation function C(τ) in Eq. (3) is applied to the four AR(1) time series shown in Fig. 3 with the parameter ϕ 1 changing from top to bottom as indicated in the figure panels, for lags 0 ≤ τ ≤ 70 (unitless), with results shown in small circles. Also shown (dashed line) is the theoretical prediction for AR(1) process, \( C\left( \tau \right) = \phi_{1}^{\tau } \) (Eq. 5)
The absolute value of the autocorrelation function for short-range correlations is bounded by an exponential decay (Beran 1994):
where κ 0 and κ are constants. For an AR(1) process (Eq. 2), if we let κ 0 = 1 and \( \exp \left( { - \kappa } \right) = \phi_{1} \) in Eq. (4), with −1 < ϕ < 1 (a condition for the process to be stationary), then, at lag τ, the autocorrelation function of the AR(1) process can be shown to be (Box et al. 1994; Swan and Sandilands 1995):
We plot this autocorrelation function of the AR(1) process (Eq. 5) in Fig. 4 (dashed lines) and find excellent agreement with each of the four realizations.
Other examples of empirical models for short-range persistence in time series include the moving average (MA) model and the combination of the AR and MA models to create the ARMA model. Reviews of many of these models are given in Box et al. (1994) and Chatfield (1996). There are many applications of short-range persistent models in the social and physical sciences, ranging from river flows (e.g., Salas 1993), and ecology (e.g., Ives et al. 2010) to telecommunication networks (e.g., Adas 1997).
As a further example of the autocorrelation function applied to time series, in Fig. 5, we show the correlogram of the three geophysical time series discussed in Sect. 2 (see Fig. 1). The autocorrelation functions shown in Fig. 5a (palaeotemperature) and Fig. 5b (river discharge) decay slowly to zero over dozens of lag values and thus indicate correlations. One potential indication of long-range versus short-range correlations is in its slow decay rate. We will find later (Sect. 10) that these correlations are in fact long-range, but for the moment, visually, this conclusion cannot be made. The autocorrelation function of the river discharge time series shown in Fig. 5b shows additional periodic components which reflect the seasonal character of the time series. In Fig. 5c (differenced AE index) the autocorrelation function does not show correlations; in Sect. 10 we will evaluate whether there is any long-range anti-persistence in the time series, but again, visually, we cannot make this conclusion at this point. We now introduce more formally and generally long-range persistence.

Autocorrelation function of the three geophysical time series shown in Fig. 1, given as a function of increasing lag. a Bi-decadal oxygen isotope data set δ18O (proxy for palaeotemperature). b Discharge of the Elkhorn river. c The differenced geomagnetic auroral electrojet index
3.2 Formal Definition of Long-range Persistence
Long-range persistence is a common property of records of the variation of spatially or temporarily aggregated variables (Beran 1994). In contrast to short-range persistent processes, a long-range persistent process exhibits a power-law scaling of the autocorrelation function (Eq. 3) such that (Beran 1994, p. 64)
holds for large time lags τ. This is a formal definition of long-range persistence. The parameter β is the strength of long-range persistence, with β = 0 a process that has no long-range persistence between values, β > 0 long-range persistence, and β < 0 long-range anti-persistence. We will discuss the parameter β in more detail in Sect. 3.4. The autocorrelation function is, however, limited over the range with which it can evaluate the long-range persistence strength of a process (if it is long range), −1 < β < 1. We therefore turn to the spectral domain, for a definition which holds for a larger range of β.
In the spectral domain, the power spectral density, S, measures the frequency content of a process. Over many realizations, approaching N very large, the average measured S at a given frequency will approach the actual processes’ power at that frequency. To avoid a detailed technical explanation here, we will discuss in depth the calculation of S, which is based on the Fourier transform, in Sect. 6. A process can be defined as long-range persistent if S (averaged over multiple realizations) scales asymptotically as a power law for frequencies close to the origin (f → 0) (Beran 1994):
where the power-law exponent, β, measures the strength of persistence. Averaged over many realizations, the power spectral density of the process will approach a scatter-free power-law curve as the number of realizations increases to large numbers.
Another way to define long-range persistence is in terms of the square of the fluctuation function, F 2 (Peng et al. 1992):
obtained by dividing the time series x t into non-overlapping segments of length l (l < N), and for each successive segment calculating the variance of the x t values, \( \sigma_{x}^{2} \), and then taking the mean, \( \overline{{\sigma_{x}^{2} }} \). The square brackets in \( \sigma^{2}\)[ ] indicate taking the variance over the terms in the bracket. The variables l and N are always integers. In the summation range, for the case that N/l is non-integer, we take the largest integer that is less than N/l, which is noted in Eq. (8) by [N/l]. For the cases of a long-range persistent time series with β > 1 the power-law shape of the power spectral density (Eq. 7) is equivalent to a power-law scaling of the fluctuation function (Peng et al. 1992):
with α ≠ 0.5. Equation (9) holds in the limit of large segment lengths l (and only for those time series with β > 1). The strength of long-range persistence, β, is related to the scaling parameter of the fluctuation function, α, as β = 2α + 1. To make this concept applicable for time series with a strength of long-range persistence β < 1, the aggregated series (also known as the running sum or integrated series, see Sect. 3.5) of the time series can be analysed, but this method works well only in the case of large number of values in the time series, N (Taqqu 1975; Mandelbrot 1999). When aggregating a time series with ‘smaller’ N, which is the case for most time series being examined in the Earth Sciences, then one must take care that the one-point probability distribution is quasi-symmetrical (e.g., Gaussian, Levy) (Mandelbrot and van Ness 1968; Samorodnitsky and Taqqu 1994).
One important aspect of a time series is the stationarity of its underlying process (Witt et al. 1998). A process is said to be strictly stationary if all moments (e.g., mean value, \( \bar{x} \); variance, \( \sigma_{x}^{2} \); kurtosis) over multiple time series realizations do not change with time t and, in particular, do not depend on the length of the considered time series. Second-order or weak stationarity (Chatfield 1996) requires that the means and standard deviations for different sections of a time series—again taken over multiple realizations (i.e. the process) and for different section lengths—have autocorrelation functions that are approximately the same.
3.3 Long-Range Persistence in the Physical and Social Sciences
As discussed in the introduction (Sect. 1), long-range persistence has been quantified and explored for many geophysical time series and processes. However, it is an important and well-studied attribute for time series and processes in many other disciplines where persistence-displaying patterns have been identified, for example:
-
The 1/f behaviour of voltage and current amplitude fluctuations in electronic systems modelled as a superposition of thermal noises (Schottky 1918; Johnson 1925; van der Ziel 1950).
-
Trajectories of tracer particles in hydrodynamic flows (Solomon et al. 1993) and in granular material (Weeks et al. 2000).
-
Condensed matter physics (Kogan 2008).
-
Neurosciences (Linkenkaer-Hansen et al. 2001; Bédard et al. 2006).
-
Econophysics (Mantegna and Stanley 2000).
In biology, long-range persistence has been identified in:
-
Receptor systems (Bahar et al. 2001).
-
Human gait (Hausdorff et al. 1996; Delignieres and Torre 2009).
-
Human sensory motor control system (Cabrera and Milton 2002; Patzelt et al. 2007) and human eye movements during spoken language comprehension (Stephen et al. 2009).
-
Heart beat intervals (Kobayashi and Musha 1982; Peng et al. 1993a; Goldberger et al. 2002).
-
Swimming behaviour of parasites (Uppaluri et al. 2011).
Furthermore, long-range persistence is typical for musical pitch, rhythms, and loudness fluctuations (Voss and Clarke 1975; Jennings et al. 2004; Hennig et al. 2011; Levitin et al. 2012) and for dynamics on networks such as internet traffic (Leland et al. 1994; Willinger et al. 1997). Long-range dependence is an established concept in describing stock market prices (Lo 1991).
However, with the widespread identification of long-range persistence in physical and social systems has come a concern by those (Rangarajan and Ding 2000; Maraun et al. 2004; Gao et al. 2006; Rust et al. 2008) who believe that long-range persistence has often been incorrectly identified in time series, and who believe instead that many time series are in fact short-range persistent. One part of the confusion surrounding the issue of short-range versus long-range persistence is that of a frequent lack of knowledge as to the process involved that drives the persistence. This can take the form of lack of knowledge of underlying driving equations, physical process, or even a lack of understanding of the variables in the system being studied.
Another major issue, which we explore in more detail in the following section, is the semantics as to what we call long-range persistence. There are at least two ways of thinking about long-range persistence, which we will call asymptotic long-range persistence and self-affine long-range persistence. These are simply called ‘long-range persistence’ in much of the literature and interchanged without the reader knowing which is being addressed.
3.4 Asymptotic Long-Range Persistence Versus Self-Affinity
Asymptotic long-range persistence is the general case where the power-law scaling in Eq. (7) holds in the limit f → 0. Self-affine long-range persistence is the more specific case, where the scaling in Eq. (7) holds for all f, the power spectral density is now scale invariant, and we call this a self-affine time series. In Fig. 6, we have drawn five cartoon examples of the frequency-domain signature of time series, where power spectral density S (Eq. 7) is given as a function of frequency f, on logarithmic axes. Self-affine behaviour (i.e. power-law scaling over the entire frequency range) is presented by the black straight line (a perfect power-law dependence). The other four curves demonstrate very different examples of the power spectral densities scaling asymptotically with a power-law for small frequencies (i.e. f → 0). The orange dashed line demonstrates two scaling ranges and is characterized by two corresponding power-law exponents.

Cartoon sketch of power spectral densities of a self-affine and four other long-range persistent processes. Self-affine behaviour (i.e. power-law scaling over the entire frequency range) is presented by the black straight line (identified by equation and arrow). The other four examples (blue, red, orange, and green dashed lines) represent cartoon examples of power spectral densities that scale asymptotically with a power law for small frequencies, with the red dashed line (second from top) an asymptotic example superimposed by a periodicity, and the orange dashed line (third from top) demonstrating two scaling ranges that are characterized by two corresponding power-law exponents
In both the more general case of asymptotic long-range persistence (i.e. scaling only in the limit f → 0) and the less general case of self-affine time series (scaling for all f), positive exponents β in Eq. (7) represent positive (long-range) persistence and negative ones (β < 0) anti-persistence. For the specific case of self-affine long-range persistence, a value of β = 0 is an uncorrelated time series (e.g., a white noise), and a value of β = 1 is known also as a 1/f or pink or flicker noise (Schottky 1918; Mandelbrot and van Ness 1968; Keshner 1982; Bak et al. 1987). Various colour names are used to refer to different strengths of long-range persistence, with some confusion in both the grey (e.g., internet) and peer-reviewed literature as to (1) whether the names referred to for some specific strengths of persistence are for asymptotic long-range persistence or the more specific self-affine case and (2) the specific colour names used for a given strength of persistence. A general survey gives the following colour names for different strengths of long-range persistence († = generally accepted terms in established literature sources or standards, e.g., see ATIS 2000):
β = −2.0 | violet, purple |
β = −1.0 | blue† |
β = 0.0 | white† |
β = 1.0 | pink†, flicker† |
β = 2.0 | brown†, red† |
β > 2.0 | black |
Brown noise is the result of a Brownian motion process which we discuss further below and which we have referred to as simply ‘Brownian motion’ in this paper.
For the general asymptotic case (scaling in the limit f → 0), a value of β = 0 stands for short-range persistence (Beran 1994). This type of persistence is typical for such linear stochastic processes as moving average (MA) or autoregressive (AR) processes (Priestley 1981) and is also known under the names of blue, pink, or red noise (Hasselmann 1976; Kurths and Herzel 1987; Box et al. 1994). However, there is different usage of colour names by different authors in the literature as to the specific type of short-range persistence being referred to. In addition, colours like ‘pink’ and ‘red’ have one meaning for short-range persistence (e.g., any increase in power in the lower frequencies) and another for long-range (a strength of long-range persistence of β = 1 and 2, for pink and red, respectively). This has caused a bit of confusion between different groups of researchers in terms of false assumptions as to the specific kind of process (e.g., short-range vs. long-range) being explored based on the terminology used. We now discuss white noises and Brownian motion.
3.5 White Noises and Brownian Motions
A Gaussian white noise is a classic example of a stationary process, with a mean \( \bar{x} \) and a variance \( \sigma_{x}^{2} \) of the values specified. A realization of a Gaussian white noise is shown in Fig. 7a. In this time series, the values are uncorrelated with one another, with an equal likelihood at each time step of a value being larger or smaller than the preceding value. The autocorrelation function (Eq. 3) for a Gaussian white noise is C(τ) = 0 for all lags τ > 0. Other one-point probability distributions can also be considered. For example, in Fig. 7b,c, respectively, are given a realization of a log-normal and a Levy-distributed white noise. In Sect. 4 we will examine in more detail the Gaussian, log-normal, and Levy one-point probability distributions. These uncorrelated time series (white noises) will provide the basis for the construction of fractional noises and motions that we will use as benchmarks for this paper. Uncorrelated time series can also be created by many computer programs (e.g., Press et al. 1994), using ‘random’ functions, but care must be taken that the time series are truly uncorrelated and that the frequency-size distribution is specified. An example where these issues are discussed in the context of landslide time series is given by Witt et al. 2010.

Realizations of uncorrelated time series, time series length N = 1,024, and the following one-point probability distributions: a Gaussian, b log-normal (constructed with Box–Cox transform), c v = 0.5, c Levy, a = 1.5. Each time series has been normalized to have mean 0 and variance 1. In d is shown the aggregation (running sum, Eq. 10) of these three uncorrelated time series
The classic example of a non-stationary process is a Brownian motion (Brown 1828; Wang and Uhlenbeck 1945), which is obtained by summing a Gaussian white noise with zero mean. Einstein (1905) showed that, for the motion of a molecule in a gas which follows a Brownian motion, the mean square displacement grows linearly with the time of observation. This corresponds to a scaling parameter of the fluctuation function (Eq. 9) of α = 0.5 and consequently to a strength of long-range persistence of β = 2. Therefore, the value β = 2 corresponds to Brownian motion and the theory of random walks (Brown 1828; Einstein 1905; Chandrasekhar 1943) and describes ‘ordinary’ diffusion. A Brownian motion is an example of a self-affine long-range persistent process that has a strength of persistence that is very strong. Persistence strength β with β ≠ 2 characterizes ‘anomalous’ diffusion with 1 < β < 2 related to subdiffusion and β > 2 to superdiffusion (Metzler and Klafter 2000; Klafter and Sokolov 2005).
A Brownian motion process is given by multiple realizations of the aggregated time series, s t :
where x i is (in this case) our white (uncorrelated) noise, ε i . These aggregated series are also known as running sums, integrated series, or first profiles. The white noises illustrated in Fig. 7a,b,c have been summed to give the Brownian motions in Fig. 7d.
The variance of a Brownian motion created from Gaussian or log-normal white noises, after t values, is given by
where \(\sigma \) x is the standard deviation of the white noise sequence. In Fig. 8a, we show the superposition of 20 Brownian motions, each created from a realization of a Gaussian white noise with mean zero and variance one. The fluctuations around zero grow with the time index of the aggregated time series. The relation from Eq. (11) is included in the figure, as the dashed line parabola, illustrating the drift of the Brownian motions. Brownian motions have no origin defined, and successive increments are uncorrelated. Shown in Fig. 8b,c, respectively, are the multiple realizations of aggregates for log-normal and Levy-distributed white noises. For aggregated log-normal white noises, the fluctuations scale, on average, following Eq. (11), but the same is not true for Levy noises, because a Levy noise has no defined variance (discussed in more depth in Sect. 4). The heavy tails of the Levy distribution in Fig. 7 lead in Fig. 8 to ‘jumps’ of the aggregated series.

Ensembles of 20 realizations of the running sums of the three different types of uncorrelated noises shown in Fig. 7. Shown are running sums with time series length N = 1,024, for the following one-point probability distributions: a Gaussian, b log-normal (constructed with Box–Cox transform), c v = 0.5, c Levy, a = 1.5. For (a) and (b), shown by the dashed line envelopes is ±t 0.5, (see Eq. (11)), the theoretical deviation with time of the ensemble of the running sum of these two uncorrelated processes
3.6 Fractional Noises and Fractional Motions
In the last section we considered white noises and Brownian motions. Here, we consider fractional noises and fractional motions. Applying our definition of (weak) stationarity given in Sect. 3.2, an asymptotic long-range persistent noise (scaling in the limit f → 0) is a (weakly) stationary time series if the strength of persistence β < 1 (Malamud and Turcotte 1999b). We will refer to these long-range persistent weakly stationary (β < 1) time series as fractional noises. For stronger values of long-range persistence (β > 1), the means and standard deviation are no longer defined since they now depend on the length of the series and the location in the time series. We will refer to these long-range persistent non-stationary (β > 1) time series as fractional motions. The value β = 1 represents a crossover value between (weakly) stationary and non-stationary processes, and between fractional noises and motions; this value is sometimes considered a fractional noise or motion, depending on the context. For very small values of the strength of long-range persistence (β < −1), the corresponding processes are unstable (Hosking 1981); these processes cannot be represented as AR models (generalization of the process in Eq. 2 to processes that incorporate more lags). In Sect. 4.2 we will construct and give examples of both fractional noises and motions, but intuitively, as the value of β increases, the contribution of the high-frequency (short-period) terms is reduced.
Just as previously we summed a Gaussian white noise with β = 0.0 to give a Brownian motion with β = 2.0 (Fig. 7), one can also sum fractional Gaussian noises (e.g., β = 0.7) to give fractional Brownian motions (e.g., β = 2.7), so that the running sum will result in a time series with β shifted by +2.0 (Malamud and Turcotte 1999a). This relationship is true for any symmetrical frequency-size distribution (e.g., the Gaussian) and long-range persistent time series. Analogous results hold for differencing a long-range persistent process (e.g., the first difference of a fractional motion with β = 1.5 will have a value of β = −0.5). However, for self-affine processes the aggregation and differencing results in processes that are asymptotic long-range persistent but not self-affine (Beran 1994), although our studies show that they are almost self-affine.
Another way of constructing long-range persistent processes is the superposition of short-memory processes with suitably distributed autocorrelation parameters (Granger 1980). This has been used to give a physical explanation of the Hurst phenomenon of long memory in river run-off (Mudelsee 2007). Eliazar and Klafter (2009) have applied two similar approaches, the stationary superposition model and the dissipative superposition model, to describe the dynamics of systems carrying heavy information traffic. The resultant processes are Levy distributed and long-range persistent.
Both the general case of asymptotic long-range persistence (e.g., temperature records, Eichner et al. 2003, see also Sects. 3.3 and 3.4 of this paper) and the more specific case of self-affine long-range persistence (many examples will be given in subsequent sections) are commonly identified in the Earth Sciences. In this paper, because self-affine time series are commonly found in the Earth Sciences and many other disciplines, and widely examined using a variety of techniques, we will restrict our analyses to them.
We will call the self-affine time series that we work with in this paper fractional noises. We have above classified fractional noises as a process that is asymptotic long-range persistent with β < 1, and fractional motions as those with β > 1. However, often in the literature, the term fractional noises or noises is used more generically, referring to an asymptotic long-range persistent time series with any value of β. We will try to take care to distinguish in this paper between fractional noises (β < 1) and motions (β > 1), but occasionally will use the more generic term ‘noises’ (or even sometimes ‘fractional noises’) to indicate the more general case (all β).
Several techniques and their associated estimators or measures for evaluating long-range persistence in a time series have been proposed. Most of them exploit the properties of long-range dependent time series as described in this section (in particular Eqs. 6, 7, 9). However, these techniques often do not perform hypothesis tests for or against long-range persistence (see Davies and Harte 1987 for an example where hypothesis tests are performed). Rather, all the techniques that will be discussed in this paper assume that the considered time series is long-range persistent, then they proceed to determine the strength of persistence. In this paper, we propose to provide a more rigorous grounding for the quantification of self-affine long-range persistence in time series and will use both existing ‘conventional’ techniques and benchmark-based improvement techniques.
In examining some of the different techniques and measures for quantifying long-range persistence, we will distinguish between techniques in the time domain (Sect. 5) and the frequency domain (Sect. 6). Five techniques will be discussed in detail: (1) (time domain techniques) Hurst rescaled range (R/S) analysis, semivariogram analysis, and detrended fluctuation analysis; and (2) (spectral domain techniques) power spectral analysis using both log-linear regression and maximum likelihood. To measure the performance of these techniques, we will apply them to a suite of synthetic fractional noise time series, the construction of which we now describe (Sect. 4).
4 Synthetic Fractional Noises and Motions
In this section we will first describe common techniques for the construction of fractional noises and motions that are commonly found in the literature (Sect. 4.1), and then introduce the extensive fractional noises and motions that we use in this paper (Sect. 4.2). We will conclude with a brief presentation of the fractional noises and motions that we include in the supplementary material, both as text files and R programs (Sect. 4.3). Accompanying this section are Appendices 1–4 which give more detailed specifics as to construction of our synthetic fractional noises and motions.
4.1 Common Techniques for Constructing Fractional Noises and Motions
There are different approaches for creating long-range dependent time series with and without short-range correlations and also with and without distinct periodic components. In each case, however, the time series come from a model or process with known properties and defined strengths of persistence. We will use the subscript ‘model’ (e.g., β model) to indicate that the process has given properties, and thus, the realizations of this process can be used as ‘benchmark’ time series.
Three of the most commonly used models for constructing fractional noises are the following:
-
(1)
Self-affine fractional noises and motions (Schottky 1918; Dutta and Horn 1981; Geisel et al. 1987; Bak et al. 1987). These are popular in the physical sciences community and are constructed to have an exact power-law scaling of the power spectral density (i.e. Eq. (7) holds for all f). These are constructed by inverse Fourier filtering of a white noise (briefly explained in Sect. 4.2). In Appendix 1–4, we give a detailed description about how to create realizations of this model, as used in this paper. For this type of construction, the autocorrelation and fluctuation functions are not self-affine, and instead scale asymptotically (Eqs. (6) and (9) hold asymptotically for τ → ∞ and l → ∞, respectively).
-
(2)
Self-similar processes (Mandelbrot and van Ness 1968; Embrechts and Maejima 2002). These constructed noises exhibit an exact power-law scaling of the fluctuation function for Gaussian one-point probability distributions so that Eq. (9) holds for all l. They exhibit an asymptotic scaling of the power spectral density (i.e. Eq. (7) holds asymptotically for f → 0), and have an autocorrelation function that scales asymptotically with a power law (Eq. (6) holds for τ → ∞).
-
(3)
Fractionally differenced noises (Granger and Joyeux 1980; Hosking 1981). These are commonly used in the stochastic time series analysis community and are based on infinite-order moving average processes whose coefficients can be represented as binomial coefficients of fractal numbers. These fractional noises have an autocorrelation function, power spectral density, and fluctuation function which scale asymptotically with a power law (i.e. Eq. (6) as τ → ∞, Eq. (7) as f → 0, Eq. (9) as l → ∞).
There are a variety of more complex models for creating a time series with long-range persistence. These models depend on more parameters than just the strength of long-range persistence. We describe some of these models below.
-
Models which capture short- and long-range correlations (ARFIMA or FARIMA) (Granger and Joyeux 1980; Hosking 1981; Beran 1994; Taqqu 2003). These can be constructed as finite order moving average (MA) or autoregressive (AR) process with a fractional noise as input.
-
Models for time series which exhibit long-range persistence and ‘seasonality’ (i.e. cyclicity) (Porter-Hudak 1990) or ‘periodicity’ (Montanari et al. 1999). These are based on fractional differencing of noise elements which are lagged by multiples of the assumed seasonal period.
-
Generalized long-memory time series models (e.g., Brockwell 2005) where the stochastic processes have time-dependent parameters and these parameters are long-range dependent.
-
Models for long-memory process with asymmetric (e.g., log-normal) one-point probability distributions. Two examples of such models that describe long-range persistence have been done for (1) varve glacial data (Palma and Zevallos 2011) and (2) solar flare activity (Stanislavsky et al. 2009).
-
Models for deterministic nonlinear systems at the edge between regularity and chaos (onset of chaos, Schuster and Just 2005; intermittency, Manneville 1980), and dynamics in Hamiltonian systems (Geisel et al. 1987). In this model class it is very difficult to find examples with a broad variety and continuity of strengths of long-range dependence, and the long-range persistence is true for only certain values of the parameters.
-
Multifractals (Hentschel and Procaccia 1983; Halsey et al. 1986; Chhabra and Jensen 1989) which depend on a continuum of parameters.
-
Alternative constructs of stochastic fractals such as cartoon Brownian motion (Mandelbrot 1999) and Weierstrass–Mandelbrot functions (Mandelbrot 1977; Berry and Lewis 1980). These have three properties that make them unsuitable for the performance tests applied in our paper (Sects. 5 and 6): (1) a complicated one-point probability distribution, (2) non-equally spaced time series, and (3) multifractality.
-
Alternative approaches for constructing time series which are approximately self-similar and discussed by Koutsoyiannis (2002): multiple time scale fluctuations, symmetric moving averages, and disaggregation.
For this paper, the only models of long-range persistence considered are self-affine fractional noises and motions. These processes are constructed to model a given (1) strength of long-range dependence and (2) one-point probability distribution. As previously mentioned, these types of processes are discussed in detail in Schepers et al. (1992), Gallant et al. (1994), Bassingthwaighte and Raymond (1995), Mehrabi et al. (1997), Wen and Sinding-Larsen (1997), Pilgram and Kaplan (1998), Malamud and Turcotte (1999a), Heneghan and McDarby (2000), Weron (2001), Eke et al. (2002), Xu et al. (2005), and Franzke et al. (2012).
Self-affine fractional noises and motions are characterized by their strength of persistence and by their one-point probability distribution. In order to model time series with symmetric distributions, the generated fractional noises and motions should be constructed as realizations of linear stochastic processes and based on Gaussian or Levy-distributed white noises, resulting in fractional noises and motions with different persistence strengths which are also Gaussian or Levy distributed (Kolmogorov and Gnedenko 1954). In order to model time series with asymmetric distributions (e.g., log-normal), one first generates fractional Gaussian or Levy noises/motions, and then these need to be transformed. This is accomplished with either of the following:
-
(1)
Box–Cox transformation (Box and Cox 1964) which is applied to each element of the fractional Gaussian or Levy noise/motion, that is, one transforms x t to f(x t ), t = 1, 2, …, N (for details, see Appendix 3).
-
(2)
The Schreiber–Schmitz algorithm (Schreiber and Schmitz 1996) is an iterative-set operation applied to the entire data series (for details, see Appendix 4).
Both of the above transformations change the one-point probability distribution of the fractional noise or motion being considered; the Box–Cox transform keeps the rank order of the elements, while the Schreiber–Schmitz algorithm maintains the linear correlations (i.e. the power spectral density). The Schreiber–Schmitz algorithm is well known and accepted in the physics and geophysics community whereas, in the hydrology community, the Box–Cox transform is a preferred estimation since the resultant series appear more visually similar to river discharge series.
4.2 Sets of Synthetic Fractional Noises and Motions Used in this Paper
To ‘benchmark’ the five estimation techniques described in Sects. 5 and 6, we have constructed time series of length N = 64, 128, 256, ..., 131,072 with Gaussian, log-normal, and Levy one-point probability distributions. Examples of these three theoretical distributions are given in Fig. 9, and the equations for their probability densities as well as the main properties are summarized in Table 2. These distributions were chosen for the following reasons:

Three one-point probability distributions which typically occur in time series. a Gaussian (normal) distribution with a mean value μ = 0.0 and standard deviation \(\sigma \) = 1.0. b Levy distribution (centred at x = 0.0) with exponents a = 1.6 and a = 1.2; for comparison Gaussian distribution (a = 2.0 with μ = 0.0 and \(\sigma \) = 20.5). c Log-normal distribution with different coefficients of variation: c v = 0.2, 0.5, 1.0, 2.0 and a mean value of μ = 1.0. In d are shown the Gaussian (μ = 0.0, \(\sigma \) = 20.5), Levy (a = 1.2, 1.6), and log-normal (c v = 0.5, μ = 1.0) distributions on logarithmic axes
-
(1)
Gaussian distributions are symmetric, thin tailed, and the most commonly used basis for synthetic fractional noises in the literature; they are also the base for the derivation of fractional noises with other thin-tailed probability distributions.
-
(2)
Log-normal distributions are asymmetric, thin-tailed, but like many natural time series (e.g., river flow, sediment varve thicknesses) have only positive values.
-
(3)
Levy distributions are symmetric and heavy-tailed (i.e. the one-point probability distribution approaches a power law for large negative and positive values). Such heavy-tailed distributions are good approximations for the frequency-size statistics of a number of natural hazards (Malamud 2004). These include asteroid impacts (Chapman and Morrison 1994; Chapman 2004), earthquakes (Gutenberg and Richter 1954), forest fires (Malamud et al. 1998, 2005), landslides (Guzzetti et al. 2002; Malamud et al. 2004; Rossi et al. 2010), and volcanic eruptions (Pyle 2000). Floods (e.g., Malamud et al. 1996; Malamud and Turcotte 2006) have also been shown in many cases to follow power-law distributions.
The fractional noises and motions that we have constructed and used in our analyses are as follows:
-
One-point probability distributions: Gaussian, log-normal (coefficient of variation, \( c_{\text{v}} = \sigma_{x} /\bar{x} = 0.0,0.2,\, \ldots,\,2.0 \)), and (symmetric and centred) Levy distributions (exponent a = 1.0, 1.1, …, 2.0). The log-normal and Levy distributions reduce to Gaussian for c v = 0 and a = 2, respectively. The log-normal distributions were constructed using two different techniques, Box–Cox transform and Schreiber–Schmitz algorithm. The parameter c v is a measure of the skewness of a distribution, but only where that distribution is asymmetrically distributed, such as a log-normal distribution. One can compare the c v of one distribution to another, but only if that distribution has the same underlying statistical family.
-
Strengths of long-range persistence: −1.0 ≤ β model ≤ 4.0, step size of 0.2 (i.e. 26 successive values of β model).
-
Length of time series: The time series were realized 100 times for a given β model and constructed with N = 4,096 and then subdivided to also have N = 2,048, 1,024, and 512. These four time series lengths are focussed on in the main body of this paper. However, a further eight noise and motion lengths (N = 64, 128, 256, 8,192, 16,384, 32,768, 65,536, and 131,072) were also constructed, with results presented in the supplementary material.
For each set of 100 time series consisting of (distribution type, modelled persistence strength β model, time series length N), we applied three time domain and two frequency-domain techniques, introduced in Sects. 5 and 6, respectively, to obtain an estimate of the strength of long-range persistence. The time domain techniques applied are (1) Hurst rescaled range (R/S), (2) semivariogram, and (3) detrended fluctuation analysis. The frequency-domain techniques applied are (1) power spectral analysis using log-periodogram regression and (2) power spectral analysis using a maximum likelihood estimator (MLE), the Whittle estimator.
All fractional noises and motions with Gaussian or Levy one-point probability density have been constructed by inverse Fourier filtering of white noises (Appendices 1 and 2) (Theiler et al. 1992; Timmer and König 1995; Malamud and Turcotte 1999a), which for −1 ≤ β ≤ 1 and large N results in fractional noises with the same one-point probability distribution as the white noise. Inverse Fourier filtering requires the multiplication of the Fourier image of a white noise with a real-valued filter function (in our case a power law) followed by an inverse Fourier transform. The construction of synthetic log-normal distributed fractional noises and motions is more complicated because of the asymmetric one-point probability distribution (Venema et al. 2006). We put two approaches into action: (1) fractional Gaussian noises and motions were Box–Cox transformed (Appendix 3), and (2) an iterative algorithm (Schreiber–Schmitz algorithm, Appendix 4) was applied that allows us to prescribe the power spectral density and the one-point probability distribution. Realizations with 512 values each are presented for synthetic fractional Gaussian noises and motions (FGN, Fig. 10), synthetic fractional Levy noises and motions (FLevyN, Fig. 11), synthetic fractional log-normal noises and motions using the Box–Cox transform (FLNNa, Fig. 12), and synthetic fractional log-normal noises and motions using the Schreiber–Schmitz algorithm (FLNNb, Fig. 13). Note that all fractional noises and motions are normalized to have a mean value of zero and a standard deviation of one.

Examples of synthetic fractional Gaussian noises and motions (FGN) (Sect. 4.2) (see Appendix 1) with different modelled strengths of long-range persistence, β model. The presented data series, which have N = 512 elements each, are normalized to have a mean value of zero and a standard deviation of one

Examples of synthetic fractional Levy noises and motions (FLevyN) (Sect. 4.2) (see Appendix 2) with different modelled strengths of long-range persistence, β model. The presented data series, which have N = 512 elements each, are normalized to have a mean value of zero and a standard deviation of one


Examples of synthetic fractional log-normal noises and motions (FLNNb) (Sect. 4.2) (constructed by Schreiber–Schmitz algorithm (see Appendix 4)) with different modelled strengths of long-range persistence, β model. The presented data series have N = 512 elements each. For β model = 2.0 and β model = 2.5 fluctuations are not apparent due to the y-axis having a much larger range than the fluctuations themselves
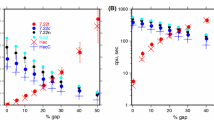
In Figs. 10, 11, 12, 13, each figure represents a different one-point probability distribution, and β (the strength of long-range persistence) increases from −1.0 to 2.5, reducing the contribution of the high-frequency (short-period) terms. For β < 0 (anti-persistence), the high-frequency contributions dominate over the low-frequency ones; adjacent values are thus anti-correlated relative to a white noise (β = 0). For these realizations of anti-persistent processes, a value larger than the mean tends to be followed by a value smaller than the mean. With β = 0 (white noise), high-frequency and low-frequency contributions are equal, resulting in an uncorrelated time series; adjacent values have no correlations with one another, and there is equal likelihood of a small or large value (relative to the mean) occurring. For β > 0, and as β gets larger, the low-frequency contributions increasingly dominate over the high-frequency ones; the adjacent values become more strongly correlated, and the time series profiles become increasingly smoothed. The strength of persistence increases, and a value larger than the mean tends to be followed by another value larger than the then mean. As the persistence increases, the tendency for large to be followed by large (and small to be followed by small) becomes greater, manifesting itself in a clustering of large values and clustering of small values. In Sect. 5 we explore different techniques for measuring the strength of long-range persistence.
4.3 Fractional Noises and Motions: Description of Supplementary Material
As an aid to the reader, we provide the following in the supplementary material:
-
(1)
Sample fractional noises and motions in tab-delimited text files. A zipped file which contains three folders:
-
FGaussianNoise contains fractional Gaussian noises.
-
FLogNormalNoise contains fractional log-normal noises constructed using the Box–Cox transform.
-
FLevyNoise contains fractional Levy noises.
-
The folders FLogNormalNoise and FLevyNoise have further subfolders for coefficient of variation c v = 0.2, 0.5, 1.0 that characterizes the log-normal shape, or for the exponent a = 0.85, 1.50 that characterizes the shape of the heavy tails of Levy distributions. Each file is related to a certain strength of persistence, β, and to a certain parameter setting for the 1D probability distribution. The strength of persistence ranges from β = –1.0 to 3.0 with sampling steps of Δβ = 0.2. The parameters that characterize the fractional noise or motion are identified in the name of each file. Each file contains ten realizations of fractional noises with N = 4,096 elements each in accordance with the parameter settings. All fractional Gaussian and log-normal noises are constructed from the single set of ten Gaussian white noises, and all fractional Levy noises are constructed from the single set of ten white Levy noises. There are 126 files contained within all the subfolders, in other words 1,260 ‘short’ (N = 4,096 values) fractional noises and motions.
-
(2)
R program. We give a commented R program that we use to create the synthetic noises and motions in this paper.
5 Time Domain Techniques for Measuring the Strength of Long-Range Persistence
There are a variety of time domain techniques for quantifying the strength of long-range persistence in self-affine time series. Here, we first discuss two broad frameworks within which these techniques are based (this introduction). We then discuss three techniques that are commonly used, each based on a scaling behaviour of the dispersion of values in the time domain as a function of different time length segments: (1) Hurst rescaled range (R/S) analysis (Sect. 5.1); (2) semivariogram analysis (Sect. 5.2); and (3) detrended fluctuation analysis (DFA) (Sect. 5.3). After this, we discuss (Sect. 5.4) other time domain techniques.
Time domain techniques typically exploit the way that the statistical properties of the original time series x t or the aggregated (summed) time series s t (Eq. 10) vary as a function of the length of different time series segments, l. A commonality to these techniques is that they are all based on either (A) the mean correlation strength of lagged elements as a function of the lag or (B) a power-law scaling of the dispersion of segments of the aggregated series as a function of the segment length l. We can broadly group these techniques into the following subclasses based on A (correlation strength) and B (scaling). We also note aggregation and non-aggregation of the original time series (□ = technique itself does not do any aggregation of the original time series, † = technique itself aggregates the original time series):
- (A):
-
Autocorrelation function □ and (semi-)variogram analysis □. These evaluate the average dependence of lagged time series elements.
- (B1):
-
Methods which rely on the scaling of the variance of fractional noises and motions. These are called variable bandwidth methods, scaled windowed variance methods, or fluctuation analysis. The most common techniques in this class are Hurst rescaled range analysis (R/S)† (Hurst 1951) and detrended fluctuation analysis (DFA)† (Peng et al. 1994; Kantelhardt et al. 2001). We mention here three less commonly used other techniques:
-
The roughness-length technique□ originally developed for use in the Earth Sciences (Malinverno 1990) is identical to DFA where linear fits are applied to the profile (called DFA1). In the roughness length, the ‘roughness’ is defined as the root-mean-squared value of the residual on a linear trend over the length of a given segment; since it is based on a ‘topographic’ profile, aggregating of the time series is not needed.
-
The detrended scaled windowed variance analysis† (Cannon et al. 1997) is similar to DFA1; the absolute values of the data from aggregated time series have been used in place of the variance, and the corresponding dependence on the segment length is studied.
-
Higuchi’s method□ (Higuchi 1988) evaluates the scaling relationship between the mean normalized curve length of the coarse-grained time series (i.e. values x kt are considered for a fixed value of k and t = 1, 2, …, N/k) and the chosen sampling step (here k).
-
- (B2):
-
Dispersional analysis □ (Bassingthwaighte and Raymond 1995) analyses the scaling of the variance of a time series that is coarse grained (averages of segments of equal length are considered) as a function of the segment length. This is very similar to relative dispersion analysis□ (Schepers et al. 1992) which describes the scaling of the standard deviation divided by the mean.
- (B3):
-
Average extreme value analysis □ (Malamud and Turcotte 1999a) examines the mean value of the extremes (minimum, maximum) as a function of segment length.
Although some techniques involve aggregation of the original time series as part of the technique itself, and other techniques involve no aggregation of the time series, any of the techniques can be applied to an aggregated (or first differenced) time series, as long as the time series has a symmetrical one-point probability distribution. We saw this in Sect. 3.6 that if one begins with a time series that has a symmetric one-point probability distribution and a given β, then aggregation or the first difference of the original time series results in a new time series with β shifted by +2 (aggregation) or −2 (first difference). However, care must be taken not to confuse aggregation of the original time series ‘before’ a technique has been applied (pre-processing the data) with aggregation that is done as a standard part of the technique itself. Some of the techniques above are generally effective (for the time series considered) only over a given range of strengths of long-range persistence (Malamud and Turcotte 1999a; Kantelhardt et al. 2001):
-
autocorrelation (−1 ≤ β ≤ 1) (Sect. 3.1).
-
Hurst rescaled range analysis (R/S) (−1 ≤ β ≤ 1) (Sect. 5.1).
-
semivariogram analysis (1 ≤ β ≤ 3) (Sect. 5.2).
-
detrended fluctuation analysis (DFA) (all β) (Sect. 5.3).
-
[frequency-domain technique]: power spectral analysis (all β) (Sect. 6).
We will in Sect. 7 explore further the ranges for all of these techniques except the first one (autocorrelation). One can always aggregate (or first difference) a time series to ‘place’ it into a specific range of β where a given technique is effective, but as discussed above only if that time series has a one-point probability distribution that is (close to) symmetrical. Therefore, as part of pre-processing, a time series should not be aggregated (or differenced) if it is, for example, log-normal distributed. The aggregation of time series has resulted in confusion for some scientists who have aggregated a time series first, when it was not appropriate, and then miscalculated their strength persistence in either direct by +2 or −2. In the next three sections (Sects. 5.1–5.3) we introduce the most common time domain techniques in more detail.
5.1 Hurst Rescaled Range (R/S) Analysis
Historically, the first approach to the quantification of long-range persistence in a time series was developed by Hurst (1951), who spent his life studying the hydrology of the Nile River, in particular the record of floods and droughts. He considered a river flow as a time series and determined the storage limits in an idealized reservoir. To better understand his empirical data, he introduced rescaled range (R/S) analysis. The concept was developed at a time (1) when computers were in their early stages so that calculations had to be done manually and (2) before fractional noises or motions were introduced. Much of Hurst’s work inspired later studies by Mandelbrot and others into self-affine time series (e.g., Mandelbrot and Van Ness 1968; Mandelbrot and Wallis 1968, 1969a, b, c). The use of Hurst (R/S) analysis (and variations of it) is still popular and often applied (e.g., human coordination, Chen et al. 1997; neural spike trains, Teich et al. 1997; plasma edge fluctuations, Carreras et al. 1998; earthquakes, Yebang and Burton 2006; rainfall, Salomão et al. 2009).
The Hurst (R/S) analysis first takes the original time series x t , t = 1, 2, …, N, and aggregates it using the running sum (Eq. 10) to give s t . This series is then divided into non-overlapping segments of length l (l < N). The mth segment contains the time series elements \( {s_{{(m - 1)l + t^{\prime}}} } \), t′ = 1, 2, …, l. The range R m,l is used to describe the dispersion of these values, looking at the maximum and minimum s t values within each segment m of length l, and is defined as:
For each segment m of length l, the variance of the original x t values in that segment is computed giving the standard deviation used in the (R/S) analysis:
The square brackets \( \sigma_{x} \)[ ] indicate taking the standard deviation over the terms in the bracket. Mean values of the range R m,l and the standard deviation S m,l for segments of length l are determined:
where as we did in Eq. (8), if N/l is non-integer, we take the largest integer less than N/l, noted here by [N/l]. For a fractional noise, the ratio, R l /S l , exhibits a power-law scaling as a function of segment length l, with a power-law exponent called the Hurst exponent, Hu:
Although in the literature it is common to denote the Hurst exponent with the symbol H, we use Hu here to avoid confusion with the Hausdorff exponent (also commonly called H, but which we will denote by Ha and introduce in Sect. 5.2). Rescaled range analysis is illustrated for a fractional log-normal noise with β model = 1.0 in Fig. 14a, where we have plotted (R/S) as a function of (l), on logarithmic axes. The Hurst exponent Hu is related to the strength of long-range persistence β as β = 2Hu−1 (Malamud and Turcotte 1999a).

Long-range dependence analysis of a fractional log-normal noise with a persistence strength of β model = 1.0, a coefficient of variation of c v = 0.5 and N = 4,096 elements. The panels represent a Hurst rescaled range (R/S) analysis, b semivariogram analysis, c detrended fluctuation analysis (DFAk with polynomials of order k applied to the profile), d power spectral analysis. All graphs are shown on logarithmic axes. Best-fit power laws are presented by dashed lines, shifted upwards slightly in the y-direction, and the corresponding exponents for each technique (Hu, Ha, α, and β PS) are given in the legend of the corresponding panel. The corresponding β are calculated from equations presented in Sect. 5: \( \beta_{\text{Hu}} = 2Hu - 1,\beta_{\text{Ha}} = 2Ha + 1,\;{\text{and}}\;\beta_{\text{DFA}} = 2\alpha - 1 \)
In this paper, the Hurst exponent Hu is derived by computing the rescaled range for segment lengths l = 8, 9, 10, 11, 12, 13, 14, 15, [24.0], [24.1], [24.2], [24.3], …, [N/4], where the square bracket symbol [ ] denotes rounding down to the closest integer and N is the length of the time series. The power-law exponent Hu from Eq. (15) is estimated by linear regression of log(R l /S l ) versus log(l/2). The errors here (fluctuations around the best-fit line) are multiplicative and, therefore, we use linear regression of the log-transformed data (vs. ordinary nonlinear regression of the data itself) as an unbiased estimate of the power-law exponent. In Appendix 5 we discuss the choice of fitting technique used along with simulations of the resultant bias when different techniques are considered. In addition to Hurst (R/S), for three other techniques used in this paper (semivariogram, detrended fluctuation, and power spectral analyses), we estimate the best-fit power law to a given set of measured data by using a linear regression of the log-transformed data.
Hurst (R/S) analysis has been examined in many investigations (e.g., Bassingthwaighte and Raymond 1994, 1995; Taqqu et al. 1995; Caccia et al. 1997; Cannon et al. 1997; Pilgram and Kaplan 1998; Malamud and Turcotte 1999a; Weron 2001; Eke et al. 2002; Mielniczuk and Wojdyłło 2007; Boutahar 2009). Through these studies, it has become apparent that rescaled range analysis can lead to significantly biased results. In order to diminish this problem, several modifications have been proposed, including the following:
-
Anis–Lloyd correction (Anis and Lloyd 1976) is a correction term for Hu (see Eq. 15) that compensates the bias caused by small values of the time series length N. It is optimized for white noises (β = 0).
-
Lo’s correction (Lo 1991) which incorporates the autocovariance.
-
Detrending (Caccia et al. 1997).
-
Bias correction (Mielniczuk and Wojdyłło 2007).
We will quantify the bias using rescaled range analyses, under a variety of conditions, in our results (Sect. 7).
5.2 Semivariogram Analysis
In Sect. 3 we discussed that, in the case of a stationary fractional noise (−1 < β < 1), there is a power-law dependence of the autocorrelation function on lag, C(τ) ~ τ −ν (Eq. 6), with power-law coefficient ν = 1 − β. However, it is difficult to use the autocorrelation function for estimating the strength of long-range dependence β. This is because there are a considerable number of negative values for the autocorrelation function C, and therefore, a linear regression of the logarithm of autocorrelation function C(τ) versus the logarithm of the lag τ is not possible. Finding the best-fit power-law function for C(τ) as a function of τ comes with some technical difficulties (particularly compared to linear regression) such as how to choose good initial values for ν, and choosing appropriate weights and convergence criteria for the nonlinear regression. Because our focus is on less technical methods, we did not use the autocorrelation function to gain information about β.
For non-stationary fractional times series, in other words, fractional motions (β > 1), it is inappropriate to use the autocorrelation function, because C(τ) (Eq. 3) has the mean, \( \bar{x} \), in its definition. An alternative way to measure long-range correlations is the semivariogram (Matheron 1963). The semivariogram, γ(τ), is given by
where τ is the time lag between two values. Note that neither the sample mean, \( \bar{x} \), nor the sample variance, \( \sigma_{x}^{2} \), is used in defining the semivariogram. For a fractional motion (β > 1), the semivariogram, γ(τ), scales with τ, the lag,
where Ha is the Hausdorff exponent and Ha = (β − 1)/2 (Burrough 1981; Burrough 1983; Mark and Aronson 1984). The Hausdorff exponent, Ha, is a measure of the strength of long-range persistence for fractional motions for which 0 ≤ Ha ≤ 1. Semivariogram analysis is illustrated for a fractional log-normal motion with β model = 1.0 in Fig. 14b.
Semivariogram analysis is widely applied in the geoscientific and ecologic communities; examples include the following:
-
Landscapes (Burrough 1981).
-
Soil variations (Burrough 1983).
-
Rock joint profiles (Huang et al. 1992).
-
Advective transport (Neuman 1995).
-
Evaluation of different management systems on crop performance (Eghball and Varvel 1997).
In this paper, we have chosen for our semivariogram analysis values for lag τ that are the same as those used for lengths l in (R/S) analysis, as described in the previous section. This is done to facilitate comparison between the different techniques. The Hausdorff exponent, Ha, is the power-law exponent in Eq. (17) and derived by linear regression of the logarithm of the semivariogram, log(γ(τ)), versus the logarithm of the lag, log(τ) (see Appendix 5 for discussion of the type of technique used for power-law fitting). General discussions of methods used to estimate Ha and other persistence measures for time series have been given by Schepers et al. (1992) and Schmittbuhl et al. (1995).
5.3 Detrended Fluctuation Analysis (DFA)
Detrended fluctuation analysis, like (R/S) analysis, is based on examining the aggregate (running sum, Eq. 10) of the time series as a function of segment length and was introduced as fluctuation analysis by Peng et al. (1994) for studying long-term correlations in DNA sequences. Kantelhardt et al. (2001) improved on this technique by generalizing the function through which the trend is modelled from linear to polynomial functions. Detrended fluctuation analysis is very popular and has been applied to characterize long-term correlations for time series in many different disciplines. Examples include the following:
-
Solar radio astronomy (Kurths et al. 1995).
-
Heart rate variability (Peng et al. 1993a; Penzel et al. 2003).
-
River run-off series (Koscielny-Bunde et al. 2006).
-
Long-term weather records and simulations (Fraedrich and Blender 2003).
Fluctuation analysis (Sect. 3.3) is based on analyses of the original time series x t and exploits the scaling properties of the fluctuation function (Eq. 9). Detrended fluctuation analysis is based on analyses of the aggregate (running sum) s t , and the idea is that there is a trend superimposed on a given self-affine fractional noise or motion that must be taken out (i.e. the signal should be detrended). For each segment, this trend is modelled as the best-fitting polynomial function with a given degree k. Then, the values in the mth segment with length l, \( s_{{\left( {m - 1} \right)l + t^{\prime } }} ,\, t^{\prime } = 1,\;2, \ldots ,l \), are detrended by subtracting the best-fit polynomial function for that segment, \( p[k]_{{\left( {m - 1} \right)l + t^{\prime } }}, \, t^{\prime } = 1,2, \ldots ,l \). The detrended values are \( \tilde{s}_{{\left( {m - 1} \right)l + t^{\prime } }} = s_{{\left( {m - 1} \right)l + t^{\prime } }} - p[k]_{{\left( {m - 1} \right)l + t^{\prime } }}, \, t^{\prime } = 1,2, \ldots ,l, \) and the square of the fluctuation of the detrended segments of length l is evaluated in terms of their mean variance; similar to Eq. (8) this gives:
For Gaussian-distributed fractional noises and motions, the fluctuation function, F DFA, has been mathematically shown (Taqqu et al. 1995) to scale with the length of the segments, l, as
if the following conditions are fulfilled: (1) the segment length l and the time series length N go to infinity, (2) the quotient l/N goes to zero, and (3) the polynomial order of detrending is k = 1 (i.e. linear trends are subtracted). Hence, if the fluctuation is averaged over all segments and if this averaged fluctuation is considered as a function of the segment length l, for large segment lengths l the fluctuation approaches a power-law function with a power-law scaling coefficient of α. Taqqu et al. (1995) further showed that the power-law exponent in Eq. (19) is equivalent to (β + 1), so that
The outcome of detrended fluctuation analysis depends on the degree of the polynomial that models the underlying trend. If polynomials of order k are considered, then the resultant estimate of the long-range dependence is called DFAk (e.g., DFA1, DFA2, and DFA3). Detrended fluctuation analysis (DFA1 to DFA4) is illustrated for a fractional log-normal noise with β model = 1.0 in Fig. 14c.
Several authors have discussed potential limitations of detrended fluctuation analysis when applied to observational data that have attributes additional to that of just a ‘pure’ fractional noise or motion and a superimposed polynomial trend. For example, Hu et al. (2001) showed that an underlying linear, periodic, or power-law trend in the signal leads to a crossover behaviour (i.e. two scaling regimes with different exponents) in the scaling of the fluctuation function. Chen et al. (2002) discussed properties of detrended fluctuation analysis for different types of non-stationarity. In other studies, Chen et al. (2005) studied the effects on detrended fluctuation analysis of nonlinear filtering of the time series.
Guerrero and Smith (2005) have proposed a maximum likelihood estimator that provides confidence intervals for the estimated strength of long-range persistence. Marković and Koch (2005) demonstrated that periodic trend removal is an important prerequisite for detrended fluctuation analysis studies. Gao et al. (2006) and Maraun et al. (2004) have discussed the misinterpretation of detrended fluctuation analysis results and how to avoid pitfalls in the assessment of long-range persistence. Kantelhardt et al. (2003) have generalized the concept of detrended fluctuation analysis such that multifractal properties of time series can be studied. Detrended moving average (DMA) analysis is very similar to detrended fluctuation analysis, but the underlining trends are not assumed to be polynomial.
Within this paper, we restrict our studies to DFA2; in other words, quadratic trends are removed. Further, we have applied the same set of segment lengths as for Hurst rescaled range analysis (R/S): l = 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, [24.0], [24.1], [24.2], [24.3],…, [N/4], where [ ] denotes rounding down to the closest integer and N is the length of the time series. This set of segment lengths was chosen carefully and optimized for DFA2, by balancing the number of segment lengths to be (1) as high as possible to have a precise estimate for β DFA and (2) as few as possible to have low computational costs. To further explore the segment length set chosen, we contrasted analyses using our chosen set (l = 8, 9, 10, 11, 12, 13, 14, 15, [24.0], [24.1], [24.2], [24.3], …, [N/4]) versus a ‘complete’ set (l = 3, 4, 5, …, N/4). We applied DFA2, using these two sets of segment lengths, on a fractional noise with strength of long-range persistence β = 0.5 and time series lengths N = 512, 1,024, 2,048, or 4,096. We found that the random error of the results from DFA2 using the segment length set chosen was as small as for the complete set of segment lengths. In our final analyses, ordinary linear regression (see Appendix 5) has been applied for the associated values of log(F 2) versus log(l), and the slope of the best-fit linear model gives α from which we obtain the long-range persistence.
5.4 Other Time Domain Techniques for Examining Long-Range Persistence
Here we discuss two other time domain methods that can be used to examine long-range persistence: (1) first-return and multi-return probability and (2) fractal geometry.
-
(1)
First-return and multi-return probability methods. The timings of threshold crossings are another feature sensitive to the strength of long-range dependence. The first-return probability method (Hansen et al. 1994) considers a given ‘height’ of the y-axis, which we will call h. It is based on the probability, conditional on starting at h, of exceeding h after a time τ (with no other crossing between t and t + τ). This probability scales with h as a power law. Alternatively, a multi-return probability (Schmittbuhl et al. 1995) can be studied (crossings between t and t + τ are allowed), which also results in a power-law scaling for the dependence on the height h. Both power-law exponents are related to the strength of long-range persistence, β. These return probability methods work for the stationary case, that is, –1 < β < 1, and for thin-tailed one-point probability distributions. For heavy-tailed, one-point probability distributions, the power-law exponent depends also on the tail parameter.
-
(2)
Fractal geometry methods. These techniques are based on describing the fractal geometry (fractal dimension) of the graph of a fractional noise. By definition, a self-affine, long-range persistent time series (fractional noises and motions) has self-affine fractal geometry, with fractal dimensions constrained between D = 1.0 (a straight line) and 2.0 (space filling time series) (Mandelbrot 1985). The oldest of fractal geometry methods is the divider/ruler method (Mandelbrot 1967; Cox and Wang 1993) that measures the length of the graph of a fractal curve either at different resolutions or by walking a given length stick along the curve. The evaluated curve length depends on the resolution/stick length, and the shorter the length of the stick used, the longer the curve. The resultant power-law relationship of curve length as a function of stick length results in a power-law exponent which is the fractal dimension D or the strength of persistence β, respectively. However, appropriate care must be taken, as the vertical and horizontal coordinates can scale differently (e.g., different types of units). See Voss (1985) and Malamud and Turcotte (1999a) for discussion. After appropriately adjusting the vertical and horizontal coordinates of the time series, other fractal dimensions that are determined directly using geometric methods include the box counting dimension, the correlation dimension (Grassberger and Procaccia 1983; Osborne and Provenzale 1989), and the Kaplan–Yorke dimension (Kaplan and Yorke 1979; Wolf et al. 1985). Note that the application of different types of fractal dimensions to a time series leads to quantitatively different results: for instance, for a fractional motion (1 < β < 3), the divider/ruler dimension is D divider/ruler = (5 – β)/2 (Brown 1987; De Santis 1997), while the correlation dimension is D corr = 2/(β – 1) (Theiler 1991), so one must be careful about ‘which’ dimension is being referred to. It might be necessary to embed the time series into a higher-dimensional space (Takens 1981) in order to extract the dimension of the time series, which in this context is the dimension of the attractor of the system from which the time series was measured. A number of the fractal dimension estimate techniques that have been discussed in this paragraph require very long and stationary time series.
We have in this section explored time domain techniques for measuring the strength of long-range persistence. The major relationships between β and other power-law scaling exponents (autocorrelation, rescaled range, semivariogram, and fluctuation function) are summarized in Table 3. We will now consider frequency-domain techniques.
6 Frequency-domain Techniques for Measuring the Strength of Long-Range Persistence: Power Spectral Analysis
It is common in the Earth Sciences and other disciplines to examine the strength of long-range persistence in self-affine time series by first transforming the data from the time domain into the frequency (spectral) domain, using techniques such as the Fourier, Hilbert, or wavelet transforms. Here we will use the Fourier transform with two methods of estimation.
6.1 The Fourier Transform and Power Spectral Density
The Fourier transformation X k , k = 1, 2, …, N, of an equally spaced time series x t , t = 1, 2, …, N, results in an equivalent representation of that time series in the frequency domain. It is defined as:
where Δ is the length of the sampling interval (including units) between successive x t and i is the square root of −1. The resultant Fourier coefficients X k are complex numbers. They are symmetric in the sense that X k is the conjugate complex of X N−k . The Fourier coefficients X k , k = 1, 2, …, N, are associated with frequencies f k = k/(NΔ).
The linear correlations of x t will be represented by the periodogram S (Priestley 1981):
with the complex coefficients X k resulting from the discrete Fourier transform (Eq. 21) and | | denoting the modulus. The periodogram is a frequently used estimator of the power spectral density of the underlying process; in this paper we will not distinguish between the terms ‘power spectral density’ and ‘periodogram’ and will use both synonymously. By using fast Fourier transform (FFT) implementations such as the Cooley–Tukey algorithm (Cooley and Tukey 1965), the power spectral density S can be computed with little computational cost.
For a fractional (self-affine) noise, the power spectral density, S k , has a power-law dependence on the frequency for all f k (Beran 1994)
This is the same as Eq. (7) but for all f, not just the limit as f → 0. The graph of S vs f is also known as the periodogram (and sometimes called a spectral plot).
6.2 Detrending and Windowing
The discrete Fourier transform as defined in Eq. (21) is designed for ‘circular’ time series (i.e. the last and first values in the time series ‘follow’ one another) (Percival and Walden 1993). In order to reduce non-desirable effects on the Fourier coefficients caused by the large values of the absolute difference of the first and the last time series element, |x N – x 1|, which typically occurs for non-stationary time series and in particular for fractional motions (β > 1), detrending and windowing can be carried out. One example of these non-desirable effects is spectral domain leakage (for a comprehensive discussion, see Priestley 1981; Percival and Walden 1993). Leakage is a term used to describe power associated with frequencies that are non-integer k in Eq. (22) becoming distributed not only to their own bin, but also ‘leaking’ into other bins. The resultant leakage can seriously bias the resultant power spectral density distribution. To reduce this leakage we will both detrend and window the original time series before doing a Fourier analysis.
Many statistical packages and books recommend removing the trend (detrending) and removing the mean of a time series before performing a Fourier analysis. The mean of a time series can be set equal to 0 and the variance normalized to 1; this will not affect the resulting Fourier coefficients. However, detrending is controversial and, therefore, care should be taken. One way of detrending (which we use here before applying Fourier analysis) is to take the best-fit straight line to the time series and subtract it from all the values. Another way of detrending is to connect a line from the first point and the last point and subtract this line from the time series, forcing x 0 = x N . If a time series shows a clear linear trend, where the series appears to be closely scattered around a straight line, the trend can be safely removed without affecting any but the lowest frequencies in the power spectrum. However, if there is no clear trend, detrending can cause the statistics of the periodogram (in particular the slope) to change.
Windowing (also called tapering, weighting, shading, and fading) involves multiplying the N values of a time series, x t , t = 1, 2, …, N, by the N values of the ‘window’, w t , t = 1, 2, …, N, before computing the Fourier transform. If w t = 1 for all t, then w t is a rectangular window and the original series is left unmodified. The window is normally constructed to change gradually from zero to a maximum to zero as t goes from 1 to N. Many books discuss the mechanics of how and which windows to use, including Press et al. (1994) and Smith and Smith (1995). We apply a commonly used window, the Welch window:
An example of the Welch window applied to a fractional log-normal noise with a coefficient of variation of c v = 0.5 and β model = 2.5 is given in Fig. 15. In Fig. 15a we show the original time series and in Fig. 15b the Welch window (grey area) and the time series after normalization (subtracting out the mean and dividing by the variance, to give mean 0 and variance 1) and application of the Welch window.

Pre-processing of a time series and the effect of windowing. a The original time series, a fractional log-normal noise with a coefficient of variation of c v = 0.5 and β model = 2.5. Also shown (horizontal dashed line) is the mean of the values. b Time series shown in (a) after normalizing (to sample mean \( \bar{x} = 0 \) and sample standard deviation \(\sigma \) x = 1) and application of a Welch window (grey area) (Eq. 24). We then apply power spectral analysis to both (a) and (b). In (c) are shown the power spectral densities as a function of frequency for the original time series and in (d) the same for the normalized and windowed time series, both on logarithmic axes. For both periodograms are given the best-fit power-law exponents: (c) original time series β PS = 1.86; (d) time series with Welch window applied: β PS = 2.43. The overall shapes of the two periodograms are very similar, while the individual values differ
The Fourier coefficients (Eq. 21) are then given by:
Windowing significantly reduces the leakage when Fourier transforms are carried out on self-affine time series, particularly for those with high positive β values (i.e. above β = 2). See Percival and Walden (1993) for a discussion of windowing, and Malamud and Turcotte (1999a) for a discussion of windowing applied to fractional noises and motions.
The variance of x t will be different from the variance of (w t x t ); this will affect the total power (variance) in the periodogram, and the amplitude of the power spectral density function will be shifted. One remedy is to normalize the time series x t so it has a mean of 0, calculate the Fourier coefficients X k based on (Eq. 25), and then calculate the final S k using
where
This will normalize the variance of (w t x t ) such that it now has the variance of the original unwindowed time series x t .
In the next two sections, we describe two techniques commonly found in the time series analysis literature for finding a best-fit power law to the power spectral density (in our case, the strength of long-range persistence β in Eq. 23) and will also present the result of the power spectral analysis applied to the windowed and unwindowed time series examples discussed above.
6.3 Estimators Based on Log-regression of the Power Spectral Densities
The strength of long-range persistence can be directly measured as a power-law decay of the power spectral density (Geweke and Porter-Hudak 1983). Robinson (1994, 1995) showed that the performance of this technique is similar for non-Gaussian and Gaussian distributed data series. However, in the case of non-Gaussian one-point probability distributions, the uncertainty of the estimate might become larger (depending on the distribution), compared to Gaussian distributions.
If the power spectral density S (Eqs. 22, 26a) is expected to scale over the entire frequency range (and not just for frequencies f → 0) with a power law, \( S(f)\sim f^{ - \beta } \), then the power-law coefficient, β, can be derived by (non-weighted) linear regression of the logarithm of the power spectral density, log(S), versus the logarithm of the frequency, log(f). Although this estimator appears simplistic (at least in comparison with the MLE estimator presented in the next section), it nevertheless has small biases in estimating β, along with tight confidence intervals, and is broadly applicable to time series with asymmetrical one-point probability distributions (Velasco 2000). In Appendix 5 we discuss in detail the use of ordinary linear regression of the log-transformed data versus nonlinear least-squares regression of the non-transformed data. Power spectral analysis, using linear regression of the log-transformed data, is illustrated for a fractional log-normal noise with β model = 1.0 in Fig. 14d; the corresponding estimator is called β PS(best-fit).
We return to the effect of windowing on spectral analysis and in Fig. 15c show the results of power spectral analysis applied to a realization of an original log-normal fractional motion (c v = 0.5, β model = 2.5) and in Fig. 15d on the windowed version of this realization (time series). The power spectral analysis of the unwindowed time series results in a best-fit power-law exponent (using linear regression of log(S) vs. log(f)) of β PS = 1.86, and for the windowed time series β PS = 2.43. The power spectral analysis of the windowed time series has significantly less bias than power spectral analysis of the unwindowed time series.
Above, we are using detrending and windowing to reduce the leakage in the Fourier domain. For the purposes of this paper, we are interested in finding the estimator for a ‘single’ realization of the process, that is, producing the power spectral densities for a given realization, and finding the best estimator for these (we will discuss this in Sect. 6.4). If one is more interested in the spectral densities of the process (i.e. the average over an ensemble of realizations), then other techniques are more appropriate. For example, some authors take a single realization and break it up into smaller segments, then compute the power spectral densities for each segment, and average over them, thus resulting in less scatter of the densities, but not covering the same frequency range as for the single realization considered as a whole (see for instance Pelletier and Turcotte 1999). Other versions include not breaking up the single realization into orthogonal segments, but rather non-orthogonal (overlapping) segments (e.g., Welch’s Overlapped Segment Averaging technique, Mudelsee 2010). Another method includes taking a single realization of a process and binning the frequency range into octave-like frequency bands where linear regression is done for the mean of the logarithm of the power (per octave) versus the mean logarithm of the frequency in that band. Taqqu et al. (1995), however, have shown that this binning-based regression dramatically increases the uncertainties (random error) of the estimate of β.
6.4 Maximum Likelihood Estimators
Maximum likelihood estimators (MLEs) (Fisher 1912) have been developed for parametric models of the power spectral density or autocorrelation function (Fox and Taqqu 1986; Beran 1994). For Eq. (23), an MLE equation that depends on the parameters of the power spectral density is required, with maximum likelihood giving the best-fit estimators. These techniques assume Gaussian or Levy-distributed time series and, in particular, a one-point probability distribution that is symmetrical. Maximum likelihood estimators have the advantage when compared with log-periodogram regression to not only output an estimate of the strength of long-range persistence, but also result in a confidence interval based on the Fisher information (the expected value of the observed information) of the estimated parameter. The Whittle estimator (Whittle 1952) is a maximum likelihood estimator for deriving the strength of long-range persistence from the power spectral density.
In our analyses, we applied an approximation of the Whittle maximum likelihood function (Beran 1994). This likelihood function L depends on the following:
-
(1)
The power spectral density, S k (Eqs. 22, 26a), versus the frequency f k (k = 1, 2, …, N/2) of the original time series x t (t = 1, 2, …, N).
-
(2)
The MLE model chosen; here, \( \tilde{S}_{{c,{\kern 1pt} \beta }} (f) = c\,f^{ - \beta } \) is used as a model for the power spectral density S k (k = 1, 2, …, N/2) and has two parameters: the strength of long-range persistence, β, and a factor c, both of which will be evaluated by the MLE.
The maximum likelihood function L, which evaluates our power-law model of the power spectral density, S c,β , has a dependence on the two parameters, c and β, and is given by Beran (1994):
The function L needs to be minimized as a function of the parameters c and β. In other words, L (Eq. 27) is calculated for one set of values for (c, β), and then for other pairs of (c, β) that are systematically chosen, and the minimum value of L is obtained. The corresponding β min is the estimated strength of long-range dependence β PS(Whittle). This function minimization is illustrated in Fig. 16a, where the maximum likelihood function, L (Eq. 27), is calculated for four realizations of a process created to have a log-normal probability distribution (c v = 0.5, Box–Cox transform), β model = 0.8, and four different time series lengths, N = 512, 1,024, 2,048, and 4,096. The value β where the minimum occurs is β PS(Whittle) = 0.74. As a lower bound of the random error \(\sigma \)(β PS(Whittle)), the Cramér–Rao bound (CRB) (Rao 1945, Cramér 1946) is obtained by evaluating the second derivative of the likelihood function L (Eq. 27):
This is illustrated in Fig. 16b, where the CRB from Eq. (28) is calculated as a function of long-range persistence strength, β. The value at β PS(Whittle) allows for the calculation of the Cramér–Rao bound that is a lower bound for the standard deviation of the estimated strength of long-range dependence. We have discussed here the case of a best-fit power-law exponent using a MLE and the assumption that the original time series is self-affine (where Eq. (7) holds for all f). There are also MLE techniques (Geweke and Porter-Hudak 1983; Beran 1994; Guerrero and Smith 2005) for fitting power spectral densities when the time series shows asymptotic power-law behaviour (i.e. as f → 0).

Whittle estimator and its corresponding maximum likelihood function. a Maximum likelihood function, L (Eq. 27), given as a function of persistence strength, β. The function L is based on the power spectral density of four realizations of a process created to have a log-normal probability distribution (c v = 0.5, Box–Cox transform), β model = 0.8, and four different time series lengths, N = 512, 1,024, 2,048, and 4,096. The value β where the minimum occurs is β PS(Whittle) = 0.74. b The second derivative, d2 L/dβ 2, of the maximum likelihood function (shown in a) is presented, a function of persistence strength, β. The value of d2 L/dβ 2 at β PS(Whittle) = 0.74 allows for the calculation of the Cramér–Rao bound (CRB) (Eq. 28) that is a lower bound for the standard error
7 Results of Performance Tests
We have been interested in how exactly the considered techniques measure the strength of long-range persistence in a time series. We have applied these techniques to many realizations of fractional noises and motions with well-defined properties, and after discussing systematic and random errors in the context of a specific example (Sect. 7.1) and confidence intervals (Sect. 7.2), we will present the overall results of our performance tests and the results of other studies (Sect. 7.3), along with reference to the supplementary material which contains all of our results. We will then give a brief summary description of the results of each performance test: Hurst rescaled range (R/S) analysis (Sect. 7.4), semivariogram analysis (Sect. 7.5), detrended fluctuation analysis (Sect. 7.6), and power spectral analysis (Sect. 7.7).
7.1 Systematic and Random Error
We now discuss systematic and random error in the context of an example of applying a given technique to our benchmark time series. We apply the fluctuation function (resulting from DFA2, see Sect. 5.3) to 1,000 realizations of fractional log-normal noises (coefficient of variation of c v = 0.5, time series length N = 1,024, β model = 0.8, Box–Cox transform construction). Ten examples of these are given in Fig. 17a, where we see that the ten DFA fluctuation functions are similar but not identical. For the 1,000 realizations, the normalized histogram of the resultant estimates of the strength of long-range persistence, β DFA, is given in Fig. 17b. We observe the normalized histogram can be well approximated by a Gaussian distribution with mean value \( \bar{\beta }_{\text{DFA}} \) and standard deviation σ(β DFA). These DFA performance test results from Fig. 17 can be considered in the context of systematic error (bias) and random error (standard deviation); in Sect. 7.2 we will also consider these DFA results in the context of confidence intervals.

Illustration of systematic and random errors using detrended fluctuation analysis. a Detrended fluctuation analysis with quadratic trend removed (DFA2) for ten realizations of fractional log-normal noises with a coefficient of variation of c v = 0.5 and N = 1,024 elements. The modelled strength of long-range persistence is β model = 0.8. b Normalized histogram of β DFA obtained from 1,000 realizations of fractional log-normal noises (same parameters as for a). The systematic error is the sample mean \( \bar{\beta }_{\text{DFA}} \) minus the persistence strength of the process, β model. The random error \(\sigma \)(β DFA) is given by the horizontal arrow
The systematic error in this DFA example is the difference between the modelled strength of persistence and the mean value of the Gaussian distribution, \( \bar{\beta }_{\text{DFA}} - \beta_{\text{model}} \). The systematic error of a particular technique in general is given by the bias:
The bias or systematic error of the technique does not only depend on β model but also on the technique, the one-point probability distribution, and the time series length N.
The performance of a technique is further described by the random error of the considered technique. In our DFA example (Fig. 17) we have used the standard deviation σ x (β DFA) of the sample values around the mean for quantifying the fluctuations of β DFA. In this paper we will measure the random error of a technique by the standard deviation σ x (\({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}\)), which is called in the statistics literature the standard error of the estimator (Mudelsee 2010). The random error can be determined from many realizations of a process modelled to have a set of given parameters. If, however, just a single realization of the process is given, the random error σ x (\({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}\)) can be derived in various ways, such as bootstrapping and jackknifing (Efron and Tibshirani 1993; Mudelsee 2010), or in case of a maximum likelihood estimator by the Cramér–Rao bound (Rao 1945; Cramér 1946). In this paper we will, in most cases, calculate the random error from an ensemble of model realizations, but we will also consider Cramér–Rao bounds (Sect. 6.4) and apply a benchmark-based improvement technique (Sect. 9).
A good measure of the persistence strength should have both of the following properties: very small systematic error (i.e. a bias approaching zero) and small random error (i.e. deviations around \( \bar{\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}} \) which are small). One can use both the systematic and random error to come up with a measure for the total error, the root-mean-squared error (RMSE) which is given by (Mudelsee 2010):
For a detailed discussion of bias, standard error, standard deviation, RMSE, and confidence intervals, see Chapter 3 of Mudelsee (2010).
Realizations of a process created to have a given strength of long-range persistence and one-point probability distribution can be contrasted with the underlying behaviour of the process itself where the parameter of a process is β model, in other words the desired β for the process. This process has realizations (the time series) which will have a distribution of their ‘true’ β values because of the finite-size effect (Peng et al. 1993b). We then measure these with a given technique, which itself has its own error, giving \({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}\). We are assuming the systematic error that is discussed here is based on the realizations having a Gaussian distribution and that we can get some handle on their ‘true’ distribution. We are also assuming that the techniques we are using reflect this, in addition to the bias in the techniques themselves. We will never know (except theoretically, if we have closed form equations) the true value of β for each realization of the process, just the parameter that we designed it for (i.e. β model), unless the realizations are taken for an infinite number of values, in which case they will asymptote to the true value of β. In other words, there will always be a finite-size effect on individual realizations. Given this finite-size effect, we can never know the exact true β for each realization, but instead what we are measuring is a measure of the technique and the finite-size effect of going from process to realization (i.e. the synthetic noises and motions we have created). We will now discuss confidence intervals within the framework of our DFA example.
7.2 Confidence Intervals
Returning to Fig. 17, with our example of DFA applied to a log-normal noise (c v = 0.5, N = 1,024, β model = 0.8), we find that approximately 95 % of the values of β DFA lie in the interval \( \left[ {\bar{\beta }_{\text{DFA}} - 1.96\;\sigma_{x} \left( {\beta_{{\,{\text{DFA}}}} } \right),\,\bar{\beta }_{\text{DFA}} + 1.96\;\sigma_{x} \left( {\beta_{{\,{\text{DFA}}}} } \right)} \right] \), in other words, the 95 % confidence interval. In general, for confidence intervals, there must be a sufficient number of values from which to make a valid estimation, for which 95 % of those values are within the confidence interval boundaries. Some authors take this as 1,000 values or more (Efron and Tibshirani 1993). However, if the values follow a Gaussian distribution, the confidence interval boundaries can be computed directly from \( \bar{\beta }_{{\,{\text{measured}}}} \pm 1.96\;\sigma_{x} \left( {\beta_{{\,{\text{measured}}}} } \right) \). Efron and Tibshirani (1993) have determined that, for Gaussian-distributed values, confidence intervals can be constructed from just 100 realizations. We note that there are a number of different ways of constructing confidence intervals for β measured, both theoretical (e.g., based on knowledge of the one-point probability distribution) and empirical (e.g., actual examining how many values for a given set of realizations of a process lie in a given interval, such as 95 %). The latter is known as the empirical coverage and is discussed in detail, along with various methods for the construction of confidence intervals by Mudelsee (2010), who also discusses the use of empirical coverage studies in the wider literature. Here we do not determine the empirical coverage, but rather take the approach of first evaluating the normality of a given set of realizations of β measured (relative to a given β model), and then by using this assumed normality calculate the theoretical confidence interval.
Because we would like to calculate confidence intervals for our performance test results, based on only 100 realizations, we first need to determine whether the values are Gaussian (or close to) distributed. We begin with three types of process constructed with Gaussian, log-normal, and Levy-distributed time series, and β model = 1.0. For each one-point probability distribution, and for time series lengths N = 256, 1,024, 4,096, and 16,384, we create 105 realizations, in other words, overall, 3 × 4 × 105 realizations. For each process created and time series length, we perform three analyses: PS(best-fit) (Fig. 18), DFA (Fig. 19), and rescaled range (R/S) (Fig. 20). Shown in each figure, for the three types of processes (a: Gaussian, b: log-normal, c v = 0.5, c: Levy, a = 1.5), and each of the time series lengths, are the results (shown in grey dots) of 5,000 of the 105 realizations. We show, using box and whisker plots (coloured boxes and symbols), the mean, mode, and percentiles of the values within each set of realizations, along with the best-fit Gaussian distributions (solid black line).

Distribution of the estimated strength of long-range persistence using power spectral analysis (β PS(best-fit)) applied to realizations of fractional noises created with β model = 1.0, time series lengths N = 256, 1,024, 4,096, and 16,384, and three types of one-point probability distributions: a fractional Gaussian noises (FGN), b fractional log-normal noises (FLNN) (coefficient of variation c v = 0.5), c fractional Levy noises (FLevyN) (tail parameter a = 1.5). For each probability distribution type, 105 realizations of time series are created for each time series length N. In each panel (a) to (c), and for each length of time series N, are given box and whisker plots and best-fit Gaussian distributions for 105 analyses results of β PS(best-fit) for the 105 realizations. Also shown (grey dots) are 5,000 of the 105 realizations. Each of the box and whisker plots gives the mean of the β PS(best-fit) values (white circle), the median (horizontal line in middle of the box), 25 and 75 % (box upper and lower edges), 5 and 95 % (ends of the vertical lines, i.e. the whiskers), 1 and 99 % (upper and lower triangles), and the minimum and maximum values (upper and lower horizontal bars). In (d) is given the skewness g for each of the distributions from (a) to (c)

Distribution of the estimated strength of long-range persistence using detrended fluctuation analysis (β DFA) applied to realizations of fractional noises created with β model = 1.0, time series lengths N = 256, 1,024, 4,096, and 16,384, and three types of one-point probability distributions: a fractional Gaussian noises (FGN), b fractional log-normal noises (FLNN) (coefficient of variation c v = 0.5), c fractional Levy noises (FLevyN) (tail parameter a = 1.5). In (d) is given the skewness g for each of the distributions from (a) to (c). See Fig. 18 caption for further explanation

Distribution of the estimated strength of long-range persistence using Hurst rescaled range (R/S) analysis (β Hu) applied to realizations of fractional noises created with β model = 1.0, time series lengths N = 256, 1,024, 4,096, and 16,384, and three types of one-point probability distributions: a fractional Gaussian noises (FGN), b fractional log-normal noises (FLNN) (coefficient of variation c v = 0.5), c fractional Levy noises (FLevyN) (tail parameter a = 1.5). In (d) is given the skewness g for each of the distributions from (a) to (c). See Fig. 18 caption for further explanation
Visually, we see that for normal and log-normal noises (Figs. 18a,b, 19a,b, 20a,b), the realizations are reasonably close to a Gaussian distribution. For the Levy realization results (Figs. 18c, 19c, 20c), these are only approximately Gaussian, although are reasonably symmetric. In Figs. 18d, 19d, 20d is given the skewness for each of the distributions from panels (a) to (c) in each figure. For the normal and log-normal results, and four lengths of time series considered, the skewness g is small (DFA: |g| < 0.10, R/S: |g| < 0.15); for Levy results, there are strong outliers in Fig. 19c (DFA) and Fig. 20c (R/S), resulting in large skew (DFA: |g| < 3; R/S: |g| < 0.8), although this is not the case for Fig. 18c (PS(best-fit)) where in Fig. 18d |g| < 0.15. A Shapiro–Wilk test of normality (Shapiro and Wilk 1965) on the different sets of realizations shows that for the smaller values of skewness, in many cases, a Gaussian distribution cannot be rejected at the 0.05 level, whereas for the larger values of skewness (FLevyN using DFA and R/S) it is rejected. Although we recognize that some of our results are only approximately Gaussian, we will use a value of 100 total realizations for a given process created and technique applied, to calculate confidence intervals based on \( \bar{\beta }_{{\,{\text{measured}}}} \pm 1.96\;\sigma_{x} \left( {\beta_{{\,{\text{measured}}}} } \right) \). The size of the 95 % confidence interval of the technique is 3.92 times the standard deviation (random error) of the technique.
7.3 Summary of Our Performance Test Results and Those of Other Studies
The benchmarks we carried out are extensive as they are based on fractional noises and motions which differ in length, one-point probability distribution, and modelled strength of persistence. The performance of the different techniques has been studied here for their dependence on the modelled persistence strengths (26 different parameter values, β model = −1.0 to 4.0, step size 0.2), the noise and motion lengths (4 different parameters, N = 512, 1,024, 2,056, and 4,096), and the type of the one-point probability distribution (three different types: Gaussian, log-normal—two different types of construction, and Levy). These will be presented graphically in this section, with a further eight noise and motion lengths (N = 64, 128, 256, 8,192, 16,384, 32,768, 65,536, and 131,072) presented in the supplementary material (discussed in this section further below). Furthermore, in this section we present results for a fixed value of long-range dependence β model, and the parameters that characterize the corresponding distribution parameters have been varied (11 values of the exponent of the Levy distribution a = 1.0 to 2.0, step size 0.1; 21 different coefficients of variation for two different log-normal distribution construction types, c v = 0.0 to 2.0, step size 0.1). Overall, we have studied fractional noises and motions with about 17,000 different sets of characterizing parameters, of which the results for a subset of these (6,500 different sets of parameters) have been included in the supplementary material. For each set of parameters, 100 realizations have been created, and their persistence strength has been evaluated by the five techniques described above.
The results of these performance tests are presented in Figs. 21, 22, 23, 24, 25 where the measured strength of long-range persistence, \({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}\), is given as a function of the ‘benchmark’ modelled value, β model. Each of the panels in Figs. 21, 22, 23, 24, 25 shows mean values (diamonds) and confidence intervals (error bars) based on the 100 fractional noises and motions run for that particular distribution type, length of series, and modelled strength of persistence. The 95 % confidence intervals for each specific technique are \( \bar{\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}} \pm 1.96\;\sigma_{x} ( {\beta_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}} }) \), where the standard deviation \(\sigma \) x is based on the 100 realizations for a given process. The four colours used represent four fractional noise and motion lengths, N = 512, 1,024, 2,048, and 4,096. Also shown in each graph is a dashed diagonal line, which represents the bias-free case, \( \bar{\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}} = \beta_{\text{model}} \). Whereas Figs. 21, 22, 23, 24, 25 show the systematic and random error of \({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}\) as a dependence on β model, Fig. 26 gives the performance of \({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}\) as a function of the log-normal distribution coefficient of variation (c v = 0.0 to 2.0, step size 0.1), and Fig. 27 the performance of \({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}\) as a function of the Levy distribution tail parameter (a = 1.0 to 2.0, step size 0.1).

Performance of Hurst rescaled range (R/S) analysis (β Hu) applied to realizations of fractional noises and motions (Sect. 4.2) created with long-range persistence −1.0 ≤ β model ≤ 4.0 and time series lengths N = 512, 1,024, 2,048, and 4,096. Mean values (diamonds) and 95 % confidence intervals (error bars, based on ±1.96 σ x ) of β Hu are presented as a function of the long-range persistence strength β model. Different colours indicate different lengths N of the analysed time series as specified in the legend. The black dashed line indicates the bias-free case of β Hu = β model. The one-point probability distributions include the following: a fractional Gaussian noises and motions (FGN), b fractional Levy noises and motions (FLevyN) with tail parameter a = 1.5, c fractional log-normal noises and motions (FLNNa, constructed by Box–Cox transform of fractional Gaussian noises) with c v = 0.5, d fractional log-normal noises and motions (FLNNb, constructed by Schreiber–Schmitz algorithm) with c v = 0.5

Performance of semivariogram analysis (β Ha) applied to realizations of fractional noises and motions (Sect. 4.2) created with long-range persistence −1.0 ≤ β model ≤ 4.0 and time series lengths N = 512, 1,024, 2,048, and 4,096. Mean values (diamonds) and 95 % confidence intervals (error bars, based on ±1.96 σ x ) of β Ha are presented as a function of the long-range persistence strength β model. Different colours indicate different lengths N of the analysed time series as specified in the legend. The black dashed line indicates the bias-free case of β Ha = β model. The one-point probability distributions include the following: a fractional Gaussian noises and motions (FGN), b fractional Levy noises and motions (FLevyN) with tail parameter a = 1.5, c fractional log-normal noises and motions (FLNNa, constructed by Box–Cox transform of fractional Gaussian noises) with c v = 0.5, d fractional log-normal noises and motions (FLNNb constructed by Schreiber–Schmitz algorithm) with c v = 0.5

Performance of detrended fluctuation analysis (β DFA) applied to realizations of fractional noises and motions (Sect. 4.2) created with long-range persistence −1.0 ≤ β model ≤ 4.0 and time series lengths N = 512, 1,024, 2,048, and 4,096. We apply DFA2 here (quadratic trends removed). Mean values (diamonds) and 95 % confidence intervals (error bars, based on ±1.96 σ x ) of β DFA are presented as a function of the long-range persistence strength β model. Different colours indicate different lengths N of the analysed time series as specified in the legend. The black dashed line indicates the bias-free case of β DFA = β model. The one-point probability distributions include the following: a fractional Gaussian noises and motions (FGN), b fractional Levy noises and motions (FLevyN) with tail parameter a = 1.5, c fractional log-normal noises and motions (FLNNa, constructed by Box–Cox transform of fractional Gaussian noises) with c v = 0.5, d fractional log-normal noises and motions (FLNNb constructed by Schreiber–Schmitz algorithm) with c v = 0.5

Performance of power spectral analysis (β PS(best-fit)) applied to realizations of fractional noises and motions (Sect. 4.2) created with long-range persistence −1.0 ≤ β model ≤ 4.0 and time series lengths N = 512, 1,024, 2,048, and 4,096. Mean values (diamonds) and 95 % confidence intervals (error bars, based on ±1.96 σ x ) of β PS(best-fit) are presented as a function of the long-range persistence strength β model. Different colours indicate different lengths N of the analysed time series as specified in the legend. The black dashed line indicates the bias-free case of β PS(best-fit) = β model. The one-point probability distributions include the following: a fractional Gaussian noises and motions (FGN), b fractional Levy noises and motions (FLevyN) with tail parameter a = 1.5, c fractional log-normal noises and motions (FLNNa, constructed by Box–Cox transform of fractional Gaussian noises) with c v = 0.5, d fractional log-normal noises and motions (FLNNb constructed by Schreiber–Schmitz algorithm) with c v = 0.5

Performance of power spectral analysis (β PS(Whittle)) applied to realizations of fractional noises and motions (Sect. 4.2) created with long-range persistence −1.0 ≤ β model ≤ 4.0 and time series lengths N = 512, 1,024, 2,048, and 4,096. Mean values (diamonds) and 95 % confidence intervals (error bars, based on ±1.96 σ x ) of β PS(Whittle) are presented as a function of the long-range persistence strength β model. Different colours indicate different lengths N of the analysed time series as specified in the legend. The black dashed line indicates the bias-free case of β PS(Whittle) = β model. The one-point probability distributions include the following: a fractional Gaussian noises and motions (FGN), b fractional Levy noises and motions (FLevyN) with tail parameter a = 1.5, c fractional log-normal noises and motions (FLNNa, constructed by Box–Cox transform of fractional Gaussian noises) with c v = 0.5, d fractional log-normal noises and motions (FLNNb, constructed by Schreiber–Schmitz algorithm) with c v = 0.5

Performance of three techniques for evaluating long-range persistence, \({\beta }_{{[{\text{Hu,}}\,{\text{DFA,}}\,{\text{PS}}]}}\), applied to realizations of processes created to have fractional log-normal noises (c v = 0.0 to 2.0, Sect. 4.2) with strength of long-range persistence β model = 0.8 and time series lengths N = 512, 1,024, 2,048, and 4,096. The three techniques applied are: a Hurst rescaled range (R/S) analysis (β Hu), b detrended fluctuation analysis (β DFA), c power spectral analysis (β PS(best-fit)). We do not consider semivariogram analysis here as it is only appropriate to apply over the range of −1.0 < β < 1.0. Fractional log-normal noises are constructed using the Box–Cox transform (FLNNa) (left panels) and the Schreiber–Schmitz algorithm (FLNNb) (right panels). For each set of process parameters, 100 realizations are done. For each panel, mean values (diamonds) and 95 % confidence intervals (error bars, based on ±1.96 σ x ) of \({\beta }_{{[{\text{Hu,}}\,{\text{DFA,}}\,{\text{PS}}]}}\) are presented as a function of the coefficient of variation, c v = 0.0 to 2.0, step size 0.1. c v = 0.0 corresponds to symmetric one-point probability distributions (Gaussian distribution), while large values of c v correspond to highly asymmetric one-point probability distributions. Different colours indicate different lengths of the analysed time series (N = 512, 1,024, 2,048, 4,096) as specified in the legend. The black horizontal dashed line indicates the bias-free case of \({\beta }_{{[{\text{Hu,}}\,{\text{DFA,}}\,{\text{PS}}]}}\) = β model = 0.8

Performance of four techniques for evaluating long-range persistence, \({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}\), applied to realizations of processes created to have fractional Levy noises (tail parameter, a = 1.0 to 2.0) with strength of long-range persistence β model = 0.8 and time series lengths N = 512, 1,024, 2,048, and 4,096. The four techniques applied are: a Hurst rescaled range (R/S) analysis (β Hu), b semivariogram analysis (β Ha), c detrended fluctuation analysis (β DFA), d power spectral analysis (β PS(best-fit)). For each panel, mean values (diamonds) and 95 % confidence intervals (error bars, based on ±1.96 σ x ) of \({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}\) are presented as a function of the tail parameter a = 1.0 to 2.0, step size 0.1. A value of a = 2.0 corresponds to a Gaussian distribution, while values close to a = 1.0 correspond to very heavy tails of the one-point probability distribution of the fractional noise. Different colours indicate different lengths of the analysed time series (N = 512, 1,024, 2,048, 4,096) as specified in the legend. The black horizontal dashed line represents the bias-free case of \({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}\) = β model = 0.8
We give in Tables 4 and 5 a tabular overview, summarizing the ranges of the systematic error (\( {\text{bias}} = \bar{\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}} - \beta_{\text{model}} \)) and the random error (standard deviation of \({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}\), σ x (\({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}\))) for the five techniques when applied to fractional noises (Table 4) and fractional motions (Table 5). These two tables are summaries for three probability distributions (Gaussian, log-normal with c v = 0.5 and two types of construction, Levy with a = 1.5) and where the number of elements is N = 4,096.
A first inspection of Figs. 21, 22, 23, 24, 25, 26, 27, and Tables 4 and 5 shows that different techniques perform very differently. These differences will be summarized, for each technique, in Sects. 7.4–7.7.
As a resource to the user, we include in the supplementary material the following:
-
(1)
An Excel Spreadsheet of a subset of our results for all of our different analyses. For each set of 100 realizations of fractional noises or motion parameters for which the process was designed (one-point probability distribution type, number of elements N, β model) and technique applied, we give the mean \( \bar{\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}} \), systematic error (bias = \( \bar{\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}} - \beta_{\text{model}} \)), random error (standard deviation σ x (\({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}\))), and root-mean-squared error \( (RMSE =( {( {{\text{systematic}}\;{\text{error}}} )^{2} + ( {{\text{random}}\,{\text{error}}} )^{2} } )^{0.5} ). \) In addition, for each set of 100 realizations, we give the minimum, 25 %, mode, 75 %, and maximum \({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}\). The analyses applied include those discussed in this paper (Hurst rescaled range analysis, semivariogram analysis, detrended fluctuation analysis, power spectral analysis [best-fit], and power spectral analysis [Whittle]) and the discrete wavelet transform (DWT, results not discussed in this paper, but ‘presented’ in the supplementary material; see Appendix 6 for a discussion of the DWT applied). These analyses results are provided for 6,500 parameter combinations (out of the 17,000 examined for this paper). See also Sect. 9.5 where the supplementary Excel spreadsheet is described in more detail in the context of benchmark-based improved estimators for long-range persistence.
-
(2)
R programs. We give the set of R programs that we use to perform the tests.
Various other studies have been conducted that simulate self-affine long-range persistent time series and examine the results of performance techniques. For a selection of these, in Table 6 we give a review of 12 of these studies (including this one), where for each study we give: (1) the type of fractional noise or motion used (the one-point probability distribution, technique used to create the fractional noises and motions, and the fractional noise or motion length), (2) the technique used to evaluate the long-range persistence, and (3) any comments. Our study complements and extends existing studies in terms of the range of fractional noises and motions constructed—including the range of β model, addition of Levy-distributed noises and motions which are rarely studied but representative of heavy-tailed processes in nature, and a wide range of lengths of time series—and the performance techniques used. For completeness, although our performance techniques are for self-affine noises and motions, in Table 7 we give a summary of 14 selected studies that simulate asymptotic long-range persistent time series to examine the performance of long-range dependence techniques. We now discuss each performance technique individually.
7.4 Hurst Rescaled Range Analysis Results (β Hu)
Here we summarize (and will do the same for the other techniques in the three subsequent sections) the following for the performance technique results applied to our fractional noises and motions: (a) range of theoretical applicability of the performance technique; (b) dependence on β model; (c) dependence on the one-point probability distribution; (d) a brief discussion; and (e) overall ‘short’ conclusions.
-
(a)
Range of theoretical applicability: As Hurst rescaled range analysis can be applied to stationary time series only, it is theoretically appropriate only for fractional noises, –1.0 < β model < 1.0.
-
(b)
Dependence on β model: The results of the Hurst rescaled range analysis are given in Fig. 21 where we see that the performance test results β Hu deviate strongly from the dashed diagonal line (β model = β Hu) and that only over (approximately) the range 0.0 < β model < 1.0 do the largest 95 % confidence intervals (for N = 512) intersect with some part of the bias-free case (β model = β Hu); as the number of elements N increases, the 95 % confidence intervals for β Hu decrease in size, and therefore there are fewer cases where the 95 % confidence intervals for β Hu overlap with β model. In terms of the bias, unbiased results are found only for fractional noises with a strength of persistence of β model ≈ 0.5. For less persistent noises, β model < 0.5, the strength of persistence is overestimated, and for more persistent noises, β model > 0.5, it is underestimated. Apart from the poor general performance, the random error (confidence intervals) of β Hu are rather small (Tables 4, 5).
-
(c)
Dependence on the one-point probability distribution: In Fig. 26a we see that at β model = 0.8 the systematic error (bias) increases with the asymmetry (c v = 0.0 to 2.0) of the one-point probability distribution while the random error (which is proportional to the 95 % confidence interval size) stays constant. In contrast (Fig. 27a), at β model = 0.8, both the systematic error (bias) and random error (confidence interval sizes) are very robust (they do not vary a lot) to changes of the tail parameter (a = 1.0 to 2.0) of the fractional noise.
-
(d)
Discussion: Our results presented in Figs. 21 and 26a show that the systematic error (bias) gets smaller as the time series length N grows from 512 to 4,096. If we consider a broader range of time series lengths (supplementary material), this can be seen more clearly. For example, consider a FGN with β model = −0.8, and then our simulations result in \( \bar{\beta }_{\text {Hu}} \) = −0.42 (N = 4,096), −0.45 (N = 8,192), −0.47 (N = 16,384), −0.49 (N = 32,768), −0.51 (N = 65,536), and −0.53 (N = 131,072), and thus, the value of β model = −0.8 is very slowly approached. The bias of Hurst rescaled range analysis is a finite-size effect; Bassingthwaighte and Raymond (1995) and Mehrabi et al. (1997) have shown for fractional Gaussian noises and motions that for very long sequences, the correct value of β model will be approached by β Hu.
-
(e)
Rescaled range (R/S) analysis brief conclusions: For most cases, it is inappropriate to use Hurst rescaled range (R/S) analysis for the types of self-affine fractional noises and motions (i.e. Gaussian, log-normal, and Levy distributed) considered in this paper, and correspondingly many of the time series found in the Earth Sciences.
7.5 Semivariogram Analysis Results (β Ha)
-
(a)
Range of theoretical applicability: The range of β Ha is the interval 1.0 < β model < 3.0, so semivariogram analysis is appropriate for fractional motions only.
-
(b)
Dependence on β model: Fig. 22a,b,c and Tables 4 and 5 demonstrates that for fractional Gaussian noises (FGN), fractional Levy noises (FLevyN), and fractional log-normal noises constructed with the Box–Cox transform (FLNNa), unbiased results are found over much (but not all) of the interval 1.0 < β model < 3.0, with larger values of the bias at the interval borders; larger biases also occur for short time series. For persistence strength β model > 2.0 (more persistent than Brownian motion), semivariograms applied to realizations of log-normal noises and motions based on the Schreiber–Schmitz algorithm (Fig. 22d, FLNNb) result in values of β PS ≈ 2.0, reflecting a failure of this algorithm for this particular setting of the parameters. Our simulations indicate that the Schreiber–Schmitz algorithm does not work for constructing noises that are asymmetric and non-stationary; thus, we cannot discuss the corresponding performance.
-
(c)
Dependence on the one-point probability distribution: For FGN, FLevyN, and FLNNa, Fig. 22, the confidence interval size depends on the strength of long-range persistence: they are small around β model ≈ 1.0, increase up to β model ≈ 2.5, and then decrease for larger values of the persistence strength. It appears plausible to increase the range of applicability of semivariogram analysis to fractional noises (–1.0 < β model < 1.0) by analysing their aggregated series, but only if the original series has a symmetric (or near-symmetric) probability distribution. In Fig. 27b, we see that at β model = 0.8 changes of the heavy-tail parameter of fractional Levy noises from a = 0.0 to 1.0 impact the systematic error (bias) in a complex way, while the random error remains almost constant and very large.
-
(d)
Discussion: Gallant et al. (1994), Wen and Sinding-Larsen (1997), and Malamud and Turcotte (1999a) have discussed the bias of Ha for time series and came to very similar conclusions. Wen and Sinding-Larsen (1997) pointed out (1) that longer lags τ lead to more accurate estimates of Ha (consequently, we have used here long lags up to N/4) and (2) that semivariogram analysis is applicable to incomplete (i.e. gap containing) measurement data. For time series that are incomplete (i.e. values in an otherwise equally spaced time series are missing), only lagged pairs of values which are not affected by the gaps are considered in the summation of (Eq. 16).
-
(e)
Semivariogram analysis brief conclusions: Semivariogram analysis is appropriate for 1.0 < β < 3.0, introduces little bias, but the resulting estimates are rather uncertain. It is appropriate for time series with asymmetric one-point probability distributions, but should not be applied if that distribution is heavy tailed.
7.6 Detrended Fluctuation Analysis Results (β DFA)
-
(a)
Range of theoretical applicability: Detrended fluctuation analysis (here performed with the quadratic trend removed, i.e. DFA2) can be applied to all persistence strengths considered in our synthetic fractional noises and motions (Sect. 4.2).
-
(b)
Dependence on β model: For fractional Gaussian, Levy, and log-normal noises and motions, detrended fluctuation analysis is just slightly biased (Fig. 23; Tables 4, 5). It shows a weak overestimation for the strongly anti-persistent noises (−1.0 < β model < −0.7) in particular for the very short time series (N = 512, N = 1,024). For fractional log-normal noises and motions created by Box–Cox transforms (FLNNa), β DFA overestimates the strength of persistence for anti-persistent noises (β model < 0.0) and slightly underestimates for fractional noises and motions with 0.5 < β model < 1.5 (Fig. 23c). For fractional log-normal noises and motions created by the Schreiber–Schmitz algorithm (FLNNb, Fig. 23d), our simulations show large values of the bias for β model ≥ 2.0. This bias is a consequence of the construction of the FLNNb rather than a limitation of detrended fluctuation analysis.
The random error (which is proportional to the 95 % confidence interval size) of detrended fluctuation analysis (Fig. 23) depends on the correlations of the investigated time series: for fractional noises and motions of all considered one-point probability distributions, the sizes of the confidence intervals increase with the persistence strength. For thin-tailed fractional noises and motions (i.e. Gaussian and log-normal), the confidence intervals for fractional Brownian motions (β model = 2.0) are twice as big as for white noises (β model = 0.0) (Fig. 23; Tables 4, 5). So, the stronger the strength of persistence in a times series, the more uncertain will be the result of detrended fluctuation analysis.
-
(c)
Dependence on the one-point probability distribution: For fractional log-normal noises (constructed by Box–Cox transform), the negative bias and the random error (proportional to the confidence interval size) are increasing gradually for increasing coefficients of variations (Fig. 26b, FLNNa). If the fractional log-normal noises are created by the Schreiber–Schmitz algorithm (Fig. 26b, FLNNb) and have positive persistence and a moderate asymmetry (0.0 < c v ≤ 1.0), β DFA is unbiased. However, for fractional noises and motions with strongly asymmetric one-point probability distribution (1.0 < c v < 2.0) and data sets that have a small number of total values, detrended fluctuation analysis underestimates β model (Fig. 26b). The corresponding 95 % confidence intervals grow with increasing asymmetry. They are bigger than those of β DFA for fractional log-normal noises constructed by the Box–Cox transform (Fig. 26b, Table 4). Detrended fluctuation analysis is unbiased for fractional Levy noises with positive persistence strength and different tail exponents, a (Fig. 27c). The corresponding confidence intervals grow with decreasing tail exponent, a.
-
(d)
Discussion: It is important to note that the random error of β DFA which arises from considering different realizations of fractional noises and motions is different from (and in case of positive persistence, β model > 0.0, much larger than) the regression error of β DFA gained by linear regression of the log(fluctuation function) versus log(segment length). The very small regression error originates in the statistical dependence of the difference between the fluctuation function of a particular noise and the average (over many realizations of the noise) fluctuation function. As a consequence, the regression error should not be used to describe the uncertainty of the measured strength of persistence.
In the case of fractional Levy noises with very heavy tails (a ≪ 2) (Fig. 27c), we do not recommend the use of detrended fluctuation analysis, as the error bars become very large with increasing a (Fig. 27c). In this case, the modified version of detrended fluctuation analysis suggested by Kiyani et al. (2006) which has not been ‘benchmarked’ in our paper might be an option.
The performance of detrended fluctuation analysis (DFA) has been studied extensively (Taqqu et al. 1995; Cannon et al. 1997; Pilgram and Kaplan 1998; Taqqu and Teverovsky 1998; Heneghan and McDarby 2000; Weron 2001; Audit et al. 2002; Xu et al. 2005; Delignieres et al. 2006; Mielniczuk and Wojdyłło 2007; Stroe-Kunold et al. 2009) for different types of fractional noises and motions and asymptotic long-range persistent time series (Tables 6, 7). In some of these studies (Taqqu et al. 1995; Pilgram and Kaplan 1998; Xu et al. 2005), it was demonstrated to be the best-performing technique. In other studies, DFA has been found to have low systematic error (bias) and low random error (confidence intervals) but was slightly outperformed by maximum likelihood techniques (Taqqu and Teverovsky 1998; Audit et al. 2002; Delignieres et al. 2006; Stroe-Kunold et al. 2009).
-
(e)
Detrended fluctuation analysis brief conclusions: Detrended fluctuation analysis is almost unbiased for fractional noises and motions, and the random errors (proportional to the confidence interval sizes) are small for fractional noises. It is inappropriate for time series whose one-point probability distributions are characterized by very heavy tails.
7.7 Power Spectral Analyses Results β PS(best-fit) and β PS(Whittle)
-
(a)
Range of theoretical applicability: Power spectral-based techniques β PS(best-fit) and β PS(Whittle) can be applied to all persistence strengths considered in our fractional noises and motions (Sect. 4.2).
-
(b)
Dependence on β model: Symmetrically distributed (i.e. Gaussian- and Levy-distributed fractional noises) power spectral-based techniques used for evaluating the strength of long-range persistence perform very well (Figs. 24, 25; Tables 4, 5). They are (1) unbiased (\( \bar{\beta }_{\text{PS}} = \beta_{\text{model}} \)), and (2) the size of confidence intervals of β PS depends on the length of the fractional noise or motion but not on the strength of long-range persistence, β model. For fractional Levy noises, power spectral techniques are very exact as the related confidence intervals are very tight. For fractional Levy motions with a β model ≥ 3.0, the β PS becomes slightly biased; the strength of persistence is overestimated in particular for the shorter time series. Looking specifically at fractional Levy noises with different strong heavy tails (Fig. 27d), we find (1) an unbiased performance of β PS and (2) that heavier tails cause smaller systematic error.
-
(c)
Dependence on the one-point probability distribution: For the fractional noises and motions with asymmetric distributions, namely the two types of fractional log-normal noises, the performance depends on how these noises and motions are created (Figs. 24c,d, 25c,d, 26c, 27d; Tables 4, 5): if they are constructed by applying a Box–Cox transform to a fractional Gaussian noise (Figs. 24c, 25c; Tables 4, 5), we find for the anti-persistent noises considered here, −1.0 < β model < 0.0, the strength of long-range persistence, β PS, is overestimated while for 0.0 < β model < 1.0, it is underestimated. Because the systematic (bias) and random error is very small compared to β model, the underestimation is somewhat hard to see on the figures themselves, but becomes much more apparent in the supplementary material. This effect of under- and overestimation of β model is stronger if fractional log-normal noises with a more asymmetric one-point probability distribution (larger coefficients of variations, c v) are considered. One can also see (Fig. 26c), for fractional log-normal noises and motions, the confidence interval size gradually grows with increasing asymmetry (increasing c v).
If the fractional log-normal noises are constructed by the Schreiber–Schmitz algorithm (Figs. 24d, 25d), then power spectral techniques perform fairly convincingly in the range of persistence −1.0 < β model < 1.8. For persistence strength β model > 2.0 (more persistent than Brownian motion), spectral techniques result in values of β PS ≈ 2.0, reflecting a failure of the Schreiber–Schmitz algorithm for this particular setting of the parameters. The confidence intervals are equally sized for the entire considered range of persistence strength, but they are approximately 10 % larger than the confidence intervals of fractional Gaussian noises (Figs. 24a, 25a). For a fixed β model, the error bar sizes rise with growing asymmetry (larger coefficients of variations, c v) (Fig. 26c). For highly asymmetric noises (c v > 1.0), the strength of long-range persistence is underestimated.
For the fractional Levy noises, we find that the performance does not depend on the heavy-tail parameter. Figure 27d presents the performance test result for a persistence strength of β model = 0.8; the power spectral technique is unbiased, and the random error (proportional to the confidence intervals) is about the same across all considered values of the exponent a.
-
(d)
Discussion: If the performance of the maximum likelihood estimator, β PS(Whittle), is compared to the performance of the log-periodogram regression, β PS(best-fit), we find that both techniques perform very similarly, except that β PS(Whittle) represents a slightly more exact estimator (Tables 4, 5). The real advantage, however, is that the Whittle estimator also gives the random error, \(\sigma \)(β PS(Whittle)), for any single time series considered.
In Fig. 28a we give the random error (standard deviation of the Whittle estimator, \(\sigma \)(β PS(Whittle)), also called the standard error of the estimator, see Sect. 7.1) as a function of the long-range persistence of 100 realizations (each) of FGN processes created to have −1.0 ≤ β model ≤ 4.0 and four time series lengths N = 256, 1,024, 4,096, and 16,384. In Fig. 28b we give \(\sigma \)(β PS(Whittle)) of 100 realizations (each) of four probability distributions (FGN, FLNN c v = 0.5, FLNN c v = 1.0, FLevyN a = 1.5) with β model = 0.5, as a function of time series length N = 64 to 65,536. For both panels and each set of process parameters in Fig. 28, we also give the maximum likelihood estimate, the Cramér–Rao bound (CRB) (Sect. 6.4, Eq. 28), for each set of 100 realizations. Both y-axes in Fig. 28 are logarithmic, as is the x-axis for Fig. 28b.
Fig. 28 
Standard error of the Whittle estimator \(\sigma \)(β PS(Whittle)) (dashed lines) and Cramér Rao bounds (CRB) (solid lines) are given as a function of the following: a long-range persistence strength −1.0 ≤ β model ≤ 4.0 of fractional Gaussian noises (FGN) and time series length N = 256, 1,024, 4,096, and 16,384; b Time series length N = 26, 27, 28, …, 216 (i.e. from N = 64 to 65,536) and fractional noise realizations with β model = 0.5 and four types of probability distribution, Gaussian (FGN, diamonds), log-normal (FLNN: circles, c v = 0.5; diamonds, c v = 1.0, created using Box–Cox transform), and Levy (FLevyN, a = 1.5). For both (a) and (b), the standard error \(\sigma \)(β PS(Whittle)) and CRB are on a logarithmic axis. Each individual symbol represents 100 realizations for a given length of time series N, one-point probability distribution, and modelled long-range persistence strength β model. The standard error of the Whittle estimator results (\(\sigma \)(β PS(Whittle)) and the average CRB are taken over all 100 realizations, except for the FLevyN, where for CRB the two smallest and two largest values (of each set of 100 realizations) are taken out before averaging
In Fig. 28a we observe that the random error of the Whittle estimator, \(\sigma \)(β PS(Whittle)), slightly increases as a function of persistence strength, β model, for −1.0 < β model < 2.8. In contrast, the CRB is slightly increasing as a function of β model over the range −1.0 < β model < 0.0 and then decreases by an order of magnitude, over the range 0.0 < β model< 2.0, after which it remains constant. The general shape of the four curves for CRB and the four curves for \(\sigma \)(β PS(Whittle)) do not depend on the length of the time series, N. The CRB is systematically smaller than the random error, (β PS(Whittle)). The ratio CRB/\(\sigma \)(\(\sigma \) β PS(Whittle)) changes significantly for different ranges of β model. Therefore, knowing only the CRB value will not give knowledge about the magnitude of the random error. We therefore do not recommend using the CRB as an estimate of the random error.
All eight curves in Fig. 28b show a power-law dependence on the time series length N (and scale with N −0.5). The Cramér–Rao bound measure is a lower bound for the random error and depends very little on the one-point probability of the fractional noise or motion. We see here that the Cramér–Rao bounds are systematically smaller than the standard errors, in other words the standard deviations of β PS(Whittle) calculated for many realizations, \(\sigma \)(β PS(Whittle)). The mean standard error is smallest for the fractional Levy noises and largest for the fractional log-normal noises, with the largest \(\sigma \)(β PS(Whittle)) for the higher coefficient of variation. The ratio CRB/\(\sigma \)(β PS(Whittle)) changes with the one-point probability distribution but not with the time series length N.
If the performance of these power spectral techniques is considered for time series with N = 4,096 elements, we find (Tables 4, 5):
-
(1)
Power spectral techniques are free of bias for fractional noises and motions with symmetric distributions and they expose a significant bias for time series with strong asymmetric probability distributions.
-
(2)
The random error (proportional to the confidence interval sizes) is rather small, as in the case of symmetrically distributed time series, 95 % of the β PS occupy an interval of length 0.2 or smaller.
For fractional noises and motions with an asymmetric probability distribution, power spectral techniques are less certain. The more asymmetric the time series is, the more uncertain is the estimated strength of long-range persistence. Spectral techniques that estimate the strength of long-range persistence are common in statistical time series analysis, particularly in the econometrics and physics communities, and their performance has been intensively investigated (Schepers et al. 1992; Gallant et al. 1994; Taqqu et al. 1995; Mehrabi et al. 1997; Wen and Sinding-Larsen 1997; Pilgram and Kaplan 1998; Taqqu and Teverovsky 1998; Heneghan and McDarby 2000; Velasco 2000; Weron 2001; Eke et al. 2002; Delignieres et al. 2006; Stadnytska and Werner 2006; Boutahar et al. 2007; Mielniczuk and Wojdyłło 2007; Boutahar 2009; Faÿ et al. 2009; Stroe-Kunold et al. 2009; see also Tables 6 and 7). The most common approach in the literature is to fit models using MLE to time series that are characterized by short- and long-range dependence. In most cases, the considered time series have a Gaussian one-point probability distribution.
-
(1)
-
(e)
Power spectral analysis brief conclusions: Power spectral techniques have small biases and small random errors (tight confidence intervals).

8 Discussion of Overall Performance Test Results
8.1 Overall Interpretation of Performance Test Results
The performance test results presented in Sect. 7 for measures of long-range persistence have shown that some techniques are more suited than others in terms of systematic and random error. In Figs. 29 and 30 we give, respectively, a visual overview of the systematic error (bias = \( \bar{\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}} - \beta_{\text{model}} \)) and random error (standard deviation of \({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}\), σ x (\({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}\))) for the five techniques applied to fractional noises and motions constructed with −1.0 ≤ β model ≤ 4.0 and three probability distributions: Gaussian (FGN), log-normal (FLNNa) with 0.2 ≤ c v ≤ 2.0 using Box–Cox, and Levy (FLevyN) with 1.0 ≤ a ≤ 1.9. For each type of fractional noise and motion, 100 realizations were created each with 4,096 elements. Note that a FGN is the same as FLNNa with c v = 0.0 and FLevyN with a = 2.0. In Fig. 31 for the same 2,730 processes considered in Figs. 29 and 30, we give a visual overview of the root-mean-squared error RMSE (Eq. 30) which is a measure for the overall performance of a technique.

Visual overview of the systematic error (bias = \( \bar{\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}} - \beta_{\text{model}} \)) of five techniques for evaluating long-range persistence: a Hurst rescaled range (R/S) analysis (β Hu), b semivariogram analysis (β Ha), c detrended fluctuation analysis (β DFA), d power spectral analysis best-fit (β PS(best-fit)), e power spectral analysis Whittle (β PS(Whittle)). For each panel are shown the biases resulting from 100 realizations each of processes created to have N = 4,096 elements and 546 different sets of parameters: [panel rows] strengths of long-range persistence −1.0 ≤ β model ≤ 4.0; [panel columns] three probability distributions: (1) Levy (FLevyN) with 1.0 ≤ a ≤ 1.9, (2) Gaussian (FGN), (3) log-normal (FLNNa) with 0.2 ≤ c v ≤ 2.0 using Box–Cox. Note that a FGN is the same as FLNNa with c v = 0.0 and FLevyN with a = 2.0. The colour coding within each panel (see legend) ranges from large negative biases (red), ‘small’ biases (green), to large positive biases (purple)

Visual overview of the random error (\( \sigma_{x} (\beta_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}) \) (abbreviated Std Dev in the figure) of five techniques for evaluating long-range persistence: a Hurst rescaled range (R/S) analysis (β Hu), b semivariogram analysis (β Ha), c detrended fluctuation analysis (β DFA), d power spectral analysis best-fit (β PS(best-fit)), e power spectral analysis Whittle (β PS(Whittle)). For each panel is shown the random error (standard deviations, abbreviated in the panel as std dev) resulting from 100 realizations each of processes created to have N = 4,096 elements and 546 different sets of parameters: [panel rows] strengths of long-range persistence −1.0 ≤ β model ≤ 4.0; [panel columns] three probability distributions: (1) Levy (FLevyN) with 1.0 ≤ a ≤ 1.9, (2) Gaussian (FGN), (3) log-normal (FLNNa) with 0.2 ≤ c v ≤ 2.0 using Box–Cox. The random error for each of the 546 process sets within each panel is represented by the size of the bar for that process (see legend)

Visual overview of the root-mean-squared error (RMSE, Eq. 30) of five techniques for evaluating long-range persistence: a Hurst rescaled range (R/S) analysis (β Hu), b semivariogram analysis (β Ha), c detrended fluctuation analysis (β DFA), d power spectral analysis best-fit (β PS(best-fit)), e power spectral analysis Whittle (β PS(Whittle)). For each panel is shown the RMSE (i.e. ((systematic error)2 + (random error)2)0.5) resulting from 100 realizations each of processes created to have N = 4,096 elements and 546 different sets of parameters: [panel rows] strengths of long-range persistence −1.0 ≤ β model ≤ 4.0; [panel columns] three probability distributions: (1) Levy (FLevyN) with 1.0 ≤ a ≤ 1.9, (2) Gaussian (FGN), (3) log-normal (FLNNa) with 0.2 ≤ c v ≤ 2.0 using Box–Cox. Note that a FGN is the same as FLNNa (c v = 0.0) and FLevyN (a = 2.0). The RMSE for each of the 546 process sets within each panel is represented by the size of the bar for that process (see legend) and colour shading behind that bar (green: 0.0 ≤ RMSE ≤ 0.1; yellow: 0.1 < RMSE ≤ 0.5; red: RMSE > 0.5)
A comparison of the systematic error (bias) of the five techniques (Fig. 29) shows that DFA (Fig. 29c) and spectral techniques (Fig. 29d,e) have small biases (green cells in the panels) over most of the range of β model considered, that is, for most fractional noises and motions. Large biases for DFA and spectral techniques (red or purple cells in Fig. 29c,d,e panels) indicate over- or underestimation of the persistence strengths and occur only for anti-persistent fractional log-normal noises (FLNNa, β model < −0.2) and for a minority of highly persistent fractional Levy motions (FLevyN, 1.0 < a < 1.2). In contrast, Hurst rescaled range analysis (Fig. 29a) leads to results with small biases only for fractional noises with 0.0 < β model < 0.8, and semivariogram analysis (Fig. 29b) has small biases only if the persistence strength is in the range 1.2 < β model < 2.8 and the one-point probability distribution does not have too heavy a tail (i.e. FLevyN with a > 1.2). Overall, when examining the five panels in Fig. 29, one can see (green cells) that DFA and the spectral analysis techniques are generally applicable for all β model, whereas rescaled range analysis (with limitations) is appropriate for −1.0 < β model < 1.0, and semivariogram analysis (again, with limitations) is appropriate for 1.0 < β model < 3.0.
If the random errors (σ x (\({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}\))) of the five techniques are compared (Fig. 30), the smallest overall random errors (horizontal bars that are very thin or zero) are found for rescaled range analysis (Fig. 30a), and then spectral techniques (Fig. 30d,e) with the Whittle estimator having slightly smaller overall random errors. DFA (Fig. 30c) has overall the largest random error when considering all strengths of persistence (β model) and variety of probability distributions and increases gradually as β model increases. In contrast, when examining semivariogram analysis (Fig. 30b), it shows the largest variation of random errors of all the techniques, particularly large for 1.0 < β model < 3.0.
The overall performance of the techniques is given by the root-mean-squared error, RMSE = ((systematic error [Fig. 29])2 + (random error [Fig. 30])2)0.5 (Eq. 30) which is displayed graphically in Fig. 31. In this figure, the length of the horizontal bar in each panel cell represents RMSE on a scale of 0.0 to 3.0, where (as above) each of the 546 cells in the panel is a combination of process parameters (−1.0 < β model < 4.0; 21 different one-point probability distribution parameter combinations) for which 100 realizations were produced. To highlight different magnitudes of RMSE, each cell has been coloured, such that green represents ‘low’ values of RMSE (0.0 to 0.1), yellow ‘medium’ values of RMSE (0.1 to 0.5), and red ‘high’ values of RMSE (0.5 to 3.0).
Figure 31 illustrates that the performance of the best-fit and Whittle spectral techniques (Fig. 31d,e) generally performs the best (compared to the other three techniques) across a large range of β model and one-point probability types (FLevyN, FGN, and FLNNa) as evidenced by the large ‘green’ regions (i.e. 0.0 ≤ RMSE ≤ 0.1). However, one also can observe for these spectral techniques (Fig. 31d,e, yellow [0.1 < RMSE ≤ 0.5] and red [RMSE > 0.5] cells) that care should be taken for very heavy-tailed fractional noises with large persistence values (FLevyN, 1.0 ≤ a ≤ 1.3, and β model > 2.0), and for fractional log-normal noises (FLNNa) that are anti-persistent (β model < 0.0) or with weak persistence (0.0 < β model < 1.0) and c v > 0.8. DFA (Fig. 31c), although it is in general applicable over all β model, does not perform as well as the spectral analysis techniques (Fig. 31d,e) as evidenced by a large number of yellow cells (0.1 < RMSE ≤ 0.5) and a few red cells (RMSE > 0.5), particularly for FLevyN across most β model. Semivariogram analysis (Fig. 31b) has large RMSE (red cells) for β model ≤ 0.4 and β model ≥ 3.6 (across FLevyN, FGN, and FLNNa), whereas rescaled range analysis (Fig. 31a) has large RMSE (red cells) for β model ≤ −0.6 and β model ≥ 1.6. The other cells for both semivariogram (Fig. 31b) and rescaled range analysis (Fig. 31a) mostly exhibit medium RMSE (yellow cells) except for narrow bands of 0.2 < β model < 0.6 (rescaled range analysis) and 1.2 < β model < 1.6 where the cells exhibit low RMSE (green cells).
We believe, based on the results shown in Figs. 29, 30, 31, that power spectral analysis techniques (best-fit and Whittle) are acceptable for most practical applications as they are almost unbiased and give tight confidence intervals. Furthermore, based on these figures, detrended fluctuation analysis is appropriate for fractional noises and motions with positive persistence and with non-heavy-tailed and near-symmetric one-point probability distributions; it is not appropriate for asymmetric or heavy-tailed distributions. Semivariogram analysis was unbiased for 1.2 < β model < 2.8 and might be used for double-checking results, if needed, for an aggregated series, but the large random errors for parts of the range over which results are unbiased need to be considered. We do not recommend the use of Hurst rescaled range analysis as it is only appropriate either for very long sequences (with more than 105 data points) (Bassingthwaighte and Raymond 1994) or for fractional noises with a strength of long-range persistence close to β model ≈ 0.5.
If we focus on the performance of β PS(best-fit) and β DFA for fractional noises and motions with N = 4,096 data points (Figs. 29, 30; Tables 4, 5), we find (1) biases of comparable size and (2) confidence interval sizes which are β model independent for β PS(best-fit) and β model dependent for β DFA. For a pink fractional noise (β model = 1.0), we calculate the absolute magnitude of the confidence intervals as 2 × 1.96 × (σ x (β [DFA, PS])). We find the following confidence intervals for [(β PS(best-fit)), (β DFA)]:
-
[0.12, 0.24] (Gaussian distribution)
-
[0.16, 0.27] (log-normal distribution with moderate asymmetry, c v = 0.6, constructed by Box–Cox transform)
-
[0.10, 0.34] (Levy distribution with a = 1.5)
The size of the confidence intervals for β DFA is a factor of 1.7 to 3.4 times the confidence intervals for β PS(best-fit). Therefore, we recommend the use of detrended fluctuation analysis only for fractional noises and motions with a ‘well-behaved’ one-point probability distribution, in other words for distributions which are almost symmetric and not heavy-tailed.
For anti-persistent noises (β < 0.0), we find a systematic overestimation of the modelled strength of long-range persistence. Rangarajan and Ding (2000) showed that a Box–Cox transform of an anti-persistent noise with a symmetric one-point probability distribution is not just changing the distribution (to an asymmetrical one); the Box–Cox transform effectively superimposes a white noise on the anti-persistent noise, which causes a weakening of the anti-persistence (i.e. β becomes larger). This implies that, for applications, if anti-persistence or weak persistence is identified for an asymmetrically distributed time series, values of long-range persistence that are more negative might be needed for appropriately modelling the original time series. In this situation, we recommend applying a complementary Box–Cox transform to force the original time series to be symmetrically distributed. Then, one should consider the strength of long-range persistence for both the original time series and the transformed time series, discussing both in the results. If a given time series (or realization of a process) has a symmetric one-point probability distribution, one can always aggregate the series and analyse the result (see Sects. 3.5 and 3.6).
With regard to log-normal distributed noises and motions, the results of our performance tests are sensitive to the construction technique used (Box–Cox vs. Schreiber–Schmitz). In this sense, our ‘benchmarks’ seem to confront the construction of the noises or motions rather than to evaluate the techniques used to estimate the strength of long-range dependence. Nevertheless, both ways of constructing fractional log-normal noises and motions are commonly used. If a log-normal distributed natural process like river run-off is measured, either the original data (in linear coordinates) can be examined, or the logarithm of the data can be taken. Our simulations show that the strength of long-range dependence can alter when going from the original to log-transformed values and vice versa. The Schreiber–Schmitz algorithm creates log-normal noises and motions that have a given power-law dependence of the power spectral density on frequency, whereas the Box–Cox transform creates log-normal noises and motions based on realizations of fractional Gaussian noises and motions with a given β model. The Box–Cox transform will slightly change the power-law dependence (for the FGN) of the power spectral densities on frequency, leading to values of β PS that are systematically (slightly) different from β model.
8.2 The Use of Confidence Interval Ranges in Determining Long-Range Persistence
From an applied point of view, it is important to discuss the size of the uncertainties (both systematic and random errors) of the estimated strength of long-range persistence. If a Gaussian-distributed time series with N data points is given that is expected to be self-affine, then the power spectral techniques have a negligible systematic error (bias) and a random error (σ x (β PS)) of approximately 2N −0.5. If we take as an actual example power spectral analysis (best-fit) applied to 100 realizations of a fractional Gaussian noise with β model = 0.2 and three lengths N = 32,768, 4,096, and 256, the average result (supplementary material) of the applied technique is, respectively, \( \bar{\beta }_{{\rm PS}(\text{best-fit})} = 0.201,\,\,0.192,\;0.204 \) giving biases = 0.001, 0.008, and 0.004. The random errors for β PS(best-fit) at N = 32,768, 4,096, and 256 are, respectively, σ x (β PS(best-fit)) = 0.011, 0.030, 0.139, compared to the theoretical random error of 2 N −0.5 = 0.011, 0.031, 0.125. The actual random error and the theoretical error are closer as N gets larger, with for N = 32,768 a negligible percentage difference between the two values, N = 4,096 a 3 % difference, and N = 256 a 11 % difference. For power spectral analysis (Whittle), this same behaviour of the random error (2 N −0.5) can be seen in Fig. 28b, where there is a power-law dependence of (σ x (β PS)) on time series length N (dashed lines, blue triangle).
Confidence intervals (Sect. 7.2) are constructed as \( \bar{\beta }_{\text{PS}} \pm 1.96\;\sigma_{x} \left( {\beta_{\text{PS}} } \right) \). Therefore, if we take the example given above for 100 realizations of a FGN constructed to have β model = 0.2 and N = 16,384, the 95 % confidence intervals are \( \bar{\beta }_{{\text{PS}}({\text{best-fit}})} \pm 1.96\;\sigma_{x}(\beta_{{\text{PS}}({\text{best-fit}})}) = 0.201 \pm (1.96 \times 0.011),\) giving (within the 95 % confidence intervals) 0.179 < β PS(best-fit) < 0.223. If we do the same for the two other lengths, then for N = 4,096, 0.132 < β PS(best-fit) < 0.252, and for N = 512, −0.074 < β PS(best-fit) < 0.482. The confidence interval sizes grow rapidly as the number of elements N decreases, such that, for N = 256, we are unable to confirm (within the 95 % confidence interval) that long-range persistence is in fact present—the confidence interval contains the value β PS = 0.0. Values of β PS that are closer to or at zero are likely to occur for short-term persistent and white (uncorrelated) noises. Thus, if we want to use this analysis technique for showing that a time series with N = 256 elements is long-range persistent (and not β = 0.0), the confidence interval must not contain zero, requiring either β PS > 0.25 or β PS < −0.25, where we have used 1.96 × (2 N −0.5) to derive these limits. In the case of non-symmetric one-point probability distributions, the larger systematic errors (biases) shift the confidence intervals even more for β PS, leading to other (sometimes larger) thresholds for identifying long-range persistence.
Similar considerations can be made for the other three techniques (\({\beta }_{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}\)). Since these techniques are less reliable, the resultant thresholds will be larger and the two thresholds will not be symmetric with respect to zero due to biases. In such cases long-range persistence can only be identified if β model has a very high or very low value. In summary, it might become difficult to identify long-range persistence for non-Gaussian or rather short or non-perfect fractional noises or motions.
Another important aspect of our analysis is stationarity, in other words to decide whether a given time series can be appropriately modelled as a fractional noise (β < 1.0) or a fractional motion (β > 1.0). The value of β = 1.0 is the strength dividing (weakly) stationary noises from non-stationary motions. For this decision, essentially the same technique as described above can be applied where we inferred whether a time series is long-range persistent (β > 0.0) or anti-persistent (β < 0.0). However, the analysis is now restricted to confidence intervals for β DFA, β PS(best-fit), and β PS(Whittle). Hurst rescaled range (R/S) and semivariogram analysis cannot be applied because the critical value of β = 1.0 is at the edge of applicability for both techniques. For investigating whether a time series is a fractional noise (stationary) or motion (non-stationary), one can check all three confidence intervals as to whether they contain β = 1.0 within their lower or upper bounds. If this is the case, the only inference one can make is that the time series is either a noise or a motion, but not specifically one or the other. If all three confidence intervals have an upper bound that is less than β = 1.0, then one can infer that the time series is a fractional noise (and not a motion).
9 Benchmark-Based Improvements to the Measured Persistence Strength of a Given Time Series
9.1 Motivation
In the previous sections, we have studied how the different techniques that measure long-range persistence perform for benchmark time series. These time series are realizations of processes modelled to have a given strength of persistence (β model), a prescribed one-point probability distributions and a fixed number of values N. Our studies have shown that the measured strength of long-range persistence of a given time series realization can deviate from the persistence strength of the processes underlining the benchmark fractional noises and motions due to systematic and random errors of the techniques. Therefore, using these benchmark self-affine time series, we can have a good idea—based on their β model, one-point probability distribution and N—about the resultant distribution of \({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}\) for each different technique, including any systematic errors (biases) and random errors. To aid a more intuitive discussion in the rest of this section, we will use the subscript word ‘measured’ for the estimators of long-range persistence that are calculated using different techniques, β measured = \({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}]}}\), where, as before, Hu, Ha, DFA, and PS represent the technique applied.
In practice, we are often confronted with a single time series and want to state whether or not this time series is long-range persistent and, if so, how strong this persistence is and how accurately this strength has been measured. As we have seen already, different techniques can be applied for analysing this single time series, with each technique having its own set of systematic and random errors. Thus, the inverse problem of that discussed in the preceding two sections must be solved: the strength of long-range persistence of what would be the best-modelled fractional noise or motion, β model, is sought, based on the time series length N, its one-point probability distribution, and the β measured persistence strength results of the technique applied. From this, assuming that the time series is self-affine, we would like to infer the ‘true’ strength of persistence β model (and corresponding confidence intervals). To explore this further, we will use in Sect. 10 the data sets presented in Fig. 1 as case examples. If they are analysed to derive parameters for models, then the 95 % confidence intervals of the persistence strength β model have to be obtained from the computed β measured and from other parameters of the time series such as the one-point probability density and the time series length.
As discussed in Sect. 7.1, the variable β model is a measure of the process that we have designed to have a given strength of long-range persistence (and one-point probability distribution); the time series (our benchmarks) are realizations of that process. These benchmark time series have a distribution of β measured, but with systematic and random errors within that ensemble of time series, due to (1) finite-size effects of the time series length N and (2) inherent biases in the construction process itself (e.g., for strongly asymmetric one-point probability distributions). These biases in the construction are difficult to document, as most research to date addresses biases in the techniques to estimate long-range persistence, not in the construction. For symmetric one-point probability distributions (Gaussian, Levy), each realization of the process, if N were very large (i.e. approaching infinity), would have a strength of long-range persistence equal to β model, in other words equal to the value for which the process was designed (e.g., Samorodnitsky and Taqqu 1994; Chechkin and Gonchar 2000; Enriquez 2004).
One can never know the ‘true’ strength of long-range persistence β of a realization of a process. Therefore, an estimate of β is introduced based on a given technique, which itself has a set of systematic and random errors. The result of each technique performed on a synthetic or a real-time series is β measured, which therefore includes both any systematic errors within the realizations and the technique itself. Given a time series with a given length N and one-point probability distribution, we can perform a given technique which gives β measured. If we believe that long-range persistence is present, we can improve on our estimate of β measured by using (1) the ensemble of benchmark time series performance results from Sect. 7 of this paper and (2) our knowledge of the number of values N and one-point probability of the given time series. This benchmark-based improvement is using the results of our performance techniques, which are all based on an ensemble of time series that are realizations of a process designed to have a given β model, and which we now explore. The rest of this section is organized as follows. We first provide an analytical framework for our benchmark-based improvement of an estimator (Sect. 9.2), followed by a derivation of the conditional probability distribution for β model given β measured (Sect. 9.3). This is followed by some of the practical issues to consider when calculating benchmark-based improved estimators (Sect. 9.4) and a description of supplementary material for the user to do their own benchmark-based improved estimations (Sect. 9.5). We conclude by giving benchmark-based improved estimators for some example time series (Sect. 9.6).
9.2 Benchmark-Based Improvement of Estimators
In order to solve the inverse problem described in Sect. 9.1, we apply a technique from Bayesian statistics (see Gelman et al. 1995). This technique will incorporate the performance, that is, the systematic and random error of the particular technique which is discussed in Sect. 7 (see Figs. 21, 22, 23, 24, 25).
For this purpose, the joint probability distribution \( P\left({\boldsymbol{\beta}}_{\mathbf{model}} ,{\boldsymbol{\beta}} _{{\mathbf{measured}}} \right) \) for fractional noises and motions of length N and with a particular one-point probability distribution is considered. This joint probability distribution now depends on both \( {\boldsymbol{\beta}}_{{\mathbf{model}}} \) and \( {\boldsymbol{\beta}}_{{\mathbf{measured}}} . \) Because we will consider in this section probability distributions as functions of two variables and/or fixed values, we will introduce bold (e.g., \( {\boldsymbol{\beta}}_{{\mathbf{model}}} \)) to indicate the set of values versus non-bold (e.g., β measured) to indicate a single value of the variable. In Fig. 32, we give a cartoon example illustrating the different combinations: \( P\left( {\boldsymbol{\beta}}_{{\mathbf{model}}}, {\boldsymbol{\beta}}_{{\mathbf{measured}}} \right) \), \( P\left( {\boldsymbol{\beta}}_{\mathbf{model}} ,\beta_{\text{measured}} \right) \), \( P\left( {\beta_{\text{model}}, {\boldsymbol{\beta}}_{{\mathbf{measured}}} } \right) \), and \( P\left( {\beta_{\text{model}},\beta_{\text{measured}} } \right) \). The probability of just one measurement β measured of one given realization of a process created with β model is given by \( P\left( {\beta_{\text{model}} ,\beta_{\text{measured}} } \right) \), the single dot in Fig. 32. In Sect. 7 we considered one β model for a given process, and the probability distribution of the resultant ensemble of \({\boldsymbol{\beta}}_{{\mathbf{measured}}} \) from a series of realizations of the process; the range of \( P\left( {\beta_{\text{model}}, {\boldsymbol{\beta}}_{{\mathbf{measured}}} } \right) \) is the blue vertical line in Fig. 32. By contrast, the benchmark-based improvements to the persistence strengths that we will explore in this Sect. 9 are one measurement β measured with a corresponding probability of the ensemble of \( {\boldsymbol{\beta}}_{{\mathbf{model}}} \) associated with it, \( P\left( {\boldsymbol{\beta}}_{\mathbf{model}}, {\beta}_{{\text{measured}}} \right) \), the red horizontal line in Fig. 32. The yellow area in Fig. 32 represents the ensemble of multiple measurements \( {\boldsymbol{\beta}}_{{\mathbf{measured}}} \) of multiple processes each created with β model, and the probability of the ensemble of \( {\boldsymbol{\beta}}_{{\mathbf{model}}} \) associated with each β measured, that is, \( P\left( {{\boldsymbol{\beta}}_{{\mathbf{model}}}, {\boldsymbol{\beta}}_{{\mathbf{measured}}} } \right) \).

Cartoon illustration of the joint probability distributions, using the measured persistence strength (β measured) as a function of modelled persistence strength (β model). The bold notation (e.g., \( {\boldsymbol{\beta}}_{{\mathbf{model}}} \)) indicates the set of values versus non-bold (e.g., β measured) to indicate a single value of the variable. Shown are joint probability distributions \( P\left( {{\boldsymbol{\beta}}_{{\mathbf{model}}}, {\boldsymbol{\beta}}_{{\mathbf{measured}}} } \right) \) (yellow region), \( P\left( {{\boldsymbol{\beta}}_{{\mathbf{model}}} ,\beta_{\text{measured}} } \right) \) (red horizontal line), \( P\left( {\beta_{\text{model}}, {\boldsymbol{\beta}}_{{\mathbf{measured}}} } \right) \) (blue vertical line), and \( \left( {\beta_{\text{model}} ,\beta_{\text{measured}} } \right) \) (black dot)
Applying Bayes rule (Bayes and Price 1763) to our two-dimensional probability distribution \( P\left( {\boldsymbol{\beta}}_{{\mathbf{model}}}, {\boldsymbol{\beta}}_{{\mathbf{measured}}} \right) \) leads to:
where \( P\left( {{\boldsymbol{\beta}}_{{{\mathbf{measured}}}} |\beta_{\text{model}} } \right) \) and \( P\left( {{\boldsymbol{\beta}}_{{{\mathbf{model}}}} |\beta_{\text{measured}} } \right) \) are conditional probability distributions with the vertical bar ‘|’ means ‘given’. In other words, \( P\left( {{\boldsymbol{\beta}}_{{{\mathbf{measured}}}} |\beta_{\text{model}} } \right) \) (i.e. \( {\boldsymbol{\beta}}_{{{\mathbf{measured}}}} \) given β model) would mean the distribution of measured values \( {\boldsymbol{\beta}}_{{{\mathbf{measured}}}} \) using a specific technique [Hu, Ha, PS, DFA], performed on multiple realizations of a process that was created to have a given strength of long-range persistence β model. The left-hand side of Eq. (31a), \( P\left( {\beta_{\text{model}} ,{\boldsymbol{\beta}}_{{{\mathbf{measured}}}} } \right), \) is the joint probability distribution. This is equal to the right-hand side (Eq. 31a) where the conditional probability distribution \( P\left( {{\boldsymbol{\beta}}_{{{\mathbf{measured}}}} |\beta_{\text{model}} } \right) \) is multiplied by P(β model), where P(β model) acts as a normalization such that \( P\left( {{\boldsymbol{\beta}}_{{{\mathbf{measured}}}} |\beta_{\text{model}} } \right) \) sums up (over \( {\boldsymbol{\beta}}_{{\mathbf{measured}}} \)) to 1.0.
To illustrate Eq. (31a), we consider the joint probability distribution \( P\left( {\beta_{\text{model}} ,{\boldsymbol{\beta}}_{{{\mathbf{measured}}}} } \right). \) In Fig. 33 we take fractional log-normal noise benchmarks with coefficient of variation c v = 0.5 and N = 1,024 data points and apply DFA. These were the same benchmarks used to produce the performance test results shown in Fig. 23c, with 100 realizations produced at each \( {\boldsymbol{\beta}}_{{\mathbf{model}}} \) = −1.0, −0.8, −0.6, …, 4.0. In Fig. 33a we give a histogram of the distribution of the estimated strength of long-range dependence \( {\boldsymbol{\beta}}_{{\mathbf{measured}}} = {\boldsymbol{\beta}}_{{\mathbf{DFA}}} \) for one given value of β model = 0.8, along with the best-fit Gaussian distribution to the probabilities \( P\left( {{\boldsymbol{\beta}}_{{\mathbf{DFA}}} |\beta_{\text{model}} = 0.8} \right) \). In Fig. 33b we show the results of performance tests for multiple realizations of processes created to have an ensemble \( {\boldsymbol{\beta}}_{{\mathbf{model}}}. \)This is shown both as given in Fig. 23c (repeated as Fig. 33b) and a subsection of the results interpolated and contoured (Fig. 33d). Thus, the joint probability density \( P\left( {{\boldsymbol{\beta}}_{{\mathbf{model}}}, {\boldsymbol{\beta}}_{{\mathbf{DFA}}} } \right) \) (the contour lines) is constructed by placing side-by-side thin ‘slices’ of Gaussian distributions which correspond to the distribution of \( {\boldsymbol{\beta}}_{{\mathbf{measured}}} \) given various values of β model. For achieving uniformly distributed values of β model, the virtual slices have to have equal thickness and equal weight. The grey region with the contours in Fig. 33d represents the two-dimensional (joint) probability distribution \( P\left( {{\boldsymbol{\beta}}_{\mathbf{model}} ,{\boldsymbol{\beta}}_{{\mathbf{DFA}}} }\right) \), whereas the vertical red line in Fig. 33d represents the one-dimensional (joint) probability distribution \( P\left( {\beta_{\text{model}} ,{\boldsymbol{\beta}}_{{{\mathbf{measured}}}} } \right) \), which is equal to (see Eq. 31a) the conditional probability distribution \( P\left( {{\boldsymbol{\beta} }_{{\mathbf{DFA}}} |\beta_{\text{model}} = 0.8} \right) \), multiplied by P(β model).

Schematic illustration of the construction of the joint probability density \( P\left( {{\boldsymbol{\beta} }_{{\mathbf{model}}}, {\boldsymbol{\beta}}_{{\mathbf{measured}}} } \right) \) for realizations of a process created to have strengths of long-range persistence \( 0.0 \le {\boldsymbol{\beta} }_{{\mathbf{model}}} \le 1.5, \) log-normal one-point probability distribution (c v = 0.5, Box–Cox transform), time series length N = 1,024, and using DFA to evaluate the strength of long-range persistence. a A histogram of the distribution of the estimated strength of long-range dependence \( {\boldsymbol{\beta}}_{{\mathbf{measured}}} = {\boldsymbol{\beta} }_{{\mathbf{DFA}}} \) for one given value of β model = 0.8 is given, along with the best-fit Gaussian distribution to the probabilities \( P\left( {{\boldsymbol{\beta}}_{{\mathbf{DFA}}} |\beta_{\text{model}} = 0.8} \right). \) b Performance of detrended fluctuation analysis (β DFA) using realizations of processes created to have different strengths of persistence \( - 1.0 \le {\boldsymbol{\beta}}_{{\mathbf{model}}} \le 4.0 \) and log-normal one-point probability distributions, c v = 0.5. The mean values (diamonds) and 95 % confidence intervals (error bars) of β DFA are presented as a function of the long-range persistence strength β model. This is a reproduction of Fig. 23c. c Enlarged version of (a). d The inset for (b) is enlarged here. Using the best-fitting Gaussian distributions for \( {\boldsymbol{\beta}}_{{\mathbf{model}}} = 0.0,0.2,0.4, \ldots ,1.6 \), and N = 1,024, these Gaussian distributions are interpolated using a spline fit, to create a contour map (diagonal grey region in d) of the joint probability distribution \( P\left({\boldsymbol{\beta}}_{{\mathbf{model}}}, {\boldsymbol{\beta}}_{{\mathbf{DFA}}} \right). \) Shown also are the interpolations of the \( \bar{\boldsymbol{\beta} }_{{\mathbf{DFA}}} \) (diagonal thick purple dashed line), their 95 % confidence interval borders (diagonal purple dotted lines), which are constructed as \( \bar{\beta}_{\text{DFA}}\, {\pm} 1.96\,\sigma_{x} ({\beta}_{\text{DFA}} ), \) and the function β DFA = β model (diagonal solid yellow line). Illustrated in (d) is an example of one value β model = 0.8 (vertical red line). This translates to the Gaussian distribution in (c) (an enlarged version of a), where the Gaussian distribution is a vertical cut of the two-dimensional joint probability distribution \( P\left( {\boldsymbol{\beta}}_{{\mathbf{model}}}, {\boldsymbol{\beta}}_{{\mathbf{DFA}}} \right) \) at β model = 0.8. Also given in (c) is the interval corresponding to \( \bar{\beta}_{\text{DFA}}\, {\pm} 1.96\,\sigma_{x} (\beta_{\text{DFA}} ) \) (vertical dark red line with arrows) that correspond to the β model = 0.8
In Fig. 33 we have shown an example of the joint probability distribution \( P\left( {\beta_{\text{model}} ,{\boldsymbol{\beta}}_{{{\mathbf{measured}}}} } \right) \). We now consider (Eq. 31b) the joint probability distribution \( P\left( {{\boldsymbol{\beta}}_{{{\mathbf{model}}}} ,\beta_{\text{measured}} } \right) = P\left( {{\boldsymbol{\beta}}_{{{\mathbf{model}}}} |\beta_{\text{measured}} } \right)P\left( {\beta_{\text{measured}} } \right); \) in other words, given a value for β measured, what is the corresponding result for an ensemble of \( {\boldsymbol{\beta}}_{{\mathbf{model}}} . \) In Fig. 34, we give a schematic illustration of the construction of the conditional probability distribution \( P\left( {{\boldsymbol{\beta}}_{{{\mathbf{model}}}} |\beta_{\text{measured}} } \right) \) for the same example as in Fig. 33, which was based on a log-normal distribution (c v = 0.5, N = 1,024) and using DFA to evaluate the strength of long-range persistence. Figure 34a gives the two-dimensional probability distribution \( P\left( {{\boldsymbol{\beta} }_{{\mathbf{model}}} ,{\boldsymbol{\beta} }_{{\mathbf{DFA}}} } \right) \) as constructed in Fig. 33d. This is now cut horizontally at three values of \( \beta_{\text{DFA}} = 0.30,\;0.86,\;1.65 \); these horizontal lines are now representing the ranges of the joint probability distributions \( P\left( {{\boldsymbol{\beta}}_{{{\mathbf{model}}}}, \beta_{\text{measured}} } \right). \) In Fig. 34b, the three conditional probability distributions \( P\left( {{\boldsymbol{\beta}}_{{{\mathbf{model}}}} |\beta_{\text{DFA}} = 0.30,\;0.86,\;1.65} \right) \) are obtained by normalizing \( P\left( {{\boldsymbol{\beta}}_{{{\mathbf{model}}}} ,\beta_{\text{measured}} } \right) \) such that the integral of \( P\left( {{\boldsymbol{\beta}}_{{{\mathbf{model}}}} ,\beta_{\text{measured}} } \right) \) is equal to 1.0.

Schematic illustration of the construction of the conditional probability distribution \( P\left( {{\boldsymbol{\beta}}_{{{\mathbf{model}}}} |\beta_{\text{measured}} } \right) \), in other words the distribution of \( {{\boldsymbol{\beta}}}_{{{\mathbf{model}}}} \) given a single value of β measured, for the same example as in Fig. 33 (log-normal distribution, c v = 0.5, time series length N = 1,024, and using DFA to evaluate the strength of long-range persistence). This illustrates the adjustment to β measured based on the benchmark performance results introduced in Sect. 7. a The two-dimensional probability distribution \( P\left( {\boldsymbol{\beta}}_{{\mathbf{model}}} , {\boldsymbol{\beta}}_{{\mathbf{DFA}}} \right) \) as constructed in Fig. 33d is cut horizontally at three values of \( \beta_{\text{DFA}} = 0.30,\;0.86,\;1.65. \) The x-axis here is from 0.0 ≤ β model ≤ 2.2; whereas Fig. 33d is 0.0 ≤ β model ≤ 1.5. b The conditional probability distributions \( P\left( {{\boldsymbol{\beta}}_{{{\mathbf{model}}}} |\beta_{\text{DFA}} } \right) \) are then derived with Eq. (36), which incorporates the performance (the systematic and random errors) of the technique used. The vertical lines indicate the benchmark-based improved estimator \( \beta_{\text{DFA}}^{*} \) (Eq. 37), which is the mean value of the adjusted probability distribution. These are slightly greater than the mode as the distributions are skewed
In the framework of Bayesian statistics, the distribution of persistence strengths \( {\boldsymbol{\beta} }_{{\mathbf{model}}} \) given the measured persistence strength β measured is called the posterior. In this paper, we will use this ‘posterior’ to derive a benchmark-based improvement of the estimator and indicate the improved estimator by a superscript *. The mean value for our improved estimator for the strength of long-range persistence is given by:
where \( \beta_{\text{measured}}^{*} \) is the benchmark-based improved estimate of β measured based on our benchmark time series results.
In practice, performing the procedure as schematically illustrated in Fig. 34 (i.e. with a two-dimensional histogram) is doable, but requires a sufficiently small bin size for β model and many realizations, such that an interpolation can be made in both directions. Therefore, we would like to derive an equation for \( P\left( {{\boldsymbol{\beta}}_{{{\mathbf{model}}}} |\beta_{\text{measured}} } \right), \) and, from this, derive \( \beta_{\text{measured}}^{*} , \) a benchmark-based improvement to a given β measured. We do this in the next section.
9.3 Deriving the Conditional Probability Distribution for \( {\boldsymbol{\beta}}_{{\mathbf{model}}} \) Given β measured
How can the distribution of persistence strength \( P\left( {{\boldsymbol{\beta}}_{{\mathbf{model}}} |\beta_{\text{measured}} } \right) \) be obtained? Two special properties of our estimators allow a manageable mathematical expression:
-
For fixed β model, the distribution \( P\left( {{\boldsymbol{\beta}}_{{\mathbf{measured}}} |\beta_{\text{model}} } \right) \) can be approximated by a Gaussian distribution.
-
The mean value of \( P\left( {{\boldsymbol{\beta}}_{{\mathbf{measured}}} |\beta_{\text{model}} } \right) \) is monotonically growing as a function of β model.
These two properties approximately hold for each of the four techniques applied in this paper, and we will now use them. Our results presented in Sects. 7 and 8 provide evidence that the conditional probability \( P\left( {{\boldsymbol{\beta}}_{{\mathbf{measured}}} |\beta_{\text{model}} } \right) \) follows a Gaussian distribution (see Figs. 18, 19, 20):
with \( \bar{\beta }_{\text{measured | model}} \) the mean value of \( {\boldsymbol{\beta}}_{{{\mathbf{measured}}}} \) for a given β model, and \( \sigma_{{\beta_{\text{measured | model}} }}^{2} \) the variance of \( {\boldsymbol{\beta}}_{{{\mathbf{measured}}}} \) for a given β model. Furthermore, we have found (Figs. 21, 22, 23, 24, 25) that \( \bar{\beta }_{\text{measured | model}} \) is monotonically (sometimes nonlinearly) increasing as a function of β model , except for the log-normal noises constructed by the Schreiber–Schmitz algorithm in the non-stationary regime (β model > 1.0) where \( \bar{\beta }_{\text{measured | model}} \) decreases with β model .
With Eq. (31a) we can derive the joint probability \( P\left( {\beta_{\text{model}} ,{\boldsymbol{\beta}}_{{{\mathbf{measured}}}} } \right). \) An assumption is that \( {\boldsymbol{\beta}}_{{\mathbf{model}}} \) is uniformly distributed over the interval β min ≤ \( {\boldsymbol{\beta}}_{{\mathbf{model}}} \) ≤ β max, where β min and β max are the minimum and maximum values, respectively. We have chosen β model = −1.0, −0.8, −0.6, …, 4.0, and an equal number of realizations for each β model. The one-dimensional probability distribution of \( {\boldsymbol{\beta}}_{{\mathbf{model}}} \) is P(β model ) = 1/(β max − β min) = c 1. Substituting P(β model ) into Eq. (31a) allows us to write the joint probability distribution as:
Using the assumption that β model is uniformly distributed and that Δβ model is small enough to give results that are smooth enough to be interpolated, along with Eqs. (33) and (34), then the joint probability distribution \( P\left( {\beta_{\text{model}} ,{\boldsymbol{\beta} }_{{\mathbf{measured}}} } \right) \) is given by:
This particular form of \( P\left({\beta}_{\text{model}},\,{\boldsymbol{\beta}}_{{\mathbf{measured}}}\right) \) can be considered for multiple values of β model, and the required calibrated probability distribution \( P\left( {\boldsymbol{\beta}}_{\mathbf{model}} |\beta_{\text{measured}} \right) \) can be derived by rearranging Eq. (31b):
The constant c 2 is based on integrating the final result of Eq. (36) such that \( \int_{{\beta_{\hbox{min}}}}^{{\beta_{\hbox{max} } }} P\left( {\boldsymbol{\beta} }_{\mathbf{model}} |\beta_{\text{measured}} \right) {\text{d}} {\boldsymbol{\beta} }_{\mathbf{model}} = 1. \) Combining Eq. (36) with Eq. (32) gives:
We now have a general equation for our improved estimator, \( \beta_{\text{measured}}^{*} \), which has been based on the conditional probability \( P\left( {{\boldsymbol{\beta}}_{{{\mathbf{model}}}} |\beta_{\text{measured}} } \right), \) in other words, an improvement based on our benchmark-based results from Sects. 7 and 8. Three examples for \( \beta_{\text{measured}}^{*} \) are given in Fig. 34 which schematically illustrates the construction of \( P\left( {{\boldsymbol{\beta}}_{{{\mathbf{model}}}} |\beta_{\text{measured}} } \right). \)
9.4 Practical Issues When Calculating the Benchmark-based Improved Estimator \( \beta_{\text{measured}}^{*} \)
For practical applications we are interested in deriving the benchmark-based improved estimator \( \beta_{\text{measured}}^{*} \) and associated 95 % confidence intervals. The approach presented above allows us to do this with moderate computational costs in the following way:
-
(A)
For the time series of interest, determine its one-point probability distribution and note its time series length, N.
-
(B)
Measure the strength of long-range dependence of the time series β measured using a specific technique [Hu, Ha, DFA, PS].
-
(C)
Construct benchmark fractional noises and motions which are realizations of processes with different strength of long-range persistence, β model, but with length N and one-point probability distributions equal to those of the analysed time series. We have provided (supplementary material) files with fractional noises and motions drawn from 126 sets of parameters and an R program to create these and other synthetic noises and motions (see Sect. 4.3 for further description).
-
(D)
Use the fractional noises and motions constructed in (C) and the technique used in (B) to determine numerically \( \bar{\boldsymbol{\beta} }_{\mathbf{measured | model}} \) and \( \boldsymbol{\sigma}_{{{\boldsymbol{\beta}}_{\mathbf{measured | model}} }}^{2} \), for a range of β model from β min to β max, such that step size for successive β model results in \( \bar{\boldsymbol{\beta} }_{\mathbf{measured | model}} \) and \( \boldsymbol{\sigma}_{{{\boldsymbol{\beta}}_{\mathbf{measured | model}} }}^{2} \) which are sufficiently smooth. Interpolation within the step size chosen (e.g., linear, spine) might be necessary. We have given these performance results measures (supplementary material) for fractional noises and motions with about 6,500 different sets of parameters (see Sect. 7.3 for further description).
-
(E)
Apply Eq. 36 to determine the ‘posterior’ of the long-range persistence strength, \( P\left( {{\boldsymbol{\beta}}_{{{\mathbf{model}}}} |\beta_{\text{measured}} } \right) \).
-
(F)
Determine the benchmark-based improved estimator for the time series, \( \beta_{\text{measured}}^{*} \), its 95 % confidence intervals from the mean and 95 % confidence intervals of the distribution obtained in (E).
In the case of unbiased techniques, we find \( {\boldsymbol{\beta }}_{\mathbf{measured | model}}={\boldsymbol{\beta}}_{\mathbf{model}}.\) If, in addition, the variance \( \boldsymbol {\sigma_{{\beta}_{\mathbf{measured | model}} }}^{2} \) does not depend on β model , then \( \boldsymbol{\sigma_{{\beta}_{\mathbf{measured | model}} }}^{2} \) = σ 2 where σ 2 is now a constant. An example of an unbiased technique where the variance does not depend on β model is power spectral analysis applied to time series with symmetric one-point probability distributions. For this case, the distribution defined in Eq. (36) simplifies to a Gaussian distribution with a mean value of β model and a variance of σ 2, giving \( P\left({\boldsymbol{\beta}}_{{\mathbf{model}}}|\beta_{\text{measured}}\right)\sim{\text{Gaussian}}\left({\boldsymbol{\beta}}_{\mathbf{model}} ,{\sigma}^{\text{2}}\right).\) This implies, for this case, that (Eq. 37) the benchmark-based improved estimator \( {\boldsymbol{\beta}}_{\mathbf{measured}}^{*} = {\boldsymbol{\beta}}_{\mathbf {model}} . \) However, in contrast, in power spectral analysis applied to time series with asymmetric one-point probability distributions and for the three other techniques considered in this paper for both symmetric and asymmetric one-point probability distributions, either the techniques are biased or the variance \( \boldsymbol{\sigma}_{{\beta}_{\mathbf{measured | model}}}^{2} \) changes as a function of β model . In these cases the corresponding distributions \( P\left( {{\boldsymbol{\beta}}_{{{\mathbf{model}}}} |\beta_{\text{measured}} } \right) \), as defined in Eq. (36), are asymmetric, and also any confidence intervals (2.5 and 97.5 % of the probability distribution) are asymmetric with respect to the mean of the probability distribution, \( \beta_{\text{measured}}^{*} \).
9.5 Benchmark-based Improved Estimators: Supplementary Material Description
We have provided (supplementary material) an Excel spreadsheet which allows a user to determine conditional probability distributions based on a user-measured β measured for a time series, and the benchmark performance results discussed in this paper. In Fig. 35 we show example of three Supplementary Material Excel Spreadsheet screenshots.
The first sheet ‘PerfTestResults’ (Fig. 35a) allows the user to see summary statistics of the results of selected performance tests (Hurst rescaled range analysis, semivariogram analysis, detrended fluctuation analysis, power spectral analysis best-fit, and power spectral analysis Whittle) as applied to benchmark synthetic time series with modelled strengths of long-range persistence (−1.0 < β model < 4.0), given one-point probability distributions (Gaussian, log-normal c v = 0.2 to 2.0, Levy a = 1.0 to 1.9), and time series lengths (N = 64, 128, 256, …, 131,072). For log-normal noises and motion, we give only the results of those constructed with the Box–Cox transform (FLNNa). An example is shown in Fig. 35a of a statistical summary of results for 100 realizations of a fractional log-normal noise process constructed with Box–Cox (FLNNa), c v = 0.8, N = 512, with power spectral analysis (best-fit) applied. Although the results are not discussed in the text of this paper, we also give the results for discrete wavelet analysis in the supplementary material (see Appendix 6 for details of how it was applied).

Example of three screen captures from Supplementary Material Excel Spreadsheet for a user to determine conditional probability distributions based on a user-measured β measured for a time series, and the benchmark performance results discussed in this paper. a Spreadsheet ‘PerfTestResults’ allows the user to select summary statistics of the results of five different techniques applied to over 6,500 combinations of parameters, as described in this paper. b Spreadsheet ‘InterpolSheet’ allows an input of a user-measured β measured for their specific time series, and based on the closest match of their time series to benchmark results given in ‘PerfTestResults’, the mean and standard deviation of the benchmark results for −1.0 < β model < 4.0. The spreadsheet linearly interpolates the performance test results and then calculates β *measured , the benchmark-based improvement to the user-measured value, along with the 97.5 and 2.5 percentiles (i.e. the 95 % confidence intervals). c The sheet ‘CalibratedProbChart’ shows the calibrated probability distribution of β model conditioned on the user-measured value for beta (measure of the strength of long-range persistence) and benchmark time series
The second sheet ‘InterpolSheet’ (Fig. 35b) allows the user to input in the yellow box the user-measured β measured for their specific time series, and then, based on the closest match of their time series to the sheet ‘PerfTestResults’ parameters of one-point probability distribution type, number of values N, and technique used, to input the mean and standard deviation of the benchmark results for −1.0 < β model < 4.0. In this example, it is assumed the user has a time series with the parameters given for Fig. 35a (FLNNa, c v = 0.8, N = 512), has applied power spectral analysis (best-fit), and has user-measured value of β measured = 0.75. The spreadsheet automatically interpolates the performance test results, which have step size Δβ model = 0.2, to Δβ model = 0.01, using linear interpolation, and then calculates β *measured , the benchmark-based improvement to the user-measured value, along with the 97.5 and 2.5 percentiles (i.e. the 95 % confidence intervals).
The third sheet ‘CalibratedProbChart’ (Fig. 35c) shows the calibrated probability distribution of β model conditioned on the user-measured value for beta (measure of the strength of long-range persistence) and benchmark time series, \( P\left( {{\boldsymbol{\beta} }_{{\mathbf{model}}} |\beta_{\text{measured}} = 0.75} \right), \) showing graphically the mean of the distribution (this gives the value for β *measured ) and the 97.5 and 2.5 percentiles of that distribution.
9.6 Benchmark-based improved estimators for example time series
Now we come back to the example of fractional log-normal noises discussed in Sect. 5 and presented and pre-analysed in Fig. 14 and the properties of the corresponding \( \beta_{\text{measured}} = \beta_{\left[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA,}}\,{\text{PS}}({\text{best-fit}}),\,{\text{PS}}({\text {Whittle}}) \right]} \) presented in Figs. 21, 22, 23, 24, 25 and Tables 4, 5. Take, for example, a time series with N = 1,024 data points whose one-point probability distribution is a log-normal with a coefficient of variation of c v = 0.5 and created to have β model = 1.0. The four functions—rescaled range, detrended fluctuation function, semivariogram, and power spectral density—result in a power-law dependence on the segment length, lag, or the frequency. In other words, the analyses expose long-range persistence. The corresponding power-law exponents are related to the strength of long-range persistence as mentioned in Sects. 5 and 6 and given in Table 3. The measured strength of long-range persistence has been determined as β Hu = 0.78, β Ha = 1.34, β DFA = 0.99, β PS(best-fit) = 0.99, and β PS(Whittle) = 0.98. We now apply the scheme in Sect. 9.4 to obtain the five calibrated distributions, \( P\left( { {\boldsymbol{\beta}}_{{\mathbf{model}}}}|{\beta_{\text{measured}}} \right) \), conditioned on the five β measured values for each technique (see Fig. 34 for an illustration).
For example, β Hu = 0.78 is put into Eq. (36) giving:
The set of \( \bar{\boldsymbol{\beta}}_{{\mathbf{Hu | model}}} \) and \( {\boldsymbol{\sigma} }_{{{\boldsymbol{\beta} }_{{\mathbf{Hu | model}}} }}^{\bf2} \) in Eq. (38) are the mean and standard deviation (i.e. the standard error), respectively, of the set of \( {\boldsymbol{\beta} }_{{\mathbf{model}}} \) for log-normal times series with c v = 0.5 and N = 1,024. Each value of \( {\boldsymbol{\beta} }_{{\mathbf{model}}} \) has its own associated mean (\( \bar{\mathcal{\beta }}_{{\text{Hu | model}}} \)) and standard deviation (\({\sigma }_{{{\beta }_{{\text {Hu | model}}} }} \)). For Hurst rescaled range (R/S) analysis, we can read this set of values directly off of Fig. 21c, where the means are the green diamonds plotted and the error bars represent ±1.96 standard deviations. However, as it is difficult to read precise numbers off of the figures, a more accurate way is to go to the supplementary material Excel spreadsheet, choose the appropriate parameters of the process, and read off (with appropriate interpolation if necessary) \( {{\boldsymbol{\beta}}}_{\mathbf{Hu | model}} \) and \( \boldsymbol{ \sigma_{{\beta}_{\mathbf{Hu | model}} }}, \) and to either apply directly Eq. (38) or to have the supplementary material Excel spreadsheet for calculating the appropriate values (Sect. 9.5) and the resultant conditional distributions \( P\left( {\boldsymbol{\beta} }_{{\mathbf{model}}} |\beta_{\text{measured}} \right) \).
In Fig. 36 we give the conditional distributions \( P\left( { {\boldsymbol{\beta}}_{{\mathbf{model}}}} |\beta_{\text{measured}} \right) \), for each of the five performance techniques, based on benchmark results and measured values for the techniques β Hu = 0.78, β Ha = 1.34, β DFA = 0.99, β PS(best-fit) = 0.99, and β (PSWhittle) = 0.98. The conditional distributions for β DFA, β PS(best-fit), and β PS(Whittle) have their modes (maximum probability for each distribution) at the measured values of β, whereas the modes of the calibrated distributions of β Hu and β Ha are shifted because the underlining β model = 1.0 is at the edge of the range of applicability of these two techniques. The calibrated strength of long-range persistence (i.e. the benchmark-based improved estimators) leads for all techniques to values close to one: \( \beta_{\text{Hu}}^{*} = 1.02,\beta_{\text{Ha}}^{*} = 1.30,\beta_{\text{DFA}}^{*} = 1.05,\beta_{{{\text{PS}}\left( {{\text{best-fit}}} \right)}}^{*} = 1.02,\;{\text{and}}\;\beta_{{{\text{PS}}\left( {\text{Whittle}} \right)}}^{*} = 1.02. \) The 95 % confidence intervals (ranging from the 2.5 to the 97.5 percentile), however, differ remarkably: 0.74 < \( \beta_{\text{Hu}}^{*} \) < 1.32, 1.05 < \( \beta_{\text{Ha}}^{*} \) < 1.62, 0.83 < \( \beta_{\text{DFA}}^{*} \) < 1.28, 0.88 < \( \beta_{{{\text{PS}}\left( {{\text{best-fit}}} \right)}}^{*} \) < 1.14 and 0.90 < \( \beta_{{{\text{PS}}\left( {\text{Whittle}} \right)}}^{*} \) < 1.11. The improved estimator \( \beta_{\text{measured}}^{*} \) through use of the power spectral method is the most certain, followed by detrended fluctuation analysis. The confidence intervals resulting from rescaled range analysis and semivariogram analysis are very wide. The confidence interval sizes of \( \beta_{\text{Hu}}^{*} ,\beta_{\text{Ha}}^{*} ,\;{\text{and}}\;\beta_{\text{DFA}}^{*} , \) are larger than the confidence intervals of β Hu, β Ha, and β DFA derived from the random errors, \(\sigma \) x (\({\beta }_{{[{\text{Hu,}}\,{\text{Ha,}}\,{\text{DFA}}]}}\)). Nevertheless, all techniques are appropriate to confirm the presence of long-range persistence, as no corresponding 95 % confidence interval contains β model = 0.0.

Conditional distributions \( P( {\boldsymbol{\beta} }_{{\mathbf{model}}} |\beta_{{\left[{{\text{Hu}},\,{\text{Ha}},\,{\text{DFA}},\,{\text{PS}}\left({{{\text{best-fit}}}} \right),\,{\text{PS}}\left( {\text{Whittle}}\right)} \right]}} ) \) of the strength of long-range persistence of a log-normal noise (c v = 0.5, N = 1,024, β model = 1.0) for values of β measured obtained by using: (1) Hurst rescaled range analysis (wine, solid line), (2) semivariogram analysis (green, long-dashed line), (3) detrended fluctuation analysis (red, dotted line), (4) power spectral analysis (log-linear regression) (blue, dash–dot–dot line), (5) power spectral analysis (Whittle estimator) (black, dashed line). Examples of how these curves are constructed are given in Figs. 34 and 35
We will now apply our benchmark-based improved estimators in the context of three geophysical examples.
10 Applications: Strength of Long-Range Persistence of Three Geophysical Records
We now return to the three data series presented in Fig. 1 and apply the techniques explored in this paper to them to investigate the long-range persistence properties of the underlying processes.
The first data set, a palaeotemperature series based on GISP2 bi-decadal oxygen isotopes data for the last 10,000 years, contains N = 500 data points which are normally distributed (see Fig. 1a). We apply the four functions, rescaled range, semivariogram, detrended fluctuation, and power spectral density to this time series (see Fig. 37), and all are found to have strong power-law dependence of the function on the segment lengths, lags, and frequencies. The resultant persistence strengths are summarized in Table 8. The four techniques (with two ways of fitting the power spectral densities, best-fit and Whittle) lead to self-affine long-range persistence strengths of β Hu = 0.42, β Ha = 1.11, β DFA = 0.43, β PS(best-fit) = 0.46, and β PS(Whittle) = 0.54. The results of the benchmark-based improved estimates of β model (Table 8) are \( \beta_{\text{Hu}}^{*} = 0.37,\,\beta_{\text{Ha}}^{*} =0.66,\;\beta_{\text{DFA}}^{*} = 0.47,\;\beta_{\text{PS(best-fit)}}^{*} = 0.46\;{\text{and}}\;\beta_{\text{PS(Whittle)}}^{*} = 0.53.\) In all cases except for semivariogram analysis, the improved estimator results are within 0.05 of the originally measured result. It is reasonable that semivariograms are so far off, as semivariogram analysis is not appropriate over the range −1.0 < β < 1.0, we thus exclude it from further consideration.

Long-range dependence analysis of the 10,000 year (500 values at 20 year intervals) GISP2 bi-decadal oxygen isotope proxy for palaeotemperatures presented in Fig. 1a. The panels represent the following: a Hurst rescaled range (R/S) analysis, b semivariogram analysis, c detrended fluctuation analysis (DFAk with polynomials of order k applied to the profile), d power spectral analysis. All graphs are shown on logarithmic axes. Best-fit power laws are presented by straight solid lines which have been slightly shifted on the y-axis. The corresponding power-law exponents are given in the legend of the corresponding panel and in Table 8
The benchmark-based improved values of the three remaining techniques (not considering confidence intervals) lie in the interval \( 0.37 < \beta_{[{\text{Hu}},\,{\text{Ha}},\,{\text{PS}}({\text{best-fit}}),\, {\text{PS}}({\text{Whittle}})]}^{*} < 0.47. \) The corresponding 95 % confidence intervals for each technique overlap, but they are different in total size, ranging from 0.30 for the Whittle estimator (95 % confidence intervals: \( 0.38 < \beta_{\text{PS(Whittle)}}^{*} < 0.68 \)) to 0.57 for rescaled range analysis (\( 0.08 < \beta_{\text{Hu}}^{*} < 0.65 \)). Since all of these confidence intervals do not contain β = 0.0, long-range persistence is qualitatively confirmed. Another important aspect of our analysis is stationarity, that is, if our time series can be modelled as a fractional noise (β < 1.0) or a fractional motion (β > 1.0). As explained in Sect. 8.2, we have to determine or diagnose whether the values in the confidence intervals just discussed are all smaller or all larger than β = 1.0. We find that these confidence intervals are covered by the interval [0.0, 1.0]. Therefore, we can conclude that the palaeotemperature series can be appropriately modelled by a fractional noise (i.e. β < 1.0).
For quantifying the strength of self-affine long-range persistence, one interpretation would be to take the most certain estimator (based on the narrowest 95 % confidence interval range) \( \beta_{{{\text{PS}}\left( {\text{Whittle}} \right)}}^{*} \) which says that with a probability of 95 %, the persistence strength β ranges between 0.38 and 0.68. Another interpretation would be that based on the results in this paper, the DFA, PS(best-fit), and PS(Whittle) techniques were much more robust (small systematic and random errors) for normally distributed noises and motions compared to (R/S), and thus to state that this palaeotemperature series exhibits long-range persistence with a self-affine long-range persistence strength \( \beta_{\left[ {\text{DFA,PS}}({\text{best-fit}}),{\text{PS}}({\text{Whittle}}) \right]}^{*} \) between 0.46 and 0.53, with combined 95 % confidence intervals for \( \beta_{\left[ {\text{DFA,PS}}({\text{best-fit}}),{\text{PS}}({\text{Whittle}}) \right]}^{*} \) between 0.23 and 0.73. In other words, there is weak long-range positive self-affine persistence.
The second data set is the daily discharge of Elkhorn River (Waterloo, Nebraska, USA) for 1929–2001 (see Fig. 1b). This measurement series has N = 26,662 data points and is log-normal distributed with a high coefficient of variation (c v = 1.68). Rescaled range, semivariogram, and detrended fluctuation analyses reveal two ranges with power-law scaling which are separated at l = 1.0 year (see Fig. 38). Dolgonosov et al. (2008) also observed two scaling ranges of the power spectral density and modelled them by integrating run-off and storage dynamics. In our own results, for the low-frequency scaling range (l > 1.0 year; f < 1.0 year–1), the different performance techniques come up with rather diverse results for the persistence strength: β Hu = 0.66, β Ha = 1.03, β DFA = 0.40, β PS(best-fit) = 0.60, and β PS(Whittle) = 0.71 (see Table 8). As in the first data set above, we will exclude semivariogram analysis from further consideration as it is not appropriate over the range −1.0 < β < 1.0.

Long-range dependence analysis of the 1929–2001 daily discharge data set (Elkhorn river at Waterloo, Nebraska, USA) presented in Fig. 1b. The panels represent the following: a Hurst rescaled range (R/S) analysis, b semivariogram analysis, c detrended fluctuation analysis, d power spectral analysis. All graphs are shown on logarithmic axes. Best-fit power laws are presented by straight solid lines which have been slightly shifted on the y-axis. The corresponding power-law exponents are given in the legend of the corresponding panel and in Table 8

Long-range dependence analysis of the 24 h period (01 February 1978, sampled per minute) geomagnetic auroral electrojet (AE) index data presented in Fig. 1c1. The panels represent the following: a Hurst rescaled range (R/S) analysis, b semivariogram analysis, c detrended fluctuation analysis, d power spectral analysis. All graphs are shown on logarithmic axes. Best-fit power laws are presented by straight solid lines which have been slightly shifted on the y-axis. The corresponding power-law exponents are given in the legend of the corresponding panel and in Table 8
The persistence strengths for the low frequency domain (Table 8) obtained by the benchmark-based improvement techniques (\( \beta_{{\left[ {\text{Hu,\,DFA,\,PS}} \right]}}^{*} \)) range between 0.65 and 0.81. The corresponding 95 % confidence intervals are very wide, ranging from the widest, 0.26 < \( \beta_{\text{PS(best-fit)}}^{*} \)< 1.10, to the ‘narrowest’, \( 0.46 < \beta_{\text{Hu}}^{*} < 1.07; \) however, all of them do include a ‘common’ range for the persistence strength interval \( 0.46 < \beta_{{\left[ {\text{Hu,\,DFA,\,PS}} \right]}}^{*} < 0.84. \) These very uncertain results are caused by both the very asymmetric one-point probability density and the consideration of very long segments (l > 1.0 year) or, respectively, very low frequencies. Based on the performance results for realizations of log-normally distributed fractional noises (Sect. 7), we believe that the best estimators are PS(best-fit) and PS(Whittle). If we use the limits of both of these, then we can conclude that this discharge series exposes self-affine long-range persistence with strength \( \beta_{\left[{\text{PS}}({\text{best-fit}}),\,{\text{PS}}({\text{Whittle}}) \right]}^{*} \) between 0.69 and 0.81, and 95 % confidence intervals for the two combined between 0.26 and 1.16. In other words, there is long-range positive persistence with a weak to medium strength. As the 95 % confidence intervals contain the value \( \beta_{\left[ {\text{PS}}({\text{best-fit}}),\,{\text{PS}}({\text{Whittle}}) \right]}^{*} \) = 1.0, we cannot decide whether our time series is a fractional noise (β < 1.0) or fractional motion (β > 1.0).
For both the palaeotemperature and discharge time series, we have modelled them as showing positive long-range persistence. For these data types, both short-range and long-range persistent models have been applied by different authors. For example, for both data types, Granger (1980) and Mudelsee (2007) model the underlying processes as the aggregation of short-memory processes with different strength of short memory.
The third data set, the geomagnetic auroral electrojet (AE) index data, sampled per minute for 01 February 1978 (Fig. 1c), contains N = 1,440 values. The differenced AE index (\( \Delta x_{\text{AE}} (t) = x_{\text{AE}} (t) - x_{\text{AE}} (t - 1) \)) is approximately Levy distributed (double-sided power law) with an exponent of a = 1.40 (Fig. 1d). The four functions that characterize the strength of long-range dependence show a power-law scaling, and the corresponding estimated strengths of long-range dependence for the AE index are as follows (Table 8; Fig. 39): β Hu = 1.02, β Ha = 2.18, β DFA = 2.01, β PS(best-fit) = 1.92, and β PS(Whittle) = 1.92, and for the differenced AE index are as follows (Table 8): β Hu = 0.12, β Ha = 1.01, β DFA = 0.13, β PS(best-fit) = 0.11, and β PS(Whittle) = 0.05.
Based on Sect. 7 performance results for realizations of Levy-distributed fractional noises, we believe that the best estimators are PS(best-fit) and PS(Whittle). If we use the limits of both of these, then we conclude (Table 8) that the AE index is characterized by \( \beta_{\left[ {\text{PS}}({\text{best-fit}}), {\text{PS}}({\text{Whittle}}) \right]}^{*} = 1.92 \), and 95 % confidence intervals for the two combined between 1.82 and 2.00. In other words, there is a strong long-range positive persistence, close to a Levy-Brownian motion. Watkins et al. (2005) have analysed longer series (recordings of an entire year) of the AE index and described it as a fractional Levy motion with a persistence strength of β = 1.90 (standard error of 0.02) with a Levy distribution (a = 1.92). With respect to the strength of long-range persistence, our results for the AE index are very similar to that of Watkins et al. (2005), and our 95 % confidence intervals for β Ha, β DFA, and β PS, do not conflict with a value of β = 1.90.
In order to apply the benchmark-based improvement technique to the differenced AE index, performance tests were run for Levy-distributed (a = 1.40) fractional noises with N = 1,440 data points. The results for \( \beta_{\left[{\text{Hu}},\,{\text{Ha}},\,{\text{DFA}},\,{\text{PS}}({\text{best-fit}}),\,{\text{PS}}({\text{Whittle}}) \right]}^{*} \) are given in Table 8. If we use the limits for both PS(best-fit) and PS(Whittle), then we conclude that the differenced AE index is characterized by \( \beta_{\left[ {\text{PS}}({\text{best-fit}}),\,{\text{PS}}({\text{Whittle}}) \right]}^{*} \) between 0.06 and 0.12, and 95 % confidence intervals for the two combined between −0.03 and 0.20. In other words, there is long-range positive persistence with weak strength. This persistence strength is very close to β = 0, and so our differenced AE index can be considered close to a white Levy noise. We concluded above that the AE index is characterized by \( \beta_{\text{PS}}^{*} = 1.92 \) [95 % confidence: 1.82 to 2.00] and here that the differenced AE index is characterized by \(\beta_{\text{PS}}^{*} = 0.06\, {\text{to}}\, 0.12 \) [95 % confidence: −0.03 to 0.20]. This is not unreasonable as (Sect. 3.6) the long-range persistence strength of a symmetrically distributed fractional noise or motion will be shifted by +2 for aggregation and −2 for the first difference (this case). The difference in the two adjusted measured strengths of long-range persistence for the original and differenced AE index is slightly smaller than two. We believe that this is caused by nonlinear correlations in the data.
We observe that when considering DFA applied to the differenced AE index series, the size of the resultant 95 % confidence intervals (\( - 0.16 < \beta_{\text{DFA}}^{*} < 0.39 \)) is two to three times bigger than that of the spectral techniques \((0.01 < \beta_{\text{PS(best-fit)}}^{*} < 0.20,\; -0.03 < \beta_{\text{PS(Whittle)}}^{*} < 0.12) \). This confirms the results we presented in Sect. 7 for the analysis of synthetic noises: in the case of fractional Levy noises, DFA has larger random errors (proportional to the confidence interval sizes) than power spectral techniques.
The three geophysical time series considered here have all been equally spaced in time. However, unequally spaced time series in the geophysics community are common (unequally spaced either through missing data or through events that do not occur equally in time). For an example of a long-range persistence analysis of an unequally spaced time series (the Nile River) see Ghil et al. (2011).
We have considered three very different geophysical time series with different one-point probability distributions: a proxy for palaeotemperature (Gaussian), discharge (log-normal), and AE index (Levy). For each, we have shown that the estimated strength of long-range persistence can often be more uncertain than one might usually assume. In each case, we have examined these time series with conventional methods that are commonly used in the literature (Hurst rescaled range analysis, semivariogram analysis, detrended fluctuation analysis, and power spectral analysis), and we have complemented these results with benchmark-based improvement estimators, putting the results from each technique into perspective.
11 Summary and Discussion
In this paper we have compared four common analysis techniques for quantifying long-range persistence: (1) rescaled range (R/S) analysis, (2) semivariogram analysis, (3) detrended fluctuation analysis, and (4) power-spectral analysis (best-fit and Whittle). Although not evaluated in this paper, we have also included in the supplementary material results of a fifth technique, discrete wavelet analysis. To evaluate the first four methods, we have constructed ensembles of realizations of self-affine noises and motions with different (1) time series lengths, N = 64, 128, 256, …, 131,072; (2) persistence strengths, β = −1.0, −0.8, −0.6, …, 4.0; and (3) one-point probability distributions (Gaussian; log-normal with c v = 0.0, 0.1, 0.2, …, 2.0, and two types of construction; Levy with a = 1.0, 1.1, 1.2, …, 2.0). A total of about 17,000 different combinations of process parameters were produced, and for each process type 100 realizations created. We have evaluated the four techniques by statistically comparing their performance. We have found the following:
-
(1)
Hurst rescaled range analysis is not recommended;
-
(2)
Semivariogram analysis is unbiased for 1.2 ≤ β ≤ 2.8, but has large random error (standard deviation or confidence intervals).
-
(3)
Detrended fluctuation analysis is well suited for time series with thin-tailed probability distributions and persistence strength of β > 0.0.
-
(4)
Spectral techniques overall perform the best of the techniques examined here: they have very small systematic errors (i.e. are unbiased), with small random error (i.e. tight confidence intervals and small standard deviations) for positive persistent noises with a symmetric one-point distribution, and they are slightly biased for noises or motions with an asymmetric one-point probability distribution and for anti-persistent noises.
In order to quantify what is the most likely strength of persistence for a fixed time series length and one-point probability distribution, a calibration scheme based on benchmark-based improvement statistics has been proposed. The most useful result of our benchmark-based improvement is realistic confidence intervals for the strength of persistence with respect to the specific properties of the considered time series. These confidence intervals can be used to demonstrate long-range persistence in a time series: if the upper and lower values of the 95 % confidence interval for a persistence strength β do not contain the value β = 0.0, then the considered series can be interpreted (in a statistical sense) to be long-range persistent.
Another outcome of our investigation is that typical confidence intervals for the strength of long-range persistence are asymmetric with respect to the benchmark-based improved estimator, \( \beta_{\text{measured}}^{*} \). The only exception (i.e. symmetric confidence intervals) corresponds to spectral analysis of time series with symmetric one-point probability distributions.
In this context, we emphasize that for time domain techniques the standard deviation of the persistence strength cannot be calculated as the regression error of the linear regression (e.g., for log(DFA) vs. log(segment length), log(R/S) vs. log(segment length), and log(semivariogram) vs. log(lag)). This would be possible only if the fluctuations around the average of the measured functions, \( \overline{{\log(\text{DFA})}}\), \( \overline{{\log({R}/{S})}}\), and \( \overline{{\log(\text {semivariograms})}}\), were independent of the abscissa (log(length) or log(lag)). However, as we characterize highly persistent time series, these fluctuations are also persistent and the assumption of independence cannot be held to be true.
One aspect of our study found limitations in the Schreiber–Schmitz algorithm. It turned out that the Schreiber–Schmitz algorithm can construct fractional noises and motions with symmetric one-point probability distributions and with persistence strength between –1.0 ≤ β ≤ 1.0. However, highly asymmetric probability distributions and with large strengths of persistence (β > 1.0) can lead to resultant time series with a persistence strength that is systematically smaller than the one that is modelled.
In the literature, the performance of detrended fluctuation analysis and spectral analysis has been benchmarked using synthetic time series with known properties (e.g., Taqqu et al. 1995; Pilgram and Kaplan 1998; Malamud and Turcotte 1999a; Eke et al. 2002; Penzel et al. 2003; Maraun et al. 2004). Our current investigations for quantifying long-range persistence of self-affine time series have shown that the systematic errors of both techniques (DFA and spectral analysis) are comparable, while the random errors of spectral analysis are lower, resulting in the fact that a total root-mean-squared error (RMSE, which takes into account both the systematic and random errors) is also lower for spectral analysis over a broad range of persistence strengths and probability distribution types. However, as the analysed time series might have nonlinear correlations, both DFA and spectral analysis should be applied, as the nonlinear nature of the correlations (even if the time series is also self-affine) can strongly influence and give very different results for the two techniques applied (see Rangarajan and Ding 2000). Detrended fluctuation analysis is also subject to practical issues, such as choice of the trend function to use.
We recommend investigation of self-affine long-range persistence of a time series by applying power spectral and detrended fluctuation analysis. In the case of time series with heavy-tailed or strongly asymmetric one-point probability distributions, benchmark-based improvement statistics for the strength of long-range persistence, which is based on a large range of model time series simulations, is required. If the considered time series are not robustly self-affine, but also have short-range correlations or have periodic signals superimposed, then the proposed framework must be appropriately modified. To aid the reader, extensive supplementary material is provided, which includes (1) fractional noises with different strengths of persistence and one-point probability distributions, along with R programs for producing them, (2) the results of applying different long-range persistence techniques to realizations from over 6,500 different sets of process parameters, (3) an Excel spreadsheet to do benchmark-based improvements on the measured persistence strength for a given time series, and (4) a PDF file of all figures from this paper in high-resolution.
Many time series in the Earth Sciences exhibit long-range persistence. For modelling purposes it is important to quantify the strength of persistence. In this paper, we have shown that techniques that quantify persistence can have systematic errors (biases) and random errors. Both types of errors depend on the measuring technique and on parameters of the considered time series such as the one-point probability distribution, the length of the time series, and the strength of self-affine long-range persistence. We have proposed the application of benchmark-based improvement statistics in order to calibrate the measures for quantifying persistence with respect to the specific properties (length, probability distribution, and persistence strength) of the considered time series. Thus, the uncertainties (systematic and random errors) of the persistence measurements obtained might be better contextualized. We give three examples of ‘typical’ geophysics data series—temperature, discharge, and AE index—and show that the estimated strength of long-range persistence is much more uncertain than might be usually assumed.
References
Adas A (1997) Traffic models in broadband networks. IEEE Commun Mag 35:82–89. doi:10.1109/35.601746
Altmann EG, Kantz H (2005) Recurrence time analysis, long-term correlation, and extreme events. Phys Rev E 71:056106
Andrews DWK, Sun Y (2004) Adaptive local polynomial Whittle estimation of long-range dependence. Econometrica 72:569–614
Andrienko N, Andrienko G (2005) Exploratory analysis of spatial and temporal data. A systematic approach. Springer, New York
Anh V, Yu Z-G, Wanliss JA (2007) Analysis of global geomagnetic variability. Nonlinear Process Geophys 14:701–708
Anis A, Lloyd EH (1976) The expected value of the adjusted rescaled Hurst range of independent normal summands. Biometrica 63:111–116
ATIS (2000) American National Standard T1.523-2001, Telecom Glossary 2000, ATIS Committee T1A1 performance and signal processing, Available online at: http://www.atis.org/glossary/. Accessed 10 July 2012
Audit B, Bacry E, Muzy J-F, Arneodo A (2002) Wavelet–based estimators of scaling behaviour. IEEE Trans Inf Theory 48:2938–2954
Bahar S, Kantelhardt JW, Neiman A, Rego HHA, Russell DF, Wilkens L, Bunde A, Moss F (2001) Long-range temporal anti-correlations in paddlefish electroreceptors. Europhys Lett 56:454–460
Bak P, Sneppen K (1993) Punctuated equilibrium and criticality in a simple model of evolution. Phys Rev Lett 71:4083–4086
Bak P, Tang C, Wiesenfeld K (1987) Self-organized criticality: an explanation of 1/f noise. Phys Rev Lett 59:381–384
Bard Y (1973) Nonlinear parameter estimation. Academic Press, San Diego
Bassingthwaighte JB, Raymond GM (1994) Evaluating rescaled range analysis for time series. Ann Biomed Eng 22:432–444
Bassingthwaighte JB, Raymond GM (1995) Evaluation of the dispersional analysis method for fractal time series. Ann Biomed Eng 23:491–505
Bates DM, Watts DG (1988) Nonlinear regression analysis and its applications. Wiley, Hoboken
Bayes T, Price R (1763) An essay towards solving a problem in the doctrine of chance. Philos Trans R Soc Lond 53:370–418
Bédard C, Kroeger H, Destexhe A (2006) Does the 1/f frequency scaling of brain signals reflect self-organized critical states? Phys Rev Lett 97:118102
Beran J (1994) Statistics for long-memory processes. Chapman & Hall/CRC, New York
Berry MV, Lewis ZV (1980) On the Weierstrass-Mandelbrot fractal function. Proceedings of the Royal Society A 370:459–484
Bershadskii A, Sreenivasan KR (2003) Multiscale self-organized criticality and powerful X-ray flares. Eur Phys J B 35:513–515
Blender R, Fraedrich K (2003) Long time memory in global warming simulations. Geophys Res Lett 30:1769–1772
Blender R, Freadrich K, Sienz F (2008) Extreme event return times in long-term memory processes near 1/f. Nonlinear Process Geophys 15:557–565
Boutahar M (2009) Comparison of non-parametric and semi-parametric tests in detecting long-memory. J Appl Stat 36:945–972
Boutahar M, Marimoutou V, Nouira L (2007) Estimation methods of the long memory parameter: Monte Carlo analysis and application. J Appl Stat 34:261–301
Box GEP, Cox DR (1964) An analysis of transformations. J R Stat Soc Series B Stat Methodol 26:211–252
Box GEP, Pierce DA (1970) Distribution of residual autocorrelations in autoregressive integrated moving average time series models. J Am Stat Assoc 65:1509–1526
Box GEP, Jenkins GM, Reinsel GC (1994) Time series analysis: forecasting and control, 3rd edn. Prentice Hall, Englewood Cliffs
Bras RL, Rodriguez-Iturbe I (1993) Random functions and hydrology. Dover, New York
Brockwell AE (2005) Likelihood-based analysis of a class of generalized long-memory time series models. J Time Ser Anal 28:386–407
Brown R (1828) A brief account of microscopical observations made in the months of June, July and August, 1827, on the particles contained in the pollen of plants; and on the general existence of active molecules in organic and inorganic bodies. Phil Mag 4:161–173
Brown SR (1987) A note on the description of surface roughness using fractal dimension. Geophys Res Lett 14:1095–1098
Bunde A, Lennartz S (2012) Long-term correlations in earth sciences. Acta Geophys 60:562–588
Bunde A, Eichner JF, Kantelardt JW, Havlin S (2005) Long-term memory: a natural mechanism for the clustering of extreme events and anomalous residual times in climate records. Phys Rev Lett 94:048701
Burrough PA (1981) Fractal dimensions of landscape and other environmental data. Nature 294:240–242
Burrough PA (1983) Multiscale sources of spatial variation in soil. I. The application of fractal concepts to nested levels of soil variation. J Soil Sci 34:577–597
Cabrera JL, Milton JM (2002) On–off intermittency in a human balancing task. Phys Rev Lett 89:158702
Caccia DC, Percival DB, Cannon MJ, Raymond GM, Bassingthwaighte JB (1997) Analyzing exact fractal time series: evaluating dispersional analysis and rescaled range methods. Phys A 246:609–632
Cannon MJ, Percival DB, Caccia DC, Raymond GM, Bassingthwaighte JB (1997) Evaluating scaled windowed variance methods for estimating the Hurst Coefficient of time series. Phys A 241:606–626
Carreras BA, van Milligen BP, Pedrosa MA, Balbin R, Hidalgo C, Newman DE, Sanchez E, Frances M, Garcia-Cortes I, Bleuel J, Endler M, Ricardi C, Davies S, Matthews GF, Martines E, Antoni V, Latten A, Klinger T (1998) Self-similarity of the plasma edge fluctuations. Phys Plasmas 5:3632–3643
Chandrasekhar S (1943) Stochastic problems in physics and astronomy. Rev Mod Phys 15:1–89
Chapman CR (2004) The hazard of near–Earth asteroid impacts on earth. Earth Planet Sci Lett 222:1–15
Chapman CR, Morrison D (1994) Impacts on the Earth by asteroids and comets: assessing the hazard. Nature 367:33–40
Chapman SC, Hnat B, Rowlands G, Watkins NW (2005) Scaling collapse and structure functions: identifying self-affinity in finite length time series. Nonlinear Process Geophys 12:767–774
Chatfield C (1996) The analysis of time series, 5th edn. Chapman & Hall, London
Chechkin AV, Gonchar VYu (2000) A model for persistent Levy motion. Phys A 277:312–326. doi:10.1016/S0378-4371(99)00392-1
Chen Y, Ding M, Kelso JA (1997) Long memory processes (1/f α type) in human coordination. Phys Rev Lett 79:4501–4504
Chen Z, Ivanov PCh, Hu K, Stanley HE (2002) Effect of nonstationarities on detrended fluctuation analysis. Phys Rev E 65:041107 (15 pp)
Chen Z, Hu K, Carpena P, Bernaola-Galvan P, Stanley HE, Ivanov PCh (2005) Effect of nonlinear filters on detrended fluctuation analysis. Phys Rev E 71:011104
Chhabra A, Jensen RV (1989) Direct determination of the f(α) singularity spectrum. Phys Rev Lett 62:1327–1330
Collette C, Ausloos M (2004) Scaling analysis and evolution equation of the North Atlantic oscillation index fluctuations. Int J Mod Phys C 15:1353–1366
Cooley JW, Tukey JW (1965) An algorithm for the machine calculation of complex Fourier series. Math Comput 19:297–301. doi:10.2307/2003354
Cox BL, Wang JSY (1993) Fractal surfaces: measurements and applications in the earth sciences. Fractals 1:87–115
Cramér H (1946) Mathematical methods of statistics. Princeton University Press, Princeton
Daerden F, Vanderzande C (1996) 1/f noise in the Bak-Sneppen model. Phys Rev E 53:4723–4728
Daubechies I (1988) Orthonormal bases of compactly supported wavelets. Commun Pure Appl Math 4:909–996
Davies RB, Harte DS (1987) Tests for Hurst effect. Biometrika 74:95–101
Davis TN, Sugiura M (1966) Auroral electrojet activity index AE and its universal time variations. J Geophys Res 71:785–801
De Santis A (1997) A direct divider method for self-affine fractal properties and surfaces. Geophys Res Lett 24:2099–2102
Delignieres D, Torre K (2009) Fractal dynamics of human gait: a reassessment of Hausdorff et al. (1996) data. J Appl Physiol 106:1272–1279
Delignieres D, Ramdani S, Lemoine L, Torre K, Fortes M, Ninot G (2006) Fractal analysis for ‘short’ time series: a reassessment of classical methods. J Math Psychol 50:525–544
Dolgonosov BM, Korchagin KA, Kirpichnikova NV (2008) Modeling of annual oscillations and 1/f-noise of daily river discharges. J Hydrol 357:174–187
Doroslovacki ML (1998) On the least asymmetric wavelets. IEEE Trans Signal Process 46:1125–1130
Dutta P, Horn PM (1981) Low frequency fluctuations in solids: 1/f noise. Rev Mod Phys 53:497–516
Efron B, Tibshirani R (1993) An introduction to the bootstrap. Chapman and Hall, London
Eghball B, Varvel GE (1997) Fractal analysis of temporal yield variability of crop sequences: Implications for site-specific management. Agron J 89:851–855
Eichner JF, Koscielny-Bunde E, Bunde A, Havlin S, Schellnhuber H-J (2003) Power-law persistence and trends in the atmosphere: a detailed study of long temperature records. Phys Rev E 68, 046133 (5 pp)
Einstein A (1905) Über die von der molekularkinetischen Theorie der Wärme geforderte Bewegung von in ruhenden Flüssigkeiten suspendierten Teilchen. Ann Phys 17:549–560
Eke A, Herman P, Kocsis L, Kozak LR (2002) Fractal characterization of complexity in temporal physiological signals. Physiol Meas 23:R1–R38
Eliazar I, Klafter J (2009) A unified and universal explanation for Lévy laws and 1/f noises. Proc Natl Acad Sci USA 106:12251–12254
Embrechts P, Maejima M (2002) Selfsimilar processes. Princeton University Press, Princeton
Enriquez N (2004) A simple construction of the fractional Brownian motion. Stoch Process Appl 109:203–223. doi:10.1016/j.spa.2003.10.008
Faÿ G, Moulines E, Roueff F, Taqqu MS (2009) Estimators of long-memory: Fourier versus wavelets. J Econom 151:159–177
Fisher RA (1912) An absolute criterion for fitting frequency curves. Messenger Math 41:155–160
Flandrin P (1992) Wavelet analysis and synthesis of fractional Brownian motion. IEEE Trans Inf Theory 38:910–917
Fox R, Taqqu MS (1986) Large-sample properties of parameter estimates for strongly dependent stationary Gaussian time series. Ann Stat 14:517–532
Fraedrich K, Blender R (2003) Scaling of atmosphere and ocean temperature correlations in observations and climate models. Phys Rev Lett 90:108501
Franzke CLE, Graves T, Watkins NW, Gramacy RB, Hughes C (2012) Robustness of estimators of long-range dependence and self-similarity under non-Gaussianity. Philos Trans R Soc A Math Phys Eng Sci 370:1250–1267
Frigg R (2003) Self-organized criticality, what it is, and what it isn’t. Stud Hist Philos Sci 34:613–632
Gallant JC, Moore ID, Hutchinson MF, Gessler P (1994) Estimating fractal dimension of profiles: a comparison of methods. Math Geol 26:455–481
Gao JB, Hu J, Tung W–W, Cao YH, Sarshar N, Roychowdhury VP (2006) Assessment of long range correlation in time series: How to avoid pitfalls. Phys Rev E 73:016117
Geisel T, Nierwetberg J, Zacherl A (1985) Accelerated diffusion in Josephson junctions and related chaotic systems. Phys Rev Lett 54:616–619
Geisel T, Zacherl A, Radons G (1987) Generic 1/f noise in chaotic Hamiltonian dynamics. Phys Rev Lett 59:2503–2506
Gelman A, Carlin JB, Stern HS, Rubin DB (1995) Bayesian data analysis. Chapman and Hall/CRC, New York
Geweke J, Porter-Hudak S (1983) The estimation and application of long-memory time series models. J Time Ser Anal 4:221–238
Ghil M, Yiou P, Hallegatte S, Malamud BD, Naveau P, Soloviev A, Friederichs P, Keilis-Borok V, Kondrashov D, Kossobokov V, Mestre O, Nicolis C, Rust HW, Shebalin P, Vrac M, Witt A, Zaliapin I (2011) Extreme events: dynamics, statistics and prediction. Nonlinear Process Geophys 18:295–350. doi:10.5194/npg-18-295-2011
Goldberger AL, Amaral LAN, Hausdorff JM, Ivanov PCh, Peng C-K, Stanley HE (2002) Fractal dynamics in physiology: alterations with disease and aging. Proc Natl Acad Sci USA 99:2466–2472
Golub GH, Pereyra V (1973) The differentiation of pseudo inverses and nonlinear least-squares problems whose variables separate. SIAM J Numer Anal 10:413–432
Govindan RB, Kantz H (2004) Long-term correlations and multifractality in surface wind speed. Europhys Lett 68:184–190
Govindan RB, Vyushin D, Bunde A, Brenner St, Havlin S, Schellnhuber H-J (2002) Global climate models violate scaling of the observed atmospheric variability. Phys Rev Lett 89:028501
Granger CWJ (1980) Long memory relationships and the aggregation of dynamic models. J Econom 14:227–238
Granger CWJ, Joyeux RJ (1980) An introduction to long-range time series models and fractional differencing. J Time Ser Anal 1:15–30
Grassberger P, Procaccia I (1983) Measuring the strangeness of strange attractors. Physica D 9:189–208
Grossmann A, Morlet J (1984) Decomposition of Hardy functions into square integrable wavelets of constant shape. SIAM J Math Anal 15:723–736
Guerrero A, Smith LA (2005) A maximum likelihood estimator for long-range persistence. Phys Lett A 355:619–632
Gutenberg B, Richter CF (1954) Seismicity of the earth and associated phenomenon, 2nd edn. Princeton University Press, Princeton
Guzzetti F, Malamud BD, Turcotte DL, Reichenbach P (2002) Power-law correlations of landslide areas in central Italy. Earth Planet Sci Lett 195:169–183
Halsey TC, Jensen MH, Kadanoff LP, Procaccia I, Shraiman BI (1986) Fractal measures and their singularities: the characterization of strange sets. Phys Rev A 33:1141–1151
Hansen A, Engoy Th, Maloy KJ (1994) Measuring Hurst exponents with the first return method. Fractals 2:527–533
Hasselmann K (1976) Stochastic climate models I: theory. Tellus 28:473–485
Hausdorff JM, Purdon PL, Peng CK, Ladin Z, Wei JY, Goldberger AL (1996) Fractal dynamics of human gait: stability of long-range correlations in stride interval fluctuation. J Appl Physiol 80:1448–1457
Heneghan C, McDarby G (2000) Establishing the relationship between detrended fluctuation analysis and power spectral analysis. Phys Rev E 62:6103–6110
Hennig H, Fleischmann R, Fredebohm A, Hagmayer Y, Nagler J, Witt A, Theis FJ, Geisel T (2011) The nature and perception of fluctuations in human musical rhythms. PLoS One 6 e26457 22046289
Hentschel HGE, Procaccia I (1983) The infinite number of generalized dimensions of fractals and strange attractors. Physica D 8:435–444
Hergarten S (2002) Self-organized criticality in earth systems. Springer, New York
Higuchi T (1988) Approach to an irregular time series on the basis of fractal theory. Physica D 31:277–293
Hosking JRM (1981) Fractional differencing. Biometrika 68:165–176
Hu K, Ivanov PCh, Chen Z, Carpena P, Stanley HE (2001) Effects on trends on detrended fluctuation analysis. Phys Rev E 64:011114
Huang SL, Oelfke SM, Speck RC (1992) Applicability of fractal characterization and modelling to rock joint profiles. Int J Rock Mech Min Sci Geomech Abstr 29:89–98
Hubbard BB (1996) The world according to wavelets: the story of a mathematical technique in the making. A. K. Peters, Wellesley
Hurst HE (1951) Long-term storage capacity of reservoirs. Trans Am Soc Civil Eng 116:770–799
Ives AR, Abbott KC, Ziebarth NL (2010) Analysis of ecological time series with ARMA(p, q) models. Ecology 91:858–871. doi:10.1890/09-0442.1
Jennings H, Ivanov P, Martins A, Dasilva A, Viswanathan G (2004) Variance fluctuations in nonstationary time series: a comparative study of music genres. Phys A 336:585–594
Johnson JB (1925) The Schottky effect in low frequency circuits. Phys Rev 26:71–85
Kantelhardt JW, Koscielny-Bunde E, Rego HHA, Havlin S, Bunde A (2001) Detecting long-range correlations with detrended fluctuation analysis. Phys A 295:441–454
Kantelhardt JW, Rybski D, Zschiegner SA, Braun P, Koscielny-Bunde E, Livina V, Havlin S, Bunde A (2003) Multifractality of river runoff and precipitation: comparison of fluctuation analysis and wavelet methods. Phys A 330:240–245
Kaplan JL, Yorke JA (1979) Chaotic behavior of multidimensional difference equations. In: Peitgen H-O, Walter H-O (eds) Functional differential equations and approximations of fixed points. Lecture Notes in Mathematics 730:204–227, Springer
Keshner MS (1982) 1/f noise. Proc IEEE 70:212–218
Khaliq MN, Ouarda TBMJ, Gachon P (2009) Identification of temporal trends in annual and seasonal low flows occurring in Canadian rivers: the effect of short- and long-term persistence. J Hydrol 369:183–197. doi:10.1016/j.jhydrol.2009.02.045
Kiss P, Müller R, Janosi IM (2007) Long-range correlations of extrapolar total ozone are determined by the global atmospheric circulation. Nonlinear Process Geophys 14:435–442
Kiyani K, Chapman SC, Hnat B (2006) Extracting the scaling exponents of a self-affine, non-Gaussian process from a finite length time series. Phys Rev E 74:051122
Klafter J, Sokolov IM (2005) Anomalous diffusion spreads its wings. Phys World 18:29–32
Klinkenberg B (1994) A review of methods used to determine the fractal dimension of linear features. Math Geol 26:23–46
Kobayashi M, Musha T (1982) 1/f fluctuation of heartbeat period. IEEE Biomed Eng 29:456–457
Kogan S (2008) Electronic noise and fluctuations in solids. Cambridge University Press, Cambridge
Kolmogorov AN, Gnedenko BW (1954) Limit distributions for sums of random variables. Addison-Wesley, Cambridge
Koscielny-Bunde E, Kantelhardt JW, Braun P, Bunde A, Havlin S (2006) Long-term persistence and multifractality of river runoff records: detrended fluctuation studies. J Hydrol 322:120–137
Koutsoyiannis D (2002) The Hurst phenomenon and fractional Gaussian noise made easy. Hydrol Sci J 47:573–595
Kurths J, Herzel H (1987) An attractor in a solar time series. Physica D 25:165–172
Kurths J, Schwarz U, Witt A (1995) Non-linear data analysis and statistical techniques in solar radio astronomy. Lecture Notes Phys 444:159–171, Springer, Berlin. doi:10.1007/3-540-59109-5_48
Kwapień J, Drożdż S (2012) Physical approach to complex systems. Phys Rep 515:115–226
Kyoto University (2012) World Data Center for Geomagnetism, Kyoto. Geomagnetic auroral electrojet index (AE) data available for 1978 and downloaded from: http://swdcwww.kugi.kyoto-u.ac.jp/aeasy/index.html. Accessed 1 May 2012
Leland WE, Taqqu MS, Willinger W, Wilson DV (1994) On the self-similar nature of ethernet traffic (Extended Version). IEEE ACM Trans Netw 2:1–15
Levitin DJ, Chordia P, Menon V (2012) Musical rhythm spectra from Bach to Joplin obey a 1/f power law. Proc Natl Acad USA 109:3716–3720
Linkenkaer-Hansen L, Nikouline V, Palva JM, Ilmoniemi RJ (2001) Long-range temporal correlations and scaling behavior in human brain oscillations. J Neurosci 21:1370–1377
Lo AW (1991) Long-term memory in stock market prices. Econometrica 59:1273–1313
Malamud BD (2004) Tails of natural hazards. Phys World 17:31–35
Malamud BD, Turcotte DL (1999a) Self-affine time series: I. Generation and analyses. Adv Geophys 40:1–90
Malamud BD, Turcotte DL (1999b) Self-affine time series I: measures of weak and strong persistence. J Stat Plan Inference 80:173–196
Malamud BD, Turcotte DL (2006) The applicability of power-law frequency statistics to floods. J Hydrol 322:168–180
Malamud BD, Turcotte DL, Barton CC (1996) The 1993 Mississippi river flood: a one-hundred or a one-thousand year event? Environ Eng Geol II(4):479–486
Malamud BD, Morein G, Turcotte DL (1998) Forest fires: an example of self-organized critical behavior. Science 281:1840–1842
Malamud BD, Turcotte DL, Guzzetti F, Reichenbach P (2004) Landslide inventories and their statistical properties. Earth Surf Proc Land 29:687–711
Malamud BD, Millington JDA, Perry GLW (2005) Characterizing wildfire regimes in the United States. Proc Natl Acad Sci USA 102:4694–4699
Malinverno A (1990) A simple method to estimate the fractal dimension of a self-affine series. Geophys Res Lett 17:1953–1956. doi:10.1029/GL017i011p01953
Mandelbrot BB (1967) How long is the coast of Britain? Statistical self-similarity and the fractional dimension. Science 156:636–638
Mandelbrot BB (1977) Fractals: form, chance, and dimension. Freeman, San Francisco
Mandelbrot BB (1985) Self-affine fractals and fractal dimension. Phys Scripta 32:257–260
Mandelbrot BB (1999) Multifractals and 1/f noise: wild self-affinity in physics. Springer, New York
Mandelbrot BB, van Ness JW (1968) Fractional Brownian motions, fractional noises and applications. SIAM Rev 10:422–437
Mandelbrot BB, Wallis JR (1968) Noah, Joseph and operational hydrology. Water Resour Res 4:909–918
Mandelbrot BB, Wallis JR (1969a) Computer experiments with fractional Gaussian noises. Parts I, II, and III. Water Resour Res 5:228–267
Mandelbrot BB, Wallis JR (1969b) Some long–run properties of geophysical records. Water Resour Res 5:321–340
Mandelbrot BB, Wallis JR (1969c) Robustness of the rescaled range R/S in the measurement of noncyclic long run statistical dependence. Water Resour Res 5:967–988
Manneville P (1980) Intermittency, self-similarity and 1/f spectrum in dissipative dynamical systems. J de Physique 41:1235–1243
Mantegna R, Stanley HE (2000) An introduction to econophysics. Cambridge University Press, Cambridge
Maraun D, Rust HW, Timmer J (2004) Tempting long-memory: on the interpretation of DFA results. Nonlinear Process Geophys 11:495–503
Mark DM, Aronson PB (1984) Scale dependent fractal dimensions of topographical surfaces: an empirical investigation with applications in geomorphology and computer mapping. Math Geol 16:671–683
Marković D, Koch M (2005) Wavelet and scaling analysis of monthly precipitation extremes in Germany in the 20th century: interannual to interdecadal oscillations and the North Atlantic oscillation influence. Water Resour Res 41:W09420, 12 p, doi:10.1029/2004WR003843
Matheron G (1963) Principles of geostatistics. Econ Geol 58:1246–1266
Mehrabi AR, Rassamdana H, Sahimi M (1997) Characterization of long-range correlations in complex distributions and profiles. Phys Rev E 56:712–722
Meirelles MC, Dias VHA, Oliva D, Papa ARR (2010) A simple 2D SOC model for one of the main sources of geomagnetic disturbances: Flares. Phys Lett A 374:1024–1027
Metzler R, Klafter J (2000) The random walk’s guide to anomalous diffusion: a fractional dynamics approach. Phys Rep 339:1–77
Mielniczuk J, Wojdyłło P (2007) Estimation of the Hurst exponent revisited. Comput Stat Data Anal 51:4510–4525. doi:10.1016/j.csda.2006.07.033
Montanari A, Rosso R, Taqqu MS (1996) Some long-run properties of rainfall records in Italy. J Geophys Res D21:431–438
Montanari A, Taqqu MS, Teverovsky V (1999) Estimating long-range dependence in the presence of periodicity: an empirical study. Math Comput Model 29:217–228
Mudelsee M (2007) Long memory of rivers from spatial aggregation. Water Resour Res 43:W01202
Mudelsee M (2010) Climate time series analysis: classical statistical and bootstrap methods. Springer, San Francisco
Nagler J, Claussen JC (2005) 1/fα spectra in elementary cellular automata and fractal signals. Phys Rev E 71:067103
Neuman SP (1995) On advective transport in fractal permeability and velocity fields. Water Resour Res 31:1455–1460
Newman MC (1993) Regression analysis of log-transformed data: Statistical bias and its correction. Environ Toxicol Chem 12:1129–1133
Osborne AR, Provenzale A (1989) Finite correlation dimension for stochastic systems with power-law spectra. Physica D 35:357–381
Palma W, Zevallos M (2011) Fitting non-Gaussian persistent data. Appl Stoch Models Bus Industry 27:23–36
Papa ARR, do Espirito Santo MA, Barbosa CS, Oliva D (2012) A generalized Bak–Sneppen model for Earth’s magnetic field reversals. arXiv:1106.4942v1 [physics.geo-ph]
Patzelt F, Riegel M, Ernst U, Pawelzik K (2007) Self-organized critical noise amplification in human closed loop control. Frontiers in Computational Neuroscience 1, doi:10.3389/neuro.10.004.2007
Pelletier JD, Turcotte DL (1997) Long-range persistence in climatological and hydrological time series: analysis, modeling and application to drought hazard assessment. J Hydrol 203:198–208
Pelletier JD, Turcotte DL (1999) Self-affine time series II. applications and models. Adv Geophys 40:91–166
Peng C-K, Buldyrev SV, Goldberger AL, Havlin S, Sciortino F, Simons M, Stanley HE (1992) Long-range correlations in nucleotide sequences. Nature 356:168–170
Peng C-K, Buldyrev SV, Havlin S, Simons M, Stanley HE, Goldberger AL (1993a) Long-range anticorrelations and non-Gaussian behavior of the heartbeat. Phys Rev Lett 70:1343–1346
Peng C-K, Buldyrev SV, Goldberger AL, Havlin S, Simons M, Stanley HE (1993b) Finite size effects on long-range correlations: implications for analyzing DNA sequences. Phys Rev E 47:3730–3733
Peng C-K, Buldyrev SV, Havlin S, Simons M, Stanley HE, Goldberger AL (1994) On the mosaic organization of DNA nucleotides. Phys Rev E 49:1685–1689
Penzel T, Kantelhardt JW, Becker HF, Peter JH, Bunde A (2003) Detrended fluctuation analysis and spectral analysis of heart rate variability for sleep stage and apnea identification. Comput Cardiol 30:307–310
Percival DB, Walden AT (1993) Spectral analysis for physical applications: Multitaper and conventional Univariate Techniques. Cambridge University Press, Cambridge
Percival DB, Walden AT (2000) Wavelet methods for time series analysis. Cambridge University Press, Cambridge
Pilgram B, Kaplan DT (1998) A comparison of estimators for 1/f noise. Physica D 114:108–122
Pinto CMA, Mendes Lopes A, Tenreiro Machado JA (2012) A review of power laws in real life phenomena. Commun Nonlinear Sci Numer Simul 17:3558–3578
Porter-Hudak S (1990) An application of the seasonal fractionally differenced model to the monetary aggregates. J Am Stat Assoc 85:338–344
Press WH, Teukolskay SA, Vetterling WT, Flannery BP (1994) Numerical recipes in C: the art of scientific computing, 2nd edn. Cambridge University Press, Cambridge
Priestley MB (1981) Spectral analysis and time series. Academic Press, London
Procaccia I, Schuster H (1983) Functional renormalization–group theory of universal 1/f noise in dynamical systems. Phys Rev A 28:1210–1212
Pyle DM (2000) Sizes of volcanic eruptions. In: Sigurdsson H, Houghton B, Rymer H, Stix J, McNutt S (eds) Encyclopedia of Volcanoes. Academic Press, London, pp 263–269
Rangarajan G, Ding MZ (2000) Integrated approach to the assessment of long-range correlation in time series data. Phys Rev E 61:4991–5001
Rao CR (1945) Information and accuracy attainable in the estimation of statistical parameters. Bull Calcutta Math Soc 37:81–91
Robinson PM (1994) Semiparametric analysis of long-memory time series. Ann Stat 22:515–539
Robinson PM (1995) Log-periodogram regression of time series with long-range dependence. Ann Stat 23:1048–1072
Rossi M, Witt A, Guzzetti F, Malamud BD, Peruccacci S (2010) Analysis of historical landslides in the Emilia–Romagna region, Northern Italy. Earth Surf Proc Land 35:1123–1137
Rust HW, Mestre O, Venema VKC (2008) Fewer jumps, less memory: homogenized temperature records and long memory. J Geophys Res 113:D19110. doi:10.1029/2008JD009919
Salas JD (1993) Analysis and modelling of hydrology time series. In: Maidment DR (ed) Handbook of hydrology. McGraw-Hill, New York, pp 19.1–19.72
Salomão LR, Campanha JR, Gupta HM (2009) Rescaled range analysis of pluviometric records in São Paulo State, Brazil. Theoret Appl Climatol 95:83–89. doi:10.1007/s00704-007-0367-4
Samorodnitsky G, Taqqu MS (1994) Stable non-gaussian processes: stochastic models with infinite variance. Chapman and Hall, London
Schepers HE, van Beek JHGM, Bassingthwaighte JB (1992) Four methods to estimate the fractal dimension from self-affine signals. IEEE Eng Med Biol 11:57–64
Schmittbuhl J, Vilotte JP, Roux S (1995) Reliability of self-affine measurements. Phys Rev E 51:131–147
Schottky W (1918) Über spontane Stromschwankungen in verschiedenen Elektrizitätsleitern. Ann Phys 362:541–567
Schreiber T, Schmitz A (1996) Improved surrogate data for nonlinearity tests. Phys Rev Lett 77:635–638
Schulz M, Mudelsee M, Wolf-Welling TCW (1994) Fractal analyses of Pleistocene marine oxygen isotope records. In: Kruhl JH (ed) Fractals and dynamic systems in geosciences. Springer, Berlin, pp 307–317
Schuster HG, Just W (2005) Deterministic Chaos. Wiley, Weinheim
Shannon CE, Weaver W (1949) The mathematical theory of communication. University of Illinois Press, Urbana
Shapiro SS, Wilk MB (1965) An analysis of variance test for normality (complete samples). Biometrika 52:591–611
Smith WW, Smith JM (1995) Handbook of real-time fast Fourier transforms. IEEE Press, Piscataway
Solomon TH, Weeks ER, Swinney HL (1993) Observations of anomalous diffusion und Levy flights in a two-dimensional rotating flow. Phys Rev Lett 24:3975–3978
Stadnytska T, Werner J (2006) Sample size and accuracy of estimation of the fractional differencing parameter. Methodology: Eur J Res Methods Behav Soc Sci 2:135–141
Stanislavsky AA, Burnecki K, Magdziarz M, Weron A, Weron K (2009) FARIMA modelling of solar flare activity from empirical time series of soft X-ray solar emission. Astrophys J 693:1877–1882
Stephen DG, Mirman D, Magnuson JS, Dixon JA (2009) Lévy-like diffusion in eye movements during spoken-language comprehension. Phys Rev E 79:056114
Stroe-Kunold E, Stadnytska T, Werner J, Braun S (2009) Estimating long-range dependence in time series: an evaluation of estimators implemented in R. Behav Res Methods 41:909–923
Stuiver M, Grootes PM, Braziunas TF (1995) The GISP2 18O climate record of the past 16,500 years and the role of the sun, ocean and volcanoes. Quatern Res 44:341–354
USGS (United States Geological Survey) (2012) Discharge data for the Elkhorn River, Station 06800500, 1 Jan 1929 to 30 Dec 2001, available online at: http://waterdata.usgs.gov/. Accessed 1 June 2012
Swan ARH, Sandilands M (1995) Introduction to geological data analysis. Blackwell Science, Oxford
Takens F (1981) Detecting strange attractors in turbulence. In: Rand DA, YoungL-S (eds) Dynamical systems and turbulence. Lecture Notes in Mathematics 898, Springer, Berlin pp 366–381
Taqqu MS (1975) Weak convergence to fractional Brownian motion and to the Rosenblatt process. Probab Theory Relat Fields 31:287–302
Taqqu MS (2003) Fractional Brownian motion and long-range dependence. In: Doukhan P, Oppenheim G, Taqqu MS (eds) Theory and applications of long-range dependence. Birkhäuser, Boston, pp 5–38
Taqqu MS, Samorodnitsky G (1992) Linear models with long-range dependence and finite or infinite variance. In: New directions in time series analysis, Part II, IMA Volumes in Mathematics and its Applications 46, Springer, pp 325–340
Taqqu MS, Teverovsky V (1998) On estimating long-range dependence in finite and infinite variance series. In: Adler RJ, Feldman RE, Taqqu MS (eds) A practical guide to heavy tails: statistical techniques and applications. Birkhäuser, pp 177–217
Taqqu MS, Teverovsky V, Willinger W (1995) Estimators for long-range dependence: an empirical study. Fractals 3:785–788
Teich MC, Heneghan C, Lowen SB, Ozaki T, Kaplan E (1997) Fractal character of the neural spike train in the visual system of the cat. J Opt Soc Am A: 14:529–546
Theiler J (1991) Some comments on the correlation dimension of 1/f α noise. Phys Lett A 155:480–493
Theiler J, Eubank S, Longtin A, Galdrikian B, Farmer JD (1992) Testing for nonlinearity in time series: the method of surrogate data. Physica D 58:77–94
Thomas RW, Hugget RJ (1980) Modelling in geography: a mathematical approach. Barnes and Noble Books, New Jersey
Timmer J, König M (1995) On generating power law noise. Astron Astrophys 300:707–710
Tukey JW (1977) Exploratory data analysis. Pearson Education
Turcotte DL (1999) Self-organized criticality. Rep Prog Phys 62:1377–1429
Uppaluri S, Nagler J, Stellamanns E, Heddergott N, Herminghaus S, Engstler M, Pfohl T (2011) Impact of microscopic motility on the overall swimming behaviour of parasites. PLoS Comput Biol 7:e1002058
van der Ziel A (1950) On the noise spectra of semi-conductor noise and of flicker effect. Physica 16:359–372
Velasco C (2000) Non-Gaussian log-periodogram regression. Econom Theory 16:44–79
Venema V, Bachner S, Rust H, Simmer C (2006) Statistical characteristics of surrogate data based on geophysical measurements. Nonlinear Process Geophys 13:449–466
Voss RF (1985) Random fractal forgeries. In Earnshaw RA (ed) Fundamental algorithms for computer graphics. NATO ASI Series, Springer F17 pp 805–835
Voss RF, Clarke J (1975) ‘1/f noise’ in music and speech. Nature 258:317–318
Wang MC, Uhlenbeck GE (1945) On the theory of the Brownian motion. Rev Mod Phys 17:323–342
Watkins NW, Credgington D, Hnat B, Chapman SC, Freeman MP, Greenhough J (2005) Towards synthesis of solar wind and geomagnetic scaling exponents: a fractional Levy motion model. Space Sci Rev 121:271–284
Weeks ER, Crocker JC, Levitt AC, Schofield A, Weitz DA (2000) Three-dimensional direct imaging of structural relaxation near the colloidal glass transition. Science 28:627–631
Wen RJ, Sinding-Larsen R (1997) Uncertainty in fractal dimension estimated from power spectra and variograms. Math Geol 29:727–753
Weron R (2001) Estimating long-range dependence: finite sample properties and confidence intervals. Phys A 312:285–299
Whitcher B (2004) Wavelet–based estimation for seasonal long-memory processes. Technometrics 46:225–238
Whittle P (1952) The simultaneous estimation of a time series harmonic components and covariance structure. Trabajos Estadística 3:43–57
Willinger W, Taqqu MS, Sherman R, Wilson DV (1997) Self-similarity through high-variability: statistical analysis of ethernet LAN traffic at the source level. IEEE ACM Trans Netw 5:71–86
Witt A, Kurths J, Pikovsky AS (1998) Testing stationarity in time series. Phys Rev E 58:1800–1810
Witt A, Malamud BD, Rossi M, Guzzetti F, Peruccacci S (2010) Temporal correlation and clustering of landslides. Earth Surf Proc Land 35:1138–1156
Wolf A, Swift JB, Swinney HL, Vastano JA (1985) Determining Lyapunov exponents from a time series. Physica D 16:285–317
Wornell GW (1990) A Karhunen–Loève-like expansion for 1/f processes via wavelets. IEEE Trans Inf Theory 36:859–861
Wornell GW (1993) Wavelet-based representations for the 1/f family of fractal processes. Proc IEEE 81:1428–1450
Wornell GW (1996) Signal processing with fractals: a wavelet-based approach. Prentice-Hall
Wornell GW, Oppenheim AV (1992) Estimation of fractal signals from noisy measurements using wavelets. IEEE Trans Signal Process 40:611–623
Xiao X, White EP, Hooten MB, Durham SL (2011) On the use of log-transformation vs. nonlinear regression for analyzing biological power laws. Ecology 92:1887–1894
Xu L, Ivanov PCh, Hu K, Chen Z, Carbone A, Stanley HE (2005) Quantifying signals with power-law correlations: a comparative study of detrended fluctuation analysis and detrended moving average techniques. Phys Rev E 71:051101
Yebang X, Burton PW (2006) Time varying seismicity in Greece: Hurst’s analysis and Monte Carlo simulation applied to a new earthquake catalogue for Greece. Tectonophysics 423:125–136. doi:10.1016/j.tecto.2006.03.006
Zolotarev VM (1986) One-dimensional stable distributions, vol 65. American Mathematical Society, Providence, pp 284
Acknowledgments
This research was supported by the European Commission Framework 6 Project 12975 (NEST) Extreme events: Causes and consequences (E2–C2), by the Stifterverband für die deutsche Wissenschaft, and by the Claussen–Simon–Stiftung. A.W. would like to thank Jan Nagler for valuable discussions about the analysis of the three environmental data sets and Maximilian Puelma Touzel for a reading of the manuscript (both from Max–Planck Institute for Dynamics and Self-Organization, Göttingen). We also thank two reviewers, Manfred Mudelsee (Climate Risk Analysis, Hannover, Germany) and Wolf-Gerrit Früh (Heriot-Watt University, Edinburgh, Scotland), both of whom provided in-depth reviews and comments which substantially improved this manuscript.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary Material 1
Sample fractional noises and motions (126 tab-delimited text files in 3 subfolders), an R program for creation of fractional noises and motions by the user (1 rtf file), and a readme file (1 rtf file). (ZIP, 27658 KB)
Supplementary Material 2
R program for five types of analyses used to evaluate long-range persistence in time series (R 17 kb)
Supplementary Material 3
Excel spreadsheet with (a) subset of our performance tests results for all of our different analyses, (b) calibration spreadsheet and graph to do benchmark-based improvement techniques (XLSX 7019 kb)
Supplementary Material 4
High resolution figures from Witt and Malamud (2013) paper in PDF format (PDF 36696 kb)
Appendices
Appendix 1: Construction of Gaussian-Distributed Fractional Noises and Motions
-
(1.1)
Choose the parameter for the strength of long-range persistence, β, and the length of the noise or motion, N.
-
(1.2)
Begin with a Gaussian-distributed white noise with 2N elements x 1, x 2, …, x 2N .
-
(1.3)
Subtract the mean \( {\bar{x}} \) (see Eq. 1) from each of the time series elements x t , t = 1, 2, …, 2N.
-
(1.4)
Apply a discrete Fourier transform to the mean-corrected white noise. This results in the (complex-valued) Fourier coefficients X k , k = 1, 2, …, N.
-
(1.5)
Filter the Fourier coefficients:
$$ {\begin{gathered} \tilde{X}_{k} = X_{k} \left( \frac{k}{N} \right)^{ - \beta / 2},\quad k = 1,2, \ldots ,N \\ \tilde{X}_{k} = \tilde{X}_{N - k}, \quad k = N + 1,\,N + 2, \ldots, 2N \\ \end{gathered} } $$(39) -
(1.6)
Apply an inverse discrete Fourier transform to the filtered Fourier coefficients to get \( {\tilde{x}_{k} ,\,k = 1,2,}\, \ldots, 2N \).
-
(1.7)
Take the first N elements of the Fourier-filtered noise or motion obtained in (1.6).
-
(1.8)
Subtract the sample mean \( \bar{\tilde{x}} \) from each noise element \( {\tilde{x}_{t} ,\,t = 1,2, \ldots ,N}. \)
-
(1.9)
Normalize the standard deviation to be one by dividing each time series element \( {\tilde{x}_{t} - \bar{\tilde{x}},\, t = 1,2,}\,\ldots,N \) by the sample standard deviation \( {\sigma_{x} \left( {\tilde{x}} \right)}. \) The resultant time series represents a realization of a Gaussian-distributed, self-affine noise or motion with β the strength of long-range persistence.
Appendix 2: Construction of Levy-Distributed Fractional Noises and Motions
-
(2.1)
Choose the parameter for the strength of long-range persistence, β, the length of the noise or motion, N, and the exponent of the Levy distribution, a.
-
(2.2)
Begin with a Levy-distributed white noise with N 2 elements \( x_{1}, x_{2},\, \ldots ,x_{{N}^{2} } \). As N 2 can become very large, it may lead to conflicts with the computer memory. Therefore, choose the number of elements as large as possible.
-
(2.3–2.6)
are identical to (1.3–1.6)
-
(2.7)
Take the first N elements of the Fourier-filtered noise or motion obtained in (2.6).
-
(2.8)
Subtract the sample mean from each of the remaining noise or motion elements.
-
(2.9)
Normalize the sample standard deviation to be one by dividing each time series element by the sample standard deviation. The resultant time series represents a realization of a Levy-distributed, self-affine noise or motion with β the strength of long-range persistence.
Appendix 3: Construction of Log-Normal Distributed Fractional Noises and Motions by Box–Cox Transformation of Fractional Gaussian Noises
-
(3.1)
Choose the parameter for the strength of long-range persistence, β, the length of the noise or motion, N, and the parameters for the log-normal distribution: the mean value μ (μ > 0) and the coefficient of variation c v = \(\sigma \)/μ (c v > 0).
-
(3.2)
Construct a Gaussian-distributed, self-affine noise or motion with 2N elements, y 1, y 2, …, y 2N , with β the strength of long-range persistence, by performing steps (1.2–1.6) of Appendix 1.
-
(3.3)
Subtract the sample mean \( \bar{y} \) from each of the noise or motion elements y t , 1 ≤ t ≤ 2N.
-
(3.4)
Normalize the standard deviation to be one by dividing each noise or motion element by the sample standard deviation of the noise. The resultant noise is called \( \hat{y}_{1} ,\hat{y}_{2} , \ldots ,\hat{y}_{2N} . \)
-
(3.5)
The transformation into a log-normal noise or motion is performed by applying the following function to each element:
-
(3.6)
Take the first N elements of the log-normal noise or motion obtained in (3.5). The resultant time series represents a realization of a log-normal distributed fractional noise or motion with β the strength of long-range persistence.
Appendix 4: Construction of Log-Normal Distributed Fractional Noises and Motions by the Schreiber–Schmitz Algorithm
-
(4.1)
Choose the parameter for the strength of long-range persistence, β, the length of the noise or motion, N, and the parameters for the log-normal distribution: the mean value μ (μ > 0) and the coefficient of variation c v = \(\sigma \)/μ (c v > 0).
-
(4.2)
Construct a very long (we recommend a length of L = N 2) Gaussian-distributed, self-affine noise or motion x 1, x 2, …, x L , with β the strength of long-range persistence by performing steps (1.2–1.6) of Appendix 1. Store the amplitudes (moduli) m 1, m 2, …, m L/2 of the Fourier coefficients, X 1, X 2, …, X L/2.
-
(4.3)
Construct a white noise n 1, n 2, …, n L of length L (i.e. length of the fractional noise or motion created in step 4.2) with the desired one-point probability distribution.
-
(4.4)
[Amplitude adjustment] The time series n 1, n 2, …, n L is sorted such that its rank order is identical to that of x 1, x 2, …, x L . This way, correlations are transferred from the fractional noise or motion x 1, x 2, …, x L to the time series n 1, n 2, …, n L .
-
(4.5)
[Adjustment of the power spectrum] Fourier transform the amplitude-adjusted data set of values, n 1, n 2, …, n L , and reset the Fourier amplitudes to the Fourier amplitudes of the fractional Gaussian noise or motion, m 1, m 2, …, m L/2 (see step 4.2), but keep the complex phases of the Fourier coefficients.
-
(4.6)
Repeat steps (4.4–4.5) until the time series elements n 1, n 2, …, n L do not change any more (we have used 10,000 iteration steps).
-
(4.7)
Take the first N elements of n 1, n 2, …, n L . The resultant time series represents a realization of a log-normal distributed self-affine noise or motion with β the strength of long-range persistence.
Appendix 5: Fitting Power-Law Functions to Data
Four of the techniques considered in this paper (R/S, semivariograms, DFA, and PS(best-fit)) that we use for evaluating long-range persistence are based on fitting power-law functions to the data. In this appendix, we will briefly discuss various methods for fitting power laws to data, explain the statistical background, perform some simulations, and will conclude that, for the purposes of analyses in this paper, a power-law regression can in most cases be effectively done by a linear regression of the log-transformed data.
We begin with a set of discrete measured values, z 1, z 2, …, z n (e.g., our power spectral densities), each associated with the values of an explanatory variable θ 1, θ 2, …, θ n (e.g., a given frequency in power spectral analysis). Assume that these pairs of values are well described by a model h that is a power-law function that has superimposed on it fluctuations (a white noise):
where c and β are constants, with β the exponent of an inverse power law. The variable ε is a (white) noise that is superimposed on the power-law trend h, in other words, the (usually unknown) contamination or fluctuation around the model function. In this case the noise is additive. Each value of the stationary white noise is uncorrelated with all other values, and the one-point probability distribution of the white noise can vary (e.g., Gaussian, log-normal, and chi-squared).
If the fluctuations systematically change as a function of the variable θ, one way of modelling this is by multiplying ε by \( c\theta^{ - \beta } \), such that the power-law function h has superimposed on it a multiplicative noise:
For the specific case of power spectral analysis, the fluctuations for power spectral densities considered as a function of frequency in the case of self-affinity have been modelled by a multiplicative chi-squared process (Eq. 42) by both Timmer and König (1995) and Chatfield (1996). Furthermore, the method by which we construct fractional Gaussian and Levy noises and motions in this paper (described in Appendix 1 and 2, respectively) is based on a transformation of a white Gaussian or white Levy noise into the spectral domain, and then a filter which is effectively a multiplier (Eq. 39), that is, a multiplicative process in the spectral domain. Thus, multiplicative processes for the power spectral density fluctuations are important to consider for the analyses done in this paper. These fluctuations are also important for the other power-law based techniques considered in this paper (R/S, semivariograms, and DFA).
We first present (Fig. 40) realizations of the processes given by Eqs. (41) and (42). In Fig. 40 we simulate an inverse power-law with exponent −0.5, and from top to bottom: (a1, a2) additive (Eq. 41) Gaussian-distributed fluctuations (mean = 0.0, standard deviation = 1.0), (b1, b2) multiplicative (Eq. 42) Gaussian-distributed fluctuations (mean = 1.0, standard deviation = 1.0), and (c1, c2) multiplicative (Eq. 42) chi-squared distributed fluctuations (2 degrees of freedom, mean = 1.0, standard deviation = 1.0). The left-hand column of Fig. 40 is given in linear–linear axes, and the right-hand column in log–log axes.

Power-law functions with additive and multiplicative noises. Shown is the power-law function z = 2.5θ −0.5 with superimposed on it the following: a additive Gaussian-distributed fluctuations (Eq. 41), b Gaussian-distributed multiplicative fluctuations (Eq. 42), c chi-squared distributed multiplicative fluctuations (Eq. 42). The left-hand column shows data on linear axes and the right-hand column the same data presented on logarithmic axes
Figure 40a shows that for a realization of the additive process and Gaussian-distributed fluctuations, on linear axes the fluctuations are stationary, but that if a log-transform were taken the fluctuations become non-stationary (i.e. the variance grows from left to right). In Fig. 40b,c, a realization of a multiplicative process, we see the opposite: on linear–linear axes the variance grows (the fluctuations are non-stationary), but on log–log axes, they are approximately stationary.
We are mainly interested in the power-law exponent β, and we need an appropriate statistical technique for estimating this coefficient from the given data. In the absence of additive or multiplicative superimposed fluctuations (our Gaussian or chi-squared white noise), then \( z_{t} = h(\theta_{t} ) = c\theta^{ - \beta } ,\, t = 1,2,\, \ldots ,n. \) However, in the presence of additive or multiplicative fluctuations (noise), we have to explore what power-law fitting method leads to the best-fit.
We consider two commonly used methods: ordinary nonlinear least-squares regression (ONL) and least-squares linear regression of the log-transformed data (LL). Xiao et al. (2011) discuss in depth the difference between these two methods for fitting power laws, coming to the conclusion that ordinary nonlinear regression (ONL) is more appropriate for additive errors and linear regression of log-transformed data (LL) is appropriate for multiplicative errors. The errors here are the fluctuations around the best-fit power-law line. In their work, Xiao et al. (2011) considered Gaussian-distributed additive and log-normal distributed multiplicative fluctuations. We will here (further below) consider Gaussian-distributed additive and Gaussian and chi-squared distributed multiplicative fluctuations over many realizations. These two methods, ONL and LL, and others (e.g., weighted nonlinear regression) for fitting power laws to measured data, have also been discussed by a number of authors (e.g., Bard 1973; Newman 1993; Schulz et al. 1994; Robinson 1995), including evaluation of different methods’ strengths and weaknesses.
We will now consider these two methods, ONL and LL. Both are based on minimizing D, the squared distance of the difference between the best-fit function and the measured values. The squared distances for the methods are as follows:
Method ONL Ordinary Nonlinear Regression (ONL)
Method LL Linear Regression of the Log-Transformed Data (LL)
where the constant c for the two equations is not the same.
We now present simulation results (Fig. 41) for additive Gaussian-distributed fluctuations (Eq. 41) and multiplicative Gaussian and chi-squared fluctuations (Eq. 42), which were shown in Fig. 40. However, we now consider, for each of the three additive and multiplicative processes, three values of the power-law exponent: β = −0.5, 0.5, and 1.5, a total of nine processes, each with 1,000 realizations. As previously mentioned, chi-squared distributions and multiplicative processes are typical of the fluctuations resulting from long-range persistence techniques we apply in this paper to self-affine time series, and we consider here typical values of power-law exponents that are within our range of −1.0 ≤ β ≤ 4.0 considered in this paper.
Our simulations are based on 500 equidistantly spaced values θ in the interval (0.0, 0.5), 1,000 realizations for each set of parameters, and estimation of the power-law coefficient with the techniques ONL and LL. The ONL method (Eq. 43) has been applied here by implementing the Golub–Pereyra algorithm which is an efficient iterative method for determining the best-fit power law \( c\theta^{ - \beta } \) (for details see Golub and Pereyra 1973; Bates and Watts 1988). In their iterative algorithm we use the following parameters: (1) for β = −0.5, 0.5, 1.5, respectively, β start = 0.0, 0.0, 1.0, and a minimum step-size factor of 2−10; (2) maximum number of iterations 500; and (3) a tolerance level for the relative offset convergence criterion of 10−6. The results are presented in Fig. 41, where from top to bottom are shown the three types of β simulated, and from left to right are the three types of fluctuation—additive Gaussian, multiplicative Gaussian, and multiplicative chi-squared—each fit by both ONL and LL. In each case we show a box plot (rectangle top and bottom 25 and 75 %, horizontal line in the rectangle the median, white circle the mean value, whiskers 5 and 95 %, and the top and bottom horizontal lines the maximum and minimum). The long-dashed horizontal line in each panel is the process modelled value for β.

Distribution of estimated power-law exponents for two different fitting techniques applied to three different power-law models shown in Fig. 40 (Gaussian-distributed additive fluctuations, Gaussian-distributed multiplicative fluctuations, chi-squared distributed multiplicative fluctuations) with three different power-law exponents in the equation z = 2.5θ −β: a β = −0.5, b β = 0.5, c β = 1.5. For each power-law exponent, 1,000 realizations of the three power-law models (Fig. 40) are created. For each realization the power-law exponent was fit by ordinary nonlinear regression (ONL) and by linear regression of the log-transformed data (LL). The resultant distribution of the fitted values of β is presented by box and whisker plots. They give the mean value (white circle), the median (horizontal line in the middle of the box), 25 and 75 % percentile (box lower and upper edges), 5 and 95 % percentiles (lower and upper whiskers), and maximum and minimum of the fitted exponents (upper and lower horizontal bar). The power-law model is colour coded: Gaussian-distributed additive fluctuations (yellow), Gaussian-distributed multiplicative fluctuations (blue), chi-squared distributed multiplicative fluctuations (pink)
We find that for multiplicative Gaussian and chi-squared distributions, β = −0.5, 0.5, and 1.5, LL estimates are on average correct and the spread of the estimated values is small, whereas for ONL the estimates are overestimated with larger spreads. For additive Gaussian-distributed noises: (1) the LL estimates (relative to the β of the process) are overestimated for β = −0.5 and underestimated for β = 0.5 and 1.5; and (2) the ONL estimates have a median value close to the β of the process and a very wide spread of values for β = –0.5 and 0.5 versus a very tight spread of values for β = 1.5. This large spread, for cases when β < 1.0, is most likely caused by the low ratio of signal \( \theta_{t}^{ - \beta } \) to noise ε t in the model for Eq. 41. In other words, in Eq. 41 if we consider ε t to be a constant scatter that does not vary with β, then over the interval considered for θ (0.0 to 0.5), and in particular as \( \theta \to 0.0 \), the term \( c\theta_{t}^{ - \beta } \) becomes of the same order as or smaller (relative to ε t ) for β < 1.0; thus, ε t superimposed on \( c\theta_{t}^{ - \beta } \) results in a very noisy signal z t which becomes more difficult to estimate the best-fit β. For β > 1.0, \( c\theta_{t}^{ - \beta } \) is not overwhelmed by ε t , and the signal z t is not as ‘noisy’, thus resulting in much better estimates (less spread) for β. We confirmed this effect by changing c in \( c\theta_{t}^{ - \beta } \) such that the term \( c\theta_{t}^{ - \beta } \) would always be much larger than ε t and found that for β < 1.0, the spread of the values of β for ONL additive Gaussian noise became much smaller, of the same order as for β > 1.0.
In this appendix we have thus far considered \( \varepsilon_{t}\, (t = 1,2,\, \ldots ,n) \) as an uncorrelated series of values (i.e. a white noise), which have been superimposed (added or multiplied) on our power-law function h, resulting in our ‘noisy’ power-law function z (e.g., our power spectral densities). Assuming a multiplicative process, we now examine the case of power spectral analysis applied to realizations of different fractional noises, the degree to which correlations are in fact present or absent. We could also consider other techniques that we have applied in this paper, but take power spectral analysis as an example.
We applied power spectral analysis to 1,000 realizations each of processes created to have Gaussian, log-normal (c v = 2.0), and Levy (a = 1.5) distributed noises and motions with two persistence strengths β = 0.0 and 2.0. For each of the six processes (each with 1,000 realizations) we calculated the average power spectral density \( \bar{{S_{k} }} \) at a given frequency f k , applying detrending and windowing (Welch) as described in Sect. 6.2. The multiplicative errors (Eq. 42), ε k , are given by:
In order to test for correlations in these error time series, ε k , the autocorrelation function C(τ) (Eq. 3) was applied to each of the time series for lags τ = 1 to 100. We found:
-
(1)
β = 0.0 (white noise). For Gaussian, log-normal (c v = 2.0), and Levy (a = 1.5) white noises, at τ = 1 (i.e. neighbouring pairs of frequencies), Eq. (45) gave average correlations (over the 1,000 realizations) of 0.14 < C(1) < 0.21. For τ > 1 (i.e. pairs of frequencies separated by 1 up to 99 frequencies), Eq. (45) gave C(τ) ≈ 0.00. Theoretically (Chatfield 1996) for stationary Gaussian noises (β < 1.0), we would expect no correlations in the power spectral density errors for all lags. We attribute the weak correlations found for all three one-point probability distributions for τ = 1, as potentially an effect of the Welch window used as part of the process of doing power spectral analysis.
-
(2)
β = 2.0 (Brownian motion). For fractional Gaussian motions we find similar results to β = 0.0 (weak correlations for τ = 1, negligible correlations for τ > 1). For the Levy (a = 1.5) Brownian motions C(1) = 0.23, and for the log-normal (c v = 2.0) Brownian motions C(1) = 0.33. In other words, both show weak correlations at lag 1. As τ increases, for both of these non-Gaussian one-point probability distributions, C( τ) decays slowly to 0.
Assuming a multiplicative error for the power spectral densities, the correlations we have found for these six example processes (both stationary β = 0.0 and non-stationary β = 2.0 examples, and for three different one-point probability distributions) are either very weak (e.g., at lag 1 for all processes, and for larger lags for β = 2.0 non-Gaussian motions) or negligible. The techniques LL and ONL both require uncorrelated errors as an assumption of their application. We believe the errors in the six sets of process realizations we have shown are so weak as to not effect this assumption.
Our results shown in this appendix for additive and multiplicative noises confirm those of Xiao et al. (2011) in that linear regression of log-transformed data is appropriate for multiplicative errors (the case for analyses done in this paper) and that simple nonlinear regression is more appropriate for additive errors. Furthermore, we find that LL works well for both Gaussian and chi-squared distributed multiplicative fluctuations. We conclude from our simulations that linear regression of the log-transformed data is appropriate for fitting power-law exponents within the context of the four long-range persistence techniques considered in this paper (R/S, semivariograms, DFA, and PS(best-fit)).
Appendix 6: Discrete Wavelet Transform
The discrete wavelet transform (DWT) was introduced by Grossmann and Morlet (1984) and Daubechies (1988). The DWT decomposes a signal into a cascade of temporally (spatially) localized sub-signals. The related basis functions, the wavelets, are localized in the time and frequency domain. The set of wavelets which are assigned to a particular scale in the cascade serves as a spectral band-pass filter. Those wavelets vary in their temporal localization (in the time domain) and can be transformed into each other by dilatation. Two excellent discussions of the wavelet transform are given by Hubbard (1996) and Wornell (1996). Flandrin (1992), Wornell (1990, 1993), and Wornell and Oppenheim (1992) have applied wavelets to fractional noises and motions. We have performed DWT analysis on the synthetic time series described in Sect. 4.2. Although in the text of this paper we have not provided a summary of the results of DWT analysis, we have included the results in our supplementary material and therefore give here details of how DWT analysis was performed.
-
(6.1)
Take a time series x t , t = 1, 2, …, N, where the time series length N is a power of 2.
-
(6.2)
Choose a discrete valued mother wavelet function \( \psi \left( t \right). \) We use here wavelets from the ‘best-localized’ family (Doroslovacki 1998), specifically ‘best-localized 20’. However, except for the Haar wavelet, we have found most discrete mother wavelet types (Daubechies 1988; Percival and Walden 2000) to give similar results.
-
(6.3)
Determine the wavelet basis functions
$$ \psi_{{kl}} \left( t \right) = 2^{ - k/2} \psi \left( {2^{ - k} \left( {t - l} \right)} \right),\quad 1 \le t \le N $$(46)where 2k is the scale, k is the level (1 ≤ k ≤ K), and l is the number of the wavelet coefficient (1 ≤ l ≤ 2K−k+1). We use a maximum level K = log2(N), and maximum number of wavelet coefficients per level is \( L(k) = 2^{K - k + 1} . \)
-
(6.4)
Perform a wavelet transform on the time series x t . We use ‘symmetric’ boundary conditions (vs. periodic boundary conditions). The result of the wavelet transform is a set of wavelet coefficients w kl which fulfil the following:
$$ x_{t} = \sum\limits_{k = 1}^{K} {\sum\limits_{l = 1}^{L(k)} {w_{{kl}} } } \psi_{{kl}} \left( t \right),\quad 1 \le t \le N $$(47)where w kl are the wavelet coefficients given by:
$$ \begin{aligned} w_{kl} &= \sum\limits_{t = 1}^{N} {x_{t} } \psi_{kl} \left( t \right) \\ &= 2^{ - k/2} \sum\limits_{t = 1}^{N} {x_{t} } \psi \left( {2^{ - k/2} \left( {t - l} \right)} \right) \\ \end{aligned} $$(48) -
(6.5)
Compute the variance of the wavelet coefficients for each scale:
$$ s_{\text DWT}^{2} \left( k \right) = \sigma^{2} \left( {\left\{ {w_{k1} ,w_{k2} , \ldots ,w_{kL} } \right\}} \right),\quad 1 \le k \le K $$(49) -
(6.6)
Apply weighted linear regression to \( \log \left( {s_{DWT}^{2} \left( k \right)} \right) \) as a function of wavelet scale k. The weights in the linear regression are chosen as w k = 1/(2K−k+1). Determine the slope of the best-fitting weighted linear model, β DWT.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article
Cite this article
Witt, A., Malamud, B.D. Quantification of Long-Range Persistence in Geophysical Time Series: Conventional and Benchmark-Based Improvement Techniques. Surv Geophys 34, 541–651 (2013). https://doi.org/10.1007/s10712-012-9217-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10712-012-9217-8
Keywords
- Fractional noises and motions
- Self-affine time series
- Long-range persistence
- Hurst rescaled range (R/S) analysis
- Semivariogram analysis
- Detrended fluctuation analysis
- Power spectral analysis
- Random and systematic errors
- Root-mean-squared error
- Confidence intervals
- Benchmark-based improvements
- Geophysical time series