
Abstract
Software developers, including those of the Android mobile platform, constantly seek to improve their applications’ maintainability and evolvability. Code smells are commonly used for this purpose, as they indicate symptoms of design problems. However, although the literature presents a variety of code smells, such as God Class and Long Method, characteristics that are specific to the underlying technologies are not taken into account. The presentation layer of an Android app, for example, implements specific architectural decisions from the Android platform itself (such as the use of Activities, Fragments, and Listeners) as well as deal with and integrate different types of resources (such as layouts and images). Through a three-step study involving 246 Android developers, we investigated code smells that developers perceive for this part of Android apps. We devised 20 specific code smells and collected the developers’ perceptions of their frequency and importance. We also implemented a tool that identifies the proposed code smells and studied their prevalence in 619 open-source Android apps. Our findings suggest that: 1) developers perceive smells specific to the presentation layer of Android apps; 2) developers consider these smells to be of high importance and frequency; and 3) the proposed smells occur in real-world Android apps. Our domain-specific smells can be leveraged by developers, researchers, and tool developers for searching potentially problematic pieces of code.
Similar content being viewed by others

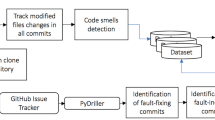

1 Introduction
“We are aware that good code matters, because we have had to deal with the lack of it for a long time,” argues Martin (2008). However, how do we find potentially problematic pieces of code? One answer might be by searching for smells. Code smells are anomalies that indicate a potential violation of design principles (Suryanarayana et al. 2014). By looking for code smells, developers find problematic code that can be refactored to improve software quality (Fowler and Beck 1999).
Several code smells have been catalogued in the literature (Fowler and Beck 1999; Martin 2008; Suryanarayana et al. 2014; Webster 1995), e.g., Long Methods and God Classes. These code smells are usually defined based on traditional concepts and technologies that emerged during the 1970s and 1990s, such as object orientation and Java. In this paper, we call these “traditional code smells.” However, in the last decade, new technologies have emerged, raising questions such as “Do traditional code smells apply to new technologies?” and “Are there code smells which are specific to new technologies?” (Aniche et al. 2019). Some researchers have already proposed technology-specific code smells for CSS (Gharachorlu 2014), JavaScript (Fard and Mesbah 2013), MVC (Aniche et al. 2016, 2017), and spreadsheets (Pinzger et al. 2012), for example.
Android (Alliance 2007), a mobile platform launched in 2008 by Google, has also attracted the attention of researchers. Some scholars have investigated the existence of traditional code smells in Android applications (Hecht 2015; Linares-Vásquez et al. 2014; Verloop 2013). Others have studied Android-specific code smells related to efficiency (i.e., proper use of features like memory and processing) and usability (i.e., software capability to be understood) (Gottschalk et al. 2012; Reimann and Brylski 2014). Other researchers have focused on understanding Android development features that set them apart from traditional software development (Minelli and Lanza 2013). However, to the best of our knowledge, no study has focused on the Android presentation layer, which follows specific concepts and models. In this paper, we investigate the existence of code smells related to the maintainability of the presentation layer of an Android application.
To understand what developers consider code smells, we collected data employing two questionnaires. In the first questionnaire (n = 45), we asked developers about good and bad practices they notice in the development of the Android presentation layer. From the responses, we derived 20 code smells. We then conducted a confirmatory questionnaire (n = 201) investigating the frequency and importance of the 20 proposed code smells. We also implemented a tool to assist in the identification of the code smells, and measured their prevalence in 619 open-source apps from the F-Droid repository.
Therefore, the main contribution of this paper is the cataloguing and validation of 20 new code smells related to the maintainability of eight types of components and resources of the Android’s presentation layer: Activities, Fragments, Adapters, and Listeners (components), Layouts, Styles, String, and Drawables (resources).
2 Background: Android and its Presentation Layer
Android is a Linux-based mobile development platform launched in 2008 by Google in partnership with several companies (Alliance 2007; Google 2017). In early 2011, Android became the leading mobile platform, having reached more than 87% market share in 2017. While its main competitor, iOS, is only used by Apple’s products, totaling approximately 30 different models (Wikipedia 2017), Android is used by more than 24,000 different models of mobile devices according to a survey conducted in 2015 (OpenSignal 2015). In terms of software development, the wide variety of hardware configurations brings significant challenges: from performance-related issues to issues related to user interface development, screens, and resolutions.
This research focuses on analyzing elements related to the presentation layer of Android apps. We reviewed the official Android documentation for the presentation layer (Google 2016), from which we identified the following components: Activities, Fragments, Adapters, and Listeners.
Activities represent a screen in the app, which the end-user sees and interacts with.
Fragments represent parts of an Activity and should indicate their corresponding layout feature. Fragments are used inside Activities.
Adapters are used to populate the UI (User Interface) with collections of data.
Listeners are Java interfaces that represent user events.
Resources are also related to the presentation layer (Google 2017), and Android provides more than fifteen different resource types (Google 2016a). They are “non-Java” files used to build user interfaces, such as image, audio, or XML files. We relied on the existing resources of the project created from the default templateFootnote 1 of Android Studio (Google 2016b), which is the official integrated development environment for Android. The selected resources are: Layout, Strings, Style, and Drawable.
Layout Resources are XML files used for the development of the UI structure of Android components. The development is done using a hierarchy of Views and ViewGroups. Views are text boxes, buttons, etc., while ViewGroups are a collection of Views with a definition of how these Views should be shown.
String Resources are XMLs used to define sets of texts for internationalization.
Style Resources are XMLs used to define styles to be applied in layout XMLs. Their goal is to separate code related to structure from code related to appearance and shape.
Drawable Resources represent a general concept for a graphic that can be drawn on the screen, including traditional images or specific XML files.
2.1 Developing a Presentation Layer in Android: A Running Example
In an Android app, a screen comprises two files: a Java class responsible for creating the screen and responding to the user events, and a layout resource, which is an XML file responsible for creating its visual interface.
An Activity is one of the major components of Android applications. It represents a UI screen, comprising buttons, listings, text input boxes, etc. To implement an Activity, it is necessary to create a class derived from the Activity, and to override some inherited methods. We highlight the onCreate() method. One of its responsibilities is to configure the user interface. In Listing 1, we illustrate the code for creating an Activity. In line 5, we find the UI configuration, which indicates the layout “main_activity” feature.

An example of an Activity class
The UI of an Activity is built using layout resources, which are composed of XML files. In the following, we show an example of a layout resource (Listing 2).

An example of a layout resource
Although the examples presented are quite simple, real-world UIs tend to be much more robust and richer in information and interactivity. Such rich and robust UIs may result in large and complex code elements. Moreover, UI components usually have long and complex life cycles. An Activity, for example, has 7 different states in its life cycle (onCreate(), onStart(), onResume(), onPause(), onStop(), and onDestroy()), while Fragments have 11 different stages. These numbers are high compared to the life cycle of non-UI related components (e.g., a Service has only four). In such contexts, challenges in developing maintainable Android presentation code emerge.
3 Related Work
In this section, we present work related to traditional code smells, domain-specific smells, and smells for Android applications.
3.1 Traditional Code Smells
Webster’s (1995) book was likely the first code smells catalog, which focused on object-oriented software. Since then, several developers and researchers have studied this subject. As an example, Riel (1996) has documented more than 60 different heuristics for object-oriented code. Fowler and Beck (1999) suggests refactoring strategies for more than 20 smells.
Some researchers have focused on understanding the impacts of code smells on project quality. Khomh et al. (2009), for example, conducted an empirical experiment in which they found that classes affected by code smells tend to suffer more changes than classes without code smells. In another study, Khomh et al. (2012) noticed that classes affected by code smells are also more prone to defects. Li and Shatnawi (2007) also empirically analyzed the impact of code smells and found a high correlation between code smells and detect-proneness. Yamashita and Moonen (2013) explored the implications of inter-smell relations and explained how different interactions impact maintainability. On a related research, Abbes et al. (2011), showed by means of a controlled experiment that the existence of a single code smell in a class does not significantly diminish developers’ performance during maintenance tasks; however, when classes suffer from more than one code smell, performance is significantly reduced.
Other researchers have studied how developers perceive code smells. Palomba et al. (2014) conducted an empirical experiment to evaluate the developers’ perception of traditional code smells. Their results showed that developers easily perceive “simple” code smells. However, experience and knowledge play a significant role in identifying code smells related to good practices of object-oriented development.
Arcoverde et al. (2011) conducted a survey to understand how developers react to the presence of code smells. The results showed that developers postpone removal to avoid API modifications. Peters and Zaidman (2012) analyzed the behavior of developers regarding the life cycle of code smells. Their results showed that awareness of a code smell is not enough to compel immediate refactoring.
3.2 Domain-Specific Code Smells
Several researchers have been investigating the existence of code smells that are specific to a given technology, for example, MVC (Aniche et al. 2016), Object-Relational Mapping (Chen et al. 2014), CSS (Gharachorlu 2014), and formulas in spreadsheets (Pinzger et al. 2012).
Chen et al. (2014) studied code smells in Object-Relational Mapping (ORM) frameworks, since developers are usually unaware of the impact of their code in database performance. The authors implemented an automated and systematic framework to detect and prioritize anti-performance standards in applications developed using ORM, and mapped two specific anti-patterns to ORM frameworks.
Aniche et al. (2016, 2017) investigated code smells related to the MVC architecture. After interviewing and surveying developers, the authors proposed a set of six smells related to the layers of an MVC application—Model, View, and Controller—and showed how each of them affects classes’ change- and defect-proneness. Aniche et al. (2016) also performed an empirical analysis in 120 open source systems and showed that each architectural role has a different code metric values distribution, which is a likely consequence of their specific responsibilities.
Gharachorlu (2014) investigated code smells in CSS code, a widely used language in the presentation layer of web applications. According to the author, despite the simplicity of CSS syntax, language-specific features make CSS creation and maintenance a challenging task. A large-scale empirical study indicated that current CSS code suffers significantly from inadequate standards. The author proposes the first CSS quality model derived from a large sample to help developers estimate the total number of code smells in their CSS code. His main contribution was a set of eight new code CSS smells that can be detected with the CSSNose tool.
Finally, Fard and Ali (2013) investigated code smells in JavaScript. The authors claimed that because of its flexibility, JavaScript is a particularly challenging language for writing and maintaining code. According to the authors, one of the challenges is that, unlike Android applications, which are compiled, JavaScript is interpreted. This means that there is usually no compiler to help developers detect incorrect or non-optimized code. Besides these challenges, the authors also fault JavaScript’s dynamic, weakly typed, and asynchronous nature. They propose a set of 13 code smells for JavaScript: seven as adaptations of traditional code smells and six as language-specific smells. They also proposed an automated technique, called JSNOSE, to detect these code smells.
3.3 Code Smells in Android Apps
Mannan et al. (2016) state that 10% of the articles published in major software maintenance conferences between 2008 and 2015 considered Android projects in their research. They also observed that, when compared to traditional software, little research has been conducted on code smells in Android applications.
A significant portion of the research dedicated to code smells in Android applications focuses on studying the effects of traditional code smells. For example, Linares-Vásquez et al. (2014) used the DECOR tool (Moha et al. 2010) to perform the detection of object-oriented anti-patterns in mobile applications developed with J2ME. Among their conclusions, the authors noticed a significant difference in the values of quality metrics in applications affected by code smells when compared to those that are not, and that while code smells occur in all domains, some code smells are more prevalent in specific domains.
Verloop (2013) investigated the presence of traditional code smells (Fowler and Beck 1999) in Android applications to determine whether these code smells occur more often in “core classes,” classes in the Android project that need to inherit from Android SDK classes, such as Activities, Fragments, and Services (as compared to “non-core” classes). To that aim, the author used four automatic code smell detection tools: JDeodorant, Checkstyle, PMD, and UCDetector. The author states that core classes tend to exhibit God Class, Long Method, Switch Commands, and Type Check code smells due to their nature of having many responsibilities. These smells were particularly high in Activities, which is the main component of the Android presentation layer. The author also found that the traditional code smell Long List Parameters is less likely to appear in core classes, as most of their method signatures come from classes defined in the Android SDK.
Reimann and Brylski (2014) correlated the concepts of code smell, quality, and refactoring to introduce a catalog of 30 smells focused on usability, resource consumption, and security. Hecht et al. (2015) used the code smells detection tool Páprika (Hecht et al. 2015) to identify 8 code smells. The author searched for the code smells in 15 popular Android applications, including Facebook, Skype, and Twitter. The author claims that traditional code smells are as prevalent in Android as in non-Android applications, except for the Swiss Army Knife code smell (Brown et al. 1998). Mannan et al. (2016) conducted a large-scale empirical study to compare the prevalence and effects of code smells on mobile and desktop applications. The authors found that while code smell density is similar in both mobile and desktop systems, some smells occur more often in mobile applications. For example, data classes and data clumps happen more often in a mobile app, while external duplication tends to happen more in desktop systems.
Researchers also showed that Android test code also contains test smells. More specifically, Peruma (2018) explored the prevalence of test code smells in several open source Android applications. The author found that Android apps exhibit test smells early on in their lifetime, with varying degrees of co-occurrences with different smell types, and that the existence of the test smells is also associated with higher change-proneness.
Gottschalk et al. (2012) conducted a study on ways to detect and refactor code smells related to energy efficiency. The authors compiled a catalog with six code smells drawn from other research. Linares-Vásquez et al. (2014), who also investigated energy consumption, showed that APIs related to user interface and database represent around 60% of the energy-greedy APIs. The authors also propose energy-saving recipes for Android developers, including “limit the use of the Model-View-Controller (MVC) pattern, especially when used in apps with many views” and “carefully design apps that make use of several views.”
Other researchers also investigated performance and resource consumption. For example, Hecht et al. (2016) studied the effects of three code smells (Internal Getter/Setter, Member Ignoring Method, and HashMap Usage) on the performance and memory-usage of two open source Android apps. Linares-Vásquez et al. (2017) investigated the effects of micro-optimization in mobile applications. After a study of more than 3,500 mobile apps, the authors concluded that developers rarely make use of micro-optimizations and that the impact of these micro-optimizations on CPU/memory consumption is often negligible. Although not directly related to code smells, Liu et al. (2014) conducted a study of 70 real-world performance bugs collected from eight Android applications. Among their findings, the authors show that most performance bugs (75%) are GUI lagging. In other words, they reduce responsiveness or the smoothness of the user interface. GUI lagging is indeed a concern of developers, as Linares-Vasquez et al. (2015) show after surveying 485 open source developers.
Palomba et al. (2017) propose 15 Android-specific smells and lightweight rules for their detection (that achieves an average precision and recall of 98%). The proposed code smells relate to different parts of an Android application, ranging from performance issues (e.g., the smell Data Transmission Without Compression arises when a method transmits a file over a network infrastructure without compressing it, and the Inefficient SQL Query, for which the authors suggest that the use of JDBC over network introduces too much overhead) to thread issues (e.g., the Leaking Thread happens when the application does not properly stop unused threads).
Android security code smells have also been explored by Ghafari et al. (2017). After reviewing scientific literature, the authors proposed a catalog of 28 smells that can lead to security vulnerabilities. The smells touch different security problems, such as insufficient attack protection, security validation, access control, data exposure, and input validation. After investigating the frequency of these code smells in around 46,000 open source mobile apps, the authors conclude that these smells occur in practice; some of them, such as Dynamic Code Loading and XSS-like Code Injection, happen in more than 50% of the apps.
4 Research Goals
The goal of our study is to catalog and empirically validate code smells that occur in the presentation layer source code of Android applications. To that aim, we employed a mixed method approach for understanding developers’ perceptions, as their points of view play an important role in defining code smells related to a specific technology (Arcoverde et al. 2011; Palomba et al. 2014; Yamashita and Moonen 2013), especially considering the smells’ intrinsic subjective nature (Fard and Mesbah 2013; Van Emden and Moonen 2002).
We investigate the following research questions (RQ):
- RQ1::
-
What code smells do developers observe in the presentation layer of Android apps?
- RQ2::
-
How often do developers observe the identified code smells and what importance do they give to them?
- RQ3::
-
How prevalent are the proposed code smells in real Android apps?
We employed two open online questionnaires to collect and confirm the smells, which were answered by 45 and 201 developers, respectively. We also developed a tool that automatically identifies the proposed code smells, and we analyzed the prevalence of the proposed code smells in 619 Android apps.
As the results of each RQ influenced the design of the subsequent step of the research, we present the method and results of each RQ in its own section.
5 A Catalog of Code Smells (RQ 1)
The first part of the study aimed to catalog code smells that occur in the presentation layer of Android apps. We employed an online questionnaire asking about good and bad practices related to components and resources of the Android’s presentation layer.
5.1 Methodology and Questionnaire
The online questionnaire comprises 25 questions organized into three sections. The first section (6 questions) traces the participant’s demographic profile (age, residence, experience in software development, experience with Android development, and schooling). The second section focuses on understanding what developers consider good and bad practices in each element of the presentation layer (Activities, Fragments, Adapters, Listeners, Layout, Strings, Styles, and Drawables). We asked about good and bad practices since developers may not be able to express code smells directly, but may report the measures they take to avoid problems. This strategy has also been applied in previous work by Aniche et al. (2016, 2017) to identify code smells in MVC applications. This part of the questionnaire comprises 16 optional open-ended questions: for each of the eight elements of the Android presentation layer, we asked a question related to good practices and another to bad practices. As an example, for the Activity element, we ask:
- Q1:
-
Do you have any good practices to deal with Activities?
- Q2:
-
Do you have anything you consider a bad practice when dealing with Activities?
The last section of the questionnaire comprises two open questions to capture any last thoughts not captured in the previous questions and one inviting participants to provide their email. The complete questionnaire can be seen in the online appendix (Carvalho et al. 2019).
Before the release, we conducted a pilot test with three Android developers. In the first configuration of the questionnaire, almost all questions were mandatory. With the result of the pilot test, we realized that developers do not always have good or bad practices to comment on all elements. Thus, we made such questions optional. The responses from the pilot study were disregarded to mitigate bias effects.
The questionnaire was released on Android forums, such as Android Dev Brasil,Footnote 2 Android Brasil Projetos,Footnote 3 and Slack Android Dev Br.Footnote 4 The authors of this paper also made use of their Twitter social networks to share the questionnaire. The questionnaire was open for approximately 3.5 months, from October 9, 2016, until January 18, 2017.
5.2 Participants

Participants’ experience in the part I of our research (N = 45). X axis represents years of experience, Y axis represents the number of participants
We obtained 45 responses. In Fig. 1, we show the experience in software and Android development of our participants. Out of the 45 respondents, 90% had two years or more of software development experience, and 71% had two years or more of experience in Android development. It is noteworthy that the Android platform reached its 10th anniversary in 2018, i.e., five years of experience in this platform represented 50% of Android’s lifetime. The questionnaire was replied to by developers from 3 continents and 7 countries. Most responses came from Brazil (81%).
5.3 Data Analysis
Our analysis was inspired by the Grounded Theory approach (GT) (Corbin and Strauss 2007; Glaser and Strauss 2017), which is increasingly popular in software engineering research (Adolph et al. 2011). GT is an inductive approach whereby qualitative data is analyzed to derive a theory. The goal of the approach is to discover new perspectives rather than confirm existing ones. Our analysis started from 45 responses to the questionnaire and occurred in 4 steps: verticalization, data cleaning, codification, and split, as detailed in the following.
The verticalization consisted of considering each good or bad practice response as an individual record to be analyzed. As each participant provided 18 answers to be analyzed, we started with 810 records.
The next step was data cleaning. This step consisted of removing answers that were not specific to the Android presentation layer, i.e., practices that could be applied to any other Android layer or even Java systems. Out of the 810 answers, 352 were considered, and 458 were disregarded. We could note that traditional code smells also apply to the Android context. The high number of responses (352) that were specifically related to the Android presentation layer shows that there are specific practices that take the architecture into account. Out of the 352 answers, 45% of them related to bad practices and 55% to good practices. In Table 1, we show how many answers we collected per survey question.
Next, we performed codification for good and bad practices (Corbin and Strauss 2007; Saldaña 2015). Codification is the process by which categories are extracted from a set of statements through the abstraction of central ideas and relations between the statements (Corbin and Strauss 2007). In our case, categories represented the code smells themselves. For each statement about bad practice, we either defined a new code smell that captured its essence or assigned it to an already identified smell. For the good practices, the authors used their knowledge of the Android platform, analyzed the goal of the good practice, and either defined a new code smell or assigned the practice to an existing one. As a single statement can belong to more than one code smell, some of them received more than one category. In this step, we also disregarded more answers that were not “obviously disposable” in the previous step. For each response not considered in this step, we recorded the reason, which can be found in our online appendix (Carvalho et al. 2019).
Finally, we performed the split step, which consisted of dividing responses that belonged to more than one category into two or more answers. As an example, “Do not make Activities to be callbacks of asynchronous executions. Always inherit from support classes, never directly from the platform.” indicates one category in the first sentence and another one in the second. In some cases, the complete response was necessary to understand both categorizations, in which case we maintained the original answer. At the end of the analysis, 359 responses were individually categorized into 46 categories.
The first author of this paper conducted the verticalization, data cleaning, codification, split, and categorization steps. The second author of the paper intervened whenever the first author had questions about a specific coding. Both authors discussed until reaching a final agreement. At the end of the coding process, the first and the second authors discussed all the derived codes and together derived the final definition of the code smells.
In the usability community, Nielsen (2000) suggests that five repetitions are enough to characterize a recurring problem, and successive repetitions tend not to aggregate new relevant information. After experimenting with the number five as the minimum number of mentions, we obtained 20 smells, which belonged to two different groups: 9 of them related to the Java classes of the Android presentation layer, and 11 related to resources (string, layout, style, and drawable). After some consideration from the authors, we decided that this catalog met our criteria of having a reasonable number of recurrent smells covering the Android presentation layer.
5.4 Results
Activities was the element with the highest number of answers: 35 (78%) out of the 45 respondents answered the question about good practices while 38 (84%) responded to the question about bad practices. The element that received the least number of responses about good practices was Listener, which was answered by 10 (22%) participants. The elements that received the fewest responses about bad practices were Style resources and Drawable, both of which were answered by 9 (20%) participants.
The coding process resulted in 46 categories. As aforementioned, to derive a code smell we considered all 22 categories that presented occurrences greater than or equal to five. Out of the 22, we disregarded 2 categories because they were either (i) too similar to a traditional code smell (Large Class) or (ii) too focused on object-oriented programming (inheritance). In the online appendix, we report the full coding results (Carvalho et al. 2019).
In Table 2, we present a summary of each code smell, and in Table 3, we show how often our participants mentioned that smell. In the following paragraphs, we present the definition of the code smells, as well as the elements affected and related symptoms. We provide more information about each smell, such as code examples and refactoring suggestions, in a dedicated website.Footnote 5
Brain UI Component
Activities, Fragments, and Adapters should be responsible for presenting, interacting, and updating the UI only. Business logic should be implemented elsewhere. This idea is similar to what Evans (2004) calls the separation of the “UI layer” and the “domain layer.” The existence in presentation layer elements of code related to business logic, I/O operations, conversion of data, or static fields is a sign of code smell.
No Naming Pattern
This smell happens when resources (layout, string, style, and drawables) do not follow a naming pattern. More specifically, it happens when the file where the resource is located and its internal name (i.e., how the resource is called inside the source code) differ. These different names cause confusion among developers.
Magic Resource
A smell that occurs when resources (e.g., layout, string, and style) are hard-coded instead of pointing to an existing resource file.
Deep Nested Layout
Deep nesting when constructing layout resources was considered a code smell. Interestingly, the official Android website has more information and provides automated tools to deal with this problem (Google 2017).
Unnecessary Image
Android has resources that can replace images. The smell occurs when the system has images with, for example, pure solid colors or gradients, which could be replaced by Android’s native shapes.
Coupled UI Component
In order to be reused, Fragments, Adapters, and Listeners should not have a direct reference to who uses them. The existence of direct reference to Activities or Fragments in these elements is an evidence of code smell.
Suspicious Behavior
Activities, Fragments, and Adapters should not contain in their source code the implementation of event handlers. First, event handling code, when embedded into one of these components, is implemented through anonymous or internal classes. As the interfaces that these event handlers need to implement are often complex, the source code of Activities, Fragments, and Adapters becomes less readable. Second, an event handler often makes use of business rules and domain models. A less attentive developer may then write these business rules directly into the event handler (which then leads us to a possible Brain UI Component smell). The use of anonymous classes or internal classes to implement Listeners to respond to user events is a sign of code smell.
Long or Repeated Layout
The code smell appears when long or duplicated layout resources occur in the source code.
Fool Adapter
This smell occurs when Adapters do not reuse instances of the views that represent the fields that will be populated for each item of a collection using the View Holder pattern.
Absence of an Architecture
This smell happens when one cannot easily identify how the components are organized. Developers cannot identify whether the application makes use of Model-View-Controller (MVC), Model-View-Presenter (MVP), or Model-View-ViewModel (MVVM).
Missing Image
This code smell happens when the system has only a single version of .png, .jpg, or .gif images. The Android platform encourages images to be available in more than one size or resolution to perform optimizations.
Excessive Use of Fragments
This smell emerges when Fragments are used without an explicit need. Examples include applications that do not need to support tablets and when Fragments are used in only a single screen of the app.
UI Component Doing I/O
Activities, Fragments, and Adapters performing I/O operations, such as database and file access, cause this smell.
No Use of Fragments
Fragments can decouple UI with behavior pieces. The non-use of fragments can be a smell in visually rich apps. Such apps have a high number of different behaviors, animations, and events to handle. If all the implementation relies on a single Activity, for example, this class will be highly complex and hard to understand. Moreover, visually rich apps are also often responsive, i.e., have different UIs for different screen sizes. In this case, not using fragments will hinder code reuse. This code smell emerges when view components (e.g., EditTexts or Spinners) are directly used by an Activity instead of a Fragment.
God Style Resource
Long style resources define this smell. Symptoms of this smell happen when all styles are defined in the same styles.xml.
God String Resource
This smell is defined by Long string resources. Developers should separate their string resources according to a rule: e.g., one string resource per screen.
Duplicate Style Attributes
Android developers often choose to define the style of a UI element directly in the layout file. However, this might lead to unnecessary duplication (e.g., the same complex style appears in different components). The existence of duplicated style definitions in different components indicates this code smell.
Flex Adapter
Adapters should be responsible for populating a view from a single object. The code smell emerges when Adapters contain business or view logic. As we discussed in the Brain UI Component smell, UI logic and business rules should remain separate from each other.
Inappropriate String Reuse
Developers reuse strings among the different UIs of the application. For example, the string “Name” might appear in many parts of the app; thus, developers write this string only once in a string resource file and reuse it whenever they need it. However, the smell happens when developers reuse the same string in different parts of the system because the string is coincidentally the same, and not because they represent the same concept in the UI. For example, in one part of the app, “name” might refer to the name of the user, whereas in another part of the app, “name” might refer to the name of the user’s favorite band. Reusing strings simply because of their similarity might lead to two problems: First, if developers decide to change the string, they need to be aware that the changes will be reflected throughout the entire application. Second, when adding support for multiple languages, one language might need two words to express what another language can communicate in one.
Hidden Listener
Layout resources should only be responsible for presenting data. This smell appears when these resources also configure the listener that will respond to events, such as the onClick event. Event handling in XML files makes it harder for developers to identify which listeners are used and where. Although the most recent versions of IDEs are able to show developers which events are declared in an XML file when reading the respective Java file, events that are declared in XML files are “hidden” from developers who primarily work in Java code.

6 Importance and Frequency of the Code Smells (RQ 2)
The second part of the research aimed to understand the perceptions of the developers regarding the frequency and importance of the proposed smells. We collected these perceptions through another survey.
6.1 Methodology and Survey
This survey has three sections (the full version is available in the appendix). The first section (6 questions), as in the first step, collects the participants’ demographic profile (age, residence, software development experience, Android development experience, and education). The second section captures developers’ perceptions about how often they come across the smells in their Android systems. The third section captures perceptions of the developers regarding the importance of mitigating the code smells. In this survey, we were not interested in collecting more code smells, but rather in confirming the ones we devised in the first part. However, we did not indicate that code smells would be presented, nor did we mention the names of the smells used in this research. We have chosen this approach to avoid having to fully explain the code smells.
To investigate frequency (second part of the survey), we presented a list of statements derived from RQ1 where each statement described in practical terms how the smells manifest themselves in the source code. For each statement, the participant could choose one of five scale options from the frequency range: very common, frequent, sometimes, rarely, and never. We presented 25 statements to contemplate the 20 code smells from RQ1. The difference in these numbers occurred because, for four of the code smells—Suspicious Behavior, Long or Repeated Layout, God Style Resource, and Duplicate Style Attributes)—more than one statement was presented, each addressing one symptom. We chose to separate the symptoms into statements to understand which ones were frequently perceived by developers.
To investigate importance (third part of the survey), we asked developers about the importance of mitigating the smells. We decided to present mitigation approaches instead of the code smells, since: 1) in the previous question, we had already introduced the smells and asked about how often they see the smells, and that would be too repetitive for the participants; and 2) showing them ways to mitigate the problem would give them a different perspective on the proposed code smells (which, we conjecture, can make them rethink their answers). The participants were asked to indicate how important they considered 21 sentences related to approaches that mitigate the proposed code smells. Again, the divergence of the total number of code smells, and the total of mitigation statements can be explained because of smells with more than one symptom. For each statement, the participant could choose one of the following options: very important, important, fairly important, slightly important, and not important.
Before publishing the questionnaire, we performed pilots with two experienced Android experts, DEV-A and DEV-B. DEV-A has 10 years of software development experience and 5 years of experience in Android development, considers himself proficient in Java, Objective C, Swift, and Android technologies, and holds a bachelor’s degree in Information Technology. DEV-B has 7 years of software development experience and 6 years of experience in Android development, considers himself proficient in Java, Objective C, and Android technologies, and has a postgraduate degree in Service Oriented Software Engineering. In these pilot studies, we walked the experts through all the sentences we devised to the questionnaire and asked them to think aloud while reading each sentence. Our primary goal was to make sure all sentences made sense and were clear. We used their feedback to improve the formulation of the sentences. After all the improvements, the two experts agreed that all the sentences in the survey were clear and conveyed our intention and that it was ready to go public. Although we did not show the definitions of the code smells to the experts (only the survey), as the survey is intrinsically related to the smells, their feedback also helped us in sharpening the final definition of the smells.

Participants’ experience in the part II of our research (N = 201). X axis represents years of experience, Y axis represents the number of participants
The questionnaire was open for approximately three weeks in mid-September 2017 and was shared in the same venues as in Part 1. The statements were presented randomly, and 201 developers answered the questionnaire. A possible explanation for the difference in the number of answers (Part 1 received 45 answers) is due to the differences in format: while Part 1 was focused on open questions that take a long time to respond to, Part 2 mostly contained closed questions, which take less time to complete and are thus more attractive to participants.
6.2 Participants
In Fig. 2, we show the experience of the 201 participants that answered our survey: 94% indicated they had two years or more of experience in software development, and 74% indicated two years or more of experience in Android development. In addition, 15% had one or more post-graduation degrees, and 61% had a bachelor’s degree. Most participants were between 20 and 35 years old. We also asked participants about their level of knowledge in various object-oriented languages. More than 80% claim to have intermediate or expert knowledge in Java and Android. Five participants (2%) stated that they did not know about Android, so their answers were disregarded in the analysis. We obtained responses from Android developers from 3 continents and 14 different countries. Similar to the previous survey, 78% of participants are from Brazil.
6.3 Results
In Fig. 3a and b, we show the participants’ perception of the importance and frequency of the identified code smells. In Table 4, we present the median, mode, and standard deviation of their answers (varying from 1 to 5).

Frequency and importance of the proposed code smells, according to our participants’ perceptions
Most code smells are considered highly important by developers.
We see that most code smells (either related to components or resources) have a mode equal to or greater than four, meaning that most developers considered them to be from “important” to “highly important.”
Too many or too few fragments?
Two of the code smells are opposite to each other: Excessive Use of Fragments and No Use of Fragments. Our data shows that there is no definite perception of their importance. Interestingly, not even popular Android best practice guides, such as Futurice (2018), have clear suggestions on when to use Fragments. Quoting the guide: “We suggest you sail carefully, making informed decisions since there are drawbacks for choosing a fragments-only architecture, or activities-only.” Our results, together with the current best practice guidelines, suggest that better guidelines for how to use Fragments are necessary.
Developers often encounter the proposed code smells in their apps.
To all other code smells (except two: Fool Adapter and Hidden Listener), developers’ perceptions of frequency range from “sometimes” to “almost always.” This means that developers often find the code smells in their apps.
Fool Adapter and Hidden Listener are highly important, but do not occur often.
The mode for these two code smells was smaller than 3, meaning that participants “seldom” or “never” noticed them. However, they both are considered highly important: Fool Adapter was considered highly important by 58% of participants (the second most important code smell), and Hidden Listener was considered highly important by 33% of participants. These results suggest that developers already know the benefits of the ViewHolder pattern (Google 2017) and are avoiding the fooladapter smell. In addition, developers are already avoiding defining events in layout resources, and thus, avoiding the Hidden Listener smell.

7 Prevalence of the Code Smells (RQ 3)
The third part of our study aimed to analyze how prevalent the proposed smells are in real Android apps. To that aim, we devised a tool, named AndroidUIDetector.Footnote 6 Our tool relies on a combination of AST visitors and heuristics and it was designed based on two parsers: (i) JavaParserFootnote 7 and (ii) JDOM.Footnote 8 The former is used to parse Java files in a lightweight and straightforward way, while the last is used to process XML files.
7.1 Code Smell Detection Strategies
We implemented detection strategies in our tool for 15 out of the 20 proposed smells. We did not implement five smells: No Naming Pattern, Unnecessary Image, Long or Repeated Layout, Inappropriate String Reuse, and Absence of an Architecture, as they are more subjective and require more than static analysis.
7.1.1 Detection Strategies for the Component-Related Smells
This section presents the detection strategies used to identify the eight component-related smells.
Coupled UI Component
Fragments, Adapters, and Listeners, to be reused, should not have direct reference to who uses them. The detection strategy is as follows: we collect all Fragments, Adapters, and Activities of the app. For each component, we check whether any of its fields is a direct reference to another Activity or Fragment. If so, we mark the component as smelly. Algorithm 1 depicts this detection strategy.

Suspicious Behavior
Activities, Fragments, and Adapters should not be responsible for implementing event behavior. The detection strategy is as follows: we collect all Fragments, Adapters, and Activities of the app. For each component, we verify whether it contains either an (i) inner class or (ii) an anonymous class (as inner and anonymous classes are how developers often implement event behavior). If a component possesses any of them, we mark it as smelly. Algorithm 2 presents this detection strategy.

Brain UI Component
Activities, Fragments, Adapters, and Listeners should only contain code responsible for presenting, interacting, and updating the UI. The detection strategy is as follows: we collect all Fragments, Adapters, and Activities of the app. For each component, we measure its (McCabe) code complexity and identify whether it makes use of I/O operations, database access, or static fields. We use this heuristic as a proxy for business rules, as there is no clear and unambiguous way of deciding whether a piece of code has business logic. Algorithm 3 presents this detection strategy. Please note that α and β are thresholds and we describe how we calculate them in the next section.

Flex Adapter
: Adapters should be responsible for populating a view from a single object. The detection strategy is as follows: for each Adapter in the app, we verify whether its complexity is below a specific threshold. We use complexity as a proxy, as highly complex Adapters often deal with more than one object. Algorithm 4 presents this detection strategy.

Fool Adapter
Adapters should use the View Holder pattern to reuse instances of the views that represent the fields that will be populated for each item of a collection. The detection strategy is as follows: for each Adapter (or any of its children, e.g., BaseAdapter, ArrayAdapter, and CursorAdapter), we detect whether there is a call to findViewById() inside its getView() method. If so, we mark the class as smelly. Algorithm 5 illustrates this detection strategy.

UI Component Doing I/O
Activities, Fragments, and Adapters should not perform I/O operations, such as database and file access. The detection strategy is as follows: for each Activity, Fragment, and Adapter, we check whether they make any call to I/O, database, or internet request APIs. We created the dataset of APIs by scraping the Android manual. Algorithm 6 depicts this detection strategy.

No Use of Fragments
UI decoupling is recommended for improving maintenance. Fragments are often used to accomplish this task. Thus, the non-use of Fragments can represent a highly coupled UI. In practice, we can observe this smell when view components, e.g., EditTexts, Spinners, and TextViews, are directly used by an Activity, instead of small Fragments. The detection strategy is similar to what we described above: for each Activity of the app, we check whether it contains any view component (e.g., EditTexts, TextViews, Spinners, etc.). If so, we mark the component as smelly. This detection strategy is depicted in Algorithm 7.

Excessive Use of Fragments
Although the use of Fragments is important for UI decoupling, these components should not be used without an explicit need. To automate the identification of this smell, we count the number of Fragments in an app. If the number is higher than a pre-defined threshold, we mark the app as smelly. We define the threshold later in this paper. In Algorithm 8, we present the detection strategy, where α represents the threshold.

7.1.2 Detection Strategies for the Resource-Related Smells
God Style Resource
This smell happens when a single style is overly complex. We detect this smell by counting the number of lines in all resources of the app (i.e., XML files). All resources that have the number of lines of code higher than a threshold are marked as smelly. The detection strategy is presented in Algorithm 9, where α represents the threshold.

Deep Nested Layout
Hierarchies of long and deeply nested views in layouts should be avoided. Any resource that has a nested view deeper than a pre-defined threshold is considered smelly. Algorithm 10 depicts the detection strategy, where α represents the threshold.

Duplicate Style Attributes
Duplicated styles are considered a smell. We detect this smell by collecting all XML files available in the “res/values” folder of the app and looking for repeated properties among these files. If we find a repeated property, we mark the resource as smelly. Algorithm 11 depicts the detection strategy.

Hidden Listener
Layouts should only handle information presentation. It is a sign of smell to use event attributes, such as “onClick,” directly in layout files. We detect this smell by searching for the usage of android:onClick in any layout resource file (i.e., any XML file inside the “res/layout” folder of the app). Algorithm 12 depicts this detection strategy.

Magic Resource
Every text or color used in the app should be created in its respective resource file, and then reused throughout the app. It is a sign of the smell when strings and colors appear directly in the source code rather than referencing an existing resource. We detect this smell by observing the usage of all Android’s text and color markers in layout resources (e.g., android:text and android:textColor). If the marker has a hard-coded text or color (rather than referencing a resource file), we mark the resource as smelly. Algorithm 13 depicts this detection strategy.

God String Resource
It is a good practice to separate string resources according to some rules, e.g., one string resource per screen. To detect this smell, we compare the amount of Activities and string resources (i.e., resource files that contain the string element in the res/values folder of the app). If they are different, we mark the app as smelly. Algorithm 14 depicts the detection strategy applied to this smell.

Missing Image
This smell happens when the system contains only a single version of its .png, .jpg, or .git images. We detect this smell by checking whether all images of the app exist in all resolutions (i.e., that the same images exist in res/folders-hdmi, res/folders-xhdpi, res/folders-xxhdpi, and res/folders-xxxhdpi folders). We also verify whether the file sizes differ from each other. Algorithm 15 depicts this detection strategy.

7.2 Sample Dataset
To study the prevalence of the proposed code smells, we randomly selected open-source apps listed in the F-Droid directoryFootnote 9 and hosted on GitHub.Footnote 10 We started with a random dataset of 1,103 repositories. We then followed the guidelines proposed by Kalliamvakou et al. (2014) to avoid “non-real apps.” For instance, we identified active mobile apps by considering projects that had a reasonable lifespan and number of commits, stars, forks, issues, and committers. We also removed repositories with no lines of Android code (typically, these projects are implemented in non-programming languages, like CSS or HTML). The final selection comprises 619 repositories. The final dataset can be found in our online appendix (Carvalho et al. 2019).
Table 5 shows descriptive statistics about the lifespan (in days), number of commits, size (number of *.Java files and number of *.XML files), and number of contributors, stars, forks, and issues of the selected repositories. For each metric, we report median, trimmed mean, median absolute deviation (MAD), and standard deviation (SD). On average, the apps have around 3,759 lines of java code and 1,363 lines of XML code. Most of the apps have up to 5 KLoC: 395 apps, which accounts for 59.6% of our sample. Approximately 40% of the analyzed apps have more than 5 KLoC (268 projects).
Table 6 presents the three largest apps and the three smallest apps (in LOC). The three smallest apps in our sample are: (i) IcsImport - imports events from calendars, (ii) FlashLight - uses the device as a flashlight, and (iii) BMI Calculator - computes the body mass index (BMI). The three largest projects are: (i) OsmAnd - provides offline access to maps from OpenStreetMap, (ii) GreenBits Wallet - a bitcoin wallet, and (iii) OpenExplorer - helps to manage files from the device.
Since an app project’s age might indicate the app’s maturity, we also investigated the lifespan of the projects. In the context of our study, a project’s lifespan represents the time (in days) since the project’s repository was created on GitHub. The most mature analyzed repository has existed for 3,340 days – approximately nine and a half years. The least mature repository has 52 days (see Table 5). On average, the selected apps have been developed and maintained for 1,786 days – almost five years.
Another indicator of project maturity is the number of commits to a project repository. The selected apps have on average 129 commits (max = 45,920 commits), with an average of 53.47 commits in the last six months.
GitHub allows its users to “star” projects to show appreciation. Starring in GitHub can be seen as the equivalent of “liking” in other social media platforms. Borges and Valente (2018) report that 73% of developers consider the number of stars before using or contributing to GitHub projects. The selected apps have on average 32 stars (max = 17,578 stars).
Forks and issues also indicate potential contributors to the repository (Borges and Valente 2018). Our sample has a median of 15 forks (Table 5), while 31 projects have never been forked.
7.3 Threshold Tuning
In this section, we report how we defined the thresholds used in the detection strategies. We use quantile analysis, similar to what has been done in previous code smells literature (Lanza and Marinescu 2007; Aniche et al. 2016). More specifically, we define the threshold as the third quantile plus 1.5 times the inter-quartile range:
The thresholds used in this paper were derived from 200 random apps from our dataset. Table 7 depicts the thresholds obtained for each smell.
7.4 Accuracy of the Detection Strategies
The ability of our heuristics to automatically detect code smells is intrinsically correlated with the validity of our results. In this sub-section, we discuss the accuracy of our detection strategies. Our smells can be divided into three groups based on their detection strategies:
Group 1 (Decidable): Some of our smells can be detected via decidable, unambiguous, rules. In our case, the smells No Use of Fragments, Duplicate Style Attributes, Hidden Listener, Magic Resource, God String Resource, and Missing Image can be detected via straightforward static analysis. For example, in the case of No Use of Fragments, our tool detects whether Fragments are present or not in the system.
Group 2 (Decidable, threshold-based): Some smells can also be detected via decidable rules, but they depend on a threshold. This is the case for the God Style Resource, Deep Nested Layout, and Excessive Use of Fragments smells.
Group 3 (Heuristic-based): Other smells do not have decidable rules and require a heuristic (i.e., an approximation) for the detection. This is the case for Brain UI Component, Coupled UI Component, Suspicious Behavior, Flex Adapter, Fool Adapter, and UI Component Doing I/O.
We use software testing to evaluate whether our tool is adequately implementing the detection strategies from Groups 1 and 2. Since the strategies in Group 2 depend on a specific threshold to consider a class smelly, and we use extreme values as thresholds, some smelly classes may not identified. We followed this approach to reduce false positives (at the expense of false negatives). Consequently, the numbers we report for Group 2 smells might underestimate the real amount of smells.
Given the nature of the strategies in Group 3, further validation is required. To measure the accuracy of these detection strategies, we manually produced an oracle and compared the results of the tool against it. To build the oracle, two authors of this paper inspected the entire source code of three apps in our dataset and identified the smells (or the lack thereof) that each class contained. Our selection procedure was as follows:
- 1.
We looked at the aggregated number of smells of each app in our dataset; we used this information to help us find a minimum set of apps that would have all the smells we proposed,
- 2.
We filtered out apps with less than 50 Java classes or with more than 200 classes. The numbers 50 and 200 were chosen arbitrarily; we considered apps with less than 50 classes as too small and apps with more than 200 classes as too expensive for manual analysis.
- 3.
We selected the largest app with the highest diversity in smells. We then repeated the process on the remaining smells.
The selected apps are: seadroid, an Android client for Seafile; tasks, an app that helps users to organize their tasks; and yaaic, an IRC client. seadroid has 228 classes; tasks, 151 classes; and yaaic, 88 classes. Our entire oracle comprises 467 Java classes.
In Table 8, we show the precision, recall, and F1 measures for each of the six smells from Group 3. We observe from these results:
- 1.
The Brain UI Component and Flex Adapter detection strategies achieve a high precision and recall (their F1 measures are 0.93 and 0.86, respectively).
- 2.
The Suspicious Behavior detection strategy achieves a high recall (0.95), but its precision is just acceptable (0.57). After manual analysis in the false positives, we observed that some classes made use of inner and anonymous classes which are not related to event handling (note that out Suspicious Behavior detection strategy looks for any usage of inner and/or anonymous classes inside Activities, Fragments, or Adapters). Future work should focus on a more precise way of detecting event handling (e.g., take the semantics of the inner/anonymous class into account).
- 3.
The Coupled UI Component and the UI Component Doing I/O detection strategies achieve high F1 measures (0.75, 0.71, and 0.73, respectively). However, while their precision are high (0.84 and 0.94, respectively), their recall are just acceptable (0.68 and 0.6, respectively). After manual analysis, we observed that, for the UI Component Doing I/O detection, our tool makes use of a pre-defined list of APIs that handle I/O (the list is available in our appendix). The false negatives made use of APIs other than the ones in our list. To improve the effectiveness of the detection strategy, we thus suggest the development of a systematic list of Android APIs that make use of I/O.
- 4.
Finally, the Fool Adapter detection strategy present less accuracy: maximum precision (1.0), but low recall (0.26), mostly because of the existence of 11 false negatives. After manual analysis, we noticed our parser failing in case developers pass the Android’s View class as a parameter to another method, and then invoke the findViewById() method (used in the detection strategy). Future work should systematically explore all the ways a developer might make use of the findViewById() method, with the goal of refining the parsing strategy.
The manually produced oracle, the complete source code of the apps we used, as well as the script that measures the precision and recall of our tool are available in our online appendix (Carvalho et al. 2019).
7.5 Results
In Table 9, we present the smells identified in the 619 Android apps. The bar chart depicted in Fig. 4 presents a macro view of the identified smells.

Identified smells. DNL=Deep Nested Layout, DSA=Duplicate Style Attributes, GStR=God Style Resource, HL=Hidden Listener, MR=Magic Resource, GSR=God String Resource, MI=Missing Image. BUIC=Brain UI Component, UIC=UI Component Doing I/O, SB=Suspicious Behavior, EUF=Excessive Use of Fragments, CUC=Coupled UI Component, NUF=No Use of Fragments, FAd=Fool Adapter, FA=Flex Adapter
We found 26,509 instances of resource smells and 18,633 instances of component smells. God String Resource and Suspicious Behavior were the most common smells, with 8,581 resources (26% of all XML files in the sample) and 8,584 components affected (23% of all Java files in the sample), respectively. On the other hand, Missing Image and Flex Adapter were the least identified smells, with 48 resources and 70 affected components, respectively.
In Tables 10 and 11, we show the distribution of each code smell per app. Although we observe that some projects have a critically high number of smells (e.g., a single project has 153 classes affected by the Brain UI Component smell), having a high number of classes affected by specific smells is not the common behavior. The median number (as well as the third quantile) of classes affected per project is quite low for all the studied smells. God String Resource is the one with the highest median (14).

8 Discussion
In this section, we discuss the main implications of our work.
A Catalog of Code Smells for the Presentation Layer of Android Apps
Developing high-quality user interface code for Android apps is challenging. Developers should make good use of the limited screen space and cannot take advantage of the full range of features that a traditional web application provides (Wasserman 2010). Our work paves the road for a catalog of bad practices that arise in such an important part of the source code. When it comes to the presentation layer, smells not only occur in classes, such as Activities and Fragments, but also in resources, such as layout and strings, which are mostly XML-based. It is common for developers to see XML files as “simple” configuration files; however, they play a key role in Android apps, and their quality should also be monitored.
In this work, we proposed smells that go beyond the “traditional smells” in the literature. In a more abstract way, one can see how foundational concepts in object-oriented design can help developers tackle smells. For example, a class affected by the Brain UI Component smell would benefit from a better separation of concerns (Booch 2006), and classes affected by the Coupled UI Component smell would benefit from better dependency management (Martin 2002). Moreover, we observe that developers considered both the intensive use and lack of use of Fragments problematic. Interestingly, the set of participants who reported the intensive use of Fragments as problematic differs from the set of participants who saw the lack of Fragments as problematic (see Table 3). Deciding whether to use small or large fragments is a similar problem as deciding how to modularize a software system (Booch 2006); in practice, it is hard to know when to stop creating more modules. Thus, as a recommendation, we suggest developers should understand foundational OO practices deeply, as some of the smells can be explained by what is already in the OO literature.
The Relationship Between our Study and the Existing Body of Knowledge
As we present in the Related Work (Section 3), different authors have proposed catalogs of code smells and/or best practices for Android mobile applications, e.g., Palomba et al. (2017) proposed a generic catalog of smells, Ghafari et al. (2017), of security code smells, Hecht et al. (2016) and Linares-Vásquez et al. (2017) of performance, and Linares-Vásquez et al. (2014) and Gottschalk et al. (2012) of energy consumption smells.
Our research complements the existing body of knowledge in the following ways:
Two security smells from Ghafari et al.’s catalog are related to the presentation layer of Android apps. More specifically, Broken WebView’s Sandbox, which is relevant to developers rendering web content in an unsafe manner, and SQL Injection, which commonly happens when user input goes straight to an SQL query. This result shows that issues in the presentation layer can also lead to security flaws. Therefore, as future work, we suggest researchers study the relationship between the presentation layer code smells and security vulnerabilities.
Palomba et al. (2017)’s code smells catalog does not touch on any presentation layer code smells, and thus, our catalog is complementary to it. However, UI developers should be aware of the Leaking Thread code smell proposed in their catalog, as most of what happens in presentation layers occurs in threads (we discuss the life cycle of the components in Section 2).
Linares-Vásquez et al. (2014) showed that UI-related APIs (GUI and image manipulation) represent around 40% of the energy greedy APIs in the Android platform. As actionable advice, authors suggest developers carefully design apps that make use of several views and to avoid refreshing views. We see their results as a complementary to ours. Our catalogue has several smells related to complex UIs (i.e., Brain UI Component, UI Component Doing I/O, Deep Nested Layout, and Unnecessary Image). Besides being harmful for maintenance, we conjecture that these smells also impact energy consumption, and therefore suggest developers consider not only the maintenance cost but also the energy costs of classes affected by these smells.
While performance studies by Hecht et al. (2016), Linares-Vásquez et al. (2017) and Liu et al. (2014) lacked focus on the presentation layer, our smells can be related to performance issues. Linares-Vásquez et al.’s study, in particular, showed that unused strings (and other resources) can be costly to mobile apps. Our catalog indeed has smells related to how developers organize their resources in their software (i.e., God String Resource, Inappropriate String Reuse, Duplicate Style Attributes, God Style Resource, Long or Repeated Layout, Deep Nested Layout). Thus, we suggest developers also consider elements affected by resource-related smells as candidates for performance improvements. In future work, we suggest researchers investigate the relationship between our smells and performance issues.
Companies and independent developers have been working on guides and best practices catalogs that go beyond “traditional smells,” such as Google’s Jetpack Best Practices (Google 2018a, 2018b) and Futurice, a software house which hosts a GitHub repository on Android best practices with around 17,000 stars (Futurice 2018). Our catalog complements this effort.
In our research, we focused on smells related to the presentation layer of Android apps. Nevertheless, we noticed that many of our participants often mentioned “traditional” smells, such as Long Methods and God Classes (Lanza and Marinescu 2007; Fowler and Beck 1999) as problems they also face in this layer. As we show in the Related Work section, researchers have also investigated the role of traditional smells in Android apps. Therefore, when developing the presentation layer, we recommend developers be aware of both traditional and presentation layer-specific smells.
Smells in Different Mobile Platforms
We acknowledge that some of our smells may become less important to practitioners over time. For example, the Flex Adapter smell, although considered an important smell for developers to tackle, was less perceived in practice. We conjecture this is due to the Android’s new Adapter component, the RecyclerView.Adapter, which appeared in Android 5.1 Lollipop and facilitates the implementation of the ViewHolder pattern. Before that, developers had to implement the pattern themselves, which required previous knowledge about best practices. We hope that our results can inspire new tools, strategies, and modifications to the underlying technology to make the mitigation strategies easier to implement.
It is also important to notice that our current catalog solely focuses on Android mobile apps. Since its launching in 2008, Android native apps have been developed using the Java language. In May 2017 (after we started this research), Google announced Kotlin as the official language for the platform (Kotlin on android 2017). Although research (Flauzino et al. 2018) shows that Kotlin leads to more concise and clearer code and tends to contain less “traditional code smells” when compared to Java, we argue that the Android framework is still the same. In other words, developers still need to write Activities, Listeners, and all the other components, as well as resources. Thus, we see our smells as important for Kotlin-based Android apps as well.
Moreover, although this catalog cannot be directly transported to iOS (Swift and Objective C), Windows Phone, or Xamarin development, it can serve as inspiration for future research on these platforms. Interestingly, previous research (Habchi et al. 2017) has shown that iOS apps contain the same proportions of code smells regardless of the development language (Swift and Objective C), but they seem to be less prone to code smells compared to Android apps. Thus, understanding whether our smells impact iOS apps as much as they do Android apps seems to be the natural continuation of this research.
9 Threats to Validity
Internal Validity
Threats to internal validity concern how external factors that we do not consider can affect the variables and relationships investigated. In the literature, code smells are derived from the empirical knowledge of experienced developers (Fowler and Beck 1999; Riel 1996; Martin 2008; Webster 1995). Research also showed that experience and knowledge play an important role in the perception of code smells (Palomba et al. 2014; Taibi et al. 2017). We removed from our analysis answers to our questionnaires (parts 1 and 2) from developers with no experience with Android development; most of our respondents have two or more years of experience.
In addition, as the participation was anonymous, we did not control for developers who participated in the multiple steps of our study. However, as all the parts of our research have different goals, and Part 2 had many more participants than Part 1, this threat has a limited effect. Nevertheless, we propose replications of this work as a way to strengthen our findings.
The coding analysis in Part I was conducted by the first author of this paper, and the second author acted as a mediator whenever a question arose (as explained in Section 5). At the time of the analysis, the first author had five years of industry experience with Android development. To improve the validity of the identification of the smells, in later stages of our research we revisited the proposed smells with external Android experts, and they all agreed with the proposed smells (RQ2 methodology, Section 6.1). Moreover, the fact that many developers also face these smells (RQ2 results, Section 6.3) is also an indication of their validity. However, we acknowledge that different researchers could interpret the data in different ways (and thus derive a different set of smells). We make all our raw data available in our online appendix (Carvalho et al. 2019) to enable researchers to further validate our work and make additional analyses.
Regarding the study on the prevalence of code smells in mobile applications, we set out to mitigate the selection bias issue by using randomization. However, no blocking factor was applied to reduce the threat of possible variations in, for instance, the complexity of the apps, usability, and performance. Thus, we cannot rule out the possibility that the chosen apps stem from other quality factors as opposed to the amount of code smells.
Construct Validity
Threats to the construct validity concern the relationship between theory and observation. The questionnaire in Part 2 aimed at measuring developers’ perceptions on the frequency and importance of the code smells. Thus, the questions were derived from our catalog of code smells. In retrospect, we noticed that we had not added any control questions that would help us measure biases from our participants. Nevertheless, while the number of answers we collected in this survey is quite significant (201 responses) and one could argue that biased answers would be a minority, we suggest the replication of this survey as future work.
Finally, in Part 3, given that all code smells have been identified by a tool, it is possible that some data is incorrect due to misguided or ill-identified code smells. Thus, our data might not reflect the actual amount of code smells (given to possible false negatives and false positives). We nevertheless discuss the accuracy of our tool in Section 7.4. As we show there, the proposed detection strategies can be improved, and we leave it as future work.
External Validity
Threats to external validity refer to the generalization of our results. We define the presentation layer as the eight elements we show in Section 2. Although this definition has been based on official documentation, we acknowledge that there are other resources and there may be less commonly used classes that also relate to the presentation layer. Therefore, we do not claim that the presentation layer is limited to the eight elements studied here.
In addition, the first part of our research aimed at devising the catalog of smells. In the end, we obtained 359 pieces of information from 45 different (mostly Brazilian) software developers. We were able to derive 20 code smells that were observed by more than 5 participants. However, we do not claim that this catalog is complete; as an example, if we reduce the number of required repetitions (e.g., from 5 to 4), we would have a broader set of code smells. In practice, we indeed expect this catalog to continue to expand as the Android framework keeps evolving. We expect researchers to join forces and use our proposed methodology to continuously collect the perceptions of developers on new code smells.
Regarding the study on the prevalence of code smells in mobile applications, the sample we collected from the open source repository might not be representative of the target population. As aforementioned, we randomly selected apps from the F-Droid repository. However, our set is diverse and includes active and largely used projects. Replications are encouraged to explore the smells in industrial settings.
10 Conclusion
In this paper, we propose a catalog of 20 code smells specific to the presentation layer of Android apps, employing two online questionnaires and a study with real projects. Our results show that developers are aware of good and bad practices specific to the Android platform. From the reported practices, we devised the smells, which were validated with a second questionnaire and analysis of the source code of real projects. The proposed smells are particularly relevant, as Android became the world’s leading mobile platform in 2011 and since then has increased its share of the market, having reached 86% (Statista 2017) in 2017.
This study answered the following questions:
RQ1: What Code Smells Do Developers Observe in the Presentation Layer of Android Apps?
We cataloged 20 code smells in the presentation layer of Android apps, 9 related to components (Activities, Fragments, Adapters, and Listeners), and 11 related to resources (Layout, String, Style, and Drawable resources). The complete catalog can be found in Section 5.4.
RQ2: How Often Do Developers Observe the Identified Code Smells and What Importance Do They Give to Them?
Developers perceive most of the proposed smells as important, and most of them have previously encountered these code smells. Their perceptions are discussed in Section 6 of this paper.
RQ3: How Prevalent are the Proposed Code Smells in Real Android Apps?
All the proposed smells can be observed in real-world Android apps. Some of them, such as Brain UI Component (29% of all components) happen very often, whereas others, such as Flex Adapter and Duplicate Style Attributes happen less often.
Our contributions are a small but important step in the search for higher code quality on the Android platform. Researchers can use our results as a starting point to conceive tools and heuristics to suggest refactorings in Android applications, and Android developers can use our catalog to search for problematic pieces of codes.
Our work opens space for future research and tool development. More specifically:
Evaluate the Effects of the Proposed Code Smells in Other Contexts
In this paper, we collected diverse empirical evidence about the relevance of the smells. Further investigation is necessary about the impacts the smells bring to software developers. Some suggestions regarding future evaluations are: 1) controlled experiments about the relationship between the proposed smells and maintainability and other development activities (e.g., do developers take more time to comprehend and maintain a smelly class when compared to a clean class?), 2) to quantitatively measure how these presentation-layer smells affect the change- and the defect-proneness of the smelly classes, 3) understand whether these code smells can have an impact on different quality attributes of a mobile app, such as performance and energy consumption.
Generalizability of our Results to Other Mobile Platforms
Although Android has a significant market share of mobile development, it is not the only one; iOS (Apple phones) and Windows phones are also popular platforms. The reasons we focused on Android are twofold: First, our research method requires in-depth knowledge of the platform. The authors of this paper are well versed on the Android platform, but not so on the other platforms. Second, by focusing on a single mobile architecture, we could ask highly focused questions to our participants, which we argue increases the quality of the answers. Nevertheless, coining code smells for other mobile platforms is also important, and our study can be replicated to other platforms.
Notes
Up to version 3.0 of Android Studio, the most current version at the time of this writing, the standard design template, which is pre-selected in the creation of a new Android project, is an Empty Activity.
References
Martin R C (2008) Clean code: A handbook of agile software craftsmanship, 1st edn. Prentice Hall PTR, Upper Saddle River
Suryanarayana G, Samarthyam G, Sharma T (2014) Refactoring for software design smells: Managing technical debt. Morgan Kaufmann
Fowler M, Beck K (1999) Refactoring: improving the design of existing code. Addison-Wesley Professional
Webster BF (1995) Pitfalls of object-oriented development. M & T Books
Aniche M, Yoder J, Kon F (2019) Current challenges in practical object-oriented software design. In: 41st ACM/IEEE international conference on software engineering. IEEE, United States
Gharachorlu G (2014) Code smells in cascading style sheets: An empirical study and a predictive model. University of British Columbia, PhD thesis
Fard A M, Mesbah A (2013) JSNOSE: Detecting javascript code smells, pp 116–125
Aniche M, Bavota G, Treude C, Gerosa M A, van Deursen A (2017) Code smells for model-view-controller architectures. Empir Softw Eng 9:1–37
Aniche M, Bavota G, Treude C, Van Deursen A, Gerosa MA (2016) A validated set of smells in model-view-controller architectures, pp 233–243
Pinzger M, Hermans F, van Deursen A (2012) Detecting code smells in spreadsheet formulas, IEEE Computer Society, Washington
Alliance O H (2007) Open handset alliance releases android SDK. https://www.openhandsetalliance.com/press_111207.html, [Last access: 25 de Novembro de 2017]
Hecht G (2015) An approach to detect android antipatterns. In: 2015 IEEE/ACM 37th IEEE international conference on software engineering, vol 2, pp 766–768. IEEE Press
Linares-Vásquez M, Klock S, McMillan C, Sabané A, Poshyvanyk D, Guéhéneuc Y-G (2014) Domain matters: bringing further evidence of the relationships among anti-patterns, application domains, and quality-related metrics in java mobile apps, pp 232–243
Verloop D (2013) Code smells in the mobile applications domain. PhD thesis. Delft University of Technology, TU Delft
Gottschalk M, Josefiok M, Jelschen J, Winter A (2012) Removing energy code smells with reengineering services. GI-Jahrestagung 208:441–455
Reimann J, Brylski M (2014) A tool-supported quality smell catalogue for android developers
Minelli R, Lanza M (2013) Software analytics for mobile applications, insights & lessons learned. In: Proceedings of the 2013 17th European conference on software maintenance and Reengineering
Google (2017) Android – plataform architecture. https://developer.android.com/guide/platform/index.html. Last access: 25 de Novembro de
Wikipedia (2017) IOS — Wikipedia, the free encyclopedia. http://en.wikipedia.org/w/index.php?IOS&oldid=812046680, [Last access: 25 de Novembro de 2017]
OpenSignal (2015) Android fragmentation visualized. http://opensignal.com/reports/2015/08/android-fragmentation, [Last access: 25 de Novembro de 2017]
Google (2016) Documentação site android developer. https://developer.android.com, [Last access: 25 de Novembro de 2017]
Google (2017) Android – fundamentals. https://developer.android.com/guide/components/fundamentals.html, [Last access: 25 de Novembro de 2017]
Google (2016) Android – resource type. https://developer.android.com/guide/topics/resources/available-resources.html, [Last access: 25 de Novembro de 2017]
Google (2016) Android – building your first app. https://developer.android.com/training/basics/firstapp/creating-project.html, [Last access: 25 de Novembro de 2017]
Riel A J (1996) Object-Oriented Design Heuristics, vol. 335. Addison-Wesley Publishing Company
Khomh F, Di Penta M, Guéhéneuc Y-G (2009) An exploratory study of the impact of code smells on software change-proneness. In: Proceedings of the 2009 16th Working Conference on Reverse Engineering, WCRE ’09. IEEE Computer Society, Washington
Khomh F, Penta M D, Guéhéneuc Y-G, Antoniol G (2012) An exploratory study of the impact of antipatterns on class change-and fault-proneness. Empirical Softw Engg 17:243–275
Li W, Shatnawi R (2007) An empirical study of the bad smells and class error probability in the post-release object-oriented system evolution. J Syst Softw 80 (7):1120–1128
Yamashita A, Moonen L (2013) Exploring the impact of inter-smell relations on software maintainability: An empirical study, IEEE Press, Piscataway
Abbes M, Khomh F, Gueheneuc Y-G, Antoniol G (2011) An empirical study of the impact of two antipatterns, blob and spaghetti code, on program comprehension. In: 2011 15th European conference on Software maintenance and reengineering (CSMR), pp 181–190 IEEE
Palomba F, Bavota G, Penta M, Oliveto R, Lucia A (2014) Do they really smell bad? a study on developers’ perception of bad code smells, pp 101–110
Arcoverde R, Garcia A, Figueiredo E (2011) Understanding the longevity of code smells: preliminary results of an explanatory survey. In: Proceedings of the 4th workshop on refactoring tools, pp 33–36. ACM
Peters R, Zaidman A (2012) Evaluating the lifespan of code smells using software repository mining. In: 2012 16th European conference on software maintenance and reengineering (CSMR), pp 411–416. IEEE
Chen T-H, Shang W, Jiang Z M, Hassan A E, Nasser M, Flora P (2014) Detecting performance anti-patterns for applications developed using object-relational mapping, pp 1001–1012
Aniche M, Treude C, Zaidman A, van Deursen A, Gerosa M A (2016) SATT: Tailoring code metric thresholds for different software architectures. In: 2016 IEEE 16th international working conference on source code analysis and manipulation (SCAM), pp 41–50. IEEE
Mannan U A, Ahmed I, Almurshed R A M, Dig D, Jensen C (2016) Understanding code smells in android applications. In: 2016 IEEE/ACM international conference on mobile software engineering and systems (MOBILESoft), pp 225–236. IEEE
Moha N, Gueheneuc Y-G, Duchien L, Le Meur A-F (2010) Decor: A method for the specification and detection of code and design smells. IEEE Trans Softw Eng 36(1):20–36
Hecht G, Rouvoy R, Moha N, Duchien L (2015) Detecting antipatterns in android apps. In: 2015 2nd ACM international conference on mobile software engineering and systems, pp 148–149
Hecht G, Rouvoy R, Moha N, Duchien L (2015 ) Páprika. https://github.com/geoffreyhecht/paprika, Last access on April 2018
Brown W H, Malveau R C, McCormick H W, Mowbray T J (1998) AntiPatterns: refactoring software, architectures, and projects in crisis. John Wiley & Sons Inc.
Peruma ASA (2018) What the smell? an empirical investigation on the distribution and severity of test smells in open source android applications
Linares-Vásquez M, Bavota G, Bernal-Cárdenas C, Oliveto R, Di Penta M, Poshyvanyk D (2014) Mining energy-greedy api usage patterns in android apps: an empirical study. In: Proceedings of the 11th working conference on mining software repositories, pp 2–11. ACM
Hecht G, Moha N, Rouvoy R (2016) An empirical study of the performance impacts of android code smells. In: Proceedings of the international conference on mobile software engineering and systems, pp 59–69. ACM
Linares-Vásquez M, Vendome C, Tufano M, Poshyvanyk D (2017) How developers micro-optimize android apps. J Syst Softw 130:1–23
Liu Y, Xu C, Cheung S-C (2014) Characterizing and detecting performance bugs for smartphone applications. In: Proceedings of the 36th international conference on software engineering, pp 1013–1024 ACM
Linares-Vasquez M, Vendome C, Luo Q, Poshyvanyk D (2015) How developers detect and fix performance bottlenecks in android apps. In: 2015 IEEE international conference on software maintenance and evolution (ICSME), pp 352–361. IEEE
Palomba F, Di Nucci D, Panichella A, Zaidman A, De Lucia A (2017) Lightweight detection of android-specific code smells: The adoctor project. In: 2017 IEEE 24th international conference on software analysis, evolution and reengineering (SANER), pp 487–491. IEEE
Ghafari M, Gadient P, Nierstrasz O (2017) Security smells in android. In: 2017 IEEE 17th international working conference on source code analysis and manipulation (SCAM), pp 121–130. IEEE
Yamashita A, Moonen L (2013) Do developers care about code smells? an exploratory survey. In: 2013 20th working conference on reverse engineering (WCRE), pp 242–251. IEEE
Van Emden E, Moonen L (2002) Java quality assurance by detecting code smells. In: Proceedings of the working conference on reverse engineering (WCRE), pp 97–106. IEEE Computer Society
Carvalho SG, Veríssimo A, Gerosa D (2019) An empirical catalog of code smells for the presentation layer of android apps: Appendix. https://doi.org/10.5281/zenodo.3256367
Corbin J, Strauss A (2007) Basics of qualitative research: Techniques and procedures for developing grounded theory. SAGE Publications Ltd 3 ed.
Glaser B G, Strauss A L (2017) Discovery of grounded theory: Strategies for qualitative research. Routledge
Adolph S, Hall W, Kruchten P (2011) Using grounded theory to study the experience of software development. Empir Softw Eng 16(4):487–513
Saldaña J (2015) The coding manual for qualitative researchers. SAGE Publications Ltd 2 ed.
Nielsen J (2000) Why you only need to test with 5 users. https://www.nngroup.com/articles/why-you-only-need-to-test-with-5-users, [Last access: 25 de Novembro de 2017]
Evans E (2004) Domain-driven design: tackling complexity in the heart of software. Addison-Wesley Professional
Google (2017) Android – optimizing view hierarchies. https://developer.android.com/topic/performance/rendering/optimizing-view-hierarchies.html, [Last access: 25 de Novembro de 2017]
Futurice (2018) Android best practices. https://github.com/futurice/android-best-practices, 2018. Last accessed on October 29th
Google (2017) Android – recyclerview. https://developer.android.com/reference/android/support/v7/widget/RecyclerView.html, [Last access: 25 de Novembro de 2017]
Kalliamvakou E, Gousios G, Blincoe K, Singer L, German D, Damian D (2014) The Promises and Perils of Mining GitHub. In: Proceedings of the 11th working conference on mining software repositoriesa (MSR), pp 92–101. ACM
Borges H, Valente M T (2018) What’s in a github star? understanding repository starring practices in a social coding platform. J Syst Softw 146:112–129
Lanza M, Marinescu R (2007) Object-oriented metrics in practice: using software metrics to characterize, evaluate, and improve the design of object-oriented systems. Springer Science & Business Media
Wasserman A I (2010) Software engineering issues for mobile application development. In: Proceedings of the FSE/SDP workshop on Future of software engineering research, pp 397–400. ACM
Booch G (2006) Object oriented analysis & design with application. Pearson Education India
Martin R C (2002) Agile software development: principles, patterns, and practices. Prentice Hall
Google (2018) Guide to app architecture. https://developer.android.com/jetpack/docs/guide, 2018. Last accessed on October 29th
Google (2018) Optimizing layout hierarchies. https://developer.android.com/training/improving-layouts/optimizing-layout, 2018. Last accessed on October 29th
Kotlin on android (2017) Now official. https://blog.jetbrains.com/kotlin/2017/05/kotlin-on-android-now-official/ https://blog.jetbrains.com/kotlin/2017/05/kotlin-on-android-now-official/, JetBrains blog
Flauzino M, Veríssimo J, Terra R, Cirilo E, Durelli VHS, Durelli RS (2018) Are you still smelling it?: A comparative study between java and kotlin language. In: Proceedings of the VII Brazilian symposium on software components, architectures, and reuse, pp 23–32. ACM
Habchi S, Hecht G, Rouvoy R, Moha N (2017) Code smells in ios apps: How do they compare to android?. In: 2017 IEEE/ACM 4th international conference on mobile software engineering and systems (MOBILESoft), pp 110–121. IEEE
Taibi D, Janes A, Lenarduzzi V (2017) How developers perceive smells in source code: A replicated study. Inf Softw Technol 92:223–235
Statista (2017) Global mobile OS market share in sales to end users from 1st quarter 2009 to 1st quarter 2017. https://www.statista.com/statistics/266136/global-market-share-held-by-smartphone-operating-systems, [Last access: 25 de Novembro de 2017]
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by: David Lo, Meiyappan Nagappan, Fabio Palomba, Sebastiano Panichella
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Carvalho, S.G., Aniche, M., Veríssimo, J. et al. An empirical catalog of code smells for the presentation layer of Android apps. Empir Software Eng 24, 3546–3586 (2019). https://doi.org/10.1007/s10664-019-09768-9
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10664-019-09768-9