
Abstract
Three-dimensional (3D) reconstruction of human organs has gained attention in recent years due to advances in the Internet and graphics processing units. In the coming years, most patient care will shift toward this new paradigm. However, development of fast and accurate 3D models from medical images or a set of medical scans remains a daunting task due to the number of pre-processing steps involved, most of which are dependent on human expertise. In this review, a survey of pre-processing steps was conducted, and reconstruction techniques for several organs in medical diagnosis were studied. Various methods and principles related to 3D reconstruction were highlighted. The usefulness of 3D reconstruction of organs in medical diagnosis was also highlighted.
Similar content being viewed by others


Explore related subjects
Find the latest articles, discoveries, and news in related topics.Introduction
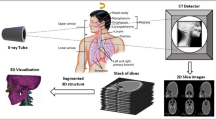
Three-dimensional (3D) reconstruction is used to create a 3D model of an object or scene from a series of two-dimensional (2D) images (Fig. 1). This process has gained significant attention in recent years owing to its wide range of applications in fields including medicine, entertainment, archaeology, and robotics. 3D reconstruction produces a digital representation of a real-world object. Use of 3D reconstruction in the medical sciences began with the invention of a computed tomography (CT) scanner by Godfrey Hounsfield [1], useful for training, virtual surgery [2], and gaining insight into the behavior of organs in vivo. 3D reconstruction can help in planning and monitoring pre-operative and post-operative medical conditions of patients. Werner et al. [3] constructed a 3D model of the respiratory behavior of the lungs at the inhale and exhale stages. Werner et al. [4] constructed a 3D model to diagnose cervical tumors from ultrasound images using virtual bronchoscopy. 2D medical image formats such as magnetic resonance imaging (MRI), CT, positron emission tomography (PET), x-rays, ultrasound, and microscopy have been used for 3D reconstruction. Of these, ultrasound is noninvasive and harmless. The choice of data acquisition method is a determining factor in the effectiveness of 3D reconstruction algorithms [5]. Hardie et al. [6] used a laser scanning confocal microscope for data acquisition; Zollhöfer et al. [7] used an RGB camera. Østergaard et al. [8] assessed abnormalities in rheumatoid arthritis using radiography, MRI, and ultrasonography in a comparative study.

a Point cloud from CT of lungs; b Point cloud reconstructed from CT scans of rib cage (gray) and lungs (black); c Coarse liver reconstructed from 28 CT scans and triangulated using marching cubes algorithm; d Smooth liver surface triangulation of key points extracted from 56 CT scans
Radiography is performed only from the posterior-anterior and lateral (LAT) angles; 3D reconstruction based on x-rays [9,10,11,12,13,14] is challenging because there are only one or two initial images. Reconstruction processes require more images to develop an organ in 3D. Thus, x-ray-based modeling requires a different methodology. Digitally reconstructed radiographs (DRRs) [15] have been used to overcome this limitation. A DRR is generated from multiple CT or MRI scans. The techniques used for 3D reconstruction from 2D x-ray images are discussed in Miscellaneous section.
Methods have been developed to generate a DRR based on statistical shape models (SSMs) [16,17,18,19]. These models are constructed from a collection of image data; their shapes and sizes can be heavily altered. SSMs create a mean model from several volumetric reference models. The accuracy of the mean model depends on the number of reference models. With a small number of reference models, the 3D reconstruction model is inaccurate. Methods based on an active contour model (ACM) [20] can be used to reform a poorly constructed SSM [21]. ACM techniques reform the model boundary according to a specified target model using a threshold limit or error metric such as the minimum contour-to-mesh distance. In some cases, an articulated shape model [22] is used, in which the reference shape is a concatenation of shapes that are movable at fixed joints, such as at the point of concatenation (knee, jaw, or hip). To reduce the complexity of handling large-point data, the dimensions of the region of interest (ROI) are reduced using principal component analysis (PCA) [23].
The 3D model can be stored in different formats including WaveFront object, polygon file format, point cloud data, and stereo lithography [9]. Jiang et al. [24] used a point cloud as the input to produce a polygon surface as the output in the structure-from-motion problem [25]. In 3D reconstruction from medical images, generating a point cloud is the first step to reconstruction. All medical imaging-based 3D reconstructions are modeled using a point set [26]; the surface is represented as a mesh of triangles [27] or an octree [28]. In an octree, a point set within a voxel is grouped under a parent node, which is referred to by another parent node within a larger voxel.
Surface reconstruction can be categorized into parametric, implicit, and spatial subdivision methods. In parametric methods [29], the surface is a function of two parameters along the \(x\) and \(y\) axes. The surface under reconstruction is updated such that its parameters align with the set of target parameters. However, this technique is not suitable for models with no known topological relationships. Another method is implicit reconstruction. The goal of the implicit method [30] is to define a zero set of roots of a function that best fits the target surface, similar to the contour-matching method. The measurements involve a distance function to approximate the closeness of the points. Reconstruction methods based on spatial subdivision techniques [31] were derived from Delaunay triangulation [32] and Voronoi graphs [33]. The point distribution is initially covered by an approximate surface. With further iterations, new points are added by dividing the initial coarse assignment into consecutive finer and smoother surfaces.
Methods
Reconstruction based on traditional approach
The reconstruction process comprises three stages: segmentation, registration, and surface reconstruction.
Segmentation
Image segmentation and segmentation mask prediction are two common problems in image pre-processing and 3D reconstruction. Thresholding-based methods [34] use a threshold to filter the noise. The output is a binary image with pixels that are either black or white. These methods are suitable for intensity-based region discovery. Region growing (RG) methods [35] start with a seed pixel as a node and join neighboring pixels with similar intensity. Region-merging and splitting [36] intake an entire image and segment it into four sub-images in iterative steps based on a similarity measure between inter-segment metrics until no further segmentation is possible. Clustering-based methods [37] use a distance measure for the intensity values to segment into multiple clusters. A limitation in clustering is that smooth edges and gradual intensity transitions are not easily grouped into non-intersecting clusters. Edge-detection methods [38] use layers of Gaussian filters, changing their sigma values for edge detection. These methods segment the image without understanding the underlying shape information or region semantics.
3D reconstruction methods require a ROI and additional features such as landmark points, curvature values, and angular variation in pairs of edges. Mumford and Shah [39] used a variational model to measure changes within a set of points. It applied a piecewise smooth representation to the image boundary. Getreuer [40] developed an ACM defined over level sets.
These methods are based on minimizing the energy functional \(F\left(u,C\right)\) (Eq. 1), where u is the set of image points, and C is the image contour or boundary. µ and ν are positive constants; Ω bounds a 2D area, and curve C ⊂ Ω.
Several studies have used level sets [41] (Eq. 2), in which the image is segmented into an inside region uI and an outside region uII.
uI and uII are functions used to approximate the image uO inside and outside the curve, respectively. The images obtained for 3D medical reconstruction were mostly 2D CT slices. The images were stacked on top of one another [42]. Figure 2 shows a CT slice segmented for the contour boundary using the snake method after providing an initial seed curve. Figure 2 shows the segmentation process using active contours that change shape based on the gradient.

a Brain CT; b Segmented white matter and gray matter; c Reconstructed model
The drawback of the described segmentation techniques is that the region boundary is not sensitive to the neighborhood. Thus, region-aware algorithms [43, 44] such as linear spectral clustering and simple linear iterative clustering have been proposed. The basic concept behind a superpixel is that adjacent pixels in an image that are continuous and contain similar color intensity and brightness are clustered into a single superpixel, and the region is marked by a boundary. Figure 3 shows superpixel segmentation.

a Brain CT; b Segmented white matter and gray matter
Registration
Registration or mapping of a point (x, y) to another point (u, v) can be performed using B-splines [45]. Formulated as an approximation problem in a Frennet frame [46] of the target spline, two points under correspondence are made to have the same normal direction. The B-spline surface approximation is formulated as (Eq. 3). Fs is the smoothing term; pk is the data point, and x (uk,vk) are the approximating surface points.
In Eq. 4, \({B}_{i}\left({u}_{k},{v}_{k}\right)\) is a basic B-spline function that is a piecewise smooth polynomial. The B-spline shape can be altered in any direction [47] such that the curve passes through a specific control point P. The spline passes through P by inserting a knot u in U, where U is the existing set of knots (Eq. 5). Figure 4 shows a set of points in 3D space auto-corrected to a given prior for registration. Figure 4 shows the movement of the curve toward the defined target, and was used for correct registration of images.

Trajectory curve (dotted) shown as Frennet frame auto-correcting to centerline (solid) for accurate registration
Reconstruction
The SSM [19] (Fig. 5) is used to establish the correspondence between different 3D shapes of the same organ. The SSM is presented as a linear model in the form shown in Eq. 6.

Mean liver model (a) and group of reference models (b)
\(\overline{V }\) is the mean shape vector, and P = pk is the matrix of the eigenvectors of the covariance matrix. The rigid transformation is expressed as (Eq. 7):
x1k and xjk are the coordinates of the two shape vectors. \(\acute{x}_{jk}\) is the new vertex location. Then, the final shape xjk = Tj,min x´jk is the optimum shape with minimum deviation from a reference. In ref. [18], a detailed survey of the use of SSMs was presented; sometimes, the points were closely registered using an elastic registration approach [48] known as the active shape model [49, 50]. Figure 5 shows the mean model of the statistical shape technique.
The marching cubes [51] algorithm (Fig. 6b) is considered the best for reconstruction of a volumetric model because its algorithm is specifically designed for medical images. In volumetric modeling, details of the texture and layers present under the top surface of the object are required. For surface reconstruction, the ball pivoting algorithm (BPA) [52] (Fig. 6a) is more suitable; only one layer of the surface is required as the output. A limitation in the BPA is that for complete surface reconstruction, the algorithm must be re-iterated with different values of ball radius ρ. Another limitation is that the normals of the vertices must be known. However, this is not the case for 2D medical scans. The normal can be estimated using algorithms such as total least squares [53]. Figure 6 shows the conversion of points into connected lines, surfaces, and volumes.

a BPA algorithm connecting random points in 3D space; b Marching cubes basic building blocks; c Output of marching cubes algorithm showing coarse and rough surfaces
Reconstruction based on deep learning approach
The traditional approaches (TAs) in Reconstruction based on TA section involve a seed boundary and initialization parameters. This limitation requires a new paradigm for segmentation and reconstruction of medical images. A convolution neural network (CNN), as shown in Fig. 7, is an artificial neural network that accepts a color image with a height of 224 pixels and a width of 224 pixels, beyond which there are convolution layers and other layers including pooling, fully connected, and SoftMax. In a CNN, the number of filters varies in each layer; the filter size can also vary. The filters are modified using a backpropagation algorithm. The weights of the filters are learned and stored for future epochs until the network is properly trained. Pooling layers reduce the feature size by averaging or selecting the maximum within a 2 × 2 neighborhood matrix. Some diagrams indicate the input size and number of filter channels as dimensions at the top of the convolution layers. The fully connected layer flattens the network toward the end and is activated using the SoftMax function. The SoftMax outputs are rendered as classification labels.

Basic CNN
Deep learning (DL) methods are state-of-the-art for image-related tasks such as segmentation and registration. The underlying structure of segmentation-based DL models is a CNN. DL methods are modified on top of the CNN such that the features of a set of images are automatically determined by the DL system through experience and training on thousands of samples. Handcrafted features tend to be more time-consuming and inferior in terms of performance compared to DL-supervised methods.
Related work
Several versions of CNNs have been proposed to improve model performance. Krizhevsky et al. [54] presented a deep convolution neural network (DCNN) model with eight learned layers: five convolutional layers and three fully connected layers. AlexNet comprises five convolutional layers and three fully connected layers. The implementation is distributed over two graphics processing units. Local response normalization [55] was used as a form of LAT inhibition for competition-based learning. Simonyan and Zisserman [56] presented the visual geometry group networks VGGNet-16 and VGGNet-19. In the VGGNet class of networks, 3 × 3 convolution filters were used with three consecutive fully connected layers with 4096, 4096, and 1000 filters. In VGGNet, there are problems with errors and overfitting. Deeper layers in deep neural networks (DNNs) can incur huge computational costs; in deeper layers, the weights are nearly zero and incur computational loss. Google designed GoogLeNet [57] based on the Hebbian principle. GoogLeNet clusters neurons based on correlation statistics from input images. The previous layers are analyzed for their correlation values and highly correlated neurons are clustered in the next layer. GoogLeNet is more computationally efficient than AlexNet.
To further reduce the computational cost, 3 × 3 and 5 × 5 convolutions were preceded by 1 × 1 convolutions in GoogLeNet V2 and V3. As in a shallow CNN, the number of layers is less than in a DCNN; thus, the network should produce fewer errors as it goes deeper into the network. The network is a copy of a shallow CNN with identity mapping. He et al. [58] proposed ResNet, which skips connections that feed the activation from one layer to another. Google developers further proposed Inception-ResNet [59], in which batch normalization was used only on top of the traditional inception layers to reduce memory consumption; 35 × 35, 17 × 17, and 8 × 8 grids were used for the inception A, inception B, and inception C layers, respectively. Ronneberger et al. [60] proposed U-Net (Fig. 8) as the standard model for biomedical image segmentation. U-Net is trained with fewer examples to achieve high accuracy. U-Net presents symmetric encoding and decoding along with skip connections. Çiçek et al. [61] proposed a modified version of the 3D U-Net for segmentation of 3D volumetric data, in which three planar segments of the ROI in each iteration carefully segmented an anisotropic body.

U-Net architecture
U-Net-based segmentation and other techniques
U-Net [60], as shown in Fig. 8, has been used for medical image segmentation since the early days of DL, originating from the electron microscopy (EM) segmentation challenge. As shown in Table 1, U-Net is ranked higher based on the warping error metric. Istituto Dalle Molle di Studi sull’Intelligenza Artificiale (IDSIA) members used a version of the CNN extending up to 10 layers. The basic idea was to label every pixel and build a classifier that can do this efficiently. The algorithm was submitted to the 2012 IEEE International Symposium on Biomedical Imaging EM challenge, and was the best-performing algorithm.
In Medical image segmentation before U-Net and Machine learning (ML)-based medical image segmentation sections, earlier automated medical image segmentation techniques are discussed.
Medical image segmentation before U-Net
Sharma and Aggarwal [63] classified segmentation techniques based on amplitude, edge, and region. These methods are categorized as gray-level-dependent techniques. Edge-based techniques include edge relaxation [64], the border detection method [65], and the Hough transform [66, 67]. Other unsupervised methods are based on k-means [68], hard C-means, and fuzzy C-means (FCM). A review of FCM segmentation was presented in ref. [69]. In ref. [70], medical image segmentation was performed by detecting image features using a feature extraction method based on stacked independent subspace analysis [71] combined with PCA to match small patches using feature matching steps such as the histogram of gradient. In ref. [72], use of RG algorithms was proposed as a segmentation technique and for feature extraction, including Zernike moments [73] with a CNN.
ML-based medical image segmentation
Cascaded networks [74, 75] are expensive for evaluating regions within and outside the target object. One layer of the cascaded network roughly estimates the ROI after rejection of redundant information. As the name suggests, region evaluations are based on the inputs received from preceding cascaded networks. The current layer reevaluates the ROI and rejects the outside boundary before forwarding it to the next network. To improve on cascaded networks, Li et al. [76] presented a lightweight regression network. Their method was improved; their main architecture was inspired by U-Net. Torbati et al. [77] used a moving-average self-organizing map. Weight vectors moved toward the filtered outputs after the trace matrix was updated, depending on the winning neuron and neighboring functions. Ultimately, clustered neurons corresponding to the topographical nodes were segmented. Al-Ayyoub et al. [78] demonstrated accelerated lung CT segmentation using brFCM [79] over the earlier FCM. A Markov random field (MRF) [80] was used for brain-image segmentation. The MRF is a powerful tool for representing an image as a stochastic model based on color intensity values. Deng and Clausi [81] proposed a new unsupervised image segmentation model built from a simple MRF; in the expectation-maximization algorithm, the parameter α was allowed to update, eliminating region-labeling and feature-labeling modeling confusion. Monaco and Madabhushi [82] introduced class-specific weights to the maximum a posteriori and maximum posterior marginal estimation criteria.
Neural network frameworks
In this study, basic bare DNN models were tested on simple image classification tasks using the Kaggle Cifar-10 dataset. The results are shown in Fig. 9. Application of these DL methods to 3D reconstruction of 2D medical images is presented in Table 2.

Validation loss in classifying Cifar-10 dataset
Modern neural network-based learning is based on application of a CNN. Mask R-CNN [92] is a framework for object instance segmentation. This method extends the faster R-CNN. The boundary-preserving Mask R-CNN [93] contains a boundary-preserving mask head, in which the object boundary and mask are mutually learned via feature fusion blocks. A mesh R-CNN [94] is built on top of Mask R-CNN with a mesh prediction branch that outputs meshes with varying topological structures through coarse voxelization; they are converted to meshes and refined using a graph convolution neural network (GCNN) [95]. Vox2Mesh [96] converts an occupancy grid into a mesh. Because a voxel grid lacks fine geometric details, the selected grid is converted into a triangular mesh. Pixel2Mesh [97] is a DL architecture that produces a 3D shape in a triangular mesh from a single-color image, and is implemented on top of a GCNN.
Point-cloud-based reconstruction applications
Some methods [98, 99] use point clouds for fully automatic surface reconstruction [23]. The problem of reconstruction is formulated as a point-cloud completion problem, as in a point completion network [100]. The objective is to reconstruct a noisy or partially missing point distribution.
In Eq. 8, Lcoarse is the point cloud from the points on the contour boundary. Ldense enforces smoothness at the local and global levels. α is the weight factor and acts as the controlling term [101]. Figure 10 shows the completion of the points in the final mesh.

a Point cloud; b Rough surface; c Final mesh
Overview of recent developments in organ-specific 3D reconstruction in medical diagnosis
Lungs
Sun et al. [49] used CUBIC and 3D imaging of solvent-cleared organs over CT scans or MRI to avoid inhaled hydrogen atoms administered to image 3D mouse lungs and used Nissl-staining [102] for rendering 3D lung structures. Bruno and Anathy [103] found that more attention was required for 3D reconstruction of ER-mitochondrial interactions during the initial phase of lung disease. Durhan et al. [104] stressed the importance of contrast-enhanced CT for 3D reconstruction. Filho et al. [105] proposed an adaptive crisp ACM 2D to diagnose pulmonary disease by lung segmentation, and used the Open GL API for visualization. Li et al. [106] proposed the use of a geometric active contour model to segment lungs in a single algorithm using a supervised segmentation method. This approach yielded faster segmentation than the coarse-to-fine method. Le Moal et al. [107] reported that medical diagnosis was performed after uploading patient CT scans to the Visual Patient™ server and downloading the 3D model. This approach is costlier; its impact on surgical efficiency is currently under investigation. González Izard et al. [108] proposed development of the NextMed platform to convert DICOM images into 3D models and visualizations, including segmentation, a tedious manual task. Joemai et al. [109] reported that CT reconstruction devices over filtered back propagation produced less similarity with ground truth images than the forward-projected model-based Iterative Reconstruction Solution and Adaptive Iteration Dose Reduction in three dimensions. Pereira et al. [110] addressed lung issues using MRI imaging technology based on 3D-ultra-short echo time to obtain morphological and functional images of the lungs over traditional 2D image registration techniques. Wang et al. [97] proposed an automatic 3D classification framework built on top of an R-CNN to predict pre-invasive or invasive lung cancer to facilitate selection of proper treatment. Jin et al. [111] proposed a generative adversarial network (GAN)-based synthetic lung nodule generation for improved CT datasets by introducing a novel multitask reconstruction loss term to generate more realistic and natural nodules. Furumoto et al. [112] proposed using fluorodeoxyglucose-PET/CT combined with high-resolution CT on the solid part of a tumor for better prediction than using only CT to identify clinical stage IA adenocarcinoma. Grothausmann et al. [113] generated a 3D reconstruction of the alveolar capillary network in the lungs using 2D histological serial slices. Morales-Navarrete et al. [114] proposed use of fluorescent markers in high-resolution microscopic images to digitally reconstruct 3D representations of cells in tissues and their critical subcellular parts.
Knee
Kasten et al. [115] proposed 3D reconstruction of knee bones using a CNN from two biplanar x-ray images. Ciliberti et al. [116] proposed 3D reconstruction of knee joints to assess the relationship between bone mineral density and cartilage status. Hess et al. [117] performed 3D reconstruction of knee joints to assess the alignment of the femur and tibia in osteoarthritis ailments using KNEE-PLAN® software. Wu and Mahfouz [118] proposed 3D representation of the knee using a single fluoroscopic x-ray based on a nonlinear SSM to design a patient-specific instrument for total joint replacement. Bao et al. [119] used MIMICS 10.01 software on a 64-slice spiral CT scan to determine the postoperative range of motion. Marzorati et al. [120] used DCNN-based segmentation of the femur and tibia, and evaluated the impact of segmentation uncertainty on surgical planning for personalized surgical instruments.
Kidney
Puelles et al. [121] used confocal microscopy for 3D imaging of kidneys up to a depth of 50-80 µm, with new advances in clearing methods to remove lower-order lipids and pigments in tissue to render it as transparent. Guliev et al. [122] proposed simple 3D reconstruction of the kidney pelvicalyceal system (PCS) through semi-autonomous PCS segmentation. Mercader et al. [123] used a 3D-printed model and CT scan images for better surgical planning for a horseshoe kidney. Chaussy et al. [124] used 3D-slicer software to semi-automatically segment 14 scans from 12 patients with Wilms’ tumors. The mean segmentation was 8.6 h. Les et al. [125] proposed use of parametric coefficients to determine the location of the kidney in a CT image.
Liver
Chen et al. [84] proposed a serial encoder-decoder (SED) DL approach. Two SEDs were used: the first to segment the ROI, and the second to further segment the results obtained from the first network. The SED was designed using a U-Net architecture. Yeo et al. [126] proposed use of 3D reconstruction of 2D CT and MRI images as a tool for training medical students in liver tumor resection. Fang et al. [127] validated 3D reconstruction of the liver in the pre-operative stage; intra-operative and post-operative stage scores were assigned based on whether 3D visualizations were helpful; the 3D visualizations produced a high score for each phase. Tatamov et al. [128] reported that use of 3D visualization in liver laparoscopic herpetology reduced the risk of intra-operative complications due to bile and paralytic cysts. In a study by Fang et al. [129], eye observations were used for intra-operative lesion identification. 3D visualization, as an intelligent imaging tool and diagnostic medium, helped solve problems using traditional methods in intra-operative stages.
Brain
Bjerke et al. [130] proposed developing a reference atlas for the rodent brain as part of the Human Brain Project and built reference atlases for the human brain as part of the BigBrain Project. Ebner et al. [131] compared the localization and segmentation of the fetal brain to manual segmentation considering the constant motion of the fetus in the prenatal stage between fast 2D scan slices. Du et al. [132] proposed a dilated encoder-decoder network to improve the MRI 2D image resolution using 3D dilated convolution.
Miscellaneous
For medical diagnosis, exposure to harmful CT rays during intra-operative stages is not desirable, and it is not possible to monitor organ status through CT scans in patients undergoing operative procedures. Thus, x-raying the area of interest and projecting instantaneous 3D reconstructions is most desirable. Use of a single x-ray image is more desirable; however, training a CNN with a single image requires a different approach. As described in ref. [12], a GAN [133] was used to reconstruct 3D bone structures using DRR. Using oral x-rays for 3D reconstruction, panoramic x-ray [134] imaging providing a linear view of the oral cavity to observe artifacts can be used to restore the mandible; 3D alignment was performed with the dental arc using the contour extraction method on the original dental structure. Such deformable shapes from two dimensional x-ray imaging are a key achievement, as described in ref. [135]; an image-to-graph convolution network (IGCN) using deformation mapping by point-to-point correspondence was proposed. The IGCN was designed as an organ-independent network.
From angiogram CT scans of older patients, 2D DRRs were generated to simulate real-world x-rays, instead of patients switching between the two devices. In ref. [115], a biplanar x-ray imaging approach was described for 3D reconstruction using supervised cross-entropy weight loss. The first loss was measured as the distance between each voxel and the surface tissue (ground truth); the second loss was the unsupervised reconstruction loss. In ref. [136], a neural network was trained using a triplet loss function to identify normal and deformed bones to relate the most closely predicted bone shape to a predefined set of bone shapes.
Performance comparison of state-of-the-art models
A detailed survey was reported in ref. [137], from which some networks were selected; their performances are compared in Table 3. The chosen networks and models indicate the most relevant recent work. The modality of the image input was not a selection criterion; irrespective of whether the data source was single- or multi-slice, some of the models were retained. Some of the models were based on supervised learning [138,139,140,141,142,143,144]; others were unsupervised [145,146,147].
Performance was measured using DICE [148] (Eq. 9) for the segmentation quality, where TP is the percentage of pixels labeled as true positives (positive in test results and positive in ground truth); TN is the percentage of pixels labeled as true negatives (marked as outliers or noise in both test results and ground truth); FP is the percentage of pixels labeled as false positives (marked as positive in test results and negative in ground truth); FN is the percentage of pixels labeled as false negatives (marked as negative in test results and positive in ground truth). Other metrics used included the signal-to-noise ratio, mean absolute error, discrimination score, and target representation error.
Pros and cons of DL and TA
3D reconstruction from 2D medical images is subject to time and data availability. Traditional methods have been used to obtain faster satisfactory results. However, as modern-day computation shifts toward a new paradigm of automation, the success of DL methods has been observed in other areas of 3D reconstruction. Thus, the DL approach has seeped into medical organ reconstruction and is the way of the future. Several subtasks, from segmentation to registration and smoothing, can also be performed using modern DL methods. However, these methods are sensitive to the input labels and are typically supervised. The final outcome of a DL approach is superior to that of TAs but is constrained by the size of the training examples. TAs require human intervention and are not automatic, as are some DL methods. Table 4 presents several strategies and their advantages and disadvantages in performing common 3D reconstruction tasks.
Summary on current trends
Most reconstruction studies have focused on deformable registration and segmentation. The DL approach has outperformed traditional semi-autonomous methods. The most common is U-Net for segmentation and CNN, and its variants for registration. DRR [15] is also gaining popularity due to the lack of large-scale medical image databases for 3D reconstruction. For registration, large deformation diffeomorphic metric mapping [150] is a metric; for the final surface reconstruction, the Dice score and structural similarity index measure score are commonly used to measure the outcome. In addition, the mean square error and average surface distance are used to assess prediction accuracy. Expected future trends and scope are presented in Table 5.
Current trends include effective 3D mesh-compression techniques, 3D mesh encryption, 3D mesh generation, medical image segmentation, 3D mesh smoothing, and real-time 3D-image processing. Compression techniques involve compression of source images to generate a concise model. However, direct compression of a 3D mesh can also be studied. 3D mesh encryption is important owing to the active role of IT-enabled services in the healthcare sector. Medical-image segmentation is an old problem; however, unsupervised segmentation using an untrained DNN has not yet been achieved. This application reduces the training time, increasing real-time error-free reconstruction for better training and analysis. Vital organs such as the heart, lungs, and arteries change shape continuously. Fast reconstruction is the only solution for real-time visualization and virtual reality-enabled services.
Major challenges
The major challenge in 3D reconstruction is image preprocessing [158]. Conventional image cleaning can omit many data points from an image; however, it can help accurately depict tissues and organs. Removing unwanted pixels such as noise is also important. Noise can cause problems in selection of the proper segmentation area, especially in cases where the left and right lobes appear to constantly touch each other in some slices in small regions after dilation and erosion operations, whereas in the ground truth, they may not. Handling unstructured point-cloud data without the related topological information is another challenging problem. These data points are scattered densely or sparsely, requiring specialized algorithms for processing. Another major limitation is the availability of 3D medical models such as ShapeNet [159] and ModelNet [160] for validation. One reason for the lack of such public datasets is that hospitals and patients are unable to obtain permission to make health records publicly available. Most datasets available for 2D medical images are concerned with larger organs; more work is required to create benchmark and gold-standard datasets.
Conclusion and future work
3D reconstruction is becoming more important in medical assistance; its application in medical science is promising. Many areas of concern remain as there is no well-defined or gold-standard dataset for 3D human organs. Thus, GAN-based DL models were used to recreate the synthetic datasets. Although SSM-based models perform well and have been studied, their application is becoming less frequent.
3D reconstruction is expensive; with the requirement of higher-resolution images, use is confined to specially designed medical devices. The motivation for research in this area is to make 3D reconstruction affordable and less time-consuming without compromising accuracy. The most common enhanced radiological methods for day-to-day diagnosis are CT, MRI, and their variations.
In the future, 3D reconstruction is expected to become a more common method of reporting to patients. Further research will include new methods of model security, compression, representation formats, holographic and virtual reality-based representations, real-time representations in operative procedures such as endoscopy, and 3D representations at the cellular level that allow lower-calibrated microscopes to efficiently observe cell structures in largely magnified 3D model representations.
Availability of data and materials
Not applicable.
Abbreviations
- 3D:
-
Three-dimensional
- 2D:
-
Two-dimensional
- ACM:
-
Active contour model
- PCA:
-
Principal component analysis
- PCS:
-
Pelvicalyceal system
- PET:
-
Positron emission tomography
- BPA:
-
Ball pivoting algorithm
- RNN:
-
Recurrent neural network
- CNN:
-
Convolution neural network
- ROI:
-
Region of interest
- CT:
-
Computed tomography
- DCNN:
-
Deep convolution neural network
- SED:
-
Serial encoder-decoder
- DL:
-
Deep learning
- DNN:
-
Deep neural network
- DRR:
-
Digitally reconstructed radiograph
- EM:
-
Electron microscopy
- FCM:
-
Fuzzy C-means
- SSM:
-
Statistical shape model
- GAN:
-
Generative adversarial network
- HU:
-
Hounsfield unit
- IDSIA:
-
Istituto Dalle Molle di Studi sull’Intelligenza Artificiale
- LAT:
-
Lateral
- MRF:
-
Markov random field
- MRI:
-
Magnetic resonance imaging
- GCNN:
-
Graph convolution neural network
- IGCN:
-
Image-to-graph convolution network
- RG:
-
Region growing
- TA:
-
Traditional approach
References
Richmond C (2004) Sir Godfrey Hounsfield. BMJ 329(7467):687. https://doi.org/10.1136/bmj.329.7467.687
He YB, Bai L, Aji T, Jiang Y, Zhao JM, Zhang JH et al (2015) Application of 3D reconstruction for surgical treatment of hepatic alveolar echinococcosis. World J Gastroenterol 21(35):10200-10207. https://doi.org/10.3748/wjg.v21.i35.10200
Werner R, Ehrhardt J, Schmidt R, Handels H (2009) Patient-specific finite element modeling of respiratory lung motion using 4D CT image data. Med Phys 36(5):1500-1511. https://doi.org/10.1118/1.3101820
Werner H, Lopes dos Santos JR, Fontes R, Belmonte S, Daltro P, Gasparetto E et al (2013) Virtual bronchoscopy for evaluating cervical tumors of the fetus. Ultrasound Obstet Gynecol 41(1):90-94. https://doi.org/10.1002/uog.11162
Haleem A, Javaid M (2019) 3D scanning applications in medical field: a literature-based review. Clin Epidemiol Glob Health 7(2):199-210. https://doi.org/10.1016/j.cegh.2018.05.006
Hardie NA, MacDonald G, Rubel EW (2004) A new method for imaging and 3D reconstruction of mammalian cochlea by fluorescent confocal microscopy. Brain Res 1000(1-2):200-210. https://doi.org/10.1016/j.brainres.2003.10.071
Zollhöfer M, Thies J, Garrido P, Bradley D, Beeler T, Pérez P et al (2018) State of the art on monocular 3D face reconstruction, tracking, and applications. Comput Graph Forum 37(2):523-550. https://doi.org/10.1111/cgf.13382
Østergaard M, Pedersen SJ, Døhn UM (2008) Imaging in rheumatoid arthritis-status and recent advances for magnetic resonance imaging, ultrasonography, computed tomography and conventional radiography. Best Pract Res Clin Rheumatol 22(6):1019-1044. https://doi.org/10.1016/j.berh.2008.09.014
Shiode R, Kabashima M, Hiasa Y, Oka K, Murase T, Sato Y et al (2021) 2D-3D reconstruction of distal forearm bone from actual X-ray images of the wrist using convolutional neural networks. Sci Rep 11:15249. https://doi.org/10.1038/s41598-021-94634-2
Kim H, Lee K, Lee D, Baek N (2019) 3D reconstruction of leg bones from X-ray images using CNN-based feature analysis. In: Proceedings of the 2019 international conference on information and communication technology convergence, IEEE, Jeju, 16-18 October 2019. https://doi.org/10.1109/ICTC46691.2019.8939984
Aubert B, Vazquez C, Cresson T, Parent S, de Guise JA (2019) Toward automated 3D spine reconstruction from biplanar radiographs using CNN for statistical spine model fitting. IEEE Trans Med Imaging 38(12):2796-2806. https://doi.org/10.1109/TMI.2019.2914400
Henzler P, Rasche V, Ropinski T, Ritschel T (2018) Single-image tomography: 3D volumes from 2D cranial X-rays. Comput Graph Forum 37(2):377-388. https://doi.org/10.1111/cgf.13369
Moura DC, Boisvert J, Barbosa JG, Labelle H, Tavares JMRS (2011) Fast 3D reconstruction of the spine from biplanar radiographs using a deformable articulated model. Med Eng Phys 33(8):924-933. https://doi.org/10.1016/j.medengphy.2011.03.007
André B, Dansereau J, Labelle H (1994) Optimized vertical stereo base radiographic setup for the clinical three-dimensional reconstruction of the human spine. J Biomech 27(8):1023-1025, 1027-1035. https://doi.org/10.1016/0021-9290(94)90219-4
Almeida DF, Astudillo P, Vandermeulen D (2021) Three-dimensional image volumes from two-dimensional digitally reconstructed radiographs: a deep learning approach in lower limb CT scans. Med Phys 48(5):2448-2457. https://doi.org/10.1002/mp.14835
Bai WJ, Shi WZ, de Marvao A, Dawes TJW, O’Regan DP, Cook SA et al (2015) A bi-ventricular cardiac atlas built from 1000+ high resolution MR images of healthy subjects and an analysis of shape and motion. Med Image Anal 26(1):133-145. https://doi.org/10.1016/j.media.2015.08.009
Ambellan F, Lamecker H, von Tycowicz C, Zachow S (2019) Statistical shape models: understanding and mastering variation in anatomy. In: Rea PM (ed) Biomedical visualisation. Advances in experimental medicine and biology, vol 1156. Springer, Cham, pp 67-84. https://doi.org/10.1007/978-3-030-19385-0_5
Prakash N N, Rajesh V, Inthiyaz S (2023) Review on Techniques and Indications of Liver Segmentation. EJMCM 10(1): 3690-3700
Lamecker H, Seebass M, Hege HC, Deuflhard P (2004) A 3D statistical shape model of the pelvic bone for segmentation. In: Proceedings of SPIE 5370, medical imaging 2004: image processing, SPIE, San Diego, 12 May 2004. https://doi.org/10.1117/12.534145
Vejjanugraha P, Kotani K, Kongprawechnon W, Kondo T, Tungpimolrut K (2021) Automatic screening of lung diseases by 3D active contour method for inhomogeneous motion estimation in CT image pairs. Walailak J Sci Technol 18(12):10573. https://doi.org/10.48048/wjst.2021.10573
Villard B, Grau V, Zacur E (2018) Surface mesh reconstruction from cardiac MRI contours. J Imaging 4(1):16. https://doi.org/10.3390/jimaging4010016
Boisvert J, Cheriet F, Pennec X, Labelle H, Ayache N (2008) Articulated spine models for 3-D reconstruction from partial radiographic data. IEEE Trans Biomed Eng 55(11):2565-2574. https://doi.org/10.1109/TBME.2008.2001125
Boisvert J, Moura DC (2011) Interactive 3D reconstruction of the spine from radiographs using a statistical shape model and second-order cone programming. In: Proceedings of the 2011 annual international conference of the IEEE engineering in medicine and biology society, IEEE, Boston, 30 August-3 September 2011. https://doi.org/10.1109/IEMBS.2011.6091386
Jiang HY, Cai JF, Zheng JM (2019) Skeleton-aware 3D human shape reconstruction from point clouds. In: Proceedings of the 2019 IEEE/CVF international conference on computer vision, IEEE, Seoul, 27 October-2 November 2019. https://doi.org/10.1109/ICCV.2019.00553
Schönberger JL, Frahm JM (2016) Structure-from-Motion revisited. In: Proceedings of the 2016 IEEE conference on computer vision and pattern recognition, IEEE, Las Vegas, 27-30 June 2016. https://doi.org/10.1109/CVPR.2016.445
Fan HQ, Su H, Guibas L (2017) A point set generation network for 3D object reconstruction from a single image. In: Proceedings of the 2017 IEEE conference on computer vision and pattern recognition, IEEE, Honolulu, 21-26 July 2017. https://doi.org/10.1109/CVPR.2017.264
Amenta N, Bern M, Kamvysselis M (1998) A new voronoi-based surface reconstruction algorithm. In: Proceedings of the 25th annual conference on computer graphics and interactive techniques, ACM, Orlando, 19-24 July 1998. https://doi.org/10.1145/280814.280947
Tatarchenko M, Dosovitskiy A, Brox T (2017) Octree generating networks: efficient convolutional architectures for high-resolution 3D outputs. In: Proceedings of the 2017 IEEE international conference on computer vision, IEEE, Venice, 22-29 October 2017. https://doi.org/10.1109/ICCV.2017.230
Allen B, Curless B, Popović Z (2003) The space of human body shapes: reconstruction and parameterization from range scans. ACM Trans Graph 22(3):587-594. https://doi.org/10.1145/882262.882311
Digne J, Cohen-Steiner D, Alliez P, de Goes F, Desbrun M (2014) Feature-preserving surface reconstruction and simplification from defect-laden point sets. J Math Imaging Vis 48(2):369-382. https://doi.org/10.1007/s10851-013-0414-y
Narkhede A, Manocha D (1995) Fast polygon triangulation based on seidel’s algorithm. In: Paeth AW (ed) Graphics gems V: a collection of practical techniques for the computer graphics programmer. Academic Press, San Diego, pp 394-397. https://doi.org/10.1016/B978-0-12-543457-7.50059-0
Boissonnat JD, Geiger B (1993) Three-dimensional reconstruction of complex shapes based on the Delaunay triangulation. In: Proceedings of SPIE 1905, biomedical image processing and biomedical visualization, SPIE, San Jose, 29 July 1993. https://doi.org/10.1117/12.148710
Oliva JM, Perrin M, Coquillart S (1996) 3D reconstruction of complex polyhedral shapes from contours using a simplified generalized voronoi diagram. Comput Graph Forum 15(3):397-408. https://doi.org/10.1111/1467-8659.1530397
Pal NR, Pal SK (1993) A review on image segmentation techniques. Pattern Recognit 26(9):1277-1294. https://doi.org/10.1016/0031-3203(93)90135-J
Haralick RM, Shapiro LG (1985) Image segmentation techniques. Comput Vis, Graph, Image Process 29(1):100-132. https://doi.org/10.1016/S0734-189X(85)90153-7
Robertson TV (1973) Extraction and classification of objects in multispectral images. Purdue University, 1973
Dhanachandra N, Manglem K, Chanu YJ (2015) Image segmentation using K-means clustering algorithm and subtractive clustering algorithm. Procedia Comput Sci 54:764-771. https://doi.org/10.1016/j.procs.2015.06.090
Lopez-Molina C, De Baets B, Bustince H, Sanz J, Barrenechea E (2013) Multiscale edge detection based on Gaussian smoothing and edge tracking. Knowl-Based Syst 44:101-111. https://doi.org/10.1016/j.knosys.2013.01.026
Mumford DB, Shah J (1989) Optimal approximations by piecewise smooth functions and associated variational problems. Commun Pure Appl Math 42(5):577-685. https://doi.org/10.1002/cpa.3160420503
Getreuer P (2012) Chan-vese segmentation. Image Process Line 2:214-224. https://doi.org/10.5201/ipol.2012.g-cv
Kee Y, Kim J (2014) A convex relaxation of the ambrosio-tortorelli elliptic functionals for the Mumford-shah functional. In: Proceedings of the 2014 IEEE conference on computer vision and pattern recognition, IEEE, Columbus, 23-28 June 2014. https://doi.org/10.1109/CVPR.2014.519
Cerveri P, Sacco C, Olgiati G, Manzotti A, Baroni G (2017) 2D/3D reconstruction of the distal femur using statistical shape models addressing personalized surgical instruments in knee arthroplasty: a feasibility analysis. Int J Med Robot Comput Assist Surg 13(4):e1823. https://doi.org/10.1002/rcs.1823
Wang MR, Liu XB, Gao YX, Ma X, Soomro NQ (2017) Superpixel segmentation: a benchmark. Signal Process: Image Commun 56:28-39. https://doi.org/10.1016/j.image.2017.04.007
Chen XT, Zhang F, Zhang RY (2017) Medical image segmentation based on SLIC superpixels. In: Proceedings of SPIE 10245, international conference on innovative optical health science, Shanghai, SPIE, 5 January 2017. https://doi.org/10.1117/12.2258384
Pottmann H, Leopoldseder S, Hofer M (2002) Approximation with active B-spline curves and surfaces. In: Proceedings of the 10th pacific conference on computer graphics and applications, IEEE, Beijing, 9-11 October 2002. https://doi.org/10.1109/PCCGA.2002.1167835
Boehm W (1990) Algebraic and differential geometric methods in C.A.G.D. In: Dahmen W, Gasca M, Micchelli CA (eds) Computation of curves and surfaces. Nato science series C, vol 307. Springer, Dordrecht, pp 425-455. https://doi.org/10.1007/978-94-009-2017-0_13
Tuli M, Reddy NV, Saxena A (2006) Constrained shape modification of b-spline curves. Comput-Aided Des Appl 3(1-4):437-446. https://doi.org/10.1080/16864360.2006.10738482
Frangi AF, Rueckert D, Schnabel JA, Niessen WJ (2002) Automatic construction of multiple-object three-dimensional statistical shape models: application to cardiac modeling. IEEE Trans Med Imaging 21(9):1151-1166. https://doi.org/10.1109/TMI.2002.804426
Sun X, Zhang XC, Ren XH, Sun HY, Wu L, Wang CF et al (2021) Multiscale co-reconstruction of lung architectures and inhalable materials spatial distribution. Adv Sci 8(8):2003941. https://doi.org/10.1002/advs.202003941
Wang Y, Kolotouros N, Daniilidis K, Badger M (2021) Birds of a feather: capturing avian shape models from images. In: Proceedings of the 2021 IEEE/CVF conference on computer vision and pattern recognition, IEEE, Nashville, 20-25 June 2021. https://doi.org/10.1109/CVPR46437.2021.01450
Lorensen WE, Cline HE (1987) Marching cubes: a high resolution 3D surface construction algorithm. ACM SIGGRAPH Comput Graph 21(4):163-169. https://doi.org/10.1145/37402.37422
Bernardini F, Mittleman J, Rushmeier H, Silva C, Taubin G (1999) The ball-pivoting algorithm for surface reconstruction. IEEE Trans Vis Comput Graph 5(4):349-359. https://doi.org/10.1109/2945.817351
Hoppe H, DeRose T, Duchamp T, McDonald J, Stuetzle W (1992) Surface reconstruction from unorganized points. In: Proceedings of the 19th annual conference on computer graphics and interactive techniques, ACM, Chicago, 27-31 July 1992. https://doi.org/10.1145/133994.134011
Krizhevsky A, Sutskever I, Hinton GE (2012) ImageNet classification with deep convolutional neural networks. In: Proceedings of the 25th international conference on neural information processing systems, ACM, Lake Tahoe, 3-6 December 2012
Jarrett K, Kavukcuoglu K, Ranzato MA, LeCun Y (2009) What is the best multi-stage architecture for object recognition? In: Proceedings of the IEEE 12th international conference on computer vision, IEEE, Kyoto, 29 September-2 October 2009. https://doi.org/10.1109/ICCV.2009.5459469
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409
Szegedy C, Liu W, Jia YQ, Sermanet P, Reed S, Anguelov D et al (2015) Going deeper with convolutions. In: Proceedings of the 2015 IEEE conference on computer vision and pattern recognition, IEEE, Boston, 7-12 June 2015. https://doi.org/10.1109/CVPR.2015.7298594
He KM, Zhang XY, Ren SQ, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the 2016 IEEE conference on computer vision and pattern recognition, IEEE, Las Vegas, 27-30 June 2016. https://doi.org/10.1109/CVPR.2016.90
Szegedy C, Ioffe S, Vanhoucke V, Alemi AA (2017) Inception-v4, inception-ResNet and the impact of residual connections on learning. In: Proceedings of the 31st AAAI conference on artificial intelligence, AAAI Press, San Francisco, 4-9 February 2017. https://doi.org/10.1609/aaai.v31i1.11231
Ronneberger O, Fischer P, Brox T (2015) U-Net: convolutional networks for biomedical image segmentation. In: Navab N, Hornegger J, Wells WM, Frangi AF (eds) Medical image computing and computer-assisted intervention. 18th international conference, Munich, October 2015. Lecture notes in computer science (Image processing, computer vision, pattern recognition, and graphics), vol 9351. Springer, Cham, pp 234-241. https://doi.org/10.1007/978-3-319-24574-4_28
Çiçek O, Abdulkadir A, Lienkamp SS, Brox T, Ronneberger O (2016) 3D U-Net: learning dense volumetric segmentation from sparse annotation. In: Ourselin S, Joskowicz L, Sabuncu MR, Unal G, Wells W (eds) Medical image computing and computer-assisted intervention - MICCAI 2016. 19th international conference, Athens, October 2016. Lecture notes in computer science (Image processing, computer vision, pattern recognition, and graphics), vol 9901. Springer, Cham, pp 424-432. https://doi.org/10.1007/978-3-319-46723-8_49
Cireşan D, Giusti A, Gambardella LM, Schmidhuber J (2012) Deep neural networks segment neuronal membranes in electron microscopy images. In: Proceedings of the 25th international conference on neural information processing systems, Curran Associates Inc, Lake Tahoe, 3-6 December 2012
Sharma N, Aggarwal LM (2010) Automated medical image segmentation techniques. J Med Phys 35(1):3-14. https://doi.org/10.4103/0971-6203.58777
Hancock ER, Kittler J (1990) Edge-labeling using dictionary-based relaxation. IEEE Trans Pattern Anal Mach Intell 12(2):165-181. https://doi.org/10.1109/34.44403
Law T, Itoh H, Seki H (1996) Image filtering, edge detection, and edge tracing using fuzzy reasoning. IEEE Trans Pattern Anal Mach Intell 18(5):481-491. https://doi.org/10.1109/34.494638
Kälviäinen H, Hirvonen P, Xu L, Oja E (1995) Probabilistic and non-probabilistic Hough transforms: overview and comparisons. Image Vis Comput 13(4):239-252. https://doi.org/10.1016/0262-8856(95)99713-B
Xu L, Oja E (1993) Randomized Hough transform (RHT): basic mechanisms, algorithms, and computational complexities. CVGIP: Image Underst 57(2):131-154. https://doi.org/10.1006/ciun.1993.1009
Shan P (2018) Image segmentation method based on K-mean algorithm. EURASIP J Image Video Process 2018(1):81. https://doi.org/10.1186/s13640-018-0322-6
Balafar MA (2014) Fuzzy C-mean based brain MRI segmentation algorithms. Artif intell Rev 41(3):441-449. https://doi.org/10.1007/s10462-012-9318-2
Liao S, Gao YZ, Oto A, Shen DG (2013) Representation learning: a unified deep learning framework for automatic prostate MR segmentation. In: Mori K, Sakuma I, Sato Y, Barillot C, Navab N (eds) Medical image computing and computer-assisted intervention. 16th international conference, Nagoya, September 2013. Lecture notes in computer science (Image processing, computer vision, pattern recognition, and graphics), vol 8150. Springer, Berlin, pp 254-261. https://doi.org/10.1007/978-3-642-40763-5_32
Le QV, Zou WY, Yeung SY, Ng AY (2011) Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis. In: Proceedings of the CVPR 2011, IEEE, Colorado Springs, 20-25 June 2011. https://doi.org/10.1109/CVPR.2011.5995496
Rouhi R, Jafari M, Kasaei S, Keshavarzian P (2015) Benign and malignant breast tumors classification based on region growing and CNN segmentation. Expert Syst Appl 42(3):990-1002. https://doi.org/10.1016/j.eswa.2014.09.020
Khotanzad A, Hong Y H (1990) Invariant image recognition by Zernike moments. IEEE T Pattern Anal 12(5): 489-497. https://doi.org/10.1109/34.55109
Gao YH, Huang R, Chen M, Wang Z, Deng JC, Chen YY et al (2019) FocusNet: imbalanced large and small organ segmentation with an end-to-end deep neural network for head and neck CT images. In: Shen DG, Liu Tm, Peters TM, Staib LH, Essert C, Zhou S et al (eds) Medical image computing and computer assisted intervention. 22nd international conference, Shenzhen, October 2019. Lecture notes in computer science (Image processing, computer vision, pattern recognition, and graphics), vol 11766. Springer, Cham, pp 829-838. https://doi.org/10.1007/978-3-030-32248-9_92
Havaei M, Davy A, Warde-Farley D, Biard A, Courville A, Bengio Y et al (2017) Brain tumor segmentation with deep neural networks. Med Image Anal 35:18-31. https://doi.org/10.1016/j.media.2016.05.004
Li HY, Liu XB, Boumaraf S, Gong XP, Liao DH, Ma XH (2020) Deep distance map regression network with shape-aware loss for imbalanced medical image segmentation. In: Liu MX, Yan PK, Lian CF, Cao XH (eds) Machine learning in medical imaging. 11th international workshop, MLMI 2020, held in conjunction with MICCAI 2020, Lima, October 2020. Lecture notes in computer science (Image processing, computer vision, pattern recognition, and graphics), vol 12436. Springer, Cham, pp 231-240. https://doi.org/10.1007/978-3-030-59861-7_24
Torbati N, Ayatollahi A, Kermani A (2014) An efficient neural network based method for medical image segmentation. Comput Biol Med 44:76-87. https://doi.org/10.1016/j.compbiomed.2013.10.029
Al-Ayyoub M, Abu-Dalo AM, Jararweh Y, Jarrah M, Sa’d MA (2015) A GPU-based implementations of the fuzzy C-means algorithms for medical image segmentation. J Supercomput 71(8):3149-3162. https://doi.org/10.1007/s11227-015-1431-y
Eschrich S, Ke JW, Hall LO, Goldgof DB (2003) Fast accurate fuzzy clustering through data reduction. IEEE Trans Fuzzy Syst 11(2):262-270. https://doi.org/10.1109/TFUZZ.2003.809902
Held K, Kops ER, Krause BJ, Wells WM, Kikinis R, Muller-Gartner HW (1997) Markov random field segmentation of brain MR images. IEEE Trans Med Imaging 16(6):878-886. https://doi.org/10.1109/42.650883
Deng HW, Clausi DA (2004) Unsupervised image segmentation using a simple MRF model with a new implementation scheme. Pattern Recognit 37(12):2323-2335. https://doi.org/10.1016/S0031-3203(04)00195-5
Monaco JP, Madabhushi A (2012) Class-specific weighting for Markov random field estimation: application to medical image segmentation. Med Image Anal 16(8):1477-1489. https://doi.org/10.1016/j.media.2012.06.007
Wang YF, Zhong ZC, Hua J (2020) DeepOrganNet: on-the-fly reconstruction and visualization of 3D/4D lung models from single-view projections by deep deformation network. IEEE Trans Vis Comput Graph 26(1):960-970. https://doi.org/10.1109/TVCG.2019.2934369
Chen WF, Ou HY, Liu KH, Li ZY, Liao CC, Wang SY et al (2021) In-series u-net network to 3D tumor image reconstruction for liver hepatocellular carcinoma recognition. Diagnostics 11(1):11. https://doi.org/10.3390/diagnostics11010011
Jeyaraj PR, Nadar ERS (2020) Dynamic image reconstruction and synthesis framework using deep learning algorithm. IET Image Process 14(7):1219-1226. https://doi.org/10.1049/iet-ipr.2019.0900
Shakarami A, Tarrah H, Mahdavi-Hormat A (2020) A CAD system for diagnosing Alzheimer's disease using 2D slices and an improved AlexNet-SVM method. Optik 212:164237. https://doi.org/10.1016/j.ijleo.2020.164237
Xie SP, Zheng XY, Chen Y, Xie LZ, Liu J, Zhang YD et al (2018) Artifact removal using improved GoogLeNet for sparse-view CT reconstruction. Sci Rep 8(1):6700. https://doi.org/10.1038/s41598-018-25153-w
Islam KT, Wijewickrema S, O’Leary S (2019) A rotation and translation invariant method for 3D organ image classification using deep convolutional neural networks. PeerJ Comput Sci 5:e181. https://doi.org/10.7717/peerj-cs.181
Ke HJ, Chen D, Li XL, Tang YB, Shah T, Ranjan R (2018) Towards brain big data classification: epileptic EEG identification with a lightweight VGGNet on global MIC. IEEE Access 6:14722-14733. https://doi.org/10.1109/ACCESS.2018.2810882
Seol YJ, Kim YJ, Kim YS, Cheon YW, Kim KG (2022) A study on 3D deep learning-based automatic diagnosis of nasal fractures. Sensors 22(2):506. https://doi.org/10.3390/s22020506
Li QF, Shen LL (2020) 3D neuron reconstruction in tangled neuronal image with deep networks. IEEE Trans Med Imaging 39(2):425-435. https://doi.org/10.1109/TMI.2019.2926568
He KM, Gkioxari G, Dollar P, Girshick R (2020) Mask R-CNN. IEEE Trans Pattern Anal Mach Intell 42(2):386-397. https://doi.org/10.1109/TPAMI.2018.2844175
Cheng TH, Wang XG, Huang LC, Liu WY (2020) Boundary-preserving mask R-CNN. In: Vedaldi A, Bischof H, Brox T, Frahm JM (eds) Computer vision. 16th European conference, Glasgow, August 2020. Lecture notes in computer science (Image processing, computer vision, pattern recognition, and graphics), vol 12359. Springer, Cham, pp 660-676. https://doi.org/10.1007/978-3-030-58568-6_39
Gkioxari G, Johnson J, Malik J (2019) Mesh R-CNN. In: Proceedings of the 2019 IEEE/CVF international conference on computer vision, IEEE, Seoul, 27 October-2 November 2019. https://doi.org/10.1109/ICCV.2019.00988
Kipf TN, Welling M (2017) Semi-supervised classification with graph convolutional networks. In: Proceedings of the 5th international conference on learning representations, OpenReview.net, Toulon, 24-26 April 2017
Shen T, Gao J, Kar A, Fidler S (2020) Interactive annotation of 3D object geometry using 2D scribbles. In: Vedaldi A, Bischof H, Brox T, Frahm JM (eds) Computer vision. 16th European conference, Glasgow, August 2020. Lecture notes in computer science (Image processing, computer vision, pattern recognition, and graphics), vol 12362. Springer, Cham, pp 751-767. https://doi.org/10.1007/978-3-030-58520-4_44
Wang N, Zhang Y, Li Z, Fu Y, Liu W, Jiang Y G (2018) Pixel2mesh: Generating 3d mesh models from single RGB images. In: Ferrari V, Hebert M, Sminchisescu C, Weiss Y (eds) Computer Vision – ECCV 2018. ECCV 2018. Lecture Notes in Computer Science(), vol 11215. Springer, Cham. https://doi.org/10.1007/978-3-030-01252-6_4
Xu TX, An D, Jia YT, Yue Y (2021) A review: point cloud-based 3D human joints estimation. Sensors 21(5):1684. https://doi.org/10.3390/s21051684
Yu Q, Yang CZ, Wei H (2022) Part-wise AtlasNet for 3D point cloud reconstruction from a single image. Knowl-Based Syst 242:108395. https://doi.org/10.1016/j.knosys.2022.108395
Yuan WT, Khot T, Held D, Mertz C, Hebert M (2018) PCN: point completion network. In: Proceedings of the 2018 international conference on 3D vision, IEEE, Verona, 5-8 September 2018. https://doi.org/10.1109/3DV.2018.00088
Huang K, Rhee DJ, Ger R, Layman R, Yang JZ, Cardenas CE et al (2021) Impact of slice thickness, pixel size, and CT dose on the performance of automatic contouring algorithms. J Appl Clin Med Phys 22(5):168-174. https://doi.org/10.1002/acm2.13207
Ding W, Li A, Wu J, Yang Z, Meng Y, Wang S et al (2013) Automatic macroscopic density artefact removal in a Nissl-stained microscopic atlas of whole mouse brain. J Microsc 251(2):168-177. https://doi.org/10.1111/jmi.12058
Bruno SR, Anathy V (2021) Lung epithelial endoplasmic reticulum and mitochondrial 3D ultrastructure: a new frontier in lung diseases. Histochem Cell Biol 155(2):291-300. https://doi.org/10.1007/s00418-020-01950-1
Durhan G, Duzgun SA, Akpınar MG, Demirkazık F, Arıyürek OM (2021) Imaging of congenital lung diseases presenting in the adulthood: a pictorial review. Insights Imaging 12(1):153. https://doi.org/10.1186/s13244-021-01095-2
Filho PPR, Cortez PC, da Silva Barros AC, Albuquerque VHC, Tavares JMRS (2017) Novel and powerful 3D adaptive crisp active contour method applied in the segmentation of CT lung images. Med Image Anal 35:503-516. https://doi.org/10.1016/j.media.2016.09.002
Li XP, Wang X, Dai YX, Zhang PB (2015) Supervised recursive segmentation of volumetric CT images for 3D reconstruction of lung and vessel tree. Comput Methods Programs Biomed 122(3):316-329. https://doi.org/10.1016/j.cmpb.2015.08.014
Le Moal J, Peillon C, Dacher JN, Baste JM (2018) Three-dimensional computed tomography reconstruction for operative planning in robotic segmentectomy: a pilot study. J Thorac Dis 10(1):196-201. https://doi.org/10.21037/jtd.2017.11.144
González Izard S, Sánchez Torres R, Alonso Plaza Ó, Juanes Méndez JA, García-Peñalvo FJ (2020) Nextmed: automatic imaging segmentation, 3D reconstruction, and 3D model visualization platform using augmented and virtual reality. Sensors 20(10):2962. https://doi.org/10.3390/s20102962
Joemai RMS, Geleijns J (2017) Assessment of structural similarity in CT using filtered backprojection and iterative reconstruction: a phantom study with 3D printed lung vessels. Br J Radiol 90(1079):20160519. https://doi.org/10.1259/bjr.20160519
Pereira LM, Wech T, Weng AM, Kestler C, Veldhoen S, Bley TA et al (2019) UTE-SENCEFUL: first results for 3D high-resolution lung ventilation imaging. Magn Reson Med 81(4):2464-2473. https://doi.org/10.1002/mrm.27576
Jin DK, Xu ZY, Tang YB, Harrison AP, Mollura DJ (2018) CT-realistic lung nodule simulation from 3D conditional generative adversarial networks for robust lung segmentation. In: Frangi A, Schnabel J, Davatzikos C, Alberola-López C, Fichtinger G (eds) Medical image computing and computer assisted intervention. 21st international conference, Granada, September 2018. Lecture notes in computer science (Image processing, computer vision, pattern recognition, and graphics), vol 11071. Springer, Cham, pp 732-740. https://doi.org/10.1007/978-3-030-00934-2_81
Furumoto H, Shimada Y, Imai K, Maehara S, Maeda J, Hagiwara M et al (2018) Prognostic impact of the integration of volumetric quantification of the solid part of the tumor on 3DCT and FDG-PET imaging in clinical stage IA adenocarcinoma of the lung. Lung Cancer 121:91-96. https://doi.org/10.1016/j.lungcan.2018.05.001
Grothausmann R, Knudsen L, Ochs M, Mühlfeld C (2017) Digital 3D reconstructions using histological serial sections of lung tissue including the alveolar capillary network. Am J Physiol - Lung Cell Mol Physiol 312(2):L243-L257. https://doi.org/10.1152/ajplung.00326.2016
Morales-Navarrete H, Segovia-Miranda F, Klukowski P, Meyer K, Nonaka H, Marsico G et al (2015) A versatile pipeline for the multi-scale digital reconstruction and quantitative analysis of 3D tissue architecture. eLife 4:e11214. https://doi.org/10.7554/eLife.11214.039
Kasten Y, Doktofsky D, Kovler I (2020) End-to-end convolutional neural network for 3D reconstruction of knee bones from Bi-planar X-ray images. In: Deeba F, Johnson P, Würfl T, Ye JC (eds) Machine learning for medical image reconstruction. 3rd international workshop, MLMIR 2020, Held in conjunction with MICCAI 2020, Lima, October 2020. Lecture notes in computer science (Image processing, computer vision, pattern recognition, and graphics), vol 12450. Springer, Cham, pp 123-133. https://doi.org/10.1007/978-3-030-61598-7_12
Ciliberti FK, Guerrini L, Gunnarsson AE, Recenti M, Jacob D, Cangiano V et al (2022) CT-and MRI-based 3D reconstruction of knee joint to assess cartilage and bone. Diagnostics 12(2):279. https://doi.org/10.3390/diagnostics12020279
Hess S, Moser LB, Robertson EL, Behrend H, Amsler F, Iordache E et al (2022) Osteoarthritic and non-osteoarthritic patients show comparable coronal knee joint line orientations in a cross-sectional study based on 3D reconstructed CT images. Knee Surg, Sports Traumatol, Arthrosc 30(2):407-418. https://doi.org/10.1007/s00167-021-06740-3
Wu J, Mahfouz MR (2021) Reconstruction of knee anatomy from single-plane fluoroscopic x-ray based on a nonlinear statistical shape model. J Med Imaging 8(1):6001. https://doi.org/10.1117/1.JMI.8.1.016001
Bao LX, Rong SW, Shi ZJ, Wang J, Zhang Y (2021) Measurement of femoral posterior condylar offset and posterior tibial slope in normal knees based on 3D reconstruction. BMC Musculoskelet Disord 22(1):486. https://doi.org/10.1186/s12891-021-04367-6
Marzorati D, Sarti M, Mainardi L, Manzotti A, Cerveri P (2020) Deep 3D convolutional networks to segment bones affected by severe osteoarthritis in CT scans for PSI-based knee surgical planning. IEEE Access 8:196394-196407. https://doi.org/10.1109/ACCESS.2020.3034418
Puelles VG, Combes AN, Bertram JF (2021) Clearly imaging and quantifying the kidney in 3D. Kidney Int 100(4):780-786. https://doi.org/10.1016/j.kint.2021.04.042
Guliev B, Talyshinskii A, Akbarov I, Chukanov V, Vasilyev P (2022) Three-dimensional reconstruction of pelvicalyceal system of the kidney based on native CT images are 1-step away from the use of contrast agent. Turk J Urol 48(2):130-135. https://doi.org/10.5152/tud.2022.21329
Mercader C, Vilaseca A, Moreno JL, López A, Sebastià MC, Nicolau C et al (2019) Role of the three-dimensional printing technology in complex laparoscopic renal surgery: a renal tumor in a horseshoe kidney. Int Braz J Urol 45(6):1129-1135. https://doi.org/10.1590/s1677-5538.ibju.2019.0085
Chaussy Y, Vieille L, Lacroix E, Lenoir M, Marie F, Corbat L et al (2020) 3D reconstruction of Wilms’ tumor and kidneys in children: variability, usefulness and constraints. J Pediatr Urol 16(6):830.e1-830.e8. https://doi.org/10.1016/j.jpurol.2020.08.023
Les T, Markiewicz T, Dziekiewicz M, Lorent M (2020) Kidney boundary detection algorithm based on extended maxima transformations for computed tomography diagnosis. Appl Sci 10(21):7512. https://doi.org/10.3390/app10217512
Yeo CT, MacDonald A, Ungi T, Lasso A, Jalink D, Zevin B et al (2018) Utility of 3D reconstruction of 2D liver computed tomography/magnetic resonance images as a surgical planning tool for residents in liver resection surgery. J Surg Educ 75(3):792-797. https://doi.org/10.1016/j.jsurg.2017.07.031
Fang CH, An J, Bruno A, Cai XJ, Fan J, Fujimoto J et al (2020) Consensus recommendations of three-dimensional visualization for diagnosis and management of liver diseases. Hepatol Int 14(4):437-453. https://doi.org/10.1007/s12072-020-10052-y
Tatamov AA, Boraeva TT, Revazova AB, Alibegova AS, Dzhanaralieva KM, Tetueva AR et al (2021) Application of 3D technologies in surgery on the example of liver echinococcosis. J Pharm Res Int 33(40A):256-261. https://doi.org/10.9734/jpri/2021/v33i40A32242
Fang CH, Zhang P, Qi XL (2019) Digital and intelligent liver surgery in the new era: prospects and dilemmas. BioMedicine 41:693-701. https://doi.org/10.1016/j.ebiom.2019.02.017
Bjerke IE, Øvsthus M, Papp EA, Yates SC, Silvestri L, Fiorilli J et al (2018) Data integration through brain atlasing: human brain project tools and strategies. Eur Psychiatry 50:70-76. https://doi.org/10.1016/j.eurpsy.2018.02.004
Ebner M, Wang GT, Li WQ, Aertsen M, Patel PA, Aughwane R et al (2020) An automated framework for localization, segmentation and super-resolution reconstruction of fetal brain MRI. NeuroImage 206:116324. https://doi.org/10.1016/j.neuroimage.2019.116324
Du JL, Wang LL, Liu YL, Zhou ZX, He ZS, Jia YY (2020) Brain MRI super-resolution using 3D dilated convolutional encoder-decoder network. IEEE Access 8:18938-18950. https://doi.org/10.1109/ACCESS.2020.2968395
Goodfellow IJ, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S et al (2014) Generative adversarial nets. In: Proceedings of the 27th international conference on neural information processing systems, MIT Press, Montreal, 8-13 December 2014
Song WN, Liang Y, Yang JW, Wang K, He L (2020) Oral-3D: reconstructing the 3D bone structure of oral cavity from 2D panoramic X-ray. arXiv preprint arXiv: 2003.08413. https://doi.org/10.1609/aaai.v35i1.16135
Nakao M, Tong F, Nakamura M, Matsuda T (2021) Image-to-graph convolutional network for deformable shape reconstruction from a single projection image. In: de Bruijne M, Cattin PC, Cotin S, Padoy N, Speidel S, Zheng YF et al (eds) Medical image computing and computer assisted intervention. 24th international conference, Strasbourg, September-October 2021. Lecture notes in computer science (Image processing, computer vision, pattern recognition, and graphics), vol 12904. Springer, Cham, pp 259-268. https://doi.org/10.1007/978-3-030-87202-1_25
Čavojská J, Petrasch J, Mattern D, Lehmann NJ, Voisard A, Böttcher P (2020) Estimating and abstracting the 3D structure of feline bones using neural networks on X-ray (2D) images. Commun Biol 3(1):337. https://doi.org/10.1038/s42003-020-1057-3
Chen X, Diaz-Pinto A, Ravikumar N, Frangi AF (2021) Deep learning in medical image registration. Prog Biomed Eng 3(1):012003. https://doi.org/10.1088/2516-1091/abd37c
de Vos BD, Berendsen FF, Viergever MA, Staring M, Išgum I (2017) End-to-end unsupervised deformable image registration with a convolutional neural network. In: Cardoso MJ, Arbel T, Carneiro G, Syeda-Mahmood T, Tavares JMRS, Moradi M et al (eds) Deep learning in medical image analysis and multimodal learning for clinical decision support. 3rd international workshop, DLMIA 2017, and 7th international workshop, ML-CDS 2017, held in conjunction with MICCAI 2017, Québec City, September 2017. Lecture notes in computer science (Image processing, computer vision, pattern recognition, and graphics), vol 10553. Springer, Cham, pp 204-212. https://doi.org/10.1007/978-3-319-67558-9_24
Lv J, Yang M, Zhang J, Wang XY (2018) Respiratory motion correction for free-breathing 3D abdominal MRI using CNN-based image registration: a feasibility study. Br J Radiol 91(1083):20170788. https://doi.org/10.1259/bjr.20170788
Fechter T, Baltas D (2020) One-shot learning for deformable medical image registration and periodic motion tracking. IEEE Trans Med Imaging 39(7):2506-2517. https://doi.org/10.1109/TMI.2020.2972616
Sokooti H, de Vos B, Berendsen F, Lelieveldt BPF, Išgum I, Staring M (2017) Nonrigid image registration using multi-scale 3D convolutional neural networks. In: Descoteaux M, Maier-Hein L, Franz A, Jannin P, Collins D, Duchesne S (eds) Medical image computing and computer assisted intervention. 20th international conference, Quebec City, September 2017. Lecture notes in computer science (Image processing, computer vision, pattern recognition, and graphics), vol 10433. Springer, Cham, pp 232-239. https://doi.org/10.1007/978-3-319-66182-7_27
Fu YB, Lei Y, Wang TH, Higgins K, Bradley JD, Curran WJ et al (2020) LungRegNet: an unsupervised deformable image registration method for 4D-CT lung. Med Phys 47(4):1763-1774. https://doi.org/10.1002/mp.14065
Mahapatra D, Ge ZY (2019) Combining transfer learning and segmentation information with GANs for training data independent image registration. arXiv preprint arXiv:1903.10139
Shen ZY, Vialard FX, Niethammer M (2019) Region-specific diffeomorphic metric mapping. In: Proceedings of the 33rd conference on neural information processing systems, Vancouver, 8-14 December 2019
Balakrishnan G, Zhao A, Sabuncu MR, Guttag J, Dalca AV (2019) VoxelMorph: a learning framework for deformable medical image registration. IEEE Trans Med Imaging 38(8):1788-1800. https://doi.org/10.1109/TMI.2019.2897538
Yan P, Xu S, Rastinehad AR, Wood BJ (2018) Adversarial image registration with application for MR and TRUS image fusion. In: Shi YH, Suk HI, Liu MX (eds) Machine learning in medical imaging. 9th international workshop, MLMI 2018, held in conjunction with MICCAI 2018, Granada, September 2018. Lecture notes in computer science (Image processing, computer vision, pattern recognition, and graphics), vol 11046. Springer, Cham, pp 197-204. https://doi.org/10.1007/978-3-030-00919-9_23
Heinrich MP (2019) Closing the gap between deep and conventional image registration using probabilistic dense displacement networks. In: Shen DG, Liu TM, Peters TM, Staib LH, Essert C, Zhou SA et al (eds) Medical image computing and computer assisted intervention. 22nd international conference, Shenzhen, October, 2019. Lecture notes in computer science (Image processing, computer vision, pattern recognition, and graphics), vol 11769. Springer, Cham, pp 50-58. https://doi.org/10.1007/978-3-030-32226-7_6
Carass A, Roy S, Gherman A, Reinhold JC, Jesson A, Arbel T et al (2020) Evaluating white matter lesion segmentations with refined sørensen-dice analysis. Sci Rep 10(1):8242. https://doi.org/10.1038/s41598-020-64803-w
Li XZ, Li RH, Zhu L, Fu CW, Heng PA (2021) DNF-Net: a deep normal filtering network for mesh denoising. IEEE Trans Vis Comput Graph 27(10):4060-4072. https://doi.org/10.1109/TVCG.2020.3001681
Risser L, Vialard FX, Wolz R, Murgasova M, Holm DD, Rueckert D (2011) Simultaneous multi-scale registration using large deformation diffeomorphic metric mapping. IEEE Trans Med Imaging 30(10):1746-1759. https://doi.org/10.1109/TMI.2011.2146787
Salih OM, Rasheed MH, Siddeq MM, Rodrigues MA (2022) Image compression for quality 3D reconstruction. J King Saud Univ - Comput Inf Sci 34(5):2271-2287. https://doi.org/10.1016/j.jksuci.2020.07.012
Strümpler Y, Postels J, Yang R, van Gool L, Tombari F (2022) Implicit neural representations for image compression. In: Avidan S, Brostow G, Cissé M, Farinella GM, Hassner T (eds) Computer vision. 17th European conference, Tel Aviv, October, 2022. Lecture notes in computer science (ECCV: European conference on computer vision), vol 13686. Springer, Cham, pp 74-91. https://doi.org/10.1007/978-3-031-19809-0_5
Xing Y, Tan JQ, Hong PL, He YY, Hu M (2022) Mesh denoising based on recurrent neural networks. Symmetry 14(6):1233. https://doi.org/10.3390/sym14061233
Raghunandan KR, Dodmane R, Bhavya K, Rao NSK, Sahu AK (2023) Chaotic-map based encryption for 3D point and 3D mesh fog data in edge computing. IEEE Access 11:3545-3554. https://doi.org/10.1109/ACCESS.2022.3232461
Lyu WL, Cheng LL, Yin ZX (2022) High-capacity reversible data hiding in encrypted 3D mesh models based on multi-MSB prediction. Signal Process 201:108686. https://doi.org/10.1016/j.sigpro.2022.108686
Hashemi M, Akhbari M, Jutten C (2022) Delve into multiple sclerosis (MS) lesion exploration: a modified attention U-Net for MS lesion segmentation in Brain MRI. Comput Biol Med 145:105402. https://doi.org/10.1016/j.compbiomed.2022.105402
Zhang WR, Yao G, Yang B, Zheng WF, Liu C (2022) Motion prediction of beating heart using spatio-temporal LSTM. IEEE Signal Process Lett 29:787-791. https://doi.org/10.1109/LSP.2022.3154317
J Chaki N Dey 2018 A beginner’s guide to image preprocessing techniques CRC Press, Boca Raton. https://doi.org/10.1201/9780429441134
Chang AX, Funkhouser T, Guibas L, Hanrahan P, Huang QX, Li ZM et al (2015) ShapeNet: an information-Rich 3D model repository. arXiv preprint arXiv: 1512.03012
Wu ZR, Song SR, Khosla A, Yu F, Zhang LG, Tang XO et al (2015) 3D ShapeNets: a deep representation for volumetric shapes. In: Proceedings of the 2015 IEEE conference on computer vision and pattern recognition, IEEE, Boston, 7-12 June 2015
Acknowledgements
All authors acknowledge the Department of Computer Science and Engineering, NIT Nagaland scholars, and staff for their suggestions and feedback.
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
MS contributed to the writing, literature survey, and background study; AN contributed to the conceptualization, supervision, and overall project guidance; HRS contributed to the surveys and reviews.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sarmah, M., Neelima, A. & Singh, H.R. Survey of methods and principles in three-dimensional reconstruction from two-dimensional medical images. Vis. Comput. Ind. Biomed. Art 6, 15 (2023). https://doi.org/10.1186/s42492-023-00142-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s42492-023-00142-7