
Abstract
Background
Diet plays an important role in Alzheimer’s disease (AD) initiation, progression and outcomes. Previous studies have shown individual food-derived substances may have neuroprotective or neurotoxic effects. However, few works systematically investigate the role of food and food-derived metabolites on the development and progression of AD.
Methods
In this study, we systematically investigated 7569 metabolites and identified AD-associated food metabolites using a novel network-based approach. We constructed a context-sensitive network to integrate heterogeneous chemical and genetic data, and to model context-specific inter-relationships among foods, metabolites, human genes and AD.
Results
Our metabolite prioritization algorithm ranked 59 known AD-associated food metabolites within top 4.9%, which is significantly higher than random expectation. Interestingly, a few top-ranked food metabolites were specifically enriched in herbs and spices. Pathway enrichment analysis shows that these top-ranked herb-and-spice metabolites share many common pathways with AD, including the amyloid processing pathway, which is considered as a hallmark in AD-affected brains and has pathological roles in AD development.
Conclusions
Our study represents the first unbiased systems approach to characterizing the effects of food and food-derived metabolites in AD pathogenesis. Our ranking approach prioritizes the known AD-associated food metabolites, and identifies interesting relationships between AD and the food group “herbs and spices”. Overall, our study provides intriguing evidence for the role of diet, as an important environmental factor, in AD etiology.
Similar content being viewed by others

Background
Alzheimer’s disease (AD) is the sixth leading cause of death and affected 5.3 million people in 2015 in the United States [1]. Diet plays an important role in the disease development [2]. Epidemiological studies have shown that higher adherence to a Mediterranean-type diet is associated with lower risk for AD [3,4,5] and mild cognitive impairment [6, 7]. Evidence suggests that improper diet habits may accelerate the progression of neuron damage through increasing the concentration of pro-inflammatory mediators [8, 9]. In addition, a number of experimental studies have investigated individual food-derived substances, such as resveratrol [10], vitamin [11], and advanced glycation end products [12], and demonstrated their neuroprotective or neurotoxic effects. Systematic study of food metabolites and their associations with AD may offer insights into the disease-environment relationship and disease prevention, but currently remains unexplored.
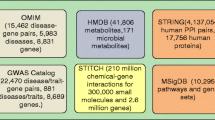
Knowledge of metabolites and their interactions with disease-associated proteins has been obtained through in vitro, in silico, and in vivo technologies [13]. Most previous studies used these data to understand drug actions [14, 15]. Recently, large amounts of data have also accumulated on food metabolites (Fig. 1): The Human Metabolome Database (HMDB) [16] provides high-quality and comprehensive information for 74,462 metabolites, including their chemical, biological, and physical properties; these metabolites can be linked to foods using the large-scale food constitute resource in the Food Database (FooDB) [17], which covers the detailed compositional information for 907 foods. On the other hand, the interactions between the metabolites and human proteins are also available in chemical-protein interaction databases, such as the Search Tool for Interactions of Chemicals (STITCH) [18]. Here, we developed a network-based approach to integrate food metabolites with foods and human proteins, and performed a systematic unbiased study to identify AD-associated food metabolites.

Link disease, chemical and genetic data to infer the food metabolites related with AD
Network-based approaches have been widely used in biomedical applications, such as predicting disease-gene associations [19,20,21], understanding disease comorbidity [22], and drug repurposing [23,24,25]. Traditional biomedical networks often model the relationships between two nodes based on pairwise similarities [26, 27]. For example, disease networks have been constructed by defining different similarities: some quantified the disease-disease similarities based on shared phenotypes [26, 27], and others used shared genetic factors [28]. These networks only captured the strength of the links, but ignored their semantic meaning. Real world interconnections are multi-typed. Specifically, in our problem, two metabolites may share commonalities because they are contained in the same food, or interact with the same protein. Recently, we introduce a novel concept—context-sensitive network [29], which preserves the context of how nodes are connected in the network. In a disease-gene prediction study, our experiment results demonstrated that the context-sensitive disease network led to significantly improved performance than the similarity-based disease network [29]. Analysis shows that the similarity-based network tends to contain noises and bury the true signals in a much denser network structure than the context-sensitive network [29]. Motivated by the benefits of context-sensitive networks, we construct a gene-metabolite-food (GMF) network in this study to model the complex relationships among food, metabolites, human proteins, and AD by seamlessly integrating heterogeneous databases in Fig. 1. Then we predict the food metabolites that are highly associated with AD using this network, and further investigate the pathways shared between AD and the prioritized food metabolites. Due to the lack of gold standard, we tested our approach in AD by manually curating a list of known AD-associated food metabolites. To the best of our knowledge, our study represents the first effort to systematically model the context-sensitive interactions among tens of thousands of human genes, food metabolites, food and diseases and to understand which and how food and food-derived metabolites are involved in disease development. In summary, the identification of food and food-derived metabolites and the understanding of their role as key mediators through which these factors promote or protect against human diseases will enable new possibilities for disease understanding, diagnosis, prevention, and treatment.
Methods
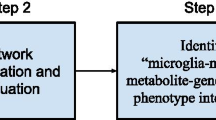
Our study consists of four steps (Fig. 2): first, we construct the GMF network using databases in Fig. 1; second, we prioritize AD-associated metabolites using a network-based ranking algorithm with the input of AD-causing genes; third, we evaluate the metabolite ranking using the known disorder-metabolite associations provided by HMDB; and finally, we investigate the common pathways shared by AD and top-ranked food metabolites to gain insights into how the metabolites affect AD. The following subsections describe each step in details.

Four steps of our study: (1) GMF network construction (blue nodes: genes; green nodes: metabolites; orange nodes: food); (2) metabolite ranking using a network-based ranking algorithm; (3) evaluation of the metabolite ranking; and (4) investigation of the common pathways between AD and prioritized food metabolites
GMF network construction
We construct a context-sensitive network to model the interconnections among foods, metabolites, and human genes. We first extract the three types of nodes for the network: the metabolite nodes are extracted from HMDB [16]; the gene nodes are obtained from The HUGO Gene Nomenclature Committee (HGNC) [30] and labeled by approved gene names. For food nodes, we extract food names from FooDB [17] and normalize these strings using the unique identifier assigned by the database. Then we use the “group” information provided in FooDB for each food to further clean the food names: we exclude the foods in the group of “dishes”, such as “pizza” and “meatball”, which contain complex and uncertain components, and remove the food names that are high level food group names, such as “herbs and spices”, “fruits”, and “green vegetables”.
Next, we identify three types of edges for the network: metabolite-gene, metabolite-food, and gene-gene links. The metabolite-food edges are extracted from FooDB: we aligned the unique metabolite identifiers provided by FooDB to the metabolite names in HMDB. We conducted distribution analysis on food metabolites (Fig. 3). Each food is averagely associated with 78 metabolites, and 95% of the metabolites are linked to less than 20 foods. The metabolite-gene connections are extracted from the STITCH18 database: we link the metabolite names to PubChem compound identifiers, which is linked to interacting genes in STITCH. In addition, genes are connected other gene nodes via the protein-protein interactions extracted from the Search Tool for the Retrieval of Interacting Genes/Proteins (STRING) [31]. Since protein-protein interactions in STRING and metabolite-gene interactions in STITCH have confidence scores provided by each own database, we establish weighted edges for gene-gene and gene-metabolite edges, and normalize the weights into the range of [0,1]. Table 1 shows the size of the entire GMF network, and the numbers of nodes and edges of each kind.

Distribution of (1) the number of metabolites for each food, and (2) the number of food associated with each metabolite
Metabolite ranking algorithm
We first extracted from the Online Mendelian Inheritance in Man (OMIM) database all 14 genes associated with AD [32], and set the corresponding gene nodes in the GMF network as the “seeds.” Then we rank the nodes in the GMF network using the random walk model, which assumes that a walker starts from the seeds and randomly jumps to the neighbor nodes. We calculate an iteratively updated score for each node as the probability of being reached by the seeds:
where M is the transition matrix, γ is the probability of restarting from the seeds, and p0 consists of the initial scores for all nodes. Here, the initial score is 1/14 for each seed and zero for all other nodes; thus all the scores add up to 1. The transition matrix M is the adjacency matrix of the GMF network after column-wise normalization. We set the restarting probability γ as 0.7 and the algorithm is insensitive to different choices of γ. We assume the algorithm converges if the difference of scores between iteration ε < 10−8. After the algorithm converges, we extract metabolites from all the nodes and rank them based on the scores.
Evaluation of metabolite ranking
HMDB provides metabolite-disorder associations curated from literature. We extract a total of 81 AD-associated metabolites from HMDB, 59 of which appear in STITCH with associated genes. We used these 56 metabolites as the evaluation set. Most of metabolite-AD associations were identified in previous animal model or human cell line studies. Here, though the 59 metabolites are not the perfect gold standard for AD-associated metabolites, we consider them as the positive examples that show relevance with AD and test if they tend to be ranked highly in our approach.
We calculate the mean and median ranks for the 59 metabolites among our ranking. We also plot the precision-recall curve, and calculated the average precision across all recall levels when considering top k retrieved metabolites as the positive. The evaluation metrics are compared between our approach and the random cases. Pure random rankings result in a mean average rank of 50% for the 59 metabolites. Here, we generate random rankings by randomly selecting the seeds on the GMF network. Comparing our ranking for the evaluation set with the randomized cases, we test if the top-ranked metabolites were prioritized by chance.
Pathway analysis for top-ranked food metabolites
Only part of the 7596 metabolites are actually linked to food nodes based on the FooDB data in the GMF network. In addition, many of the food metabolites are components of hundreds of different foods. We first extract the metabolites that were uniquely identified in less than ten foods. Then we identify the significantly enriched pathways for each top-ranked food-specific metabolite: we import the metabolite interacting genes into the QIAGEN’s Ingenuity Pathway Analysis software (IPA®, QIAGEN Redwood City, https://www.qiagenbioinformatics.com/products/ingenuity-pathway-analysis/) and download the significant canonical pathways. To compare the pathways for prioritized metabolites and AD, we also identified significant pathways for AD using the 14 AD-associated genes from OMIM.
We developed a method to rank the common significant pathways between AD and each prioritized metabolite. Intuitively, we intended to prioritize the pathways that are highly enriched for both AD- and metabolite-associated genes. The IPA software provides a coverage score for each AD- or metabolite-associated significant pathway; the score measures the percentage of AD- or metabolite-associated genes in each pathway. We design a score for each common pathway between AD and a metabolite to ensure the balanced coverage:
where cAD and cm are the coverage of AD-associated genes and the metabolite-associated genes, respectively. The score was inspired by the definition of F1 measure, which is a measure of a test’s accuracy, and considers precision and recall at the same time. Last, we examine the top-ranked common significant pathways between AD and each metabolite based on the balanced score.
Results
Metabolite ranking based on the context-sensitive GMF network are supported by existing knowledge
Our approach averagely ranked the 59 known AD-associated food metabolites in top 4.9% among the 5192 food metabolites in the GMF network (metabolite nodes that have connections to food nodes). Comparing with the randomized rankings (generated with random seeds placed on the GMF network), we achieved significantly higher mean rank (p < e-12, student’s T test) and median rank (p < e-14, Wilcoxon ranked sum test). Also, 55 out of the 59 (93%) positive examples of AD-associated metabolites were ranked within top 10%. In addition, the precision-recall curve in Fig. 4 demonstrates a better performance of our ranking comparing with the randomized rankings; the mean average precision calculated from the precision-recall curve is also significantly higher than the random case (Table 2, p < e-8). Together, the results demonstrate that our ranking for the food metabolites was able to prioritize relevant compounds for AD. Note that our ranking algorithm is unbiased, and did not use any prior knowledge about the known AD-associated food metabolites.

Precision recall curve for GMF network ranking algorithm for food-contained metabolites and the average of 100 random rankings
Besides the ranking for metabolites, our approach also automatically generated the ranking for all foods based on the strength of their associations with AD. We grouped the foods into categories and ranked the categories based on the average of food ranks in each category. The ranking shows a trend that high-fiber foods, such as grains, vegetables and legumes, tend to have higher scores than meats, sweets and milk products. Interestingly, our ranking is approximately correlated with the Mediterranean diet pyramid, which suggests an eating pattern with many healthy grains, fruits, vegetables, beans and nuts, and small amounts of dairy, red wine and meats [33] (Fig. 5). Here, the ranking of food categories only reflects the average ranks for foods of each class, and individual food in lowly ranked food categories may also contain metabolites that are closely relevant to AD. Next, we specifically examined each top-ranked food metabolites.

Mediterranean diet pyramid and food category ranking based on the GMF network
Top-ranked food metabolites contain interesting candidates of AD-associated compounds
Many top-ranked metabolites are common nutrients found in hundreds of different foods, such as calcium and glycerol. Here, we focus on the unique metabolites that were exclusively identified in several specific foods or food categories. Table 3 lists the top-ranked food metabolites that were identified in less than ten foods. Seven out of ten metabolites were constituents of “healthy foods,” which include fruits, vegetables, grains, nuts and legumes. Among them, tetramethylpyrazine has been shown to exhibit the neuroprotective effects in rats [34]; and resveratrol is widely-known nutritional supplement with a number of beneficial health effects, such as anti-cancer [35], antiviral [36], neuroprotective [37,38,39,40], anti-aging [41], anti-inflammatory [42], cardioprotective [43], and life-prolonging effects. Among the top ten food-specific metabolites, only 4-hydroxynonenal was in the evaluation set of food metabolites that were known to be associated with AD based on the HMDB data. This also shows that many AD-associated food metabolites may not be readily included in existing databases. The ultimate goal of our study is to identify these new relevant food metabolites, which may might shed lights on the disease prevention.
Surprisingly, we found that three metabolites in Table 3 are uniquely identified in the group of “herbs and spices”. Previous studies point out that the incidence of neurodegenerative diseases among people living in the Asian subcontinent, where people regularly consume spices, is much lower than in countries of the western world [44]. In addition, both in vitro and in vivo studies have indicated that nutraceuticals derived from herbs and spices, such as red pepper, black pepper, ginger, garlic, and cinnamon, target inflammatory pathways, and may show effects in preventing neurodegenerative diseases [45, 46]. We filtered our metabolite ranking and systematically extracted the compounds that are specifically found in herbs and spices. Table 4 lists the top ten spice-specific metabolites. Among these chemicals, capsaicin has been studied in animal models to investigate if it may attenuate memory impairment [47, 48]. Next, we systematically investigated the pathways targeted by the top AD-associated spice-specific metabolites.
Top-ranked spice-specific metabolites share significant pathways with AD
We identified 58 significantly enriched pathways for AD, and found that each top-ranked herb-and-spice metabolite has many overlapping pathways with AD. Figure 5 shows the overlapping pathways that are mostly enriched for both AD- and metabolite-associated genes. Importantly, we found that amyloid processing (highlighted in Fig. 6) appears repetitively among the enriched pathways for herb-and-spice metabolites. The accumulation of the beta-amyloid protein is a major neuropathological hallmark in AD-affected brains and has a pathological role in AD [49]. The pathway analysis supports that the identified herb-and-spice metabolites are potentially involved with the development of AD. Other AD-involved pathways, including melatonin degradation [50], neuroprotective role of THOP1 [51], and Reelin signaling in neurons [52], were also found enriched for the herb-and-spice metabolite interacting genes. As a control, we also investigated the pathways for guanosine 2′,3′-cyclic phosphate, which is food metabolite ranked in the bottom by our approach; the metabolite has no overlapping pathways with AD.

Overlapping pathways between the top-ranked herbs and spices specific metabolites and AD
Discussions
We developed a novel context-sensitive network approach to analyze interactions among food, food metabolites, host genetics and pathways in the context of specific diseases. In this study, we use the approach to identify relevant food metabolites for AD, which is a complex disease affected by both genetic and environmental factors. Our study provides intriguing evidence for the role of diet, as an important environmental factor, in AD etiology. We also provide the hypotheses for the subsequent biological and clinical studies of host-environment interactions in AD. Due to the lack of gold standard (i.e., known food metabolites for many diseases), we did not test our algorithm on all other diseases. Our approach is not biased towards to AD; it is highly generic and can be applied to any other diseases.
The future work of this study includes the following aspects. (1) We will test and apply the algorithms to other food-related diseases, such as cancers, inflammatory bowel diseases, and allergy. (2) We will further classify food metabolites into neuroprotective and neurotoxic. In the future, as more detailed and quantitative data become increasingly available, we will be able to further classify the effects of food metabolites into AD-promoting or protective. (3) We constructed a network that contains gene, food, and metabolite nodes in this study. Other types of data, such as disease-phenotype relationships and disorder-metabolites in HMDB, may also be helpful in inferring AD-associated food metabolites. However, the usefulness of these data requires further evaluation. In the future, we will investigate effective approaches to rationally integrate more comprehensive data to predict AD-affecting food metabolites. (4) We will further improve the prediction algorithm based on the context-sensitive networks. In social network analysis, researchers have developed improved random walk algorithms that consider the semantic meanings of the paths in networks [53]. However, these approaches usually require prior knowledge or sufficient training data, to define or learning meaningful paths for the random walker in the network; the knowledge and training data cannot be easily obtained in most biomedical prediction scenarios. We will explore new algorithms in the unsupervised fashion that could further take the advantages of the context-sensitive networks. (5) In addition, we need further validation on the prioritized AD-associated food metabolites and how they might affect AD. Currently, we investigated the common significantly enriched pathways between AD and the prioritized metabolites, and found that a few metabolites are involved in the amyloid processing pathways. Amyloid processing is a major activity in AD-affected brains and involves with the cause of AD. The result shows that the top-ranked food metabolites are highly associated with AD development. However, further validations are essential through in vitro and in vivo experiments (6) Finally, AD may be related with the interactions of different food metabolites. More generally, other environmental factors, including toxins, drugs, and gut microbiome may also contribute to the AD development. In our previous work, we have studied brain-gut-microbiome connections in AD [54]. In the future, we will develop approaches in identifying chemicals from other sources that are associated with AD. We will also explore more complex computational models to investigate the combined effects of multiple environmental factors.
Conclusions
In summary, we developed a novel network-based approach to understanding how food and food-derived metabolites are involved in complex human diseases, and conducted an exploratory study in AD. The identification of disease-associated food metabolites and their underlying pathways may provide insights into disease mechanism and offer the opportunities for disease prevention and treatment.
Abbreviations
- AD:
-
Alzheimer’s disease
- FooDB:
-
The Food Database
- GMF:
-
Gene-metabolite-food
- HMDB:
-
The Human Metabolome Database
- OMIM:
-
The Online Mendelian Inheritance in Man
- STITCH:
-
Search Tool for Interactions of Chemicals
- STRING:
-
The Search Tool for the Retrieval of Interacting Genes/Proteins
References
Alzheimer’s A. 2015 Alzheimer’s disease facts and figures. Alzheimer’s Dementia. 2015;11(3):332.
Creegan R, Hunt W, McManus A, Rainey-Smith SR. Diet, nutrients and metabolism: cogs in the wheel driving Alzheimer's disease pathology? Br J Nutr. 2015;113(10):1499-517.
Scarmeas N, Stern Y, Mayeux R, Luchsinger JA. Mediterranean diet, Alzheimer disease, and vascular mediation. Arch Neurol. 2006;63(12):1709–17.
Scarmeas N, Stern Y, Tang MX, Mayeux R, Luchsinger JA. Mediterranean diet and risk for Alzheimer's disease. Ann Neurol. 2006;59(6):912–21.
Lourida I, Soni M, Thompson-Coon J, Purandare N, Lang IA, Ukoumunne OC, Llewellyn DJ. Mediterranean diet, cognitive function, and dementia: a systematic review. Epidemiology. 2013;24(4):479–89.
Scarmeas N, Stern Y, Mayeux R, Manly JJ, Schupf N, Luchsinger JA. Mediterranean diet and mild cognitive impairment. Arch Neurol. 2009;66(2):216–25.
Tangney CC, Kwasny MJ, Li H, Wilson RS, Evans DA, Morris MC. Adherence to a Mediterranean-type dietary pattern and cognitive decline in a community population. Am J Clin Nutr. 2011;93(3):601–7.
Scarmeas N, Luchsinger JA, Schupf N, Brickman AM, Cosentino S, Tang MX, Stern Y. Physical activity, diet, and risk of Alzheimer disease. JAMA. 2009;302(6):627–37.
Heneka MT, Kummer MP, Latz E. Innate immune activation in neurodegenerative disease. Nat Rev Immunol. 2014;14(7):463–77.
Rege SD, Geetha T, Griffin GD, Broderick TL, Babu JR. Neuroprotective effects of resveratrol in Alzheimer disease pathology. Front Aging Neurosci. 2014;6(218):1–2.
Luchsinger JA, Tang MX, Shea S, Mayeux R. Antioxidant vitamin intake and risk of Alzheimer disease. Arch Neurol. 2003;60(2):203–8.
Cai W, Ramdas M, Zhu L, Chen X, Striker GE, Vlassara H. Oral advanced glycation endproducts (AGEs) promote insulin resistance and diabetes by depleting the antioxidant defenses AGE receptor-1 and sirtuin 1. Proc Natl Acad Sci. 2012;109(39):15888–93.
Yang GX, Li X, Snyder M. Investigating metabolite–protein interactions: an overview of available techniques. Methods. 2012;57(4):459–66.
Matsuda R, Bi C, Anguizola J, Sobansky M, Rodriguez E, Badilla JV, Zheng X, Hage B, Hage DS. Studies of metabolite–protein interactions: a review. J Chromatogr B. 2014;966:48–58.
Chen S, Jiang H, Cao Y, Wang Y, Hu Z, Zhu Z, Chai Y. Drug target identification using network analysis: taking active components in Sini decoction as an example. Sci Rep. 2016;6(Article number: 24245).
Wishart DS, Jewison T, Guo AC, Wilson M, Knox C, Liu Y, Djoumbou Y, Mandal R, Aziat F, Dong E, Bouatra S. HMDB 3.0—the human metabolome database in 2013. Nucleic Acids Res. 2013;41(Database issue):D801-7.
Scalbert A, Andres-Lacueva C, Arita M, Kroon P, Manach C, Urpi-Sarda M, Wishart D. Databases on food phytochemicals and their health-promoting effects. J Agric Food Chem. 2011 Apr 12;59(9):4331–48.
Kuhn M, von Mering C, Campillos M, Jensen LJ, Bork PSTITCH. Interaction networks of chemicals and proteins. Nucleic Acids Res. 2008;36(suppl 1):D684–8.
Chen Y, Li L, Zhang GQ, Xu R. Phenome-driven disease genetics prediction toward drug discovery. Bioinformatics. 2015;31(12):i276–83.
Ni J, Koyuturk M, Tong H, Haines J, Xu R, Zhang X. Disease gene prioritization by integrating tissue-specific molecular networks using a robust multi-network model. BMC bioinformatics. 2016;17(1):453.
Chen Y, Xu R. Network-based gene prediction for plasmodium falciparum malaria towards genetics-based drug discovery. BMC Genomics. 2015;16(7):S9.
Chen Y, Li L, Xu R. Disease comorbidity network guides the detection of molecular evidence for the link between colorectal cancer and obesity. AMIA Summits on Translational Science Proceedings. 2015;2015:201.
Gottlieb A, Stein GY, Ruppin E, Sharan RPREDICT. A method for inferring novel drug indications with application to personalized medicine. Mol Syst Biol. 2011 Jan 1;7(1):496.
Chen Y, Cai X, Xu R. Combining human disease genetics and mouse model phenotypes towards drug repositioning for Parkinson’s disease. In AMIA annual symposium proceedings 2015 (Vol. 2015, p. 1851). American Medical Informatics Association.
Chen Y, Xu R. Drug repurposing for glioblastoma based on molecular subtypes. J Biomed Inform. 2016;64:131–8.
Chen Y, Zhang X, Zhang GQ, Xu R. Comparative analysis of a novel disease phenotype network based on clinical manifestations. J Biomed Inform. 2015;53:113–20.
Robinson PN, Köhler S, Bauer S, Seelow D, Horn D, Mundlos S. The human phenotype ontology: a tool for annotating and analyzing human hereditary disease. Am J Hum Genet. 2008;83(5):610–5.
Goh KI, Cusick ME, Valle D, Childs B, Vidal M, Barabási AL. The human disease network. Proc Natl Acad Sci. 2007;104(21):8685–90.
Chen Y, Xu R. Context-sensitive network-based disease genetics prediction and its implications in drug discovery. Bioinformatics. 2017 Apr 1;33(7):1031–9.
Gray KA, Yates B, Seal RL, Wright MW, Bruford EA. Genenames. Org: the HGNC resources in 2015. Nucleic Acids Res. 2015;43(Database issue):D1079-85.
Szklarczyk D, Franceschini A, Kuhn M, Simonovic M, Roth A, Minguez P, Doerks T, Stark M, Muller J, Bork P, Jensen LJ. The STRING database in 2011: functional interaction networks of proteins, globally integrated and scored. Nucleic Acids Res. 2011;39(Database issue):D561-8.
Hamosh A, Scott AF, Amberger JS, Bocchini CA, McKusick VA. Online Mendelian inheritance in man (OMIM), a knowledgebase of human genes and genetic disorders. Nucleic Acids Res. 2005;33(suppl 1):D514–7.
Willett WC, Sacks F, Trichopoulou A, Drescher G, Ferro-Luzzi A, Helsing E, Trichopoulos D. Mediterranean diet pyramid: a cultural model for healthy eating. Am J Clin Nutr. 1995;61(6):1402S–6S.
Hu J, Lang Y, Cao Y, Zhang T, Lu H. The neuroprotective effect of Tetramethylpyrazine against contusive spinal cord injury by activating PGC-1α in rats. Neurochem Res. 2015;40(7):1393–401.
Aluyen JK, Ton QN, Tran T, Yang AE, Gottlieb HB, Bellanger RA. Resveratrol: potential as anticancer agent. Journal of dietary supplements. 2012;9(1):45–56.
Campagna M, Rivas C. Antiviral activity of resveratrol. Biochem Soc Trans. 2010;38(1):50–3.
Albani D, Polito L, Signorini A, Forloni G. Neuroprotective properties of resveratrol in different neurodegenerative disorders. Biofactors. 2010;36(5):370–6.
Bastianetto S, Ménard C, Quirion R. Neuroprotective action of resveratrol. Biochimica et Biophysica Acta (BBA)-Molecular Basis of Disease. 2015;1852(6):1195-201.
Bastianetto S, Zheng WH, Quirion R. Neuroprotective abilities of resveratrol and other red wine constituents against nitric oxide-related toxicity in cultured hippocampal neurons. Br J Pharmacol. 2000;131(4):711–20.
Han YS, Zheng WH, Bastianetto S, Chabot JG, Quirion R. Neuroprotective effects of resveratrol against β-amyloid-induced neurotoxicity in rat hippocampal neurons: involvement of protein kinase C. Br J Pharmacol. 2004 Mar 1;141(6):997–1005.
Alarcon De La Lastra C, Villegas I. Resveratrol as an anti-inflammatory and anti-aging agent: mechanisms and clinical implications. Mol Nutr Food Res. 2005;49(5):405–30.
Zordoky BN, Robertson IM, Dyck JR. Preclinical and clinical evidence for the role of resveratrol in the treatment of cardiovascular diseases. Biochimica et Biophysica Acta (BBA)-Molecular Basis of Disease. 2015;1852(6):1155–77.
Prasad S, Gupta SC, Tyagi AK, Aggarwal BB. Curcumin, a component of golden spice: from bedside to bench and back. Biotechnol Adv. 2014;32(6):1053–64.
Kannappan R, Gupta SC, Kim JH, Reuter S, Aggarwal BB. Neuroprotection by spice-derived nutraceuticals: you are what you eat! Mol Neurobiol. 2011;44(2):142–59.
Aggarwal BB. Targeting inflammation-induced obesity and metabolic diseases by curcumin and other nutraceuticals. Annu Rev Nutr. 2010;30:173.
Aggarwal BB, Van Kuiken ME, Iyer LH, Harikumar KB, Sung B. Molecular targets of nutraceuticals derived from dietary spices: potential role in suppression of inflammation and tumorigenesis. Exp Biol Med. 2009;234(8):825–49.
Sharma SK, Vij AS, Sharma M. Mechanisms and clinical uses of capsaicin. Eur J Pharmacol. 2013;720(1):55–62.
Jiang X, Jia LW, Li XH, Cheng XS, Xie JZ, Ma ZW, Xu WJ, Liu Y, Yao Y, Du LL, Zhou XW. Capsaicin ameliorates stress-induced Alzheimer's disease-like pathological and cognitive impairments in rats. J Alzheimers Dis. 2013;35(1):91–105.
O’Brien RJ, Wong PC. Amyloid precursor protein processing and Alzheimer’s disease. Annu Rev Neurosci. 2011;34:185.
Lin L, Huang QX, Yang SS, Chu J, Wang JZ, Tian Q. Melatonin in Alzheimer’s disease. Int J Mol Sci. 2013;14(7):14575–93.
Pollio G, Hoozemans JJ, Andersen CA, Roncarati R, Rosi MC, van Haastert ES, Seredenina T, Diamanti D, Gotta S, Fiorentini A, Magnoni L. Increased expression of the oligopeptidase THOP1 is a neuroprotective response to Aβ toxicity. Neurobiol Dis. 2008;31(1):145–58.
Krstic D, Pfister S, Notter T, Knuesel I. Decisive role of Reelin signaling during early stages of Alzheimer’s disease. Neuroscience. 2013;246:108–16.
Sun Y, Han J, Yan X, Yu PS, Pathsim WT. Meta path-based top-k similarity search in heterogeneous information networks. Proceedings of the VLDB Endowment. 2011;4(11):992–1003.
Xu R, Wang Q. Towards understanding brain-gut-microbiome connections in Alzheimer’s disease. BMC Syst Biol. 2016;10(3):63.
Acknowledgements
Not applicable.
Funding
This work was supported by the Eunice Kennedy Shriver National Institute of Child Health & Human Development of the National Institutes of Health under the NIH Director’s New Innovator Award number DP2HD084068 (Xu), NIH National Institute of Aging (1 R01 AG057557–01, Xu), NIH National Institute of Aging (1 R01 AG061388–01, Xu), NIH National Institute of Aging (1 R56 AG062272–01, Xu), American Cancer Society Research Scholar Grant (RSG-16-049-01 - MPC, Xu), NIH Clinical and Translational Science Collaborative of Cleveland (1UL1TR002548–01, Konstan). Publication of this article was sponsored by the Eunice Kennedy Shriver National Institute of Child Health & Human Development of the National Institutes of Health under the NIH Director’s New Innovator Award number DP2HD084068.
Availability of data and materials
Not applicable.
About this supplement
This article has been published as part of BMC Medical Genomics Volume 12 Supplement 1, 2019: Selected articles from the International Conference on Intelligent Biology and Medicine (ICIBM) 2018: medical genomics. The full contents of the supplement are available online at https://bmcmedgenomics.biomedcentral.com/articles/supplements/volume-12-supplement-1.
Author information
Authors and Affiliations
Contributions
RX conceived the study. YC and RX designed the experiment. YC performed the experiment and wrote the manuscript. All authors have participated in study discussion and manuscript preparation. All of the authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Chen, Y., Xu, R. Context-sensitive network analysis identifies food metabolites associated with Alzheimer’s disease: an exploratory study. BMC Med Genomics 12 (Suppl 1), 17 (2019). https://doi.org/10.1186/s12920-018-0459-2
Published:
DOI: https://doi.org/10.1186/s12920-018-0459-2