
Abstract
The incidence of cancer and its associated mortality are increasing globally, indicating an urgent need to develop even more effective and sensitive sets of biomarkers that could help in early diagnosis and consequent intervention. Given that many cellular processes are carried out by proteins, cancer research has recently shifted toward an exploration of the full proteome for such discovery. Among the advanced methodologies that are being developed for analyzing the proteome, antibody microarrays have become a prominent tool for gathering the information required for a better understanding of disease biology, early detection, discrimination of tumors and monitoring of disease progression. Here, we review the technical aspects and challenges in the development and use of antibody microarray assays and examine recently reported applications in oncoproteomics.
Similar content being viewed by others


Introduction
Over the past two decades, there have been tremendous advances in the understanding of the molecular processes by which normal cells transform into cancer and of the importance of signaling pathways in cancer initiation and progression. This progress has paved the way for the development of numerous therapeutic leads. In addition, the enormous leap in biotechnology and bioinformatics raises hopes for substantial progress in cancer diagnosis and treatment. Despite the increased knowledge and improved technical capabilities, however, global mortality from cancer is projected to continue rising, mainly because of the aging of the population, with an estimated 9 million people dying from cancer in 2015 and 11.4 million in 2030 [1]. A major obstacle to the reversion of this trend is the fact that cancer is frequently detectable only at late stages. Current cancer diagnosis also still relies on the testing of classical cancer markers, such as cancer antigen (CA)-125, CA19-9, CA72-4 and carcinoembryonic antigen (CEA), in combination with histopathological examination of tissue biopsies. Furthermore, there is a growing need for individual monitoring of the response to therapy and disease progression, as the effect of a particular treatment is not uniform among affected subjects with the same diagnosis. In consequence, approaches are urgently required that enhance the power of detection and diagnosis of cancer at early stages.
Prompted by the sequencing of the human genome, high-throughput technologies have evolved, shifting attention towards a non-reductionist approach to investigating biological phenomena. The explosion of interest in exploring the genome and proteome for biomarkers has already provided a better understanding of the molecular basis of cancer. Among the high-throughput technologies, DNA analysis by microarrays [2] and, more recently, second-generation sequencing [3] have become prominent approaches. However, the similarity in genetic alteration shared among various cancers limits the possibility of linking the genetic portrait to a particular disease feature [4]. The genomic sequence does not specify which proteins interact, how interactions occur or where in a cell a protein localizes under various conditions. Transcript abundance levels do not necessarily correlate with protein abundance [5], and frequently one cannot tell from the sequence whether a gene is translated into protein or rather functions as RNA.
Recent developments in genetic analysis have been paralleled by a surge in interest in the comprehensive study of proteins and protein networks. From a biomedical perspective, the field of proteomics has great potential because most pharmacological interventions and diagnostic tests are directed at proteins rather than genes. The inherent advantage of proteomics over genomics is that the identified protein itself is the biological end-product [6]. There are several sophisticated technologies that enable proteome-wide analysis of multiple proteins in a variety of specimens. Among these, two-dimensional gel electrophoresis and mass spectrometry have been widely used and have evolved into indispensable tools for proteomic research [7, 8]. Optimization processes have been significantly improved with regard to their performance at handling small sample sizes and analyzing complex protein mixtures [9]. However, they still suffer from limitations in terms of resolution, sensitivity and reproducibility, high cost and the great amount of time and labor required. Affinity protein-array technology seems to be a promising tool to overcome some of these limitations.
Technical aspects of antibody microarrays
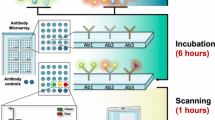
Antibody microarrays are miniaturized analytical systems generated by spatially arraying small amounts (volumes at a picoliter scale or less) of individual capture molecules, mostly antibodies, onto a solid support (Figure 1) [10–14]. So far, the number of antibodies has varied from a few to several hundred. Upon incubation with a protein sample, bound antigens are detected by fluorescence detection or surface plasmon resonance, for example. The acquired signal intensity images are converted to numerical values reflecting the protein profiles within the samples. Assay sensitivities in the picomole to femtomole range have been reported [15, 16]. Although antibody microarrays were introduced after DNA microarrays, the feasibility of miniaturized and multiplexed immunoassays was first reported and discussed by Ekins in the late 1980s [17, 18]. The technical factors that determine the set-up of a high-performing antibody microarray are the array surface, the antibodies, sample processing, incubation and signal generation and data analysis.

Schematic diagram of the basic processes of analyzing protein extracts on antibody microarrays. Although many details such as the binder type, the protein labeling, the surface structure of the solid support or the detection procedure may change considerably, the principal components and steps of the assay remain the same.
Array surface
The choice of surface is critical for array performance because, unlike DNA, proteins are very divergent and inhomogeneous in structure and properties and prone to loss of function by denaturation and/or modification [19]. The most frequently used solid supports for antibody microarrays are microscopic glass, plastic or silicon slides that are coated with a variety of substrates [20–22]. Examples of chemical substrates are nitrocellulose, aldehydes, amino-polyethylene glycol, Ni-nitrilotriacetic acid, streptavidin, epoxysilane and polyacrylamide-gel coatings. The choice of a specific substrate depends on several factors, such as the complexity and nature of the analyzed sample (whether it consists of individual proteins, proteins from plasma or other body liquids, or samples from cultured cells or tissues), the mode of antibody coupling, biocompatibility and array density. In addition to flat slides, arrays using nanovials and attovials [23] have been used in an attempt to enhance sensitivity and multiplexing.
Antibodies
There are several types of affinity reagents that can act as capture molecules, such as monoclonal and polyclonal antibodies, recombinant antibody fragments (scFab, scFv, and so on), binders with different scaffolds (such as affibodies or anchorins), nucleic acid scaffolds (aptamers), peptides and small chemical entities [24]. Each molecule class has its advantages and disadvantages. Nevertheless, currently antibodies and antibody fragments continue to be the most attractive affinity probes. Mono-specific polyclonal antibodies [25] are attractive because of the cooperative effect obtained from the generation of a mixture of antibodies to several epitopes of the target protein. This allows more antibodies to bind to each target, concomitantly improving affinity, and makes the binding assay less dependent on a single epitope. This is particularly important for multi-platform applications, in which the protein target may be denatured in different ways by factors such as detergent, alcohol, formalin or mechanical stress.
So far, the vast majority of microarrays have been generated using monoclonal and polyclonal antibodies from commercial sources. Concerns are rising, however, over how many of these commercial antibodies meet the expected performance and specificity requirements [26]. In addition, there is an imbalance in representation. Hundreds of antibodies exist against particular targets - for instance, more than 900 antibodies for p53 - whereas none are available for many others. Recombinant-antibody phage-display libraries have been suggested as a way to reduce the limitations associated with monoclonal and polyclonal antibodies in terms of specificity, functionality, stability and availability [10, 14]. Furthermore, programs have been initiated for the creation of a global resource of well characterized affinity reagents for an analysis of the human proteome, most prominently the Swedish Human Proteome Atlas project [27] or, transnationally, the European ProteomeBinders consortium [26].
Sample processing
In any proteomic study, sample preparation is a critical factor. Owing to the complexity of the proteome, the enormous dynamic range in concentration and the susceptibility of proteins to minimal changes in the milieu and the relative abundance in a mixture, processing a sample for proteomic analysis is a challenging task. The majority of recent antibody microarray applications studied serum samples. However, other types of specimens were also targeted, such as extracts of cell surface proteins [28], cultured cells [29] or tissue biopsies [30]. Although many reports have focused on the optimization of protocols for protein extraction from mammalian cells for gel separation and mass spectrometry [31], proteins for antibody microarray assays are mostly isolated by procedures long used for immunoblotting or enzyme-linked immunosorbent assays (ELISAs). Introducing an advanced protein extraction protocol that is more representative of a whole cellular proteome would be advantageous for microarray-based global protein analysis. In all proteomic approaches, sample complexity can give rise to non-specific binding and complicate uniform labeling. Strategies have been developed to remove high-abundance proteins [32] or to fractionate the proteins [33] in order to reduce complexity.
Sample labeling and signal read-out
Subsequent to isolation, samples are further processed by labeling either directly with fluorescent dyes or indirectly with biotin or biotin derivatives. Biotin is recognized by labeled streptavidin. Testing of labeling tags showed a superior sensitivity and signal-to-background ratio when samples were labeled with biotin [34, 35]. However, although sample-labeling approaches allow high-sensitivity detection in the picomole to femtomole range, there are some concerns regarding the introduction of too many label molecules, which might affect the antibody-antigen binding capacity. There are several label-free detection techniques that bypass labeling complications. The oldest one is the sandwich approach known from ELISA, in which two antibodies are used for selective binding to a specific protein. An arrayed antibody serves as capture reagent. Upon protein binding, the bound molecule is detected by the second antibody, which carries the label directly or is identified by a third, labeled antibody. However, since the process necessitates a working pair of antibodies for each individual analyte, technological issues prevent this approach for multiplex arrays that consist of several hundreds to thousands of antibodies.
Emerging methods use matrix assisted laser desorption ionization time-of-flight (MALDI-TOF) mass spectrometry [36], surface plasmon resonance [37], nanowires [38], microcantilevers [39], quartz crystal microbalances [40] or light scattering [41] for read-out. However, with fluorescence-based array detection approaching single-molecule sensitivity [42], the alternative methods still need to prove their practical feasibility and competitiveness. Incubation conditions have been found to be critical for analysis, especially in view of the huge dynamic range of protein concentrations. Mass transport and kinetics are crucial for reproducible and sensitive studies [16]. Appropriate mixing, for example, is of critical importance to such ends [16].
Data analysis
Data analysis and interpretation are usually carried out using approaches adopted directly from DNA microarray studies. Data normalization can be tackled with a variety of methods, such as an internally normalized ratio algorithm following dual-color labeling [43], spike-in protein control(s) of known concentration, and relative normalization to a particular analyte assayed independently by other methods (such as ELISA) [44]. In addition to measurements at equilibrium, new technology enables the analysis of association and particularly dissociation [45], adding extra quality to the analysis.
Antibody microarrays in oncoproteomics
Although still very much under development, the antibody microarray technique has already shown wide application potential for clinical cancer research and diagnostics [45]. Table 1 lists some recent applications of antibody microarrays in oncoproteomics. The antibody platforms had either been fabricated in-house or obtained from commercial sources. The number of binders varied from a few tens, as in the analysis of cytokine networks [46] or functional pathways [47], to hundreds, as in studies focused on a more global protein expression analysis [29, 30, 48]. Several sources of samples have been used, including culture cell extracts [29, 49–51], dissected tissue biopsies [25, 51–53], exhaled breath [46] and body fluids [30, 54–60]. Nevertheless, the most studied specimens were sera taken from both cancer patients and healthy controls [30, 54–56, 58–60]. The rationale is that serum reflects the body's whole cellular metabolic harvest, and leakage of proteins from a particular organ or group of cells to the circulation provides some reflection of biochemical alterations during disease. In addition, in more technical terms, protein complexity is relatively low in serum and protein extraction is easy to perform.
Hudelist et al. [52] used antibody microarrays for profiling expressed proteins in normal and malignant breast tissues. They found increased expression levels of several proteins in malignant breast tissues, such as casein kinase Ie, p53, annexin XI, the cell-cycle protein CDC25C, the general transcription initiation factor eIF-4E and mitogen-activated protein (MAP) kinase 7, using commercial arrays of 378 antibodies. In another report [61], 224 antibodies revealed proteins that are related to doxorubicin therapy resistance in breast cancer cell lines. A decrease in the expression of MAP kinase-activated monophosphotyrosine, cyclin D2, cytokeratin 18, cyclin B1 and heterogeneous nuclear ribonucleoprotein m3-m4 was found to be associated with doxorubicin resistance. Other recent investigations helped identify a marker involved in invasion (interleukin (IL)-8) [62]. Studying the serum proteome from metastatic breast cancer patients and healthy controls with recombinant single-chain variable fragment (scFv) microarrays [54], breast cancer was identified with a specificity and sensitivity of 85% on the basis of 129 serum analytes.
In bladder cancer, an array of 254 antibodies showed 93.7% sensitivity to discriminate between serum samples of 58 healthy subjects versus 37 bladder cancer patients [53]. The impact of radiation treatment was evaluated in LoVo colon carcinoma cells [63]. An array of 146 antibodies showed increased expression of apoptosis regulators paralleled by downregulation of CEA, pointing to a possible application for monitoring response to radiation therapy in colon cancer. In colorectal cancer, the marker IPO-38 [30], cytokeratin 13, calcineurin, the serine/threonine kinase CHK1, clathrin light chain, MAP kinase 3, phosphoprotein tyrosine kinase 2 (also called focal adhesion kinase, phosphorylated at Ser-910) and the p53 regulator MDM2 [64] were found as possible biomarkers. They were further validated with standard protocols such as ELISA, immunoblotting, immunohistochemistry and MALDI-TOF/TOF mass spectroscopy. However, the number of patients evaluated in these colorectal cancer studies was low. The application of antibody microarrays to prostate cancer also identified several potential marker proteins [65, 66]. Analysis of cytokines from prostate fluid of patients with minimal and maximal cancer volume revealed a possibility for early detection of the disease [67].
Several publications have recently reported the use of antibody microarrays in assessing markers of lung cancer, which is the leading cancer-related cause of death. Kullmann et al. [46] tested cytokine profiles with a 120-antibody array in breath condensates of 50 smoking lung cancer patients and 25 smokers without clinical or radiological sign of a pulmonary tumor and were able to differentiate the two groups by nine cytokines, including eotaxin, fibroblast growth factors, IL-10 and macrophage inflammatory protein (MIP)-3. However, the results were not stratified according to stages and histological subtypes owing to the use of pooled samples. Gao et al. [55] constructed an array of 48 antibodies against distinctive serum proteins. They analyzed 24 newly diagnosed subjects with lung cancer, 24 healthy controls and 32 subjects with chronic obstructive pulmonary disease. C-reactive protein, serum amyloid A, mucin 1 and α1-antitrypsin were among the proteins that showed higher abundances in the lung cancer samples than in the control samples.
Pancreatic cancer has received much attention, being one of the most deadly forms of cancer with basically no current treatment available. Initial observations of serum profiles came from Haab and colleagues [59], revealing individual and combined protein markers associated with pancreatic cancer and variations in specific glycans on multiple proteins. In another study from the same group [68], antibody microarrays were used to analyze post-translation modification of serum protein in pancreatic cancer patients. By profiling both protein and glycan variations [69], they found cancer-associated glycan alteration on the proteins MUC1 and CEA [68]. The Borrebaeck group [56] used an array of recombinant scFv antibodies in an attempt to classify sera derived from pancreatic adenocarcinoma patients versus samples from healthy subjects. They reported a protein signature based on 19 non-redundant analytes discriminating between cancer patients and healthy subjects.
Conclusions and future perspectives
The antibody microarray is a technology that still requires maturation. Although some technical factors have been dealt with, others remain to be optimized. In particular, appropriate binders need to be produced and validated. However, from the initial and mostly still rather preliminary studies, one can already conclude that important information can be gathered in an efficient and probably even quantitative process. The technology has the advantage of targeting the actual effector molecules of many biochemical processes, thus providing information that is of immediate clinical relevance. Sensitivity issues should be overcome by new detection modes, which could enable sensitivity up to the level of counting individual molecules. The method's practical usefulness will be particularly enhanced once the analysis of samples obtained by non-invasive means provides the required clinical information.
As is the case for other profiling procedures, indirect biomarkers - molecules that indicate a cellular state without necessarily being the cause for it - provide only limited diagnostic and prognostic accuracy if studied individually. Indeed, the use of multiple biomarkers rather than a single one improves diagnostic accuracy, enhances the predictive power for patient outcome and may enable adequate monitoring of the response to treatment. Because of the decisive role of proteins in cellular activities, antibody or other binder microarrays have the potential to quickly become a routine diagnostic tool, eventually even in relatively simple formats with few binder molecules.
Abbreviations
- CEA:
-
carcinoembryonic antigen
- ELISA:
-
enzyme-linked immunosorbent assay
- MALDI-TOF:
-
matrix assisted laser desorption ionization time of flight
- MAP:
-
mitogen activated protein
- scFv:
-
single-chain variable fragment.
References
World Health Organization: Facts about cancer. http://www.who.int/mediacentre/factsheets/fs297/en/index.html
Hoheisel JD: Microarray technology: beyond transcript profiling and genotype analysis. Nat Rev Genet. 2006, 7: 200-210.
Ansorge WJ: Next-generation DNA sequencing techniques. N Biotechnol. 2009, 25: 195-203.
Hahn WC, Weinberg RA: Rules for making human tumor cells. N Engl J Med. 2002, 347: 1593-1603.
Schmidt MW, Houseman A, Ivanov AR, Wolf DA: Comparative proteomic and transcriptomic profiling of the fission yeast Schizosaccharomyces pombe. Mol Syst Biol. 2007, 3: 79-
Martin DB, Nelson PS: From genomics to proteomics: techniques and applications in cancer research. Trends Cell Biol. 2001, 11: S60-S65.
Han X, Aslanian A, Yates JR: Mass spectrometry for proteomics. Curr Opin Chem Biol. 2008, 12: 483-490.
Wittmann-Liebold B, Graack HR, Pohl T: Two-dimensional gel electrophoresis as tool for proteomics studies in combination with protein identification by mass spectrometry. Proteomics. 2006, 6: 4688-4703.
Aebersold R, Mann M: Mass spectrometry-based proteomics. Nature. 2003, 422: 198-207.
Wingren C, Borrebaeck CA: Antibody-based microarrays. Methods Mol Biol. 2009, 509: 57-84.
Kusnezow W, Hoheisel JD: Antibody microarrays: promises and problems. Biotechniques. 2002, 14-23. Suppl
MacBeath G: Protein microarrays and proteomics. Nat Genet. 2002, 32 (Suppl): 526-532.
Haab BB: Methods and applications of antibody microarrays in cancer research. Proteomics. 2003, 3: 2116-2122.
Wingren C, Borrebaeck CA: Antibody microarrays: current status and key technological advances. OMICS. 2006, 10: 411-427.
Wingren C, Borrebaeck CA: High-throughput proteomics using antibody microarrays. Expert Rev Proteomics. 2004, 1: 355-364.
Kusnezow W, Syagailo YV, Ruffer S, Baudenstiel N, Gauer C, Hoheisel JD, Wild D, Goychuk I: Optimal design of microarray immunoassays to compensate for kinetic limitations: theory and experiment. Mol Cell Proteomics. 2006, 5: 1681-1696.
Ekins RP: Multi-analyte immunoassay. J Pharm Biomed Anal. 1989, 7: 155-168.
Ekins R, Chu F: Multianalyte microspot immunoassay. The microanalytical 'compact disk' of the future. Ann Biol Clin (Paris). 1992, 50: 337-353.
Doerr A: Protein microarray velcro. Nat Methods. 2005, 2: 642-643.
Angenendt P, Glokler J, Murphy D, Lehrach H, Cahill DJ: Toward optimized antibody microarrays: a comparison of current microarray support materials. Anal Biochem. 2002, 309: 253-260.
Kusnezow W, Hoheisel JD: Solid supports for microarray immunoassays. J Mol Recognit. 2003, 16: 165-176.
Angenendt P, Lehrach H, Kreutzberger J, Glokler J: Subnanoliter enzymatic assays on microarrays. Proteomics. 2005, 5: 420-425.
Ghatnekar-Nilsson S, Dexlin L, Wingren C, Montelius L, Borrebaeck CA: Design of attovial based recombinant antibody arrays combined with a planar wave-guide detection system. Proteomics. 2007, 7: 540-547.
Uhlen M: Affinity as a tool in life science. Biotechniques. 2008, 44: 649-654.
Nilsson P, Paavilainen L, Larsson K, Odling J, Sundberg M, Andersson AC, Kampf C, Persson A, Al-Khalili Szigyarto C, Ottosson J, Bjorling E, Hober S, Wernerus H, Wester K, Ponten F, Uhlen M: Towards a human proteome atlas: high-throughput generation of mono-specific antibodies for tissue profiling. Proteomics. 2005, 5: 4327-4337.
Taussig MJ, Stoevesandt O, Borrebaeck CA, Bradbury AR, Cahill D, Cambillau C, de Daruvar A, Dubel S, Eichler J, Frank R, Gibson TJ, Gloriam D, Gold L, Herberg FW, Hermjakob H, Hoheisel JD, Joos TO, Kallioniemi O, Koegl M, Konthur Z, Korn B, Kremmer E, Krobitsch S, Landegren U, Maarel van der S, McCafferty J, Muyldermans S, Nygren PA, Palcy S, Pluckthun A, Polic B, Przybylski M, Saviranta P, Sawyer A, Sherman DJ, Skerra A, Templin M, Ueffing M, Uhlen M: ProteomeBinders: planning a European resource of affinity reagents for analysis of the human proteome. Nat Methods. 2007, 4: 13-17.
Uhlen M, Hober S: Generation and validation of affinity reagents on a proteome-wide level. J Mol Recognit. 2009, 22: 57-64.
Dexlin L, Ingvarsson J, Frendeus B, Borrebaeck CA, Wingren C: Design of recombinant antibody microarrays for cell surface membrane proteomics. J Proteome Res. 2008, 7: 319-327.
Wong LL, Chang CF, Koay ES, Zhang D: Tyrosine phosphorylation of PP2A is regulated by HER-2 signalling and correlates with breast cancer progression. Int J Oncol. 2009, 34: 1291-1301.
Hao Y, Yu Y, Wang L, Yan M, Ji J, Qu Y, Zhang J, Liu B, Zhu Z: IPO-38 is identified as a novel serum biomarker of gastric cancer based on clinical proteomics technology. J Proteome Res. 2008, 7: 3668-3677.
Rabilloud T: Detergents and chaotropes for protein solubilization before two-dimensional electrophoresis. Methods Mol Biol. 2009, 528: 259-267.
Tirumalai RS, Chan KC, Prieto DA, Issaq HJ, Conrads TP, Veenstra TD: Characterization of the low molecular weight human serum proteome. Mol Cell Proteomics. 2003, 2: 1096-1103.
Borner A, Warnken U, Schnolzer M, Hagen J, Giese N, Bauer A, Hoheisel J: Subcellular protein extraction from human pancreatic cancer tissues. Biotechniques. 2009, 46: 297-304.
Kusnezow W, Banzon V, Schroder C, Schaal R, Hoheisel JD, Ruffer S, Luft P, Duschl A, Syagailo YV: Antibody microarray-based profiling of complex specimens: systematic evaluation of labeling strategies. Proteomics. 2007, 7: 1786-1799.
Wingren C, Ingvarsson J, Dexlin L, Szul D, Borrebaeck CA: Design of recombinant antibody microarrays for complex proteome analysis: choice of sample labeling-tag and solid support. Proteomics. 2007, 7: 3055-3065.
Timm W, Scherbart A, Bocker S, Kohlbacher O, Nattkemper TW: Peak intensity prediction in MALDI-TOF mass spectrometry: a machine learning study to support quantitative proteomics. BMC Bioinformatics. 2008, 9: 443-
Visser NF, Heck AJ: Surface plasmon resonance mass spectrometry in proteomics. Expert Rev Proteomics. 2008, 5: 425-433.
Bangar MA, Shirale DJ, Chen W, Myung NV, Mulchandani A: Single conducting polymer nanowire chemiresistive label-free immunosensor for cancer biomarker. Anal Chem. 2009, 81: 2168-2175.
Alvarez M, Carrascosa LG, Zinoviev K, Plaza JA, Lechuga LM: Biosensors based on cantilevers. Methods Mol Biol. 2009, 504: 51-71.
Hirst ER, Yuan YJ, Xu WL, Bronlund JE: Bondrupture immunosensors - a review. Biosens Bioelectron. 2008, 23: 1759-1768.
Olkhov RV, Fowke JD, Shaw AM: Whole serum BSA antibody screening using a label-free biophotonic nanoparticle array. Anal Biochem. 2009, 385: 234-241.
Hesse J, Jacak J, Kasper M, Regl G, Eichberger T, Winklmayr M, Aberger F, Sonnleitner M, Schlapak R, Howorka S, Muresan L, Frischauf AM, Schutz GJ: RNA expression profiling at the single molecule level. Genome Res. 2006, 16: 1041-1045.
Andersson O, Kozlowski M, Garachtchenko T, Nikoloff C, Lew N, Litman DJ, Chaga G: Determination of relative protein abundance by internally normalized ratio algorithm with antibody arrays. J Proteome Res. 2005, 4: 758-767.
Hamelinck D, Zhou H, Li L, Verweij C, Dillon D, Feng Z, Costa J, Haab BB: Optimized normalization for antibody microarrays and application to serum-protein profiling. Mol Cell Proteomics. 2005, 4: 773-784.
Sanchez-Carbayo M: Antibody arrays: technical considerations and clinical applications in cancer. Clin Chem. 2006, 52: 1651-1659.
Kullmann T, Barta I, Csiszer E, Antus B, Horvath I: Differential cytokine pattern in the exhaled breath of patients with lung cancer. Pathol Oncol Res. 2008, 14: 481-483.
Ahn EH, Kang DK, Chang SI, Kang CS, Han MH, Kang IC: Profiling of differential protein expression in angiogenin-induced HUVECs using antibody-arrayed ProteoChip. Proteomics. 2006, 6: 1104-1109.
Nonomura T, Masaki T, Morishita A, Jian G, Uchida N, Himoto T, Izuishi K, Iwama H, Yoshiji H, Watanabe S, Kurokohchi K, Kuriyama S: Identification of c-Yes expression in the nuclei of hepatocellular carcinoma cells: involvement in the early stages of hepatocarcinogenesis. Int J Oncol. 2007, 30: 105-111.
Perera CN, Spalding HS, Mohammed SI, Camarillo IG: Identification of proteins secreted from leptin stimulated MCF-7 breast cancer cells: a dual proteomic approach. Exp Biol Med (Maywood). 2008, 233: 708-720.
Vazquez-Martin A, Colomer R, Brunet J, Lupu R, Menendez JA: Overexpression of fatty acid synthase gene activates HER1/HER2 tyrosine kinase receptors in human breast epithelial cells. Cell Prolif. 2008, 41: 59-85.
Celis JE, Moreira JM, Cabezon T, Gromov P, Friis E, Rank F, Gromova I: Identification of extracellular and intracellular signaling components of the mammary adipose tissue and its interstitial fluid in high risk breast cancer patients: toward dissecting the molecular circuitry of epithelial-adi-pocyte stromal cell interactions. Mol Cell Proteomics. 2005, 4: 492-522.
Hudelist G, Pacher-Zavisin M, Singer CF, Holper T, Kubista E, Schreiber M, Manavi M, Bilban M, Czerwenka K: Use of high-throughput protein array for profiling of differentially expressed proteins in normal and malignant breast tissue. Breast Cancer Res Treat. 2004, 86: 281-291.
Sanchez-Carbayo M, Socci ND, Lozano JJ, Haab BB, Cordon-Cardo C: Profiling bladder cancer using targeted antibody arrays. Am J Pathol. 2006, 168: 93-103.
Carlsson A, Wingren C, Ingvarsson J, Ellmark P, Baldertorp B, Ferno M, Olsson H, Borrebaeck CA: Serum proteome profiling of metastatic breast cancer using recombinant antibody microarrays. Eur J Cancer. 2008, 44: 472-480.
Gao WM, Kuick R, Orchekowski RP, Misek DE, Qiu J, Greenberg AK, Rom WN, Brenner DE, Omenn GS, Haab BB, Hanash SM: Distinctive serum protein profiles involving abundant proteins in lung cancer patients based upon antibody microarray analysis. BMC Cancer. 2005, 5: 110-
Ingvarsson J, Wingren C, Carlsson A, Ellmark P, Wahren B, Engstrom G, Harmenberg U, Krogh M, Peterson C, Borrebaeck CA: Detection of pancreatic cancer using antibody microarray-based serum protein profiling. Proteomics. 2008, 8: 2211-2219.
Loch CM, Ramirez AB, Liu Y, Sather CL, Delrow JJ, Scholler N, Garvik BM, Urban ND, McIntosh MW, Lampe PD: Use of high density antibody arrays to validate and discover cancer serum biomarkers. Mol Oncol. 2007, 1: 313-320.
Lukesova S, Kopecky O, Vroblova V, Hlavkova D, Andrys C, Moravek P, Cermakova E: Determination of angiogenic factors in serum by protein array in patients with renal cell carcinoma. Folia Biol (Praha). 2008, 54: 134-140.
Orchekowski R, Hamelinck D, Li L, Gliwa E, vanBrocklin M, Marrero JA, Woude Vande GF, Feng Z, Brand R, Haab BB: Antibody microarray profiling reveals individual and combined serum proteins associated with pancreatic cancer. Cancer Res. 2005, 65: 11193-11202.
Scholler N, Gross JA, Garvik B, Wells L, Liu Y, Loch CM, Ramirez AB, McIntosh MW, Lampe PD, Urban N: Use of cancer-specific yeast-secreted in vivo biotinylated recombinant antibodies for serum biomarker discovery. J Transl Med. 2008, 6: 41-
Smith L, Watson MB, O'Kane SL, Drew PJ, Lind MJ, Cawkwell L: The analysis of doxorubicin resistance in human breast cancer cells using antibody microarrays. Mol Cancer Ther. 2006, 5: 2115-2120.
Lin Y, Huang R, Chen L, Li S, Shi Q, Jordan C, Huang RP: Identification of interleukin-8 as estrogen receptor-regulated factor involved in breast cancer invasion and angiogenesis by protein arrays. Int J Cancer. 2004, 109: 507-515.
Sreekumar A, Nyati MK, Varambally S, Barrette TR, Ghosh D, Lawrence TS, Chinnaiyan AM: Profiling of cancer cells using protein microarrays: discovery of novel radiation-regulated proteins. Cancer Res. 2001, 61: 7585-7593.
Madoz-Gurpide J, Canamero M, Sanchez L, Solano J, Alfonso P, Casal JI: A proteomics analysis of cell signaling alterations in colorectal cancer. Mol Cell Proteomics. 2007, 6: 2150-2164.
Miller JC, Zhou H, Kwekel J, Cavallo R, Burke J, Butler EB, Teh BS, Haab BB: Antibody microarray profiling of human prostate cancer sera: antibody screening and identification of potential biomarkers. Proteomics. 2003, 3: 56-63.
Shafer MW, Mangold L, Partin AW, Haab BB: Antibody array profiling reveals serum TSP-1 as a marker to distinguish benign from malignant prostatic disease. Prostate. 2007, 67: 255-267.
Fujita K, Ewing CM, Sokoll LJ, Elliott DJ, Cunningham M, De Marzo AM, Isaacs WB, Pavlovich CP: Cytokine profiling of prostatic fluid from cancerous prostate glands identifies cytokines associated with extent of tumor and inflammation. Prostate. 2008, 68: 872-882.
Chen S, LaRoche T, Hamelinck D, Bergsma D, Brenner D, Simeone D, Brand RE, Haab BB: Multiplexed analysis of glycan variation on native proteins captured by antibody microarrays. Nat Methods. 2007, 4: 437-444.
Li C, Simeone DM, Brenner DE, Anderson MA, Shedden KA, Ruffin MT, Lubman DM: Pancreatic cancer serum detection using a lectin/glyco-antibody array method. J Proteome Res. 2009, 8: 483-492.
Song XC, Fu G, Yang X, Jiang Z, Wang Y, Zhou GW: Protein expression profiling of breast cancer cells by dissociable antibody microarray (DAMA) staining. Mol Cell Proteomics. 2008, 7: 163-169.
Vazquez-Martin A, Colomer R, Menendez JA: Protein array technology to detect HER2 (erbB-2)-induced 'cytokine signature' in breast cancer. Eur J Cancer. 2007, 43: 1117-1124.
McLachlan E, Shao Q, Wang HL, Langlois S, Laird DW: Connexins act as tumor suppressors in three-dimensional mammary cell organoids by regulating differentiation and angiogenesis. Cancer Res. 2006, 66: 9886-9894.
Celis JE, Gromov P, Cabezon T, Moreira JM, Ambartsumian N, Sandelin K, Rank F, Gromova I: Proteomic characterization of the interstitial fluid perfusing the breast tumor microenvironment: a novel resource for biomarker and therapeutic target discovery. Mol Cell Proteomics. 2004, 3: 327-344.
Ellmark P, Belov L, Huang P, Lee CS, Solomon MJ, Morgan DK, Christopherson RI: Multiplex detection of surface molecules on colorectal cancers. Proteomics. 2006, 6: 1791-1802.
Hung KE, Kho AT, Sarracino D, Richard LG, Krastins B, Forrester S, Haab BB, Kohane IS, Kucherlapati R: Mass spectrometry-based study of the plasma proteome in a mouse intestinal tumor model. J Proteome Res. 2006, 5: 1866-1878.
Belov L, Mulligan SP, Barber N, Woolfson A, Scott M, Stoner K, Chrisp JS, Sewell WA, Bradstock KF, Bendall L, Pascovici DS, Thomas M, Erber W, Huang P, Sartor M, Young GA, Wiley JS, Juneja S, Wierda WG, Green AR, Keating MJ, Christopherson RI: Analysis of human leukaemias and lymphomas using extensive immunophenotypes from an antibody microarray. Br J Haematol. 2006, 135: 184-197.
Takemura A, Gemma A, Shibuya M, Matsuda K, Okano T, Nara M, Noro R, Minegishi Y, Yoshimura A, Kudoh S: Gemcitabine resistance in a highly metastatic subpopulation of a pulmonary adenocarcinoma cell line resistant to gefitinib. Int J Oncol. 2007, 31: 1325-1332.
Bartling B, Hofmann HS, Boettger T, Hansen G, Burdach S, Silber RE, Simm A: Comparative application of antibody and gene array for expression profiling in human squamous cell lung carcinoma. Lung Cancer. 2005, 49: 145-154.
Moschos SJ, Smith AP, Mandic M, Athanassiou C, Watson-Hurst K, Jukic DM, Edington HD, Kirkwood JM, Becker D: SAGE and antibody array analysis of melanoma-infiltrated lymph nodes: identification of Ubc9 as an important molecule in advanced-stage melanomas. Oncogene. 2007, 26: 4216-4225.
Qi W, Cooke L, Stejskal A, Riley CJ, Della Croce K, Saldanha JW, Bearss D, Mahadevan D: MP470, a novel receptor tyrosine kinase inhibitor, in combination with Erlotinib inhibits the HER family/PI3K/Akt pathway and tumor growth in prostate cancer. BMC Cancer. 2009, 9: 142-
Acknowledgements
Financial support of the authors' experimental work by the NGFN program of the German Federal Ministry of Education and Research (BMBF) and the EU projects MolTools, DropTop and Proteome-Binders is gratefully acknowledged. MSSA received a long-term fellowship of the Deutscher Akademischer Austausch Dienst.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors' contributions
All authors contributed equally to this work.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
About this article
Cite this article
Alhamdani, M.S., Schröder, C. & Hoheisel, J.D. Oncoproteomic profiling with antibody microarrays. Genome Med 1, 68 (2009). https://doi.org/10.1186/gm68
Published:
DOI: https://doi.org/10.1186/gm68