
Abstract
Background
Previous studies have examined the associations between polymorphisms of adiponectin gene (ADIPOQ) and cardiovascular disease (CVD), but those studies have been inconclusive. The aim of this study was to access the relationship between three single nucleotide polymorphisms (SNPs), +45 T > G (rs2241766), +276 G > T (rs1501299) and -11377 C > G (rs266729) in ADIPOQ and CVD.
Methods
A comprehensive search was conducted to identify all studies on the association of ADIPOQ gene polymorphisms with CVD risk. The fixed and random effect pooled measures (i.e. odds ratio (OR) and 95% confidence interval (CI)) were calculated in the meta-analysis. Heterogeneity among studies was evaluated using Q test and the I2. Publication bias was estimated using modified Egger’s linear regression test.
Results
Thirty-seven studies concerning the associations between the three polymorphisms of ADIPOQ gene and CVD risk were enrolled in this meta-analysis, including 6,398 cases and 10,829 controls for rs2241766, 8,392 cases and 18,730 controls for rs1501299 and 7,835 cases and 14,023 controls for rs266729. The three SNPs were significantly associated with CVD, yielding pooled ORs of 1.22 (95%CI: 1.07, 1.39; P = 0.004), 0.90 (95%CI: 0.83, 0.97; P = 0.007) and 1.09(95%CI: 1.01, 1.17; P = 0.032) for rs2241766, rs1501299 and rs266729, respectively. Rs2241766 and rs1501299 were significantly associated with coronary heart disease (CHD), yielding pooled ORs of 1.29 (95%CI: 1.09, 1.52; P = 0.004) and 0.89 (95%CI: 0.81, 0.99; P = 0.025), respectively. The pooled OR for rs266729 and CHD was 1.09 (95%CI: 0.99, 1.19; P = 0.090). Significant between-study heterogeneity was found in our meta-analysis. Evidence of publication bias was observed in the meta-analysis.
Conclusions
The present meta-analysis showed that the associations between rs2241766, rs1501299 and rs266729 in the ADIPOQ and CVD were significant but weak. High quality studies are still needed to confirm the associations, especially for rs2241766.
Similar content being viewed by others
Background
Adiponectin is a 30-kDa protein that consists of an N-terminal collagenous domain and a C-terminal globular domain[1], with circulating levels ranging from 0.5 to 30 μg/ml and accounting for 0.05% of total plasma protein[2, 3].
Adiponectin plays a role in preventing atherosclerosis. Epidemiology studies have found that adiponectin levels were associated with risk of cardiovascular disease (CVD). Some cross-sectional studies have demonstrated that hypoadiponectinemia was associated with the prevalence of CVD[4–7]. Prospective studies also found significant inverse association between adiponectin and CVD. Health Professionals Follow-up Study found that high plasma adiponectin levels were associated with lower risk of myocardial infarction (MI) over a follow-up period of 6 years among men without previous cardiovascular disease[8]. The Nurses’ Health Study recently found that high levels of total adiponectin were associated with lower risk of CVD among women during 14 years of follow-up [9].
There have been a number of studies reported that certain polymorphisms in the adiponectin coding gene ADIPOQ were strongly associated with adiponectin levels [10–13]. A recent genome wide association study (GWAS) identified that a single nucleotide polymorphism (SNP) rs266717 at the ADIPOQ locus demonstrated the strongest associations with adiponectin levels (P-combined = 9.2 × 10−19, n = 14,733) [14]. In that study, the authors also re-evaluated other SNPs in ADIPOQ and found that rs266729 and rs182052 showed significant association. Previous studies have examined the association of several polymorphisms in the ADIPOQ gene, including rs822395 (−4034A > C), rs822396 (−3964A > G), +2019delA, rs17300539 (−11391 G > A), rs266729 (−11377 C > G), rs2241766 (+45 T > G) and rs1501299 (+276 G > T), with CVD and subclinical CVD [15]. The three SNPs, rs266729, rs2241766 and rs1501299, were most widely studied.
Lacquemant et al. reported that rs2241766 was associated with an increased risk of coronary artery disease among patients with type 2 diabetes[16]. Bacci et al. reported that polymorphism rs1501299 was associated with a decreased coronary artery disease risk [17]. However, these early studies have been limited by the small sample size and case–control design. Subsequent researches on this issue reported different results. A large genetic association case–control study conducted by Chiodini et al. confirmed the association for rs1501299, but SNP rs2241766 showed no significant association [18]. The studies conducted by Pischon et al. also failed to confirm these associations [9]. The result for rs266729 has also been inconsistent [19–21].
Meta-analysis is a powerful tool for summarizing results from different studies by producing a single estimate of the major effect with enhanced precision. In this study, we conducted a meta-analysis to examine the associations between the three SNPs in the ADIPOQ gene and CVD.
Methods
Retrieval of published studies
Two independent reviewers (Zhang and Mo) conducted a systematic computerized literature search for papers published before February 12, 2012. PubMed, Embase and Wanfang databases were searched, using various combinations of keywords, such as ‘cardiovascular disease’ or ‘coronary heart disease’ or ‘coronary artery disease’ or ‘myocardial infarction’ or ‘stroke’ combined with ‘ADIPOQ’ or ‘APM1’ or ‘ACDC’ or ‘adiponectin’ and ‘polymorphism’ and ‘genetic association’, without language restriction. The full texts of the retrieved articles were read to decide whether information on the topic of interest should be included. The reference lists of the retrieved articles as well as those of review articles and previous meta-analyses on this topic were searched to identify other studies that were not identified initially. Articles were included in the meta-analysis if they examined the hypothesis that ADIPOQ polymorphisms were associated with CVD using case–control or cohort design, and had sufficient published data on the genotypes or allele frequencies for determining an estimate of relative risk (i.e. odds ratio (OR)) and confidence interval (CI). Our meta-analysis was conducted according to the Meta-analysis of Observational Studies in Epidemiology (MOOSE) guidelines [22].
Data extraction
Two reviewers (Zhang and Mo) independently examined the retrieved articles using a data collection form, in order to extract the information needed. From each study, the following data were abstracted: first author, year of publication, country of the population studied, study subjects and main outcomes, the mean age and body mass index (BMI) and the percentage of men in case and control groups, polymorphisms tested, genotyping methods, the number of persons with different genotypes in cases and controls, and main results. Following data extraction, the reviewers checked for any discordance until a consensus was reached.
Quality score assessment
Quality of studies was also independently assessed by the same two reviewers, using guidelines proposed by the NCI-NHGRI Working Group on Replication in Association Studies [23]. These guidelines provided a checklist of 53 conditions for authors, journal editors and referees to allow clear and unambiguous interpretation of the data and results of genome-wide and other genotype–phenotype association studies. The first 34 conditions were considered for quality assessment of each study in our meta-analysis. One score is assigned to each condition. If one study met a requirement, it gained 1 score and otherwise, it gained 0. The sum of the score for each study was described as total quality score.
Statistical analysis
The OR was used to compare alleles between cases and controls. We computed the genetic contrast of the mutant alleles (G for rs2241766, T for rs1501299 and G for rs266729) versus the wildtype alleles. In secondary analyses, we calculated specific ORs according to the racial descent of subjects (separated analyses for Caucasian, East Asian, West Asian and African populations), study subjects (normal subjects or subjects with type 2 diabetes or other diseases), sample size (<1000 or ≥1000), genotyping methods (PCR-RFLP or Taqman genotyping assay or other). The association for coronary heart disease (CHD) was also examined. We assessed the presence of between-study heterogeneity using the chi-square based Cochran’s Q statistic. The inconsistency index I2 (ranging from 0 to 100%) was also calculated, where higher values of the index (I2 > 50%) indicate the existence of heterogeneity[24]. Publication bias was assessed with Egger regression test [25]. The pooled OR was calculated by the inverse-variance weighted method, and the significance of the pooled OR was tested by Z statistic. The combined ORs along with their 95% CIs were estimated using the fixed effects and random effects method. The random-effects method[26], which in the presence of heterogeneity, is more appropriate as it is prudent to take into account an estimate of the between-study variance (I2). On the other hand, the random effects hypothesis is appropriate for clinical trials but results in relatively reduced power for genetic association/GWAS detection of SNPs which show association in at least one study [27]. The random effects model has less power to detect effects than fixed effects in almost all situations [28]. To examine specific subsets in these studies, separate analyses were undertaken. This was achieved by performing a sensitivity analysis, in which an individual study was removed each time to assess the influence of each study. Likewise, a cumulative analysis was performed according to the ascending date of publication to identify the influence of the first published study on the subsequent publications and the evolution of the combined estimate over time [29]. For all analyses performed here, the statistical package Stata 10 (Stata Corporation, College Station, Texas, USA) was used. In all analyses statistically significant results were declared as those with a P value < 0.05, except for tests of publication bias where 0.1 was used as significant level.
Results
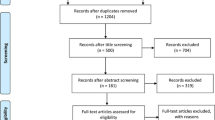
After the literature searching and the subsequent screening, we came up with 34 research papers consisting of 37 case–control or cohort studies concerning the association of rs2241766 or rs1501299 or rs266729 polymorphisms with CVD (Figure 1). The detailed characteristics of each study were summarized, including authors, publication year, mean age, percentage of men, sample size, genotyping method and study population (Table 1). We also summarized the mean BMI in case and control groups and genotype data in case and control groups (Additional file 1: Table S1) and the main results of each study (Additional file 2: Table S2). Details of the quality score assessment were presented in Additional file 3: Table S3.

Flow diagram for study selection process in the meta-analysis of ADIPOQ gene polymorphisms and CVD.
Meta-analysis for rs2241766 polymorphism
The 24 retrieved studies that investigated the association of rs2241766 with CVD contained information about 6,398 cases and 10,829 control subjects (Table 2). The pooled frequency of the minor G allele in controls was 15.7%.
Figure 2 showed that the combined ORs (fixed-effects and random-effects method) for the rs2241766G allele on CVD were 1.12 (95%CI: 1.05, 1.19; P < 0.0001) and 1.22 (95%CI: 1.07, 1.39; P = 0.004). There was a significant between-study heterogeneity as indicated by the P value of the corresponding test (P < 0.001) and the value of the I2 index (I2 =74.2%). The sensitivity analysis revealed that there was not a single study influencing the result significantly. Cumulative analysis found the influence of the first published study on the subsequent publications and the evolution of the combined estimate over time. Lacquemant et al. reported the significant association in 2003 [14], while the subsequent publications added to the meta-analysis, the significance disappeared. The overall estimation became significant after the large study reported by Chiodini et al. in 2010 included in the analysis [16]. Evidence of publication bias was found in the studies (Egger’s test, P = 0.007). The association for CHD alone was also significant, with an OR of 1.29(95%CI: 1.09, 1.52) (Table 2).

Meta-analysis for the relationship between rs2241766 and CVD risk. Year represents publish year. The solid squares represent odds ratios (ORs) from individual studies; the diamonds are shown as overall effect. The combined ORs along with their 95% CIs were in the contrast of G allele vs. T allele and estimated using the random-effects method.
Meta-analysis for rs1501299 polymorphism
Twenty-seven studies investigating the association of rs1501299 with CVD were enrolled in this meta-analysis, containing about 8,392 cases and 18,730 control subjects (Table 2). The pooled frequency of the T allele in control groups was 28.3%.
A significant association was observed between the rs1501299T allele and risk of CVD (Figure 3), yielding overall ORs (fixed-effects and random-effects method) of 0.93 (95%CI: 0.89, 0.97; P = 0.001) and 0.90 (95% CI: 0.83, 0.97; P = 0.007). Significant heterogeneity was observed (I2 = 58.0%, P < 0.001). The sensitivity analysis revealed that there was not a single study influencing the result significantly. Cumulative analysis did not find the influence of the first published study on the subsequent publications and the evolution of the combined estimate over time. There was publication bias in the studies (Egger’s test, P = 0.077). The combined OR for rs1501299 and CHD was 0.89(95%CI: 0.81, 0.99) (Table 2).

Meta-analysis for the relationship between rs1501299 and CVD risk. Year represents publish year. The solid squares represent odds ratios (ORs) from individual studies; the diamonds are shown as overall effect. The combined ORs along with their 95% CIs were in the contrast of T allele vs. G allele and estimated using the fixed-effects method.
Meta-analysis for rs266729 polymorphism
Twenty studies including about 7,835 cases and 14,023 controls were enrolled in this meta-analysis for the association between rs266729 and CVD (Table 2). For all the studies included, we found that the control groups were in HWE. The pooled frequency of the G allele was 24.8% in the control groups.
The association for rs266729 and CVD was significant, with ORs (fixed-effects and random-effects method) of 1.07 (95%CI: 1.02, 1.13; P = 0.003) and 1.09(95%CI: 1.01, 1.17; P = 0.032), and significant heterogeneity (I2 = 53.6%, P = 0.002) (Figure 4). By performing subgroup analyses we found that the East Asian studies indicated significant association (OR = 1.29, 95% CI: 1.18, 1.42). Heterogeneity disappeared in this subgroup analysis, I2 indexes equal to 26.1% and 0 for European subgroup and Asian subgroup, respectively (Table 2). The sensitivity analysis revealed that there was not a single study influencing the result significantly. Cumulative analysis did not find the influence of the first published study on the subsequent publications and the evolution of the combined estimate over time. The results of Egger’s test did not suggest publication bias in the studies, P = 0.624. No significant association was found between rs266729 and the risk of CHD (OR = 1.09, 95% CI: 0.99, 1.19, random-effects method), with significant between-study heterogeneity (I2 = 51.8%, P = 0.023) (Table 2).

Meta-analysis for the relationship between rs266729 and CVD risk. Year represents publish year. The solid squares represent odds ratios (ORs) from individual studies; the diamonds are shown as overall effect. The combined ORs along with their 95% CIs were in the contrast of G allele vs. C allele and estimated using the random-effects method.
Discussion
The present meta-analysis, involving 6 to 8 thousand cases and more than 10 thousand controls for each polymorphism, provides a clear indication of significant associations between the three SNPs, rs2241766, rs1501299 and rs266729, in ADIPOQ and CVD. The findings of this study suggest that the rs2241766G allele and rs266729G allele increase odds of CVD, while the rs1501299T allele decreases. Rs2241766 and rs1501299 are significantly associated with CHD. However, the results were nearly “crude” ones, other important risk factors for CVD or CHD might diminish the significance of the results, so the associations were significant but weak. Nevertheless, the magnitude of these associations is in the range of all positive associations found with SNPs in multifactorial polygenic disorders, even with the “top ten” SNPs from GWAS.
Qi et al. have conducted a meta-analysis to summarize the association between rs1501299 and CVD risk among diabetic patients [34]. 827 CVD cases and 1,887 CVD-free control subjects were included in their meta-analysis. They found that the minor allele T homozygote was significantly associated with ~45% reduction in CVD risk. A recent meta-analysis for rs1501299 and CVD also reported the protect effect of rs1501299T allele in type 2 diabetes population [58]. Our meta-analysis included more studies and collected more information than previous meta-analyses. We also evaluated the association for the SNP rs1501299 under a recessive model among type 2 diabetic patients. The result was very similar to that of previous meta-analyses, with an OR of 0.71(95%CI: 0.56, 0.91). Previous meta-analysis did not evaluate the associations between rs2241766 and rs266729 and CVD risk. According to our results, significant associations were also observed for these two important SNPs.
The findings of our study may shed light on the underlying disease mechanism in CVD. Previous studies and meta-analysis demonstrated that rs1501299T carriers had higher adiponectin levels [10, 59], which were associated with lower odds of CVD [8, 9, 60, 61]. Besides, these SNPs were reported to be associated with many conventional CVD risk factors, such as hypertension, obesity, diabetes mellitus, insulin restriction and metabolic syndrome. The HOMA-IR (homeostasis model assessment of insulin resistance) index was higher in rs1501299GG carriers as compared with TG and TT subjects, indicating higher insulin sensitivity in carriers of allele T, the same allele that showed an association with increased adiponectin levels [59]. Rs1501299 was also found to be associated with the presence of hypertension in metabolic syndrome individuals [62]. The rs266729G allele was reported to be significantly associated with higher odds of hypertension in Hong Kong Chinese, after adjusting for covariates. In stepwise multiple logistic regression, this SNP was a significant independent risk factor of hypertension, together with age, body mass index, triglycerides, and insulin resistance index. Also, rs266729 was significantly associated with adiponectin level after adjusting for covariates [63]. Previous meta-analysis also detected a significant association between rs266729 and an increased risk of T2D [64]. As mentioned above, the effect of rs1501299 and rs266729 on CVD risk might be regulated by adiponectin concentrations, as well as other CVD risk factors. Nevertheless, these particular SNPs are far from being the most influent on adiponectin levels and CVD risk factors, and the association is weak and/or controversial, especially for rs266729 and rs2241766.
Several potential limitations of our study should be noted. First, significant between-study heterogeneities were observed in our study, we tried to explored the source of heterogeneities with factors such as ethnicity, study subjects, sample size, genotyping methods in the subgroup analyses. However, for rs2241766 and rs1501299 polymorphisms, significant heterogeneities still remained, only the heterogeneity for rs266729 disappeared by performing subgroup analyses according to ethnicity. Second, as significant publication bias was observed in the analysis of rs2241766, the association for this SNP still needs to be confirmed in future studies. Third, the eligible studies in our research were mainly from Asia and Europe, data of other populations, like African, was limited. Fourth, because we did not have access to individual data, we could not control for population stratification, nor could we adjust for variables in possible intermediate pathways. Finally, we should realize that the results might be distorted by potential weakness and biases of genetic association studies, such as genotyping error, phenotype misclassification, population stratification, gene-gene or gene-environment interactive effect, and selective reporting biases [29, 65].
Further studies should be conducted to confirm the functional variants. More studies are needed to elucidate the complete range of the signal transduction pathways that the variant is implicated in, and thus, throw light in the underlying molecular mechanisms that confer susceptibility to CVD. The particular polymorphism associated with CVD itself may not play a functional role, but rather it may be located physically close to the actual disease-predisposing gene.
In addition to the genetic markers described in this meta-analysis, many other polymorphisms have been studied. Those polymorphisms may be candidates for a multivariate analysis. Future haplotypic approaches and further haplotype-based meta-analyses will provide more powerful and informative results than current single genotype-based data.
Conclusions
The present meta-analysis showed that the associations between rs2241766, rs1501299 and rs266729 in the ADIPOQ and CVD were significant but weak. The rs2241766G allele and rs266729G allele increase risk of CVD, while the rs1501299T allele decreases. High quality studies are still needed to confirm the associations, especially for rs2241766.
Abbreviations
- ACI:
-
atherothrombotic cerebral infarction
- ADIPOQ:
-
adiponectin gene
- CAD:
-
coronary artery disease
- CHD:
-
coronary heart disease
- CVD:
-
cardiovascular disease
- CI:
-
confidence interval
- HWE:
-
hardy-Weinberg equilibrium
- MAF:
-
Minor Allele Frequency
- MetS:
-
Metabolic syndrome
- MI:
-
myocardial infarction
- NA:
-
Not available
- OR:
-
odds ratio
- RA:
-
Rheumatoid arthritis
- RD:
-
Renal disease
- T2D:
-
Type 2 diabetes.
References
Pajvani UB, Du X, Combs TP, Berg AH, Rajala MW, Schulthess T, Engel J, Brownlee M, Scherer PE: Structure-function studies of the adipocyte-secreted hormone Acrp30/adiponectin. Implications for metabolic regulation and bioactivity. J Biol Chem. 2003, 278 (11): 9073-9085. 10.1074/jbc.M207198200.
Scherer PE, Williams S, Fogliano M, Baldini G, Lodish HF: A novel serum protein similar to C1q, produced exclusively in adipocytes. J Biol Chem. 1995, 270 (45): 26746-26749. 10.1074/jbc.270.45.26746.
Stefan N, Stumvoll M: Adiponectin–its role in metabolism and beyond. Horm Metab Res. 2002, 34 (9): 469-474. 10.1055/s-2002-34785.
Koz C, Uzun M, Yokusoglu M, Baysan O, Erinc K, Sag C, Hasimi A, Isik E: Evaluation of plasma adiponectin levels in young men with coronary artery disease. Acta Cardiol. 2007, 62 (3): 239-243.
Lu G, Chiem A, Anuurad E, Havel PJ, Pearson TA, Ormsby B, Berglund L: Adiponectin levels are associated with coronary artery disease across Caucasian and African-American ethnicity. Transl Res. 2007, 149 (6): 317-323. 10.1016/j.trsl.2006.12.008.
Otsuka F, Sugiyama S, Kojima S, Maruyoshi H, Funahashi T, Sakamoto T, Yoshimura M, Kimura K, Umemura S, Ogawa H: Hypoadiponectinemia is associated with impaired glucose tolerance and coronary artery disease in non-diabetic men. Circ J. 2007, 71 (11): 1703-1709. 10.1253/circj.71.1703.
Rothenbacher D, Brenner H, Marz W, Koenig W: Adiponectin, risk of coronary heart disease and correlations with cardiovascular risk markers. Eur Heart J. 2005, 26 (16): 1640-1646. 10.1093/eurheartj/ehi340.
Pischon T, Girman CJ, Hotamisligil GS, Rifai N, Hu FB, Rimm EB: Plasma adiponectin levels and risk of myocardial infarction in men. JAMA. 2004, 291 (14): 1730-1737. 10.1001/jama.291.14.1730.
Pischon T, Hu FB, Girman CJ, Rifai N, Manson JE, Rexrode KM, Rimm EB: Plasma total and high molecular weight adiponectin levels and risk of coronary heart disease in women. Atherosclerosis. 2011, 219 (1): 322-329. 10.1016/j.atherosclerosis.2011.07.011.
Hivert MF, Manning AK, McAteer JB, Florez JC, Dupuis J, Fox CS, O’Donnell CJ, Cupples LA, Meigs JB: Common variants in the adiponectin gene (ADIPOQ) associated with plasma adiponectin levels, type 2 diabetes, and diabetes-related quantitative traits: the Framingham Offspring Study. Diabetes. 2008, 57 (12): 3353-3359. 10.2337/db08-0700.
Kyriakou T, Collins LJ, Spencer-Jones NJ, Malcolm C, Wang X, Snieder H, Swaminathan R, Burling KA, Hart DJ, Spector TD, et al: Adiponectin gene ADIPOQ SNP associations with serum adiponectin in two female populations and effects of SNPs on promoter activity. J Hum Genet. 2008, 53 (8): 718-727. 10.1007/s10038-008-0303-1.
Siitonen N, Pulkkinen L, Lindstrom J, Kolehmainen M, Eriksson JG, Venojarvi M, Ilanne-Parikka P, Keinanen-Kiukaanniemi S, Tuomilehto J, Uusitupa M: Association of ADIPOQ gene variants with body weight, type 2 diabetes and serum adiponectin concentrations: the Finnish Diabetes Prevention Study. BMC Med Genet. 2011, 12: 5-
Wassel CL, Pankow JS, Jacobs DR, Steffes MW, Li N, Schreiner PJ: Variants in the adiponectin gene and serum adiponectin: the Coronary Artery Development in Young Adults (CARDIA) Study. Obesity (Silver Spring). 2010, 18 (12): 2333-2338. 10.1038/oby.2010.85.
Richards JB, Waterworth D, O’Rahilly S, Hivert MF, Loos RJ, Perry JR, Tanaka T, Timpson NJ, Semple RK, Soranzo N, et al: A genome-wide association study reveals variants in ARL15 that influence adiponectin levels. PLoS Genet. 2009, 5 (12): e1000768-10.1371/journal.pgen.1000768.
Wassel CL, Pankow JS, Rasmussen-Torvik LJ, Li N, Taylor KD, Guo X, Goodarzi MO, Palmas WR, Post WS: Associations of SNPs in ADIPOQ and subclinical cardiovascular disease in the multi-ethnic study of atherosclerosis (MESA). Obesity (Silver Spring). 2011, 19 (4): 840-847. 10.1038/oby.2010.229.
Lacquemant C, Froguel P, Lobbens S, Izzo P, Dina C, Ruiz J: The adiponectin gene SNP + 45 is associated with coronary artery disease in Type 2 (non-insulin-dependent) diabetes mellitus. Diabet Med. 2004, 21 (7): 776-781. 10.1111/j.1464-5491.2004.01224.x.
Bacci S, Menzaghi C, Ercolino T, Ma X, Rauseo A, Salvemini L, Vigna C, Fanelli R, Di Mario U, Doria A, et al: The +276 G/T single nucleotide polymorphism of the adiponectin gene is associated with coronary artery disease in type 2 diabetic patients. Diabetes Care. 2004, 27 (8): 2015-2020. 10.2337/diacare.27.8.2015.
Chiodini BD, Specchia C, Gori F, Barlera S, D’Orazio A, Pietri S, Crociati L, Nicolucci A, Franciosi M, Signorini S, et al: Adiponectin gene polymorphisms and their effect on the risk of myocardial infarction and type 2 diabetes: an association study in an Italian population. Ther Adv Cardiovasc Dis. 2010, 4 (4): 223-230. 10.1177/1753944710371483.
Oguri M, Kato K, Yokoi K, Itoh T, Yoshida T, Watanabe S, Metoki N, Yoshida H, Satoh K, Aoyagi Y, et al: Association of genetic variants with myocardial infarction in Japanese individuals with metabolic syndrome. Atherosclerosis. 2009, 206 (2): 486-493. 10.1016/j.atherosclerosis.2009.02.037.
Prior SL, Jones DA, Gill GV, Bain SC, Stephens JW: Association of the adiponectin rs266729 C > G variant and coronary heart disease in the low risk ‘Golden Years’ type 1 diabetes cohort. Diabetes Res Clin Pract. 2011, 91 (3): e71-e74. 10.1016/j.diabres.2010.12.007.
Qi L, Li T, Rimm E, Zhang C, Rifai N, Hunter D, Doria A, Hu FB: The +276 polymorphism of the APM1 gene, plasma adiponectin concentration, and cardiovascular risk in diabetic men. Diabetes. 2005, 54 (5): 1607-1610. 10.2337/diabetes.54.5.1607.
Stroup DF, Berlin JA, Morton SC, Olkin I, Williamson GD, Rennie D, Moher D, Becker BJ, Sipe TA, Thacker SB: Meta-analysis of observational studies in epidemiology: a proposal for reporting. Meta-analysis Of Observational Studies in Epidemiology (MOOSE) group. JAMA. 2000, 283 (15): 2008-2012. 10.1001/jama.283.15.2008.
Chanock SJ, Manolio T, Boehnke M, Boerwinkle E, Hunter DJ, Thomas G, Hirschhorn JN, Abecasis G, Altshuler D, Bailey-Wilson JE, et al: Replicating genotype-phenotype associations. Nature. 2007, 447 (7145): 655-660. 10.1038/447655a.
Higgins JP, Thompson SG, Deeks JJ, Altman DG: Measuring inconsistency in meta-analyses. BMJ. 2003, 327 (7414): 557-560. 10.1136/bmj.327.7414.557.
Egger M, Davey Smith G, Schneider M, Minder C: Bias in meta-analysis detected by a simple, graphical test. BMJ. 1997, 315 (7109): 629-634. 10.1136/bmj.315.7109.629.
DerSimonian R, Laird N: Meta-analysis in clinical trials. Control Clin Trials. 1986, 7 (3): 177-188. 10.1016/0197-2456(86)90046-2.
Lebrec JJ, Stijnen T, van Houwelingen HC: Dealing with heterogeneity between cohorts in genomewide SNP association studies. Stat Appl Genet Mol Biol. 2010, 9 (1): Article 8-
Han B, Eskin E: Random-effects model aimed at discovering associations in meta-analysis of genome-wide association studies. Am J Hum Genet. 2011, 88 (5): 586-598. 10.1016/j.ajhg.2011.04.014.
Ioannidis JP, Trikalinos TA: Early extreme contradictory estimates may appear in published research: the Proteus phenomenon in molecular genetics research and randomized trials. J Clin Epidemiol. 2005, 58 (6): 543-549. 10.1016/j.jclinepi.2004.10.019.
Ohashi K, Ouchi N, Kihara S, Funahashi T, Nakamura T, Sumitsuji S, Kawamoto T, Matsumoto S, Nagaretani H, Kumada M, et al: Adiponectin I164T mutation is associated with the metabolic syndrome and coronary artery disease. J Am Coll Cardiol. 2004, 43 (7): 1195-1200. 10.1016/j.jacc.2003.10.049.
Stenvinkel P, Marchlewska A, Pecoits-Filho R, Heimburger O, Zhang Z, Hoff C, Holmes C, Axelsson J, Arvidsson S, Schalling M, et al: Adiponectin in renal disease: relationship to phenotype and genetic variation in the gene encoding adiponectin. Kidney Int. 2004, 65 (1): 274-281. 10.1111/j.1523-1755.2004.00370.x.
Filippi E, Sentinelli F, Romeo S, Arca M, Berni A, Tiberti C, Verrienti A, Fanelli M, Fallarino M, Sorropago G, et al: The adiponectin gene SNP + 276 G > T associates with early-onset coronary artery disease and with lower levels of adiponectin in younger coronary artery disease patients (age < or = 50 years). J Mol Med (Berl). 2005, 83 (9): 711-719. 10.1007/s00109-005-0667-z.
Ru Y, Ma M, Ma T, Wang CJ, Wang YM, Zhang Q, Chen MW, Yang MG: Relations of Adiponectin Gene SNP276 With Coronary Heart Disease and Insulin Sensitivity. Chinese circulation journal. 2005, 20 (5): 332-335.
Qi L, Doria A, Manson JE, Meigs JB, Hunter D, Mantzoros CS, Hu FB: Adiponectin genetic variability, plasma adiponectin, and cardiovascular risk in patients with type 2 diabetes. Diabetes. 2006, 55 (5): 1512-1516. 10.2337/db05-1520.
Gable DR, Matin J, Whittall R, Cakmak H, Li KW, Cooper J, Miller GJ, Humphries SE: Common adiponectin gene variants show different effects on risk of cardiovascular disease and type 2 diabetes in European subjects. Ann Hum Genet. 2007, 71 (Pt 4): 453-466.
Wang JN, Li SM: Adiponectin gene polymorphism in han people of Jilin region and its association with coronary heart disease. Chinese Journal of Laboratory Diagnosis. 2006, 10 (11): 1272-1274.
Hegener HH, Lee IM, Cook NR, Ridker PM, Zee RY: Association of adiponectin gene variations with risk of incident myocardial infarction and ischemic stroke: a nested case–control study. Clin Chem. 2006, 52 (11): 2021-2027. 10.1373/clinchem.2006.074476.
Jung CH, Rhee EJ, Kim SY, Shin HS, Kim BJ, Sung KC, Kim BS, Lee WY, Kang JH, Oh KW, et al: Associations between two single nucleotide polymorphisms of adiponectin gene and coronary artery diseases. Endocr J. 2006, 53 (5): 671-677. 10.1507/endocrj.K06-020.
Pischon T, Pai JK, Manson JE, Hu FB, Rexrode KM, Hunter D, Rimm EB: Single nucleotide polymorphisms at the adiponectin locus and risk of coronary heart disease in men and women. Obesity (Silver Spring). 2007, 15 (8): 2051-2060. 10.1038/oby.2007.244.
Lu F, Wang LS, Yang ZJ, Zhu TB, Wang ZG, Zhu HJ, Tang NP, Cao KJ, Huang J, Gui M: Correlation between single nucleotide polymorphism(SNP + 276 G/T) of adiponectin gene and coronary artery disease in non-diabetic population. Acta universitatis medicinalis nanjing. 2007, 27 (7): 736-739.
Liang XZ XJ, Wang J, Yu P, Qi WG, Ma L, Hu B, Luo Y, Zhang DF: Correlation between single nucleotide polymorphism (SNP + 276G/T) of adiponectin gene and coronary artery disease. Chinese Journal of Cardiovascular Review. 2008, 6 (11): 838-840.
Yamada Y, Kato K, Oguri M, Yoshida T, Yokoi K, Watanabe S, Metoki N, Yoshida H, Satoh K, Ichihara S, et al: Association of genetic variants with atherothrombotic cerebral infarction in Japanese individuals with metabolic syndrome. Int J Mol Med. 2008, 21 (6): 801-808.
Chang YC, Jiang JY, Jiang YD, Chiang FT, Hwang JJ, Lien WP, Chuang LM: Interaction of ADIPOQ genetic polymorphism with blood pressure and plasma cholesterol level on the risk of coronary artery disease. Circ J. 2009, 73 (10): 1934-1938. 10.1253/circj.CJ-09-0228.
Foucan L, Ezourhi N, Maimaitiming S, Hedreville S, Inamo J, Atallah A, Bangou-Bredent J, Aubert R, Chout R, Fumeron F, et al: Adiponectin multimers and ADIPOQ T45G in coronary artery disease in Caribbean type 2 diabetic subjects of African descent. Obesity (Silver Spring). 2010, 18 (7): 1466-1468. 10.1038/oby.2009.441.
Zhang XL PW, Lu L, Wu LiQ, Gu G, Wand LJ, Yan XX, Chen QJ, Shen WF: Correlation of adiponectin gene polymorphisms with coronary artery disease and plaque progression. Journal of shanghai jiaotong university (medical science). 2009, 29 (4): 435-439.
Zhong C, Zhen D, Qi Q, Genshan M: A lack of association between adiponectin polymorphisms and coronary artery disease in a Chinese population. Genet Mol Biol. 2010, 33 (3): 428-433. 10.1590/S1415-47572010005000064.
De Caterina R, Talmud PJ, Merlini PA, Foco L, Pastorino R, Altshuler D, Mauri F, Peyvandi F, Lina D, Kathiresan S, et al: Strong association of the APOA5-1131 T > C gene variant and early-onset acute myocardial infarction. Atherosclerosis. 2011, 214 (2): 397-403. 10.1016/j.atherosclerosis.2010.11.011.
Xu L, Ling WH: Correlation of adiponectin gene SNP + 45 T/G polymorphism with coronary heart disease. Chinese Journal of Pathophysiology. 2010, 26 (6): 1064-1068.
Al-Daghri NM, Al-Attas OS, Alokail MS, Alkharfy KM, Hussain T: Adiponectin gene variants and the risk of coronary artery disease in patients with type 2 diabetes. Mol Biol Rep. 2011, 38 (6): 3703-3708. 10.1007/s11033-010-0484-5.
Rodriguez-Rodriguez L, Garcia-Bermudez M, Gonzalez-Juanatey C, Vazquez-Rodriguez TR, Miranda-Filloy JA, Fernandez-Gutierrez B, Llorca J, Martin J, Gonzalez-Gay MA: Lack of association between ADIPOQ rs266729 and ADIPOQ rs1501299 polymorphisms and cardiovascular disease in rheumatoid arthritis patients. Tissue Antigens. 2011, 77 (1): 74-78. 10.1111/j.1399-0039.2010.01580.x.
Leu HB, Chung CM, Chuang SY, Bai CH, Chen JR, Chen JW, Pan WH: Genetic variants of connexin37 are associated with carotid intima-medial thickness and future onset of ischemic stroke. Atherosclerosis. 2011, 214 (1): 101-106. 10.1016/j.atherosclerosis.2010.10.010.
Liu F, He Z, Deng S, Zhang H, Li N, Xu J: Association of adiponectin gene polymorphisms with the risk of ischemic stroke in a Chinese Han population. Mol Biol Rep. 2011, 38 (3): 1983-1988. 10.1007/s11033-010-0320-y.
Chen XL, Cheng JQ, Zhang RL, Liu JP, Li XX, Tong YQ, Geng YJ: Study on the relationship between polymorphism of adiponectin gene and risk of ischemic stroke among Han population in the Northern parts of China. Chin J Epidemiol. 2010, 31 (2): 129-132.
Sabouri S, Ghayour-Mobarhan M, Moohebati M, Hassani M, Kassaeian J, Tatari F, Mahmoodi-kordi F, Esmaeili HA, Tavallaie S, Paydar R, et al: Association between 45 T/G polymorphism of adiponectin gene and coronary artery disease in an Iranian population. ScientificWorldJournal. 2011, 11: 93-101.
Esteghamati A, Mansournia N, Nakhjavani M, Mansournia MA, Nikzamir A, Abbasi M: Association of +45(T/G) and +276(G/T) polymorphisms in the adiponectin gene with coronary artery disease in a population of Iranian patients with type 2 diabetes. Mol Biol Rep. 2012, 39 (4): 3791-3797. 10.1007/s11033-011-1156-9.
Boumaiza I, Omezzine A, Rejeb J, Rebhi L, Ben Rejeb N, Nabli N, Ben Abdelaziz A, Boughzala E, Bouslama A: Single-nucleotide polymorphisms at the adiponectin locus and risk of coronary artery disease in Tunisian coronaries. J Cardiovasc Med (Hagerstown). 2011, 12 (9): 619-624. 10.2459/JCM.0b013e328348f1f8.
Katakami N, Kaneto H, Matsuoka TA, Takahara M, Maeda N, Shimizu I, Ohno K, Osonoi T, Kawai K, Ishibashi F, et al: Adiponectin G276T gene polymorphism is associated with cardiovascular disease in Japanese patients with type 2 diabetes. Atherosclerosis. 2012, 220 (2): 437-442. 10.1016/j.atherosclerosis.2011.11.010.
Sun K, Li Y, Wei C, Tong Y, Zheng H, Guo Y: Recessive protective effect of ADIPOQ rs1501299 on cardiovascular diseases with type 2 diabetes: a meta-analysis. Mol Cell Endocrinol. 2012, 349 (2): 162-169. 10.1016/j.mce.2011.10.001.
Menzaghi C, Trischitta V, Doria A: Genetic influences of adiponectin on insulin resistance, type 2 diabetes, and cardiovascular disease. Diabetes. 2007, 56 (5): 1198-1209. 10.2337/db06-0506.
Kanaya AM, Wassel Fyr C, Vittinghoff E, Havel PJ, Cesari M, Nicklas B, Harris T, Newman AB, Satterfield S, Cummings SR: Serum adiponectin and coronary heart disease risk in older Black and White Americans. J Clin Endocrinol Metab. 2006, 91 (12): 5044-5050. 10.1210/jc.2006-0107.
Laughlin GA, Barrett-Connor E, May S, Langenberg C: Association of adiponectin with coronary heart disease and mortality: the Rancho Bernardo study. Am J Epidemiol. 2007, 165 (2): 164-174.
Leu HB, Chung CM, Lin SJ, Jong YS, Pan WH, Chen JW: Adiponectin gene polymorphism is selectively associated with the concomitant presence of metabolic syndrome and essential hypertension. PLoS One. 2011, 6 (5): e19999-10.1371/journal.pone.0019999.
Ong KL, Li M, Tso AW, Xu A, Cherny SS, Sham PC, Tse HF, Lam TH, Cheung BM, Lam KS: Association of genetic variants in the adiponectin gene with adiponectin level and hypertension in Hong Kong Chinese. Eur J Endocrinol. 2010, 163 (2): 251-257. 10.1530/EJE-10-0251.
Gong M, Long J, Liu Q, Deng HC: Association of the ADIPOQ rs17360539 and rs266729 polymorphisms with type 2 diabetes: a meta-analysis. Mol Cell Endocrinol. 2010, 325 (1–2): 78-83.
Daly AK, Day CP: Candidate gene case–control association studies: advantages and potential pitfalls. Br J Clin Pharmacol. 2001, 52 (5): 489-499. 10.1046/j.0306-5251.2001.01510.x.
Pre-publication history
The pre-publication history for this paper can be accessed here:http://www.biomedcentral.com/1471-2350/13/40/prepub
Acknowledgement
This work was supported by National Basic Research Program of China (Grant No. 2011CB503901), National Natural Science Foundation of China (Grant No. 30930047).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no conflict of interest.
Authors’ contributions
HZ and DFG conceived of the study, and participated in its design and coordination. HZ, XBM and YCH carried out the literature searching and data extraction, independently. XBM and HZ performed the statistic analysis and draft the manuscript. All authors read and approved the final manuscript.
Electronic supplementary material
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is published under license to BioMed Central Ltd. This is an Open Access article is distributed under the terms of the Creative Commons Attribution License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Zhang, H., Mo, X., Hao, Y. et al. Association between polymorphisms in the adiponectin gene and cardiovascular disease: a meta-analysis. BMC Med Genet 13, 40 (2012). https://doi.org/10.1186/1471-2350-13-40
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2350-13-40