
Abstract
Wireless sensor networks are widely used in monitoring and managing environmental factors like air quality, humidity, temperature, and pressure. The recent works show that clustering is an effective technique for increasing energy efficiency, traffic load balancing, prolonging the lifetime of the network and scalability of the sensor network. In this paper, a new energy-efficient clustering technique has been proposed based on a genetic algorithm with the newly defined objective function. The proposed clustering method modifies the steady-state phase of the LEACH protocol in a heterogeneous environment. The proposed objective function considers three main clustering parameters such as compactness, separation, and number of cluster heads for optimization. The simulation result shows that the proposed protocol is more effective in improving the performance of wireless sensor networks as compared to other state-of-the-art methods, namely SEP, IHCR, and ERP.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The current technological advancements in the fields of microelectronics, sensing devices, and wireless communication technology have given world-wide attention to wireless sensor networks (WSNs). WSNs contain several low power small devices called motes or sensor nodes. They communicate over wireless media at close range and perform various kinds of tasks like environmental monitoring, battlefield surveillance, and many more. However, the sensor nodes have some limitations such as short transmission range, less processing capacity, low storage capacity, and limited energy resources [11, 15, 16]. An optimized sensor network became a promising area of protection and control, facilitating real-time and controlled communication systems with the physical environment. One of the critical challenges of the WSN is to extend the network lifetime. In the literature, several definitions and metrics have been used to define and measure the lifetime of the sensor network. To increase the network lifetime, clustering is performed, which divides the sensor network into many independent groups called clusters. A cluster head (CH) is selected as the leader node of the cluster. The CH supervises the communication between its member nodes, aggregates the information received from them, and finally sends it to the sink node [24, 26].
Clustering has many advantages, such as energy minimization, load balancing, scalability, and bandwidth reuse. Bandwidth reuse improves the system capacity achieved through spatial reuse. For spatial reuse, if two clusters are not adjacent, the same bandwidth can be used in two clusters. Clustering also helps efficient routing for the formation of a virtual backbone with cluster heads. In the literature, several cluster-based routing protocols have been proposed which can be divided into broad categories, namely probabilistic approaches, greedy approaches, unequal clustering approach, clustering based on fuzzy logic, and computational intelligence-based approach [6]. In the probabilistic approach of clustering, each node is assigned a priori probability for selection of initial cluster heads which also work as a primary criterion for individual nodes to get themselves elected as CHs. Besides the primary criteria, the secondary criteria such as residual energy may also be considered for prolonging the network lifetime and energy conservation. The prominent protocols in this category are LEACH [9], SEP [29], HEED [4], and many more.
Moreover, greedy-based approaches are used to form a chain of nodes to transmit data instead of dynamic clustering. This approach is also called chain-based routing. One of the popular protocols in this category is PEGASIS [17]. However, in the multi-hop clustering environment, CHs nearer to the base station deplete their energy faster because of extra inter-cluster traffic at these CHs than the CHs located away from the base station. This kind of situation creates a hot spot area or energy hole problem in the network and degrades the performance of the network [25]. Different types of techniques have been proposed in the literature to address energy imbalances and energy hole problems in WSNs where clustering is used. Some of these techniques are the mobility of nodes and base stations, data aggregation and compressions, and unequal clustering. Their primary purpose is to save energy by generating clusters of uniform size, minimizing the distance between sensor nodes and CH.
The clustering problem can be considered as an NP–complete problem [20,21,22,23]. For any network topology, getting an optimal number of CHs with locations can be solved by the exponential search. For a sensor network having N sensor nodes, many solution sets exist. In each solution set, a sensor node can be a CH or non-CH. In the recent works, computational intelligence-based techniques based on fuzzy logic [24], neural network, and meta-heuristics techniques are extensively applied to solve various kinds of challenging problems in WSN [3]. The meta-heuristic algorithms inspired by nature are accepted widely for solving optimization problems [20, 23, 8]. These algorithms can solve an extensive set of problems because they do not require an explicit definition of the function. Genetic algorithm (GA) is one of the most popular and widely used meta-heuristic algorithms for solving combinatorial optimization problems such as clustering [15, 16]. The clustering problems can also be mapped as discrete optimization problems for which GA is a more suitable algorithm to solve it than the other meta-heuristic algorithm like PSO and DE. These methods are generally used to solve continuous optimization problems [12]. In this work, GA is used to solve the clustering problem in a wireless sensor network with a newly defined fitness function. The proposed fitness function considered separation, compactness, and ratio of a number of non-CH and CH nodes as the decision variables for the selection of optimal cluster heads.
Related work
In the literature, various routing protocols have been introduced by the researcher to make the sensor networks more energy efficient. Most of the protocols used cluster formation and different communication strategies for data dissemination. Moreover, the cluster-based routing protocols use the sensor nodes more efficiently than non-cluster-based routing methods. The whole sensor network is divided into different clusters, and the cluster head (CH) node is responsible to collect, aggregate, and disseminate the data of its cluster to the sink. In this way, energy consumption, to send the data directly to the sink, is reduced.
To increase the overall network lifetime of the sensor network, many cluster-based routing protocols have been proposed in literature specifically for WSNs. LEACH (low energy adaptive clustering hierarchy) [9] is the most widely used hierarchical routing protocol in which the formation of clusters is done without centralized control. The CHs are elected based on probability. Further, SEP (stable election protocol) [29] is proposed which is based on LEACH but works in a heterogeneous environment. In this protocol, some of the sensor nodes in the network (called advanced nodes) are having higher battery capacity as compared to normal senor nodes. The probability that an advanced node becomes a CH is higher than that of a normal node. A more improved version of SEP is SEP-E (RCH) [26]. It is more energy efficient than SEP and redundantly selects CH to improve the lifetime and reliability of the network. Moreover, GA is widely used in WSN to select the optimal number of CHs and enhance the lifetime and stability of the sensor network. Bara’a et al. [2] proposed GA-based clustering method finds the optimum number of CHs to reduce the total network distance. Its fitness function (F) is a combination of the total number of distances (dist) and the number of CHs for minimization and given in Eq. (1).
where N is the total number of sensor nodes, and w refers to a predefined weight value. The objective is to maximize the fitness value. Further, Matin et al. [14] proposed a fitness function based on compactness (C), a direct distance of sensor node to the base station (D), cluster distance standard deviation (SD), the transmission energy (E), and many packets transferred (T). The objective is to select those chromosomes which take less energy for more transmissions. The fitness function is defined in Eq. (2).
Further, Petre-Cosmin et al. [10] extend the above-defined fitness function by incorporating the residual energy (RE) and many transmitted frames (FT) and shown in Eq. (3).
Elhabyan [5] proposed a hybrid algorithm based on GA and PSO to optimize the power consumption of WSN nodes. GA finds the optimal set of CHs, while PSO is used to select the members of the cluster. The considered fitness function is defined by Eqs. (4) and (5) for GA and PSO, respectively.
where SHD denotes the summation of all distances from CHs to BS, SHDS is the sum of density of CHs, SHC is the sum of centrality of CHs, SHRE is the overall residual energy of all CHs, SMD is sum of member’s distance to CHs, ED represents the difference between current node and the local best node, and SREL denotes the overall residual energy of the nodes.
Moreover, Singh et al. [28] proposed the objective function that considers the sum of the total consumed energy by non-CH nodes to transmit data to those CHs nodes, the overall aggregation energy at CH, and finally the sum of the consumed energy in the transmission of aggregate data to BS. The formulation of the fitness function is given in Eq. (6).
where nc is the total CHs, \( s \in {\text{CH}}_{i} \) is a non-CHs associated with ith CH, and E and R represent energy dissipated during transmission and receiving information.
Pal and Sharma [24] proposed a new protocol FSEP-E to enhance the performance of a stable election protocol by selecting the cluster heads based on fuzzy logic. The fuzzy inference rules are defined over three linguistic variables, namely distance from the sink, heterogeneity threshold, and node density. Further, Pal and Sharma [25] introduce the multi-hop communication among the CHs toward the sink and between the sensor nodes toward CHs in SEP protocol. Moreover, Pal et al. [19] proposed a new clustering method in HWSNs based on biogeography-based optimization. The optimal set of cluster heads are selected based on the two objectives, namely to minimize cluster density and to maximize cluster dispersion. Further, Mehta and Pal [16] modified the fitness function by incorporating the total energy to enhance the performance and network lifetime.
Background
Genetic algorithm
GA (genetic algorithm) [7] is a well-known optimization method for solving the optimization problem and based on the survival of the fittest theory. It initializes with the various randomly generated solutions. Each solution, also known as chromosome, can be considered as an array of genes. These genes are evolved iteratively based on some criteria (or objective function) to search for the best solution.
There are mainly three operators used by GA; firstly, selection in which it selects the chromosomes having better fitness values and their genes will be used in the successive generations; secondly, crossover, in which mating is performed between chromosomes; two chromosomes are selected randomly, and a crossover site is chosen; these crossover sites, exchange of genes is performed and creates entirely new chromosomes (offspring); thirdly, the mutation operator, in which a gene is randomly chosen from the randomly selected chromosome and replaces it by some random value between the search bounds. This operator is used to maintain the diversity in the population and to bypass the premature convergence.
In the last 2 decades, GA has been used widely in many application areas such as microarray data analysis, image segmentation, image compression, document and text clustering, and clustering in mobile and ad hoc networks [30]. Recently, GA has been widely used in clustering the WSNs [15, 16]. Various modifications have been suggested in GA to improve its performance for selecting the optimal set of cluster heads. Bhushan et al. [3] modified the population initialization phase of GA by incorporating the K-means algorithm. This results in better solutions in the population which enhances the overall performance of GA for clustering the WSNs.
Network model
In this paper, sensor nodes are deployed randomly in 100 × 100 m2 area. There are two types of nodes, namely advance nodes and normal nodes. Advanced nodes have a higher battery capacity than normal nodes. The base station (BS) or sink is situated in the middle of the sensor network. For the communication and network operations, the clustering-based approach is followed in which some cluster head nodes are selected for aggregating the sensed data from normal nodes and sending the aggregated information to the base station for further processing. Figure 1 shows one snapshot of the network simulated under the MATLAB environment. In the figure, the base station, situated in the middle, is represented by the filled blue circle; normal nodes and advanced nodes are represented by plus sign and triangle sign, respectively. Moreover, the selected cluster centroids are represented by the star symbol.

Snapshot of a simulated wireless sensor network [3]
Energy model
The sensor node depletes its energy, mainly in transmitting and receiving the data. For the same, a radio energy model [9] is considered which works in two-channel modes, namely free space and multi-path fading channel model. The depleted energy is proportional to distance. Equation (7).
where Eelec, Ɛfs and Ɛmp are the energy required by the electronic circuit, amplifier in free space and multi-path, respectively, and \( d_{0} \) is considered as distance threshold.
Further, the energy consumed \( (E_{Rx} (l)) \) by sensor node in receiving l bit data packet is given by Eq. (8).
The proposed clustering method
In this paper, the sensor network is hierarchically clustered based on LEACH. LEACH protocols generally have two phases, namely set-up phase and steady-state phase, to divide the sensor network into the clustering hierarchy. In the set-up phase, cluster formation is performed, and in the steady-state phase, the communication in the network is established between the sensor node and base station via cluster heads. In this paper, the set-up phase of the LEACH protocol has been modified using genetic algorithm. The overall flow of the proposed method is depicted in Fig. 2, which consists of two main phases. The details of both phases have been provided in the following sections.

The overall flowchart of the proposed method
Set-up phase
In set-up phase sensor nodes are grouped into various clusters. The quality of clustering has a high impact on the energy consumption of the sensor network. Therefore, there is a requirement of finding an optimal set of cluster heads so that quality clusters can be formed. To find such a set of cluster heads from the given number of n sensor nodes can be mapped as a combinatorial problem which is considered as an NP-complete problem. Various meta-heuristic methods, like GA, PSO, DE, etc., have been widely used in the literature, to solve these problems. Hence, in this paper, GA is used to find a set of optimal cluster heads.
GA-based clustering method
In GA, firstly a population of feasible solutions is initialized, which is known as the initial population. The generated population is refined by applying the crossover, mutation, and selection operators on the solutions. After the defined number of iterations is achieved, the solution with the best fitness value of a defined objective function is considered as the optimal solution. The GA-based clustering method is used to select the optimal cluster set from given cluster sets. For the same, a new fitness criterion is defined, which is described below. Further, the design of various cluster sets is also essential for the proper working of the method. In this paper, binary encoding is used to represent the cluster sets.
Chromosome encoding
To represent each solution or chromosome in the population, binary encoding scheme is considered. The size of the chromosomes is equal to the number of sensor nodes. The index value of chromosome array is considered as the sensor node number, and the value of that index denotes whether the node is working as a cluster head or not. If the value is represented by bit ‘1’, then the corresponding sensor nodes are working as the cluster head for that solution and if the value is ‘0’, then the corresponding sensor node is working the member node.
Moreover, a bit ‘− 1’ is also used to represent the sensor node which depletes all of its energy. One example of chromosome representation is shown in Fig. 3. In the figure, nine sensor nodes are considered, and the structure of one chromosome is shown. Sensor nodes 1, 3, and 7 are working as the cluster heads, and other nodes are working the normal nodes.

Chromosome encoding for WSN
Fitness function
The fitness function is required to measure the quality of each chromosome in the population. Therefore, the design of better fitness function is the prime concern of the researchers, as discussed in the literature survey. In this paper, a weighted fitness function is designed, which considers cluster compactness, cluster separation, and the normalized number of cluster heads. Each factor gives its contribution based on the weight value associated with it. An empirical analysis is performed on different values of these weights, and it is observed that for w1 = 0.3, w2 = 0.4, and w3 = 0.2, the proposed method gives better results. Hence, for further investigations, only these values of weights are considered.
The formulation of a new fitness function is depicted in Eq. (9).
where \( {\text{Comp}} \), \( {\text{Sep}} \), \( n{\text{CH}}, \) and N represent overall compactness, overall separation, number of cluster heads, and the total number of sensor nodes. \( w_{1} \), \( w_{2} \), \( w_{3} \) are the weights defined between 0 and 1. For better clustering, the compactness between each cluster should be minimized, and separation between the cluster heads should be maximized. As the objective of the fitness function F is to minimize the fitness value, the compactness is kept directly proportional to the F and separation is inversely proportional to the F. Moreover, the ratio of \( {\raise0.7ex\hbox{$N$} \!\mathord{\left/ {\vphantom {N {n{\text{CH}}}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${n{\text{CH}}}$}} \) is considered to be minimized which is a very important factor to increase the optimal number CHs in proportion with the number of sensor nodes. The overall objective of the fitness function is to minimize the fitness value. Therefore, the solution with minimum fitness value after the given number of iterations is considered as the best solution.
Cluster set-up phase
After the selection of optimal cluster heads at each round, each cluster head sends an advertisement message to other nodes using carrier sense multiple access (CSMA) MAC protocol. The other nodes receive the advertisement messages from all cluster heads and then decide which cluster head it is going to belong for the current round. The decision is based on the RSSI (received signal strength indication) of the advertisement message, and it is proportional to the distance of the node to the cluster head. Once the decision is finalized, each node sends the response to join message to the cluster head to notify that it is a member of the corresponding cluster. The join message is sent by each node to corresponding cluster heads using CSMA–MAC protocol. Figure 4 depicts the one possible configuration of the cluster set-up phase.

A formation of the cluster after set-up phase
Further, each cluster head node defines a transmission schedule based on the join messages received from the member nodes. For the same, time division multiple access protocol (TDMA) is used. Once the schedule is prepared, it is broadcasted by cluster heads among the cluster member nodes.
Steady-state phase
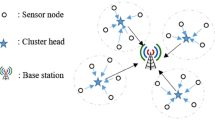
In set-up phase clusters are formed and, in each cluster, a TDMA schedule is defined. Each member node of the cluster sends the sensed data to its cluster head in its allocated slots only and it can turn-off its radio when there is no data to send. This enhances the energy efficiency and the network lifetime of the sensor network. Once the cluster heads receive all the data from its member sensor nodes, it performs data aggregation using some signal processing functions and sends the compressed data to another nearby cluster head on the way to the base station. After the transmission from all the cluster head nodes is completed, then the next round begins and repeats the process explained in “Set-up phase” section. Figure 5 depicts the communication flow in the clustered wireless sensor network.

Communication directions in the steady-state phase of WSNs
Simulation results
The extensive experimental analysis is performed using MATLAB 2018b. The simulation results have been compared against one classical cluster-based routing method, namely stable election protocol (SEP), and two GA-based clustering and routing methods, namely intelligent hierarchical clustering and routing protocol (IHCR), and evolutionary routing protocol (ERP). The effectiveness of the proposed method has been evaluated with other state-of-the-art methods on one of the benchmark network scenarios, i.e., WSN #1, having the sensing field of 100 × 100 m2 with 100 sensor nodes. The parameter settings for GA are kept similar to the comparative literature and also depicted in Table 1. The performance is evaluated in terms of stability period, average remaining energy, the throughput of the overall network, and network lifetime.
Furthermore, as the heterogeneous sensor network has been considered for simulation, two types of energy heterogeneity are incorporated in the network, i.e., the network with 10% advanced nodes and 20% advanced nodes. These nodes are having more energy than normal nodes. The initial energy of normal nodes is kept as 0.5 J while for advance nodes the initial energy is 1 J. The snapshot of the clustered network for a particular round is depicted in Fig. 6. Each voronoi cell in the figure represents one cluster, and ‘*’ represents the cluster head. After some rounds, the sensor nodes deplete their energy entirely, and hence they are dead, as shown in Fig. 7 by the red colored nodes.

Clustered sensor network

Dead sensor nodes
The lifetime of a network can be shown by capturing the number of alive nodes that are survived for a longer time. Figures 8 and 9 depict the network lifetime of SEP, IHCR, ERP, and EEWC. The considered network contains 10% and 20% of the node with high energy heterogeneities. In each of the scenarios, EEWC shows better performance than the remaining protocols. Tables 2 and 3 show the result quantitatively for 10% energy heterogeneity and 20% energy heterogeneity, respectively. It can be observed from Table 2 that in SEP, IHCR, ERP, nodes die much earlier than EEWC. In EEWC, 10% nodes die at 1348th round while in the remaining protocols, nodes die at 1268th, 1152th, and 1326th round, respectively. All nodes die in ERP at 3649th round, giving a better performance than SEP and IHCR, whereas in EEWC, this process is significantly delayed. In EEWC, all nodes die at 4347th rounds. Similarly, with 20% advanced nodes, the performance of EEWC is significantly better than ERP. All nodes died at 4770th round in EEWC.

Network lifetime returned by considered protocols with 10% advanced nodes

Network lifetime returned by considered protocols with 20% advanced nodes
Moreover, Figs. 10 and 11 exhibit the result of EEWC for the residual energy of the network per round for 10% and 20% node heterogeneities, respectively. It is shown that there is a less steepness of the curve due to fairness in the energy load distribution and gradual dissipation of energy in EEWC. The result is further validated in Tables 4 and 5. These tables represent the residual energy remaining in the number of different round intervals. The results till 3600 rounds for all the considered protocols are shown. It can be observed from both the tables that the total remaining energy while using the EEWC method is higher than other considered methods which validate the efficacy of the proposed method.

The total residual energy returned by considered protocols with 10% advanced nodes (on logarithmic scale)

The total residual energy returned by considered protocols with 20% advanced nodes (on logarithmic scale)
The stability period of the networks plays a crucial role in network performance. Table 6 shows the stability period for all the considered protocols for both heterogeneity levels. From the table, it is observed that EEWC has increased the stability period significantly in comparison to SEP, IHCR, and ERP, respectively.
Conclusion
In this paper, a new clustering method for wireless sensor networks has been proposed. The proposed method used a newly introduced fitness weighted fitness function which considers compactness, separation, and number of cluster heads as the parameters for clustering quality. The proposed fitness function is used in the genetic algorithm to find the optimal set of cluster heads in the steady-state phase of the LEACH protocol. The simulation results have been compared with other state-of-the-art clustering methods, namely SEP, IHCR, and ERP, and it has been validated from the results that the EEWC method outperforms other considered methods in terms of stability period, network lifetime, and overall residual energy.
References
Bagci H, Yazici A (2013) An energy aware fuzzy approach to unequal clustering in wireless sensor networks. Appl Soft Comput 13(4):1741–1749
Bara’a AA, Khalil EA (2012) A new evolutionary based routing protocol for clustered heterogeneous wireless sensor networks. Appl Soft Comput 12(7):1950–1957
Bhushan S, Pal R, Antoshchuk SG (2018) Energy efficient clustering protocol for heterogeneous wireless sensor network: a hybrid approach using GA and K-means. In: Proceedings of IEEE second international conference on data stream mining and processing (DSMP), Lviv, Ukraine, 21–25 August 2018, pp 381–385
Chand S, Singh S, Kumar B (2014) Heterogeneous HEED protocol for wireless sensor networks. Wirel Pers Commun 77(3):2117–2139
Elhabyan R (2015) Clustering and routing protocols for wireless sensor networks: design and performance evaluation. Doctoral dissertation, University of Ottawa
Gherbi C, Aliouat Z, Benmohammed M (2017) A survey on clustering routing protocols in wireless sensor networks. Sens Rev 37(1):12–25
Goldberg DE (2006) Genetic algorithms. Pearson Education, Bengaluru
Gupta R, Pal R (2018) Biogeography-based optimization with lévy-flight exploration for combinatorial optimization. In: 2018 8th international conference on cloud computing, data science & engineering (Confluence), pp 664–669
Heinzelman WB, Chandrakasan AP, Balakrishnan H (2002) An application-specific protocol architecture for wireless microsensor networks. IEEE Trans Wirel Commun 1(4):660–670
Huruială P-C, Urzică A, Gheorghe L (2010) Hierarchical routing protocol based on evolutionary algorithms for wireless sensor networks. In: Proceedings of 9th RoEduNet IEEE international conference, Sibiu, Romania, 24–26 June 2010, pp 387–392
Jiang C, Yuan D, Zhao Y (2009) Towards clustering algorithms in wireless sensor networks—a survey. In: Proceedings of IEEE wireless communications and networking conference, Budapest, Hungary, 5–8 April 2009, pp 1–6
Kachitvichyanukul V (2012) Comparison of three evolutionary algorithms: GA, PSO, and DE. Ind Eng Manag Syst 11(3):215–223
Kumar D, Aseri TC, Patel RB (2009) EEHC: energy efficient heterogeneous clustered scheme for wireless sensor networks. Comput Commun 32(4):662–667
Matin AW, Hussain S (2006) Intelligent hierarchical cluster-based routing. Life 7:8–18
Mehta K, Pal R (2017) Energy efficient routing protocols for wireless sensor networks: a survey. Int J Comput Appl 165(3):398–406
Mehta K, Pal R (2017) Biogeography based optimization protocol for energy efficient evolutionary algorithm: (BBO: EEEA). In: Proceedings of international conference on computing and communication technologies for smart nation (IC3TSN), Gurgaon, India, 12–14 October 2017, pp 281–286
Nehra V, Pal R, Sharma AK (2013) Fuzzy-based leader selection for topology controlled PEGASIS protocol for lifetime enhancement in wireless sensor network. Int J Comput Technol 4(3):755–764
Pal R, Pandey HMA, Saraswat M (2016) BEECP: biogeography optimization-based energy efficient clustering protocol for HWSNs. In: Proceedings of ninth international conference on contemporary computing (IC3), Noida, 11–13 Aug. 2016, pp 1–6
Pal R, Saraswat M (2017) Data clustering using enhanced biogeography-based optimization. In: Proceedings of Tenth international conference on contemporary computing (IC3), Noida, 10–12 August 2017, pp 1–6
Pal R, Saraswat M (2018) Enhanced bag of features using AlexNet and improved biogeography-based optimization for histopathological image analysis. In: Proceedings of eleventh international conference on contemporary computing (IC3), Noida, 2–4 Aug, pp 1–6
Pal R, Saraswat M (2019) Grey relational analysis based keypoints selection in bag-of-features for histopathological image classification. Recent Pat Comput Sci 12(4):260–268
Pal R, Saraswat M (2019) Histopathological image classification using enhanced bag-of-feature with spiral biogeography-based optimization. Appl Intell 49(9):3406–3424
Pal R, Saraswat M (2018) A new bag-of-features method using biogeography-based optimization for categorization of histology images. Int J Inf Syst Manag Sci 1(2):1–6
Pal R, Sharma A (2013) FSEP-E: enhanced stable election protocol based on fuzzy logic for cluster head selection in WSNs. In: Proceedings of sixth international conference on contemporary computing, Noida, 8–10 August, pp 427–432
Pal R, Sharma AK (2014) MSEP-E: enhanced stable election protocol with multihop communication. Global J Comput Sci Technol 14(8):1–8
Pal R, Sindhu R, Sharma A (2013) SEP-E (RCH): Enhanced stable election protocol based on redundant cluster head selection for HWSNs. In: Proceedings of international conference on heterogeneous networking for quality, reliability, security and robustness, Greater Noida, 11–12 Jan, pp 104–114
Pandey AC, Pal R, Kulhari A (2018) Unsupervised data classification using improved biogeography based optimization. Int J Syst Assur Eng Manag 9(4):821–829
Singh S, Chand S, Kumar R, Malik A (2016) NEECP: novel energy-efficient clustering protocol for prolonging lifetime of WSNs. IET Wirel Sens Syst 6(5):151–157
Smaragdakis G, Matta I, Bestavros A (2004) SEP: a stable election protocol for clustered heterogeneous wireless sensor networks. Boston University Computer Science Department, pp 1–8
Ujjwal M, Bandyopadhyay S (2000) Genetic algorithm-based clustering technique. Pattern Recognit 33(9):1455–1465
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Pal, R., Yadav, S., Karnwal, R. et al. EEWC: energy-efficient weighted clustering method based on genetic algorithm for HWSNs. Complex Intell. Syst. 6, 391–400 (2020). https://doi.org/10.1007/s40747-020-00137-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-020-00137-4