
Abstract
Models used for reservoir prediction are subject to various types of uncertainty, and interpretational uncertainty is one of the most difficult to quantify due to the subjective nature of creating different scenarios of the geology and due to the difficultly of propagating these scenarios into uncertainty quantification workflows. Non-uniqueness in geological interpretation often leads to different ways to define the model. Uncertainty in the model definition is related to the equations that are used to describe the modelled reality. Therefore, it is quite challenging to quantify uncertainty between different model definitions, because they may include completely different model parameters. This paper is a continuation of work to capture geological uncertainties in history matching and presents a workflow to handle uncertainty in the geological scenario (i.e. the conceptual geological model) to quantify its impact on the reservoir forecasting and uncertainty quantification. The workflow is based on inferring uncertainty from multiple calibrated models, which are solutions of an inverse problem, using adaptive stochastic sampling and Bayesian inference. The inverse problem is solved by sampling a combined space of geological model parameters and a space of reservoir model descriptions, which represents uncertainty across different modelling concepts based on multiple geological interpretations. The workflow includes building a metric space for reservoir model descriptions using multi-dimensional scaling and classifying the metric space with support vector machines. The proposed workflow is applied to a synthetic reservoir model example to history match it to the known truth case reservoir response. The reservoir model was designed using a multi-point statistics algorithm with multiple training images as alternative geological interpretations. A comparison was made between predictions based on multiple reservoir descriptions and those of a single one, revealing improved performance in uncertainty quantification when using multiple training images.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
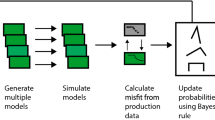
Geological uncertainties can be quantified in producing assets by a Bayesian process of first history matching (HM) geological parameters of the reservoir to production data using a least-squares misfit objective function, then using a Markov chain Monte Carlo (MCMC)-based post-processor to estimate the Bayesian credible intervals. This general workflow was described previously in Arnold et al. (2018), which covers the first part of this work on geological history matching. The basic workflow is given again in Fig. 1, where geological uncertainties are included as parameters of the static model, which are sampled from within complex non-uniform priors based on measured geological data sets.
This workflow has been shown to perform well in forecasting uncertainty based on the assumption that the following are correct:
-
1.
The geological interpretation of the system is known, and there is no ambiguity in the key geological features or their correlation structure.
-
2.
The stratigraphic approach to dividing up the reservoir is correct. There is no ambiguity in the use of, for instance lithostratigraphic versus sequence stratigraphic concepts implemented in the model (Larue and Legarre 2004).
-
3.
The data chosen for characterising the model and for history matching are appropriate for the task, and all errors in the data are accounted for in an appropriate error model (O’Sullivan and Christie 2005).
-
4.
The misfit definition is appropriate for the available data, given its errors.
-
5.
The modelling approach chosen to capture the reservoir is ideal for the geological scenario.
-
6.
The model parameterisation covers all key uncertainties such that the forecast uncertainties are robust.

Uncertainty quantification workflow for history matching using geological prior information
Often, the above criteria are violated due to lack of knowledge about the reservoir, therefore there is a need to understand where the ambiguities come from and at what level. The list above demonstrates the hierarchical nature of handling geological reservoir uncertainties, which therefore should be dealt with in a hierarchical way. At the highest level, one may not have a good interpretational understanding of the reservoir, therefore all choices made on the data, modelling approaches and parameterisations cascade from the initial decision on what the geology “is”.
Uncertainty in geological interpretation has been mentioned by a number of authors, including Rankey and Mitchell (2003) and Bond et al. (2007). Both showed the ambiguity present in the geological interpretation based on seismic data. Rankey and Mitchell (2003) showed a great example of over-confidence in expert opinion. Six experts were asked to interpret seismic data from a carbonate reservoir and comment on their belief in their estimates. All believed theirs was closer to reality based on the fact that the interpretation was easy for the majority of the field. However, portions of the reservoir off-ramp were less well defined and added considerable variation to the volumetric estimates (up to 20 % variation in gross rock volume), even though the other parts of the field were the same for all interpretations. Bond et al. (2007) showed that the same piece of seismic, given to 412 different geologists, produced a spread of different structural interpretations, which were biased by their expertise and experience.
Part of the issue is due to the various psychological biases that come into play when data must be interpreted. Baddeley et al. (2004) provides a good overview of the sources and impacts of bias in geological interpretations. In addition, geologists must also use both quantitative and qualitative information in the construction of their interpretational models (Wood and Curtis 2004).
This paper demonstrates workflows that improve the coverage of geological uncertainties by including interpretational and parameter uncertainties together. We outline a number of examples of workflows that include interpretational uncertainty and show outcomes of reservoir prediction case studies. To help with clarity in what is being discussed, this paper uses the following nomenclature to describe the hierarchical levels of uncertainty:
- Scenario :
-
This is the particular interpretation of the reservoir geology and stratigraphic model that is chosen as a basis for the modelling effort. The number of Scenarios is equal to the number of geological interpretations that exist of the geology and stratigraphic correlation.
- Model: :
-
This is a particular combination of data and modelling method used to capture a Scenario. For any geological interpretation, there may be a number of modelling methods that are possible [e.g. the reservoir facies could be modelled using an object modelling method, a variogram-based geostatistical method such as sequential indicator simulations (SIS), multi-point statistics or a sedimentary process model] and many different data that can be applied in different ways.
- Parameterisation :
-
This is the collection of Model parameters, and their related prior probabilities, chosen to represent the uncertainty of a reservoir. For instance, one might, for a given geomodel, have two parameterisations that focus on different sets of model parameters.
- Misfit Definition :
-
This is the model used to describe the likelihood model of the reservoir based on the available production data and the errors in that data.
- Reservoir Description :
-
This is the particular set-up of previous levels/parts above being applied to the uncertainty quantification workflow.
- Realisation :
-
This is a particular combination of parameters, for a particular Parameterisation of a particular Model of a particular Scenario. If one has produced, for example, 2000 iterations of a particular Parameterisation, then 1 of those 2000 iterations is a Realisation.
2 Multiple Scenarios in Uncertainty Quantification
A complete space of all possible reservoir descriptions would encompass the true prior uncertainty for the reservoir, and sampling this space with adequate realisations would allow us to predict the Bayesian posterior probability accurately. This reality is hard to accomplish, as demonstrated by the case study in Arnold et al. (2012), where a small set of uncertain Scenarios (81) made matching all these possibilities to the production data all but impossible to achieve practically.
The space of reservoir descriptions will also change over time as new data are made available, new interpretations/ideas become available from experts interrogating the data and existing reservoir descriptions become redundant. Ideally, this should be observed as a reduction in the spread/degree of estimated uncertainty, but this rarely occurs in real examples, as demonstrated by Dromgoole and Speers (1992).
The reality is that engineers are restricted computationally in how many models they can run, typically work separately from geologists during the history matching process, and tend to calibrate the most likely initial model to data rather than attempt to calibrate several. This makes including many geological uncertainties in, for instance, the structural model all but impossible without complex structural parameterisation techniques such as those demonstrated in Hu (2000) and Cherpeau and Caumon (2015). Caers et al. (2006) identified a number of modelling scenarios based on alternative training images (TIs) and different combinations of conditioning data (wells, seismic, production). Ensemble methods, such as ensemble Kalman filters, have also been used for reservoir model history matching and uncertainty prediction in combination with multi-point statistics (MPS) in Hu et al. (2013), where they considered a single training image for simplification. A machine learning approach, namely multiple kernel learning, was recently applied in Demyanov et al. (2015) to handle multiple geological scenarios in history matching by selecting and blending the most relevant spatial features from a prior ensemble of realisations.
A distance metric approach in reservoir predictions pioneered at Stanford University (Suzuki and Caers 2008) was extended to scenario modelling and optimisation with multiple training images in Jung et al. (2013). This approach was used more recently for updating development decisions through reservoir life stages under uncertainty in geological model scenarios (depositional Scheidt and Caers (2014); production Arnold et al. (2016)). More research on uncertainty quantification across multiple scenarios was published in Jiang et al. (2016), considering different reservoir performance metrics, and in Sun et al. (2017) on inverse modelling with different fracture scenarios. A closed-loop workflow through reservoir development life stages—appraisal and development, early production, history matching, infill well optimisation—was presented in Arnold et al. (2016).
In this paper, we demonstrate the importance of geological interpretational uncertainty, the resulting uncertainty in appropriate model description choice and its impact on reservoir predictions. We present a workflow to account for uncertainty in the reservoir description and the model parameters which accounts for geological realism (Arnold et al. 2018). To demonstrate the issues in assessing uncertainty using only one reservoir description, we create a simple reservoir case study for history matching and uncertainty quantification in Sect. 2.1.
2.1 Case Study 1: An Example of Solving the Inverse Problem with Different Scenarios
This study compares the production responses of three possible reservoir scenarios, described by three different object shapes, with respect to history match quality and uncertainty forecasting. These were defined in three different model descriptions created in IRAP RMS™ object modelling software, and each is used to generate reservoir simulation model grids for the purposes of history matching (an oil industry term for calibrating the model response to measured reservoir production data). The geological models are included in the history matching workflow as shown in Fig. 1 for the purposes of quantifying the uncertainty in reservoir forecasts based on the match quality. Misfit is calculated using the least-squares misfit definition, matching on oil and water rates. The model grid is a simple Cartesian grid with 30,000 grid cells with model dimensions of 2.5 by 2 km by 80 m thick, located at depth of 2500 m. The field is produced initially from a single producer/injector pair running for 5000 days at 5500 STBD. The truth case scenario in this case was synthetic, produced using channel objects with associated level and channel fill facies. Therefore, the shapes of objects are reproducible by one of the three chosen history match scenarios. The truth model was created using the same grid as the HM cases and run with the same well settings and placements.
As each of the object shapes has different numbers and types of parameters, each must have its own geological prior description—hence, it would not be appropriate to sample from the same prior for each scenario. Priors for each of the three scenarios are created (in this simple case uniform priors are used) to describe the uncertainty in object dimensions, net reservoir to gross thickness (NTG) and petrophysical properties.
The three examples represent increasing degrees of geological realism from (a) Pac-Man through (b) Geological Hammers to (c) Channel objects. These scenarios are shown in Fig. 2, and the maximum likelihood values for the uncertain model parameters are given in Table 1. Each of the three scenarios are matched to the same production data set from a high-resolution channelised model of 300, 000 cells with added Gaussian random noise. Models are matched using a stochastic optimisation algorithm, then the misfit ensemble is resampled using NA-Bayes (NAB) (Sambridge 2008) to calculate the unbiased Bayesian credible intervals.

Geological scenarios for reservoir include (a) Pac-Man, (b) Geological Hammers, and (c) Channels. The prior description for each model is given in Table 1, with Pac-Man and Hammer having four parameters and Channels requiring eight
All scenarios produced approximately equivalent quality history matches, as shown in Fig. 3, with the geological hammer objects producing the best overall match to the production data. All scenarios have NTG values in excess of the percolation threshold (King 1990) and a simple porosity/permeability model such that the match quality becomes driven by dynamic connectivity issues such as tortuosity, as discussed in Larue and Legarre (2004). The production forecasts for the reservoir are produced before (Fig. 4) and after inclusion of a new well in three different locations (Fig. 5) in the reservoir. These wells are added at 5100 days to add incremental production to the field.

Maximum-likelihood models for each of the three scenarios plotted against historical data. All three very different scenarios match the production response well

Production forecasts from three geological scenarios: Pac-Man (a), Hammer (b), and Channel (c). All predict different P10–P90 envelopes given similar levels of match quality

P10–P90 forecasts for each of three geological scenarios for three new possible well locations. Channel objects provide the best overall P10–P90 match when forecasts are compared with the truth case actual future production
While the production forecasts with the existing well configuration are quite similar, the addition of a new well leads to larger variations in the forecast response. The Pac-Man model forecasts production rates lower than reality in the forecast period, while the Hammer model shows upsides in production of several hundreds of barrels per day by the end of the forecast period. Indeed, the Hammer model, which provided the best results in terms of minimum misfit (Table 1), has a wider variation in the forecast response for the three different well locations and a much larger estimate of uncertainty (Fig. 5). The use of minimum misfit as a criterion for choosing the best scenario is, therefore, not appropriate, even in this simple case. Such discrepancy between model history match and forecast quality was noted previously by Erbas and Christie (2007).
This case study demonstrates the need for a workflow that can allow history matching of multiple reservoir descriptions, where one cannot choose between multiple geological scenarios, modelling methods or parameterisations. The rest of this paper lays out a methodology to achieve a useable workflow for history matching multiple geological scenarios with geological priors using machine learning. This is demonstrated on two field examples (cases 2 and 3) and for different levels of variability between geological scenarios (cases 2 and 2a).
3 Machine Learning Approach to Handling Multi-scenario Uncertainty Analysis
Uncertainty in the interpretation of the depositional environment can be addressed by a multi-point statistics (MPS) approach which uses different training images parameterised through the rotation and scaling (affinity) properties. Tuning these model parameters allows one to introduce the body size variation in aspect ratio and orientation of a training image. This approach was tested previously in Rojas et al. (2011) to account for uncertainty in training image modifications with rotation and affinity. In that work, a machine learning technique (artificial neural network) was applied to predict the uncertainty in geomorphic parameter values in a fluvial reservoir model based on the MPS training image transformation.
In this work, multi-dimensional scaling (MDS) was applied to the MPS reservoir model realisations based on different training images in order to map them into a unique model space and then classify the model space to group similar-“looking” models. The purpose of MDS in this workflow is to reduce the complexity of the classification problem by representing the distance between the models as a point in a reduced-dimensionality metric space (where the metric is the difference between, for instance, two production measurements taken at the same time).
Classification in the model space is performed using a support vector machine (SVM) trained on the initial set of realisations. The SVM classifier contoured the regions where the model realisations are based on one of the training images used. It is then possible to search the classified space in order to obtain the model realisation that would best match the historical production data. SVM classification of the model space has already been used to improve the search for better-fitting models in a HM exercise, for instance, Demyanov et al. (2010). In this work we used the adaptive stochastic algorithm particle swarm optimisation (PSO) (Mohamed et al. 2010) to navigate the combination of the SVM-classified metric space of geological scenarios and the space of the geomorphic model parameters for each reservoir description.
3.1 Mapping Reservoir Models Based on Multiple Training Images into the Metric Space Using MDS
Multi-dimensional scaling (MDS) has been used previously for the purposes of model clustering and classification for reservoir modelling (Scheidt and Caers 2009a, b, 2014; Arnold et al. 2016), including an application to a turbidite reservoir (Scheidt and Caers 2009b). MDS in this study uses the Euclidean distance (though other distance metrics are available) of some chosen metric (grid cell properties, production time series data) to measure the similarity/dissimilarity between models. Similar models are located closer together in metric space (Borg and Groenen 2005). MDS represents each model as a point in N-dimensional space such that the distances between models in metric space represent those of the model in the original coordinate space, where N is user defined. MDS can be used as a form of non-linear dimensionality reduction, for instance, if the comparison is based on grid cell data (matrix) and there will frequently be more than \(1 \times 10^6\) dimensions. The dimensionality of the MDS eigenvector space depends on the number of components being considered, which can be evaluated with a stress energy diagram that shows the stress decrease with the number of eigencomponents (Wickelmaier 2003). We show an example of this later in Fig. 16a for the second case study. The reason for applying MDS to these kinds of problems is that the reduced dimensionality of metric space has advantages in improving the performance of clustering or classification processes.
A different application of distance-based methods to the petroleum industry was demonstrated by Jung et al. (2013), who used the modified Hausdorff distance metric (instead of Euclidean) between the values of grid properties then used these measures to obtain representative training images for faster MPS modelling. Park et al. (2013) performed history matching with multiple geological interpretations using the metric space, estimating the likelihood surface with a kernel density estimator. Their approach used the production data rather than the grid properties to form a distance metric (i.e. how similar the production profiles were) which compared the production of a few models with the actual production of a reservoir (pre-history matching any model) then selected the training images of the models with the production response closest to historical data.
In this work, we tackle the history matching problem in the metric space by using SVM classification and a combined search in geomorphic parameter space. MPS facies reservoir models were built based on three training images representing different interpretations of a fluvial depositional environment: sinuous, parallel and twin channels (Fig. 6). Three sets of stochastic reservoir model realisations were produced with the MPS algorithm SNESIM (Strebelle 2002) and mapped into the MDS eigenvector space (see a two-dimensional projection in Fig. 6).

MPS realisations with corresponding training images mapped into the MDS space, where the circles depict locations of the initial realisations in a two-dimensional projection used for SVM training. SVM classifier provides regions (colour flooded) corresponding to each of the three training images used. Location of the region of the good HM model is identified with a red rectangular with the best HM model location (red circle)
Classification of the high-dimensional metric space to aid the search for good-fitting models is a challenging problem. Classification aims to establish the correspondence between a location in the metric space and in the training image (model concept) to be used to generate a realisation. The classification solution may not be unique and is subject to how smooth or wiggly the boundaries between different classes are in the metric space. This non-uniqueness can be controlled by the complexity of the classification solution and depends on the information provided by the data realisation that describes the metric space.
3.2 Support Vector Machine Classification in Metric Space
In this work, we applied an SVM classifier that aims to balance the complexity of the model with the goodness of data fit. The SVM applied for classification in the MDS space was good at tackling the high-dimensionality problem, because it controls the smoothness of the class boundaries.
SVM is a constructive learning algorithm based on statistical learning theory (Vapnik 1998). SVM implements a set of decision functions and uses the structural risk minimisation (SRM) principle. SVM uses the Vapnik–Chervonenkis (VC) dimension to build a set of functions whose detailed description does not depend on the dimensionality of the input space. This is possible by generating a special loss function (margin) to have control on the complexity (VC dimension). The margin is known as the distance between two labelled classes (Fig. 7). Statistical learning theory states that the maximum margin principle prevents over-fitting in high-dimensional input spaces to control the generalisation ability and to balance the model complexity and the goodness of data fit.

Modified from Kanevski et al. (2009)
Margin maximisation principle: the basic idea of support vector machine (SVM).
The simplest approach to the classification problem is to separate two classes with a linear decision surface (a line in two dimensions, a plane in three dimensions or a hyper-plane in higher dimensions). Soft margin classifiers are algorithms that allow for training errors and find a linear decision hyperplane for data that is not linearly separable (real data). This problem is avoided by using the kernel trick (which is explained below), which generates a non-linear classifier known as SVM.
The SVM decision function used to classify the data is linear, defined as
where the coefficient vector w and the threshold constant b are optimised in order to maximise the margin. This is a quadratic optimisation problem with linear constraints which has unique solution. Moreover, w is a linear combination of the training samples \(y_{i}\), taken with some weights \(\alpha _{i}\), therefore
The samples with non-zero weights are the only ones which contribute to this maximum margin solution. They are the closest samples to the decision boundary and are called support vectors (SVs) (Fig. 7). SVs are penalised such that \(0<\alpha < {C}\) to allow for misclassification of training data (taking into account mislabelled samples or noise).
The so-called kernel trick is used to make this classifier non-linear. This implies that a dot product operator [kernel \(K(x,x')\)] transforms the data in a higher-dimensional space (reproducing kernel Hilbert space, RKHS), where they become linearly separable. This is the case for linear SVM, where the decision function Eq. (1) relies on the dot products between samples, as is clearly seen by substituting Eqs. (2) into (1). The final classification model is a kernel expansion
The choice of the kernel function is an open research issue. Using some typical kernels like a Gaussian radial basis function (RBF), one takes into account some knowledge like the distance-based similarity of the samples. The parameters of the kernel are the hyper-parameters of the SVM and have to be tuned using cross-validation (Kanevski et al. 2009) or another comparable technique.
3.3 Combined Workflow for History Matching with Multiple Reservoir Descriptions and Geological Priors
The generalised workflow discussed in this paper can be applied to solving the problem of multiple reservoir descriptions. This workflow can also be combined with the geological history matching workflow in part 1 of this work (Arnold et al. 2018) to create a robust method for estimating uncertainty as shown in Fig. 8, which is an evolution of the general Bayesian workflow in Fig. 1.

Combined workflow for history matching and uncertainty quantification that allows for multiple reservoir descriptions (denoted here as TI space) to be matched to production data while sampling from geologically realistic spaces of model parameters (denoted as geological prior). This consists of a two-stage pre-workflow that builds the geological prior then identifies the space of model descriptions. The history matching workflow then samples from the non-uniform geological prior and (in this case) uniform reservoir description space prior. Different coloured models in the history matching workflow represent different reservoir descriptions
Figure 8 shows a four-step overall process to uncertainty quantification:
-
1.
Use SVM classification to generate the geological prior description from available data for the model parameters for each training image. In part 1 of this work (Arnold et al. 2018), we applied the OC-SVM workflow to generate the prior for each training image though a multi-class SVM (MC-SVM) that could be applied for this classification task.
-
2.
Sample a number of realisations of a set of reservoir descriptions using realistic regions of parameter space (taken from step 1) and multiple TIs to generate a reservoir description space in the form of an MDS metric space and then partition it using SVM multiclass classification.
-
3.
Sample the geological prior (space of geomorphic parameters) in combination with the reservoir description prior (MDS metric space) to calibrate to production data.
-
4.
Infer the uncertainty of the reservoir flow response prediction from the ensemble of calibrated (history matched) models using NAB (MCMC) of the misfit ensemble to estimate the uncertainty.
The following sections return to the Stanford VI case studies that were used in paper 1 of this two-part study Arnold et al. (2018) to demonstrate the capability of this workflow.
3.4 Case Study 2: History Matching Using Multiple Training Images—Similar Geological Concepts
A history matching study was set up to illustrate how the approach in Sect. 3.3 helps quantify reservoir uncertainty from different reservoir descriptions, in this case using the set of training images. A simplified (three facies) three-dimensional section from the synthetic Stanford VI reservoir (Castro et al. 2005) was selected as the truth case to generate the history production profiles. Stanford VI is a fluvial field with 29 wells, 11 injectors and 18 producers, the details of which are provided in Table 2. The facies present in this reservoir are channel sand, point bars and floodplain deposits, and the petrophysical properties (porosity, vertical and horizontal permeability) were assigned as constant for each facies in order to observe only the effect of varying facies geometry on the history matching results.
The characteristics of the channel geomorphic parameters are shown in Table 3 and represent uniform priors for the model parameters chosen. These were then validated using the combined OC-SVM and MLP workflow described in the previous paper (part 1) (Arnold et al. 2018). Synthetic seismic data are available for Stanford VI to generate soft conditioning for each facies.
Table 4 summarises the history match settings for this case, which are the same as those used in case study 2 in Arnold et al. (2018). Forecasting the credible intervals using NAB also used the same setup as defined in that paper.
The three alternative training images to be used in this HM exercise are presented in Fig. 9. History matching was performed in both metric space and the space of geomorphic parameters. The sampling for the training image was performed in the metric space where the eigenvectors correspond to one of the classified training images. The space of geomorphic parameters described the relationship between the channel geometric properties: wavelength, amplitude, width and thickness (Arnold et al. (2018)). Channel geometry parameters are then used to estimate the MPS algorithm parameters (affinity) to build realistic reservoir geomodels, which are consistent with the prior information from modern river analogues (Rojas et al. 2011; Arnold et al. 2018).

Multiple training images used for history matching case study 2: TI1 (a), TI2 (b), TI3 (c)

Comparison of misfit evolution through history matching: with a single training image TI3 (a); with three TIs (b). Red dots correspond to unrealistic models which have not been flow simulated (details in Arnold et al. (2018))

Evolution of the reservoir model parameters in history matching: (a) meander wavelength, (b) meander amplitude, (c) channel width, (d) channel thickness. Solid line depicts the parameter values for the truth case

Evolution of the reservoir model parameters in history matching: eigenvalues corresponding to the coordinates of the realisations in the MDS space
Evolution of the misfit through HM iterations with PSO is compared in Fig. 10 for the case with a single TI (using TI3 from Fig. 9c) and with the three TIs. It clearly shows that HM with multiple TIs is able to reach lower misfit values (least-squares norm of production history \(<2000\), versus \(\approx 6000\) with a single TI) and the misfit decreases faster, with a larger number of better models being generated.
Figures 11 and 12 show the evolution of the uncertain parameters while they are being optimised though history matching. The points, which correspond to each of the newly generated models, home in around the better solutions close to the truth case geomorphic parameter values (Fig. 11). Figure 12 shows the scatter of the generated models homing in around the location of the truth case in the metric space (plotted in three projections for each of the eigenvalues). The region of the low-misfit models in the metric space covers a region across two out of three training images in Fig. 6. The relation between the model misfit and the location in the metric space is shown in Fig. 13, where the points are colour coded according to the training image (1, 2, 3) used to build them. Clustering similar to the one in Fig. 12 can be observed for the low misfit values. The lowest misfit values correspond to the models based on TI1 and 2 (Fig. 13). Production profiles of the low-misfit models plotted against the historical field production are presented in Fig. 14.

Misfit distribution of the models based on multiple training images (TI1 (blue dot), TI2 (red dot), TI3 (green dot)) along metric space dimensions (eigenvalues)

Multiple best HM models for field oil production (a) and field water production (b) versus the observed historical data for case study 2

Multiple training images used for history matching case study 3: TI1 (a), TI2 (b), TI3 (c)

Results of MDS for realisations of TI1, TI2 and TI3 as shown in (b) as three coloured regions of MDS space (shown for first two eigenvectors). The points represent realisations of the training images showing the inherent variability from the stochastic process. The region of good history matches are located in the dashed line box, thus on the border between two different training images. (a) Shows the energy value versus eigenvector, revealing that the majority of the information is retained by four dimensions

Comparison between the misfit evolution of the case of using (a) one training image and (b) multiple training images. Note that case (b) starts better than case (a); this is due to the randomness in the parameter selection associated with the optimisation algorithm (PSO)

Comparison between the history matching and forecasting of the oil production rate (WOPR) in three wells, considering models using a single training image and using multiple training images
The case study setup used here demonstrates one issue in choosing very similar training images TI1 and TI2, that provide effectively the same information. This potentially under-predicts the uncertainty and adds a bias due to the truth TI coming from the space covered by the two of the three TIs used in history matching. This issue is addressed in the next section in an adaptation to this case study (case study 2a) that uses a set of three more diverse training images to capture more variation in the geological scenarios.
3.5 Case Study 2a: History Matching Using Multiple Training Images with More Varied Geological Scenarios
Case study 2 was extended to test how the workflow performs in cases where more significant differences exist between geological concepts (training images) to be used for history matching. Three training images presented in Fig. 15 represent meandering, parallel and anastomosing fluvial channel types. The MPS realisations based on these TIs are more different and, therefore, result in a more diverse clustering in the metric space (Fig. 16b). The classification problem becomes more straightforward and low dimensional, which is illustrated in the energy diagram dropping down to 99 % stress energy at 3–4 dimensions (Fig. 16a).
Figure 17 compares the misfit evolution through the history matching process with a single and multiple training images. We can observe that a lower misfit is reached using multiple training images and that more models are generated with low misfit (\(<3000\)). Figure 17 illustrates how the inclusion of multiple training images (b) reduced the misfit when compared with history matching models with a single training image. From Fig. 17, it is clear that the lowest misfit has been reduced from 3366 in case (a) to 2794 in case (b). This can be associated with the fact that, in case (b), the models with the lowest misfit were generated with a training image that describes the facies distribution of the reservoir better than the models generated with the single training image used in case (a). This is only possible by having the opportunity to sample from different training images.
Figure 18 compares history matches and the forecasts of the oil production rate (WOPR) in three wells based on one training image and multiple training images. The use of multiple training images reduced the uncertainty in wells P12 and P5, but in well P1 the uncertainty (P10–P90 range) increased. This can be due to a local connectivity effect of the facies distribution around well P1.
4 Conclusions
The paper presents a workflow to integrate multiple geological scenarios into uncertainty quantification of reservoir forecasts. The workflow demonstrates how reservoir models based on multiple training images can be updated through history matching while also ensuring that the resulting history-matched models are geologically realistic and consistent with a priori geological knowledge. Uncertainty quantification based on multiple training images demonstrated that adaptive stochastic sampling is capable of providing a close match to the observed production whilst maintaining geologically realistic model parameter relationships for a range of geological scenarios.
Automated history matching with geologically realistic priors for MPS parameterisation was applied to a meandering fluvial section of the synthetic full-field Stanford VI reservoir case study. Application of the proposed workflow was able to identify regions of good-fitting models, which correspond to the more than one training image used. The outcomes of history matching with multiple training images were compared with those from a single training image. This comparison showed that use of multiple training images in history matching results in an ensemble of better-matched models as well as more robust uncertainty quantification. This methodology can be seen as a way to include the widest variety of different geological interpretations available into history matching to better capture all the subsurface uncertainties.
References
Arnold D, Demyanov V, Tatum D, Christie M, Rojas T, Geiger S, Corbett P (2012) Hierachical benchmark case study for history matching, uncertainty quantification and reservoir characterisation. Comput Geosci 50:4–15
Arnold D, Demyanov V, Christie M, Bakay A, Gopa K (2016) Optimisation of decision making under uncertainty throughout field lifetime: a fractured reservoir example. Comput Geosci 95:123–139
Arnold D, Demyanov V, Rojas T, Christie M (2018) Uncertainty quantification in reservoir predictions: part 1 - Model realism in history matching using geological prior definitions. Comput Geosci (accepted)
Baddeley MC, Curtis A, Wood R (2004) An introduction to prior information derived from probabilistic judgements: elicitation of knowledge, cognative bias and herding. In: Wood R, Curtis A (eds) Geological prior information, vol 239. Geological Society Special Publication, London, pp 15–27
Bond CE, Gibbs AD, Shipton ZK, Jones S (2007) What do you think this is? Conceptual uncertainty in geoscience interpretation. GSA Today 11(17):4–10
Borg I, Groenen PJF (2005) Modern multidimensional scaling: theory and applications. Springer, Berlin
Caers J, Hoffman T, Strebelle S, Wen X-H (2006) Probabilistic integration of geologic scenarios, seismic, and production data a West Africa turbidite reservoir case study. Lead Edge 25:240–244
Castro SA, Caers J, Mukerji T (2005) The Stanford VI reservoir: 18th annual report. Stanford Centre for Reservoir Forecasting, Stanford University
Chang C-C, Lin C-J (2011) LIBSVM: a library for support vector machines. ACM Trans Intell Syst Technol 2(3):1–39
Cherpeau N, Caumon G (2015) Stochastic structural modelling in sparse data situations. Pet Geosci 21(4):233–247
Demyanov V, Backhouse L, Christie M (2015) Geological feature selection in reservoir modelling and history matching with multiple kernel learning. Comput Geosci 85:16–25
Demyanov V, Pozdnoukhov A, Christie M, Kanevski M (2010) Detection of optimal models in parameter space with support vector machines. In: Proceedings of geoENV VII Geostatistics for Environmental Applications, Springer, pp 345–358
Dromgoole P, Speers R (1992) Managing uncertainty in oilfield reserves. Middle EastWell Eval Rev 12:30–41
Erbas D, Christie M (2007) Effect of sampling strategies on prediction uncertainty estimation. SPE 106229
Hu L (2000) Gradual deformation and iterative calibration of Gaussian-related stochastic models. Math Geol 32:87–108
Hu L, Zhao Y, Liu Y, Scheepens C, Bouchard A (2013) Updating multipoint simulations using the ensemble Kalman filter. Comput Geosci 51:7–15
Jiang R, Stern D, Halsey TC, Manzocchi T (2016) Scenario discovery workflow for robust petroleum reservoir development under uncertainty. Int J Uncertain Quantif 6(6):533–559
Jung A, Fenwick DH, Caers J (2013) Training image-based scenario modeling of fractured reservoirs for flow uncertainty quantification. Comput Geosci 17:1015–1031
Kanevski M, Pozdnoukhov A, Timonin V (2009) Machine learning for spatial environmental data. Theory, applications and software. EPFL Press, Lausanne
King PR (1990) The connectivity and conductivity of overlapping sand bodies. In: Buller AT, Berg E, Hjelmeland O, Kleppe J, Torsæter O, Aasen JO (eds) North Sea oil and gas reservoirs—II: Proceedings of the 2nd North Sea oil and gas reservoirs conference organized and hosted by the Norwegian Institute of Technology (NTH), Trondheim, Norway, May 8–11, 1989, Dordrecht: Springer, Netherland, pp 353–362
Larue DK, Legarre H (2004) Flow units, connectivity and reservoir characterisation in a wave-dominated deltaic reservoir: Meren reservoir, Nigeria. AAPG Bull 88:303–324
Mohamed L, Christie M, Demyanov V (2010) Comparison of stochastic sampling algorithms for uncertainty quantification. Comput Geosci 15:31–38
O’Sullivan A, Christie M (2005) Error models for reducing history match bias. Comput Geosci 9:125–153
Park H, Scheidt C, Fenwick D, Boucher A, Caers J (2013) History matching and uncertainty quantification of facies models with multiple geological interpretations. Comput Geosci 17:609–621
Rankey EC, Mitchell JC (2003) Interpreter’s corner. That’s why it’s called interpretation: impact of horizon uncertainty on seismic attribute analysis. Lead Edge 22(9):820–828
Remy N, Boucher A, Wu J (2009) Applied geostatistics with SGeMS: a user’s guide. Cambridge University Press, Cambridge
Rojas T, Demyanov V, Christie M, Arnold D (2011) Use of geological prior information in reservoir facies modelling. In: Proceedings of IAMG Annual Conference, Saltzburg
Sambridge M (2008) Geophysical inversion with a neighbourhood algorithm-II. Appraising the ensemble. Geophys J Int 138:727–746
Scheidt C, Caers J (2009a) Representing spatial uncertainty using distances and kernels. Math Geosci 41(4):397–419
Scheidt C, Caers J (2009b) Uncertainty quantification in reservoir performance using distances and kernel methods–application to a West Africa deepwater turbidite reservoir. SPE J 14(4):680–692
Scheidt C, Caers J (2014) Updating joint uncertainty in trend and depositional scenario for exploration and early appraisal stage. EAGE 2nd Uncertainty Quantification Workshop, Dubai
Strebelle S (2002) Conditional simulation of complex geological structures using multiple-points statistics. Math Geol 34:1–21
Sun W, Hui MH, Durlofsky LJ (2017) Production forecasting and uncertainty quantification for naturally fractured reservoirs using a new data-space inversion procedure. Comput Geosci 21(5):1443–1458
Suzuki S, Caers J (2008) A distance-based prior model parameterization for constraining solutions of spatial inverse problems. Math Geosci 40:445–469
Vapnik VN (1998) Statistical learning theory. Wiley, New York
Wickelmaier F (2003) An introduction to MDS. Sound Quality Research Unit, Aalborg University, Denmark
Wood R, Curtis A (2004) Geological prior information and its applications to geoscientific problems. In: Wood R, Curtis A (eds) Geological Prior Information: informing science and engineering, vol 239. Geological Society Special Publication, London, pp 1–14
Acknowledgements
The work was funded by the industrial sponsors of the Heriot-Watt Uncertainty Project (phase IV). Authors thank Stanford University for providing Stanford VI case study data, SGeMS geostatistical modelling software (Remy et al. 2009) and advice on MDS computation. Authors acknowledge the use of Eclipse reservoir flow simulator provided by Schlumberger, tNavigator flow simulator provided by Rock Flow Dynamics and Raven history matching software from Epistemy Ltd. LibSVM R package was used for SVM classification (Chang and Lin 2011).
Author information
Authors and Affiliations
Corresponding author
Appendix–Abbreviations
Appendix–Abbreviations
- HM:
-
History match / history matching
- MCMC:
-
Markov chain Monte Carlo
- MC-SVM:
-
Multi-class support vector machine
- MDS:
-
Multi-dimensional scaling
- MKL:
-
Multiple kernel learning
- ML:
-
Machine learning
- MOO:
-
Multi-objective optimisation
- MPS:
-
Multi-point statistics
- NAB:
-
Neighbourhood approximation algorithm—Bayesian
- OC-SVM:
-
One-class support vector machine
- PSO:
-
Particle swarm optimisation
- P10–P90:
-
Credible interval inferred from a posterior probability distribution
- RKHS:
-
Reproducing kernel Hilbert space
- SIS:
-
Sequential indicator simulation
- SVM:
-
Support vector machine
- SVR:
-
Support vector regression
- TI:
-
Training image
- VC:
-
Vapnik–Chervonenkis
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Demyanov, V., Arnold, D., Rojas, T. et al. Uncertainty Quantification in Reservoir Prediction: Part 2—Handling Uncertainty in the Geological Scenario. Math Geosci 51, 241–264 (2019). https://doi.org/10.1007/s11004-018-9755-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11004-018-9755-9