
Abstract
When the COVID-19 pandemic broke out in the beginning of 2020, it became crucial to enhance early diagnosis with efficient means to reduce dangers and future spread of the viruses as soon as possible. Finding effective treatments and lowering mortality rates is now more important than ever. Scanning with a computer tomography (CT) scanner is a helpful method for detecting COVID-19 in this regard. The present paper, as such, is an attempt to contribute to this process by generating an open-source, CT-based image dataset. This dataset contains the CT scans of lung parenchyma regions of 180 COVID-19-positive and 86 COVID-19-negative patients taken at the Bursa Yuksek Ihtisas Training and Research Hospital. The experimental studies show that the modified EfficientNet-ap-nish method uses this dataset effectively for diagnostic purposes. Firstly, a smart segmentation mechanism based on the k-means algorithm is applied to this dataset as a preprocessing stage. Then, performance pretrained models are analyzed using different CNN architectures and with our Nish activation function. The statistical rates are obtained by the various EfficientNet models and the highest detection score is obtained with the EfficientNet-B4-ap-nish version, which provides a 97.93% accuracy rate and a 97.33% F1-score. The implications of the proposed method are immense both for present-day applications and future developments.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
A pandemic is a widely spread infectious disease that rapidly moves across a vast geographic area and affects a large number of people. The Black Death, which caused an estimated 25–200 million people deaths in the fourteenth century [1], was an epidemic with the highest deaths in human history. The term “pandemic” was coined in the aftermath of the Spanish Flu [2] that led to the demise of 17–50 million people between 1918 and 1920. The COVID-19 was declared a pandemic by the World Health Organization (W.H.O.) on March 11, 2020, after it first appeared in China’s Wuhan province in December 2019 and started to expand all over the world. This disease, which causes sore throats, headaches, fevers, runny nose, coughing, and other symptoms, is easily spread among people and weakens the immune system [3], leading to multiple organ failures and death [4]. The W.H.O. has announced 265,194,191 cases of COVID-19 up until December 7, 2021, with a death toll of 5,254,116 due to a significant rise in cases across the world. For the same date in Turkey, these statistics stand at 8,901,117 cases and 77,830 deaths [5].
According to the Chinese government, the COVID-19 cases are diagnosed using Real-Time Polymerase Chain Reaction (RT-PCR), which takes a long time and has a high false-negative rate [6]. The majority of RT-PCR-positive patients either show no symptoms or minor once. The lungs are the most critically exposed organ, the examination of which helps in predicting the prognosis of COVID-19. Thus, treatment planning based on detecting COVID-19-triggered pneumonia in its early stages can reduce mortality by allowing the disease to be addressed before it advances; however, making a definitive diagnosis and avoiding treatment delays might be difficult. To compensate for this shortcoming, thorax Computer Tomography (CT) can be utilized as a more reliable and rapid method, allowing for speedier intervention because almost all medical institutes have this equipment.
One of the most effective strategies used by biomedical applications is the deep learning-based approach. Many diseases are detected with high-accuracy rates using this quick and effective procedure. Radiologists use CT scans to detect whether a patient is COVID-19 positive or negative. Misdiagnosis and treatment delays can be avoided with an effective automated deep learning-based solution. Several studies [7,8,9,10,11] have developed high-accuracy strategies for identifying COVID-19 instances using CTs. For diagnostic purposes, open-access COVID-19 chest X-ray image files [12] and the COVID-19 Radiography Database [13] are also available. These datasets, which include three types of chest images—COVID-19, pneumonia, and normal—are also used in [14]. Before being trained with deep learning models, each image is preprocessed. The dataset is reconstructed using the Fuzzy and Stacking techniques in this preprocessing stage. The developed dataset is then used to train the MobileNetV2 and SqueezeNet deep learning models, which are then classified using the SVM approach as described in [14].
Using transfer learning, the integration of deep learning to detect the presence of COVID-19 in X-ray images was proposed in [15]. The network activation layers are shown as an extra contribution to identify the areas that the model considered in order to create predictions and increase predictability. Furthermore, in [15], an algorithm was established that radiologists can use to quickly highlight the X-ray areas that need to be investigated further. In [16], an automated deep learning-based technique for detecting COVID-19 infection in chest X-rays was presented on a new dataset. This key contribution of this paper was to overcome the lack of RT-PCR sensitivity by using chest X-ray images to detect and diagnose COVID-19. The same work employed an extreme variant of the inception (Xception) algorithm, which can be taught with network weights for large datasets, as well as with fine-tuning the weights of pretrained networks on small datasets. An intelligent COVID-19 infection diagnosis model based on convolutional neural networks (CNNs) and machine learning techniques was developed in [17]. This model guarantees an end-to-end learning scheme that can learn discriminative features directly from the input chest CT X-ray images, avoiding the need for a handcrafted feature engine. The model established in this study can be utilized to aid field specialists, physicians, and radiologists in making decisions. Its goals are to decrease the rate of misdiagnosis and to use the proposed model as a retrospective evaluation tool.
Recently, some studies have worked on COVID-19 detection using CT scan images. In [18], researchers used data augmentation and transfer learning approaches to overcome overfitting problems in utilizing deep learning models (DenseNet-169 and Resnet-50), achieving 89% accuracy. In another study [19], the potential capacity of a EfficientNet-B4 model was analyzed on a large multi-class COVID-19 chest X-ray dataset including 135 samples of COVID-19 positive, 939 samples of normal, and 941 samples of pneumonia. The accuracy is reported with 99.62% and 96.70% classification scores for binary and multi-class cases, respectively. Similarly, the ECOVNet [20] revealed the performance of the EfficientNet-B5 model for COVID-19 identification. Simulations were carried out in an open-access dataset (COVIDx) [8] with 14,914 samples for training and 1,579 samples for testing. The performance is about 97% in case of three classes including COVID-19, normal, and pneumonia. Another image classification model utilizing EfficientNet for COVID-19 detection using CT images is proposed in [21]. The Contrast Limited Adaptive Histogram Equalization (CLAHE) technique is used in the preprocessing stage to enrich the images before implementing the detection model in that study. The accuracy of the model using CLAHE transformation on EfficientNet is evaluated as 94.56%.
Despite the promising results reported in previous studies, many issues remain unsolved in terms of how to train deep learning models for COVID-19 detection with optimal recognition rates; for instance, whether image preprocessing algorithms can aid in improving the performance and robustness of deep learning models. The current study uses a collection of tests on effective deep neural network models, specifically concentrated on EfficientNet models, to better address some of the problems and technical issues. These models are used to detect COVID-19 among patients after determining the appropriate set of parameters. After mapping the COVID-19 feature with large-size filters, the proposed models allow us to investigate the essential visual aspects related with COVID-19 infection. The educated models not only help experts make better decisions, but they also decrease the number of procedures needed to diagnose COVID-19.
Furthermore, the significance and novelty of the present study stem from the fact that it includes a preprocessing stage before mapping raw image data to CNN features. It accomplishes this by using a simple but effective preprocessing step to an open-source dataset, Turkish COVID-19, collected for this purpose. A senior radiologist who has been diagnosing and treating COVID-19 patients since the start of the pandemic confirms the benefit of this dataset. When training a conventional CNN algorithm, a smart data augmentation procedure is used to prevent overfitting and underfitting. Experimental investigations are undertaken after data augmentation to further demonstrate that this dataset is effective for constructing AI-based COVID-19 diagnosis algorithms. After conducting simulations on this custom dataset, the findings of the proposed methods are reported to have a detection accuracy of 97.03% for our EfficientNet-ap-nish model.
This paper is organized as follows. Firstly, the potential of the proposed deep NN models is investigated in terms of detection potential in Sect. 2. The Turkish COVID-19 CT dataset is introduced in Sect. 3. Then, the experimental results are reported and compared with other studies. Finally, the conclusion appears in Sect. 4.
2 Methods and tools
2.1 Proposed method
In order to gain insight into the details, we encapsulate the general outline of our proposed system with Fig. 1. The proposed framework involves the following stages:
-
(1)
Preprocessing: Lung region segmentation using k-means and extracting the Region of Interest (ROI) from the segmented image;
-
(2)
Training: Using four pretrained EfficientNet models and modifying internal layers in order to produce COVID-19 models; and
-
(3)
Performance: Evaluation of the outcomes in terms of statistical measures.

An overview of the framework for the proposed approach
For the preprocessing phase, we performed an operative method that relies on the k-means clustering combined with morphological operators to focus on the lung region of the input frames. One can observe that the proposed segmentation methodology is simple, efficient, and effective, and it only considers the mean value of the lung regions as a threshold. A positive correlation was observed between the performance of detection and focusing on the lung regions, which significantly boosts the performance of the proposed diagnostic COVID-19 framework. Once the lung regions are segmented, the unnecessary homogeneous black parts that are neighboring outside of the lungs are eliminated with morphological operators. Finally, four EfficientNet model versions are applied on these regions to obtain discriminative information with CNN weights.
The key contribution of this study is threefold. First, it investigates an efficient and effective CNN model based on the forecasting of COVID-19 from limited samples. For this purpose, the deep learning methodology has conducted on a new dataset in order to examine the possible contribution of well-established CNN models to the accurate detection of COVID-19. Second, this study incorporates the impact of preprocessing with an aim of focusing on COVID regions. The k-means clustering method was utilized in order to remove lung parenchyma regions containing redundant information, as well as preserving the disease available areas in lung tissue. Consequently, an algorithm for fully automatic lung segmentation was utilized instead of feeding full image into CNN model, which is the primary focus of conventional approaches. Third, we altered the internal layers of the EfficientNet-B4-ap model by incorporating our Nish Activation function, which highlights the benefits of modifying an already existing CNN model. Eventually, this study reviews the advantages of estimating efficient regression weights of the model for early identification and proper discrimination of COVID-19 positive/negative cases.
2.2 Deep learning models
The deep learning structures, a subset of different convolutions, are mostly integrated into medical diagnostic systems and potentially contribute to decision-making processes for classification or segmentation tasks. In line with such purposes, researchers have shown an increased interest in assessing the factors and modifications that can enhance the performance of a typical CNN framework, which generally includes important key components: convolutional layer, activation function, pooling layer, fully connected layer, optimizer function, and hyper-parameters. The main objective is to determine the performance of various combinations of these components, as well as to set the accurate hyper-parameters to achieve global optimum weights. As a deduction, a complete image is converted to reduce the size of the features using convolutional filters, which are gradually optimized through feed-forward and feed-backward phases. Therefore, the optimizer function becomes a key contribution to obtaining optimum global weights that provide a minimal error cost. The main factors that influence an optimizer performance include a smart regulation path, learning rate, batch size, and epochs.
Meanwhile, of particular concern is seeking an effective and efficient consensus between the number of layers and hyper-parameters (filter size, number of batch size, epochs), which have a considerable impact on obtaining a valuable accuracy score. This key factor was first introduced in the AlexNet architecture [22], which outperforms the handcrafted features in object classification in the ImageNet 2012 competition. However, the weakness and limitations of AlexNet were later compensated by the VGG16 model [23], which investigates the optimal depth and size of filters on performance improvement. For the sake of comparing complexity and accuracy, various CNN types have been applied on different image-driven problems. After extensive research to determine the potential capability of CNN variations, one can note that the EfficientNet models obtain outstanding scores for classification tasks and reducing the amount of memory required. On the basis of such facts, we evaluate the different EfficientNet models in order to analyze the correlation between model parameters and its performance.
Simulating the deep learning models on CT scan images plays an important role in addressing the issue of detecting COVID-19 among patients. The use of different EfficientNet structures is evaluated in order to best determine the presence of COVID-19 among individuals. For this purpose, the COVID-19 information is encoded with a subset of global CNN features through activations that primarily provide a minimal error rate between prediction outcomes and ground truths. In detail, by unraveling the effects of spatiotemporal EfficientNet blocks, the present study makes an important contribution to determining patients with and without the COVID-19 infection.
The key contribution of EfficientNet model [24] is determining the optimal balance between CNN’s depth, width and resolution. To obtain the better performance from a CNN architecture (MobileNet or ResNet), the baseline of an optimal model has found by uniformly scaling width, depth, or resolution dimensions with a fixed ratio. As a result, the EfficientNet baseline model provides better accuracy and efficiency in terms of memory consumption due to waste usage of parameters. Compared to a typical ConvNet, these models are 8.4 × smaller and 6.1 × faster. The researchers present an effort to improve the performance EfficientNet original architecture by modifying or integration different parts. In a study [25], namely EfficientNet-AdvProp, considerably improved the robustness of the model by introducing the adversarial training to enhance generalizability and discriminative traits of CNN’s features. Another study [26], called Noisy Students (Efficient-ns), investigated the benefits of distillation learning on the basis of teacher and student concepts. A larger student model was chosen and noise injected to achieve a better learning process on the guide of teacher. Also, the authors of EfficientNet baseline proposed a faster model (EfficientNet-v2) [27] by introducing progressive learning concept for the trade-off between accuracy and training speed (FLOPs), which makes the model being 6.8 × smaller than original model, as well as maintaining the competitive performance. The parameter settings of four EfficientNet-B4 models are given in Table 1.
To reduce the memorization problem, we have applied some data augmentation techniques, as well as increasing the generalizability of models. For this purpose, random rotation between − 40° and − 40° angles, random horizontal flip and random vertical operations are online carried out on a batch of lung parenchyma images. The images are normalized by using ImageNet’s mean (0.485, 0.456, 0.406) and standard deviation (0.229, 0.224, 0.225). The selection of batch size is specified on the capacity of GPU memory.
2.3 Proposed activation function: Nish
The choice of activation function is important to activate the weighted sum of inputs and biases and regularizing the deep CNN buildings in terms of minimizing error between output and expected value. In this study, we have utilized an efficient activation function, called Nish [28], in order to bring a new contribution to the deep learning literature. The Rectified Linear Unit \(\left( {{\text{Re}} {\text{LU}}(x) = \max (0,x)} \right)\) [22, 29] has been generally used in many deep models. However, it has some drawbacks, such as the “dying ReLU” problem and if a large negative bias is learned causing the output of the neuron to be always zero regardless of the input [30]. Nish tries to avoid this problem due to the small amount of gradient existing in the negative region, especially closed to the origin. Our Nish activation function is formulated as follows:
It behaves as the ReLU for positive values, however, it applies sinus-sigmoidal function for negative outputs. Although, in the ReLU activation function, the output of a neuron is multiplied by 1 or 0, Nish is limited below and unlimited above with a range of [≈ − 0.31, ∞). As comparison, the graph of ReLU and Nish and first-order derivatives are shown in Fig. 2. In order gain a novel contribution to the literature, we have integrated the Nish with a purpose of improving the taxonomy performance of a typical CNN algorithm.

The activation functions of the ReLU and the Nish (left), and the dReLU and the dNish (right)
3 Experimental study
3.1 Dataset and preprocessing
We generate our ‘Turkish Covid-19’ special dataset by gathering the patients’ CT data from Bursa Yüksek Ihtisas Education and Research Hospital as an affiliate of the Ministry of Health, Republic of Turkey. In compliance with the national procedures, ethical approval was obtained from the ethics committee of the hospital. This dataset consists of 266 lung parenchymal CT scans; 180 COVID-19 pneumonias and 86 Normal (non-COVID-19) patients, all registered into university from March 29th, 2020 to October 20th, 2020. Table 2 illustrates the summary statistics for the demographic characteristics of included samples. From Table 2, we can see that distribution of age and sex rate is close to each other. According to the treatment program of COVID-19 researchers at the hospital, the patients were classified into three clinical groups as mild, moderate, and severe. In this study, the COVID-19 dataset involves 49 milds, 53 moderate and 78 severe patients.
Although it is fair to say that our dataset is modest in terms of generality, it is still significantly larger than the data that are often presented in many of the studies that are devoted to the diagnosis of COVID-19. By augmenting data in real-time online, we enhance the model universality and improve learning process. When the number of observations grows beyond the millions, overfitting becomes inevitable due to the curse of the large data set.
After segmentation and cropping process, we have gathered a total of 9729 lung parenchymal samples. For a benchmark evaluation, the data are divided into fivefold. For experimental purposes, each split is consisting of 80% training (6226 samples) and 20% testing (1946 samples). Also, the 20% of training is reserved for validation phase (1557 samples). In case of model compiling, each sample was resized at a resolution of 380 × 380 pixels. We have highlighted the details about presence and absence of COVID-19 on CT images in the last part of experimental results. One advantage of the ROI-based image processing is that it avoids the problem of facing certain challenges to reach an accepted accuracy value [16]. With the help of a smart lung region segmentation, redundant noises can be removed at background of Digital Imaging and Communications in Medicine (DICOM) samples. By considering such needs, k-means clustering was applied for its reliability and validity in terms of revealing the complete shape of parenchymal region in the lungs. Later, the morphological operations are applied to preserve boundaries of lungs and fill holes stated in a sample. Figure 3 demonstrates details and outcomes of the preprocessing phase for COVID-19 positive case and negative case, in first and second rows, respectively. The cropped region in the binary mask was erased with a \(3\times 3\) filter and dilated with an \(8\times 8\) filter to preserve exact lung information.

An overview of the preprocessing stage
3.2 Experimental results
The COVID-19 detection on the basis of patients’ CT imaging is one of the most common challenges in medical image processing-based diagnostic systems. However, the deep learning-based systems, for instance, can maximize the accuracy of diagnosis, as well as improving the speed for the clinical decisions [8, 17]. Besides, the performance of a robust deep learning algorithm can be improved with an effective preprocessing method. In line with this fact, this study provides a useful account for importance of lung region segmentation with the help of k-means segmentation.
The F1-score is calculated from statistics of the True Positive (TP), True Negative (TN), False Positive (FP) and False-Negative (FN) rates. For this purpose, the estimated and ground truth values are utilized to compute these counts.
As can be seen from Eq. (2), the F1-score is the harmonic mean of precision and recall as an efficient means of performance projection. Moreover, it is a more benchmark evaluation for imbalanced class distribution, where the curse of sample size occurred. Accuracy and F1-score evaluation metrics describe the performance of utilized EfficientNet models.
For a detailed performance inspection, the F1-score and accuracy rates of each EfficientNet versions are presented in Tables 3 and 4. The best average score is denoted as bold. From the overall scores given in Tables 3 and 4, it can be noted that the EfficientNet-ap-nish model takes the first rank with its superior results. When comparing the EfficientNet-ns and EfficientNet-v2, one can observe that the EfficientNet-v2 model presents dominant results for all the evaluation metrics. As shown in Fig. 4, the performance of the pretrained EfficientNet-ap approach is greatly enhanced by our activation function. Moreover, Fig. 5 displays a visualization of the confusion matrices that illustrates the underestimations caused by each approach. It is possible to deduce from Fig. 5 that the number of samples that were incorrectly classified was rather low in the event that our Nish activation function was integrated with the EfficientNet-ap model. For this reason, it should come as no surprise that the Nish activation function is superior to the SiLU [31] activation function when it comes to solving an image-driven classification problem.

The detailed recognition rates of COVID-19 Positive and Negative cases

The average confusion matrix obtained with fivefold cross-validation technique
Another objective of this study is to compare the performance of EfficientNets with state-of-the-art method on COVID-19 detection. For this purpose, the accuracy score and details about these methods are presented at Table 5. The best performances of using EfficientNet models are denoted as bold. In order to gain a detailed understanding of each method, the type of imaging, focused region, number of categories about phenotyping, utilized CNN model, and related accuracy scores are highlighted in the given Table 5. One can say that each method is robust for its own specific purpose, however, we will review the weakness and robustness of each one when it comes to detecting the COVID-19 case. By inspecting the accuracy scores, it is clear that the deepest models are particularly useful in studying COVID-19 detection. However, there are certain drawbacks associated with the use of ResNeTs in case training with large batch sizes as consuming a significant amount of CPU or GPU memory. An ideal method should provide an efficient detection score while offering economic use of memory resources. Therefore, effective and efficient methods can be more useful for identifying and encapsulating the COVID-19 information included in samples.
Consistent with the literature, this study presents competitive results as shown in Table 5. In contrast to earlier findings, the results of the method of Song et al. [32] do not support previous research carried by Narin et al. [33], which points out that ResNet-50 yields higher discriminative scores for detecting COVID-19 positive cases. Notwithstanding, these variations can also be explained with challenges and complexity concerning the imaging technique. To compare results, the study by Nour et al. [17] presents an outstanding overall recognition rate was 98.97%, much higher than that of previously reported scores in the work of Toraman et al. [34] and Zheng et al. [35]. On the other hand, Nour et Al. [17] developed a modest CNN architecture by arranging the number of convolutional layers and the large number of filters, which resembles to VGG16 in terms of functionality. Although using a large number of weights and layers may achieve higher recognition performance, it may lead to overfitting, as well as reducing the generalization of trained weights. To continue, the DRE-Net provides 86.00% discrimination score as an investigation of Song et al. [32], which falls behind those obtained in DarkCovNet by Ozturk et al. [36], which accounts to 98.08% accuracy rate. In the study of [32], the DRE-Net was built on top of a pretrained ResNet-50 [37] architecture by integrating Feature Pyramid Network (FPN) component to yield the K-dimension features from each processed sample. The theoretical implications of these findings support that the generalizability of Toraman et al. [34] is higher when considering large dataset; the large number of positive COVID-19 cases (1050) and negative cases (1050).
Upon inspecting the results obtained by the proposed methods, it can be stated that the performance of EfficientNet-orj (97.27%), EfficientNet-ap (97.45%), EfficientNet-ns (97.13%), EfficientNet-v2 (97.26%) and EfficientNet-ap-nish (97.93%) competes with top scores. The key contribution of this experimental study reveals that the weights of pretrained EfficientNet-ns model not only boost the recognition scores, but also reduce the memory consumption when it comes to COVID-19 detection. Moreover, one can say that the experimental results of our methods corroborate these earlier findings in [19, 20]. The higher detection performance of is coming from tenfold cross-validation since the test samples are smaller compared to training data and results in higher detection score. One can observe that the score of EfficientNet-B5-orj [20] is closed to the proposed method. In addition, we have found that the activation has a direct effect on the capacity of a model in terms of avoiding overfitting or underfitting. We improve the overall performance of the preexisting EfficientNet model by incorporating our Nish activation function.
Additionally, we have compared the generalizability of our methods in terms of dataset size. From the given statistics about our dataset, we can observe that the number of COVID-19 positive and negative samples is 180:86, which is higher than the average number of other datasets when compared with some existing works. Contrary to expectations, the VGG16 model is not able to produce sufficient performance on COVID-19 detection, which means inadequate potential to capture the variations between positive and negative cases when taking the CT scans of Lung Parenchyma regions as reference. With regards to curse of dimension, after a certain limit within the layers and filters, an increase in the filters’ depth or the number of layers fails to enhance the performance of any CNN model due to overfitting case. For ResNet-50, DenseNet-169, InceptionV3, and VGG16 models, one can emphasize that the low accuracy scores can be attributed to overfitting. The overfitting refers that the accuracy could not enhance after converging to a global optimum point even with the best set of tuned parameters.
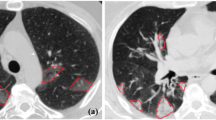
Additionally, expert radiologists commented on interpretations of the COVID-19 findings on CT scans. Figure 6 gives insight into the findings of lung abnormalities on the CT scans of COVID-19 positive and negative cases. Figure 6a shows normal Thorax CT findings without any infiltration. Figure 6b illustrates a Thorax CT image that denotes Bilateral Peripheral Groundglass Opacities.

The comments of the radiologist on COVID-19 positive and negative cases: a Normal Thorax CT findings without any infiltration, b Bilateral Peripheral Groundglass Opacities in Thorax
4 Conclusion
The purpose of the present study is to investigate the capability of EfficientNet models for COVID-19 detection. After empirical evaluations, EfficientNet-b4-ap model can be considered as reliable predictors to detect the presence of COVID-19 cases. Additionally, the most apparent finding of this study is that the preprocessing stage significantly improves the performance. In a study, the performance of the system was evaluated at around 86% accuracy rate, before the segmentation of lung parenchyma regions [38]. This lack is caused by the remaining redundant information on the CT scans. Therefore, the preprocessing stages are certainly necessary to detect the presence of COVID-19 among patients. In this regard, focusing on the most susceptible regions is a practical way for the purpose of reliable measurements with the deep learning concept. The following conclusions can be demonstrated from the current study:
-
Using a parameter-free model, namely EfficientNet-b4-ap, provides effective results.
-
Using the fivefold cross-validation techniques with the EfficientNet models shows that it is possible to set up an effective model with promising performances.
-
The running time of the chosen model is important for real-time applications. After analyzing the cost for each test image, it turns out that the execution time of EfficientNet model is about 117 ms (ms). This duration can be evaluated when doing the experiments with a standard Google Colab environment (Tesla P100-PCIE, GPU, 16 GB memory).
-
All of the observed quantitative results support the robustness and efficiency by integrating proposed Nish activation function for COVID-19 detection.
Data availability
The datasets generated during and/or analyzed during the current study are not publicly available due to privacy preserving of patient data but are available from the corresponding author on reasonable request.
References
Ziegler P (2013) The black death. Faber & Faber
Trilla A, Trilla G, Daer C (2008) The 1918 “Spanish flu” in Spain. Clin Infect Dis 47:668–673
Razai MS, Doerholt K, Ladhani S, Oakeshott P (2020) Coronavirus disease 2019 (covid-19): a guide for UK GPs. BMJ 368:1-5
Li L, Qin L, Xu Z, Yin Y, Wang X, Kong B, Bai J, Lu Y, Fang Z, Song Q (2020) Artificial intelligence distinguishes COVID-19 from community acquired pneumonia on chest CT. Radiology. https://doi.org/10.1148/radiol.2020200905
World Health Organization (WHO) Accessed: Nov. 8, 2020. [Online]. https://covid19.who.int/.
WHO (2019) Report of the WHO-China Joint Mission on Coronavirus Disease 2019. https://www.who.int/publications/i/item/report-of-the-who-china-joint-mission-on-coronavirus-disease-2019-(covid-19). Accessibility verified February, 28
Ardakani AA, Kanafi AR, Acharya UR, Khadem N, Mohammadi A (2020) Application of deep learning technique to manage COVID-19 in routine clinical practice using CT images: results of 10 convolutional neural networks. Comput Biol Med 121:103795
Gunraj H, Wang L, Wong A (2020) Covidnet-ct: a tailored deep convolutional neural network design for detection of covid-19 cases from chest CT images. arXiv (2020)
Barbosa Jr EJM, Georgescu B, Chaganti S, Aleman GB, Cabrero JB, Chabin G, Flohr T, Grenier P, Grbic S, Gupta N (2021) Machine learning automatically detects COVID-19 using chest CTs in a large multicenter cohort. Eur Radiol 31:8775–8785
Shah V, Keniya R, Shridharani A, Punjabi M, Shah J, Mehendale N (2021) Diagnosis of COVID-19 using CT scan images and deep learning techniques. Emerg Radiol 28:497–505
Shalbaf A, Vafaeezadeh M (2021) Automated detection of COVID-19 using ensemble of transfer learning with deep convolutional neural network based on CT scans. Int J Comput Assist Radiol Surg 16:115–123
Cohen JP (2020) COVID-19 chest X-ray dataset or CT dataset, GitHub. https://github.com/ieee8023/covid-chestxray-dataset. Accessed 10 Mar 2020.
Rahman MCT, Khandakar A (2020) COVID-19 radiography database, Kaggle. https://www.kaggle.com/tawsifurrahman/covid19-radiography-database/data#. Accessed 20 April 2020
Toğaçar M, Ergen B, Cömert Z (2020) COVID-19 detection using deep learning models to exploit Social Mimic Optimization and structured chest X-ray images using fuzzy color and stacking approaches. Comput Biol Med 121:103805
Brunese L, Mercaldo F, Reginelli A, Santone A (2020) Explainable deep learning for pulmonary disease and coronavirus COVID-19 detection from X-rays. Comput Methods Prog Biomed 196:105608
Das NN, Kumar N, Kaur M, Kumar V, Singh D (2022) Automated deep transfer learning-based approach for detection of COVID-19 infection in chest X-rays. Ing Rech Biomed 43(2):114–119
Nour M, Cömert Z, Polat K (2020) A novel medical diagnosis model for COVID-19 infection detection based on deep features and Bayesian optimization. Appl Soft Comput 97:106580
Yang X, He X, Zhao J, Zhang Y, Zhang S, Xie P (2020) COVID-CT-dataset: a CT scan dataset about COVID-19. arXiv: arXiv: 2003.13865
Marques G, Agarwal D, de la Torre DI (2020) Automated medical diagnosis of COVID-19 through EfficientNet convolutional neural network. Appl Soft Comput 96:106691
Chowdhury NK, Kabir MA, Rahman M, Rezoana N (2020) ECOVNet: an ensemble of deep convolutional neural networks based on EfficientNet to detect COVID-19 from chest X-rays. arXiv preprint arXiv:2009.11850
Ebenezer AS, Kanmani SD, Sivakumar M, Priya SJ (2022) Effect of image transformation on EfficientNet model for COVID-19 CT image classification. Mater Today Proc 51:2512–2519
Krizhevsky A, Sutskever I, Hinton GE (2017) Imagenet classification with deep convolutional neural networks. Commun ACM 60:84–90
Simonyan K, Zisserman A (2014) Very deep convolutional networks for large-scale image recognition. In: Proceedings of the 3rd international conference on learning representations
Tan M, Le Q (2019) EfficientNet: rethinking model scaling for convolutional neural networks, international conference on machine learning, PMLR2019, pp 6105–6114
Xie C, Tan M, Gong B, Wang J, Yuille AL, Le QV (2020) Adversarial examples improve image recognition. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp 819–828
Xie Q, Luong M-T, Hovy E, Le QV (2020) Self-training with noisy student improves imagenet classification, In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 10687–10698
Tan M, Le QV (2021) Efficientnetv2: smaller models and faster training, arXiv preprint arXiv:2104.00298
Anagun Y, Isik S, Nish S (2022) A novel negative stimulated hybrid activation function. arXiv (2022)
Nair V, Hinton GE (2010) Rectified linear units improve restricted Boltzmann machines. In: Icml2010
Maas AL, Hannun AY, Ng AY (2013) Rectifier nonlinearities improve neural network acoustic models. In: Proceedings of ICML, Citeseer2013, p 3
Elfwing S, Uchibe E, Doya K (2018) Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw 107:3–11
Song Y, Zheng S, Li L, Zhang X, Zhang X, Huang Z, Chen J, Zhao H, Jie Y, Wang R (2020) Deep learning enables accurate diagnosis of novel coronavirus (COVID-19) with CT images. medRxiv
Narin A, Kaya C, Pamuk Z (2020) Automatic detection of coronavirus disease (covid-19) using x-ray images and deep convolutional neural networks, arXiv preprint arXiv:10849
Toraman S, Alakus TB, Turkoglu I (2020) Convolutional capsnet: a novel artificial neural network approach to detect COVID-19 disease from X-ray images using capsule networks. Chaos Solitons Fractals 140:110122
Zheng C, Deng X, Fu Q, Zhou Q, Feng J, Ma H, Liu W, Wang X (2020) Deep learning-based detection for COVID-19 from chest CT using weak label. medRxiv
Ozturk T, Talo M, Yildirim EA, Baloglu UB, Yildirim O, Acharya UR (2020) Automated detection of COVID-19 cases using deep neural networks with X-ray images. Comput Biol Med 121:103792
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp 770–778
Kaya Z, Kurt Z, Işık Ş, Koca N, Çiçek S (2022) Deep learning-based COVID-19 detection using lung parenchyma CT scans. In: Proceedings of international conference on computing and communication networks. Springer, pp 261–275
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest to this work.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Kurt, Z., Işık, Ş., Kaya, Z. et al. Evaluation of EfficientNet models for COVID-19 detection using lung parenchyma. Neural Comput & Applic 35, 12121–12132 (2023). https://doi.org/10.1007/s00521-023-08344-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-023-08344-z