
Abstract
Early diagnosis of the coronavirus disease in 2019 (COVID-19) is essential for controlling this pandemic. COVID-19 has been spreading rapidly all over the world. There is no vaccine available for this virus yet. Fast and accurate COVID-19 screening is possible using computed tomography (CT) scan images. The deep learning techniques used in the proposed method is based on a convolutional neural network (CNN). Our manuscript focuses on differentiating the CT scan images of COVID-19 and non-COVID 19 CT using different deep learning techniques. A self-developed model named CTnet-10 was designed for the COVID-19 diagnosis, having an accuracy of 82.1%. Also, other models that we tested are DenseNet-169, VGG-16, ResNet-50, InceptionV3, and VGG-19. The VGG-19 proved to be superior with an accuracy of 94.52% as compared to all other deep learning models. Automated diagnosis of COVID-19 from the CT scan pictures can be used by the doctors as a quick and efficient method for COVID-19 screening.
Similar content being viewed by others


Introduction
The new coronavirus infection was first reported in Wuhan, China, and since then it has strongly spread out since January 2020 worldwide. The World Health Organization (WHO) [1] declared the outbreak from the Coronavirus disease 2019 (COVID-19) to be a public health emergency of international concern on the 30th of January, 2020. COVID-19 is a respiratory ailment caused by the coronavirus [2]. The most common symptoms include fever [3], fatigue, dry cough, loss of appetite, body aches, and mucus. Some non-specific symptoms may include sore throat, headache, chills with shaking sometimes, loss of smell or taste, running nose, vomiting, or diarrhea [4]. Symptoms may usually take 5 to 6 days [5] to show after a person comes in contact with the virus. People with mild symptoms may recover on their own [6]. People suffering from other health conditions such as diabetes or heart problems may suffer from serious symptoms [7]. Animals are also able to transmit this infection while getting affected themselves. Mainly two similar viruses were reported earlier, which were severe acute respiratory syndrome coronavirus (SARS-CoV) [8] and the Middle East respiratory syndrome coronavirus (MERS coronavirus) [9]. These viruses caused major respiratory problems and are zoonotic in nature.
In comparison to RT-PCR, the thorax computer tomography (CT) is possibly more reliable, useful, and quicker technology for the classification and assessment of COVID-19, in particular to the epidemic region [10]. Almost all hospitals have CT image screening; hence, the thorax CT pictures can be used for the early detection of COVID-19 patients. However, the COVID-19 classification based on the thorax CT requires a radiology expert, and a lot of valuable time is lost. In the current scenario, the COVID-19 test results take more than 24 h to detect the virus in the human body. There is an urgent need to recognize the illness in the early stage and to put the infected immediately under quarantine because no specific drugs are available for COVID-19. The Chinese government reported that the diagnosis for confirmation of COVID-19 is done with the help of the real-time polymerase chain reaction (RT-PCR) [11]. RT-PCR suffers from high false-negative rates and utilizes a lot of time since the machine which is used for the test takes around 4–8 h to process the samples of the patients. The low sensitivity RT-PCR test is not satisfactory in the present pandemic situation. In some cases, the infected are not possibly recognized on time and do not receive suitable treatment. The infected can be assigned sometimes as COVID-19 negative because of a false-negative result [12]. Hence, automated analysis of the thorax CT pictures is desirable to save the valuable time of the medical specialist staff. This will also avoid delays in starting treatment.
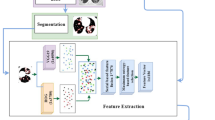
Deep learning is the most efficient technique that can be used in medical science [13]. It is a fast and efficient method for the diagnosis and prognosis of various illnesses with a good accuracy rate. There are specifically trained models to classify the inputs into different categories desired by the programmers. In the medical field, they are used to detect heart problems, tumors using image analysis, diagnosing cancer, and many other applications [14]. It is also used to differentiate the CT scan images of the patients infected with COVID-19 as positive or not infected, i.e., negative. A self-developed model CTnet-10 was created having an accuracy of 82.1%. To improve the accuracy, we had also passed the CT scan image through multiple pre-existing models. We found that the VGG-19 model is best to classify the images as COVID-19 positive or negative as it gave a better accuracy of 94.52%. A graphical representation of our proposed model is demonstrated in Fig. 1. The CT scan image is passed through a VGG-19 model that categorizes the CT scan into COVID-19 positive or COVID-19 negative.

System flow diagram. The CT scan machine gives the CT scan image of a patient for the screening of COVID-19. The input image is passed through a VGG-19 model that categorizes the image as COVID-19 positive or negative
Literature review
Several studies and research work have been carried out in the field of diagnosis from medical images such as computed tomography (CT) scans using artificial intelligence and deep learning. DenseNet architecture and recurrent neural network layer were incorporated for the analysis of 77 brain CTs by Grewal et al. [15]. RADnet demonstrates 81.82% hemorrhage prediction accuracy at the CT level. Three types of deep neural networks (CNN, DNN, and SAE) were designed for lung cancer classification by Song et al. [16]. The CNN model was found to have better accuracy as compared to the other models. Using deep learning, specifically convolutional neural network (CNN) analysis, Gonzalez et al. [17] could detect and stage chronic obstructive pulmonary disease (COPD) and predict acute respiratory disease (ARD) events and mortality in smokers.
During the outbreak of COVID-19, CT was found to be useful for diagnosing COVID-19 patients. The key point that can be visualized from the CT scan images for the detection of COVID-19 was ground-glass opacities, consolidation, reticular pattern, and crazy paving pattern [18]. A study was done by Zhao et al. [19] to investigate the relation between chest CT findings and the clinical conditions of COVID-19 pneumonia. Data on 101 cases of COVID-19 pneumonia were collected from four institutions in Hunan, China. Basic clinical characteristics and detailed imaging features were evaluated and compared. A study on the chest CTs of 121 symptomatic patients infected with coronavirus was done by Bernheim et al. [20]. The hallmarks of COVID-19 infection as seen on the CT scan images were bilateral and peripheral ground-glass and consolidative pulmonary opacities. As it is difficult to obtain the datasets related to COVID-19, an open-sourced dataset COVID-CT, which contains 349 COVID-19 CT images from 216 patients and 463 non-COVID-19 CTs, was built by Zhao et al. [21]. Using the dataset, they developed an AI-based diagnosis model for the diagnosis of COVID-19 from the CT images. On a testing set of 157 international patients, an AI-based automated CT image analysis tools for detection, quantification, and tracking of coronavirus was designed by Gozes et al. [22]. The accuracy of the model developed was 95%. The common chest CT findings of COVID-19 are multiple ground-glass opacity, consolidation, and interlobular septal thickening in both lungs, which are mostly distributed under the pleura [23]. A deep learning–based software system for automatic COVID-19 detection on chest CT was developed by Zheng et al. [24] using 3D CT volumes to detect COVID-19. A pre-trained UNet and a 3D deep neural network were used to predict the probability of COVID-19 infections on a set of 630 CT scans. Out of 1014 patients, 601 patients tested positive for COVID-19 based on RT-PCR and the results were compared with the chest CT. The sensitivity of chest CT in suggesting COVID-19 was 97% as shown by Ai et al. [25]. In a series of 51 patients with chest CT and RT-PCR tests performed within 3 days by Fang et al. [26], the sensitivity of CT for COVID-19 infection was 98% compared to RT-PCR sensitivity of 71%. An AI system (CAD4COVID-Xray) was trained on 24,678 CXR images including 1540 used only for validation while training. The radiographs were independently analyzed by six readers and by the AI system. Using RT-PCR test results as the reference standard, the AI system correctly classified CXR images as COVID-19 pneumonia with an AUC of 0.81 [27].
Methodology
The COVID-19 CT dataset consisted of the images of patients that had tested positive for COVID-19 and the subsequent was also confirmed by the RT-PCR method. From a total of 738 CT scan images, 349 images from 216 patients were confirmed to have COVID-19 whereas 463 images were of the non-COVID-19 patients [21]. These images were split into a training set, validation set, and test set with a split of 80%, 10%, and 10% respectively.
The workflow diagram of the proposed system is shown in Fig. 2. The CT scan procedure starts by either walk-in or getting an appointment. It is then followed by the registration and the filling of the prep or consent form by the patient. The procedure for the examination of the CT scan by the radiologist can be done in two ways. The first way consists of getting a wet film. After making the payment, the wet film is handed to the patient. In the second way, the wet film captured by the radiographer is given to the radiologist for preparing a report. The patient then collects the report. The CT scan images are then fed to the deep learning models for detecting COVID-19. After the examination, the CT scan images can be directly fed to the deep learning model to classify the CT scan images as COVID-19 positive or COVID-19 negative.

Workflow diagram of the proposed system. The procedure of getting a CT scan starts by either walk-in or getting an appointment. It is followed by the registration and the filling of the prep or consent form by the patient. The actual procedure of getting a CT scan by the radiographer starts in two ways: one being the wet film and the other film and getting a report. The reports are then collected by the patients and the CT scan images can be fed to the deep learning models. After the examination, the CT scan images can be directly fed to the deep learning model to classify the CT scan images as COVID-19 positive or COVID-19 negative
Our self-developed network (CTnet-10) was fed with an input image of dimension 128×128×3 and at every layer, the dimensions of the activations were changed. Convolutional blocks are major building blocks of neural networks. Pooling layers are helpful in reducing the number of computations to be performed. Both the convolutional block I and II consisted of 2 layers and a pooling layer with a flattening layer to convert 2D to 1D layer, which was fed to a dense layer of 256 neurons (as shown in Fig. 3). A dropout of value 0.3 had been added in which the output layer contained 1 neuron and then the result had been predicted to classify the CT scan images.

Configuration of the CTnet-10 model. The model was fed with an input image of size 128×128×3. There are a total of 4 convolutional blocks. It passes through 2 convolutional blocks of dimensions 126×126×32, 124×124×32 respectively. Then it passes through a max-pooling of dimension 62×62×32 followed by 2 convolutional layers of dimensions 60×60×32, 58×58×32 respectively. This is further passed through a pooling layer of dimension 29×29×32. It is then passed through 26912 neurons of the flattened layer, which is further passed through dense and dropout layers of 256 neurons each. After passing it through a single neuron of a dense layer, the CT scan images are classified as COVID-19 positive or negative
For the VGG-19 model, the image dimensions used were 224×224×3, and the output was a number between 0 and 1. For this case, less than 0.5 corresponds to COVID-19 positive and greater than or equal to 0.5 implies COVID-19 negative. As mentioned above, we used VGG-19 architecture with pre-trained weights of imagenet. It is a 24- layer model (as shown in Fig. 4) which consists a total of 5 convolutional blocks, 3 max pool layers, and 3 FC layers, but we did a fine-tuning by using pre-trained weights for all convolutional blocks, removing the last two fully connected (FC) layer and then adding 2 FC layer with 4096 neurons. Dropout was used with each of these layers for regularization with a rate of 0.3. The final binary classification layer of single-neuron governed by sigmoid activation was added. The model was compiled with ADAM optimization with the default learning rate; the loss function used was binary cross-entropy. The model was trained on a batch size of 32 and EarlyStoping was used to prevent overfitting. First, it was trained on 30 epochs without EarlyStoping, and then on 20 epochs with EarlyStoping, the model stopped at epoch no. 10.

Configuration of the model of VGG-19. The model was fed with an input image of size 224×224×3. There are a total of 5 convolutional blocks. It passes through one of the convolutional layers and a ramp of dimension 224×224×64. Then it passes through a next pooling and convolutional layer of dimension 112×112×128. Then it again passes through two pooling layers of dimensions 56×56×128, 28×28×512 respectively. This is further passed through the consecutive layer of dimensions 14×14×512, and a pooling layer of 7×7×512. It is then passed through 25088 neurons of the flattened layer, which is consecutively passed through an FC layer of 4096 neurons, in which the dropout layer was used in each of these. After passing it through a single neuron sigmoid and linear, the CT scan images are classified as COVID-19 positive or negative
The input images were fed to the visual geometry group-16 (VGG-16) model with a dimension of 150×150×3. The model consists of 19 layers, having 5 convolutional blocks. Each block consists of two or three convolutional layers and 5 max-pooling layers, finally ending with 2 fully connected (FC) and a softmax layer. We replaced the softmax layer with the sigmoid layer for binary classification purposes. The model was trained with root mean square propagation (RMSPROP) and a learning rate of (2e − 5) for 30 epochs. We also tried image augmentation on the same model and trained it for 100 epochs.
For the Inception V3 model, the image resolution was kept at 224×224×3. Two dense layers were added of 1000 and 500 neurons with an L1 and L2 regularization respectively, which were set to 0.01. The ResNet-50 model’s resolution was also kept at 224×224×3. It had 50 layers of dropout. The top layer was not included in this model.
Then we tried the DenseNet-169 model. It is a state of art model which has 169 layers in it. The learning rate used was (1*e ̂-4) with RMSPROP and the model was trained for 30 epochs. The size of the images was kept at 224×224×3, and a total of 73 images were used for this model. All the deep learning codes are provided in the ?? ??.
Results
To validate the results, we first trained the CTnet-10 model network using 592 labeled images via supervised learning with 74 validation images. The accuracy of the CTnet-10 model was 82.1%. A total of 73 images were used to test the pre-trained VGG16 network which resulted in an accuracy of 89% between COVID-19 infected and non-infected CT scans. Using image augmentation and fine-tuning, we could get an accuracy of up to 93.15%. For the Inception V3 model, we achieved 53.4% accuracy. Next, we used the ResNet model, which did not contain a top layer. The accuracy achieved was 60%. To improve this, the images were used to train the DenseNet-169 Network, and the ratio of training, validation, and testing was 80:10:10, giving 93.15% accuracy. Then, 73 images were used to test the model, which resulted in an accuracy of 84% between COVID-19-positive and negative CT scans. Due to limited data to create our models, we used a VGG-19 pre-trained network for transfer learning and that resulted in 91.78% accuracy. After doing some fine-tuning, we were able to reach up to an accuracy of 94.52% which was by far the best of all other models we tried out.
The performance of different models used for the study was evaluated using the confusion matrix as shown in Fig. 5 The confusion matrix is extremely useful for calculating the accuracy of the models and represents the information in a better and understandable format. Amongst all the models that we studied, VGG-19 (Fig. 5a) gave the least error in classifying the CT scans into COVID-19 and non-COVID-19. In the case of the Inception V3 model (Fig. 5f), all the COVID-19 CT scan images were wrongly classified into non-COVID-19, thus giving the least accuracy for the classification.

Confusion matrix of the different deep learning models used. a Confusion matrix of VGG-19: Out of 34 COVID-19-positive CT scans, 32 were classified as COVID-19 whereas 2 were wrongly classified as non-COVID-19. Out of 39 non-COVID-19 CT scans, 37 were correctly labeled as non-COVID-19, and 2 were wrongly classified. b Confusion matrix of the self-developed model. 28 out of 35 images were correctly classified as COVID-19. Out of 38 images, 32 were correctly labeled as non-COVID-19 whereas 6 were labeled as COVID-19. c Confusion matrix of VGG-16. Out of 34 CT scans for COVID-19, 32 were correctly labeled as COVID-19 whereas 4 were wrongly classified. Thirty-five out of 39 CT scans were correctly labeled as non-COVID-19 and 4 were labeled as COVID-19. d Confusion matrix for DenseNet-169. Thirty-one images were correctly labeled as COVID-19 and 3 were wrongly classified as non-COVID-19. Out of 39 non-COVID-19 CT scans, 37 were correctly labeled as non-COVID-19. e Confusion matrix for ResNet-50. 29 images were correctly classified as COVID-19 whereas 5 were wrongly classified. Thirty-nine out of 39 images were correctly classified as non-COVID-19. e Confusion matrix of InceptionV3. Thirty-four out of 34 images were wrongly classified as COVID-19 and 39 images were correctly labeled as non-COVID-19
The graph shown in Fig. 6 is a comparison between accuracy in percentage for 6 different deep learning networks that have been used in our study. The VGG-19 network got the highest accuracy of 94.52%. The next highest accuracy of 93.15% was seen in a DenseNet-169 network. The VGG-16 model has an accuracy of 89%. Our self-developed model achieved an accuracy of 82.1%, more than the ResNet-50 network which has an accuracy of 60%, and InceptionV3 with an accuracy of 53.4%.

Comparison of accuracy vs. different deep learning networks. VGG-19 has the highest accuracy amongst the different models used in our work. DenseNet-169 has the second-highest accuracy of 93.15%. The least accurate model was InceptionV3. VGG-16 model shows an accuracy of 89%. Our self-developed model shows a better accuracy of 82.1% as compared to ResNet-50 with 60% accuracy and InceptionV3
As shown in Table 1, we have analyzed 738 CT scan images of the patients available as an open-source data set which is a comparable number to the number reported by Ai et al. [25]. Fang et al. [26] have achieved the highest accuracy of 98%, but they have less number of samples. It is then followed by Ai et al. [25] and Gozes et al. [22] with an accuracy of 97% (1014 samples) and 95% (157 samples) respectively. Our proposed method using the VGG-19 (proposed method—2) model gave us an accuracy of 94.52% and CTnet-10 model (proposed method—1) with an accuracy of 82.1% using 738 CT scan samples. The accuracy of CTnet-10 can be improved further by optimization and fine-tuning.
Time analysis
As shown in Table 2, we had analyzed the time taken by the models for training, testing, and its execution purposes. The models on which speed testing and time savings were done are CTnet-10, VGG-19, Inception V3, and DenseNet-169. The CTnet-10, Inception V3, and VGG-19 models were trained and tested on the Tesla K80 GPU (graphics processing unit) of about 12GB which is provided by the Google Colab. The training time includes the time taken to train the model, whereas the testing time includes the time taken by the model to test 73 images to check the correctness of the model. The execution time includes the time wherein one CT scan image is provided to the model, the output which includes whether the person is COVID-19 positive or COVID-19 negative will be generated. The execution time will remain the same for different samples, provided the image dimensions of the CT scan images are the same and as specified by the individual models. The CTnet-10 took 130 s for training, 900 ms for testing, and 12.33 ms for execution. The VGG-19 model covered 513 s for training, 1 s for testing, and 13.69 ms for execution, whereas the Inception V3 model covered 630 s for training time, 1 s for testing, and 13.69 ms for execution. For the DenseNet-169 model, the 8th generation Intel i5 processor has been used. The DenseNet-169 model took 391.26 s for training, 57.213 s for testing, and 35.47 s for execution.
Discussions
CT scan images can be used for the COVID-19 screening of patients. It gives a detailed image of the particular area, using which we can detect the internal defects, injuries, dimensions of the parts, tumors, etc. Compared to the current RT-PCR method, a CT scan is a reliable method. It is an efficient method for the classification of the images of COVID-19 patients. The results are provided accurately and quickly. There are some side effects of CT scan screening that patients can get exposed to radiation if multiple CT scans are conducted. Early diagnosis generally increases the better treatment of the disease or virus. But at times some mild symptoms can lead to a diagnosis of a major or a minor disease which is wrongly predicted. Early and basic symptoms can be for both a major disease like cancer and also for a simple viral. With an early diagnosis, this disease can be wrongly predicted which will cause a lot of problems for the patient.
Clinical testing and image testing do not have a lot of difference, but major differences are the procedures that take place. In a clinical testing form, filing procedures can be very annoying at times of an emergency unlike image testing where no long procedure needs to be followed. Of course, the accuracy of clinical testing is slightly greater as doctors themselves analyze the reports and in image testing a machine, a computer does this which is only intelligent till it is given instructions very precisely. One more factor that does arise is the cost. Image testing is more cost-effective than clinical testing. Larger concerns arise as to the research methods about the use of CT screening for lung cancer. Most radiologists agreed that CT screening is not unique to lung cancer and that the procedure cannot distinguish between benign tumors and malignant ones. In addition, the risk of radiation-induced lung cancer in other areas of the body is the greatest in those, as compared to radiation-induced cancer [28]. CT scan screening can also affect the nearby bones. The radiation-induced during the scan is harmful to the pregnant ladies and for people who have metal implants.
Our current technique classifies the CT scans into COVID-19 positive or COVID-19 negative. With the help of deep learning techniques, we can incorporate different models to evaluate the CT scan for other viruses that will help in distinguishing other viruses from the coronavirus. Also, we can extend our models to classify the COVID-19 positive CT scan images based on the severity of the spread of the COVID-19 in the lungs area.
Conclusion
Convolutional neural network (CNN) is quite an efficient deep learning algorithm in the medical field since we get an output just by processing the CT scan images to the respective model. The CTnet-10 model had very well classified the images as COVID-19 positive or negative. Our other models have provided us with much better accuracy. Our self-developed model, CTnet-10, took the lowest time for training, testing, and execution. The time taken by the CTnet-10 model to predict the results is only 12.33 ms, whereas for the VGG-19 and Inception V3 models, the time taken is 13.69 ms. The method used by us is well-organized one that can be used by the doctors for the mass screening of the patients. It will yield better accuracy and at a faster rate as compared to the current RT-PCR method. With the above method for the classification of the CT scan images of the COVID-19 patients, data can be extracted, which would help the doctors to get the information feasibly and quickly.
References
Wang C, Horby PW, Hayden FG, Gao GF (2020) A novel coronavirus outbreak of global health concern. Lancet 395(10223):470
Wang LS, Wang YR, Ye DW, Liu QQ (2020) A review of the 2019 novel coronavirus (covid-19) based on current evidence. International journal of antimicrobial agents, 105948
Singhal T (2020) A review of coronavirus disease-2019 (covid-19). The Indian Journal of Pediatrics, 1–6
Wang R, Pan M, Zhang X, Han M, Fan X, Zhao F, Miao M, Xu J, Guan M, Deng X et al (2020) Epidemiological and clinical features of 125 hospitalized patients with covid-19 in Fuyang, Anhui, China. Int J Infect Dis 95:421
Tang YW, Schmitz JE, Persing DH, Stratton CW (2020) Laboratory diagnosis of covid-19: current issues and challenges. J Clin Microbiol 58(6):512–520. https://doi.org/10.1128/JCM.00512-20
Hussain A, Kaler J, Tabrez E, Tabrez S, Tabrez SS (2020) Novel covid-19: a comprehensive review of transmission, manifestation, and pathogenesis. Cureus 12(5):8184. https://doi.org/10.7759/cureus.8184
Li B, Yang J, Zhao F, Zhi L, Wang X, Liu L, Bi Z, Zhao Y (2020) Prevalence and impact of cardiovascular metabolic diseases on covid-19 in China. Clin Res Cardiol 109(5):531
Liu Z, Xiao X, Wei X, Li J, Yang J, Tan H, Zhu J, Zhang Q, Wu J, Liu L (2020) Composition and divergence of coronavirus spike proteins and host ace2 receptors predict potential intermediate hosts of sars-cov-2. J Med Virol 92(6):595
Breban R, Riou J, Fontanet A (2013) Interhuman transmissibility of Middle East respiratory syndrome coronavirus: estimation of pandemic risk. Lancet 382(9893):694
Ozturk T, Talo M, Yildirim EA, Baloglu UB, Yildirim O, Acharya UR (2020) Automated detection of covid-19 cases using deep neural networks with x-ray images. Computers in Biology and Medicine, 103792
Singh D, Kumar V, Kaur M (2020) Classification of covid-19 patients from chest ct images using multi-objective differential evolution–based convolutional neural networks. European Journal of Clinical Microbiology & Infectious Diseases, 1–11
Anjishnu Das SK (2020) Why covid testing is a slow process and types of tests available
Shen D, Wu G, Suk HI (2017) Deep learning in medical image analysis. Ann Rev Biomed Eng 19:221
Ker J, Wang L, Rao J, Lim T (2017) Deep learning applications in medical image analysis. Ieee Access 6:9375
Grewal M, Srivastava MM, Kumar P, Varadarajan S (2018) Radnet: Radiologist level accuracy using deep learning for hemorrhage detection in ct scans. In: IEEE 15th International symposium on biomedical imaging (ISBI 2018). IEEE, pp 281–284
Song Q, Zhao L, Luo X, Dou X (2017) Using deep learning for classification of lung nodules on computed tomography images. Journal of healthcare engineering, 2017
González G, Ash SY, Vegas-Sánchez-Ferrero G, Onieva Onieva J, Rahaghi FN, Ross JC, Díaz A, San José Estépar R, Washko GR (2018) Disease staging and prognosis in smokers using deep learning in chest computed tomography. Am J Respir Crit Care Med 197(2):193
Ye Z, Zhang Y, Wang Y, Huang Z, Song B (2020) Chest ct manifestations of new coronavirus disease 2019 (covid-19): a pictorial review. European Radiology, 1–9
Zhao W, Zhong Z, Xie X, Yu Q, Liu J (2020) Relation between chest CT findings and clinical conditions of coronavirus disease (covid-19) pneumonia: a multicenter study. Am J Roentgenol 214 (5):1072
Bernheim A, Mei X, Huang M, Yang Y, Fayad ZA, Zhang N, Diao K, Lin B, Zhu X, Li K et al (2020) Chest CT findings in coronavirus disease-19 (covid-19): relationship to duration of infection. Radiology, 200463
Zhao J, Zhang Y, He X, Xie P (2020) Covid-CT-dataset: a CT scan dataset about covid-19. arXiv:2003.13865
Gozes O, Frid-Adar M, Greenspan H, Browning PD, Zhang H, Ji W, Bernheim A, Siegel E (2020) Rapid ai development cycle for the coronavirus (covid-19) pandemic: initial results for automated detection & patient monitoring using deep learning ct image analysis. arXiv:2003.05037
Wu J, Wu X, Zeng W, Guo D, Fang Z, Chen L, Huang H, Li C (2020) Chest CT findings in patients with coronavirus disease 2019 and its relationship with clinical features. Investig Radiol 55 (5):257
Zheng C, Deng X, Fu Q, Zhou Q, Feng J, Ma H, Liu W, Wang X (2020) Deep learning-based detection for covid-19 from chest CT using weak label, medRxiv
Ai T, Yang Z, Hou H, Zhan C, Chen C, Lv W, Tao Q, Sun Z, Xia L (2020) Correlation of chest CT and RT-PCR testing in coronavirus disease 2019 (covid-19) in China: a report of 1014 cases. Radiology, 200642
Fang Y, Zhang H, Xie J, Lin M, Ying L, Pang P, Ji W (2020) Sensitivity of chest CT for covid-19: comparison to RT-PCR. Radiology, 200432
Murphy K, Smits H, Knoops AJ, Korst MB, Samson T, Scholten ET, Schalekamp S, Schaefer-Prokop CM, Philipsen RH, Meijers A et al (2020) Covid-19 on the chest radiograph: a multi-reader evaluation of an AI system. Radiology, 201874
Lee CI, Forman HP (2007) Ct screening for lung cancer: implications on social responsibility. Am J Roentgenol 188(2): 297
Acknowledgments
The authors would like to thank the colleagues
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Involvement of human participant and animals
This article does not contain any studies with animals or humans performed by any of the authors. All the necessary permissions were obtained from the Institute Ethical Committee and concerned authorities.
Information about informed consent
No informed consent was required as the study does not involve any human participant.
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Rights and permissions
About this article

Cite this article
Shah, V., Keniya, R., Shridharani, A. et al. Diagnosis of COVID-19 using CT scan images and deep learning techniques. Emerg Radiol 28, 497–505 (2021). https://doi.org/10.1007/s10140-020-01886-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10140-020-01886-y