
Abstract
Feature selection techniques are considered one of the most important preprocessing steps, which has the most significant influence on the performance of data analysis and decision making. These FS techniques aim to achieve several objectives (such as reducing classification error and minimizing the number of features) at the same time to increase the classification rate. FS based on Metaheuristic (MH) is considered one of the most promising techniques to improve the classification process. This paper presents a modified method of the Slime mould algorithm depending on the Marine Predators Algorithm (MPA) operators as a local search strategy, which leads to increasing the convergence rate of the developed method, named SMAMPA and avoiding the attraction to local optima. The efficiency of SMAMPA is evaluated using twenty datasets and compared its results with the state-of-the-art FS methods. In addition, the applicability of SMAMPA to work with real-world problems is evaluated by using it as a quantitative structure-activity relationship (QSAR) model. The obtained results show the high ability of the developed SMAMPA method to reduce the dimension of the tested datasets by increasing the prediction rate. In addition, it provides results better than other FS techniques in terms of performance metrics.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The rapid growth of computer applications and information technologies produces a tremendous amount of data generated from various devices. The vast amount of data causes a critical problem for data mining which requires implementing practical data pre-processing steps using different techniques. Pr-processing is a necessary step that is employed to prepare and clean the data for the subsequent processing steps of the machine learning [1, 2]. Feature selection (FS) is an essential pre-processing step which is employed to reduce the size of the dataset. It is employed to select a small subset of the relevant features that capture the characteristics of the input data [3, 4]. Generally, FS methods remove noisy, unnecessary, and repeated features. Thus, an effective FS technique can boost the efficiency of data mining applications and various machine learning classification applications [5]. In general, FS methods can be classified into two types, wrapper-based and filter-based [6]. The wrapper-based techniques usually apply a classifier to obtain features, whereas the filter-based methods use data-reliant specifications to evaluate the merits of the features [6, 7]. Therefore, filter-based methods are more effective due to their fast implementation because they do not require classifiers to be involved in the FS process. To obtain a subset of features, we face some challenges. Thus, different search methods are applied to find the best features, including depth search, breadth search, random search, and hybrid search. However, exhaustive search requires a long time for extensive data, which is considered time-consuming.
Recently, with the great developments of the metahuristics (MH) optimization algorithms, that inspired from nature, various optimization problems, including FS can be solved using these MH algorithms. In the literature, different MH algorithms have been employed for this purpose, such as particle swarm optimization (PSO) [8], genetic algorithm (GA) [9], artificial bee colony (ABC) [10], firefly algorithm (FA) [11], grey wolf algorithm (GOA) [12], sine cosine algorithm (SCA) [13], salp swarm algorithm [14], multi-verse optimizer (MVO) [15], Arithmetic Optimization Algorithm (AOA) [16], and others [17, 18]. However, individual MH algorithms may face severe limitations, such as slow convergence and trapping at local optima. Therefore, the hybridization concept has recently been implemented to overcome these limitations. This concept is performed by combining the operators of two MH algorithms to leverage their proprieties and advantages and avoid their shortcomings. Thus, in literature, we can find various hybrid MH methods for FS, such as a hybrid of PSO and SSA [19], differential evaluation (DE) and ABC [20], GOA and crow search algorithm (CSA) [21], DE and SCA [22], moth flame optimization (MFO) and DE [23], SSA and SCA [24], and many other hybrid MH methods [25].
Following the concept of the MH hybridization, this study proposes a new and efficient FS technique using a modified version of the slim mould algorithm (SMA) by the marine predators algorithm (MPA). The SMA was developed by [26], as a new MH optimizer that can be utilized to solve various optimization problems. The oscillation mode of slime mould inspires it in nature. More so, it is adopted to solve several optimization problems in literature, such as finding optimal parameters in energy applications [27, 28], air quality forecasting [29], and other engineering applications [30,31,32]. In addition, MPA is recently proposed by [33] by simulating the conduct of the marine prey and predators. It has received wide attention due to its efficiency and it is adopted in various domains, for example, time series forecasting [34, 35], image segmentation [36], medical image classification [37], parameter estimation [38], and other applications [39, 40].
However, the SMA performance requires more improvements, mainly when applied to real-world applications, which motivated us to develop a new version of SMA to improve its local search process using the operators of the MPA. The main aim of using MPA operators is to enhance the exploitation ability of SMA during the process of finding the optimal solution inside the feasible region. MPA is applied as a local search method since it has been established its performance in several applications, including forecasting cases of COVID-19 [35], and photovoltaic array reconfiguration [41].
The contribution of this study can be summarized as follows:
-
Develop a feature selection technique using an enhancement version of the SMA.
-
Boost the capability of the local search of the SMA using the operators of MPA.
-
Assess the efficiency of the SMAMPA developed method by using a set of twenty UCI datasets and comparing it with other FS methods.
-
Verify the applicability of the SMAMPA by implementing it with real-world applications, such as QSAR model.
The structure of this study is as follows. The related works are presented in Sect. 2, where the preliminaries of the applied techniques, SMA, and MPA are described in Sect. 3. In Sect. 4, we describe the proposed SMAMPA approach, and in Sect. 5, the experimental evaluation is presented, including different benchmark datasets and comparisons to existing methods. Finally, the conclusions and future direction are highlighted in Sect. 6.
2 Related works
In this section, we summarize a number of the existing FS methods based on modified and improved optimization algorithms proposed in recent years. In [4], a modified version of the ABC algorithm, called a binary ABC, is proposed for FS. The searchability of the ABC is improved using the evolutionary-based similarity search mechanism, which is integrated into the existing binary ABC variants. It was evaluated using several datasets and compared to the original PSO and ABC besides several modified versions of PSO and ABC. In [42], the authors suggested an FS method based on a hybrid of the Flower Pollination Algorithm (FPA) and Clonal Selection Algorithm (CSA). The proposed BCFA was evaluated using the optimum-path forest classifier, and it showed significant performance with three different datasets. Also, It showed better performance in comparison to several optimization methods.
In [43], two binary variants of the whale optimization algorithm (WOA) were proposed for FS. The first variant is implemented by improving the search process using Tournament and Roulette Wheel selection mechanisms. In the second variant, the exploitation of the whale optimization algorithm is improved by using crossover and mutation operators. Sayed et al. [44] proposed a chaotic crow search algorithm (CSA) to overcome the limitations of the original CSA, such as trapping at local optima and low convergence rate. The new modified version, CCSA, was applied as an FS method evaluated using twenty datasets. The CCSA also was compared to different optimization techniques, and it achieved superior performance against several previous FS methods.
The authors in [45] suggested two binary versions of butterfly optimization algorithm (BOA) for FS. They used two transfer functions for mapping continuous search spaces to discrete ones. Several UCI benchmark datasets were used to evaluate the proposed method. More so, wide comparisons to some existing FS methods were performed. Evaluation outcomes showed the superior performance of the BOA. Too and Abdullah [46] proposed an FS method using a new variant of the genetic algorithm (GA) and a fast rival GA. They applied a competition strategy to combine crossover schemes and the new selection to boost the global search ability of the GA. Twenty-three UCI benchmark datasets were utilized to test the performance of the modified GA.
Zhang et al. [47] presented an improved variant of the Harris hawks optimization algorithm, called IHHO for FS. The main idea of the IHHO is by applying the salp swarm algorithm to enhance the search ability of the HHO. Several UCI datasets were used to evaluate the IHHO, and it achieved competitive performance compared to several FS methods. Another modified HHO, called Chaotic HHO (CHHO), is proposed for FS by Elgamal et al. [48]. Chaotic maps are applied to improve the population diversity of the HHO in the search space. Moreover, simulated annealing (SA) is applied to the best solution to enhance the exploitation of the HHO. They used Fourteen datasets to evaluate the CHHO compared to several optimization algorithms. Overall results showed that CHHO got the best outcomes.
The authors of [49] proposed a FS method, called ECSA, using a modified version of the crow search algorithm (CSA). The authors proposed three modifications to the traditional CSA to enhance its search capability. Sixteen UCI benchmark datasets were applied to evaluate the ESCA compared to the traditional CSA and several existing FS methods. The ESCA showed competitive performance in all experiments. Too and Mirjalili [6] suggested an FS method called hyper learning binary dragonfly algorithm. They applied a hyper learning strategy to improve the binary dragonfly algorithm, to avoid its limitations, such as trapping at local optima. They evaluate the proposed method using different UCI datasets and a new COVID-19 dataset. Zhong et al. [7] proposed a new FS method based on a modified Tree Growth Algorithm (TGA). A binary TGA is applied for FS applications, and also the evolutionary population dynamic strategy is employed to enhance the search capability of the TGA. Different UCI benchmark datasets were utilized to test the TGA performance.
Several works from the previous review were conducted for addressing FS problems by developing new methods to overcome the drawbacks of the algorithms’ original versions using benchmark and real datasets. The proposed methods showed good abilities to escape getting trapped in local optima, improve the convergence rate, and improve population diversity. However, there is no optimization technique to solve all problems, as stated by the No-Free-Lunch (NFL) theorem. Accordingly, this paper proposes a new optimization method by improving the slime mould algorithm’s local search ability using the MPA operators to solve different feature selection problems using benchmark and real datasets. This improvement can help balance the search methods and avoid local search problems such as traping in a local optimum and degrading the convergence rate.
3 Background
This section presents the basic definitions of the SMA and MPA, as in what follows.
3.1 Slime mould algorithm
The SMA was firstly introduced by [26] as a novel optimization mechanism for global optimization. The SMA simulates the natural behaviour of the slime mould’s oscillation. The mathematical formulation of SMA is given as:
-
1.
Phase 1 (The food approach): This step models the approach for the slime mould. The following equation describes this phase:
$$\begin{aligned} Z=\left\{ \begin{array}{cc} Z_{b}+v_{b} . \left( W . Z_{A}-Z_{B} \right) &{} r<p \\ v_{c}.Z &{} r\ge p \end{array}\right. \end{aligned}$$(1)where \(v_{b}\) is defined in the range of \([-a,a]\) and \(v_{c}\) decreases from 1 to 0. \(Z_{b}\) corresponds to the best solutions. Additionally, \(Z_{A}\) and \(Z_{B}\) are two solutions selected from a randomly, whereas W represents the mould weight of the slime. While p is computed as:
$$\begin{aligned} p= \tanh \left| S(i)-DF\right| , \, i=1,2,...,N \end{aligned}$$(2)From Eq. 2, S(i) corresponds to the fitness values of the Z solution. DF is the best fitness value. The value a that defines \(v_{b}\) in Eq. 1 is computed as:
$$\begin{aligned} a= arctanh \left( -\left( \frac{t}{max_t} \right) +1 \right) \end{aligned}$$(3)where, t is the current iteration. \({max_t}\) is the maximum number of iteration. Also, the value of W is obtained as follows:
$$\begin{aligned} W(S_{Ind}(i))=\left\{ \begin{array}{cc} 1+r \log ((b_F-S(i))/(b_F-w_F)+1) &{} Cond \\ 1-r \log ((b_F-S(i))/(b_F-w_F)+1) &{} otherwise \end{array} \right. \end{aligned}$$(4)in which Cond denotes that S(i) ranks first half of the population. More so, \(r\in [0,1]\) is randomly generated. \(b_F\) and \(w_F\) and \(b_F\) represent the best and worst fitness values, respectively. Finally, \(S_{Ind}\) stores the sorted fitness values, as defined in the following formula:
$$\begin{aligned} S_{Ind}=sort(S) \end{aligned}$$(5) -
2.
Phase 2 (Wrap food): in this step, SMA imitates the updating position of the slime mould. The following equation is applied to compute this update.
$$\begin{aligned} Z^{*}=\left\{ \begin{array}{cc} rand (UB-LB)+LB &{} rand<z \\ Z_b (t)+v_b(WZ_A(t)-Z_B (t)) &{} r<p\\ v_c Z(t) &{} r\ge p \end{array}\right. \end{aligned}$$(6)where LB and UB represent the lower and upper bounds of the search space, respectively. r and rand are obtained from a random distribution between [0, 1].
-
3.
Phase 3 (Oscillation): at this step the value of \(v_b\) is updated within \([-a,a]\) and \(v_c\) inside [−1, 1].
3.2 Marine predators algorithm
The MPA is a global optimization mechanism introduced in [33]. The MPA mimics the elements of marine prey and predators during hunting. As other metaheuristics, the MPA begins by taking random solutions from the search space as in Eq. 7
where, rand a random variable is generated in the range [0,1]. LB and UB are the upper and lower bounds that define the search space. Once the candidate solutions are generated, two matrices (named Elite matrix, which contains the fitness values and prey matrix) are formulated as:
The three phases of MPA modify the candidate solution using the velocity ratio of the predator and prey. Each step of the MPA is described below.
-
1.
Phase 1 (High-velocity ratio): here, the prey is extremely fast, then the predator decides to be quiet and not move. This phase occurs at the beginning of the optimization process, and the movement of the prey is modeled as follows:
$$\begin{aligned}&S_i=R_B \times (Elite_i-R_B\times Z_i), i=1,2,...,N \end{aligned}$$(9)$$\begin{aligned}&Z_i=Z_i+P\times R \times S_i \end{aligned}$$(10)in which \(R\in [0,1]\) refers to a vector of random numbers \(P=0.5\), and \(R_B\) is Brownian motion vector.
-
2.
Phase 2 (Unit velocity ratio): at this phase, the velocity of the prey and the predator is the same. This case is present in half of the iterative procedure. Here, the predator updates his position using Brownian movements, and the prey uses lévy flights. In this phase, Z is divided into two parts, and to update the solution in the first part; it applies Eqs. (11)-(12) and the second one uses Eq. (13)-(14).
$$\begin{aligned} S_i\,\,\,= & {} R_L \times (Elite_i-R_L\times Z_i), i=1,2,...,N \end{aligned}$$(11)$$\begin{aligned} Z_i\,\,\,= & {} Z_i+P \times R \times S_i \end{aligned}$$(12)where \(R_L\) is generated randomly by a Lévy distribution.
$$\begin{aligned}&S_i=R_B \times (R_B \times Elite_i- Z_i), i=1,2,...,N \end{aligned}$$(13)$$\begin{aligned}&Z_i=Elite_i+P \times CF\times S_i, \nonumber \\&\quad CF=\left(1-\frac{t}{max_{t}} \right)^{2\frac{t}{max_{t}})} \end{aligned}$$(14)From Eqs. 13 and 14 the values of t and \(max_{t}\) are the current and total number of iterations, respectively.
-
3.
Phase 3 (low-velocity ratio): Within this phase, the predator has velocity faster than the prey, which occurred in the last third of the updating process using Eq. (15)
$$\begin{aligned}&S_i=R_L \times (R_L \times Elite_i- Z_i), i=1,2,...,N \end{aligned}$$(15)$$\begin{aligned}&Z_i=Elite_i+P \times CF\times S_i,\ \end{aligned}$$(16)
According to [33] the MPA has another two key points.
-
The first one is related to the Eddy formation and the effect of fish aggregating devices (FADS) that can modify the behavior of the predators. The MPA employs the following equation to handle these situations:
$$\begin{aligned} Z_i=\left\{ \begin{array}{cc} Z_i+CF [Z_{min}+R \times (Z_{max}-Z_{min})]\times U &{} r_5 < FAD \\ Z_i+[FAD(1-r)+r](Z_{r1}-Z_{r2}) &{} r_5 > FAD\\ \end{array}\right. \end{aligned}$$(17)From Eq. 17U refers to a binary vector. \(FAD=0.2\). \(r\in [0,1]\). \(r_1\) and \(r_2\) denote random prey.
-
The second one is the marine memory, here Z remembers its position, so, this behavior gives MPA ability to save the previous \(Z_b\). This solution is used and compared with the new \(Z_b\).
4 The SMAMPA method
The SMAMPA is described in this section. It applies both SMA and MPA algorithms to improve its performance. In this context, the MPA applies as a local search of the original version of SMA to improve its ability to solve optimization problems. This improvement adds more flexibility to the method to explore the search space and improve diversity.
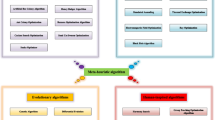
The basic structure of the SMAMPA is shown in Fig. 1. It starts by defining the parameters and creating the search space by initialling the problem population. After this step, the best solution is determined and saved by evaluating the fitness function. Furthermore, each solution is updated by either the SMA or MPA algorithms; this switching is based on the quality of the fitness function value; the quality is calculated as in Equation 19. Therefore, if the probability of the solution is more significant than \(\alpha\), the solution will be updated by SMA, else it will be updated by MPA. In this paper, the probability value (\(\alpha\)) is set to 0.5. These steps are iterated for all solutions; then, the best solution, among all solutions, is selected. This sequence loops till reaching the stop condition, then the final results are presented. In detail, the SMAMPA begins by initializing the parameters of both SMA and MPA. Then the SMA generates a Z [\(x_i, i=1, 2, .., X_N\)] random binary population with N and D size and dimension. Then, the first fitness values are computed by the operators of the SMA. The following equation is used to calculate the fitness function value Eq. (18):
where \(E_{x_i(t)}\) defines the classification error (in this study we use kNN as a classifier). \(\xi \in [0,1]\) balances between the classification error and the number of the selected features. The proposed method calculates the probability (\(Pro_i\)) by Eq. 19 to update the solution by the operators of MPA or SMA (i.e., if \(Pro_i>0.5\) the SMA will be used else, MPA will be used)
where, f is the values of the fitness function. These sequences are iterated until meeting the stop condition. In the final step, the best solution is presented as the output of the proposed method.

The SMAMPA structure and workflow
5 Experiment results and discussion
5.1 Performance metrics
Minimum (Min) result and maximum (Max) result of the fitness value are applied using Eqs. 20 and 21, respectively.
where F is the fitness function values
Accuracy: It is used to compute the classification accuracy in the experiments. It is calculated using Eq. 22.
where TP and TN define true positive and true negative. FP and FN define false positive and false negative.
Standard deviation (Std): It is computed using Eq. 23. It evaluates the stability of the algorithms. The results of the fitness function are used to compute this measure (\({\overline{F}}\) is the mean of F).
5.2 Compared techniques and parameter settings
The SMAMPA is evaluated and compared to nine recently published metaheuristic algorithms (i.e., MPA, GA, SMA, PSO, HHO, SSA, MFO, WOA, and GOA) in the fitness values (i.e., minimum and maximum), standard deviation, accuracy, classification accuracy, and computational time. The SMAMPA method is also compared with eight advanced metaheuristic algorithms (i.e., BDA [50], BSSAS3 [14], bGWO2 [12], GLR [51], SbBOA [45], BGOAM [52], Das [53], and S-bBOA [45]).
The parameters setting of these algorithms is identical to that declared in their original studies. Table 1 presents the settings of the parameters of all applied methods. The MATLAB 2015a executes all the algorithms. All methods run on a 16GB RAM Intel Core i7 1.8 GHz 2.3 GHz processor. The solution numbers applied in this paper are set to to 30. The maximum iteration number is set to 500. Each competitor algorithm is applied 30 independent runs and the average of its results are presented in the tables.
5.3 Experiment series 1: UCI datasets
In this section, twenty benchmark datasets are tested to demonstrate the SMAMPA optimizer’s efficiency. These datasets were taken from the Machine Learning Repository (UCI) [61]. Table 2 shows the tested datasets that contain different numbers of features, number of instances, and number of classes. The applied datasets are collected from different areas, including biology, games, physics, and biomedical.
The results obtained by the given SMAMPA method in the average measure of the fitness function, as stated in (18), are recorded in Table 3. SMAMPA is observed to beat the other comparative well-known methods in 85% of the tested datasets. PSO algorithm is the second-best method. SMAMPA got better performance than other comparative methods for all tested datasets except Sonar, ExactlyD, and krvskpD datasets. According to the average fitness values measure, the results demonstrated that the given SMAMPA has a promising ability in addressing this kind of problem.
The results are given by the introduced SMAMPA in terms of minimum fitness values, as stated in Eq. (20), are recorded in Table 4. SMAMPA is observed to defeat the other comparative well-known methods in 75% of the tested datasets. PSO algorithm is the second-best method. Based on minimum fitness values, SMAMPA has achieved the minimum fitness values with promising results for most datasets compared to other rival algorithms. It got better results in almost all the tested datasets except glassD, WaveformD, SpectD, Exactly2D, and krvskpD datasets. The results confirmed that the proposed SMAMPA could solve different feature selection challenges according to the minimum fitness values.
The results achieved by the SMAMPA for the maximum fitness values, as declared in Eq. (21), are shown in Table 5. SMAMPA is recognized to overcome the other comparative methods in 95% of the tested datasets. PSO method is also the second-best method. Except for the ExactlyD dataset, the proposed SMAMPA improved performance in all tested datasets than other comparative approaches. The outcomes demonstrated that the proposed integration method between the SMA and MPA search processes has a powerful ability to trade with complicated feature selection problems.
Figure 2 displays the average, minimum, and maximum fitness values for the comparative methods overall used datasets. It can be seen that the developed SMAMPA reached the best results in terms of the three measures (i.e., average, minimum, and maximum fitness values). SMAMPA got the smallest values using all measures in the tested datasets, which is strong evidence regarding the ability of SMAMPA in solving the FS problems. The modification of the proposed method proved its searchability in finding better solutions than the original SMA and MPA, as well as, this modification got all the best outcomes compared to the comparative algorithms.

Error values average for all algorithms
Table 6 displays each algorithm’s accuracy measure values overall the used datasets. The proposed SMAMPA gathered the best high accuracy values in 95% of the tested datasets, pursued by PSO. However, the PSO obtained the best values in three datasets (i.e., ExactlyD, Exactly2, and M-of-n). In general, the SMAMPA exhibited an excellent ability to select the most vital features in the selection stage and produce the highest accuracy values in the classification stage. Figure 3 illustrates the average of the accuracy values for the all methods. We can recognise that the proposed method got the highest accuracy values compared to all comparative techniques; this supports our claim regarding the proposed SMAMPA; it works more efficiently than traditional methods and is also more efficient than other comparative algorithms. The second best method is the PSO algorithm; it got more reliable results than the rest of the comparison techniques in solving these widespread problems.

Accuracy average for all algorithms
Table 7 displays each algorithm’s Std measure of the fitness function assessments using all the given datasets. The proposed SMAMPA obtained stable results according to Std values in 50% of the tested datasets, pursued by PSO, WOA, HHO, GA, and finally, the MPA. This result declares that the SMAMPA’s stability is better than other comparative methods according to its performance. The obtained results’ distribution is excellent and smaller than other comparative methods overall, the tested datasets. Figure 4 illustrates the average of the Std of the fitness function values for all compared methods. We can see obviously that the suggested SMAMPA got the smallest Std values compared to all comparative techniques; this supports our claim regarding the performance of the proposed SMAMPA again; it achieves promising results compared to other methods by giving low distribution and similar outcomes across a wide range of executions. The following best method is the PSO algorithm, pursued by HHO.

Standard deviation average for all algorithms
Table 8 lists the numbers of the selected features for all the tested methods. Table 8 shows the shorter length of the obtained optimal subset of features acquired by the comparative techniques. Investigating the results, SMA produced the nominal feature size in ten datasets, pursued by SMAMPA (six datasets). Compared with MPA, SMA, GA, HHO, PSO, SSA, WOA, MFO, and GOA, the SMAMPA can typically find the nominal subset of selected features that can adequately represent the main idea, as shown in Fig. 5. Owing to the MPA method, SMAMPA can override the local optima problem and thoroughly recognize the most helpful feature selection solution.

Selected features of each optimization method
According to the computational time given in Table 9 and Fig. 6, the proposed SMAMPA got comparable computational time to solve the given problems. The main important thing in these experiments to tackle the FS problem is the evaluation measures, like the accuracy, because the given problem needs to be solved one time and not more.

Computational time Average of all algorithms
5.4 Comparison with the state-of-the-art
This part evaluates the SMAMPA and compares further with different advanced and well-known published methods in the literature. These methods are BDA [50], BSSAS3 [14], bGWO2 [12], GLR [51], SbBOA [45], BGOAM [52], Das [53], and S-bBOA [45].
Table 10 shows all the tested methods using versions benchmark datasets. The given values of the comparative methods in this table are taken from their original papers. The \(``-''\) sign denotes no given results for this case. The proposed SMAMPA obtained better results in 70% of the tested datasets according to given values. It got the most high-grade results in almost all the tested datasets except ionosphereD, BreastcancerD, LymphographyD, ExactlyD, Exactly2D, and VoteD. The following best method is BDA, which got the most beneficial results in 53%, as this method has results for 15 datasets, followed by BSSAS3.
Recap, SMAMPA has a more trustworthy exploration experience than other comparative optimization techniques. This result is confirmed because the other tested algorithms did not allow SMAMPA to investigate other search areas in the search regions. Moreover, this proved the proposed SMAMPA to sustain solutions heterogeneity remarkably better than other feature selection methods. Besides, SMAMPA always got superior fitness values than other algorithms, proving its ability to evade restricted optima. In comparison, the other methods may quickly fall into the local optima problem. Investigating the selected number of optimal features by SMAMPA has sufficient exploration energy than other comparative algorithms, proved by selecting fewer features over the tested benchmark datasets.
5.5 Experiment series 2: real−world quantitative structure-activity relationship application
In this section, we evaluate ability of the proposed method in selecting the most relevant features using real−world problems. Quantitative structure-activity relationship (QSAR) models is a mathematical framework in chemometrics to explain the structural relationship between chemical compounds and biological activity [62,63,64,65]. The QSAR modelling has been conducted to study the proposed algorithm and verify its effectiveness. Six high-dimensional datasets are adopted. The first dataset is the inhibitors of influenza A viruses (H1N1). An RNA virus called influenza causes a respiratory infection. It is a highly dangerous illness that is associated with high rates of mortality and morbidity. The influenza virus has two main glycoproteins on its surface: neuraminidase and haemagglutinin. Thus, utilizing compounds that block neuraminidase can prevent host cells from becoming infected with viruses and prevent the virus from spreading across cells. According to IC50, this dataset contained two classes of active compound (IC50 < 20 \(\mu \hbox {M}\)) and weakly active compound (IC50 > 20 \(\mu\)M). This data consists of 2644 features and 479 instances [66].
The second dataset represents the anti-hepatitis C virus (hepatitis). Hepatitis C virus (HCV)-related liver conditions are among the most prevalent medical issues in the world today. The compounds employed have anti-hepatitis C virus action and were thiourea derivatives. This dataset containing 2952 features and 121 instances. According to EC50, the compounds were split into two sets: active and inactive compounds when EC50 < 0.1 \(\mu \hbox {M}\) and EC50 \(\ge\) 0.1 \(\mu \hbox {M}\), respectively [67].
The third dataset, called Chalcone, relates to a wide range of antibiotics with unique bioactivities against Candida albicans. The minimum inhibitory concentration (MIC) against C. albicans in mM/L was used to measure the antibacterial activities, which were expressed as pMIC, or the logarithm of the reciprocal of MIC. The median, or 1.30, of all 212 pMICs was taken into consideration as the cut-off to categorize these antimicrobial drugs into two groups based on the bioactivity distribution over the entire datasets. The first group consisted of 108 active compounds with pMIC values more than 1.30, and the remaining 104 inactive compounds made up the second group. The fourth, fifth, and the sixth datasets were publicly available in the UCI repository [61].
The proposed algorithm results, SMAMPA, are evaluated in terms of classification accuracy, selected features, and standard deviation (Std). All results are summarized in Tables 13, 14 and 15.
From the Table 12, we assess the superiority of proposed algorithms, compared to others well-known algorithms. However, SMAMPA can be described as stable methods in most of all datasets except Biodeg dataset in which GA algorithm is better.
As can be seen from Table 13, the proposed algorithm, SMAMPA, has a significantly larger accuracy. These results demonstrated that the reduction in features contributes to the improvement of the accuracy resulting from the other algorithms. In terms of the selected features (Table 14), it can see that the SMAMPA obtained better values than the compared methods. It selected fewer features with high classification accuracy. Related to Std in Table 15, the SMAMPA algorithm achieved the low Std results in the H1N1, OralToxicity, and AndrogenReceptor datasets and was considered the most stable algorithm than the other algorithms. Furthermore, the hepatitis and Chalcone datasets presented competitive results for the SMAMPA with other algorithms. In general, SMAMPA algorithm can be considered as stable algorithm. From the above analysis, the SMAMPA method showed a high selecting ability for the essential features with high accuracy and good stability.
6 Conclusion and future work
This study developed a new feature selection (FS) method by enhancing the original style of the slime mould algorithm (SMA). We leverage the exploration ability of the marine predators algorithm (MPA) to work as a local search method for the proposed method. The modified version, namely, SMAMPA, was evaluated on twenty well-known UCI benchmark datasets, using different evaluation metrics. Moreover, it was compared to the traditional SMA, MPA, and several state-of-art optimization methods. The developed SMAMPA showed superior performance over several optimization algorithms and several modified optimization algorithms. Furthermore, to verify the efficiency of the SMAMPA on more complicated and high-dimensional real-world problems, six datasets related to chemometrics, were used. Evaluation outcomes also showed the high performance of the SMAMPA, and it obtained the best results compared to other optimization algorithms. According to the superior results of the developed SMAMPA, in future work, it could be further investigated in more complicated problems, such as multi-optimization problems, big data mining, and medical image processing.
Data Availability
The datasets generated during and/or analysed during the current study are available in the UCI repository [61].
References
Quiroz Juan C, Amit B, Dascalu Sergiu M, Lun Lau S (2017) Feature selection for activity recognition from smartphone accelerometer data. Intelli Autom Soft Comput 87:1–9
Han C, Zhou G, Zhou Y (2019) Binary symbiotic organism search algorithm for feature selection and analysis. IEEE Access 7:166833–166859
Han J, Pei J, Kamber M (2011) Data mining: concepts and techniques. Elsevier, Amsterdam
Hancer E, Xue B, Karaboga D, Zhang M (2015) A binary abc algorithm based on advanced similarity scheme for feature selection. Appl Soft Comput 36:334–348
Hua J, Tembe Waibhav D, Dougherty Edward R (2009) Performance of feature-selection methods in the classification of high-dimension data. Pattern Recogn 42(3):409–424
Jingwei T, Seyedali M (2020) A hyper learning binary dragonfly algorithm for feature selection: a covid-19 case study. Knowl-Based Syst 87:106553
Zhong C, Chen Y, Jian P (2020) Feature selection based on a novel improved tree growth algorithm. Int J Comput Intell Syst 13(1):247–258
Xue B, Zhang M, Browne WN (2014) Novel initialisation and updating mechanisms. particle swarm optimisation for feature selection in classification. Appl Soft Comput 18:261–276
Tan F, Xuezheng F, Zhang Y, Bourgeois Anu G (2008) A genetic algorithm-based method for feature subset selection. Soft Comput 12(2):111–120
Mustafa Serter U, Nihat Y, Onur I(2013) Feature selection method based on artificial bee colony algorithm and support vector machines for medical datasets classification. The Scientific World Journal 2013
Selvakumar B, Muneeswaran K (2019) Firefly algorithm based feature selection for network intrusion detection. Computers Secur 81:148–155
Emary E, Zawbaa Hossam M, Hassanien Aboul E (2016) Binary grey wolf optimization approaches for feature selection. Neurocomputing 172:371–381
Sindhu R, Ngadiran R, Yacob YM, Zahri Nik Adilah H, Hariharan M (2017) Sine-cosine algorithm for feature selection with elitism strategy and new updating mechanism. Neural Comput Appl 28(10):2947–2958
Faris H, Mafarja Majdi M, Heidari Ali A, Aljarah I, Ala’M A-Z, Mirjalili S, Fujita H (2018) An efficient binary salp swarm algorithm with crossover scheme for feature selection problems. Knowl-Based Syst 154:43–67
Ewees Ahmed A, Aziz Mohamed AE, Hassanien Aboul E (2019) Chaotic multi-verse optimizer-based feature selection. Neural Comput Appl 31(4):991–1006
Abualigah L, Diabat A, Mirjalili S, Elaziz MA, Gandomi AH (2021) The arithmetic optimization algorithm. Computer Methods Appl Mech Eng 376:113609
Laith A, Ali D (2021) Advances in sine cosine algorithm: a comprehensive survey. Artif Intell Rev 25:1–42
Ewees Ahmed A, Al-qaness Mohammed AA, Abualigah L, Oliva D, Algamal ZY, Anter AM, Ibrahim RA, Ghoniem RM, Elaziz MA (2021) Boosting arithmetic optimization algorithm with genetic algorithm operators for feature selection: case study on cox proportional hazards model. Mathematics 9(18):2321
Ibrahim Rehab A, Ewees Ahmed A, Oliva D, Elaziz MA, Songfeng L (2019) Improved salp swarm algorithm based on particle swarm optimization for feature selection. J Amb Intell Humanized Comput 10(8):3155–3169
Zorarpaci E, Aycseozel S (2016) A hybrid approach of differential evolution and artificial bee colony for feature selection. Expert Syst Appl 62:91–103
Arora S, Singh H, Sharma M, Sharma S, Anand P (2019) A new hybrid algorithm based on grey wolf optimization and crow search algorithm for unconstrained function optimization and feature selection. IEEE Access 7:26343–26361
Abd Mohamed E, Elaziz Ahmed A, Diego Oliva E, Pengfei D, Shengwu X (2017) A hybrid method of sine cosine algorithm and differential evolution for feature selection. In International conference on neural information processing, 145–155 Springer,
Elaziz MA, Ewees Ahmed A, Ibrahim RA, Songfeng L (2020) Opposition-based moth-flame optimization improved by differential evolution for feature selection. Math Computers Simul 168:48–75
Neggaz N, Ewees Ahmed A, Elaziz MA, Mafarja M (2020) Boosting salp swarm algorithm by sine cosine algorithm and disrupt operator for feature selection. Expert Syst Appl 145:113103
Laith A, Ali D (2020) A comprehensive survey of the grasshopper optimization algorithm: results, variants, and applications. Neural Comput Appl 25:1–24
Shimin L, Huiling C, Mingjing W, Asghar Heidari A, and Mirjalili S (2020) A new method for stochastic optimization. future generation computer systems, Slime mould algorithm
Kumar C, Dharma Raj T, Premkumar M, Dhanesh Raj T (2020) A new stochastic slime mould optimization algorithm for the estimation of solar photovoltaic cell parameters. Optik 223:165277
Chen Z, Liu W (2020) An efficient parameter adaptive support vector regression using k-means clustering and chaotic slime mould algorithm. IEEE Access 8:156851–156862
Al-Qaness Mohammed AA, Hong F, Ewees Ahmed A, Dalia Y, Mohammed Abd E (2020) Improved anfis model for forecasting Wuhan city air quality and analysis covid-19 lockdown impacts on air quality. Environ Res 871:110607
Ali D (2020) The optimal synthesis of thinned concentric circular antenna arrays using slime mold algorithm. Electromagnetics 58:1–13
Sun K, Jia H, Li Y, Jiang Z (2021) Hybrid improved slime mould algorithm with adaptive \(\beta\) hill climbing for numerical optimization. J Intell Fuzzy Syst (Preprint) 14:1667–1679
Ewees Ahmed A, Laith A, Dalia Y, Zakariya Yahya A, Al-Ganess Mohammed AA, Rehab Ali I, Mohamed Abd E (2021) Improved slime mould algorithm based on firefly algorithm for feature selection: a case study on qsar model. Eng Computers 69:1–15
Afshin F, Mohammad H, Seyedali M, Gandomi Amir H (2020) Marine predators algorithm: a nature-inspired metaheuristic. Expert Syst Appl 5:113377
Al-Qaness Mohammed AA, Saba Amal I, Elsheikh Ammar H, Elaziz MA, Ibrahim Rehab A, Songfeng L, Hemedan Ahmed A, Shanmugan S, Ewees Ahmed A (2020) Efficient artificial intelligence forecasting models for covid-19 outbreak in russia and brazil. Process Safety and Environmental Protection
Al-Qaness Mohammed AA, Ewees Ahmed A, Fan H, Abualigah L, Elaziz MA (2020) Marine predators algorithm for forecasting confirmed cases of Covid-19 in Italy, USA, Iran and Korea. Int J Environ Res Publ Health 17(10):3520
Elaziz MA, Ewees Ahmed A, Yousri D, Naji Husein S, Alwerfali Qamar A, Awad Songfeng L, Al-Qaness Mohammed AA (2020) An improved marine predators algorithm with fuzzy entropy for multi-level thresholding: Real world example of Covid-19 ct image segmentation. IEEE Access 8:125306–125330
Sahlol Ahmed T, Yousri D, Ewees Ahmed A, Al-Qaness MAA, Damasevicius R, Elaziz MA (2020) Covid-19 image classification using deep features and fractional-order marine predators algorithm. Scientif Rep 10(1):1–15
Yousri D, Hasanien Hany M, Fathy A (2020) Parameters identification of solid oxide fuel cell for static and dynamic simulation using comprehensive learning dynamic multi-swarm marine predators algorithm. Energy Conver Manage 228:113692
Elaziz MA, Shehabeldeen Taher A, Elsheikh Ammar H, Zhou J, Ewees Ahmed A, Al-qaness Mohammed AA (2020) Utilization of random vector functional link integrated with marine predators algorithm for tensile behavior prediction of dissimilar friction stir welded aluminum alloy joints. J Mater Res Technol 9(5):11370–11381
Al-qaness MAA, Ewees AA, Fan H, Abualigah L, Elaziz MA (2022) Boosted anfis model using augmented marine predator algorithm with mutation operators for wind power forecasting. Appl Energy 314:118851
Yousri D, Babu TS, Beshr E, Eteiba Magdy B, Allam D (2020) A robust strategy based on marine predators algorithm for large scale photovoltaic array reconfiguration to mitigate the partial shading effect on the performance of pv system. IEEE Access 8:112407–112426
Sayed Safinaz A-F, Nabil E, Badr A (2016) A binary clonal flower pollination algorithm for feature selection. Pattern Recognit Lett 77:21–27
Mafarja M, Mirjalili S (2018) Whale optimization approaches for wrapper feature selection. Appl Soft Comput 62:441–453
Sayed GI, Hassanien AE, Azar AT (2019) Feature selection via a novel chaotic crow search algorithm. Neural Comput Appl 31(1):171–188
Arora S, Anand P (2019) Binary butterfly optimization approaches for feature selection. Expert Syst Appl 116:147–160
Jingwei T, Abdul Rahim A (2020) A new and fast rival genetic algorithm for feature selection. J Supercomput 58:1–31
Zhang Y, Liu R, Wang X, Chen H, Li C (2020) Boosted binary harris hawks optimizer and feature selection. Structure 58(25):26
Elgamal Zenab M, Yasin Norizan BM, Tubishat M, Alswaitti M, Mirjalili S (2020) An improved harris hawks optimization algorithm with simulated annealing for feature selection in the medical field. IEEE Access 8:186638–186652
Salima O, Mohamed AE (2020) Enhanced crow search algorithm for feature selection. Expert Syst Appl 25:113572
Mafarja M, Aljarah I, Heidari AA, Faris H, Fournier-Viger P, Li X, Mirjalili S (2018) Binary dragonfly optimization for feature selection using time-varying transfer functions. Knowl-Based Syst 161:185–204
Zhang H, Wang J, Sun Z, Zurada Jacek M, Pal Nikhil R (2019) Feature selection for neural networks using group lasso regularization. IEEE Trans Knowl Data Eng 32(4):659–673
Mafarja M, Aljarah I, Faris H, Hammouri Abdelaziz I, Ala’M A-Z, Mirjalili S (2019) Binary grasshopper optimisation algorithm approaches for feature selection problems. Expert Syst Appl 117:267–286
Das A, Das S (2017) Feature weighting and selection with a pareto-optimal trade-off between relevancy and redundancy. Pattern Recognit Lett 88:12–19
Whitley D (1994) A genetic algorithm tutorial. Stat Comput 4(2):65–85
Ali Asghar H, Seyedali M, Hossam F, Ibrahim A, Majdi M, Huiling C (2019) Algorithm and applications, Harris hawks optimization. Fut Gener Computer Syst 97:849–872
Eberhart R, Kennedy J (1995) A new optimizer using particle swarm theory. In MHS’95. Proceedings of the Sixth International Symposium on Micro Machine and Human Science, pp. 39–43. Ieee,
Mirjalili S, Gandomi Amir H, Mirjalili Seyedeh Z, Saremi S, Faris H, Mirjalili SM (2017) Salp swarm algorithm: a bio-inspired optimizer for engineering design problems. Adv Eng Softw 114:163–191
Mirjalili S, Lewis A (2016) The whale optimization algorithm. Adv Eng Softwa 95:51–67
Mirjalili S (2015) Moth-flame optimization algorithm: a novel nature-inspired heuristic paradigm. Knowl-Based Syst 89:228–249
Saremi S, Mirjalili S, Lewis A (2017) Grasshopper optimisation algorithm: theory and application. Adv Eng Softw 105:30–47
Dua D, Graff C (2017) UCI machine learning repository,
Algamal ZY, Alhamzawi R, Ali Haithem TM (2018) Gene selection for microarray gene expression classification using bayesian lasso quantile regression. Computers Biol Med 97:145–152
Algamal Zakariya Y, Lee MH, Al-Fakih AM (2016) High-dimensional quantitative structure-activity relationship modeling of influenza neuraminidase a/pr/8/34 (h1n1) inhibitors based on a two-stage adaptive penalized rank regression. J Chemometr 30(2):50–57
Algamal ZY, Lee MH, Al-Fakih AM, Aziz M (2017) High-dimensional qsar classification model for anti-hepatitis c virus activity of thiourea derivatives based on the sparse logistic regression model with a bridge penalty. J Chemometr 31(6):e2889
Algamal ZY, Qasim MK, Ali HTM (2017) A qsar classification model for neuraminidase inhibitors of influenza a viruses (h1n1) based on weighted penalized support vector machine. SAR and QSAR Environ Res 28(5):415–426
Al-Thanoon Niam A, Qasim Omar S, Algamal ZY (2019) A new hybrid firefly algorithm and particle swarm optimization for tuning parameter estimation in penalized support vector machine with application in chemometrics. Chemometr Intell Lab Syst 184:142–152
Al-Dabbagh ZT, Algamal ZY (2019) A robust quantitative structure-activity relationship modelling of influenza neuraminidase a/pr/8/34 (h1n1) inhibitors based on the rank-bridge estimator. SAR and QSAR Environ Res 30(6):417–428
Acknowledgements
This work was supported by National Natural Science Foundation of China (Grant No. 62150410434) and in part by LIESMARS Special Research Funding.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Ewees, A.A., Al-qaness, M.A.A., Abualigah, L. et al. Enhanced feature selection technique using slime mould algorithm: a case study on chemical data. Neural Comput & Applic 35, 3307–3324 (2023). https://doi.org/10.1007/s00521-022-07852-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-022-07852-8