
Abstract
We introduce a calculus for incremental pre-processing for SMT and instantiate it in the context of z3. It identifies when powerful formula simplifications can be retained when adding new constraints. Use cases that could not be solved in incremental mode can now be solved incrementally thanks to the availability of pre-processing. Our approach admits a class of transformations that preserve satisfiability, but not equivalence. We establish a taxonomy of pre-processing techniques that distinguishes cases where new constraints are modified or constraints previously added have to be replayed. We then justify the soundness of the proposed incremental pre-processing calculus.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



1 Introduction
Pre-processing is a central ingredient for scaling automated deduction. These techniques apply targeted global simplification steps that can drastically reduce the complexity of problems before search techniques that use mainly local inference steps are invoked. They are used across several solver domains, spanning SAT, to SMT, first-order automated theorem proving, constraint programming, and integer programming. With the exception of SAT solvers, prior techniques do not combine well when new constraints are added incrementally to a pre-processed state. Solvers have the option to restart pre-processing from scratch. This model is viable if the overall number of solver calls is small compared to time spent solving, but is not practical for scenarios where many minor variations of a set of main constraints are queried. Such scenarios may be found in applications of dynamic symbolic execution or symbolic model checking.
A procedure to incorporate pre- and in-processing techniques [27] into incremental SAT solvers was introduced in [18], where such incremental in-processing allowed a dramatic improvement in the performance of bounded model checking applications. In the case of SAT, the effect of a simplification step is recorded in a reconstruction stack. Each eliminated clause is saved on that stack together with a partial assignment, called its witness, that is used to show the redundancy of the eliminated clause. For example, the redundancy of blocked clauses are witnessed by their blocked literal, a literal that upon all resolvents are tautological [26, 32]. The reconstruction stack has two very important roles in SAT solvers. First of all, it has all the information that is necessary for model reconstruction [25]. When the elimination of a clause is not model-preserving, its witness on the stack tells how to modify or extend any found solution of the simplified formula such that it then satisfies the removed clause as well. Beyond that, the reconstruction stack allows to recognize all those previous simplification steps that are potentially invalidated by an incrementally added new constraint. For example, literals that were blocked in the global state of the previous clauses might not be blocked any more in the presence of some new constraints. Finding these clauses and their cone of influence on the reconstruction stack allows to undo only the problematic previous simplification steps, thereby allows pre- and in-processing to be incremental [18].
Motivated by incremental in-processing SAT solvers, our goal here is to pave a path towards a similar mechanism in the context of SMT solvers. However, SMT problems extend propositional SAT formulas in several dimensions: the base theory of SMT is the theory of equality over uninterpreted functions and predicates, SMT formulas may contain quantifiers, and constants and functions that have interpretations over theories. Concrete cases of incremental SMT pre-processing was considered in [19]. While most of the formula simplification techniques of SAT solvers are captured by well studied redundancy properties [23], such a unified understanding and description of SMT pre-processing techniques is not yet introduced. Though some redundancy notions of SAT solvers can be directly embedded or generalized to SMT [30], a notion that appears to capture simplifications in SMT in many cases is that of a substitution: an uninterpreted constant or function is defined into a solved form and the constraints are simplified based on the solution. When new constraints, containing the solved function symbols, are added after pre-processing, our method distinguishes between simplifications that allow applying the substitution to the new formula or removing the substitution and re-adding the old constraints that were simplified. We have found it useful to characterize pre-processing simplifications by the following categories.
Equivalence Preserving Simplifications. Many simplification methods are based on equivalence preserving simplifications. For example \(x > x - y + 1\) simplifies to \(y > 1\). They are automatically incremental by virtue of not changing the set of models. Developing equivalence preserving simplifications is a significant area of research and engineering by itself. A good example is using and-inverter graphs (AIGs) for simplifying propositional and first-order formulas [24, 45]. The main challenge with developing equivalence preserving simplifications in an incremental setting is to make them efficient.
Rigid Constrained Simplifications. An important class of simplifications are based on eliminating variables by finding solutions to them. In the formula \(x \le y + 1 \wedge x \ge y + 1 \wedge \varphi [x,y]\) we can solve for x (or y) by setting \(x \simeq y + 1\) and then substituting in the solution for x into \(\varphi \). The simplified formula is \(\varphi [y + 1, y]\). The set of models of the original formula must all satisfy the equality \(x \simeq y + 1\). This property allows to reuse the simplification when later adding a formula \(\psi [x,y]\). It can be added by applying the solution for x: \(\psi [y + 1, y]\). A model of \(\varphi [y + 1, y] \wedge \psi [y + 1, y]\) must conversely correspond to a model of the original formulas \(\varphi [x,y]\) and \(\psi [x,y]\). The equality \(x \mapsto y + 1\) is used in a model converter to establish the original model. Some pre-processing techniques translate constraints from one domain to another. For example, formulas over bounded integers can be solved by translation into bit-vectors. This translation can be described with a set of equalities where bounded integers are solved for their bit-vector representation (see later an example in Table 1).
Under Constrained Simplifications. The rigid constrained simplifications already cover a significant class of pre-processing methods. Allowing incrementally solving for variables has a profound practical effect on using z3 incrementally in user scenarios. There is however a larger class of simplifications that also allow eliminating variables but do not preserve solutions to the eliminated variable. These simplifications have the same or more solutions for symbols in the original formula and we call them under-constrained. For example, the formula \(((x \simeq y \wedge y < z + u) \vee y \ge z \cdot u)\) contains x in only one position. It can be replaced by the formula \(((b \wedge y < z + u) \vee y \ge z \cdot u)\) where b is fresh. Similarly introducing definitions of fresh symbols does not eliminate solutions to symbols in the original formula. Lastly, when removing redundant clauses, the new formula may have more solutions. Tseitin transformation introduces definitions that allow removing redundant, non-CNF, formulas.
Over Constrained Simplifications. Symmetry reduction [14, 38] and strengthening using propagation redundancy criteria [37] are prominent examples of simplifications that apply strengthening to reduce the search space. These transformations are not covered by the classes covered by our main result. We leave it to future work to examine whether or how to incorporate strengthening: one avenue is to leverage assumption literals [16] to temporarily enable strengthenings either as part of pre-processing or during search [39].
Table 1 summarizes the main categories of pre-processing techniques discussed so far. This paper develops a calculus of incremental pre-processing for rigid constrained, under-constrained, clause elimination, and introduction of definitions. However, it does not discuss further over-constrained simplifications.
In this paper we introduce the concept of simplification modulo substitutions and show that the main SMT pre-processing methods maintain such a property. Based on that, we show how to apply or revert the effect of previous pre-processing steps when new formulas are added after simplification.
2 Preliminaries
We assume the usual notions of first-order logic with equality, satisfiability, logical consequence and theory, as described e.g. in [17]. An interpretation \(\mathcal {M}\) for a signature \(\varSigma \) (or \(\varSigma \)-model) consists of a non-empty set \(\mathcal {U}_\mathcal {M} \) called the universe of the model, and a mapping \((\_)^\mathcal {M} \) assigning to each variable and constant symbol an element of \(\mathcal {U}_\mathcal {M} \), to each n-ary function symbol f in \(\varSigma \) an n-ary function \(f^\mathcal {M} \) from \(\mathcal {U}_\mathcal {M} ^n\) to \(\mathcal {U}_\mathcal {M} \), and to each n-ary predicate symbol p in \(\varSigma \) an n-ary function from the set \(\mathcal {U}_\mathcal {M} ^n\) to distinguished values representing true and false. Note that to keep the presentation simple, we only consider a single universe in the models. Interpretations extend to terms by composition.
We use the terminology symbols referring to uninterpreted symbols (variables) and function symbols. Given a model \(\mathcal {M}\) and a symbol x, the model \(\mathcal {M} [{x \mapsto a}]\) is exactly the same as \(\mathcal {M}\), except that \(x^\mathcal {M} = a\) where \(a \in \mathcal {U}_\mathcal {M} \) for 0-ary symbols and a is a function over \(\mathcal {U}_\mathcal {M} \) for n-ary function or predicate symbols.
Lemma 1
(Translation Lemma [41]). If F is a formula and t is a term s.t. no variable in t occurs bound in F, then \(\mathcal {M} \models F[t/x]\) iff \(\mathcal {M} [{x \mapsto t^\mathcal {M}}] \models F\).
Note that we may use \(\lambda \) terms to represent updates to function and predicate symbols. The interpretation of a \(\lambda \) term is a function.
We denote Skolem symbols for n-ary functions (where \(n = 0\) is possible) that cannot occur in input formulas. Only pre-processing methods may introduce the Skolem symbols as a guarantee that they are fresh.
Convention 1
(Variable non-capture). Throughout this paper we assume that free and bound variables are disjoint, such that when we substitute a term t for a variable x in formula F, none of the variables in t are captured.
Definition 1
(Labeled substitution). \(\langle x\!\leftarrow \!t;\varPsi \rangle ^{\mathbb {B}} \) represents a substitution of x by t, justified by the formula \(\varPsi \). The label \(\mathbb {B}\) is either \(\top \) or \(\bot \) and it indicates whether the map \(x \mapsto t\) may be used as an equal replacement of \(\varPsi \).
Example 1
The labeled substitution \(\langle x\!\leftarrow \!y+1;x \simeq y + 1\rangle ^{\bot } \) represents the substitution of x by \(y+1\) justified by the formula \(x \simeq y + 1\). The label \(\bot \) of the substitution indicates that applying the substitution on a formula F where \(x \simeq y + 1\) is present does not change the set of models of the formula.
Definition 2
Given \(\theta = \langle x_1\!\leftarrow \!t_1;\varPsi _1\rangle ^{\mathbb {B}_1} \langle x_2\!\leftarrow \!t_2;\varPsi _2\rangle ^{\mathbb {B}_2} \dots \langle x_n\!\leftarrow \!t_n;\varPsi _n\rangle ^{\mathbb {B}_n} \) and an interpretation \(\mathcal {M}\), we define the interpretation \(\mathcal {M} \theta \) as follows:
Definition 3
Given \(\theta = \langle x_1\!\leftarrow \!t_1;\varPsi _1\rangle ^{\mathbb {B}_1} \langle x_2\!\leftarrow \!t_2;\varPsi _2\rangle ^{\mathbb {B}_2} \dots \langle x_n\!\leftarrow \!t_n;\varPsi _n\rangle ^{\mathbb {B}_n} \) and a formula F, we define the formula \(F\theta \) as follows:
Informally, a sequence of substitutions \(\theta \) is applied to interpretations from right to left (i.e. backwards), while to formulas from left to right (i.e. forward). Further, note that the translation lemma generalizes in a straight-forward way to substitutions.
3 Incremental Pre-processing
In this section we introduce a calculus to describe incremental pre-processing for SMT based on the following notion.
Definition 4
(Simplification modulo \(\theta \)). We say that the formula F simplifies to \(F'\) modulo \(\theta \), denoted \(F \succeq _{\theta } F'\) if
-
If \(\mathcal {M} \models F\) then there is a model \(\mathcal {M} '\) such that, \(\mathcal {M} ' \models F'\) and \(\mathcal {M} '\) agrees with \(\mathcal {M} \) on all symbols that are in F or in background theories or not in \(F'\).
-
If \(\mathcal {M} ' \models F'\) then \(\mathcal {M} '\theta \models F\).
It follows that simplification allows transitive chaining assuming that symbols are not recycled.
Lemma 2
(Transitivity of simplification). Let \(F \succeq _{\theta } F'\) and \(F' \succeq _{\theta '} F''\) such that every symbol that is both in F and \(F''\) also occurs in \(F'\) (i.e. old symbols are not re-introduced). Then \(F \succeq _{\theta \theta '} F''\).
3.1 Simplification Rules
There are several possible situations where the concept of simplification modulo substitutions can be used to capture potential simplification steps. For example, a useful special case for simplification modulo \(\theta \) is when a formula F implies an equality \(x \simeq t\) that can then be turned into a substitution to simplify F.
Example 2
The formula \( isCons (x) \wedge F[x]\) implies \(\exists h, t \ . \ x \simeq cons (h, t)\), where h, t are fresh variables (corresponding to the head and tail of a cons list). We may substitute x by \( cons (h, t)\) in F[x] to eliminate x. The literal \( isCons ( cons (h,t))\) is equivalent true and \(F[ cons (h,t)]\) is a model simplification of the original formula modulo \(x \simeq cons (h, t)\).
There are also useful special cases where a formula F does not imply an equality \(x \simeq t\), but the same equality may still be used to simplify F.
Example 3
In the formula \(F := ((x \simeq 3 \wedge x> u) \vee y> u) \wedge u > z\) we can substitute \(x \mapsto 3\) and retain simplification. The formula F simplifies to \(F[3/x] := (3> u \vee y> u) \wedge u > z\), but F does not imply \(x = 3\).
There are also cases where substitutions are not suitable to describe the relation between F and \(F'\). It is easier to characterize these by the property that \(F'\) is a proper subset of F.
Example 4
A blocked clause \(p \vee C\) can be removed from a set of formulas without changing satisfiability: \(F, (p \vee C) \succeq _{p \mapsto p \vee \lnot C} F\). If we were to substitute p by \(p \vee \lnot C\) everywhere in F it would weaken clauses where p occurs positively.
Finally, it is possible to accomodate cases where pre-processing introduces definitions, such as through the unfold transformation (see Sect. 6.5), or by Skolemization and Tseitin transformations.
Example 5
The Skolemization of \(\forall x \ . \ \exists y \ . \ p(x, y)\) is \(\forall x \ . \ p(x, f_{sk}(x))\). Here the original quantified formula is replaced by the Skolemized formula.
We model the pre-processing performed by an SMT solver as a sequence of abstract states where each state consists of two components: a formula F and an ordered sequence of labeled substitutions \(\theta \). Based on the shown cases, we formulate the following conditions for applying simplification rules in Fig. 1.

A calculus for pre-processing in SMT
We formulated the side conditions that allow to identify a minimal set of conjuncts \(\varPsi \) of F involved with the solution for x. Note that a simplification remains valid when adding conjuncts that do not contain x. The
 rule handles broadly a set of simplifications, including proof rules from DRAT systems and introduction of definitions and Skolemization. It may be presented in forms where \(\varPhi \) or \(\varPsi \) or the substitution are empty. The substitution \(x \mapsto t\) generally represents a tuple of symbols x replaced by terms t. To simplify presentation we only discuss the case where x is a single symbol and we elide rules that preserve equivalence. The
rule handles broadly a set of simplifications, including proof rules from DRAT systems and introduction of definitions and Skolemization. It may be presented in forms where \(\varPhi \) or \(\varPsi \) or the substitution are empty. The substitution \(x \mapsto t\) generally represents a tuple of symbols x replaced by terms t. To simplify presentation we only discuss the case where x is a single symbol and we elide rules that preserve equivalence. The
 rule records \(\varPsi \) so it can later be re-added in case a new constraint mentions x. This may be overkill when \(\varPhi [t/y] = \varPsi \) for y fresh (in Sect. 4 we will show another rule,
rule records \(\varPsi \) so it can later be re-added in case a new constraint mentions x. This may be overkill when \(\varPhi [t/y] = \varPsi \) for y fresh (in Sect. 4 we will show another rule,
 , that adds only the equality \(y \simeq t\) in such cases).
, that adds only the equality \(y \simeq t\) in such cases).
Lemma 3
If \(F \Rightarrow \exists y \ . \ x \simeq t[y]\), s.t. \(y \not \in F\), \(x \not \in t\), and t is substitutable for x in F, then \(F \succeq _{x \mapsto t} F[t[y]/x]\).
Proof
Let \(\mathcal {M} \) be an interpretation s.t. \(\mathcal {M} \models F\). Then \(\mathcal {M} \models F \wedge \exists y \ . \ x \simeq t[y]\) and by definition of the satisfaction relation, there must exists an \(a \in \mathcal {U}_\mathcal {M} \), s.t. \(\mathcal {M} [{y \mapsto a}] \models F \wedge x \simeq t[y]\). Let \(\mathcal {M} '\) note \(\mathcal {M} [{y \mapsto a}]\). From \(\mathcal {M} ' \models F \wedge x \simeq t[y]\) follows that \(x^{\mathcal {M} '} = t[y]^{\mathcal {M} '}\) and so \(F^{\mathcal {M} '} = F[t[y]/x]^{\mathcal {M} '}\). Since \(\mathcal {M} ' \models F\), we have that \(\mathcal {M} ' \models F[t[y]/x]\). For the other direction, when \(\mathcal {M} ' \models F[t[y]/x]\), due to Lemma 1, \(\mathcal {M} '[{x \mapsto t[y]^{\mathcal {M} '}}] \models F\). Hence, \(F \succeq _{x \mapsto t} F[t[y]/x]\). \(\square \)
Corollary 1
The side-condition for
 implies that \(F \succeq _{x \mapsto t} F[t/x]\).
implies that \(F \succeq _{x \mapsto t} F[t/x]\).
Lemma 4
Assume \(\varPsi \subseteq F, x \not \in F \setminus \varPsi \) and \(\varPsi \succeq _{x \mapsto t} \varPsi [t/x]\), then \(F \succeq _{x \mapsto t} F[t/x]\).
Proof
Since \(x \not \in F\), \((F\setminus \varPsi ) = (F\setminus \varPsi )[t/x]\), thus \((F\setminus \varPsi ) \succeq _{x \mapsto t} (F\setminus \varPsi )[t/x]\). Then, from \(\varPsi \succeq _{x \mapsto t} \varPsi [t/x]\) follows that \(F \succeq _{x \mapsto t} F[t/x]\).
Lemma 3 established that the side-condition for
 ensures simplification modulo \(\theta \). We therefore have the following corollaries.
ensures simplification modulo \(\theta \). We therefore have the following corollaries.
Corollary 2
If a formula \(F'\) is derived from F by the inferences from Fig. 1, then it has the property \(F \succeq _{x \mapsto t} F'\).
The other rules enforce preservation of satisfiability in their side-conditions.
Corollary 3
The rules from Fig. 1 preserve satisfiability.
The transitive application of the simplifications also preserve satisfiability in a way that extends the notion of simplification modulo a substitution.
Proposition 1
Consider a formula \(F_0\) and a state \({F\,\parallel \,\theta } \) derived from \({F_0\,\parallel \,\varepsilon } \) using the rules from Fig. 1. Then \(F_0 \succeq _{\theta } F\).
Proof
It follows as Corollary 2 notes that each application of a rule from Fig. 1 is a simplification modulo and Lemma 2 notes that simplification modulo is transitive.
Informally, Proposition 1 means that using \(\theta \), one can transform any model of the simplified formula into a model of the original input formula. Note that the simplified F may contain fresh Skolem symbols that are not occurring in \(F_0\).
3.2 Pre-processing Replay
Rules of Fig. 1 captured possible pre-processing steps that can be applied on a single SMT problem. We now describe the scenario where we add additional constraints \(\varPhi \) to a pre-processed state. Without incremental pre-processing we have the option to conjoin \(\varPhi \) to the original formula \(F_0\) and re-run pre-processing. The goal of incremental pre-processing is to retain as much of the effect of previous work as possible.
We will show that for pre-processing steps derived by rule
 it is possible to apply the corresponding substitution to \(\varPhi \) directly, while the other simplification steps may require to re-introduce formulas that were previously removed. We call this process of applying the effect of simplifications on a new formula as pre-processing replay. Figure 2 shows an imperative implementation of pre-processing replay.
it is possible to apply the corresponding substitution to \(\varPhi \) directly, while the other simplification steps may require to re-introduce formulas that were previously removed. We call this process of applying the effect of simplifications on a new formula as pre-processing replay. Figure 2 shows an imperative implementation of pre-processing replay.

Algorithm

Our main proposition summarizes the main property of
 and ensures that an arbitrary formula \(\varPhi \) can be added mid-stream after pre-processing.
and ensures that an arbitrary formula \(\varPhi \) can be added mid-stream after pre-processing.
Proposition 2
Let \({F\,\parallel \,\theta } \) be a state resulting from pre-processing \(F_0\), and let \({F \wedge \varPhi '\,\parallel \,\theta '} \) be a state produced by applying procedure
 to \(\varPhi \) and \(\theta \), then \(F_0 \wedge \varPhi \) is equi-satisfiable to \(F \wedge \varPhi '\).
to \(\varPhi \) and \(\theta \), then \(F_0 \wedge \varPhi \) is equi-satisfiable to \(F \wedge \varPhi '\).
To establish Proposition 2 we will introduce a calculus for reverting the effect of simplifications. It is shown in Fig. 3 and comprises of two rules, one for adding a formula with a substitution to F, the other both reverts the effect of a simplification and adds the reverted formula to F. The inferences rely on a side-condition that the formulas \(\varPhi , \varPsi \) are clean relative to the substitution \(\theta \).

A calculus for reverting pre-processing.
 reverts a simplification by re-introducing a constraint. It prunes \(\theta \) until
reverts a simplification by re-introducing a constraint. It prunes \(\theta \) until
 applies for a new constraint \(\varPhi \).
applies for a new constraint \(\varPhi \).
Definition 5
A formula \(\varPhi \) is clean w.r.t. a substitution sequence \(\theta \) iff
-
\(\theta = \varepsilon \), or
-
\(\theta = \langle x\!\leftarrow \!t;\varPsi \rangle ^{\mathbb {B}} \theta '\), \(x\not \in \varPhi \) and \(\varPhi \) is clean with respect to \(\theta '\), or
-
\(\theta = \langle x\!\leftarrow \!t;\varPsi \rangle ^{\bot } \theta '\) and \(\varPhi [t/x]\) is clean with respect to \(\theta '\).
Thus, intuitively, \(\varPhi \) is clean w.r.t. \(\theta \) if \(\varPhi \theta \) uses only
 substitutions from \(\theta \).
substitutions from \(\theta \).
We now establish that formulas that are clean relative to \(\theta \) can be added (after substitution) to formulas while maintaining models. The substitution used in rigid updates corresponds to equalities that are consequences.
Lemma 5
Given a state \({F'\,\parallel \,\theta \theta '} \) derived from the state \({F\,\parallel \,\theta } \) and formula \(\varPhi \) that is clean with respect to \(\theta '\), then \(F \wedge \varPhi \succeq _{\theta '} F' \wedge \varPhi \theta '\).
Proof
We examine the two directions.
-
Let \(\mathcal {M} \models F \wedge \varPhi \). Induction on the length of the derivation from F to \(F'\) establishes that if \(\mathcal {M} \models F\), then there is a corresponding \(\mathcal {M} '\) such that \(\mathcal {M} ' \models F' \wedge \bigwedge _{(x\mapsto t)\in \theta '} x \simeq t\): Each time
 is applied a new equality is used for simplification \(F_1[t_1/x_1]\). The equality can be added to the result, \(F_1[t_1/x_1] \wedge x_1 \simeq t_1\) without changing satisfiability because \(x_1\) does not occur in \(F_1[t_1/x_1]\). Thus, the resulting model \(\mathcal {M} '\) can be constrained to satisfy all equalities used in rigid substitutions. Since \(\mathcal {M} ' \models \varPhi \) already, then \(\mathcal {M} ' \models \varPhi \theta '\).
is applied a new equality is used for simplification \(F_1[t_1/x_1]\). The equality can be added to the result, \(F_1[t_1/x_1] \wedge x_1 \simeq t_1\) without changing satisfiability because \(x_1\) does not occur in \(F_1[t_1/x_1]\). Thus, the resulting model \(\mathcal {M} '\) can be constrained to satisfy all equalities used in rigid substitutions. Since \(\mathcal {M} ' \models \varPhi \) already, then \(\mathcal {M} ' \models \varPhi \theta '\). -
Let \(\mathcal {M} ' \models F' \wedge \varPhi \theta '\). Then from the assumption of simplification modulo \(\theta '\), we get \(\mathcal {M} '\theta ' \models F\). Lemma 1 ensures \(\mathcal {M} '\theta ' \models \varPhi \). Thus, \(\mathcal {M} '\theta ' \models F \wedge \varPhi \).
 is applied a new equality is used for simplification
is applied a new equality is used for simplification The correctness of the
 rule is now immediate:
rule is now immediate:
Corollary 4
Let \({F\,\parallel \,\theta } \) be derived from \({F_0\,\parallel \,\varepsilon } \), and \(\varPhi \) clean with respect to \(\theta \), then \(F_0 \wedge \varPhi \) simplifies modulo \(\theta \) to \(F \wedge \varPhi \theta \).
Proof
It follows from Lemma 5.
With Proposition 1 we established that
 ,
,
 and
and
 maintain \(F_0 \succeq _{\theta } F\). We need to show that also for rule
maintain \(F_0 \succeq _{\theta } F\). We need to show that also for rule
 . The first step is to establish that the formula removed by each of the pre-processing rules can be re-added without affecting simplification.
. The first step is to establish that the formula removed by each of the pre-processing rules can be re-added without affecting simplification.
Lemma 6
Given an inference \({F\,\parallel \,\theta } \Longrightarrow {F'\,\parallel \,\theta \langle x\!\leftarrow \!t;\varPsi \rangle ^{\mathbb {B}}} \) by either of the rules
 ,
,
 ,
,
 the formula F simplifies to \(F', \varPsi \) modulo \(\varepsilon \).
the formula F simplifies to \(F', \varPsi \) modulo \(\varepsilon \).
Proof
The proof is by case analysis by the rule that is applied.
-
 : Then \(F' = F[t/x]\), \(\varPsi \subseteq F\) and therefore \(F' \wedge \varPsi = F \wedge \varPsi [t/x]\). From the side condition \(\varPsi \succeq _{x \mapsto t} \varPsi [t/x]\) every model of F there is a model of \(\varPsi [t/x]\) that agrees with symbols from F. Conversely \(F', \varPsi \) properly contains F and therefore implies it. Therefore, \(F \succeq _{\varepsilon } F', \varPsi \).
: Then \(F' = F[t/x]\), \(\varPsi \subseteq F\) and therefore \(F' \wedge \varPsi = F \wedge \varPsi [t/x]\). From the side condition \(\varPsi \succeq _{x \mapsto t} \varPsi [t/x]\) every model of F there is a model of \(\varPsi [t/x]\) that agrees with symbols from F. Conversely \(F', \varPsi \) properly contains F and therefore implies it. Therefore, \(F \succeq _{\varepsilon } F', \varPsi \). -
 : We want to show that \(F, \varPsi \) simplifies to \(F, \varPsi , \varPhi \) modulo \(\varepsilon \). The premise of
: We want to show that \(F, \varPsi \) simplifies to \(F, \varPsi , \varPhi \) modulo \(\varepsilon \). The premise of
 ensures that for every \(\mathcal {M} \models F, \varPsi \) there is a model agreeing with \(\mathcal {M} \) on symbols in \(F, \varPsi \), that satisfies \(F, \varPhi \). Since interpretation of the symbols in \(\varPsi \) is unchanged it also satisfies \(\varPsi \). Conversely, if \(\mathcal {M} ' \models F, \varPsi , \varPhi \), then already \(\mathcal {M} ' \models F, \varPsi \) and therefore \(\mathcal {M} '\varepsilon \models F, \varPsi \).
ensures that for every \(\mathcal {M} \models F, \varPsi \) there is a model agreeing with \(\mathcal {M} \) on symbols in \(F, \varPsi \), that satisfies \(F, \varPhi \). Since interpretation of the symbols in \(\varPsi \) is unchanged it also satisfies \(\varPsi \). Conversely, if \(\mathcal {M} ' \models F, \varPsi , \varPhi \), then already \(\mathcal {M} ' \models F, \varPsi \) and therefore \(\mathcal {M} '\varepsilon \models F, \varPsi \). -
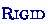 : We wish to establish that \(F \succeq _{\varepsilon } F', \varPsi \). First observe that \(F', \varPsi = F, \varPsi [t/x]\). Since \(\varPsi \) implies the equation \(\exists y \ . \ x \simeq t\), every model of F implies there is a solution to y such that \(\varPsi [t/x]\) that agrees with the variables in F. Conversely, if \(F, \varPsi [t/x]\) is satisfied by \(\mathcal {M} '\), then \(\mathcal {M} '\) already satisfies F.
: We wish to establish that \(F \succeq _{\varepsilon } F', \varPsi \). First observe that \(F', \varPsi = F, \varPsi [t/x]\). Since \(\varPsi \) implies the equation \(\exists y \ . \ x \simeq t\), every model of F implies there is a solution to y such that \(\varPsi [t/x]\) that agrees with the variables in F. Conversely, if \(F, \varPsi [t/x]\) is satisfied by \(\mathcal {M} '\), then \(\mathcal {M} '\) already satisfies F.
 : Then
: Then  : We want to show that
: We want to show that  ensures that for every
ensures that for every 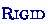 : We wish to establish that
: We wish to establish that Lemma 7
Given
 , s.t. \(F_0 \succeq _{\theta \langle x\!\leftarrow \!t;\varPsi \rangle ^{\mathbb {B}} \theta '} F\), then \(F_0 \succeq _{\theta \theta '} F,\varPsi \theta '\) holds.
, s.t. \(F_0 \succeq _{\theta \langle x\!\leftarrow \!t;\varPsi \rangle ^{\mathbb {B}} \theta '} F\), then \(F_0 \succeq _{\theta \theta '} F,\varPsi \theta '\) holds.
Proof
Given an inference \({F_1\,\parallel \,\theta } \Longrightarrow {F_2\,\parallel \,\theta \langle x\!\leftarrow \!t;\varPsi \rangle ^{\mathbb {B}}} \). Lemma 6 establishes that the formula \(F_1\) simplifies to \(F_2,\varPsi \) modulo \(\epsilon \). Lemma 5 establishes that \(F_2, \varPsi \) simplifies to \(F, \varPsi \theta '\) modulo \(\theta '\). Chaining the definition of simplification modulo transitively establishes the lemma.
With Corollary 4 and Lemma 7 we have then established Proposition 2.
It is worth examining why the side-conditions for simplification modulo are used. As the following example shows, transformations that only preserve satisfiability but strengthen formulas cannot be used easily in an incremental setting.
Example 6
Let \(F_0\) be the satisfiable formula \(x \simeq y \wedge y \le z \wedge z \simeq v\). In that formula x, y are equal, and z, v are equal. Lets assume that we simplify via the solution where the classes are merged (i.e. where \(y\simeq z\)). It is satisfiability preserving. It suggests a transformation that we call
 .
.

The resulting state is still satisfiable. Now
 can be applied without any problems. The result is still satisfiable, but not equivalent to \(F_0\) (does not have the models where the two equivalence classes are not merged).
can be applied without any problems. The result is still satisfiable, but not equivalent to \(F_0\) (does not have the models where the two equivalence classes are not merged).

Adding the constraint \(y \simeq z - 1\) to \(F_0\) would be satisfiable, but adding it to our formula is unsatisfiable.
4 Simplification Methods
Many simplification methods used in practice during pre-processing are equivalence preserving. These methods include formula rewriting, constant propagation, NNF conversion, quantifier elimination, and bit-blasting. They do not require the methodology from this paper and have been integral in Z3 since its inception. We will here discuss main simplification pre-processing routines that do not preserve equivalence and how they relate to our taxonomy.
4.1 Equality Solving
One of the most useful pre-processing techniques eliminates symbols when they can be solved, that is, a constraint implies an equality \(x \simeq t\), where t is a term that does not contain x. Equality solving corresponds to finding unitary solutions to unification problems modulo theories. Most uses of equality solving are captured by transformations justified by rule
 . In Z3, equality solving comprises of a two stage process:
. In Z3, equality solving comprises of a two stage process:
-
1.
Extract a set of solution candidates \(\mathcal {E}\) implied by the current formula \(\varphi \).
-
2.
Extract from \(\mathcal {E}\) a subset of solutions that can be oriented without introducing cyclic dependencies.
To elaborate, let \(\mathcal {E}\) be a set of solution candidates \(x_1 = t_1, \ldots x_n = t_n\). The candidates may contain multiple equalities using the same symbol. For example, \(\mathcal {E}\) could be \(x = f(x), x = g(y), y = h(z)\). We can’t use the solution \(x = f(x)\) because x already occurs in f(x). But we can use the solution \(x = g(y), y = h(z)\) processed in this order as first x is replaced by g(y), then y is replaced by h(z). In the second stage we extract from \(\mathcal {E}\) a subset of equalities \(x_{i_1} = t_{i_1}, \ldots , x_{i_k} = t_{i_k}\), where \(x_{i_j}\) are distinct and \(t_{i_j}\) are terms such that \(x_{i_j} \not \in t_{i_{j'}}\) for \(j \le j'\). The subset is in triangular form.
Example 7
We illustrate two application of
 for eliminating two symbols from three equations. The choice of the first two equations is arbitrary. An alternative simplification could choose to eliminate x and z instead. It is not possible, however, to eliminate all three variables.
for eliminating two symbols from three equations. The choice of the first two equations is arbitrary. An alternative simplification could choose to eliminate x and z instead. It is not possible, however, to eliminate all three variables.

The set of unification modulo theories facilities used in Z3 is based on extracting simple definitions. Foremost, for a conjunct \(x \simeq t\) of \(\varphi \), where x is uninterpreted, \(x \ne t\), include the equality candidate \(x \simeq t\). Other equality candidates are included from formulas of the form \( ite (c, x \simeq t, x \simeq s)\) and arithmetic equalities of the form \(x + s \simeq t\), such that \(x \simeq t - s\) is a solution candidate for x. Note that solution candidates are not necessarily unique for an equality. The constraint \(x + y \simeq t\) can be used as solution to both x and y. If x has a nested occurrence within t, the solution for y, but not x, can be used. Equality solving interacts with simplification pre-processing: equalities over algebraic data-types can be assumed to be in decomposed form already since rewriting simplification decomposes equalities of the form \( cons (h_1, t_1) \simeq cons (h_2, t_2)\) into \(h_1 \simeq h_2 \wedge t_1 \simeq t_2\). Equality solving can be extended modulo theories in several directions. Arithmetical equalities can be extracted from Diophantine equations solving and polynomial equality factorization as part of establishing a Gröbner basis. Equalities can be extracted from inequalities [6, 31], other theories, such as the theory of arrays allow extracting solutions from equalities \( store (a, i, v) \simeq t\), where a is a symbol that does not occur in t, i, v, as \(a \simeq store (t, i, w)\), together with the constraint \( select (t,i) \simeq v\), where w is fresh. We leave a study of the cost/benefits of these approaches within the context of incremental pre-processing to future work.
Equality solving is extended to sub-formulas in the following way: When a positive sub-formula implies an equality \(x \simeq t\) and the symbol x does not occur outside of the sub-formula then x can be replaced by t within the subformula. The solution is no longer rigid constrained but can be justified by
 .
.
Example 8
Suppose \(x \not \in F, \varPsi \), then we can use
 to justify the simplification
to justify the simplification

4.2 Unconstrained Sub-terms
Symbols that have a single occurrence in a formula may be solved for based on context. For example, with the formula \(x \le y, y < z, z \le u, p(u), q(u)\), the constant x can be eliminated by using the solution \(x \simeq y\). Then y can be eliminated by setting \(y \simeq z - 1\), and finally \(z \simeq u\).
Invertibility of unconstrained symbols (see e.g. [7, 8]) in an incremental setting for bit-vectors was introduced in [19]. The method implements the following proof-rule, exemplified for the term \(x + t\), containing the only occurrence of x.

To justify rule
 in our setting, it suffices to check the condition from Lemma 6. Alternatively, we can use the generic rule
in our setting, it suffices to check the condition from Lemma 6. Alternatively, we can use the generic rule
 when applying unconstrained simplifications. The rule
when applying unconstrained simplifications. The rule
 is more efficient than using
is more efficient than using
 because the latter requires adding back an entire conjunction \(\varPsi \) where the invertible term \(x + t\) occurs. Invertibility can also be used to justify elimination of nested definitions. For a definition \(F \wedge ((x \simeq t \wedge \varPhi [x]) \vee \varPsi )\) (see Example 8), where \(x \not \in F, \varPsi \) can first be rewritten as \(F \wedge ((x \simeq t \wedge \varPhi [t]) \vee \varPsi )\). Then \(x \simeq t\) is invertible because it contains the only occurrence of x. The new constraint is \(F \wedge ((y \wedge \varPhi [t]) \vee \varPsi )\) where y is a fresh Boolean symbol.
because the latter requires adding back an entire conjunction \(\varPsi \) where the invertible term \(x + t\) occurs. Invertibility can also be used to justify elimination of nested definitions. For a definition \(F \wedge ((x \simeq t \wedge \varPhi [x]) \vee \varPsi )\) (see Example 8), where \(x \not \in F, \varPsi \) can first be rewritten as \(F \wedge ((x \simeq t \wedge \varPhi [t]) \vee \varPsi )\). Then \(x \simeq t\) is invertible because it contains the only occurrence of x. The new constraint is \(F \wedge ((y \wedge \varPhi [t]) \vee \varPsi )\) where y is a fresh Boolean symbol.
Invertibility conditions are theory dependent. Figure 4 exemplifies main invertibility conditions for arithmeticFootnote 1.

Invertibility rules for symbols \(x, x'\) that occur uniquely in F; y is fresh.
Z3 uses a heap ordered by occurrence counts to identify candidates for invertibility. It first processes all symbols with occurrence count 1. If it is possible to eliminate a symbol with occurrence count 1, the occurrence counts of sub-terms under the term that gets eliminated are decreased. The elimination process stops once the heap only contains symbols with occurrence counts above 1.
4.3 Symbol Elimination and Macros
SAT solvers use symbol elimination [15] to simplify clauses. The first-order version [11] remains timely in more recent works as well [28]. A predicate p can be eliminated if it occurs at most once in every clause either positively or negatively. Clauses that contain p are replaced by resolvents by applying binary resolution exhaustively, and then remove clauses containing p.
Example 9
We illustrate symbol elimination for the ground case with two clauses, and F such that \(p\not \in F\), as an instance of the
 rule.
rule.

The same elimination technique can also be applied to Horn clauses where p does not occur both in the head and body of any rule. A solution for the eliminated predicate is a conjunction of the upper bounds for p or a disjunction of lower bounds for p. It is generally a quantified formula. If the involved clauses admit quantifier free interpolants, the solution can also be computed using an interpolant from a solution to the reduced system [4]. Thus, the term t in a substitution \(x \mapsto t\) may only be computed after an initial model is known.
There are many cases where symbols can be eliminated incrementally and justified by the
 rule:
rule:
-
Macros \(\forall x \ . \ f(x) \simeq t[x]\), \(\forall x \ . \ f(x) + s \simeq t\) are handled as \(\forall x \ . \ f(x) \simeq t - s\), assuming f is not free in s, t. Then replace occurrences f(a) by t[a], respectively \(t[a] - s[a]\).
-
Quasi macros \(\forall x, y \ . \ f(x,y,x+y) \simeq t[x,y]\), then replace f(a, b, c) by \( ite (c \simeq a + b, t[a,b], f'(a,b,c))\), assuming \(f\not \in t\).
-
Conditional macros \(\forall x \ . \ f(x) \simeq t[x] \vee C[x]\), then replace f(a) by \( ite (C[a],f'(a),\) t[a]), where \(f \not \in t, C\).
-
\((f(x) \simeq t) \equiv \psi \), where \(f \not \in t, \psi \). Then replace f(a) by \( ite (\psi , t, f'(a))\) and add the clause \(\forall x \ . \ f'(x) \not \simeq t\).
Macro elimination can be extended to ordered structures and in combination of theories [42]. It has been integral to making quantified reasoning with bit-vectors [44] practical. We claim that first-order in-processing rules based on blocked clauses, asymmetric tautology elimination, covered clauses known from SAT [29] can also be captured by
 . We substantiate the claim with an example, but leave a comprehensive treatment for future work:
. We substantiate the claim with an example, but leave a comprehensive treatment for future work:
Example 10
Consider the clause \(C := p(x) \vee q(x)\) and \(F := \lnot p(x) \vee p(f(x)) \vee r(x), \lnot p(x) \vee p(f(x)) \vee p(g(x))\). The variable x is universally quantified. Then C can be rewritten to \(p(x) \vee q(x) \vee p(f(x))\) without affecting satisfiability. The covered literal p(f(x)) was added to C as it occurs in every resolvent with p(x). The model for p has to be fixed, however. The model update is a first-order lifting of the propositional case.

To illustrate unification constraints in model updates, consider the clause \(C := p(h(x)) \vee q(x)\) and \(p' := \lambda x \ . \ p(x) \vee \exists y \ . \ x \simeq h(y) \wedge \lnot q(y)\):

5 Implementation
We have implemented incremental pre-processing as an integral component of a new SMT solver, part of Z3. It can be enabled by setting the option sat.smt=true from the command line. It includes simplification by equality solving, elimination of uninterpreted sub-terms and macro detection as described in Sect. 4Footnote 2. The primary reason for supporting incremental pre-processing has been usability. GitHub issues pointing to performance cliffs when switching to incremental mode are recurrent. A distilled example where pre-processing can solve formulas is as follows:
Example 11
Consider the benchmark.

The legacy solver of z3 cannot solve it because it only knows about constant folding when expanding the definition of exponentiation (the symbol ^). With incremental propagation, the equality (not (= 2 (^ 2 exp))) simplifies to false.
Simplifiers interoperate with user scopes: SMT solvers support scoping using operations push and pop. All assertions made within a push are invalidated by a matching pop. To allow simplifiers to inter-operate with recursive function definitions they track symbols used in the bodies of recursive functions as frozen. Those symbols are excluded from solving. Similar to CaDiCaL’s implementation for replaying clauses (see [18]), our implementation of
 stores the domain of \(\theta \) in a hash-set to bypass processing formulas that have no symbols in \(\theta \).
stores the domain of \(\theta \) in a hash-set to bypass processing formulas that have no symbols in \(\theta \).
6 Related Work
6.1 Pre- and In-processing for SAT and QBF
Pre-processing for SAT has received significant attention with the milestone work in Satellite [15] and then using notions of blocked clauses [27] and solution reconstruction [25]. Pre-processing techniques for QBF are discussed for example in [3, 22]. The main pre-processing methods for propositional satisfiability solvers can be captured using our rule
 (see Example 4 for an instance of blocked clause elimination simplification). For the case where \(\lnot p \vee D\) is a blocked clause, the model update is the de-Morgan dual: removing \(\lnot p \vee D\) triggers the update \(\mathcal {M} [{p \mapsto (p \wedge D)^\mathcal {M}}]\).
(see Example 4 for an instance of blocked clause elimination simplification). For the case where \(\lnot p \vee D\) is a blocked clause, the model update is the de-Morgan dual: removing \(\lnot p \vee D\) triggers the update \(\mathcal {M} [{p \mapsto (p \wedge D)^\mathcal {M}}]\).
The work [18] introduces an inference system that also addresses redundant clauses and represents model updates using a notion of witness labeled clauses. The semantic content of the rules used for SAT are captured by
 . However, we elided tracking redundant clauses in this work. The case for SMT motivate specialized rules
. However, we elided tracking redundant clauses in this work. The case for SMT motivate specialized rules
 ,
,
 and
and
 .
.
6.2 Pre-processing for SMT
Pre-processing simplification is integral in all main SMT solvers, including [2, 33]. Incremental pre-processing with special attention to bit-vectors was introduced in [19]. Transformations considered in this thesis can be represented by the
 and
and
 rules. Z3 exposes pre-processing simplifications as tactics [13] and allows users to compose them to suit specific needs of applications.
rules. Z3 exposes pre-processing simplifications as tactics [13] and allows users to compose them to suit specific needs of applications.
Invertibility conditions are used in [34] to guide local search. This work considers also a candidate value of all symbols. For example, \(F[x \cdot t]\) is invertible to F[y] if t evaluates to 1.
6.3 Pre-processing for MIP
Pre-solving is terminology for pre-processing for mixed-integer linear programming solvers. There is a significant repertoire of pre-solving methods integrated in leading MIP solvers. Their effects are well documented in the newer survey [1], which provides an updated perspective to [20]. Pre-solving was developed earlier in [40]. The main methods can be categorized as operating on single rows (single constraints) or single columns (single variables), multiple rows, and multiple columns, and use global information about the tableau. They include also methods known from other domains, such as literal probing also found in SAT solvers, and symmetry reduction for sparse systems [38]. We are not aware of under-constrained simplifications used in mainstream MIP solvers. Only symmetry reduction stands out as outside the scope of incremental pre-solve methods.
Example 12
Pre-processing that combines two rows or combines two columns relies on efficient indexing [21] to be effective. The two column non-zero cancellation method considers the situation where the coefficients to two variables maintain a high degree of correlation. Consider the following formula
The coefficients to x, y in the first two inequalities are related by the affine relation given by \(\lambda = 2\). In this case the system can be reformulated, justified by rule
 , by introducing a fresh variable v and using the inequalities
, by introducing a fresh variable v and using the inequalities
6.4 Pre-processing in First- and Higher-Order Provers
Pre-processing is also an important part of first-order theorem provers. Techniques for creating small clausal normal forms have long attracted attention [35]. Main simplifications [24] are based on detecting definitions similar to what is described in Sect. 4.3, but with the extra twist of ensuring that simplifications preserve first-order decidability, such as ensuring that formulas remain within the EPR fragment. Furthermore a variant of AIGs with nodes representing quantifiers are used to detect shared structure. While [24] is only concerned establishing preservation of satisfiability we note that the classification as model equivalent from Sect. 4.3 extends to the cases considered. In-processing inspired by SAT was pursued for first-order [29, 43] and recently for higher-order settings [5].
6.5 Constrained Horn Clauses
Constrained Horn Clauses [4], enjoy a tight connection with Logic Programming where several transformation techniques were developed [10, 12], including incremental consequence propagation [36]. Fold [9] transformations introduce auxiliary predicates and rules that correspond to replacing a code-block with an auxiliary procedure. It is justified by
 . Unfold transformations can be justified by
. Unfold transformations can be justified by
 and correspond to macro elimination.
and correspond to macro elimination.
7 Summary
We introduced a calculus of pre-processing for SMT. It distinguishes simplifications that are rigid and so can be applied to new formulas as substitutions. Other simplified formulas may need to be re-introduced similar to re-introducing removed clauses in SAT. We examine several of the pre-processing methods studied in SAT, ATP, MIP and SMT as instances of the calculus. We leave empirical and algorithmic studies of new pre- and in-processing methods to future work. Another angle we have left on the table is reconciling pre-processing with in-processing. For SAT, it was useful to develop a calculus that accounted for both irredundant and redundant clauses. In our current effort we have set this angle aside in favour of establishing main properties on replaying substitutions.
Notes
- 1.
A summary of rules used for other theories can be found online: https://microsoft.github.io/z3guide/docs/strategies/summary#tactic-elim-uncnstr.
- 2.
See https://microsoft.github.io/z3guide/docs/strategies/simplifiers for a summary of simplifiers.
References
Achterberg, T., Bixby, R.E., Zonghao, G., Rothberg, E., Weninger, D.: Presolve reductions in mixed integer programming. INFORMS J. Comput. 32(2), 473–506 (2020)
Barbosa, H., et al.: cvc5: a versatile and industrial-strength SMT solver. In: Fisman, D., Rosu, G. (eds.) TACAS 2022. LNCS, vol. 13243, pp. 415–442. Springer, Cham (2022). https://doi.org/10.1007/978-3-030-99524-9_24
Biere, A., Lonsing, F., Seidl, M.: Blocked clause elimination for QBF. In: Bjørner, N., Sofronie-Stokkermans, V. (eds.) CADE 2011. LNCS (LNAI), vol. 6803, pp. 101–115. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-22438-6_10
Bjørner, N., Gurfinkel, A., McMillan, K., Rybalchenko, A.: Horn clause solvers for program verification. In: Beklemishev, L.D., Blass, A., Dershowitz, N., Finkbeiner, B., Schulte, W. (eds.) Fields of Logic and Computation II. LNCS, vol. 9300, pp. 24–51. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-23534-9_2
Blanchette, J., Vukmirović, P.: SAT-inspired higher-order eliminations (2023)
Bromberger, M., Weidenbach, C.: New techniques for linear arithmetic: cubes and equalities. Formal Methods Syst. Des. 51(3), 433–461 (2017). https://doi.org/10.1007/s10703-017-0278-7
Brummayer, R.: Efficient SMT solving for bit vectors and the extensional theory of arrays. Ph.D. thesis, Johannes Kepler University of Linz (2010)
Bruttomesso, R.: RTL Verification: From SAT to SMT(BV). Ph.D. thesis, University of Trento (2008)
Burstall, R.M., Darlington, J.: A transformation system for developing recursive programs. J. ACM 24(1), 44–67 (1977)
Calzavara, S., Grishchenko, I., Maffei, M.: HornDroid: practical and sound static analysis of Android applications by SMT solving. In: IEEE European Symposium on Security and Privacy, EuroS &P 2016, Saarbrücken, Germany, 21–24 March 2016, pp. 47–62. IEEE (2016)
Davis, M., Putnam, H.: A computing procedure for quantification theory. J. ACM 7(3), 201–215 (1960)
De Angelis, E., Fioravanti, F., Gallagher, J.P., Hermenegildo, M.V., Pettorossi, A., Proietti, M.: Analysis and transformation of constrained horn clauses for program verification. CoRR, abs/2108.00739 (2021)
de Moura, L., Passmore, G.O.: The strategy challenge in SMT solving. In: Bonacina, M.P., Stickel, M.E. (eds.) Automated Reasoning and Mathematics. LNCS (LNAI), vol. 7788, pp. 15–44. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-36675-8_2
Déharbe, D., Fontaine, P., Merz, S., Woltzenlogel Paleo, B.: Exploiting symmetry in SMT problems. In: Bjørner, N., Sofronie-Stokkermans, V. (eds.) CADE 2011. LNCS (LNAI), vol. 6803, pp. 222–236. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-22438-6_18
Eén, N., Biere, A.: Effective preprocessing in SAT through variable and clause elimination. In: Bacchus, F., Walsh, T. (eds.) SAT 2005. LNCS, vol. 3569, pp. 61–75. Springer, Heidelberg (2005). https://doi.org/10.1007/11499107_5
Eén, N., Sörensson, N.: An extensible SAT-solver. In: Giunchiglia, E., Tacchella, A. (eds.) SAT 2003. LNCS, vol. 2919, pp. 502–518. Springer, Heidelberg (2004). https://doi.org/10.1007/978-3-540-24605-3_37
Enderton, H.B.: A Mathematical Introduction to Logic. Academic Press (1972)
Fazekas, K., Biere, A., Scholl, C.: Incremental inprocessing in SAT solving. In: Janota, M., Lynce, I. (eds.) SAT 2019. LNCS, vol. 11628, pp. 136–154. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-24258-9_9
Franzén, A.: Efficient solving of the satisfiability modulo bit-vectors problem and some extensions to SMT. Ph.D. thesis, University of Trento, Italy (2010)
Gamrath, G., Koch, T., Martin, A., Miltenberger, M., Weninger, D.: Progress in presolving for mixed integer programming. Math. Program. Comput. 7(4), 367–398 (2015). https://doi.org/10.1007/s12532-015-0083-5
Gemander, P., Chen, W., Weninger, D., Gottwald, L., Gleixner, A.M., Martin, A.: Two-row and two-column mixed-integer presolve using hashing-based pairing methods. EURO J. Comput. Optim. 8(3), 205–240 (2020)
Giunchiglia, E., Marin, P., Narizzano, M.: sQueezeBF: an effective preprocessor for QBFs based on equivalence reasoning. In: Strichman, O., Szeider, S. (eds.) SAT 2010. LNCS, vol. 6175, pp. 85–98. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-14186-7_9
Heule, M.J.H., Kiesl, B., Biere, A.: Strong extension-free proof systems. J. Autom. Reason. 64(3), 533–554 (2020)
Hoder, K., Khasidashvili, Z., Korovin, K., Voronkov, A.: Preprocessing techniques for first-order clausification. In: Cabodi, G., Singh, S. (eds.) Formal Methods in Computer-Aided Design, FMCAD 2012, Cambridge, UK, 22–25 October 2012, pp. 44–51. IEEE (2012)
Järvisalo, M., Biere, A.: Reconstructing solutions after blocked clause elimination. In: Strichman, O., Szeider, S. (eds.) SAT 2010. LNCS, vol. 6175, pp. 340–345. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-14186-7_30
Järvisalo, M., Biere, A., Heule, M.: Blocked clause elimination. In: Esparza, J., Majumdar, R. (eds.) TACAS 2010. LNCS, vol. 6015, pp. 129–144. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-12002-2_10
Järvisalo, M., Heule, M.J.H., Biere, A.: Inprocessing rules. In: Gramlich, B., Miller, D., Sattler, U. (eds.) IJCAR 2012. LNCS (LNAI), vol. 7364, pp. 355–370. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-31365-3_28
Khasidashvili, Z., Korovin, K.: Predicate elimination for preprocessing in first-order theorem proving. In: Creignou, N., Le Berre, D. (eds.) SAT 2016. LNCS, vol. 9710, pp. 361–372. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-40970-2_22
Kiesl, B., Suda, M.: A unifying principle for clause elimination in first-order logic. In: de Moura, L. (ed.) CADE 2017. LNCS (LNAI), vol. 10395, pp. 274–290. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-63046-5_17
Kiesl, B., Suda, M., Seidl, M., Tompits, H., Biere, A.: Blocked clauses in first-order logic. In: Eiter, T., Sands, D. (eds.) LPAR-21, 21st International Conference on Logic for Programming, Artificial Intelligence and Reasoning, Maun, Botswana, 7–12 May 2017. EPiC Series in Computing, vol. 46, pp. 31–48. EasyChair (2017)
Kincaid, Z., Koh, N., Zhu, S.: When less is more: consequence-finding in a weak theory of arithmetic. Proc. ACM Program. Lang. 7(POPL), 1275–1307 (2023)
Kullmann, O.: On a generalization of extended resolution. Discret. Appl. Math. 96–97, 149–176 (1999)
Niemetz, A., Preiner, M., Biere, A.: Boolector 2.0. J. Satisf. Boolean Model. Comput. 9(1), 53–58 (2014)
Niemetz, A., Preiner, M., Biere, A.: Precise and complete propagation based local search for satisfiability modulo theories. In: Chaudhuri, S., Farzan, A. (eds.) CAV 2016. LNCS, vol. 9779, pp. 199–217. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-41528-4_11
Nonnengart, A., Weidenbach, C.: Computing small clause normal forms. In: Robinson, J.A., Voronkov, A. (eds.) Handbook of Automated Reasoning, vol. 2, pp. 335–367. Elsevier and MIT Press (2001)
Puebla, G., Hermenegildo, M.: Optimized algorithms for incremental analysis of logic programs. In: Cousot, R., Schmidt, D.A. (eds.) SAS 1996. LNCS, vol. 1145, pp. 270–284. Springer, Heidelberg (1996). https://doi.org/10.1007/3-540-61739-6_47
Reeves, J.E., Heule, M.J.H., Bryant, R.E.: Preprocessing of propagation redundant clauses. In: Blanchette, J., Kovács, L., Pattinson, D. (eds.) IJCAR 2022. LNCS, vol. 13385, pp. 106–124. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-10769-6_8
Sakallah, K.A.: Symmetry and satisfiability. In: Biere, A., Heule, M., van Maaren, H., Walsh, T. (eds.) Handbook of Satisfiability. Frontiers in Artificial Intelligence and Applications, 2nd edn., vol. 336, pp. 509–570. IOS Press (2021)
Saouli, S., Baarir, S., Dutheillet, C., Devriendt, J.: CosySEL: improving SAT solving using local symmetries. In: Dragoi, C., Emmi, M., Wang, J. (eds.) VMCAI 2023. LNCS, vol. 13881, pp. 252–266. Springer, Cham (2023). https://doi.org/10.1007/978-3-031-24950-1_12
Savelsbergh, M.W.P.: Preprocessing and probing techniques for mixed integer programming problems. INFORMS J. Comput. 6(4), 445–454 (1994)
Schöning, U.: Logik für Informatiker. Reihe Informatik, vol. 56. Bibliographisches Institut (1987)
Sofronie-Stokkermans, V.: Hierarchical and modular reasoning in complex theories: the case of local theory extensions. In: Konev, B., Wolter, F. (eds.) FroCoS 2007. LNCS (LNAI), vol. 4720, pp. 47–71. Springer, Heidelberg (2007). https://doi.org/10.1007/978-3-540-74621-8_3
Vukmirović, P., Blanchette, J., Heule, M.J.H.: SAT-inspired eliminations for superposition. ACM Trans. Comput. Log. 24(1), 7:1–7:25 (2023)
Wintersteiger, C.M., Hamadi, Y., de Moura, L.M.: Efficiently solving quantified bit-vector formulas. Formal Methods Syst. Des. 42(1), 3–23 (2013)
Cunxi, Yu., Ciesielski, M., Mishchenko, A.: Fast algebraic rewriting based on and-inverter graphs. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 37(9), 1907–1911 (2018)
Acknowledgment
Thanks to the reviewers for their extensive constructive feedback and to Diego Olivier Fernandez Pons for introducing us to MIP pre-solving. The research was partially funded by the Austrian Science Fund (FWF) under project No. T-1306.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2023 The Author(s)
About this paper

Cite this paper
Bjørner, N., Fazekas, K. (2023). On Incremental Pre-processing for SMT. In: Pientka, B., Tinelli, C. (eds) Automated Deduction – CADE 29. CADE 2023. Lecture Notes in Computer Science(), vol 14132. Springer, Cham. https://doi.org/10.1007/978-3-031-38499-8_3
Download citation
DOI: https://doi.org/10.1007/978-3-031-38499-8_3
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-38498-1
Online ISBN: 978-3-031-38499-8
eBook Packages: Computer ScienceComputer Science (R0)