
Abstract
The Collaboratory for the Study of Earthquake Predictability (CSEP) is an international partnership to support research on rigorous earthquake prediction in multiple tectonic environments. This paper outlines the first earthquake forecast testing experiment for the Japan area conducted within the CSEP framework. We begin with some background and briefly describe efforts in setting up the experiment. The experiment, which closely follows CSEP concepts, is of a prospective sort and is highly objective. Its major feature consists in using Japan, one of the most seismically active and well-instrumented regions in the world, as a natural laboratory. To make full use of this location and of the earthquake catalog maintained by the Japan Meteorological Agency, rules for this experiment have been set up. The experiment consists of 12 categories, with four testing classes each with different time spans (1 day, 3 months, 1 year, and 3 years, respectively) and three testing regions called “All Japan,” “Mainland,” and “Kanto.” A total of 91 models were submitted; these are currently under the CSEP official suite of tests for evaluating the performance of forecasts. This paper briefly describes each model but does not attempt to pass judgment on individual models. Comparative appraisal of the different models will be presented in future publications. Moreover, this is only the first experiment, and more trials are forthcoming. Our aim is to describe what has turned out to be the first occasion for setting up a research environment for rigorous earthquake forecasting in Japan. We argue that now is the time to invest considerably more efforts in related research fields.
Similar content being viewed by others

1. Introduction
The Collaboratory for the Study of Earthquake Predictability (CSEP) (Jordan, 2006) is a global project for earthquake predictability research (http://www.cseptesting.org/). It is a successor to the “Regional Likelihood Models (RELM)” project (special issue in Seismol. Res. Lett., 78(1), 2007) that implemented an earthquake forecast testing study in the California area. The primary purpose of the CSEP is to develop a virtual, distributed laboratory—a collaboratory—that can support a wide range of scientifically objective and transparent prediction experiments in multiple natural laboratories, regional or global. The final outcome goal is to investigate, through experiments, the intrinsic predictability of earthquake rupture processes. The experiments have to be fully specified and conducted in controlled environments, called testing centers (Schorlemmer and Gerstenberger, 2007). To date, CSEP testing centers have been set up in California, Europe (Schorlemmer et al., 2010a), and New Zealand (Gerstenberger and Rhoades, 2010). The CSEP was introduced to Japan in the summer of 2008. This paper presents an overview of the first CSEP experiment in Japan, and we begin with some background.
Japan is one of the most earthquake-prone countries in the world (Mogi, 1986; Hirata, 2004, 2009). The country and its surrounding areas are characterized by a high risk of major earthquakes, with magnitudes M up to about 8 or larger for offshore events and up to about 7 or larger for inland events. Earthquakes are of great scientific, societal, and economic significance. This point is exemplified by a risk assessment report, issued by the Cabinet Office of the Japanese government, for hypothetical large earthquakes of M = 7.3 occurring beneath the Tokyo metropolitan area, similar to the 1855 Ansei-Edo shock (Central Disaster Management Council, 2005). The report estimates that, depending on the wind’s ability to spread earthquake-induced fires and the time of the day, a M = 7.3 earthquake could leave 11,000 people dead, 210,000 wounded, and 96 million tons of rubble. A similar scenario-based computation is possible for other urban areas in Japan. A sound development of scientific research on earthquake prediction and forecasting is long overdue because of rising social demand in Japan for protecting people’s lives and properties.
In response to such demand, an “Observation and Research Program for the Prediction of Earthquakes and Volcanic Eruptions (Fiscal 2009–2013)” was initiated in 2009 (Hirata, 2009; see Mogi (1986) and Hirata (2004) for foregoing national programs for earthquake prediction research). One of the objectives newly introduced in the current prediction program is to both develop and integrate existing streams of research with a view to developing systems for the quantitative probabilistic forecasting of future earthquakes. The quality of a forecast should be evaluated on the basis of both its reliability (agreement with observed data to be collected over many trials) and skill (performance relative to a standard forecast). The reliability and skill of a given forecasting model have to be evaluated objectively according to how well a forecast based on that model agrees with data collected after the forecast is made (prospective testing) and also by checks against previously accumulated data (retrospective testing) (International Commission on Earthquake Forecasting for Civil Protection, 2009). One key element of the current prediction program should therefore lie in setting up a testing center for establishing standards and infrastructures that can be used for such forecast testing. To make a smooth launch into this direction of research, Japan joined the CSEP in the summer of 2008. As in the case of other CSEP testing centers, the Japanese testing center defined Japan as a natural laboratory and initiated a prospective earthquake forecast testing experiment. The starting date was set for 1 November 2009. The main purpose was to conduct objective and comparative tests of forecast models in a well-instrumented and seismically active region. This experiment has turned out to be the first occasion for setting up a research environment for rigorous earthquake forecasting in Japan and provides an opportunity to further develop forecast models through multiple experiments, which can then be invoked as references in future predictability research.
This special issue of Earth, Planets and Space (EPS) presents a summary of this experiment. Eight of the papers herein describe different models under test. There is another paper on the Japanese test center, where forecast models are submitted and stored under rigorous supervision, with a brief summary of the experiment rule (Tsuruoka et al., 2011 submitted). As Field (2007) has already given an overview of the RELM, the present paper does not attempt to pass judgment on individual models (even though virtually every single paper justifies its own assumptions using declarative statements which others may argue with). Comparative appraisal and hazard implications of the different models will hopefully be discussed by Tsuruoka et al. with regards to the first results and in future publications for the results of comprehensive analyses. What this paper provides is an overview of the testing experiment, including the models submitted and the testing center. The EPS special issue includes additional nine papers that explore future directions of earthquake forecasting research; their outline will also be given in the present article.
2. Japanese Testing Center
The framework used for the Japanese testing center is the same as that for other centers within the CSEP framework and for the RELM testing centers (Schorlemmer and Gerstenberger, 2007; Zechar et al., 2010b). We give a brief summary of the first testing experiment below. The reader is referred to Tsuruoka et al. (2011 submitted) for more details.
The first step in launching the experiment was posting a call for forecast models, both on a Website for the international audience (Nanjo et al., 2009) and in newsletters for the domestic audience (Nanjo et al., 2008; Research group “Earthquake Forecast System based on Seismicity of Japan”, 2009), with the aim of encouraging researchers to participate. The next step was to obtain a consensus among potential participants. An international symposium was held in May 2009, where the attendees decided on using all applicable rules that had been defined for the RELM experiment (Schorlemmer and Gerstenberger, 2007; Schorlemmer et al., 2007). While details of the rules in the Japan experiment are available in the Tsuruoka et al. (2011 submitted) paper and also on a Website (http://wwweic.eri.u-tokyo.ac.jp/ZISINyosoku/), some specifications will be given below.
The starting date of the experiment was set for 1 November 2009. The experiment is conducted in a prospective and objective way.
An earthquake catalog maintained by the Japan Meteorological Agency (JMA) is used for the experiment. To use this catalog complete with final solutions for the earthquake parameters, tests in the experiment have to be performed with a certain time delay, not in a real-time fashion. Currently, the time delay is 6 months or longer.
It is vital to establish clear quality benchmarks of the catalog for the current experiment. A common benchmark is the completeness magnitude, M C , above which all events are assumed to be detected by the seismic network. Nanjo et al. (2010) show a comprehensive analysis of Mc in Japan, adopting a commonly used method based on the Gutenberg-Richter (GR) frequency-magnitude law (Gutenberg and Richter, 1944). At the present time, MC = 1.0 might be typical in the mainland, but to have a complete catalog, one needs to use earthquakes with magnitudes ≤1.9. M c in offshore regions is, as expected, higher than within the network, with M c gradually increasing with distance from the coast. Nanjo et al. (2010) also show that MC has decreased with time in and around Japan by two to three magnitude units during the last four decades, highlighting the success of network modernization. The reader is referred to Nanjo et al. (2010) for more details.
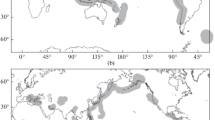
To be able to accommodate a wide range of models targeted at different space and time scales, 12 categories were set up for the experiment, with four testing classes (1 day, 3 months, 1 year, and 3 years, respectively) and three testing regions, namely “All Japan,” “Mainland,” and “Kanto” (Fig. 1). The depth range defined for the “All Japan” region is from 0 to 100 km in order to include seismicity caused by the Pacific and Philippine-Sea plates subducting beneath the continental Eurasian plate. Tests using the “Kanto” region, which covers the Kanto district of Japan again down to a depth of 100 km, focus on seismicity under the complex tectonic condition: the triple junction of the three plates. Tests in the “Mainland” region down to a depth of 30 km can provide a unique opportunity: models specific to this region can intensively utilize the information on active faults identified on the surface of the Japan’s inland; the earthquakes used are only intraplate ones that are cataloged more completely and located more precisely here than in offshore regions. The reader is referred to Tsuruoka et al. (2011 submitted) for more details.

Testing regions: (a) All Japan, covering the whole territory of Japan down to a depth of 100 km with a node spacing of 0.1°. Including the grid would make the figure very dense and dark so that we plot only the outline of the testing region, (b) Mainland, covering Japan’s mainland alone down to a depth of 30 km with a node spacing of 0.1°. (c) Kanto, covering the Kanto district of Japan down to a depth of 100 km with a node spacing of 0.05°.
The suite of tests defined in the CSEP and RELM is applied to all testing classes and regions: at the present time, the suite consists of N-, L-, R-, M- and S-tests (Schorlemmer et al., 2007; Zechar et al., 2010a).
The participants had to submit their models to the testing center before the formal launch of the experiment. A total of 91 models were submitted. Most of the submissions were in the form of a numerical code, except for two models that came in the form of numerical tables.
3. Models
Table 1 is the list of participating forecast models with the following information: testing region, testing class, mod-eler(s), model name, and the mode of submission. Table 2 shows statistics of the 91 participating models, of which 35 were for the testing region “All Japan”, five were for the testing class “1 day”, and nine were for the “3 year” class.
3.1 ALM models
D. Schorlemmer submitted an Asperity-based Likelihood Model (ALM) to 1- and 3-year forecasts of the “All Japan” region. This model assumes a GR distribution of events at each grid point based on declustered, observed seismic-ity. However, in addition to spatially variable a-values, the model also incorporates spatial variability of the b-values where these are well constrained by smaller events. The assumption here is that the a- and b-values, inferred from mi-croseismicity, can and should be extrapolated to predict the rates of larger events—all the way up to M = 9. See also Wiemer and Schorlemmer (2007) and Gulia et al. (2010) for application to California and Italy, respectively.
3.2 Coulomb model
S. Toda and B. Enescu (2011) submitted a Coulomb stress transfer model, incorporating a rate- and state-dependent friction law, to the 1- and 3-year classes as applied to the “Mainland” region. Their forecast rates are based on using data on large earthquakes during the past 120 years. Toda and Enescu’s model differs from other statistical earthquake clustering models as follows: (1) off-fault aftershock zones can be modeled not just as a set of point sources but also as a set of finite, fault-shaped zones; (2) spatial distribution patterns of seismicity to be triggered by Coulomb stresses are determined by taking account of the most likely source mechanisms of future earthquakes; (3) stresses imparted by large earthquakes create stress shadows where smaller numbers of earthquakes are predicted to occur. Although the model has its own weaknesses, such as a number of uncertainty factors and unknown parameters, it is the first physics-based model ever participating in the CSEP. With modifications, this model has the potential to be used for short-term forecasting, possibly even quasi-real-time off-fault aftershock forecasting in the immediate aftermath of a large earthquake.
3.3 DBM model
A. M. Lombardi and W. Marzocchi (2011) presented a 1-year forecast model for “All Japan”. It is called a Double Branching Model (DBM) and is a stochastic time-dependent model which assumes that every earthquake can generate, or is correlated to, other earthquakes through different physical mechanisms (Marzocchi and Lombardi, 2008). More specifically, it consists of a sequential application of two branching processes in which any earthquake can trigger a family of subsequent events on different space-time scales. The first part of their model consists of the well-known Epidemic-Type Aftershock Sequence (ETAS) model (Ogata, 1998) that describes the short-term clustering of earthquakes due to coseismic stress transfer. The second branching process works on larger space-time scales than do the short-term clustering domains. This step consists in re-applying the branching process to a dataset obtained by using the ETAS-type declustering procedure, with the aim of describing long-term stationary seismic background that is not ascribable to coseismic stress perturbations. See also Lombardi and Marzocchi (2010) for a CSEP model as applied to Italy.
3.4 EEPAS and PPE models
The EEPAS and PPE models were contributed by D. Rhoades (2011) to the 3-month and 1-year testing classes for “Mainland.” The “Every Earthquake a Precursor According to Scale” (EEPAS) model is a long-range forecasting method that had previously been applied to a number of regions, including Japan. The model sums up contributions to the rate density from earthquakes in the past on the basis of predictive scaling relations that are derived from the precursory scale increase phenomenon (Rhoades and Evison, 2004). Two features in the earthquake catalog for the Japan’s mainland region make it difficult to apply this model, namely, the magnitude-dependence of the proportion of aftershocks and of the GR b-value. To account for these features, the model was fit separately to earthquakes in three different target magnitude classes over the period 2000–2009 and made suitable to 3-month testing for M ≥ 4 and to 1-year testing for M ≥ 5. The “Proximity to Past Earthquakes” (PPE) model is a spatially smoothed seismic-ity model that could in principle be applied to any testing class. This model has no predictive elements, but it can play the role of a spatially varying reference model against which the performance of time-varying models can be compared. In retrospective analysis, the mean probability gain of the EEPAS model over the PPE model increases with magnitude. The same trend is expected for prospective testing.
3.5 ERS and ETES models
M. Murru, R. Console, and G. Falcone submitted ETES and ERS models to 1-day forecasts in all three testing regions. The two models consider short-term clustering properties of earthquakes. The first is purely stochastic and is called the Epidemic Type Earthquake Sequence (ETES) model, in which the temporal aftershock decay rate is supposed to be governed by an Omori-Utsu law, and the distance decay is supposed to follow a power law. The second kind of short-term forecast (named Epidemic Rate-State: ERS) is constrained physically by the application of Dieterich’s rate-and-state constitutive law (Dieterich, 1994) to earthquake clustering. For the computation of earthquake rates, both of these short-term models assume the validity of the GR distribution. The reader is referred to Console et al. (2007) for a California RELM model and Falcone et al. (2010) for a Italy CSEP model, respectively.
3.6 ETAS model
A variant of the space-time ETAS model, submitted by J. Zhuang (2011) to the 1-day class as applied to “All Japan” is based on the studies of Zhuang et al. (2002, 2004, 2005) and Ogata and Zhuang (2006). The background (spontaneous) seismicity rate varies with location in space but remains constant in time. The model defines two space-time windows to solve the problem of data censoring: events in the smaller “target windows” are used to obtain model parameters, whereas events in the bigger “auxiliary window”, which contains more than one “target window”, are used to calculate triggering effects that contribute to the occurrence of target events. The implementation of this model consists of three steps: (1) the estimation procedure, which is a combination of nonparametric estimation (variable kernel estimation) of the background rate and parametric (maximum likelihood) estimation of model parameters in an iterative manner; (2) the simulation procedure, which simulates thousands of possible scenarios for earthquake occurrence within a future time interval; (3) the smoothing procedure, which smoothes the events generated during the simulation step to obtain more stable spatiotemporal occurrence rates. Because the iterative algorithm for the simultaneous estimation of the background and model parameters involves heavy calculations, off-line optimization and on-line forecasting implementation are used to alleviate the computational costs.
3.7 HIST-ETAS and HIST-POISSON models
A space-time variant of the ETAS model (Ogata, 1998) has been designed for earthquake clustering with a certain space-time function form on the basis of empirical laws for aftershocks. For more accurate seismicity prediction, Y. Ogata (2011) has modified it so that it can deal not only with anisotropic clustering but also with regionally distinct characteristics of seismicity. The former requires the identification of the centroid and correlation coefficient of each spatial cluster, while the latter requires the development of a space-time ETAS model with location-dependent parameters, called a hierarchical space-time ETAS (HIST-ETAS) model. Together with the GR law of magnitude frequencies with location-dependent b-values, the proposed models have been applied to short-term, mid-term, and long-term forecasting. Ogata submitted two slightly different variants of his HIST-ETAS model (HIST-ETAS5pa and HIST-ETAS7pa), plus a Poisson model (HIST-POISSON), based on the background seismicity rate that is used in the HIST-ETAS models. The first two are applied to all testing classes and the last one only to long-term classes (1 and 3 years). All models are applied to the “All Japan” and “Kanto” regions.
3.8 MARFS and MARFSTA models
C. Smyth and J. Mori (2011) have presented a model for forecasting the rate of earthquakes during a specified period and in a specified area. The model explicitly predicts, by applying an autoregressive process, the number of earthquakes and the b-value of the GR distribution for the period of interest. The model also introduces a time dependency adjustment for larger magnitude ranges, assuming that the probability of another large earthquake increases with increasing time after the last large event within the area. These predictions are superimposed on a spatial density map obtained with a multivariate normal mixture model for historical earthquakes that occurred in the area. This forecast model differs from conventional models currently in use because of its density estimation and its assumption of temporal changes. Two variants, one using a base algorithm (MARFS) and the other using its optional adjustment (MARFSTA), have been submitted to the 3-month and 1-year testing classes and applied to the “All Japan” and “Mainland” regions.
3.9 MGR model
Although the frequency-magnitude distribution, as expressed by the GR law, gives a basis for simple methods to forecast earthquakes, F. Hirose and K. Maeda (2011) point out that this distribution can sometimes be approximated by a modified GR law that imposes a maximum magnitude. For their model development, these authors tested three earthquake forecast models: (1) the Cbv (Constant b-value) model, based only on the GR law with a spatially constant b-value; (2) the Vbv (Variable b-value) model, based only on the GR law with regionally variable b-values; (3) the MGR (Modified GR) model, based either on the original or a modified GR law (the choice is made according to the Akaike Information Criterion) with regionally variable b-values. They also incorporated both aftershock decay and minimum limits on expected seismicity in these models. Comparing the results of retrospective forecasts by the three models, Hirose and Maeda found that the MGR model was almost always better than the Vbv model; that the Cbv model was better than the Vbv model for 1-year forecasts; that the MGR and Vbv models tended to be better than the Cbv model for forecasts of ≥3 years. These researchers submitted the MGR-based model to two long-term (1- and 3-years) classes for the “Mainland” region.
3.10 RI model
K. Z. Nanjo (2011) contributed his model to nine categories: three testing classes (3 years, 1 year, and 3 months, respectively) as applied to all three testing regions. His RI algorithm is originally a binary-forecast system based on the working hypothesis that future large earthquakes are more likely to occur at locations of higher seismicity rates. The measure used here is simply to count the number of earthquakes in the past, resulting in the name of the model, i.e., the Relative Intensity (RI) of seismicity (Tiampo et al., 2002; Holliday et al., 2005). To improve its forecasting performance, Nanjo first expanded the RI algorithm so that it can be adapted to a general class of smoothed seismic-ity models. He then converted the RI representation from a binary system to a CSEP-testable model that gives forecasts for the number of earthquakes with prescribed magnitudes. The final submission consists of 36 variants, with four different smoothing representations (smoothing radii of 10, 30, 50, and 100 km, respectively) for each of the nine categories, so that it is possible to see which categories and which smoothing methods can make the most of the RI hypothesis.
3.11 Triple-S-Japan model
The Simple Smoothed Seismicity (Triple-S) model is based on Gaussian smoothing of historical seismicity. Epicenters of past earthquakes are supposed to contribute to earthquake density estimates, after those epicenters have been smoothed using a fixed length scale; this scale is optimized so that it minimizes the average area skill score misfit function in a retrospective experiment (Zechar and Jordan, 2010b). The density map is scaled to match the average rate of historical seismicity. J. Zechar optimized the Triple-S model specifically for Japan and submitted it (called Triple-S-Japan) to nine categories: three testing classes (3 years, 1 year, and 3 months) for all three testing regions. The reader is referred to Zechar and Jordan (2010a) for the CSEP Italy experiment.
4. Discussion
The main characteristic of the current experiment consists in targeting Japan, one of the most seismically active regions in the world. To demonstrate that Japan provides sufficient numbers of observed earthquakes, we have compared seismic activities for the CSEP’s Californian, Italian, and Japanese laboratories. The testing region consists of 7,862 nodes in California and 8,993 nodes in Italy, and both spread down to a depth of 30 km with a spatial resolution of 0.1° × 0.1°. We pay attention to the annual average number of earthquakes per node with magnitudes M ≥ 4.95 because this is the same range that is applied to observed earthquakes in the forecasts of long-term classes in all CSEP laboratories. According to Schorlemmer et al. (2010b), the annual average number of M ≥ 4.95 earthquakes in the California testing region is 6.18. Normalizing this figure by the number of nodes, we obtain an annual average of 6.87 × 10−4 earthquakes per node. For the testing region in Italy, we use data from the Italian Seismic Bulletin, recorded by the Istituto Nazionale di Geofisica e Vulcanologia (INGV) between 16 April 2005 and 31 March 2009. The number of M ≥ 4.95 earthquakes during this period is 4, giving an annual average number of 1.03. Dividing this figure by the number of nodes (8,993), we obtain an annual average of 1.34 × 10−4 earthquakes per node. For the natural laboratory in Japan, we take the “All Japan” testing region and use the JMA catalog from 1 January 1999 to 31 December 2008. During this 10-year period, there were 792 earthquakes of M ≥ 4.95 down to a depth of 100 km, with an average of 79.2 earthquakes per year. Dividing this figure by the number of nodes (20,662), we obtain an annual average of 3.83 × 10−3 earthquakes per node. This figure is approximately 5.6-fold larger than that for California (6.87 × 10−4) and 28.7-fold larger than that for Italy (1.34 × 10−4), underscoring the argument that sufficient numbers of earthquakes are expected to be observed in the Japanese laboratory. Assuming the reader would like to know the seismicity in “All Japan” down to a depth of 30 km in order to fairly compare this with California and Italy: the obtained annual number per node (1.81 × 10−3) is again larger than that for these two regions. We have performed the same analysis for the “Mainland” and “Kanto” regions and obtained annual averages of 1.35x 10−3 and 8.00× 10−3 earthquakes, respectively, per node, where the smaller node spacing of 0.05° × 0.05° for “Kanto” (Fig. 1(c)) was taken into consideration. These figures are again larger than those obtained for the Californian and Italian test fields. While most other CSEP testing regions are using the 5-year testing as a long-term class, a mere 1-year class in Japan is sufficient to obtain stable or at least interesting results.
Prospective testing is the gold standard of model validation and a promising clue to model improvement—however, at the same time, it is time-consuming because moderate to large earthquakes do not occur frequently. To speed up the process of validation and sophistication, trading space for time is a viable alternative: models are tested simultaneously for a number of regions using standardized testing procedures. This was in fact one of the major goals of the international CSEP initiative. Comparison with California and Italy has shown that the experiment in Japan is expected to provide sufficiently large numbers of observed earthquakes, hopefully helping to accelerate the process of validating and sophisticating forecast models.
Another characteristic feature of the current experiment is that multiple models have been submitted to each of the testing categories. While CSEP tests can determine which models have the highest forecasting accuracy, the availability of multiple models presents the possibility to design mixtures of different models that potentially could be more informative than any of the individual forecast models taken alone. Possible mixtures include weighted combinations of individual models, with weights to be assigned to each model according to test results. To date, few mixture models have been designed. Rare examples include two models presented by Rhoades and Gerstenberger (2009): the EEPAS described in Section 3.4 and a Short-Term Earthquake Probability (STEP) forecasting model that applies the Omori-Utsu aftershock-decay relation and the GR relation to clusters of earthquakes. Using the Advanced National Seismic System catalog of Californian earthquakes over the period 1984–2004, these authors found that the optimal mixture model for forecasting earthquakes with M ≥ 5.0 was a convex linear combination of 0.42 part the EEPAS model and 0.58 part the STEP model. This mixture gave an average probability gain of more than 2 compared to each of the individual models. However, designing a mix of more than two models still presents a challenge because the interpretation of test results is not always obvious. To the best of our knowledge, the weights must be assigned in a Bayesian sense. Creating such mixed models will be crucial for developing forecast models with large enough probability gains to have societal impacts. This approach needs to be validated within a CSEP-type framework, where the performance of a given forecasting model can be tested objectively in a verifiable way.
A third feature of note is that a physics-based Coulomb model has been submitted for the first time to the CSEP. Most existing models have generated forecasts using the JMA catalog alone, but the model presented by Toda and Enescu (2011) makes extensive use of the Coulomb failure criterion. Coulomb stress changes are known to be a useful index for explaining the rates and distributions of damaging shocks, and therefore is a promising tool. Support for the utility of the Coulomb criterion comes from a number of applications to California, Japan, and other regions (e.g., Stein et al., 1992; Toda, 2008; Toda et al., 2008). A challenge lies in moving from specific case studies to systematic prospective testing, such as the CSEP’s Japan experiment under well-controlled environments. This is one of the main interests in the Japanese experiment.
In this special issue, there are nine papers that are not directly associated with CSEP forecast models or the testing center, but rather with more general questions of model development and the improvement of different hypotheses on earthquake generation. In these articles, the authors use P-wave velocity structures (Imoto, 2011), seismic quiescence (Nagao et al., 2011), very low-frequency (VLF) events (Ariyoshi et al., 2011 in press), seismicity rates (Yamashina et al., 2011 submitted; Yamashina and Nanjo, 2011 in press), Coulomb stress change (Ishibe et al., 2011), and combined data from GPS monitoring, a seismotectonic zoning map, and active fault maps (Triyoso and Shimazaki, 2011 in press). While these papers point to future directions of model development and improvement, two other papers (Imoto et al., 2011; Okada et al., 2011 in press) may have implications for the current activities of the CSEP as we explain below.
None of the observed earthquake parameters (location, origin time, etc.) can be estimated without uncertainties, and each parameter uncertainty is incorporated in the testing (Schorlemmer et al., 2007). The CSEP and RELM testing suite is computationally expensive because it uses a Monte Carlo approach to take the parameter uncertainties into account. Without sizeable computational resources, it is not possible to perform this type of statistical treatment for large study areas and large numbers of models. Imoto et al. (2011) propose an alternative way, that of using an analytical solution to incorporate the uncertainties of earthquake parameters into the test results. These authors also demonstrate, by comparing a seismicity-based forecast model that uses seismic hazard maps for Japan with the EEPAS model described in Section 3.4, that such an approach is applicable to retrospective testing for central Japan. While their approach has only been applied to a few simple cases, there is a great scientific interest in better understanding the difference between analysis and simulation under more complicated problem settings. Even without verification of complicated situations, however, it should still be worthwhile for a modeler without sufficient computational resources to rely on the analytical approach to evaluate models.
Although the current experiment, which is outlined in this special issue, provides a good representation of earthquake predictability research in Japan, another type of experiment is possible based on the seismicity of Japan. This point is discussed by Okada et al. (2011 in press) who use hundreds of sequences of several to tens of small repeating events with identical waveforms taking place off the east coast of northeastern Japan. Repeating earthquakes are thought to occur on a small asperity along a plate boundary surrounded on all sides by creeping areas (Uchida et al., 2003). These repeaters present a unique opportunity to test earthquake recurrence time models because each event can be defined objectively and also because observed recurrence intervals are typically in the range of 1–4 years, short enough to evaluate model performance. One of the interesting findings is that the timing of repeating earthquakes depend considerably on the time elapsed after the last event, although the dependence became insignificant in the aftermath of the 2008 M = 7.0 earthquake off Ibaraki Prefecture because of a large slow slip event along the plate boundary that was triggered by that earthquake. This type of result could not have been obtained without systematic testing of a large number of samples under a controlled experimental environment, as was done so by Okada et al. (2011 in press). The experiment is not part of the CSEP, but it serves as a good example of alternative types of predictive statements, demonstrating the extensive role that Japan can play as a natural laboratory for earthquake predictability research.
5. Conclusion
The main purpose of this paper is to give a summary of the first earthquake forecast testing experiment for the Japan area conducted within the CSEP framework. It was launched on 1 November 2009. Just as in the case of testing experiments in other CSEP natural laboratories, our approach is a prospective one, in the sense that the performance of every participating forecast model is assessed by a check against earthquakes that occur in the future. Prospective assessment makes the tests more rigorous and objective because the target results are not known when the scientific prediction experiment is launched. This objective approach is useful to efforts for further improving the forecast accuracy of the participating models. This is only the first testing experiment, and more trials are forthcoming. This article does not attempt to pass judgment on individual models. Comparative appraisal and hazard implications of the different models will be discussed by Tsuruoka et al. (2011 submitted) and in future publications for the results of comprehensive analyses.
More importantly, the experiment turns out to be the first occasion for setting up a research environment for rigorous earthquake forecasting in Japan. The aim of the present national prediction program is to make prototype systems that can quantify probabilistic forecasting of future earthquakes through developing and integrating existing streams of research, given the high quality of the Japanese seismic monitoring and energy already invested in Japanese seismology. Little attention was paid to this theme in previous national prediction programs. A fundamental question that we have to address within the current prediction program is how we develop testable forecast models and then evaluate these in terms of their reliability and skill in a community-supported way. We understand that a set of the present testing center and registered models is not the complete answer. However, it does represent a first attempt to find a better solution to the community-endorsed infrastructure standard, which must be improved before the current program is terminated. Thus, we conclude that “Now” is in fact the right time to invest considerably more efforts in related research fields. We consider this paper, and the special issue as a whole, as a description of the first occasion, at least in earthquake predictability research of a rigorous experiment targeted at the Japan area.
References
Ariyoshi, K., T. Matsuzawa, J.-P. Ampuero, R. Nakata, T. Hori, Y. Kaneda, R. Hino, and A. Hasegawa, Migration process of very low-frequency events based on a chain-reaction model and its application to the detection of preseismic slip for megathrust earthquakes, Earth Planets Space, 2011 (in press).
Central Disaster Management Council, Report of the 15th Special Committee on the Earthquake just beneath the Tokyo Metropolis, 25 February, Cabinet Office, Government of Japan, Tokyo, 2005. 25 February,
Console, R., M. Murru, F. Catalli, and G. Falcone, Real time forecasts through an earthquake clustering model constrained by the rate-and- state constitutive law: Comparison with a purely stochastic ETAS model, Seismol. Res. Lett., 78(1), 49–56, doi:10.1785/gssrl.78.1.49, 2007.
Dieterich, J. H., A constitutive law for rate of earthquake production and its application to earthquake clustering, J. Geophys. Res., 99(B2), 2,601–2,618, doi:10.1029/93JB02581, 1994.
Falcone, G., R. Console, and M. Murru, Short-term and long-term earthquake occurrence models for Italy: ETES, ERS and LTST, Ann. Geo-phys., 53(3), 41–50, doi:10.4401/ag-4760, 2010.
Field, E. D., Overview of the working group for the development of Regional Earthquake Likelihood Models (RELM), Seismol. Res. Lett., 78(1), 7–16, doi:10.1785/gssrl.78.1.7, 2007.
Gerstenberger, M. C. and D. A. Rhoades, New Zealand earthquake forecast testing centre, Pure Appl. Geophys., 167(8–9), 877–892, doi:10.1007/ s00024-010-0082-4, 2010.
Gulia, L., S. Wiemer, and D. Schorlemmer, Asperity-based earthquake likelihood models for Italy, Ann. Geophys., 53(3), 63–75, 2010. doi:10.4401/ ag-4843
Gutenberg, B. and C. F. Richter, Frequency of earthquakes in California, Bull. Seismol. Soc. Am., 34(4), 185–188, 1944.
Hirata, N., Past, current and future of Japanese national program for earthquake prediction research, Earth Planets Space, 56, xliii–l, 2004. 10.1186/BF03353075
Hirata, N., Japanese national research program for earthquake prediction, J. Seismol. Soc. Jpn. (Zisin), 61, S591–S601, 2009 (in Japanese with English abstract).
Hirose, F. and K. Maeda, Earthquake forecast models for inland Japan based on the G-R law and the modified G-R law, Earth Planets Space, 63, this issue, 239–260, 2011. 10.5047/eps.2010.10.002, this issue,
Holliday, J. R., K. Z. Nanjo, K. F. Tiampo, J. B. Rundle, and D. L. Turcotte, Earthquake forecasting and its verification, Nonlin. Processes Geophys., 12, 965–977, 2005. 10.5194/npg-12-965-2005
Imoto, M., Performance of a seismicity model for earthquakes in Japan (M ≥ 5.0) based on P-wave velocity anomalies, Earth Planets Space, 63, this issue, 289–299, 2011. 10.5047/eps.2010.06.005, this issue,
Imoto, M., D. A. Rhoades, H. Fujiwara, and N. Yamamoto, Conventional N-, L-, and R-tests of earthquake forecasting models without simulated catalogs, Earth Planets Space, 63, this issue, 275–287, 2011. 10.5047/eps.2010.08.007, this issue,
International Commission on Earthquake Forecasting for Civil Protection, Operational earthquake forecasting: state of knowledge and guidelines for utilization, http://earthquake.usgs.gov/aboutus/nepec/meetings/09Nov_Pasadena/ICEF_ExSum3Oct9_USformat.pdf, 2009.
Ishibe, T., K. Shimazaki, H. Tsuruoka, Y. Yamanaka, and K. Satake, Correlation between Coulomb stress changes imparted by large historical strike-slip earthquakes and current seismicity in Japan, Earth Planets Space, 63, this issue, 301–314, 2011. 10.5047/eps.2011.01.008, this issue,
Jordan, T. H., Earthquake predictability, brick by brick, Seismol. Res. Lett., 77(1), 3–6, doi:10.1785/gssrl.77.1.3, 2006.
Lombardi, A. M. and W. Marzocchi, A double-branching model applied to long-term forecasting of Italian seismicity (M L = 5.0) within the CSEP project, Ann. Geophys., 53(3), 31–39, doi:10.4401/ag-4762, 2010.
Lombardi, A. M. and W. Marzocchi, The double branching model for earthquake forecast applied to the Japanese seismicity, Earth Planets Space, 63, this issue, 187–195, 2011. 10.5047/eps.2011.02.001, this issue,
Marzocchi, W. and A. M. Lombardi, A double branching model for earthquake occurrence, J. Geophys. Res., 113, B08317, doi:10. 1029/2007JB005472, 2008.
Mogi, K., Recent earthquake prediction research in Japan, Science, 233, 324–330, 1986. 10.1126/science.233.4761.324
Nagao, T., A. Takeuchi, and K. Nakamura, A new algorithm for the detection of seismic quiescence: introduction of the RTM algorithm, a modified RTL algorithm, Earth Planets Space, 63, this issue, 315–324, 2011. 10.5047/eps.2010.12.007, this issue,
Nanjo, K. Z., Earthquake forecasts for the CSEP Japan experiment based on the RI algorithm, Earth Planets Space, 63, this issue, 261–274, 2011. 10.5047/eps.2011.01.001, this issue,
Nanjo, K. Z., H. Tsuruoka, S. Toda, and N. Hirata, Research on testing earthquake forecasts based on seismicity: Recent trend in Japan and worldwide, Newslett. Seismol. Soc. Jpn., 20(4), 16–20, 2008 (in Japanese).
Nanjo, K. Z., N. Hirata, and H. Tsuruoka, The first earthquake forecast testing experiment for Japan: Call for forecast models, testing regions, and forecast evaluation methods, http://wwweic.eri.u-tokyo.ac.jp/ZISINyosoku/wiki.en/wiki.cgi?page=Extended+summary, 2009.
Nanjo, K. Z., T. Ishibe, H. Tsuruoka, D. Schorlemmer, Y. Ishigaki, and N. Hirata, Analysis of the completeness magnitude and seismic network coverage of Japan, Bull. Seismol. Soc. Am., 100(6), 3261–3268, doi:10.1785/0120100077, 2010.
Ogata, Y., Space-time point-process models for earthquake occurrences, Ann. Inst. Statist. Math., 50, 379–402, 1998. 10.1023/A:1003403601725
Ogata, Y., Significant improvements of the space-time ETAS model for forecasting of accurate baseline seismicity, Earth Planets Space, 63, this issue, 217–229, 2011. 10.5047/eps.2010.09.001, this issue,
Ogata, Y. and J. Zhuang, Space-time ETAS models and an improved extension, Tectonophysics, 413(1–2), 13–23, 2006. 10.1016/j.tecto.2005.10.016
Okada, M., N. Uchida, and S. Aoki, Statistical forecasts and tests for small interplate repeating earthquakes along the Japan Trench, Earth Planets Space, 2011 (in press).
Research group “Earthquake Forecast System based on Seismicity of Japan”, Earthquake forecast testing experiment for Japan, Newslett. Seismol. Soc. Jpn., 20(6), 7–10, 2009 (in Japanese).
Rhoades, D. A., Application of the EEPAS model to forecasting earthquakes of moderate magnitude in southern California, Seismol. Res. Lett., 78(1), 110–115, 2007. 10.1785/gssrl.78.1.110
Rhoades, D. A., Application of a long-range forecasting model to earthquakes in the Japan mainland teasting region, Earth Planets Space, 63, this issue, 197–206, 2011. 10.5047/eps.2010.08.002, this issue,
Rhoades, D. A. and F. F. Evison, Long-range earthquake forecasting with every earthquake a precursor according to scale, Pure Appl. Geophys., 161, 47–72, 2004. 10.1007/s00024-003-2434-9
Rhoades, D. A. and M. C. Gerstenberger, Mixture models for improved short-term earthquake forecasting, Bull. Seismol. Soc. Am., 99(2A), 636–646, doi:10.1785/0120080063, 2009.
Schorlemmer, D. and M. Gerstenberger, RELM testing center, Seismol. Res. Lett., 78(1), 30–36, doi:10.1785/gssrl.78.1.30, 2007.
Schorlemmer, D., M. Gerstenberger, S. Wiemer, and D. D. Jackson, Earthquake likelihood model testing, Seismol. Res. Lett., 78(1), 17–29, doi: 10.1785/gssrl.78.1.17, 2007.
Schorlemmer, D., A. Christophersen, A. Rovida, F. Mele, M. Stucchi, and W. Marzocchi, Setting up an earthquake forecast experiment in Italy, Ann. Geophys., 53(3), 1–9, doi:10.4401/ag-4844, 2010a.
Schorlemmer, D., J. D. Zechar, M. J. Werner, E. H. Field, D. D. Jackson, T. H. Jordan, and the RELM Working Group, First results of the Regional Earthquake Likelihood Models experiment, Pure Appl. Geo-phys., doi:10.1007/s00024-010-0081-5, 2010b.
Smyth, C. and J. Mori, Statistical models for temporal variations of seis-micity parameters to forecast seismicity rates in Japan, Earth Planets Space, 63, this issue, 231–238, 2011. 10.5047/eps.2010.10.001, this issue,
Stein, R. S., G. C. P. King, and J. Lin, Change in failure stress on the southern San Andreas fault system caused by the 1992 magnitude = 7.4 Landers earthquake, Science, 258, 1328–1332, 1992. 10.1126/science.258.5086.1328
Tiampo, K. F., J. B. Rundle, S. A. McGinnis, S. J. Gross, and W. Klein, Mean-field threshold systems and phase dynamics: An application to earthquake fault systems, Europhys. Lett., 60(3), 481–487, doi:10.1209/epl/i2002-00289-y, 2002.
Toda, S., Coulomb stress imparted by the 25 March 2007 Mw = 6.6 Noto-Hanto, Japan, earthquake explain its ‘butterfly’ distribution of aftershocks and sugget a heightened seismic hazard, Earth Planets Space, 60, 1041–1046, 2008. 10.1186/BF03352866
Toda, S. and B. Enescu, Rate/state Coulomb stress transfer model for the CSEP Japan seismicity forecast, Earth Planets Space, 63, this issue, 171–185, 2011. 10.5047/eps.2011.01.004, this issue,
Toda, S., J. Lin, M. Meghraoui, and R. S. Stein, 12 May 2008 M=7.9 Wenchuan, China earthquake calculated to increase failure stress and seismicity rate on three major fault systems, Geophys. Res. Lett., 35, L17305, doi:10.1029/2008GL034903, 2008.
Triyoso, W. and K. Shimazaki, Testing various seismic potential models for hazard estimation against a historical earthquake catalog in Japan, Earth Planets Space, 2011 (in press).
Tsuruoka, H., N. Hirata, D. Schorlemmer, F. Euchner, K. Z. Nanjo, and T. H. Jordan, CSEP Testing Center and the first results of the earthquake forecast testing experiment in Japan, Earth Planets Space, 2011 (submitted).
Uchida, N., T. Matsuzawa, T. Igarashi, and A. Hasegawa, Interplate qua-sistatic slip off Sanriku, NE Japan, estimated from repeating earthquakes, Geophys. Res. Lett., 30, doi:10.1029/2003GL017452, 2003.
Wessel, P. and W. H. F. Smith, New, improved version of Generic Mapping Tools released, Eos Trans. AGU, 79(47), 579, 1998. 10.1029/98EO00426
Wiemer, S. and D. Schorlemmer, ALM: An asperity-based likelihood model for California, Seismol. Res. Lett., 78(1), 134–140, doi:10. 1785/gssrl.78.1.134, 2007.
Yamashina, K. and K. Z. Nanjo, An improved relative intensity model for earthquake forecast in Japan, Earth Planets Space, 2011 (in press).
Yamashina, K., T. Ishibe, K. Z. Nanjo, and H. Tsuruoka, An improved model for forecasting aftershocks applicable to the current prediction test in Japan, Earth Planets Space, 2011 (submitted).
Zechar, J. D. and T. H. Jordan, Simple smoothed seismicity earthquake forecasts for Italy, Ann. Geophys., 53(3), 99–105, doi:10.4401/ag-4845, 2010a.
Zechar, J. D. and T. H. Jordan, The area skill score statistic for evaluating earthquake predictability experiments, Pure Appl. Geophys., 167(8/9), 893–906, doi:10.1007/s00024-010-0086-0, 2010b.
Zechar, J. D., M. C. Gerstenberger, and D. A. Rhoades, Likelihood-based tests for evaluating space-rate-magnitude earthquake forecasts, Bull. Seismol. Soc. Am., 100(3), 1184–1195, doi:10.1785/0120090192, 2010a.
Zechar, J. D., D. Schorlemmer, M. Liukis, J. Yu, F. Euchner, P. J. Maechling, and T. H. Jordan, The Collaboratory for the Study of Earthquake Predictability perspective on computational earthquake science, Concurrency Comput.: Pract. Exper., 22(12), 1836–1847, doi:10.1002/cpe.1519, 2010b.
Zhuang, J., Next-day earthquake forecasts for the Japan region generated by the ETAS model, Earth Planets Space, 63, this issue, 207–216, 2011. 10.5047/eps.2010.12.010, this issue,
Zhuang, J., Y. Ogata, and D. Vere-Jones, Stochastic declustering of space-time earthquake occurrences, J. Am. Stat. Assoc., 97, 369–380, 2002. 10.1198/016214502760046925
Zhuang, J., Y. Ogata, and D. Vere-Jones, Analyzing earthquake clustering features by using stochastic reconstruction, J. Geophys. Res., 109(B5), B05301, doi:10.1029/2003JB002879, 2004.
Zhuang, J., C.-P. Chang, Y. Ogata, and Y.-I. Chen, A study on the background and clustering seismicity in the Taiwan region by using a point process model, J. Geophys. Res., 110, B05S18, doi:10.1029/2004JB003157, 2005.
Acknowledgments
We thank D. Schorlemmer and F. Euchner for setting up a prototype for the Japanese testing center. We also acknowledge the suggestions of two reviewers (Y. Koshun and J. D. Zechar) who improved the paper. We thank the following colleagues for their contribution to the first earthquake forecast testing experiment: R. Console, B. Enescu, G. Falcone, F. Hirose, A. M. Lombardi, K. Maeda, W. Marzocchi, M. Murru, Y. Ogata, D. Rhoades, D. Schorlemmer, C. Smyth, S. Toda, J. D. Zechar, and J. Zhuang. Discussions with H. Kamogawa, Q. Huang, M. Imoto, T. Ishibe, T. Iwata, S. Matsumura, Y. Nagao, M. Okada, K. Shimazaki, S. Uyeda, and K. Yamashina were beneficial. Maps were created using the Generic Mapping Tools (Wessel and Smith, 1998). This work was conducted under the auspices of the Special Project for Earthquake Disaster Mitigation in Tokyo Metropolitan Area of the Japanese Ministry of Education, Culture, Sports, Science and Technology (MEXT).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
To view a copy of this licence, visit https://creativecommons.org/licenses/by/4.0/.
About this article
Cite this article
Nanjo, K.Z., Tsuruoka, H., Hirata, N. et al. Overview of the first earthquake forecast testing experiment in Japan. Earth Planet Sp 63, 159–169 (2011). https://doi.org/10.5047/eps.2010.10.003
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.5047/eps.2010.10.003