
Abstract
Studies of word production often make use of picture-naming tasks, including the picture-word-interference task. In this task, participants name pictures with superimposed distractor words. They typically need more time to name pictures when the distractor word is semantically related to the picture than when it is unrelated (the semantic interference effect). The present study examines the distributional properties of this effect in a series of Bayesian meta-analyses. Meta-analytic estimates of the semantic interference effect first show that the effect is present throughout the reaction time distribution and that it increases throughout the distribution. Second, we find a correlation between a participant’s mean semantic interference effect and the change in the effect in the tail of the reaction time distribution, which has been argued to reflect the involvement of selective inhibition in the naming task. Finally, we show with simulated data that this correlation emerges even when no inhibition is used to generate the data, which suggests that inhibition is not needed to explain this relationship.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
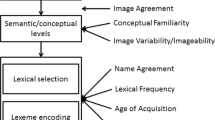
The cognitive processes underlying word production are often assessed using picture-naming tasks. In one such task, the picture-word interference task, participants are asked to name a picture in the presence of a superimposed distractor word (see Fig. 1). Participants typically take longer to name a picture when the distractor word is semantically related to the picture than when the distractor is unrelated (semantic interference effect; e.g., Bürki et al., 2020; Lupker, 1979). Findings from this paradigm have been used to inform a variety of issues, including the relationship between linguistic processes and other cognitive functions (e.g., Shao et al., 2013). Specifically, the distributional properties of the semantic interference effect have been argued to inform the mechanisms underlying the effect and involvement of cognitive abilities, such as attention or inhibition. The current study presents a series of Bayesian meta-analyses targeting different aspects of the distributional properties of the semantic interference effect. Our first aim is to provide estimates of the magnitude of the effect at different points in the distribution. Our second aim is to examine the relationship between the magnitude of the semantic interference effect and the change in effect size in slow response times, a relationship assumed to reflect the involvement of selective inhibition.

Examples of trials in a picture-word-interference task. Participants typically need more time to name the picture in the presence of semantically related distractor words (left) than semantically unrelated distractor words (right)
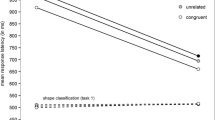
Distributional analyses examine how an experimental effect evolves with the response time distribution (e.g., Balota & Yap, 2011). One way this is examined is by using Vincentile or delta plots (Balota & Yap, 2011). To produce delta plots, reaction times for each trial are first rank ordered per participant and condition and divided into quantiles (percentile bins). Mean reaction times are computed for each condition in each quantile and the difference between the two conditions (delta) is plotted for each quantile, which shows how the effect changes over the response time distribution (see Fig. 2). Studies that have examined distributional properties of the semantic interference effect in this way all agree that semantic interference increases with increasing reaction times (e.g., Roelofs & Piai, 2017). Some studies find the effect across the entire response time distribution; in others, the effect is restricted to the slowest quantiles of the distribution (Scaltritti et al., 2015). This distributional pattern has been related to attention. It has been argued, for example, that lapses of attention generate both longer naming times and greater interference from the distractor word (De Jong et al., 1999; see also discussion in Roelofs, 2008). According to Van Maanen and Van Rijn (2008), an increase in the effect in the tail of the distribution could come from a restricted number of trials where the distractor was wrongly selected as a response, an error that is then corrected so that the correct response can be selected. In the present study, we take advantage of multiple data sets to determine whether the semantic interference effect is present over the entire distribution of response times or restricted to slow responses.

Example distributional patterns of the semantic interference effect calculated over five quantiles. A positive slope between the last two quantiles indicates that the effect increased over the slowest trials (a). A negative slope between the last two quantiles indicates that the interference effect turned into a facilitation effect over the slowest trials (b). Note the difference in scales on the y-axis
In classical conflict tasks such as the Stroop or flanker task, changes in effect size toward the end of the distribution have been related to selective inhibition abilities (Proctor et al., 2011; Ridderinkhof et al., 2004; Ridderinkhof et al., 2005; van den Wildenberg et al., 2010). In such tasks, participants respond to a stimulus on each trial, and some trials provide congruent information, and some provide incongruent information that needs to be inhibited. According to the activation suppression hypothesis, (Ridderinkhof et al., 2004; Ridderinkhof et al., 2005) inhibition takes time to build up, making it more effective in trials with slower reaction times than faster trials. Interference or congruency effects (i.e., the difference in reaction times between incongruent and congruent trials or between incongruent and neutral trials) are expected to increase with reaction times (see Fig. 2a); however, when inhibition is applied, the difference between congruent and incongruent trials tends to decrease with increasing reaction times and can even become negative (i.e., a facilitation effect, Fig. 2b). The slope (or change in effect size) for the last delta segment derived following the delta or Vincentile procedure described above (e.g., the line between the slowest two quantiles in Fig. 2) has been taken as a measure of selective inhibition and has been used with different tasks and populations (e.g., Ridderinkhof et al., 2005). Interestingly for our purposes, studies have applied this procedure to measure individual or group differences in inhibition deployed in the picture-word-interference task when pictures are presented with semantically related or unrelated distractor words.
For example, Shao et al. (2013) found that a participant’s slope of the slowest delta segment was correlated with the magnitude of the semantic interference effect: Participants who had a less positive slope for the slowest delta segment showed a smaller semantic interference effect overall. This finding was replicated and extended to another task (the semantic blocking task) in Shao et al. (2015), and a similar pattern has been found in bilingual participants (Roelofs et al., 2011). These findings were taken to reflect interindividual variability in the ability to apply selective inhibition. According to this view, participants with larger effects are less able to apply selective inhibition than are participants with smaller effects.
In at least one analysis, Shao et al. (2013) observed a similar relationship by item. For this analysis, the mean by-item semantic interference effect was correlated with the change in effect size in the last delta segment, which Shao et al. (2013) took to further confirm the inhibition explanation. In a within-participant design, all participants name all items in both conditions. This finding is therefore interesting because it suggests that differences in inhibition are also visible, for a given participant, across trials.
According to the activation suppression hypothesis, inhibition requires time to build up. Shao et al. (2015) reasoned that under this hypothesis, no correlation should be found with the fastest segment. Shao et al. (2015) found that the slope of the fastest delta plot segment was correlated with the magnitude of the semantic interference effect in one of two picture-word-interference experiments (but not in two experiments using a semantic blocking task). The fact that they saw a relationship with the slope of the slowest delta segment, but not with the fastest (with the exception of the one experiment), was taken to lend support to claims made by the activation suppression hypothesis by Ridderinkhof et al. (2004)—that inhibition takes time to build up and is mostly reflected in the slope of the slowest delta segment. We note that if the effect increases with response times, more power is likely necessary to detect a correlation in earlier segments, where the effect is smaller. More evidence is therefore needed to determine whether only the slope of the slowest delta segment reflects selective inhibition. With a meta-analysis, the chances of detecting even small effects are increased. In the present study, we present meta-analyses of the correlation between the magnitude of the semantic interference effect and the increase in effect size in the first and last delta segments.
Meta-analyses
We report several meta-analyses (see Table 1) examining the distributional properties of the semantic interference effect. In all studies included in the meta-analysis, participants performed a picture-word-interference task: They named pictures while ignoring distractors either semantically related or unrelated to the target. Meta-analyses provide information on the reliability of a pattern across data sets and provide estimates of effect sizes and their uncertainty. On top of informing theoretical issues, estimates of effect sizes and of uncertainty are useful to calculate power for subsequent studies.
Our first set of meta-analyses tests whether the semantic interference effect is present across the whole reaction time distribution or only in the slower portion, and it provides estimates of the effect for different parts of the distribution. Our second set of meta-analyses provides estimates of the correlation between the mean effect size of the semantic interference effect and the effect size in the slowest and fastest segments, both by participant and by item.
To anticipate, our analyses provide evidence that the semantic interference effect is present over the entire distribution and increases with response times. They also confirm the correlation between effect size and slowest as well as fastest segments, both by participant and by item. These results lead us to consider an alternative account of this relationship, which we examine using simulations.
Methods
Data set
We worked with a subset of data collected for a previous meta-analysis of the semantic interference effect (Bürki et al., 2020). We selected all the studies for which we had the raw data (a response time for each trial) and that had a stimulus onset asynchrony (SOA) between −160 and 160 ms. Several studies have reported semantic interference effects in this SOA range (e.g., Damian & Martin, 1999; Glaser & Düngelhoff, 1984; Starreveld & La Heij, 1996), a pattern supported by a recent meta-analysis (Bürki et al., 2020). We included two additional data sets that were recently collected from our lab.
Participants in all studies were adult native speakers of the language being tested, and they did not have language disorders. Languages tested in the various studies included German, English, French, Italian, Dutch, Spanish, and Mandarin. Only trials with distractor items that were semantically related or unrelated to the target picture were considered. Multiple experiments within a paper were treated as independent data sets. Experiments where the same items were tested at different SOAs or with and without familiarization were split to generate one data set for each level of these variables. This resulted in a total of 54 data sets from 22 different experiments. More details on these studies can be found in Appendix 2.
Extraction of estimates
Only correct responses were included in the analyses. Reaction time data were first separated by participant and condition (semantically related or unrelated trials). Reaction times were then sorted and divided into quantiles and the mean difference between conditions for each quantile was computed. We used five quintiles (i.e., 20% bins) as in Shao et al. (2013) and Shao et al. (2015). A total of nine participants from all data sets were eliminated because they did not have enough data points to calculate quantiles.
Estimates of semantic interference in each quintile
For each study, we fit a linear mixed-effects model using the lme4 package (Bates et al., 2015) in R (R Core Team, 2020). Each model predicted naming latencies (the dependent variable) and included fixed effects of quintile (1–5), and condition (deviation coded, semantically related = .5, semantically unrelated = −.5), which was nested within quintile. Nested fixed effects allow us to test for simple effects (Schad et al., 2020), and in this case, we were interested in testing the difference in reaction times between semantically related and unrelated conditions at each level of the factor quintile (i.e., in each quintile separately). Random effects included by-participant random intercepts and slopes for quintile and by-participant random intercepts and slopes for condition, which were nested within quintile. Item random effects included by-item random intercepts and slopes for quintile and random intercepts and slopes for condition, which were nested within quintile. Correlations between random effects were set to zero.
Estimates of correlations
We first calculated the mean semantic interference effect as well as the slope for the slowest delta segment (i.e., the slope between quintiles four and five) and fastest delta segments (the slope between quintiles one and two) for each participant. We followed the procedure in, for example, De Jong et al. (1994), Ridderinkhof et al. (2004), Roelofs et al. (2011), and Shao et al. (2013) to calculate the slope as follows:
slope(quintile 4, quintile 5) = (delta(quintile 5) − delta(quintile 4))/(mean(quintile 5) − mean(quintile 4))
For each study, we computed the correlation between the slope of the slowest delta segment and the mean semantic interference effect and also for the slope of the fastest delta segment and the mean semantic interference effect. We then used the Fisher z-transformation to transform correlation coefficients (r values) to z values (Fisher, 1915) using the FisherZ function from the DescTools package (Signorell et al., 2020) in R. The z-transformed scores and their estimated standard error were entered into the meta-analyses described below. The whole process was repeated for by-item analyses.
Meta-analyses
Meta analyses estimate the size and uncertainty of an effect in question from the effect sizes and standard errors of individual studies. Both fixed-effects and random-effects meta-analyses can be performed, but they make different assumptions. Fixed-effects meta-analyses assume that all studies have the same true effect θ (e.g., Chen & Peace, 2013), but random-effects meta-analyses assume that the different studies have different true effects θi (e.g., Sutton & Abrams, 2001). Each of the studies included in our data set was performed in different languages and in different labs; therefore, we assume a different underlying effect for each study and thus performed a random-effects meta-analysis.
For meta-analyses testing the magnitude of the semantic interference effect in each quintile, we made the following assumptions: Each study i has a true effect of θi that is normally distributed with a mean of θ and a variance of τ2 = 1002. The observed effect of the predictor yi in each study is assumed to stem from a normal distribution with mean θi and variance \({\sigma}_i^2\), the true standard error of the study. Details of the model specifications can be found in Equations (1).
yi represents the observed effect of the predictor in each study i; θ is the true effect of the predictor estimated by the model; \({\sigma}_i^2\) represents the variance for study i, estimated from the standard error of the effect of the predictor for this study; and τ2 represents the between-study variance.
For the meta-analyses testing the magnitude of the semantic interference effect in each quintile, we chose weakly informative priors from a normal distribution with a mean of zero and a standard deviation of 100. For the standard deviation, we chose weakly informative priors from a truncated normal distribution with a mean of zero and a standard deviation of 100.
For the meta-analyses of correlations (note that the meta-analysis is performed on the Fisher z-transformed correlations: assumptions and prior pertain to the z-transformed score), we assumed the following: Each study i has a true z-transformed correlation of ζi that is normally distributed with a mean of ζ and a variance of τ2 = 102. The observed z-transformed correlation zi in each study is assumed to stem from a normal distribution with mean ζi and variance \({\upphi}_i^2\), the true standard error of the study. Details of the model specifications can be found in Equations (2).
zi represents the observed z-transformed correlation in each study i; ζ is the true z-transformed correlation estimated by the model; \({\upphi}_i^2\) represents the standard error for this study; and τ2 represents the between-study variance.
For the intercept and standard deviation for meta-analyses of correlations, we chose weakly informative priors from a normal distribution with a mean of zero and a standard deviation of 10. For the standard deviation, we chose weakly informative priors from a truncated normal distribution with a mean of zero and a standard deviation of 10.
We additionally did sensitivity analyses for each meta-analysis. Effect sizes did not change with different priors for any of the meta-analyses, and details on sensitivity analyses can be found in Appendix 16. We also did Bayes factor tests to test whether we have relative evidence for the effect (the alternative hypothesis) over the null hypothesis. Bayes factors of one indicate no evidence, and Bayes factors greater than 10 or less than 1/10 are typically considered to reflect “substantial evidence” for one model over the other (e.g., Wetzels & Wagenmakers, 2012). Meta-analyses were performed in R (R Core Team, 2020) with the brms package (Bürkner, 2018). Data and analysis code can be found on our OSF page (https://osf.io/v2fx5/).
Results
Results of the meta-analyses are summarized in Tables 2, 3 and 4. Meta-analytic estimates, their 95% credible intervals (CrI), tau (between-study standard deviation), and Bayes factors in favor of the alternative hypothesis (BF10) are reported.
Discussion
Our analyses suggest that the semantic interference effect increases with response times.Footnote 1 Several mechanisms have been put forward to explain this increase—for example, fluctuations of attention (Roelofs & Piai, 2017; Scaltritti et al., 2015), selection of wrong responses (Van Maanen & Van Rijn, 2008), or differences in temporal alignment between the processing of the distractor and the encoding of the target word (Bürki & Madec, accepted for publication). We further found that the effect is indeed present even at the fastest response times (the first quintile of the distribution), which suggests that the effect is not solely due to trials where participants selected the wrong response. Using a computational model and a behavioral experiment in which attention was manipulated, San José et al. (2021) attributed the differences in results between Roelofs and Piai (2017) and Scaltritti et al. (2015) to between-study differences lapses of attention. As San José et al. (2021) discuss, characteristics of the experiment such as the rate of stimulus presentation, number of item repetitions, or properties of the items may influence how attentive participants are to the task. Here, we show that the general pattern across many studies (without a direct manipulation of attention) is that the effect is present at the fastest reaction times. The small size of this effect in the first quintile (6 ms) may also contribute to between-study variability: It is unsurprising that some studies have not found this very small effect, as it will likely require a much larger sample size to detect it.
Interestingly, the increase in the effect size increases with each quintile, with increases of 5 ms, 6 ms, 10 ms, and 21 ms, respectively. At first sight, this pattern does not seem to fit well with the hypothesis that at least a subset of participants applies more inhibition in the slower quintiles. However, we cannot rule out the possibility that without inhibition, the increase in the magnitude of the effect in the last two quintiles would have been even greater.
The next meta-analysis showed that participants’ slopes of the slowest delta segment are positively correlated with the magnitude of their semantic interference effects. This is in line with the hypothesis that participants who apply less inhibition during the task as indexed by a steeper, more positive slope, show larger semantic interference effects. Our analyses confirm the same correlation when we calculated quintiles by item instead of by participant. In a within-item design, each participant names both related and unrelated trials for the same pictures. As a consequence, this correlation cannot only be due to an individual-specific ability to apply inhibition but suggests that the slope of the last delta segment also captures intra-individual variability in selective inhibition.
We additionally found a correlation between the semantic interference effect and the fastest delta segment. According to the activation suppression hypothesis, inhibition takes time to build up, which is why the slope of the slowest delta segment is typically used to index inhibition (e.g., Ridderinkhof et al., 2004). Although we found a positive relationship between the slope of the fastest delta segment and the semantic interference effect, it was smaller than the size of the correlation with the slowest delta segment. It is possible that with higher-powered studies or with a meta-analysis, we will see that delta slopes start leveling off much earlier. We note that this finding is not necessarily inconsistent with the activation suppression hypothesis because the effect size of the relationship with the slowest delta segment slope was larger than with the fastest segment. It could be argued that inhibition takes time to build up, but this does not mean that it is completely absent at shorter response times. Shorter response times likely correspond to words that can be named much more quickly, and in the time course of word production, on some trials, inhibition had already had time to build up (response times ranged from 400 to 2,000 ms).
In the following paragraphs, we consider an alternative explanation to these correlations. Notably, the data in the last (or first) two quantiles are used in both the computation of the mean effect size for the participant (or item) and the computation of the slope of each delta segment. In other words, a correlation may be expected even in the absence of inhibition simply because some of the same data are used to compute the two measures that are then correlated with one another. Moreover, given the increase in effect size throughout the response time distribution, the correlation can be expected to be higher for delta segments where the effect is larger. As the semantic interference effect becomes greater between the last two quintiles, participants who show less of an effect overall could be expected to show less of an increase in the last two quintiles, irrespective of whether they deploy inhibition or not. The question therefore arises as to whether these correlations reflect something in addition to this, or whether they are only a by-product of circularity in the procedure.Footnote 2 We address this question with simulated data.

Posterior distributions of meta-analytic estimates of the semantic interference effect in each quintile. Quintiles were calculated by participant

Posterior distributions of meta-analytic estimates (Fisher z-transformed correlations) of the relationship between the semantic interference effect and the slope of the fastest delta segment (a) and the semantic interference effect and the slope of the slowest delta segment (b). Quintiles were calculated by participant

Posterior distributions of meta-analytic estimates (Fisher z-transformed correlations) of the relationship between the semantic interference effect and the slope of the fastest delta segment (a) and the semantic interference effect and the slope of the slowest delta segment (b). Quintiles were calculated by items rather than participants

Correlations from simulated data between the mean semantic interference effect and the slope of the slowest delta segment (participants; a), slope of the fastest delta segment (participants; b), slope of the slowest delta segment (items; c), and slope of the fastest delta segment (items; d)
Simulations
The mechanistic explanation assumes that the increase in effect size with response times combined with the fact that the data in the last two quantiles are used twice in the correlation suffices to generate the correlations we observe. The inhibition account assumes that there is an additional mechanism at play (the application of inhibition on some trials/by some participants). In the first account, negative slopes are due to natural variation, whereas in the inhibition account, they are due to an additional mechanism of inhibition. The goal here is to simulate data under the assumption that no inhibition was applied to test whether the patterns we see in the meta-analysis are due to something more than what we would expect from distributional properties of the semantic interference effect alone.
Methods
We chose to simulate data generated from an ex-Gaussian distribution. An ex-Gaussian distribution is a convolution of a normal and an exponential distribution and provides a good fit to most reaction time data (Balota & Yap, 2011). Ex-gaussian distributions consist of three parameters: μ, σ, and τ. μ and σ represent the mean and standard deviation of the normal portion of the distribution, respectively, and τ represents the mean of the exponential portion of the distribution. As we demonstrated in the first set of meta-analyses, the size of the semantic interference effect increases throughout the response time distribution, a pattern that is produced when the variance of the slower condition (in this case, semantically related trials) is set to be larger than the variance of the faster condition (unrelated trials, Bürki & Madec, accepted for publication; Pratte et al., 2010; J. Zhang & Kornblum, 1997). We therefore simulated data with greater variance in the slower condition. The code to reproduce the simulations can be found on our OSF page (https://osf.io/v2fx5/).
Data generation
We simulated data to mimic a well-powered picture-word-interference experiment with 100 participants, 50 items, and two within-participant and within-item conditions (semantically related and unrelated distractors; see Bürki et al., 2020, for power analyses for this experimental design). To obtain realistic ex-Gaussian parameter estimates, we pooled data from the studies used in the meta-analyses and estimated the ex-Gaussian parameters for each condition (related and unrelated) separately using the mexgauss() function in the retimes package (Massidda, 2013). We obtained the following estimates for the related condition in milliseconds: μ = 578, σ = 68, and τ = 219; and for the unrelated condition: μ = 570, σ = 53, and τ = 202. Ex-Gaussian distributions were simulated for each condition separately with these parameters, and by-participant random intercept adjustments, by-item random intercept adjustments, and residual error were added to the μ parameter for each simulated trial. Random by-participant intercept adjustments were generated from a normal distribution with a mean of zero and a standard deviation of 100, by-item random intercepts were generated from a normal distribution with a mean of zero and a standard deviation of 70 (estimated from a previous data set, Fuhrmeister et al., under review), and residual error was generated from a normal distribution with a mean of zero and a standard deviation of 100.
Analysis approach
For each participant and item of the simulated data, we calculated the slope of the first and last delta segments as described in the meta-analyses, and we correlated these values with the mean interference effect for participants and items.
Results
Results of the simulated correlations are summarized in Table 5 and depicted in Fig. 6.
The stimulated data suggest that even when we assume no mechanism of inhibition, a similar pattern of correlations emerges between the mean semantic interference effect and the slope of the fastest and slowest delta segments. As can be seen in Fig. 6, we additionally see some negative slopes, even when we assume no mechanism of inhibition.
Discussion
The correlation between the slowest delta segment and the mean semantic interference effect has been argued to reflect individual differences in the ability to deploy inhibition. However, we showed with simulated data that this relationship is found even when no inhibition is assumed (i.e., when participants did not generate the data), suggesting an inhibition account is not needed to explain this relationship. To be clear, we have not demonstrated that inhibition is not involved in the picture-word-interference task, nor that the slope of the last delta segment does not reflect inhibition. We have simply demonstrated that the correlation between the mean interference effect and the delta segments can also be produced from simulated ex-Gaussian distributions, in which the sigma and tau parameters are larger for the slower condition (see also Bürki & Madec, 2021; Pratte et al., 2010; J. Zhang & Kornblum, 1997).
It is a reasonable assumption that inhibition is involved in a picture-word-interference task. To conclude that the slope of the last delta segment reflects inhibition in picture-naming tasks, we would need some evidence that is not taken from a correlation with some of the same response times. Shao et al. (2014) provide such evidence in a study in which they asked participants to name pictures with low and high name agreement (the number of different names people assign to an object). The authors reasoned that pictures with low name agreement, for which many potential candidate names would be activated, should require more inhibition than pictures with high name agreement, which have fewer or maybe only one possible name. They calculated delta slopes for this task and found that for action words, but not object words, these correlated with the difference in amplitude of the electrophysiological component N2 between high and low agreement words, and the N2 is thought to index inhibition. This was taken as evidence that delta slopes in picture-naming tasks reflect inhibition. This correlation suggests that the last delta segment may indeed reflect inhibition—note, however, that this reasoning implies that the difference in the N2 between conditions reflects a measure that is independent of the reaction time difference between the two conditions. In any case, our simulations suggest that the correlation between the slope of the last delta segment and the mean semantic interference effect is there regardless of inhibition.
Notes
We additionally confirmed this increase with a Bayes factor test. To do this, we computed the meta-analytic estimate of the interaction between quantile (1–5) and the semantic interference effect and compared this to a null model (BF10 = 291048962304).
A reviewer mentioned that an argument against a purely mechanistic account is the fact that some participants show a negative slope in the last delta segment or negative deltas in the last quintile, such as in Shao et al. (Shao et al., 2013, e.g., Fig. 3; Shao et al., 2015, p. 1812). In the context of the selective inhibition account, negative slopes signal a greater amount of inhibition. We note, however, that negative slopes are also expected under the mechanistic account. Most experimental effects in the language production literature, and this is also true for the semantic interference effect, show variability across participants (as can be seen in the variance associated with by-participant random slopes). As a result, a subset of participants shows no effect; another subset shows effects in the other direction. Here, many participants with negative slopes have a negative effect or close to no effect. Again, if the effect is most visible in slower quantiles, it is expected that participants with no or negative effects overall will show flat or negative slopes. Notably, however, if a subset of participants with negative slopes are expected under a mechanistic account, the present data do not allow us to determine whether these are also partly driven by the application of inhibition. In order to shed light on this issue, we conducted simulations.
References
Aristei, S., & Abdel Rahman, R. (2013). Semantic interference in language production is due to graded similarity, not response relevance. Acta Psychologica, 144(3), 571–582. https://doi.org/10.1016/j.actpsy.2013.09.006
Aristei, S., Melinger, A., & Abdel Rahman, R. (2011). Electrophysiological chronometry of semantic context effects in language production. Journal of Cognitive Neuroscience, 23(7), 1567–1586. https://doi.org/10.1162/jocn.2010.21474
Balota, D. A., & Yap, M. J. (2011). Moving beyond the mean in studies of mental chronometry: The power of response time distributional analyses. Current Directions in Psychological Science, 20(3), 160–166. https://doi.org/10.1177/0963721411408885
Bates, D. Maechler, M., Bolker, B., & Walker, S. (2015). Fitting linear mixed-effects models using lme4. Journal of Statistical Software, 67(1), 1–48. https://doi.org/10.18637/jss.v067.i01
Bürki, A., & Madec, S. (accepted for publication). Picture-word interference in language production studies: Exploring the roles of attention and processing times. Journal of Experimental Psychology: Learning, Memory & Cognition.
Bürki, A., Elbuy, S., Madec, S., & Vasishth, S. (2020). What did we learn from forty years of research on semantic interference? A Bayesian meta-analysis. Journal of Memory and Language, 114, Article 104125.
Bürkner, P. C. (2018). Advanced Bayesian multilevel modeling with the R Package brms. The R Journal 10 (1), 395–411.
Chen, D. G. D., & Peace, K. E. (2013). Applied meta-analysis with R. CRC Press.
Cutting, J. C., & Ferreira, V. S. (1999). Semantic and phonological information flow in the production lexicon. Journal of Experimental Psychology: Learning, Memory, and Cognition, 25(2), 318.
Damian, M. F., & Bowers, J. S. (2003). Locus of semantic interference in picture-word interference tasks. Psychonomic Bulletin & Review, 10(1), 111–117. https://doi.org/10.3758/BF03196474
Damian, M. F., & Martin, R. C. (1999). Semantic and phonological codes interact in single word production. Journal of Experimental Psychology: Learning, Memory, and Cognition, 25(2), 345–361. https://doi.org/10.1037//0278-7393.25.2.345
Damian, M. F., & Spalek, K. (2014). Processing different kinds of semantic relations in picture-word interference with non-masked and masked distractors. Frontiers in Psychology, 5. https://doi.org/10.3389/fpsyg.2014.01183
De Jong, R., Liang, C. C., & Lauber, E. (1994). Conditional and unconditional automaticity: A dual-process model of effects of spatial stimulus-response correspondence. Journal of Experimental Psychology: Human Perception and Performance, 20(4), 731.
De Jong, R., Berendsen, E., & Cools, R. (1999). Goal neglect and inhibitory limitations: Dissociable causes of interference effects in conflict situations. Acta Psychologica, 101(2/-3), 379–394.
de Zubicaray, G. I., Hansen, S., & McMahon, K. L. (2013). Differential processing of thematic and categorical conceptual relations in spoken word production. Journal of Experimental Psychology. General, 142(1), 131–142. https://doi.org/10.1037/a0028717
Finocchiaro, C., & Navarrete, E. (2013). About the locus of the distractor frequency effect: Evidence from the production of clitic pronouns. Journal of Cognitive Psychology, 25(7), 861–872. https://doi.org/10.1080/20445911.2013.832254
Fisher, R. A. (1915). Frequency distribution of the values of the correlation coefficient in samples from an indefinitely large population. Biometrika, 10(4), 507-521.
Fuhrmeister, P., Madec, S., Lorenz, A., Elbuy, S., & Bürki, A. (under review). Behavioural and EEG evidence for inter-individual variability in late encoding stages of word production.
Gauvin, H. S., Jonen, M. K., Choi, J., McMahon, K., & Zubicaray, G. I. de. (2018). No lexical competition without priming: Evidence from the picture–word interference paradigm. Quarterly Journal of Experimental Psychology, 71(12), 2562–2570. https://doi.org/10.1177/1747021817747266
Glaser, W. R., & Düngelhoff, F.-J. (1984). The time course of picture-word interference. Journal of Experimental Psychology: Human Perception and Performance, 10(5), 640–654. https://doi.org/10.1037/0096-1523.10.5.640
Hartendorp, M. O., Van der Stigchel, S., & Postma, A. (2013). To what extent do we process the nondominant object in a morphed figure? Evidence from a picture–word interference task. Journal of Cognitive Psychology, 25(7), 843–860.
Hutson, J., & Damian, M. F. (2014). Semantic gradients in picture-word interference tasks: Is the size of interference effects affected by the degree of semantic overlap? Frontiers in Psychology, 5. https://doi.org/10.3389/fpsyg.2014.00872
Janssen, N., Schirm, W., Mahon, B. Z., & Caramazza, A. (2008). Semantic interference in a delayed naming task: Evidence for the response exclusion hypothesis. Journal of Experimental Psychology: Learning, Memory, and Cognition, 34(1), 249–256. https://doi.org/10.1037/0278-7393.34.1.249
Lupker, S. J. (1979). The semantic nature of response competition in the picture-word interference task. Memory & Cognition, 7(6), 485–495. https://doi.org/10.3758/BF03198265
Mädebach, A., Oppermann, F., Hantsch, A., Curda, C., & Jescheniak, J. D. (2011). Is there semantic interference in delayed naming? Journal of Experimental Psychology: Learning, Memory, and Cognition, 37(2), 522–538. https://doi.org/10.1037/a0021970
Massidda, D. (2013). retimes: Reaction Time Analysis (R Package Version 0.1-2) [Computer software]. https://CRAN.R-project.org/package=retimes
Piai, V., Roelofs, A., & Schriefers, H. (2012). Distractor strength and selective attention in picture-naming performance. Memory & Cognition, 40(4), 614–627. https://doi.org/10.3758/s13421-011-0171-3
Piai, V., Roelofs, A., Jensen, O., Schoffelen, J.-M., & Bonnefond, M. (2014). Distinct Patterns of brain activity characterise lexical activation and competition in spoken word production. PLoS One, 9(2), Article e88674. https://doi.org/10.1371/journal.pone.0088674
Pratte, M. S., Rouder, J. N., Morey, R. D., & Feng, C. (2010). Exploring the differences in distributional properties between Stroop and Simon effects using delta plots. Attention, Perception, & Psychophysics, 72(7), 2013-2025. https://doi.org/10.3758/APP.72.7.2013
Proctor, R. W., Miles, J. D., & Baroni, G. (2011). Reaction time distribution analysis of spatial correspondence effects. Psychonomic Bulletin & Review, 18(2), 242–266.
R Core Team (2020). R: A language and environment for statistical computing. R Foundation for Statistical Computing. https://www.R-project.org/
Ridderinkhof, K. R., van den Wildenberg, W. P., Wijnen, J., & Burle, B. (2004). Response inhibition in conflict tasks is revealed in delta plots. Cognitive neuroscience of attention, 369, 377.
Ridderinkhof, K. R., Scheres, A., Oosterlaan, J., & Sergeant, J. A. (2005). Delta plots in the study of individual differences: new tools reveal response inhibition deficits in AD/HD that are eliminated by methylphenidate treatment. Journal of Abnormal Psychology, 114(2), 197.
Rodríguez-Ferreiro, J., Davies, R., & Cuetos, F. (2014). Semantic domain and grammatical class effects in the picture–word interference paradigm. Language, Cognition and Neuroscience, 29(1), 125–135. https://doi.org/10.1080/01690965.2013.788195
Roelofs, A. (2008). Dynamics of the attentional control of word retrieval: Analyses of response time distributions. Journal of Experimental Psychology: General, 137(2), 303.
Roelofs, A., & Piai, V. (2017). Distributional analysis of semantic interference in picture naming. Quarterly Journal of Experimental Psychology, 70(4), 782-792.
Roelofs, A., Piai, V., & Garrido Rodriguez, G. (2011). Attentional inhibition in bilingual naming performance: evidence from delta-plot analyses. Frontiers in Psychology, 2, 184.
Sailor, K., Brooks, P. J., Bruening, P. R., Seiger-Gardner, L., & Guterman, M. (2009). Exploring the time course of semantic interference and associative priming in the picture–word interference task: Quarterly Journal of Experimental Psychology. https://doi.org/10.1080/17470210802254383
San José, A., Roelofs, A., & Meyer, A. S. (2021). Modeling the distributional dynamics of attention and semantic interference in word production. Cognition, 211, Article 104636. https://doi.org/10.1016/j.cognition.2021.104636
Scaltritti, M., Navarrete, E., & Peressotti, F. (2015). Distributional analyses in the picture–word interference paradigm: Exploring the semantic interference and the distractor frequency effects. The Quarterly Journal of Experimental Psychology, 68(7), 1348–1369. https://doi.org/10.1080/17470218.2014.981196
Schad, D. J., Vasishth, S., Hohenstein, S., & Kliegl, R. (2020). How to capitalize on a priori contrasts in linear (mixed) models: A tutorial. Journal of Memory and Language, 110, Article 104038.
Shao, Z., Meyer, A. S., & Roelofs, A. (2013). Selective and nonselective inhibition of competitors in picture naming. Memory & Cognition, 41(8), 1200–1211.
Shao, Z., Roelofs, A., Acheson, D. J., & Meyer, A. S. (2014). Electrophysiological evidence that inhibition supports lexical selection in picture naming. Brain Research, 1586, 130–142.
Shao, Z., Roelofs, A., Martin, R. C., & Meyer, A. S. (2015). Selective inhibition and naming performance in semantic blocking, picture-word interference, and color–word Stroop tasks. Journal of Experimental Psychology: Learning, Memory, and Cognition, 41(6), Article 1806.
Signorell, A., et al. (2020). DescTools: Tools for descriptive statistics (R Package Version 0.99.38) [Computer software]. https://cran.r-project.org/web/packages/DescTools/index.html
Starreveld, P. A., & La Heij, W. (1996). Time-course analysis of semantic and orthographic context effects in picture naming. Journal of Experimental Psychology: Learning, Memory, and Cognition, 22(4), 896–918. https://doi.org/10.1037/0278-7393.22.4.896
Starreveld, P. A., La Heij, W., Verdonschot, R. (2013) Time course analysis of the effects of distractor frequency and categorical relatedness in picture naming: An evaluation of the response exclusion account. Language and Cognitive Processes 28(5) 633–654. https://doi.org/10.1080/01690965.2011.608026
Sutton, A. J., & Abrams, K. R. (2001). Bayesian methods in meta-analysis and evidence synthesis. Statistical Methods in Medical Research, 10(4), 277–303.
van Den Wildenberg, W. P., Wylie, S. A., Forstmann, B. U., Burle, B., Hasbroucq, T., & Ridderinkhof, K. R. (2010). To head or to heed? Beyond the surface of selective action inhibition: a review. Frontiers in Human Neuroscience, 4, 222.
Van Maanen, L., & Van Rijn, H. (2008). The picture-word interference effect is a Stroop effect after all. Proceedings of the Annual Meeting of the Cognitive Science Society, 30(30).
Vieth, H. E., McMahon, K. L., & de Zubicaray, G. I. (2014). The roles of shared vs. Distinctive conceptual features in lexical access. Frontiers in Psychology, 5.https://doi.org/10.3389/fpsyg.2014.01014
Wetzels, R., & Wagenmakers, E. J. (2012). A default Bayesian hypothesis test for correlations and partial correlations. Psychonomic Bulletin & Review, 19(6), 1057–1064. https://doi.org/10.3758/s13423-012-0295-x
Zhang, J., & Kornblum, S. (1997). Distributional analysis and De Jong, Liang, and Lauber's (1994)dual-process model of the Simon effect. Journal of Experimental Psychology: Human Perception and Performance, 23(5), 1543. https://doi.org/10.1037/0096-1523.23.5.1543
Zhang, Q., Feng, C., Zhu, X., & Wang, C. (2016). Transforming semantic interference into facilitation in a picture–word interference task. Applied PsychoLinguistics, 37(5), 1025-1049.
Acknowledgements
The authors would like to thank all the authors who shared their data sets. This research was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation)—project number 317633480 – SFB 1287, Project B05 (Bürki).
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Open practices statement
The data and materials for all experiments are available at https://osf.io/v2fx5/, and the analyses were not preregistered.
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1. Sensitivity analyses
1. Magnitude of the semantic interference effect in first quintile | |||||
Prior | Estimate in ms | 95% CrI | tau | 95% CrI | BF10 |
normal(0, 200) | 6 | [4, 8] | 3 | [0, 7] | 294 |
uniform(−200, 200) | 6 | [4, 8] | 3 | [0, 7] | 365 |
normal(0, 50) | 6 | [4, 8] | 3 | [0, 7] | 1169 |
2. Magnitude of the semantic interference effect in second quintile | |||||
Prior | Estimate in ms | 95% CrI | tau | 95% CrI | BF10 |
normal(0, 200) | 11 | [8, 14] | 6 | [3, 9] | 11245248 |
uniform(−200, 200) | 11 | [8, 14] | 6 | [3, 9] | 14182916 |
normal(0, 50) | 11 | [8, 14] | 6 | [3, 9] | 43744919 |
3. Magnitude of the semantic interference effect in third quintile | |||||
Prior | Estimate in ms | 95% CrI | tau | 95% CrI | BF10 |
normal(0, 200) | 17 | [13, 21] | 10 | [7, 14] | 1011365624 |
uniform(−200, 200) | 17 | [13, 21] | 10 | [7, 14] | 1276973848 |
normal(0, 50) | 17 | [13, 21] | 10 | [7, 14] | 3801047197 |
4. Magnitude of the semantic interference effect in fourth quintile | |||||
Prior | Estimate in ms | 95% CrI | tau | 95% CrI | BF10 |
normal(0, 200) | 27 | [21, 32] | 15 | [11, 20] | 189255695890 |
uniform(−200, 200) | 27 | [21, 32] | 15 | [11, 20] | 239038151769 |
normal(0, 50) | 27 | [21, 32] | 15 | [11, 20] | 660001055163 |
5. Magnitude of the semantic interference effect in fifth quintile | |||||
Prior | Estimate in ms | 95% CrI | tau | 95% CrI | BF10 |
normal(0, 200) | 49 | [39, 58] | 21 | [12, 32] | 131974119264 |
uniform(−200, 200) | 49 | [39, 58] | 22 | [12, 32] | 170870439222 |
normal(0, 50) | 48 | [39, 58] | 21 | [12, 32] | 338676295050 |
6. Correlation between the magnitude of the semantic interference effect and the slowest delta plot segment (participant analysis) | |||||
Prior | Estimate in ms | 95% CrI | tau | 95% CrI | BF10 |
uniform(−3, 3) | 0.52 | [0.44, 0.6] | 0.23 | [0.16, 0.31] | 462984688776847 |
uniform(−10, 10) | 0.52 | [0.44, 0.6] | 0.23 | [0.16, 0.31] | 138850859865120 |
7. Correlation between the magnitude of the semantic interference effect and the fastest delta plot segment (participant analysis) | |||||
Prior | Estimate in ms | 95% CrI | tau | 95% CrI | BF10 |
uniform(−3, 3) | 0.18 | [0.11, 0.24] | 0.13 | [0.04, 0.22] | 545 |
uniform(−10, 10) | 0.18 | [0.11, 0.24] | 0.13 | [0.03, 0.22] | 165 |
8. Correlation between the magnitude of the semantic interference effect and the slowest delta plot segment (item analysis) | |||||
Prior | Estimate in ms | 95% CrI | tau | 95% CrI | BF10 |
uniform(−3, 3) | 0.49 | [0.43, 0.54] | 0.07 | [0, 0.15] | 21708059521281818624 |
uniform(−10, 10) | 0.49 | [0.43, 0.54] | 0.07 | [0, 0.15] | 6435398699980771328 |
9. Correlation between the magnitude of the semantic interference effect and the fastest delta plot segment (item analysis) | |||||
Prior | Estimate in ms | 95% CrI | tau | 95% CrI | BF10 |
uniform(−3, 3) | 0.31 | [0.26, 0.36] | 0.04 | [0, 0.12] | 11955213341732 |
uniform(−10, 10) | 0.31 | [0.26, 0.36] | 0.04 | [0, 0.12] | 3600807965423 |
Appendix 2. Studies used in meta-analyses
Experiments | Reference |
|---|---|
Aristei.2011 | Aristei et al. (2011) |
Aristei.2013 | Aristei and Abdel Rahman (2013) |
Cutting.1999.1 | Cutting and Ferreira (1999) |
Cutting.1999.2 | |
Cutting.1999.3a.1 | |
Cutting.1999.3a.2 | |
Damian.2003.SOA-100 | Damian and Bowers (2003) |
Damian.2003.SOA0 | |
Damian.2003.SOA100 | |
Damian.2014 | Damian and Spalek (2014) |
deZubicaray.2013 | De Zubicaray et al. (2013) |
Finocchiaro.2013.1 | Finocchiaro and Navarrete (2013) |
Fuhrmeister.unpublished | – |
Fuhrmeister2.unpublished | – |
Gauvin.2018.1.fam | Gauvin et al. (2018) |
Gauvin.2018.1.nofam | |
Gauvin.2018.2.fam | |
Gauvin.2018.2.nofam | |
Hartendorp.2013.1 | Hartendorp et al. (2013) |
Hartendorp.2013.2 | |
Hutson.2014.1 | Hutson and Damian (2014) |
Hutson.2014.2 | |
Janssen.2008.1a | Janssen et al. (2008) |
Janssen.2008.2a | |
Maedebach.2011.2 | Mädebach et al. (2011) |
Maedebach.2011.4 | |
Maedebach.2011.5a | |
Maedebach.2011.6 | |
Piai.2012 | Piai et al. (2012) |
Piai.2012.2 | |
Piai.2014 | Piai et al. (2014) |
Piai.unpublished | – |
Python.unpublished | – |
Rodriguez.2014 | Rodríguez-Ferreiro et al. (2014) |
Roelofs.2008.3 | Roelofs (2008) |
Sailor.2009.1.SOA-150 | Sailor et al. (2009) |
Sailor.2009.1.SOA150 | |
Sailor.2009.2.SOA0 | |
Scaltritti.2015.1 | Scaltritti et al. (2015) |
Scaltritti.2015.3 | |
Shao.2015.Exp.1 | Shao et al. (2015) |
Shao.2015.Exp.2 | |
Starreveld.2013.1.SOA0 | Starreveld et al. (2013) |
Starreveld.2013.1.SOA43 | |
Starreveld.2013.1.SOA86 | |
Starreveld.2013.1.SOAminus43 | |
Starreveld.2013.1.SOAminus86 | |
vanRijn.unpublished | – |
Vieth.2014.SOA-160 | Vieth et al. (2014) |
Vieth.2014.SOA0 | |
Zhang.2016.1.SOA-100 | Zhang et al. (2016) |
Zhang.2016.1.SOA0 | |
Zhang.2016.1.SOA100 | |
Zhang.2016.2.SOA0 |
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Fuhrmeister, P., Bürki, A. Distributional properties of semantic interference in picture naming: Bayesian meta-analyses. Psychon Bull Rev 29, 635–647 (2022). https://doi.org/10.3758/s13423-021-02016-6
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-021-02016-6