
Abstract
In this study we explored the locus of semantic interference in a novel picture–sound interference task in which participants name pictures while ignoring environmental distractor sounds. In a previous study using this task (Mädebach, Wöhner, Kieseler, & Jescheniak, in Journal of Experimental Psychology: Human Perception and Performance, 43, 1629–1646, 2017), we showed that semantically related distractor sounds (e.g., BARKINGdog) interfere with a picture-naming response (e.g., “horse”) more strongly than unrelated distractor sounds do (e.g., DRUMMINGdrum). In the experiment reported here, we employed the psychological refractory period (PRP) approach to explore the locus of this effect. We combined a geometric form classification task (square vs. circle; Task 1) with the picture–sound interference task (Task 2). The stimulus onset asynchrony (SOA) between the tasks was systematically varied (0 vs. 500 ms). There were three central findings. First, the semantic interference effect from distractor sounds was replicated. Second, picture naming (in Task 2) was slower with the short than with the long task SOA. Third, both effects were additive—that is, the semantic interference effects were of similar magnitude at both task SOAs. This suggests that the interference arises during response selection or later stages, not during early perceptual processing. This finding corroborates the theory that semantic interference from distractor sounds reflects a competitive selection mechanism in word production.
Similar content being viewed by others

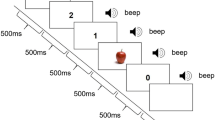
In a recent study (Mädebach, Wöhner, Kieseler, & Jescheniak, 2017) we observed that semantically related environmental distractors sounds (e.g., BARKINGdog) interfere with picture naming (e.g., „horse”) more strongly than unrelated environmental distractor sounds (e.g., DRUMMINGdrum). This semantic interference effect from distractor sounds resembles the one typically obtained with distractor words, which has been central for the debate on the mechanism of lexical selection. According to one (competitive selection) view, this latter effect is seen as an indicator of a general, competitive lexical selection mechanism (e.g., Levelt, Roelofs, & Meyer, 1999; Roelofs, 1992). According to another (non-competitive selection) view, it is seen as an indicator of control mechanisms specific to the processing of distractor words (e.g., Finkbeiner & Caramazza, 2006; Mahon, Costa, Peterson, Vargas, & Caramazza, 2007). The finding of a similar semantic interference effect with distractors sounds has the potential to advance the debate about the mechanism guiding lexical selection. However, relating this effect to the debate rests on the assumption that it indeed reflects response selection processes and not earlier, preselection processes. In the present study we explored the locus of this effect by applying the classical psychological refractory period (PRP) approach (e.g., Pashler, 1994).
ᅟ
ᅟ
Selection mechanisms in models of word production
There is wide consensus that during preparation of an utterance (e.g., “horse”), not only the target word but also a cohort of semantically related lexical representations (e.g., “cow,” “dog,” “donkey”) are activated. Disagreement exists about how a target word is selected among these concurrently activated representations. According to the competitive selection view (e.g., Levelt et al., 1999), a target word is selected as soon as its activation exceeds the activation of other words by a critical amount. According to the non-competitive selection view (e.g., Mahon et al., 2007), a target word is selected as soon as a critical activation threshold is exceeded, regardless of the activation levels of other words.
Much of the theoretical debate on this issue has focused on the observation of semantic interference in the picture–word interference task and its proper interpretation (for a review, see Spalek, Damian, & Bölte, 2013). In this task participants name pictures while ignoring distractor words. When the target picture and distractor word are semantic-categorically related (e.g., horse–dog), naming responses are slower than when picture and word are unrelated (e.g., horse–drum). According to the competitive selection view this effect reflects increased competitor activation. A related distractor is thought to further increase activation in the semantic cohort, whereas an unrelated distractor only activates otherwise inactive representations. According to the noncompetitive selection view, the effect is attributed to postlexical control processes specific to processing distractor words (Mahon et al., 2007). Perceiving a (distractor) word is thought to lead inadvertently and quickly to the preparation of an articulatory response. This distractor response then has to be excluded from an articulatory buffer before the target picture naming response can enter it and then be produced. This exclusion is assumed to be delayed if the distractor response is semantically similar to the target response.
In short, the competitive lexical selection account views semantic interference in the picture–word interference task as a reflection of a general cognitive mechanism involved in word production that operates at the lexical level and for which—in principle—the modality (visual or auditory) or type (picture, word, or environmental sound) of the distractor should not matter. By contrast, the noncompetitive response exclusion account views it as a task-dependent phenomenon that operates at a postlexical level and is specific to distractor words.
Semantic interference from distractor sounds in picture naming
In a recent study we tested this proposed specificity of the effect by using environmental distractor sounds instead of distractor words (e.g., BARKINGhorse vs. DRUMMINGdrum, when the picture shows a horse; Mädebach et al., 2017). We likewise observed semantic interference, which shows that semantic interference is not restricted to tasks that involve distractor words. We argued that the postlexical control mechanism proposed by the noncompetitive account of picture–word interference effects does not provide a viable explanation for semantic interference from sounds. First, there is no apparent reason to assume that environmental sounds trigger the automatic generation of an articulatory response. Second, even if this would be the case, preparation of an articulatory response to an environmental sound would be too slow to affect postlexical processes of picture naming (e.g., Thompson & Paivio, 1994). Therefore, we concluded that semantic interference from distractor sounds results from competitive selection during conceptual or lexical processing. However, this conclusion crucially rests on the assumption that the effect does not result from early perceptual processes such as, for instance, an impairment in picture identification.
The present study
The present study served two aims. First, we sought to replicate the novel finding of semantic interference from distractor sounds. Second and central to this study, we sought distinguish between two possible loci of this effect. One possibility is that this effect reflects response selection in picture naming. This assumption is based on the predictions of word production models assuming a competitive selection mechanism. Another possibility is that the effect reflects preselection processes like visual processing and object identification. This assumption is motivated by previous studies showing that congruent environmental sounds (e.g., NEIGHINGhorse when the target picture is a horse) facilitate detection and identification of corresponding pictures (e.g., Chen & Spence, 2010, 2011).
To address these questions we employed the psychological refractory period (PRP) procedure (Pashler, 1994) in which participants respond to two tasks in a fixed sequence. The critical manipulation in PRP studies concerns the stimulus onset asynchrony (SOA) between the two tasks. Dual-task interference denotes the fact that T2 responses are delayed as task SOA decreases. A common interpretation is that response selection in each task is subject to a central processing bottleneck, so that T2 response selection has to wait until T1 response selection is completed (e.g., Pashler & Johnston, 1989). Importantly, this implies that manipulations of T2 response selection should be unaffected by task SOA (i.e., the two effects should be additive). In contrast, manipulations of T2 precentral processes should only be visible at sufficiently long task SOAs because at short task SOAs they are absorbed in a “cognitive slack” arising during T1 response selection (i.e., the two effects should be underadditive).
The PRP approach has previously been used to investigate the locus of semantic interference in the picture–word interference task. Additivity of the semantic interference effect of distractor words with dual-task interference was found in multiple studies (Piai, Roelofs, & Roete, 2015; Piai, Roelofs, & Schriefers, 2014; Schnur & Martin, 2012; van Maanen, van Rijn, & Taatgen, 2012, Exp. 2; cf. Ayora et al., 2011; Dell’Acqua, Job, Peressotti, & Pascali, 2007; van Maanen et al., 2012, Exp. 1). Overall the available evidence from these studies supports the view that semantic interference in the picture–word interference task arises during response selection (for discussions, see Kleinman, 2013; Piai et al., 2014).
In our experiment, a geometric shape classification task (requiring a manual response) figured as Task 1 (T1) and the picture–sound interference task (requiring a vocal response) as Task 2 (T2). For the latter task, we expected to replicate the semantic interference effect found in our previous study. Furthermore, if this effect reflects response selection (or later) processes that are subject to a central processing bottleneck, then the effect should be additive with dual-task interference (i.e., independent of task SOA). In contrast, if the effect reflects preselection processes that are not subject to a central processing bottleneck (e.g., object identification; see Green, Johnston, & Ruthruff, 2011), then the effect should be underadditive with dual task interference (i.e., attenuated or absent with shorter task SOA). Apart from the critical semantic and unrelated conditions we also included a congruent condition in the picture–sound task for which we expected to facilitation effect (relative to the unrelated condition) as in our previous study. Because similar congruency facilitation effects have also found in picture detection and identification of briefly presented (and backward-masked) pictures (Chen & Spence, 2010), we assumed that it might—in part—reflect early perceptual processes (i.e., preselection processes). Therefore, we expected the congruency facilitation effect to be underadditive with dual task interference.
Method
Participants
Twenty-four native speakers of German participated (21 female, three male; mean age = 20.3 years, range = 18–24 years). All participants had normal or corrected-to-normal vision and no known hearing impairment. Two additional participants were replaced due to technical problems (button press frequently triggering the voice key, leading to massive data loss).
Materials
For the shape classification task (T1) a filled red square and circle were used (diameter 1.1° at 60 cm distance). For the picture naming task (T2) the same materials as Mädebach et al., 2017) were used (for a full list see the supplement). Stimuli were 32 black line drawings of objects (maximum 8.4° × 8.4°) and corresponding sounds (normalized in amplitude; sampling rate = 48 kHz; mean duration = 1,246 ms, range = 702–1,572 ms). Pictures were either paired with a sound from the same semantic category (semantic condition), with an unrelated sound (unrelated condition), with their corresponding sound (congruent condition), or with a 500-Hz sine tone (500-ms duration; neutral condition). In the semantic, unrelated, and congruent condition the same sounds were used. Six additional pictures and sounds were used for practice and warmup trials.
Design
Task SOA (0, 500 ms) and distractor condition (semantic, unrelated, congruent, neutral) were varied within participants and within items. The neutral condition was included to keep the number of target repetitions and the proportion of conditions identical to our previous study. However, because of physical differences between a sine tone and natural sounds, the neutral condition is not theoretically informative and, thus, was not included in the data analyses reported here.
We created two blocks. In the first block, half of the items were presented with task SOA 0 ms in all distractor conditions and the other half of the items with task SOA 500 ms in all distractor conditions. In the second block, the item subsets were presented with the complementary task SOAs. The sequence of these two blocks was counterbalanced across participants. Within blocks the sequence of distractor conditions per item was counterbalanced with a sequentially balanced Latin square. For each block four parallel lists (parallel regarding the sequence of items but different regarding the sequence of conditions per item) were constructed. There were three different randomizations per parallel list, which each were used once in the first and once in the second block, resulting in 24 experimental lists overall.
Trials were pseudorandomized using Mix (van Casteren & Davis, 2006). Restrictions were: (a) picture repetitions were separated by a minimum of eight trials, (b) specific sequences of any two pictures were not repeated, (c) a picture and its corresponding sound did not appear in consecutive trials, (d) distractor condition, SOA, and T1 shape were repeated in max. three consecutive trials, (e) pictures with phonologically similar names did not appear in consecutive trials, (f) max. two pictures from the same semantic category appeared in consecutive trials.
Apparatus
Visual stimuli were presented on a 19-in. TFT monitor and auditory stimuli via headphones. Naming latencies were registered via a microphone connected to a hardware voice key. Manual responses were registered with a push-button box. Stimulus presentation and data collection were controlled by NESU (Nijmegen Experimental Setup).
Procedure
At the beginning of the experiment participants were familiarized with the materials. First, each picture was presented together with its corresponding sound and its designated name that was read aloud by the participants. Second, each picture–sound pair was presented without the name and had to be named by the participants. Then the two tasks were introduced. The shape classification task (T1) was introduced first (12 trials). Participants were asked to press a left or a right push button, depending on the stimulus, as quickly as possible. A printed sign indicating the button assignment remained visible throughout the experiment. Button assignment was reversed for half of the participants. The picture–sound interference task (T2) was introduced next (12 trials). Finally, the dual task was introduced (12 trials, six with each task SOA). Participants were instructed to always give the manual response first and to respond to either task as fast as possible. Then the 256 experimental trials were presented with a short break after every 64 experimental trials. Two warm-up trials preceded each block of experimental trials.
Experimental trials were structured as follows: The T1 shape was presented for 100 ms centered on the screen. The T2 picture was also presented centered on the screen for 800 ms starting simultaneously with the T1 shape (i.e., the T1 shape was superimposed on it) or with a 500-ms delay, depending on task SOA. The T2 sound started 200 ms before T2 picture onset. This distractor SOA had proved most sensitive to the semantic interference effect in Mädebach et al. (2017). T1 and T2 responses were registered starting with their respective target stimulus onsets until 3 s after T2 picture onset.
Results
We discarded trials in which (a) responses were out of order, (b) no response was registered in either task, (c) another technical problem occurred (i.e., response latencies were not accurately registered; e.g., because the voice key was triggered by external noise), and (d) T1 latency < 100 ms or T2 latency < 300 ms (overall 2.2%). For T1, incorrect button presses were treated as errors. For T2, trials were treated as errors, when no response, an unexpected response, or a disfluent response was given, or when a nonspeech sound produced by the participant triggered the voice key. Trials in which an error was coded in either task were excluded from the latency analysis (8.3%). The analyses were conducted in R (R Development Core Team, 2017). We submitted averaged response latencies and error rates to analyses of variance (ANOVAs) involving the factors Task SOA and Condition. Generalized eta-squared, as provided by the ez package (Lawrence, 2015), is reported as an effect size estimate. Greenhouse–Geisser-corrected df and p values are also reported, if the sphericity assumption was violated (Mauchly test p < .05). Additionally, we report Bayes factors for corresponding analyses conducted with the BayesFactor package (Morey & Rouder, 2015) using the default priors. The data and scripts are available at https://osf.io/3aurs/. Mean response latencies are presented in Fig. 1; both mean response latencies and error rates are listed in Table 1.

Mean response latencies per task, distractor condition, and task SOA. The means are based on participants.
T1: Shape classification
There were no significant effects in the latency analyses, ps > .300. The preferred model in these Bayesian ANOVAs was the null model. The latency data here were slightly more likely under the null model than under a model containing only the main effect of SOA (BF = 1.9) and were substantially more likely than under models containing the main effect of condition or an interaction of the two factors (in each case, BF > 10).
In the error analysis, SOA was significant, F(1, 23) = 45.77, p < .001, η g 2 = .234, with more errors at SOA 0 ms than at SOA 500 ms. We found no significant effect of distractor condition, F(2, 46) = 2.51, p = .092, and no interaction of SOA and distractor condition, F(1.56, 35.80) = 2.22, p = .120. The preferred model in these Bayesian ANOVAs contained only the main effect of SOA. The data were more likely under this model than under the null model, BF > 1,000; the model containing both main effects, BF = 2.8; and the model containing both main effects and their interaction, BF = 4.4.
T2: Picture naming
Naming latencies were longer at SOA 0 ms than at SOA 500 ms, F 1(1, 23) = 288.61, p < .001, η g 2 = .470; F 2(1, 31) = 846.51, p < .001, η g 2 = .775. There was also a main effect of distractor condition, F 1(1.49, 34.37) = 28.04, p < .001, η g 2 = .031; F 2(2, 62) = 42.16, p < .001, η g 2 = .114. As compared to the unrelated condition, naming latencies were longer in the semantic condition, F 1(1, 23) = 7.20, p = .013, η g 2 = .006; F 2(1, 31) = 7.59, p = .010, η g 2 = .020, but shorter in the congruent condition, F 1(1, 23) = 43.30, p < .001, η g 2 = .024; F 2(1, 31) = 41.18, p < .001, η g 2 = .101. No interaction of distractor condition and SOA was apparent, Fs < 1. The preferred model in Bayesian ANOVAs contains both main effects but not their interaction. The data are more likely under this model than under models containing only one of the main effects, for participants and items BF > 1,000, and the model containing both main effects and their interaction, for participants BF = 7.4, for items BF = 7.0. Additional Bayesian t tests on the two condition contrasts provide evidence for the semantic interference effect, for participants BF10 = 3.8 and for items BF10 = 4.5, and substantial evidence for the congruency facilitation effect, for participants and items BF10 > 1,000.
Error rates did not differ significantly between SOA, F 1(1, 23) = 2.33, p = .140; F 2(1, 31) = 2.41, p = .131, or distractor condition, Fs < 1. The interaction of SOA and distractor condition was significant, F 1(2, 46) = 8.31, p < .001, η g 2 = .068; F 2(2, 62) = 6.90, p = .002, η g 2 = .054. We observed no semantic effect overall, Fs < 1, and no significant interaction with SOA, F 1(1, 23) = 2.87, p = .104; F 2(1, 31) = 2.37, p = .134. There was also no congruency effect overall, Fs < 1, but this contrast differed across SOAs, F 1(1, 23) = 17.22, p < .001, η g 2 = .091; F 2(1, 31) = 11.03, p = .002, η g 2 = .072. At SOA 0 ms, fewer errors were made in the congruent condition, t 1(23) = 3.37, p = .003; t 2(31) = 3.46, p = .002, but there was no significant difference at SOA 500 ms, t 1(23) = 1.94, p = .065; t 2(31) = 1.49, p = .146. The Bayesian ANOVAs yielded no clearly preferred model. Instead, the data appeared similarly likely under the null model and the full model containing both main effects and their interaction: for participants, BF = 1.5 in favor of the full model; for items, BF = 1.1 in favor of the null model. This suggests that the significant interaction between task SOA and condition (driven by the congruency contrast) might be spurious. This was also suggested by the results of an additional experiment (with the same materials but including more task SOAs), in which this interaction was not replicated.Footnote 1
Discussion
Our experiment explored the locus of distractor sound effects in the picture–sound interference task. We combined a shape classification task (Task 1) and the picture–sound interference task (Task 2) in a PRP design. There were three main findings. First, we observed interference from semantically related distractor sounds (mean effect of 22 ms [95% CI: 5–38 ms]), and facilitation from congruent distractor sounds (mean effect of 40 ms [95% CI: 27–52 ms]) during picture naming. Both effects were of similar size in the previous study (Mädebach et al., 2017, Exps. 1–3, distractor SOA – 200 ms only) in which we observed semantic interference of 24 ms [95% CI: 17–30 ms] and congruency facilitation of 56 ms [95% CI: 48–64 ms]. This testifies to the robustness of the effects. Second, picture naming (in Task 2) was slower with the short than with the long task SOA. The presence of this typical PRP effect shows that the implementation of the dual task and the choice of task SOAs were appropriate. Third, and most important, the semantic interference effect was of similar magnitude across task SOAs (as was, with some qualification, the congruency facilitation effect, see below), which—according to the PRP logic—suggests that it originates during response selection rather than during early perceptual processing.
The observation that the congruency effect was not affected by task SOA is somewhat surprising. We expected that it might—in part—reflect early perceptual processes (i.e., preselection processes) because similar effects had also been observed in picture detection and identification tasks (Chen & Spence, 2010, 2011) and, thus, should have been smaller at the short task SOA. This was not the case. A critical factor in this regard might be our choice of distractor SOA. We used a fixed distractor SOA of – 200 ms at which the critical semantic interference effect had peaked in Mädebach et al. (2017). In contrast, the congruency facilitation was somewhat larger with more negative distractor SOAs in that study. Possibly, only with earlier distractor sound onset, semantic representations associated with the sounds become activated in time to affect early visual processing of the target picture in addition to affecting later semantic–lexical processing (Chen & Spence, 2011). If so, underadditivity of the congruency facilitation effect might be found with more negative distractor SOAs. Another, related, explanation might be that, although the distractor SOA was fixed, processing of the distractor sounds affected picture processing differently depending on task SOA because at short task SOA sounds were processed for a longer time before the picture naming response was initiated than at the long task SOA. In other words, the “effective” distractor SOA (time between sound onset and response selection in picture naming) might shift between task SOAs due to the cognitive slack delaying the preparation of the T2 target picture name, but not the processing of the T2–distractor sound. In this case, at short-task SOA, the base congruency facilitation effect might have been larger than at the long task SOA. This might have masked underadditivity of the congruency facilitation effect with dual task interference to some degree. However, importantly, this caveat does not apply to the critical semantic interference effect. This effect peaked at SOA – 200 ms in the previous study (i.e., it decreased with more negative distractor SOAs). Therefore, if anything, the shift to a more negative “effective” distractor SOA at the short task SOA would have promoted underadditivity of the semantic interference effect with dual task interference.
Another unexpected finding was the task SOA effect on T1 error rates: more errors with the short task SOA than with the long task SOA. This effect does not correspond to the classical assumption of a structural response selection bottleneck. According to this assumption, only T2 performance should be subject to dual-task interference, and T1 performance should not (Pashler, 1994). However, similar effects of T2 processing on T1 performance have been found in a number of PRP studies (e.g., Paucke, Oppermann, Koch, & Jescheniak, 2015), including PRP studies on semantic interference in the picture–word interference task (Piai et al., 2015; Piai et al., 2014; Schnur & Martin, 2012) and such results might be better accounted for by capacity-sharing accounts of dual-task performance (e.g., Tombu & Jolicœur, 2003). But when adopting a capacity sharing account, the additivity of the dual task interference and picture–sound interference would also suggest a response selection locus of the effect.
Our conclusion that picture–sound interference effects arise during response selection does not necessarily imply a lexical locus of these effects. Response selection in word production is often attributed to the lexical level and this has also been the perspective taken by previous PRP studies on word production (see Piai et al., 2014). However, other word production models assume selection at the conceptual level (e.g., Bloem & La Heij, 2003; Mahon & Navarrete, 2015). The present results would be compatible with both a prelexical and a lexical response selection locus of picture–sound interference because both conceptualization and lexicalisation have been argued to draw on central processing capacity (Ferreira & Pashler, 2002; Levelt, 1989).
Finally, we want to clarify that the main result of the present study (additivity of picture–sound interference and dual task interference) does not principally rule out a noncompetitive explanation of the semantic interference effect. Demonstrating that this effect arises during response selection corroborates predictions from models assuming competitive selection and thus a competitive explanation is supported by the present results. In contrast, noncompetitive models cannot account well for semantic interference from distractor sounds because the noncompetitive mechanism, which was proposed to account for semantic interference in the picture–word task (postlexical response exclusion) is fundamentally incompatible with semantic interference in the picture–sound task (Mädebach et al., 2017). Nonetheless, other noncompetitive explanations of this effect might be viable (e.g., conflict monitoring) and these would be compatible with the present results if they demand central processing capacity or arise at a postselection stage.
Conclusion
The present PRP study provides evidence that semantic interference in the picture–sound interference task results from response selection processes. This fact qualifies the picture–sound interference task as a novel and promising tool complementing the rather limited set of experimental tasks that are available for investigating details of word production. The results presented here also show that semantic interference in picture naming is not specific to conditions in which distractor words are used and thus support word production models incorporating a competitive selection mechanism.
Author note
M.-L.K. is now at the Helen Wills Institute for Neuroscience, University of California, Berkeley. Our research was supported by grant MA 6633/1-1 awarded to Andreas Mädebach by the German Research Foundation (DFG). We thank Laura Babeliowsky for her help in data collection.
Notes
The results of this additional experiment were consistent with the main results reported here (see the supplement to this article for details).
References
Ayora, P., Peressotti, F., Alario, F.-X., Mulatti, C., Pluchino, P., Job, R., & Dell’Acqua, R. (2011). What phonological facilitation tells about semantic Interference: A dual-task study. Frontiers in Psychology, 2, 57. https://doi.org/10.3389/fpsyg.2011.00057
Bloem, I., & La Heij, W. (2003). Semantic facilitation and semantic interference in word translation: Implications for models of lexical access in language production. Journal of Memory and Language, 48, 468–488. https://doi.org/10.1016/S0749-596X(02)00503-X
Chen, Y.-C., & Spence, C. (2010). When hearing the bark helps to identify the dog: Semantically-congruent sounds modulate the identification of masked pictures. Cognition, 114, 389–404. https://doi.org/10.1016/j.cognition.2009.10.012
Chen, Y.-C., & Spence, C. (2011). Crossmodal semantic priming by naturalistic sounds and spoken words enhances visual sensitivity. Journal of Experimental Psychology: Human Perception and Performance, 37, 1554–1568. https://doi.org/10.1037/a0024329
Dell’Acqua, R., Job, R., Peressotti, F., & Pascali, A. (2007). The picture–word interference effect is not a Stroop effect. Psychonomic Bulletin & Review, 14, 717–722. https://doi.org/10.3758/BF03196827
Ferreira, V. S., & Pashler, H. (2002). Central bottleneck influences on the processing stages of word production. Journal of Experimental Psychology: Learning, Memory, and Cognition, 28, 1187–1199. https://doi.org/10.1037/0278-7393.28.6.1187
Finkbeiner, M., & Caramazza, A. (2006). Now you see it, now you don’t: On turning semantic interference into facilitation in a Stroop-like task. Cortex, 42, 790–796. https://doi.org/10.1016/S0010-9452(08)70419-2
Green, C., Johnston, J. C., & Ruthruff, E. (2011). Attentional limits in memory retrieval-revisited. Journal of Experimental Psychology: Human Perception and Performance, 37, 1083–1098. https://doi.org/10.1037/a0023095
Kleinman, D. (2013). Resolving semantic interference during word production requires central attention. Journal of Experimental Psychology: Learning, Memory, and Cognition, 39, 1860–1877. https://doi.org/10.1037/a0033095
Lawrence, M. A. (2015). ez: Easy analysis and visualization of factorial experiments, R package, Version 4.3. Retrieved from https://CRAN.R-project.org/package=ez
Levelt, W. J. M. (1989). Speaking: From intention to articulation. Cambridge, MA: MIT Press.
Levelt, W. J. M., Roelofs, A., & Meyer, A. S. (1999). A theory of lexical access in speech production. Behavioral and Brain Sciences, 22, 1–75. https://doi.org/10.1017/S0140525X99001776
Mädebach, A., Wöhner, S., Kieseler, M.-L., & Jescheniak, J. D. (2017). Neighing, barking, and drumming horses—Object related sounds help and hinder picture naming. Journal of Experimental Psychology: Human Perception and Performance, 43, 1629–1646. https://doi.org/10.1037/xhp0000415
Mahon, B. Z., Costa, A., Peterson, R., Vargas, K. A., & Caramazza, A. (2007). Lexical selection is not by competition: A reinterpretation of semantic interference and facilitation effects in the picture–word interference paradigm. Journal of Experimental Psychology: Learning, Memory, and Cognition, 33, 503–535. https://doi.org/10.1037/0278-7393.33.3.503
Mahon, B. Z., & Navarrete, E. (2015). Modelling lexical access in speech production as a ballistic process. Language, Cognition, and Neuroscience, 31, 521–523. https://doi.org/10.1080/23273798.2015.1129060
Morey, R. D., & Rouder, J. N. (2015). BayesFactor: Computation of Bayes factors for common designs. Retrieved from https://CRAN.R-project.org/package=BayesFactor
Pashler, H. (1994). Dual-task interference in simple tasks: Data and theory. Psychological Bulletin, 116, 220–244. https://doi.org/10.1037/0033-2909.116.2.220
Pashler, H., & Johnston, J. C. (1989). Chronometric evidence for central postponement in temporally overlapping tasks. Quarterly Journal of Experimental Psychology, 41, 19–45. https://doi.org/10.1080/14640748908402351
Paucke, M., Oppermann, F., Koch, I., & Jescheniak, J. D. (2015). On the costs of parallel processing in dual-task performance: The case of lexical processing in word production. Journal of Experimental Psychology: Human Perception and Performance, 41, 1539–1552. https://doi.org/10.1037/a0039583
Piai, V., Roelofs, A., & Roete, I. (2015). Semantic interference in picture naming during dual-task performance does not vary with reading ability. Quarterly Journal of Experimental Psychology, 68, 1758–1768. https://doi.org/10.1080/17470218.2014.985689
Piai, V., Roelofs, A., & Schriefers, H. (2014). Locus of semantic interference in picture naming: Evidence from dual-task performance. Journal of Experimental Psychology: Learning, Memory, and Cognition, 40, 147–165. https://doi.org/10.1037/a0033745
R Development Core Team. (2017). R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing. Retrieved from www.R-project.org/
Roelofs, A. (1992). A spreading-activation theory of lemma retrieval in speaking. Cognition, 42, 107–142. https://doi.org/10.1016/0010-0277(92)90041-F
Schnur, T. T., & Martin, R. (2012). Semantic picture–word interference is a postperceptual effect. Psychonomic Bulletin & Review, 19, 301–308. https://doi.org/10.3758/s13423-011-0190-x
Spalek, K., Damian, M. F., & Bölte, J. (2013). Is lexical selection in spoken word production competitive? Introduction to the special issue on lexical competition in language production. Language and Cognitive Processes, 28, 597–614. https://doi.org/10.1080/01690965.2012.718088
Thompson, V. A., & Paivio, A. (1994). Memory for pictures and sounds: Independence of auditory and visual codes. Canadian Journal of Experimental Psychology, 48, 380–398. https://doi.org/10.1037/1196-1961.48.3.380
Tombu, M., & Jolicœur, P. (2003). A central capacity sharing model of dual-task performance. Journal of Experimental Psychology: Human Perception and Performance, 29, 3–18. https://doi.org/10.1037/0096-1523.29.1.3
van Casteren, M., & Davis, M. H. (2006). Mix, a program for pseudorandomization. Behavior Research Methods, 38, 584–589. https://doi.org/10.3758/BF03193889
van Maanen, L., van Rijn, H., & Taatgen, N. (2012). RACE/A: An architectural account of the interactions between learning, task control, and retrieval dynamics. Cognitive Science, 36, 62–101. https://doi.org/10.1111/j.1551-6709.2011.01213.x
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
ESM 1
(PDF 163 kb)
Rights and permissions
About this article

Cite this article
Mädebach, A., Kieseler, ML. & Jescheniak, J.D. Localizing semantic interference from distractor sounds in picture naming: A dual-task study. Psychon Bull Rev 25, 1909–1916 (2018). https://doi.org/10.3758/s13423-017-1386-5
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-017-1386-5