
Abstract
In contrast to earlier research, evidence for semantic preview benefit in reading has been reported by Hohenstein and Kliegl (Experimental Psychology: Learning, Memory, and Cognition, 40, 166–190, 2013) in an alphabetic writing system; they also implied that prior demonstrations of lack of a semantic preview benefit needed to be reexamined. In the present article, we report a rather direct replication of an experiment reported by Rayner, Balota, and Pollatsek (Canadian Journal of Psychology, 40, 473–483, 1986). Using the gaze-contingent boundary paradigm, subjects read sentences that contained a target word (razor), but different preview words were initially presented in the sentence. The preview was identical to the target word (i.e., razor), semantically related to the target word (i.e., blade), semantically unrelated to the target word (i.e., sweet), or a visually similar nonword (i.e., razar). When the reader’s eyes crossed an invisible boundary location just to the left of the target word location, the preview changed to the target word. Like Rayner et al. (Canadian Journal of Psychology, 40, 473–483, 1986), we found that fixations on the target word were significantly shorter in the identical condition than in the unrelated condition, which did not differ from the semantically related condition; when an orthographically similar preview had been initially present in the sentence, fixations were shorter than when a semantically unrelated preview had been present. Thus, the present experiment replicates the earlier data reported by Rayner et al. (Canadian Journal of Psychology, 40, 473–483, 1986), indicating evidence for an orthographic preview benefit but a lack of semantic preview benefit in reading English.
Similar content being viewed by others
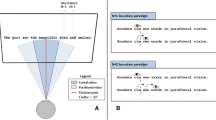


It is well established that readers obtain information from the word to the right of fixation (word n + 1). The fact that they sometimes skip over word n + 1 without making a regression back to the word is at least consistent with the argument that it is possible to obtain semantic information from word n + 1 (Rayner, 2009). However, there is some controversy concerning the case in which word n + 1 is not skipped. Here, the evidence is less clear, although much of it indicates that readers of English do not obtain morphological or semantic information from word n + 1 (for reviews, see Hohenstein & Kliegl, 2013; Rayner, 1998, 2009; Schotter, Angele, & Rayner, 2012). When they have a valid preview of that word, fixation time on it, when it is subsequently fixated, is shorter than when there was an invalid preview; this effect of shorter fixation times on word n + 1 is typically referred to as preview benefit. The effect has been examined numerous times by the use of the gaze-contingent boundary paradigm (Rayner, 1975). In this paradigm, readers’ eye movements are monitored as they read text, and a specified target word is changed from a preview word to the target word when the reader’s eyes cross an invisible boundary located just to the left of the beginning of the target word. Because vision is suppressed during a saccade, and provided that the display change occurs during the saccade or shortly after it ends (within 10 ms of the end of the saccade; Slattery, Angele, & Rayner, 2011), readers typically do not notice the change.
It has been confirmed a number of times that both orthographically similar (for examples, see Balota, Pollatsek, & Rayner, 1985; Drieghe, Rayner, & Pollatsek, 2005; Inhoff, 1989; Rayner, 1975) and phonologically similar (for examples, see Ashby & Rayner, 2004; Miellet & Sparrow, 2004; Pollatsek, Lesch, Morris, & Rayner, 1992) previews yield preview benefit (for reviews, see Rayner, 1998, 2009; Schotter et al., 2012). Furthermore, prior research has largely indicated no reliable evidence for the effectiveness of morphological previews in alphabetic writing systems (Bertram & Hyönä, 2007; Inhoff, 1989; Kambe, 2004; Lima, 1987), although morphological preview benefit has been demonstrated for Hebrew script (Deutsch, Frost, Peleg, Pollatsek, & Rayner, 2003; Deutsch, Frost, Pollatsek, & Rayner, 2000, 2005). More central for the present report, a number of studies have also failed to find evidence of semantic preview benefit (Altarriba, Kambe, Pollatsek, & Rayner, 2001; Dimigen, Kliegl, & Sommer, 2012; Hyönä & Häikiö, 2005; Rayner et al., 1986; Rayner, McConkie, & Zola, 1980) in alphabetic writing systems. It has generally been assumed that semantic preview benefit is difficult to observe because the properties of a semantically related preview and a given target word typically do not match on either orthography or phonology and, hence, this mismatch overrides any potential benefit that a reader might obtain from a semantically related preview (Schotter et al., 2012).
While the evidence for semantic preview benefit is not clear with alphabetic writing systems (especially English), evidence for it has been obtained in nonalphabetic writing systems such as Chinese (see Hohenstein & Kliegl, 2013, for an excellent review). Because the Chinese writing system is more densely packed than English, the preview word is generally much closer to the fixation point (or foveal vision) than is typically the case with alphabetic writing systems. Furthermore, semantic/morphological information is more directly coded in the writing system in nonalphabetic writing systems like Chinese.
Critically, semantic preview benefit has also recently been demonstrated across seven different experiments in German (Hohenstein & Kliegl, 2013; Hohenstein, Laubrock, & Kliegl, 2010). Specifically, Hohenstein and KlieglFootnote 1 utilized the boundary paradigm as subjects read sentences containing a critical target noun for which a parafoveal preview was either semantically related or unrelated to the target. They found that fixation times on the target word were shorter when there was a semantically related preview word than when there was an unrelated preview. More important for present purposes, in a very thorough analysis of studies failing to demonstrate semantic preview benefit, Hohenstein and Kliegl raised doubts about most of these prior studies because (1) they did not really involve subjects in the task of reading (Dimigen et al., 2012; Rayner et al., 1980), (2) they relied on emotion words and didn’t really manipulate semantic relatedness (Hyönä & Häikiö, 2005), or (3) they involved presenting a preview in one language and the target word in another language (i.e., a Spanish word as a preview for an English word; Altarriba et al., 2001) and, hence, involved code switching that could have influenced the results. Their analysis thus renders these studies as somewhat questionable as evidence against semantic preview benefit, leaving Rayner et al. (1986) as the only study in which semantic preview benefit was not obtained while subjects were actually reading. This raises the question, very much implied in Hohenstein and Kliegl’s analysis, as to whether or not Rayner et al.’s (1986) results are replicable. Here, we examined this specific issue via a rather direct replication (i.e., same subject pool, same eye-tracking system, and same stimuli) of Rayner et al. (1986). More specifically, in the Drieghe et al. (2005) study, which focused on word skipping of predictable words, 36 out of the 40 stimuli from the original Rayner et al. (1986) study were analyzed here, allowing for a nearly perfect replication.
Method
Subjects
Twenty-four members of the University of Massachusetts at Amherst community participated in the experiment. All were native speakers of English and had 20/20 vision or contacts. They either received extra credit in a psychology course or were paid $8 for their participation.
Apparatus
Eye movements were recorded via a Fourward Technologies Dual Purkinje Eyetracker (Generation V) interfaced with a Pentium computer, which in turn was interfaced with a 15-in. NEC MultiSync FGE color monitor. The display monitor used in the present investigation was much better than that used by Rayner et al. (1986) and led to much sharper resolution of the letters in the sentences (and hence, the preview; see Drieghe et al., 2005, for further discussion). Subjects were seated 61 cm from the monitor; at this distance, 3.8 character spaces equaled 1° of visual angle. Display changes occurred within 5 ms of detection of when the invisible boundary was crossed; the boundary was located between the last letter of the prior word and the space preceding the target word. Although reading was binocular, eye movements were recorded only from the subject’s right eye (which was sampled every millisecond).
Materials
The stimuli consisted of 36 sentences from Rayner et al. (1986).Footnote 2 Within each sentence, we focused on four possible previews for the target word. For example, for the target word razor, the previews could be razor (identical [ID]), blade (semantically related [SR]), sweet (semantically unrelated [UR]), or razar (visually similar nonword [VSN]). The VSN preview was created by replacing the penultimate letter with a visually similar letter. The average word length of the target word was 4.83 letters (with a range of 4–6 letters), and the average word frequency (based on Francis & Kučera, 1982) was 96.8 per million for the target word, 70.4 per million for the SR preview, and 115.6 per million for the UR preview. The SR preview word fit easily into the sentence context, whereas the UR preview word typically did not. To confirm this, 20 subjects who did not participate in the eye movement experiment were given the sentence frames up to and including the preview words. The ID and SR previews were rated as good continuations—4.5 and 4.4, respectively (on a scale of 1–5, with 5 being highly acceptable and 1 being unacceptable)—whereas the UR previews were rated as 1.1. The target sentences were embedded in 108 other sentences that the subjects read. For the SR, UR, and target words used in the Rayner et al. (1986) study, they reported a 20-ms priming effect in a standard priming study in which subjects named target words (i.e., razor) preceded by either an SR prime (i.e., blade) or a UR prime (i.e., sweet); the prime words were presented for 200 ms, followed by a blank screen and then the target word (which remained visible until the subjects responded).
Procedure
When subjects arrived for the present experiment, a bite bar was prepared, which served to eliminate head movements. Subjects were first given general instructions about the task, and the eye-tracking system was calibrated; the initial calibration took about 5 min. Each subject read 10 practice sentences, followed by the entire set of 144 sentences. Prior to the presentation of each sentence, a series of five fixation points (extending from the first to the last letter position of an 80-letter space line) appeared on the monitor, and subjects looked at each point to verify that eye position was accurately recorded; if it was not, the tracker was recalibrated. If calibration was accurate, the subject looked at the first fixation point, and the experimenter displayed the sentence. Questions were asked about the meaning of sentence after 25 % of the sentences; subjects answered the questions correctly 96 % of the time.
Results
For details on data cleaning prior to running the analyses, Drieghe et al. (2005) should be consulted. Given that the target word received a single fixation 92 % of the time, the primary dependent variable reported is single-fixation duration (the duration of a fixation on a word when it receives only one fixation). However, given that Rayner et al. (1986) reported gaze duration (the sum of all fixations on a word prior to moving to another word), we also report that measure. In addition, fixation probabilities are reported, since there were differences in fixation probability on the target word across conditions. The means for each of these measures are presented in Table 1. Data were analyzed using inferential statistics based on generalized linear mixed-effects models (LMMs), with preview entered as a fixed effect with default contrasts (see below) and subjects and items as crossed random effects (see Baayen, Davidson, & Bates, 2008). Following Barr, Levy, Scheepers, and Tily (2013), we used the maximal random effects structure possible: random intercepts for subjects and items, as well as random slopes for each of the preview contrasts and correlations between all of these effects.Footnote 3 To assess preview benefit, the unrelated condition was set as the intercept (baseline condition), and each of the other conditions was compared with it individually. In order to fit the LMMs, the lmer function from the lme4 package (Bates, Maechler, & Bolker, 2011) was used within the R Environment for Statistical Computing (R Development Core Team, 2012). For single-fixation duration and gaze duration, linear mixed-effects regressions were used, and regression coefficients (b), which estimate the effect size (in milliseconds) of the comparison, and the t-value of the effect coefficient are reported.Footnote 4 Absolute values of the t statistic greater than or equal to 1.96 indicate an effect that is significant at approximately the .05 alpha level. For fixation probability (a binary dependent measure), we conducted a logistic mixed-effects regression and report regression coefficients (b), which represent effect size in log-odds space, and the z value and p value of the effect coefficient. Importantly, fixations on the pretarget word were unaffected by any of the preview conditions (all ts < 1), indicating no evidence of parafoveal-on-foveal effects (i.e., the notion that characteristics of word n + 1 can influence the amount of time readers look at word n).
Fixation probability
The target word was less likely to be fixated in the ID condition (.81) than in the UR condition (.88), z = 2.66, p < .01; it was also less likely to be fixated in the SR condition (.79) than in the UR condition, z = 3.47, p < .001. The fixation probability in the VSN condition (.89) was not significantly different from that in the UR condition (p > .78). It is interesting that fixation probabilities in the ID condition and SR condition were quite similar (81 % and 79 %, respectively). To further investigate this, we examined regression rates as a function of preview condition and whether the target word was skipped during first-pass reading. Formal analyses were not possible because of very low skipping rates, but the qualitative pattern of data suggests that skipping did influence the likelihood of a regression to the target. When the target word was fixated (the majority of the time), regression rates were quite low and varied very little across conditions (.02 in the ID condition, .02 in the SR condition, .08 in the VSN condition, and .00 in the UR condition). When the target word was skipped, regression rates were overall higher and varied more across condition (.13 in the ID condition, .47 in the SR condition, .02 in the VSN condition, and .33 in the UR condition).
The fixation/skipping data seem consistent with the following view. On about 20 % of the trials in both the ID and SR conditions, the target/preview word was identified and skipped, since in both cases, the word fits into the sentence context. However, on nearly half of the skips in the SR condition, the reader regressed to the target region after skipping it. This was most likely due to the processing system noticing that the word to the left of fixation in the target location differed from the preview (see Binder, Pollatsek, & Rayner, 1999). It may also be the case that on a small percentage of the trials, the reader identified the SR preview word and went with that meaning, since it fit into the sentence context (see Schotter, Reichle, & Rayner, in press). In the UR and VSN conditions, readers skipped the target word less frequently, but they regressed quite often in the UR condition. However, while interesting, the primary focus of the present study is the fixation time on the target word when it was not skipped (since preview benefit is assessed from this time).
Fixation time measures
Single-fixation durations on the target word were significantly shorter in the ID condition (M = 252 ms) than in the UR condition (M = 307 ms), b = −57.70, SE = 12.20, t = 4.73. Single fixations were also shorter in the VSN condition (M = 278 ms) than in the UR condition, b = −25.48, SE = 11.98, t = 2.13. Single fixations were not significantly different in the SR condition (M = 293 ms) than in the UR condition, t = 1.32.Footnote 5 Similarly, gaze durations on the target word were significantly shorter in the ID condition (M = 267 ms) than in the UR condition (314 ms), b = −51.38, SE = 15.25, t = 3.37. Neither the comparison between the VSN condition (292 ms) and the UR condition nor the comparison between the SR condition (311 ms) and the UR condition was significant (both ts < 1.21).Footnote 6
The fixation time measures were both very consistent in showing no evidence for semantic preview benefit. Fixation times were shorter in the ID condition than in the other conditions, and fixation times did not differ between the SR and UR conditions.
Discussion
In a close replication of Rayner et al. (1986), we found no evidence of semantic preview benefit. Thus, with respect to the issue implicitly raised by Hohenstein and Kliegl (2013), the results reported by Rayner et al. (1986) are replicable. The present results are also quite consistent with two other recent reports using the boundary paradigm to investigate semantic preview benefit. First, Rayner and Schotter (2013) found that when target words were presented normally in lowercase (i.e., navy, church), there was no evidence of semantic preview benefit. However, when the first letter of the target word was capitalized (i.e, Navy, Church), there was evidence of semantic preview benefit in later eye movement measures (reflecting refixations on the target word or regressions from the target word). The latter result is consistent with the findings reported by Hohenstein and Kliegl, given that the first letter of German nouns (which were target words in their study) were capitalized. We will return to this finding later in this section. Second, Schotter (2013) found no evidence for semantic preview benefit when the previews were semantic associates of the target word. However, when the preview was a synonym of the target word, she did find preview benefit.
Together, the present results and those of Rayner and Schotter (2013) and Schotter (2013) suggest that semantic preview benefit in English might be rather difficult to observe. Actually, the stimuli used by Rayner et al. (1986) and, therefore, in the present study as well are a mix of synonyms, antonyms, and semantic associates. Schotter’s results demonstrate that synonyms yield semantic preview benefit but semantic associates do not. Clearly, other types of semantic relationships between words should be investigated, as well, perhaps, as the relationship between the prior context and the preview/target words.
We suspect that preview benefit is most likely to occur when there is some type of match between the preview word and the target word. Thus, with orthographically and phonologically related previews, there are matches between the preview and the target word; even when phonologically related previews do not match on orthography but do match on phonology (i.e., shoot, chute), preview benefit is obtained (Pollatsek et al., 1992). Likewise, given that synonyms match on meaning, this results in preview benefit (Schotter, 2013). However, with semantic associates, there is no match in terms of orthography, phonology, or meaning.
Another factor that is likely to be quite relevant is the nature of the writing system. With Chinese, for example, semantic information is more transparently encoded in the writing system. Likewise, German is a more shallow writing system than the deep orthography of English. As was noted earlier, Hohenstein and Kliegl (2013) obtained semantic preview benefit for German readers. One reason for this may be that the first letter of their target words were capitalized, and this may draw more attention to the preview word than is the case with standard lowercase (as in English). However, Hohenstein and Kliegl (their Experiment 2) also reported preview benefit even when the first letter of the target word was not capitalized (even though this violates German rules of orthography). Thus, preview benefit may simply be easier to demonstrate in shallow orthographies (see Schotter, 2013, for a discussion).
Finally, it may be the case that evidence for semantic preview benefit can be obtained for a deep orthography like English, given the right circumstances.Footnote 7 Of course, this remains to be seen. However, as is indicated by the present results, as well as the results of Rayner et al. (1986), Rayner and Schotter (2013), and Schotter (2013), semantic preview benefit in English seems to be rather elusive.
Notes
For fixation probability, the model with the maximal random effects structure did not converge, so we removed the correlation between the contrast for the VSN condition and the other contrasts in the random effects structure for items.
Log transforming the dependent variables increased the t-values of the comparisons, generally, but did not change the patterns of significance.
One could interpret the numerical difference between the means of the single-fixation durations for the SR and UR conditions as a suggestion of a semantic preview benefit. However, a post hoc power analysis revealed that on the basis of the mean difference, the effect size observed in the present study (d = 0.25) would require 128 subjects to obtain statistical power at the recommended .80 level (Cohen, 1988). This high number of required subjects casts doubts on whether this suggestion of an effect has the potential of becoming significant in eye movement experiments run on subject numbers remotely typical for the field. Moreover, close examination of the difference scores for the subjects revealed that for 12 out of 24 subjects, the sign of the difference score was positive and, for the remaining 12, was negative. Again, this casts doubt on whether our design was failing to pick up an existing effect.
We also ran additional models on the fixation duration data, including the length of the incoming saccade and the duration of the fixation preceding the fixation on the target word. There was no indication that a semantic preview was observed for those instances when the eyes were close to the target word on the prior saccade and/or when this preceding fixation was long.
While it is widely assumed that semantic preview benefit effects are more consistent with the SWIFT model (Engbert, Nuthmann, Richter, & Kliegl, 2005) than with the E-Z Reader model (Reichle, Pollatsek, Fisher, & Rayner, 1998), it is the case that the latter model can account for semantic preview benefit effects (see Hohenstein & Kliegl, 2013, for a discussion and, especially, Schotter et al., in press, for simulations demonstrating this).
References
Altarriba, J., Kambe, G., Pollatsek, A., & Rayner, K. (2001). Semantic codes are not used in integrating information across eye fixations in reading: Evidence from fluent Spanish-English bilinguals. Perception & Psychophysics, 63, 875–890.
Ashby, J., & Rayner, K. (2004). Representing syllable information during silent reading: Evidence from eye movements. Language and Cognitive Processes, 19, 391–426.
Baayen, R. H., Davidson, D. J., & Bates, D. M. (2008). Mixed-effects modeling with crossed random effects for subjects and items. Journal of Memory and Language, 59, 390–412.
Balota, D. A., Pollatsek, A., & Rayner, K. (1985). The interaction of contextual constraints and parafoveal visual information in reading. Cognitive Psychology, 17, 364–390.
Barr, D. J., Levy, R., Scheepers, C., & Tily, H. J. (2013). Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language, 68, 255–278.
Bates, D. M., Maechler, M., & Bolker, B. (2011). Lme4: Linear mixed-effects models using S4classes. R package version 0.999375–42. http://CRAN.R-project.org/package.lme4
Bertram, R., & Hyönä, J. (2007). The interplay between parafoveal preview and morphological processing in reading. In R. P. G. van Gompel, M. H. Fischer, & R. L. Hill (Eds.), Eye movements: A window on mind and brain (pp. 391–407). Amsterdam, the Netherlands: Elsevier.
Binder, K. S., Pollatsek, A., & Rayner, K. (1999). Extraction of information to the left of the fixated word in reading. Journal of Experimental Psychology: Human Perception and Performance, 25, 1162–1172.
Cohen, J. (1988). Statistical power analysis for the behavioral sciences. Hillsdale, NJ: LEA.
Deutsch, A., Frost, R., Peleg, S., Pollatsek, A., & Rayner, K. (2003). Early morphological effects in reading: Evidence from parafoveal preview benefit. Psychonomic Bulletin & Review, 10, 415–422.
Deutsch, A., Frost, R., Pollatsek, A., & Rayner, K. (2000). Early morphological effects in word recognition in Hebrew: Evidence from parafoveal preview benefit. Language and Cognitive Processes, 15, 487–506.
Deutsch, A., Frost, R., Pollatsek, A., & Rayner, K. (2005). Morphological parafoveal preview benefit effects in reading: Evidence from Hebrew. Language and Cognitive Processes, 20, 341–371.
Dimigen, O., Kliegl, R., & Sommer, W. (2012). Trans-saccadic parafoveal preview benefits in fluent reading: A study with fixation-related brain potentials. NeuroImage, 62, 381–393.
Drieghe, D., Rayner, K., & Pollatsek, A. (2005). Eye movements and word skipping during reading revisited. Journal of Experimental Psychology: Human Perception and Performance, 31, 954–969.
Engbert, R., Nuthmann, A., Richter, E., & Kliegl, R. (2005). SWIFT: A dynamical model of saccade generation during reading. Psychological Review, 112, 777–813.
Francis, W. N., & Kucera, H. (1982). Frequency analysis of English usage: Lexicon and grammar. Boston: Houghton Mifflin.
Hohenstein, S., & Kliegl, R. (2013). Semantic preview benefit during reading. Journal of Experimental Psychology: Learning, Memory, and Cognition, 40, 166–190.
Hohenstein, S., Laubrock, J., & Kliegl, R. (2010). Semantic preview benefit in eye movements during reading: A parafoveal fast-priming study. Journal of Experimental Psychology: Learning, Memory, and Cognition, 36, 1150–1170.
Hyönä, J., & Häikiö, T. (2005). Is emotional content obtained from parafoveal words during reading? An eye movement analysis. Scandinavian Journal of Psychology, 46, 475–483.
Inhoff, A. W. (1989). Lexical access during eye fixations in reading: Are word access codes used to integrate lexical information across interword fixations? Journal of Memory and Language, 28, 444–461.
Kambe, G. (2004). Parafoveal processing of prefixed words during eye fixations in reading: Evidence against morphological influences on parafoveal preprocessing. Perception & Psychophysics, 66, 279–292.
Lima, S. D. (1987). Morphological analysis in sentence reading. Journal of Memory and Language, 26, 84–99.
Miellet, S., & Sparrow, L. (2004). Phonological codes are assembled before word fixation: Evidence from boundary paradigm in sentence reading. Brain and Language, 90, 299–310.
Pollatsek, A., Lesch, M., Morris, R. K., & Rayner, K. (1992). Phonological codes are used in integrating information across saccades in word identification and reading. Journal of Experimental Psychology: Human Perception and Performance, 18, 148–162.
Rayner, K. (1975). The perceptual span and peripheral cues in reading. Cognitive Psychology, 7, 65–81.
Rayner, K. (1998). Eye movements in reading and information processing: 20 years of research. Psychological Bulletin, 124, 372–422.
Rayner, K. (2009). The Thirty Fifth Sir Frederick Bartlett Lecture: Eye movements and attention during reading, scene perception, and visual search. Quarterly Journal of Experimental Psychology, 62, 1457–1506.
Rayner, K., Balota, D. A., & Pollatsek, A. (1986). Against parafoveal semantic preprocessing during eye fixations in reading. Canadian Journal of Psychology, 40, 473–483.
Rayner, K., McConkie, G. W., & Zola, D. (1980). Integrating information across eye movements. Cognitive Psychology, 12, 206–226.
Rayner, K., & Schotter, E.R. (2013). Semantic preview benefit in reading: Initial letter capitalization. In preparation.
Reichle, E. D., Pollatsek, A., Fisher, D. L., & Rayner, K. (1998). Toward a model of eye movement control in reading. Psychological Review, 105, 125–157.
R Development Core Team (2012). R: A language and environment for statistical computing [Computer software]. Vienna, Austria: R Foundation for Statistical Computing.
Schotter, E. R. (2013). Synonyms provide semantic preview benefit in English but other semantic relationships do not. Journal of Memory and Language, 69, 619–633.
Schotter, E. R., Angele, B., & Rayner, K. (2012). Parafoveal processing in reading. Attention, Perception, & Psychophysics, 74, 5–35.
Schotter, E.R., Reichle, E.D., & Rayner, K. (in press). Re-thinking parafoveal processing during reading: Serial attention models can explain semantic preview benefit and N+2 preview effects. Visual Cognition.
Slattery, T. J., Angele, B., & Rayner, K. (2011). Eye movements and display change detection during reading. Journal of Experimental Psychology: Human Perception and Performance, 37, 1924–1938.
Author Notes
The research was supported by grants HD26765 and DC000041 from the National Institutes of Health. We thank Reinhold Kliegl, Kevin Paterson, and Melvin Yap for their helpful comments on an earlier draft.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Rayner, K., Schotter, E.R. & Drieghe, D. Lack of semantic parafoveal preview benefit in reading revisited. Psychon Bull Rev 21, 1067–1072 (2014). https://doi.org/10.3758/s13423-014-0582-9
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-014-0582-9