
Abstract
I address a recent extension of the generalized context model (GCM), a model which excludes prototypes, to the visual short-term memory (VSTM) literature, which is currently deluged with prototype effects. The paper includes a brief review whose aim is to discuss the background and key findings suggesting that prototypes have an obligatory influence on visual short-term memory responses in the same VSTM task that the GCM’s random walk extension, EBRW, was extended to account for: Sternberg scanning. I present a new model that incorporates such “central tendency representations” in memory, as well as several other regularities of the literature, and compare its prediction and postdictions to those of the GCM on some unpublished Sternberg scanning data. The GCM cannot account for the pattern in those data without post hoc modifications but the pattern is predicted nicely by the central tendency representation model. Although the new model is certainly wrong, the review and modeling exercise suggest a reconsideration of prototype models may be warranted, at least in the VSTM literature.
Similar content being viewed by others
The Atkinson–Shiffrin model of memory (Atkinson & Shiffrin, 1968) has motivated a great deal of theoretical development in memory research. Indeed, many of the most useful and successful models of long-term memory retrieval can be seen as attempts to expand upon the modal model’s basic structure and control mechanisms. Yet, despite such developments in the long-term memory literature, modeling of short-term memory seemed to develop in a somewhat different manner, with a landscape divided by overly general verbal theories and narrowly focused mathematical models. To quote Shiffrin (1993, p. 195): “A few well-worked-out models, roughly consistent with the framework, do a good job of predicting the data from particular paradigms [...], but a generally applicable model remains a goal for the future.”
In many ways, the trend toward development of mathematical models tailored to specific STM paradigms has continued (Ma, Husain, & Bays, 2014; Zhang & Luck, 2011). However, there have been notable exceptions. For instance, the feature-matching ideas embodied in global matching models have recently been extended to account for visual short-term memory (VSTM) data via the exemplar-based random walk model (EBRW; Nosofsky, Little, Donkin, & Fific, 2011; Nosofsky, Cox, Cao, & Shiffrin, 2014). EBRW is an extension of the generalized context model (GCM; Nosofsky, 1984, 1992, 2000; Zaki & Nosofsky, 2001), and uses the same basic representational and retrieval scheme as GCM to account for reaction times via addition of the well-known “Gambler’s Ruin” process (Feller, 1968; Nosofsky & Palmeri, 1997; Parzen, 1962). Thus, while EBRW has dealt with a specific task in VSTM (Sternberg scanning), it is built on a long history of success applying GCM and EBRW to perceptual categorization and in this sense the EBRW may very well represent the kind of STM model Shiffrin (1993) hoped to see developed. That is, a detailed mathematical account with some degree of generality and scope.
Interestingly, the VSTM literature has maintained a great deal of interest in representational schemes and ideas that seem contrary to a core aspect of the EBRW, namely, its exclusion of any kind of memory representation of prototypes or other memories of summary information. The model instead assumes that decisions are based solely on a global match between the features of a given probe, for a categorization or old/new recognition decision depending on the task, and the features of memory representations of each of the items from recent study or training trials. Specifically, in the generalized context model (McKinley & Nosofsky, 1995; Nosofsky, 1984, 1986a, 1992, 2000; Zaki, Nosofsky, Stanton, & Cohen, 2003), the basic model of response choice that the EBRW builds upon, responses to a categorization probe p reflect a global match in which the probe’s similarity to each previously seen exemplar a of category A and b of category B is computed. Similarity is an exponential decay function of Euclidean distance d in a multidimensional feature space estimated through multidimensional scaling (MDS):
This means that the mental representation of similarity between a probe p and a given exemplar’s memory representation j falls off exponentially as the MDS solution’s Euclidean distance increases.
Probe-exemplar similarities within Category A are summed and divided by probe-exemplar similarities summed over all studied categories K (in this case that would mean all the exemplars, regardless of whether they were in A or B). This computation, an application of Luce’s Choice Ratio (Luce, 1961), estimates the response probability for each test item.
As I mentioned, this pure exemplar approach to VSTM stands in clear contrast to a large and growing literature that is usually interpreted as showing that participants are quite good at estimating and remembering the summary statistics of recently encountered stimuli, that use of such representations can improve VSTM accuracy, and that those memories appear to obligatorily influence responding. That is, several of those demonstrations appear to show distorting effects of “central tendency representations” on memory and perceptual responses to subsequent stimuli presented in experiments with parameters comparable to those of the VSTM and categorization tasks to which the EBRW has been applied.
In what follows, I discuss this literature with the aim of substantiating a key claim that VSTM responses in tasks such as Sternberg scanning may show an obligatory influence of central tendency representations for stimuli presented both simultaneously and sequentially. I then describe a simple model incorporating some of the regularities discussed in the review and compare its predictions to those of the GCM, EBRW’s core, in unpublished data using a stripped-down, one-dimensional version of the Sternberg task.
To preview, the results show an effect that ranges from problematic to impossible for GCM to explain, but which can be easily explained by assuming the matching process includes matches to a stored prototype (which has also been termed a “summary statistical” or “ensemble” representation, when the word “prototype” is not used; the preference appears to vary by lab but not by task or aspects of the relevant data). Though the model I propose is most certainly “wrong,” its ability to account for the data in this way suggests a reconsideration of prototype models, at least within the domain of VSTM, may be warranted. Such results may suggest an important difference between the mechanisms of VSTM and perceptual categorization that should be embraced by unifying mathematical accounts.
Central tendency representation
Ariely (2001) conducted an experiment that has had a major impact on subsequent work in the perception and short-term memory literatures. In the study, subjects were shown displays containing circles whose diameters differed. Following each display, subjects were shown one or two test probes. The number of probes differed only with respect to the judgment (Yes/No or 2AFC), but produced analogous results. Hence, we describe the single-probe variant. Here, subjects were to make one of two judgments on a given trial. On some trials they were asked whether the probe circle had been in the memory set (Member Identification), and on others they were asked whether the probe was larger or smaller than the mean size of the study circles (Mean Discrimination). Ariely found that, despite chance performance on Member Identification, subjects were highly accurate in Mean Discrimination. Ariely speculated that such summary statistical representation of the items could be adaptive, increasing the efficiency of the visual memory system when item representations are degraded or forgotten.
Ariely’s study inspired a massive amount of subsequent research that continues to this day. This work promptly and clearly established that central tendency representation occurs for tasks as varied as multiple object tracking (Alvarez and Oliva, 2008), rapid serial visual presentation (Corbett & Oriet, 2011), change detection (Wilken & Ma, 2004), and Sternberg scanning (Dubé, Zhou, Kahana, & Sekuler, 2014), to name a few. Several studies by Sperling and colleagues have even used judgments of the centroids of spatially arrayed stimuli to estimate the parameters of attentional filtering operations (Drew, Chubb, & Sperling, 2009, 2010; Sun, Chubb, Wright, & Sperling, 2016).
Besides establishing that central tendency representation occurs at a basic level, spanning tasks and processing domains within perception and memory, this subsequent work also suggests that i) central tendency representation is obligatory, influencing subjects’ responding regardless of whether any instruction to compute an average is given (e.g., Dubé et al., 2014), ii) perceptual averages occur across time, affecting memory for items presented in sequence (e.g., Haberman, Harp, & Whitney, 2009, using face stimuli varying in emotional expression), and iii) the effects on memory retrieval of this latter, temporal mode of averaging are greater when visual attention at encoding is compromised (e.g., Dubé et al., 2014). Such reliance on averages under conditions of reduced or divided visual attention makes sense given Ariely’s finding that iv) memory for the average is preserved even when subjects have no memory for the individual stimuli that were presented and v) the demonstration by Alvarez (2011) that central tendency representation can improve VSTM performance and compensate for information loss in memory.
Although initial investigations of central tendency representation typically followed Ariely (2001) in explicitly asking participants for an estimate of some summary statistic (usually central tendency, which I focus on here), the key claim I wish to advance in this review is that the influence of central tendency representations on memory and perception responses is obligatory. This claim is, of course, open to question and alternative explanations for the results I will discuss are possible (as I detail below).Footnote 1 Yet, the overall consistency of the various results with the hypothesis suggests the hypothesis is worthy of consideration in theoretical development and empirical tests (work which is initiated to a modest extent later in this paper).
To start at the beginning, it is interesting that obligatory and biasing “central tendency effects” on perceptual judgments were a major subject of investigation in the early years of psychophysics, important enough to warrant considerable discussion in Woodworth and Schlosberg’s classic text (Woodworth & Schlosberg, 1954). Work conducted somewhat later also appears to show effects of central tendency representations, though the effects were discussed in different terms (but with what appears to be equivalent meaning to today’s terminology).
For instance, Ball and Sekuler (1980) used what is nominally a perceptual task, motion detection, to test models of stimulus uncertainty involving memory representations of prior stimuli. All of their experiments involved presentation of random dot cinematograms (RDC) in which the dots were initially stationary but began to “move” after an unpredictable interval. The subject’s task was simply to respond as quickly as possible with a keypress as soon as they detected the onset of motion. In some of their experiments, blocks contained RDCs with net movement along the same vector; these were termed “Certain” conditions. In other blocks, a given trial could present one of two possible directions: the direction from Certain blocks and another direction. Across blocks of this “Uncertainty” condition, the second direction varied parametrically with respect to the Certain RDC direction. Inflation in reaction times with uncertainty was measured via a ratio of RT to the Certain direction in Certain blocks to the RT for that same direction in each of the Uncertain blocks. The results showed a clear parabolic relation across several experiments, a result that has subsequently been replicated in RT along with a similar pattern in the corresponding N1 ERP component (Zanto, Sekuler, Dube, & Gazzaley, 2013).
Of the models Ball and Sekuler considered, one, termed the “Midway” model, is of particular interest. That model assumed that, when faced with uncertainty about which of two directions could appear on a given trial, subjects relied in part on a memory representation of the direction that would be midway between the two directions in the block. The authors conceptualized this notion as a bank of feature detectors with particular directional tuning profiles, with attention directing the system toward detectors tuned to the midway direction. The key test of this model occurred in experiments in which uncertain blocks included a third RDC direction occurring on a small subset (5-10%) of trials, the direction of this RDC’s motion matching the average of the two other directions. Such a stimulus would normally be considered an oddball, and as in a typical oddball task one would predict slower RT on trials presenting this RDC direction (Hyman, 1953). However, if subjects were actually encoding a memory representation of the midway direction over trials and using it to improve their RT under uncertainty, then the feature detectors for this direction should be primed and produce faster RTs, contrary to expectation.
The midway RT prediction is precisely what the authors found, leading them to conclude that subjects mitigate uncertainty by reliance on a midway representation. These results complement other work showing that RDC motion detection requires averaging over the motion vectors within an RDC (Watamaniuk & Sekuler, 1992), suggesting somewhat similar averaging operations occur at different timescales.
Turning to studies of recall from VSTM, it appears that a similar mechanism may be at work. In one such study, Huang and Sekuler (2010a, Experiment 2) presented pairs of Gabor patches in rapid succession, followed by a probe Gabor patch. Subjects used the method of reproduction to adjust the spatial frequency of the probe Gabor to match one of the two study items. The study item in question was indicated by a cue that was presented after both study items had been presented. The results showed distortions in recall in the direction of the spatial frequency of the non-target Gabor, as well as an independent distorting effect of the average spatial frequency of the previously-presented study items (i.e., from prior study-test cycles). The latter “prototype effect” was subsequently found by Huang and Sekuler (2010b) using a similar design and with the addition of EEG recording during encoding. The results demonstrated that encoding-related pre-stimulus, posterior alpha power, long considered a marker of visual attention (see, e.g., Dubé, Payne, Sekuler, & Rotello, 2013), was negatively correlated with the prototype effect. This suggests, consistent with other proposals in the VSTM literature (e.g., Wilken & Ma, 2004), that subjects rely on central tendency representations to compensate for processing limitations that reduce the fidelity of the memory representations that are subsequently probed at test (see also Payne & Sekuler, 2014; Payne, Guillory, & Sekuler, 2013).
Nonetheless, it seems possible that the distortions were due at least in part to confusions among the study items in memory (i.e., matching the probe to the irrelevant/uncued study item). Huang and Sekuler (2010a) addressed this by examining the relation between reproduction bias (distortion toward the irrelevant item) and skew of the response distributions, finding that the two were statistically independent. This argues against a confusion of items because if the distortion reflected such a confusion that distortion should have been greater when the error distribution showed greater skew in the direction of the irrelevant item, but this did not occur. Additionally, other data from a similar task using a recognition probe argue against this as I mention below (a central tendency effect remains despite a near-zero false alarm rate, or FAR, to Gabor probes matching the irrelevant study item).
Note that none of the foregoing experiments conducted by Sekuler and his colleagues included any instruction or requirement to produce an average. This suggests that, not only are subjects adept at doing so as a wealth of prior VSTM studies suggest, but they do so obligatorily. Such obligatory averaging, if true, would make sense when taken along with the simulations reported by Alvarez (2011) showing that VSTM can be improved by incorporating central tendency representations. The variation in a prototype’s influence with markers of attention (greater influence when attention was reduced immediately preceding the study Gabors) and the findings from Ball and Sekuler (1980) regarding stimulus uncertainty are all consistent with the idea that reliance on or influence from the prototype is an adaptive phenomenon, right in line with Alvarez (2011) and Wilken and Ma (2004). In other words, reliance on summary information may constitute a kind of control process (Atkinson and Shiffrin, 1968) applied to visual STM at the time of retrieval.
Going a step further, Dubé et al., (2014) explored the within-trial “attractor” effect reported by Huang and Sekuler (2010a), using an analysis of mnemometric functions. The basic task followed the original study closely: On each trial, subjects viewed two Gabor patches presented sequentially. Each Gabor contained vertically and horizontally oriented sinusoid components. Following the presentation of the second Gabor, a recognition probe was presented that either did or did not match one of the two study Gabors. Subjects made a Yes-No recognition response to the probe. Important differences include a manipulation of attention and parametric variation in the stimuli used to construct the mnemometric functions.
Specifically, the Gabor stimuli were constructed in such a way that only the vertical spatial frequency dimension of each Gabor pattern could be used to make a response. The precise values of spatial frequency for each subject were obtained using a staircase technique, allowing each stimulus to be expressed in just noticeable difference (JND) units above a fixed base frequency. The recognition probes presented to each subject in the experiment took on 15 different JND values, including the value that matched the relevant study item (Target trials) and 14 degrees of mismatch (Lure trials). Relevant and irrelevant study items were always separated by eight JNDs, with the relevant item taking on a value of either four or 12 JNDs. With this technique, the distributions of recognition response rates (P(“Yes”) values) at each of several levels of feature matching could be constructed. These distributions, termed mnemometric functions (Sekuler & Kahana, 2007), were then modeled using a truncated skew-normal distribution (Azzalini, 1986), which allowed separate estimates of the Gaussian variance and skew of the resulting response distributions.
A key manipulation in the experiment involved the presentation of an attention cue. This cue was included at several timepoints in order to examine how selective visual attention affects stimulus representations. The cue indicated which stimulus (1 or 2) would serve as the trial’s relevant study item, to be compared to the probe, and appeared either before the first study item (Pre Cue condition), between the items (Mid Cue), or after both items had been presented (Post Cue). The results showed an effect consistent with an influence of a central tendency representation on responses to the probe stimulus, distorting subjects’ response distributions. Specifically, subjects’ response distributions were inflated (relative to a baseline that involved presentation of a single study item) in the region spanning the average of the two study items’ spatial frequencies (5-11 JNDs). This occurred regardless of whether the first or second study item served as the task-relevant item. Crucially, the analysis of the skew-normal parameters revealed a greater influence of central tendency representation (an increase in skew, but not variance) when the attention cue could not be used to selectively attend to the relevant stimulus (Post Cue conditions). The key results can be seen in Fig. 1. They suggest that i) central tendency representation obligatorily influences recognition performance, and ii) such effects are most pronounced when selective attention is lacking during study.

False alarms to Gabor Lures matching the average spatial frequency of two study Gabors in a Sternberg recognition task, as well as a control Lure whose spatial frequency fell outside of the range spanned by the study items. The “central tendency” effect was largest when attention cues followed both study items, compromising visual attention relative to the Pre- and Mid-Cue conditions (see text). The d values are Cohen’s d. Data from Dubé et al., (2014)
As pointed out by Dubé et al., the results are unlikely to be due to confusions regarding which study item should be matched to the probe, as FAR to “lures” matching the irrelevant study item were essentially nonexistent. And given the similarity to the prior studies of Sekuler and colleagues using Gabors as well as their own analysis of this potential confound discussed previously, it seems likewise unlikely that the distortion effects reported in those studies were due to such confusions (the behavioral study by Huang and Sekuler, for instance, differs from Dubé et al. mainly in that the former used a recall probe).
It is possible, however, that the increase in FAR is due to an exemplar-matching process since the critical lures, falling between the two study items’ spatial frequencies, will have higher summed similarities than the control lure which falls outside of the range spanned by the two study items. This suggests a more diagnostic test may be needed to definitively conclude that the effects described in these VSTM studies are due to the influence of central tendency representations.
Obligatory averaging effects have also been demonstrated for perceptual judgments using the adaptation paradigm (Corbett & Melcher, 2014; Corbett & Song, 2014; Corbett, Wurnitsch, Schwartz, & Whitney, 2012). For instance, Corbett and Melcher (2014) had subjects view two clusters of dots differing in the dots’ diameters. The clusters were presented to the left and right of fixation, with one cluster having a higher mean dot diameter than the other. The clusters remained in view for 1 min, functioning as an adaptor. After the adaptation period, two test clusters replaced the adaptation clusters. Subjects were asked to select the cluster in this new display that had the larger average diameter. Subjects’ responses were distorted away from the average diameter of each adaptation cluster: clusters preceded by an adaptor cluster with a large diameter appeared to have a smaller diameter, and vice-versa, and the effects were nonretinotopic. This is another example of a perceptual task that nonetheless shows results consistent with an obligatory influence of a central tendency representation held in VSTM.
A study by Oriet and Hozempa (2016) shows additional evidence for obligatory central tendency encoding. They showed subjects several displays each containing ensembles of circles varying in features such as their diameter and color fill. Each trial involved perceptual judgments that should have been unrelated to central tendency memory, such as judging whether a color was repeated in the display. Later, after several thousand circles had been viewed, the subjects were incidentally asked to judge the statistical properties of the stimuli they had seen, such as drawing a circle with a diameter that matches the average circle they had seen. Subjects were highly accurate in this task, as in so many prior central tendency tasks. However, this was again an implicit task in which subjects were presumably encoding the stimulus statistics incidentally. In discussing their results, the authors pointed out that “..the present finding that subjects retain a very accurate summary representation of an irrelevant, unattended feature would seem to be at odds with the claim that no prototype is extracted as the set of exemplars is learned.” Of course, it is always possible to argue that prototype extraction does not necessarily mean prototypes are always used to complement retrieval or other cognitive processes. However, as Alvarez (2011) has demonstrated, reliance on central tendency information can compensate for information loss, in which case it would seem disadvantageous for subjects to ignore such information if it had in fact been obligatorily encoded. It does remain unclear, however, whether central tendency representations were formed during encoding of the stimuli, or calculated at the time the statistical judgments were queried from memory of (at least some of) the prior items.
Interestingly, obligatory central tendency effects may not be limited to effects of the first moment. The spread of the feature distributions can have an impact as well. Specifically, several studies have demonstrated an influence of the similarity between items within a Sternberg study set (i.e., their homogeneity) on the following test responses (Kahana & Sekuler, 2002; Nosofsky & Kantner, 2006; Sekuler & Kahana, 2007). This phenomenon was incorporated into the Noisy Exemplar Model of Kahana and Sekuler (2002), a matching model closely related to the GCM. In several tests of the model, Kahana and colleagues consistently found that higher homogeneity is associated with lower FAR. At present, however, it remains unclear whether homogeneity is a memory representation or the result of a computation carried out at test. Existing models appear to be agnostic regarding the locus of the computation (during study or at retrieval).
An interaction between homogeneity and obligatory central tendency effects has also been reported. In one such study, Corbett et al., (2012) used the adaptation task described previously and found that the size of the effect increased as the variance of the adaptor dots’ diameters decreased. This suggests reliance on central tendency representations may be greatest under conditions of high homogeneity. An anologous pattern can be seen in the mnemometric functions reported by Kahana, Zhou, Geller, and Sekuler (2007), for visual textures in a two-item Sternberg task.
Can the EBRW, a VSTM model that conspicuously lacks memory representations of central tendency information, account for the foregoing effects in VSTM? The answer seems to be “probably.” That is, Zaki and Nosofsky (2001) showed that the GCM (EBRW’s core model) can account for various increases in FAR to prototype lures relative to other lures. However, for the GCM model which assumed an exponential similarity gradient, prototype effects in designs with two study items are limited to cases in which FAR to prototype lures approximates but does not exceed HR (see Fig. 2A in Zaki & Nosofsky, 2001). As noted by Zaki and Nosofsky (2001) with respect to the exponential GCM applied to the two-item case:
“there are no parameter values in the model that allow it to predict that the false-alarm rates to the prototypes would exceed the hit rates of the old items. Furthermore, it is only for values of the sensitivity parameter that are virtually equal to zero that the model predicts that false alarms to the prototypes will be nearly equal to hit rates for the old items, (p. 1026).”
In the exponential GCM, FAR to prototype lures may exceedHR only in cases where there is i) high sensory noise, ii) multiple feature dimensions relevant to the judgment(s), and iii) more than two study items (training exemplars; see, e.g., Fig. 2B in Zaki & Nosofsky, 2001). All three conditions must hold. Further, Nosofsky (1985a) has argued that when confusable stimuli are used and sensitivity is in fact low, a Gaussian similarity gradient provides a more accurate description of generalization performance (see also Nosofsky, 1985b, 1986b). As a Gaussian gradient is capable of producing FAR > HR even in the two-item, one-dimensional case, it is of particular interest in explaining prototype effects in VSTM. I will return to this point later.
Next, I develop an alternative VSTM scanning account that incorporates some of the central tendency representation ideas discussed in the VSTM literature. Simulations with the model show a prototype enhancement for a one-dimensional, two-item task (in this case, a Sternberg task similar to the ones to which EBRW was applied). The increase in FAR is predicted, under certain experimental conditions, to not only meet but exceed HR. Following the simulation, I test this prediction using unpublished data (Huang & Sekuler, unpublished manuscript). Included are comparisons of the central tendency representation model, the exponential GCM (which cannot predict FAR > HR in this one-dimensional, two-item case), and the Gaussian GCM (which can) in fits to the unpublished data as well as to published data from Kahana et al., (2007).
Compression model
To illustrate how memory representations of central tendency statistics (including homogeneity) could be incorporated into a matching model, consider a model of performance in the Sternberg recognition task with two study items (as in Dubé et al., 2014), in which only two matches directly factor into memory evidence: The match between the probe and the best matching item in memory, and the match between the probe and the average stored in memory.
The model is situated within the logistic approach exemplified by, e.g., Luce (1961). The memory evidence is a combination of two match values: the match between the probe p and its best-matching study item, smin, defined as follows
and the match between p and the central tendency representation of the two items, the latter referred to as sμ:
The term dmin in Eq. 3 is the Euclidean distance (d) between the probe (p) and its best-matching study item, smin, and dμ in Eq. 4 is the distance between the probe and the average of the study items (sμ). In general terms:
where 𝜖 is a Gaussian noise term to mimic imperfections in memory representations and/or noise in the matching process.
The exponents on the evidence expressions, r and v, govern the degree of sensitivity to mismatches: larger values of r and v produce more extreme changes in evidence as the degree of mismatch between p and s increases.
Finally, the weighting parameter 𝜃 captures the effect of the distance D between the two study items, i.e., their dissimilarity or inverse homogeneity, on the combination of evidence.
The parameter δ controls the rate of change in 𝜃 with changes in D, and the exponents n control the shape of the function. The functional form, sometimes referred to as a “Naka-Rushton” function, is widely used in computational neuroscience as a model of gain control in the visual and various other sensory systems (Billock and Tsou, 2011; Carandini & Heeger, 2012; Graham, 2011; Naka & Rushton, 1966). Here it is used to selectively amplify the matches to an item feature and an ensemble average of that feature.
The choice of using only the best match to an individual exemplar is motivated by the success and widespread application of the winner-take-all activation rule in machine learning and neural computation (Grossberg, 1982; Riesenhuber & Poggio, 1999). 𝜃, the model’s attentional weighting parameter, could be expanded into or rewritten as a function relating changes in endogenous visual attention to internal noise (Carrasco, 2011; Lu & Dosher, 1998) of the memory representations of the study items. In this way, the parameter could serve as an inverse measure of sensitivity akin to modulating the standard deviation in the denominator of discrimination measures such as the signal detection measure, d′ (Macmillan & Creelman, 2005). It is also possible to characterize the weight in terms of control processes (Atkinson & Shiffrin, 1968), for instance by incorporating the notion that participants may increase the weight on central tendency information when greater noise or uncertainty are present in the system. In order to retain the simplicity of the model at present, however, the variable δ on which the attention weight 𝜃 depends is simply a free parameter.
Matches provide memory evidence to the response system in support of a “Yes” response. The evidence corresponding to a particular threshold t∗, similar to the “activation” at threshold in many neural networks, is:
The probability of an “Old” response in this model is based on the total evidence for thresholds exceeding t∗, for a given probe condition p and study-item spatial frequencies (in JNDs, e.g.) smin and smax. This fraction can be calculated by integrating the evidence with respect to t∗ using a partial fraction decomposition:
The quantity denoted Z above corresponds to the total activation in the system and normalizes the evidence favoring a “Yes” response:
in which b is an arbitrary upper bound.
Performing a similar computation with Z and substituting the result into Eq. 8 produces:
Finally, taking the limit as the upper bound approaches infinity produces the final expression of choice probability:
To examine the model’s predictions, I conducted a simulation to examine predicted mnemometric functions with varying D. The scenario is a two-item one-dimensional Sternberg recognition task as in Dubé et al., (2014). The parameter values, chosen by hand, were r = 2, v = 3, n = 9, δ = 4 (low attention) and 1 (high attention), and t∗ = .3. The values of s1 and s2 features (arbitrary units) were varied to create three levels of homogeneity: -5 and 5, -4 and 4, -3 and 3. Though ideally the parameter 𝜖 should be a random draw from a Gaussian, for simplicity it was set to a small arbitrary value (.001). Probes were integers spanning the range [-10, 10].
The results, shown in Fig. 2, demonstrate the model’s ability to produce quasi-normal mnemometric functions and decreasing FAR with increasing homogeneity (compare to, e.g., Kahana et al., 2007, Fig. 2). More importantly, the figure shows an increase in P(“Yes”) to Lures matching the average of the two study items as homogeneity increases from panel A to C, and as the attention weight 𝜃 decreases (open vs. closed circles). A novel prediction of this model is that, under conditions of very high homogeneity (i.e., low D) and relatively low attentional fidelity, the FAR to the central Lure (henceforth, FARa to Lurea) will not only meet, but will exceed, HR.

Simulated mnemometric functions using the compression model. Open circles used δ = 1, and closed circles used δ = 4. Vertical lines denote the locations of s1 (left line) and s2, where the probe feature value equals that of either s1 or s2. As homogeneity increases from the leftmost to rightmost panel, 𝜃, the model’s attention-based weighting parameter, approaches 0. This puts more weight on the match to the central tendency representation, inflating FAR to Lurea, located at a feature value of 0 in the figure. A key prediction is that highly homogeneous study items in a two-item, one-dimensional Sternberg task will generally produce FARa > HR unless visual selection is engaged at study
This prediction is tested next, using unpublished data from Huang and Sekuler. The design involved a stripped-down Sternberg recognition task with study set size = 2, no attention precue, and only one variable dimension on which judgments can be supported, controlled and varied experimentally, as well as much higher homogeneity than in the Dubé et al., (2014) data (in which HR always exceeded FAR). The design affords a straightforward test of the compression model prediction that, under such conditions, FAR s to “prototype” lures may exceed HR.
Methods
Subjects
Ten paid subjects (two males) were recruited from Brandeis University’s student population. Subjects ranged from 18 to 24 years old (\(\bar {x}\) = 20.6 years) and were paid for participating. The experiment entailed two sessions per subject; successive sessions were separated by a minimum of three hours, and successive sessions were completed within 2 weeks of one another.
Stimuli
Subjects viewed Gabor patches. The Gabors’ mean luminance was 30 cd/m2 (as was their uniform, constant background); their peak Michelson contrast was 0.30. Each Gabor’s sinusoidal component subtended 5.38deg visual angle (v.a.) at a viewing distance of 59 cm. The sinusoidal component was windowed with a circular Gaussian envelope whose space constant was 1.12deg v.a. The phase of the sinusoidal component within a Gabor varied randomly over the range [0,π/2]. The Gabor patches were created and displayed using Matlab’s Psychtoolbox package (Brainard, 1997). Subjects viewed these stimuli on a 32×24 cm CRT monitor with resolution 1152×864 pixels. CRT monitor luminances were calibrated using Eye-One MatchⒸ hardware and software from GretagMacbeth.
Procedure
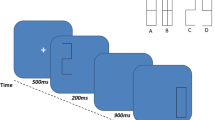
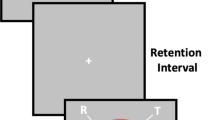
A representative trial sequence from Huang and Sekuler’s experiment is illustrated schematically in Fig. 3. On each trial, the two study set Gabors were presented simultaneously with locations equidistant from fixation. This presentation was brief (200 ms). Following a short retention interval (800±50 ms), a probe Gabor was presented and subjects indicated whether the probe matched the remembered spatial frequency of either study item. Subjects advanced to the next trial via key press.

Schematic diagram illustrating the stimulus sequence on a trial. Subjects fixated on a black dot at the center of the screen for the entire duration of the trial. The stimuli were Gabor patches of varying spatial frequency. All stimuli (study items and probe) were centered on the circumference of an invisible, notional circle (dashed circle in the figure). The pair of study-items and then the probe were each displayed for 200 ms, separated by a retention delay of 800±50 ms. A trial ended when the subject made a response, pressing one of two computer keyboard keys to signal either “yes, the probe shared the spatial frequency of one of the study items” or “no.” The locations and the feature (spatial frequency) values of stimuli varied from trial to trial, as explained in the text. Figure from Huang and Sekuler (unpublished manuscript), with permission
Spatial frequency conditions
Huang and Sekuler systematically varied not only the spatial frequency similarity between the probe and the study items, but also the probe’s location relative to the locations previously occupied by the study items. However, subjects were instructed to ignore spatial location, judging only whether the probe did or did not match one of the study items. Since the degree of spatial frequency match between items is key to the models’ predictions, I collapse over the location variable in the analysis. Target probes occurred on half of the trials (and on these trials, they matched the study item with the higher spatial frequency as often as they matched the study item with lower spatial frequency). Lures occurred on the remaining trials. Target and Lure trials were randomly intermixed. Crucially, Lures varied systematically in their position on the spatial frequency dimension with respect to the two study items, while Targets maintained a very small, constant separation of three JNDs.
Figure 4 depicts the relationships among the test probe conditions on the spatial frequency dimension. The study item with the minimum distance from a trial’s probe is designated smin, and the remaining study item smax.

Spatial frequency relationships among the items of the Sternberg task. The horizontal line represents the spatial frequency dimension. Blue dots represent the study items, and red diamonds represent Lures. A gray arrow represents a Target. The subscripts on the lures indicate how many spatial frequency units (“sf”, scaled in JNDs in the text) the items fall from smin, the best-matching (minimally distant) study item. The sign indicates whether the lure fell between the study items (“-”) or whether it fell outside of the range spanned by the study items (“+”). Note: Though the spatial frequencies of the study items, smin and smax, varied across trials, they always differed in spatial frequency by a constant: D = 3 JNDs. Figure adapted from Huang and Sekuler (unpublished manuscript) with permission
As depicted in Fig. 4, a Lure’s spatial frequency could be (i) Luresf− 1, one JND from the spatial frequency of smin and thus two JNDs from smax; (ii) Luresf+ 1, one JND from smin and four from smax; or (iii) Luresf+ 4, four JNDs from smin, but seven JNDs from smax. With equal frequency, smin was either the study item with higher spatial frequency or the study item with lower spatial frequency. Luresf− 1 approaches the average spatial frequency of smin and smax, so I refer to it as Lurea.
Stimulus set
Following the procedure suggested by Zhou, Kahana, and Sekuler (2004), the set of spatial frequencies that would be used as each subject’s stimuli was generated by a subject-specific scaling procedure. Specifically, each subject’s stimulus set comprised Gabors whose sinusoidal components’ spatial frequencies were defined by the relation
where f0 is a fixed base frequency, and Ks is a subject’s Weber fraction.
where Δf is the difference threshold (just noticeable difference, JND) for spatial frequency. Here, the JND estimated the smallest difference in spatial frequency that a subject could successfully discriminate (with an accuracy of 79%) between two iso-eccentric, simultaneously-presented stimuli having a separation of 11.81deg v.a. on a line through the fixation point.
The variable n, denoting the spatial frequency difference f - f0 in JNDs, took on integer values in the range [0,12]. This defined a set of 13 normalized stimuli whose pairwise spatial frequencies differed by a variable, but known number of JND units. To reduce the possibility that subjects might learn particular stimuli over the experiment, on each trial,the base frequency f0 was varied randomly and uniformly over the range 0.4–1.0 cycles/degree. Trial-to-trial variation in study items’ spatial frequencies forced subjects to base their recognition judgments on short-term visual memory for that particular trial’s study items.
The experiment entailed 1200 trials per subject. Of these trials, 50% were target trials (the probe’s spatial frequency matched the spatial frequency of one of the study items), and 50% were Lure trials (the probe’s spatial did not match either study item’s spatial frequency). A Target probe was presented equally often at each of the five eligible locations on 120 trials; and each of three categories of lure probes was presented at each of the five possible locations on 40 trials. All told, the probes coincided with the location of one of the study items on 40% of all trials. The order in which probe types and locations were presented was randomized across trials.
Modeling
The core of the EBRW VSTM model, the GCM recognition model, was fit to the data. The model equations are as stated in Zaki and Nosofsky (2001). Two variants were used, one with the exponential gradient and one in which the distance is squared, producing a Gaussian curve. Both GCM models had a total of 2 free parameters: c and k′. A single value of memory strength m is reasonable since the data are from a task using simultaneous presentation of the study items (published data from a sequential variant are considered subsequently). However, in the current design m and k are not identifiable: m can be set to 1 and k replaced with k′ = \(\frac {k}{m}\).
The compression model (CM) was also simplified somewhat by setting the exponent r to 1 and treating 𝜃 as a free parameter, since there is only one level of homogeneity in the current dataset. The free parameters were 𝜃, t∗, and v. In sum, there were 3 free parameters of CM and 2 parameters, c and k′, of GCM.
The models were fit in R (R Development Core Team, 2008) by using the Nelder-Mead algorithm to minimize the RMSE between the model estimates and the data. Multiple starting values were used to avoid local minima.
Results
Results are displayed in Fig. 5. Consistent with the high-homogeneity prediction in Fig. 2, there is a clear increase in FAR to Lurea relative to Lure trials in this (high-homogeneity) dataset, t(9) = 5.56, p < 0.001, BF10 = 98. Also consistent with the predictions, FAR to Lurea exceeds even the HR, by nearly 10%, t(9) = 2.93, p < 0.05, BF10 = 4.

Barplots show observed and predicted Yes rates from a two-item Sternberg experiment with a small (three JND) separation between the study items’ spatial frequencies. Data are from ten individual participants and the aggregate. Solid points and lines represent CM fits, dashed lines and open circles represent Gaussian GCM fits, dotted lines and squares represent exponential GCM fits. Data from Huang and Sekuler (unpublished manuscript). Also shown are observed mnemometric functions from Kahana et al., (2007) shown as solid points. The left function shows the fit of the CM as crosses and lines, and the right function shows the fit of the Gaussian GCM in like manner
As shown in Table 1, the CM provided a better fit to the data than the exponential GCM in all ten individuals and in the aggregate data, and the magnitude of the fit differences was substantial, t(9) = 6.49, p < 0.001, BF10 = 258. The Gaussian GCM did show an improvement over the Exponential GCM, t(9) = 4.28, p < 0.01, BF10 = 22. However, the CM still clearly outperformed even the Gaussian GCM, t(9) = 6.34, p < 0.001, BF10 = 221.
A similar pattern holds in comparisons of the Akaike Information Criterion (AIC), which includes a penalty term for the number of free parameters (recall that the CM has three free parameters, and GCM 2). In AIC, the CM fared better than the exponential GCM in all comparisons, and outperformed the Gaussian GCM in eight of ten cases and in the group data. The magnitude of the fit differences was again substantial in comparisons of CM with the exponential, t(9) = 3.66, p < 0.01, BF10 = 11, as well as the Gaussian GCM, t(9) = 3.23, p < 0.05, BF10 = 6. Also as expected, the latter outperformed the exponential GCM, t(9) = 3.11, p < 0.05, BF10 = 5.
The best-fitting parameter values, listed in Table 2, show that CM places 53% of the weight in the evidence on the central tendency representation. However, if the two participants who do not show HR < FAR to Lurea are excluded, the weight is closer to 70%. Turning to the exemplar models, the main difference between the exponential and Gaussian GCMs is in the sensitivity parameter c, which is consistently lower in the estimates provided by GCM-G. The low values of c are consistent with the discussion of prototype enhancements in GCM-E applied to two-item tasks by Zaki and Nosofsky (2001) (see Introduction). Also consistent with Zaki and Nosofsky (2001), estimating c to be zero in GCM-E can only produce FAR ≾ HR, it cannot produce FAR > HR.
In sum, the pattern in these fits suggests that the Gaussian gradient in GCM does allow the model to produce the key pattern in response choice, as expected. However, it cannot match the magnitude of the difference: the effect is consistently underpredicted by GCM-G in all eight participants who show the effect. This is consistent with the notion that participants are supplementing their responses with a central tendency representation, and inconsistent with the alternative explanation that the effect is a by-product of the form of the underlying generalization curve. Nonetheless, both models, though they only have two (GCM) and three (CM) free parameters, are being fit to small datasets including only four observations in each fit. Perhaps, under greater constraint from a larger dataset, the results would be different.
For this reason, I also include some mnemometric function data from Kahana et al., (2007). In this study, the authors used a very similar procedure and stimuli to the unpublished Huang and Sekuler study just discussed. As in Huang and Sekuler’s experiment, the study items were two Gabor patches, and their presentation was followed by a recognition probe Gabor. The main differences were: i) the homogeneity of the study items varied, and did so either across trials (“mixed” condition) or across blocks (“blocked” condition), ii) the study items were presented in succession rather than simultaneously, and iii) the study included 29 possible values of match between the probe and a given study item, varied parametrically in steps of .5 JNDs. The resulting mnemometric functions, plotted as filled circles in Fig. 5, were taken from the high-homogeneity, blocked condition (mixed and blocked homogeneity conditions produced similar results, as is apparent in Fig. 2 of Kahana et al.). The results are collapsed across two functions differing in whether the first or second study item had the higher spatial frequency; the authors do report a recency effect in these data however they do not report any interaction with spatial frequency.
The data show a single-peaked and roughly symmetric distribution of responses centered on the value of the prototypical spatial frequency value (scaled to 0 in Figure 5). This is consistent with the high-homogeneity, low-attention results of the CM simulation reported earlier. Both the CM and GCM-G were fit to these data. Since the study items were presented in sequence, unlike the simultaneous presentation in the unpublished Huang and Sekuler data, two values of m are reasonable in GCM-G in addition to c and k. As in the prior analysis, however, one of them (m1) can be absorbed into the k parameter without loss of generality, and in the present case m2 is by the same manipulation replaced with M′=\(\frac {m_{2}}{m_{1}}\). For CM, the parameters 𝜃, t∗, v, and r were estimated. Thus both models use a small number of parameters (three in GCM, four in CM) to estimate 29 datapoints. The best-fitting parameter values are listed in Table 3.
As is clear in Fig. 5, the CM (left panel, crosses and lines) provides a better fit to the data, RMSE = .027, than does the GCM-G (right panel), RMSE = .045. Incorporating a penalty for the difference in number of parameters (four in CM vs. three in GCM) results in ΔAIC = -155.50 favoring the CM. The reason for the difference in fit is clearly the same as in the fits to the unpublished data: the GCM cannot match the degree of prototype enhancement that is observed empirically. Kullback − Leibler (K − L) divergence for CM is .08 and for GCM-G it is -.18. The ratio of the two (ignoring sign) is .18/.08 = 2.25. In other words, the divergence between the distributional predictions and the data is more than twice as great in GCM-G as in the CM, and as is apparent in the figure, a majority of this difference across 29 data points stems from the large discrepancy apparent in the three data points spanning the location of the prototype.
Discussion
The current results are consistent with the predictions of the compression model in showing an inflation in FAR to Lures matching the average of the study items presented in a Sternberg scanning task. Crucially, and also as predicted, the FAR to these critical Lures exceeds even the response rate to items that were actually studied by a substantial amount.
This pattern also held in analyses of a published data set from Kahana et al., (2007), though in this case presentation of the study items was sequential and a full distribution of responses over a large range of similarity matching was obtained. Both sets of data were difficult for the GCM to account for, though the CM provided a good account of all of these data. The results suggest that a reconsideration of the prototype approach is warranted, at least in the VSTM literature.
Do these results call the GCM and its RT extension, EBRW, into question? The answer to this question is “No,” for several reasons. First, it is quite possible that a suitable modification of GCM/EBRW could account for the present data without necessitating memory representations of central tendency information, though admittedly these would be posthoc modifications. Second, out of all the results reviewed in the Introduction the data that are most challenging for EBRW and GCM are found in only the very specific circumstances of the current dataset and paradigm. Specifically, while the small three JND study-item separation, one-dimensional stimuli, and two-item study set size provide ideal conditions for testing the models’ predictions, it is only a single small dataset and only a single class of stimulus, certainly not enough evidence for making any claims about the validity or generality of the exemplar approach.
For instance, one potential issue is that the current design, with only one level of homogeneity, encourages a strategy to rely on the average in order to reduce memory load. Though this seems consistent with the idea of compensatory, adaptive reliance on remembered averages discussed in the Introduction, it nonetheless raises questions about the generality of the finding since homogeneity was fixed. However, the fact that the same pattern was observed in the experiments of Kahana et al. discussed earlier, which included trial-by-trial variation in homogeneity, does seem to suggest that the key results of the current analysis are not simply a by-product of the design.
Furthermore, the compression model is most certainly a “comically oversimplified” model: it is what mathematicians would call a toy model, used to illustrate a point in a convenient but admittedly oversimplified way. Though it may provide a useful direction or framework for future models of ensemble effects, it seems doubtful whether the current model can compete seriously with EBRW on larger datasets with more parameters varying across experiments, particularly in light of the fact that GCM and EBRW have already withstood over two decades of scrutiny in the perceptual categorization literature. The point of the present exercise is, rather, to raise questions relevant to our understanding of VSTM.
The most crucial question raised here is whether VSTM is likely to operate using a pure exemplar matching approach, or whether it is worth (at least) entertaining alternative approaches incorporating central tendency representations. I believe the large and growing literature on central tendency representation, along with the current results, suggest such a consideration is not ill-advised and that such effects should not be ignored in modeling work. Though the compression model is most certainly a model of a specific task, the modeling exercise reported here suggests an important difference may exist between the perceptual categorization and VSTM literatures, one that any future, unifying mathematical account will need to explain.
Although much research remains to be done to establish firmly the details involved in producing ensemble effects, the literature review and modeling suggest that statistical information may be useful to control processes of the sort originally detailed in Atkinson and Shiffrin (1968). Specifically, reliance on central tendency information appears to serve an adaptive function, improving memory performance and compensating for noise in the system (Dubé & Sekuler, 2015). From this perspective, it is a reasonable hypothesis that participants might vary the extent to which they use such information at the time of retrieval, weighting such information more heavily when noise or uncertainty surrounds item representations. A useful direction for future work may be to examine the extent to which use of such information is under the participant’s control, as it seems to be, and to determine the limits and extent of such processes in both unidimensional and multidimensional stimuli across a broad range of memory tasks.
Notes
I thank Robert Nosofsky for pointing out several of the alternative explanations.
References
Alvarez, G. A. (2011). Representing multiple objects as an ensemble enhances visual cognition. Trends in Cognitive Sciences, 15, 122–131.
Alvarez, G. A., & Oliva, A. (2008). The representation of simple ensemble visual features outside the focus of attention. Psychological Science, 19, 392–398.
Ariely, D. (2001). Seeing sets: Representation by statistical properties. Psychological Science, 12, 157–162.
Atkinson, R.C., & Shiffrin, R.M. (1968). Human memory: A proposed system and its control processes 1. In: Psychology of learning and motivation (vol. 2, pp. 89–195). Elsevier.
Azzalini, A. (1986). Further results on a class of distributions which includes the normal ones. Statistica, 46, 199–208.
Ball, K., & Sekuler, R. (1980). Models of stimulus uncertainty in motion perception. Psychological Review, 87, 435–469.
Billock, V. A., & Tsou, B. H. (2011). To honor Fechner and obey Stevens: Relationships between psychophysical and neural nonlinearities. Psychological Bulletin, 137(1), 1.
Brainard, D. H. (1997). The psychophysics toolbox. Spatial Vision, 10, 433–436.
Carandini, M., & Heeger, D. J. (2012). Normalization as a canonical neural computation. Nature Reviews Neuroscience, 13(1), 51.
Carrasco, M. (2011). Visual attention: The past 25 years. Vision Research, 51(13), 1484–1525.
Corbett, J. E., & Melcher, D. (2014). Characterizing ensemble statistics: Mean size is represented across multiple frames of reference. Attention, Perception. Psychophysics, 76(3), 746–758.
Corbett, J. E., & Oriet, C. (2011). The whole is indeed more than the sum of its parts: Perceptual averaging in the absence of individual item representation. Acta Psychologica, 138(2), 289–301.
Corbett, J. E., & Song, J.-H. (2014). Statistical extraction affects visually guided action. Visual Cognition, 22(7), 881–895.
Corbett, J. E., Wurnitsch, N., Schwartz, A., & Whitney, D. (2012). An aftereffect of adaptation to mean size. Visual Cognition, 20(2), 211–231.
Drew, S. A., Chubb, C., & Sperling, G. (2009). Quantifying attention: Attention filtering in centroid estimations. Journal of Vision, 9(8), 229–229.
Drew, S. A., Chubb, C. F., & Sperling, G. (2010). Precise attention filters for Weber contrast derived from centroid estimations. Journal of Vision, 10(10), 20–20.
Dubé, C., & Sekuler, R. (2015). Obligatory and adaptive averaging in visual short-term memory. Journal of Vision, 15(4), 13–13.
Dubé, C., Payne, L., Sekuler, R., & Rotello, C. M. (2013). Paying attention to attention in recognition memory: Insights from models and electrophysiology. Psychological Science, 24(12), 2398–2408.
Dubé, C., Zhou, F., Kahana, M., & Sekuler, R. (2014). Similarity-based distortion of visual short-term memory is due to perceptual averaging. Vision Research, 96, 18–6.
Feller, W. (1968) An introduction to probability theory and its applications Vol. 1. New York: Wiley.
Graham, N. V. (2011). Beyond multiple pattern analyzers modeled as linear filters (as classical v1 simple cells): Useful additions of the last 25 years. Vision Research, 51(13), 1397–1430.
Grossberg, S. (1982). How does a brain build a cognitive code? In: Studies of mind and brain (pp. 1–52). Springer.
Haberman, J., Harp, T., & Whitney, D. (2009). Averaging facial expressions over time. Journal of Vision, 9, 1–13.
Huang, J., & Sekuler, R. (2010a). Distortions in recall from visual memory: Two classes of attractors at work. Journal of Vision, 10(24), 1–27.
Huang, J., & Sekuler, R (2010b). Attention protects the fidelity of visual memory: Behavioral and electrophysiological evidence. The Journal of Neuroscience.
Hyman, R. (1953). Stimulus information as a determinant of reaction time. Journal of Experimental Psychology, 45(3), 188.
Kahana, M. J., & Sekuler, R. (2002). Recognizing spatial patterns: A noisy exemplar approach. Vision Research, 42(18), 2177–2192.
Kahana, M. J., Zhou, F., Geller, A. S., & Sekuler, R. (2007). Lure similarity affects visual episodic recognition: Detailed tests of a noisy exemplar model. Memory Cognition, 35(6), 1222–1232.
Lu, Z.-L., & Dosher, B. A. (1998). External noise distinguishes attention mechanisms. Vision Research, 38 (9), 1183–1198.
Luce, R. D. (1961). A choice theory analysis of similarity judgments. Psychometrika, 26(2), 151–163.
Ma, W. J., Husain, M., & Bays, P. M. (2014). Changing concepts of working memory. Nature Neuroscience, 17(3), 347.
Macmillan, N.A., & Creelman, C.D. (2005). Detection theory: A user’s guide (2nd ed.). Lawrence Erlbaum Associates.
McKinley, S. C., & Nosofsky, R. M. (1995). Investigations of exemplar and decision bound models in large, ill-defined category structures. Journal of Experimental Psychology: Human Perception and Performance, 21(1), 128–148.
Naka, K., & Rushton, W. (1966). S-potentials from colour units in the retina of fish (Cyprinidae). The Journal of Physiology, 185(3), 536–555.
Nosofsky, R. M. (1984). Choice, similarity, and the context theory of classification. Journal of Experimental Psychology: Learning. Memory, and Cognition, 10(1), 104–114.
Nosofsky, R. M. (1985a). Luce’s choice model and thurstones categorical judgment model compared: Kornbrot’s data revisited. Perception and Psychophysics, 37(1), 89–91.
Nosofsky, R. M. (1985b). Overall similarity and the identification of separable-dimension stimuli: A choice model analysis. Perception and Psychophysics, 38(5), 415–432.
Nosofsky, R. M. (1986a). Attention, similarity, and the identification-categorization relationship. Journal of Experimental Psychology: General, 115(1), 39–61.
Nosofsky, R. M. (1986b). Attention, similarity, and the identification–categorization relationship. Journal of Experimental Psychology: General, 115(1), 39.
Nosofsky, R. M. (1992). Multidimensional models of perception and cognition (p. 363–393). In F.G. Ashby (Ed.) Hillsdale: Lawrence Erlbaum Associates, Inc.
Nosofsky, R. M. (2000). Exemplar representation without generalization? Comment on Smith and Minda’s (2000) Thirty categorization results in search of a model. Journal of Experimental Psychology: Learning Memory, and Cognition, 26(6), 1735–1743.
Nosofsky, R. M., & Palmeri, T. J. (1997). An exemplarbased random walk model of speeded classification. Psychological Review, 104(2), 266.
Nosofsky, R. M., & Kantner, J. (2006). Exemplar similarity, study list homogeneity, and short-term perceptual recognition. Memory Cognition, 34(1), 112–124.
Nosofsky, R. M., Little, D. R., Donkin, C., & Fific, M. (2011). Short-term memory scanning viewed as exemplar-based categorization. Psychological Review, 118(2), 280.
Nosofsky, R. M., Cox, G. E., Cao, R., & Shiffrin, R. M. (2014). An exemplar-familiarity model predicts short-term and long-term probe recognition across diverse forms of memory search. Journal of Experimental Psychology: Learning Memory, and Cognition, 40(6), 1524.
Oriet, C., & Hozempa, K. (2016). Incidental statistical summary representation over time. Journal of Vision, 16(3), 3–3.
Parzen, E. (1962) Stochastic processes. San Francisco: Holden-Day.
Payne, L., & Sekuler, R. (2014). The importance of ignoring: alpha oscillations protect selectivity. Current Directions in Psychological Science, 23(3), 171–177.
Payne, L., Guillory, S., & Sekuler, R. (2013). Attention-modulated alpha-band oscillations protect against intrusion of irrelevant information. Journal of Cognitive Neuroscience, 25(9), 1463–1476.
R Development Core Team (2008). R: A language and environment for statistical computing [Computer software manual]. Vienna, Austria. Retrieved from http://www.R-project.org (ISBN 3-900051- 07-0).
Riesenhuber, M., & Poggio, T. (1999). Hierarchical models of object recognition in cortex. Nature Neuroscience, 2(11), 1019.
Sekuler, R., & Kahana, M. J. (2007). A stimulus-oriented approach to memory. Current Directions in Psychological Science, 16, 305–310.
Shiffrin, R. M. (1993). Short-term memory: a brief commentary. Memory & Cognition, 21(2), 193–197.
Sun, P., Chubb, C., Wright, C. E., & Sperling, G. (2016). The centroid paradigm: quantifying feature-based attention in terms of attention filters. Attention, Perception, & Psychophysics, 78(2), 474–515.
Watamaniuk, S. N. J., & Sekuler, R. (1992). Temporal and spatial integration in dynamic random-dot stimuli. Vision Research, 32(12), 2341–2347.
Wilken, P., & Ma, W. J. (2004). A detection theory account of change detection. Journal of Vision, 4, 1120–1135.
Woodworth, R. S., & Schlosberg, H. (1954). Experimental psychology. Oxford and IBH Publishing.
Zaki, S. R., & Nosofsky, R. M. (2001). Exemplar accounts of blending and distinctiveness effects in perceptual old-new recognition. Journal of Experimental Psychology: Learning, Memory and Cognition, 27(4), 1022–1041.
Zaki, S. R., Nosofsky, R. M., Stanton, R. D., & Cohen, A. L. (2003). Prototype and exemplar accounts of category learning and attentional allocation: a reassessment. Journal of Experimental Psychology: Learning, Memory, and Cognition, 29(6), 1160–1173.
Zanto, T. P., Sekuler, R., Dube, C., & Gazzaley, A. (2013). Age-related changes in expectation based modulation of motion detectability. PLoS One, 8, 1–10.
Zhang, W., & Luck, S. J. (2011). The number and quality of representations in working memory. Psychological Science, 22(11), 1434–1441. https://doi.org/10.1177/0956797611417006
Zhou, F., Kahana, M. J., & Sekuler, R. (2004). Short-term episodic memory for visual textures: a roving probe gathers some memory. Psychological Science, 15(2), 112–118.
Acknowledgements
I thank Robert Sekuler for sharing data and the methodological details of the previously unpublished data to which the models were fit.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Dubé, C. Central tendency representation and exemplar matching in visual short-term memory. Mem Cogn 47, 589–602 (2019). https://doi.org/10.3758/s13421-019-00900-0
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-019-00900-0