
Abstract
Verbal information is coded naturally as ordered representations in working memory (WM). However, this may not be true for spatial information. Accordingly, we used memory span tasks to test the hypothesis that serial order is more readily bound to verbal than to spatial representations. Removing serial-order requirements improved performance more for spatial locations than for digits. Furthermore, serial order was freely reproduced twice as frequently for digits as for locations. When participants reordered spatial sequences, they minimized the mean distance between items. Participants also failed to detect changes in serial order more frequently for spatial than for verbal sequences. These results provide converging evidence for a dissociation in the binding of serial order to spatial versus verbal representations. There may be separable domain-specific control processes responsible for this binding. Alternatively, there may be fundamental differences in how effectively temporal information can be bound to different types of stimulus features in WM.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Converging evidence indicates a dissociation in working memory (WM) between verbal information, such as words and numbers, and visuospatial information, such as objects and locations (for reviews, see Jonides, Reuter-Lorenz, Smith, Awh, Barnes, Drain et al. 1996; Smith & Jonides, 1995, 1999). Accordingly, the most widely cited model of WM (Baddeley & Hitch, 1974) postulated separate memory stores for verbal and visuospatial information: the “phonological loop” and the “visuospatial sketchpad,” respectively. Recent neuroimaging and neuropsychological evidence suggests, moreover, that verbal and spatial storage systems involve different types of information coding and control mechanisms (e.g., Courtney, Roth, & Sala, 2007; Curtis and D’Esposito 2004; Levy & Goldman-Rakic, 2000). In the present study, we examined whether there is specifically a dissociation in the binding of serial-order information to verbal versus spatial stimulus representations in WM.
Differences in the degree to which, or the mechanisms by which, temporal information can be effectively bound to stimulus representations in WM would warrant a new interpretation of performance on tests that are widely used to quantify WM ability in both healthy participants and patients, such as the standardized digit span and spatial span tests (Wechsler Adult Intelligence Scale III, The Psychological Corporation, 1997; see also Berch, Krikorian & Huha, 1998, for a review of the related Corsi block-tapping task). These tests require the reproduction of items (digits or locations) in the same order as that in which they were presented. Sequence length is incremented until the participant fails to reproduce sequences of the same length on two successive trials. There are a number of scoring methods, but the conventional span score is the longest sequence length recalled in the correct order.
We hypothesized that serial order is more readily bound to verbal information, which is usually encountered in a temporally ordered manner (e.g., Tallal, Merzenich, Miller, & Jenkins, 1998) and appears to be rehearsed serially (Baddeley, 1986; Lee & Estes, 1977), than to spatial information. The latter might naturally be coded in WM as multilocation configurations (Bor, Duncan, & Owen, 2001; Gmeindl, Nelson, Wiggin, & Reuter-Lorenz, 2010; Jiang, Olson, & Chun, 2000) and not rehearsed serially. As a result, requiring memory for the serial order of spatial stimuli (as in the standardized spatial span test) may oblige participants to recruit alternative, more effortful encoding or rehearsal mechanisms than they would otherwise adopt, thereby masking effective memory capacity for spatial information (Smyth & Scholey, 1994a). In contrast, if verbal items are naturally coded and rehearsed using serial mechanisms, requiring maintenance of serial order in addition to item identity should have a smaller negative impact on verbal than on spatial WM performance.
This hypothesis is consistent with the results of previous research. For example, several studies (e.g., Dutta & Nairne, 1993; Healy, 1975, 1977; Jones, 1976) provided evidence consistent with separable codes and/or mechanisms employed for representing serial order and spatial locations in WM. In contrast, memory for serial order may normally rely on the same WM mechanisms (e.g., the phonological loop) that code and maintain verbal material (Healy, 1975, 1977). Moreover, maintenance of the serial order of verbal stimuli might be a fortuitous by-product of the serial rehearsal naturally employed for the short-term maintenance of verbal representations; the serial rehearsal of verbal stimuli (e.g., F–B–L–M) may simultaneously refresh the serial order as well as the identities of those stimuli held in WM. Serial rehearsal could allow order to be reconstructed from the relative strength of contextual information associated with stimulus representations held in memory (see, e.g., Howard & Kahana, 2002), without an explicit coding, or “tagging,” of serial positions. In contrast, if spatial locations are naturally maintained as multilocation configural representations, memory for the serial order of spatial locations may necessitate either the coordination of separable verbal and spatial WM subsystems (if serial order is coded verbally) or the recruitment of alternative (e.g., serial) spatial coding or rehearsal mechanisms.
However, perhaps serial mechanisms, such as covert shifts of attention (Awh, Jonides, & Reuter-Lorenz, 1998) or motor sequencing operations (e.g., Postle, Idzikowski, Della Sala, Logie, & Baddeley, 2006), are used for rehearsal of spatial information, just as an articulatory motor system is used for subvocal rehearsal of verbal information. In this case, the serial nature of the spatial rehearsal system might allow temporal information to be bound effectively to spatial locations. Thus, contrary to our primary hypothesis, serial order might be bound equally well to both verbal and spatial stimulus representations in WM. In this case, poorer performance on spatial span tests (or Corsi block-tapping) than on digit span tests (as is observed in normative studies; e.g., Isaacs & Vargha-Khadem, 1989; Kessels, van den Berg, Ruis, & Brands, 2008) would indeed reflect more severe limitations on the representational capacity or precision of spatial, relative to verbal, WM, rather than a dissociation in the ability to bind serial order to spatial versus verbal representations. In other words, spatial information may be fundamentally more difficult to encode, maintain, and/or retrieve than is verbal information, independently of requirements to remember serial order. This alternative hypothesis leads to the prediction that, whereas removal of the requirement to reproduce the serial order of stimuli should improve performance for both spatial and verbal tasks, spatial task performance should not improve more than verbal task performance improves.
To test these hypotheses, we administered parallel verbal and visuospatial tasks to healthy adults in two experiments. In Experiment 1, in one condition (same order), participants were required to reproduce target items in the same order as that in which those items had been presented. In a separate condition (any order), participants were allowed to reproduce the target items in any order. In Experiment 2, participants were not required to reproduce item sequences. Rather, they were required to judge whether target and test sequences contained the same items in the same serial order.
Experiment 1
Method
Participants
Twenty-four adults (17 females, 7 males; ages 18-30 years, M = 21.9 years, SE = 0.8) provided written, informed consent and received $20 per hour. The study protocol was approved by the Institutional Review Boards of the Johns Hopkins University and the Johns Hopkins Medical Institutions. All participants but one were right-handed, and all reported normal or corrected-to-normal vision and hearing. All participants were naïve as to the purpose of the study.
Apparatus and stimuli
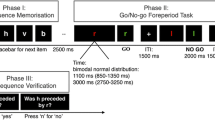
A Dell Inspiron 8200 laptop computer presented stimuli and recorded responses (Berch et al., 1998). Responses in the verbal tasks were made using the top-row number keys “0” through “9,” and a touch screen (KEYTEC, Inc.) was used to record responses (in terms of pixel coordinates) in the spatial tasks. A chinrest located ~38 cm from the display was used to control the visual angle of the stimuli. Custom MATLAB 7.3 code (The MathWorks, Inc.; Brainard, 1997) ensured precise timing of stimulus presentation and data collection. Visual stimuli were presented against a gray background. In the verbal tasks, white digits subtending ~0.9° of visual angle in width and ~1.2° of visual angle in height appeared sequentially at the center of the display. In the spatial tasks (described below), an array of ten filled blue squares (Fig. 1) approximated the layout of blocks used in the standardized spatial span test (Wechsler Adult Intelligence Scale III, The Psychological Corporation, 1997). Some squares were indicated as memory targets by changing color from blue to orange; these colors were isoluminant to minimize afterimages. Each square subtended ~4.4° of visual angle in width and in height, and the maximum eccentricity of the display elements was ~22.8°. Participants wore headphones for auditory-stimulus presentation and to minimize distraction. One auditory stimulus (approximately 600 Hz) provided a response cue, and another (approximately 300 Hz) provided acknowledgment of each detected response (keypress or finger tap). In the verbal tasks, a white dash (–) subtending ~0.9° of visual angle provided a visual response cue as well.

Schematic illustration of the spatial (upper panel) and verbal (lower panel) task structure in Experiment 1. Following presentation of a target sequence, a tone instructed the participant to report the target items either by touching the squares (spatial task) or by typing keyboard number keys (verbal task) with his or her index finger. Spatial target squares are indicated in the figure by black borders; in the actual experiment, spatial targets were indicated by a change in color. See the text for additional details
Procedure
Participants first were given instructions and demonstrations and then performed four practice blocks, each consisting of five trials. One practice block was presented for each of the four combinations of the two primary independent variables (stimulus type and serial-order requirements, described below). Within the set of practice blocks, stimulus type (verbal, spatial) was presented in a blocked and alternating fashion (ABAB), with the particular stimulus type presented first counterbalanced across participants. Serial-order requirements (same order, any order) were crossed with stimulus type. Practice blocks began with sequences of two items. A staircase adjustment procedureFootnote 1 was used whereby the sequence length following a correct/incorrect response sequence was incremented/decremented, respectively, by one item.
Following completion of all four practice blocks, four test blocks (one block per condition) were presented. Each block contained 14 trials and began with a sequence of three items. The sequence length was subsequently adjusted by the staircase procedure as the trial block progressed. As with the set of practice blocks, stimulus type (verbal, spatial) was presented in a blocked and alternating fashion (ABAB), and serial-order requirements (same order, any order) were crossed with stimulus type.
A schematic illustration of the trial structure is shown in Fig. 1. Target stimuli were presented sequentially for 750 ms each, with an interstimulus interval (ISI) of 250 ms. In the verbal tasks, target digits were presented at the center of the screen. In the spatial tasks, each target square in the sequence turned orange for 750 ms, during which time the other nine squares in the array remained blue. All ten squares were blue during the ISI. In both verbal and spatial tasks, 250 ms after the offset of the final stimulus in the sequence, an auditory response cue was presented. In the verbal tasks, a dash appeared at the center of the screen simultaneously with the auditory response cue and persisted while the subject reported the digit sequence by pressing the number keys. In the spatial tasks, the array of blue squares persisted while the subject reported the spatial sequence by tapping squares; squares remained blue throughout the response phase. For both verbal and spatial tasks, an acknowledgment beep was sounded upon detection of each response (buttonpress or finger tap). Participants were instructed to use only their preferred index finger for all responses.
To minimize the possibility of adopting a (nonoptimal) strategy of remembering which items were not presented, especially in the any-order conditions, each target item had, on average, a .28 probability of being repeated within the same target sequence, and participants were required to reproduce items the correct number of times (i.e., in the digit tasks, each key corresponding to a target digit had to be pressed the same number of times that that digit was presented within the target sequence, and in the spatial tasks, each square had to be touched the same number of times that it was presented as a target square within the target sequence); critically, this repetition procedure was implemented for both same-order and any-order conditions. It should be noted that stimulus repetition is a departure from the standardized span tests. This repetition is illustrated in the following example digit sequence: 5–2–9–3–2, where the digit 2 is repeated. The sets of pseudorandom target sequences that we constructed prior to testing were matched across corresponding verbal and spatial conditions; thus, for example, for the three-item sequence 4–7–2, included in our set of target sequences, the digits 4, 7, and 2 were presented as a digit sequence and target squares at locations 4, 7, and 2 were presented as a spatial sequence (see Fig. 1).Footnote 2
In the same-order conditions, a response sequence was incorrect if it did not match both the identity (digit or location) and serial order of target items (i.e., target items had to be reproduced in the same serial order as that in which they had been presented, including repeated items). In the any-order conditions, a response sequence was incorrect if it included items not presented in the target sequence, omitted target items, and/or included an incorrect number of repetitions. The WM performance score was operationally defined as the mean sequence length of the last ten sequences of each test block, including the sequence length that would have been presented had there been a 15th trial in the block.
Data analysis
Repeated measures analyses of variance were conducted on WM scores. In addition, response sequences in the any-order condition were analyzed to reveal the degree to which participants freely reproduced the serial order of target sequences when they were not required to do so. Because we hypothesized that serial order might be more readily bound to verbal than to spatial information in WM, we predicted that participants would freely reproduce serial order more frequently in the digit/any-order task than in the spatial/any-order task.
Results
Replicating the pattern of normative data from standardized span tests (e.g., Isaacs & Vargha-Khadem, 1989; Kessels et al., 2008), performance (Fig. 2) was better for the digit task (95% CI: [6.68, 7.60]) than for the spatial task (95% CI: [6.22, 7.11]) when participants were required to maintain serial order, t(23) = 2.36, p = .03, partial η2 = .20. Performance reliably improved when the serial-order requirement was omitted, F(1, 23) = 44.65, p < .001, partial η2 = .66; this finding held for both the digit task, t(23) = 2.44, p = .02, partial η2 = .21, and the spatial task, t(23) = 5.74, p < .001, partial η2 = .59. Of particular importance, however, the improvement in performance was greater for the spatial task than for the verbal task, F(1, 23) = 14.27, p = .001, partial η2 = .38. In fact, with removal of serial-order requirements, participants performed reliably better on the spatial task (95% CI: [7.66, 9.23]) than on the verbal task (95% CI: [7.22, 7.83]), t(23) = 2.70, p = .01, partial η2 = .24.

Experiment 1: mean (± SE) sequence length (number of items) as a function of stimulus type and serial-order requirements
When serial-order requirements were removed, the proportion of correct responses in which serial order was nevertheless reproduced in the digit/any-order task (95% CI: [0.34, 0.62]) was twice that observed in the spatial/any-order task (95% CI: [0.12, 0.37]), as shown in Fig. 3a; the corresponding main effect of stimulus type was reliable, F(1, 23) = 10.78, p = .003, partial η2 = .32. The stimulus type × sequence length interaction was not reliable, p > .05.

Experiment 1: results from only the any-order trials on which response sequences were correct. Panel a: Mean (± SE) proportion of correct-response sequences in which serial order was freely reproduced, despite removal of serial-order requirements. Panel b: Mean (± SE) distance between successive items in the spatial/any-order condition for trials on which serial order was not reproduced; correct-response sequences are plotted with white circles, and for comparison, the target sequences of those same trials are plotted with gray squares
Because performance improved much more for the spatial task (25%) than for the verbal task (5%) when serial-order requirements were removed, we next conducted supplementary analyses of performance in the spatial/any-order condition to investigate whether participants might have strategically reorganized target items. In particular, we considered that participants may have implemented a chunking strategy whereby subsets of items were grouped into local spatial configurations (Bor, Duncan, Wiseman, & Owen, 2003), a strategy that would tend to result in a reduction of the mean distance between successive locations reported in the recall phase, relative to the mean distance between successive locations presented in the corresponding target sequences. In contrast, if participants simply had benefited from the reduced memory load conferred by removal of serial-order requirements and had not strategically reorganized target items, there should be no reliable reduction in the mean distance between successive items at the recall phase. We therefore calculated the mean interitem distance between successive squares touched during correct response sequences in which serial order was not reproduced (i.e., when target locations were touched the correct number of times, but in orders different from those of target sequences). We then compared this distance with the mean distance between successive targets presented on the very same trials (Fig. 3b). For all sequence lengths from 3 to 11 items, the mean interitem distance was reliably shorter for response sequences than for the corresponding target sequences (Wilcoxon signed-rank tests: Ws ≤ 11, ps ≤ .02).Footnote 3 Furthermore, when we omitted immediate repetitions of target and response locations from mean distance calculations, this pattern held for all sequence lengths except for 9-item sequences, for which the difference between mean target and mean response distances just failed to reach significance, W = 24, p = .07.
Because interitem distances may have been strategically minimized to reduce the duration of recall responses (a possibility discussed below), we also analyzed the interresponse intervals (time between successive touch responses), response sequence durations, and the time between the recall cue and the first response, for all correct responses in the spatial/any-order condition. We compared these measures between sequences in which the serial order of targets was freely reproduced and sequences in which participants reordered items. Sequence lengths from three to eight items were analyzed because they were the only ones that provided observations for both types of response sequences. Neither mean interresponse interval (serial order reproduced, M = 586 ms, SE = 52; serial order not reproduced, M = 589 ms, SE = 44), mean recalled-sequence duration (serial order reproduced, M = 3.7 s, SE = 0.3; serial order not reproduced, M = 3.9 s, SE = 0.2), nor mean latency from the recall cue to the first response (serial order reproduced, M = 1,114 ms, SE = 129; serial order not reproduced, M = 1,291 ms, SE = 109) indicated reduced means for reordered sequences. Differences between these two sequence types also did not vary systematically with sequence length.
Discussion
In order to test whether serial order is more readily bound to verbal than to spatial representations in WM, we compared performance on digit span and spatial span tests that either required participants to reproduce the serial order of target items or allowed them to recall target items in any order. Perhaps unsurprisingly, performance improved when we removed the requirement to reproduce serial order. However, of particular theoretical importance, Experiment 1 revealed a larger improvement in spatial than in verbal performance. Furthermore, participants freely reproduced serial order twice as often in the verbal task as in the spatial task. In the absence of serial-order requirements, participants also reduced the mean distance between items correctly reproduced at the recall phase, relative to the mean distance between targets presented in the very same trials, suggesting strategic reorganization. In sum, several findings of Experiment 1 indicate that serial order is more readily bound to verbal than to spatial representations in WM.
We next conducted an experiment in which recognition test versions of the WM tasks (cf. Smyth & Scholey, 1996a, b) were administered to test a corollary prediction: If serial order is more difficult to bind to spatial than to verbal representations in WM, participants should fail to detect changes in serial order more frequently for spatial than for verbal sequences. On recognition test trials, a target sequence was followed by a test sequence that was identical to the target sequence, contained a nontarget item that replaced a target item, or consisted of the same target items but presented in a different order. Furthermore, because participants indicated whether the test sequence matched or did not match the target sequence simply by pressing one of two response keys, motor processing requirements were minimized and equated across the verbal and spatial recognition tasks, thereby eliminating the possibility that differences in demand for overt motor control or sequence generation could account for any observed differences in performance across stimulus modalities.
Experiment 2
Method
Participants
Sixteen young adults (12 females, 4 males; ages 18-40 years, M = 29.1 years, SE = 1.8) provided informed consent. Participants received $20 per hour of participation. All participants but one were right-handed, and all reported normal or corrected-to-normal vision and hearing.
Apparatus and stimuli
The apparatus and stimuli were the same as those in Experiment 1.
Procedure
Participants performed two sets of tasks in Experiment 2. In one half of the testing session, the digit/same-order and spatial/same-order recall tasks used in Experiment 1 were given, with the exception that a 2.25-s delay separated target sequences from the onset of the recall cue in order to match the timing of the other conditions described below. Completion of two 5-trial recall practice blocks, one for each stimulus type, preceded recall test blocks. Two 14-trial recall test blocks, one for each stimulus type, were then given, with order counterbalanced across participants.
In the other half of the testing session, a set of recognition test versions of the tasks were given that differed from the recall tasks in the following ways. A 1-s auditory cue (approximately 450 Hz) was presented 250 ms after presentation of a target sequence, followed by a 1-s delay and then presentation of a test sequence. The auditory cue and delay, with a total duration of 2.25 s, were interposed to clearly distinguish target from test sequences. A different auditory cue (approximately 600 Hz) presented 250 ms after offset of the test sequence indicated that the participant could respond. Each test sequence (1) matched the target sequence in both identity and order, (2) contained a nontarget item that replaced a target item, or (3) consisted of target items, but with the order of two serially adjacent items reversed. Participants indicated a match by pressing the “y” keyboard key and an identity or order mismatch by pressing the “n” key. In test blocks, sequence lengths of four, six, and eight items were varied pseudorandomly across trials, and for each sequence length, 50% of the trials contained matches, 25% contained identity mismatches, and 25% contained order mismatches. Participants completed two 5-trial recognition practice blocks, one for each stimulus type, before completing the recognition test blocks. One hundred twenty recognition test trials (60 verbal, 60 spatial) were presented across four test blocks, each containing 30 trials. Stimulus type was presented in a blocked and alternating fashion (ABAB).
Results
Replicating Experiment 1 and normative data from standardized span tests (e.g., Isaacs & Vargha-Khadem, 1989; Kessels et al., 2008), performance (Fig. 4a) was better for the digit recall task (95% CI: [6.41, 7.09]) than for the spatial recall task (95% CI: [5.51, 6.46]), F(1, 15) = 19.33, p = .001, partial η2 = .56, suggesting that our sample of participants was not unusual.Footnote 4 For the recognition tests (Fig. 4b), overall accuracy (proportion correct across both match and mismatch trials) was reliably greater for the digit task (95% CI: [0.81, 0.89]) than for the spatial task (95% CI: [0.76, 0.86]), F(1, 15) = 4.69, p = .047, partial η2 = .24. For match trials, accuracy (hit rate) did not reliably differ, p = .12, between the digit recognition tasks (M = 0.78, SE = 0.03; 95% CI: [0.72, 0.84]) and spatial recognition tasks (M = 0.74, SE = 0.04; 95% CI: [0.66, 0.81]). It was of critical importance, however, that whereas participants detected identity mismatches (correct rejectionsFootnote 5) equally often for digits (95% CI: [0.87, 0.96]) as for locations (95% CI: [0.88, 0.98]), they detected order mismatches reliably more frequently for digits (95% CI: [0.89, 0.96]) than for locations (95% CI: [0.74, 0.90]); the corresponding interaction (see Fig. 5) was reliable, F(1,15) = 11.95, p = .004, partial η2 = .44.

Experiment 2: Panel a: mean (± SE) sequence length (number of items) in the recall tasks as a function of stimulus type. Panel b: mean (± SE) accuracy (proportion correct) for the recognition tasks as a function of stimulus type

Experiment 2: mean (± SE) accuracy (correct rejections) for item mismatch and order mismatch conditions in the recognition tasks as a function of stimulus type
Discussion
The results of Experiment 2 confirmed our prediction that participants would fail to detect changes in serial order between target and test sequences more frequently for spatial than for verbal sequences. This prediction followed directly from our hypothesis that serial order is more readily bound to verbal than to spatial representations in WM.
General discussion
This study revealed that the effective storage capacity of WM for verbal and spatial information per se can be masked by serial-order reproduction demands—demands that are imposed in the standardized digit span and spatial span tests widely used to measure WM ability in both healthy participants and patients. In fact, our results suggest the possibility that low span scores, particularly those ostensibly reflecting a deficit in memory for spatial information, may be due, instead, to difficulty in the binding of serial order to the representation of other stimulus features.
The requirement to reproduce serial order not only adds order information to the memory load participants must bear, but also may preclude the use of encoding or rehearsal mechanisms that would otherwise be engaged (Smyth & Scholey, 1994a), particularly for the maintenance of spatial information. Furthermore, it has been proposed that auditorily presented stimuli (as in the standardized digit span test) are encoded with greater temporal precision than are visually presented stimuli, resulting in greater feature-based distinctiveness among, and therefore better retrieval of, auditory representations held in memory (Glenberg & Swanson, 1986; Nairne, 1988, 1990). A related proposal might generalize to the type of code or rehearsal mechanism (phonological vs. spatial) used to represent items in WM, regardless of presentation modality. Indeed, we hypothesized that serial order is more readily bound to verbal than to spatial information even when both types of stimuli are presented visually. Consistent with this hypothesis, removing the serial-order requirement resulted in a larger improvement in spatial performance (25% increase) than in verbal performance (5% increase); spatial performance actually surpassed verbal performance under these conditions. Moreover, even when unnecessary, participants freely reproduced serial order twice as frequently for digits (Lewandowsky, Brown, & Thomas, 2009; Lewandowsky, Nimmo, & Brown, 2008; Tan & Ward, 2007) as for spatial locations, and we found some evidence that this difference was greatest at relatively long sequences. These results suggest that the effective capacity of spatial WM might be substantially underestimated in standardized memory span tests, thereby bringing into question the construct validity of the standardized spatial span measure. Of particular theoretical importance, however, these results also suggest that the binding of serial order to spatial representations in WM is an effortful process that is abandoned as the memory load approaches effective capacity limits and when serial order is irrelevant to explicit task demands.
A corollary of our hypothesis that serial order is more readily bound to verbal than to spatial representations in WM is the prediction that participants would fail to detect changes in the order of items more frequently for spatial than for verbal sequences. The results from recognition tests (Experiment 2) revealed that participants were equally likely to detect nontarget items introduced into test sequences for both types of stimuli but were reliably worse at detecting changes in serial order for spatial sequences than for verbal sequences, providing converging evidence for our hypothesis.
One potential limitation of the present study that should be noted here is that spatial stimuli might have differed from verbal stimuli in the degree to which each item could be discriminated from, rather than confused with, other items (regarding the role of distinctiveness in memory performance, see, e.g., Guérard, Neath, Surprenant, & Tremblay, 2010; Hay, Smyth, Hitch, & Horton, 2007; Kelley & Nairne, 2001; Nairne, 1990; Neath, 1993; Neath & Crowder, 1990, 1996). Indeed, it is possible that spatial span performance is generally found to be worse than digit span performance because spatial locations are less discriminable from each other than are digits. Furthermore, it may be more difficult to bind serial-order codes to less discriminable items. However, the better performance in the spatial task than in the verbal task in the absence of serial-order requirements (Experiment 1) does not support this alternative explanation. Instead, this finding indicates that the spatial stimuli used in our study were easier to remember than were the digits when serial order was made irrelevant, suggesting that spatial stimuli were no more confusable, on average, than were digit stimuli. Furthermore, whereas participants failed to detect changes in the order of items more frequently for spatial than for verbal sequences, they detected changes in the identity of items equally well across stimulus types (Experiment 2). The latter finding is inconsistent with a hypothesized difference in discriminability; if the items within one stimulus modality were less discriminable than those within the other, participants should have been worse at detecting changes in the identity of the less discriminable items. Nevertheless, future researchers could attempt to equate discriminability across verbal and spatial items by psychophysical adjustment of stimulus parameters, or they could parametrically vary the discriminability of items to investigate directly its effects on the reproduction of serial order across these and other stimulus domains.
Because the removal of serial-order reproduction requirements might provide insight into how sequential spatial information is naturally represented in WM, we further examined spatial response sequences that did not preserve the serial order of target sequences (Experiment 1). If participants simply had benefited from the reduced memory load conferred by removal of serial-order requirements and had not strategically reorganized target items, there should have been no reliable difference in the mean interitem distance between target sequences and response sequences. In contrast, this analysis revealed that participants ordered their responses so that the mean distance between successive response locations was reliably less than the mean distance between successive target locations presented on the very same trials, suggesting that participants strategically reorganized spatial sequences. Two potential explanations for this behavior occur to us. The first is that participants may have maintained the serial order of targets until the recall phase but then may have programmed a response sequence (e.g., from leftmost locations to rightmost locations) that differed from the target sequence. Perhaps this was done to minimize the distance spanned by and, therefore, the duration of recall responses—time during which yet-to-be-reproduced items could be forgotten. However, neither interresponse interval, response sequence duration, nor latency to first response was reduced when participants reordered spatial sequences. These findings are consistent with those of Smyth and Scholey (1994a), who manipulated motor movement duration by varying the distances between, and sizes of, target items (Fitts, 1954) in a nine-location spatial span task. They concluded that spatial span performance in their study was not explained by overt movement time. Our study warrants the same conclusion.
Alternatively, perhaps target sequences were reorganized into representations that were more easily maintained in WM. For example, if spatial locations are rehearsed in WM via shifts of covert attention (Awh et al., 1998, 1999; Jha, 2002; Postle, Awh, Jonides, Smith, & D'Esposito, 2004; Smyth & Scholey, 1994b), minimizing the distance spanned during shifts of attention from location to location during a memory delay by reordering items (e.g., from left to right) might result in more effective maintenance because more time could be spent attending to target locations and less time spent traversing space (Schmitt, Postma, & de Haan, 2001; although see Kwak, Dagenbach, & Egeth, 1991). Minimizing the distance between successive locations might also facilitate, or reflect, the representation of locations as subsets of configurations (analogous to the chunking of verbal items; Bor et al., 2003) that do not overlap in space, thereby reducing path crossings (Busch, Farrell, Lisdahl-Medina, & Krikorian, 2005; Parmentier, Elford, & Maybery, 2005) and/or interference between memoranda.
Additional work might localize more precisely when, in task processing, the voluntary reorganization of spatial sequences occurs. Nevertheless, these intriguing results provide converging evidence for a dissociation in the binding of serial order to spatial versus verbal representations in WM. Separable domain-specific control processes or mechanisms may be responsible for this binding. For example, the preservation of verbal order may be a direct consequence of the serial rehearsal mechanism used to maintain verbal information (Burgess & Hitch, 1992). In contrast, neural mechanisms that maintain spatial information in WM may not, in isolation, be sufficient to preserve serial order; a currently unidentified control process also may be required to bind serial order to spatial information. Alternatively, or in addition, the dissociation revealed here may reflect a fundamental difference in how effectively order information can be bound to different types of stimulus features in WM.
Notes
To provide a more reliable and precise measure of WM performance than memory span as it is commonly defined, we applied a method widely used in psychophysics research, staircase adjustment, to the length of sequences (see Bor, Duncan, Lee, Parr, & Owen, 2006).
Squares were tacitly indexed as locations 0 through 9 for purposes of equating stimulus sequences across verbal and spatial tasks; participants were not informed of these indices.
Only 4 and 3 participants produced correct responses at sequence lengths of 12 and 13 items, respectively. As a result, even though, in every case, the observed mean interitem distance for response sequences was shorter than the mean interitem distance for the corresponding target sequences, these differences failed to reach a conventional level of statistical significance, due to the small number of observations (12 items: W = 0, p = .07; 13 items: W = 0, p = .11).
Mean recall scores were lower in Experiment 2 than in Experiment 1, although an ANOVA conducted with experiment as a between-subjects factor indicated that the main effect of experiment failed to reach statistical significance, F(1,38) = 3.73, p = .061. Of greater importance, however, there was no interaction of experiment with stimulus type for recall scores, F(1,38) = 1.02, p = .32.
Because the prediction tested in Experiment 2 concerned the ability to detect mismatches between target and test sequences (i.e., when the correct response was an “n” buttonpress), we report the proportions of responses in the mismatch conditions that were correct rejections. False alarm rate is simply the inverse of the correct-rejection rate (1.0 minus proportion of correct rejections), so both measures equivalently indicate worse performance in the spatial order mismatch condition than in all other mismatch conditions. Furthermore, it may be noted that any response bias (e.g., to press the “n” key) could not account for the observed difference in correct-rejection rate between item and order-mismatches for the spatial task, nor could a difference in response bias between the verbal and spatial tasks account for the observed stimulus type × mismatch type interaction.
References
Awh, E., Jonides, J., & Reuter-Lorenz, P. A. (1998). Rehearsal in spatial working memory. Journal of Experimental Psychology: Human Perception and Performance, 24(3), 780–790.
Awh, E., Jonides, J., Smith, E. E., Buxton, R. B., Frank, L. R., Love, T., et al. (1999). Rehearsal in spatial working memory: Evidence from neuroimaging. Psychological Science, 10(5), 433–437.
Baddeley, A. D. (1986). Working memory. Oxford: Oxford University Press.
Baddeley, A. D., & Hitch, G. J. (1974). Working memory. In G. Bower (Ed.), The psychology of learning and motivation: Advances in research and theory, vol 8 (pp. 47–89). New York: Academic Press.
Berch, D. B., Krikorian, R., & Huha, E. M. (1998). The Corsi block-tapping task: Methodological and theoretical considerations. Brain and Cognition, 38, 317–338.
Bor, D., Duncan, J., Lee, A. C. H., Parr, A., & Owen, A. M. (2006). Frontal lobe involvement in spatial span: Converging studies of normal and impaired function. Neuropsychologia, 44, 229–237. doi:10.1016/j.neuropsychologia.2005.05.010.
Bor, D., Duncan, J., & Owen, A. M. (2001). The role of spatial configuration in tests of working memory explored with functional neuroimaging. Scandinavian Journal of Psychology, 42, 217–224.
Bor, D., Duncan, J., Wiseman, R. J., & Owen, A. M. (2003). Encoding strategies dissociate prefrontal activity from working memory demand. Neuron, 37, 361–367.
Brainard, D. H. (1997). The psychophysics toolbox. Spatial Vision, 10, 433–436.
Burgess, N., & Hitch, G. J. (1992). Toward a network model of the articulatory loop. Journal of Memory and Language, 31(4), 429–460.
Busch, R. M., Farrell, K., Lisdahl-Medina, K., & Krikorian, R. (2005). Corsi block-tapping task performance as a function of path configuration. Journal of Clinical and Experimental Neuropsychology, 27, 127–134. doi:10.1080/138033990513681.
Courtney, S. M., Roth, J. K., & Sala, J. B. (2007). A hierarchical biased-competition model of domain-dependent working memory maintenance and executive control. In N. Osaka, R. H. Logie, & M. D'Esposito (Eds.), The cognitive neuroscience of working memory (pp. 369–383). Oxford: Oxford University Press.
Curtis, C. E., & D’Esposito, M. (2004). The effects of prefrontal lesions on working memory performance and theory. Cognitive, Affective & Behavioral Neuroscience, 4(4), 528–539.
Dutta, A., & Nairne, J. S. (1993). The separability of space and time: Dimensional interaction in the memory trace. Memory & Cognition, 21(4), 440–448.
Fitts, P. M. (1954). The information capacity of the human motor system in controlling the amplitude of movement. Journal of Experimental Psychology, 47(6), 381–391.
Glenberg, A. M., & Swanson, N. G. (1986). A temporal distinctiveness theory of recency and modality effects. Journal of Experimental Psychology. Learning, Memory, and Cognition, 12(1), 3–15.
Gmeindl, L., Nelson, J. K., Wiggin, T., & Reuter-Lorenz, P. A. (2010). Configural representations in spatial working memory: Modulation by perceptual segregation and voluntary attention. Manuscript submitted for publication.
Guérard, K., Neath, I., Surprenant, A. M., & Tremblay, S. (2010). Distinctiveness in serial memory for spatial information. Memory & Cognition, 38(1), 83–91. doi:10.3758/MC.38.1.83.
Hay, D. C., Smyth, M. M., Hitch, G. J., & Horton, N. J. (2007). Serial position effects in short-term visual memory: A SIMPLE explanation? Memory & Cognition, 35(1), 176–190.
Healy, A. F. (1975). Coding of temporal-spatial patterns in short-term memory. Journal of Verbal Learning and Verbal Behavior, 14, 481–495.
Healy, A. F. (1977). Pattern coding of spatial order information in short-term memory. Journal of Verbal Learning and Verbal Behavior, 16, 419–437.
Howard, M. W., & Kahana, M. J. (2002). A distributed representation of temporal context. Journal of Mathematical Psychology, 46, 269–299. doi:10.1006/jmps.2001.1388.
Isaacs, E. B., & Vargha-Khadem, F. (1989). Differential course of development of spatial and verbal memory span: A normative study. British Journal of Developmental Psychology, 7, 377–380.
Jha, A. P. (2002). Tracking the time-course of attentional involvement in spatial working memory: An event-related potential investigation. Cognitive Brain Research, 15(1), 61–69.
Jiang, Y. H., Olson, I. R., & Chun, M. M. (2000). Organization of visual short-term memory. Journal of Experimental Psychology. Learning, Memory, and Cognition, 26(3), 683–702.
Jones, G. V. (1976). A fragmentation hypothesis of memory: Cued recall of pictures and of sequential position. Journal of Experimental Psychology: General, 105(3), 277–293.
Jonides, J., Reuter-Lorenz, P. A., Smith, E. E., Awh, E., Barnes, L. L., Drain, H. M., et al. (1996). Verbal and spatial working memory. In D. Medin (Ed.), Psychology of learning and motivation (Vol. 34, pp. 43–83). San Diego: Academic Press.
Kelley, M. R., & Nairne, J. S. (2001). von Restorff revisited: Isolation, generation, and memory for order. Journal of Experimental Psychology. Learning, Memory, and Cognition, 27(1), 54–66.
Kessels, R. P. C., van den Berg, E., Ruis, C., & Brands, A. M. A. (2008). The backward span of the Corsi block-tapping task and its association with the WAIS-III Digit Span. Assessment, 15(4), 426–434. doi:10.1177/1073191108315611.
Kwak, H.-W., Dagenbach, D., & Egeth, H. (1991). Further evidence for a time-independent shift of the focus of attention. Perception & Psychophysics, 49(5), 473–480.
Lee, C. L., & Estes, W. K. (1977). Order and position in primary memory for letter strings. Journal Of Verbal Learning And Verbal Behavior, 16(4), 395–418.
Levy, R., & Goldman-Rakic, P. S. (2000). Segregation of working memory functions within the dorsolateral prefrontal cortex. Experimental Brain Research, 133(1), 23–32.
Lewandowsky, S., Brown, G. D. A., & Thomas, J. L. (2009). Traveling economically through memory space: Characterizing output order in memory for serial order. Memory & Cognition, 37(2), 181–193. doi:10.3758/MC.37.2.181.
Lewandowsky, S., Nimmo, L. M., & Brown, G. D. A. (2008). When temporal isolation benefits memory for serial order. Journal of Memory and Language, 58(2), 415–428. doi:10.1016/j.jml.2006.11.003.
Nairne, J. S. (1988). A framework for interpreting recency effects in immediate serial recall. Memory & Cognition, 16(4), 343–352.
Nairne, J. S. (1990). A feature model of immediate memory. Memory & Cognition, 18(3), 251–269.
Neath, I. (1993). Distinctiveness and serial position effects in recognition. Memory & Cognition, 21(5), 689–698.
Neath, I., & Crowder, R. G. (1990). Schedules of presentation and temporal distinctiveness in human memory. Journal of Experimental Psychology. Learning, Memory, and Cognition, 16(2), 316–327.
Neath, I., & Crowder, R. G. (1996). Distinctiveness and very short-term serial position effects. Memory, 4(3), 225–242.
Parmentier, F. B. R., Elford, G., & Maybery, M. (2005). Transitional information in spatial serial memory: Path characteristics affect recall performance. Journal of Experimental Psychology. Learning, Memory, and Cognition, 31(3), 412–427. doi:10.1037/0278-7393.31.3.412.
Postle, B. R., Awh, E., Jonides, J., Smith, E. E., & D'Esposito, M. (2004). The where and how of attention-based rehearsal in spatial working memory. Cognitive Brain Research, 20(2), 194–205. doi:10.1016/j.cogbrainres.2004.02.008.
Postle, B. R., Idzikowski, C., Della Sala, S., Logie, R. H., & Baddeley, A. D. (2006). The selective disruption of spatial working memory by eye movements. The Quarterly Journal of Experimental Psychology, 59(1), 100–120. doi:10.1080/17470210500151410.
Schmitt, M., Postma, A., & de Haan, E. H. F. (2001). Cross-modal exogenous attention and distance effects in vision and hearing. European Journal of Cognitive Psychology, 13(3), 343–368.
Smith, E. E., & Jonides, J. (1995). Working memory in humans: Neuropsychological evidence. In M. S. Gazzaniga (Ed.), The cognitive neurosciences (pp. 1009–1020). Cambridge: MIT Press.
Smith, E. E., & Jonides, J. (1999). Storage and executive processes in the frontal lobes. Science, 283(5408), 1657–1661.
Smyth, M. M., & Scholey, K. A. (1994a). Characteristics of spatial memory span: Is there an analogy to the word length effect, based on movement time? The Quarterly Journal of Experimental Psychology, 47A(1), 91–117.
Smyth, M. M., & Scholey, K. A. (1994b). Interference in immediate spatial memory. Memory & Cognition, 22(1), 1–13.
Smyth, M. M., & Scholey, K. A. (1996a). Serial order in spatial immediate memory. The Quarterly Journal of Experimental Psychology, 49A(1), 159–177.
Smyth, M. M., & Scholey, K. A. (1996b). The relationship between articulation time and memory performance in verbal and visuospatial tasks. British Journal of Psychology, 87, 179–191.
Tallal, P., Merzenich, M. M., Miller, S., & Jenkins, W. (1998). Language learning impairments: Integrating basic science, technology, and remediation. Experimental Brain Research, 123(1–2), 210–219.
Tan, L., & Ward, G. (2007). Output order in immediate serial recall. Memory & Cognition, 35(5), 1093–1106.
Wechsler Adult Intelligence Scale III, © The Psychological Corporation (1997), a Harcourt Assessment Company.
Author information
Authors and Affiliations
Corresponding author
Additional information
Funding was provided to Leon Gmeindl by a National Institute on Aging Training Fellowship (AG027668-01) and to Susan Courtney by the National Multiple Sclerosis Society through a Daniel Haughton Senior Faculty Award (SF1752-A-1) made possible by a grant from the Brodsky Family Foundation. We thank Eunice Awuah, Sue Borchardt, Jason Brandt, Regina Brock-Simmons, Farai Chidavaenzi, Simon Fischer-Baum, Joshua Gootzeit, Deepti Harshavardhana, Lisa Jefferies, Ben Kallman, Derek Leben, Patricia Reuter-Lorenz, and Amy Shelton for assistance and/or helpful suggestions.
Rights and permissions
About this article
Cite this article
Gmeindl, L., Walsh, M. & Courtney, S.M. Binding serial order to representations in working memory: a spatial/verbal dissociation. Mem Cogn 39, 37–46 (2011). https://doi.org/10.3758/s13421-010-0012-9
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-010-0012-9