
Abstract
Background
After the first infection in December 2019, the mutating strains of SARS-CoV2 have already affected a lot of healthy people around the world. But situations have not been as devastating as before the first pandemic of the omicron strains of SARS-CoV2. As of January 2023, five more Omicron offshoots, BA.4, BA.5, B.Q.1, B.Q.1.1 and XBB are now proliferating worldwide. Perhaps there are more variants already dormant that require only minor changes to resurrect. So, this study was conducted with a view to halting the infection afterwards. The spike protein found on the virus outer membrane is essential for viral attachment to host cells, thus making it an attractive target for vaccine, drug, or any other therapeutic development. Small interfering RNAs (siRNAs) are now being used as a potential treatment for various genetic conditions or as antiviral or antibacterial therapeutics. Thus, in this study, we looked at spike protein to see if any potential siRNAs could be discovered from it.
Results
In this study, by approaching several computational assays (e.g., GC content, free energy of binding, free energy of folding, RNA–RNA binding, heat capacity, concentration plot, validation, and finally molecular docking analysis), we concluded that two siRNAs could be effective to silence the spike protein of the omicron variant. So, these siRNAs could be a potential target for therapeutic development against the SARS-CoV2 virus by silencing the spike protein of this virus.
Conclusion
We believe our research lays the groundwork for the development of effective therapies at the genome level and might be used to develop chemically produced siRNA molecules as an antiviral drug against SARS-CoV2 virus infection.
Graphical abstract

Similar content being viewed by others
Background
Severe acute respiratory syndrome coronavirus-2 (SARS-CoV-2), a new Beta coronavirus, was discovered in December 2019, infecting more than 0.318 billion people worldwide and resulting in 5.5 million deaths [1, 2]. Different strains (Alpha, Beta, Gamma, Delta, Kappa, and so on) of this virus have developed during the pandemic due to mutations in the SARS-CoV-2 genome. Both the antigenic evasion mechanism as well as the rate of infection are more affected by these modifications [3, 4]. The advent of numerous variations causes waves of destructive pandemics to spread worldwide [5]. The World Health Organization (WHO) designated this new type as a variation of concern on November 26, 2021, after it was discovered on November 24, 2021, in Botswana, South Africa (variant of concern- VOC) [6]. The appearance of this highly modified SARS-CoV-2 strain (B.1.1.529, Omicron) and its fast spread across six continents within a week of its discovery have heightened global public health concerns [7]. After that, this variant changed several times, causing several spikes worldwide. As of June 2022, two more Omicron offshoots, BA.4 and BA.5 were started to proliferate worldwide [8]. Also, when compared to the BA.1 strain, which sparked the Omicron wave in most countries late last year, these two variants of concern (VOC) are far more similar to BA.2. However, from December, 2022 these two subvariants were started to replace by newer omicron subvariants, BQ.1, BQ.1.1 and XBB specifically in United States of America. Now, as of January 2023, the variants that are proliferating worldwides are BA.4, BA.5, BQ.1, BQ.1.1 and XBB.1.5 with the most potent distribution of BQ.1 pango lineage which is 49.0% [9, 10]. The major mutations that are found in each of the subliniages are follows: S135R (NSP1), F486V (S-protein), L11F (ORF7b) and P151S (N-protein) for BA.4. For BA.5 the major mutations are S135R (NSP1) and F486V (S-protein). For BQ.1 defining mutations are: Y272H (RdRP), M233I (NSP13), K444T (S-protein) and N460K (S-protein). For BQ.1.1 the mutations are similar to the BQ.1 except to two new muations which are N268S (NSP13) and R346T (S-protein). The all defining mutations in XBB.1.5 are from spike proteins which are V83A (S-protein), H146Q (S-protein), Q183E (S-protein), G252V (S-protein), F486L () and F486S (S-protein) [11].
Alphacoronavirus, Betacoronavirus, Gammacoronavirus, and Deltacoronavirus are the four genetically distinct groups of coronaviruses [12]. Mammals are the primary hosts for the first two species, whereas birds are the hosts for the latter two. Coronavirus genomes are generally 26–32 kb in size and include 6–11 open reading frames (ORFs) [13]. The four essential structural proteins of coronavirus are nucleocapsid protein (N), a small envelope protein (E), spike surface glycoprotein (S), and matrix protein (M), and each one is necessary to produce a physically complete virus [14, 15].
The human angiotensin converting enzyme 2 (hACE2) present in lung cells is recognized and can bind to the Spike glycoprotein (S), which starts the pathogenesis of SARS-CoV-2 when viral particles adhere to host cell cellular surface receptors [2, 16]. So, virus entry into cells is made possible by this spike glycoprotein (S), which forms homotrimers on the viral surface [17, 18]. S consists of two functioning parts, S1, and S2 subunits. The membrane-anchored S2 subunit, which contains the fusion machinery, is stabilized by the S1 subunit, which contains receptor-binding domains [19]. Because coronavirus S glycoprotein is surface-exposed and aids host cell entry, it may be recognized as a therapeutic target [20]. Previous research, however, found that all identified variations had most of the mutations in their Spike glycoprotein [21]. As a result, finding an antiviral medication that targets Spike protein is a promising option for blocking COVID-19 variant transmission [22].
A biological regulatory process called RNA interference (RNAi) uses post-transcriptional gene silencing to silence mRNA. RNAi is a technology that also shows promise for reducing human viral infections [23, 24]. Non coding RNA like small interfering RNAs (siRNAs) can inhibit gene expression by hybridizing to complementary mRNA and neutralizing it [25]. The siRNA is a 19–25 base pair long RNA duplex with two nucleotide overhangs on the 3′ end. It binds to target complementary mRNA and degrades its enzymatic quality to trigger post-translational gene silencing (PTGS) [26].
However, the process of binding of the siRNA’s with complementary mRNA is not an easy task. The siRNA-mediated inhibition of gene expression is a very intricate process. After entering the cell, the siRNA duplex is splitted by dicer, an enzyme similar to RNase III, and integrated into the protein complex known as the RNA-induced silencing complex (RISC) [27, 28]. The RNA strands within RISC are divided by the ATP-dependent RNA helicase domain. RISC eliminates the target mRNA's sense strand, but the catalytic RISC protein, an argonaute protein, can align RISC on the target mRNA and cleave the target mRNA’s strand [29].
Following the discovery of its mechanism, this method has evolved into a robust experimental gene-silencing tool in fundamental research [30]. For instance, studies show that combining chemically made siRNA duplexes that target SARS-CoV genomic RNA leads to up to 80% virus suppression [31]. Because the spike protein produced by the S gene of SARS-CoV2 omicron variant is part of the cell surface entry complex, it can be used as a viable target for suppressing SARS-CoV-2-induced infection. In this paper, siRNA molecules for the SARS-CoV- 2 “S” gene were rationally generated using various computational methods. Designed siRNAs might aid in the discovery of effective treatment medicines against this killer virus. The RNAi therapies GIVLAARITM and ONPATTRO® are now recognized for use in treating acute hepatic porphyria and polyneuropathy, respectively [32]. We believe this research will aid in developing a similar therapeutic technique for SARS-CoV-2.
Methods
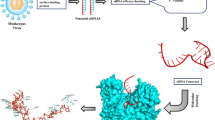
The complete methodology for designing of the siRNA molecules against the SARS-Cov2 omicron variant is shown in the graphical abstract.
Sequence retrieval of CDS of spike genome
The National Health Laboratory South Africa reported the Omicron spike genomic sequence to the Global Initiative for Sharing all Influenza Data (GISAID) with the accession number EPI ISL 8616776. We selected this variant as this is the first reported sub lineage of omicron variant. Then we identified and sorted out the Spike CDS (coding sequence) from the EPI ISL 8616776 through NCBI BLAST search.
Designing of siRNA from the CDS of spike genome
To identify the siRNA molecule from the CDS of spike genome, siDirect version 2.0 webserver was used (https://sidirect2.rnai.jp/doc/) [33]. To achieve this, first of all the retrieved fasta sequence of omicron variant spike genome submitted in the siDirect web server. The web server then identified potential siRNAs employing three rules: Ui-Tei, Renold, and Amarguioui [34,35,36]. The seed duplex’s melting temperature (Tm) is by default, set lower than 21.5 °C on the webserver. It is essential because the seed duplex melting temperature influences the efficacy of siRNAs, such as off-target effect reduction [33]. The equation to calculate melting temperature is below:
Tm = (1000*ΔH)/(A + ΔS + R ln (CT/4)) − 273.15 + 16.6log [Na+].
Here,
-
The sum of the nearest neighbor enthalpy change is represented by ΔH (kcal/ mol)
-
The helix initiation constant (− 10.8) is represented by A
-
ΔS represents the sum of the nearest neighbor entropy change
-
The gas constant (1.987 cal/deg./mol) is characterized by R
-
The total molecular concentration (100 μM) of the strand is represented by CT and
-
The concentration of Sodium, [Na+] was fixed at 100 mM
The three algorithms chosen for siRNA prediction each have unique characteristics. For example, the Ui-Tei algorithm follows specific rules, such as (i) 5′ terminus of the antisense/guide strand has to include A/U nucleotide, (ii) 5′ end of the sense/passenger strand must contain G/C nucleotide, (iii) 5′ terminal 7 base pairs of sense/passenger strand has to contain at least 4 A/U nucleotides, and (iv) GC stretch should not be longer than nine nucleotides [34]. Meanwhile, Amarzguioui rules include the parameters such as (i) robust binding of 5′ sense/passenger strand, (ii) the A/U differential of the duplex end should be more than zero, (iii) position six should always contain A, (iv) position one must contain any base except U, v) weak binding of 3′ sense/passenger strand and (vi) position 19 must contain any base except G [35]. Reynolds algorithm also follows several criteria, such as (i) the sense/passenger strand must maintain ≥ 3 base pairs at the position between 15 and 19, (ii) maintenance of GC content in the designed siRNA between 30 to 52%, (iii) position 19 and 3 of the sense/passenger strand must contain A, (iv) internal stability has to be low at a target site, (v) sense/passenger strand should contain U at position 10, (vi) position 13 of the sense/passenger strands must contain any bases other than G [36].
Investigation of parameters for siRNA refinement
To identify the most effective siRNA’s from the bulk siRNAs that was initially reported through siDirect webserver, we used several refinement procedures for highly effective siRNA selection. First, GC content of the siRNA molecules was calculated through the OligoCalc web server (http://biotools.nubic.northwestern.edu/OligoCalc.html) [37]. Any siRNA’s that showed GC content under 30% were excluded from the study. Next, the secondary structure and free energy of folding of the siRNAs were predicted using the RNA structure website https://rna.urmc.rochester.edu/RNAstructureWeb/ [38]. We excluded from further analysis of any siRNAs that displayed negative free energy of folding in the website. Then, we anticipate the interaction of the target and guide strands of siRNAs with RNA. The thermodynamic interaction between the target and guide strands was consequently calculated using the Bifold tool of the RNA structure website [33]. The heat capacity and concentration charts were then created using the DINA Melt web server (http://www.unafold.org/hybrid2.php) [39]. The melting temperature Tm (Cp) is displayed in the detailed heat capacity figure along with the ensemble heat capacity (Cp) as a function of temperature. The melting temperature Tm (Conc), which may be determined using the concentration plot, is obtained at the point where double-stranded molecules’ concentration is half their maximum value. Finally, SMEpred webserver (https://bioinfo.imtech.res.in/manojk/smepred/) was used to validate the final siRNAs [40]. SMEpred is the world's first website for designing and predicting the efficiency of chemically modified siRNAs. The anticipated siRNAs are tested on different datasets: standard siRNAs dataset (2182) and cm-siRNA dataset (3031 cm-siRNAs), both of which have been experimentally validated. SMEpred was also used to do a tenfold cross-validation employing Support Vector Machine (SVM).
Conservancy checking against the other sub-lineages and human genomic transcript
In the final step of siRNA prediction, a conservancy checking was performed against the 59 sub-lineages of the omicron variant through NCBI Blastn search [41] and multiple sequence alignment through CLC Drug Discovery Workbench 3.0 software. In the NCBI Blastn database, we manually uploaded the spike CDS of all sub-lineages and all other parameters were selected as default for Blast search. For phylogenetic tree construction, we employed a neighbor-joining phylogenetic tree with a bootstrap value of 1000. First, the phylogenetic tree was generated using the Tamura Nei assessment model [37]. Then, the phylogenetic tree was constructed using the MEGA-11 tool [38]. Finally, we used NCBI Blastn to perform a specific blast analysis to compare the generated siRNAs to human genomic transcripts. The e-value was adjusted to 1e−10 to lessen the search criterion's stringency and hence increase the likelihood of arbitrary matches.
Molecular docking of guide siRNA and argonaute-2 protein
The right interaction between siRNA duplex (primarily guide strand) and RISC complex protein (mostly human argonaute protein) is required to initiate an adequate antiviral response via RNAi-mediated viral gene silencing [30]. After eliminating the target mRNA’s sense strand, the catalytic RISC protein, which is the argonaute protein, can align RISC on the target mRNA and cleave the target mRNA's strand [29]. That is why docking of the siRNA with argonaute protein is an indicator of successful RISC complex formation and siRNA efficacy. So, we docked our siRNA’s with argonaute-2, one of the protein of RISC complex.
Molecular docking of the siRNA guide strand with argonaute-2 protein was conducted with HDOCK web server [42]. Before molecular docking we predicted the 3D model of the siRNAs and argonaute-2 protein. For identifying the 3D structure of human argonaute-2 Robetta webserver was used [43]. This homology modeling webserver employs deep learning algorithms, RoseTTAFold and TrRosetta, and an integrated reporting facility for specific sequence alignments for homology modeling. For predicting the 3D structure of siRNA guide strand, we used Mfold and RNA Composer webserver [44, 45]. For predicting the 3D structure of siRNA guide strand, we used Mfold and RNA Composer web server [44]. The mfold web server, used to calculate the folding pattern of DNA/RNA at 37 °C, is one of the oldest known online servers in computational molecular biology. The RNA Composer system, on the other hand, provides a new user-friendly technique to fully autonomous modeling of immense RNA 3D structures. The method relies on the automatic translation concept and uses the RNA FRABASE database as a lexicon to connect RNA secondary and tertiary design components. Finally, after modeling of the guide siRNA and human argonaute-2 protein, we docked the siRNA with RISC complex (argonaute-2) through molecular docking. After docking, we visualize the interaction pattern through the PDBsum web server [46]. Web server PDBsum provides structural data on Protein Data Bank entries (PDB), protein secondary structure, protein–ligand, and protein-DNA.
Results
Sequence retrieval and 702 siRNA prediction through SiDirect
The complete CDS of omicron spike protein was retrieved from the EPI ISL 8616776 by blast searching against Sars-cov2 genomic data. After that, the siDirect webserver was used to identify the potential siRNA’s from the CDS of the omicron spike protein. siDirect used several parameters, including Ui-Tei, Renold and Amarguioui rules to identify potential siRNA’s with melting temperatures below 21.5 °C to reduce the seed-dependent off-target binding. Initially, siDirect webserver predicted 702 potential siRNA’s from CDS of the omicron spike protein. We then filtered this 702 siRNA’s to 17 siRNa’s by combining the three parameters (Ui-Tei, Renold and Amarguioui rules) and by selecting those siRNA’s whose melting temperature is below 10 °C. So, this 17 siRNA’s are highly off target reduced siRNA’s (Table 1).
GC content Calculation of the predicted 17 siRNA’s
The amount of GC content in the indicated 17 siRNA molecules was identified through the GC-content calculator (Additional file 1: Table S1). However, we found only 5 siRNAs showing GC content greater than 30% after prediction. Therefore, to be a potential siRNA, the GC content of the siRNA’s must be ranged from 30 to 60% [47]. We then filtered the rest 12 siRNAs from this study as the GC content of those siRNA’s were less than 30%.
Secondary structure prediction of the 5 siRNA’s
The calculated free energy of folding as well as the secondary structure of the 5 siRNA’s was predicted through RNA Structure webserver. The calculated free energy of folding of the 5 siRNA’s ranged from − 1.4 to 1.8 (Additional file 1: Table S2 and Fig. 1). Among them siRNA target number S3 showed no binding pairs for secondary structure prediction. However, only two targets, e.g., S2 and S10 showed positive free energy of folding after calculation. Those two siRNA’s were selected for further studies as these siRNAs are counted as less prone to folding.

Prediction of free energy of folding of the putative siRNA’s. (S2), (S10), (S12) and (S14) consecutively denoted the guide strand of siRNA molecules S2, S10, S12 and S14. Among them only siRNA S10 and S10 showed positive free energy calculated by RNA Structure webserver
Computation of RNA–RNA binding, heat capacity, concentration plot, and validation
The free energy of hybridization between the guide and target strand of the final two siRNA’s was computed. For S2 and S10 the free energy of binding was calculated as − 30.2 and − 28.4, respectively (Fig. 2). After, we calculated the heat capacity (TmCp) and duplex concentration (TmConc). The more these melting temperature values the better is the candidate molecules. The Tm(Cp) and Tm(Conc) of S2 molecule were calculated as 81.4 and 80.2, respectively, which is slightly more significant than the Tm(Cp) and Tm(Conc) of S10, e.g., 76.3 and 75.1, respectively (Additional file 2: Fig. S1). Finally, we validated both of the siRNA molecules by checking the effectivity through SMEpred webserver. The web server calculated better candidacy for S2 molecule with a score of 89.5 rather than S10 molecule, which was calculated as 78.2 (Table 2). This result resolved that both siRNA molecules could be effective for advanced molecular docking.

Prediction of free energy of binding of the putative siRNA’s with target RNA. (S2) denoted the siRNA molecule S2 and (S10) denoted the siRNA molecule S10. Both of this siRNA molecule (guide strand) showed greater binding efficacy with the target RNA strand
Calculation of off-target effect and conservancy search against other sub-lineages
Standalone blast search for both siRNA molecules was conducted against human transcriptome genome to find out possible homology. This results in our predicted siRNA’s being unique and not interacting with any off-target genome other than viral targets. After that, we employed a conservancy analysis of these 2 siRNA molecules against 59 sub-lineages of omicron variants through multiple sequence alignment NCBI Blast search. S2 molecule showed 100% conservancy, whereas S10 molecule showed 96% conservancy (out of 59, 57 sub-lineages matched with S10) (Additional file 3: Fig. 2). We also build a phylogenetic tree of the 59 sub-lineages for Spike protein (Additional file 4: Fig. S3). Only a handful number of lineages Showed significant divergence after tree analysis (bootstrap value > 0.74). These results stated that our predicted siRNA’s targets are mostly conserved among the other sub-lineages of omicron variant (Table 2).
Molecular modeling and docking analysis of final siRNA’s & Ago2
Mfold and RNA Composer webserver conducted molecular modeling of the final siRNA molecules. First, we attributed the guide siRNA sequence in the Mfold webserver to form the RNAdraw format. Then we used this RNAdraw format in the RNA Composer webserver to compose the final 3D structure of the final siRNA molecules. After designing the 3D models of siRNAs, we modeled the 3D structure of the human Ago2 (argonaute 2) protein through Robetta homology modeling web server. We used the refseq sequence of the human Arg2, e.g., UniprotKB: Q9UKV8 to model the Ago2 protein. The template for the homology modeling was selected was 4Z4D crystal structure (Human argonaute protein bound to t1-G target RNA) as this protein showed maximum sequence similarity with our Ago2 sequence. The modeled protein was then refined in the GalaxyRefine webserver. Finally, the quality of the model was checked using Ramachandran plot analysis of ZLab webserver [48]. Ramachandran's analysis of Ago2 3D structure revealed a good plot with 99.062% residues in the highly preferred observation. Only 0.938% of residues were found in the preferred region and no residues were found in the questionable region (Fig. 3).

(A) Homology modeling and (B) Ramachandran plot analysis of human argonaute-2 protein. Ramachndran plot analysis revealed 99.062% residues in the highly preferred observation, 0.938% residues in the preferred region and no residues in the questionable part
Finally, molecular docking of the final siRNA molecules (S2 and S10) and human Ago2 was conducted by HDOCK webserver. We then selected the best-docked complex with low energy for interaction analysis through Pymol and PDBsum webserver. Docking analysis revealed slightly better interaction of S10 molecule with Ago2 (docking score − 350.23); for S2 molecule the docking score was found as − 300.17 (Table 3). These siRNA’s are docked in the same pocket spanning between the Paz, Mid and PIWI domains of Ago2. The PDBsum analysis of both docked complexes S2 and S10 is shown in Figs. 4 and 5 respectably.

Molecular docking of the siRNA molecule “S2” with human argonaute-2 protein. Argonaute-2 protein is shown as a three dimensional surface structure (aqua) as well as the siRNA molecule S2 is shown as red. The interacting residues and bonds of the arogonaute-2 protein with siRNA molecule is also shown

Molecular docking of the siRNA “S10” with human argonaute-2 protein. Argonaute-2 protein is shown as a three dimensional surface structure (aqua) as well as the siRNA molecule S10 is shown as red. The interacting residues and bonds of the arogonaute-2 protein with siRNA molecule is also shown
Discussion
COVID-19 was considered a pandemic, and mortality rates increased as a result of multiple transmissible variants (e.g., delta/B.1.1.7.2; alpha/ B.1.1.7; gamma/P.1; beta/B.1.351 and as of January 2023, now Omicron sub variant B.4, BA.5, BQ.1, BQ.1.1 and XBB.1.5). BA.4 and BA.5 now account for more than 21% of new cases in the U.S., according to U.S centers for Disease Control and Prevention (CDC) estimates [49]. Also, according to the ECDC (European Centre for Disease Prevention and Control), as of 8 January 2023, the estimated distribution of variants of concern (VOC) or variants of interest (VOI) was 49.0% (from eight countries) for BQ.1, 24.3% (from 10 countries) for BA.5, 12.7% (from 10 countries) for BA.2.75, 2.7% (from eight countries) for XBB, 1.4% (from six countries) for XBB.1.5, 0.8% (from eight countries) for BA.2, and 0.8% (from nine countries) for BA.4 [9]. While, on the other hand, in USA the dominant variant nationwide is the XBB.1.5 with 43% cases. The second dominant sublineage in USA is the BQ.1.1 with 29% cases. According to researchers, these novel subvariants developed from the Omicron lineages to become much more contagious and can circumvent immunity from a prior infection [8]. Vaccine-induced antibodies are consistently more successful at blocking earlier Omicron strains, such as BA.1 and BA.2, than they are at blocking BA.4 and BA.5 [50,51,52]. So, a newer treatment method is now at the peak of concern in the scientific research community.
The Omicron variant, B.1.1.529 was first detected in South Africa’s Gauteng area in November 2021 [53]. This Variant of Concern (VOC) has different epidemiological changes in transmission rate and at least 32 mutations in its spike protein, which may be affecting the current pandemic trajectory [54]. Without regard for region, this pandemic has a global reach; for example, this type has infected nearly 60 countries, and no continent is protected [55]. Furthermore, there is no effective vaccine to prevent the omicron variant, and no RNAi-based treatment is now in use or has been developed. A successful vaccination campaign in early 2021 significantly increased population immunity; however, the emergence of the delta or omicron lineages of SARS-CoV-2 has posed a new challenge to immunization-delaying methods [56, 57]. The current vaccinations are based on the SARS-CoV-2 Wuhan strain; however, the virus no longer looks like that [55]. Researchers are currently relying mainly on omicron sequencing data, which reveals a cluster of novel mutations in the spike protein, on which the COVID-19 vaccines are based, indicating that the variant is partially resistant to pre-existing immunity [55].
Additionally, a recent study found that primary immunization with two doses of the ChAdOx1 nCoV-19 (AstraZeneca) or BNT162b2 (Pfizer-BioNTech) vaccine showed inadequate protection against the omicron variant [58]. Moreover, after either the ChAdOx1 nCoV-19 or BNT162b2 primary course, a booster dose of BNT162b2 or mRNA-1273 (Moderna) significantly improved protection, but this protection diminished with time [58]. It is also not negligible that the original strain of SARS-CoV-2 has an R0 of 2·5, while the delta variant (B.1.617.2) has an R0 of under 7 and now the omicron variant outcompetes this number with an R0 of 10 [55]. So, as a result of the strong transmission and immune evasion of the continuing Omicron variety, therapeutic research is critical to halt the spread of the fifth wave of the pandemic. Thus, siRNA, the next-generation therapy, must be effective in this scenario, which is why it is the focus of our research.
Here, in this study, first of all we have identified the possible siRNAs (21nt + 2nt overhang region) with possible targets from the CDS of spike protein of omicron variant. This was done using the siDirect website, which conducts the work in three steps: highly functional siRNA selection, seed-dependent off-target effects minimization, and near-perfect matched genes deletion. The siDirect web server initially predicted 702 potential siRNA’s with target from the CDS of spike protein. However, we sorted this 702 siRNAs to only 17 by selecting both combined U,R A method (Ui-Tei, Renold and Amarguioui rules) and selecting those siRNA’s whose seed-target duplex Tm is under 10 °C. Generally, siRNA’s thermodynamic stability or seed-target duplex Tm under 21.5 °C is considered a benchmark as this minimizes the off-target effects [33]. This assured that our siRNAs are distinctive and have a low off-target binding rate.
The GC content of siRNA duplexes is one of the essential criteria for siRNA effectiveness, and GC content has an antagonistic connection with siRNA function [35]. When the content of GC is too high, the RISC complex-related helicase may take longer to unwind the siRNA duplex. On the other hand, the smaller GC content may limit the efficacy of target mRNA identification and hybridization. It is, thus, recommended to pick siRNA sequences with low GC content (between 30 and 52%) [47]. In our study, we evaluated the siRNAs for GC content and eliminated the siRNAs whose GC content is fewer than 30%. This subsequently sorted our 17 siRNA’s to 5.
According to previous research, an RNA molecule should have the highest free energy of folding [59]. The formation of secondary structure in siRNA molecules owing to lower folding free energy may prevent target cleavage by RISC complex. As a result, it is critical to calculate the potential secondary structure and free energy of folding. SiRNA molecules with positive free energy of folding of the guide strands may have more access to the target and have a greater chance of interacting with it, resulting in successful gene silencing [60]. In our study, out of 5 siRNA’s two siRNA’s showed positive free energy after analysis of secondary structure by RNA structure webserver. We then selected these two siRNAs (S2 & S10) for further analysis.
Because RNAi efficacy is highly connected with the binding energies of siRNAs to their respective target mRNAs, the free energy of binding with the target (i.e., computational RNA–RNA interaction) is another significant metric [61]. Lower binding energy suggests a stronger interaction, and hence an increased likelihood of inhibiting the target. After analysis, our final two siRNAs showed more negative free energy of binding (− 30.2 for S2 and − 28.4 for S10).
Additionally, the higher values of Tm (Cp) and Tm suggest that the siRNAS are more effective (Conc). The heat capacity plot indicates the Cp as a function of temperature, and when the Cp is a function of Tm, it is expressed as TmCp. Similar to a concentration plot, the mole fractions plotted as a function of temperature is represented by Tm (Conc). The concentration of the double-stranded molecule is half its greatest value at the location Tm (Conc) [39]. The DINAMelt web server calculated the full equilibrium melting profiles as a function of temperature. Here, The better the RNAi molecules are, the higher the TmCp and Tm(Conc) values are, and our projected siRNAs had high melting profiles, as shown in Table 3.
Finally, the inhibitory efficacy of the anticipated siRNAs was determined using the SMEpred website. Here, both of this siRNA (S2 & S10) showed inhibition efficacy greater than 75%.
Despite our siRNAs reducing off-target binding, we BLASTn the final two siRNAs against the human genomic transcript to confirm the off-target silencing effect. These findings revealed that our projected siRNAs are unique and have no link to any human genomic target. We also BLASTn the target of these final two siRNAs with 59 sub-lineages of the omicron variant. Finally, we did a multiple sequence alignment to find out the conservancy of the target of the siRNA molecule. This result revealed that the target of S2 molecule is 100% conserved whereas the target of S10 molecule is somewhat 94.92% conserved e.g., out of 59, 56 sub-lineages is matched with the target.
To know the binding pattern of the siRNA with human Ago2 protein for RISC cleavage, in silico molecular docking was performed between the guide strands of our final two siRNAs with Ago2 protein. In silico molecular docking is an advanced techniques used in several studies to study the vaccine docking, epitope docking or other small molecule docking with several protein complexes [62,63,64,65,66,67]. Targeting the CDS with siRNA is suggested for modulating transcript levels via Argonaute 2 (Ago2) mediated transcript cleavage. However, complementary siRNA targeting the 3′untranslated region (UTR) of mRNA causes translational repression, which is mediated by Ago1, Ago3, and Ago4 [47]. Therefore, we have targeted the CDS of omicron variant, so we docked our siRNAs with human Ago2 protein [68, 69]. So for this purpose, first of all we predicted the 3D structure of Ago2 protein with Robetta homology modeling web server. Afterward, we refined the modeled protein with Galaxy refine webserver. The resulting model had 99.062% residues laid in the highly preferred observation analyzed by Ramachandran plot analysis. Subsequently, we also modeled the 3D structure of our final two siRNAs with Mfold and RNA Composer webserver.
After modeling, we used the HDOCK website to dock our candidate siRNAs with human Ago2 protein. The docking complexes were downloaded from the web server and manually evaluated to determine the best-docked complex based on the docking score, the visual likeness of the complex to the 4Z4D structural composite, and the positioning of siRNA in the same binding pocket of 4Z4D. This analysis showed that model no 5 of S2 and model no 1 of S10 bind in the same pocket of the Ago2 protein and resembled the 4Z4D siRNA-Ago2 complex. Finally, we selected these modeled complexes for further RNA–protein interaction analysis.
The RNA–protein interaction of the S2, S10 and Ago2 complex showed that this siRNA binds in the same pocket of Ago2 spanning between the L1, PAZ, PIWI and Mid domain. However, both of these siRNA’s strongly anchored in the PIWI domain of Ago2 wherever none of the siRNA’s docked with the N-terminal site of Ago2. The docking score also revealed strong binding affinity with a score of − 300.17 for S2 and − 350.23 for the S10 molecule. However, it is clearly visible that S10 molecule outcompetes the S2 with greater binding affinity. The binding residues are also found better in the S10-Ago2 complex compared to the S2-Ago2 complex. We also analyzed the binding residues with a previous experimental analysis and found similarities for both of these complexes. For S2 molecule, interacting residues that found similarities with previous studies are ALA221, Thr222, ILE365, GLY524, ASN551, LYS709, ARG710, GLN757, THR759, ARG76, ARG792, SER798 [70,71,72]. And, for S10 molecule, residues that were found to be similar to previously reported residues are SER220, ALA221, THR222, ARG351, ILE365, LYS709, ARG710, GLN757, THR759, ARG761, TYR792, SER798, TYR804 [70,71,72]. However, both of these complex shares some common residues, e.g., ALA221, Thr222, ILE365, LYS709, ARG710, GLN757, THR759, ARG792, SER798. These residues are also found in previously reported experimental studies [70]. So, it can be stated that these residues are conserved for binding the siRNA’s with human Ago2 protein.
From this structural perspective, though the S10-Ago2 complex showed better binding efficacy than S2-Ago2 complex, S2 molecules is 100% conserved against all 59 sub-lineages of the omicron variant. S10 molecule is not 100% conserved; however, S2 molecule could be performed as 100% conserved against all sub-lineages of the omicron variant. A study revealed that small RNAs with an inaccurate match to native mRNA can also suppress translation [73]. In RISC-mediated RNA degradation, we know that a 21-base pair RNA duplex that matches perfectly an endogenous target mRNA selectively degrades the mRNA and reduces gene expression in mammalian tissue culture cells or viral cells. A study found that a mismatched RNA (up to 3–4 nt) directed to a particular spot in an endogenous gene's coding sequence can effectively inhibit gene expression by suppressing translation [73]. In our study, the target site of S10 molecule is 96.61% (out of 59, 57 is conserved), so we analyzed the mismatch pattern of the rest two sub-lineages with our target. This result revealed that these mismatches are due to one base alteration (Additional file 5: Fig. S4). So, according to the previous study, we can account for the fact that S10 molecules can affect the expression of spike protein of omicron variant through translational repression. This further revealed that S10 molecule can outperform S2 molecule in RNAi activity.
However, various obstacles, such as siRNA instability, limited cellular absorption, and the absence of a trustworthy delivery pathway, could pose difficulties for siRNAs' therapeutic potential for targeted gene silencing [74]. For effective gene therapy, a suitable promoter-controlled vector can help deliver therapeutic genes to the targeted cell [75]. Vector-based siRNA in plasmid form can also be used to target targeted genes within a given cell line to examine the potency of a newly created siRNA [76]. In our study, we have just identified the possible siRNA molecules for RNAi activity in the spike protein of the omicron variant. Further vector-based in-vitro research is needed to test our proposed two siRNAs. Various research groups have also proposed a similar RNAi treatment strategy for COVID 19 since the pandemic began [71, 72, 77]. However, no study is done yet on RNAi-mediated gene silencing against the omicron variant. Several pharmaceutical companies, including Siranomics, Vir Biotechnology, and OilX Pharmaceuticals, have discovered several SARS-CoV-2 RNAi targets and related siRNA agents. We hope our research will contribute to this landscape well [78]. Finally, the discovery of this siRNA therapeutic approach could be a potential alternative to traditional vaccine design in slowing down the COVID-19 pandemic.
Conclusion
RNAi treatment is a novel method for creating a variety of possible siRNA molecules for the post-transcriptional gene silencing of key genes in diverse biological organisms. The current study identified two single possible siRNA molecule as an effective option for inhibiting the expression of spike protein in the omicron variant of Sars-cov-2 virus. We have specifically targeted the recent omicron offshoots which are now proliferating around the world, e.g., BA.4, BA.5, BQ.1, BQ1.1. and XBB. In the fight against viral infection, these two synthetic compounds might be exploited as innovative antiviral therapy, providing a foundation for academics and the pharmaceutical sector to create antiviral medicines at the genome level.
Availability of data and materials
All data supporting the findings of this study are available within the article and its supplementary materials.
Abbreviations
- SARS-CoV-2:
-
Severe acute respiratory syndrome coronavirus-2
- WHO:
-
World Health Organization
- ORF:
-
Open reading frame
- hACE2:
-
Human angiotensin converting enzyme 2
- RNAi:
-
RNA interference
- PTGS:
-
Post-translational gene silencing
- RISC:
-
RNA-induced silencing complex
- GISAID:
-
Global Initiative for Sharing all Influenza Data
- CDS:
-
Coding sequence
- Tm:
-
Seed duplex’s melting temperature
- Cp:
-
Ensemble heat capacity
- UTR:
-
3′Untranslated region
- GC:
-
Guanine–cytosine content
- RISC:
-
RNA-induced silencing complex
- VOC:
-
Variant of concern
References
Poon LL, Peiris M (2020) Emergence of a novel human coronavirus threatening human health. Nat Med 26(3):317–319. https://doi.org/10.1038/s41591-020-0796-5
Rakib A, Sami SA, Mimi NJ, Chowdhury MM, Eva TA, Nainu F, Emran TB (2020) Immunoinformatics-guided design of an epitope-based vaccine against severe acute respiratory syndrome coronavirus 2 spike glycoprotein. Comput Biol Med 124:103967. https://doi.org/10.1016/j.compbiomed.2020.103967
Tao K, Tzou PL, Nouhin J, Gupta RK, de Oliveira T, Kosakovsky Pond SL, Shafer RW (2021) The biological and clinical significance of emerging SARS-CoV-2 variants. Nat Rev Genet 22(12):757–773. https://doi.org/10.1038/s41576-021-00408-x
Thakur V, Bhola S, Thakur P, Patel SKS, Kulshrestha S, Ratho RK, Kumar P (2021) Waves and variants of SARS-CoV-2: understanding the causes and effect of the COVID-19 catastrophe. Infection. https://doi.org/10.1007/s15010-021-01734-2
Kumar A, Parashar R, Kumar S, Faiq MA, Kumari C, Kulandhasamy M, Kant K (2022) Emerging SARS-CoV-2 variants can potentially break set epidemiological barriers in COVID-19. J Med Virol 94(4):1300–1314. https://doi.org/10.1002/jmv.27467
Poudel S, Ishak A, Perez-Fernandez J, Garcia E, León-Figueroa DA, Romaní L, Rodriguez-Morales AJ (2022) Highly mutated SARS-CoV-2 omicron variant sparks significant concern among global experts–What is known so far? Travel Med Inf Dis 45:102234. https://doi.org/10.1016/j.tmaid.2021.102234
Nishiura H, Ito K, Anzai A, Kobayashi T, Piantham C, Rodríguez-Morales AJ (2021) Relative reproduction number of SARS-CoV-2 omicron (B. 1.1. 529) compared with delta variant in South Africa. J Clin Med 11(1):30. https://doi.org/10.3390/jcm11010030
What Omicron’s, B. A. (4). and BA. 5 variants mean for the pandemic (2022)
SARS-CoV-2 variants of concern as of 1 June 2023. https://www.ecdc.europa.eu/en/covid-19/variants-concern. Accessed 17 May 2023
What COVID-19 variants are going around in May 2023? https://www.nebraskamed.com/COVID/what-covid-19-variants-are-going-around. Accessed 02 June 2023
SARS-CoV-2 Variants Overview. https://www.ncbi.nlm.nih.gov/activ?lineage=BA.4. Accessed 2 June 2023
Li F (2016) Structure, function, and evolution of coronavirus spike proteins. Ann Rev Virol 3:237–261. https://doi.org/10.1146/annurev-virology-110615-042301
Song Z, Xu Y, Bao L, Zhang L, Yu P, Qu Y, Qin C (2019) From SARS to MERS, thrusting coronaviruses into the spotlight. Viruses 11(1):59. https://doi.org/10.3390/v11010059
Masters PS, JAivr (2006) The molecular biology of coronaviruses. Adv Virus Res 66:193–292. https://doi.org/10.1016/S0065-3527(06)66005-3
Wang C, Zheng X, Gai W, Zhao Y, Wang H, Wang H, Xia X (2017) MERS-CoV virus-like particles produced in insect cells induce specific humoural and cellular imminity in rhesus macaques. Oncotarget 8(8):12686. https://doi.org/10.18632/oncotarget.8475
Harrison AG, Lin T, Wang P (2020) Mechanisms of SARS-CoV-2 transmission and pathogenesis. Trends Immunol 41(12):1100–1115. https://doi.org/10.1016/j.it.2020.10.004
Tortorici MA, Veesler D (2019) Structural insights into coronavirus entry. Adv Virus Res 105:93–116. https://doi.org/10.1016/bs.aivir.2019.08.002
Howard MW, Travanty EA, Jeffers SA, Smith MK, Wennier ST, Thackray LB, Holmes KV (2008) Aromatic amino acids in the juxtamembrane domain of severe acute respiratory syndrome coronavirus spike glycoprotein are important for receptor-dependent virus entry and cell-cell fusion. J Virol 82(6):2883–2894. https://doi.org/10.1128/jvi.01805-07
Walls AC, Tortorici MA, Bosch BJ, Frenz B, Rottier PJ, DiMaio F, Veesler D (2016) Cryo-electron microscopy structure of a coronavirus spike glycoprotein trimer. Nature 531(7592):114–117. https://doi.org/10.1038/nature16988
Park JE, Li K, Barlan A, Fehr AR, Perlman S, McCray PB Jr, Gallagher T (2016) Proteolytic processing of Middle East respiratory syndrome coronavirus spikes expands virus tropism. Proc Natl Acad Sci 113(43):12262–12267. https://doi.org/10.1073/pnas.160814711
Harvey WT, Carabelli AM, Jackson B, Gupta RK, Thomson EC, Harrison EM, Robertson DL (2021) SARS-CoV-2 variants, spike mutations and immune escape. Nat Rev Microbiol 19(7):409–424. https://doi.org/10.1038/s41579-021-00573-0
Rakib A, Nain Z, Sami SA, Mahmud S, Islam A, Ahmed S, Simal-Gandara J (2021) A molecular modelling approach for identifying antiviral selenium-containing heterocyclic compounds that inhibit the main protease of SARS-CoV-2: an in silico investigation. Brief Bioinform 22(2):1476–1498. https://doi.org/10.1093/bib/bbab045
Levanova A, Poranen MM (2018) RNA interference as a prospective tool for the control of human viral infections. Front Microbiol 9:2151. https://doi.org/10.3389/fmicb.2018.02151
Sharif Shohan MU, Paul A, Hossain M (2018) Computational design of potential siRNA molecules for silencing nucleoprotein gene of rabies virus. Futur Virol 13(3):159–170. https://doi.org/10.2217/fvl-2017-0117
Hamilton AJ, Baulcombe DC (1999) A species of small antisense RNA in posttranscriptional gene silencing in plants. Science 286(5441):950–952. https://doi.org/10.1126/science.286.5441.950
Elbashir SM, Lendeckel W, Tuschl T (2001) RNA interference is mediated by 21-and 22-nucleotide RNAs. Genes Dev 15(2):188–200. https://doi.org/10.1101/gad.862301
Bernstein E, Caudy AA, Hammond SM, Hannon GJ (2001) Role for a bidentate ribonuclease in the initiation step of RNA interference. Nature 409(6818):363–366. https://doi.org/10.1038/35053110
Hammond SM, Bernstein E, Beach D, Hannon GJ (2000) An RNA-directed nuclease mediates post-transcriptional gene silencing in Drosophila cells. Nature 404(6775):293–296. https://doi.org/10.1038/35005107
Dana H, Chalbatani GM, Mahmoodzadeh H, Karimloo R, Rezaiean O, Moradzadeh A, Gharagouzlo E (2017) Molecular mechanisms and biological functions of siRNA. Int J Biomed Sci: IJBS 13(2):48
Jana S, Chakraborty C, Nandi S (2004) Mechanisms and roles of the RNA-based gene silencing. Electron J Biotechnol 7(3):15–16
Zheng BJ, Guan Y, Tang Q, Cheng D, Xie FY, He ML, Zhong N (2004) Prophylactic and therapeutic effects of small interfering RNA targeting SARS-coronavirus. Antivir Ther 9(3):365–374. https://doi.org/10.1177/135965350400900310
Hu B, Zhong L, Weng Y, Peng L, Huang Y, Zhao Y, Liang XJ (2020) Therapeutic siRNA: state of the art. Signal Transduct Target Ther 5(1):101. https://doi.org/10.1038/s41392-020-0207-x
Naito Y, Yoshimura J, Morishita S, Ui-Tei K (2009) siDirect 20: updated software for designing functional siRNA with reduced seed-dependent off-target effect. BMC Bioinform 10(1):1–8. https://doi.org/10.1186/1471-2105-10-392
Ui-Tei K, Naito Y, Takahashi F, Haraguchi T, Ohki-Hamazaki H, Juni A, Saigo K (2004) Guidelines for the selection of highly effective siRNA sequences for mammalian and chick RNA interference. Nucl Acids Res 32(3):936–948. https://doi.org/10.1093/nar/gkh247
Amarzguioui M, Prydz H (2004) An algorithm for selection of functional siRNA sequences. Biochem Biophys Res Commun 316(4):1050–1058. https://doi.org/10.1016/j.bbrc.2004.02.157
Reynolds A, Leake D, Boese Q, Scaringe S, Marshall WS, Khvorova A (2004) Rational siRNA design for RNA interference. Nat Biotechnol 22(3):326–330. https://doi.org/10.1038/nbt936
Kibbe WA (2007) OligoCalc: an online oligonucleotide properties calculator. Nucl Acids Res 35:43–46. https://doi.org/10.1093/nar/gkm234
Bellaousov S, Reuter JS, Seetin MG, Mathews DH (2013) RNAstructure: web servers for RNA secondary structure prediction and analysis. Nucl Acids Res 41(W1):W471–W474. https://doi.org/10.1093/nar/gkt290
Markham NR, Zuker M (2005) DINAMelt web server for nucleic acid melting prediction. Nucl Acids Res 33:W577–W581. https://doi.org/10.1093/nar/gki591
Dar SA, Gupta AK, Thakur A, Kumar M (2016) SMEpred workbench: a web server for predicting efficacy of chemicallymodified siRNAs. RNA Biol 13(11):1144–1151. https://doi.org/10.1080/15476286.2016.1229733
Camacho C (2009) BLAST+: architecture and applications. 10: 421, https://doi.org/10.1186/1471-2105-10-421
Yan Y, Tao H, He J, Huang SY (2020) The HDOCK server for integrated protein–protein docking. Nat Protoc 15(5):1829–1852. https://doi.org/10.1038/s41596-020-0312-x
Kim DE, Chivian D, Baker D (2004) Protein structure prediction and analysis using the Robetta server. Nucl Acids Res 32:W526–W531. https://doi.org/10.1093/nar/gkh468
Zuker M (2003) Mfold web server for nucleic acid folding and hybridization prediction. Nucl Acids Res 31(13):3406–3415. https://doi.org/10.1093/nar/gkg595
Popenda M, Szachniuk M, Antczak M, Purzycka KJ, Lukasiak P, Bartol N, Adamiak RW (2012) Automated 3D structure composition for large RNAs. Nucl Acids Res 40(14):112–112. https://doi.org/10.1093/nar/gks339
Laskowski RA, Jabłońska J, Pravda L, Vařeková RS, Thornton JM (2018) PDBsum: structural summaries of PDB entries. Protein Sci 27(1):129–134. https://doi.org/10.1002/pro.3289
Safari F, Barouji SR, Tamaddon AM (2017) Strategies for improving siRNA-induced gene silencing efficiency. Adv Pharm Bull 7(4):603. https://doi.org/10.15171/apb.2017.072
Anderson RJ, Weng Z, Campbell RK, Jiang X (2005) Main-chain conformational tendencies of amino acids. Proteins: Struct Funct Bioinform 60(4):679–689. https://doi.org/10.1002/prot.20530
Tracker CCD. Centers for Disease Control and Prevention. https://covid.cdc.gov/covid-data-tracker/#variant-proportions. Accessed 23 Nov 2022
Cao Y, Yisimayi A, Jian F, Song W, Xiao T, Wang L, Xie XS (2022) BA 2.12 1, BA. 4 and BA. 5 escape antibodies elicited by omicron infection. Nature 608(7923):593–602. https://doi.org/10.1038/s41586-022-04980-y
Tuekprakhon A, Nutalai R, Dijokaite-Guraliuc A, Zhou D, Ginn HM, Selvaraj M, Screaton GR (2022) Antibody escape of SARS-CoV-2 omicron BA. 4 and BA. 5 from vaccine and BA. 1 serum. Cell 185(14):2422–2433. https://doi.org/10.1016/j.cell.2022.06.005
Shahriar A, Mahmud A, Ahmed H, Rahman N, Khatun MJAJM (2021) A comprehensive review of possible immune responses against novel SARS-CoV-2 coronavirus: vaccines strategies and challenges. Austin J Microbiol 6:1028
Callaway E (2021) Heavily mutated omicron variant puts scientists on alert. Nature 600(7887):21. https://doi.org/10.1038/d41586-021-03552-w
Callaway E, Ledford H (2021) How bad is omicron? What scientists know so far. Nature 600(7888):197–199. https://doi.org/10.1038/d41586-021-03614-z
Burki TK (2022) Omicron variant and booster COVID-19 vaccines. Lancet Respir Med 10(2):e17. https://doi.org/10.1016/S2213-2600(21)00559-2
Yang W, Shaman J (2021) COVID-19 pandemic dynamics in India and impact of the SARS-CoV-2 Delta (B. 1.617. 2) variant. https://doi.org/10.1101/2021.06.21.21259268
Khandia R, Singhal S, Alqahtani T, Kamal MA, Nahed A, Nainu F, Dhama K (2022) Emergence of SARS-CoV-2 omicron (B. 1.1. 529) variant, salient features, high global health concerns and strategies to counter it amid ongoing COVID-19 pandemic. Environ Res 209:112816. https://doi.org/10.1016/j.envres.2022.112816
Kirsebom FC, Andrews N, Stowe J, Toffa S, Sachdeva R, Gallagher E, Bernal JL (2022) COVID-19 vaccine effectiveness against the omicron (BA. 2) variant in England. Lancet Infect Dis 22(7):931–933. https://doi.org/10.1056/NEJMoa2119451
Vickers TA, Wyatt JR, Freier SM (2000) Effects of RNA secondary structure on cellular antisense activity. Nucl Acids Res 28(6):1340–1347. https://doi.org/10.1093/nar/28.6.1340
Shawan MMAK, Hossain MM, Hasan MA, Hasan MM, Parvin A, Akter S, Rahman SMB (2015) Design and prediction of potential RNAi (siRNA) molecules for 3′ UTR PTGS of different strains of Zika virus: a computational approach. Nat Sci 13(2):37–50
Schubert S, Grünweller A, Erdmann VA, Kurreck J (2005) Local RNA target structure influences siRNA efficacy: systematic analysis of intentionally designed binding regions. J Mol Biol 348(4):883–893. https://doi.org/10.1016/j.jmb.2005.03.011
Islam R, Parvez MSA, Anwar S, Hosen MJ (2020) Delineating blueprint of an epitope-based peptide vaccine against the multiple serovars of dengue virus: a hierarchical reverse vaccinology approach. Informat Med Unlock 20:100430. https://doi.org/10.1016/j.imu.2020.100430
Khan MT, Islam R, Jerin TJ, Mahmud A, Khatun S, Kobir A, Mondal SI (2021) Immunoinformatics and molecular dynamics approaches: next generation vaccine design against West Nile virus. PLoS One 16(6):e0253393. https://doi.org/10.1371/journal.pone.0253393
Hoque H, Islam R, Ghosh S, Rahaman MM, Jewel NA, Miah MA (2021) Implementation of in silico methods to predict common epitopes for vaccine development against Chikungunya and Mayaro viruses. Heliyon. https://doi.org/10.1016/j.heliyon.2021.e06396
Khan MT, Islam MJ, Parihar A, Islam R, Jerin TJ, Dhote R, Halim MA (2021) Immunoinformatics and molecular modeling approach to design universal multi-epitope vaccine for SARS-CoV-2. Inform Med Unlock 24:100578. https://doi.org/10.1016/j.imu.2021.100578
Rahaman MM, Islam R, Jewel GNA, Hoque H (2022) Implementation of computational approaches to explore the deleterious effects of non-synonymous SNPs on pRB protein. J Biomol Struct Dyn 40(16):7256–7273. https://doi.org/10.1080/07391102.2021.1896385
Islam R, Rahaman M, Hoque H, Hasan N, Prodhan SH, Ruhama A, Jewel NA (2021) Computational and structural based approach to identify malignant nonsynonymous single nucleotide polymorphisms associated with CDK4 gene. PLoS ONE 16(11):e0259691. https://doi.org/10.1371/journal.pone.0259691
Rivas FV, Tolia NH, Song JJ, Aragon JP, Liu J, Hannon GJ, Joshua-Tor L (2005) Purified Argonaute2 and an siRNA form recombinant human RISC. Nat Struct Mol Biol 12(4):340–349. https://doi.org/10.1038/nsmb918
Su H, Trombly MI, Chen J, Wang X (2009) Essential and overlapping functions for mammalian Argonautes in microRNA silencing. Genes Dev 23(3):304–317. https://doi.org/10.1101/gad.1749809
Elkayam E, Kuhn CD, Tocilj A, Haase AD, Greene EM, Hannon GJ, Joshua-Tor L (2012) The structure of human argonaute-2 in complex with miR-20a. Cell 150(1):100–110. https://doi.org/10.1016/j.cell.2012.05.017
Shawan MMAK, Sharma AR, Bhattacharya M, Mallik B, Akhter F, Shakil MS, Chakraborty C (2021) Designing an effective therapeutic siRNA to silence RdRp gene of SARS-CoV-2. Infect Genet Evol 93:104951. https://doi.org/10.1016/j.meegid.2021.104951
Chowdhury UF, Shohan MUS, Hoque KI, Beg MA, Siam MKS, Moni MA (2021) A computational approach to design potential siRNA molecules as a prospective tool for silencing nucleocapsid phosphoprotein and surface glycoprotein gene of SARS-CoV-2. Genomics 113(1):331–343. https://doi.org/10.1016/j.ygeno.2020.12.021
Saxena S, Jónsson ZO, Dutta A (2003) Small RNAs with imperfect match to endogenous mRNA repress translation: implications for off-target activity of small inhibitory RNA in mammalian cells. J Biol Chem 278(45):44312–44319. https://doi.org/10.1074/jbc.M307089200
Tanaka K, Kanazawa T, Ogawa T, Takashima Y, Fukuda T, Okada H (2010) Disulfide crosslinked stearoyl carrier peptides containing arginine and histidine enhance siRNA uptake and gene silencing. Int J Pharm 398(1–2):219–224. https://doi.org/10.1016/j.ijpharm.2010.07.038
Glorioso JC, DeLuca NA, Fink DJ (1995) Development and application of herpes simplex virus vectors for human gene therapy. Annu Rev Microbiol 49(1):675–710. https://doi.org/10.1146/annurev.mi.49.100195.003331
ElHefnawi M, Kim T, Kamar MA, Min S, Hassan NM, El-Ahwany E, Windisch MP (2016) In silico design and experimental validation of siRNAs targeting conserved regions of multiple hepatitis C virus genotypes. PLoS ONE 11(7):e0159211. https://doi.org/10.1371/journal.pone.0159211
Hasan M, Ashik AI, Chowdhury MB, Tasnim AT, Nishat ZS, Hossain T, Ahmed S (2021) Computational prediction of potential siRNA and human miRNA sequences to silence orf1ab associated genes for future therapeutics against SARS-CoV-2. Inform Med Unlock 24:100569. https://doi.org/10.1016/j.imu.2021.100569
Uludağ H, Parent K, Aliabadi HM, Haddadi A (2020) Prospects for RNAi therapy of COVID-19. Front Bioeng Biotechnol 8:916. https://doi.org/10.3389/fbioe.2020.00916
Acknowledgments
No specific acknowledgment
Funding
No specific grant was received for this study.
Author information
Authors and Affiliations
Contributions
RI contributed to conceptualization, project administration, supervision, writing. AS contributed to writing—review and editing. NF contributed to writing—review and editing. MRU contributed to writing—review and editing. MA contributed to writing—review and editing. MMRS contributed to data curation, investigation, former analysis, writing. AS contributed to data curation, writing—review and editing, visualization. KJA contributed to review and editing.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Ethical approval not required.
Consent for publication
All authors have consent to publish this manuscript.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1
. Table S1GC content analysis of the predicted siRNA’s. Table S2: RNA Structure webserver prediction of free energy of folding of the predicted siRNA’s.
Additional file 2
. Figure S1: Heat capacity and concentration plot analysis of putative siRNA’s. For siRNA molecula S2, the TmConc and TmCp is showed in (S2). For siRNA molecule S10, TmConc and TmCp is denoted in (S10).
Additional file 3
. Figure S2: Conservancy analysis of the target RNA of the final two siRNA’s against 59 omicron sub-lineages of SARS-CoV-2 virus. Target S2 molecule showed 100% conservancy wheras target of S10 molecule calculated 96% conservancy. Both of the consensus target sequences (denoted as black box) of siRNA molecule S2 and S10 is found 100% conserved in variant BA.4 and BA.5 (Shown in red box).
Additional file 4
. Figure S3: Phylogenetic tree analysis of the 59 sub-lineages for spike protein of the SARS-CoV-2 omicron variant. A few number of lineages Showed significant divergence after tree analysis (bootstrap value>0.74).
Additional file 5
. Figure S4: Mismatch pattern analysis of the target of siRNA S10 molecule with two sub-lineages (B.1.1.529 and BA.1). The mismatched is found for only one residual changes. Rest of the all sublineages found matched with the target.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

{kind=link}
{kind=link}
{kind=link}
Cite this article
Islam, R., Shahriar, A., Fatema, N. et al. In silico prediction of siRNA to silence the SARS-CoV-2 omicron variant targeting BA.4, BA.5, BQ.1, BQ1.1. and XBB: an alternative to traditional therapeutics. Futur J Pharm Sci 9, 63 (2023). https://doi.org/10.1186/s43094-023-00510-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s43094-023-00510-3