
Abstract
Background
It is valuable to analyze the genome-wide association studies (GWAS) data for a complex disease phenotype in the context of the protein–protein interaction (PPI) network, as the related pathophysiology results from the function of interacting polyprotein pathways. The analysis may include the design and curation of a phenotype-specific GWAS meta-database incorporating genotypic and eQTL data linking to PPI and other biological datasets, and the development of systematic workflows for PPI network-based data integration toward protein and pathway prioritization. Here, we pursued this analysis for blood pressure (BP) regulation.
Methods
The relational scheme of the implemented in Microsoft SQL Server BP-GWAS meta-database enabled the combined storage of: GWAS data and attributes mined from GWAS Catalog and the literature, Ensembl-defined SNP-transcript associations, and GTEx eQTL data. The BP-protein interactome was reconstructed from the PICKLE PPI meta-database, extending the GWAS-deduced network with the shortest paths connecting all GWAS-proteins into one component. The shortest-path intermediates were considered as BP-related. For protein prioritization, we combined a new integrated GWAS-based scoring scheme with two network-based criteria: one considering the protein role in the reconstructed by shortest-path (RbSP) interactome and one novel promoting the common neighbors of GWAS-prioritized proteins. Prioritized proteins were ranked by the number of satisfied criteria.
Results
The meta-database includes 6687 variants linked with 1167 BP-associated protein-coding genes. The GWAS-deduced PPI network includes 1065 proteins, with 672 forming a connected component. The RbSP interactome contains 1443 additional, network-deduced proteins and indicated that essentially all BP-GWAS proteins are at most second neighbors. The prioritized BP-protein set was derived from the union of the most BP-significant by any of the GWAS-based or the network-based criteria. It included 335 proteins, with ~ 2/3 deduced from the BP PPI network extension and 126 prioritized by at least two criteria. ESR1 was the only protein satisfying all three criteria, followed in the top-10 by INSR, PTN11, CDK6, CSK, NOS3, SH2B3, ATP2B1, FES and FINC, satisfying two. Pathway analysis of the RbSP interactome revealed numerous bioprocesses, which are indeed functionally supported as BP-associated, extending our understanding about BP regulation.
Conclusions
The implemented workflow could be used for other multifactorial diseases.
Similar content being viewed by others


Background
For more than a decade now, genome-wide associations studies (GWAS) have been an important method in genomic analysis, furthering our knowledge of the genetic basis of complex phenotypes through the identification of hundreds to thousands associated genetic variants [1]. GWAS data are usually augmented by expression quantitative trait loci (eQTL) measurements, which identify variant-gene associations based on changes in gene expression [2]. Over the years, few publicly available general repositories of GWAS data over various phenotypes have been developed, with GWAS Catalog being the most prominent resource as a collaborative effort of EMBL-EBI and NHGRI [3]. However, there is a lack of specialized GWAS meta-databases for specific diseases or complex phenotypes, developed based on a systematic mining of the large repositories and the literature over the associated traits, to provide a comprehensive resource for exploring the currently known genetic basis of the particular disease or phenotype. To date, new GWAS publications present mainly the newly identified loci for a particular phenotype, and there are a limited number of reported meta-analyses over phenotype-associated variants or genes reported in multiple studies. Comprehensive specialized GWAS data collections will enable the prioritization of disease-related genes based on an extended set of criteria, including, apart from the associated p-value, the number of supporting studies and the number of identified variants per gene locus among others. Furthermore, disease-specific GWAS meta-databases connecting GWAS with biological data will enable the direct integration of the GWAS measurements into high-throughput molecular phenotyping analyses of the particular pathophysiology [4].
Collecting and analyzing the full GWAS dataset for a particular complex phenotype is very important, as the specific physiology results from the combined inter-regulation of multiple interacting polygenic pathways, rather than the isolated effect of certain genes [5,6,7]. Hence, considering the GWAS-identified disease-related genes individually may explain only a small portion of the underlying molecular mechanisms of the specific pathophysiology [8]. It is of value to upgrade the information content of GWAS data through their analysis in the context of biomolecular interaction networks [9]. Proteins being the main functional and regulatory biomolecules, usually operating in interacting modules, the protein–protein interaction networks provide a reliable representation of the interconnectivity between molecular functions [10, 11]. In this context, protein–protein interaction (PPI) networks have been widely used in network medicine for the investigation of the molecular architecture of diseases and pathophysiologies through the collective analysis of genomic data [12,13,14]. Reconstructing the disease-associated protein interactome by reflecting comprehensive disease-specific GWAS data collections over the human PPI network provides a wider perspective of the involved molecular pathways, the combined deregulation of which could lead to disease conditions. Prioritization of proteins based on their position and role in the reconstructed disease-associated network can lead to more reliable risk factor indicators [15,16,17]. Furthermore, analysis of the GWAS-based network could direct to the identification of newly implicated genes through the underlying assumption of “guilt-by-association” principle [18, 19], according to which genes involved in the same biological processes are more likely to be associated with the same or similar phenotypes.
Derailment of blood pressure (BP) regulation is associated with a vast number of pathophysiologies, including heart failure and cardiovascular diseases, stroke and renal failure [20]. Elucidating its genetic basis would have a positive effect in the development of diagnostic tools, effective therapeutic treatments and new drugs in a spectrum of diseases that affect a large portion of the human population. Many GWAS focusing on BP traits have been performed since 2007 and have revealed a high number of associated genetic loci [21,22,23,24]. However, no BP-specific GWAS database currently exists, collecting all this information into one resource. BP-GWAS data have been analyzed in the context of PPI networks [25,26,27], but these studies are mainly based on one or few GWAS. A comprehensive BP-specific GWAS data resource, augmented with eQTL measurements and involving information of variant-gene associations, could be a very useful tool in systems and network biology investigations to understand BP regulation and related dysfunctions.
To this end, we aimed at developing a systematically literature-curated BP-GWAS meta-database, augmented with cis-eQTL and gene-variant association data. Using the included information in an integrated way, extended GWAS-based prioritization criteria for disease-associated genes can be considered. A second major objective of the study was to reconstruct the BP-associated PPI network considering the comprehensive GWAS data collection and use it to identify new BP-related genes. The extended GWAS-based network was used to identify important BP-related pathways and prioritize the proteins based on their position according to network interconnectivity metrics.
Methods
GWAS data
Τhe GWAS Catalog database (https://www.ebi.ac.uk/gwas/) [3] was used as the main resource to retrieve BP-associated GWAS data, mining the spreadsheet files “All Associations”, “All studies” and “All ancestry data”. It is noted that for each single nucleotide polymorphism (SNP), GWAS Catalog records mainly the most significant (i.e., with the lowest p-value) SNP-trait association from a particular study. Thus, for multi-stage studies, it may focus on the combined stage, skipping significant association p-values at other stages. In the same context, for BP multi-trait studies, only the trait with the most significant association p-value is usually reported for a particular SNP. Thus, we proceeded to manually curate many large-study publications retrieved from GWAS Catalog along with some not reported in this repository at the time of BP-GWAS data collection, to extend the collected information from the literature. More specifically, for the manually curated publications, (i) we collected all significant SNP—BP trait associations at each of the initial, replication and combined stages of multi-stage studies, (ii) we recorded all BP traits significantly associated with a particular SNP at any of the study stages and the corresponding p-values, and (iii) we collected all significant SNPs for each reported independent locus. The Manhattan plot for the BP-GWAS meta-dataset was visualized using the R package qqman [28].
SNP genotypic information
SNP genotypic information was collected from Ensembl using the BioMart software suite [29]. The severity of the SNP-transcript consequences (GWAS-transcripts) was recorded as defined in Sequence Ontology (http://www.sequenceontology.org/) [30] and reported in Ensembl Variation database. The corresponding genes of the GWAS-transcripts (to be called GWAS-genes) were retrieved from Ensembl. In the rest of the text, BP-genes will be referred to by their gene symbol. The chromosome map for the recorded BP-associated SNPs was visualized using the PhenoGram software tool [31].
eQTL data
Significant tissue-specific SNP-gene associations (q-value ≤ 0.05) based on cis-eQTL measurements were collected from the Genotype-Tissue Expression Portal (GTEx) v.8 (https://gtexportal.org) [32, 33].
Human PPI network: PICKLE meta-database
The human PPI network was retrieved from the Protein InteraCtion KnowLedgebasE (PICKLE) (www.pickle.gr) [10, 11, 34, 35]. The unique feature of PICKLE is that primary datasets of experimental PPIs are integrated on the genetic information ontology network of the UniProt/SwissProt-defined reviewed human complete proteome (RHCP) (https://www.uniprot.org/) [36], without a priori transformations to a pre-selected genetic information level. The PICKLE ontology network includes the associations between the RHCP UniProt IDs and their encoding genes and transcripts [34]. PICKLE reports three versions of the human PPI network, i.e., unfiltered, standard, cross-checked (default), with increasing experimental reliability for the involved PPIs of being direct. In this study, we used mainly the default version, mentioning the cases where investigated PPIs or UniProt IDs are involved only in other versions. In the rest of the text, proteins will be referred to by their UniProt Entry Name (excluding the extension _HUMAN).
Network visualization and analysis
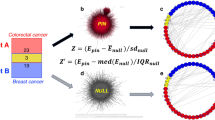
PPI network visualization was carried out using Cytoscape version 3.7.2 (https://cytoscape.org/) [37]. Network analysis was carried out with the relevant Cytoscape plugin. The role of the nodes in a PPI network was also evaluated based on the “Integrated Value of Influence (IVI)” metric [38]. IVI combines six topological features of a node as follows:
where \({\text{DC}}_{i}^{\prime }\), \({\text{LH}}_{{{\text{index}}_{i} }}^{\prime }\), \({\text{NC}}_{i}^{\prime }\), \({\text{CR}}_{i}^{\prime }\), \({\text{BC}}_{i}^{\prime }\), \({\text{CI}}_{i}^{\prime }\) are, respectively, the [1–100] min–max range-normalized, degree centrality [39], local H index [40], neighborhood connectivity [41], ClusterRank [42], betweenness centrality [39] and collective influence [43], of node i. The sum in the first parenthesis, \(\left( {{\text{DC}}_{i}^{\prime } + {\text{ LH}}_{{{\text{index}}_{i} }}^{\prime } } \right)\), is a measure of the node “hubness”, depending on the number of the node interactions and the semi-local centrality measure, LH index. The complex product in the second parenthesis, \(\left( {\left( {{\text{NC}}_{i}^{\prime } + {\text{CR}}_{i}^{\prime } } \right) \left( {{\text{BC}}_{i}^{\prime } + {\text{CI}}_{i}^{\prime } } \right)} \right)\), is a measure of the node “spreading”. Τhe first part of the spreading measure, \(\left( {{\text{NC}}_{i}^{\prime } + {\text{CR}}_{i}^{\prime } } \right)\), combines the semi-local and local, respectively, centrality measures, neighborhood connectivity and ClusterRank, and may reveal semi-local hubs of the network too. Τhe second part, \(\left( {{\text{BC}}_{i}^{\prime } + {\text{CI}}_{i}^{\prime } } \right),\) reveals proteins important in maintaining the connectivity of the network.
Gene/Protein Prioritization Threshold: In all cases of gene/protein scores or metrics, including IVI, unless otherwise specified, the used threshold of significance for gene/protein prioritization is as follows:
where \({\text{mean}}\left( {{\text{Score}}_{i = 1,\ldots,\text{N}} } \right)\) and \({\text{std}}\left( {{\text{Score}}_{i = 1,\ldots,\text{N}} } \right)\) are, respectively, the mean and standard deviation of the \({\text{Scores}}\;{\text{ or}} \, {\text{Metric}}\,\,{\text{values}}\) of all (N) considered genes/proteins and most significant are considered the genes/proteins with \({\text{Score or}} \,{\text{Metric}}\,\,{\text{value}} \ge {\text{Significance}}\_{\text{threshold}}.\)
Pathway enrichment analysis
Pathway enrichment analysis was performed using the Database for Annotation, Visualization and Integrated Discovery (DAVID) version 6.8 (https://david.ncifcrf.gov/) [44, 45] and the pathway maps of Kyoto Encyclopedia of Genes and Genomes (KEGG) release 92.0 (https://www.kegg.jp/), through KEGG mapper [46,47,48].
Drug–protein and gene–disease associations
Antihypertensive drugs targeting BP-proteins were mined from UniProtKB (as curated in PICKLE) and DrugBank version 5.1.4 (https://www.drugbank.ca/) [49]. In the latter, we searched for drug descriptions that contained at least one of the “hyperten-” or “blood pressure reduction” text strings. OMIM (https://www.omim.org/) [50], UniProtKB and GAD (as curated in DAVID) [51] databases were used to retrieve gene–disease associations for the BP-proteins.
Results
The workflow followed in this study, as shown in Fig. 1, includes: (1) the implementation of a systematically literature-curated BP-GWAS meta-database enriched with SNP-transcript associations and eQTL data, which was linked with the RHCP genetic information ontology network of PICKLE augmented by gene–disease and drug–protein association data, (2) the reconstruction of the BP-associated PPI network using PICKLE, from the interactions between the proteins encoded by the GWAS-genes (to be called as GWAS-proteins), extended by the shortest interaction paths connecting all GWAS proteins into one component, and (3) the PPI network-based integration of the GWAS and the functional data for pathway enrichment analysis and protein prioritization. The latter was accomplished by a newly proposed integration of a GWAS-based and two network-based criteria. The various steps of the workflow are described in detail below.

The workflow of the integrated BP-GWAS data and PPI network analyses
Implementation of the BP-GWAS meta-database
Relational scheme
The meta-database was designed as shown in Fig. 2, to systematically store BP-GWAS data and their attributes (GWAS-related ontology part), and include SNP-transcript associations and eQTL data (SNP genotypic information part). The SNP–transcript associations link the GWAS data to the genetic information ontology network connecting genes, transcripts and proteins, and thus consequently, to any type of biological, omic and functional data, including drug–protein associations, gene–disease associations and PPIs. In more detail, the two meta-database parts are structured as follows:

The relational scheme of the BP-GWAS meta-database. The scheme comprises two parts: the GWAS-related ontology part (bottom) and the SNP genotypic information part (top). The meta-database is connected to the RHCP-based genetic information ontology network of the PICKLE PPI meta-database at the transcript and gene levels, through SNP–transcript consequences and eQTL measurements, respectively
GWAS-related ontology part
Each recorded SNP–trait association p-value is related to the study in which the association was identified and the publication reporting the study. In our ontology, each independent study is uniquely defined by a profile of attributes adapted from the GWAS Catalog data files, excluding thus any ambiguity about the study that revealed a SNP–trait association in the case of multi-study publications. Furthermore, the GWAS meta-database can be queried for any combination of study attributes to identify more specific BP-GWAS data subsets. The unique study attribute profile comprises: (a) the analysis stage (i.e., initial, replication or combined); (b) the number of involved samples; (c) the ancestry profile of the involved individuals based on the GWAS Catalog-defined ancestry categories [52]; (d) the broader ancestry and the number of the concerned individuals; (e) the country/ies of the individuals’ recruitment; (f) the country/ies of the individuals’ origin (if available); (g) the type of study (GWA or exome array study); (h) the genotyping array used; (h) the gender and age of the individuals (if any or both are specified in specialized studies), and (i) the statistical measure based on which the SNP–trait association p-values are calculated.
SNP genotypic information part
It is structured based on the relevant part of the Ensembl variation database scheme, and the information stored for each GWAS-identified SNP includes the chromosomal location, the minor allele, the global minor allele frequency and the transcript, regulatory and motif consequences. The transcript consequences of a SNP (GWAS-transcripts) are assigned an Ensembl-defined severity score, using a scale from 1 (most severe— “transcript_ablation”) to 35 (least severe—“feature_truncation”). Intergenic SNPs, considered of the lowest severity, are recorded separately. In this way, our meta-database can store all transcript consequences for the GWAS-identified SNPs, independently of their severity. This is a distinctive feature over other GWAS data collections, usually storing only the most severe transcript consequence per SΝP. Recording all GWAS-transcripts enlarges the perspective of the BP-associated molecular physiology that can be extracted from GWAS. It also provides the ability for the user to only select the BP-associated transcripts above a particular severity threshold and investigate any potential variations in the derived information about the investigated phenotype. Finally, our meta-database stores locally eQTL information for the GWAS-identified SNP-gene associations.
Importantly, as structured, the proposed meta-database scheme is not specific to BP, but it is applicable to GWAS data collections of any multifactorial disease.
Populating the meta-database with BP-GWAS data
The GWAS-related part of the meta-database was populated with the SNP-BP trait associations with p-value < 10−5 and their attributes, as mined from: (i) the GWAS Catalog and (ii) manually curated BP-GWAS publications. GWAS Catalog “mapped” traits were identified as BP-related (Additional file 1: Table S1), if comprising at least one BP-associated Experimental Factor Ontology term (EFO, https://www.ebi.ac.uk/efo/) (Additional file 1: Table S2). Then, we mined all information from the 69 identified as BP-related publications as stored in GWAS Catalog, and proceeded to manually curate 22 more recent and larger of them and one additional publication not at the time curated by GWAS Catalog (Additional file 1: Table S3), as described in Methods. In the eQTL measurement section, we mined from GTEx any significant cis-eQTL association q-values, i.e. < 0.05, for the GWAS-identified SNP-gene pairs in tissues and their regions (27 terms in total), considered to be involved in BP regulation: the heart, artery, whole blood, kidney, adipose tissue, brain, adrenal gland, thyroid, skeletal muscle, liver, and tibial nerve. The eQTL-significant genes (by any of the GWAS-identified SNPs) in a particular tissue or tissue region will be referred to as eGenes in this tissue or tissue region.
The stored GWAS data were connected to the human genetic information ontology network via the GWAS-transcripts (Fig. 2). The corresponding GWAS-genes were connected to diseases through relevant databases, and the PPI network reconstruction was based on the encoded GWAS-proteins, which were also investigated as drug targets (Fig. 1). The RHCP-included GWAS-proteins in the PICKLE PPI database ontology network were used to reconstruct the GWAS-deduced BP-protein interactome. The eQTL data were integrated with the rest through the eGenes.
Statistics of the BP-GWAS meta-database
At the SNP level
The systematic curation of 70 BP-GWAS research papers published since 2007 (Additional file 1: Table S3), involving more than 1.5 million samples from 14 ancestries and 212 independent studies, led to the collection of 7401 SNPs associated with BP trait(s) with p-value < 10−5 (Table 1). The collected SNP-BP trait association p-values sum up to 27,480, 98% of which are reported in the after 2016 publications (Additional file 1: Table S3). Notably, 95% of the p-values are from the 23 manually curated publications. If the stricter, presently used, 5 × 10−8 p-value significance threshold is considered, our dataset comprises 21,788 SNP−BP trait association p-values for 6687 SNPs. These data were acquired in 151 independent studies involving samples from 13 ancestries, reported in 54 publications (Table 1, Additional file 1: Table S3). In this narrower GWAS dataset, which will be used in the rest of the analysis as the significantly BP-associated, 98% of the p-values were retrieved from the manually curated references. This indicates that the vast majority of the stored and analyzed BP-GWAS data are based on our systematic and extended mining of the BP-GWAS literature.
The 6687 BP-associated SNPs are distributed in all 22 human autosomes with only two (rs141216986, rs6609273) in chromosome X and none in chromosome Y (Additional file 1: Table S4). The vast majority of the SNPs are associated with at least one of the systolic or diastolic or pulse pressure measurement traits (6591) and are supported by at most two publications (5688 by one and 768 by two). Four SNPs were reported in 11 publications, i.e., rs17249754 (ATP2B1, 16 studies), rs11191548 (CNNM2, 14 studies), rs3184504 (SH2B3, 13 studies) and rs1458038 (intergenic, 19 studies), and two SNPs in 10 publications, i.e., rs880315 (CASZ1, 16 studies), rs13107325 (SLC39A8, 13 studies). The two SNPs supported by the maximum number (21) of independent studies, i.e., rs167479 (RGL3) and rs16998073 (intergenic), were reported in 6 and 9 publications, respectively.
About 56% (3738) of the significant SNPs have RHCP-coding transcript consequences, while ~ 16% have only non-coding transcript consequence(s) and ~ 24% are intergenic (Additional file 1: Table S5). The 3738 SNPs are associated with 1167 RHCP-coding genes (Fig. 3; Additional file 1: Table S5; complete list in Additional file 2). The median of the minimum BP-association p-values of the RHCP-related SNPs is 2.2 × 10−12 (Fig. 4). Half (585) of the 1167 RHCP-coding genes are associated with SNPs of minimum BP-association p-value smaller than the median (Fig. 5A, Additional file 2). This observation may indicate the 2.2 × 10−12 p-value as a new stricter genome-wide significance threshold for SNP-BP trait associations identified in GWAS, compared to the current generally considered 5 × 10−8 value. Any further analysis will refer to the BP-associated RHCP-coding genes or transcripts.

Chromosome map of the BP-SNPs indicating the GWAS-prioritized RHCP-coding gene sites. The numbers of all and the GWAS-prioritized (in parenthesis) RHCP-coding BP-genes of each human chromosome are also shown

Manhattan plot of the RHCP-coding SNPs based on their minimum BP-association p-value. The red, black and purple lines denote, respectively, the presently used 5 × 10−8 p-value threshold for significant SNP-trait associations, the mean, and the median minimum BP-association p-value of the GWAS-identified SNPs. The genes with the smallest BP-association p-values are also shown

RHCP-coding BP-gene distributions by minimum p-value (A), SNP number (B), supporting publication number (C)
At the protein-coding gene level
Among the RHCP-coding BP genes, ~ 41% are related with at least two significant SNPs, ~ 9% (101) with at least five and nine genes with more than fifty SNPs (Fig. 5B, Additional file 2). These 9 genes are: ULK4 (Chromosome 3, 276 SNPs), ZNF831 (Chromosome 20, 124 SNPs), FTO (Chromosome 16, 103 SNPs), SLC4A7 (Chromosome 3, 85 SNPs), MSRA (Chromosome 8, 82 SNPs), CLCN6 (Chromosome 1, 79 SNPs), PINX1 (Chromosome 8, 68 SNPs), CNNM2 (Chromosome 10, 59 SNPs) and CABCOCO1 (Chromosome 10, 58 SNPs). For 9% (105) of the genes, the minimum BP-association p-value is smaller than 10−30, and for 18 genes it is smaller than 10−80 (Fig. 5A, Additional file 2). The smallest p-values encountered in our dataset correspond to SNPs associated with Ataxin 2 (ATXN2, p-value = 4.8 × 10−180) and SH2B adapter protein 3 (SH2B3, p-value = 8 × 10−180), both mapped on chromosome 12 (Fig. 4, Additional file 2). The association of ~ 45% of the RHCP-coding BP-genes is supported by at least two publications, for 13% (155) by at least four and for eight genes by more than ten independent GWAS publications (Fig. 5C, Additional file 2). These genes are: ATP2B1 (Chromosome 12, 18 publications), CNNM2 (14 publications), CASZ1 (Chromosome 1, 13 publications), ULK4 (13 publications), ARHGAP42 (Chromosome 11, 12 publications), SH2B3 (11 publications), FES (Chromosome 15, 11 publications) and ZNF831 (11 publications). These observations indicate that while the vast majority of the BP-associated SNPs have been reported in a single publication, considering all significant SNPs per gene increases the reliability of the BP-association at the gene level as this is now supported by multiple publications and multiple SNPs.
Overall, 56 RHCP-coding genes can be considered as the most BP-significant set based on the GWAS data, as they are in the top 10% with respect to all three GWAS attributes, i.e., they are related to at least five SNPs with a minimum p-value < 10−30 as reported in at least two publications. Chromosomes 1, 2 and 11 are the most enriched in BP-associated genes (Additional file 1: Table S4). Only 2% of the BP-associated genes are related to other BP-traits than the systolic (710), or diastolic (472), or pulse (418) pressure (Fig. 6, Additional file 2). Sixty-seven genes are associated with all three of these three traits. It needs to be noted, however, that the number of GWAS publications investigating pulse pressure is much smaller compared to those for systolic or diastolic pressure (Additional file 2).

Venn diagram of the RHCP-coding BP-genes associated with systolic, diastolic and pulse pressure traits. SBP, DBP and PP depict, respectively, the systolic blood pressure, the diastolic blood pressure and the pulse pressure traits. The respective gene numbers in the GWAS-prioritized set are shown in parenthesis
eQTL measurements and tissue specificity
We discovered that 665 (57%) out of the 1167 RHCP-coding genes in the BP-GWAS dataset were detected as eGenes in at least one of the 27 selected as BP-related tissues (Additional file 3). Thirty-eight of them are eGenes in more than 14 tissues and one (AMH; Anti-Mullerian hormone) in all 27 tissues. Οn the other hand, the tissues with more than 200 eGenes are the artery tibial, the nerve tibial, the thyroid, the adipose subcutaneous, the artery aorta, the muscle skeletal and the whole blood (Fig. 7). Finally, after flagging an eGene as significant in a tissue when exhibiting in this tissue its minimum q-value over the 27 tissues, the tissues observed with the highest number of significant eGenes were the whole blood, the artery tibial, the nerve tibial, the thyroid and the skeletal muscle (Fig. 7, Additional file 3).

The tissue distribution of RHCP-coding BP-eGenes. The distribution is shown for the 27 selected as BP-related tissues in ascending number of eGenes per tissue. Significant eGenes for a tissue are those exhibiting in that tissue their minimum q-value among all 27 tissues
Gene prioritization by integrated GWAS-based criterion
Integrated GWAS-based gene scoring scheme
The proposed gene scoring scheme is based on the combined consideration of three GWAS data attributes: the gene association p-value with the GWAS-investigated phenotype, the number of significant SNPs per gene and the number of supporting GWAS publications. Thus, we propose an integrated score for gene i, \(s_{i}\), defined as the weighted sum of these three GWAS-attribute values, \(p - {\text{value}}_{i} , \# {\text{SNPs}}_{i} , \# {\text{Pubs}}_{i,}\) [1–100] min–max range-normalized (denoted by the symbol \(\widehat{{}}\) in Eq. 3):
\(w_{{p - {\text{value}}}}\), \(w_{{{\text{SNP}}}}\) and \(w_{{{\text{Pub}}}}\) are the respective % weights of the three GWAS attributes.
Among the three GWAS attributes in Eq. 3, we consider the p-value as being the most indicative for the association of a gene with the GWAS-investigated phenotype. While the number of significant SNPs per gene is also important, we consider it of lower weight for gene prioritization, because of the current, still considerate, bias in these data. To our knowledge, until recently (2016) the researchers tended to report only the characteristic SNP per locus [21], independently of which SNP(s) had been identified as significant. The weight for the number of independent publications supporting the association of a gene/locus with the investigated phenotype may be the lowest among the three factors in the integrated score, because GWAS publications usually report only the newly identified loci and skip information about confirmed loci that have already been reported in previous publications. As observed in the BP-GWAS data too, a vast number of GWAS-identified loci/genes tend still to be supported by a single publication. In this context, our present suggestion is for the \(w_{{p - {\text{value}}}}\), \(w_{{{\text{SNP}}}}\) and \(w_{{{\text{Pub}}}}\) to be, respectively, 45%, 35% and 20%. These relative weights may be re-evaluated in the near future, as the contribution of the above-mentioned biases diminishes with the progress of GWAS and genomic analyses.
For the prioritization of genes based on their integrated GWAS-based score, we opted for the normal distribution-based lenient significance threshold of Eq. 4:
where \({\text{mean}}\left( {s_{i = 1 ,\ldots, N}} \right)\) and \({\text{std}}\left( {s_{i = 1 ,\ldots, N}} \right)\) are, respectively, the mean and standard deviation of all gene scores. Significantly associated with the GWAS-investigated phenotype are considered the genes with scores equal to or greater than the cut-off value (Criterion 1).
The prioritized BP-associated gene set by the integrated GWAS-based score
The integrated GWAS-based scores for all 1167 RHCP-coding BP-associated genes are shown in Additional file 2. Based on Eq. 4 significance threshold, the Criterion 1-prioritized set includes 103 genes (~ 9%) (Table 2, Additional file 2), comprising all but one of the 56 genes identified in the top 10% for all three GWAS attributes combined in the integrated score. Namely, ULK4 (Unc-51 Like Kinase 4, sULK4 = 100) and ATP2B1 (ATPase Plasma Membrane Ca2+ Transporting 1, sATP2B1 = 99.5) exhibit the highest scores. Thirteen (13) genes have a score greater than 50.
The prioritized gene set is mapped on all human autosomes but chromosomes 13 and 21 (Fig. 3). Notably ~ 45% of the genes are mapped on chromosomes 1 (10 genes), 10 (12 genes), 11 (12 genes) and 12 (11 genes) (Additional file 1: Table S4). Regarding the BP-traits, 47 of the prioritized genes, including the highest scored ULK4 and ATP2B1, are associated with all three of the systolic, diastolic and pulse pressure (Fig. 6, Additional file 2). Finally, 69 of the prioritized genes are also eGenes in at least one of the 27 BP-related tissues (Table 2, Additional file 3), with ULK4 supported by eQTLs in 25 tissues.
The BP-associated PPI network reconstruction
The GWAS-deduced PPI network
In general, the GWAS-deduced PPI network comprises the PPIs between the GWAS-proteins. In our BP-GWAS meta-dataset, 1065 of the 1170 RHCP-proteins have at least one PPI of high-confidence of being direct (Additional file 4). Extracting their PPI subnetwork from the human protein interactome revealed one large component of 672 GWAS-proteins connected through 1700 PPIs (excluding self-interactions) (Additional file 1: Fig. S1A), with most of the rest 393 proteins as 1-mers or homo-dimers and very few in heterodimers (Fig. 8A). The BP-GWAS proteins in the connected component will be referred to as “blue” nodes (BNs) and the rest as “green” nodes (GNs) of the BP-PPI network (Additional file 4). The BN set comprises 372 eGene proteins (55%) and 55 proteins (8%) encoded by GWAS-prioritized genes. The respective numbers in the GN set are 231 (59%) and 34 (~ 9%) (Additional files 3 and 4).

The GWAS-deduced (A), and the GWAS-RbSP (B) BP PPI networks. Protein-nodes are shown at their position in the force-directed representation of the PICKLE human protein interactome. Nodes are colored based on their type: blue for GWAS-proteins connected in one component (“blue” nodes, BNs); green for the rest of the GWAS-proteins (“green” nodes, GNs) and yellow for the shortest-path intermediates between GNs and BNs (“yellow” nodes, YNs)
The BN PPI network has a scale-free structure with a very good fit (R2 = ~ 91%) (Additional file 1: Figs. S1B, C). P53 is the protein with the highest number of interactions (68), followed by UBC9 (58), ESR1 (56) and FYN (43). The scale-free structure implies that BNs cover a wide range of protein degrees in the human PPI network, in a similar relative representation. Indeed, only seven BNs (1%), i.e., P53, ESR1, UBC9, FYN, TF65, KDM1A and SMAD3, are among the 65 protein-hubs of the human network with > 300 PPIs. The rest of BNs are from all degree zones of the human protein interactome, with ~ 24% having fewer than 11 PPIs (Additional file 4). The particular BN network structure supports the complexity of BP regulation, which is connected to a variety of biological processes.
Extending the GWAS-deduced PPI network by the shortest-path approach
Starting from the hypothesis that BNs and GNs should be biologically associated, participating in related molecular processes in the context of BP regulation, we proceeded to investigate their relationship through the identification of the shortest PPI paths that connect GNs to BNs into one connected network. Based on the BN-GN association rationale, there is a high probability for the intermediates of these shortest paths to be BP-associated too (“guilt-by-association”) [18]. The shortest-path intermediates will be referred to as “yellow” nodes, YNs, of the BP PPI network. Hence, we can exploit the human PPI network to enrich the set of the GWAS-identified as BP-associated proteins with the YNs and extend the GWAS-deduced protein interactome with the YN–BN, YN–GN and YN–YN interactions, upgrading and expanding the information that can be derived from GWAS. Thus, the final protein set considered as BP-associated will consist of the GWAS-proteins and the YNs. The extended PPI network, to be referred to as “GWAS-reconstructed by the shortest-path approach” (GWAS-RbSP), will be the corresponding subnetwork of the human protein interactome.
Following our proposed algorithm for the reconstruction of the BP-associated GWAS-RbSP PPI network, we identified 1443 shortest-path intermediates (YNs) (Additional file 4) and observed that almost all GNs are at most second neighbors of a BN, having a common YN neighbor. This result validates our initial hypothesis of a close BN–GN relationship. Finally, the BP-associated GWAS-RbSP PPI network comprises 2505 protein-nodes with 31,439 PPIs (Fig. 8B), providing a considerable extension over the GWAS-deduced network of 672 BNs and 390 GNs with 1700 BN–BN and 7 GN–GN PPIs. The GWAS-RbSP interactome contains 15% and 17%, respectively, of the protein-nodes and PPIs of the human protein interactome, including 62 (7 BNs and 55 YNs) of its 65 hubs (i.e., with > 300 PPIs), further supporting the BP-association with core biological processes (Additional file 1: Fig. S2A). The rest of the proteins cover all degree zones, with 22% (553) having fewer than eleven interactors in the human network (Additional file 4). Network analysis showed that the GWAS-RbSP PPI network follows a scale-free structure with a good fit (R2 = 83%) (Additional file 1: Figs. S2B, C), even though this had not been necessarily expected due to the specialized way of this network reconstruction. The observed scale-free form may be explained from the fact that the GWAS-RbSP PPI network is reconstructed “around” the scale-free BN network. The amyloid beta A4 protein (ΥΝ; APP) is the node with the highest number of interactions (376) in the GWAS-RbSP PPI network, while five more proteins have more than 200 interactors: UBC (YN), P53 (BN, BN network hub), EGFR (YN), ESR1 (BN, GWAS-prioritized, BN network hub) and EP300 (YN) (Additional file 4). All six proteins are hubs (> 300 interactions) of the human protein interactome.
Prioritizing BP proteins based on their role in the extended BP PPI network
The role and position of the nodes in the GWAS-RbSP network were evaluated based on their IVI (Eq. 1). Using the cut-off of (Eq. 2), we IVI-prioritized (Criterion 2) 106 proteins (22 BNs, 84YNs) (Table 3, Additional file 4). The most influential nodes of the GWAS-RbSP network were P53 (BN), UBC (YN), ESR1 (BN) and EP300 (YN); all other proteins have IVI lower than 60. Notably, ESR1 is the only common protein with the GWAS-prioritized set; thus, combination of Criteria 1 and 2 extends the BP-prioritized set to 208 proteins in total.
By the IVI definition (Eq. 1), the set of the IVI-prioritized proteins of the BP PPI network was indeed expected to be mainly populated with the top-scored in the “hubness” feature of the IVI (Additional file 4). However, it is of value to mention the protein-nodes with the highest scores in the first and second part of the “spreading” index (Eq. 1), as they may reveal specialized players in BP regulation, which are not directly apparent when only the comprehensive IVI of a protein-node is considered (Additional file 4). The four top-scored in the first “spreading” part, which reveals semi-local hubs too, are: SP1 (YN), MINY4 (BN), AKT1 (YN) and HIF1A (YN); all but MINY4 are in the IVI-prioritized set. The top-scored in the second part of the “spreading” index, which reveals proteins important in maintaining the connectivity of the network, are: A4 (YN), AQP6 (YN, not IVI-prioritized), F209A (YN, not IVI-prioritized) and GP152 (YN, not IVI-prioritized).
Prioritizing YNs through their association with GWAS-prioritized proteins
The novel, second network-based prioritization criterion that we proposed promotes the YNs that are common neighbors of GWAS-prioritized proteins. More specifically, we identified the YNs that are common interactors of any two of the 88 (55 BNs, 33 GNs) GWAS-prioritized proteins included in the GWAS-RbSP BP PPI network, and then, we isolated the subnetwork of these YNs and their GWAS-prioritized neighbors (Additional file 1: Fig. S3). The protein-nodes of this final subnetwork were considered prioritized according to Criterion 3. They included 175 YNs and 78 (50 BNs, 28 GNs) GWAS-prioritized proteins (Additional file 5); 48 of the YNs were also IVI-prioritized (Criterion 2). The IVI-ranking of the 253 proteins in this interactome is shown in Table 4. ESR1 (BN) is the protein with the highest IVI, followed by three YNs (AKT1, EGFR and CTNB1) with an IVI higher than 50. In total, only 15 proteins (ESR1 and 14 YNs) had an IVI higher than the significance cutoff of Eq. 2 (i.e., > 25), all of which were also IVI-prioritized in the GWAS-RbSP PPI network. The next two highest ranked BNs are INSR and PTN11, in the 24th and 25th positions, respectively.
Ranking the complete set of prioritized BP-associated proteins
Overall, 335 BP-proteins were prioritized based on any of the three prioritization criteria (Fig. 1, Additional file 1: Fig. S4, Additional file 5), i.e., 103 proteins according to the GWAS-based Criterion 1, 106 proteins according to the network-based Criterion 2 and 253 proteins according to the network-based Criterion 3. We proposed to rank the prioritized protein-set based on the number of satisfied prioritization criteria. ESR1 (BN) was ranked at the top as the only protein prioritized based on all three criteria, underlining its high ranking in the network-based Criterion 2 (3rd) and Criterion 3 (1st) (Tables 2, 3 and 4). Additional 77 (49 BNs, 28 GNs) GWAS-prioritized proteins (Criterion 1) had common YN interactors (Criterion 3) and 48 YNs were prioritized by both network-based Criteria 2 and 3 (Table 4, Additional file 5). The rest 209 BP-proteins were prioritized based on a single criterion. In the protein group with two satisfied prioritization criteria, we proposed to rank higher the 77 GWAS-prioritized proteins with common YN interactors compared to the 48 YNs prioritized by both network-based criteria. In both subgroups, the internal ranking was made according to the network-based Criterion 3. Finally, in the single criterion group, the 26 GWAS-prioritized proteins (Criterion 1) were ranked higher than the 127 YNs of Criterion 3, leaving last the 57 BP-proteins (BNs and YNs) of Criterion 2. Based on this ranking scheme, the nine proteins following ESR1 in the BP-associated top-10 are all GWAS-prioritized BNs: INSR, PTN11, CDK6, CSK, NOS3, SH2B3, ATP2B1, FES and FINC (Table 5, Additional file 5). Interestingly, INSR, PTN11, CDK6, NOS3, FES and FINC emerged among the most BP-significant due to the network-based Criterion 3, while in the GWAS-prioritized list ranked from position 14 (for FES), to position 91 (for FINC). INSR and FES are also supported by eQTLs in 5 and 10 BP-related tissues, respectively.
We observed that 93% (313; 74 BNs, 28 GNs, 243 YNs) of the 335 prioritized BP-proteins are connected through a network of 3868 PPIs (excluding self-loops), as shown in Fig. 9. From the 126 BP-proteins prioritized by at least two criteria, 111 (88%, 46 BNs, 17 GNs, 48 YNs) form a connected network of 642 interactions (excluding self-loops). The genes of the 335 prioritized BP-associated proteins map on all chromosomes but Y, revealing chromosomes 1, 12, 17 and 11 as the most enriched, with 33, 25, 25 and 24 prioritized genes, respectively. In the group of the 126 BP-proteins backed by two prioritization criteria, all chromosomes but Y are represented, with most enriched chromosomes 12, 1 and 11 with 13, 11, and 9 genes, respectively. These observations further support the higher enrichment of chromosomes 1, 11 and 12 in BP-associated genes, which was indicated from the GWAS-genes too.

The prioritized BP-protein PPI network. Nodes are color-coded as explained in Fig. 8. Node size corresponds to the IVI of the protein in the GWAS-RbSP PPI network. The UniProt Entry Names (excluding the _HUMAN extension) of the protein nodes with the highest IVI are shown
Pathway enrichment analysis
Pathway and functional analyses were performed on the full set of the 2613 BP-associated proteins. KEGG pathway enrichment analysis indicated that about half of the BP-proteins belong to at least one of 314 KEGG-defined pathways. Eighty-seven (28%) of these pathways are significantly enriched in BP-proteins according to DAVID (i.e., q < 0.05) (Table 6). The BP-enriched pathways include the dilated (DCM), hypertrophic (HCM) and arrhythmogenic right ventricular cardiomyopathy (ARVC) pathways, thirty (30) signaling pathways, among which the adrenergic signaling in cardiomyocytes and the PI3K-Akt, the Rap1, the cGMP-PKG, the cAMP, the HIF-1 (hypoxia-inducible factor 1) and the calcium signaling pathways, four (4) focal adhesion/axon guidance-related pathways, the vascular smooth muscle contraction and the regulation of actin cytoskeleton pathway. The BP-associated ‘aldosterone synthesis and secretion’, ‘renin secretion’, ‘insulin resistance’, ‘insulin secretion’ and ‘thyroid hormone synthesis’ pathways were also identified among the significantly BP-enriched. Notably, the 87-pathway list includes thirty (30) cancer or viral/bacterial infection-associated pathways.
To investigate and validate the significance of the PPI network-deduced YN proteins in BP regulation and connect the protein interactome to BP functional information, we selected four of the significantly BP-enriched KEGG-defined pathways, i.e., adrenergic signaling in cardiomyocytes (Fig. 10), HIF-1 signaling (Fig. 11), cGMP-PKG signaling (Additional file 1: Fig. S5) and DCM (Additional file 1: Fig. S6), which have been directly associated with hypertension and/or heart pathophysiology, e.g., [53,54,55,56,57,58,59]. The selected pathways integrate also parts of the PI3K-Akt, calcium and cAMP signaling, the vascular smooth muscle contraction, insulin resistance, insulin secretion and renin secretion pathways. To investigate any BP-associated metabolic mechanisms, we also considered the KEGG-defined “Metabolic Pathways” (Additional file 1: Fig. S7). In general, in 31 (~ 36%) of the 87 BP-enriched KEGG pathways, YNs constitute more than 65% of the involved proteins. In all cases, YNs enhance the statistical significance of the BP-association of the pathways, while pathways such as the HIF-1 signaling would not have been revealed as BP-enriched if only the GWAS-proteins had been considered. Moreover, there are numerous YNs, which are proteins of crucial role in BP-associated functional pathways, validating thus their BP-association and supporting the pursued network-based analysis of the GWAS data that revealed this association. Some characteristic ΥΝ examples are: HIF1A (central protein of the HIF-1 signaling pathway (Fig. 11)), ADRB2, GNAI1, GNAI3, GNAQ, ADΑ1A (proteins involved in the adrenergic signaling in cardiomyocytes pathway (Fig. 10)), KAPCA, PPLA, TNNI3, TPM3, ACTC (proteins involved both in the adrenergic signaling in cardiomyocytes (Fig. 10) and the DCM (Additional file 1: Fig. S6) pathways), and LMNA and ACTB (proteins involved in the DCM pathway (Additional file 1: Fig. S6)). Furthermore, 39% of the proteins in the “Metabolic Pathways” are YNs, contributing to the elucidation of the steroid hormone synthesis, the biosynthesis of unsaturated fatty acids, the fatty acid elongation in mitochondria and the purine metabolism as BP-associated based on the GWAS data (Additional file 1: Fig. S7B). Not significant conclusions could have been made about these pathways if only the GWAS proteins had been mapped on the KEGG Metabolic Pathways (Additional file 1: Fig. S7A).

The BP-proteins in the KEGG-defined adrenergic signaling in cardiomyocytes pathway and their PPI network. The BP-proteins are shown (A) in the context of the KEGG pathway map, (B) with their gene symbols in respect to the numbered pathway map node symbols, and (C) in their subnetwork in the GWAS-RbSP protein interactome. BP-proteins in (C) are denoted by the number of the associated pathway map node. The color code in (A–C) indicates the protein-type (BN, GN, YN) as explained in Fig. 8. The prioritized BP-proteins are denoted with an asterisk in (B). Τhe proteins that are antihypertensive drug targets are indicated with a red eclipse in (A) and by their UniProt entry name in (C); the number of the targeting drugs is shown in parenthesis (Additional file 4)

The BP-proteins in the KEGG-defined HIF-1 signaling pathway and their PPI network. The BP proteins are shown (A) in the context of the KEGG pathway map, (B) with their gene symbols in respect to the numbered pathway map node symbols, and (C) in their subnetwork of the GWAS-RbSP protein interactome. BP-proteins in (C) are denoted by the number of the associated pathway map node. The figure is color-coded and structured as described in the legend of Fig. 10
Pathway enrichment analysis of the 335 BP-prioritized protein group indicated similar enrichment as in the overall BP-protein set for the PI3K-AKT signaling, MAPK signaling, Ras signaling, focal adhesion, estrogen signaling and regulation of actin cytoskeleton pathways. On the other hand, the BP-prioritized set showed higher enrichment over the full BP-protein set in the thyroid hormone and neurotrophin signaling pathways.
BP-proteins as antihypertensive drug targets
A total of 61 antihypertensive drugs were identified in DrugBank, targeting 34 BP proteins (13 BNs, 10 GNs, 11 YNs) (Additional file 4), 8 of which belong to the prioritized set (Additional file 5): PDE1A (BN), ADRB1 (GN), CACB2 (BN), CAC1D (GN), JUN (YN), MTHR (GN), ADRB2 (YN), PPARG (YN). For the 11 YNs, which are antihypertensive drug targets, this is an additional validation of their association with BP. Twenty-five out of the 34 proteins are involved in 47 BP-enriched KEGG pathways and seven (four uniquely) in “Metabolic Pathways”. Three antihypertensive drug targets, two in the prioritized set, are involved in at least 17 BP-enriched pathways: JUN (24), CAC1C (BN; 18) and CAC1D (17). On the other hand, the calcium and cGMP-PKG signaling pathways are the most enriched with antihypertensive drug BP-protein targets (i.e., 10 targets). ‘Renin secretion’, ‘cAMP signaling’, ‘Adrenergic signaling in cardiomyocytes’, ‘Vascular smooth muscle contraction’, ‘Insulin secretion’ and ‘Oxytocin signaling pathway’ complete the set of BP-enriched KEGG pathways involving at least 6 antihypertensive drug targets (Table 7).
Eleven BP-proteins are targeted by at least 8 drugs each, fifteen being the maximum number of drugs targeting one protein, ACE (BN) (Fig. 12A). The rest of the proteins (23) are targeted by at most 3 drugs and thirteen of them are targets of only one drug. At the pathway level, 20 BP-enriched KEGG pathways and the “Metabolic Pathways” are targeted by at least 9 antihypertensive drugs (Table 7). Four pathways involve protein targets of at least 30 drugs: Renin secretion (45), cGMP-PKG signaling (39), calcium signaling (32) and cAMP signaling (30). The vast majority (41) of the 61 antihypertensive drugs target at most two BP-proteins (Fig. 12B). Nicardipine, a calcium channel blocker (DrugBank ID:DB00622), has the maximum number of BP-protein targets (9), followed by clonidine, “an agonist of alpha-2 adrenoceptors” (DB00575) and two other calcium channel blockers, felodipine (DB01023) and nilvadipine (DB06712), which target five BP proteins each.

Distribution of the antihypertensive drugs regarding their BP-protein targets (A) and of the BP-proteins regarding targeting drugs (B)
BP-proteins and their association with diseases
Twenty-two of the 34 antihypertensive drug protein-targets, i.e., nine BNs (one prioritized), 6 GNs (three prioritized) and seven YNs (two prioritized), have been associated with complex diseases by OMIM, including diabetes mellitus, insulin resistance, obesity, myocardial infarction, vascular abnormalities, heart failure associated syndromes, ischemic stroke and Alzheimer’s disease (Additional file 4). The proteins associated with the highest number of OMIM disease IDs are ΑCE (BN; 8), PPARG (YN; 8), MTHR (GN; 7) and KCJ11 (BN; 6).
According to the Genetic Association Database (GAD) Resource (DAVID version), 78% of all the identified as BP-associated proteins have been related to diseases. About 80% of the disease-related BP-proteins have statistically significant association (q-value < 0.05) with at least one of 100 GAD terms in total (Additional file 4), including five terms directly associated with BP, i.e., “hypertension”, “blood pressure”, “blood pressure arterial”, “diastolic blood pressure” and “systolic blood pressure”. These five GAD terms are linked to 251 identified as BP-proteins from our analysis, i.e., 101 BNs (27 prioritized), 51 GNs (15 prioritized), 87 YNs (16 prioritized), 10 proteins (3 prioritized) with PPIs of low experimental confidence of being direct and 2 proteins (1 prioritized) with no known PPIs (Additional files 4, 5). These observations further support the validity of the YNs and the proposed BP-protein prioritization scheme.
Six KEGG-defined pathways involve more than 20 proteins related with the five BP-associated GAD terms: cGMP-PKG signaling pathway (28), Pathways in Cancer (26), Metabolic Pathways (23), calcium signaling pathway (21), cAMP signaling pathway (21), PI3K-Akt signaling pathway (21). Searching for potential comorbidities, we grouped the rest 95 BP-protein-enriched GAD terms in 12 wider phenotype clusters and found that 89% of the 251 proteins linked to the five BP-related GAD term group have also been associated with at least one other phenotype than BP (Fig. 13, Additional file 4). Ninety-four (42%) are linked to at least four other phenotype clusters up to a maximum of 11 for five BP-proteins, i.e., TNFA (YN), APOE (BN), IGF1 (BN), ACE (BN), MTHR (GN, prioritized). The phenotype clusters that involve at least 100 BP-proteins linked to the five BP-related GAD terms are ‘tobacco or alcohol use’ (136), ‘diabetes, metabolic syndrome related’ (133), ‘neurological and mood disorders’ (103) and ‘heart failure related, cardiovascular, stroke’ (102).

Distribution of BP-enriched GAD phenotype clusters regarding the number of included BP-proteins related to the BP-associated GAD terms
Discussion
Introducing a BP-GWAS meta-database
In the present study, we implemented a BP-GWAS meta-database comprehensively collecting BP-associated data from both the GWAS Catalog database and by manual curation of the literature, with the latter subset constituting the majority of the retrieved GWAS data. The design of our meta-database (Fig. 2) enables for a GWAS study to be uniquely defined by a set of attributes. In this way, it is possible to distinctly store data from various studies reported in the same publication. Moreover, from the manually curated publications, we collected all significant variants associated with a particular gene locus. Similarly, if multiple BP-traits had been investigated in a GWAS, we collected all significant association p-values of a variant with any of the traits. In this way, our meta-database provides a comprehensive collection of all BP-associated GWAS data, enabling the querying of the dataset based on any combination of stored parameters. Thus, we can evaluate the significance of the BP-association of SNPs or gene loci based on a combination of attributes, strengthening the reliability of the suggested information and of relevant SNP or gene prioritization schemes.
Through the SNP genotypic information part of our meta-database, the recorded SNPs are linked to all their transcript consequences along with their Ensembl-defined severity score, widening the perspective of the BP-associated molecular physiology that can be extracted from GWAS. Our meta-database is designed to store locally eQTL measurement information, adding a supporting feature for the BP-association of the GWAS-identified SNPs and genes. At present, we have collected eQTL data from GTEx for 27 tissues considered to be involved in BP regulation. Through the human genetic information ontology network, one can now link the GWAS and the supporting eQTL data with any type of functional or omic data at various genetic information levels, including gene-disease and drug–protein associations, and collectively analyze the GWAS information based on combinations of GWAS attributes and biological criteria in the context of the associated biomolecular networks.
Among the main observations about GWAS-identified as BP-associated SNPs and genes enabled by the analysis of our comprehensive BP-GWAS data collection, we note: (i) the suggestion of a new stricter genome-wide significance threshold for SNP-BP trait associations identified in GWAS, i.e., 2.2 × 10−12, compared to the current generally considered 5 × 10−8 value, (ii) ~ 56% of the BP-SNPs are related to 1167 RHCP-coding genes, while 24% are intergenic, (iii) 665 of the 1167 RHCP-coding BP-GWAS genes are also supported by eQTLs in any of the 27 selected as BP-related tissues, and (iv) the most enriched in BP-GWAS genes human chromosomes are 1, 2 and 11. The genes ATXN2 and SH2B3, which are at the core of the 12q24 chromosomal region, have been identified with the lowest BP-association p-value. The particular locus has been GWAS-associated with many diseases, including hypertension and cardiovascular infarction, along with autoimmune diseases, like diabetes 1 and hypothyroidism [60]. Loss of ATΧN2 function can lead to insulin resistance and obesity [61], while SH2B3, the SH2B adapter protein 3, has been causally associated with BP regulation [62].
Introducing a new gene prioritization criterion based on an integrated GWAS score
Having all this information collected in a meta-database, we possess a valuable tool that enables the creation of BP-gene prioritization schemes based on integrated GWAS scores, taking into consideration more GWAS data attributes in addition to the minimum SNP/gene-trait association p-value, which has traditionally been the main prioritization criterion. These additional attributes include the number of significant SNPs per gene and the number of independent GWAS publications supporting the BP-association of a gene. In our newly proposed integrated BP-gene association score equaling the weighted sum of these three GWAS attributes, we still allocate the maximum significance to the p-value, assigning a corresponding weight of 45%, followed by a 35% weight for the number of SNPs per gene and a 20% weight for the number of independent publications, as the vast majority of the BP-genes are currently supported by at most two publications (Fig. 5). As GWAS evolve, the relative weight of the publication criterion could be increased and/or other criteria, including number of ancestries or eQTL measurements may also be considered in the combined score to enhance the validity of the prioritization scheme.
Our proposed GWAS data-based metric prioritized 103 RHCP-coding BP genes, of which 45 are mapped on chromosomes 1, 10, 11 and 12, and 69 are supported by eQTLs (Table 2, Additional file 1: Table S4, Additional file 3). The top-10 genes in decreasing score order are: ULK4, ATP2B1, SH2B3, ATXN2, ZNF831, CNNM2, CLCN6, MTHFR, CABCOCO1 and CSK (Table 2). Among these, seven (ULK4, ATP2B1, CNNM2, CLCN6, MTHFR, CABCOCO1, CSK) are also supported by eQTLs in at least two of the BP-related tissues (Additional file 3). Notably, ULK4 (unc-51 like kinase 4), ZNF831 (zinc finger protein 831), CNNM2 (cyclin and CBS domain divalent metal cation transport mediator 2) and CABCOCO1 (ciliary-associated calcium binding coiled-coil 1), would not have been in the top-10 if only the BP-association p-value had been considered, but emerge as prioritized based on the number of significant SNPs and/or the number of independent publications (Table 2). We underline the BP-association of ULK4, which is supported by a very high number of SNPs, independent publications and eQTL measurements in 25 of the 27 BP-related tissues, and was first identified by early GWAS studies [63, 64]. Even though ULK4 has been traditionally considered as BP-associated based on GWAS, as also documented by its inclusion in the BP-associated protein set of GAD, its biological role remains unclear. There has been evidence that ULK4, a serine/threonine kinase, is responsible for over 90% of total Ser/Thr dephosphorylation in eukaryotes [65]. Through its interaction with the two most abundant phosphatases PP2A and PP1α, ULK4 regulates the expression of p-Akt and p-GSK-3α/β and may be involved in the remodeling of cytoskeletal components, participating in the regulation of neurite elongation and cell motility. ULK4 has been proposed to be a rare susceptibility gene for psychiatric disorders, especially schizophrenia [65, 66]. The plasma membrane calcium-transporting ATPases as ATP2B1 play a major role in maintaining intracellular calcium homeostasis [67], being thus directly associated with BP regulation. Deficiency of the divalent cation metal transporter CNNM2 has been causally associated with hypomagnesemia and BP deregulation [68]. CLCN6, the transmembrane chloride transport protein 6, has been for long associated with BP through GWAS, but the actual mechanism has been recently elucidated as its inactivation is associated with arterial stiffness and alterations of vascular smooth muscle contractility by changing calcium concentration in the Golgi apparatus [69]. Methylenetetrahydrofolate reductase, encoded by MTHFR, is the enzyme catalyzing the biosynthesis of folate, the homocysteine co-substrate in its conversion to methionine, essential in keeping the homocysteine-methionine balance [70]. Its loss leads to increase in serum homocysteine, which has been associated with premature coronary disease [71] and cardiovascular risks in general [70]. MTHFR is an antihypertensive drug target. CSK suppresses the activity of Src-family kinases (SRKs) [72], and has been indicated as a key modulator of BP by influencing aldosterone production in adrenal gland [73] and vascular remodeling [74].
Reconstructing a protein interactome of BP regulation through a newly proposed method
Α major objective of our study was to upgrade the information content of the BP-GWAS data by investigating their relationship and interconnectivity in the context of the human protein interactome. To this end, we mapped the protein products of the GWAS-identified as BP-related genes on the human PPI network and observed that 91% are nodes of the network (Fig. 8A; Additional file 4). About two-thirds of the network proteins form a large interconnected component and were color-coded and named “blue nodes” (BNs), with the rest called “green nodes” (GNs). The top 1% BN protein nodes with respect to their degree in the BN network are P53, UBC9, ESR1 (GWAS-prioritized), FYN, HDAC4, SMAD3 and STAT3 (Additional file 4). Cellular tumor antigen p53 (P53), along with HIF-1A/2A, have been associated with pulmonary hypertension [75] and demonstrated to have a regulatory role in cardiovascular pathophysiology [76, 77]. UBC9-mediated sumoylation has been associated with good cardiac function and efficient protein quality control in cardiomyocytes [78, 79]. The role of estrogen receptor (ESR1) in BP and cardiac pathophysiology has been largely acknowledged in recent years through combination of available evidence in various studies [80,81,82]. In cardiomyocytes, the SFK FYN has been identified as a negative feedback regulator of the GWAS-prioritized NADPH oxidase 4, NOX4 (GN), which produces ROS, with FYN expression being substantially decreased in failing human hearts [83]. The network-based elucidation of both FYN and STAT3 as BP-significant proteins is functionally supported, as the SFKs inhibit the STAT3 signaling, playing thus a significant role in vascular remodeling and pulmonary arterial vasoconstriction [84]. STAT3 has been largely discussed for its cardioprotective role [85, 86]. Histone deacetylase 4, HDAC4, has been identified as a crucial regulator of cardiac function [87], mediating vascular inflammation involved in the pathophysiology of hypertension [88], and has been recognized to play a pivotal role in myocardial ischemia–reperfusion injury [89]. Finally, SMAD3, an intracellular signal transducer and transcriptional modulator, has been implicated in pulmonary arterial hypertension through vascular remodeling [90], cardiac fibrosis [91] and renal inflammation and fibrosis [92].
Considering that the GNs should be closely related to the BNs as both protein-sets are BP-associated based on GWAS, we proposed a new method of extending the GWAS-identified BP PPI network through the shortest interaction paths bridging GNs to BNs into one connected component. The “reconstructed by shortest path” (RbSP) BP PPI network (Fig. 8B, Additional file 1: Fig. S2A; Additional file 4) comprises 15% and 17%, respectively, of the protein nodes and the interactions of the human interactome, including 62 of its 65 proteins with more than 300 interactions, underlying that BP regulation involves a large number of pathways of human physiology. Indeed, the BP-related network confirms the close relationship between BNs and GNs as 98% of GNs are second neighbors to a BN. Furthermore, this observation strongly supports the BP-association of the “in silico” identified as BP-related shortest-path intermediates, named “yellow nodes” (YNs), as the vast majority of YNs are common neighbors of the experimentally identified as BP-related BNs and GNs (Fig. 8B).
Pathway-enrichment analysis and the role of the network-identified as BP-related proteins (YNs)
The in silico identified ΥΝs extend the knowledge about BP regulation beyond the experimentally identified by GWAS. Any functional validation of the BP-association of YNs could further support our shortest-path approach to extend the BP PPI network beyond the GWAS data. First, YNs enhance the acquired information about BP-related pathways as their presence substantially increases the number of functional KEGG-defined pathways that are identified as significantly BP-protein enriched; 87 compared to 26 pathways when only GWAS proteins are considered. Most of the 87 pathways (Table 6) have been strongly associated with BP regulation and/or heart pathophysiology through functional studies, including the three cardiomyopathy-associated pathways, i.e., dilated cardiomyopathy (DCM) (Additional file 1: Fig. S6), hypertrophic cardiomyopathy (HCM), and arrhythmogenic right ventricular cardiomyopathy (ARVC), the adrenergic signaling in cardiomyocytes (Fig. 10) [55, 93, 94], the hypoxia-induced factor-1 (HIF-1) pathway (Fig. 11) [95,96,97,98,99], the calcium signaling [100,101,102], the thyroid hormone signaling [103,104,105], the renin–angiotensin–aldosterone system/RAAS [106, 107], the insulin secretion and resistance [108,109,110,111] and the vascular smooth muscle contraction [112,113,114]. Notably, the main protein of the HIF-1 pathway, HIF-1A, is itself a YN and the pathway would not have been identified as significant, if the BP PPI network had not been accordingly extended by the shortest-path approach.
Other functionally BP-associated signaling pathways that emerged as significantly BP-enriched based on the RbSP PPI network node-set, include: the phosphoinositide-3-kinase (PI3K)–protein kinase B (PKB/Akt) signaling pathway [115,116,117,118], the cyclic adenosine monophosphate (cAMP) signaling pathway [119, 120] and the guanosine monophosphate (cGMP)-protein kinase G (PKG) signaling pathway (Additional file 1: Fig. S5) [54, 121]. These pathways encompass or interconnect with pathways that have been directly associated with BP, such as the adrenergic signaling in cardiomyocytes (Fig. 10), the calcium signaling pathway, the vascular smooth muscle contraction and the DCM pathway (Additional file 1: Fig. S6). Notably, the cGMP-PKG signaling, the calcium signaling, the cAMP signaling and the renin secretion pathways contain the highest number of antihypertensive drug targets (Table 7).
Crucial proteins in the aforementioned BP-related pathways are network-identified YNs. This observation adds to the validity of the PPI network analysis and our proposed way of extending the GWAS-deduced PPI network of BP and identifying the YNs. To support this last argument, we point out some characteristic examples of YNs with key role in BP-associated pathways. In the PI3K/AKT pathway, PI3K can be activated by multiple signals, including receptor tyrosine kinases e.g., EGFR (ΥΝ), INSR (BN), ERBB2 (YN), ERBB3 (YN) and IGF1R (YN) and cellular matrix components, leading to the activation of serine/threonine kinase AKT, including the isoforms AKT1 (YN) and AKT2 (BN). AKT regulates the activation of downstream targets, such as mTOR (YN), GSK-3 (isoform GSK3B is a YN) and NOS (isoform NOS3 is a BN) [117]. m-TOR [122], GSK-3 [123] and NOS [124, 125] play a major role in cardiovascular homeostasis and any deregulation could lead to heart failure.
Regarding the cAMP and cGMP signaling, both cAMP and cGMP are major regulators of cardiac function, contractility, and integrity [126]. cAMP, as the main second messenger of beta-adrenergic receptor signaling, is formed in response to G protein-coupled receptors as ADRB1 (GN) and ADRB2 (YN) [119, 120]. Notably, ADRB1 and ADRB2, along with the ADRAs, ADA1A (YN) and ADA2A (YN), are targets of a large number of antihypertensive drugs (Fig. 12A; Fig. 10C; Additional file 1: Figs. S5C, S6C; Additional file 4). The cAMP response element-binding (CREB)-binding protein (CBP; YN) and its closely related paralog EP300 (YN) have been indicated to participate in vascular smooth muscle contraction [127] and skeletal muscle homeostasis [128]. CBP and EP300 interact with many proteins, including, P53 (BN; GWAS-prioritized), HIF-1A (YN), JUN (YN), FOS (YN), TYY1 (BN), TF65 (BN) and steroid receptors, including ESR1 (BN; GWAS-prioritized), glucocorticoid receptor (GCR; YN) and androgen receptor (ANDR; YN) [129]. JUN is an antihypertensive drug target (Additional file 4). cGMP is formed in response to NO and natriuretic peptides, including the atrial natriuretic factor ANF (NPPA) (BN) and the brain natriuretic factor ANFB (NPPB) (BN), and has been shown to modulate hypertension via different mechanisms, as vasorelaxation or renin reduction [54].
Pathway enrichment analysis underlined the association of BP regulation with well-functioning cell–cell junctions, including adherens junctions, gap junctions and focal adhesions, along with the strongly related to cell junctions Hippo signaling pathway. Deregulation of intercellular interactions have been implicated in vascular and cardiac-related diseases, as discussed in detail in relevant reviews, e.g., [130,131,132,133,134]. CTNB1, the catenin-beta 1 protein (YN), plays an important role in cell–cell junctions and is a key component of WNT signaling pathway [135]. Changes in the activity of the WNT/β-catenin signaling pathway [136,137,138] and Hippo pathway [139, 140] have been associated with heart diseases and hypertension. Suppression of the Hippo and WΝΤ signaling pathways mediated by the activation of EP300/p53 pathway has been associated with severe deregulation of the apical junction in ARVC [141]. From the lipid-modified WNT proteins, we encounter WNT3A (YN), WNT2B (GN; GWAS-prioritized) and WNT9A (GN) in the GWAS-RbSP PPI network. A recent review summarizes the interplay between the WNT/β-catenin signaling pathway and the renin-angiontensin system (RAS) with PPARG (YN), a crucial member of lipid metabolism and antihypertensive drug target [142]. The functionally associated with BP and/or cardiovascular physiology lipid metabolism was indeed revealed as BP-protein enriched based on the extended BP-protein set, with respect to the biosynthesis of unsaturated fatty acids [143,144,145], the elongation of fatty acids in mitochondria and the β-oxidation of fatty acids [146], along with the steroid hormone synthesis [147], and the purine/pyrimidine biosynthesis [148, 149] metabolic pathways (Additional file 1: Fig. S7B).
Introducing two network-based criteria for BP-protein prioritization
As the pathway analysis of the RbSP PPI network revealed processes that are indeed functionally supported as BP-related, with many of their crucial nodes being in silico identified YNs, we could trust the BP-association of the extended network and search for BP-protein prioritization criteria in the network metrics. Regarding the BP-relation of A4 (YN), the most connected node of the GWAS-RbSP PPI network, recent studies have established association between the progression of Alzheimer-like pathology and hypertension [150, 151]. EGFR (YN) and EP300 (YN), which are among the RbSP PPI network hubs with more than 200 interactions are documented as BP-related by their involvement in the PI3K-Akt, cAMP, HIF-1A, and the calcium, thyroid hormone, Hippo, and WNT signaling pathways (Additional file 4).
In this study, we opted to analyze the role of each protein-node in the RbSP BP interactome and use this information to develop a prioritization criterion, based on an integrated network metric, IVI, taking into consideration additional node characteristics beyond the number of interactions (degree). The top-10 of the 106 IVI-prioritized proteins are P53 (BN, BN network hub), UBC (YN), ESR1 (BN, GWAS-prioritized, BN network hub), EP300 (YN), A4 (YN), EGFR (YN), AKT1 (YN), BRCA1 (YN), CBP (YN) and heat shock protein HSP 90-alpha (HS90A, YN) (Table 3). As mainly expected from the IVI metric definition, all but CBP belong to the top-21 of the degree distribution. It is the high IVI-spreading index of CBP that contributes to its IVI being in the top-10. We have already discussed that CBP, a protein-lysine acetyltransferase, interacts with many proteins as a major component of the cAMP pathway. The role of the heat shock proteins in general, and the HSA90 molecular chaperone family, in particular, in cardiac homeostasis has been demonstrated through multiple studies, e.g., [152,153,154,155,156,157]. HSP90A interacts with many proteins including AKT1 (YN), AKT2 (BN), ANDR (YN), NOS3 (BN, GWAS-prioritized), GSK3B (YN), STAT3 (ΒN, ΒΝ network hub), P53 (BN) and HIF1A (YN), which have already been discussed as associated with cardiovascular pathophysiologies and/or as members of BP-related pathways. The role of BRCA1 in BP has been argued in the context of the high cardiovascular disease risk of BRCA1/2 mutation carriers [158] and the comorbidity of hypertension and breast cancer [159]. Other prioritized proteins that rank high in the IVI score distribution because of high spreading indices include SP1 (YN), HIF1A (YN) and TF65 (BN). SP1, a general transcription factor, is involved in the regulation of sarcoplasmic reticulum Ca2+-ATPase (SERCA) pump in cardiomyocytes [160, 161].
Interestingly, most of the BNs, including TF65 (alternatively, NF-kappa B p65 subunit) and the BN network hubs UBC9, SMAD3 and MAPK1 (or ERK2), which are prioritized based on the IVI metric (19 of 22 in total), have a low ranking in the integrated GWAS score list, an observation further supporting the value of the network-based analysis of the GWAS data. ESR1 is the only prioritized based on both criteria (Table 3, Additional file 5), while the IVI-prioritized BNs, P53 and IKBA rank slightly below the significance threshold of the GWAS-based prioritization criterion. The NF-κB signaling pathway has been linked to several heart pathologic processes [162]. TF65, in particular, promotes apoptosis in heart failure [163] and is required for the pressure overload compensation by cardiomyocytes; in its absence, cardiomyocytes fail to increase the expression of HIF1A (YN), the TF65 target protein [164]. Finally, the role of MAPKs in heart failure has been long known, e.g., [165,166,167].
Apart from the overall network metrics, as the degree or the IVI, we propose a novel network-based method to prioritize the in silico identified YNs, while still taking advantage of the information derived from the integrated GWAS-based prioritization scheme. Specifically, we assigned higher BP-relevance to the YNs that are common neighbors of GWAS-prioritized BNs and GNs, while the GWAS proteins gain additional credit from their involvement in this network. The 253 protein nodes identified in this connected subnetwork of the RbSP BP interactome were IVI-ranked (Table 4; Additional file 1: Fig. S3) and the top ten (all IVI-prioritized) proteins are: ESR1 (BN, GWAS- and IVI- prioritized, BN and RbSP PPI network hub), AKT1 (YN), EGFR (YN, RbSP PPI network hub), CTNB1 (YN), UBC (YN, RbSP PPI network hub), BRCA1 (YN), GRB2 (YN), A4 (YN, RbSP PPI network hub), SRC (YN) and EP300 (YN, RbSP PPI network hub). From the two proteins not in the top-10 of the IVI-prioritized, GRB2 is essential for cardiac hypertrophy upon pressure overload [168] and atherosclerotic cell formation [169], while it ,also, induces cardiorenal syndrome type 3 [170]. SRC is required for mechanical stress (MS)-induced cardiomyocyte hypertrophy [171] and activates various signaling pathways involved in cardiovascular diseases [172, 173].
Introducing an integrated BP-protein prioritization scheme
In summary, the analysis of the collected BP-GWAS meta-dataset in the context of the human PPI network extended by the YNs enabled us to define one GWAS-based and two network-based criteria for gene/protein prioritization with respect to their association with BP and determine three respective BP-significant protein sets (Fig. 1). The union of the three sets is proposed as the complete set of prioritized BP-proteins (Additional file 1: Fig. S4), ranked based on the number of the satisfied prioritization criteria, formulating thus, an integrated BP-protein prioritization scheme (Additional file 5).
Notably, the only protein satisfying all three criteria is ESR1, strongly supporting its BP-association, with this observation emerging as a major result of our study. ESR1 has a very influential role in the BP RbSP PPI network, as it ranks very high in the network-based criteria (Tables 3 and 4), while it is only in position 51 in the GWAS-prioritized list. ESR1 is one of the three predominant estrogen receptors, and has been long known to protect against hypertension [174, 175]. Nine GWAS-prioritized BNs (INSR, PTN11, CDK6, CSK, NOS3, SH2B3, ATP2B1, FES and FINC) complete the top-10 BP-significant protein-set (Table 5, Additional file 5). The significant role of insulin receptors in cardioprotection has been demonstrated through the activation of the PI3K-AKT and the Ras-MAPK signaling pathways [176], while the first genetic variation associated with essential hypertension was in INSR [177]. Deletion of PTPN11 has been shown to cause DCM, through loss of MAPK signaling pathway activation [178], while mutations of this gene have been associated with cardiac defects and insulin resistance [179]. CDK6, mainly discussed as an anti-cancer drug target, has been implicated in pulmonary arterial hypertension [180], loss of its activity can lead to heart failure [181] and is a major regulator of atherosclerosis [182]. FES has been shown to play a protective role against atherosclerosis [183]. Fibronectin (FINC, encoded by FN1) has a cardioprotective role, potentially through its contribution to the formation of a functional vascular wall extracellular matrix [184].
Overall, the integrated BP-prioritized protein set provides a valuable resource of proteins suggested as BP-significant according to quantitative criteria, which combine GWAS-based importance with the influential role of a protein in the topology of the PPI network, increasing thus the confidence in the validity of the prioritization. Interestingly, thyroid hormone and neurotrophin signaling pathways have been identified of higher enrichment in the BP-prioritized compared to the overall BP-protein set, further supporting the association of these pathways with BP. Thyroid hormones regulate mechanisms underlying hypertension [103, 185]. Neurotrophins, as the brain-derived neurotrophic factor (BDNF; BN), have been directly linked to hypertension through the regulation of angiotensin signaling [186, 187]. Recent studies causally implicate neurotrophins with Alzheimer’s and Huntington’s diseases [188]. Comorbidity analysis based on the BP-associated GAD ontology terms indicated higher comorbidity of BP deregulation with alcohol and tobacco use, diabetes and metabolic syndrome, neurological and mood disorders, cardiovascular diseases, cancer, and renal failure, e.g., [189,190,191,192].
Conclusions
In this study, we introduced an integrated workflow for upgrading the information content of ΒP-GWAS data through PPI network analysis, starting from the development of a systematically curated BP-GWAS meta-database, combining GWAS data with their transcript effects and eQTL measurements, leading to their projection on the human PPI network. The information stored in the meta-database lead to the definition of an integrated GWAS-based prioritization criterion for BP-associated genes, considering not only the minimum SNP-trait p-value per gene, but also the number of BP-associated SNPs per gene and the number of independent supporting publications. The projection of the GWAS data on the human protein interaction network revealed connected and non-connected components, which we proposed to link through shortest paths (GWAS-RbSP PPI network). Thus, we introduced a novel extension method for GWAS-based disease-related PPI networks, considering the intermediate nodes of the shortest paths (YNs) as also related to the investigated phenotype. Pathway enrichment analysis of the RbSP PPI network revealed BP-enriched pathways, indicating underlying mechanisms and targets for drugs and therapeutic treatments, which were interpreted in the context of available functional information. The role of each protein-node in the RbSP PPI network based on network metrics provided a second BP-protein prioritization criterion. A third prioritization criterion proposed in this study revealed the YNs that are common neighbors of GWAS-prioritized proteins. The integrated BP-prioritization set was topped by the proteins satisfying at least two of the prioritization criteria, ESR1 emerging as the most BP-significant. This analysis extends our knowledge about BP regulation and could be effectively applied to GWAS datasets of any multifactorial disease. In the limitations of our study, we note that our results were obtained without making any distinction between the origin/ancestry profile of the cohorts to which the combined GWAS data referred. At the moment, such distinction is expected to be biased toward the European origin, as this represents the vast majority of the GWAS cohorts. As GWAS data from other ancestries increase, such distinction, which is accommodated by the structure of our meta-database could lead to useful ancestry-specific results about BP. Furthermore, there may be a bias in the significance of the number of SNPs per gene criterion for certain genes in the integrated GWAS score, due to dependencies in the reported SNPs. Finally, the selection of the weights of the three gene attributes in the integrated GWAS score has been carried out based on the current relevant distributions of the GWAS genes. The relative weights may be modified in the future as more GWAS publications and/or information about independent SNPs becomes available.
Availability of data and materials
All data generated or analyzed during this study are included in this article and its supplementary information files.
References
Uffelmann E, Huang QQ, Munung NS, de Vries J, Okada Y, Martin AR, et al. Genome-wide association studies. Nat Rev Methods Prim. 2021;1(1):59.
Nica AC, Dermitzakis ET. Expression quantitative trait loci: present and future. Philos Trans R Soc B Biol Sci. 2013;368(1620):20120362.
Buniello A, MacArthur JAL, Cerezo M, Harris LW, Hayhurst J, Malangone C, et al. The NHGRI-EBI GWAS catalog of published genome-wide association studies, targeted arrays and summary statistics 2019. Nucleic Acids Res. 2019;47(D1):D1005–12.
Akiyama M. Multi-omics study for interpretation of genome-wide association study. J Hum Genet. 2021;66(1):3–10.
Yan J, Risacher SL, Shen L, Saykin AJ. Network approaches to systems biology analysis of complex disease: integrative methods for multi-omics data. Brief Bioinform. 2017;19(6):1370–81.
Yang X. Multitissue Multiomics systems biology to dissect complex diseases. Trends Mol Med. 2020;26(8):718–28.
Barabási AL, Gulbahce N, Loscalzo J. Network medicine: a network-based approach to human disease. Nat Rev Genet. 2011;12(1):56–68.
Chimusa ER, Dalvie S, Dandara C, Wonkam A, Mazandu GK. Post genome-wide association analysis: dissecting computational pathway/network-based approaches. Brief Bioinform. 2019;20(2):690–700.
Wu S, Chen D, Snyder MP. Network biology bridges the gaps between quantitative genetics and multi-omics to map complex diseases. Curr Opin Chem Biol. 2022;66:102101.
Klapa MI, Tsafou K, Theodoridis E, Tsakalidis A, Moschonas NK. Reconstruction of the experimentally supported human protein interactome: what can we learn? BMC Syst Biol. 2013;7:96.
Dimitrakopoulos GN, Klapa MI, Moschonas NK. How far are we from the completion of the human protein interactome reconstruction? Biomolecules. 2022;12(1):140.
Goh KI, Cusick ME, Valle D, Childs B, Vidal M, Barabási AL. The human disease network. Proc Natl Acad Sci U S A. 2007;104:8685–90.
Ratnakumar A, Weinhold N, Mar JC, Riaz N. Protein-Protein interactions uncover candidate ‘core genes’ within omnigenic disease networks. Liu X, editor. PLOS Genet. 2020;16(7):e1008903.
Guo X, Song Y, Liu S, Gao M, Qi Y, Shang X. Linking genotype to phenotype in multi-omics data of small sample. BMC Genomics. 2021;22(1):537.
Jia P, Zhao Z. Network-assisted analysis to prioritize GWAS results: principles, methods and perspectives. Hum Genet. 2014;133(2):125–38.
Raj MR, Sreeja A. Analysis of Computational gene prioritization approaches. Proc Comput Sci. 2018;143:395–410.
Kim Y, Park JH, Cho YR. Network-based approaches for disease-gene association prediction using protein–protein interaction networks. Int J Mol Sci. 2022;23(13):7411.
Oliver S. Guilt-by-association goes global. Nature. 2000;403(6770):601–2.
Oti M, Brunner H. The modular nature of genetic diseases. Clin Genet. 2006;71(1):1–11.
Kjeldsen SE. Hypertension and cardiovascular risk: general aspects. Pharmacol Res. 2018;129:95–9.
Ehret GB, Ferreira T, Chasman DI, Jackson AU, Schmidt EM, Johnson T, et al. The genetics of blood pressure regulation and its target organs from association studies in 342,415 individuals. Nat Genet. 2016;48(10):1171–84.
Surendran P, Drenos F, Young R, Warren H, Cook JP, Manning AK, et al. Trans-ancestry meta-analyses identify rare and common variants associated with blood pressure and hypertension. Nat Genet. 2016;48(10):1151–61.
Feitosa MF, Kraja AT, Chasman DI, Sung YJ, Winkler TW, Ntalla I, et al. Novel genetic associations for blood pressure identified via gene-alcohol interaction in up to 570K individuals across multiple ancestries. Kuivaniemi H, editor. PLoS ONE. 2018;13(6):e0198166.
Giri A, Hellwege JN, Keaton JM, Park J, Qiu C, Warren HR, et al. Trans-ethnic association study of blood pressure determinants in over 750,000 individuals. Nat Genet. 2019;51(1):51–62.
Huan T, Meng Q, Saleh MA, Norlander AE, Joehanes R, Zhu J, et al. Integrative network analysis reveals molecular mechanisms of blood pressure regulation. Mol Syst Biol. 2015;11(4):799–799.
Botzer A, Grossman E, Moult J, Unger R. A system view and analysis of essential hypertension. J Hypertens. 2018;36(5):1094–103.
Zhao Y, Blencowe M, Shi X, Shu L, Levian C, Ahn IS, et al. Integrative genomics analysis unravels tissue-specific pathways, networks, and key regulators of blood pressure regulation. Front Cardiovasc Med. 2019;6:21.
Turner SD. qqman: an R package for visualizing GWAS results using Q–Q and manhattan plots. J Open Source Softw. 2018;3(25):731.
Cunningham F, Allen JE, Allen J, Alvarez-Jarreta J, Amode MR, Armean IM, et al. Ensembl 2022. Nucleic Acids Res. 2022;50(D1):D988–95.
Eilbeck K, Lewis SE, Mungall CJ, Yandell M, Stein L, Durbin R, et al. The sequence ontology: a tool for the unification of genome annotations. Genome Biol. 2005;6(5):R44.
Wolfe D, Dudek S, Ritchie MD, Pendergrass SA. Visualizing genomic information across chromosomes with PhenoGram. BioData Min. 2013;6(1):18.
GTEx Consortium. The GTEx Consortium atlas of genetic regulatory effects across human tissues. Science (80-). 2020;69(6509):1318–30.
Lonsdale J, Thomas J, Salvatore M, Phillips R, Lo E, Shad S, et al. The genotype-tissue expression (GTEx) project. Nat Genet. 2013;45(6):580–5.
Gioutlakis A, Klapa MI, Moschonas NK. PICKLE 2.0: a human protein-protein interaction meta-database employing data integration via genetic information ontology. Oliva B, editor. PLoS ONE. 2017;12(10):e0186039.
Dimitrakopoulos GN, Klapa MI, Moschonas NK. PICKLE 3.0: enriching the human meta-database with the mouse protein interactome extended via mouse–human orthology. Bioinformatics. 2021;37(1):145–6.
Bateman A, Martin MJ, Orchard S, Magrane M, Agivetova R, Ahmad S, et al. UniProt: the universal protein knowledgebase in 2021. Nucleic Acids Res. 2021;49(D1):D480–9.
Shannon P, Markiel A, Ozier O, Baliga NS, Wang JT, Ramage D, et al. Cytoscape: a software Environment for integrated models of biomolecular interaction networks. Genome Res. 2003;13:2498–504.
Salavaty A, Ramialison M, Currie PD. Integrated value of influence: an integrative method for the identification of the most influential nodes within networks. Patterns. 2020;1(5):100052.
Koschützki D, Schreiber F. Centrality Analysis Methods for Biological Networks and Their Application to Gene Regulatory Networks. Gene Regul Syst Bio. 2008;2:193–201.
Liu Q, Zhu YX, Jia Y, Deng L, Zhou B, Zhu JX, et al. Leveraging local h-index to identify and rank influential spreaders in networks. Phys A Stat Mech Appl. 2018;512:379–91.
Maslov S, Sneppen K. Specificity and stability in topology of protein networks. Science (80-). 2002;296(5569):910–3.
Chen DB, Gao H, Lü L, Zhou T. Identifying influential nodes in large-scale directed networks: the role of clustering. PLoS ONE. 2013;8(10):e77455.
Morone F, Makse HA. Influence maximization in complex networks through optimal percolation. Nature. 2015;524(7563):65–8.
Sherman BT, Hao M, Qiu J, Jiao X, Baseler MW, Lane HC, et al. DAVID: a web server for functional enrichment analysis and functional annotation of gene lists (2021 update). Nucleic Acids Res. 2022;50(W1):W216–21.
Huang DW, Sherman BT, Lempicki RA. Systematic and integrative analysis of large gene lists using DAVID bioinformatics resources. Nat Protoc. 2009;4(1):44–57.
Kanehisa M. KEGG: Kyoto encyclopedia of genes and genomes. Nucleic Acids Res. 2000;28(1):27–30.
Kanehisa M, Sato Y, Furumichi M, Morishima K, Tanabe M. New approach for understanding genome variations in KEGG. Nucleic Acids Res. 2019;47(D1):D590–5.
Kanehisa M, Furumichi M, Sato Y, Ishiguro-Watanabe M, Tanabe M. KEGG: integrating viruses and cellular organisms. Nucleic Acids Res. 2021;49(D1):D545–51.
Wishart DS, Feunang YD, Guo AC, Lo EJ, Marcu A, Grant JR, et al. DrugBank 5.0: a major update to the DrugBank database for 2018. Nucleic Acids Res. 2018;46(D1):D1074–82.
Amberger JS, Bocchini CA, Schiettecatte F, Scott AF, Hamosh A. OMIM.org: Online Mendelian Inheritance in Man (OMIM®), an Online catalog of human genes and genetic disorders. Nucleic Acids Res. 2015;43:D789–98.
Becker KG, Barnes KC, Bright TJ, Wang SA. The genetic association database. Nat Genet. 2004;36(5):431–2.
Morales J, Welter D, Bowler EH, Cerezo M, Harris LW, McMahon AC, et al. A standardized framework for representation of ancestry data in genomics studies, with application to the NHGRI-EBI GWAS Catalog. Genome Biol. 2018;19(1):21.
Drazner MH. The progression of hypertensive heart disease. Circulation. 2011;123(3):327–34.
Ataei A, Golshiri K, Jüttner A, Krenning G, Danser AHJ, Roks AJM. Nitric oxide-cGMP signaling in hypertension. Hypertension. 2020;76(4):1055–68.
Hering L, Rahman M, Potthoff SA, Rump LC, Stegbauer J. Role of α2-adrenoceptors in hypertension: focus on renal sympathetic neurotransmitter release, inflammation, and sodium homeostasis. Front Physiol. 2020;11:566871.
Muangritdech N, Hamlin MJ, Sawanyawisuth K, Prajumwongs P, Saengjan W, Wonnabussapawich P, et al. Hypoxic training improves blood pressure, nitric oxide and hypoxia-inducible factor-1 alpha in hypertensive patients. Eur J Appl Physiol. 2020;120(8):1815–26.
Lucero García Rojas EY, Villanueva C, Bond RA. Hypoxia inducible factors as central players in the pathogenesis and pathophysiology of cardiovascular diseases. Front Cardiovasc Med. 2021;8:709509.
Perez DM. Current developments on the role of α1-adrenergic receptors in cognition, cardioprotection, and metabolism. Front Cell Dev Biol. 2021;9:652152.
Heusch G. Coronary blood flow in heart failure: cause, consequence and bystander. Basic Res Cardiol. 2022;117(1):1.
Auburger G. 12q24 locus association with type 1 diabetes: SH2B3 or ATXN2? World J Diabetes. 2014;5(3):316–27.
Meierhofer D, Halbach M, Şen NE, Gispert S, Auburger G. Ataxin-2 (Atxn2)-knock-out mice show branched chain amino acids and fatty acids pathway alterations. Mol Cell Proteomics. 2016;15(5):1728–39.
Keefe JA, Hwang SJ, Huan T, Mendelson M, Yao C, Courchesne P, et al. Evidence for a causal role of the SH2B3 -β 2 M axis in blood pressure regulation. Hypertension. 2019;73(2):497–503.
Franceschini A, Szklarczyk D, Frankild S, Kuhn M, Simonovic M, Roth A, et al. STRING v9.1: protein–protein interaction networks, with increased coverage and integration. Nucleic Acids Res. 2013;41:D808–15.
Levy D, Ehret GB, Rice K, Verwoert GC, Launer LJ, Dehghan A, et al. Genome-wide association study of blood pressure and hypertension. Nat Genet. 2009;41(6):677–87.
Luo S, Zheng N, Lang B. ULK4 in neurodevelopmental and neuropsychiatric disorders. Front Cell Dev Biol. 2022;10:873706.
Lang B, Pu J, Hunter I, Liu M, Martin-Granados C, Reilly TJ, et al. Recurrent deletions of ULK4 in schizophrenia: a novel gene crucial for neuritogenesis and neuronal motility. J Cell Sci. 2013;127(3):630–40.
Rahimi MJ, Urban N, Wegler M, Sticht H, Schaefer M, Popp B, et al. De novo variants in ATP2B1 lead to neurodevelopmental delay. Am J Hum Genet. 2022;109(5):944–52.
Funato Y, Yamazaki D, Miki H. Renal function of cyclin M2 Mg2+ transporter maintains blood pressure. J Hypertens. 2017;35(3):585–92.
Klemens CA, Chulkov EG, Wu J, Hye Khan MA, Levchenko V, Flister MJ, et al. Loss of chloride channel 6 (CLC-6) affects vascular smooth muscle contractility and arterial stiffness via alterations to Golgi calcium stores. Hypertension. 2021;77(2):582–93.
Raghubeer S, Matsha TE. Methylenetetrahydrofolate (MTHFR), the one-carbon cycle, and cardiovascular risks. Nutrients. 2021;13(12):4562.
Zaghloul A, Iorgoveanu C, Desai A, Balakumaran K, Chen K. Methylenetetrahydrofolate Reductase Polymorphism and Premature Coronary Artery Disease. Cureus. 2019;11(6):e5014.
Okada M. Regulation of the Src family kinases by csk. Int J Biol Sci. 2012;8(10):1385–97.
Kim SM, Kang JO, Lim JE, Hwang SY, Oh B. Csk regulates blood pressure by controlling the synthetic pathways of aldosterone. Circ J. 2018;82(1):168–75.
Duan LJ, Imamoto A, Fong GH. Dual roles of the C-terminal Src kinase (Csk) during developmental vascularization. Blood. 2004;103(4):1370–2.
Wang Z, Yang K, Zheng Q, Zhang C, Tang H, Babicheva A, et al. Divergent changes of p53 in pulmonary arterial endothelial and smooth muscle cells involved in the development of pulmonary hypertension. Am J Physiol Cell Mol Physiol. 2019;316(1):L216–28.
Men H, Cai H, Cheng Q, Zhou W, Wang X, Huang S, et al. The regulatory roles of p53 in cardiovascular health and disease. Cell Mol Life Sci. 2021;78(5):2001–18.
Chan GHH, Chan E, Kwok CTK, Leung GPH, Lee SMY, Seto SW. The role of p53 in the alternation of vascular functions. Front Pharmacol. 2022;13:981152.
Gupta MK, McLendon PM, Gulick J, James J, Khalili K, Robbins J. UBC9-mediated sumoylation favorably impacts cardiac function in compromised hearts. Circ Res. 2016;118(12):1894–905.
Gupta MK, Gulick J, Liu R, Wang X, Molkentin JD, Robbins J. Sumo E2 enzyme UBC9 Is required for efficient protein quality control in cardiomyocytes. Circ Res. 2014;115(8):721–9.
Visniauskas B, Kilanowski-Doroh I, Ogola BO, Mcnally AB, Horton AC, Imulinde Sugi A, et al. Estrogen-mediated mechanisms in hypertension and other cardiovascular diseases. J Hum Hypertens. 2022;37(8):609–18.
Chen P, Li B, Ou-Yang L. Role of estrogen receptors in health and disease. Front Endocrinol (Lausanne). 2022;13:839005.
Aryan L, Younessi D, Zargari M, Banerjee S, Agopian J, Rahman S, et al. The role of estrogen receptors in cardiovascular disease. Int J Mol Sci. 2020;21(12):4314.
Matsushima S, Kuroda J, Zhai P, Liu T, Ikeda S, Nagarajan N, et al. Tyrosine kinase FYN negatively regulates NOX4 in cardiac remodeling. J Clin Invest. 2016;126(9):3403–16.
Kurahara LH, Hiraishi K, Yamamura A, Zhang Y, Abe K, Yahiro E, et al. Eicosapentaenoic acid ameliorates pulmonary hypertension via inhibition of tyrosine kinase Fyn. J Mol Cell Cardiol. 2020;148:50–62.
Comità S, Femmino S, Thairi C, Alloatti G, Boengler K, Pagliaro P, et al. Regulation of STAT3 and its role in cardioprotection by conditioning: focus on non-genomic roles targeting mitochondrial function. Basic Res Cardiol. 2021;116(1):56.
Harhous Z, Booz GW, Ovize M, Bidaux G, Kurdi M. An update on the multifaceted roles of STAT3 in the heart. Front Cardiovasc Med. 2019;6:150.
Zhang LX, Du J, Zhao YT, Wang J, Zhang S, Dubielecka PM, et al. Transgenic overexpression of active HDAC4 in the heart attenuates cardiac function and exacerbates remodeling in infarcted myocardium. J Appl Physiol. 2018;125(6):1968–78.
Usui T, Okada M, Mizuno W, Oda M, Ide N, Morita T, et al. HDAC4 mediates development of hypertension via vascular inflammation in spontaneous hypertensive rats. Am J Physiol Circ Physiol. 2012;302(9):H1894–904.
Li Q, Zhu L, Niu F, Li Q, Wang C, Yang H, et al. Histone deacetylase HDAC4 participates in the pathological process of myocardial ischemia-reperfusion injury via MEKK1/JNK pathway by binding to miR-206. Cell Death Discov. 2021;7(1):240.
Zabini D, Granton E, Hu Y, Miranda MZ, Weichelt U, Breuils Bonnet S, et al. Loss of SMAD3 promotes vascular remodeling in pulmonary arterial hypertension via MRTF disinhibition. Am J Respir Crit Care Med. 2018;197(2):244–60.
Hanna A, Humeres C, Frangogiannis NG. The role of smad signaling cascades in cardiac fibrosis. Cell Signal. 2021;77:109826.
Wu W, Wang X, Yu X, Lan HY. Smad3 Signatures in renal inflammation and fibrosis. Int J Biol Sci. 2022;18(7):2795–806.
Papa A, Kushner J, Marx SO. Adrenergic Regulation of calcium channels in the heart. Annu Rev Physiol. 2022;84(1):285–306.
de Lucia C, Eguchi A, Koch WJ. New insights in cardiac β-adrenergic signaling during heart failure and aging. Front Pharmacol. 2018;9:904.
Pullamsetti SS, Mamazhakypov A, Weissmann N, Seeger W, Savai R. Hypoxia-inducible factor signaling in pulmonary hypertension. J Clin Invest. 2020;130(11):5638–51.
Liu M, Galli G, Wang Y, Fan Q, Wang Z, Wang X, et al. Novel therapeutic targets for hypoxia-related cardiovascular diseases: the role of HIF-1. Front Physiol. 2020;11:774.
da Sousa Fialho ML, Abd Jamil AH, Stannard GA, Heather LC. Hypoxia-inducible factor 1 signalling, metabolism and its therapeutic potential in cardiovascular disease. Biochim Biophys Acta: Mol Basis Dis. 2019;1865(4):831–43.
Knutson AK, Williams AL, Boisvert WA, Shohet R V. HIF in the heart: development, metabolism, ischemia, and atherosclerosis. J Clin Invest. 2021;131(17) 131:e137557.
Luo Z, Tian M, Yang G, Tan Q, Chen Y, Li G, et al. Hypoxia signaling in human health and diseases: implications and prospects for therapeutics. Signal Transduct Target Ther. 2022;7(1):218.
Terrar DA. Calcium Signaling in the Heart. Adv Exp Med Biol. 2020;1131:395–443.
Sutanto H, Lyon A, Lumens J, Schotten U, Dobrev D, Heijman J. Cardiomyocyte calcium handling in health and disease: insights from in vitro and in silico studies. Prog Biophys Mol Biol. 2020;157:54–75.
Villa-Etchegoyen C, Lombarte M, Matamoros N, Belizán JM, Cormick G. Mechanisms involved in the relationship between low calcium intake and high blood pressure. Nutrients. 2019;11(5):1112.
Jankauskas SS, Morelli MB, Gambardella J, Lombardi A, Santulli G. Thyroid hormones regulate both cardiovascular and renal mechanisms underlying hypertension. J Clin Hypertens. 2021;23(2):373–81.
Yamakawa H, Kato TS, Noh JY, Yuasa S, Kawamura A, Fukuda K, et al. Thyroid Hormone plays an important role in cardiac function: from bench to bedside. Front Physiol. 2021;12:606931.
Razvi S, Jabbar A, Pingitore A, Danzi S, Biondi B, Klein I, et al. Thyroid hormones and cardiovascular function and diseases. J Am Coll Cardiol. 2018;71(16):1781–96.
Azushima K, Morisawa N, Tamura K, Nishiyama A. Recent research advances in renin-angiotensin-aldosterone system receptors. Curr Hypertens Rep. 2020;22(3):22.
Pugliese NR, Masi S, Taddei S. The renin-angiotensin-aldosterone system: a crossroad from arterial hypertension to heart failure. Heart Fail Rev. 2020;25(1):31–42.
Brosolo G, Da Porto A, Bulfone L, Vacca A, Bertin N, Scandolin L, et al. Insulin resistance and high blood pressure: mechanistic insight on the role of the kidney. Biomedicines. 2022;10(10):2374.
Abel ED. Insulin signaling in the heart. Am J Physiol Metab. 2021;321(1):E130–45.
Mancusi C, Izzo R, di Gioia G, Losi MA, Barbato E, Morisco C. Insulin resistance the hinge between hypertension and type 2 diabetes. High Blood Press Cardiovasc Prev. 2020;27(6):515–26.
Ormazabal V, Nair S, Elfeky O, Aguayo C, Salomon C, Zuñiga FA. Association between insulin resistance and the development of cardiovascular disease. Cardiovasc Diabetol. 2018;17(1):122.
Touyz RM, Alves-Lopes R, Rios FJ, Camargo LL, Anagnostopoulou A, Arner A, et al. Vascular smooth muscle contraction in hypertension. Cardiovasc Res. 2018;114(4):529–39.
Yang Q, Hori M. Characterization of contractile machinery of vascular smooth muscles in hypertension. Life. 2021;11(7):702.
Zhuge Y, Zhang J, Qian F, Wen Z, Niu C, Xu K, et al. Role of smooth muscle cells in cardiovascular disease. Int J Biol Sci. 2020;16(14):2741–51.
Ghigo A, Laffargue M, Li M, Hirsch E. PI3K and calcium signaling in cardiovascular disease. Circ Res. 2017;121(3):282–92.
Huang Y, Wu X, Wu M, Chu J, Yu N, Shen A, et al. Antihypertensive and Vasodilatory effects of qingda granules by suppression of calcium influx and the AKT pathway. J Cardiovasc Pharmacol. 2019;74(6):549–57.
Qin W, Cao L, Massey IY. Role of PI3K/Akt signaling pathway in cardiac fibrosis. Mol Cell Biochem. 2021;476(11):4045–59.
Ghafouri-Fard S, Khanbabapour Sasi A, Hussen BM, Shoorei H, Siddiq A, Taheri M, et al. Interplay between PI3K/AKT pathway and heart disorders. Mol Biol Rep. 2022;49(10):9767–81.
Boularan C, Gales C. Cardiac cAMP: production, hydrolysis, modulation and detection. Front Pharmacol. 2015;6:203.
Harvey RD, Clancy CE. Mechanisms of cAMP compartmentation in cardiac myocytes: experimental and computational approaches to understanding. J Physiol. 2021;599(20):4527–44.
Numata G, Takimoto E. Cyclic GMP and PKG signaling in heart failure. Front Pharmacol. 2022;13:792798.
Sciarretta S, Forte M, Frati G, Sadoshima J. New insights into the role of mTOR signaling in the cardiovascular system. Circ Res. 2018;122(3):489–505.
Tariq U, Uppulapu SK, Banerjee SK. Role of GSK-3 in cardiac health: focusing on cardiac remodeling and heart failure. Curr Drug Targets. 2021;22(13):1568–76.
Schulz R, Rassaf T, Massion PB, Kelm M, Balligand JL. Recent advances in the understanding of the role of nitric oxide in cardiovascular homeostasis. Pharmacol Ther. 2005;108(3):225–56.
Farah C, Michel LYM, Balligand JL. Nitric oxide signalling in cardiovascular health and disease. Nat Rev Cardiol. 2018;15(5):292–316.
Preedy MEJ. Cardiac cyclic nucleotide phosphodiesterases: roles and therapeutic potential in heart failure. Cardiovasc Drugs Ther. 2020;34(3):401–17.
Chakraborty R, Ostriker AC, Xie Y, Dave JM, Gamez-Mendez A, Chatterjee P, et al. Histone acetyltransferases p300 and CBP coordinate distinct chromatin remodeling programs in vascular smooth muscle plasticity. Circulation. 2022;145(23):1720–37.
Svensson K, LaBarge SA, Sathe A, Martins VF, Tahvilian S, Cunliffe JM, et al. p300 and cAMP response element-binding protein-binding protein in skeletal muscle homeostasis, contractile function, and survival. J Cachexia Sarcopenia Muscle. 2020;11(2):464–77.
Sivelman ES, Du J, Williams AJ, Wadgaonkar R, Drazen JM, Collins T. cAMP-response-element-binding-protein-binding protein (CBP) and p300 are transcriptional co-activators of early growth response factor-1 (Egr-1). Biochem J. 1998;336(1):183–9.
Murphy JM, Jeong K, Lim STS. FAK Family kinases in vascular diseases. Int J Mol Sci. 2020;21(10):3630.
Figueroa XF, Isakson BE, Duling BR. Vascular gap junctions in hypertension. Hypertension. 2006;48(5):804–11.
Rodríguez-Sinovas A, Sánchez JA, Valls-Lacalle L, Consegal M, Ferreira-González I. Connexins in the Heart: regulation, function and involvement in cardiac disease. Int J Mol Sci. 2021;22(9):4413.
Ribeiro-Silva JC, Miyakawa AA, Krieger JE. Focal adhesion signaling: vascular smooth muscle cell contractility beyond calcium mechanisms. Clin Sci. 2021;135(9):1189–207.
Ni B, Sun M, Zhao J, Wang J, Cao Z. The role of β-catenin in cardiac diseases. Front Pharmacol. 2023;14:1157043.
van der Wal T, van Amerongen R. Walking the tight wire between cell adhesion and WNT signalling: a balancing act for β-catenin. Open Biol. 2020;10(12):200267.
Ziki MD, Mani A. Wnt signaling, a novel pathway regulating blood pressure? State of the art review. Atherosclerosis. 2017;262:171–8.
Młynarczyk M, Kasacka I. The role of the Wnt/β-catenin pathway and the functioning of the heart in arterial hypertension: a review. Adv Med Sci. 2022;67(1):87–94.
Liu J, Xiao Q, Xiao J, Niu C, Li Y, Zhang X, et al. Wnt/β-catenin signalling: function, biological mechanisms, and therapeutic opportunities. Signal Transduct Target Ther. 2022;7(1):3.
Xie J, Wang Y, Ai D, Yao L, Jiang H. The role of the Hippo pathway in heart disease. FEBS J. 2022;289(19):5819–33.
Myers R, Chen K, Sun Z. Inhibition of the Hippo pathway prevents arterial stiffness and hypertension in vascular smooth muscle cell specific kdm6a knockout mice. FASEB J. 2022. https://doi.org/10.1096/fasebj.2022.36.S1.R5124.
Rouhi L, Fan S, Cheedipudi SM, Braza-Boïls A, Molina MS, Yao Y, et al. The EP300/TP53 pathway, a suppressor of the Hippo and canonical WNT pathways, is activated in human hearts with arrhythmogenic cardiomyopathy in the absence of overt heart failure. Cardiovasc Res. 2022;118(6):1466–78.
Vallée A, Lévy BL, Blacher J. Interplay between the renin-angiotensin system, the canonical WNT/β-catenin pathway and PPARγ in hypertension. Curr Hypertens Rep. 2018;20(7):62.
Visioli F, Poli A. Fatty acids and cardiovascular risk. Evidence, lack of evidence, and diligence. Nutrients. 2020;12(12):3782.
Kotlyarov S, Kotlyarova A. Clinical significance of polyunsaturated fatty acids in the prevention of cardiovascular diseases. Front Nutr. 2022;9:998291.
Musazadeh V, Kavyani Z, Naghshbandi B, Dehghan P, Vajdi M. The beneficial effects of omega-3 polyunsaturated fatty acids on controlling blood pressure: an umbrella meta-analysis. Front Nutr. 2022;9:985451.
Lopaschuk GD, Ussher JR, Folmes CDL, Jaswal JS, Stanley WC. Myocardial fatty acid metabolism in health and disease. Physiol Rev. 2010;90(1):207–58.
Bernasochi GB, Boon WC, Delbridge LM, Bell JR. The myocardium and sex steroid hormone influences. Curr Opin Physiol. 2018;6:1–9.
Borghi C, Agnoletti D, Cicero AFG, Lurbe E, Virdis A. Uric acid and hypertension: a review of evidence and future perspectives for the management of cardiovascular risk. Hypertension. 2022;79(9):1927–36.
Irshad N, Khan AU, Iqbal MS. Antihypertensive potential of selected pyrimidine derivatives: explanation of underlying mechanistic pathways. Biomed Pharmacother. 2021;139:111567.
Faraco G, Park L, Zhou P, Luo W, Paul SM, Anrather J, et al. Hypertension enhances A β -induced neurovascular dysfunction, promotes β -secretase activity, and leads to amyloidogenic processing of APP. J Cereb Blood Flow Metab. 2016;36(1):241–52.
Cifuentes D, Poittevin M, Dere E, Broquères-You D, Bonnin P, Benessiano J, et al. Hypertension accelerates the progression of alzheimer-like pathology in a mouse model of the disease. Hypertension. 2015;65(1):218–24.
Qi S, Yi G, Yu K, Feng C, Deng S. The role of HSP90 inhibitors in the treatment of cardiovascular diseases. Cells. 2022;11(21):3444.
Roberts RJ, Hallee L, Lam CK. The potential of Hsp90 in targeting pathological pathways in cardiac diseases. J Pers Med. 2021;11(12):1373.
Ranek MJ, Stachowski MJ, Kirk JA, Willis MS. The role of heat shock proteins and co-chaperones in heart failure. Philos Trans R Soc B Biol Sci. 2018;373(1738):20160530.
Tamura S, Marunouchi T, Tanonaka K. Heat-shock protein 90 modulates cardiac ventricular hypertrophy via activation of MAPK pathway. J Mol Cell Cardiol. 2019;127:134–42.
Dabravolski SA, Sukhorukov VN, Kalmykov VA, Orekhov NA, Grechko AV, Orekhov AN. Heat shock protein 90 as therapeutic target for CVDs and HEART AGEING. Int J Mol Sci. 2022;23(2):649.
Zhang X, Wu J, Sha J, Yang B, Sun J, Bao E. Heat shock protein 90 relieves heat stress damage of myocardial cells by regulating Akt and PKM2 signaling in vivo. Int J Mol Med. 2020;45(6):1888–908.
van Westerop LLM, Arts-de Jong M, Hoogerbrugge N, de Hullu JA, Maas AHEM. Cardiovascular risk of BRCA1/2 mutation carriers: a review. Maturitas. 2016;91:135–9.
Wang W, He Q, Zhang H, Zhuang C, Wang Q, Li C, et al. A narrative review on the interaction between genes and the treatment of hypertension and breast cancer. Ann Transl Med. 2021;9(10):894–894.
Takizawa T. Transcription factor Sp1 regulates SERCA2 gene expression in pressure-overloaded hearts: a study using in vivo direct gene transfer into living myocardium. J Mol Cell Cardiol. 2003;35(7):777–83.
Brady M. Sp1 and Sp3 transcription factors are required for trans-activation of the human SERCA2 promoter in cardiomyocytes. Cardiovasc Res. 2003;60(2):347–54.
Hall G, Hasday JD, Rogers TB. Regulating the regulator: NF-κB signaling in heart. J Mol Cell Cardiol. 2006;41(4):580–91.
Hamid T, Guo SZ, Kingery JR, Xiang X, Dawn B, Prabhu SD. Cardiomyocyte NF-κB p65 promotes adverse remodelling, apoptosis, and endoplasmic reticulum stress in heart failure. Cardiovasc Res. 2011;89(1):129–38.
Javan H, Szucsik AM, Li L, Schaaf CL, Salama ME, Selzman CH. Cardiomyocyte p65 nuclear Factor-κB Is necessary for compensatory adaptation to pressure overload. Circ Hear Fail. 2015;8(1):109–18.
Muslin AJ. MAPK signalling in cardiovascular health and disease: molecular mechanisms and therapeutic targets. Clin Sci. 2008;115(7):203–18.
Li CY, Yang LC, Guo K, Wang YP, Li YG. Mitogen-activated protein kinase phosphatase-1: a critical phosphatase manipulating mitogen-activated protein kinase signaling in cardiovascular disease (Review). Int J Mol Med. 2015;35(4):1095–102.
Zhang W, Elimban V, Nijjar MS, Gupta SK, Dhalla NS. Role of mitogen-activated protein kinase in cardiac hypertrophy and heart failure. Exp Clin Cardiol. 2003;8(4):173–83.
Zhang S, Weinheimer C, Courtois M, Kovacs A, Zhang CE, Cheng AM, et al. The role of the Grb2–p38 MAPK signaling pathway in cardiac hypertrophy and fibrosis. J Clin Invest. 2003;111(6):833–41.
Proctor BM, Ren J, Chen Z, Schneider JG, Coleman T, Lupu TS, et al. Grb2 Is required for atherosclerotic lesion formation. Arterioscler Thromb Vasc Biol. 2007;27(6):1361–7.
Wang J, Sun X, Wang X, Cui S, Liu R, Liu J, et al. Grb2 induces cardiorenal syndrome Type 3: roles of IL-6, cardiomyocyte bioenergetics, and Akt/mTOR pathway. Front Cell Dev Biol. 2021;9:630412.
Wang S, Gong H, Jiang G, Ye Y, Wu J, You J, et al. Src Is required for mechanical stretch-induced cardiomyocyte hypertrophy through angiotensin II type 1 receptor-dependent β-arrestin2 pathways. PLoS ONE. 2014;9(4):e92926.
Hussain M, Ikram W, Ikram U. Role of c-Src and reactive oxygen species in cardiovascular diseases. Mol Genet Genomics. 2023;298(2):315–28.
Zhai Y, Yang J, Zhang J, Yang J, Li Q, Zheng T. Src-family protein tyrosine kinases: a promising target for treating cardiovascular diseases. Int J Med Sci. 2021;18(5):1216–24.
Xue B, Pamidimukkala J, Lubahn DB, Hay M. Estrogen receptor-α mediates estrogen protection from angiotensin II-induced hypertension in conscious female mice. Am J Physiol Circ Physiol. 2007;292(4):H1770–6.
Hinton AO, He Y, Xia Y, Xu P, Yang Y, Saito K, et al. Estrogen receptor-α in the medial amygdala prevents stress-induced elevations in blood pressure in females. Hypertension. 2016;67(6):1321–30.
Clerk A, Sugden PH. The insulin receptor family in the heart: new light on old insights. Biosci Rep. 2022;42(7):BSR20221212.
Morris BJ. Insulin receptor gene in hypertension. Clin Exp Hypertens. 1997;19(5–6):551–65.
Kontaridis MI, Yang W, Bence KK, Cullen D, Wang B, Bodyak N, et al. Deletion of Ptpn11 (Shp2) in cardiomyocytes causes dilated cardiomyopathy via effects on the extracellular signal-regulated kinase/mitogen-activated protein kinase and RhoA signaling pathways. Circulation. 2008;117(11):1423–35.
Saint-Laurent C, Mazeyrie L, Tajan M, Paccoud R, Castan-Laurell I, Valet P, et al. The tyrosine phosphatase SHP2: a new target for insulin resistance? Biomedicines. 2022;10(9):2139.
Weiss A, Neubauer MC, Yerabolu D, Kojonazarov B, Schlueter BC, Neubert L, et al. Targeting cyclin-dependent kinases for the treatment of pulmonary arterial hypertension. Nat Commun. 2019;10(1):2204.
Bryan C, Blanton R, Aronovitz M, Karas R, Hu M, Hinds PW. The role of cyclin‐dependent kinase 6 in cardiac development and hypertrophy. FASEB J. 2013;27(S1).
Kang L, Jia H, Huang B, Lu S, Chen Z, Shen J, et al. Identification of differently expressed mRNAs in atherosclerosis reveals CDK6 is regulated by circHIPK3/miR-637 Axis and promotes cell growth in human vascular smooth muscle cells. Front Genet. 2021;12:596169.
Karamanavi E, McVey DG, van der Laan SW, Stanczyk PJ, Morris GE, Wang Y, et al. The FES gene at the 15q26 Coronary-artery-disease locus inhibits atherosclerosis. Circ Res. 2022;131(12):1004–17.
Soubeyrand S, Lau P, Nikpay M, Dang AT, McPherson R. Common polymorphism that protects from cardiovascular disease increases fibronectin processing and secretion. Circ Genomic Precis Med. 2022;15(2):e003428.
Berta E, Lengyel I, Halmi S, Zrínyi M, Erdei A, Harangi M, et al. Hypertension in thyroid disorders. Front Endocrinol (Lausanne). 2019;10:482.
Erdos B, Backes I, McCowan ML, Hayward LF, Scheuer DA. Brain-derived neurotrophic factor modulates angiotensin signaling in the hypothalamus to increase blood pressure in rats. Am J Physiol Circ Physiol. 2015;308(6):H612–22.
Thorsdottir D, Einwag Z, Erdos B. BDNF shifts excitatory-inhibitory balance in the paraventricular nucleus of the hypothalamus to elevate blood pressure. J Neurophysiol. 2021;126(4):1209–20.
Mitre M, Mariga A, Chao MV. Neurotrophin signalling: novel insights into mechanisms and pathophysiology. Clin Sci. 2017;131(1):13–23.
Qiu T, Jiang Z, Chen X, Dai Y, Zhao H. Comorbidity of anxiety and hypertension: common risk factors and potential mechanisms. Int J Hypertens. 2023;2023:1–14.
Bozkurt B, Aguilar D, Deswal A, Dunbar SB, Francis GS, Horwich T, et al. Contributory Risk and Management of Comorbidities of Hypertension, Obesity, Diabetes Mellitus, Hyperlipidemia, and Metabolic Syndrome in Chronic Heart Failure: A Scientific Statement From the American Heart Association. Circulation. 2016; 134(23):e535–e578.
Cohen JB, Brown NJ, Brown SA, Dent S, van Dorst DCH, Herrmann SM, et al. Cancer therapy-related hypertension: a scientific statement from the American heart association. Hypertension. 2023;80(3):e46–57.
Hu Y, Huang Y, Wang L, Liu Z, Wang L, Yan J, et al. Disability and comorbidity of mood disorders and anxiety disorders with diabetes and hypertension: evidences from the China mental health survey and chronic disease surveillance in China. Front Psychiatry. 2022;13:889823.
Funding
This work was supported by a Hellenic Foundation for Research and Innovation (HFRI) PhD scholarship grant to EPGT (#2082), by Greek national projects “ELIXIR-GR: Hellenic Research Infrastructure for the Management and Analysis of Data from the Biological Sciences” (MIS 5002780), “EATRIS-GR: Infrastructure for preclinical and early-phase clinical development of drugs, therapeutics and biomedical devices” (MIS 5028091), “BBMRI-GR: Infrastructure for Biobanking and biomolecular resources in health and life sciences” (MIS 5028275), and “INSPIRED: The National Research Infrastructures on Integrated Structural Biology, Drug Screening Efforts & Drug target functional characterization” (MIS 5002550), implemented under the Action “Reinforcement of the Research and Innovation Infrastructure”, funded by the Operational Program “Competitiveness, Entrepreneurship and Innovation” (NSRF 2014–2020) and co-financed by Greece and the European Union (European Regional Development Fund), and by the EU-funded H2020 projects “DIAGONAL: Development and scaled Implementation of sAfe by design tools and Guidelines for multicOmponent aNd hArn nanomateriaLs” (ID 95152), “JOINTPROMISE: Precision Manufacturing of Microengineered Complex Joint Implants” (ID 874837) and “AIDPATH: “AIDPATH: Artificial Intelligence-driven, Decentralized Production for Advanced Therapies in the Hospital” (ID 101016909).
Author information
Authors and Affiliations
Contributions
MIK and NKM contributed to the conceptualization of the study. All authors contributed to the selection and curation of data resources. EPGT and MIK designed the relational scheme and implemented the BP-GWAS meta-database and contributed to the BP PPI network reconstruction and analysis. All authors contributed to the design of GWAS-based prioritization scoring scheme; EPGT and MIK proposed and implemented the network-based gene prioritization criteria. All authors contributed to the visualization, interpretation, and discussion of the results. All authors contributed to writing—original draft preparation and writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1
. Table S1: The GWAS Catalog mapped traits associated with BP; Table S2: The 10 BP-associated EFO terms included in the GWAS Catalog mapped traits; Table S3: The curated BP-associated GWAS publications; Table S4: Chromosomal distribution of SNPs & associated RHCP-coding genes, including the prioritized genes by Criterion 1; Table S5: Categorization of the BP SNPs based on the type and number of transcript consequences. Figure S1: The PPI Network of BNs and its characteristics; Figure S2: The GWAS-RbSP PPI Network and its characteristics; Figure S3: The IVI-scaled PPI network of the GWAS-prioritized BP-proteins and their common YN neighbours; Figure S4: Venn diagram of the complete set of prioritized BP-proteins, regarding the three prioritization criteria; Figure S5: The BP-proteins in the KEGG-defined cGMP-PKG signaling pathway and their PPI network; Figure S6: The BP-proteins in the KEGG-defined dilated cardiomyopathy (DCM) pathway and their PPI network; Figure S7: The metabolic reactions catalyzed by BP-GWAS proteins (A) and RbSP PPI network proteins (B).
Additional file 2
. The BP-associated RHCP-coding genes and their attributes.
Additional file 3
. SNP-gene associations supported by cis-eQTL measurements in at least one of the 27 selected tissues.
Additional file 4
. The BP-proteins in the GWAS-RbSP PPI network and their attributes.
Additional file 5
. The overall and criterion-specific rankings of the prioritized BP-proteins.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Tsare, EP.G., Klapa, M.I. & Moschonas, N.K. Protein–protein interaction network-based integration of GWAS and functional data for blood pressure regulation analysis. Hum Genomics 18, 15 (2024). https://doi.org/10.1186/s40246-023-00565-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40246-023-00565-6