
Abstract
In this paper, we consider an iterative learning control (ILC) problem for a class of multiinput-multioutput (MIMO) second-order hyperbolic distributed parameter systems with uncertainties. A P-type ILC scheme is proposed in the iteration procedure for distributed systems with an initial deviation in the state. A convergence of tracking error with respect to the iteration index can be guaranteed in the sense of \(\mathbf{L}^{2}\) norm. Feasibility in theory of the iterative learning algorithm with difference method is proposed. Numerical simulation results are presented to illustrate the effectiveness of the proposed ILC approach.
Similar content being viewed by others

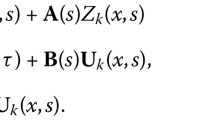
1 Introduction
ILC is an intelligent control methodology for repetitive processes and tasks over a finite interval. ILC was first formulated mathematically by Arimoto et al. [1]. In the last three decades, it has been constantly studied and widely applied in various engineering practice, such as robotics, freeway traffic control, biomedical engineering, industrial process control, et cetera [2–9]. The major benefit of ILC are completely tracking feasible reference trajectories (or evolutional profiles) for that complex systems include uncertainty or nonlinear. It can be achieved only based on the input and output signals [10–14]. It is a truly model-free method motivated by the human trial-and-error experience in practice.
Despite ILC has been widely investigated for finite-dimensional systems, research work of related to spatial temporal processes are quiet few and even less using infinite-dimensional framework. Qu [15] proposed an iterative learning algorithm for boundary control of a stretched moving string, which is a pioneer work of extending the ILC framework to distributed parameter systems. Tension control system is studied in [16] by using the PD-type learning algorithm. Both P-type and D-type iterative learning algorithms based on the operator semigroup theory are designed for one-dimensional distributed parameter systems governed by parabolic PDEs in [17] and have been extended to a class of impulsive first-order distributed parameter systems in [18]. In [19], a steady state ILC scheme is proposed for single-input-single-output nonlinear PDEs. A D-type anticipatory ILC scheme is applied to the boundary control of a class of inhomogeneous heat equations in [20], where the heat flux at one side is the control input, whereas the temperature measurement at the other side is the control output. The learning convergence of ILC is guaranteed by transforming the inhomogeneous heat equation into its integral form and exploiting the properties of the embedded Jacobi theta functions. In [21], for applied convenience, using Crank-Nicholson discretization, ILC for a heat equation is designed, where the control allows the selection of a finite number of points for sensing and actuation. Recently, a frequency domain design and analysis framework of ILC for inhomogeneous distributed parameter systems are proposed in [22]. However, these works did not involve MIMO second-order hyperbolic distributed parameter systems.
The control problem of hyperbolic distributed parameter systems has been frequently encountered in many dynamic processes, for example, wave transportation, fluid dynamics, elastic vibration. In [23], a P-type ILC algorithm is proposed for a first-order hyperbolic distributed parameter system arising in a nonisothermal tubular reactor using a set of ordinary differential equations (ODEs) for model approximation. In addition, ILC problem is considered in [24] for a first-order strict hyperbolic distributed parameter system in a Hilbert space, where convergence conditions are given based on P-type algorithms and require the initial state value to be identical.
In this paper, an ILC problem is considered for a class of MIMO second-order hyperbolic distributed parameter systems with uncertainties. A P-type ILC scheme is introduced, and a sufficient condition for tracking error convergence in the sense of \(\mathbf{L}^{2}\) norm is given. The conditions do not require analytical solutions but only bounds and an appropriate norm space assumption for uncertainties of the system coefficients matrix. The proposed control scheme is the first work on extension to MIMO second-order hyperbolic distributed parameter systems with admissible initial state error. On the other hand, the convergence analysis is more complex than for finite-dimensional systems because it involves time, space, and the iterative domain. We do not simplify the infinite-dimensional systems to finite-dimensional systems or replace them with discrete-time equivalences (see [23]). Only in simulation, in order to illustrate the effectiveness of the presented ILC approach, we used the forward difference method to discretize the infinite-dimensional systems.
Notation
The superscript ‘T’ denotes the matrix transposition; I and 0 denote the identity matrix and zero matrix of appropriate dimensions, respectively. For an n-dimensional constant vector \({\mathbf{q}}=(q_{1},q_{2},\ldots ,q_{n})^{\mathrm{T}}\), its Euclid norm is defined as \(\|{\mathbf{q}}\|=\sqrt{\sum_{i=1}^{n}q_{i}^{2}}\). The spectrum norm of an \(n \times n\)-order square matrix A is defined as \(\|A\|=\sqrt{\lambda_{\mathrm{max}}(A^{\mathrm{T}}A)}\), where \(\lambda_{\mathrm{max}}(\cdot)\) (\(\lambda_{\mathrm{min}}(\cdot)\)) represents the maximum (minimum) eigenvalue. Let \({\mathbf{L}}^{2}(\Omega)\) be the set of measurable functions q defined on a bounded domain \(\Omega\in\mathbf{R}^{m} \) such that \(\|q\|_{{\mathbf{L}}^{2}}^{2}=\int_{\Omega}|q(x)|^{2}\, \mathrm{d}x<\infty\). If \(q_{i}(x)\in {\mathbf{L}}^{2}(\Omega)\) (\(i=1,2,\ldots,k\)) (for convenience, we denote \({\mathbf{L}}^{2}(\Omega)\) as \(\mathrm{L}^{2}(\Omega;\mathbf{R})\)), then we write \({\mathbf{q}}(x)=(q_{1}(x),\ldots,q_{n}(x))\in \mathbf{R}^{n}\cap{\mathbf{L}}^{2}(\Omega)\), and \(\|{\mathbf{q}}\|_{{\mathbf{L}}^{2}}^{2}=\int_{\Omega}{\mathbf{q}}^{\mathrm{T}}(x){\mathbf{q}}(x)\, \mathrm{d}x\). For \({\mathbf{w}}(x,t):\Omega \times[0,T]\rightarrow\mathbf{R}^{m}\) such that \({\mathbf{w}}(\cdot,t)\in \mathbf{R}^{m}\cap{\mathbf{L}}^{2}(\Omega)\), \(t\in[0,T]\), given \(\lambda >0\), its \(({\mathbf{L}}^{2};\lambda)\) norm is defined as
2 ILC system description
We consider the following MIMO second-order hyperbolic distributed parameter system governed by partial differential equations:
where \((x,t)\in \Omega\times[0,T]\), that is, x, t denote the space and time variables, respectively, T is given, Ω is a bounded open subset of \(\mathbf{R}^{m}\) with smooth boundary ∂Ω, \({\mathbf{q}}(\cdot,\cdot)\in\mathbf{R}^{n}\), \({\mathbf{u}}(\cdot,\cdot)\in \mathbf{R}^{u}\), and \({\mathbf{y}}(\cdot,\cdot)\in\mathbf{R}^{y}\) are the state vector, input vector, and output vector of the systems, respectively, D is a bounded positive constant diagonal matrix, that is, \(D=\operatorname{diag}\{d_{1},d_{2},\ldots,d_{n}\}\), \(0< p_{i}\leqslant d_{i}<\infty\) (\(i=1,2,\ldots,n\)), and \(p_{i}\) are known, \(\triangle=\sum_{i=1}^{m}{\frac{\partial^{2}}{\partial x_{i}^{2}}}\) is the Laplacian operator defined over Ω, \(A(t)\) is a bounded and positive definite matrix for all \(t\in[0, T]\), and \(B(t)\), \(C(t)\), and \(G(t)\) are the bounded time-varying uncertain matrices of appropriate dimensions.
The initial and boundary conditions of (1) are given as
The control target is to determine an input vector \({\mathbf{u}}_{d}(x,t)\) such that the output vector \({\mathbf{y}}(x,t)\) is capable tracking a desired feasible trajectory \({\mathbf{y}}_{d}(x,t)\), namely seeking a corresponding desired input \({\mathbf{u}}_{d}(x,t)\) such that the actual output of the system (1),
approximates the desired output \({\mathbf{y}}_{d}(x,t)\). Because in the system there exists uncertainty, it is difficult to obtain a complete tracking, so we will gradually gain the control sequence \({{\mathbf{u}}_{k}(x,t)}\), using the ILC method, such that
where the kth iteration control input satisfies
Assumption 2.1
We assume that there exists a unique bounded classic solution \({\mathbf{q}}(x,t)\) for system (1). Thus, for a desired output \({\mathbf{y}}_{d}(x,t)\), there exists a unique \({\mathbf{u}}_{d}(x,t)\) such that
satisfying the initial and boundary conditions
where \({\mathbf {q}}_{d}(x,t)\) is the desired state, and \(({\mathbf{q}}_{d0}(x),{\dot{\mathbf{q}}}_{d0}(x))\) is the initial value of the desired state.
Assumption 2.2
In a learning process, we assume the following boundary and initial conditions:
The functions \(\varphi_{k}(x)\), \(\psi_{k}(x)\) satisfy
where \(l_{1}\), \(l_{2}\) are constants, and \(\alpha,\beta\in[0,1)\).
Remark 2.1
Assumption 2.1 is a necessary condition for ILC method. Assumption 2.2 means that, in the initial state, there may exist an error and the identical initial condition in ILC systems (4) is not required. On the other hand, from practical point of view, in iterations, the initial condition reset should be closer and closer to the initial value of the desired state, so condition (10) is reasonable.
3 ILC design and convergence analysis
In this paper, we employ the following P-type ILC law:
where \(\Gamma(t)\) is the learning gain.
For a brief presentation, let
where \({\mathbf{e}}_{k+1}(x,t)\) is the tracking error of the \((k+1)\)th iteration. Then the control target can be rewritten as
Remark 3.1
The ILC law (11) is distributed, that is, it depends on both time and space. although many distributed systems require that only boundary control can be used as physical constraint, but distributed sensors/actuators can be effectively applied in recent developments in supporting material science and technologies [21], such as piezoelectric ceramics.
We need the following technical lemmas, which are widely used in the proof of the main theorem.
Lemma 3.1
([25])
Let \(A\in\mathbf{R}^{n\times m}\), \(B\in\mathbf{R}^{n\times l}\), \(\zeta\in\mathbf{R}^{ m}\), \(\eta\in \mathbf{R}^{l}\). Then we have
Lemma 3.2
([13])
Let a nonnegative real series \(\{ a_{k}\}_{k=0}^{\infty}\) satisfy
where \(0\leqslant r<1\) and \(\lim_{k\rightarrow\infty}z_{k}=0\). Then we have
Theorem 3.1
Consider the ILC updating law (11) applied to the repetitive system (1) under (2), (3) and satisfying Assumptions 2.1 and 2.2. If the gain matrix \(\Gamma(t)\) satisfies
then the tracking error converges to zero in the sense of \(\mathbf{L}_{2}\) norm for all \(t\in[0,T]\) as \(k\rightarrow\infty\), that is,
Proof
According to the learning law (11), we have
where
Then, by Lemma 3.1 we have
where
From (4) and from
we have
We define
Then by (21) we obtain
where
Note that
Using the boundary condition and noting that \(D=\operatorname{diag}\{ d_{1},d_{2},\ldots,d_{n}\}\), \(0< p_{i}\leqslant d_{i}<\infty\) (\(i=1,2,\ldots,n\)), and \(p_{i}\) are known, we have
Meanwhile, because
using Lemma 3.1 again for \(I_{3}\), we get
So from (22) and (24)-(26) we obtain
that is,
Because \(A(t)\) is positive definite matrix for all \(t\in[0,T]\), we get
By the Bellman-Gronwall inequality we have
Due to the Poincaré inequality, there exists a constant \(c_{0}=c_{0}(\Omega)\) such that
Therefore, by (29) and (30) we have
Choosing a sufficiently large constant \(\lambda>1\) and multiplying both sides of (31) by \(e^{-\lambda t}\), we have
On the other hand, according to the P-type ILC law (11), we have
Letting \(\lambda_{\Gamma}=\max_{0\leqslant t\leqslant T}\{\lambda_{\mathrm{max}}(\Gamma^{T}(t)\Gamma(t))\}\), we have
and also
From (18), (23), and (24) we have
Then, by (16), we can select a suitable large λ such that
Let \(z_{k}=\frac{2 c_{0}\lambda_{C}}{\lambda_{\mathrm{min}}(D)}(\lambda_{\mathrm{min} }(D)l_{1}\alpha^{k}+l_{2}\beta^{k})\). Then by Lemma 3.2 and (36)-(37) we have
Finally, by the inequality
we have the convergence
This completes the proof of Theorem 3.1. □
Remark 3.2
In Theorem 3.1, we must point out that (16) requires \(G(t)\) to be a nonsingular matrix (or regular matrix), that is, there exists a direct channel in between the output and input for systems (1). We will consider the case \(G(t)=0\) in the future.
4 Numerical simulations
In order to illustrate the effectiveness of the proposed ILC scheme, we give the following specific numerical example:
where
and \((x,t)\in[0,1]\times[0,1]\). The desired evolutionary profile vector is given as the iterative learning:
Both the initial state profiles are \(\varphi_{1}(x)=0.02x\), \(\varphi_{2}(x)=0.01\sin x\), so \(\psi_{1}(x)=\psi_{2}(x)=0\), and the input value of the controlling at the beginning of learning are set to be 0 and \(\alpha=\beta=0\) in (10). Then the condition of Theorem 3.1 is satisfied. that is, \(\|I-G\Gamma\|=0.15<0.5\). We use the following forward difference method:
where h, τ are space and time sizes, respectively, and \((x_{i},t_{j})\) is discrete point.
The iterative learning process is the following:
-
Step 1. Iterative number \(k=0\) (for convenience, the iterative time begins from 0).
-
1.1.
Let control input \({\mathbf{u}}_{0}(x,t)=0\) with \({\mathbf{q}}_{0}(0,t)=0={\mathbf{q}}_{0}(1,t)\), \({\mathbf{q}}_{0}(x,0)\), \(\frac{\partial{\mathbf{q}}_{0}(x,0)}{\partial t}\), \(A(t)\), \(B(t)\), D. Based on the second-order differential equations and above difference method, we can solve (4) and obtain \({\mathbf{q}}_{0}(x,t)\).
-
1.2.
By the output equation \({\mathbf{y}}_{0}(x,t)=C(t){\mathbf{q}}_{0}(x,t)+G(t){\mathbf{u}}_{0}(x,t)\) we calculate \({\mathbf{y}}_{0}(x,t)\).
-
1.3.
Calculate \({\mathbf{e}}_{0}(x,t)={\mathbf{y}}_{d}(x,t)-{\mathbf{y}}_{0}(x,t)\).
-
1.1.
-
Step 2. Iterative number \(k=1\), \({\mathbf{u}}_{1}(x,t)={\mathbf{u}}_{0}(x,t)+\Gamma(t){\mathbf{e}}_{0}(x,t)\).
-
Step 3. Repeating Step 1, but with control input \({\mathbf{u}}_{1}(x,t)\) (≠0), we obtain \({\mathbf{e}}_{1}(x,t)\).
-
Step 4. At the kth iteration, if the tracking error \({\mathbf{e}}_{k}(x,t)\) is less than the given error, then end, else continue.
It should be pointed out that we did not need know (but require to be bounded) the uncertain coefficients \(A(t)\), \(B(t)\), \(C(t)\), \(G(t)\) in practical process control; we only need remember the tracking error and calculate (offline) the next time control input \({\mathbf{u}}_{k+1}(x,t)\).
The simulation results obtained using this iterative learning algorithm and difference method are shown in Figures 1-7.

Desired surface \(\pmb{y_{d1}(x,t)}\) .
Figures 1 and 2 show the desired profile, Figures 3 and 4 show the relative profile at the twentieth iteration, Figures 5 and 6 show the error curved surface, where \(e_{ki}(x,t)=y_{di}(x,t)-y_{ki}(x,t)\), \(i=1,2\), \(k=20\). Figure 7 is the curve chart describing the variation of the maximum tracking error with iteration numbers. Numerically, in the twentieth iteration, the absolute values of the maximum tracking error are \(1.9185\times10^{-8}\) and \(1.5564\times10^{-9}\). These simulation results demonstrate the efficacy of the ILC law (11).

Desired surface \(\pmb{y_{d2}(x,t)}\) .

Output surface \(\pmb{y_{k1}(x,t)}\) .

Output surface \(\pmb{y_{k2}(x,t)}\) .

Error surface \(\pmb{e_{k1}(x,t)}\) .

Error surface \(\pmb{e_{k2}(x,t)}\) .

Max error-iterative number curve.
5 Conclusions
In this paper, a P-type ILC law is applied to a class of MIMO second-order hyperbolic PDEs with dissipation and bounded coefficient uncertainty. We established sufficient conditions that guarantee the tracking error convergence in the sense of \(\mathbf{L}^{2}\) norm. A simulation example is given to illustrate the effectiveness of the proposed algorithm.
References
Arimoto, S, Kawamura, S, Miyazaki, F: Bettering operation of robots by learning. J. Robot. Syst. 1(2), 123-140 (1984)
Oh, S, Bien, Z, Suh, I: An iterative learning control method with application for the robot manipulator. IEEE J. Robot. Autom. 4(5), 508-514 (1988)
Hou, ZS, Xu, JX, Freeway, ZHW: Traffic control using iterative learning control based ramp metering and speed signaling. IEEE Trans. Veh. Technol. 56(2), 466-477 (2007)
Wang, YQ, Dassau, E, Doyle, FJ III: Close-loop control of artificial pancreatic β-cell in type diabetes mellitus using model predictive iterative learning control. IEEE Trans. Biomed. Eng. 57(2), 211-219 (2010)
Ruan, XE, Wan, BW: The iterative learning control for saturated nonlinear industrial control systems with delay. Acta Autom. Sin. 27(2), 219-223 (2001)
Chen, HF: Almost sure convergence of iterative learning control for stochastic systems. Sci. China, Ser. F, Inf. Sci. 46(1), 67-70 (2003)
Chen, WS, Zhang, ZQ: Nonlinear adaptive learning control for unknown time-varying parameters and unknown time-varying delays. Asian J. Control 13(6), 903-913 (2011)
Liu, SD, Wang, JR, Wei, W: A study on iterative learning control for impulsive differential equations. Commun. Nonlinear Sci. Numer. Simul. 24(1-3), 4-10 (2015)
Zhang, CL, Li, JM: Adaptive iterative learning control of non-uniform trajectory tracking for strict feedback nonlinear time-varying systems with unknown control direction. Appl. Math. Model. 39(10-11), 2942-2950 (2015)
Moore, KL: Iterative Learning Control for Deterministic Systems. Springer, London (1993)
Bien, Z, Xu, JX: Iterative Learning Control-Analysis, Design, Integration and Applications. Kluwer Academic, Boston (1998)
Xu, JX, Tan, Y: Linear and Nonlinear Iterative Learning Control. Lecture Notes in Control and Information Science, vol. 291. Springer, Berlin (2003)
Chen, YQ, Wen, CY: Iterative Learning Control-Convergence, Robustness and Applications. Lecture Notes in Control and Information Sciences, vol. 248. Springer, Berlin (2003)
Ahn, HS, Moore, KL, Chen, YQ: Iterative Learning Control: Robustness and Monotonic Convergence for Interval Systems. Springer, Berlin (2007)
Qu, ZH: An iterative learning algorithm for boundary control of a stretched moving string. Automatica 38(1), 821-827 (2002)
Zhao, H, Rahn, CD: Iterative learning velocity and tension control for single span axially moving materials. J. Dyn. Syst. Meas. Control 130(5), 051003 (2008)
Xu, C, Arastoo, R, Schuster, E: On iterative learning control of parabolic distributed parameter systems. In: Proc. of 17th Mediterranean Conference on Control Automation, Makedonia Palace, Thessaloniki, Greece, pp. 510-515 (2009)
Yu, XL, Wang, JR: Uniform design and analysis of iterative learning control for a class of impulsive first-order distributed parameter systems. Adv. Differ. Equ. 2015, 261 (2015)
Huang, DQ, Xu, JX: Steady-state iterative learning control for a class of nonlinear PDE processes. J. Process Control 11(8), 1155-1163 (2011)
Huang, DQ, Xu, JX, Li, XF, Xu, C, Yu, M: D-type anticipator iterative learning control for a class in homogeneous heat equations. Automatica 49(8), 2397-2408 (2013)
Cichy, B, Gakowski, K, Rogers, E: Iterative learning control for spatio-temporal dynamics using Crank-Nicholson discretization. Multidimens. Syst. Signal Process. 23(1-2), 185-208 (2012)
Huang, DQ, Li, XF, Xu, JX, Xu, C, He, W: Iterative learning control of inhomogeneous distributed parameter systems - frequency domain design and analysis. Syst. Control Lett. 72, 22-29 (2014)
Choi, JH, Seo, BJ, Lee, KS: Constrained digital regulation of hyperbolic PDE: a learning control approach. Korean J. Chem. Eng. 18(5), 606-611 (2001)
Dai, XS, Tian, SP: Iterative learning control for first order strong hyperbolic distributed parameter systems. Control Theory Appl. 29(8), 1086-1089 (2012)
Xie, SL, Tian, SP, Xie, ZD: Theory and Application of Iterative Learning Control. Science Press, Beijing (2005)
Acknowledgements
The authors are grateful to the referees for their careful reading of the manuscript and valuable comments. The authors thank for the help from the editor too. The work was supported by the National Natural Science Foundation of China (Nos. 61364006, 61374104) and Key Laboratory of Intelligent integrated automation of Department of Guangxi Education, Project of Outstanding Young Teachers’ Training in Higher Education Institutions of Guangxi.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
This work was carried out in collaboration between all authors. XD raised these interesting problems in this research. CX, ST, and XD proved the theorems, interpreted the results, and wrote the article. The numerical example is given by ZL. All authors defined the research theme, read, and approved the manuscript.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Dai, X., Xu, C., Tian, S. et al. Iterative learning control for MIMO second-order hyperbolic distributed parameter systems with uncertainties. Adv Differ Equ 2016, 94 (2016). https://doi.org/10.1186/s13662-016-0820-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13662-016-0820-8