
Abstract
Fast Fourier Transform is widely used in communication and signal processing. I propose an improved multipath delay commutator pipelining architecture based on the radix-2 time decimation algorithm. By optimizing the intermediate data processing process and the first stage of pipelining, the architecture improves the system's computing speed and reduces the use of registers. I propose a multiplication scheme based on CORDIC and binary decomposition coding to realize complex number multiplication and constant multiplication and to eliminate the use of a multiplier. Experimental results suggest that proposed implementation has less latency and hardware utilization as compared to recently proposed implementations.
Similar content being viewed by others


1 Introduction
Discrete Fourier Transform (DFT) plays a vital role digital signal processing [1]. Fast Fourier Transform (FFT) is a fast algorithm of DFT, which is widely used in communication [2, 3], image processing [4, 5], composite material science [6], signal processing [7,8,9], and other fields. DFT has a very high computational complexity (\({\varvec{O}}\left( {{\varvec{N}}^{2} } \right)\)), so it is difficult to implement on Very Large-Scale Integration (VLSI). FFT is an efficient algorithm for calculating N-point DFT [10], which can be implemented in VLSI and is widely used in engineering practice. In the past few decades, FFT implementation has been a research hotspot in the field of information technology [11]. To meet the high performance and real-time requirements of modern applications, hardware designers have been trying to implement an efficient architecture for FFT calculation [12]. The goal of hardware designers is to provide efficient implementations primarily for high performance, low hardware resource utilization (adder, rotator, and memory), high precision, or low power consumption [13].
Most of the existing FFT processor architectures are memory-free pipelined architectures [14,15,16,17,18,19,20] and memory-based pipelined architectures [21,22,23,24,25]. The pipelined architecture enables all phases of the FFT processor to be executed in parallel, thus reducing execution time and latency, making it more suitable for real-time applications. Literature [14] put forward a kind of applicable to zero-fill area-efficient fast Fourier transform (FFT) processor, through the use of the input data is the first phase zero filling sequence and FFT operation characteristics of the rotating factor value are 1, the FFT processor can effectively reduce the number of delay elements required, reduced the registers using the number, However, it does not improve the butterfly operation, consumes a lot of multiplier resources and increases the hardware complexity. Literature [15] proposed an improved parallel dual-path delay converter architecture and proposed a multiplication scheme based on the combination of the expanded coordinate rotation digital computer (CORDIC) algorithm and the binary expression based on the standard signed number (CSDBE) to realize the butterfly operation so that there is no multiplier used in the whole system. Its design improves the execution speed and throughput, but it does not improve the data transmission process and consumes a lot of register resources. FFT processor based on memory pipeline architecture uses RAM to store intermediate data in the process of data operation, which consumes a lot of storage resources, increases the hardware area and delay, so it cannot meet the requirements of modern engineering applications.
Through analysis, the major disadvantage of the existing design is that complex multiplication is usually implemented by embedded Digital Signal Process (DSP) block and a large number of delay elements are needed in the architecture. All these make FFT processors occupy more hardware area on FPGA and increase latency [26]. This paper proposes an improved multipath delay commutation (MDC) architecture based on the radix-2 decimation-in-time (R2DIT) FFT algorithm. The proposed architecture does not require complex multiplication and does not require on-chip memory to store the rotation factor, which reduces resource consumption and improves the processor performance. To eliminate the use of a multiplier in the system, a multiplication scheme based on CORDIC and binary decomposition coding (BDC) is proposed to realize complex multiplication and constant multiplication. The proposed multiplication scheme does not need to store the calculated rotation factor, but only stores the rotation factor Angle used for calculation, which reduces the storage requirements of memory, saves the area on the chip, and significantly improves the computing speed. The main contribution of this work is to propose the improved MDC architecture based on 2 DIT, double input and double output of data, and use the multiplication scheme based on CORDIC and BDM to realize complex multiplication and constant multiplication, replacing the multiplier in the system, to improve the resource utilization and performance. These reasonable architectural improvements eliminate the need for embedded dedicated functional blocks (DSP, BRAM). In addition, using shift registers instead of slower memory blocks to store data at each pipelining stage and reducing the use of shift registers through improvements to the MDC architecture can increase speed and reduce latency. The proposed design achieves better results in terms of speed, latency, throughput, and resource utilization.
2 Introduction to the basic principle of the algorithm
2.1 Base 2 DIT FFT algorithm
The Fast Fourier Transform (FFT) is a fast algorithm of the Discrete Fourier Transform (DFT). DFT is a method to analyze and process signals and systems. It realizes the analysis of signals and systems from the frequency domain, which analyzes complex signals and systems more conveniently and intuitively.
According to the definition, the discrete Fourier transform (DFT) of a sequence \(x\left( n \right)\) of length N can be expressed as:
In the formula \(W_{N}^{kn} = e^{{ - \frac{j2\pi nk}{N}}}\).
From Eq. (1), it can be seen that the direct calculation of \(X\left( k \right)\) involves \(N\) complex multiplication and n-1 complex addition. The N complex multiplication can be decomposed into 4N real multiplication and 2N real addition, and the N − 1 complex addition can be decomposed into 2 (N − 1) real addition. Therefore, every \(X\left( k \right)\) value evaluated requires 4N real multiplications and 4N minus 2 real addition. Thus, to compute a DFT of length \(N\) requires \(N^{2}\) complex multiplication and \(N^{2} - N\) complex addition, corresponding to 4\(N^{2}\) real multiplication and \(4N^{2} - 2N\) real addition. When \(N\) is very large, the computation amount is very large and it is difficult to realize in hardware. Therefore, it is necessary to improve the calculation method of DFT to reduce the computation amount of DFT.
By using the inherent characteristics of rotation factors, such as symmetry, periodicity, and reducibility, the computation of DFT can be greatly reduced. By using these characteristics, a long sequence of DFT can be decomposed into a short sequence of DFT, and the sequence can be decomposed into shorter sub-sequences according to the odd and even time sequence. Known as the time domain extraction method FFT algorithm (base -2 DIT-FFT algorithm), also known as Cooley-Tukey algorithm.
The calculation formula of the base-2 DIT-FFT algorithm is directly given here without process derivation, as shown in Equation (2) :
In the formula
Here, \(X_{1} \left( K \right)\) and \(X_{2} \left( K \right)\) represent the N/2-point DFT of even and odd sequences of \(x\left( n \right)\), respectively. Formula (3) describes the base 2 butterfly operation in the DIT algorithm, as shown in Fig. 1. FFT algorithm is implemented by iterating the butterfly operation, and its corresponding implementation circuit is shown in Fig. 2. This operation requires one addition and one subtraction, followed by multiplication of complex rotation factors. Base 2 DIT-FFT is mainly to decompose n-point sequence \(x\left( n \right)\) into an even sequence and an odd sequence, and then perform odd–even decomposition of the dual sequence and odd sequence, respectively, and repeat the operation until it cannot be decomposed. Where N is an integer power of 2. The corresponding 8-point base 2 DIT-FFT iteration process is shown in Fig. 1. The 8-point base 2 DIT-FFT data flow diagram is shown in Fig. 2, which has 3 stages and a total of 16 butterfly cells. Note that the input and output are a bit reversed, with the input in reverse order and the output in positive order.

Base 2 DIT butterfly operation

8-point base 2 DIT-FFT data flow graph
2.2 Complex multiplication based on CORDIC algorithm
The CORDIC algorithm is widely used and is extended in literature [27] to compute a set of arithmetic functions, including multiplication, division, sine, cosine, arctangent, and hyperbolic functions. Based on the CORDIC algorithm, this paper uses simple shift, addition, and subtraction operations to achieve complex multiplication. It does not require the use of dedicated multipliers or embedded functional blocks. The use of CORDIC in the proposed architecture eliminates the complex multiplier and memory blocks needed to store the rotation factor values. The advanced complex multiplication scheme based on CORDIC enables the proposed FFT processor to improve its processing speed and save a lot of hardware resources.
The key operation of the FFT algorithm is multiplying the operand by the rotation factor \(W_{N}^{k} x\left( n \right)\), which essentially rotates \(x\left( n \right)\) in the complex plane, where \(\theta = \frac{2\pi k}{N}\). As shown in Fig. 3, when the coordinate is the vector rotation Angle \(\theta\) of \(\left( {x_{i} ,y_{i} } \right)\), its new coordinate can be expressed as:

Rotation mode of CORDIC algorithm in a circular system. a Vector rotation; b vector pseudo rotation; c it breaks down into smaller angles
Extract \(\cos \theta\), Eq. (4) can be expressed as:
From Eq. (5), it can be seen that \(\cos \theta\) only changes the magnitude of the vector. If \(\cos \theta\) is removed, this rotation is called pseudo rotation, as shown in Fig. 3b. As shown in Fig. 3c, for pseudo rotation, rotation Angle \(\theta\) can be decomposed into a series of a small sum of angles.
We can know by using the property of tangent function \(\tan \theta = d_{i} 2^{ - i}\), in there \(d_{i} \in \left\{ { - 1,1} \right\}\).
The introduction of the variable \(z\), \(z_{0} = \theta\), defines
Thus, the rotation mode iteration process of the CORDIC algorithm can be expressed as
In the formula, \(K = \mathop \prod \limits_{i = 0}^{n - 1} \frac{1}{{\sqrt {1 + 2^{ - 2i} } }}\) is the Mold length compensation factor. When the number of iterations is large enough \(K \approx 0.60725\). From Eq. (8), it can be seen that complex multiplication can be achieved by shifting, adding, and subtracting.
3 Hardware implementation of FFT processor
The key to hardware implementation of the FFT algorithm is the realization of complex multiplication and architecture. In this paper, a multiplication scheme based on CORDIC and BDC is proposed to realize complex multiplication and constant multiplication, eliminating the use of a multiplier in the system. The traditional MDC architecture is optimized reasonably and an improved MDC architecture is proposed. The proposed architecture reduces the use of delay units and improves the throughput and speed of computation.
3.1 Hardware realization of complex multiplication based on CORDIC algorithm
In this study, the CORDIC algorithm is used to implement complex multiplication through the simple shift, addition, and subtraction operations. CORDIC algorithm is implemented using a parallel pipeline structure, and its implementation block diagram is shown in Figure 4. It can be seen from Figure 4 that the whole CORDIC algorithm is implemented using a 16-level pipeline, where the CORDIC iteration unit carries out iterative calculation according to the CORDIC iteration algorithm rules, and the pipeline structure at all levels is the same except for different right shift and rotation Angle. The logical structure diagram of the CORDIC iteration unit is shown in Figure 5. Figure 5 shows that the CORDIC iteration unit consists of a shifter, an adder, and a subtracter.

Block diagram of complex multiplication based on CORDIC

CORDIC iteration module hardware architecture
At each clock cycle, the controller determines the right shift and the type of operation based on the \(Z_{i}\) symbol bit of the Angle accumulator value. The initial Angle \(Z_{0}\) is equal to the desired vector rotation Angle, and the Angle accumulator value approaches zero after 16 iterations. The accuracy of the algorithm can be improved by the number of iterations. In general, N CORDIC iterations are needed to achieve n-bit output accuracy. In this design, 16 iterations are used to implement the CORDIC algorithm, and the modulus length compensation factor K≈0.60725 is constant. The output result of the CORDIC operation module is multiplied by the modulus length compensation factor to be the final calculation result. The module length compensation factor is decomposed by BDC, and the result is shown in Eq. (9). Therefore, constant multiplication can be realized through the shift addition circuit, which improves the operation speed. The realization circuit is shown in Fig. 6.

Mold length compensation circuit
3.2 Improved hardware implementation of the MDC architecture
The dual-channel delay commutator (DDC) pipeline architecture is proposed in this paper, which is a reasonable improvement on the traditional MDC architecture [28]. The traditional MDC architecture is shown in Figure 7. It can be seen from Figure 7 that the traditional MDC architecture has only one data input, and the butterfly operation unit is idle for half of the clock cycle from the first stage of operation. The working frequency of the whole system is consistent with the input data sampling rate so that the system throughput rate and system working speed is very low. Moreover, it uses RAM to store rotation factors and multipliers to realize complex multiplication, which consumes a lot of hardware resources. Therefore, the architecture can be improved from the above two points.

Traditional MDC architecture
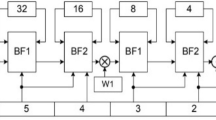
In the proposed DDC architecture, the data flow is continuous, and each stage has a special butterfly operation processing unit for butterfly operation. Except for the first stage, complex number multiplication in butterfly operation in each stage is realized by the CORDIC algorithm. The sample of input is divided into two parallel inputs by the shift register, which is used to store intermediate data and provide caching, with sufficient delay between the two inputs to adjust the data. The proposed architecture is shown in Fig. 8. In the first phase of the architecture, since the rotation factor is 1, the input can be directly added and subtracted according to the DIT FFT algorithm. In the subsequent stage, the shift register is used to delay the data alignment, and the commutator is used to adjust the data. The commutator consists of two data selectors, which are controlled by the control signal S. When the control signal level is high, the input data are exchanged, and when the control signal level is low, the data are transmitted as-is. And in the last phase, because there are only two rotation factors \(W_{N}^{0} = 1\) and \(W_{N}^{\frac{N}{2}} = - J\), the last stage does not need to do complex number multiplication, you can use the adder and subtracter to achieve the butterfly operation. The data input and commutator require a delay to rearrange the data, so the last stage only has a delay of two clocks.

8 points FFT proposed DDC architecture
The key of design is how to generate control signals at all levels. This paper adopts counter, delay unit and commutator to constitute the control signal generation unit. Figure 9 shows the 8-point FFT control signal generation unit. Figure 9 shows that the first-level control signal is equal to the first bit of the input operand address, and the last level control signal is equal to the 0th bit of the input address. This shows that for FFT processor with M stages pipeline, the value of the control signal in the p stage is equal to the value of the m-P bit of the input operand address.

8 points FFT Control signal generation circuit
The 16-point data flow diagram of the improved MDC architecture is shown in Fig. 10. In the data flow diagram, the number represents the address of the data for ease of illustration. According to the data flow diagram, the data of the improved MDC architecture is input through two channels, \(x_{1} \left( n \right)\) and \(x_{2} \left( n \right)\). In the first level operation unit, the data can be operated directly without delay and transform direction. In the second level operation unit, the upper operand is delayed first, and then under the control of the reversing control signal, reverse the two inputs, and finally, the lower operand is delayed. The two inputs are now aligned, and the next step is to do the butterfly operation and output the result to the next stage. The operation process of each subsequent level is the same as that of the second level, except for the change of reversing control signal, delay depth, and rotation Angle address.

16 points to improve the MDC architecture data flow diagram
4 Analysis of experimental results
In the FFT algorithm, if the input is assumed to be real, and in the interval [−1,1), the output is in the interval [−N, N). In practice, it can be expressed as FPX (16,14). To prevent data overflow and ensure the accuracy of data, 16-bit truncation is used in the final output butterfly stage.
Verilog HDL is used to synthesize and implement the proposed FFT processor architecture. The CORDIC algorithm is used to realize the complex multiplication operation in the FFT algorithm, and the improved MDC architecture proposed in this paper is used to realize the 512 points, 1024 points, 2048 points, and 4096 points FAST Fourier transform. The input signal of FFT algorithm is: \(s\left( t \right) = 0.5\cos 2\pi f_{1} t + 0.5\sin 2\pi f_{2} t\), \(f_{1} = 1000\;{\text{Hz}}\), \(f_{2} = 2000\;{\text{Hz}}\). The proposed FFT processor is evaluated in terms of execution time, logical resource consumption, and delay period. Table 1 shows a comparison between the proposed design and the traditional full-line DDC implementation of the FFT algorithm [15], in which two parameters are considered, namely the resource utilization of the slices used and the delay of the clock cycle used to calculate the input sequence FFT. In reference [15], the traditional full-pipelined DC architecture is introduced, it uses CLB to multiply complex numbers. Table 1 shows that our proposed implementation uses an average of 36.96% less LUT slicing and uses fewer resources than a traditional DDC architecture. The reduction in resources is possible because of the CORDIC algorithm for complex number multiplication, simple shift for constant multiplication through BDC, and architectural improvements that reduce the use of delay elements. As shown in Table 1, the proposed implementation has a 60.13% reduction in latency compared to traditional pipelined DC, and the proposed construction has less latency.
To further illustrate the feasibility and performance of the FFT processor architecture proposed in this paper, different clock frequencies are used to implement THE FFT processor. The running speed of the Proposed FFT processor architecture at each frequency is shown in Figure 11.

The processing speed of the proposed architecture at various operating frequencies
To illustrate the advantages of the proposed architecture, Table 2 shows a detailed comparison between our proposed pipeline architecture and other pipeline architectures, taking into account the parameters: input data width, resource utilization, latency, throughput. The length of FFT is considered a classification of the FFT architecture. The different the architecture for im-lamenting FFT algorithms are compared in Table 2. Since the order of the input and output samples depends on different applications, the hardware required to sort the data before and after FFT is not considered for comparison purposes. Some architectures use special functional blocks of FPGA, namely DSP and block RAM. For comparison, these functional blocks are converted into their equivalent pieces. A block of RAM is approximately 550 slices because a slice can be configured to store 64-bit data. A DSP block can be approximately 385 pieces because the HEIGHT of the DSP block matches a block of RAM, with each DSP block horizontally aligned to an 18K block of RAM. As you can see from Table 2, the proposed architecture is superior to the existing architecture in terms of latency, throughput, and resource utilization.
In terms of power consumption, the total power consumption of the whole FPGA design is, respectively, composed of chip static power consumption, design static power consumption, and design dynamic power consumption. The size of chip static power consumption and design static power consumption mainly depends on the level used by the chip and the occupation of logic and wiring resources in FPGA [32]. The power consumption of these two parts depends on the FPGA chip and hardware itself and has nothing to do with FFT implementation architecture. The design dynamic power consumption is related to the FFT implementation architecture and accounts for 90% of the total power consumption. The size of the designed dynamic power is related to the size of the resource consumption in FPGA, that is, when the resource consumption is the smallest, the power consumption is the lowest. Therefore, when analyzing the power consumption of the proposed FFT architecture, we mainly analyze the hardware resources consumed by FFT implementation. It can be seen from Table 2 that of all the architectures, our proposed architecture consumes the least hardware resources and therefore the lowest power consumption.
5 Conclusion
A full-flow DDC architecture is proposed, which uses the CORDIC algorithm to multiply complex numbers and simple shift and addition to multiply real numbers, with high throughput and low latency. By implementing 1024- points, 2048- points, and 4096-points fast Fourier transforms, the performance of the proposed design is evaluated in terms of throughput, latency, speed, and resource utilization, and compared with existing designs. The design effectively improves the multi-data center architecture, reduces the use of delay elements in the processor, and improves the computing speed of the system. CORDIC algorithm is used to realize complex multiplication, which improves the design performance and resource utilization. CORDIC complex multipliers run faster and require fewer hardware resources. The design also optimizes the storage of rotation factors typically stored in block memory in traditional designs, thereby reducing the chip area and cost of the FFT processor while improving its performance due to slower memory operations. The proposed architecture is faster, simpler, more efficient, and less costly than existing architectures, providing better performance with fewer hardware resources, costs, and power consumption. Experimental results show that this algorithm achieves the highest performance in throughput, latency, speed, and resource utilization.
Availability of data and materials
Data sharing does not apply to this article as no datasets were generated or analyzed during the current study.
References
M.S. Kavitha, P. Rangarajan, An efficient FPGA architecture for reconfigurable FFT processor incorporating an integration of an improved CORDIC and Radix-2 r Algorithm. Circuits Syst. Signal Process. 39, 5801–5829 (2020)
H.J. Lin, C.A. Shen, The architectural optimizations of a low-complexity and low-latency FFT processor for MIMO-OFDM communication systems. J. Signal Process. Syst. 93, 67–78 (2020)
J.S. Bruno, V. Almenar, J. Valls, FPGA implementation of a 10 GS/s variable-length FFT for OFDM-based optical communication systems. Microprocess. Microsyst. 64, 195–204 (2019)
L. Li, A.M. Wyrwicz, Parallel 2D FFT implementation on FPGA suitable for real-time MR image processing. Rev. Sci. Instrum. 89(9), 093706 (2018)
C. Tian, Q. Zhang, G. Sun et al., FFT consolidated sparse and collaborative representation for image classification. Arab. J. Sci. Eng. 43(2), 741–758 (2018)
S. Brisard, L. Dormieux, FFT-based methods for the mechanics of composites: A general variational framework. Comput. Mater. Sci. 49(3), 663–671 (2010)
A. Chen, X. Wang, An image watermarking scheme based on DWT and DFT. In: 2017 2nd International Conference on Multimedia and Image Processing (ICMP). IEEE, 2017, pp. 177–180
A. Wahbi, A. Roukhe, L. Helou, Enhancing the quality of voice communications by acoustic noise cancellation (ANC) using a low-cost adaptive algorithm based Fast Fourier Transform (FFT) and circular convolution. In: 2014 9th International Conference on Intelligent Systems: Theories and Applications (SITA-14). IEEE, 2014, pp. 1–7
S.N. Tang, F.C. Jan, Energy-efficient and calibration-aware Fourier-domain OCT imaging processor. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 27(6), 1390–1403 (2019)
Y. Gao, Digital Signal Processing Based on FPGA. Publishing House of Electronics Industry, 2012
V. Kumar, D. Selvakumar, P.M. Sobha, Area, and frequency optimized 1024 point Radix-2 FFT processor on FPGA. In: 2015 International Conference on VLSI Systems, Architecture, Technology and Applications (VLSI-SATA). IEEE, 2015, pp. 1–6
M. Garrido, J. Grajal, M.A. Sanchez et al., Pipelined radix-2k feedforward FFT architectures. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 21(1), 23–32 (2011)
M. Garrido, M.L. López-Vallejo, S.G. Chen, Guest editorial: special section on fast Fourier transform (FFT) hardware implementations. J. Signal Process. Syst. 90(11), 1581–1582 (2018)
Y. Jung, J. Cho, S. Lee et al., Area-Efficient Pipelined FFT Processor for Zero-Padded Signals. Electronics 8(12), 1397 (2019)
N.H. Nguyen, S.A. Khan, C.H. Kim et al., A high-performance, resource-efficient, reconfigurable parallel-pipelined FFT processor for FPGA platforms. Microprocess. Microsyst. 60, 96–106 (2018)
P.K. Godi, B.T. Krishna, P. Kotipalli, Design optimization of multiplier-free parallel pipelined FFT on field-programmable gate array. IET Circuits Devices Syst. 14(7), 995–1000 (2020)
C. Ingemarsson, P. Källström, F. Qureshi et al., Efficient FPGA mapping of pipeline SDF FFT cores. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 25(9), 2486–2497 (2017)
S.L.M. Hassan, N. Sulaiman, I.S.A. Halim, Low power pipelined FFT processor architecture on FPGA. In: 2018 9th IEEE Control and System Graduate Research Colloquium (ICSGRC). IEEE, 2018, pp. 31–34
T. Siu, C.W. Sham, F.C.M. Lau, Operating frequency improvement on FPGA implementation of a pipeline large-FFT processor. In: 2017 19th International Conference on Advanced Communication Technology (ICACT). IEEE, 2017, pp. 5–9
A. Manimaran, S. Parasuraman, Design of optimized Radix-4 FFT processor with multiplier sharing method. In: IOP Conference Series: Materials Science and Engineering. IOP Publishing, 2020, 925(1), 012067
Q.J. Xing, Z.G. Ma, Y.K. Xu, A novel conflict-free parallel memory access scheme for FFT processors. IEEE Trans. Circuits Syst. II Express Briefs 64(11), 1347–1351 (2017)
C.F. Hsiao, Y. Chen, C.Y. Lee, A generalized mixed-radix algorithm for memory-based FFT processors. IEEE Trans. Circuits Syst. II Express Briefs 57(1), 26 (2010)
A. Yazdanialahabadi, M. Ardakani, A distributed low-complexity coding solution for large-scale distributed FFT. IEEE Trans. Commun. 68(11), 6617–6628 (2020)
K. Elango, K. Muniandi, VLSI implementation of an area and energy-efficient FFT/IFFT core for MIMO-OFDM applications. Ann. Telecommun. 75, 215–227 (2019)
J. Wang, S. Li, X. Li, Scheduling of data access for the Radix-2k fft processor using single-port memory. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 28, 1676–1689 (2020)
S.M. Joshi, FFT architectures: a review. Int. J. Comput. Appl 116(7), 887 (2015)
J.S. Walther, A unified algorithm for elementary functions. Proc. Spring Joint Comput. Conf. 38, 379–385 (1971)
Y.W. Lin, H.Y. Liu, C.Y. Lee, A 1-GS/s FFT/IFFT processor for UWB applications. IEEE J. Solid-State Circuits 40, 1726–1735 (2005)
D.S. Chandra Inguva, D.J.B. Seventiline, Implementation of FPGA design of FFT architecture based on CORDIC algorithm. Int. J. Electron. 108, 1914–1939 (2021)
A. Changela, M. Zaveri, D. Verma, FPGA implementation of high-performance, resource-efficient Radix-16 CORDIC rotator based FFT algorithm. Integration 73, 89–100 (2020)
J. Wang, C. Xiong, K. Zhang et al., A mixed-decimation MDF architecture for Radix-2k parallel FFT. IEEE Trans. Very Large Scale Integr. Syst. 24(1), 67–78 (2015)
A. Drozd, S. Antoshchuk, J. Drozd, et al. Checkable FPGA design: energy consumption, throughput and trustworthiness. In: Green IT Engineering: Social, Business and Industrial Applications. Springer, Cham, 2019, pp. 73–94
Acknowledgements
Not applicable.
Funding
This research was funded by the National Natural Science Foundation of China (No. 61372094, 61071001).
Author information
Authors and Affiliations
Contributions
All the work was done under the guidance of Professor Hong Lv.Conceptualization, YZ and HL .; investigation, YZ,LZ and HL; methodology, YZ,JL and HL; project administration, HL; software, YZ and LZ; supervision, HL; validation, YZ,JL and HL ; writing—original draft, YZ ,JL and HL. All authors read and approved the final manuscript.
Authors’ Information
Yupu Zhao He was born in Fuyang, Anhui Province, China in 1997. He received his bachelor's degree in communication engineering from the School of Electronics and Information Engineering, Anhui Jianzhu University in 2019, and is currently pursuing a master's degree in circuits and systems at Anhui Jianzhu University. His research interests include digital signal processing and the design of FPGA architectures for digital communications.
Lv Hong, female, born in 1959 in Huining, Anhui Province, professor, master tutor, academic technology leader in Anhui Province. She has presided over and completed 7 provincial and ministerial level or above projects, such as national Natural Science Foundation of China and provincial Natural Science Foundation of China. She has published more than 60 papers in academic journals and conference proceedings at home and abroad. It has obtained eight invention patents and utility model patents, and more than a dozen software Copyrights. Her research interest covers intelligent detection, signal processing and computer applications.
Jun Li He was born in 1995. A master's degree. His research interests are in signal and information processing.
Lulu Zhu He was born in 1995. A master's degree. His research interests are in the hardware design.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
YuPu Zhao, Hong Lv, Jun Li, and LuLu Zhu declare that they have no conflict of interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhao, Y., Lv, H., Li, J. et al. High performance and resource efficient FFT processor based on CORDIC algorithm. EURASIP J. Adv. Signal Process. 2022, 23 (2022). https://doi.org/10.1186/s13634-022-00855-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13634-022-00855-6