
Abstract
Background
Mortality in patients with acute respiratory failure remains high. Predicting progression of acute respiratory failure may be critical to improving patient outcomes. Machine learning, a subset of artificial intelligence is a rapidly expanding area, which is being integrated into several areas of clinical medicine. This manuscript will address the knowledge gap in predicting the onset and progression of respiratory failure, provide a review of existing prognostic strategies, and provide a clinical perspective on the implementation and future integration of machine learning into clinical care.
Main body
Existing strategies for predicting respiratory failure, such as prediction scores and biomarkers, offer both strengths and limitations. While these tools provide some prognostic value, machine learning presents a promising, data-driven approach to prognostication in the intensive care unit. Machine learning has already shown success in various areas of clinical medicine, although relatively few algorithms target respiratory failure prediction specifically. As machine learning grows in the context of respiratory failure, outcomes such as the need for invasive mechanical ventilation and escalation of respiratory support (e.g. non-invasive ventilation) have been identified as key targets. However, the development and implementation of machine learning models in clinical care involves complex challenges. Future success will depend on rigorous model validation, clinician collaboration, thoughtful trial design, and the application of implementation science to ensure integration into clinical care.
Conclusion
Machine learning holds promise for optimizing treatment strategies and potentially improving outcomes in respiratory failure. However, further research and development are necessary to fully realize its potential in clinical practice.
Similar content being viewed by others


Background/Introduction
Mortality among patients requiring invasive mechanical ventilation for acute respiratory failure remains high [1]. Several observations suggest that the ability to predict progression of respiratory failure may improve outcomes in these patients. Recent data underscore several important points. First, delayed intubation is associated with an increase in mortality [2]. Second, prolonged invasive mechanical ventilation is associated with higher costs, morbidity, and mortality [3]. Beyond financial costs, invasive mechanical ventilation imposes substantial psychosocial burdens and other complications stemming from prolonged critical illness [4]. On the other hand, identifying patients at very low risk of respiratory failure may also be useful as they may be better served outside of the Intensive Care Unit (ICU) or even outside of the hospital. Predictive analytics offer a promising solution to optimize resource utilization and potentially improve patient-centered outcomes in respiratory failure. However, current methods to predict respiratory failure onset and progression remain limited, with only moderate accuracy [5,6,7]. This gap highlights the need for further research in this area.
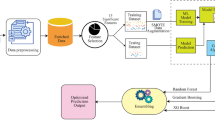
Machine learning (ML), a rapidly advancing subset of artificial intelligence (AI), offers a considerable opportunity. ML enables the ingestion of vast amounts of data and has the potential to outperform existing approaches at predicting respiratory failure (Fig. 1). To explore this potential, we convened a panel of experts to review the current literature regarding predictors of respiratory failure and discussed the potential for ML applications to aid in the prediction of respiratory failure onset and progression. We chose the panel members based on contributions to the published literature (in artificial intelligence, mechanical ventilation, respiratory physiology, ICU trial design etc.) but also attempted to achieve geographic as well as demographic diversity among participants. Our goal was not an exhaustive systematic review but rather focus on key topics that our expert panel felt were most critical in this area. The panel’s discussion focused on several key areas: (1) A review of established strategies, such as prediction scores and biomarkers, to predict respiratory failure and related outcomes (Table 1). (2) The current state of ML in predictive analytics for medicine. (3) Future objectives for ML in respiratory failure prediction, including outcomes of interest, model development, implementation, and approaches to trial design. (4) Health equity considerations in ML applications.

Timeline of possible impact of deep learning algorithms to influence clinical progression of patients with respiratory failure. Counterfactual models can be used to assess “what if” scenarios to prevent intubation or reintubation as a possible means to guide clinical management. Abbreviations: NIV = Noninvasive ventilation; HFNC = High flow nasal cannula; EHR = Electronic health record; SBT = Spontaneous breathing trial
Traditional predictors of respiratory failure
There are several existing prognostic scores/indices to predict outcomes related to respiratory disease including the development of Acute Respiratory Distress Syndrome (ARDS), failure of high flow nasal cannula (HFNC) support or respiratory failure progression despite non-invasive ventilation (NIV), and risk of need for invasive mechanical ventilation. The Lung Injury Prediction Score (LIPS), developed in 2011, was designed to identify patients at high risk for the development of acute lung injury during hospital admission using 25 variables including demographic, laboratory, and vital data [5, 8]. The score performed well at the time of patient admission from the ED to the hospital; however, in patients already admitted to the hospital, the Lung Injury Prediction score did not perform as well, limiting its applicability beyond the initial ED cohort [9].
The ROX index, another frequently cited scoring system, first described in 2016 [6] with subsequent multicenter validation in 2019 [10], is a simple tool used to predict the need for invasive mechanical ventilation in ICU patients with pneumonia on high-flow nasal cannula (HFNC). The ROX index is calculated as ([SpO2/FiO2]/Respiratory Rate) [6]. At 12 h following HFNC initiation, a ROX index > 4.88 correlates with a lower risk of intubation, while a value < 3.85 indicates a higher risk [10]. A subsequent meta-analysis showed an AUC of 0.81 for predicting intubation [11]. More recently, the VOX index was introduced, while similar to the ROX index, the VOX index replaced the respiratory rate variable with tidal volume [7]. The authors proposed that tidal volume is a more sensitive indicator of changes in respiratory drive than respiratory rate [7]. Tidal volume measurements were obtained during a brief NIV trial in patients treated with HFNC [7]. Evaluated in a small single-center study, the VOX index outperformed the ROX index and provided greater discriminatory power earlier after HFNC initiation at the 0, 2, and 6-hour windows [7]. Despite the ease of bedside calculation, these indices target a narrow patient population, only including patients with HFNC as their oxygen delivery modality. They also provide information on a patient who is already at high-risk, e.g. on high amounts of respiratory support (HFNC) and requiring ICU admission.
More complicated scoring systems also exist, examining a wider range of respiratory pathologies and oxygen delivery modalities. For example, the HACOR score predicts the risk of mechanical ventilation after the initiation of NIV in patients with acute hypoxemic respiratory failure of any etiology [12]. The HACOR score incorporates heart rate, acidosis (pH), consciousness (GCS), oxygenation (PaO2/FiO2 ratio), and respiratory rate. At 1-hour, a HACOR score > 5 is associated with a high risk of NIV failure with an AUC 0.71 [12]. Refinements to the HACOR score, adding six additional variables— sequential organ failure assessment (SOFA) score, presence of pneumonia, septic shock, cardiogenic pulmonary edema, ARDS, and immunosuppression—improved its predictive capabilities, raising the AUC to 0.78 [13]. Despite the earlier prognostication time (1–2 h after initiation of NIV) offered by the HACOR score compared to other prediction scores, its limitations include the scoring system complexity and number of variables required for calculation. Additionally, the use of NIV has decreased in the pneumonia/ARDS population following the High-Flow Oxygen through Nasal Cannula in Acute Hypoxemic Respiratory Failure (FLORALI) trial, which demonstrated a 90-day mortality benefit of HFNC over NIV in acute hypoxemic non-hypercapnic respiratory failure [14].
Expert panel members agreed that these scores are rarely used in clinical practice. Lack of routine use of existing scoring systems may be due to multiple factors. Some highlighted limitations include that current algorithms can identify, but not necessarily predict, respiratory failure. Instruments which rely on tachypnea and hypoxemia are likely identifying established or impending respiratory failure but not truly predicting a future event. Instead, expertise and clinical gestalt are heavily relied upon when assessing a patient and their risk of respiratory failure progression. However, it was recognized that even experienced clinicians provide incomplete evaluations based on variable time at the bedside, particularly overnight, with a high patient census, and may not be aware of decompensating patients outside the ICU setting in the absence of effective warning systems. There may also be some value in these indices in early medical education to help learners contextualize and form their own mental frameworks for understanding disease and illness severity.
Role for biomarkers in respiratory failure predictions
PaO2 and PaCO2 are plasma biomarkers that are widely used to identify patients with impending respiratory failure and are embedded in many of the prognostic scores noted above. These biomarkers are also tested frequently and change over a short period of time, making them useful for identifying high-risk patients.
In contrast, other plasma biomarkers in respiratory failure have focused not on the prediction of respiratory failure but rather prognostic enrichment of patients with established respiratory failure, particularly ARDS [15, 16]. These plasma biomarkers focus on known pathways of ARDS and sepsis pathogenesis including inflammation [e.g. Tumor necrosis factor receptors (TNFR), Interleukin-6 (IL-6), Interleukin-8, Interleukin-18)], endothelial damage (e.g. Ang2), and epithelial damage [e.g. receptor for advanced glycation end products (RAGE) and Surfactant Protein D (SPD)].These ARDS biomarkers also define high-risk endotypes of disease (e.g. the “Hyperinflammatory class” of ARDS identified by Latent Class Analysis and other ML approaches in numerous cohorts and associated with differential response to therapies [17,18,19,20], or IL-18 which similarly identifies high-risk subset with a differential response to simvastatin) [21].
Despite a clear role for biomarkers in prognosis and endotyping of established ARDS, the role of these biomarkers prior to the onset of respiratory failure is less established. While the same inflammatory, epithelial, and endothelial biomarkers could serve a prognostic role in not-yet-critically ill patients, this has not been rigorously tested to date. Multiple ARDS biomarkers have been studied in large cohorts of critically ill patients with sepsis and/or ARDS and are higher in patients with ARDS than septic controls, suggesting potential prognostic value, but this is not the same as rigorous longitudinal sampling [17]. Few biomarkers have been tested in patients that initially presented without ARDS but later developed the condition, with Ang2 being an exception [22]. In the COVID-19 pandemic, large cohorts of patients with SARS-CoV-2 pneumonia who presented prior to progression to ARDS or respiratory failure were enrolled in biobanking studies or clinical trials. In these cohorts, RAGE and viral antigen levels have both been highly associated with progression to respiratory failure [23,24,25]. Most plasma biomarkers are measured at single time points or with several days between measurements; shorter interval trends have not been tested for rapidly developing respiratory failure, which is more classically seen in non-COVID pneumonias. Additionally, many of these biomarkers are primarily research based and not yet available for rapid testing in most clinical laboratories limiting their ability to guide clinical management in real-time.
While lung-specific samples like exhaled breath are already established biomarkers in other pulmonary diseases [e.g. exhaled NO levels as a marker for inflammation in asthma [26]] they are less studied in patients with impending respiratory failure. Elevated volatile organic compounds (VOCs) have been associated with pneumonia in multiple cohorts [27], but most of these studies focus on intubated patients. In non-intubated patients on high levels of respiratory support, there may be technical challenges in measuring VOCs, for example, a patient on HFNC may have difficulty performing testing to capture this sample adequately. Bronchoalveolar lavage (BAL) or HME filter testing can identify signatures of high-risk patients but can be challenging to obtain in non-intubated patients. Thus, the potential role of such lung specific samples in identifying high-risk patients is not established despite mechanistic promise. A synergistic approach between ML and biomarkers (e.g. ML model identifies a high-risk patient and triggers more frequent breath and plasma biomarker collection, which in turn informs ML risk score) may offer a powerful approach for risk prediction.
Machine learning in critical care
Over the past 10 years, interest in the application of machine learning (ML) methods in clinical medicine has substantially increased [28, 29]. Machine learning techniques train computers to do what comes naturally to humans: learning by example. ML models use digitized data (input features) to make predictions for specified outcomes (or outputs/labels). Deep learning (DL), a branch of ML, achieves this task by using layers of non-linear processing (artificial neural networks), to produce a distributed and hierarchical representation of input features [30]. The hospital is an environment rich with patient data, requiring the integration of multiple data sources (e.g., vital signs, imaging, labs, and provider notes). Given the breadth and wealth of patient data available, ML can compute complex interactions or temporal relationships among multivariate risk factors that clinicians may overlook [31]. Large language model (LLM) integration may also add valuable information by incorporating unstructured patient data, like clinical notes. Integrating information from clinical notes and structured EHR data may improve predictive capabilities [32] as well as enhance clinical decision making [33].
In modern healthcare systems, ML/DL algorithms can be applied to clinical decision support (CDS) systems [34]. Some examples of CDS systems include prediction algorithms for sepsis [35], acute kidney injury [36], physiological deterioration [37], 30-day unplanned hospital readmissions [38], and emergency department triage [39]. Additionally, ML models have been applied in acute respiratory failure, particularly during the invasive mechanical ventilation phase, for example to identify patient-ventilator asynchrony [40, 41], to optimize ventilator settings [42], and predict response to lung recruitment [43] and prone positioning [44].
Several deep learning models exist that predict respiratory failure in the hospital setting [45,46,47,48,49]. Models were trained to predict various outcomes, including predicting HFNC failure [47], NIV failure [48], and need for invasive mechanical ventilation (IMV) [46]. However, limitations to these models exist. These models were retrospective and few have been prospectively validated [45]. In some models, the timeframe between prediction and event onset was relatively short or predictions were only created at 4-hour intervals, potentially limiting ability to implement meaningful interventions [45, 49]. Outside of a handful of academic institutions, these models are rarely integrated into clinical workflow. Barriers to implementation include challenges in analytic platform integration into the electronic health record (EHR) [50], costs to the health system [51], clinician acceptance [52], and model maintenance over time and among different patient populations and clinical practice variations [53]. Despite these challenges and limitations, these models provide an excellent starting point for ML models in the prediction of acute respiratory failure.
Key objectives and outcomes for ML in respiratory failure
Part of the discussion focused on what respiratory outcomes are most critical. Panelists agreed that predicting emergence and progression of respiratory failure would be the most ‘actionable’. Specifically, panelists identified that the requirement for invasive mechanical ventilation was a critical outcome of interest. However, initiation of high flow nasal cannula (HFNC) and/or non-invasive ventilation (NIV) was also felt to be important, particularly if these therapies require transfer to the ICU. Local practice varies, as some centers require ICU transfer for initiation of therapy whereas others have intermediate care units which allow for these oxygen delivery modalities. The considerable variation across centers did not appear to be data driven but rather reflected local/regional practices and experiences, perhaps emphasizing the need for further study to inform such decisions. Additional potential outcomes of interest for future studies included both patient-related and health system-related [34]. Relevant patient related outcomes may include mortality, duration of mechanical ventilation, ICU length of stay (LOS), and tracheostomy rates among others [54]. For the health system, in addition to some parallel outcomes of interest (e.g. ICU LOS), system related outcomes such as cost, and resource utilization may also be of interest.
The panel also discussed several priorities for predictive analytics in the respiratory failure. Panelists emphasized the important impact of early knowledge of a patient’s likelihood of respiratory failure progression [e.g. nasal cannula (NC) to HFNC to IMV]. Providing advanced warning is most useful when it gives clinicians enough lead time to collect and interpret focused diagnostics and potentially intervene to prevent deterioration. There was debate regarding the optimal prediction horizon length (the time frame in which the outcome could occur or when prediction should apply), but most agreed that a 12 to 24-hours before the onset of respiratory failure would be a useful window to implement preventative strategies. This time frame would also allow the design of randomized controlled trials to test interventions to prevent progression of respiratory failure.
Another key element is clinical collaboration and incorporating appropriate risk thresholds that are important to clinical decision-making. For example, working with clinicians to identify appropriate risk thresholds for notification is crucial. This approach helps notify clinicians only at thresholds they believe to be clinically important, avoiding alarm fatigue and over-notification.
Predicting response to specific interventions, via methods such as counterfactual prediction [55], may also be of use and enhance the actionability of ML models and be applied to trial design. The approach of using counterfactual predictions allows a simulation of various different treatment responses. In other words, this approach answers the “what if” the patient were to receive HFNC scenario over another therapy. Such predictions can be used to inform clinical decision making and/or trial design and be locally adapted as needed. While predicting level of care may be valuable, there are regional practice variations in the use of respiratory modalities at different levels of care. It was generally agreed that predicting and tracking progression along the continuum of escalating respiratory support may be the most valuable and generalizable approach across systems. We recognize there may be variations in timing of endotracheal intubation across institutions; thus, strategies such as transfer learning and site-specific tuning will be essential. Transfer learning involves fine tuning of knowledge gained from a specific ML task or dataset is used to improve model performance on a similar task or different clinical site [56, 57].
Challenges in ML model development, implementation and deployment
There are many challenges in the development, implementation, and deployment of risk related models in the clinical setting, especially for syndromic conditions like respiratory failure [58]. The development and validation of deep learning models can be challenging at both a patient level and a systems level. At the patient level, the diverse pathology underlying respiratory failure, different types of respiratory failure, and variability of treatment make model development challenging. Additionally, many of these patients experience concomitant organ failure, such as renal failure or cardiovascular failure, further complicating their clinical presentation. In contrast, existing models that have shown measurable clinical impact, such as the sepsis prediction model implemented by Boussina et al. [59] benefit from sepsis being a well-defined pathological construct with an established treatment paradigm.
Missing data and data heterogeneity, including inconsistencies in data sources, formats, frequency and quality, represent another major hurdle that can undermine the accuracy of ML models [60]. Specifically in respiratory failure, emergency procedures such as intubation and initiation of mechanical ventilation are not always well delineated or accurately time stamped in the EHR, leading to challenges with appropriate classification and model accuracy. At a systems level, there is substantial heterogeneity across health systems, regional practice patterns, and available resources. This variability complicates the creation of generalizable ML models [53]. For example, the decision to intubate may vary across institutions, thus a model developed at one institution may not perform well when tested at another with a different intubation threshold. Descriptions of different types of respiratory support may also vary, making it more difficult to accurately capture a patient’s condition from one hospital to another. Recent data suggest that ML approaches, such as transfer learning may mitigate this shortcoming [56]. Other groups are attempting to harmonize data capture to facilitate across system collaboration [61].
Beyond development challenges, there are several barriers to the successful implementation of these models into clinical care. Successful integration and deployment rely on several factors, including appropriate systems to ensure an efficient, adequate, and safe interface between the electronic health record and analytics platform, ensuring system performance, cost coverage, clinician buy-in, and a positive impact on patient-centered outcomes [62]. ICU physicians have expressed hesitancy surrounding the idea of deploying AI models in the ICU environment [52]. Avoiding “black box” models and promoting transparency in model determinants can help promote clinician acceptance and collaboration [63]. Fostering a symbiotic relationship between ML experts and clinicians is essential. Post-implementation, a robust system to monitor and iteratively improve model performance is necessary to avoid model drift [62].
ML development and implementation into clinical practice and trial design
The successful integration of ML systems into clinical practice requires several steps, from creation to implementation, that involves diligent testing and validation. To advance ML integration in clinical settings, future research must focus on prospective randomized studies. However, several intermediary stages must be carefully addressed before reaching the point of prospective testing and validation. It is crucial to ensure that the models demonstrate adequate performance and maintain robust performance across systems and populations. One promising strategy is the use of “silent trials”, where the predictive model is integrated into the electronic health record but works in the background without interaction with end users [64]. Such strategies can allow enhancement of predictive abilities [64], identify bugs, and evaluate false positives and negatives, prior to full-scale clinical deployment.
Once a model is ready for prospective testing, several approaches can be considered for determining both what to test and how to evaluate its effectiveness. A key question is whether the risk score alone is sufficient or if it must be combined with an intervention or predicted treatment effect to impact patient outcomes meaningfully. The panel agreed that comparing model integration into clinical practice versus the existing standard of care is essential for evaluating its effectiveness.
There were several approaches suggested for future trial design. While single-center pilot trials may be an important approach early in ML validation due to their efficiency, thy may lack generalizability and require replication, as well as assessment of portability and scalability. Therefore, prospective, multicenter testing will likely be needed to garner widespread acceptance and ensure generalizability. While randomized controlled trials (RCTs) are often regarded as the gold standard, they are expensive and challenging to undertake. Alternative designs such as stepped-wedge or pragmatic trials may be more practical for testing the impact of incorporating ML models into clinical practice. Cluster randomized clinical trial designs may be more appropriate since these ML models are designed to intervene on the function of systems of care, not merely on mechanisms of injury in individual patients. The utility of predictive model could also be demonstrated by showing that treatment effects of interventions designed to prevent respiratory failure varies according to risk strata defined by predictive analytics. The panel acknowledged the role of different trial designs but emphasized that prospective, multicenter trials remain an important step towards broader acceptance.
The use of implementation science is also key. The implementation of new evidence-based practices within the healthcare setting is often challenging and can benefit from using standardized frameworks [65]. For example, approaches such as the Exploration, Preparation, Implementation, Sustainment (EPIS) framework can be used to facilitate implementation of ML in the clinical setting [65, 66]. Evaluation of implementation response and end-user interaction is crucial to understand better how clinicians interact with the algorithm and how to improve adoption and enhance user experience [67].
Health equity
One concern with technological advancements in healthcare is patients who are socioeconomically advantaged may benefit disproportionately due to better access to resources and infrastructure that support successful implementation. Biased data or inconsistencies in the frequency of measurements may unintentionally promote disparities- systematic differences in model performance or predictive accuracy according to social characteristics [47, 68, 69]. However, ML algorithms, if designed correctly, could be used to achieve health equity rather than to worsen disparities. By relying on objective data accessible to all patients, models can be designed to for sex, race/ethnicity, religion, and skin color in an unbiased manner. A few noteworthy points must be considered in the context of a health equity discussion:
First, health systems with fewer resources, serving people with lower socioeconomic status, may be late to adopt new technologies which may further exacerbate existing health disparities and will need to be carefully considered.
Second, even when data are available, that data may be fundamentally biased. For example, skin color can influence the accuracy of some diagnostic methods, such as pulse oximetry [70, 71]. Accounting for differential accuracy of pulse oximetry based on skin color could help to improve its accuracy. Careful quantification of skin melanin using spectrophotometry can provide rigorous data, enabling adjustments to oximetry values if necessary. Technologies which are independent of skin color such as the measurement of tensions in exhaled gases (alveolar gas meter) could be used to avoid potential biases [72]. Alternatively, corrective factors may be applied for groups at-risk of bias related to pulse oximetry.
Third, natural language processing (NLP) or large language models can be quite helpful in analyzing progress notes by nurses, respiratory therapists, and physicians. However, implicit bias can influence subtle language patterns that are used preferentially for certain groups [73]. Refining NLP algorithms could help them recognize these biases and ensure that decisions are based on objective data rather than preconceived notions or historical tendencies.
Advocates for health equity emphasize the need to evaluate potential disparities in model performance and patient outcomes across different socioeconomic groups, promoting transparency in model development and deployment [74]. It will be important to address health disparities in the development of any ML model to ensure equitable performance and minimize bias.
Conclusion
Prediction of respiratory failure progression is a critical topic that may benefit from the integration of ML models into clinical practice. ML offers powerful tools for predicting respiratory failure by integrating multimodal data to elucidate complex patterns that clinicians cannot always recognize. These models are particularly well-suited to the area of respiratory failure given the high number of data streams (compared to other areas of the hospital) and its resource intensive management. Additionally, current management of acute respiratory failure is often reactive. Enhancing predictive capabilities through ML could facilitate a more proactive approach to patient care, potentially improving outcomes. However, many challenges must be addressed to achieve meaningful integration into clinical care. These challenges include ensuring data consistency and quality, defining important outcomes, prospective implementation and validation of ML models, conducting clinical trials to evaluate their effectiveness, and ensuring equitable model performance across socioeconomic groups. Despite the challenges, ML offers a promising avenue to advance critical care and improve patient outcomes.
Data availability
No datasets were generated or analysed during the current study.
Abbreviations
- ML:
-
machine learning
- AI:
-
artificial intelligence
- ICU:
-
Intensive Care Unit
- HFNC:
-
high flow nasal cannula
- NIV:
-
non-invasive ventilation
- LIPS:
-
lung injury prediction score
- GCS:
-
Glasgow coma score
- SOFA:
-
sequential organ failure assessment
- ARDS:
-
Acute Respiratory Distress Syndrome
- DL:
-
Deep Learning
- CDS:
-
clinical decision support
- IMV:
-
Invasive mechanical ventilation
- NLP:
-
natural language processing
References
Bellani G, Laffey JG, Pham T, Fan E, Brochard L, Esteban A, et al. Epidemiology, patterns of care, and mortality for patients with acute respiratory distress syndrome in intensive care units in 50 countries. JAMA. 2016;315(8):788–800.
Kangelaris KN, Ware LB, Wang CY, Janz DR, Zhuo H, Matthay MA, et al. Timing of intubation and clinical outcomes in adults with acute respiratory distress syndrome. Crit Care Med. 2016;44(1):120–9.
Mietto C, Pinciroli R, Patel N, Berra L. Ventilator associated pneumonia: evolving definitions and preventive strategies. Respir Care. 2013;58(6):990–1007.
Girard TD, Shintani AK, Jackson JC, Gordon SM, Pun BT, Henderson MS, et al. Risk factors for post-traumatic stress disorder symptoms following critical illness requiring mechanical ventilation: a prospective cohort study. Crit Care. 2007;11(1):R28.
Trillo-Alvarez C, Cartin-Ceba R, Kor DJ, Kojicic M, Kashyap R, Thakur S, et al. Acute lung injury prediction score: derivation and validation in a population-based sample. Eur Respir J. 2011;37(3):604–9.
Roca O, Messika J, Caralt B, Garcia-de-Acilu M, Sztrymf B, Ricard JD, et al. Predicting success of high-flow nasal cannula in pneumonia patients with hypoxemic respiratory failure: the utility of the ROX index. J Crit Care. 2016;35:200–5.
Chen D, Heunks L, Pan C, Xie J, Qiu H, Yang Y, et al. A novel index to predict the failure of High-Flow nasal cannula in patients with acute hypoxemic respiratory failure: A pilot study. Am J Respir Crit Care Med. 2022;206(7):910–3.
Gajic O, Dabbagh O, Park PK, Adesanya A, Chang SY, Hou P, et al. Early identification of patients at risk of acute lung injury: evaluation of lung injury prediction score in a multicenter cohort study. Am J Respir Crit Care Med. 2011;183(4):462–70.
Soto GJ, Kor DJ, Park PK, Hou PC, Kaufman DA, Kim M, et al. Lung injury prediction score in hospitalized patients at risk of acute respiratory distress syndrome. Crit Care Med. 2016;44(12):2182–91.
Roca O, Caralt B, Messika J, Samper M, Sztrymf B, Hernandez G, et al. An index combining respiratory rate and oxygenation to predict outcome of nasal High-Flow therapy. Am J Respir Crit Care Med. 2019;199(11):1368–76.
Zhou X, Liu J, Pan J, Xu Z, Xu J. The ROX index as a predictor of high-flow nasal cannula outcome in pneumonia patients with acute hypoxemic respiratory failure: a systematic review and meta-analysis. BMC Pulm Med. 2022;22(1):121.
Duan J, Han X, Bai L, Zhou L, Huang S. Assessment of heart rate, acidosis, consciousness, oxygenation, and respiratory rate to predict noninvasive ventilation failure in hypoxemic patients. Intensive Care Med. 2017;43(2):192–9.
Duan J, Chen L, Liu X, Bozbay S, Liu Y, Wang K, et al. An updated HACOR score for predicting the failure of noninvasive ventilation: a multicenter prospective observational study. Crit Care. 2022;26(1):196.
Frat JP, Thille AW, Mercat A, Girault C, Ragot S, Perbet S, et al. High-flow oxygen through nasal cannula in acute hypoxemic respiratory failure. N Engl J Med. 2015;372(23):2185–96.
Heijnen NFL, Hagens LA, Smit MR, Cremer OL, Ong DSY, van der Poll T, et al. Biological subphenotypes of acute respiratory distress syndrome show prognostic enrichment in mechanically ventilated patients without acute respiratory distress syndrome. Am J Respir Crit Care Med. 2021;203(12):1503–11.
Wilson JG, Calfee CS. ARDS subphenotypes: Understanding a heterogeneous syndrome. Crit Care. 2020;24(1):102.
Maddali MV, Churpek M, Pham T, Rezoagli E, Zhuo H, Zhao W, et al. Validation and utility of ARDS subphenotypes identified by machine-learning models using clinical data: an observational, multicohort, retrospective analysis. Lancet Respir Med. 2022;10(4):367–77.
Sinha P, Churpek MM, Calfee CS. Machine learning classifier models can identify acute respiratory distress syndrome phenotypes using readily available clinical data. Am J Respir Crit Care Med. 2020;202(7):996–1004.
Calfee CS, Delucchi K, Parsons PE, Thompson BT, Ware LB, Matthay MA, et al. Subphenotypes in acute respiratory distress syndrome: latent class analysis of data from two randomised controlled trials. Lancet Respir Med. 2014;2(8):611–20.
Calfee CS, Delucchi KL, Sinha P, Matthay MA, Hackett J, Shankar-Hari M, et al. Acute respiratory distress syndrome subphenotypes and differential response to simvastatin: secondary analysis of a randomised controlled trial. Lancet Respir Med. 2018;6(9):691–8.
Moore AR, Pienkos SM, Sinha P, Guan J, O’Kane CM, Levitt JE, et al. Elevated plasma Interleukin-18 identifies High-Risk acute respiratory distress syndrome patients not distinguished by prior latent class analyses using traditional inflammatory cytokines: A retrospective analysis of two randomized clinical trials. Crit Care Med. 2023;51(12):e269–74.
Agrawal A, Matthay MA, Kangelaris KN, Stein J, Chu JC, Imp BM, et al. Plasma angiopoietin-2 predicts the onset of acute lung injury in critically ill patients. Am J Respir Crit Care Med. 2013;187(7):736–42.
Wick KD, Leligdowicz A, Willmore A, Carrillo SA, Ghale R, Jauregui A, et al. Plasma SARS-CoV-2 nucleocapsid antigen levels are associated with progression to severe disease in hospitalized COVID-19. Crit Care. 2022;26(1):278.
Wick KD, Siegel L, Neaton JD, Oldmixon C, Lundgren J, Dewar RL et al. RAGE has potential pathogenetic and prognostic value in nonintubated hospitalized patients with COVID-19. JCI Insight. 2022;7(9):e157499.
Group A-TS, Rogers AJ, Wentworth D, Phillips A, Shaw-Saliba K, Dewar RL, et al. The association of baseline plasma SARS-CoV-2 nucleocapsid antigen level and outcomes in patients hospitalized with COVID-19. Ann Intern Med. 2022;175(10):1401–10.
Dweik RA, Boggs PB, Erzurum SC, Irvin CG, Leigh MW, Lundberg JO, et al. An official ATS clinical practice guideline: interpretation of exhaled nitric oxide levels (FENO) for clinical applications. Am J Respir Crit Care Med. 2011;184(5):602–15.
Bos LD, Sterk PJ, Schultz MJ. Volatile metabolites of pathogens: a systematic review. PLoS Pathog. 2013;9(5):e1003311.
Ohno-Machado L. Data science and artificial intelligence to improve clinical practice and research. J Am Med Inf Assoc. 2018;25(10):1273.
Esteva A, Robicquet A, Ramsundar B, Kuleshov V, DePristo M, Chou K, et al. A guide to deep learning in healthcare. Nat Med. 2019;25(1):24–9.
LeCun Y, Bengio Y, Hinton G. Deep learning. Nature. 2015;521(7553):436–44.
Shashikumar SP, Josef CS, Sharma A, Nemati S. DeepAISE - An interpretable and recurrent neural survival model for early prediction of sepsis. Artif Intell Med. 2021;113:102036.
Apostolova E, Uppal A, Galarraga JE, Koutroulis I, Tschampel T, Wang T et al. Towards Reliable ARDS Clinical Decision Support: ARDS Patient Analytics with Free-text and Structured EMR Data. AMIA Annu Symp Proc. 2019;2019:228 – 37.
Cabral S, Restrepo D, Kanjee Z, Wilson P, Crowe B, Abdulnour RE, et al. Clinical reasoning of a generative artificial intelligence model compared with physicians. JAMA Intern Med. 2024;184(5):581–3.
Boussina A, Krishnamoorthy R, Quintero K, Joshi S, Wardi G, Pour H et al. Large Language models for more efficient reporting of hospital quality measures. NEJM AI. 2024;1(11).
Adams R, Henry KE, Sridharan A, Soleimani H, Zhan A, Rawat N, et al. Prospective, multi-site study of patient outcomes after implementation of the TREWS machine learning-based early warning system for sepsis. Nat Med. 2022;28(7):1455–60.
Vagliano I, Chesnaye NC, Leopold JH, Jager KJ, Abu-Hanna A, Schut MC. Machine learning models for predicting acute kidney injury: a systematic review and critical appraisal. Clin Kidney J. 2022;15(12):2266–80.
Churpek MM, Yuen TC, Winslow C, Meltzer DO, Kattan MW, Edelson DP. Multicenter comparison of machine learning methods and conventional regression for predicting clinical deterioration on the wards. Crit Care Med. 2016;44(2):368–74.
Hao S, Wang Y, Jin B, Shin AY, Zhu C, Huang M, et al. Development, validation and deployment of a real time 30 day hospital readmission risk assessment tool in the Maine healthcare information exchange. PLoS ONE. 2015;10(10):e0140271.
Levin S, Toerper M, Hamrock E, Hinson JS, Barnes S, Gardner H, et al. Machine-Learning-Based electronic triage more accurately differentiates patients with respect to clinical outcomes compared with the emergency severity index. Ann Emerg Med. 2018;71(5):565–74. e2.
Sottile PD, Albers D, Higgins C, McKeehan J, Moss MM. The association between ventilator dyssynchrony, delivered tidal volume, and sedation using a novel automated ventilator dyssynchrony detection algorithm. Crit Care Med. 2018;46(2):e151–7.
Tlimat A, Fowler C, Safadi S, Johnson RB, Bodduluri S, Morris P, et al. Artificial intelligence for the detection of Patient-Ventilator asynchrony. Respir Care. 2025;70(5):583–92.
Peine A, Hallawa A, Bickenbach J, Dartmann G, Fazlic LB, Schmeink A, et al. Development and validation of a reinforcement learning algorithm to dynamically optimize mechanical ventilation in critical care. NPJ Digit Med. 2021;4(1):32.
Pennati F, Aliverti A, Pozzi T, Gattarello S, Lombardo F, Coppola S, et al. Machine learning predicts lung recruitment in acute respiratory distress syndrome using single lung CT scan. Ann Intensive Care. 2023;13(1):60.
Fosset M, von Wedel D, Redaelli S, Talmor D, Molinari N, Josse J, et al. Subphenotyping prone position responders with machine learning. Crit Care. 2025;29(1):116.
Dziadzko MA, Novotny PJ, Sloan J, Gajic O, Herasevich V, Mirhaji P, et al. Multicenter derivation and validation of an early warning score for acute respiratory failure or death in the hospital. Crit Care. 2018;22(1):286.
Shashikumar SP, Wardi G, Paul P, Carlile M, Brenner LN, Hibbert KA, et al. Development and prospective validation of a deep learning algorithm for predicting need for mechanical ventilation. Chest. 2021;159(6):2264–73.
Yang P, Gregory IA, Robichaux C, Holder AL, Martin GS, Esper AM, et al. Racial differences in accuracy of predictive models for High-Flow nasal cannula failure in COVID-19. Crit Care Explor. 2024;6(3):e1059.
Martin-Gonzalez F, Gonzalez-Robledo J, Sanchez-Hernandez F, Moreno-Garcia MN. Success/Failure prediction of noninvasive mechanical ventilation in intensive care units. Using multiclassifiers and feature selection methods. Methods Inf Med. 2016;55(3):234–41.
Wong AI, Kamaleswaran R, Tabaie A, Reyna MA, Josef C, Robichaux C, et al. Prediction of acute respiratory failure requiring advanced respiratory support in advance of interventions and treatment: A multivariable prediction model from electronic medical record data. Crit Care Explor. 2021;3(5):e0402.
Baxter SL, Bass JS, Sitapati AM. Barriers to implementing an artificial intelligence model for unplanned readmissions. ACI Open. 2020;4(2):e108–13.
Joshi M, Mecklai K, Rozenblum R, Samal L. Implementation approaches and barriers for rule-based and machine learning-based sepsis risk prediction tools: a qualitative study. JAMIA Open. 2022;5(2):ooac022.
Mlodzinski E, Wardi G, Viglione C, Nemati S, Crotty Alexander L, Malhotra A. Assessing barriers to implementation of machine learning and artificial Intelligence-Based tools in critical care: Web-Based survey study. JMIR Perioper Med. 2023;6:e41056.
Luijken K, Groenwold RHH, Van Calster B, Steyerberg EW, van Smeden M. Impact of predictor measurement heterogeneity across settings on the performance of prediction models: A measurement error perspective. Stat Med. 2019;38(18):3444–59.
Blackwood B, Ringrow S, Clarke M, Marshall JC, Connolly B, Rose L, et al. A core outcome set for critical care ventilation trials. Crit Care Med. 2019;47(10):1324–31.
Feuerriegel S, Frauen D, Melnychuk V, Schweisthal J, Hess K, Curth A, et al. Causal machine learning for predicting treatment outcomes. Nat Med. 2024;30(4):958–68.
Amrollahi F, Shashikumar SP, Holder AL, Nemati S. Leveraging clinical data across healthcare institutions for continual learning of predictive risk models. Sci Rep. 2022;12(1):8380.
Ding C, Yao T, Wu C, Ni J. Advances in deep learning for personalized ECG diagnostics: A systematic review addressing inter-patient variability and generalization constraints. Biosens Bioelectron. 2024;271:117073.
Le JP, Shashikumar SP, Malhotra A, Nemati S, Wardi G. Making the improbable possible: generalizing models designed for a Syndrome-Based, heterogeneous patient landscape. Crit Care Clin. 2023;39(4):751–68.
Boussina A, Shashikumar SP, Malhotra A, Owens RL, El-Kareh R, Longhurst CA, et al. Impact of a deep learning sepsis prediction model on quality of care and survival. NPJ Digit Med. 2024;7(1):14.
Nijman S, Leeuwenberg AM, Beekers I, Verkouter I, Jacobs J, Bots ML, et al. Missing data is poorly handled and reported in prediction model studies using machine learning: a literature review. J Clin Epidemiol. 2022;142:218–29.
Rojas JC, Lyons PG, Chhikara K, Chaudhari V, Bhavani SV, Nour M et al. A common longitudinal intensive care unit data format (CLIF) to enable multi-institutional federated critical illness research. Intensive Care Med. 2025; 51(3):556-569
Wardi G, Owens R, Josef C, Malhotra A, Longhurst C, Nemati S. Bringing the promise of artificial intelligence to critical care: what the experience with Sepsis analytics can teach Us. Crit Care Med. 2023;51(8):985–91.
Abgrall G, Holder AL, Chelly Dagdia Z, Zeitouni K, Monnet X. Should AI models be explainable to clinicians? Crit Care. 2024;28(1):301.
Kwong JCC, Erdman L, Khondker A, Skreta M, Goldenberg A, McCradden MD, et al. The silent trial - the Bridge between bench-to-bedside clinical AI applications. Front Digit Health. 2022;4:929508.
Moullin JC, Dickson KS, Stadnick NA, Rabin B, Aarons GA. Systematic review of the exploration, preparation, implementation, sustainment (EPIS) framework. Implement Sci. 2019;14(1):1.
Aarons GA, Hurlburt M, Horwitz SM. Advancing a conceptual model of evidence-based practice implementation in public service sectors. Adm Policy Ment Health. 2011;38(1):4–23.
Cotton S, Mcguire WC, Hussain A, Pearce AK, Zawaydeh Q, Meehan M et al. Prone positioning in COVID-19 acutre respiratory distress syndrome: role of paralytics. Crit Care Explor. 2022;4(2):e0646.
Obermeyer Z, Powers B, Vogeli C, Mullainathan S. Dissecting Racial bias in an algorithm used to manage the health of populations. Science. 2019;366(6464):447–53.
Abramoff MD, Tarver ME, Loyo-Berrios N, Trujillo S, Char D, Obermeyer Z, et al. Considerations for addressing bias in artificial intelligence for health equity. NPJ Digit Med. 2023;6(1):170.
Wong AI, Charpignon M, Kim H, Josef C, de Hond AAH, Fojas JJ, et al. Analysis of discrepancies between pulse oximetry and arterial oxygen saturation measurements by race and ethnicity and association with organ dysfunction and mortality. JAMA Netw Open. 2021;4(11):e2131674.
Valbuena VSM, Seelye S, Sjoding MW, Valley TS, Dickson RP, Gay SE, et al. Racial bias and reproducibility in pulse oximetry among medical and surgical inpatients in general care in the veterans health administration 2013-19: multicenter, retrospective cohort study. BMJ. 2022;378:e069775.
Mcguire WC, Pearce AK, Elliott AR, Fine JM, West JB, Crouch DR et al. Noninvasive assessment of impaired gas exchange with the alveolar gas monitor predicts clinical deterioration in COVID-19 patients, J Clin Med. 2023;12(19):6203.
Penn JA, Newman-Griffis D. Half the picture: Word frequencies reveal racial differences in clinical documentation, but not their causes. AMIA Jt Summits Transl Sci Proc. 2022;2022:386 – 95.
Rojas JC, Fahrenbach J, Makhni S, Cook SC, Williams JS, Umscheid CA, et al. Framework for integrating equity into machine learning models: A case study. Chest. 2022;161(6):1621–7.
Qadir N, Sahetya S, Munshi L, Summers C, Abrams D, Beitler J, et al. An update on management of adult patients with acute respiratory distress syndrome: an official American thoracic society clinical practice guideline. Am J Respir Crit Care Med. 2024;209(1):24–36.
Acknowledgements
Not applicable.
Funding
Not applicable.
Author information
Authors and Affiliations
Contributions
All authors made substantial contributions to the conception and design of the work. AKP, AR, and SN drafted the initial work and provided substantial revisions. The remaining authors provided substantial revisions to the work. All authors have reviewed the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Pearce, A.K., Nemati, S., Goligher, E.C. et al. Can we predict the future of respiratory failure prediction?. Crit Care 29, 253 (2025). https://doi.org/10.1186/s13054-025-05484-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1186/s13054-025-05484-7