
Abstract
Background
Non-invasive risk stratification contributes to the precise treatment of prostate cancer (PCa). In previous studies, lymphocyte subsets were used to differentiate between low-/intermediate-risk and high-risk PCa, with limited clinical value and poor interpretability. Based on functional subsets of peripheral lymphocyte with the largest sample size to date, this study aims to construct an easy-to-use and robust nomogram to guide the tripartite risk stratifications for PCa.
Methods
We retrospectively collected data from 2039 PCa and benign prostate disease (BPD) patients with 42 clinical characteristics on functional subsets of peripheral lymphocyte. After quality control and feature selection, clinical data with the optimal feature subset were utilized for the 10-fold cross-validation of five Machine Learning (ML) models for the task of predicting low-, intermediate- and high-risk stratification of PCa. Then, a novel clinic-ML nomogram was constructed using probabilistic predictions of the trained ML models via the combination of a multivariable Ordinal Logistic Regression analysis and the proposed feature mapping algorithm.
Results
197 PCa patients, including 56 BPD, were enrolled in the study. An optimal subset with nine clinical features was selected. Compared with the best ML model and the clinic nomogram, the clinic-ML nomogram achieved the superior performance with a sensitivity of 0.713 (95% CI 0.573–0.853), specificity of 0.869 (95% CI 0.764–0.974), F1 of 0.699 (95% CI 0.557–0.841), and AUC of 0.864 (95% CI 0.794–0.935). The calibration curve and Decision Curve Analysis (DCA) indicated the predictive capacity and net benefits of the clinic-ML nomogram were improved.
Conclusion
Combining the interpretability and simplicity of a nomogram with the efficacy and robustness of ML models, the proposed clinic-ML nomogram can serve as an insight tool for preoperative assessment of PCa risk stratifications, and could provide essential information for the individual diagnosis and treatment in PCa patients.
Similar content being viewed by others


Introduction
Prostate cancer (PCa) is one of the leading cancer types for the estimated new cancer cases and deaths in men worldwide [1]. Proper management of PCa patients required accurately assess the presence of, and a diagnostic evaluation of the characteristic severity of, the disease, thereby avoiding misestimation of patients [2]. Prostate-specific antigen (PSA) is a commonly used clinical biomarker for screening and diagnosis of PCa, while its high false-positive rate for diagnosis as a PCa biomarker has been questioned [3]. In clinical practice, multiparametric MRI (mpMRI) techniques are promising in detection and characterization of PCa [4]. However, mpMRI is still restricted by benign confounding appearances and substantial intra- and inter-reader variability. Systematic prostate biopsy is commonly performed for cancer detection with relatively low sensitivity and specificity, which could lead to delayed diagnosis as well as over-diagnosis with unnecessary discomfort and cost [5, 6]. Urologists are looking for a novel, non-invasive way to improve the accuracy of PCa detection, staging, and risk stratifications.
Minimally blood or urine-based approaches (“liquid biopsies”) are increasingly being used for cancer detection, enabling a precision oncology approach [7]. Information about tumors (e.g., circulating tumor cells, cell-free DNA and RNA) and immune responses (e.g., immune cell subsets, cytokines and exosome expression profiles) are potential diagnostic, prognostic and therapeutic targets of PCa [8, 9]. Inflammation and immune response contribute to tumorigenesis [10]. Many peripheral blood markers of inflammation and immune response are diagnostic and prognostic indicators of PCa [11,12,13]. Lymphocyte subsets, including T cells, B cells, and innate lymphoid cells, can distinguish between benign prostate disease (BPD) and PCa and predict clinical risk (low-/intermediate-risk disease and high-risk disease) in asymptomatic men [9, 13]. Clinically significant PCa (CSPCa) refers to intermediate- and high-risk PCa that still requires treatment in clinical practice according to the EAU guidelines [14]. Therefore, “indolent cancers” (low-risk PCa) and BPD are more appropriately grouped together than intermediate-risk PCa in PCa screening. Furthermore, treatment options for intermediate-risk patients range from focal therapy, radical prostatectomy to various radiotherapy approaches, whereas high-risk PCa is candidate for systemic therapy, indicating that a distinction should be made between intermediate-risk disease and high-risk disease [14, 15]. Unfortunately, few studies have examined the ability of lymphocyte subsets to distinguish among low-, intermediate-, and high-risk PCa [9, 13]. In addition, functional status of lymphocytes if not all, have rarely been studied in terms of diagnostic performance.
Automated methods to detect PCa and distinguish indolent from aggressive disease based on clinical records can assist in early diagnosis and treatment planning. Machine learning (ML), which employs computational algorithms that can accurately extract features without explicit pre-instructions, has been introduced as an advanced technique for aiding in the detection and characterization of PCa [9, 16,17,18,19,20]. ML approaches based on peripheral blood lymphocyte subsets can distinguish BPD from PCa, or low-/intermediate-risk from high-risk PCa from a small sample size in a hospital-based study [9, 13]. Thus, despite success of existing studies, these ML approaches don’t match the unmet medical need, with poor interpretation and low generalizability.
To address these challenges, this study included subjects ranging from BPD, low-risk, intermediate-risk, and high-risk PCa with clinical characteristics collected from two campuses of Wuhan Tongji Hospital, forming the largest sample size to date regarding functional subsets of peripheral lymphocyte for the diagnosis of PCa. We aimed to develop an easy-to-use and robust clinic-ML nomogram to aid in the non-invasive diagnosis and tripartite risk stratification of PCa.
Methods
Patient data collection
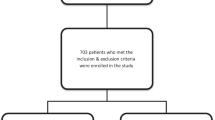
The study was approved by the Research Ethics Commission of Tongji Hospital and the requirement for informed consent was waived by the Ethics Commission (IRB ID: TJ- IRB20211246). The study screened 2039 patients with PCa and BPD who were admitted to Wuhan Tongji Hospital (China) from August 1st, 2020 to October 20th, 2022. Patients with missing laboratory, radiological or pathological data, or poor-quality MRI images were excluded from the study. Ultimately, 197 PCa patients, including 56 BPD, were enrolled in the study (Fig. 1). To maximize the utilization of the collected data, both nCSPCa and BPD were grouped into low-risk PCa category. All enrolled patients had the records of 42 clinic characteristics in functional subsets of peripheral lymphocyte (Table 1). The subsets of peripheral lymphocyte were detected by flow cytometry. The serum concentrations of interleukins were measured using the electrochemiluminescence immunoassay method (Cobas E602, Roche). The procedure for flow cytometry and interleukins detection by the clinical laboratory of Wuhan Tongji Hospital has been previously described [21].

The flowchart of patient enrollment and data preprocessing
Procedures
The workflow of this study is depicted in Fig. 2. Figure 3 illustrates the construction pipeline of the clinic nomogram and the proposed clinic-machine learning nomogram.
Data preprocessing and feature selection
The clinical records of the patients were manually inspected for quality control to identify any missing or abnormal values. Each clinic characteristic was visualized through boxplots (Additional file 1: Fig. S1) during this inspection process. To address uncertainty in the input data, a few recorded values were truncated. For example, if the Prostate-Specific Antigen (PSA) values exceeded 1000, they were re-processed and recorded as 1000. Similarly, in the case of ATL, Interleukin-6, Interleukin-1β, and Interleukin-10, certain characteristic values below a specific threshold cannot be accurately recorded due to machine measurement precision. Consequently, all these values for ATL, Interleukin-6, and Interleukin-1β were uniformly truncated to 5, 1.5 and 5, respectively. Additionally, Interleukin-10 was removed from the records due to too many duplicate values. As a result, a total of 41 clinic characteristics in functional subsets were used for the subsequent analysis.
After manual inspection, the clinical records were normalized using a min-max normalization scheme (Fig. 2A). The risk stratification of each patient was then manually assigned in accordance with the EAU guideline [14], resulting in 59 low-risk, 48 intermediate-risk, and 90 high-risk PCa patients.
These preprocessed clinic records, along with the corresponding risk stratification assignment, were fed into a Lasso regression algorithm, which selected the most significant features, generating the dataset used for the subsequent analysis (Fig. 2B). The Lasso-selected clinical records were randomly split into a training set and a test set in a 4:1 ratio. Consequently, a total of 157 records are used to train the machine learning (ML) models and construct the nomograms, and 40 records reserved for performance evaluation.
Machine learning models
Five commonly used ML algorithms were employed in this study for the task of predicting the risk stratification of PCa, including Support Vector Machine (SVM), Decision Tree (DT), Random Forest (RF), XGBoost and AdaBoost. These ML models were trained using a 10-fold cross-validation approach on the training set (Fig. 2B). The optimal ML model was then selected based on its performance evaluated in the test set (Additional file 1: Table S1) and served as the performance baseline for comparison with nomograms.
Development and validation of the clinic-machine learning nomogram
First, a clinic nomogram was created using a multivariable Ordinal Logistic Regression (OLR) algorithm on the clinic data from the training set (Fig. 2C). Second, a ML nomogram was built through the application of a multivariable OLR algorithm utilizing the probabilistic predictions of the five trained ML models. Third, to fully leverage the interpretability of the nomogram, a feature mapping algorithm (FMA) was developed to convert the ML monogram into a clinic-ML nomogram, using clinic features as variables (Fig. 3). Finally, the performance of the clinic nomogram and the proposed clinic-ML nomogram was evaluated on the test set using the Area Under the Curve (AUC) of the Receiver Operating Characteristic (ROC) and the calibration curve, and the clinical utility was measured through Decision Curve Analysis (DCA) (Fig. 2D).
The FMA generates for the clinic-ML nomogram the values of clinic features (CF) as
where FIi,j is the feature importance of the ith clinic feature in the jth trained ML model, MVj is the value of the jth ML models in the ML nomogram with i∈(1,M) and j∈(1,N) where M is the number of clinic features and N is the number of ML models, respectively. With the help of the FMA, the ML nomogram can be conveniently converted into a new clinic-ML nomogram whose variables are clinic features. The conversion enhances the interpretability while keeping the efficiency and power of the ML models.

Workflow for development and validation of the proposed clinic-ML nomogram for predictions of the risk stratification of PCa based on functional subsets of peripheral lymphocyte

Diagram of the clinic-ML nomogram and the clinic nomogram. The clinic-ML nomogram (g) is converted from the ML nomogram (e) via FMA (f) which extracts the feature importance (d) from ML models (b) trained on patients’ records with clinical features (a). The clinic nomogram (h) is constructed directly based on clinical features (a)
Statistical analysis
T-test or Mann-Whitney U-test were used for continuous variables conforming to normal distribution and homogeneity of variance. The Kruskal-Wallis H-test was used for testing other continuous and categorical variables. The implementation of ML algorithms, Lasso regression and ROC analysis was carried out using the Scikit-learn package in Python 3.6. All other statistical analyses were performed using the R statistical software Version 3.4.1. The “rms” package was utilized for the univariate, multivariate, and ordinal logistic regression analyses. The calibration plots and DCA were performed using the “rms” and “dca” package, respectively. The statistically significant difference between the AUCs of two ROCs was analyzed using the Delong test. A two-sided p value of less than 0.05 was considered statistically significant.
Results
Characteristics of patients
There were no significant differences arising in most clinic features between patients in the training and test sets (Table 1). However, significant differences were detected among low-, intermediate- and high-risk PCa patients in twelve clinic features in the training set, including Age, PSA, Neutrophil percentage, Neutrophils, Hemoglobing, Alkaline phosphatase, Lactate dehydrogenase, Th/Ts, Activated Ts cells, Interleukin-1β, Interleukin-2R, and Interleukin-6 (p < 0.05) (Table 2).
Selection of clinic features for ML models and the clinic nomogram
The Lasso regression was applied to determine the optimal subset of the clinic features (Fig. 4), yielding a total of nine features, i.e., Age, Alkaline phosphatase, B cells (CD3−CD19+), Interleukin-1β, Interleukin-2R, Lactate dehydrogenase, Neutrophil percentage, PSA and Th/Ts. These nine features were then utilized for the construction of both the ML models and the clinic monogram.

Lasso regression to generate the selected clinic features with iterative fitting using 5-fold cross-validation. Variation of the hyperparameter λ in Lasso regression is plotted vs. MSE (mean-squared-error) (A) and the coefficient profiles of clinic features (B). The light-blue vertical lines in (A) were drawn at the optimal values with one standard-deviation criteria. The vertical dashed line was drawn at the value selected at the logarithmic scale (λ), and nine features with non-zero coefficients are indicated
Performance assessment of ML algorithms
The data with Lasso-selected nine features were fed into five ML algorithms with a 10-fold cross validation. All ML algorithms show competitive performance in discriminating various risk stratifications (Fig. 5). The best performance was achieved by XGBoost which indicated favorable predictive efficacy in both training and test sets with AUC values of 0.989 and 0.842, sensitivity of 0.930 and 0.700, and specificity of 0.965 and 0.850, respectively (Table 5).

ROC of five ML algorithm in the training set (A) and the test set (B)
Development and performance assessment of the clinic-ML nomogram
Results of the univariate and multivariate logistic regression analysis (Table 3) suggested that predictions of four ML models, i.e., AdaBoost, Decision Tree, Random Forest, and XGBoost, were independent predictors of risk stratifications of PCa. Therefore, a multivariate OLR using probabilistic predictions of the four ML models was employed to construct the ML nomogram, which is then converted to a clinic-ML nomogram through the proposed FMA (Fig. 6B). VIFs of the variables in the ML nomogram were found to be within acceptable limits, as 5.13, 1.92, 5.08, and 2.39, respectively.

(upper) The clinic nomogram and (lower) the clinic-ML nomogram
The predictive scores of the clinic-ML nomogram were strongly correlated with the risk stratifications of PCa in both the training and test set (Fig. 7A). Using cutoff values of 2.24 and 6.00 for the clinic-ML nomogram predictive scores, the patients were classified into three risk stratification groups, and the results indicated the pattern of PCa patients was substantially different among the low-, intermediate- and high-risk stratification groups (Fig. 7B). For instance, in the test set, the probability of PCa patients was found to be significantly higher in the low-risk group compared to those in the intermediate- and high-risk groups (p < 0.05).

A Box plots indicating patterns of correlation between risk stratifications and the clinic-ML nomogram predictive scores in the training (upper left) and test set (upper right). B Number of PCa patients in low-, intermediate- and high-risk groups according to the clinic-ML nomogram predictive scores in the training (lower left) and test set (lower right)
Meanwhile, for the purpose of performance comparison, the Lasso-selected clinic features were utilized to construct the clinic monogram (Fig. 3). Analysis of univariate and multivariate logistic regressions revealed that five clinic variables, i.e., Age, B cells (CD3−CD19+), Neutrophil percentage, PSA and Th/Ts, were independent predictors of risk stratifications (Table 4). Subsequently, the corresponding clinic nomogram was constructed (Fig. 6A).
Performance of the clinic-ML nomogram and clinic nomogram was assessed using ROC analysis, showing the clinic-ML nomogram outperformed the clinic nomogram, with an AUC value of 0.998 vs. 0.897 in the training set, and 0.864 vs. 0.837 in the test set, respectively (Fig. 8; Table 5). The Delong test indicated that there was a significant difference in the AUC values of two nomograms in the training and test sets (p < 0.05). In addition, the performance of the clinic-ML nomogram was also superior to that of the optimal ML model, i.e., XGBoost (Table 5). The calibration curve demonstrated improved prediction performance of the clinic-ML nomogram compared to the other models (Fig. 9), which was further validated by the DCA, showing improved net benefits of the clinic-ML nomogram over both XGBoost and the clinic nomogram in both the training and test set (Fig. 10).

ROC of the clinic-ML nomogram, the clinic nomogram and XGBoost in the training set (A) and the test set (B)

Calibration curve of the clinic-ML nomogram in the training set (A) and the test set (B). Dashed lines indicate the reference line where an ideal nomogram would be. Red solid lines indicate the performance of the nomogram, while green solid lines indicate bias correction in the nomogram

DCA for predicting risk stratifications (low-risk vs. intermediate- and high-risk) of PCa using XGBoost, the clinic nomogram, and the clinic-ML nomograms in the training (A) and test set (B)
Discussion
The retrospective study aims to develop a clinic-ML nomogram for predicting risk stratifications of PCa patients based on functional subsets of peripheral lymphocyte. A total of 197 PCa patients were included and 41 clinic characteristics were collected, forming the largest number of samples used in a study of its kind. After Lasso regression, an optimal subset of nine clinic features, i.e., Age, Alkaline phosphatase, B cells (CD3−CD19+), Interleukin-1β, Interleukin-2R, Lactate dehydrogenase, Neutrophil percentage, PSA and Th/Ts, was selected and explored for the prognostic validity of the proposed clinic-ML nomogram by comparing it with a conventional clinic nomogram and various ML models both of which were constructed directly based on clinic characteristics. The results demonstrated that the clinic-ML nomogram fully leveraged the predictive capability of ML algorithms and outperformed the conventional nomogram and the best ML model in terms of accuracy and clinical utility. Meanwhile, the clinic-ML nomogram was more distinguishable and easier to manipulate than the clinic nomogram among three risk stratifications (Fig. 6), and had a strong guiding effect on active surveillance treatment for low-risk PCa patients (Fig. 7). Thus, the clinic-ML nomogram can serve as an insight tool for preoperative assessment of risk stratifications of PCa, combining the interpretability and simplicity of a nomogram with the efficacy and robustness of ML algorithms.
This study divided PCa patients into three risk groups, which is more closely related to the clinical treatment. However, few studies have been conducted to predict three-levels of risk stratifications of PCa using lymphocyte subsets with a nomogram. Our study combined the nomogram and the ML models to further improve the diagnostic efficiency. Meanwhile, some other studies utilized imaging data (such as PSMA PET/CT, MRI, TRUS) with other clinic indicators to establish the nomogram for the prediction of PCa risk stratifications [22,23,24,25]. Despite of the improved performance with the imaging data modality, those studies achieved comparable, if not slightly inferior, results compared to the present study (Additional file 1: Table S2). In addition, the use of “scores” calculated by sophisticated algorithms as variables in the nomogram may be helpful in improving prediction accuracy, but may also increase the complexity of the nomogram and make it more difficult to interpret [17, 26]. The approach taken in this study, which used the most significant examination feature as variables in the clinical ML nomogram, may provide a more direct and simple method for assessing patient risk stratifications.
The study presented several limitations that should be acknowledged. Firstly, all the data were collected exclusively from one medical center with two campuses located in the same city. Therefore, the generalizability of the proposed clinic-ML nomogram to other populations and settings remains unknown and requires further evaluation in other cohorts. To address this issue, a multi-center study is planned to assess the external validity and robustness of the clinic-ML nomogram. Secondly, the number of ML algorithms used in the development of the clinic-ML nomogram was limited, and future studies may benefit from the inclusion of additional ML algorithms to enhance the performance of the nomogram. Thirdly, the imaging data plays a crucial role in the diagnosis and staging of PCa, and its integration into the clinic-ML nomogram could further improve its diagnostic efficiency and predictive power.
The application of nomograms in clinic diagnosis has gained popularity in recent years due to their simplicity, intuition, and interpretability [27]. The integration of nomograms with powerful ML algorithms to improve the performance while maintaining interpretability of the nomogram is a research hot-spot [28,29,30]. The proposed clinic-ML nomogram is an easy-to-use and powerful tool for accurately predicting the risk stratification of PCa patients, which could provide essential information for individual diagnosis and treatment in PCa.
Availability of data and codes
Datasets and codes for the study are available from the corresponding author upon reasonable request with a signed agreement for scientific research purposes only.
Abbreviations
- AUC:
-
Area Under the ROC Curve
- BPD:
-
Benign prostate disease
- CSPCa:
-
Clinically significant PCa
- DCA:
-
Decision curve analysis
- DT:
-
Decision tree
- FMA:
-
Feature mapping algorithm
- ML:
-
Machine Learning
- mpMRI:
-
Multiparametric MRI
- OLR:
-
Ordinal logistic regression
- PCa:
-
Prostate cancer
- PSA:
-
Prostate-specific antigen
- ROC:
-
Receiver operating characteristic curve
- RF:
-
Random forest
- SVM:
-
Support vector machine
References
Siegel RL, Miller KD, Fuchs HE, Jemal A. Cancer statistics, 2022. Cancer J Clin. 2022;72(1):7–33. https://doi.org/10.3322/caac.21708.
Sandhu S, Moore CM, Chiong E, Beltran H, Bristow RG, Williams SG. Prostate cancer. Lancet. 2021;398(10305):1075–90. https://doi.org/10.1016/S0140-6736(21)00950-8.
Castle PE. PSA testing for prostate cancer screening. Lancet Oncol. 2015;16(1):e2–3. https://doi.org/10.1016/S1470-2045(14)71108-8.
Grey ADR, Scott R, Shah B, Acher P, Liyanage S, Pavlou M, Omar R, Chinegwundoh F, Patki P, Shah TT, Hamid S, Ghei M, Gilbert K, Campbell D, Brew-Graves C, Arumainayagam N, Chapman A, McLeavy L, Karatziou A, Alsaadi Z, Ahmed HU. Multiparametric ultrasound versus multiparametric MRI to diagnose prostate cancer (CADMUS): a prospective, multicentre, paired-cohort, confirmatory study. Lancet Oncol. 2022;23(3):428–38. https://doi.org/10.1016/S1470-2045(22)00016-X.
Ukimura O, Coleman JA, de la Taille A, Emberton M, Epstein JI, Freedland SJ, Giannarini G, Kibel AS, Montironi R, Ploussard G, Roobol MJ, Scattoni V, Jones JS. Contemporary role of systematic prostate biopsies: indications, techniques, and implications for patient care. Eur Urol. 2013;63(2):214–30. https://doi.org/10.1016/j.eururo.2012.09.033.
Borghesi M, Ahmed H, Nam R, Schaeffer E, Schiavina R, Taneja S, Weidner W, Loeb S. Complications after systematic, random, and image-guided prostate biopsy. Eur Urol. 2017;71(3):353–65. https://doi.org/10.1016/j.eururo.2016.08.004.
Nikanjam M, Kato S, Kurzrock R. Liquid biopsy: current technology and clinical applications. J Hematol Oncol. 2022;15(1):131. https://doi.org/10.1186/s13045-022-01351-y.
Trujillo B, Wu A, Wetterskog D, Attard G. Blood-based liquid biopsies for prostate cancer: clinical opportunities and challenges. Br J Cancer. 2022;127(8):1394–402. https://doi.org/10.1038/s41416-022-01881-9.
Hood SP, Cosma G, Foulds GA, Johnson C, Reeder S, McArdle SE, Khan MA, Pockley AG. Identifying prostate cancer and its clinical risk in asymptomatic men using machine learning of high dimensional peripheral blood flow cytometric natural killer cell subset phenotyping data. eLife. 2020;9: e50936. https://doi.org/10.7554/eLife.50936.
Kiely M, Lord B, Ambs S. Immune response and inflammation in cancer health disparities. Trends Cancer. 2022;8(4):316–27. https://doi.org/10.1016/j.trecan.2021.11.010.
Bauckneht M, Rebuzzi SE, Signori A, Frantellizzi V, Murianni V, Lodi Rizzini E, Mascia M, Lavelli V, Donegani MI, Ponzano M, Gaudiano A, Stazza ML, Licari M, Cavallini L, Laghi V, Cindolo L, Maggi M, Sciarra A, Mammucci P, Sambuceti G, Fornarini G. The prognostic power of inflammatory indices and clinical factors in metastatic castration-resistant prostate cancer patients treated with radium-223 (BIO-Ra study). Eur J Nucl Med Mol Imaging. 2022;49(3):1063–74. https://doi.org/10.1007/s00259-021-05550-6.
Mao F, Yang C, Luo W, Wang Y, Xie J, Wang H. Peripheral blood lymphocyte subsets are associated with the clinical outcomes of prostate cancer patients. Int Immunopharmacol. 2022;113(Pt A): 109287. https://doi.org/10.1016/j.intimp.2022.109287.
Cosma G, McArdle SE, Foulds GA, Hood SP, Reeder S, Johnson C, Khan MA, Pockley AG. Prostate cancer: early detection and assessing clinical risk using deep machine learning of high dimensional peripheral blood flow cytometric phenotyping data. Front Immunol. 2021;12: 786828. https://doi.org/10.3389/fimmu.2021.786828.
Mottet N, van den Bergh RCN, Briers E, Van den Broeck T, Cumberbatch MG, De Santis M, Fanti S, Fossati N, Gandaglia G, Gillessen S, Grivas N, Grummet J, Henry AM, van der Kwast TH, Lam TB, Lardas M, Liew M, Mason MD, Moris L, Oprea-Lager DE, Cornford P. EAU-EANM-ESTRO-ESUR-SIOG guidelines on prostate Cancer-2020 update. Part 1: screening, diagnosis, and local treatment with curative intent. Eur Urol. 2021;79(2):243–62. https://doi.org/10.1016/j.eururo.2020.09.042.
Hopstaken JS, Bomers JGR, Sedelaar MJP, Valerio M, Fütterer JJ, Rovers MM. An updated systematic review on focal therapy in localized prostate cancer: what has changed over the past 5 years? Eur Urol. 2022;81(1):5–33. https://doi.org/10.1016/j.eururo.2021.08.005.
Elmarakeby HA, Hwang J, Arafeh R, Crowdis J, Gang S, Liu D, AlDubayan SH, Salari K, Kregel S, Richter C, Arnoff TE, Park J, Hahn WC, Van Allen EM. Biologically informed deep neural network for prostate cancer discovery. Nature. 2021;598(7880):348–52. https://doi.org/10.1038/s41586-021-03922-4.
Hiremath A, Shiradkar R, Fu P, Mahran A, Rastinehad AR, Tewari A, Tirumani SH, Purysko A, Ponsky L, Madabhushi A. An integrated nomogram combining deep learning, Prostate Imaging-Reporting and Data System (PI-RADS) scoring, and clinical variables for identification of clinically significant prostate cancer on biparametric MRI: a retrospective multicentre study. Lancet Digit Health. 2021;3(7):e445–54. https://doi.org/10.1016/S2589-7500(21)00082-0.
Nir G, Karimi D, Goldenberg SL, Fazli L, Skinnider BF, Tavassoli P, Turbin D, Villamil CF, Wang G, Thompson DJS, Black PC, Salcudean SE. Comparison of Artificial Intelligence Techniques to evaluate performance of a classifier for automatic grading of prostate cancer from digitized histopathologic images. JAMA Netw Open. 2019;2(3):e190442. https://doi.org/10.1001/jamanetworkopen.2019.0442.
Mokoatle M, Mapiye D, Marivate V, Hayes VM, Bornman R. Discriminatory gleason grade group signatures of prostate cancer: an application of machine learning methods. PLoS One. 2022;17(6): e0267714. https://doi.org/10.1371/journal.pone.0267714.
Goldenberg SL, Nir G, Salcudean SE. A new era: artificial intelligence and machine learning in prostate cancer. Nat Rev Urol. 2019;16(7):391–403. https://doi.org/10.1038/s41585-019-0193-3.
Yang L, Cai Y, Fu X. Impact of perioperative multiple doses of glucocorticoids on peripheral blood lymphocyte subsets and inflammatory cytokines in patients with non-small cell lung cancer. Front Surg. 2022;9: 859984. https://doi.org/10.3389/fsurg.2022.859984.
Varghese B, Chen F, Hwang D, Palmer SL, De Castro Abreu AL, Ukimura O, Aron M, Aron M, Gill I, Duddalwar V, Pandey G. Objective risk stratification of prostate cancer using machine learning and radiomics applied to multiparametric magnetic resonance images. Sci Rep. 2019;9(1):1570. https://doi.org/10.1038/s41598-018-38381-x.
Xiang M, Ma TM, Savjani R, Pollom EL, Karnes RJ, Grogan T, Wong JK, Motterle G, Tosoian JJ, Trock BJ, Klein EA, Stish BJ, Dess RT, Spratt DE, Pilar A, Reddy C, Levin-Epstein R, Wedde TB, Lilleby WA, Fiano R, et al. Performance of a prostate-specific membrane antigen positron emission tomography/computed tomography-derived risk-stratification tool for high-risk and very high-risk prostate cancer. JAMA Netw Open. 2021;4(12): e2138550. https://doi.org/10.1001/jamanetworkopen.2021.38550.
Osman SOS, Leijenaar RTH, Cole AJ, Lyons CA, Hounsell AR, Prise KM, O’Sullivan JM, Lambin P, McGarry CK, Jain S. Computed tomography-based radiomics for risk stratification in prostate cancer. Int J Radiat Oncol Biol Phys. 2019;105(2):448–56. https://doi.org/10.1016/j.ijrobp.2019.06.2504.
Montoya Perez I, Jambor I, Pahikkala T, Airola A, Merisaari H, Saunavaara J, Alinezhad S, Väänänen RM, Tallgrén T, Verho J, Kiviniemi A, Ettala O, Knaapila J, Syvänen KT, Kallajoki M, Vainio P, Aronen HJ, Pettersson K, Boström PJ, Taimen P. Prostate cancer risk stratification in men with a clinical suspicion of prostate cancer using a unique biparametric MRI and expression of 11 genes in apparently benign tissue: evaluation using machine-learning techniques. J Magn Reson Imaging. 2020;51(5):1540–53. https://doi.org/10.1002/jmri.26945.
Gui S, Lan M, Wang C, Nie S, Fan B. Application value of radiomic nomogram in the differential diagnosis of prostate Cancer and Hyperplasia. Front Oncol. 2022;12: 859625. https://doi.org/10.3389/fonc.2022.859625.
Dong D, Fang MJ, Tang L, Shan XH, Gao JB, Giganti F, Wang RP, Chen X, Wang XX, Palumbo D, Fu J, Li WC, Li J, Zhong LZ, De Cobelli F, Ji JF, Liu ZY, Tian J. Deep learning radiomic nomogram can predict the number of lymph node metastasis in locally advanced gastric cancer: an international multicenter study. Ann Oncol. 2020;31(7):912–20. https://doi.org/10.1016/j.annonc.2020.04.003.
Chen S, Shu Z, Li Y, Chen B, Tang L, Mo W, Shao G, Shao F. Machine learning-based radiomics nomogram using magnetic resonance images for prediction of Neoadjuvant chemotherapy efficacy in breast Cancer patients. Front Oncol. 2020;10: 1410. https://doi.org/10.3389/fonc.2020.01410.
Liu S, Yu X, Yang S, Hu P, Hu Y, Chen X, Li Y, Zhang Z, Li C, Lu Q. Machine learning-based radiomics nomogram for detecting extramural venous Invasion in rectal Cancer. Front Oncol. 2021;11: 610338. https://doi.org/10.3389/fonc.2021.610338.
Yan C, Hao P, Wu G, Lin J, Xu J, Zhang T, Li X, Li H, Wang S, Xu Y, Woodruff HC, Lambin P. Machine learning-based combined nomogram for predicting the risk of pulmonary invasive fungal infection in severely immunocompromised patients. Ann Transl Med. 2022;10(9):514. https://doi.org/10.21037/atm-21-4980.
Acknowledgements
The authors are grateful to the doctors in Department of Urology, Wuhan Tongji Hospital, Tongji Medical College, Huazhong University of Science and Technology for the support in collecting the clinical data.
Funding
This work was supported by the National Natural Science Foundation of China (No. 81702989) and the Hubei Key Laboratory of Intelligent Robot in Wuhan Institute of Technology (Grant No. HBIRL 202201).
Author information
Authors and Affiliations
Contributions
CY and XW contributed to the conceptualization and design of the study. CY, ZL, ZW, ZH and SW collected the data. YF, XC and XW conducted the analysis. CY and XW led the writing of the original draft. GX, ZW, ZH, and SW edited the manuscript, discussed results, and provided feedback regarding the manuscript. CY supervised the study and acquired funding. XW has verified the underlying data. All authors had full access to the data and approved the manuscript for publication.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The study was approved by the Research Ethics Commission of Wuhan Tongji Hospital and the requirement for informed consent was waived by the Ethics Commission (IRB ID: TJ- IRB20211246).
Consent for publication
Not applicable.
Competing interests
The authors have declared that no conflict of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1: Fig. S1.
Boxplot of the quality control data of 41 characteristics in functional subsets of peripheral lymphocyte for 197 PCapatients enrolled in this study. Table S1. Performance evaluation of five ML algorithms in the training (first line in each cell) and test set (second line in each cell). Better results in the test set are shown in bold. Table S2. Comparison of this study with selected previous works.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Yang, C., Liu, Z., Fang, Y. et al. Development and validation of a clinic machine-learning nomogram for the prediction of risk stratifications of prostate cancer based on functional subsets of peripheral lymphocyte. J Transl Med 21, 465 (2023). https://doi.org/10.1186/s12967-023-04318-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12967-023-04318-w