
Abstract
Background
The Functional Assessment of Cancer Therapy-Breast (FACT-B) is the most commonly used scale for assessing quality of life in patients with breast cancer. The lack of preference-based measures limits the cost-utility of breast cancer in China. The goal of this study was to explore whether a mapping function can be established from the FACT-B to the EQ-5D-5 L when the EQ-5D health-utility index is not available.
Methods
A cross-sectional survey of adults with breast cancer was conducted in China. All patients included in the study completed the EQ-5D-5 L and the disease-specific FACT-B questionnaire, and demographic and clinical data were also collected. The Chinese tariff value was used to calculate the EQ-5D-5 L utility scores. Five models were evaluated using three different modelling approaches: the ordinary least squares (OLS) model, the Tobit model and the two-part model (TPM). Total scores, domain scores, squared terms and interaction terms were introduced into models. The goodness of fit, signs of the estimated coefficients, and normality of prediction errors of the model were also assessed. The normality of the prediction error is determined by calculating the root mean squared error (RMSE), the mean absolute deviation (MAD), and the mean absolute error (MAE). Akaike information criteria (AIC) and Bayes information criteria (BIC) were also used to assess models and predictive performances. The OLS model was followed by simple linear equating to avoid regression to the mean.
Results
The performance of the models was improved after the introduction of the squared terms and the interaction terms. The OLS model, including the squared terms and the interaction terms, performed best for mapping the EQ-5D-5 L. The explanatory power of the OLS model was 70.0%. The AIC and BIC of this model were the smallest (AIC = -705.106, BIC = -643.601). The RMSE, MAD and MAE of the OLS model, Tobit model and TPM were similar. The MAE values of the 5-fold cross-validation of the multiple models in this study were 0.07155~0.08509; meanwhile, the MAE of the TPM was the smallest, followed by that of the OLS model. The OLS regression proved to be the most accurate for the mean, and linearly equated scores were much closer to observed scores.
Conclusions
This study establishes a mapping algorithm based on the Chinese population to estimate the EQ-5D-5 L index of the FACT-B and confirms that OLS models have higher explanatory power and that TPMs have lower prediction error. Given the accuracy of the mean prediction and the simplicity of the model, we recommend using the OLS model. The algorithm can be used to calculate EQ-5D scores when EQ-5D data are not directly collected in a study.
Similar content being viewed by others

Background
Breast cancer has a devastating effect on global population health, accounting for 0.52 million annual deaths [1]. In China, the morbidity rate of breast cancer significantly outweighs that of other cancers, although the survival rate of breast cancer patients has dramatically increased with the development of clinical practice and disease management [2]. As survival rates have improved, health-related quality of life has gained significant attention recently, since the vast majority of survivors suffer from a loss of functions, including arm activity, sexual activity, and sleep quality [3,4,5]. At the same time, the growing number of survivors and the comprehensive application of advanced medical technology are increasing the burden of the disease on society [6], which calls for an economic re-evaluation, such as a cost-utility analysis.
Extensive generic non-preference-based questionnaires were administered in a prior study to measure health-related quality of life; these questionnaires included the SF-36 [7], the EORTC [8], the QLQ-C30 [9], the IBCSG, the WHO-QOL BREF, and the FACT-B. For breast cancer patients, the chief among these is the FACT-B, which can most accurately measure quality of life [10]. Non-preference-based questionnaires are not appropriate for a cost-utility analysis, since their results cannot derive quality-adjusted life years (QALYs) directly. The QALY is a widely used measure of health improvement that is used to guide health-care resource allocation decisions [11]. Therefore, preference-based measures are highly recommended in health-economic evaluations, such as the EQ-5D and SF-6D, for these measures can directly assess health utility [12, 13].
Although generic preference-based measures, especially the EQ-5D, are highly recommended, they are usually excluded in clinical trials [14]. A recent systematic review of breast cancer health utility values in China found that all three studies of health economics models in China cited measurements of breast cancer patients in the UK or Hong Kong, China [15]. The lack of health utility values limits the development of health economics research. One potential solution is to perform a mapping function, mapping from non-preference-based to preference-based measures. Although a mapping function would lose some information and increase uncertainty, it is currently the only solution for conducting a cost-utility analysis when straightforward health utility data are unavailable [16]. Therefore, it is of great significance to establish a health utility value mapping model for Chinese populations, which can broaden the sources of health utility values and provide important parameters for health economics evaluation.
Currently, there are 3 studies focusing on mapping from FACT-B to EQ-5D [16]. Two prior studies from Singapore performed mapping functions from FACT-B to EQ-5D-5 L among breast cancer patients, and applied the utility-scoring systems, which were derived from data of British and Japanese patients [17, 18]. A study from the UK used the EQ-5D-3 L scale and UK tariffs [19]. However, the study pointed to disparities in utility-scoring systems among nations, owing to different utility weights [20]. Therefore, a utility-scoring system of one nation will not necessarily be applicable to other nations.
A prior study demonstrated that several socio-demographic and clinical factors are associated with the health utility of breast cancer patients [21,22,23], including age, gender, income, education, and treatment. It is unknown whether these factors could generalize to the overall Chinese population.
The present study will first develop three sophisticated mapping functions from the FACT-B to the EQ-5D-5 L using three modelling algorithms, including the ordinary least squares (OLS) model, the Tobit model, and the two-part model (TPM). Second, this study will compare the predictability of the three models, and the resulting data will be used to select the most appropriate model for this purpose.
Method
Participants
The study included 446 breast cancer patients meeting the following criteria:1) diagnosed by pathology or clinical tests; 2) aged 18 or above; and 3) indicated no mental disorders, thus demonstrating full communicative capacity. Patients with severe chronic comorbidities, including cardiovascular and psychiatric disorders, were excluded from this study. All patients came from a tertiary oncology hospital in West China.
Informed consent from all participants was obtained prior to the study. Ethical permission was granted by the Ethics Committee, West China School of Medicine/West China Hospital, Sichuan University (approval number 2017–255).
Data source
Health-related quality of life data were sourced from two measures, namely, the FACT-B and the EQ-5D-5 L. Demographic data came from field investigation, while clinical data were obtained from electronic medical records. Data were collected in the period from November 2017 to May 2018. Data was collected by the research team. To ensure data qualification, a data collection manual was prepared and the interviewers were trained strictly prior to data collection.
Independent variables
Health-related quality of life from the FACT-B
The FACT-B contains 37 questions along five dimensions: physical wellbeing (PWB), social/family wellbeing (SWB), emotional wellbeing (EWB), functional wellbeing (FWB), and additional concerns about breast cancer (BCS) [24]. The values for each question range from 0 to 4, and final scores are anchored on a scale of 0 to 148, where 148 represents the highest quality of life. There are 7 items for physical wellbeing (PWB), 7 items for social/family wellbeing (SWB), 6 items for emotional wellbeing (EWB), 7 items for functional wellbeing (FWB), and 10 items for additional concerns about breast cancer (BCS). The total scores for each dimension are as follows: PWB, 28; SWB, 28; EWB, 24; FWB, 28; and BCS, 40. The validity and reliability of the FACT-B in the Chinese version were confirmed [25].
Clinical data
From electronic patient records, this study obtained clinical data, including morbidity status, clinical stages, clinical practice, and menopausal status.
Demographic determinants
Self-reported demographic determinants include patient age, education status, marriage, type of medical insurance, profession, and household income.
Dependent variable from EQ-5D-5 L
This study used the widely validated EQ-5D-5 L to measure health utility as a dependent variable [26]. The EQ-5D-5 L comprises five self-reported dimensions and the EQ-VAS. The self-reported dimensions are mobility, self-care, usual activities, pain/discomfort, and anxiety/depression; each of these is measured along 5 levels of severity. To investigate the correlation between the FACT-B and the EQ-5D-5 L, this study assigned the values of severity to range from 5 to 1, where 5 indicates that patients can perform activities in the dimension without difficulty. Additionally, the respondents agreed to complete the EQ-VAS test to measure their health status. Values of health status are anchored on a scale of 0 to 100, where 100 represents the best health status imaginable.
Data analysis
The value set of China was used to transfer overall scores from the EQ-5D-5 L to health utility [27].
The Wilcoxon test and the Kruskal-Wallis H test were performed to screen potential demographic and clinical determinants of health utility. Only those of statistical significance were introduced into the modelling process. The skewness of the results from the EQ-5D-5 L and the FACT-B was assessed.
The Spearman correlation coefficient was used to evaluate the correlation between the FACT-B and the EQ-5D-5 L.
Three modelling algorithms, namely, the OLS model, the Tobit model, and the two-part model, were used to develop mapping functions from the FACT-B to the EQ-5D-5 L.
OLS is commonly used in econometrics to estimate parameters by minimizing the sum of squared errors of data. Although it performs well in many fields of research, its predictability could be restricted by the scale of health utility, ranging from 0 to 1. The ceiling effects of health utility could also lead to skewed distribution and heteroscedasticity, which invalidates the normality assumption of OLS. Therefore, OLS is theoretically not the most appropriate model in mapping health utility [28]. However, OLS was concluded to be the best model in a prior study and was referred to by approximately 80% of publications conducting mapping functions with regard to health utility [17, 29, 30].
The Tobit model is an alternative that improves the ability to cope with ceiling effects. Another alternative is the censored least absolute deviations (CLAD), a median-based method. However, most econometric models are based on the mean, which is a consideration that led this study not to include or evaluate CLAD [31].
The two-part model has been suggested for use in mapping health utility due to its predictability and ability to cope with ceiling effects [32, 33]. This model is divided into two steps. The first step involves estimating the entire estimated sample to predict the occurrence of ceiling effects, usually using a logistic regression model. The second step estimates the utility value in the non-complete health state and ultimately calculates the overall utility value [34]. Separate models were conducted for each domain and for the overall scores of the FACT-B, as suggested in the literature [31, 33]. Squared terms and interaction terms of statistical significance were also examined. Three modelling approaches were performed in each model. A two-tailed P value of less than 0.10 was considered statistically significant.
-
Model 1:Overall score of the FACT-B
-
Model 2: All domain scores on the FACT-B
-
Model 3: Domain scores on the FACT-B of statistical significance in model2
-
Model 4: Model3 + squared terms of statistical significance in model2
-
Model 5: Model 4 + interaction terms of statistical significance in model2
To compare the models, we considered their goodness of fit, applicability, and simplicity. Goodness of fit indicates the extent to which the model interprets the observed data. Mean absolute error (MAE), root mean square error (RMSE), mean absolute deviation (MAD), Akaike information criteria (AIC) and Bayes information criteria (BIC) were used as important indicators for model selection:lower MAE, RMSE, MAD, AIC and BIC represent better models. R2 was computed to measure the predictability of the OLS model. In the Tobit and TPM regression methods, the determination coefficient R2 is not clearly defined. Referring to the study by Cheung YB et al. [17] and comparing the results of the two studies, we calculated the square of the correlation coefficient (r) between the observed and predicted values of each model. Here, r2 is equivalent to R2 in OLS. To avoid overestimating r2 due to an increase in independent variables, we define the adjusted r2 as follows: 1- \( \frac{\left(n-1\right)}{\left(n-p-1\right)}\left(1-{\mathrm{r}}^2\right) \). In this formula, n represents the sample size, and p is the number of parameters in the model. Finally, if the model shows similar MAE, RMSE, MAD, AIC, BIC and r2 values, applicability and model simplicity will be considered. Due to the lack of available external data in this study, 5-fold cross-validation was used to examine the stability and reliability of the model, and the result of the cross-validation was measured using the MAE.
Observed and predicted EQ-5D values were plotted to measure model performance.
We also performed non-parametric tests (Mann-Whitney U tests for two categories or Kruskal-Wallistests for more than two categories) to examine differences in EQ-5D-5 L index scores from different models by demographic and clinical features. Simple linear equating was used to model OLS 5 to avoid regression to the mean. We used the following linking function that transforms the X-scores to have the same mean and standard deviation as the Y-scores [35]:Y= \( {\upmu}_{\mathrm{Y}}+\left(\frac{\upsigma_{\mathrm{Y}}}{\upsigma_{\mathrm{X}}}\right)\left(\mathrm{X}-{\upmu}_{\mathrm{X}}\right) \), where μX and μY are the mean values of X and Y, and σX and σY the standard deviations. The mean of the model OLS 5 was 0.857, and the variance was 0.161. Therefore , μX was 0.857 and σX was 0.161.
Data analyses were performed in Stata version 12.0(StatCorp, College Station, TX).
Results
The average age of the 446 patients was 52.03 years (SD, 8.79). Demographic and clinical characteristics are summarized in Table 1.
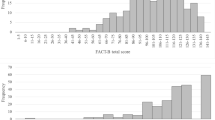
Figures 1 and 2 present the histograms of the results from the EQ-5D-5 L and the FACT-B, both of which were skewed to the right. The values of the two measures are summarized in Table 2. The value of the EQ-5D-5 L ranged from − 0.349 to 1;the mean was 0.857(SD, 0.193), and the median was 0.197. The ceiling effects existed in the health utility of 25.11% of participants, which did not exist in the results from the FACT-B. The mean of the results from the FACT-B was 104.31(SD, 19.732), and the median was 106.

Histogram of EQ-5D-5 L scores

Histogram of FACT-B scores
Table 3 presents the Spearman correlation coefficients between the results from the EQ-5D-5 L and those from the FACT-B. The correlation coefficient between the overall score of the two measures was 0.642. The correlation coefficients between the overall value from the EQ-5D-5 L and the values of each dimension of the FACT-B ranged from 0.389 to 0.601. The correlation coefficients between the overall score of the FACT-B and the values of each dimension in the EQ-5D-5 L ranged from 0.316 to 0.627. The correlation coefficients among each dimension from the two measures ranged from 0.203 to 0.535. The P value of each correlation coefficient was less than 0.001.
Correlations between demographic and clinical characteristics and results from the EQ-5D-5 L were examined. Correlations between results from the EQ-5D-5 L and type of health insurance, clinical stage, TNM stage, admission, the practice of endocrine therapy, and morbidity status were statistically significant (P value less than 0.05). Age, minority status, education, marital status, registered location (Hukou), profession, household income, hormone receptor, HER2, surgical procedures, chemotherapy, radiotherapy, targeted therapy, and menopausal status were not found to be statistically significant.
Five models developed by OLS are presented in Tables 4 and 6. With respect to goodness of fit, models with squared terms and interaction terms performed better. Models developed by Tobit analysis and TPM are presented in Table 5. Compared with models 1 to 4, model 5 performed better for both Tobit models and TPMs. Although interaction terms and squared terms were introduced to OLS 5, Tobit 5 and TPM 5, the interaction terms of statistical significance were different in each model. PWBxBCS was statistically significant in OLS 5 and Tobit 5, while PWBxBCS and PWBxFWB were statistically significant in TPM 5.
Fifteen models using three modelling approaches are presented in Table 6. Table 6 shows all 15 models of the three technology modelling constructions, namely, the OLS model, the Tobit model, and the TPM.
From the perspective of r2, the OLS model (0.503~0.700) had the largest r2, in comparison to that of the TPM (0.534~0.695) and the Tobit model (0.575~0.694). In models 1–4, the r2 values of the OLS model and the TPM were slightly smaller than that of the Tobit model. However, it was significantly improved in model 5, exceeding that of the Tobit model. Independent variables varied among models 1–5. Model 2 generally performed better than model 1 within each domain with respect to the overall score, while model 2 performed consistently with model 3, which had fewer independent variables and was more concise. The introduction of squared terms and interaction terms in models 4 and 5 improved model performance. For the three indicators of RMSE, MAD, and MAE, the value of model 5 was the smallest. Compared with RMSE, MAD, MAE of OLS 5, Tobit 5 and TPM 5, the values of the three indicators were very similar. OLS 5 had the smallest AIC and BIC values. Thus, considering the simplicity of the model, the best-performing model of the 15 models was TPM 5.
The predicted values from model 4 and model 5 are presented in Table 7. The Tobit model had a poor prediction of the mean. While predicted values from OLS were much closer to observed values, the OLS model overestimated poor health. Moreover, 0.897% of the predicted values from OLS 4 were larger than 1. In contrast to the OLS model, the TPM performed well for lower values.
Table 8 used a 5-fold cross-validation method to randomly divide the samples into 5, each of which was selected as the verification set, and the remaining 4 were used as training sets. This was repeated 5 times, and the average MAE was calculated for each. The results showed that the MAEs were 0.07155~0.08509 after the six best models were verified by 5-fold cross-validation. The TPM had the smallest MAE, followed by the OLS model and the Tobit model.
Table 9 shows the EQ-5D-5 L values for patients with different demographic and clinical characteristics in the three best models. The estimated health utilities from model OLS 5 were closer to the measured ones than those from model Tobit 5 and TPM 5. When the linear equated scores were used for model OLS 5, the predicted values were closer to the means of the actual values.
Predicted values and observed values were plotted based on the best model among the three modelling approaches in Fig. 3. Compared with Tobit 5, the predicted values from OLS 5 and TPM 5 were much closer to the observed values from the EQ-5D-5 L. When linear equivalence was used, the value of the model OLS 5 was closest to that of the EQ-5D-5 L.

Observed and predicted EQ-5D-5 L for best fitting models for OLS, Tobit and TPM
Discussion
This study performed several mapping functions, mapping from values of the FACT-B to the health utility of the EQ-5D-5 L. Three modelling approaches, namely, OLS, Tobit, and TPM, performed heterogeneously with respect to r2. From the perspective of r2 and adjusted r2, the OLS model is the largest in model 5. Three modelling approaches performed similarly in the RMSE, MAD and MAE in model 5. The AIC and BIC of model OLS 5 were the smallest, although the TPM achieved a slightly smaller MAE value than the OLS model at the 5-fold cross-validation. Considering the comprehensive performance and simplicity of the OLS model, OLS 5 was selected as the best model (r2 = 0.700, adjusted r2 = 0.690, RMSE = 0.108, MAD = 0.101, MAE = 0.071, AIC = -705.106, BIC = -643.601).
To the best of our knowledge, this is a pioneering study for conducting mapping functions based on data from breast cancer patients in China. Although extensive research has been conducted onhealth utility mapping functions, only three prior studies performed mapping functions for breast cancer patients [16]. One study used adjusted limited dependent variable mixture models (ALDVMMs) to establish mapping between the FACT-B and the EQ-5D-3 L scales [19]. However, we chose a 5-dimensional scale to avoid ceiling effects. The only two articles that used the EQ-5D-5 L scale were from the same study and were based on data from 238 Singaporean women [17, 18]. Five regression models mapping from the FACT-B to the EQ-5D-5 L were conducted, which may or may not set the upper limit of health utility to 1 [17]. The OLS model, which had the best performance in the Singaporean study, performed better in this study with respect to goodness of fit(r2 = 0.497, adjusted r2 = 0.489, RMSE = 0.013, MAD = 0.091). Consistent with prior studies, the Tobit model presented lower predictability in our study [17].
Although the EQ-5D-5 L mitigated ceiling effects and floor effects, compared with the EQ-5D-3 L, the ceiling effects still existed for 25.11% of participants in the current study. The skewed distribution of EQ-5D-5 L values is presented in Fig. 1. The TPM was conducted separately for health utility values of 1 and other values to cope with data limitations, which was consistent with prior studies [36]. In Table 7, we also found that the TPM has a better predictive effect than the OLS model on larger values. However, Table 9 shows that the OLS regression had the most accurate means by different demographic and clinical characteristics, and the linear equated scores were more similar to the observed scores.
Correlation coefficients among domains of the EQ-5D-5 L and the FACT-B were assessed in this study, and the correlation coefficients were statistically significant (P values less than 0.001). In the past, there were mapping studies to explore the correlation between scales [37, 38]; in the case of a conceptual overlap between the two tools, the mapping is more likely to succeed. It is notable that the values of SWB did not predict health utility from the EQ-5D-5 L in the OLS model, which may result from the lack of domains related to social function onthe EQ-5D-5 L. Similarly, SWB was not statistically significant in prior mapping studies of lung cancer, prostate cancer and breast cancer [17, 39, 40].
A systematic review reported that R2 for the mapping function from a specific questionnaire to a generic health utility measure usually ranged from 0.4 to 0.6 [28]. The introduction of squared terms and interaction terms could significantly increase R2 to 0.8, which suggested that the association was non-linear [41, 42]. The introduction of squared terms and interaction terms in models 4 and 5 in our study improved model performance. The r2 of the model OLS 5 reached 0.700, which indicated good results. In addition, in contrast to prior studies [17], this study selected its value set in China instead of using a non-native crosswalk project to convert the EQ-5D-3 L and the EQ-5D-5 L, thus leading to improved model performance.
Overall, the mapping functions performed well in this study. Although the predicted average health utility of the OLS models much closer to the observed values, OLS would overestimate poor health and underestimate higher health utility, which was consistent with prior studies [33, 43, 44]. To solve this problem, we used simple linear equating to avoid regression to the mean [35]. This method achieved similar results in previous mapping studies [18, 45]. As shown in Fig. 3, model OLS 5 had the closest predictive values to actual EQ-5D-5 L scores after a linear equivalent method was applied.
The present study suffers from several limitations. First, the study was based on a small sample size from a single hospital. Future studies should consider collecting data from larger sample sizes and from multiple treatment centres. Second, it is impossible to conduct cross-validation for external validity in independent data sets. Therefore, although cross-validation is considered to be “second best”, it was used in this study due to a lack of external data sources. Finally, the study only used three modelling approaches in mapping functions; many advanced technologies, including the three-part model and the probit mapping function based on Bayesian networks, could be potential alternative approaches to mapping functions.
Conclusion
Mapping is primarily used to obtain utility scores from disease-specific non-preference tools, allowing a large amount of existing survey data to be used for economic analysis. The use of mapping algorithms has facilitated the development of cost-utility research. To the best of the author’s knowledge, this study is the first to develop a mapping algorithm between the FACT-B and the EQ-5D-5 L in the Chinese patient population and to adopt the recently developed EQ-5D-5 L tariff value based on Chinese population preferences. The best model for estimating the EQ-5D-5 L value includes the FACT-B subscale scores. The addition of squared terms and interaction terms improves the predictability of the model. When using several algorithms developed by these data, we found that the prediction performance of the OLS model was better than that of the Tobit model and the TPM. It is hoped that this algorithm will help to develop cost-utility studies to evaluate breast cancer treatments in China’s healthcare environment.
Availability of data and materials
The dataset are available from the corresponding author on reasonable request.
Abbreviations
- AIC:
-
Akaike information criteria
- BCS:
-
Additional concerns for breast cancer
- BIC:
-
Bayes information criteria
- CLAD:
-
Censored least absolute deviations
- EQ-5D:
-
EuroQol-5 dimension
- EWB:
-
Emotional wellbeing
- FACT-B:
-
Functional Assessment of Cancer Therapy – Breast
- FWB:
-
Functional wellbeing
- MAD:
-
Mean absolute deviation
- MAE:
-
Mean absolute error
- OLS:
-
Ordinary least-square
- PWB:
-
Physical wellbeing
- QALYs:
-
Quality-adjusted life years
- RMSE:
-
Root mean squared error
- SWB:
-
Social/family wellbeing
- TPM:
-
Two-part model
References
Desantis C, Ma J, Bryan L, Jemal A. Breast cancer statistics, 2013. CA Cancer J Clin. 2014;64(1):52–62.
Chen WQ, Zheng RS. Incidence, mortality and survival analysis of breast cancer in China. Chin J Clin Oncol. 2015;42(13):668–74 Chinese.
Jones SM, LaCroix AZ, Li W, Zaslavsky O, Wassertheil-Smoller S, Weitlauf J, Brenes GA, Nassir R, Ockene JK, Caire-Juvera G, Danhauer SC. Depression and quality of life before and after breast cancer diagnosis in older women from the Women’s health initiative. J Cancer Surviv. 2015;9(4):620–9.
Karlsson KY, Wallenius I, Nilsson-Wikmar LB, Lindman H, Johansson BB. Lymphoedema and health-related quality of life by early treatment in long-term survivors of breast cancer. A comparative retrospective study up to 15 years after diagnosis. Support Care Cancer. 2015;23(10):2965–72.
Stover AM, Mayer DK, Muss H, Wheeler SB, Lyons JC, Reeve BB. Quality of life changes during the pre-to postdiagnosis period and treatment-related recovery time in older women with breast cancer. Cancer. 2014;120(12):1881–9.
Wang L, Zhang Y, Shi JF, Dai M. Disease burden of famale breast cancer in China. Chinese J Epidemiol. 2016;37(7):970–6 Chinese.
Boyle FM, Smith IE, O’Shaughnessy J, Ejlertsen B, Buzdar AU, Fumoleau P, Gradishar W, Martin M, Moy B, Piccart-Gebhart M, Pritchard KI, Lindquist D, Amonkar M, Huang Y, Rappold E, Williams LS, Wang-Silvanto J, Kaneko T, Finkelstein DM, Goss PE. Health related quality of life of women in TEACH, a randomised placebo controlled adjuvant trial of lapatinib in early stage Human Epidermal Growth Factor Receptor (HER2) overexpressing breast cancer. Eur J Cancer. 2015;51(6):685–96.
Cerezo O, Oñate-Ocaña LF, Arrieta-Joffe P, González-Lara F, García-Pasquel MJ, Bargalló-Rocha E, Vilar-Compte D. Validation of the Mexican-Spanish version of the EORTC QLQ-C30 and BR23 questionnaires to assess health-related quality of life in Mexican women with breast cancer. Eur J Cancer Care. 2012;21(5):684–91.
Schleife H, Sachtleben C, Finck Barboza C, Singer S, Hinz A. Anxiety, depression, and quality of life in German ambulatory breast cancer patients. Breast Cancer. 2014;21(2):208–13.
Maratia S, Cedillo S, Rejas J. Assessing health-related quality of life in patients with breast cancer: a systematic and standardized comparison of available instruments using the EMPRO tool. Qual Life Res. 2016;25(10):2467–80.
Weinstein MC, Torrance G, Mcguire A. QALYs: the basics. Value Health. 2009;12(s1):5–9.
Hanmer J. Predicting an SF-6D preference-based score using MCS and PCS scores from the SF-12 or SF-36. Value Health. 2009;12(6):958–66.
Dolan P. Modeling valuations for EuroQol health states. Med Care. 1997;35(11):1095–108.
National Institute for Health and Care Excellence. Guide to the methods of technology appraisal 2013. 2013. https://www.nice.org.uk/process/pmg9/chapter/foreword. Accessed 29 July 2018.
Zhu J, Wang L, He SJ, Huang HY, Li J, Yan SP, Fang Y, Dai M, Shi JF. Health utility score of breast cancer in China: a systematic review. Chin J Evidence-based Med. 2017;17(9):1066–71 Chinese.
Dakin H, Abel L, Burns R, Yang Y. Review and critical appraisal of studies mapping from quality of life or clinical measures to EQ-5D: an online database and application of the MAPS statement. Health Qual Life Outcomes. 2018;16(1):31.
Cheung YB, Luo N, Ng R, Lee CF. Mapping the functional assessment of cancer therapy-breast (FACT-B) to the 5-level EuroQoL Group’s 5-dimension questionnaire (EQ-5D-5L) utility index in a multi-ethnic Asian population. Health Qual Life Outcomes. 2014;12(1):180.
Lee CF, Ng R, Luo N, Cheung YB. Development of conversion functions mapping the FACT-B total score to the EQ-5D-5L utility value by three linking methods and comparison with the ordinary least square method. Appl Health Econ Health Policy. 2018;16(5):685–95.
Gray LA, Wailoo AJ, Hernandez AM. Mapping the FACT-B instrument to EQ-5D-3L in patients with breast cancer using adjusted limited dependent variable mixture models versus response mapping. Value Health. 2018;21(12):1399–405.
Norman R, Cronin P, Viney R, King M, Street D, Ratcliffe J. International comparisons in valuing EQ-5D health states: a review and analysis. Value Health. 2009;12(8):1194–200.
Trogdon JG, Ekwueme DU, Chamiec-Case L, Guy GP Jr. Breast cancer in young women: health state utility impacts by race/ethnicity. Am J Prev Med. 2016;50(2):262–9.
Knuttel FM, van den Bosch MA, Young-Afat DA, Emaus MJ, van den Bongard DH, Witkamp AJ, Verkooijen HM. Patient preferences for minimally invasive and open locoregional treatment for early-stage breast cancer. Value Health. 2017;20(3):474–80.
Shih V, Chan A, Xie F, Ko Y. Health state utility assessment for breast cancer. Value Health Reg Issues. 2012;1(1):93–7.
Brady MJ, Cella DF, Mo F, Bonomi AE, Tulsky DS, Lloyd SR, Deasy S, Cobleigh M, Shiomoto G. Reliability and validity of the functional assessment of Cancer therapy-breast quality-of-life instrument. J Clin Oncol. 1997;15(3):974–86.
Wan CH, Zhang DM, Tang XL, Zhang WL, Li WH, Ren HX, He RS, Wang W. Revision of the Chinese version of the FACT-B for patients with breast cancer. Chin Mental Health J. 2003;17(5):298–300 Chinese.
Xin YB, Ma AX. Study on reliability and validity of Chinese version of EQ-5D-5L. Shanghai Med Pharmaceutical J. 2013;34(9):40–3 Chinese.
Luo N, Liu G, Li M, Guan H, Jin X, Rand-Hendriksen K. Estimating an EQ-5D-5L value set for China. Value Health. 2017;20(4):662–9.
Brazier JE, Yang Y, Tsuchiya A, Rowen DL. A review of studies mapping (or cross walking) non-preference based measures of health to generic preference-based measures. Eur J Health Econ. 2010;11(2):215–25.
Kim SH, Kim SO, Lee S, Jo MW. Deriving a mapping algorithm for converting SF-36 scores to EQ-5D utility score in a Korean population. Health Qual Life Outcomes. 2014;12(1):145.
Dakin H. Review of studies mapping from quality of life or clinical measures to EQ-5D: an online database. Health Qual Life Outcomes. 2013;11(1):151.
Longworth L, Rowen D. Mapping to obtain EQ-5D utility values for use in NICE health technology assessments. Value Health. 2013;16(1):202–10.
Dow WH, Norton EC. Choosing between and interpreting the Heckit and two-part models for corner solutions. Health Serv Outcome Res Methodol. 2003;4(1):5–18.
Acaster S, Pinder B, Mukuria C, Copans A. Mapping the EQ-5D index from the cystic fibrosis questionnaire-revised using multiple modelling approaches. Health Qual Life Outcomes. 2015;13(1):33.
Dakin H, Gray A, Murray D. Mapping analyses to estimate EQ-5D utilities and responses based on Oxford knee score. Qual Life Res. 2013;22(3):683–94.
Fayers PM, Hays RD. Should linking should replace regression when mapping from profile to preference-based measures? Value Health. 2014;17(2):261–5.
Young TA, Mukuria C, Rowen D, Brazier JE, Longworth L. Mapping functions in health-related quality of life: mapping from two cancer-specific health-related quality-of-life instruments to EQ-5D-3L. Med Decis Mak. 2015;35(7):912–26.
McDonough CM, Grove MR, Elledge AD, Tosteson AN. Predicting EQ-5D-US and SF-6D societal health state values from the osteoporosis assessment questionnaire. Osteoporos Int. 2012;23(2):723–32.
Ali FM, Kay R, Finlay AY, Piguet V, Kupfer J, Dalgard F, Salek MS. Mapping of the DLQI scores to EQ-5D utility values using ordinal logistic regression. Qual Life Res. 2017;26(11):3025–34.
Cheung YB, Thumboo J, Gao F, Ng GY, Pang G, Koo WH, Sethi VK, Wee J, Goh C. Mapping the English and Chinese versions of the functional assessment of Cancer therapy-general to the EQ-5D utility index. Value Health. 2009;12(2):371–6.
Wu EQ, Mulani P, Farrell MH, Sleep D. Mapping FACT-P and EORTC QLQ-C30 to patient health status measured by EQ-5D in metastatic hormone-refractory prostate cancer patients. Value Health. 2007;10(5):408–14.
Crott R, Briggs A. Mapping the QLQ-C30 quality of life cancer questionnaire to EQ-5D patient preferences. Eur J Health Econ. 2010;11(4):427–34.
Rowen D, Brazier J, Roberts J. Mapping SF-36 onto the EQ-5D index: how reliable is the relationship? Health Qual Life Outcomes. 2009;7(1):27.
Ara R, Brazier J. Deriving an algorithm to convert the eight mean SF-36 dimension scores into a mean EQ-5D preference-based score from published studies (where patient level data are not available). Value Health. 2008;11(7):1131–43.
Versteegh MM, Rowen D, Brazier JE, Stolk EA. Mapping onto Eq-5D for patients in poor health. Health Qual Life Outcomes. 2010;8(1):141.
Hays RD, Revicki DA, Feeny D, et al. Using linear equating to map PROMIS global health items and the PROMIS-29 V. 2 profile measure to the health utilities index—mark 3. Pharmacoeconomics. 2016;34(10):1015–22.
Acknowledgements
Not applicable.
Funding
This study was supported by a project of Health Commission of Sichuan Province, China (number of study:18PJ224).
Author information
Authors and Affiliations
Contributions
All authors have contributed to design of the study, the acquisition of data, and the interpretation of the results. QY and XXY analyzed the data and involved in drafting the manuscript; WZ and HL were involved in revising the manuscript critically for important intellectual content. All authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The study obtained the approval by the Ethics Committee, West China school of Medicine/ West China Hospital, Sichuan University. Informed consent from all participants was obtained prior to the study.
Consent for publication
Not applicable. All results are reported as aggregated data.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Yang, Q., Yu, X.X., Zhang, W. et al. Mapping function from FACT-B to EQ-5D-5 L using multiple modelling approaches: data from breast cancer patients in China. Health Qual Life Outcomes 17, 153 (2019). https://doi.org/10.1186/s12955-019-1224-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12955-019-1224-8