
Abstract
Background
Acute kidney injury (AKI) after coronary artery bypass grafting (CABG) surgery is associated with poor outcomes. The objective of this study was to apply a new machine learning (ML) method to establish prediction models of AKI after CABG.
Methods
A total of 2,780 patients from two medical centers in East China who underwent primary isolated CABG were enrolled. The dataset was randomly divided for model training (80%) and model testing (20%). Four ML models based on LightGBM, Support vector machine (SVM), Softmax and random forest (RF) algorithms respectively were established in Python. A total of 2,051 patients from two other medical centers were assigned to an external validation group to verify the performances of the ML prediction models. The models were evaluated using the area under the receiver operating characteristics curve (AUC), Hosmer-Lemeshow goodness-of-fit statistic, Bland-Altman plots, and decision curve analysis. The outcome of the LightGBM model was interpreted using SHapley Additive exPlanations (SHAP).
Results
The incidence of postoperative AKI in the modeling group was 13.4%. Similarly, the incidence of postoperative AKI of the two medical centers in the external validation group was 8.2% and 13.6% respectively. LightGBM performed the best in predicting, with an AUC of 0.8027 in internal validation group and 0.8798 and 0.7801 in the external validation group. The SHAP revealed the top 20 predictors of postoperative AKI ranked according to the importance, and the top three features on prediction were the serum creatinine in the first 24 h after operation, the last preoperative Scr level, and body surface area.
Conclusion
This study provides a LightGBM predictive model that can make accurate predictions for AKI after CABG surgery. The LightGBM model shows good predictive ability in both internal and external validation. It can help cardiac surgeons identify high-risk patients who may experience AKI after CABG surgery.
Similar content being viewed by others
Introduction
Coronary artery bypass grafting (CABG) surgery is currently the main clinical treatment for serious coronary heart disease (CHD) and is increasingly applied to patients worldwide. Postoperative complications of CABG include perioperative myocardial ischemia, arrhythmias, acute kidney injury (AKI), neurological complications, and bleeding. AKI is a common complication after cardiac surgery with a typical incidence of 15-30% [1,2,3]. In practice, failure to identify patients at high risk of AKI in the early stages following CABG and to pre-empt treatment may cause AKI to develop to chronic renal failure or even end-stage renal disease, ultimately increasing the risk of death. The high postoperative incidence and associated high mortality make AKI a great concern of cardiac surgery. However, the pathogenesis of AKI after CABG is very complex and not completely understood [4]. As such, it is urgent to identify the risk factors of postoperative AKI and to explore prediction models of AKI after CABG.
Machine learning (ML) is a branch of artificial intelligence that has been increasingly used in various fields to analyze massive data. With the development of information technology recently, hospital electronic medical record systems generate huge amounts of data yearly, which have led many health and biomedical researchers to apply ML, especially prediction models, to extract valuable insights from the growing biomedical database. Unlike traditional statistical methods that use selected variables for further calculations, ML can easily combine a large number of variables using a computer algorithm, which improves the forecasting accuracy. ML-based models outperform traditional statistical models based on the logistic regression algorithm [5, 6]. However, predicting AKI in CABG patients with ML methods has not attracted much attention from researchers.
This study aims to use ML based on Light gradient boosting machine (Light GBM), Support vector machines (SVM), Softmax and random forest (RF) to establish models enabling early and effective prediction of AKI after CABG, which are needed to identify high-risk patients and have practical guiding significance to clinical decision-making.
Methods
Study population
This project is a multi-center retrospective study. A total of 4,170 patients undergoing CABG from two medical centers of East China (the Jiangsu Province Hospital Affiliated to Nanjing Medical University, JSPH, and Shanghai Chest Hospital Affiliated to Shanghai Jiaotong University, SHCH) were enrolled. The inclusion criterion was: CABG surgery for severe CHD. The exclusion criteria were: (1) age less than 18 years; (2) redo CABG surgery; (3) combined with other cardiac procedures (e.g., valve, ventricular aneurysm, ventricular septum); (4) absence of perioperative medical records; (5) preoperative chronic renal failure; (6) preoperative hemodialysis treatment. Ultimately, 2,780 patients were enrolled and randomly assigned to a model training group and an internal validation group at a ratio of 8:2.
Another 2,414 patients from two medical centers (Qilu Hospital of Shandong University, QLH, General Hospital of Ningxia Medical University, GHN) were also enrolled, which were more than 500 km apart from the previous medical centers, located in North China and North West China respectively. According to the same inclusion and exclusion criteria, 2,051 patients were assigned to an external validation group to verify the performances of the ML models. The patients screening process was shown in Fig. 1.

Flowchart of patient selection. (JSPH: Jiangsu Province Hospital, the First Affiliated Hospital of Nanjing Medical University; SHCH: Shanghai Chest Hospital of Shanghai Jiao Tong University; QLH: Qilu Hospital of Shandong University; GHN: General Hospital of Ningxia Medical University; CABG: Coronary artery bypass grafting)
Informed consent
This study was conducted in accordance with the Declaration of Helsinki (revised 2013). Approval was obtained from the hospital ethics committees (No. 2023-SR-229 from JSPH; No. IS23002 from SHCH; No. KYLL-202204-016 from QLH; No. KYLL20230330 from GHN). Written informed consent was waived for this retrospective analysis because all the protected health information was anonymized.
Definition and endpoints
According to the Kidney Disease Improving Global Outcome (KDIGO) clinical practice guidelines [7], AKI is defined when any of the following three criteria is met: increase in serum creatinine (Scr) by ≥ 0.3 mg/dl (≥ 26.5 umol/l) within 48 h or an increase in Scr by ≥ 1.5 times from the baseline, which is known or presumed to have occurred within the preceding 7 days; or a urine volume < 0.5 ml/kg/h for 6 h. Baseline creatinine level was defined as the preoperative value obtained closest to the date of the operation (within 48 h before the operation). Because of the application of diuretics and the difficulty in collecting clinical records, urine volume was not used to diagnose preoperative AKI. The preoperative estimated glomerular filtration rate (eGFR) was calculated with the CKD-EPIscr Eq. [8]. Proposed KDIGO staging of AKI was as follows: stage 1 was defined as increase in Scr by 1.5–1.9 times from the baseline or ≥ 0.3 mg/dl (26.5 µmol/l); Stage 2 was defined as increase in Scr by 2.0-2.9 times from the baseline; Stage 3 was defined as increase in Scr by 3 times from the baseline or ≥ 4.0 mg/dl (353.6 µmol/l) or initiation of renal replacement therapy [9].
The study outcome was the occurrence of postoperative AKI.
Feature selection
Features were selected by referring to the European System for Cardiac Operative Risk Evaluation II (EuroSCORE II), which was improved on the basis of EuroSCORE. It not only better predicts the mortality risk of CABG, but also applies to Chinese patients [10,11,12,13,14]. Therefore, to comprehensively reflect the specific circumstances of patients, the risk factors selected here were based on relevant EuroSCORE II items. A total of 26 variables were collected according to relevant studies and clinical availability (Table 1). All data for the included variables were extracted from inpatient electronic medical records.
Machine learning modeling
Light gradient boosting machine (LightGBM)
In 2017, a team at Microsoft introduced a new efficient gradient boosting algorithm based on decision trees, named LightGBM. Building upon the foundation of GBDT, LightGBM incorporates the Histogram algorithm and a leaf-wise growth strategy [15].
The basic idea of Histogram algorithm is illustrated in Fig. 2 (A) and the process is as follows. For continuous features, convert them into N distinct values, and then build a histogram that spans these N values. In the case of discrete features, place each unique value into a specific bin. If the number of unique values exceeds the available bins, less frequent values are ignored. When traversing the data, the statistical information is accumulated in the histogram using the discretized values as indices. This accumulation ensures that after one traversal, the histogram contains the necessary statistical data, which is subsequently used to determine the best split point by traversing the discretized values of the histogram.

The introduction of (A) histogram algorithm, (B) leaf-wise strategy and (C) the specific process of LightGBM
The basic idea of the leaf-wise growth strategy is illustrated in Fig. 2 (B), the process is as follows. For each splitting process of a leaf node, identify the leaf node with the highest splitting gain in the current layer (the green node), then split it, and so on.
In the context of the relationship between the Histogram algorithm and the leaf-wise growth strategy, they work in tandem. The histogram algorithm prioritizes speed and memory efficiency, while the Leaf-wise growth strategy focuses on accuracy optimization. Together, these strategies form a harmonious partnership. And the specific process of the model was shown in Fig. 2 (C).
In addition, in this study, the SHapley Additive exPlanation (SHAP) method was used to explain the LightGBM model. SHAP, a unified approach for explaining the outcome of any machine learning model, was used to provide consistent and locally accurate attribution values for each feature within the ML model. In SHAP, all features are considered as contributors, and the model generates a prediction value (SHAP value) indicating the contribution of the feature for each prediction sample. SHAP values are very different from traditional variable screening methods (e.g., subset selection methods, coefficient compression methods, dimensionality reduction methods), which rely on model judging metrics. The SHAP value is a game-theoretic approach to interpret the output of any ML model, and interprets the model-predicted value as the sum of the inputted values of each feature, where the imputed values are the SHAP values. It has several advantages: (1) SHAP can explain the output of a single sample, not just the global importance; (2) SHAP can explain the effects of each feature on the model output, including positive and negative effects; (3) SHAP values can be used to visually interpret the output of an ML model [16].
Support vector machines (SVMs)
Support Vector Machines (SVMs) began as binary classifiers but have since expanded to multi-class classification using strategies like “one-vs-one” (OvO) and “one-vs-rest” (OvR). In essence, SVMs find a hyperplane in the feature space that best divides data into classes. For non-linear data, the “kernel trick” allows SVMs to map data into a higher dimension, making it linearly separable.
In our work, we used hinge loss to maximize the margin between data points and the hyperplane. The kernel function, a pivotal component of SVMs, must meet the Mercer condition to ensure the kernel matrix’s positive semi-definiteness, crucial for SVM’s numerical stability. Our chosen kernel function is the standard dot product, emphasizing our model’s interpretability in multi-class scenarios [17].
Softmax regression
Softmax regression, also known as multinomial logistic regression, distinguishes itself by employing a discriminative vector instead of the Sigmoid function found in standard logistic regression. Specifically designed for multi-class classification, this model predicts a probability for each category through a linear function. The Softmax function then steps in to convert these scores into normalized probabilities, ensuring the sum of probabilities across all classes is unity.
The primary objective of this model is to minimize the cross-entropy loss, serving as a measure of disparity between the predicted and actual probability distributions. Owing to its straightforward structure, rapid classification speed, and minimal space requirements, Softmax regression frequently serves as a benchmark model for multi-class classification problems [18].
Random forest (RF)
Random Forest is a supervised machine learning algorithm rooted in decision tree methodologies. Unlike single decision trees, RF constructs an ensemble of trees, each representing a distinct instance of either classification or regression based on input data. For classification tasks, the RF output is the class chosen by the majority of the trees. For regression tasks, it offers the mean or average prediction of the individual trees. A unique characteristic of RF is its use of both bagging and feature randomness, ensuring an uncorrelated forest of decision trees, setting it apart from other tree-based models. This approach affords RF a flexibility and adaptability to handle nonlinear data with remarkable accuracy. While both RF and LightGBM employ decision trees as base learners, their construction, optimization, and overall methodologies differ significantly. We have chosen to evaluate both to provide a comprehensive comparison and understanding of their performances in our specific application and also make RF as a benchmark model [19].
Statistical and technical specifications
Categorical variables were expressed as total numbers and percentages, and differences between groups were compared using χ2 test or Fisher’s exact test. Continuous variables were shown as mean ± standard deviation (SD) and median with 95% confidence interval (CI). Continuous variables in normal distribution and skewed distribution were analyzed with Student’s t-test and Mann–Whitney U-test respectively (P < 0.05 was considered significant).
Receiver’s operating characteristics (ROC) curve and the area under the ROC curve (AUC) were used to measure the discrimination ability of ML models. Sensitivity analysis was performed to examine the predictive power of ML models. The analyses included sensitivity, specificity, positive and negative predictive values.
The net reclassification index (NRI) and integrated discrimination improvement (IDI) were used to further assess the predictive power of the two models concerning postoperative AKI [20, 21]. If the values of NRI and IDI were positive, then the first model showed a positive improvement over the other model. Conversely, it implies a negative improvement.
Calibration (statistical precision) of models was analyzed by Hosmer–Lemeshow (H-L) goodness-of-fit statistic. When P is larger than 0.05, the predicted postoperative AKI rate and the actual postoperative AKI rate were in good agreement.
Bland-Altman plots were used to estimate the agreement of models in pairs [22]. If the difference between the two models lies within the consistency bounds, it suggests good agreement. A higher agreement between the two models means the solid line representing the mean of the differences is closer to the dashed line with a zero value. About 95% of the difference between the values of the two models falls within the range of values described by the consistency limits, indicating that the two models are in good agreement.
In addition, decision curve analysis (DCA) was performed to assess the utility of the model in decision-making by quantifying the net utility at different threshold probabilities. Clinical net benefit was defined as the minimum probability of the disease, when further intervention was warranted [23].
The current study was designed following the transparent report of a ML architecture and the Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) reporting guideline [24, 25]. All statistical analyses, including descriptive statistics, inferential tests, and specific data preprocessing steps, were performed using SPSS (R23.0.0.0) and GraphPad Prism (version 8.2.1). Python (open-source Scipy python package) was utilized for developing machine learning models based on the LightGBM, SVM, Softmax, and RF algorithms.
Results
Baseline characteristics
The model training group included 2,224 patients total, with a mean age of 66.00 ± 12.00 years, including 1,694 men (76.17%) and 530 women (23.83%). The preoperative renal functions of all patients were generally normal, with all eGFR ≥ 30 ml/min/1.73 m2, mean eGFR of 77.32 ± 33.16 ml/min/1.73 m2. There were 556 patients in the internal validation group. Due to the random assignment, the differences in the main clinical characteristics between the two groups were not significant (Table 1).
The external validation group was formed by 1,648 patients from QLH and 403 patients from GHN. The baseline characteristics of each group were also listed in Table 1.
Explanation of LightGBM model with the SHAP method
The SHAP algorithm was used to obtain the importance of each predictor variable to the outcome predicted by the LightGBM model. The top 26 importance of variables for predicting postoperative AKI were shown in Fig. 3. Scr in the first 24 h after surgery had the strongest predictive value for all prediction horizons, followed quite closely by the last preoperative Scr level, the body surface area (BSA), pulmonary hypertension, and preoperative eGFR. Furthermore, to detect the positive and negative relationships of the predictors with the target result, SHAP values were applied to uncover the postoperative AKI risk factors. As shown in plot B in Fig. 3, the horizontal location showed whether the effect of a value was associated with a higher or lower prediction, and the color indicated whether a variable was high (in red) or low (in blue) for that observation. For example, Scr in the first 24 h after surgery had a positive impact and pushed the prediction toward postoperative AKI. Figure 4 shows the individual plots for patients who did not suffer postoperative AKI and suffered postoperative AKI. The SHAP values indicated risk factors and their contribution to the prediction of postoperative AKI. Where f(x) was the predicted value of postoperative AKI, red indicated risk factors that increased postoperative AKI, and blue indicated risk factors that decreased postoperative AKI, where longer arrows indicated a greater degree of impact on postoperative AKI.

(A) The weights of variable importance and (B) the SHapley Additive exPlanation (SHAP) values of variables (Scr: serum creatinine; BSA: body surface area; eGFR: estimated glomerular filtration rate; LVEF: left ventricular ejection fraction; NYHA: New York Heart Association Class; BMI: body mass index; IABP: intra-aortic balloon pump; CAD: coronary heart disease; COPD: chronic obstructive pulmonary disease; PCI: percutaneous coronary intervention)

The individual SHAP force plots for patients who (B) did not suffer postoperative AKI and (A) suffered postoperative AKI
Model evaluation
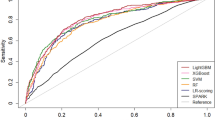
Within the model training group, the LightGBM, SVM, Softmax and RF models were established, and the AUCs with the internal validation group were 0.8027 (95% CI: 0.7511–0.8542), 0.7805 (0.7277–0.8333), 0.7568 (0.7042–0.8094) and 0.7292 (0.6725–0.7858), respectively (Table 2; Fig. 5). The LightGBM model showed the largest AUC with a sensitivity of 70.11% and specificity of 78.89%, while the RF model had the smallest AUC with a sensitivity of 71.89% and specificity of 62.22%. Similar results were also present in the two external validation groups. In the QLH external validation group, the LightGBM exhibited robust discriminatory power with an AUC of 0.8798 (95% CI: 0.8446–0.9150), showcasing a sensitivity of 83.54% and a specificity of 80.00%. On the other hand, the SVM model demonstrated superior performance, achieving the highest AUC of 0.8819 (0.8483–0.9156), along with a sensitivity of 91.13% and a specificity of 70.37%. In the GHN external validation group, the LightGBM model outperformed the other three models with an AUC of 0.7801 (0.7128–0.8475), demonstrating a sensitivity of 77.59% and a specificity of 69.09%. (Table 2).

Receiver’s operating characteristic (ROC) curves of the risk evaluation models in (A) the internal test group and in external test groups of (B) QLH and (C) GHN (SVM: support vector machine; RF: random forest)
The H-L goodness-of-fit statistic was used to verify the calibration of two ML models. Only the SVM model was poorly calibrated in the internal validation group with a P equal to 0.046. The calibration of the remaining three models was good. In the external validation group of QLH, SVM and Softmax models were poorly calibrated with P less than 0.05. In comparison, LightGBM and RF models performed better with P above 0.05. In the external validation group of GHN, all four models showed P larger than 0.05.
NRI and IDI are two new evaluation metrics to assess the degree of improvement in one model over another one. Compared with SVM, RF and Softmax models, the NRIs of the LightGBM model were 0.5852 (95%CI: 0.3651–0.8053), 0.8988 (0.6860–1.1116) and 0.6847 (0.4665–0.9028) in the internal validation group, respectively; the corresponding IDIs were 0.0144 (-0.0022-0.0311), 0.1632 (0.1168–0.2097) and 0.1082 (0.0708–0.1455) respectively. The LightGBM model also showed positive gains in all two external validation groups compared to the other three ML models (Table 3).
DCA was performed for four ML models to compare the net benefit of the best model and alternative approaches for clinical decision-making. The DCA plot can visually display the clinical net benefits of the models under certain threshold probability. Because the research population varied in characteristics, treatment methods guided by any of the four ML models outperformed the default strategy of treating all or no patients. The net benefit of the LightGBM model surpassed those of the other ML models at 0–50% threshold probability in the internal validation group. In the QLH external validation group, LightGBM and SVM outperformed RF and Softmax at 9 − 21% threshold probability. Similarly, in the GHN external validation group, LightGBM and SVM have similar net benefits at 2–34% threshold probability and both outperformed the other two ML models (Fig. 6).

Decision curve analysis (DCA) of the four prediction models plotting the net benefit at different threshold probabilities. (A) DCA of the four models in the in the internal test group; (B) DCA of the four models in the QLH external test group; (C) DCA of the four models in the GHN external test group
The Bland-Altman analysis can assess the degree of agreement between two ML models. As shown in the Bland-Altman plots, in the internal validation group, the mean of the differences between the probabilities predicted by LightGBM model and by SVM, Softmax and RF were − 0.001 ± 0.153, 0.019 ± 0.129 and 0.023 ± 0.061 respectively. Only 4%, 6% and 4% points fell outside the 95% limits of agreement (95% LoA), suggesting the agreement between the LightGBM and the other three ML models was good (Fig. 7). Similarly, the consistency between LightGBM and the other three ML models also performed relatively well in the two external validation groups (Fig. 7).

The Bland-Altman plots for postoperative AKI prediction. Consistency tests between LightGBM and (A) SVM, (B) Softmax, or (C) RF in the internal validation dataset; Consistency tests between LightGBM and (D) SVM, (E) Softmax, or (F) RF in the QLH external test group; Consistency tests between LightGBM and (G) SVM, (H) Softmax, or (I) RF in the GHN external test group
Discussion
In this multicenter retrospective cohort study, four ML models were developed and validated using 26 features to predict AKI after CABG surgery. The LightGBM model performed the best in prediction both in the internal and external validation group, whereas the SVM model exhibited the largest AUC in the QLH external validation group. In multiaspect comprehensive evaluations, ML models especially the LightGBM model are feasible and practical in prediction of AKI after CABG surgery.
AKI is a syndrome of sudden loss of renal excretory function, and is usually accompanied by oliguria, which happens over the course of a few hours to a few days [7]. The pathogenesis of postoperative AKI is multifactorial, including ischemia–reperfusion injury, operative trauma inflammation and oxidation [26, 27]. AKI is a relatively common complication after CABG surgery. A recent retrospective study involving 32,013 patients reported a 14.3% incidence of AKI after CAGB surgery [28], which is similar to the present study. CHD is one manifestation of systemic atherosclerosis in coronary artery. Many CHD patients also suffer renal vascular diseases. Moreover, the haemodynamic instability and hypoperfusion syndrome reduced renal perfusion and raised the risk of pre-renal AKI, which, if left untreated, may lead to nephrogenic AKI [29]. Despite technological advances in renal replacement therapy, AKI is still associated with a poor outcome [30] and dramatically impacts operative mortality, intensive care unit resources, and hospital length of stay. Currently, there is no a widely-recognized model in China that can predict AKI after cardiac surgery.
In clinical practice, some medical centers had tried to establish some risk prediction models for AKI after cardiac surgery, such as the AKI following cardiac surgery score, Cleveland Clinic score, Mehta score, and simplified renal index score [31]. Nevertheless, discrimination and calibration of those models are barely satisfactory and not convincible or applicable. Therefore, AKI prediction models that are suitable for clinical practice and have predictive efficiency are urgently needed.
With advances in medical informatics, ML as a branch of artificial intelligence has become a promising tool for clinical predictive models [32, 33]. Although predictive models based on traditional statistics have been reported, ML models specifically those for AKI after CABG surgery have not been established. The fundamental distinction from ML is that the first step in traditional statistics is to build an important relationship between variables and specific outcomes. Then an equation or function that links them together is generated. This makes the predictive models based on traditional statistics understandable and more interpretable. In contrast, ML methods presuppose a meaningful relationship between a set of independent variables and the dependent variable, and then directly find the path that most strongly connects the two variables. Due to the inherent power of capturing the nonlinear relationships with ML algorithms, some cardiac surgeons advocate new ML-based models to predict cardiac surgery-associated AKI rather than traditional clinical scoring tools [34]. However, ML methods generate algorithms that are more often ‘black boxes’ of opacity to varying degrees. The nature of black-box is difficult to explain, which partially hampers their use in clinical practice.
Considering the imperative facets of model interpretability alongside its efficacy in the realm of classification, this research exercise made a deliberate selection to employ the lightGBM, SVM, Softmax, and RF algorithms for the purpose of constructing predictive models. These models are well-known for their strong predictive performance and have been widely used in various prediction tasks, including those of medical relevance [34,35,36,37,38].
In recent years, more and more researchers have tried to explain ML models by using the feature attribution framework of SHAP. With SHAP to explain the LightGBM model, several variables associated with AKI after CABG surgery were identified. In this study, the Scr in the first 24 h after surgery and the last preoperative Scr level were recognized as the most important predictor variables. As an accepted laboratory indicator for the diagnosis of kidney injury, the preoperative Scr is reportedly the key predictor of cardiac surgery-associated AKI with ML algorithms [34, 39]. Preoperative eGFR as an independent risk factor for AKI after CABG surgery has been confirmed by some studies [3, 40, 41]. Charat et al. listed eGFR as an important risk factor in their ML model for predicting postoperative AKI of cardiac surgery [42]. Nevertheless, more research is needed to determine if body surface area (BSA) is an independent risk factor for postoperative AKI of CABG surgery, although there is no doubt that eGFR, Scr, and BSA are inextricably linked. In fact, BSA and Scr are incorporated in the Cockcroft-Gault (CG) equation for estimating eGFR [43]. Our previous study shows that the CG equation has significantly high discriminatory power to predict in-hospital mortality in patients undergoing CABG [8]. Therefore, there is logical reason to believe that these factors also play important roles in the occurrence of postoperative AKI. Notably, pulmonary arterial hypertension (PAH) is ranked as the fourth significant variable. PAH is an important risk factor for AKI after transcatheter aortic valve implantation [44] and is closely related to right heart function [45, 46]. Reportedly, right ventricular failure is associated with severe postoperative AKI of cardiac surgery [47] and PAH is one of the top five risk factors, providing a new viewpoint on clinical decision making.
GBDT (Gradient Boosting Decision Tree), a long-lasting model in ML, mainly aims to use weak classifiers (decision trees) to iteratively train and get the optimal model that has good training effect and less overfitting. LightGBM, a framework to implement GBDT, supports efficient parallel training, and has faster training speed, lessr memory consumption, higher accuracy, supporting distributed and rapid processing of massive data [15]. For the first time, this study utilized LightGBM to develop prediction models of AKI after CABG surgery. It achieved optimal predictive performance, and outperformed the SVM, Softmax and RF models.
Limitations
There are several limitations. First, urine output criteria are not used due to missing records, while standard diagnosis of AKI is Scr or urine output criteria. Second, there are patients with impaired GFR but normal SCr levels before the operation, which are called occult renal impairment in clinical practice [48]. Thus, relying only on Scr may lead to bias in diagnosis [49]. Third, this observational study has a long duration, so there may be factors that affect our results due to improvements in surgical techniques and perioperative care. Fourth, a noteworthy limitation of our study is the exclusion of 885 patients from JSPH, constituting a significant proportion of the registered patients. Although these exclusions were applied consistently across both medical centers, they could potentially introduce selection bias and impact the generalizability of our findings. Fifth, in this retrospective study, we did not have access to physician assessments as direct comparisons for our predictive models.
Conclusions
This study provides a LightGBM-based predictive model that can accurately predict AKI after CABG surgery. This ML-based model shows good predictive ability in both internal and external validation. It may help cardiac surgeons to intervene early in patients undergoing CABG with high risk of AKI and reduce associated complications.
Data Availability
We are pleased to share data. The data involved in our research are available from the corresponding author. We will respond in 7 days on reasonable request.
References
Bell J, Sartipy U, Holzmann MJ, Hertzberg D. The Association between Acute Kidney Injury and Mortality after Coronary Artery Bypass Grafting was similar in women and men. J Cardiothorac Vasc Anesth. 2022;36(4):962–70.
Chan MJ, Lee CC, Chen SW, Tsai FC, Lin PJ, Fan PC, Hsu HH, Chang MY, Chen YC, Chang CH. Effect of different surgical type of coronary artery bypass grafting on kidney injury: a propensity score analysis. Med (Baltim). 2017;96(45):e8395.
Yue Z, Yan-Meng G, Ji-Zhuang L. Prediction model for acute kidney injury after coronary artery bypass grafting: a retrospective study. Int Urol Nephrol. 2019;51(9):1605–11.
Zhou B, Ao Q, Zhao H, Ye P. Rosuvastatin alleviates renal injury in cardiorenal syndrome model rats through anti-inflammatory and antioxidant pathways. Emerg Crit Care Med. 2022;2(4):203–8.
Li YM, Li ZL, Chen F, Liu Q, Peng Y, Chen M. A LASSO-derived risk model for long-term mortality in Chinese patients with acute coronary syndrome. J Transl Med. 2020;18(1):157.
Xiao J, Ding R, Xu X, Guan H, Feng X, Sun T, Zhu S, Ye Z. Comparison and development of machine learning tools in the prediction of chronic Kidney Disease progression. J Transl Med. 2019;17(1):119.
Goyal A, Daneshpajouhnejad P, Hashmi MF, Bashir K. Acute Kidney Injury. In: StatPearls Treasure Island (FL); 2022.
Li Z, Ge W, Han C, Lv M, He Y, Su J, Liu B, Zhang Y. Prognostic values of three equations in estimating glomerular filtration rates of patients undergoing Off-Pump coronary artery bypass grafting. Ther Clin Risk Manag. 2020;16:451–9.
Kellum JA, Lameire N, Aspelin P, Barsoum RS, Burdmann EA, Goldstein SL, Herzog CA, Joannidis M, Kribben A, Levey AS. Kidney Disease: improving global outcomes (KDIGO) acute kidney injury work group. KDIGO clinical practice guideline for acute kidney injury. Kidney Int Supplements. 2012;2(1):1–138.
Gao F, Shan L, Wang C, Meng X, Chen J, Han L, Zhang Y, Li Z. Predictive ability of European heart Surgery risk Assessment System II (EuroSCORE II) and the Society of thoracic surgeons (STS) score for in-hospital and medium-term mortality of patients undergoing coronary artery bypass grafting. Int J Gen Med. 2021;14:8509–19.
Shen L, Chen X, Gu J, Xue S. Validation of EuroSCORE II in Chinese patients undergoing coronary artery bypass Surgery. Heart Surg Forum. 2018;21(1):E036–9.
Li X, Shan L, Lv M, Li Z, Han C, Liu B, Ge W, Zhang Y. Predictive ability of EuroSCORE II integrating cardiactroponin T in patients undergoing OPCABG. BMC Cardiovasc Disord. 2020;20(1):463.
Shan L, Ge W, Pu Y, Cheng H, Cang Z, Zhang X, Li Q, Xu A, Wang Q, Gu C, et al. Assessment of three risk evaluation systems for patients aged >/=70 in East China: performance of SinoSCORE, EuroSCORE II and the STS risk evaluation system. PeerJ. 2018;6:e4413.
Ma X, Wang Y, Shan L, Cang Z, Gu C, Qu N, Li Q, Li J, Wang Z, Zhang Y. Validation of SinoSCORE for isolated CABG operation in East China. Sci Rep. 2017;7(1):16806.
Ke GL, Meng Q, Finley T, Wang TF, Chen W, Ma WD, Ye QW, Liu TY. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Advances in Neural Information Processing Systems 30 (Nips 2017) 2017, 30.
Lundberg SM, Lee S-I. A unified approach to interpreting model predictions. Adv Neural Inf Process Syst 2017, 30.
Zou C, Zheng E-h, Xu H-w, Chen L. SVM-Based Multiclass Cost-sensitive Classification with Reject Option for Fault Diagnosis of Steam Turbine Generator. In: Proceedings of the 2010 Second International Conference on Machine Learning and Computing IEEE Computer Society; 2010: 66–70.
She X, Zhu Y, Text Classification Research Based on Improved SoftMax Regression Algorithm. 2018 11th International Symposium on Computational Intelligence and Design (ISCID) 2018, 02:273–276.
Yuan D, Huang J, Yang X, Cui JR. Improved random forest classification approach based on hybrid clustering selection. Chin Autom Congr 2020:1559–63.
Pencina MJ, Fine JP, D’Agostino RB, Sr. Discrimination slope and integrated discrimination improvement - properties, relationships and impact of calibration. Stat Med. 2017;36(28):4482–90.
Pencina MJ, Steyerberg EW, D’Agostino RB, Sr. Net reclassification index at event rate: properties and relationships. Stat Med. 2017;36(28):4455–67.
Bland JM, Altman DG. Statistical methods for assessing agreement between two methods of clinical measurement. Lancet. 1986;1(8476):307–10.
Lee C, Light A, Alaa A, Thurtle D, van der Schaar M, Gnanapragasam VJ. Application of a novel machine learning framework for predicting non-metastatic prostate cancer-specific mortality in men using the Surveillance, Epidemiology, and end results (SEER) database. Lancet Digit Health. 2021;3(3):e158–65.
Luo W, Phung D, Tran T, Gupta S, Rana S, Karmakar C, Shilton A, Yearwood J, Dimitrova N, Ho TB, et al. Guidelines for developing and reporting machine learning predictive models in Biomedical Research: a multidisciplinary view. J Med Internet Res. 2016;18(12):e323.
Cuschieri S. The STROBE guidelines. Saudi J Anaesth. 2019;13(Suppl 1):31–S34.
Kramer RS, Herron CR, Groom RC, Brown JR. Acute kidney Injury subsequent to cardiac Surgery. J Extra Corpor Technol. 2015;47(1):16–28.
Takaki S, Shehabi Y, Pickering JW, Endre Z, Miyashita T, Goto T. Perioperative change in creatinine following cardiac Surgery with cardiopulmonary bypass is useful in predicting acute kidney injury: a single-centre retrospective cohort study. Interact Cardiovasc Thorac Surg. 2015;21(4):465–9.
Bell J, Sartipy U, Holzmann MJ, Hertzberg D. The Association between Acute Kidney Injury and Mortality after Coronary Artery Bypass Grafting was similar in women and men. J Cardiothor Vasc An. 2022;36(4):962–70.
Warren J, Mehran R, Baber U, Xu K, Giacoppo D, Gersh BJ, Guagliumi G, Witzenbichler B, Magnus Ohman E, Pocock SJ, et al. Incidence and impact of acute kidney injury in patients with acute coronary syndromes treated with coronary artery bypass grafting: insights from the Harmonizing outcomes with revascularization and stents in Acute Myocardial Infarction (HORIZONS-AMI) and Acute catheterization and urgent intervention triage strategy (ACUITY) trials. Am Heart J. 2016;171(1):40–7.
Oh TK, Song IA. Postoperative acute kidney injury requiring continuous renal replacement therapy and outcomes after coronary artery bypass grafting: a nationwide cohort study. J Cardiothorac Surg. 2021;16(1):315.
Jiang W, Xu J, Shen B, Wang C, Teng J, Ding X. Validation of four prediction scores for cardiac surgery-Associated Acute kidney Injury in Chinese patients. Braz J Cardiovasc Surg. 2017;32(6):481–6.
Kresoja KP, Unterhuber M, Wachter R, Thiele H, Lurz P. A cardiologist’s guide to machine learning in Cardiovascular Disease prognosis prediction. Basic Res Cardiol. 2023;118(1):10.
Douglas MJ, Callcut R, Celi LA, Merchant N. Interpretation and use of Applied/Operational machine learning and Artificial Intelligence in Surgery. Surg Clin North Am. 2023;103(2):317–33.
Penny-Dimri JC, Bergmeir C, Reid CM, Williams-Spence J, Cochrane AD, Smith JA. Machine Learning algorithms for Predicting and Risk Profiling of Cardiac surgery-Associated Acute kidney Injury. Semin Thorac Cardiovasc Surg. 2021;33(3):735–45.
Ishikawa M, Iwasaki M, Namizato D, Yamamoto M, Morita T, Ishii Y, Sakamoto A. The neutrophil to lymphocyte ratio and serum albumin as predictors of acute kidney injury after coronary artery bypass grafting. Sci Rep. 2022;12(1):15438.
Li J, Liu S, Hu Y, Zhu L, Mao Y, Liu J. Predicting Mortality in Intensive Care Unit patients with Heart Failure using an interpretable machine learning model: Retrospective Cohort Study. J Med Internet Res. 2022;24(8):e38082.
Song Z, Yang Z, Hou M, Shi X. Machine learning in predicting cardiac surgery-associated acute kidney injury: a systemic review and meta-analysis. Front Cardiovasc Med. 2022;9:951881.
Luo XQ, Kang YX, Duan SB, Yan P, Song GB, Zhang NY, Yang SK, Li JX, Zhang H. Machine learning-based prediction of Acute kidney Injury following Pediatric Cardiac Surgery: Model Development and Validation Study. J Med Internet Res. 2023;25:e41142.
Lv M, Hu B, Ge W, Li Z, Wang Q, Han C, Liu B, Zhang Y. Impact of Preoperative Occult Renal dysfunction on early and late outcomes after off-pump coronary artery bypass. Heart Lung Circ. 2021;30(2):288–95.
Seelhammer TG, Maile MD, Heung M, Haft JW, Jewell ES, Engoren M. Kinetic estimated glomerular filtration rate and acute kidney injury in cardiac Surgery patients. J Crit Care. 2016;31(1):249–54.
Ortega-Loubon C, Fernandez-Molina M, Paneda-Delgado L, Jorge-Monjas P, Carrascal Y. Predictors of postoperative acute kidney Injury after coronary artery bypass graft Surgery. Braz J Cardiovasc Surg. 2018;33(4):323–9.
Thongprayoon C, Pattharanitima P, Kattah AG, Mao MA, Keddis MT, Dillon JJ, Kaewput W, Tangpanithandee S, Krisanapan P, Qureshi F et al. Explainable Preoperative Automated Machine Learning Prediction Model for Cardiac surgery-Associated Acute kidney Injury. J Clin Med 2022, 11(21).
Levey AS, Bosch JP, Lewis JB, Greene T, Rogers N, Roth D. A more accurate method to estimate glomerular filtration rate from serum creatinine: a new prediction equation. Modification of Diet in Renal Disease Study Group. Ann Intern Med. 1999;130(6):461–70.
Tang M, Liu X, Lin C, He Y, Cai X, Xu Q, Hu P, Gao F, Jiang J, Lin X, et al. Meta-analysis of outcomes and evolution of pulmonary Hypertension before and after transcatheter aortic valve implantation. Am J Cardiol. 2017;119(1):91–9.
Gudsoorkar PS, Thakar CV. Acute kidney Injury, Heart Failure, and Health outcomes. Cardiol Clin. 2019;37(3):297–305.
Wang S, Lian Y, Wang H, Fan X, Zhao H. Prognostic implications of elevated pulmonary artery systolic pressure on 6-month mortality in elderly patients with acute Myocardial Infarction. Emerg Crit Care Med. 2022;2(4):197–202.
Bianco JC, Stang MV, Denault AY, Marenchino RG, Belziti CA, Musso CG. Acute kidney Injury after Heart Transplant: the Importance of Pulmonary Hypertension. J Cardiothorac Vasc Anesth. 2021;35(7):2052–62.
Marui A, Okabayashi H, Komiya T, Tanaka S, Furukawa Y, Kita T, Kimura T, Sakata R, Investigators CR-K. Impact of occult renal impairment on early and late outcomes following coronary artery bypass grafting. Interact Cardiovasc Thorac Surg. 2013;17(4):638–43.
Kaddourah A, Basu RK, Bagshaw SM, Goldstein SL, Investigators A. Epidemiology of Acute kidney Injury in critically Ill children and young adults. N Engl J Med. 2017;376(1):11–20.
Acknowledgements
Not applicable.
Funding
This research received no grant from any funding agency in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Contributions
T.J., K.X., and Y.B. analyzed data and wrote the paper. X.Z., M.L., and Y.Z. designed the research. M.L., L.S., W.L., X.Z., Z.L. and Z.W. contributed to data collection and data correction. X.Z., M.L., and Y.Z. are responsible for the overall content as guarantors. All authors contributed to processed and edited the manuscript. All authors provided critical revisions of the manuscript and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethics approval and consent to participate
This study was approved by the Ethics Committees of Jiangsu Province Hospital (No. 2023-SR-229), the Ethics Committees of Shanghai Chest Hospital (No. IS23002), the Ethics Committees of Qilu Hospital (No. KYLL-202204-016) and, the Ethics Committees of General Hospital of Ningxia Medical University (No. KYLL20230330).
Patients provided informed consent to undergo treatment, but the requirement for informed consent for participation in the current study was exempted by the ethics committees (Ethics Committees of Jiangsu Province Hospital, Ethics Committees of Shanghai Chest Hospital, Ethics Committees of Qilu Hospital and, Ethics Committees of General Hospital of Ningxia Medical University), due to its retrospective nature.
All methods were performed in accordance with the relevant guidelines and regulations.
Consent for publication
Not applicable.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Jia, T., Xu, K., Bai, Y. et al. Machine-learning predictions for acute kidney injuries after coronary artery bypass grafting: a real-life muticenter retrospective cohort study. BMC Med Inform Decis Mak 23, 270 (2023). https://doi.org/10.1186/s12911-023-02376-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12911-023-02376-0